
RTP Sessions
The RTP Data Transfer Packet
Packet Validation
Translators and Mixers
This chapter explains the RTP data transfer protocol, the means by which real-time media is exchanged. The discussion focuses on the “on-the-wire” aspects of RTP—that is, the packet formats and requirements for interoperability; the design of a system using RTP is explained in later chapters.
A session consists of a group of participants who are communicating using RTP. A participant may be active in multiple RTP sessions—for instance, one session for exchanging audio data and another session for exchanging video data. For each participant, the session is identified by a network address and port pair to which data should be sent, and a port pair on which data is received. The send and receive ports may be the same. Each port pair comprises two adjacent ports: an even-numbered port for RTP data packets, and the next higher (odd-numbered) port for RTCP control packets. The default port pair is 5004 and 5005 for UDP/IP, but many applications dynamically allocate ports during session setup and ignore the default. RTP sessions are designed to transport a single type of media; in a multimedia communication, each media type should be carried in a separate RTP session.
A session can be unicast, either directly between two participants (a point-to-point session) or to a central server that redistributes the data. Or it can be multicast to a group of participants. A session also need not be restricted to a single transport address space. For example, RTP translators can be used to bridge a session between unicast and multicast, or between IP and another transport, such as IPv6 or ATM. Translators are discussed in more detail later in this chapter, in the section titled Translators and Mixers. Some examples of session topologies are shown in Figure 4.1.
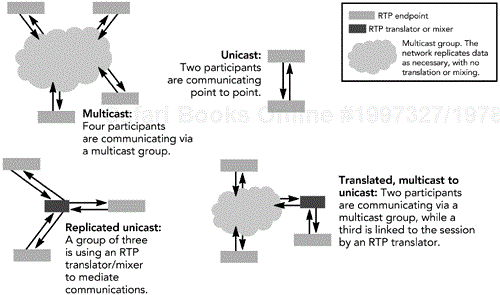
The range of possible sessions means that an RTP end system should be written to be essentially agnostic about the underlying transport. It is good design to restrict knowledge of the transport address and ports to your low-level networking code only, and to use RTP-level mechanisms for participant identification. RTP provides a “synchronization source” for this purpose, described in more detail later in this chapter.
In particular, note these tips:
You should not use a transport address as a participant identifier because the data may have passed through a translator or mixer that may hide the original source address. Instead, use the synchronization source identifiers.
You should not assume that a session has only two participants, even if it is using unicast. The other end of the unicast connection may be an RTP translator or mixer acting as a gateway for a potentially unlimited number of other participants.
A good design makes the actual means of communication all but invisible to the participants.
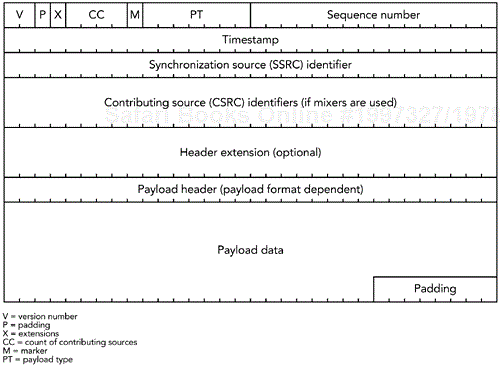
The format of an RTP data transfer packet is illustrated in Figure 4.2. There are four parts to the packet:
The mandatory RTP header
An optional header extension
An optional payload header (depending on the payload format used)
The payload data itself
The entire RTP packet is contained within a lower-layer payload, typically UDP/IP.
The mandatory RTP data packet header is typically 12 octets in length, although it may contain a contributing source list, which can expand the length by 4 to 60 additional octets. The fields in the mandatory header are the payload type, sequence number, time-stamp, and synchronization source identifier. In addition, there is a count of contributing sources, a marker for interesting events, support for padding and a header extension, and a version number.
The payload type, or PT, field of the RTP header identifies the media transported by an RTP packet. The receiving application examines the payload type to determine how to treat the data—for example, passing it to a particular decompressor. The exact interpretation of the payload field is defined by an RTP profile, which binds the payload type numbers to payload format specifications, or by a non-RTP means.
Many applications operate under the RTP profile for audio and video conferences with minimal control (RFC 1890).7 This profile (commonly called the audio/video profile) defines a table of default mappings between the payload type number and payload format specifications. Examples of these static assignments are shown in Table 4.1 (this is not a complete list; the profile defines additional assignments). In addition to the static assignments, out-of-band signaling—for example, using SIP, RTSP, SAP, or H.323—may be used to define the mapping. Payload types in the range 96 to 127 are reserved for dynamic assignment in this manner when the audio/video profile is being used; other profiles may specify different ranges.
Payload formats are named in terms of the MIME namespace. This namespace was originally defined for e-mail, to identify the content of attachments, but it has since become a general namespace for media formats and is used in many applications. The use of MIME types with RTP is relatively new—payload type names originally occupied a separate namespace—but it is a powerful feature, providing a central repository of transport and encoding options for each type of media.
Table 4.1. Examples of Static Payload Type Assignments
Payload Type Number | Payload Format | Specification | Description |
|---|---|---|---|
0 | AUDIO/PCMU | RFC 1890 | ITU G.711 µ-law audio |
3 | AUDIO/GSM | RFC 1890 | GSM full-rate audio |
8 | AUDIO/PCMA | RFC 1890 | ITU G.711 A-law audio |
12 | AUDIO/QCELP | RFC 2658 | PureVoice QCELP audio |
14 | AUDIO/MPA | RFC 2250 | MPEG audio (e.g., MP3) |
26 | VIDEO/JPEG | RFC 2435 | Motion JPEG video |
31 | VIDEO/H261 | RFC 2032 | ITU H.261 video |
32 | VIDEO/MPV | RFC 2250 | MPEG I/II video |
All payload formats should now have a MIME type registration. Newer payload formats include it in their specification; a group registration for the older ones is in progress.51 The complete list of MIME types is maintained online at http://www.iana.org/assignments/media-types.
Whether the payload type assignment is static or dynamic, it is necessary to describe the session to the application so that the application knows which payload types are to be used. A common means of describing sessions is the Session Description Protocol (SDP).15 A sample session description might be as follows:
v=0 o=bloggs 2890844526 2890842807 IN IP4 10.45.1.82 s=- [email protected](Joe Bloggs) c=IN IP4 224.2.17.12/127 t=2873397496 2873404696 m=audio 49170 RTP/AVP 0 m=video 51372 RTP/AVP 98 a=rtpmap:98 H263-1998/90000
Of interest in our discussion of RTP are the c= and m= lines, which communicate addresses and ports for the RTP session and define the profile and payload types in use, and the a=rtpmap: line, which makes a dynamic payload type assignment.
The example describes two RTP sessions: Audio is being sent to the IPv4 multicast group 224.2.17.12 on port 49170 with time-to-live 127, and video is being sent to the same multicast group on port 51372. Both audio and video use RTP/AVP as their transport; this is RTP transport using the RTP profile for audio and video conferences with minimal control.7
The payload type used for audio is 0. This is a static assignment in the profile, the payload format for AUDIO/PCMU. The payload type for video is 98, which is mapped to the payload format for VIDEO/H263-1998 by the a=rtpmap: line. By referencing the table of MIME type assignments, we find that the definition of VIDEO/H263-1998 is in RFC 2429.22
Although SDP is a common solution for describing RTP sessions, nothing in RTP requires SDP to be used. For example, applications based on ITU recommendation H.323 use RTP for their media transport but use a different mechanism (H.245) for describing sessions.
The choice of payload format has various other implications: It defines the rate of the RTP media clock, and the format of any payload header and the payload itself. For static assignments, the clock rate is specified in the profile; dynamic assignments must indicate the clock rate along with the mapping between payload type and payload format. For example, in the previous session description the a=rtpmap: line specifies a 90,000-Hz clock for the VIDEO/H263-1998 payload format. Most payload formats operate with a limited set of clock rates, with the payload format specification defining which rates are valid.
An RTP session is not required to use only a single payload format; multiple payload formats can be used within a session, with the different formats being identified by different payload types. The format can change at any time within a session, and as long as the mapping from payload type to payload format has been communicated in advance, there is no requirement for signaling before the change occurs. An example might be encoding of DTMF tones within a voice-over-IP session, to support the “Press 0 to speak to an operator” style of automated service, in which one format is used for speech and another for the tones.
Even though multiple payload formats may be used within a session, the payload type is not intended to be used to multiplex different classes of media. For example, if both audio and video are being sent by an application, they should be sent as two different RTP sessions, on different addresses/ports, rather than being sent as a single RTP session and demultiplexed by the payload type. This separation of media allows applications to request different network quality of service for the different media, and it is also required for correct operation of the RTP control protocol.
The RTP sequence number is used to identify packets, and to provide an indication to the receiver if packets are being lost or delivered out of order. It is not used to schedule playout of the packets—that is the purpose of the timestamp—although it does allow the receiver to reconstruct the order in which packets were sent.
The sequence number is an unsigned 16-bit integer, which increases by one with each data packet sent and wraps around to zero when the maximum value is reached. An important consequence of the 16-bit space is that sequence number wrap-around happens relatively often: A typical voice-over-IP application sending audio in 20-millisecond packets will wrap the sequence number approximately every 20 minutes.
This means that applications should not rely on sequence numbers as unique packet identifiers. Instead, it is recommended that they use an extended sequence number, 32 bits or wider, to identify packets internally, with the lower 16 bits being the sequence number from the RTP packet and the upper 16 being a count of the number of times the sequence number has wrapped around:
extended_seq_num = seq_num + (65536 * wrap_around_count)
Because of possible packet loss or reordering, maintaining the wrap-around counter (wrap-around-count) is not a simple matter of incrementing a counter when the sequence number wraps to zero. The RTP specification has an algorithm for maintaining the wrap-around counter:
uint16_t udelta = seq – max_seq
if (udelta < max_dropout) {
if (seq < max_seq) {
wrap_around_count++
}
max_seq = seq;
} else if (udelta <= 65535 – max_misorder) {
// The sequence number made a very large jump
if (seq == bad_seq) {
// Two sequential packets received; assume the
// other side has restarted without telling us
...
} else {
bad_seq = seq + 1;
}
} else {
// Duplicate or misordered packet
...
}
Note that all calculations are done with modulo arithmetic and 16-bit unsigned quantities. Both seq and max_seq are the unextended sequence numbers from the RTP packets. The RTP specification recommends that max_misorder = 100 and max_dropout = 3000.
If the extended sequence number is calculated immediately on reception of a packet and used thereafter, most of the application can be made unaware of sequence number wrap-around. The ability to hide the wrap-around greatly simplifies loss detection and concealment, packet reordering, and maintenance of statistics. Unless the packet rate is very high, the wrap-around time for a 32-bit sequence number is such that most applications can ignore the possibility. For example, the voice-over-IP example given earlier will take over two years to wrap around the extended sequence number.
If the packet rate is very high, a 32-bit extended sequence number may wrap around while the application is running. When designing applications for such environments, you must either use a larger extended sequence number (for example, 64 bits) to avoid the problem, or build the application to handle wrap-around by performing all calculations on sequence numbers using 32-bit modulo arithmetic. Incorrect operation during wrap-around of the sequence number is a common problem, especially when packets are lost or reordered around the time of wrap-around.
The initial value of the sequence number should be chosen randomly, rather than starting from zero. This precaution is intended to make known plain-text attacks on an encrypted RTP stream more difficult. Use of a random initial sequence number is important even if the source does not encrypt, because the stream may pass through an encrypting translator that is not known to the source, and adding the random offset in the translator is not trivial (because sequence numbers are reported in RTCP reception report packets; see Chapter 5, RTP Control Protocol). A common implementation problem is to assume that the sequence numbers start from zero; receivers should be able to play out a stream irrespective of the initial sequence number (this capability is also needed to handle late joins).
The sequence number should always follow a continuous sequence, increasing by one for each packet sent, and never jumping forward or backward (except for wrap-around, of course). This requirement should apply across changes in payload format regardless of how the media is generated. For example, when you're splicing together video clips—perhaps to insert advertisements—the RTP sequence number space must be continuous, and it must not be reset at the start of each clip. This has implications for the design of streaming media servers because they cannot rely on sequence numbers stored with a media file and must generate sequence numbers on the fly.
The primary use of the sequence number is loss detection. A gap in the sequence number space indicates to the receiver that it must take action to recover or conceal the missing data. This is discussed in more detail in Chapters 8, Error Concealment, and 9, Error Correction.
A secondary use of the sequence number is to allow reconstruction of the order in which packets were sent. A receiver does not necessarily care about this—because many payload formats allow for decoding of packets in any order—but sorting the packets into order as they are received may make loss detection easier. The design of playout buffer algorithms is discussed in more detail in Chapter 6, Media Capture, Playout, and Timing.
The RTP timestamp denotes the sampling instant for the first octet of media data in a packet, and it is used to schedule playout of the media data. The timestamp is a 32-bit unsigned integer that increases at a media-dependent rate and wraps around to zero when the maximum value is exceeded. With typical video codecs, a clock rate of 90kHz is used, corresponding to a wrap-around of approximately 13 hours; with 8kHz audio the interval is approximately 6 days.
The initial value of the timestamp is randomly chosen, rather than starting from zero. As with the sequence number, this precaution is intended to make known plain-text attacks on an encrypted RTP stream more difficult. Use of a random initial timestamp is important even if the source does not encrypt, because the stream may pass through an encrypting translator that is not known to the source. A common implementation problem is to assume that the timestamp starts from zero. Receivers should be able to play out a stream irrespective of the initial timestamp and be prepared to handle wrap-around; because the timestamp does not start at zero, a wrap-around could occur at any time.
Timestamp wrap-around is a normal part of RTP operation and should be handled by all applications. The use of extended timestamps, perhaps 64-bit values, can make most of the application unaware of the wrap-around. Extended timestamps are not recommended, though, because 64-bit arithmetic is often inefficient on today's processors.
A better design performs all timestamp calculations using 32-bit modulo arithmetic. This approach allows differences between timestamps to be calculated, provided that the packets compared are within half the timestamp space of each other.
The timestamp is derived from a media clock that must increase in a linear and monotonic fashion (except for wrap-around, of course), producing a single timeline for each RTP session. This is true irrespective of the means by which the media stream is generated.
An example is useful to clarify the implications of the way in which the timestamp increases: When audio clips are spliced together within a single RTP session, the RTP timestamps must form a continuous sequence and must not be reset at the start of each clip. These requirements are illustrated in Figure 4.3, which shows that an RTP receiver cannot tell from the RTP headers that a change has occurred.
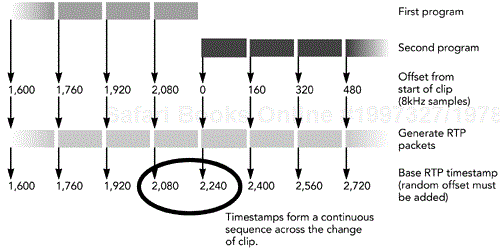
Figure 4.3. Formation of a Continuous Timestamp Sequence across Two Clips That Have Been Spliced Together
The same is true when a fast-forward or rewind operation occurs: The timestamps must form a continuous sequence and not jump around. This requirement is evident in the design of the Real-Time Streaming Protocol (RTSP),14 which includes the concept of “normal play time” representing the time index into the stream. Because the continuity of RTP timestamps must be maintained, an RTSP server has to send an updated mapping between RTP timestamps and the normal play time during a seek operation.
The continuity of RTP timestamps has implications for the design of streaming media servers. The servers cannot rely on timestamps (or sequence numbers) stored with a media file but must generate them on the fly, taking into account seek operations within the media and the duration of any previous data that has been played out within the RTP session.
The requirement for a media clock that increases in a linear and monotonic fashion does not necessarily imply that the order in which media data is sampled is the order in which it is sent. After media frames have been generated—and hence have obtained their timestamps—they may be reordered before packetization. As a result, packets may be transmitted out of timestamp order, even though the sequence number order is maintained. The receiver has to reconstruct the timestamp order to play out the media.
An example is MPEG video, which contains both key frames and delta-encoded frames predicted from them forward (P-frames) and backward (B-frames). When B-frames are used, they are predicted from a later packet and hence must be delayed and sent out of order. The result is that the RTP stream will have non-monotonically increasing timestamps.12 Another example is the use of interleaving to reduce the effects of burst loss (see the section titled Interleaving in Chapter 8, Error Concealment). In all cases, a single timeline, which the receiver must reconstruct to play out the media, is retained.
Timestamps on RTP packets are not necessarily unique within each wrap-around cycle. If two packets contain data from the same sampling instant, they will have the same timestamp. Duplication of timestamps typically occurs when a large video frame is split into multiple RTP packets for transmission (the packets will have different sequence numbers but the same timestamp).
The nominal rate of the media clock used to generate timestamps is defined by the profile and/or payload format in use. For payload formats with static payload type assignments, the clock rate is implicit when the static payload type is used (it is specified as part of the payload type assignment). The dynamic assignment process must specify the rate along with the payload type (see the section titled Payload Type earlier in this chapter). The chosen rate must be sufficient to perform lip synchronization with the desired accuracy, and to measure variation in network transit time. The clock rate may not be chosen arbitrarily; most payload formats define one or more acceptable rates.
Audio payload formats typically use the sampling rate as their media clock, so the clock increases by one for each full sample read. There are two exceptions: MPEG audio uses a 90kHz clock for compatibility with non-RTP MPEG transport; and G.722, a 16kHz speech codec, uses an 8kHz media clock for backward compatibility with RFC 1890, which mistakenly specified 8kHz instead of 16kHz.
Video payload formats typically use a 90kHz clock, for compatibility with MPEG and because doing so yields integer timestamp increments for the typical 24Hz, 25Hz, 29.97Hz, and 30Hz frame rates and the 50Hz, 59.94Hz, and 60Hz field rates in widespread use today. Examples include PAL (Phase Alternating Line) and NTSC (National Television Standards Committee) television, plus HDTV (High-Definition Television) formats.
It is important to remember that RTP makes no guarantee as to the resolution, accuracy, or stability of the media clock—those properties are considered application dependent, and outside the scope of RTP—and in general, all that is known is its nominal rate. Applications should be able to cope with variability in the media clock, both at the sender and at the receiver, unless they have specific knowledge to the contrary.
The process by which a receiver reconstructs the correct timing of a media stream based on the timestamps is described in Chapter 6, Media Capture, Playout, and Timing.
The synchronization source (SSRC) identifies participants within an RTP session. It is an ephemeral, per-session identifier that is mapped to a long-lived canonical name, CNAME, through the RTP control protocol (see the section titled RTCP SDES: Source Description, in Chapter 5, RTP Control Protocol).
The SSRC is a 32-bit integer, chosen randomly by participants when they join the session. Having chosen an SSRC identifier, the participant uses it in the packets it sends out. Because SSRC values are chosen locally, two participants can select the same value. Such collisions may be detected when one application receives a packet from another that contains the SSRC identifier chosen for itself.
If a participant detects a collision between the SSRC it is using and that chosen by another participant, it must send an RTCP BYE for the original SSRC (see the section titled RTCP BYE: Membership Control, in Chapter 5, RTP Control Protocol) and select another SSRC for itself. This collision detection mechanism ensures that the SSRC is unique for each participant within a session.
It is important that a high-quality source of randomness is used to generate the SSRC, and that collision detection is implemented. In particular, the seed for the random number generator should not be based on the time at which the session is joined or on the transport addresses of the session, because collisions can result if multiple participants join at once.
All packets with the same SSRC form part of a single timing and sequence number space, so a receiver must group packets by SSRC for playback. If a participant generates multiple streams in one RTP session—for example, from separate video cameras—each must be identified as a different SSRC so that the receivers can distinguish which packets belong to each stream.
Under normal circumstances, RTP data is generated by a single source, but when multiple RTP streams pass through a mixer or translator, multiple data sources may have contributed to an RTP data packet. The list of contributing sources (CSRCs) identifies participants who have contributed to an RTP packet but were not responsible for its timing and synchronization. Each contributing source identifier is a 32-bit integer, corresponding to the SSRC of the participant who contributed to this packet. The length of the CSRC list is indicated by the CC field in the RTP header.
Packets containing a CSRC list are produced by the operation of an RTP mixer, as described later in this chapter, in the section titled Mixers. When receiving a packet containing a CSRC list, the SSRC is used to group packets for playout in the usual manner, and each CSRC is added to the list of known participants. Each participant identified by a CSRC will have a corresponding stream of RTP control protocol packets, providing fuller identification of the participant.

The marker (M) bit in the RTP header is used to mark events of interest within a media stream; its precise meaning is defined by the RTP profile and media type in use.
For audio streams operating under the RTP profile for audio and video conferences with minimal control, the marker bit is set to one to indicate the first packet sent after a period of silence, and otherwise set to zero. A marker bit set to one serves as a hint to the application that this may be a good time to adjust its playout point, because a small variation in the length of a silence period is not usually noticeable to listeners (whereas a change in the playout point while audio is being played is audible).
For video streams operating under the RTP profile for audio and video conferences with minimal control, the marker bit is set to one to indicate the last packet of a video frame, and otherwise set to zero. If set to one, the marker serves as a hint that the application can begin decoding the frame, rather than waiting for the following packet—which will have a different timestamp—to detect that the frame should be displayed.
In all cases, the marker bit provides only a hint to the application, which should be designed to operate even if packets with the marker set are lost. For audio streams, it is usually possible to intuit the end of a silent period because the relationship between sequence number and timestamp changes. The start of a video frame can be detected by a change in the timestamp. An application can use these observations to operate with reduced performance if the packets containing the marker bit are lost.
It is possible for an RTP profile to specify that additional marker bits exist, at the expense of a smaller payload type field. For example, a profile could mandate two marker bits and a six-bit payload type. No current profiles use this feature.

The padding (P) bit in the RTP header is used to indicate that the payload has been padded out past its natural length. If padding is added to an RTP packet, the P bit is set and the last octet of the payload is filled with a count of the number of padding octets. Padding is rarely used, but it is needed for some encryption schemes that work with particular block sizes, and to adapt a payload format to a fixed-capacity channel.
As an example of the use of padding, Figure 4.4 shows a GSM audio frame packetized in RTP that has been padded out to 48 octets from its natural length of 45 octets (33 for the GSM frame, 12 for the RTP header). This padding might be needed if the packet were encrypted with the Data Encryption Standard (DES),56 which requires 8-octet (64-bit) blocks.


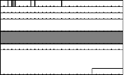
RTP allows for the possibility that extension headers, signaled by the X bit being set to one, are present after the fixed RTP header, but before any payload header and the payload itself. The extension headers are of variable length, but they start with a 16-bit type field followed by a 16-bit length field (which counts the length of the extension in octets, excluding the initial 32 bits), allowing the extension to be ignored by receivers that do not understand it.
Extension headers provide for experiments that require more header information than that provided by the fixed RTP header. They are rarely used; extensions that require additional, payload format–independent header information are best written as a new RTP profile. If additional headers are required for a particular payload format, they should not use a header extension and instead should be carried in the payload section of the packet as a payload header.
Although header extensions are extremely rare, robust implementations should be prepared to process packets containing an unrecognized header extension by ignoring the extension.
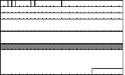
The mandatory RTP header provides information that is common to all payload formats. In many cases a payload format will need more information for optimal operation; this information forms an additional header that is defined as part of the payload format specification. The payload header is included in an RTP packet following the fixed header and any CSRC list and header extension. Often the definition of the payload header constitutes the majority of a payload format specification.
The information contained in a payload header can be either static—the same for every session using a particular payload format—or dynamic. The payload format specification will indicate which parts of the payload header are static and which are dynamic, and it must be configured on a per-session basis. Those parts that are dynamic are usually configured through SDP,15 with the a=fmtp: attribute used to define “format parameters,” although other means are sometimes used. The parameters that can be specified fall into three categories:
Those that affect the format of the payload header, signaling the presence or absence of header fields, their size, and their format. For example, some payload formats have several modes of operation, which may require different header fields for their use.
Those that do not affect the format of the payload header but do define the use of various header fields. For example, some payload formats define the use of interleaving and require header fields to indicate the position within the interleaving sequence.
Those that affect the payload format in lieu of a payload header. For example, parameters may specify the frame size for audio codecs, or the video frame rate.
Features of the payload format that do not change during a session usually are signaled out of band, rather than being included in the payload header. This reduces overheads during the session, at the expense of additional signaling complexity. The syntax and use of format parameters are usually specified as part of the payload format specification.
The primary reason for specifying payload headers is to provide error resilience for those formats that were not designed for use over lossy packet networks. The first example of this was the payload format for H.261 video, as discussed in RFC 2032 and RFC 2736.9,33 More recent examples are the more loss-tolerant payload formats for MP3 and AMR (Adaptive Multi-Rate) audio.38,41 The issue of error resilience is discussed further in Chapters 8, Error Concealment, and 9, Error Correction.
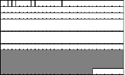
One or more frames of media payload data, directly following any payload header, make up the final part of an RTP packet (other than padding, if needed). The size and format of the payload data depend on the payload format and format parameters chosen during session setup.
Many payload formats allow for multiple frames of data to be included in each packet. There are two ways in which a receiver can determine how many frames are present:
In many cases frames are of a fixed size, and it is possible to determine the number present by inspecting the size of the packet.
Other payload formats include an identifier in each encapsulated frame that indicates the size of the frame. An application needs to parse the encapsulated frames to determine the number of frames and their start points. This is usually the case when the frames can be variable sizes.
Usually no limit on the number of frames that may be included is specified. Receivers are expected to handle reception of packets with a range of sizes: The guidelines in the audio/video profile suggest up to 200 milliseconds worth of audio, in multiples of the frame size, and video codecs should handle both fragmented and complete frames.
There are two key issues to consider when you're choosing the amount of payload data to include in each packet: the maximum transmission unit (MTU) of the network path that will be traversed, and the latency induced by waiting for more data to be produced to fill a longer packet.
Packets that exceed the MTU will be either fragmented or dropped. It is clearly undesirable if oversize packets are dropped; less obvious are the problems due to fragmentation. A fragmented packet will be reassembled at the receiver, provided that all fragments arrive. If any fragment is lost, the entire packet must be discarded even though some parts of it were correctly received. The result is a loss multiplier effect, which can be avoided if the packets are sized appropriately, and if the payload format is designed such that each packet can be independently decoded (as discussed in relation to payload headers).
Latency is another concern because a packet cannot be sent until the last octet of data it will contain is produced. The data at the start of the packet is delayed until the complete packet is ready. In many applications, the latency concern provides a tighter constraint on the application than the MTU does.
Because RTP sessions typically use a dynamically negotiated port pair, it is especially important to validate that packets received really are RTP, and not misdirected other data. At first glance, confirming this fact is nontrivial because RTP packets do not contain an explicit protocol identifier; however, by observing the progression of header fields over several packets, we can quickly obtain strong confidence in the validity of an RTP stream.
Possible validity checks that can be performed on a stream of RTP packets are outlined in Appendix A of the RTP specification. There are two types of tests:
Per-packet checking,. based on fixed known values of the header fields. For example, packets in which the version number is not equal to 2 are invalid, as are those with an unexpected payload type.
Per-flow checking,. based on patterns in the header fields. For example, if the SSRC is constant, and the sequence number increments by one with each packet received, and the timestamp intervals are appropriate for the payload type, this is almost certainly an RTP flow and not a misdirected stream.
The per-flow checks are more likely to detect invalid packets, but they require additional state to be kept in the receiver. This state is required for a valid source, but care must be taken because holding too much state to detect invalid sources can lead to a denial-of-service attack, in which a malicious source floods a receiver with a stream of bogus packets designed to use up resources.
A robust implementation will employ strong per-packet validity checks to weed out as many invalid packets as possible before committing resources to the per-flow checks to catch the others. It should also be prepared to aggressively discard state for sources that appear to be bogus, to mitigate the effects of denial-of-service attacks.
It is also possible to validate the contents of an RTP data stream against the corresponding RTCP control packets. To do this, the application discards RTP packets until an RTCP source description packet with the same SSRC is received. This is a very strong validity check, but it can result in significant validation delay, particularly in large sessions (because the RTCP reporting interval can be many seconds). For this reason we recommend that applications validate the RTP data stream directly, using RTCP as confirmation rather than the primary means of validation.
In addition to normal end systems, RTP supports middle boxes that can operate on a media stream within a session. Two classes of middle boxes are defined: translators and mixers.
A translator is an intermediate system that operates on RTP data while maintaining the synchronization source and timeline of a stream. Examples include systems that convert between media-encoding formats without mixing, that bridge between different transport protocols, that add or remove encryption, or that filter media streams. A translator is invisible to the RTP end systems unless those systems have prior knowledge of the untranslated media. There are a few classes of translators:
Bridges. Bridges are one-to-one translators that don't change the media encoding—for example, gateways between different transport protocols, like RTP/UDP/IP and RTP/ATM, or RTP/UDP/IPv4 and RTP/UDP/IPv6. Bridges make up the simplest class of translator, and typically they cause no changes to the RTP or RTCP data.
Transcoders. Transcoders are one-to-one translators that change the media encoding—for example, decoding the compressed data and reencoding it with a different payload format—to better suit the characteristics of the output network. The payload type usually changes, as may the padding, but other RTP header fields generally remain unchanged. These translations require state to be maintained so that the RTCP sender reports can be adjusted to match, because they contain counts of source bit rate.
Exploders. Exploders are one-to-many translators, which take in a single packet and produce multiple packets. For example, they receive a stream in which multiple frames of codec output are included within each RTP packet, and they produce output with a single frame per packet. The generated packets have the same SSRC, but the other RTP header fields may have to be changed, depending on the translation. These translations require maintenance of bidirectional state: The translator must adjust both outgoing RTCP sender reports and returning receiver reports to match.
Mergers. Mergers are many-to-one translators, combining multiple packets into one. This is the inverse of the previous category, and the same issues apply.
The defining characteristic of a translator is that each input stream produces a single output stream, with the same SSRC. The translator itself is not a participant in the RTP session—it does not have an SSRC and does not generate RTCP itself—and is invisible to the other participants.
A mixer is an intermediate system that receives RTP packets from a group of sources and combines them into a single output, possibly changing the encoding, before forwarding the result. Examples include the networked equivalent of an audio mixing deck, or a video picture-in-picture device.
Because the timing of the input streams generally will not be synchronized, the mixer will have to make its own adjustments to synchronize the media before combining them, and hence it becomes the synchronization source of the output media stream. A mixer may use playout buffers for each arriving media stream to help maintain the timing relationships between streams. A mixer has its own SSRC, which is inserted into the data packets it generates. The SSRC identifiers from the input data packets are copied into the CSRC list of the output packet.
A mixer has a unique view of the session: It sees all sources as synchronization sources, whereas the other participants see some synchronization sources and some contributing sources. In Figure 4.5, for example, participant X receives data from three synchronization sources—Y, Z, and M—with A and B contributing sources in the mixed packets coming from M. Participant A sees B and M as synchronization sources with X, Y, and Z contributing to M. The mixer generates RTCP sender and receiver reports separately for each half of the session, and it does not forward them between the two halves. It forwards RTCP source description and BYE packets so that all participants can be identified (RTCP is discussed in Chapter 5, RTP Control Protocol).
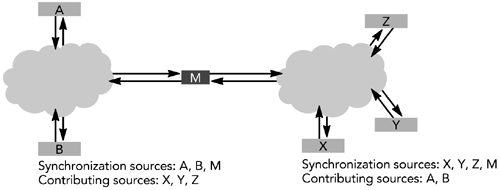
Figure 4.5. Mixer M Sees All Sources as Synchronization Sources; Other Participants (A, B, X, Y, and Z) See a Combination of Synchronization and Contributing Sources.
A mixer is not required to use the same SSRC for each half of the session, but it must send RTCP source description and BYE packets into both sessions for all SSRC identifiers it uses. Otherwise, participants in one half will not know that the SSRC is in use in the other half, and they may collide with it.
It is important to track which sources are present on each side of the translator or mixer, to detect when incorrect configuration has produced a loop (for example, if two translators or mixers are connected in parallel, forwarding packets in a circle). A translator or mixer should cease operation if a loop is detected, logging as much diagnostic information about the cause as possible. The source IP address of the looped packets is most helpful because it identifies the host that caused the loop.
This chapter has described the on-the-wire aspects of the RTP data transfer protocol in some detail. We considered the format of the RTP header and its use, including the payload type for identification of the format of the data, sequence number to detect loss, timestamp to show when to play out data, and synchronization source as a participant identifier. We also discussed the minor header fields: marker, padding, and version number.
The concept of the payload format, and its mapping onto payload type identifier and payload header, should now be apparent, showing how RTP is tailored to different types of media. This is an important topic, to which we will return in later chapters.
Finally, we discussed RTP translators and mixers: intermediate systems that extend the reach of RTP in a controlled manner, allowing sessions to bridge heterogeneity of the network.
Associated with the RTP data transfer protocol is a control channel, RTCP, which has been mentioned several times in this chapter. The next chapter focuses on this control channel in some depth, completing our discussion of the network aspects of RTP.