
Chapter 5
Knowing the Major Components of SQL
IN THIS CHAPTER
![]() The Data Definition Language (DDL)
The Data Definition Language (DDL)
![]() The Data Maintenance Language (DML)
The Data Maintenance Language (DML)
![]() The Data Control Language (DCL)
The Data Control Language (DCL)
You can view SQL as being divided into three distinct parts, each of which has a different function. With one part, the Data Definition Language (DDL), you can create and revise the structure (the metadata) of a database. With the second part, the Data Manipulation Language (DML), you can operate on the data contained in the database. And with the third part, the Data Control Language (DCL), you can maintain a database’s security and reliability.
In this chapter, I look at each of these SQL components in turn.
Creating a Database with the Data Definition Language
The Data Definition Language (DDL) is the part of SQL that you use to create a database and all its structural components, including tables, views, schemas, and other objects. It is also the tool that you use to modify the structure of an existing database or destroy it after you no longer need it.
In the text that follows, I tell you about the structure of a relational database. Then I give you instructions for creating your own SQL database with some simple tables, views that help users access data easily and efficiently, schemas that help keep your tables organized in the database, and domains, which restrict the type of data that users can enter into specified fields.
Creating a database can be complicated, and you may find that you need to adjust a table after you’ve created it. Or you may find that the database users’ needs have changed, and you need to create space for additional data. It’s also possible that you’ll find that at some point, a specific table is no longer necessary. In this section, I tell you how to modify tables and delete them altogether.
The containment hierarchy
The defining difference between databases and flat files — such as those described in Chapter 1 of this minibook — is that databases are structured. As I show you in previous chapters, the structure of relational databases differs from the structure of other database models, such as the hierarchical model and the network model. Be that as it may, there’s still a definite hierarchical aspect to the structure of a relational database. Like Russian nesting dolls, one level of structure contains another, which in turn contains yet another, as shown in Figure 5-1.
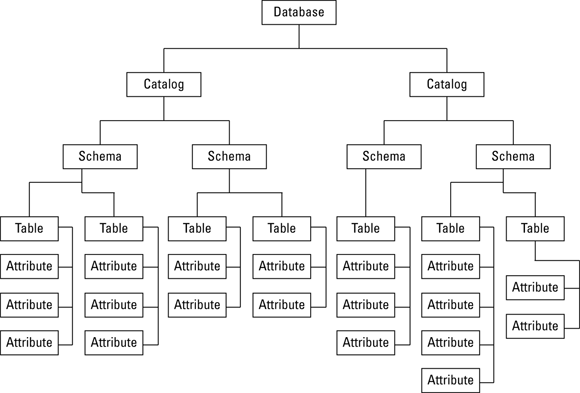
FIGURE 5-1: The relational database containment hierarchy.
Not all databases use all the available levels, but larger databases tend to use more of them. The top level is the database itself. As you would expect, every part of the database is contained within the database, which is the biggest Russian doll of all. From there, a database can have one or more catalogs. Each catalog can have one or more schemas. Each schema can include one or more tables. Each table may consist of one or more columns.
For small to moderately large databases, you need concern yourself only with tables and the columns they contain. Schemas and catalogs come into play only when you have multiple unrelated collections of tables in the same database. The idea here is that you can keep these groups separate by putting them into separate schemas. If there is any danger of confusing unrelated schemas, you can put them in separate catalogs.
Creating tables
At its simplest, a database is a collection of two-dimensional tables, each of which has a collection of closely related attributes. The attributes are stored in columns of the tables. You can use SQL’s CREATE statement to create a table, with its associated columns. You can’t create a table without also creating the columns, and I tell you how to do all that in the next section. Later, using SQL’s Data Manipulation Language, you can add data to the table in the form of rows. In the “Operating on Data with the Data Manipulation Language (DML)” section of this chapter, I tell you how to do that.
Specifying columns
The two dimensions of a table are its columns and rows. Each column corresponds to a specific attribute of the entity being modeled. Each row contains one specific instance of the entity.
As I mention earlier, you can create a table with an SQL CREATE statement. To see how that works, check out the following example. (Like all examples in this book, the code uses ANSI/ISO standard syntax.)
CREATE TABLE CUSTOMER (
CustomerID INTEGER,
FirstName CHAR (15),
LastName CHAR (20),
Street CHAR (30),
City CHAR (25),
Region CHAR (25),
Country CHAR (25),
Phone CHAR (13) ) ;
In the CREATE TABLE statement, you specify the name of each column and the type of data you want that column to contain. Spacing between statement elements doesn’t matter to the DBMS. It is just to make reading the statement easier to humans. How many elements you put on one line also doesn’t matter to the DBMS, but spreading elements out on multiple lines, as I have just done, makes the statement easier to read.
In the preceding example, the CustomerID column contains data of the INTEGER type, and the other columns contain character strings. The maximum lengths of the strings are also specified. (Most implementations accept the abbreviation CHAR in place of CHARACTER.)
Creating other objects
Tables aren’t the only things you can create with a CREATE statement. A few other possibilities are views, schemas, and domains.
Views
A view is a virtual table that has no physical existence apart from the tables that it draws from. You create a view so that you can concentrate on some subset of a table, or alternatively on pieces of several tables. Some views draw selected columns from one table, and they’re called single-table views. Others, called multitable views, draw selected columns from multiple tables.
Sometimes what is stored in database tables is not exactly in the form that you want users to see. Perhaps a table containing employee data has address information that the social committee chairperson needs, but also contains salary information that should be seen only by authorized personnel in the human resources department. How can you show the social committee chairperson what she needs to see without spilling the beans on what everyone is earning? In another scenario, perhaps the information a person needs is spread across several tables. How do you deliver what is needed in one convenient result set? The answer to both questions is the view.
SINGLE-TABLE VIEW
For an example of single-table view, consider the social committee chairperson’s requirement, which I mention in the preceding section. She needs the contact information for all employees, but is not authorized to see anything else. You can create a view based on the EMPLOYEE table that includes only the information she needs.
CREATE VIEW EMP_CONTACT AS
SELECT EMPLOYEE.FirstName,
EMPLOYEE.LastName,
EMPLOYEE.Street,
EMPLOYEE.City,
EMPLOYEE.State,
EMPLOYEE.Zip,
EMPLOYEE.Phone,
EMPLOYEE.Email
FROM EMPLOYEE ;
This CREATE VIEW statement contains within it an embedded SELECT statement to pull from the EMPLOYEE table only the columns desired. Now all you need to do is grant SELECT rights on the EMP_CONTACT view to the social committee chairperson. (I talk about granting privileges in Book 4, Chapter 3.) The right to look at the records in the EMPLOYEE table continues to be restricted to duly authorized human resources personnel and upper-management types.
Most implementations assume that if only one table is listed in the FROM clause, the columns being selected are in that same table. You can save some typing by eliminating the redundant references to the EMPLOYEE table.
CREATE VIEW EMP_CONTACT AS
SELECT FirstName,
LastName,
Street,
City,
State,
Zip,
Phone,
Email
FROM EMPLOYEE ;
 There is a danger in using the abbreviated format, however. A query may use a join operation to pull some information from this view and other information from another view or table. If the other view or table has a field with the same name, the database engine doesn’t know which to use. It’s always safe to use a fully qualified column name — meaning the column’s table name is included — but don’t be surprised if you see the abbreviated form in somebody else’s code. I discuss joins in Book 3, Chapter 5.
There is a danger in using the abbreviated format, however. A query may use a join operation to pull some information from this view and other information from another view or table. If the other view or table has a field with the same name, the database engine doesn’t know which to use. It’s always safe to use a fully qualified column name — meaning the column’s table name is included — but don’t be surprised if you see the abbreviated form in somebody else’s code. I discuss joins in Book 3, Chapter 5.
MULTITABLE VIEW
Although there are occasions when you might want to pull a subset of columns from a single table, a much more common scenario would be having to pull together selected information from multiple related tables and present the result in a single report. You can do this with a multitable view. (Creating multitable views involves joins, so to be safe you should use fully qualified column names.)
Suppose, for example, that you’ve been tasked to create an order entry system for a retail business. The key things involved are the products ordered, the customers who order them, the invoices that record the orders, and the individual line items on each invoice. It makes sense to separate invoices and invoice lines because an invoice can have an indeterminate number of invoice lines that vary from one invoice to another. You can model this system with an ER diagram. Figure 5-2 shows one way to model the system. (If the term “ER diagram” doesn’t ring a bell, check out Chapter 2 in this minibook.)

FIGURE 5-2: The ER diagram of the database for an order entry system.
The entities relate to each other through the columns they have in common. Here are the relationships:
- The CUSTOMER entity bears a one-to-many relationship to the INVOICE entity. One customer can make multiple purchases, generating multiple invoices. Each invoice, however, applies to one and only one customer.
- The INVOICE entity bears a one-to-many relationship to the INVOICE_LINE entity. One invoice may contain multiple lines, but each line appears on one and only one invoice.
- The PRODUCT entity bears a one-to-many relationship to the INVOICE_LINE entity. A product may appear on more than one line on an invoice, but each line deals with one and only one product.
The links between entities are the attributes they hold in common. Both the CUSTOMER and the INVOICE entities have a CustomerID column. It is the primary key in the CUSTOMER entity and a foreign key in the INVOICE entity. (I discuss keys in detail in Book 2, Chapter 4, including the difference between a primary key and a foreign key.) The InvoiceNumber attribute connects the INVOICE entity to the INVOICE_LINE entity, and the ProductID attribute connects PRODUCT to INVOICE_LINE.
CREATING VIEWS
The first step in creating a view is to create the tables upon which the view is based.
These tables are based on the entities and attributes in the ER model. I discuss table creation earlier in this chapter, and in detail in Book 2, Chapter 4. For now, I just show how to create the tables in the sample retail database.
CREATE TABLE CUSTOMER (
CustomerID INTEGER PRIMARY KEY,
FirstName CHAR (15),
LastName CHAR (20) NOT NULL,
Street CHAR (25),
City CHAR (20),
State CHAR (2),
Zipcode CHAR (10),
Phone CHAR (13) ) ;
The first column in the code contains attributes; the second column contains data types, and the third column contains constraints — gatekeepers that keep out invalid data. I touch on primary key constraints in Book 2, Chapter 2 and then describe them more fully in Book 2, Chapter 4. For now, all you need to know is that good design practice requires that every table have a primary key. The NOT NULL constraint means that the LastName field must contain a value. I say (much) more about null values (and constraints) in Book 1, Chapter 6.
Here’s how you’d create the other tables:
CREATE TABLE PRODUCT (
ProductID INTEGER PRIMARY KEY,
Name CHAR (25),
Description CHAR (30),
Category CHAR (15),
VendorID INTEGER,
VendorName CHAR (30) ) ;
CREATE TABLE INVOICE (
InvoiceNumber INTEGER PRIMARY KEY,
CustomerID INTEGER,
InvoiceDate DATE,
TotalSale NUMERIC (9,2),
TotalRemitted NUMERIC (9,2),
FormOfPayment CHAR (10) ) ;
CREATE TABLE INVOICE_LINE (
LineNumber Integer PRIMARY KEY,
InvoiceNumber INTEGER,
ProductID INTEGER,
Quantity INTEGER,
SalePrice NUMERIC (9,2) ) ;
You can create a view containing data from multiple tables by joining tables in pairs until you get the combination you want.
Suppose you want a display showing the first and last names of all customers along with all the products they have bought. You can do it with views.
CREATE VIEW CUST_PROD1 AS
SELECT FirstName, LastName, InvoiceNumber
FROM CUSTOMER JOIN INVOICE
USING (CustomerID) ;
CREATE VIEW CUST_PROD2 AS
SELECT FirstName, LastName, ProductID
FROM CUST_PROD1 JOIN INVOICE_LINE
USING (InvoiceNumber) ;
CREATE VIEW CUST_PROD AS
SELECT FirstName, LastName, Name
FROM CUST_PROD2 JOIN PRODUCT
USING (ProductID) ;
The CUST_PROD1 view is created by a join of the CUSTOMER table and the INVOICE table, using CustomerID as the link between the two. It combines the customer’s first and last name with the invoice numbers of all the invoices generated for that customer. The CUST_PROD2 view is created by a join of the CUST_PROD1 view and the INVOICE_LINE table, using InvoiceNumber as the link between them. It combines the customer’s first and last name from the CUST_PROD1 view with the ProductID from the INVOICE_LINE table. Finally, the CUST_PROD view is created by a join of the CUST_PROD2 view and the PRODUCT table, using ProductID as the link between the two. It combines the customer’s first and last name from the CUST_PROD2 view with the Name of the product from the PRODUCT table. This gives the display that we want. Figure 5-3 shows the flow of information from the source tables to the final destination view. I discuss joins in detail in Book 3, Chapter 5.

FIGURE 5-3: Creating a multitable view using joins.
There will be a row in the final view for every purchase. Customers who bought multiple items will be represented by multiple lines in CUST_PROD.
Schemas
In the containment hierarchy, the next level up from the one that includes tables and views is the schema level. It makes sense to place tables and views that are related to each other in the same schema. In many cases, a database may have only one schema, the default schema. This is the simplest situation, and when it applies, you don’t need to think about schemas at all.
However, more complex cases do occur. In those cases, it is important to keep one set of tables separated from another set. You can do this by creating a named schema for each set. Do this with a CREATE SCHEMA statement. I won’t go into the detailed syntax for creating a schema here because it may vary from one platform to another, but you can create a named schema in the following manner:
CREATE SCHEMA RETAIL1 ;
There are a number of clauses that you can add to the CREATE SCHEMA statement, specifying the owner of the schema and creating tables, views, and other objects. However, you can create a schema as shown previously, and create the tables and other objects that go into it later. If you do create a table later, you must specify which schema it belongs to:
CREATE TABLE RETAIL1.CUSTOMER (
CustomerID INTEGER PRIMARY KEY,
FirstName CHAR (15),
LastName CHAR (20) NOT NULL,
Street CHAR (25),
City CHAR (20),
State CHAR (2),
Zipcode CHAR (10),
Phone CHAR (13) ) ;
This CUSTOMER table will go into the RETAIL1 schema and will not be confused with the CUSTOMER table that was created in the default schema, even though the table names are the same. For really big systems with a large number of schemas, you may want to separate related schemas into their own catalogs. Most people dealing with moderate systems don’t need to go to that extent.
Domains
A domain is the set of all values that a table’s attributes can take on. Some implementations of SQL allow you to define domains within a CREATE SCHEMA statement. You can also define a domain with a standalone CREATE DOMAIN statement, such as
CREATE DOMAIN Color CHAR (15)
CHECK (VALUE IS "Red" OR "White" OR "Blue") ;
In this example, when a table attribute is defined as of type Color, only Red, White, and Blue will be accepted as legal values. This domain constraint on the Color attribute will apply to all tables and views in the schema that have a Color attribute. Domains can save you a lot of typing because you have to specify the domain constraint only once, rather than every time you define a corresponding table attribute.
Modifying tables
After you create a table, complete with a full set of attributes, you may not want it to remain the same for all eternity. Requirements have a way of changing, based on changing conditions. The system you are modeling may change, requiring you to change your database structure to match. SQL’s Data Definition Language gives you the tools to change what you have brought into existence with your original CREATE statement. The primary tool is the ALTER statement. Here’s an example of a table modification:
ALTER TABLE CUSTOMER
ADD COLUMN Email CHAR (50) ;
This has the effect of adding a new column to the CUSTOMER table without affecting any of the existing columns. You can get rid of columns that are no longer needed in a similar way:
ALTER TABLE CUSTOMER
DROP COLUMN Email;
I guess we don’t want to keep track of customer email addresses after all.
The ALTER TABLE statement also works for adding and dropping constraints. (See Book 1, Chapter 6 for more on working with constraints.)
Removing tables and other objects
It’s really easy to get rid of tables, views, and other things that you no longer want. Here’s how easy:
DROP TABLE CUSTOMER ;
DROP VIEW EMP_CONTACT ;
DROP COLUMN Email ;
When you drop a table, it simply disappears, along with all its data.
 Actually, it is not always that easy to get rid of something. If two tables are related with a primary key/foreign key link, a referential integrity constraint may prevent you from dropping one of those tables. I discuss referential integrity in Book 2, Chapter 3.
Actually, it is not always that easy to get rid of something. If two tables are related with a primary key/foreign key link, a referential integrity constraint may prevent you from dropping one of those tables. I discuss referential integrity in Book 2, Chapter 3.
Operating on Data with the Data Manipulation Language (DML)
Just as the DDL is that part of SQL that you can use to create or modify database structural elements such as schemas, tables, and views, the Data Manipulation Language (DML) is the part of SQL that operates on the data that inhabits that structure. There are four things that you want to do with data:
- Store the data in a structured way that makes it easily retrievable.
- Change the data that is stored.
- Selectively retrieve information that responds to a need that you currently have.
- Remove data from the database that is no longer needed.
SQL statements that are part of the DML enable you to do all these things. Adding, updating, and deleting data are all relatively straightforward operations. Retrieving the exact information you want out of the vast store of data not relevant to your current need can be more complicated. I give you only a quick look at retrieval here and go into more detail in Book 3, Chapter 2. Here, I also tell you how to add, update, and delete data, as well as how to work with views.
Retrieving data from a database
The one operation that you’re sure to perform on a database more than any other is the retrieval of needed information. Data is placed into the database only once. It may never be updated, or at most only a few times. However, retrievals will be made constantly. After all, the main purpose of a database is to provide you with information when you want it.
The SQL SELECT statement is the primary tool for extracting whatever information you want. Because the SELECT statement inquires about the contents of a table, it is called a query. A SELECT query can return all the data that a table contains, or it can be very discriminating and give you only what you specifically ask for. A SELECT query can also return selected results from multiple tables. I cover that in depth in Book 3, Chapter 3.
In its simplest form, a SELECT statement returns all the data in all the rows and columns in whatever table you specify. Here’s an example:
SELECT * FROM PRODUCT ;
The asterisk (*) is a wildcard character that means everything. In this context, it means return data from all the columns in the PRODUCT table. Because you’re not placing any restrictions on which rows to return, all the data in all the rows of the table will be returned in the result set of the query.
I suppose there may be times when you want to see all the data in all the columns and all the rows in a table, but usually you’re going to have a more specific question in mind. Perhaps you’re not interested in seeing all the information about all the items in the PRODUCT table right now, but are interested in seeing only the quantities in stock of all the guitars. You can restrict the result set that is returned by specifying the columns you want to see and by restricting the rows returned with a WHERE clause.
SELECT ProductID, ProductName, InStock
FROM PRODUCT
WHERE Category = 'guitar' ;
This statement returns the product ID number, product name, and number in stock of all products in the Guitar category, and nothing else. An ad hoc query such as this is a good way to get a quick answer to a question. Of course, there is a lot more to retrieving information than what I have covered briefly here. In Book 3, Chapter 2, I have a lot more to say on the subject.
I call the query above an ad hoc query because it is something you can type in from your keyboard, execute, and get an immediate answer. This is what a user might do if there is an immediate need for the number of guitars in stock right now, but this is not a question asked repeatedly. If it is a question that will be asked repeatedly, you should consider putting the preceding SQL code into a procedure that you can incorporate into an application program. That way, you would only have to make a selection from a menu and then click OK, instead of typing in the SQL code every time you want to know what your guitar situation is.
Adding data to a table
Somehow, you have to get data into your database. This data may be records of sales transactions, employee personnel records, instrument readings coming in from interplanetary spacecraft, or just about anything you care to keep track of. The form that the data is in determines how it is entered into the database. Naturally, if the data is on paper, you have to type it into the database. But if it is already in electronic form, you can translate it into a format acceptable to your DBMS and then import it into your system.
Adding data the dull and boring way (typing it in)
If the data to be kept in the database was originally written down on paper, in order to get it into the database, it will have to be transcribed from the paper to computer memory by keying it in with a computer keyboard. This used to be the most frequently used method for entering data into a database because most data was initially captured on paper. People called data entry clerks worked from nine to five, typing data into computers. What a drag! It was pretty mind-deadening work. More recently, rather than first writing things down on paper, the person who receives the data enters it directly into the database. This is not nearly so bad because entering the data is only a small part of the total task.
The dullest and most boring way to enter data into a database is to enter one record at a time, using SQL INSERT statements. It works, if you have no alternative way to enter the data, and all other methods of entering data ultimately are translated into SQL INSERT statements anyway. But after entering one or two records into the database this way, you will probably have had enough. Here’s an example of such an INSERT operation:
INSERT INTO CUSTOMER (CustomerID, FirstName, LastName, Street, City, State, Zipcode, Phone)
VALUES (:vcustid, 'Abe', 'Lincoln', '1600 Pennsylvania
Avenue NW', 'Washington', 'DC', '20500', '202-555-1414') ;
The first value listed, :vcustid, is a variable that is incremented each time a new record is added to the table. This guarantees that there will be no duplication of a value in the CustomerID field, which serves as the table’s primary key.
There are single quotes enclosing the values in the previous INSERT statement because the values are all of the CHAR type, which requires that values be enclosed in single quotes. INTEGER data on the other hand is not enclosed in single quotes. You might say, “Wait a minute! The zip code in the INSERT statement is an integer!” Well, no. It is only an integer if I define it as such when I create the CUSTOMER table. When I created this CUSTOMER table, CustomerID was the only column of the INTEGER type. All the rest are of the CHAR type. I am never going to want to add one zip code to another or subtract one from another, so there is no point in making them integers.
In a more realistic situation, instead of entering an INSERT statement into SQL, the data entry person would enter data values into fields on a form. The values would be captured into variables, which would then be used, out of sight of humans, to populate the VALUES clause of an INSERT statement.
Adding incomplete records
Sometimes you might want to add a record to a table before you have data for all the record’s columns. As long as you have the primary key and data for all the columns that have a NOT NULL or UNIQUE constraint, you can enter the record. Because SQL allows null values in other columns, you can enter such a partial record now and fill in the missing information later. Here’s an example of how to do it:
INSERT INTO CUSTOMER (CustomerID, FirstName, LastName)
VALUES (:vcustid, 'Abe', 'Lincoln') ;
Here you enter a new customer into the CUSTOMER table. All you have is the person’s first and last name, but you can create a record in the CUSTOMER table anyway. The CustomerID is automatically generated and contained in the :vcustid variable. The value placed into the FirstName field is Abe and the value placed into the LastName field is Lincoln. The rest of the fields in this record will contain null values until you populate them at a later date.
A NOT NULL constraint on a column raises a stink if you (or your data entry person) leave that particular column blank. A UNIQUE constraint gets similarly upset if you enter a value into a field that duplicates an already existing value in that same field. For more on constraints, check out Book 1, Chapter 6.
Adding data in the fastest and most efficient way: Bypassing typing altogether
Keying in a succession of SQL INSERT statements is the slowest and most tedious way to enter data into a database table. Entering data into fields on a video form on a computer monitor is not as bad because there is less typing and you probably have other things to do, such as talking to customers, checking in baggage, or consulting patient records.
Fast food outlets make matters even easier by giving you a special data entry panel rather than a keyboard. You can enter a double cheeseburger and a root beer float just by touching a couple of buttons. The correct information is translated to SQL and put into the database and also sent back to the kitchen to tell the culinary staff what to do next.
If a business’s data is input via a bar code scanner, the job is even faster and easier for the clerk. All he has to do is slide the merchandise past the scanner and listen for the beep that tells him the purchase has been registered. He doesn’t have to know that besides printing the sales receipt, the data from the scan is being translated into SQL and then sent to a database.
Although the clerks at airline ticket counters, fast food restaurants, and supermarkets don’t need to know anything about SQL, somebody does. In order to make the clerks’ life easier, someone has to write programs that process the data coming in from keyboards, data entry pads, and bar code scanners, and sends it to a database. Those programs are typically written in a general-purpose language such as C, Java, or Visual Basic, and incorporate SQL statements that are then used in the actual “conversation” with the database.
Updating data in a table
The world in the twenty-first century is a pretty dynamic place. Things are changing constantly, particularly in areas that involve technology. Data that was of value last week may be irrelevant tomorrow. Facts that were inconsequential a year ago may be critically important now. For a database to be useful, it must be capable of rapid change to match the rapidly changing piece of the world that it models.
This means that in addition to the ability to add new records to a database table, you also need to be able to update the records that it already contains. With SQL, you do this with an UPDATE statement. With an UPDATE statement, you can change a single row in a table, a set of rows that share one or more characteristics, or all the rows in the table. Here’s the generalized syntax:
UPDATE <i>table_name</i>
SET <i>column_1</i> = <i>expression_1</i>, <i>column_2</i> = <i>expression_2</i>,
…, <i>column_n</i> = <i>expression_n</i>
[WHERE predicates] ;
The SET clause specifies which columns will get new values and what those new values will be. The optional WHERE clause (square brackets indicate that the WHERE clause is optional) specifies which rows the update applies to. If there is no WHERE clause, the update is applied to all rows in the table.
Now for some examples. Consider the PRODUCT table shown in Table 5-1.
TABLE 5-1 PRODUCT Table
ProductID |
Name |
Category |
Cost |
1664 |
Bike helmet |
Helmets |
20.00 |
1665 |
Motorcycle helmet |
Helmets |
30.00 |
1666 |
Bike gloves |
Gloves |
15.00 |
1667 |
Motorcycle gloves |
Gloves |
19.00 |
1668 |
Sport socks |
Footwear |
10.00 |
Now suppose that the cost of bike helmets increases to $22.00. You can make that change in the database with the following UPDATE statement:
UPDATE PRODUCT
SET Cost = 22.00
WHERE Name = 'Bike helmet' ;
This statement makes a change in all rows where Name is equal to Bike helmet, as shown in Table 5-2.
TABLE 5-2 PRODUCT Table
ProductID |
Name |
Category |
Cost |
1664 |
Bike helmet |
Helmets |
22.00 |
1665 |
Motorcycle helmet |
Helmets |
30.00 |
1666 |
Bike gloves |
Gloves |
15.00 |
1667 |
Motorcycle gloves |
Gloves |
19.00 |
1668 |
Sport socks |
Footwear |
10.00 |
 Because there is only one such row, only one is changed. If there is a possibility that more than one product might have the same name, you might erroneously update a row that you did not intend, along with the one that you did. To avoid this problem, assuming you know the ProductID of the item you want to change, you should use the ProductID in your
Because there is only one such row, only one is changed. If there is a possibility that more than one product might have the same name, you might erroneously update a row that you did not intend, along with the one that you did. To avoid this problem, assuming you know the ProductID of the item you want to change, you should use the ProductID in your WHERE clause. In a well-designed database, ProductID would be the primary key and thus guaranteed to be unique.
UPDATE PRODUCT
SET Cost = 22.00
WHERE ProductID = 1664 ;
You may want to update a select group of rows in a table. To do that, you specify a condition in the WHERE clause of your update, that applies to the rows you want to update and only the rows you want to update. For example, suppose management decides that the Helmets category should be renamed as Headgear, to include hats and bandannas. Because their wish is your command, you duly change the category names of all the Helmet rows in the table to Headgear by doing the following:
UPDATE PRODUCT
SET Category = 'Headgear'
WHERE Category = 'Helmets' ;
This would give you what is shown in Table 5-3:
TABLE 5-3 PRODUCT Table
ProductID |
Name |
Category |
Cost |
1664 |
Bike helmet |
Headgear |
22.00 |
1665 |
Motorcycle helmet |
Headgear |
30.00 |
1666 |
Bike gloves |
Gloves |
15.00 |
1667 |
Motorcycle gloves |
Gloves |
19.00 |
1668 |
Sport socks |
Footwear |
10.00 |
Now suppose management decides it would be more efficient to lump headgear and gloves together into a single category named Accessories. Here’s the UPDATE statement that will do that:
UPDATE PRODUCT
SET Category = 'Accessories'
WHERE Category = 'Headgear' OR Category = 'Gloves' ;
The result would be what is shown in Table 5-4:
TABLE 5-4 PRODUCT Table
ProductID |
Name |
Category |
Cost |
1664 |
Bike helmet |
Accessories |
22.00 |
1665 |
Motorcycle helmet |
Accessories |
30.00 |
1666 |
Bike gloves |
Accessories |
15.00 |
1667 |
Motorcycle gloves |
Accessories |
19.00 |
1668 |
Sport socks |
Footwear |
10.00 |
All the headgear and gloves items are now considered accessories, but other categories, such as footwear, are left unaffected.
Now suppose management sees that considerable savings have been achieved by merging the headgear and gloves categories. The decision is made that the company is actually in the active-wear business. To convert all company products to the new Active-wear category, a really simple UPDATE statement will do the trick:
UPDATE PRODUCT
SET Category = 'Active-wear' ;
This produces the table shown in Table 5-5:
TABLE 5-5 PRODUCT Table
ProductID |
Name |
Category |
Cost |
1664 |
Bike helmet |
Active-wear |
22.00 |
1665 |
Motorcycle helmet |
Active-wear |
30.00 |
1666 |
Bike gloves |
Active-wear |
15.00 |
1667 |
Motorcycle gloves |
Active-wear |
19.00 |
1668 |
Sport socks |
Active-wear |
10.00 |
Deleting data from a table
After you become really good at collecting data, your database starts to fill up with the stuff. With hard disk capacities getting bigger all the time, this may not seem like much of a problem. However, although you may never have to worry about filling up your new 6TB (that’s 6,000,000,000,000 bytes) hard disk, the larger your database gets, the slower retrievals become. If much of that data consists of rows that you’ll probably never need to access again, it makes sense to get rid of it. Financial information from the previous fiscal year after you’ve gone ahead and closed the books does not need to be in your active database. You may have to keep such data for a period of years to meet government regulatory requirements, but you can always keep it in an offline archive instead of burdening your active database with it. Additionally, data of a confidential nature may present a legal liability if compromised.
If you no longer need it, get rid of it. With SQL, this is easy to do. First, decide whether you need to archive the data that you are about to delete, and save it in that location. After that is taken care of, deletion can be as simple as this:
DELETE FROM TRANSACTION
WHERE TransDate < '2019-01-01' ;
Poof! All of 2018’s transaction records are gone, and your database is speedy again. You can be as selective as you need to be with the WHERE clause and delete all the records you want to delete — and only the records you want to delete.
Updating views doesn’t make sense
Although ANSI/ISO standard SQL makes it possible to update a view, it rarely makes sense to do so. Recall that a view is a virtual table. It does not have any existence apart from the table or tables that it draws columns from. If you want to update a view, updating the underlying table will accomplish your intent and avoid problems in the process. Problems? What problems? Consider a view that draws salary and commission data from the SALESPERSON table:
CREATE VIEW TOTALPAY (EmployeeName, Pay)
AS SELECT EmployeeName, Salary + Commission AS Pay
FROM SALESPERSON ;
The view TOTALPAY has two columns, EmployeeName and Pay. The virtual Pay column is created by adding the values in the Salary and the Commission columns in the SALESPERSON table. This is fine, as long as you don’t ever need to update the virtual Pay column, like this:
UPDATE TOTALPAY SET Pay = Pay + 100
You may think you are giving all the salespeople a hundred dollar raise. Instead, you are just generating an error message. The data in the TOTALPAY view isn’t stored as such on the system. It is stored in the SALESPERSON table, and the SALESPERSON table does not have a Pay column. Salary + Commission is an expression, and you cannot update an expression.
You’ve seen expressions a couple of times earlier in this minibook. In this case, the expression Salary + Commission is a combination of the values in two columns in the SALESPERSON table. In this case, you don’t really want to update Pay. You probably want to update Salary, since Commission is based on actual sales.
Another source of potential problems can be views that draw data from more than one table. If you try to update such a view, even if expressions are not involved, the database engine may get confused about which of the underlying tables to apply the update to.
The lesson here is that although it is possible to update views, it is generally not a good practice to do so. Update the underlying tables instead, even if it causes you to make a few more keystrokes. You’ll have fewer problems in the long run.
Maintaining Security in the Data Control Language (DCL)
The third major component of SQL performs a function just as important as the functions performed by the DDL and the DML. The Data Control Language consists of statements that protect your precious data from misuse, misappropriation, corruption, and destruction. It would be a shame to go to all the trouble of creating a database and filling it with data critical to your business, and then have the whole thing end up being destroyed. It would be even worse to have the data end up in the possession of your fiercest competitor. The DCL gives you the tools to address all those concerns. I discuss the DCL in detail in Book 4, Chapter 3. For now, here’s an overview of how you can grant people access to a table, revoke those privileges, and find out how to protect your operations with transactions.
Granting access privileges
Most organizations have several different kinds of data with several different levels of sensitivity. Some data, such as the retail price list for your company’s products, doesn’t cause any problems even if everyone in the world can see it. In fact, you probably want everyone out there to see your retail price list. Somebody might buy something. On the other hand, you don’t want unauthorized people to make changes to your retail price list. You might find yourself giving away product for under your cost. Data of a more confidential nature, such as personal information about your employees or customers, should be accessible to only those who have a legitimate need to know about it. Finally, some forms of access, such as the ability to erase the entire database, should be restricted to a very small number of highly trusted individuals.
You have complete control over who has access to the various elements of a database, as well as what level of access they have, by using the GRANT statement, which gives you a fine-grained ability to grant specific privileges to specific individuals or to well-defined groups of individuals.
One example might be
GRANT SELECT ON PRICELIST TO PUBLIC ;
The PUBLIC keyword means everyone. No one is left out when you grant access to the public. The particular kind of access here, SELECT, enables people to retrieve the data in the price list, but not to change it in any way.
Revoking access privileges
If it is possible to grant access to someone, it better be possible to revoke those privileges too. People’s jobs change within an organization, requiring different access privileges than those that were appropriate before the change. An employee may even leave the company and go to a competitor. Privilege revocation is especially important in such cases. The REVOKE statement does the job. Its syntax is almost identical to the syntax of the GRANT statement. Only its action is reversed.
REVOKE SELECT ON PRICELIST FROM PUBLIC ;
Now the pricelist is no longer accessible to the general public.
Preserving database integrity with transactions
Two problems that can damage database integrity are
- System failures: Suppose you are performing a complex, multistep operation on a database when the system goes down. Some changes have been made to the database and others have not. After you get back on the air, the database is no longer in the condition it was in before you started your operation, and it is not yet in the condition you hoped to achieve at the end of your operation. It is in some unknown intermediate state that is almost surely wrong.
- Interactions between users: When two users of the database are operating on the same data at the same time, they can interfere with each other. This interference can slow them both down or, even worse, the changes each makes to the database can get mixed up, resulting in incorrect data being stored.
The common solution to both these problems is to use transactions. A transaction is a unit of work that has both a beginning and an end. If a transaction is interrupted between the beginning and the end, after operation resumes, all the changes to the database made during the transaction are reversed in a ROLLBACK operation, returning the database to the condition it was in before the transaction started. Now the transaction can be repeated, assuming whatever caused the interruption has been corrected.
Transactions can also help eliminate harmful interactions between simultaneous users. If one user has access to a resource, such as a row in a database table, other users cannot access that row until the first user’s transaction has been completed with a COMMIT operation. In Book 4, Chapter 2, I discuss these important issues in considerable detail.