
Chapter 2
Building a Database Model
IN THIS CHAPTER
![]() Finding and listening to interested parties
Finding and listening to interested parties
![]() Building consensus
Building consensus
![]() Building a relational model
Building a relational model
![]() Knowing the dangers of anomalies
Knowing the dangers of anomalies
![]() Avoiding anomalies with normalization
Avoiding anomalies with normalization
![]() Denormalizing with care
Denormalizing with care
Asuccessful database system must satisfy the needs of a diverse group of people. This group includes the folks who’ll actually enter data and retrieve results, but it also includes a host of others. People at various levels of management, for example, may rely on reports generated by the system. People in other functional areas, such as sales or manufacturing, may use the products of the system, such as reports or bar code labels. The information technology (IT) people who set overall data processing standards for the organization may also weigh in on how the system is constructed and the form of the outputs it will produce. When designing a successful database system, consider the needs of all these groups — and possibly quite a few others as well. You’ll have to combine all these inputs into a consensus that database creators call the users’ data model.
Back in Book 1, I mention how important it is to talk to all the possible stakeholders in a project so you can discover for yourself what is important to them. In this chapter, I revisit that topic and go into a bit more depth by discussing specific cases typical of the kinds of concerns that stakeholders might have. The ultimate goal in all this talking is to have the stakeholders arrive at a consensus that they can all support. If you’re going to develop a database system, you want everybody to be in agreement about what that system should be and what it should do, as well as what it should not be and not do.
Finding and Listening to Interested Parties
When you’re assigned the task of building a database system, one of the first things that you must do is determine who all the interested parties are and what their level of involvement is.
Human relations is an important part of your job here. When the views of different people in the organization conflict with each other, as they often do, you have to decide on a path to follow. You cannot simply take the word of the person with the most impressive title. Often unofficial lines of authority in an organization (which are the ones that really count) differ significantly from what the official organization chart might show.
Take into account the opinions and ideas of the person you report to, the database users, the IT organization that governs database projects at the company where you’re doing the project, and the bigwigs who have a stake in the database system.
Your immediate supervisor
Generally, if you are dealing with a medium- to large-sized organization, the person who contacts you about doing the development project is a middle manager. This person typically has the authority to find and recommend a developer for a needed application, but may not have the budget authority to approve the total development cost.
The person who hired you is probably your closest ally in the organization. She wants you to succeed because it will reflect badly on her if you don’t. Be sure that you have a good understanding of what she wants and how important her stated desires are to her. It could be that she has merely been tasked with obtaining a developer and does not have strong opinions about what is to be developed. On the other hand, she may be directly responsible for what the application delivers and may have a very specific idea of what is needed. In addition to hearing what she tells you, you must also be able to read between the lines and determine how much importance she ascribes to what she is saying.
The users
After the manager who hires you, the next group of people you are likely to meet are the future hands-on users of the system you will build. They enter the data that populates the database tables. They run the queries that answer questions that they and others in the organization may have. They generate the reports that are circulated to coworkers and managers. They are the ones who come into closest contact with what you have built.
In general, these people are already accustomed to dealing with the data that will be in your system, or data very much like it. They are either using a manual system, based on paper records, or a computer-based system that your system will replace. In either case, they have become comfortable with a certain look and feel for forms and reports.
 To ease the transition from the old system to the new one you are building, you’ll probably want to make your forms and reports look as much like the old ones as possible. Your system may present new information, but if it’s presented in a familiar way, the users may accept it more readily and start making effective use of it sooner.
To ease the transition from the old system to the new one you are building, you’ll probably want to make your forms and reports look as much like the old ones as possible. Your system may present new information, but if it’s presented in a familiar way, the users may accept it more readily and start making effective use of it sooner.
The people who’ll use your system probably have very definite ideas about what they like and what they don’t like about the system they are currently using. In your new system, you’ll want to eliminate the aspects of the old system that they don’t like, and retain the things they do like. It is critical for the success of your system that the hands-on users like it. Even if your system does everything that the Statement of Requirements (which I tell you about in Chapter 1 of this minibook) specifies, it will surely be a failure if the everyday users just don’t like it. Aside from providing them with what they want, it is also important to build rapport with these people during the development effort. Make sure they agree with what you are doing, every step along the way.
The standards organization
Large organizations with existing software applications have probably standardized on a particular hardware platform and operating system. These choices can constrain which database management system you use because not all DBMSs are available on all platforms. The standards organization may even have a preferred DBMS. This is almost certain to be true if they already support other database applications.
Supporting database applications on an ongoing basis requires a significant infrastructure. That infrastructure includes DBMS software, periodic DBMS software upgrades, training of users, and training of support personnel. If the organization already supports applications based on one DBMS, it makes sense to leverage that investment by mandating that all future database applications use the same DBMS. If the application you have been brought in to create would best be built upon a foundation of a different DBMS, you’re going to have to justify the increased support burden. Often this can be done only if the currently supported DBMS is downright incapable of doing the job.
Aside from your choice of DBMS, the standards people might also have something to say about your coding practices. They might have standards requiring structured programming and modular development, as well as very specific documentation guidelines. Where such standards and guidelines exist, they are usually all to the good. You just have to make sure that you comply with all of them. Your product will doubtless be better for it anyway.
Smaller organizations probably will not have any IT people enforcing data processing standards and guidelines. In those cases, you must act as if you were the IT people. Try to understand what would be best for the client organization in the long term. Make your selection of DBMS, coding style, and documentation with those long-term considerations in mind, rather than what would be most expedient for the current project. Be sure that your clients are aware of why you make the choices you do. They may want to participate in the decision, and at any rate, will appreciate the fact that you have their long-term interests at heart.
Upper management
Unless you’re dealing with a very small organization, the manager who hired you for this project is not the highest-ranking person who has an interest in what you’ll be producing. It’s likely that the manager with whom you are dealing must carry your proposals to a higher level for approval. It’s important to find out who that higher-up is and get a sense of what he wants your application to accomplish for the organization. Be aware that this person may not carry the most prestigious title in the organization, and may not even be on a direct line on the company organization chart to the person who hired you. Talk to the troops on the front line, the people who’ll actually be using your application. They can tell you where the real power resides. After you find out what is most important to this key person, make sure that it’s included in the final product.
Building Consensus
The interested parties in the application you are developing are called stakeholders, and you must talk to at least one representative of each group.
Just so you know: After you talk to them, you’re likely to be confused. Some people insist that one feature is crucial and they don’t care about a second feature. Others insist that the second feature is very important and won’t even mention the first. Some will want the application to look and act one way, and others will want an entirely different look and feel. Some people consider one particular report to be the most important thing about the application, and other people don’t care about reports at all, but only about the application’s ad hoc query ability. It’s just not practical to expect everyone in the client organization to want the same things and to ascribe the same levels of importance to those things.
Your job is to bring some order out of this chaos. You’ll have to transform all these diverse points of view into a consensus that everyone can agree upon. This requires compromise on the part of the stakeholders. You want to build an application that meets the needs of the organization in the best possible way.
Gauging what people want
As the developer, it should not be your job to resolve conflicts among the stakeholders regarding what the proposed system should do. However, as the technical person who is building it and has no vested interest in exactly what it should look like or what it should do, you may be the only person who can break the gridlock. This means that negotiating skills are a valuable addition to your toolkit of technical know-how.
Find out who cares passionately about what the system will provide, and whose opinions carry the most weight. The decisions that are ultimately made about project scope, functionality, and appearance will affect the amount of time and budget that will be needed to complete development.
Arriving at a consensus
Somehow, the conflicting input you receive from all the stakeholders must be combined into a uniform vision of what the proposed system should be and do. You may need to ask disagreeing groups of people to sit down together and arrive at a compromise that is at least satisfactory to all, if not everything they had wished for.
To specify a system that can be built within the time and budget constraints that have been set out for the project, some people may have to give up features they would like to have, but which are not absolutely necessary. As an interested but impartial outsider, you may be able to serve as a facilitator in the discussion.
After the stakeholders have agreed upon what they want the new database system to do for them, you need to transform this consensus into a model that represents their thinking. The model should include all the items of interest. It should describe how these items relate to each other. It should also describe in detail the attributes of the items of interest. This users’ data model will be the basis for a more formal Entity-Relationship (ER) model that you will then convert into a relational model. I cover both the users’ data model and the ER model in Chapter 2 of Book 1.
Building a Relational Model
Newcomers to database design sometimes get confused when listening to old-timers talk. This is due to the historical fact that those old-timers come out of three distinct traditions, each with its own set of terms for things. The three traditions are the relational tradition, the flat file tradition, and the personal computer tradition.
Reviewing the three database traditions
The relational tradition had its beginnings in a paper published in 1970 by Dr. E.F. Codd, who was at that time employed by IBM. In that paper, Dr. Codd gave names to the major constituents of the relational model. The major elements of the relational model correspond closely to the major elements of the ER model (see Book 1, Chapter 2), making it fairly easy to translate one into the other.
In the relational model, items that people can identify and that they consider important enough to track are called relations. (For those of you keeping score, relations in the relational model are similar to entities in the ER model. Relations have certain properties, called attributes, which correspond to the attributes in the ER model.)
Relations can be represented in the form of two-dimensional tables. Each column in the table holds the information about a single attribute. The rows of the table are called tuples. Each tuple corresponds to an individual instance of a relation. Figure 2-1 shows an example of a relation, with attributes and tuples. Attributes are the columns: Title, Author, ISBN, and Pub. Date. The tuples are the rows.
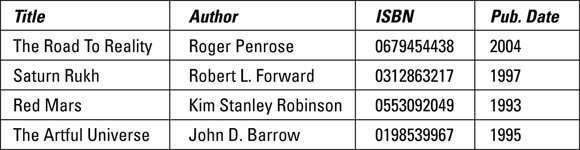
FIGURE 2-1: The BOOK relation.
I mentioned that current database practitioners come out of three different traditions, the relational tradition being one of them. A second group consists of people who were dealing with flat files before the relational model became popular. Their terms files, fields, and records correspond to what Dr. Codd called relations, attributes, and tuples. The third group, the PC community, came to databases by way of the electronic spreadsheet. They used the spreadsheet terms tables, columns, and rows, to mean the same things as files, fields, and records. Table 2-1 shows how to translate terminology from the three segments of the database community.
TABLE 2-1 Describing the Elements of a Database
Relational community says … |
Relation |
Attribute |
Tuple |
Flat-file community says … |
File |
Field |
Record |
PC community says … |
Table |
Column |
Row |
Don’t be surprised if you hear database veterans mix these terms in the course of explaining or describing something. They may use them interchangeably within a single sentence. For example, one might say, “The value of the TELEPHONE attribute in the fifth record of the CUSTOMER table is Null.”
Knowing what a relation is
Despite the casual manner in which database old-timers use the words relation, file, and table interchangeably, a relation is not exactly the same thing as a file or table. Relations were defined by a database theoretician, and thus the definition is very precise. The words file and table, on the other hand, are in general use and are often much more loosely defined. When I use these terms in this book, I mean them in the strict sense, as alternates for relation. That said, what’s a relation? A relation is a two-dimensional table that must satisfy all the following criteria:
- Each cell in the table must contain a single value, if it contains a value at all.
- All the entries in any column must be of the same kind. For example, if a column contains a telephone number in one row, it must contain telephone numbers in all rows that contain a value in that column.
- Each column has a unique name.
- The order of the columns is not significant.
- The order of the rows is not significant.
- No two rows can be identical.
 A table qualifies as a relation if and only if it meets all the above criteria. A table that fails to meet one or more of them might still be considered a table in the loose sense of the word, but it is not a relation, and thus not a table in the strict sense of the word.
A table qualifies as a relation if and only if it meets all the above criteria. A table that fails to meet one or more of them might still be considered a table in the loose sense of the word, but it is not a relation, and thus not a table in the strict sense of the word.
Functional dependencies
Functional dependencies are relationships between or among attributes. For example, two attributes of the VENDOR relation are State and Zipcode. If you know a vendor’s zip code, you can determine the vendor’s state by a simple table lookup because each zip code appears in only one state. Therefore, State is functionally dependent on Zipcode. Another way of describing this situation is to say that Zipcode determines State, thus Zipcode is a determinant of State. Functional dependencies are shown diagrammatically as follows:
Zipcode ⇒ State (Zipcode determines State)
Sometimes, a single attribute may not be a determinant, but when it is combined with one or more other attributes, the group of them collectively is a determinant. Suppose you receive a bill from your local department store. It would list the bill number, your customer number, what you bought, how many you bought, the unit price, and the extended price for all of them. The bill you receive represents a row in the BILLS table of the store’s database. It would be of the form
BILL(BillNo, CustNo, ProdNo, ProdName, UnitPrice, Quantity, ExtPrice)
The combination of UnitPrice and Quantity determines ExtPrice.
(UnitPrice, Quantity) ⇒ ExtPrice
Thus, ExtPrice is functionally dependent upon UnitPrice and Quantity.
Keys
A key is a group of one or more attributes that uniquely identifies a tuple in a relation. For example, VendorID is a key of the VENDOR relation. VendorID determines all the other attributes in the relation. All keys are determinants, but not all determinants are keys. In the BILL relation, (UnitPrice, Quantity) is a determinant because it determines ExtPrice. However, (UnitPrice, Quantity) is not a key. It does not uniquely identify its tuple because another line in the relation might have the same values for Price and Quantity. The key of the BILL relation is BillNo, which identifies one particular bill.
Sometimes it is hard to tell whether a determinant qualifies as a key. In the BILL case, I consider BillNo to be a key, based on the assumption that bill numbers are not duplicated. If this assumption is valid, BillNo is a unique identifier of a bill and qualifies as a key. When you are defining the keys for the relations that you build, you must make sure that your keys uniquely identify each tuple (row) in the relation. Often you don’t have to worry about this because your DBMS will automatically assign a unique key to each row of the table as it is added.
Being Aware of the Danger of Anomalies
Just because a database table meets the qualifications to be a relation does not mean that it is well designed. In fact, bad relations are incredibly easy to create. By a bad relation, I mean one prone to errors or confusing to users. The best way to illustrate a bad relation is to show you an example.
Suppose an automotive service shop specializes in transmissions, brakes, and suspension systems. Let’s say that Tyson is the lead mechanic for transmissions, Dave is the lead mechanic for brakes, and Keith is the lead mechanic for suspension systems. Tyson works out of the Alabama Avenue location, Dave works at the Perimeter Road shop, and Keith operates out of the Main Street garage. You could summarize this information with a relation MECHANICS, as shown in Figure 2-2.
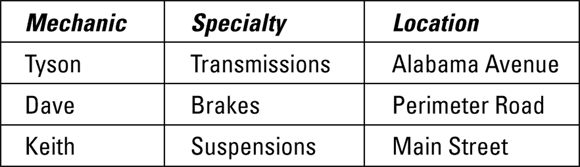
FIGURE 2-2: The MECHANICS relation.
This table qualifies as a relation, for the following reasons. Each cell contains only one value. All entries in each column are of the same kind — all names, or all specialties, or all locations. Each column has a unique name. The order of the columns and rows is not significant. If the order were changed, no information would be lost. And finally, no two rows are identical.
So what’s the problem? Problems can arise when things change, and things always change, sooner or later. Problems caused by changes are known as modification anomalies and come in different types, two of which I describe here:
- Deletion anomaly: You lose information that you don’t want to lose, as a result of a deletion operation. Suppose that Dave decides to go back to school and study computer science. When he quits his job, you can delete the second row in the table shown in Figure 2-2. If you do, however, you lose more than the fact that Dave is the brakes mechanic. You also lose the fact that brake service takes place at the Perimeter Road location.
- Insertion anomaly: You can insert new data only when other data is included with it. Suppose you want to start working on engines at the Alabama Avenue facility. You cannot record that fact until an engine mechanic is hired to work there. This is an insertion anomaly. Because Mechanic is the key to this relation, you cannot insert a new tuple into the relation unless it has a value in the Mechanic column.
If modification anomalies are even remotely possible in a database, more than likely they’re going to occur. If they occur, they can seriously degrade a database’s usefulness. They may even cause users to draw incorrect conclusions from the results of queries they pose to the database.
Eliminating anomalies
When Dr. Codd created the relational model, he recognized the possibility of data corruption due to modification anomalies. To address this problem, he devised the concept of normal forms. Each normal form is defined by a set of rules, similar to the rules stated previously for qualification as a relation. Anything that follows those particular rules is a relation, and by definition is in First Normal Form (1NF). Subsequent normal forms add progressively more qualifications. As I discuss in the preceding section, tables in 1NF are subject to certain modification anomalies. Codd’s Second Normal Form (2NF) removes these anomalies, but the possibility of others still remains. Codd foresaw some of those anomalies and defined Third Normal Form (3NF) to deal with them. Subsequent research uncovered the possibility of progressively more obscure anomalies, and a succession of normal forms was devised to eliminate them. Boyce-Codd Normal Form (BCNF), Fourth Normal Form (4NF), Fifth Normal Form (5NF), and Domain/Key Normal Form (DKNF) provide increasing levels of protection against modification anomalies.
It is instructive to look at the normal forms to gain an insight into the kinds of anomalies that can occur, and how normalization eliminates the possibility of such anomalies.
For a relation to be in Second Normal Form, every nonkey attribute must be dependent on the entire key.
To start, consider the Second Normal Form. Suppose Tyson receives certification to repair brakes and spends some of his time at the Perimeter Road garage fixing brakes as well as continuing to do his old job repairing transmissions at the Alabama Avenue shop. This leads to the table shown in Figure 2-3.

FIGURE 2-3: The modified MECHANICS relation.
This table still qualifies as a relation, but the Mechanic column no longer is a key because it does not uniquely determine a row. However, the combination of Mechanic and Specialty does qualify as a determinant and as a key.
(Mechanic, Specialty) ⇒ Location
This looks fine, but there is a problem. What if Tyson decides to work full time on brakes, and not fix transmissions any longer. If I delete the Tyson/Transmissions/Alabama row, I not only remove the fact that Tyson works on transmissions, but also lose the fact that transmission work is done at the Alabama shop. This is a deletion anomaly. This problem is caused by the fact that Specialty is a determinant, but is not a key. It is only part of a key.
Specialty ⇒ Location
I can meet the requirement of every nonkey attribute depending on the entire key by breaking up the MECHANICS relation into two relations, MECH-SPEC and SPEC-LOC. This is illustrated in Figure 2-4.
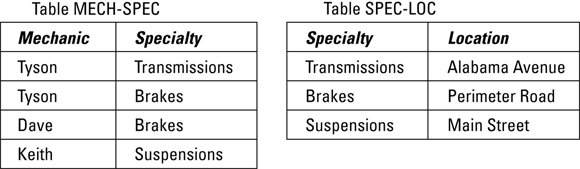
FIGURE 2-4: The MECHANICS relation has been broken into two relations, MECH-SPEC and SPEC-LOC.
The old MECHANICS relation had problems because it dealt with more than one idea. It dealt with the idea of the specialties of the mechanics, and it also dealt with the idea of where various specialties are performed. By breaking the MECHANICS relation into two, each one of which deals with only one idea, the modification anomalies disappear. Mechanic and Specialty together comprise a composite key of the MECH-SPEC relation, and all the nonkey attributes depend on the entire key because there are no nonkey attributes. Specialty is the key of the SPEC-LOC relation, and all of the nonkey attributes (Location) depend on the entire key, which in this case is Specialty. Now if Tyson decides to work full time on brakes, the Tyson/Transmissions row can be removed from the MECH-SPEC relation. The fact that transmission work is done at the Alabama garage is still recorded in the SPEC-LOC relation.
To qualify as being in second normal form, a relation must qualify as being in first normal form, plus all non-key attributes must depend on the entire key. MECH-SPEC and SPEC-LOC both qualify as being in 2NF.
A relation in Second Normal Form could still harbor anomalies. Suppose you are concerned about your cholesterol intake and want to track the relative levels of cholesterol in various foods. You might construct a table named LIPIDLEVEL such as the one shown in Figure 2-5.

FIGURE 2-5: The LIPIDLEVEL relation.
This relation is in First Normal Form because it satisfies the requirements of a relation. And because it has a single attribute key (FoodItem), it is automatically in Second Normal Form also — all nonkey attributes are dependent on the entire key.
Nonetheless, there is still the chance of an anomaly. What if you decide to eliminate all beef products from your diet? If you delete the Beefsteak row from the table, you not only eliminate beefsteak, but you also lose the fact that red meat is high in cholesterol. This fact might be important to you if you are considering substituting some other red meat such as pork, bison, or lamb for the beef you no longer eat. This is a deletion anomaly. There is a corresponding insertion anomaly. You cannot add a FoodType of Poultry, for example, and assign it a Cholesterol value of High until you actually enter in a specific FoodItem of the Poultry type.
The problem this time is once again a matter of keys and dependencies. FoodType depends on FoodItem. If the FoodItem is Apple, the FoodType must be Fruit. If the FoodItem is Salmon, the FoodType must be Fish. Similarly, Cholesterol depends on FoodType. If the FoodType is Egg, the Cholesterol value is Very High. This is a transitive dependency — called thus because one item depends on a second, which in turn depends on a third.
FoodItem ⇒ FoodType ⇒ Cholesterol
Transitive dependencies are a source of modification anomalies. You can eliminate the anomalies by eliminating the transitive dependency. Breaking the table into two tables, each one of which embodies a single idea, does the trick. Figure 2-6 shows the resulting tables, which are now in Third Normal Form (3NF). A relation is in 3NF if it qualifies as being in 2NF and in addition has no transitive dependencies.

FIGURE 2-6: The ITEM-TYPE relation and the TYPE-CHOL relation.
Now if you delete the Beefsteak row from the ITEM-TYPE relation, the fact that red meat is high in cholesterol is retained in the TYPE-CHOL relation. You can add poultry to the TYPE-CHOL relation, even though you don’t have a specific type of poultry in the ITEM-TYPE relation.
Examining the higher normal forms
Boyce-Codd Normal Form (BCNF), Fourth Normal Form (4NF), and Fifth Normal Form (5NF) each eliminate successively more obscure types of anomalies. In all likelihood, you might never encounter the types of anomalies they remove. There is one higher normal form, however, that is worth discussing: the Domain/Key Normal Form (DKNF), which is the only normal form that guarantees that a database contains no modification anomalies. If you want to be absolutely certain that your database is anomaly-free, put it into DKNF.
Happily, Domain/Key Normal Form is easier to understand than most of the other normal forms. You need to understand only three things: constraints, keys, and domains.
A relation is in Domain/Key Normal Form if every constraint on the relation is a logical consequence of the definition of keys and domains:
- A constraint is a rule that restricts the static values that attributes may assume. The rule must be precise enough for you to tell whether the attribute follows the rule. A static value is one that does not vary with time.
- A key is a unique identifier of a tuple.
- The domain of an attribute is the set of all values that the attribute can take.
If enforcing key and domain restrictions on a table causes all constraints to be met, the table is in DKNF. It is also guaranteed to be free of all modification anomalies.
As an example of putting a table into DKNF, look again at the LIPIDLEVEL relation in Figure 2-5. You can analyze it as follows:
- LIPIDLEVEL(FoodItem, FoodType, Cholesterol)
- Key: FoodItem
- Constraints: FoodItem ⇒ FoodType
- FoodType ⇒ Cholesterol
- Cholesterol level may be (None, Low, Medium, High, Very High)
This relation is not in DKNF. It is not even in 3NF. However, you can put it into DKNF by making all constraints a logical consequence of domains and keys. You can make the Cholesterol constraint a logical consequence of domains by defining the domain of Cholesterol to be (None, Low, Medium, High, Very High). The constraint FoodItem ⇒ FoodType is a logical consequence of keys because FoodItem is a key. Those were both easy. One more constraint to go! You can handle the third constraint by making FoodType a key. The way to do this is to break the LIPIDLEVEL relation into two relations, one having FoodItem as its key and the other having FoodType as its key. This is exactly what I did in Figure 2-6. Putting LIPIDLEVEL into 3NF put it into DKNF at the same time.
Every relation in DKNF is, by necessity, also in 3NF. However, the reverse is not true. A relation can be in 3NF and not satisfy the criteria for DKNF.
Here is the new description for this system:
- Domain Definitions:
- FoodItem in CHAR(30)
- FoodType in CHAR(30)
- Cholesterol level may be (None, Low, Medium, High, Very High)
- CHAR(30) defines the domain of FoodItem and also of FoodType, stating that they may be character strings up to 30 characters in length. The domain of cholesterol has exactly five values, which are None, Low, Medium, High, and Very High.
- Relation and Key Definitions:
- ITEM-TYPE (FoodItem, FoodType)
- Key: FoodItem
- TYPE-CHOL (FoodType, Cholesterol)
- Key: FoodType
All constraints are a logical consequence of keys and domains.
The Database Integrity versus Performance Tradeoff
In the previous section, I talk about some of the problems that can arise with database relations, and how they can be solved through normalization. I point out that the ultimate in normalization is Domain/Key Normal Form, which provides solid protection from the data corruption that can occur due to modification anomalies. It might seem that whenever you create a database, you should always put all its tables into DKNF. This, however, is not true.
When you guarantee a database’s freedom from anomalies by putting all its tables into DKNF, you do so at a cost. Why? When you make your original unnormalized design, you group attributes together into relations because they have something in common. If you normalize some of those tables by breaking them into multiple tables, you are separating attributes that would normally be grouped together. This can degrade your performance on retrievals if you want to use those attributes together. You’ll have to combine these now-separated attributes again before proceeding with the rest of the retrieval operation.
Consider an example. Suppose you are the secretary of a club made up of people located all around the United States who share a hobby. It is your job to send them a monthly newsletter as well as notices of various sorts. You have a database consisting of a single relation, named MEMBERS.
- MEMBERS(MemID, Fname, Lname, Street, City, State, Zip)
- Key: MemID
- Functional Dependencies:
- MemID ⇒ all nonkey attributes
- Zip ⇒ State
This relation is not in DKNF because State is dependent on Zip and Zip is not a key. If you know a person’s zip code, you can do a simple table lookup and you’ll know what state that person lives in.
You could put the database into DKNF by breaking the MEMBERS table into two tables as follows:
- MEM-ZIP(MemID, Fname, Lname, Street, City, Zip)
- ZIP-STATE(Zip, State)
MemID is the key of MEM-ZIP and Zip is the key of ZIP-STATE. The database is now in DKNF, but consider what you have gained and what you have lost:
What you have gained: In MEMBERS, if I delete the last club member in zip code 92027, I lose the fact that zip code 92027 is in California. However, in the normalized database, that information is retained in ZIP-STATE when the last member with that zip code is removed from MEM-ZIP.
In MEMBERS, if you want to add the fact that zip code 07110 is in New Jersey, you can’t, until you have a member living in that zip code. The normalized database handles this nicely by allowing you to add that state and zip code to ZIP-STATE, even though no members in the MEM-ZIP table live there.
- What you have lost: Because the primary purpose of this database is to facilitate mailings to members, every time a mailing is made, the MEM-ZIP table and the ZIP-STATE table have to be joined together to generate the mailing labels. This is an extra operation that would not be needed if the data were all kept in a single MEMBERS table.
- What you care about: Considering the purpose of this database, the club secretary probably doesn’t care what state a particular zip code is in if the club has no members in that zip code. She also probably doesn’t care about adding zip codes where there are no members. In this case, both of the gains from normalization are of no value to the user. However, the cost of normalization is a genuine penalty. It will take longer for the address labels to print out based on the data in the normalized database than it would if they were stored in the unnormalized MEMBERS table. For this case, and others like it, normalization to DKNF does not make sense.