
SQL/XML
15.1 Introduction
For the last several decades, most of the world’s critical data has been stored in SQL databases, managed and queried using the SQL language. More recently, people have turned to XML to represent their data in a more natural way, and they need a new language to manage and query that data – a language that takes account of the structure of an XML document as well as its data values. You read in previous chapters how first XPath and then XQuery were defined to do just that. But many experts have asked the question, “why not just use SQL?” – perhaps converting all your data into XML and all your applications into XQuery amounts to throwing the baby out with the bathwater. Relational databases and the SQL language have stood the test of time, evolving and growing to embrace new technologies such as OLAP, data warehousing, and objects. Why not just add XML extensions to SQL? As you will discover in this chapter, it’s not quite as simple as that, but that is what the SQLX Group set out to do in 2000. The goal of the SQLX Group was to define a set of extensions to the SQL standard to integrate SQL and XML, supporting bidirectional movement of data and allowing SQL programmers to manage and query XML data. Specifically, they worked to:
• Query SQL data and publish the results as XML
• Store and manage XML natively in a SQL database
• Query XML and publish the results as either XML or as SQL data
SQLX, SQL/XML, and SQLXML
The SQLX group started as an informal group of companies, including Oracle and IBM, interested in extending the SQL standard to embrace XML. The group’s output was blessed by INCITS (the U.S. body chartered with development of standards in IT, including SQL), as “SQL part 14, XML-Related Specifications (SQL/XML).” The SQLX group became formally known as “INCITS Task Group H2.3” (and later an “INCITS H2 ad hoc working group”), but they still maintain a website under the catchier name “SQLX.”1
We take a moment here to emphasize the difference between SQLX, SQL/XML, and SQLXML (three terms that many people use interchangeably). SQL/XML is the short name for part 14 of the SQL standard, that part that deals with XML. SQLX is the informal name of the group that creates and presents proposals for SQL/XML to INCITS. And SQLXML (without a slash)2 is a Microsoft term for Microsoft’s proprietary SQL extensions that do roughly the same thing as the SQL/XML publishing functions.3
Chapter Overview
In this chapter, we present an overview of SQL/XML:2003 and SQL/XML:2006, focusing on querying XML, with some simple worked examples. In Section 15.2, we describe the SQL/XML publishing functions, which allow you to query SQL data and produce (or publish) the results as XML, either to send to a customer or partner or, more likely, to display the results as a web page. This is not strictly “Querying XML,” rather it is “Querying to XML.”
In Section 15.3, we describe the XML type – a native SQL data type for XML. This forms the basis for storing, managing, and querying XML natively in a SQL database. Section 15.4 covers the XQuery-related functions that are part of SQL/XML:2006, including XMLQUERY and XMLTABLE. With these functions you can query XML, stored natively in a SQL database as an XML type, using the power of XQuery in the context of SQL. This is the most detailed section in the chapter, focusing on XMLTABLE.
Section 15.5 talks briefly about managing XML data in a SQL database. And Section 15.6 describes the mappings of character sets, names, types, and values, from SQL to XML and from XML to SQL. Section 15.6 also introduces the casting functions XMLSERIALIZE, XMLPARSE, and XMLCAST.
The SQL and SQL/XML Standards
The SQL/XML Standard, like the XQuery Recommendation, is an ongoing process (that is, it’s not yet finished). The first SQL/XML standard to be published was SQL/XML:2003, which was part 14 of the SQL:2003 standard. SQL/XML is currently on a shorter publication schedule tha SQL, so that the next SQL/XML standard, expected to be SQL/XML:2006, will probably be published as an update to SQL:2003. After that, we expect SQL/XML:2007, which may incorporate future XQuery additions such as XQuery Update and XQuery Full Text, to be part of SQL:2007. (All publication dates past 2003 are, at the time of writing, estimates only.)
The SQUXML Functions
While we refer to “the SQL/XML functions” (e.g., publishing functions and XQuery functions) in the rest of this chapter, the alert reader will notice that they are not actually functions at all. Their syntax looks quite a lot like the syntax of a function, but with extra keywords and clauses thrown in (alternatively, the syntax is keyword-based grammar extensions that use parentheses to look like function). In SQL terms, they are pseudo-functions.
The Examples
All the examples in this chapter were tested against a prerelease version of Oracle database 10g Release 2. The examples generally conform to the SQL/XML standard – where they are specific to Oracle, or where they illustrate a part of the standard not implemented by our test implementation, we have made an effort to note it.4
15.2 SQL/XML Publishing Functions
The first piece of useful query functionality to come out of the SQL/XML effort is the ability to publish the results of a SQL query to XML. Strictly speaking, this is not “Querying XML” – rather, it is “Querying to XML.” The data to be queried can be any SQL data, and the query can be any SQL query. These SQL extension functions transform the result of the query to XML. Each of the extension functions takes in a SQL thing (part of a SQL tuple, or row), and returns an XML thing (e.g., an element or an attribute). In the rest of this section, we give examples of some of the SQL/XML publishing functions in SQL queries against the movies data.
15.2.1 Examples
The Data
In Figure 15-1, we reproduce the SQL (relational) representation of the movies data from Chapter 1, “XML,” for your convenience.

Figure 15-1 movie, SQL Representation (Reproduced from Chapter 1, XML).
XMLELEMENT
Let’s start with a simple case of XML publishing. Suppose you want to want to publish the title of all the movies in your collection, with each title in a separate XML element. Example 15-1 does just that.

The first argument to XMLELEMENT is the name of the element to be produced (preceded by the keyword “NAME”). This is an identifier, in the same way that a table name or column name is an identifier. In Example 15-1, we put quotes around this first argument because we wanted the element name to be lowercase – the same query without quotes around the first argument would result in an element called “TITLE” (since SQL uppercases identifiers by default).
XMLELEMENT takes an optional second argument, a call to the function XMLATTRIBUTES, which defines attributes for the result element. When XMLATTRIBUTES is not used, as in Example 15-1, the second argument to XMLELEMENT is an expression that fills in the content of the element. In Example 15-1, it’s just the name of the column – title – but it could be a function call, or even a subquery.
We added a column alias – AS “Movie Titles” – to make the output look nicer. Note that the result is two rows, each of which is a title element (as opposed to a single XML fragment consisting of two elements). That’s because the SQL query iterates over each row in the table, returning XMLELEMENT (NAME “title”, title) for each row. If you want to return one XML fragment that contains all the titles, use XMLAGG (see the next section). There is, of course, a major difference between a set of results (which we get from Example 15-1), and a single result that is an XML fragment. We try to distinguish between the two kinds of results in the rest of this chapter.


Example 15-2 illustrates how much you can do with XMLELEMENT. It includes a call to XMLATTRIBUTES to define two attributes, RunningTime and Director, where Director is derived from a query on the DIRECTORS table. The third argument, which populates the element body, is a more complex expression than in Example 15-1. It consists of a string literal (this could have been a subquery), a concatenation operator (| |), and a column identifier (m. title). We have added table aliases d and m to make the query (somewhat) more readable.
XMLATTRIBUTES is a bit of an oddity. It’s not a top-level function – it can only occur as the second argument to XMLELEMENT. This maps nicely to the notion of attributes in the XML InfoSet, since an attribute must always have an element owner. But it’s more restrictive than the XQuery Data Model, where the basic unit is the sequence, which may contain attributes without a parent element. Also, the XMLATTRIBUTES argument is optional, which is unusual for the second of three arguments. The arrangement works (does not pose problems for parsers) because this optional second argument can only be a call to XMLATTRIBUTES, and a call to XMLATTRIBUTES is not allowed as any other argument.
15.2.2 XMLAGG
Now you know how to get the result of a SQL query into a set of XML elements. But if you want to publish, say, an XML report summarizing your relational data, you probably want to aggregate all the similar XML elements into a single element. For that, you would use the XMLAGG function. XMLAGG takes an XMLELEMENT function call as its argument, and produces a single result that is the aggregate of all the elements produced by XMLELEMENT. It’s an aggregate function in the same way that MIN, MAX, and COUNT are aggregate functions in SQL.
Let’s suppose you want to create an XML report that shows the title of each movie in your collection, inside a single element “all-titles.” Example 15-3 shows a query that uses only XMLELEMENT. It calls XMLELEMENT to create the element “all-titles,” with a second argument that uses XMLELEMENT to fetch a title from the movies table. This query gives the wrong result – since XMLELEMENT is not an aggregate function, it gets evaluated once for each row in the table, so we get an all-titles element for each title.


Example 15-4 shows the right way to get a single “all-titles” element containing a “title” element for each title in the table movies. The second argument to XMLELEMENT is now wrapped in the aggregate function XMLAGG, which produces a single result (in the same way that COUNT() produces a single result) containing an element for each row in the MOVIES table. Example 15-4 also introduces the ORDER BY clause which is part of XMLAGG, to produce titles of movies ordered by the year the movie was released.


15.2.3 XMLFOREST
In Example 15-1 and Example 15-2, we used XMLELEMENT to create XML elements from the values in one column of a SQL table (the title column of the MOVIES table), and in Example 15-4 we used XMLAGG to aggregate all the values in a column into a single all-titles element. Now suppose you want to create XML elements for several columns in a table (“across the row”). You could achieve this by simply calling XMLELEMENT several times, as in Example 15-5.



Another way to achieve this forest of XML elements is to use XMLFOREST, as in Example 15-6.


Example 15-6 gives the same results as Example 15-5, but it is more concise and more natural to read and write. XMLFOREST has another advantage over a series of calls to XMLELEMENT – it ignores NULL values in a column. Consider Example 15-7.


Example 15-7 yields producer-details containing XML elements for given name, family name, and other names. But for NULL values such as the producers’ other names, it produces an empty element. You could, of course, filter out these NULL values using SQL (e.g., use a CASE statement), but the SQL gets quite ugly.5 A better solution is shown in Example 15-8 – XMLFOREST skips NULL values and does not produce empty elements for otherNames.


While XMLFOREST gives shorter, more natural queries than a series of calls to XMLELEMENT, and eliminates NULL values, it has the disadvantage that you cannot add attributes to elements produced by XMLFOREST. If you need attributes on the elements, you have to use XMLELEMENT.
15.2.4 XMLCONCAT
XMLCONCAT takes a list of XML values and concatenates them into a single XML value. In Example 15-9, XMLCONCAT concatenates the first, last, and other names into a single XML value, resulting in one XML value (an XML forest) for each row.


There are three results in Example 15-9, each one an XML value consisting of three elements.
XMLCONCAT and XMLFOREST both take in a list of values, and output an XML forest. Both ignore NULL values (i.e., produce no output for a NULL value). The difference is that the input to XMLCONCAT is a list of XML values, while the input to XMLFOREST is a list of SQL values. Hence in Example 15-8, we passed column names to XMLFOREST, while in Example 15-9, we had to wrap the column names in a call to XMLELEMENT (to create an XML value) before passing them to XMLCONCAT.
15.2.5 Summary
Table 15-1 shows all the publishing functions in SQL:2003.
Table 15-1

*XMLAGG aggregates values of a single column over many rows – “down the table” – as opposed to XMLFOREST, which aggregates values of several columns in a single row – “across the row.”
As you can see from the examples, the SQL/XML publishing functions are somewhat verbose, and they can be a little tricky to use, but they are extremely powerful. The examples in this section are simple queries, designed to illustrate the functions individually. But these functions can be combined with each other, and with the rest of the SQL language, into arbitrarily complex queries. Of course, we would not expect end users to formulate complicated ad hoc queries – in most cases, programmers write SQL queries that include the publishing functions, e.g., to create an XML view of the data.
In SQL/XML:2006, there are at least two additional publishing functions – XMLCOMMENT and XMLPI create a comment node and a processing instruction node, respectively. In addition, XMLAGG, XMLCONCAT, XMLELEMENT, and XMLFOREST acquire an optional RETURNING {CONTENT | SEQUENCE} clause, so each of these functions can return either an XML content or an XML sequence. This is a direct consequence of the decision in SQL/XML:2006 to upgrade the publishing functions from use of the XML Infoset to the XQuery Data Model.
15.3 XML Data Type
SQL/XML:2003 introduced the notion of a native SQL data type for XML, called “XML.” Values of type XML are XML values. With the XML type in place, you need no longer restrict yourself to queries against SQL data – now you can manage and query XML data in a SQL database. While the publishing functions take in SQL data and output a serialized form of XML, the functions in the following sections can take in XML values as arguments, and output XML values as results.
SQL/XML:2006 extends the notion of an XML data type in two ways. First, SQL/XML:2006 adopts the XQuery Data Model rather than the XML Infoset,6 so that any XML value (an instance of the XML data type) is now an XQuery sequence, as defined in the XQuery Data Model. Second, SQL/XML:2006 defines three subtypes of XML, represented as modifiers to the XML type – XML(DOCUMENT), XML(CONTENT), and XML(SEQUENCE). In the subtype notations, “DOCUMENT” means the XML value is a well-formed XML document, “CONTENT” is an XML fragment (there may be multiple top-level elements or text nodes) wrapped in a document node, and “SEQUENCE” is any sequence of nodes and/or values.
Let’s look more closely at the definitions of these subtypes. For each XML value, there are two properties that may or may not hold. Below, we describe the properties and assign them shorthand names:
• The sequence may consist of a single Document node (Document node).
• If the sequence is a single Document node, it may have only the children that are valid for a Document node in a well-formed XML Document – exactly one element node plus zero or more comment nodes, Processing Instruction nodes, etc. (legal Document children).
Given these properties, we can say that:
• Every XML value is an XML(SEQUENCE).
• An XML(SEQUENCE) that is a Document node is an XML(CONTENT).
• An XML(SEQUENCE) that is a Document node (i.e., an XML(CONTENT)) that has legal Document children is an XML(DOCUMENT).
The SQL:2005 XML type forms the structure hierarchy illustrated in Figure 15-2. In the figure, the subtypes of XML are in rectangular boxes and the properties necessary to match the more restrictive types are in ovals. Note that, like all SQL data types, the value of an XML type may be null, and that a null XML value matches all the XML types.

The XML type may have a second modifier, one of UNTYPED, XMLSCHEMA (with some associated Schema information), or ANY.
• “UNTYPED” means there is no associated XML Schema (i.e., every element is of type “xdt:untypedAny” and every attribute is of type “xdt:untypedAtomic”).7
• “XMLSCHEMA” means there is an associated XML Schema.
• “ANY” means there may or may not be an XML Schema associated with this XML value.
This second (optional) modifier appears in parentheses after the first modifier so that, for example, an untyped document node has the type “XML(DOCUMENT(UNTYPED)).”
If the second modifier is “XMLSCHEMA,” there are two ways to identify the actual Schema instance. First, you can supply a SQL identifier for some registered Schema (some Schema instance that is “known” to the SQL environment). An example is:
![]()
This form is very SQL-like – “smith” is the SQL schema (owner), and “movies-schema” is a SQL identifier. The second form is more XML-like:
![]()
This is the type of a document with an XML Schema with the target namespace URI “http://example.com/movies/” and top-level element “movie.” The full syntax for the XML type is described in Grammar 15-1.

The observant reader will notice that everything after “XML” is optional. The spec leaves it up to the implementation to define the meaning of the type “XML” with no modifier, but says it must be XML(SEQUENCE), XML (CONTENT(ANY)), or XML(CONTENT(UNTYPED)).
15.4 XQuery Functions
The SQL/XML publishing functions described in Section 15.2 use XPath (and, in SQL/XML:2006, XQuery) to address parts of an XML value. In SQL/XML:2006, three additional functions are defined – XMLQUERY, XMLTABLE, and XMLEXISTS – which use XQuery. In this section, we describe each new function, with examples, then discuss some of the benefits of these new functions.
For these examples we introduce a new table, MOVIES_XML. Many people want to store XML in a database as a single document – i.e., many will store the movies data as a single XML document with top-level element movies, containing child elements movie. Others want to store each movie in a separate XML document (or file or cell). For the examples in this section, we have chosen the multiple-document approach (though we illustrate the single-document approach when querying a file in Example 15-11). The examples are a little more complex when dealing with multiple XML documents, so the single-document storage choice is a degenerate case of the multiple-document choice.8
Table 15-2 shows part of the MOVIES_XML table, which has two columns – ID, of type INTEGER, and MOVIE_XML, of type XML. Notice that, in this section, we are querying XML stored natively in the database. In Section 15.2, we were querying relational data and representing the output as XML.

15.4.1 XMLQUERY
XMLQUERY is a function that fits naturally in the SQL SELECT clause. It takes an XQuery string (i.e., an XQuery expression in a string), plus arguments for XQuery variables and the context item, and returns an XML value (an instance of the XML type). The syntax of XMLQUERY is summarized in Grammar 15-2.


Example 15-10 is a simple SQL query using XMLQUERY. The XQuery-expression is the string “for $m in $col/movie return $m/title “, and the data to be queried is the data in the column MOVIE, passed in to the variable named col. The keywords RETURNING CONTENT ensure that the result is serialized and returned BY VALUE to the SQL engine – BY REF or BY VALUE can only be specified with RETURNING SEQUENCE. This makes sense – the main advantage of using BY REF is that you can go “up the tree” (access the parent and ancestors) of the result. Since an XMLTYPE (CONTENT) is an XML value with a single root node, there is no parent. The SQL/XML implementation we used does not support RETURNING SEQUENCE (and hence does not support RETURNING BY REF). We expect this to be the case with most mainstream SQL/XML implementations.


Note that the query in Example 15-10 returns two results – one for each row in the table – and not a single XML value containing all the results. Note also that, given a suitable input function (such as fn:doc ( ) or fn:collection ( )) you can use XMLQUERY to query a file as well as a table, subject to the restrictions and security mechanisms in your SQL engine. For example, we could execute the same query in Example 15-10 against an XML file, as in Example 15-11.


Example 15-11 returns only a single result – instead of iterating over the column of a table, now we are just querying a single document that contains a movies element that wraps all the movie elements. Note that we could have queried over many documents using the fn:collection( ) function, just as we could have queried over a single XML document stored in a table cell in Example 15-10.
Example 15-11 really doesn’t interact with SQL in any useful way – it queries over a file, and does not use the result as part of a bigger SQL expression. The FROM clause uses FROM DUAL, where DUAL is a dummy, 1-row table available in every Oracle schema, for syntactic convenience. Some SQL implementations allow you to leave out the FROM clause altogether. In this case, XMLQUERY merely provides a convenient harness (a context) for running an XQuery. The real power of XMLQUERY is in its ability to query over data stored in the database and/or to use the result of an XQuery as part of some more complex SQL expression, as in Example 15-12.


In Example 15-12, we use XMLQUERY to find the running time of each movie, then we cast the result to decimal9 and plug the result into the SQL function AVG to get the average running time. While it is possible to do this kind of SQL processing with XMLQUERY, in general it’s easier with XMLTABLE (see Section 15.4.2). We expect the most common use for XMLQUERY to be querying XML stored in the database and producing XML as a result, possibly for input to XMLTABLE.



Example 15-13 shows an XMLQUERY query that:
• Queries across XML data stored in the database – movie data in the MOVIES_XML table.
• Restricts the query according to some value in the XML data – in this case, yearReleased.
• Concatenates the givenName and FamilyName of each producer to form a new element, prodFullName
• Returns an XML result for each row in the table – Example 15-13 uses element construction to return an XML result in a different form from the input.
15.4.2 XMLTABLE
XMLTABLE uses XQuery to query some XML, and returns the result in the same form as a SQL table. You might think of XMLTABLE as the “opposite” of the publishing functions, which allow you to query SQL tables and return the results as XML. In the examples in this section, we show queries that produce pseudo-tables. The pseudo-table can be used anywhere you would use a table name – in the FROM clause of a SELECT statement, for example. You could also create a real, persistent table whose contents are the same as the pseudo-table, by using CREATE TABLE mytable AS, or you could create a simple view.
As with XMLQUERY, we start with a syntax summary (Grammar 15-3) and a simple example (Example 15-14).


The first argument to XMLTABLE is a namespace-declaration, which lets you declare namespaces to be used in the evaluation of the function. XQuery-expression is a string containing an XQuery expression that expresses the contents of each row. In the rest of this chapter, we refer to this XQuery expression as the row pattern. The argument list is the same as for XMLQUERY, except that arguments in the list are always passed by reference. XMLtbl-column-definitions defines the name, type, and value of each column. In the rest of this chapter, we refer to the XMLtbl-column-definitions clause as the column definitions, and to the XQuery expression in the column definitions as the column pattern. The column definitions are optional – let’s see a simple example without them.


In Example 15-14,10 we use the same XQuery as in the simple XMLQUERY example at Example 15-10, but instead of using XMLQUERY in the SELECT clause, we use XMLTABLE in the FROM clause. The XQuery-expression string is the same, and we pass in the movie column of the MOVIES_XML table as before, except that we cannot rely on a following FROM clause to provide the source table – we are already in the FROM clause. Instead, we must qualify the column name with its table name – MOVIES_XML. MOVIE – and include the MOVlES_XML table in the FROM clause. The result is a SQL table with a single column of type XML(CONTENT), and one row for each member of the sequence returned by the XQuery-expression.11 The table is called result (we used an alias to provide the table name), and the column is called COLUMN_VALUE (our implementation provided this column name by default – yours may provide a different default, or insist that you explicitly name the column).
Let’s look at this in a bit more detail. For each row in the passed-in table (MOVIES_XML), XMLTABLE evaluates the row pattern (the XQuery-expression).12 The row pattern includes a variable, $col, whose value is passed in using the PASSING keyword. $col is an XML sequence, formed by casting the contents of the column movie in the table MOVIES_XML to XML(CONTENT) (see Section 15.6.3 for more on casting). This sequence is passed in by reference, so the row pattern is free to use reverse axes on the data passed in (to find its parent and ancestors).13 The result of evaluating an XQuery expression is always a sequence of items,14 in this example a sequence of two title elements. Each item in the sequence becomes a row in the resulting table. This example does not include any column definitions, so the output table has a single column whose name is COLUMN_VALUE (the default for our implementation) and whose type is XML(CONTENT) (also the default for our implementation). The output table is called result, since we aliased the result of XMLTABLE using “… AS result.” This allows us to ask for only the columns of result, in the SELECT clause (“SELECT result.* …”). If we use “SELECT * …,” the query returns the columns resulting from the join of MOVIES_XML with the table created by XMLTABLE (i.e., id, movie, and column_value), which is not what we want.
So far, we have achieved the same result as we achieved with XMLQUERY in Example 15-10. So why do we need both functions, XMLQUERY and XMLTABLE? XMLQUERY lets you query any XML and return XML, while XMLTABLE lets you query any XML and return a SQL table, which you can use as part of any SQL statement. Let’s build out our XMLTABLE example, and the difference will become clear.
First, let’s take a look at the column definitions. This lets you define columns for the table that XMLTABLE returns, rather than having it return a single column of type XML(CONTENT). For each column that you want to see in this output table, you specify the column name, the SQL data type of the column, and the XQuery expression that addresses the contents for the column (the column pattern). This XQuery expression has as its context the result of the row pattern (the XQuery expression that is the first [nonoptional] argument of XMLTABLE). You can also specify a default value, to be used in case the column would otherwise contain a NULL value, and a passing mechanism (BY REF or BY VALUE, where the default is BY VALUE). In addition, you can specify a column name followed by the keywords FOR ORDINALITY, which captures the document order of the results within each sequence passed to the row pattern (i.e., within each row passed in).
The alert reader will have noticed that there is an interesting interaction between the row pattern and the column pattern. The query writer can, in many cases, choose to do more of the path processing in the row pattern, leaving the column pattern very simple, or to do more of the path processing in the column pattern, over leaving the row pattern simpler. Also, note that the column pattern is an XPath (or XQuery) expression whose context is the result of the row pattern, and XQuery allows element construction in the return clause. So it’s quite reasonable for the row pattern to construct result elements, and “offer them up” to the column pattern (see Example 15-26).
We promised to build out the example – let’s do that now. Example 15-15 shows an XMLTABLE call that does include column definitions.


Instead of producing a table with a single column of type XML (CONTENT), in Example 15-15 XMLTABLE produces a table with three columns – the first is a column named title, of type VARCHAR (80), which contains the result of evaluating the XPath “title” in the context of the result of the row pattern. The column pattern can be any XQuery expression, but in most cases it will be an XPath expression, hence the keyword “PATH.”
Variations on Syntax – Column Definitions, PASSING, Examples
In this simple example (Example 15-15), the column name is exactly the same as the column pattern. In such cases, you can leave out the column pattern altogether and just specify the column name and type. In SQL, a column name can contain upper and lowercase characters and special characters such as “/,” as long as it is enclosed in double-quotes. So
![]()
is a valid column definition, resulting in a column called “director [1]/familyName.” Just remember that if you do define a column name that is not all-uppercase alphanumerics, then you must quote the column-name every time you use it. For example, in Example 15-15, if you want to select only the title column, you need to say
![]()
since, without the quotes around “title,” your SQL processor will look for a column named “TITLE.”15
Some people will find it natural and useful to end up with column names that look like XPath expressions, since the column name will say something about how the data was derived. For others, the column names will be too ugly to live with. You can change the column names by aliasing the columns along with the table, as in Example 15-16.



In Example 15-16, the column names in the columns definition double as paths, and then the column names are changed by aliasing them along with the table alias.
Before we leave our simple examples, we should mention that there is a variation on the way you pass in arguments to the row pattern. In our examples so far, we passed in a column as an XQuery variable. You can pass in a list of value expressions (a column is an example of a value expression) as variables, and you can pass in at most one value expression as the context16 of the row pattern – this value expression is specified on its own, without an “AS” keyword and variable name.
Personally, we prefer the column pattern syntax:
![]()
It seems more natural and straightforward. And we prefer passing in an argument as an XQuery variable, rather than as the context item – it makes it absolutely clear to the reader of the query where and how the column value is used in the row pattern. This is largely a matter of personal taste, but we will continue to use these syntax flavors in the examples in the rest of this chapter.
Dealing with Repeating Elements
One of the major differences between XML and SQL is that an XML element at any level may repeat any number of times. In SQL, a table is made up of rows where typically each cell (row/column intersection) contains only a single value. In the examples so far, we have chosen XML elements that do not repeat – title, runningTime, yearReleased – or, in the case of the producer in Example 15-16, we have used a positional predicate ([1]) so we only have to deal with the first element. There are a number of other ways to deal with repeating elements in SQL:
In the SQL representation of the movies data in Figure 15-1, we chose to store all the information about producers in a separate table (PRODUCERS). Then, instead of putting producer information directly into the MOVIE table, we created a table MOVIES_PRODUCERS that maps movies to their producers. This is part of the normalization17 process that many believe is important when designing SQL data stores.
One way of representing repeating XML elements is to denormalize the data – in our example, to insert the information for each producer into the row for each movie. Some consider this bad practice for a couple of reasons. First, it leads to duplication of data – the information for any particular producer appears in many rows in the new table. This may take more disk space and, more importantly, there is no longer a single place to read or update information about a particular producer, so the information may become inconsistent. Second, there may be “holes” in the data. In Example 15-4, we choose to represent producers in three columns in the result table. If some movie has fewer than three producers, there will be an empty cell in the table – a “hole.” Despite these arguments against denormalizing SQL data, in some cases it will be the simplest and/or best performing way to represent the data.18


In Example 15-17, we represent the repeating XML element producer in three separate columns in the result table. Then we use the XPath in the column pattern to select the familyName of each producer in turn. Finally, we introduce the DEFAULT clause to define a default value for “holes” in the data – in this case, if there is no second or third producer, then that cell will contain the string “none.19
2. Use XML for repeating elements.
One of the beauties of SQL/XML is that it allows you to “mix’n’match” SQL and XML data. In some cases, the most appropriate way to store repeating XML elements is as XML data right in the table. In Example 15-18, we do just that. Since the result of the column pattern is coerced to the type of the column, and XML is now a SQL type, the result column can be of type XML20 and the column pattern can return XML.



We have discussed two ways to represent repeating XML elements as denormalized SQL data. Now let’s consider some normalized forms of the same data. One common SQL technique for storing repeating data is to move that data into a separate table, where the data can repeat as multiple rows (rather than multiple columns, as in Example 15-17). This table is known as a detail table. A single row in the master table – in our example, MOVIES – is mapped to multiple rows in the detail table via some key that is unique in the master table. The key is generally some number, made up specifically to be the ID of some record (row) in the master table. For the MOVIES table, we’ll just use the title. So a single movie (row in the master table, MOVIES) maps to multiple producers (rows in the detail table) via the title (a column in both tables, which is unique in the master table but not in the detail table). This is known as a master-detail relationship, and the key is a primary key in the master table and a foreign key in the detail table.
Example 15-19 produces a detail table for producers, using two calls to XMLTABLE. Just as we can pass in values from the MOVIES_XML table to the first call to XMLTABLE, so we can also pass in values from the result table of the first XMLTABLE call to a second XMLTABLE call. In Example 15-19:
• MOVIES_XML contains the XML data for each movie.
• RESULT (the name we gave to the table that is output from the first XMLTABLE call by aliasing it with “AS result”) has one row per movie. Each row has a title column and a producers column.
• RESULT2 (the name we gave to the table that is output from the second XMLTABLE call) has one row per producer. Each row has a familyName column and an ord column. This example introduces the ordinality column definition. At most one of the column definitions may be a column name followed by the keywords “FOR ORDINALITY.” This column is populated with the ordinality of the result. Remember, XMLTABLE outputs a row for each member of the sequence that is the result of the row pattern. Each member of the sequence has an ordinality – a number that designates its order in the sequence. Using this ordinality column, we can keep track of the order in which producers were represented in the original XML.
• In the SELECT clause, we select the title (the foreign key) and all the columns from RESULT2 (familyName and ord).
The output of this SQL query is a producers SQL table – to use the detail table in some other query, simply use this query to create a view.



We have talked about the SQL/XML contribution to the SQL standard, but it’s important to note that the rest of the SQL standard has progressed significantly since SQL-92. The SQL:2003 standard introduced a number of ways of modeling data that is not naturally “table-shaped,” notably ARRAYS, nested tables, and objects. It would be natural to model a repeating element as an ARRAY (and a complex element as a nested table). Unfortunately, XMLTABLE does not allow an ARRAY or nested table in the result table – SQL/XML only allows casting of XML to SQL predefined types, and ARRAY and nested table are constructed types. Is this a severe limitation? Not really – the SQL ARRAY is useful when you want to iterate over a repeating element. But you can iterate over XML using XMLTABLE (as in Example 15-19), so we don’t need to be able to represent result columns as ARRAY.
Dealing with Complex Elements
In the preceding sections, we showed a number of ways of dealing with XML elements that repeat – something that is common (“natural”) in XML, but has to be dealt with in a special way in SQL. Complex elements also fall into this category – in XML it is common for an element such as producers to contain subelements (or child elements) such as familyName and givenName (and for those child elements to contain child elements that contain child elements, and so on). Let’s look at how we might represent complex elements in SQL using XMLTABLE. We use the producers element again – it is complex as well as repeating.
When looking at repeating elements, our first example (Example 15-17) showed a denormalized table. We could use the same technique to deal with producer as a complex element. This is not useful in the general case (where there are likely to be many levels of child elements) but we show an example of this simple case (with just one level of child elements) in Example 15-20, for completeness.


In our second “repeating elements” example, we used XML to represent the repeating elements (Example 15-18). This example also shows producer as a complex element – i.e., pulling producers into a column of type XML will solve both “repeating elements” and “complex elements” problems.
That brings us to the SQL storage layout in Figure 15-1. That’s the SQL storage we came up with to best represent the MOVIES_XML data as (normalized) SQL data. We showed in Section 15.2 that we can use the SQL/XML publishing functions to represent that SQL data as XML. Now, can we go the other way? Can we write a SQL query with XMLTABLE to represent our XML data as the SQL data in Figure 15-1? The answer, of course, is yes. In this section, we show how to produce (a representation of) the producer data as SQL data; we leave it as an exercise for the reader to produce the others.
The producer element is both repeating and complex. In Figure 15-1, we chose to put all the producer-related data into a table called PRODUCERS, with some unique key. Then we defined a table MOVIES_PRODUCERS that mapped movies to producers. The PRODUCERS table allows us to model a complex element – each child element is a column in the PRODUCERS table. We now have a hierarchy of depth three (movie, producer, familyName) and, by extension, the hierarchy could be of any depth. If there were only one producer per movie, we could put the producer_id in the movies table (as we did with director_id). Since producer is repeating as well as complex, we introduce the MOVIES_PRODUCERS table to map movies to producers. This allows us to represent any number of producers per movie.
Example 15-21 almost gives us a usable PRODUCERS table.



Example 15-21 uses XMLTABLE to pull the child elements of producer into columns, it uses the SQL DISTINCT keyword to make sure we only get each producer once (we could have used the XQuery function distinct-values inside the XQuery), and it uses a FOR ORDINALITY column to produce a key value for the ID column. If our XML table stored just a single movies XML document, Example 15-21 would work just fine. Since we chose to store our movies in separate XML documents (separate table rows), one per movie, the ordinality numbering restarts for each row (each movie) – the ID column does not hold a unique key! There are a number of ways around this. We chose to use a combination of the ID value in the MOVIES table and the ORDINALITY column in the XMLTABLE result table. Note that we need to multiply the MOVIES. ID by some number (the maximum number of producers we ever expect to see in one movie – we chose 10) to avoid collisions. This satisfies all the requirements for the PRODUCERS. ID column – it must be a unique number, and it must be derivable from the data (so that we can use it in the MOVlES_PRODUCERS table). Of course, it doesn’t matter what the actual values are.

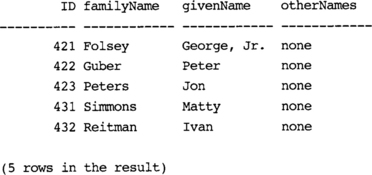
Example 15-22 gives us a usable PRODUCERS table. We assume that the order of producers in the XML document is important (perhaps the first producer mentioned in the document is the primary producer), and we retain this ordering information by using “result. “ord”” as part of the ID, and ordering by ID.
Now we need a MOVIES_PRODUCERS table that maps the MOVIES. ID to the PRODUCERS. ID that we just created. We produce MOVLES_PRODUCERS simply by adding MOVIES_XML.ID to the select list of Example 15-22 and removing the producers information, see Example 15-23.


Representing XML as SQL Data
In the preceding sections, we have shown how to represent the movies XML documents as SQL data. This is tremendously useful for two reasons. First, it frees the data administrator from the pressure of having to decide how to store data. If the data is born as XML, he now has the freedom to leave the data as XML and process it as XML, or to convert the data to SQL and physically store it relationally (but still publish it as XML), or to create a set of SQL views that make the XML data look like SQL. There are good reasons for choosing each of these options – the important point here is, SQL/XML makes all those options available.
Second, you can now apply all the power of SQL21 to your XML data, without necessarily shredding the data and storing it in tables. SQL has evolved far beyond a simple query language that can find and extract items that meet certain criteria. There are many applications of advanced SQL functionality in fields such as Business Intelligence and Data Mining.
Let’s look at one small illustration of the power of SQL, the analytic functions rollup and cube. Analytic functions22 are generally used to analyze vast amounts of data, so our tiny movies_xml table won’t do. For these examples, we use a slightly larger table, movies_xml_big. Let’s suppose you want to know how the running time of movies varies with the director and the year released. You could write a set of queries, each showing one aspect of the data. Or you could use rollup, as illustrated in Example 15-24. This query shows the average running time of all movies directed by each director in each year – e.g., the average running time for movies directed by Besson in 1997 was 126 minutes. This average is then rolled up to show the average running time for all movies in each year – e.g., in 1997 the average running time for all movies (all directors) was 123 minutes. And finally, the average running time is rolled up to the whole sample – the average running time for all movies in the sample (all directors, all years) is 116.7 minutes.



Using the rollup function, you can quickly get a feel for the trends in your data. The cube function takes this one step further, showing more “slices” on the data. For example, the results in Example 15-25 show not only averages rolled up by director and year, but also average running times for each director across all years. Our sample data (movies) is not ideally suited to this kind of example – it’s difficult to imagine anyone wanting to do this kind of in-depth analysis on running times in movies. But we hope you can imagine the power of this kind of analysis on more structured data, perhaps some data that you deal with.
The rollup and cube functions are widely used to show trends and spot anomalies in data such as sales by product over time, or soil contamination by region over time. The same data could, of course, be gleaned from a set of queries, each one showing some aspect of the data, but a single query is much easier to use, manipulate, and optimize.


Using XMLTABLE
The examples of XMLTABLE in this section have been quite simple. This is deliberate – we wanted to illustrate a number of points with the simplest possible queries. But it would be wrong to end this section without presenting one not-so-simple query. XMLTABLE is a part of the SQL standard, so not only can we combine the features of XMLTABLE in arbitrarily complex ways, but we can combine XMLTABLE with other SQL features. Also, the row pattern can be any arbitrarily complex XQuery expression – it’s not limited to the simple XQuery expressions used in the examples thus far.


Some notes on Example 15-26:
• This query joins two data sources, the MOVIES_XML table and a new table, REVIEWS_XML, containing reviews and a star rating. We do the join in the row pattern XQuery by passing in two data sources, in this case two XML type columns. We could have made two separate calls to XMLTABLE, and joined the results in SQL (outside of XMLTABLE).
• The let clause in the row pattern identifies the elements we are interested in.
• The where clause in the row pattern applies the join criterion, i.e., it says we are joining the two data sources via the common item “title.” It also restricts the reviews to movie reviews (we don’t want to consider book reviews with the same title), and it excludes reviews with the word “awful” in them (these unnecessarily harsh reviews might bias our sample).
• Note that the contains in the where clause is doing a strict substring search and not a full text search. For more on full text search, see Chapter 13, “What’s Missing?”
• The row pattern includes an order by clause. Note that the order in which the results are displayed is controlled by the SQL statement – the order by clause in the row pattern only affects the order within each row. If the XML were stored in a single movies document, the order by in the row pattern would affect the result, but could still be overridden by a SQL order by clause.
• The return clause uses element construction to create elements that are pulled out by the column patterns. In this way, you can use an arbitrarily complex XQuery expression – including a complete FLWOR expression – to express each cell in the result table. In this example, the row pattern returns a single element called output, with a child element containing the value to be used in each of the column patterns. In the general case, the row pattern returns a sequence (not a document). The column pattern is evaluated with its context set to each member of the sequence in turn, and the results merged to form a new sequence. In Example 15-26, the sequence has only one member – the element called output. Why is this distinction (between sequence and document) important? Since the context of the column pattern is the output element, the column pattern for, e.g., title is “./t,” or simply “t” for short. If the row pattern returned a document, then the context of the column pattern would have been the document node, and the path would have been “output/t.”
• Finally, the SQL query groups the results by title and, for each title, reports the average rating and the number of ratings considered.
15.4.3 XMLEXISTS
XMLEXISTS23 is the last XQuery function in SQL/XML that we discuss in this section. While XMLQUERY fits naturally into the SELECT clause of a SQL query, and XMLTABLE fits naturally into the FROM clause, XMLEXISTS sits comfortably in the WHERE clause. XMLEXISTS is defined as part of the definition of XMLTABLE, and is surfaced as a callable function in the SQL/XML standard. (By contrast, XMLIterate is also defined as part of the definition of XMLTABLE, but it is not exposed as a callable function – it exists solely to support the definition of XMLTABLE.)
XMLEXISTS has just about the same syntax as XMLQUERY. It returns false if the result of the XQuery expression is the empty sequence, otherwise it returns true.
In our movies sample data, some of the movies have a studio element telling us which studio produced the movie, others do not. Example 15-27 finds the ID of the movies that do have a studio element (there are none in our small test table).

The XQuery expression in Example 15-27 is a simple XPath, but it could be any XQuery expression. In Example 15-28, the XPath includes a simple contains predicate (again, this is the substring contains, not a full text contains).


XMLEXISTS does not add new functionality – i.e., any query written with XMLEXISTS could be written with XMLQUERY and/or XMLTABLE. The XMLTABLE justifies the inclusion of XMLEXISTS in the standard by comparing it to the SQL predicate EXISTS, which could similarly be displaced by COUNT. The additional convenience that comes with XMLEXISTS, as with EXISTS, justifies its inclusion as part of the standard.
A Note on Proprietary Extensions
Many vendors have released proprietary extensions to SQL to achieve the same goals as the SQL/XML functions – the ability to publish SQL data to XML, and to query XML data using SQL. Often, this is simply a matter of timing – a vendor’s customers ask for some functionality, and it must be released in a product before the standard is finished (or, in some cases, before the standardization effort has begun). We have already mentioned Microsoft’s SQLXML, a proprietary extension with roughly the same functionality as the SQL/XML publishing functions. Oracle also has proprietary extensions in this area, including functions to extract data from inside an XML value using XPath (extract, extractValue), a function to test for node existence using XPath (existsNode), and an XML native type (XMLTYPE), as well as the standard functions XMLQUERY, XMLTABLE, and the publishing functions. Oracle’s proprietary functions map quite well to the functions that are emerging in the standard (this is, of course, by design and not by accident). Over time, we expect Oracle and other vendors to (re)implement this functionality using the standard’s syntax.
15.5 Managing XML in the Database
The XML native SQL type allows us to store XML in a SQL database. Since it is a native type, data of type XML can be inserted, updated, and deleted in a SQL statement just like a date or an integer. This is necessary, but not sufficient for many users. Values of most data types can only reasonably be managed as a whole – you would not try to insert, update, or delete a part of an integer, for example. While you might want to insert/update/delete a part of a string or a LOB (Large OBject), in general it’s acceptable to insert a whole string, or to replace a whole string with a slightly-modified copy. With XML, this approach is cumbersome for the user and inefficient for the database engine.
In Example 15-27, you saw that some of the movies in our sample data include a studio element, but not all. Suppose you just found out that one of the movies – An American Werewolf in London – was released by Universal Studios. Using SQL with the functions we have already described (XMLQUERY and XMLTABLE), you could find the entry for An American Werewolf in London, pull out the XML data, do something with it to add the studio information, then update the movie column in MOVIES_XML with the new version. But SQL/XML does not help you with that “do something with it” in the middle, and neither does XQuery – they do not provide any way for you to express “add an element called studio, as a child of movie, immediately after runningTime, and give it the value ‘Universal Studios’.” You would need to use some other tool, perhaps a Java application that built and modified a DOM. Having to do this makes the operation very cumbersome for the user.
What about efficiency? Pulling out all the data about one movie, and then replacing it all using a SQL update statement, is inefficient. It would be much worse if all the movies were stored in a single movies document – you could be updating many megabytes of data, plus any associated indexes, just to add one tiny string.
What we need is the ability to express a piecewise insert, update, or delete of the XML as part of the SQL statement. This would be simple and intuitive for the user, and could be efficiently implemented by the database engine. At the time of writing, efforts are under way within the W3C XML Query Working Group (which has spawned an Update Task Force) to produce the language for piecewise updates of XML. See Chapter 13, “What’s Missing?” for more details.
15.6 Talking the Same Language – Mappings
So far in this chapter we have talked about publishing SQL data to XML, and querying XML data in SQL to produce either SQL data (XMLTABLE) or XML data (XMLQUERY) or a Boolean result (XMLEXISTS). We have assumed that the two languages – SQL and XQuery/XPath – have the same context, or at least that there is an obvious mapping from the SQL context to the XQuery/XPath context and vice versa. In fact, these mappings are neither obvious nor trivial, and a great deal of the early work of the SQLX group involved defining these mappings. In this section we look a bit more closely at the way character sets, names, data types, and values are mapped.
15.6.1 Character Sets
SQL data can be stored and managed in a database using one or more named character sets. For example, you might choose to store data in US7ASCII plus ISO-8859-1. XML data, on the other hand, is Unicode – the W3C XML specification24 says that “All XML processors MUST accept the UTF-8 and UTF-16 encodings of Unicode 3.1.” To address this possible inconsistency between character sets (the most basic building blocks of language and data exchange), the SQL/XML standard insists that any SQL/XML implementation provides a mapping from strings of each character set supported in its database to strings in Unicode, and vice versa.
15.6.2 Names
When using SQL/XML, we need to be able to map SQL identifiers to XML Names. The simplest example is where we map a SQL column name to an XML element name, e.g., in XMLATTRIBUTES and XMLFOREST. Many people who use SQL use only uppercase alphabetic characters and numbers in their identifiers but, as we saw in some of the XMLTABLE examples, a SQL identifier can contain almost any character if you enclose the identifier in double-quotes. We were careful to double-quote the column names in some of our examples in this chapter, so they would be read by the SQL engine as lowercase identifiers and not converted to uppercase. We also saw that a SQL identifier can look like an XPath expression – “producer [1] /familyName” – as long as you double-quote it.
How do you map an arbitrary SQL identifier to an XML name, which can only contain letters, digits, hyphens, underscores, colons, or full stops?25 First you map the SQL identifier characters to Unicode. Then, for each character, apply the following rules:
• If it is a valid XML Name character, leave it unchanged.26
• If it is not a valid XML Name character, convert it to a hexadecimal number (derived from its Unicode encoding), consisting of either four or six uppercase hexadecimal digits. Add a prefix of “_x” (underscore-x) and a suffix of “_” (underscore) to this number.
This set of rules comprises the partially escaped mapping.27 SQL/XML also defines a fully escaped mapping – in addition to the rules in the partially escaped mapping, apply these rules:
• Map all colons in the SQL identifier to “_x003A_” (not just a leading colon).
• If the SQL identifier begins with “XML,” in any combination of cases, then prefix the XML Name with “_xFFFF_.”
So, for example, the SQL identifier “title” maps to the XML Name “title,” while the SQL identifier “Running Time” maps to the XML Name “Running_x0020_Time.”
SQL/XML also defines the rules to map from an XML Name to a SQL identifier – essentially, apply the rules above in reverse. When you map a SQL identifier to an XML Name and back, you are guaranteed to get the same SQL identifier (i.e., the operation is fully reversible). When you start with an XML Name and map to a SQL identifier, the operation is not fully reversible (in the case where the XML Name contains a sequence of characters that looks like an escape sequence, e.g., “_x003A_”).
15.6.3 Types and Values
For any meaningful exchange of data between two languages (in this case, SQL and XQuery/XPath), there must be a bidirectional mapping between the typed values of those languages. If this were not the case, then a string, say, passed from SQL to XQuery would not have a clearly defined value in XQuery. SQL/XML defines a mapping from each of SQL’s scalar data types to an XML Schema data type, possibly with facets and annotations. This type mapping determines the mapping of SQL values to typed XML values. In the other direction, SQL/XML defines a mapping from XQuery atomic types to SQL types, and hence a mapping from XML typed atomic values to SQL values.
Mapping SQL Data Types to XML Schema Data Types
SQL/XML defines a mapping from each of SQL’s scalar data types to its closest analog in the XML Schema data types. In general, the XML Schema data type will be less restrictive than the SQL data type, so XML Schema facets are used to further restrict the type. Where there are distinctions between SQL data types that have no corresponding distinctions in XML Schema, SQL/XML defines XML Schema annotations in the sqlxml namespace. The following mappings are defined, with an optional annotation to indicate the exact SQL type.
• The SQL character string types are mapped to xs:string, with either the facet xs:length (for SQL type fixed-length CHARACTER in which the character set mapping from SQL character set to Unicode is homomorphic), or the facet xs:maxLength (for CHARACTER VARYING and CHARACTER LARGE OBJECT, as well as CHARACTER where the character set mapping is not homomorphic). There are optional annotations to show the character set and default collation.
• The SQL binary string type (BLOB) is mapped to xs:hexBinary or xs:base64Binary, with the facet xs:maxLength to indicate the maximum length in octets.
• The SQL exact numeric types NUMERIC and DECIMAL are mapped to xs:decimal, with the facets xs:totalDigits and xs:fractionDigits. INTEGER, SMALLINT, and BIGINT are mapped to either xs:integer, with the facets xs:maxInclusive and xs:minInclusive, or to a subtype of xs:integer, possibly with the facets xs:maxInclusive and xs:minInclusive. There are optional annotations to show the precision (NUMERIC), user-specified precision (DECIMAL), and scale (NUMERIC and DECIMAL).
• The SQL approximate numeric types REAL, DOUBLE PRECISION, and FLOAT are mapped to either xs:float (if the binary precision is less than or equal to 24 binary digits and the range of the binary exponent lies between -149 and 104), or xs:double. There are optional annotations to show the binary precision, the minimum and maximum values of the range of binary exponents, and the user-specified binary precision (FLOAT).
• The SQL type BOOLEAN is mapped to xs:boolean.
• The SQL type DATE is mapped to xs:date, with the xs:pattern facet.
• The SQL TIME types are mapped to xs:dateTime and xs:time, with the xs:pattern facet.
• The SQL interval types are mapped to xdt:yearMonthDuration and xdt:day-TimeDuration, with the xs:pattern facet.
Mapping XML Schema Atomic Values to SQL Values
The rules for mapping XML Schema values with atomic data types to SQL values are approximately the reverse of the rules in the previous section:
• A value with XML Schema type xs:string28 maps to a Unicode string.
• A value with XML Schema types xs:hexBinary and xs:base64Binary map to a binary string.
• A value with XML Schema type xs:decimal maps to an exact numeric value.
• A value with XML Schema type xs:float or xs:double maps to an approximate numeric value.
• A value with XML Schema type xs:time maps to a value of SQL type TIME.
• A value with XML Schema type xs:dateTime maps to a value of SQL type TIMESTAMP.
• A value with XML Schema type xs:date maps to a value of SQL type DATE.
• A value with XML Schema type xs:boolean maps to a value of SQL type BOOLEAN.
The Casting Functions – XMLSERIALIZE, XMLPARSE, XMLCAST
SQL/XML:2003 includes two functions to cast an XML value to a SQL character string and vice versa. XMLSERIALIZE takes an XML value and serializes it to some SQL character string type, while XMLPARSE takes some SQL character string type and converts it to an XML value.
Example 15-29 shows how to convert movies from the MOVIES_XML table, of type XML, to CLOB (Character Large OBject) type.29 The first keyword inside the parentheses may be “DOCUMENT” (an XML document) or ”CONTENT“ (and XML forest, or fragment).


Example 15-30 shows the reverse – converting from a string value to an XML type, in this case to insert into a column of type XML.

SQL/XML:2006 introduces a more general-purpose function for casting between XML values and any SQL type (actually, any SQL predefined type). XMLCAST takes two arguments, an operand and a target type. Either the operand’s type or the target type must be XML, so XMLCAST will convert both to and from XML. Both the operand and the target type may be XML, so XMLCAST can also be used to cast from one flavor of the XML type to another. You have already seen an example of XMLCAST – Example 15-12 casts the result of a call to XMLQUERY to a decimal, so it can be fed into the SQL function AVG.
Mapping SQL Tables, Schemas, Catalogs to XML
In addition to defining mappings for data types and atomic values, SQL/XML defines a structure mapping, from a SQL table or schema or catalog to an XML document. The idea is that you should be able to take any SQL table and represent it as XML in a standard way. That involves not just mapping the values of the individual cells to XML atomic values, but also mapping the structure of that table to an XML Schema.
Let’s take as an example the MOVIES table in Figure 15-1. The SQL/XML table mapping would produce a root element whose name is the name of the table (“MOVIES”), with a child element called “row” representing each row in the table. The row element in turn has a child element representing each column in the table, as in Figure 15-4.

Somewhat mysteriously, though SQL/XML spells out exactly how to produce an XML document and an XML Schema from any SQL table, it stops short of defining a table function to actually implement this mapping, i.e., a SQL/XML function to produce an XML document from a SQL table. At the time of writing, such a function is under discussion in both the XQuery and the SQL/XML Working Groups. (One vendor, Oracle, already has a proprietary extension, ora : view, to produce an XML document from a SQL table.)
Once you know how to map a SQL table to an XML document, you can easily map a schema or collection, by wrapping a sequence of table elements with a schema or collection element.
15.7 Chapter Summary
We have covered a lot of ground in this chapter, but we have only scratched the surface of SQL/XML. First, we described the SQL/XML publishing functions, which let you query SQL data using the SQL query language and publish the results as XML. Then we discussed the XML type, which allows you to store XML as SQL data in a native SQL data type. The SQL/XML:2006 XQuery functions (XMLQUERY, XMLTABLE, and XMLEXISTS) were then described in some detail, especially XMLTABLE. XMLQUERY lets you query any XML, including XML stored in SQL’s XML data type, using the XQuery language, and produces results in XML. XMLTABLE, on the other hand, queries XML and produces results as a SQL table. This opens up your XML data to the full power of SQL – we illustrated this with some examples of the OLAP rollup and cube functions applied to our XML sample data. We talked briefly about managing XML in a SQL database, then described mappings between SQL and XML character sets, names, types, and values. This description included the XML-to-string function XMLSERIALIZE and the string-to-XML function XMLPARSE, and the more general-purpose XML-to-SQL/SQL-to-XML/XML-to-XML casting function, XMLCast.
SQL/XML is still a relatively new part of the SQL standard, but we believe it provides a powerful basis for storing, managing, and querying XML data, leveraging both the power and robustness of SQL and the XML-centric capabilities of XPath and XQuery. If this chapter has whetted your appetite – and we hope it has – we suggest the following follow-up reading:
• ISO/IEC FCD 9075-14, Information Technology – Database Languages – SQL – Part 14: XML-Related Specifications, (SQL/XML). Available from your country’s standards body; in the United States, that body is ANSI (http://www.ansi.org).
• Andrew Eisenberg and Jim Melton, SQL/XML and the SQLX Informal Group of Companies, ACM SIGMOD Record, Vol. 30 No. 3, September 2001. Available at: http://www.acm.org/sigmod/record/issues/0109/standards.pdf.
• Andrew Eisenberg and Jim Melton, SQL/XML Is Making Good Progress, ACM SIGMOD Record, Vol. 31, No. 2, June 2002. Available at: http://www.acm.org/sigmod/record/issues/0206/standard.pdf.
• Andrew Eisenberg and Jim Melton, Advancements in SQL/XML, ACM SIGMOD Record, Vol. 33, No. 3, September 2004. Available at: http://www.sigmod.org/sigmod/record/issues/0409/11.JimMelton.pdf.
• Stephen Buxton, Querying XML – XQuery, SQL/XML, and SQL in Context, XML 2004 Conference. Available at: http://www.idealliance.org/proceedings/xml04/abstracts/paper218.html.
2http://mscn.microsoft.com/sqlxml/.
3At the time of writing, SQL Server 2000 is Microsoft’s latest database offering, and it includes SQLXML. We look forward to seeing the soon-to-be-released SQL Server 2005 database, which is expected to include some XQuery support – see http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnsql90/html/sql2k5_xqueryintro.asp.
4For example, in an effort to make the examples conform to the most recent version of the SQL/XML spec available at the time of writing, we have added the mandatory “(NULL | EMPTY) ON EMPTY” clause to the XMLQUERY examples. This is a recent addition to the spec and is not supported in the Oracle implementation we used for testing.
5For a worked example, see SQL in, XML out, Jonathan Gennick, Oracle Magazine 2003. Available at: http://www.oracle.com/technology/oramag/oracle/03-may/o33xml.html.
6See Chapter 6, “The XML Information Set (Infoset) and Beyond,” and Chapter 10, “Introduction to XQuery 1.0.”
7“xdt” is the namespace prefix used for XPath (XQuery) data types. This namespace prefix is predeclared in XQuery, and is used elsewhere by convention.
8This is a matter of some debate in the XML world. Taking the single-document approach to the extreme, all the world’s data could be represented in a single XML document, with a top-level element <everything>. We’ve thought about this approach and have concluded that it may cause performance problems.
9See Section 15.6.3 for a description of XMLCAST. Note that not all implementations will return a zero suppressed result.
10The observant reader will notice this example doesn’t quite match the syntax in Grammar 11-5. The standard says the COLUMNS clause is mandatory, while in our test implementation it’s optional.
11In this example, the result has one row for each row that was passed in, but this is coincidental (it’s because each movie happens to have only one title).
12Since the XMLTABLE call includes a column from the xml_movies table, this is a left correlated join.
13In the general case – passing in a column, as in this first XMLTABLE example – this is moot, since the column data has no parent.
14Where an item is either a node or a value.
15In SQL, all nondelimited identifiers are implicitly uppercased.
16See Chapter 9, “XPath 1.0 and XPath 2.0,” Chapter 10, “Introduction to XQuery 1.0,” and Chapter 11, “XQuery 1.0 Definition,” for a description of context.
17For a full description of normalization, see one of the classic texts on relational database systems, such as: An Introduction to Database Systems, eighth edition, C. J. Date (Boston: Addison-Wesley, 2003).
18Note that XML data is, by its nature, highly denormalized, with all the disadvantages this brings. On the other hand, XML is very good at representing data with lots of holes (sparse data).
19In Example 15-19, we are pivoting the data.
20The SQL/XML:2006 standard keyword for the XML type is “XML,” and not “XMLTYPE.” In our test implementation, “XMLTYPE” is used instead of “XML” (more precisely, it is used instead of “XML(CONTENT)”). The examples in this chapter will work in an Oracle SQL/XML context – if they don’t work for you, try substituting “XML” or “XML(CONTENT)” for “XMLTYPE.”
21Some say that SQL is a dinosaur – well, maybe it is, but the dinosaurs were tremendously powerful creatures that evolved over more than 165 million years until they were perfectly suited to their environment. Similarly, SQL has evolved over several decades into a hugely powerful language. By comparison, XQuery is still in its infancy – still swimming in the ocean, you might say.
22Also known as OLAP (online analytic processing) functions.
23Our test implementation does not currently support XMLEXISTS. Instead, Oracle supports a similar function, existsNode(), as a proprietary extension.
24See Extensible Markup Language (XML) 1.0, third edition, Section 2.2 (Cambridge, MA: World Wide Web Consortium, 2004). Available at: http://w3.org/TR/2004/REC-xml-20040204/#charsets.
25The W3C XML 1.0 Recommendation defines a Name thusly: “A Name is a token beginning with a letter or one of a few punctuation characters, and continuing with letters, digits, hyphens, underscores, colons, or full stops, together known as name characters. Names beginning with the string “xml”, or with any string which would match ((‘x’ | ‘x’) (’M‘ | ‘m’) (’L’ | ‘1’)), are reserved for standardization in this or future versions of this specification.”
26There is an exception to this rule. “_” (underscore) is a valid character in a SQL identifier and in an XML Name. But what if the SQL identifier contains a sequence of characters that looks just like an escape sequence, e.g., “_x003A_”? Applying the mappings rules, this would be mapped to “_x003A_” in the XML Name. Then if you wanted to reverse the mapping (map the XML Name back into a SQL identifier), “_x003A_” would be mapped to a “:” (colon). To address this problem, there is an extra rule that says that an underscore character that is immediately followed by an “x” is escaped (mapped to “_x005F_”), so that the SQL identifier mapping to XML Name is fully reversible.
27At the time of writing, there is a proposal to eliminate the partially escaped mapping from SQL/XML:2006 and to keep only the fully escaped mapping.
28“xs” is the namespace prefix used for XML Schema data types. This namespace prefix is predeclared in XQuery, and is used elsewhere by convention.
29A cautionary note: when storing XML data in a CLOB, you need to be aware that CLOB data is stored in the character set of the database (as opposed to a Binary LOB, which stores data in raw form). Most databases will attempt to do character set conversion on data inserted into a CLOB. Depending on your database and the way it is installed and configured, Unicode text may fail to insert correctly.