
The Example
A.1 Introduction
Throughout this book there are examples – XML data, relational data, XQueries, SQL queries, and so on – based on data about a collection of movies. The examples in the chapters of this book are not entirely consistent, since they were produced to illustrate specific points made in the text, and they are not always complete, due to space considerations. The purpose of this appendix is to set out in one place a more complete, consistent set of example data, metadata, and queries. Many of the examples are copied directly from previous chapters, some have been changed only slightly, and some are completely new. An appendix provides more space to lay out more data and queries, but even here we have made some tradeoffs between completeness and trees – some queries, for example, have somewhat arbitrary predicates to reduce the number of results.
We begin by reproducing the movies XML data, showing complete contents for 10 movies. Then we present metadata for the movies data – a possible XML Schema and a DTD. That’s followed by the XML data, XML Schema, and DTD for reviews. Then we look at some SQL/XML queries to convert the XML data into relational data and back again. These queries exercise SQL/XML to address a specific task (converting data), and they constitute substantial examples. After the data we present example queries – first XQueries and then SQL/XML queries. We finish with a complete web application written in XQuery.
The SQL/XML queries in this appendix were tested against an Oracle database, version 10.2.0.1. A fully functional trial copy of the Oracle database can be downloaded for free (after registration) from Oracle’s website. We encourage anyone interested in trying the examples for themselves to visit http://www.oracle.com/technology/index.html and download and install Oracle.
The XQueries and the web application were tested against Mark-Logic Server version 3.0-3. Mark Logic also offers a fully functional trial copy of its software, with registration. We encourage anyone interested in trying the XQuery examples in this appendix to visit http://marklogic.com/ and download and install the MarkLogic Server. We also used “Altova XMLSpy 2006 Enterprise Edition” and “Stylus Studio 6, XML Enterprise Edition, Release 3” to produce the XML data, metadata, and queries.
Some queries in this appendix have been changed slightly to use vendor-specific syntax or extensions so that they will run in our test environment. The downside is that the examples in this appendix do not exactly match similar examples in the chapters, and they do not all conform to the latest standard syntax. The upside is that they all actually run and yield results against a stated software configuration.
The data and queries in this appendix, plus additional examples and explanations, are available for download from the website for this book’s examples, http://xqzone.marklogic.com/queryingxmlbook/.
A.2 Example Data
Throughout the book we have used movie data and review data. In this section we present the data in a number of forms, along with some metadata.
A.2.1 Movies We Own
Most of the examples in this book are based on the data in Data A-1, which might be stored in a file called “movies-we-own.xml.” In the interests of saving trees, the data don’t include every movie we own, but we have managed to squeeze in all four “Alien” movies, “Animal House,” and “An American Werewolf in London” – not a bad selection.


















“Movies We Own” Schema
Data A-2 is one possible XML Schema for the data in Data A-1.
There are a number of decisions to be made when creating an XML Schema. Some have an effect on the variations in data that can be “caught” by schema validation, others are largely a question of style. For example, in Example 1-6, we defined an element for each of givenName and familyName and referenced those elements in producer, director, writer, and cast. In Data A-2, on the other hand, we chose to create a type for person and then to define producer, director, writer, and cast to be of type person (sometimes with extensions).
We have included a liberal sprinkling of comments in the schema. There are two possible styles of comment in a schema – either you can use the schema style (add an annotation element with a documentation child) or, since the schema is an XML document, you can use XML comments (<!-- like this -->). The annotation element lends itself to easier querying (if you want to do XQueries against comments in your schema), and its contents show up in the schema design view in XMLSpy. But the XML comments are simpler and less verbose, so we chose the XML comment style. Note that comments are very necessary in a schema – the schema supplies lots of information about syntax, but the schema author still needs to document syntax and style choices, and the semantics underlying the data.
When writing and testing the schema, we were reminded just how useful a schema is – in the original movies data, there was a near-even split between “Male” and “male,” “Female” and “female,” “Story” and “story,” “Screenplay” and “screenplay.” The enumeration in the schema caught that inconsistency. If there were no schema and the inconsistency had not been caught, queries would not fail but they would silently give “wrong” answers.
Of course, there are a number of ways that the same data can be represented in a schema. We have already mentioned that we abstracted out persons, for example. Similarly, there are a number of ways to represent the same data in an XML document. As one example, in movies-we-own storyOrScreenplay is a child of writer. We could have decided to make story and screenplay children of movie, each with a writer child.
Finally, take a look at the schema definition of plotSummary. Here is an example of presentation markup – a plotSummary contains text with an arbitrary number of emph tags bracketing parts of the text.





“Movies We Own” DTD
The DTD in Data A-3 is based on the DTD produced from Data A-2 by XMLSpy. Note how much richness is lost when going from XML Schema to DTD.

“Movies We Own” SQL Tables for XML Data
When considering a storage/representation strategy for XML data, you need to consider what constitutes a document. There are two obvious strategies for the movies data – a document could be all the movies wrapped in a single <movies> tag, or it could be a set of documents, each representing a single movie. These two options are illustrated by the ALL_MOVIES_XML table (Data A-4) and the MOVIES_XML table (Data A-5) respectively. In both examples, we create a SQL table and store the data natively in a column of type XMLTYPE. Again, the syntax throughout this appendix is vendor-specific (the SQL standard calls the special XML type “XML,” for example).



“Movies We Own” SQL Tables for Relational Data
The data in Data A-1 could be stored as relational data (as well as, or instead of, XML data) in SQL tables. In this section we present one possible representation. For each table we show a CREATE TABLE statement followed by a listing of the data in that table. For the largest table (MOVIES) we have split the data into three separate listings. Note that the CREATE TABLE statements use Oracle, rather than standard SQL, syntax. For example, some columns are of type VARCHAR2 rather than CHARACTER VARYING. There is some other proprietary syntax (such as CREATE DIRECTORY and CREATE SEQUENCE) – if you want to run these samples on a database from some vendor other than Oracle, you’ll need to work around these differences.
The main table, MOVIES, has a column for each property of a movie, minus repeating properties. Data A-6 shows how to create MOVIES and populate it from the data in the MOVIES_XML table. Note that MOVIES, and the other SQL tables we present, could be created as a view instead of a table.







Of course, you could split the MOVIES table into any number of tables – for example, it might be useful to split the sound fields into their own table.
In the body of the book, we created tables for producers and directors. In this appendix, we decided to abstract out all the persons into a single table, and then to create tracking tables to link producers with movies, directors with movies, writers with movies, and cast with movies. SQL readers will be familiar with this notion of normalizing data so that common facts (such as a person’s names) are stored only once, no matter how many roles and movies he is associated with. Data A-7 through Data A-11 create and populate these tables from the data in the MOVIES_XML table.




















Check on Relational Tables
We now have a couple of tables that store the movies-we-own.xml data in XML columns in relational tables, and we have a set of purely relational tables (with no XML columns) built from the XML data in the MOVIES_XML table. Now let’s turn this relational data back into XML, and check the result against the original XML file.
We assume that the order of repeating elements is not significant. The movies were inserted into the relational tables in title order, though we could have done that in document order, in which case we could have used ORDER BY id to get them back in the same order. If we’d gone with a movies_producer table instead of normalizing to persons, we could have done the same with producers (and directors and writers and cast). Note that if the order of any of these fields were important, you could add an “order” column to the table to preserve the original document order.



The output from Data A-12 does indeed match movies-we-own.xml, modulo ordering of repeating properties (see http://xqzone.marklogic.com/queryingxmlbook/ for a listing of the output). As we explained earlier, in our example the ordering is not significant, but the ordering could be captured if it were important.
“Movie Reviews” XML
In this section, we present movie-reviews.xml and its associated metadata and SQL tables. The movie reviews data are a small sample of ratings and reviews of some of the movies. They are presented here so that we can illustrate queries across more than one data source (XML file or table).


“Movie Reviews” Schema
Just for fun, we use a slightly different style for defining elements in Data A-14. Instead of defining a set of complex types, as in Data A-2, we define a set of elements up front and reference them in the definition of the reviews element. Neither style is particularly appropriate for our rather simple data set; we just used them to show some variations in schema styles.




“Movie Reviews” XML Table
Instead of using SQL/XML to populate the REVIEWS table from reviews.xml (as we did with movies), we created an XSLT stylesheet that, when run over reviews.xml, outputs a SQL script to create and populate the REVIEWS table. (Our first pass at creating the movies tables was to write XQueries that output SQL scripts – see the examples website).





A.3 Some Examples from the Book
Most of the examples in this section are from the body of the book. Some have been changed slightly to make the examples or the results fit on the page, or to make the example queries and data consistent throughout this appendix. Some of the XPath expressions assume that a context has been established.
A.3.1 XQuery Examples




Example A-12 is an XPath expression that calculates the average star ratings for movies directed by John Landis. Of course, we could use the function avg() instead of sum(), div, and count(). Although most of our XPath examples are shown on a single line, XPaths can include whitespace as in Example A-12.

Example A-13 introduces for to iterate over a sequence, such as the sequence produced by an XPath. If there is more than one title in the result then you probably want to format the results – Example A-14 formats results with a direct constructor.




Example A-16 and Example A-17 illustrate the composability of XQuery expressions. Example A-16 is an expression that evaluates to the newer of two movies. Because XQuery expressions are composable, this expression can be used as part of another expression – Example A-17 uses this expression on the right-hand side of a comparison.


It’s common to want to query across data from more than one source, joining the data according to some common criterion (or key). Example A-18 shows one way to do a join in XQuery, using two expressions in the for clause.



Example A-19 also joins data from movies and reviews, but it uses an inner for loop (or subquery), this time with movies in the outer loop and reviews in the inner loop. In addition, Example A-19 uses if to insert a different element if there are no reviews available.



A.3.2 SQL/XML Examples
Most of the examples in this section are from the body of the book, modified to make them consistent with the other examples and the data in this appendix.
Publishing Functions – Representing SQL Data as XML









In Example A-24 and some following examples, we introduced a spurious condition to keep the results size down (to save some paper).
Example A-24 and Example A-25 give similar results, but Example A-25 uses XMLFOREST to skip null values (for otherNames).








XMLQUERY and XMLTABLE—Manipulating XML in SQL






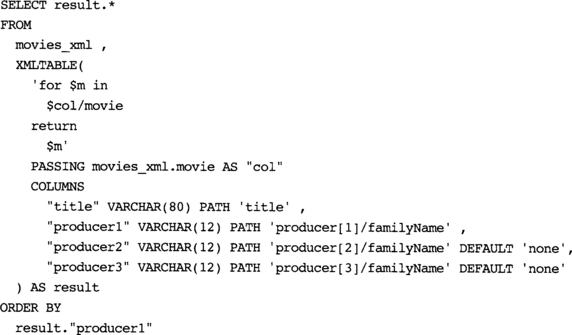
Of course, you could use XMLTABLE to create MOVIES_XML from ALL_MOVIES_XML; see Example A-29.






Note that in Example A-31, there are 10 rows in the result, since we are iterating over all 10 rows in the table.


















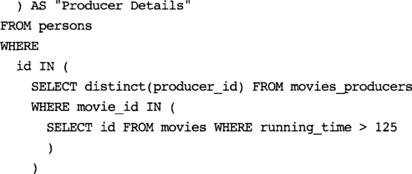
In Example A-39, we use a sequence to yield an ID. Any unique, increasing number would serve. Note that Example A-39 uses the SQL DISTINCT keyword to ensure that producer details are distinct (each producer is represented only once in the table, no matter how many movies he produced).





To end this section, we present two analytic functions, rollup and cube, in Example A-41 and Example A-42, respectively. These examples illustrate the power of SQL/XML, providing the ability to perform sophisticated functions on XML data.





A.4 A Simple Web Application
XQuery is a powerful query language for expressing precise queries against XML data. It is also (with a few extensions) a powerful programming language for querying, storing, managing, manipulating, and publishing XML content. This section presents a complete web application written in XQuery. All the code needed to run the application is included, and of course the application runs against the movies and reviews data reproduced at the beginning of this appendix.
The application runs on the MarkLogic application server. The application server, which is a part of the MarkLogic Content Server, executes XQuery modules (.xqy files) stored in the file system or in MarkLogic, and it outputs html or xhtml to be displayed in a browser (there are also Java and .NET APIs). The data were loaded into Mark-Logic via the built-in WebDAV server – we simply dragged movies-we-own.xml and reviews.xml from the desktop into a WebDAV folder, and they became available for querying.
The application code is not meant to be particularly efficient, it just needs to work. We’ve picked up the coding style from several people/examples; for tips on XQuery coding style, see http://xqdoc.org/xquery-style.pdf.
The example application runs in a browser, see Figure A-1.

The general idea of the application is to query movies and reviews. Looking at the form fields in Figure A–1 from left to right, you can do full-text search on words in the title (“all words” or “any word”), you can query by year released (”<”, “>“, or “=”), by director (from a pull-down list of values), or by the average rating over all available reviews. In addition, you can choose to order the results either by title or by rating.
The results of the query are shown in the bottom section of the screen. The application counts the results and shows the title, year released, and star rating of each movie found. The title is a hot link to a listing of the movie data. The star rating is an image of a number of stars, hot-linked to a dynamically produced listing of all the reviews for that movie.
The application consists of a main module and two library modules, one to handle generic processing and the other to handle display-specific processing. Example A–43 is the main module – it simply imports the two libraries, picks up any parameters that have been passed in, and calls functions to paint the query and results.



Example A–44 is the display library. It returns a bunch of xhtml, with values inserted dynamically by XQuery calls. It uses XQuery to determine what xhtml to return, and calls functions in movies-lib.xqy for any generic processing (such as querying).
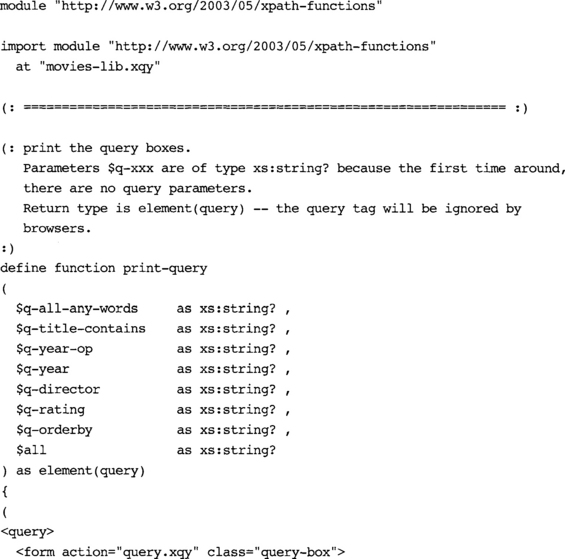








Example A-45 does any generic processing the application needs. Keeping the display functions and generic functions separate means we could write a similar application with a completely different user interface quite easily.





Example A-46 and Example A-47 are main modules that print a single movie and print all reviews for a single movie, respectively. These modules are called when you click on the movie title or the star rating in the results list.




Finally, Example A-48 is the configuration file. Currently, it only contains the designation of the CSS stylesheet to be used, but it could contain a collection of defaults, preferences, and other settings, such as the location of the movies data or the maximum number of results to display.

That’s it! The only file not reproduced here is the CSS stylesheet we used to get the appearance in Figure A-1. That’s left as an exercise for the reader (or, of course, it’s available for download at the example website).
A.5 Summary
In this appendix we presented some sample data for movies and reviews in an XML format, along with their metadata (an XML Schema and a DTD for each file). We showed you how to load these data into a SQL table with an XML column and how to query them using SQL/XML. You also saw how to store the data in a set of normalized SQL tables (or represent the data in a set of SQL views). We reviewed some of the SQL/XML examples from the body of the book, and we added some new ones, exercising the publishing functions and the newer XMLTABLE and XMLQUERY. We also reviewed some of the XPath and XQuery examples from earlier in the book, and we added some new ones. While the examples throughout this book are somewhat consistent, each example was presented to echo a particular point in the text. The examples and data in this appendix, on the other hand, are all completely consistent and can be run from the scripts on the example website (though some examples necessarily have vendor-specific syntax and extensions).