
Chapter 2
Modeling a System
IN THIS CHAPTER
![]() Picturing how to grab the data you want to grab
Picturing how to grab the data you want to grab
![]() Mapping your data retrieval strategy onto a relational model
Mapping your data retrieval strategy onto a relational model
![]() Using Entity-Relationship diagrams to visualize what you want
Using Entity-Relationship diagrams to visualize what you want
![]() Understanding the relational database hierarchy
Understanding the relational database hierarchy
SQL is the language that you use to create and operate on relational databases. Before you can do that database creation, however, you must first create a conceptual model of the system to be built. In order to have any hope of developing a database system that delivers the results, performance, and reliability that the users need, you must understand, in a highly detailed way, what those needs are. Your understanding of the users’ needs enables you to create a model of what they have in mind.
After perfecting the model through much dialog with the user, you need to translate the model into something that can be implemented with a relational database. This chapter takes you through the steps of taking what might be a vague and fuzzy idea in the minds of the users and transforming it into something that can be converted directly into a robust and high-performance database.
Capturing the Users’ Data Model
The whole purpose of a database is to hold useful data and enable one or more people to selectively retrieve and use the data they want. Generally, before a database project is begun, interested parties have some idea of what data they want to store, and what subsets of the data they are likely to want to retrieve. More often than not, people’s ideas of what should be included in the database and what they want to get out of it are not terribly precise. Nebulous as they may be, the concepts each interested party may have in mind comes from her own data models. When all those data models from various users are combined, they become one (huge) data model.
To have any hope of building a database system that meets the needs of the users, you must understand this collective data model. In the text that follows, I give you some tips for finding and querying the people who will use the database, prioritizing requested features, and getting support from stakeholders.
Beyond understanding the data model, you must help to clarify it so that it can become the basis for a useful database system. In the “Translating the Users’ Data Model to a Formal Entity-Relationship Model” section that follows this one, I tell you how to do that.
Identifying and interviewing stakeholders
The first step in discovering the users’ data model is to find out who the users are. Perhaps several people will interact directly with the system. They, of course, are very interested parties. So are their supervisors, and even higher management.
But identifying the database users goes beyond the people who actually sit in front of a PC and run your database application. A number of other people usually have a stake in the development effort. If the database is going to deal with customer or vendor information, the customers and vendors are probably stakeholders, too. The IT department — the folks responsible for keeping systems up and running — is also a major stakeholder. There may be others, such as owners or major stockholders in the company. All of these people are sure to have an image in their mind of what the system ought to be. You need to find these people, interview them, and find out how they envision the system, how they expect it to be maintained, and what they want it to produce.
If the functions to be performed by the new system are already being performed, by either a manual system or an obsolete computerized system, you can ask the users to explain how their current system works. You can then ask them what they like about the current system and what they don’t like. What is the motivation for moving to a new system? What desirable features are missing from what they have now? What annoying aspects of the current system are frustrating them? Try to gain as complete an understanding of the current situation as possible.
Reconciling conflicting requirements
Just as the set of stakeholders will be diverse, so will their ideas of what the system should be and do. If such ideas are not reconciled, you are sure to have a disaster on your hands. You run the risk of developing a system that is not satisfactory to anybody.
It is your responsibility as the database developer to develop a consensus. You are the only independent, outside party who does not have a personal stake in what the system is and does. As part of your responsibility, you’ll need to separate the stated requirements of the stakeholders into three categories, as follows:
- Mandatory: A feature that is absolutely essential falls into this category. The system would be of limited value without it.
- Significant: A feature that is important and that adds greatly to the value of the system belongs in this category.
- Optional: A feature that would be nice to have, but is not actually needed, falls into this category.
Once you have appropriately categorized the want lists of the stakeholders, you are in a position to determine what is really required, and what is possible within the allotted budget and development time. Now comes the fun part. You must convince all the stakeholders that their cherished features that fall into the third category (optional), must be deleted or changed if they conflict with someone else’s first-category or second-category feature. Of course, politics also intrudes here. Some stakeholders have more clout than others. You must be sensitive to this. Sometimes the politically acceptable solution is not exactly the same as the technically optimal solution.
Obtaining stakeholder buy-in
One way or another, you will have to convince all the stakeholders to agree on one set of features that will be included in the system you are planning to build. This is critical. If the system does not adequately meet the needs of all those for whom it is being built, it is not a success. You must get the agreement of everyone that the system you propose meets their needs. Get it in writing. Enumerate everything that will be provided in a formal Statement of Requirements, and then have every stakeholder sign off on it. This will potentially save you from much grief later on.
Translating the Users’ Data Model to a Formal Entity-Relationship Model
After you outline a coherent users’ data model in a clear, concise, concrete form, the real work begins. Somehow, you must transform that model into a relational model that serves as the basis for a database. In most cases, a users’ data model is not in a form that can be directly translated into a relational model. A helpful technique is to first translate it into one of several formal modeling systems that clarify the various entities in the users’ model and the relationships between them. Probably the most popular of those formal modeling techniques is the Entity-Relationship (ER) model. Although there are other formal modeling systems, I focus on the ER model because it is the most widespread and thus easily understood by most database professionals.
Graphing tools — Microsoft Visio, for example — make provision for drawing representations of an ER model. I guess I am old fashioned in that I prefer to draw them by hand on paper with a pencil. This gives me a little more flexibility in how I arrange the elements and how I represent them.
SQL is the international standard language for communicating with relational databases. Before you can fully appreciate SQL, you must understand the structure of well-designed relational databases. In order to design a relational database properly — in hopes that it will be reliable as well as giving the level of performance you need — you must have a good understanding of database structure. This is best achieved through database modeling, and the most widely used model is the Entity-Relationship model.
Entity-Relationship modeling techniques
In 1976, six years after Dr. Codd published the relational model, Dr. Peter Chen published a paper in the reputable journal ACM Transactions on Database Systems, introducing the Entity-Relationship (ER) model, which represented a conceptual breakthrough because it provided a means to translate a users’ data model into a relational model.
Back in 1976, the relational model was still nothing more than a theoretical construct. It would be three more years before the first standalone relational database product (Oracle) appeared on the market.
 The ER model was an important factor in turning theory into practice because one of the strengths of the ER model is its generality. ER models can represent a wide variety of different systems. For example, an ER model can represent a physical system as big and complex as a fleet of cruise ships, or as small as the collection of livestock maintained by a gentleman farmer on his two acres of land.
The ER model was an important factor in turning theory into practice because one of the strengths of the ER model is its generality. ER models can represent a wide variety of different systems. For example, an ER model can represent a physical system as big and complex as a fleet of cruise ships, or as small as the collection of livestock maintained by a gentleman farmer on his two acres of land.
Any Entity-Relationship model, big or small, consists of four major components: entities, attributes, identifiers, and relationships. I examine each one of these concepts in turn.
Entities
Dictionaries tell you that an entity is something that has a distinct, separate existence. It could be a material entity, such as the Great Pyramid of Giza, or an abstract entity, such as a tetrahedron. Just about any distinct, separate thing that you can think of qualifies as being an entity. When used in a database context, an entity is something that the user can identify and that she wants to keep track of.
A group of entities with common characteristics is called an entity class. Any one example of an entity class is an entity instance. A common example of an entity class for most organizations is the EMPLOYEE entity class. An example of an instance of that entity class is a particular employee, such as Duke Kahanamoku.
In the previous paragraph, I spell out EMPLOYEE with all caps. This is a convention that I will follow throughout this book so that you can readily identify entities in the ER model. I follow the same convention when I refer to the tables in the relational model that correspond to the entities in the ER model. Other sources of information on relational databases that you read may use all lowercase for entities, or an initial capital letter followed by lowercase letters. There is no standard. The database management systems that will be processing the SQL that is based on your models do not care about capitalization. Agreeing to a standard is meant to reduce confusion among the people dealing with the models and with the code generated based on those models — the models themselves don’t care.
Attributes
Entities are things that users can identify and want to keep track of. However, the users probably don’t want to use up valuable storage space keeping track of every conceivable aspect of an entity. Some aspects are of more interest than others. For example, in the EMPLOYEE model, you probably want to keep track of such things as first name, last name, and job title. You probably do not want to keep track of the employee’s favorite surfboard manufacturer or favorite musical group.
In database-speak, aspects of an entity are referred to as attributes. Figure 2-1 shows an example of an entity class — including the kinds of attributes you’d expect someone to highlight for this particular (EMPLOYEE) entity class. Figure 2-2 shows an example of an instance of the EMPLOYEE entity class. EmpID, FirstName, LastName, and so on are attributes.

FIGURE 2-1: EMPLOYEE, an example of an entity class.

FIGURE 2-2: Duke Kahanamoku, an example of an instance of the EMPLOYEE entity class.
Identifiers
In order to do anything meaningful with data, you must be able to distinguish one piece of data from another. That means each piece of data must have an identifying characteristic that is unique. In the context of a relational database, a “piece of data” is a row in a two-dimensional table. For example, if you were to construct an EMPLOYEE table using the handy EMPLOYEE entity class and attributes spelled out back in Figure 2-1, the row in the table describing Duke Kahanamoku would be the piece of data, and the EmpID attribute would be the identifier for that row. No other employee will have the same EmpID as the one that Duke has.
In this example, EmpID is not just an identifier — it is a unique identifier. There is one and only one EmpID that corresponds to Duke Kahanamoku. Nonunique identifiers are also possible. For example, a FirstName of Duke does not uniquely identify Duke Kahanamoku. There might be another employee named Duke — Duke Snyder, let’s say. Having an attribute such as EmpID is a good way to guarantee that you are getting the specific employee you want when you search the database.
Another way, however, is to use a composite identifier, which is a combination of several attributes that together are sufficient to uniquely identify a record. For example, the combination of FirstName and LastName would be sufficient to distinguish Duke Kahanamoku from Duke Snyder, but would not be enough to distinguish him from his father, who, let’s say, has the same name and is employed at the same company. In such a case, a composite identifier consisting of FirstName, LastName, and BirthDate would probably suffice.
Relationships
Any nontrivial relational database contains more than one table. When you have more than one table, the question arises as to how the tables relate to each other. A company might have an EMPLOYEE table, a CUSTOMER table, and a PRODUCT table. These become related when an employee sells a product to a customer. Such a sales transaction can be recorded in a TRANSACTION table. Thus the EMPLOYEE, CUSTOMER, and PRODUCT tables are related to each other via the TRANSACTION table. Relationships such as these are key to the way relational databases operate. Relationships can differ in the number of entities that they relate.
DEGREE-TWO RELATIONSHIPS
Degree-two relationships are ones that relate one entity directly to one other entity. EMPLOYEE is related to TRANSACTION by a degree-two relationship, also called a binary relationship. CUSTOMER is also related to TRANSACTION by a binary relationship, as is PRODUCT. Figure 2-3 shows a diagram of a degree-two relationship.
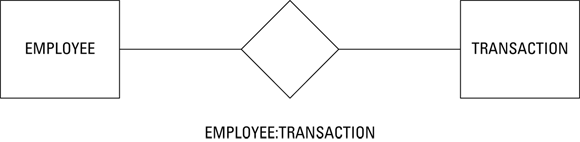
FIGURE 2-3: An EMPLOYEE: TRANSACTION relationship.
Degree-two relationships are the simplest possible relationships, and happily, just about any system that you are likely to want to model consists of entities connected by degree-two relationships, although more complex relationships are possible.
There are three kinds of binary (degree-two) relationships:
- One-to-one (1:1) relationship: Relates one instance of one entity class (a group of entities with common characteristics) to one instance of a second entity class.
- One-to-many (1:N) relationship: Relates one instance of one entity class to multiple instances of a second entity class.
- Many-to-many (N:M) relationship: Relates multiple instances of one entity class to multiple instances of a second entity class.
Figure 2-4 is a diagram of a one-to-one relationship between a person and that person’s driver’s license. A person can have one and only one driver’s license, and a driver’s license can apply to one and only one person. This database would contain a PERSON table and a LICENSE table (both are entity classes), and the Duke Snyder instance of the PERSON table has a one-to-one relationship with the OR31415927 instance of the LICENSE table.

FIGURE 2-4: A one-to-one relationship between PERSON and LICENSE.
Figure 2-5 is a diagram of a one-to-many relationship between the PERSON entity class and the traffic violation TICKET entity class. A person can be served with multiple tickets, but a ticket can apply to one and only one person.
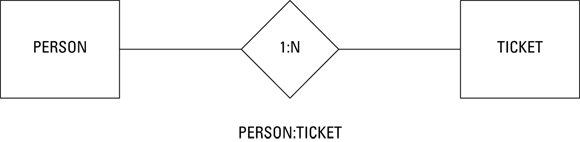
FIGURE 2-5: A one-to-many relationship between PERSON and TICKET.
When this part of the ER model is translated into database tables, there will be a row in the PERSON table for each person in the database. There could be zero, one, or multiple rows in the TICKET table corresponding to each person in the PERSON table.
Figure 2-6 is a diagram of a many-to-many relationship between the STUDENT entity class and the COURSE entity class, which holds the route a person takes on her drive to work. A person can take one of several routes from home to work, and each one of those routes can be taken by multiple people.
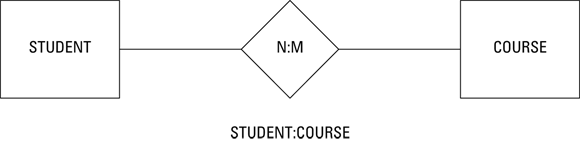
FIGURE 2-6: A many-to-many relationship between STUDENT and COURSE.
Many-to-many relationships can be very confusing and are not well represented by the two-dimensional table architecture of a relational database. Consequently, such relationships are almost always converted to simpler one-to-many relationships before they are used to build a database.
COMPLEX RELATIONSHIPS
Degree-three relationships are possible, but rarely occur in practice. Relationships of degree higher than three probably mean that you need to redesign your system to use simpler relationships. An example of a degree-three relationship is the relationship between a musical composer, a lyricist, and a song. Figure 2-7 shows a diagram of this relationship.

FIGURE 2-7: The COMPOSER: SONG: LYRICIST relationship.
 Although it is possible to build a system with such relationships, it is probably better in most cases to restructure the system in terms of binary relationships.
Although it is possible to build a system with such relationships, it is probably better in most cases to restructure the system in terms of binary relationships.
Drawing Entity-Relationship diagrams
I’ve always found it easier to understand relationships between things if I see a diagram instead of merely looking at sentences describing the relationships. Apparently a lot of other people feel the same way; systems represented by the Entity-Relationship model are universally depicted in the form of diagrams. A few simple examples of such ER diagrams, as I refer to them, appear in the previous section. In this section, I introduce some concepts that add detail to the diagrams.
One of those concepts is cardinality. In mathematics, cardinality is the number of elements in a set. In the context of relational databases, a relationship between two tables has two cardinalities of interest: the cardinality — number of elements — associated with the first table and the cardinality — you guessed it, the number of elements — associated with the second table. We look at these cardinalities two primary ways: maximum cardinality and minimum cardinality, which I tell you about in the following sections. (Cardinality only becomes truly important when you are dealing with queries that pull data from multiple tables. I discuss such queries in Book 3, Chapters 3 and 4.)
Maximum cardinality
The maximum cardinality of one side of a relationship shows the largest number of entity instances that can be on that side of the relationship.
For example, the ER diagram’s representation of maximum cardinality is shown back in Figures 2-4, 2-5, and 2-6. The diamond between the two entities in the relationship holds the two maximum cardinality values. Figure 2-4 shows a one-to-one relationship. In the example, a person is related to that person’s driver’s license. One driver can have at most one license, and one license can belong at most to one driver. The maximum cardinality on both sides of the relationship is one.
Figure 2-5 illustrates a one-to-many relationship. When relating a person to the tickets he has accumulated, each ticket belongs to one and only one driver, but a driver may have more than one ticket. The number of tickets above one is indeterminate, so it is represented by the variable N.
Figure 2-6 shows a many-to-many relationship. The maximum cardinality on the STUDENT side is represented by the variable N, and the maximum cardinality on the COURSE side is represented by the variable M because although both the number of students and the number of courses are more than one, they are not necessarily the same. You might have 350 different students that take any of 45 courses, for example.
Minimum cardinality
Whereas the maximum cardinality of one side of a relationship shows the largest number of entity instances that can be on that side of the relationship, the minimum cardinality shows the least number of entity instances that can be on that side of the relationship. In some cases, the least number of entity instances that can be on one side of a relationship can be zero. In other cases, the minimum cardinality could be one or more.
Refer to the relationship in Figure 2-4 between a person and that person’s driver’s license. The minimum cardinalities in the relationship depend heavily on subtle details of the users’ data model. Take the case where a person has been a licensed driver, but due to excessive citations, his driver’s license has been revoked. The person still exists, but the license does not. If the users’ data model stipulates that the person is retained in the PERSON table, but the corresponding row is removed from the LICENSE table, the minimum cardinality on the PERSON side is one, and the minimum cardinality on the LICENSE side is zero. Figure 2-8 shows how minimum cardinality is represented in this example.
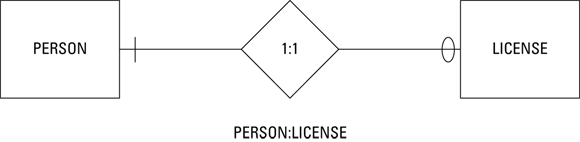
FIGURE 2-8: ER diagram showing minimum cardinality, where a person must exist, but his corresponding license need not exist.
The slash mark on the PERSON side of the diagram denotes a minimum cardinality of mandatory, meaning at least one instance must exist. The oval on the LICENSE side denotes a minimum cardinality of optional, meaning at least one instance need not exist.
For this one-to-one relationship, a given person can correspond to at most one license, but may correspond to none. A given license must correspond to one person.
If only life were that simple … Remember that I said that minimum cardinality depends subtly on the users’ data model? What if the users’ data model were slightly different, based on another possible case? Suppose a person has a very good driving record and a valid driver’s license in her home state of Washington. Next, suppose that she accepts a position as a wildlife researcher on a small island that has no roads and no cars. She is no longer a driver, but her license will remain valid until it expires in a few years. This is the reverse case of what is shown in Figure 2-8; a license exists, but the corresponding driver does not (at least as far as the state of Washington is concerned). Figure 2-9 shows this situation.

FIGURE 2-9: ER diagram showing minimum cardinality, where a license must exist, but its corresponding person need not exist.
The lesson to take home from this example is that minimum cardinality is often difficult to determine. You’ll need to question the users very carefully and explore unusual cases such as those cited previously before deciding how to model minimum cardinality.
If the minimum cardinality of one side of a relationship is mandatory, that means the cardinality of that side is at least one, but might be more. Suppose, for example, you were modeling the relationship between a basketball team in a city league and its players. A person cannot be a basketball player in the league and thus in the database unless she is a member of a basketball team in the league, so the minimum cardinality on the TEAM side is mandatory, and in fact is one. This assumes that the users’ data model states that a player cannot be a member of more than one team. Similarly, it is not possible for a basketball team to exist in the database unless it has at least five players. This means that the minimum cardinality on the PLAYER side is also mandatory, but in this case is five. Once again, depending on the users’ data model, the rule might be that a team cannot exist in the database unless it has at least five players. The minimum cardinality of the PLAYER side of the relationship is five.
Primarily, you are interested in whether the minimum cardinality on a side of a relationship is either mandatory or optional and less interested in whether a mandatory minimum cardinality has a value of one or more than one. The difference between mandatory and optional is the difference between whether an entity exists or not. The difference between existence and nonexistence is substantial. In contrast, the difference between one and five is just a matter of degree. Both cases refer to a mandatory minimum cardinality. For most applications, the difference between one mandatory value and another does not matter.
Understanding advanced ER model concepts
In the previous sections of this chapter, I talk about entities, relationships, and cardinality. I point out that subtle differences in the way users model their system can modify the way minimum cardinality is modeled. These concepts are a good start, and are sufficient for many simple systems. However, more complex situations are bound to arise. These call for extensions of various sorts to the ER model. To limber up your brain cells so you can tackle such complexities, take a look at a few of these situations and the extensions to the ER model that have been created to deal with them.
Strong entities and weak entities
All entities are not created equal. Some are stronger than others. An entity that does not depend on any other entity for its existence is considered a strong entity. Consider the sample ER model in Figure 2-10. All the entities in this model are strong, and I tell you why in the paragraphs that follow.

FIGURE 2-10: The ER model for a retail transaction database.
To get this “depends on” business straight, do a bit of a thought experiment. First, consider maximum cardinality. A customer (whose data lies in the CUSTOMER table) can make multiple purchases, each one recorded on a sales order (the details of which show up in the SALES_ORDER table). A SALESPERSON can make multiple sales, each one recorded on a SALES_ORDER. A SALES_ORDER can include multiple PRODUCTs, and a PRODUCT can appear on multiple SALES_ORDERs.
Minimum cardinality may be modeled a variety of ways, depending on how the users’ data model views things. For example, a person might be considered a customer (someone whose data appears in the CUSTOMER table) even before she buys anything because the store received her information in a promotional campaign. An employee might be considered a salesperson as soon as he is hired, even though he hasn’t sold anything yet. A sales order might exist before it lists any products, and a product might exist on the shelves before any of them have been sold. According to this model, all the minimum cardinalities are optional. A different users’ data model could mandate that some of these relationships be mandatory.
In a model such as the one described, where all the minimum cardinalities are optional, none of the entities depends on any of the other entities for its existence. A customer can exist without any associated sales orders. An employee can exist without any associated sales orders. A product can exist without any associated sales orders. A sales order can exist in the order pad without any associated customer, salesperson, or product. In this arrangement, all these entities are classified as strong entities. They all have an independent existence. Strong entities are represented in ER diagrams as rectangles with sharp corners.
Not all entities are strong, however. Consider the case shown in Figure 2-11. In this model, a driver’s license cannot exist unless the corresponding driver exists. The license is existence-dependent upon the driver. Any entity that is existence-dependent on another entity is a weak entity. In an ER diagram, a weak entity is represented with a box that has rounded corners. The diamond that shows the relationship between a weak entity and its corresponding strong entity also has rounded corners. Figure 2-11 shows this representation.
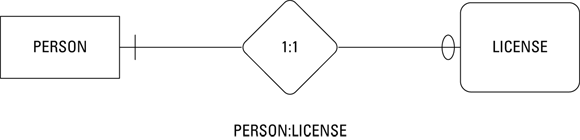
FIGURE 2-11: A PERSON: LICENSE relationship, showing LICENSE as a weak entity.
ID-dependent entities
A weak entity cannot exist without a relationship to a strong entity. A special case of a weak entity is one that depends on a strong entity not only for its existence, but also for its identity — this is called an ID-dependent entity. One example of an ID-dependent entity is a seat on an airliner flight. Figure 2-12 illustrates the relationship.

FIGURE 2-12: The SEAT is ID-dependent on FLIGHT via the FLIGHT: SEAT relationship.
A seat number, for example 23-A, does not completely identify an airline seat. However, seat 23-A on Hawaiian Airlines flight 25 from PDX to HNL, on May 2, 2019, does completely identify a particular seat that a person can reserve. Those additional pieces of information are all attributes of the FLIGHT entity — the strong entity without whose existence the weak SEAT entity would basically be just a gleam in someone’s eye.
Supertype and subtype entities
In some databases, you may find some entity classes that might actually share attributes with other entity classes, instead of being as dissimilar as customers and products. One example might be an academic community. There are a number of people in such a community: students, faculty members, and nonacademic staff. All those people share some attributes, such as name, home address, home telephone number, and email address. However, there are also attributes that are not shared. A student would also have attributes of grade point average, class standing, and advisor. A faculty member would have attributes of department, academic rank, and phone extension. A staff person would have attributes of job category, job title, and phone extension.
You can create an ER model of this academic community by making STUDENT, FACULTY, and STAFF all subtypes of the supertype COMMUNITY. Figure 2-13 shows the relationships.
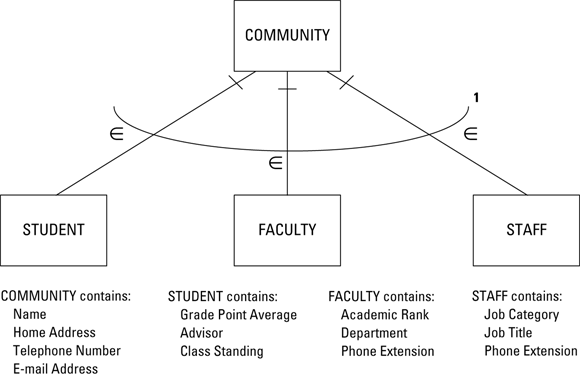
FIGURE 2-13: The COMMUNITY supertype entity with STUDENT, FACULTY, and STAFF subtype entities.
Supertype/subtype relationships borrow the concept of inheritance from object-oriented programming. The attributes of the supertype entity are inherited by the subtype entities. Each subtype entity has additional attributes that it does not necessarily share with the other subtype entities. In the example, everyone in the community has a name, a home address, a telephone number, and an email address. However, only students have a grade point average, an advisor, and a class standing. Similarly, only a faculty member can have an academic rank, and only a staff member can have a job title.
Some aspects of Figure 2-13 require a little additional explanation. The ε next to each relationship line signifies that the lower entity is a subtype of the higher entity, so STUDENT, FACULTY, and STAFF are subtypes of COMMUNITY. The curved arc with a number 1 at the right end represents the fact that every member of the COMMUNITY must be a member of one of the subtype entities. In other words, you cannot be a member of the community unless you are either a student, or a faculty member, or a staff member. It is possible in some models that an element could be a member of a supertype without being a member of any of the subtypes. However, that is not the case for this example.
The supertype and subtype entities in the ER model correspond to supertables and subtables in a relational database. A supertable can have multiple subtables and a subtable can also have multiple supertables. The relationship between a supertable and a subtable is always one-to-one. The supertable/subtable relationship is created with an SQL CREATE command. I give an example of an ER model that incorporates a supertype/subtype structure later in this chapter.
Incorporating business rules
Business rules are formal statements about how an organization does business. They typically differ from one organization to another. For example, one university may have a rule that a faculty member must hold a PhD degree. Another university could well have no such rule.
Sometimes you may not find important business rules written down anywhere. They may just be things that everyone in the organization understands. It is important to conduct an in-depth interview of everyone involved to fish out any business rules that people failed to mention when the job of creating the database was first described to you.
A simple example of an ER model
In this section, as an example, I apply the principles of ER models to a hypothetical web-based business named Gentoo Joyce that sells apparel items with penguin motifs, such as T-shirts, scarves, and dresses. The business displays its products and takes credit card orders on its website. There is no brick and mortar store. Fulfillment is outsourced to a fulfillment house, which receives and warehouses products from vendors, and then, upon receiving orders from Gentoo Joyce, ships the orders to customers.
The website front end consists of pages that include descriptions and pictures of the products, a shopping cart, and a form for capturing customer and payment information. The website back end holds a database that stores customer, transaction, inventory, and order shipment status information. Figure 2-14 shows an ER diagram of the Gentoo Joyce system. It is an example typical of a boutique business.
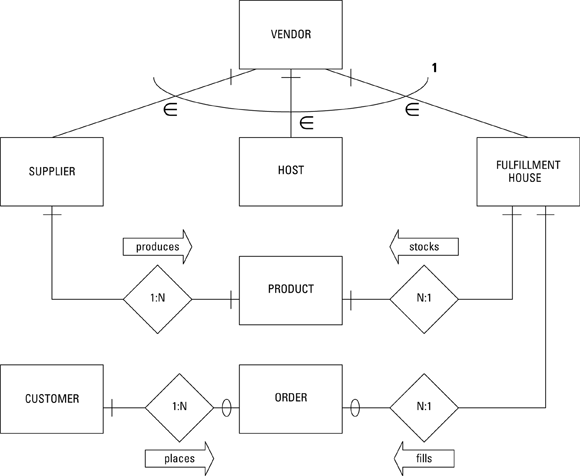
FIGURE 2-14: An ER diagram of a small, web-based retail business.
Gentoo Joyce buys goods and services from three kinds of vendors: product suppliers, web hosting services, and fulfillment houses. In the model, VENDOR is a supertype of SUPPLIER, HOST, and FULFILLMENT_HOUSE. Some attributes are shared among all the vendors; these are assigned to the VENDOR entity. Other attributes are not shared and are instead attributes of the subtype entities.
This is only one of several possible models for the Gentoo Joyce business. Another possibility would be to include all providers in a VENDOR entity with more attributes. A third possibility would be to have no VENDOR entity, but separate SUPPLIER and FULFILLMENT_HOUSE entities, and to just consider a host as a supplier.
A many-to-many relationship exists between SUPPLIER and PRODUCT because a supplier may provide more than one product, and a given product may be supplied by more than one supplier. Similarly, any given product will (hopefully) appear on multiple orders, and an order may include multiple products. Such many-to-many relationships can be problematic. I discuss how to handle such problems in Book 2.
The other relationships in the model are one-to-many. A customer can place many orders, but each order comes from one and only one customer. A fulfillment house can stock multiple products, but each product is stocked by one and only one fulfillment house.
A slightly more complex example
The Gentoo Joyce system that I describe in the preceding section is an easy-to-understand example, similar to what you often find in database textbooks. Most real-world systems are much more complex. I don’t try to show a genuine, real-world system here, but to move at least one step in that direction, I model the fictitious Clear Creek Medical Clinic (CCMC). As I discuss in Book 2 as well as earlier in this chapter, one of the first things to do when assigned the project of creating a database for a client is to interview everyone who has a stake in the system, including management, users, and anyone else who has a say in how things are run. Listen carefully to these people and discern how they model in their minds the system they envision. Find out what information they need to capture and what they intend to do with it.
CCMC employs doctors, nurses, medical technologists, medical assistants, and office workers. The company provides medical, dental, and vision benefits to employees and their dependents. The doctors, nurses, and medical technologists must all be licensed by a recognized licensing authority. Medical assistants may be certified, but need not be. Neither licensure nor certification is required of office workers.
Typically, a patient will see a doctor, who will examine the patient, and then order one or more tests. A medical assistant or nurse may take samples of the patient’s blood, urine, or both, and take the samples to the laboratory. In the lab, a medical technologist performs the tests that the doctor has ordered. The results of the tests are sent to the doctor who ordered them, as well as to perhaps one or more consulting physicians. Based on the test results, the primary doctor, with input from the consulting physicians, makes a diagnosis of the patient’s condition and prescribes a treatment. A nurse then administers the prescribed treatment.
Based on the descriptions of the envisioned system, as described by the interested parties (called stakeholders), you can come up with a proposed list of entities. A good first shot at this is to list all the nouns that were used by the people you interviewed. Many of these will turn out to be entities in your model, although you may end up classifying some of those nouns as attributes of entities. For this example, say you generated the following list:
- Employee
- Office worker
- Doctor (physician)
- Nurse
- Medical technologist
- Medical assistant
- Benefits
- Dependents
- Patients
- Doctor’s license
- Nurse’s license
- Medical technologist’s license
- Medical assistant’s certificate
- Examination
- Test order
- Test
- Test result
- Consultation
- Diagnosis
- Prescription
- Treatment
In the course of your interviews of the stakeholders, you found that one of the categories of things to track is employees, but there are several different employee classifications. You also found that there are benefits, and those benefits apply to dependents as well as to employees. From this, you conclude that EMPLOYEE is an entity and it is a supertype of the OFFICE_WORKER, DOCTOR, NURSE, MEDTECH, and MEDASSIST entities. A DEPENDENT entity also should fit into the picture somewhere.
Although doctors, nurses, and medical technologists all must have current valid licenses, because a license applies to one and only one professional and each professional has one and only one license, it makes sense for those licenses to be attributes of their respective DOCTOR, NURSE, and MEDTECH entities rather than to be entities in their own right. Consequently, there is no LICENSE entity in the CCMC ER model.
PATIENT clearly should be an entity, as should EXAMINATION, TEST, TESTORDER, and RESULT. CONSULTATION, DIAGNOSIS, PRESCRIPTION, and TREATMENT also deserve to stand on their own as entities.
After you have decided what the entities are, you can start thinking about how they relate to each other. You may be able to model each relationship in one of several ways. This is where the interviews with the stakeholders are critical. The model you arrive at must be consistent with the organization’s business rules, both those written down somewhere and those that are understood by everyone, but not usually talked about. Figure 2-15 shows one possible way to model this system.
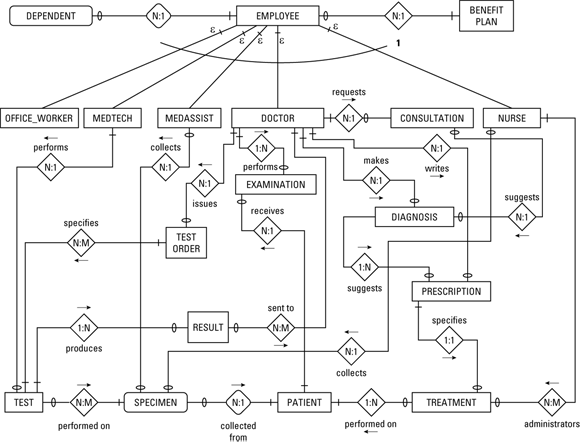
FIGURE 2-15: The ER diagram for Clear Creek Medical Clinic.
From this diagram, you can extract certain facts:
- An employee can have zero, one, or multiple dependents, but each dependent is associated with one and only one employee. (Business rule: If both members of a married couple work for the clinic, for insurance purposes, the dependents are associated with only one of them.)
- An employee must be either an office worker, a doctor, a nurse, a medical technologist, or a medical assistant. (Business rule: An office worker cannot, for example, also be classified as a medical assistant. Only one job classification is permitted.)
- A doctor can perform many examinations, but each examination is performed by one and only one doctor. (Business rule: If more than one doctor is present at a patient examination, only one of them takes responsibility for the examination.)
- A doctor can issue many test orders, but each test order can specify one and only one test.
- A medical assistant or a nurse can collect multiple specimens from a patient, but each specimen is from one and only one patient.
- A medical technologist can perform multiple tests on a specimen, and each test can be applied to multiple specimens.
- A test may have one of several results; for example, positive, negative, below normal, normal, above normal, as well as specific numeric values. However, each such result applies to one and only one test.
- A test result can be sent to one or more doctors. A doctor can receive many test results.
- A doctor may request a consultation with one or more other doctors.
- A doctor may make a diagnosis of a patient’s condition, based on test results and possibly on one or more consultations.
- A diagnosis could suggest one or more prescriptions.
- A doctor can write many prescriptions, but each prescription is written by one and only one doctor for one and only one patient.
- A doctor may order a treatment, to be administered to a patient by a nurse.
Often after drawing an ER diagram, and then determining all the things that the diagram implies by compiling a list such as that given here, the designer finds missing entities or relationships, or realizes that the model does not accurately represent the way things are actually done in the organization. Creating the model is an iterative process of progressively modifying the diagram until it reflects the desired system as closely as possible. (Iterative here meaning doing it over and over again until you get it right — or as right as it will ever be.)
Problems with complex relationships
The Clear Creek Medical Clinic example in the preceding section contains some many-to-many relationships, such as the relationship between TEST and SPECIMEN. Multiple tests can be run on a single specimen, and multiple specimens, taken from multiple patients, can all be run through the same test.
That all sounds quite reasonable, but in point of fact there’s a bit of a problem when it comes to storing the relevant information. If the TEST entity is translated into a table in a relational database, how many columns should be set aside for specimens? Because you don’t know how many specimens a test will include, and because the number of specimens could be quite large, it doesn’t make sense to allocate space in the TEST table to show that the test was performed on a particular specimen.
Similarly, if the SPECIMEN entity is translated into a table in a relational database, how many columns should you set aside to record the tests that might be performed on it? It doesn’t make sense to allocate space in the SPECIMEN table to hold all the tests that might be run on it if no one even knows beforehand how many tests you may end up running. For these reasons, it is common practice to convert a many-to-many relationship into two one-to-many relationships, both connected to a new entity that lies between the original two. You can make that conversion with no loss of accuracy, and the problem of how to store things disappears. In Book 2, I go into detail on how to make this conversion.
Simplifying relationships using normalization
Even after you have eliminated all the many-to-many relationships in an ER model, there can still be problems if you have not conceptualized your entities in the simplest way. The next step in the design process is to examine your model and see if adding, changing, or deleting data can cause inconsistencies or even outright wrong information to be retained in your database. Such problems are called anomalies, and if there’s even a slight chance that they’ll crop up, you’ll need to adjust your model to eliminate them. This process of model adjustment is called normalization, and I cover it in Book 2.
Translating an ER model into a relational model
After you’re satisfied that your ER model is not only correct, but economical and robust, the next step is to translate it into a relational model. The relational model is the basis for all relational database management systems. I go through that translation process in Book 2.