
Chapter 1
Protecting Against Hardware Failure and External Threats
IN THIS CHAPTER
![]() Dealing with trouble in paradise
Dealing with trouble in paradise
![]() Maintaining database integrity
Maintaining database integrity
![]() Enhancing performance and reliability with RAID
Enhancing performance and reliability with RAID
![]() Averting disaster with backups
Averting disaster with backups
![]() Defending against Internet threats
Defending against Internet threats
![]() Piling on layers of protection
Piling on layers of protection
Database applications are complex pieces of software that interact with databases, which in turn are complex collections of data that run on computer systems, which in their own right are complex assemblages of hardware components. The more complex something is, the more likely it is to have unanticipated failures. That being the case, a database application is an accident waiting to happen. With complexity piled upon complexity, not only is something sure to go wrong, but also, when it does, you’ll have a hard time telling where the problem lies.
Fortunately, you can do some things to protect yourself against these threats. The protections require you to spend time and money, of course, but you must evaluate the trade-off between protection and expense to find a level of protection you are comfortable with at a cost you can afford.
What Could Possibly Go Wrong?
Problems can arise in several areas. Here are a few:
- Your database could be structured incorrectly, making modification anomalies inevitable. Modification anomalies, remember, are inconsistencies introduced when changes are made to the contents of a database.
- Data-entry errors could introduce bad data into the database.
- Users accessing the same data at the same time could interfere with one another.
- Changes in the database structure could “break” existing database applications.
- Upgrading to a new operating system could create problems with existing database applications.
- Upgrading system hardware could “break” existing database applications.
- Posing a query that has never been asked before could expose a hidden bug.
- An operator could accidentally destroy data.
- A malicious person could intentionally destroy or steal data.
- Hardware could age or wear out and fail permanently.
- An environmental condition such as overheating or a stray cosmic ray could cause a “soft” error that exists long enough to alter data and then disappear. (These types of errors are maddening.)
- A virus or worm could arrive over the Internet and corrupt data.
From the preceding partial list, you can clearly see that protecting your data can require a significant effort, which you should budget for adequately while planning a database project. In this chapter, I highlight hardware issues and malicious threats that arrive over the Internet. I address the other concerns in the next chapter.
Equipment failure
Great strides have been made in recent years toward improving the reliability of computer hardware, but we’re still a long way from perfect hardware that will never fail. Anything with moving parts is subject to wear and tear. As a consequence, such devices fail more often than do devices that have no moving parts. Hard drives, CD-ROM drives, and DVD-ROM drives all depend on mechanical movement and, thus, are possible points of failure. So are cooling fans and even on/off switches. Cables and connectors — such as USB ports and audio or video jacks that are frequently inserted and extracted — are also liable to fail before the nonmoving parts do.
Even devices without moving parts, such as solid state drives or processor chips can fail due to overheating or carrying electrical current for too long. Also, anything can fail if it’s physically abused (dropped, shaken, or drenched with coffee, for example).
You can do several things to minimize, if not eliminate, problems caused by equipment failure. Here are a few ideas:
Check the specifications of components with moving parts, such as hard drives and DVD-ROM drives, and pick components with a high mean time between failures (MTBF).
 Do some comparison shopping. You’ll find a range of values. When you’re shopping for a hard drive, for example, the number of gigabytes per dollar shouldn’t be the only thing you look at.
Do some comparison shopping. You’ll find a range of values. When you’re shopping for a hard drive, for example, the number of gigabytes per dollar shouldn’t be the only thing you look at.- Make sure that your computer system has adequate cooling. It’s especially important that the processor chips have sufficient cooling, because they generate enormous amounts of heat.
- Buy memory chips with a high MTBF.
- Control the environment where your computer is located. Make sure that the computer gets adequate ventilation and is never subjected to high temperatures. If you cannot control the ambient temperature, turn the system off when the weather gets too hot. Humans can tolerate extreme heat better than computers can.
- Isolate your system from shock and vibration.
- Establish a policy that prohibits liquids such as coffee, or even water, from being anywhere near the computer.
- Restrict access to the computer so that only those people who agree to your protection rules can come near it.
Platform instability
What’s a platform? A platform is the system your database application is running on. It includes the operating system, the basic input/output subsystem (BIOS), the processor, the memory, and all the ancillary and peripheral devices that make up a functioning computer system.
Platform instability is a fancy way of saying that you cannot count on your platform to operate the way it is supposed to. Sometimes, this instability is due to an equipment failure or an impending equipment failure. At other times, instability is due to an incompatibility introduced when one or another element in the system is changed.
Because of the danger of platform instability, many database administrators (DBAs) are extremely reluctant to upgrade when a new release of the operating system or a larger, higher-capacity hard drive becomes available. The person who coined the phrase “If it ain’t broke, don’t fix it” must have been a database administrator. Any change in a happily functioning system is liable to cause platform instability, so DBAs resist such changes fiercely, allowing them grudgingly only when it becomes clear that important work cannot be performed without the upgrade.
So how do you protect against platform instability, aside from forbidding any changes in the platform? Here are a few things you can do to protect yourself:
- Install the upgrade when nothing important is running and nothing important is scheduled to be run for several days. (Yes, this means coming in on the weekend.)
- Change only one thing at a time, and deal with any issues that arise before making another change that could interact with the first change.
- Warn users before you make a configuration change so that they can protect themselves from any possible adverse consequences.
- If you can afford to do so, bring up the new environment on a parallel system, and switch over your production work only when it’s clear that the new system has stabilized.
- Make sure everything is backed up before making any configuration change.
Database design flaws
The design of robust, reliable, and high-performing databases is a topic that goes beyond SQL and is worthy of a book in its own right. I recommend my Database Development For Dummies (published by Wiley). Many problems that show up long after a database has been placed in service can be traced back to faulty design at the beginning. It’s important to get database design right from the start. Give the design phase of every development project the time and consideration it deserves.
Data-entry errors
It’s really hard to draw valid conclusions from information retrieved from a database if faulty data was entered in the database to begin with. Book 1, Chapter 5 describes how to enter data into a database with SQL’s INSERTUPDATE statement. If a person is entering a series of such statements, keyboarding errors are a real possibility. Even if you’re entering records through a form that does validation checks on what you enter, mistypes are still a concern. Entered data can be valid but nonetheless incorrect. Although 0 through 9 are all valid decimal digits, if a field is supposed to contain 7, 6 is just as wrong as Tuesday. The best defense against data-entry errors is to have someone other than the person who entered the data check it against the source document.
Operator error
People make mistakes. You can try to minimize the impact of such mistakes by making sure that only intelligent, highly trained, and well-meaning people can get their hands on the database, but even the most intelligent, highly trained, and well-meaning people make mistakes from time to time, and sometimes those mistakes destroy data or alter it in a way that makes it unusable.
Your best defense against such an eventuality is a robust and active backup policy, which I discuss in “Backing Up Your System,” later in this chapter.
Taking Advantage of RAID
Equipment failure is one of the things that can go wrong with your database. Of all the pieces of equipment that make up a computer system, the one piece that’s most likely to fail is the hard drive. A motor is turning a spindle at 7,000 to 10,000 revolutions per minute. Platters holding data are attached to the spindle and spinning with it. Read/write heads on cantilevers are moving in and out across the platter surfaces. Significant heat is generated by the motor and the moving parts. Sooner or later, wear takes its toll, and the hard drive fails. When it does, whatever information it contained becomes unrecoverable.
Disk failures are inevitable; you just don’t know when they will occur. You can do a couple of things, however, to protect yourself from the worst consequences of disk failure:
- Maintain a regular backup discipline that copies production data at intervals and stores it in a safe place offline.
- Put some redundancy in the storage system by using RAID (Redundant Array of Independent Disks).
RAID technology has two main advantages: redundancy and low cost. The redundancy aspect gives the system a measure of fault tolerance. The low-cost aspect comes from the fact that several disks with smaller capacities are generally cheaper than a single disk of the same capacity, because the large single disk is using the most recent, most advanced technology and is operating on the edge of what is possible. In fact, a RAID array can be configured to have a capacity larger than that of the largest disk available at any price.
In a RAID array, two or more disks are combined to form a logical disk drive. To the database, the logical disk drive appears to be a single unit, although physically, it may be made up of multiple disk drives.
Striping
A key concept of RAID architecture is striping — spreading data in chunks across multiple disks. One chunk is placed on the first disk, the next chunk is placed on the next disk, and so on. After a chunk is placed on the last disk in the array, the next chunk goes on the first disk, and the cycle starts over. In this way, the data is evenly spread across all the disks in the array, and no single disk contains anything meaningful. In a five-disk array, for example, each disk holds one fifth of the data. If the chunks are words in a text file, one disk holds every fifth word in the document. You need all of the disks to put the text back together again in readable form.
Figure 1-1 illustrates the idea of striping.
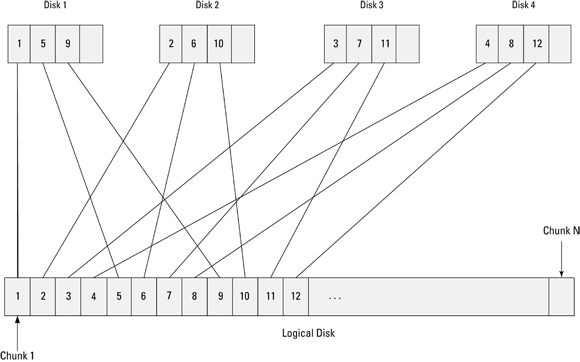
FIGURE 1-1: RAID striping.
In Figure 1-1, chunks 1, 2, 3, and 4 constitute one stripe; chunks 5, 6, 7, and 8 constitute the next stripe, and so on. A stripe is made up of contiguous chunks on the logical drive, but physically, each chunk is on a different hard drive.
RAID levels
There are several levels of RAID, each with its own advantages and disadvantages. Depending on your requirements, you may decide to use one RAID level for some of your data and another RAID level for data that has different characteristics.
When deciding which RAID level is appropriate for a given database and its associated applications, performance, fault tolerance, and cost are the main considerations. Table 1-1 shows the comparison of these metrics in the most commonly used RAID levels.
TABLE 1-1 RAID Level Comparison
RAID Level |
Performance |
Fault Tolerance |
Disk Capacity/Data Size |
RAID 0 |
Best: One disk access per write |
Worst: None |
Best: 1 |
RAID 1 |
Good: Two disk accesses per write |
Good: No degradation with single failure |
Worst: 2 |
RAID 5 |
Fair: Four disk accesses per write |
Fair: Full recovery possible |
Good: N/(N–1) |
RAID 10 |
Good: Two disk accesses per write |
Excellent: No degradation with multiple failures |
Worst: 2 |
In the following sections, I briefly discuss these RAID levels.
RAID 0
RAID 0 is the simplest of the RAID levels. A round-robin method distributes data across all the disks in the array in a striped fashion. Striping enhances performance because multiple disks can perform seeks in parallel rather than sequentially, as would be the case with a single large disk. RAID 0 offers no fault tolerance or redundancy, however. If you lose any one disk in the array, you lose all your data. The data remaining on the disks that are still functioning is of no use without the missing chunks. It’s as though, in a five-disk array, every fifth word of a text document is missing or every fifth reservation in an airline reservation system has disappeared. Reality is even worse than these examples, because the chunks typically don’t match text words or database records exactly, and what remains is unintelligible.
Although it increases performance, RAID 0 provides no benefit over running on a non-RAID disk in terms of fault tolerance. It’s not wise to put mission-critical data on a RAID 0 array.
RAID 1
RAID 1 is the simplest of the fault-tolerant RAID levels. It doesn’t employ striping. Also known as disk mirroring, RAID 1 duplicates the content of one disk on a second disk. Performance is somewhat worse than the performance of a non-RAID disk because every write operation has to go to two disks rather than one. A second disadvantage is that you use two hard disks to hold one hard disk’s worth of data, which doubles your disk cost.
The benefit of RAID 1 is in the area of fault tolerance. If either of the mirrored disks fails, the other one contains all the data, and performance is unaffected. You can replace the failed disk and fill it with data to match the surviving disk and return to the same level of fault tolerance you had at the beginning.
RAID 1 is a good choice when both fault tolerance and performance are important, when all your data will fit on a single disk drive, and when cost is not a primary concern.
RAID 5
RAID 5 uses parity rather than data duplication to achieve fault tolerance. In an array of, say, six physical disks, each stripe consists of five data chunks and one parity chunk. If any of the physical drives fails, its contents can be deduced from the information on the other five drives. The advantage of RAID 5 is that the space available to hold data is N–1, where N is the number of disk drives. This compares favorably with RAID 1, where the space available to hold data is N/2. A six-drive RAID 5 array holds up to five disks full of data. Three two-drive RAID 1 arrays hold only up to three disks full of data. You pay a performance penalty for the additional capacity. In a RAID 5 system, every write operation requires four disk accesses: two reads and two writes. Both the target disk stripe and the parity stripe must be read and the parity calculated, and then both stripes must be written.
Because of the performance penalty RAID 5 exacts on writes, RAID 5 isn’t a good choice for disks that are written to often. RAID 5 is fine for databases that are read-only or read-mostly. If more than 10 percent of disk operations are writes, RAID 5 probably isn’t the best choice.
RAID 10
RAID 10 combines aspects of RAID 0 and RAID 1. Like RAID 1, RAID 10 mirrors disks. Each disk has an exact duplicate. Like RAID 0, the disks in the array are striped. RAID 10 provides the fault tolerance of RAID 1 and the performance of RAID 0. A RAID 10 array can consist of a large number of disks, so it’s a good level to use when a large amount of data is being stored. It’s also good from a fault-tolerance point of view because it can tolerate the loss of more than one disk, although it cannot handle the loss of both members of a mirror pair.
Backing Up Your System
Fault tolerance, as described in the preceding section on RAID and also as implemented with redundant hardware that goes beyond RAID, responds to some — but not all — of the threats listed at the beginning of this chapter. The most effective defense you have against the full spectrum of potential problems is an effective backup procedure. Backing up means making copies of all your important programs and data as often as necessary so that you can easily and quickly regain full functionality after some misfortune corrupts or destroys your system. The means you employ to protect your assets depend on how critical your application is.
Preparation for the worst
On September 11, 2001, a terrorist attack destroyed the twin towers of the World Trade Center in lower Manhattan. Along with the lives of thousands of people, the financial hub of the American economy was snuffed out. Virtually all of America’s major financial institutions, including the New York Board of Trade (NYBOT), had their center of operations in the World Trade Center. The lives that were lost that day were gone for good. Within hours, however, the NYBOT was up and running again, hardly missing a beat. This was possible because the NYBOT had prepared for the worst. It had implemented the most effective (and most expensive) form of backup. It continuously sent its information offsite to a hot site in Queens. (A hot site, as compared to one at a lower “temperature,” is always powered up and on standby, ready to take over if the need arises.) The hot site was close enough so that employees who had evacuated the World Trade Center could get to it quickly and start the recovery effort, yet far enough away that it wasn’t affected by the disaster.
Many companies and government entities can justify the investment in the level of backup employed by the NYBOT. That investment was made because analysis showed that downtime would cost the NYBOT and its clients close to $4 million a day. For enterprises in which downtime isn’t so costly, a lesser investment in backup is justified, but if loss of your data or programs would cause you any pain at all, some level of backup is called for. This backup may be no more than copying your active work onto a thumb drive every night after work and taking it home with you. It could mean putting removable hard disks in a fireproof safe in another building. It could mean distributing copies of your data to remote sites over your corporate network.
In choosing a backup method, think carefully about what your threats are; what losses are possible; what the consequences of those losses are; and what investment in backup is justified in light of those threats, losses, and consequences.
Full or incremental backup
Perhaps only 1MB or 2MB of data that you’re actively working with would cause pain if you were to lose them. Alternatively, you may have a critical database in the terabyte (TB) range. In the first case, it won’t take much time for you to back up the entire database and remove the backup copy to a safe place. On the other hand, you probably don’t want to back up a 10TB database completely several times a day or even once a day.
The size of your database, the speed of your backup procedure, and the cost of your backup medium dictate whether you implement a full backup procedure or back up only the changes that have been made since the last backup. Backing up only the changes is called incremental backup. When a failure occurs, you can go back to your last full backup and then restore all the incremental backups that followed it one by one.
Frequency
A big question about backup is “How often should I do it?” I answer that question with another question: “How much pain are you willing to endure if you were to suddenly and unexpectedly lose your data?” If you don’t mind redoing a couple of hours of work, there’s no point in backing up more frequently than every couple of hours. Many organizations perform backups at night, after the workers have gone home for the day. These organizations run the risk of losing no more than a day’s work.
Think carefully about your total situation and what effect data loss could have on you; then choose an appropriate backup interval.
 Be sure to adhere to your backup schedule without fail. Long intervals without a failure shouldn’t weaken your resolve to maintain your schedule. You’re defending against the unexpected.
Be sure to adhere to your backup schedule without fail. Long intervals without a failure shouldn’t weaken your resolve to maintain your schedule. You’re defending against the unexpected.
Backup maintenance
When your latest backup is sent to offsite storage or your hot site, don’t recycle the backup media from the previous backup immediately. Sometimes, problems in the data aren’t noticed right away, and several backup generations can be made before anyone recognizes that the data is corrupted.
One good discipline, if you’re backing up on a daily basis, is to keep a whole week of daily backups, as well as a month’s worth of weekly backups and a year’s worth of monthly backups. That should cover most possibilities.
The important point is to maintain the number of backups you need for as long as you need them to ensure that you will be able to continue operating, with minimum downtime, regardless of what might happen.
Another thing you should do is restore a backup occasionally, just to see whether you recover all the data that you backed up. I once went into a company (which shall remain nameless) as a database consultant. The employees very proudly showed me their backup disks and the fireproof safe they kept those disks in. There was only one problem: The backup disks were all empty! The employee who dutifully did the backups every night didn’t have a full understanding of the backup procedure and was actually recording nothing. Luckily, I asked the employee to do a test restore, and the problem was discovered before the company had to do a restoration for real.
Coping with Internet Threats
In addition to all the bad things that can happen to your hardware due to random failures and human mistakes, the Internet is a potential source of major problems. People with malicious intent (called crackers) don’t have to get anywhere near your hardware to do great damage to your computer system and your organization. The Internet is your connection to your customers, clients, suppliers, friends, news organizations, and entertainment providers. It’s also a connection to people who either want to harm you or to steal the resources of your computer.
Attacks on your system can take a variety of forms. I briefly discuss a few of the most common ones in the following sections. Most of these attacks are carried out by malware — any kind of software that has a malicious intent. Examples are viruses, Trojan horses, and worms.
Viruses
A virus is a self-replicating piece of software that spreads by attaching itself to other programs or to documents. When a human launches the host program or performs some other action on it, the virus is activated. After it’s activated, the virus can propagate by copying itself to other programs. The virus’s payload can perform other actions, such as erasing disk files; crashing the computer; displaying mocking messages on the user’s screen; or commandeering system resources to perform a computation for, and send results back to, the attacker who originated the virus.
Initially, virus writers created and released viruses to show off their knowledge and skill to their peers. They would cause their viruses to display a message on a computer screen, along with their signatures. Nowadays, viruses have evolved in a much more destructive direction. Criminal enterprises, political groups, and even national governments release viruses that can steal critical data, resulting in millions of dollars in losses. Aside from data theft, considerable damage can be done by modifying or destroying data.
At any given time, hundreds of viruses of varying virulence are circulating on the Internet. If one happens to infect your computer, you may experience an annoyance or a disaster. Consider these options to protect yourself:
- Never connect your computer to the Internet. This technique is very effective. It’s a viable idea if none of the work you intend to do on that computer relies on the Internet’s resources, and the computer never exchanges files with any computers that are connected to the Internet.
- Install antivirus software on your computer, and keep it up to date by maintaining a subscription. New viruses are emerging all the time. To thwart them, you need the latest antivirus protection.
- Make sure users are aware of virus threats and know how to recognize suspicious emails. Awareness is an important defense against viruses. Caution users not to open email attachments from unknown sources and to be careful about visiting websites of unknown character. Set their browser settings at a high security level.
- Disable USB ports so that thumb drives cannot be connected. Some of the most serious security breaches have been caused by viruses or worms placed on a system with a thumb drive.
Even if you take all the preceding recommended actions, your computer still may become infected with a virus. Be on the lookout for any change in the way your computer operates. A sudden slowdown in performance could be a sign that a virus has taken over your system, which is now doing the bidding of some unknown attacker rather than doing what you want it to do.
Trojan horses
In an ancient legend recounting the war between the Greeks and the city of Troy, after a 10-year siege, the Greek commander, Odysseus, thought of a trick to beat the Trojans. He ordered a huge wooden horse to be built, knowing that the Trojans considered the horse to be the symbol of their city, and hid 30 soldiers inside it. Then he loaded the rest of his army onto ships and sailed away. The Trojans were jubilant, figuring the Greeks had finally given up. They pulled the horse within the walls of their city as a trophy of war. That night, the Greek soldiers climbed out of the horse and opened the city gates to the waiting Greek army, which had sailed back under cover of darkness. Troy was conquered and destroyed, never again to challenge the Greeks.
Today, malware creators can create a different kind of Trojan horse: a program that has some useful purpose but that has a secret payload. When the program is activated inside the target computer, it does what the malware writer wants rather than what the computer owner wants. It may steal data and send it out over the computer’s Internet connection, or it may have some other destructive effect. Making the useful purpose of the program seem desirable is a form of social engineering.
It always pays to bear Trojan horses in mind. If you do download a program from the web or even from a CD-ROM or DVD, make sure that you’re getting it from a reputable source.
 I know that you would never be tempted to download pornographic images from the web, but you may know someone who could be so tempted. Be aware that a very high percentage of such material contains malicious Trojan horses that can do a lot of damage.
I know that you would never be tempted to download pornographic images from the web, but you may know someone who could be so tempted. Be aware that a very high percentage of such material contains malicious Trojan horses that can do a lot of damage.
Worms
Worms are similar to viruses in some respects and different in others. The defining characteristic of a virus is that it spreads by attaching itself to other programs. The defining characteristic of a worm is that it spreads via networks. Both viruses and worms are self-replicating, but viruses typically need some action by a human to become active, whereas worms have no such limitation. They can enter an unsuspecting computer via a network connection at any time of day or night without any action by a human.
Worms can take over thousands of computers in a matter of hours, as an exponentially expanding wave of infection flows out from a single infected computer. An infected computer can send a copy of the worm to every address in the computer’s email address book, for example. Each of those computers, which are now infected too, sends the worm on to all the computers in their respective address books. It doesn’t take long for the infection to spread around the world. The worm clogs communication channels as bandwidth is consumed by thousands of copies of the worm, which are sent from one computer to another. Depending on the worm’s payload, infected computers may start performing a computation (such as password cracking) for the originator of the worm, or they may start erasing files or causing other damage.
You can do a few things to protect yourself from being infected or, failing that, from passing on the infection:
- Employ all patches from the vendors of your software as soon as possible. Worms generally take advantage of some weakness in your operating system or some other program on your computer. As soon as such a vulnerability becomes known, the software vendor responsible for that program will develop a modification of the program called a patch. The patch closes the window of vulnerability without degrading the performance of the software.
- Harden your system to prevent bad stuff from getting in. This precaution may involve closing ports that are normally open.
- Block arbitrary outbound connections. When you do so, if your computer does get infected, it won’t pass on the infection.
If everyone did these things, worms would fizzle out before they got very far.
Denial-of-service attacks
Worms need not actively perform computations or cause damage to the systems they infect. Instead, they can lie dormant, in stealth mode, waiting for a specific time and date or some other trigger to occur. At the appointed time, thousands of infected computers, now under the control of a malicious cracker, can simultaneously launch what is referred to as a denial-of-service attack on some target website. The thousands of incoming messages from the worms completely overwhelm the ability of the target site to handle the traffic, preventing legitimate messages from getting through and bringing the website down.
SQL injection attacks
SQL injection attacks, like denial-of-service attacks, are attacks carried out on websites. If your website takes input from site visitors, such as their names and contact information, you could be vulnerable to an SQL injection attack. The information that visitors enter goes into an SQL database on your server. Everything is fine as long as people enter the information that they are supposed to enter in the appropriate text boxes. Attackers, however, will attempt to take control of your database and all the information in it by entering things that are not appropriate for the text boxes in which they enter data.
Chipping away at your wall of protection
Unlike what you may see in a movie or on TV, breaching database security isn’t a simple matter of making an educated guess and then typing a few keystrokes. Breaking into an online database can be a laborious and tedious process. To a sufficiently motivated attacker, however, the prize is worth the effort. The goal is to find the smallest chink in the armor of your application. The attacker can poke into that chink and discover another small opening. Through a series of small actions that reveal progressively more about your installation — and, thus, more about its vulnerabilities — your adversary can penetrate farther into your sanctuary, ultimately gaining system administrator privileges. At this point, your opponent can destroy all your data or, even worse, alter it subtly and undetectably in a way that benefits him, perhaps bankrupting you in the process.
Database hacking through SQL injection is a serious threat, not only to the database you are exposing on the web, but also to all the other databases that may reside on your database server.
Understanding SQL injection
Any database application that solicits input from the user is potentially susceptible to an SQL injection attack. You expect users to enter the asked-for data in the text boxes that your database application uses to accept input. An SQL injection attack occurs when a cracker fools your application into accepting and executing an SQL command that has been entered in the text box rather than the expected data. This attack isn’t a simple matter of entering an SQL statement in the text box that asks for the user’s first name; doing that probably will net the attacker nothing more than an error message. Ironically, however, that error message itself is the first chink in your armor. It could tell the attacker what to do next to gain the next bit of information that will extend her penetration of your defenses.
An SQL injection attack is an incremental process in which attackers gain one bit of information after another until it becomes clear what to do to escalate their privilege level to the point where they can do whatever they want. When a database application fails to properly handle parameters that are passed to dynamically created SQL statements, it becomes possible for an attacker to modify those SQL statements. Then the attacker has the same privileges as the application user. When the database server executes commands that interact with the operating system, the attacker gains the privilege level of the database server, which in many cases is very high.
Using a GET parameter
Typically, parameters are passed from a web application to a database server with a GET or a POST command. GET is usually used to retrieve something from the database server, and POST is usually used to write something to the database server. Either command can provide an avenue for an SQL injection attack. In the following sections, I look at some ways that GET can be dangerous.
THE DANGERS OF DYNAMIC STRING BUILDING
If a user is entering a parameter in a text box, it must be true that the application doesn’t already know which of several possibilities the user will enter. That means that the complete syntax of the SQL statement that the user wants to execute wasn’t known when the application was written; thus, that data couldn’t be hard-coded into the application. SQL statements that are hard-coded into an application are called static SQL. SQL statements that aren’t put together until runtime are called dynamic SQL. By necessity, any SQL that includes parameters passed from user input in a text box to the DBMS is dynamic SQL. Because the SQL being generated is incorporating user input, it’s susceptible to being co-opted by an SQL injection attack.
You have two ways to incorporate user input into an SQL query, one of which is much more secure than the other:
- The safer alternative is to pass a parameter containing validated user input from your host language application code to an SQL procedure that will incorporate the parameter, treating it as data.
- The less-safe alternative is to use dynamic SQL to build an SQL statement at runtime that incorporates the user input. This dynamic method of handling user input is susceptible to an SQL injection attack. When you build an SQL statement at runtime with dynamic SQL, an SQL injection attack can piggyback a malicious SQL statement on top of the benign one your application is building.
Suppose that your application has a feature in which the user enters a customer name in a text box, and in response, the database returns that customer’s full record. The SQL would be of the following form:
SELECT * FROM CUSTOMER WHERE LastName = 'Ferguson';
When you wrote the application, you didn’t know that the information desired was for customer Ferguson. You wrote it so that the user could enter a customer name at runtime. One way to do that is to create a dynamic SQL statement on the fly at runtime. Here’s how to do that when your host language is PHP, which is the host language most commonly used with MySQL:
$query = "SELECT * FROM CUSTOMER WHERE LastName = '$_GET["lastname"]'";
This example assumes that the user enters the last name of the person desired in a text box named lastname. If the user enters Ferguson in the text box, Ferguson’s full record will be returned.
A similar dynamic SQL string can be built in a .NET environment, as follows:
query = "SELECT * FROM CUSTOMER WHERE LastName = '" +
request.getParameter("lastname") + "'";
A parameterized query is safer than a query built from a dynamic string because the database engine isn’t expecting to build an SQL statement. It expects only a parameter, which isn’t executable; thus, it won’t be fooled by an SQL injection.
Here’s an ADO.NET example of a parameterized query equivalent to the query above:
sqlConnection con = new SqlConnection (ConnectionString);
string Sql = "SELECT * FROM CUSTOMER WHERE LastName=@lastname" ;
cmd = new SqlCommand(Sql, con) ;
// Add parameter
cmd.Parameters.Add("@lastname", //name
SqlDbType.NvarChar, //data type
20) ; //length
cmd.Parameters.Value["@lastname"] = LastName ;
reader = cmd.ExecuteReader () ;
MISHANDLING ESCAPE CHARACTERS
An escape character is a character that has a special meaning in a text string. A text string, for example, may be delimited by quote characters at the beginning and the end of the string. The quote characters aren’t part of the string. They indicate to the database management system (DBMS) that the characters between the beginning and the ending quote characters are to be treated as a text string. What happens, however, if the text string contains a quote character? There must be a way to tell the DBMS that the quote character located within the string is part of the string rather than a delimiter for the string. You typically do this by preceding the character that you want to be treated as a text character with an escape character. In this context, the escape character tells the DBMS to interpret the following character as a text character.
Some of the most devastating SQL injection attacks, in which millions of credit-card records have been stolen, have resulted from inadequately filtered escape characters. Mishandling an escape character can lead to a successful SQL injection attack.
Suppose that you have a database that only authorized users can access. To gain database access, a user must enter a username and a password in text boxes. Assuming that the authorized user GoodGuy enters his name and password (Secret), the following SQL statement is built dynamically:
SELECT UserID
FROM USERS
WHERE User = 'GoodGuy' AND Password = 'Secret';
The single quotes mark the beginning and the end of a text string.
Now suppose that an attacker has deduced, from previous probes of your system, that the names of authorized users are contained in a table named USERS, that usernames are contained in the User column of that table, and that user passwords are contained in the Password column. Now the attacker can enter anything — ABC in the User text box and XYZ' OR 'V' = 'V in the Password text box, for example. The DBMS will dutifully incorporate this data into the following dynamic SQL statement:
SELECT UserID
FROM USERS
WHERE user = 'ABC' AND password = 'XYZ' OR 'V' = 'V';
It doesn’t matter that the attacker doesn’t know any valid usernames or passwords. The compound predicate partitioned by the OR keyword requires only one of the two predicates to be true. Because V is always equal to V, the condition of the WHERE clause is satisfied, and all the UserIDs in the USERS table are returned. Furthermore, the attacker is logged in, probably with the privileges of the first user in the USERS table. The DBMS assumes that because more than zero records have been returned, a valid authentication credential must have been entered.
Now that the attacker is logged in, it’s relatively easy for him to discover that sensitive information about users is contained in a table named USERINFO. Stealing the information in that table is easy, as follows:
SELECT * FROM USERINFO;
At this point, the attacker can slink out with his ill-gotten gains, and you won’t even know that you’ve been compromised.
Alternatively, on the way out, the attacker could issue this command:
DROP TABLE USERS; DROP TABLE USERINFO;
Your USERS and USERINFO tables are toast. Now you know that you’ve been compromised. I hope you have a recent backup of your database.
As long as an SQL statement is syntactically correct, a DBMS will execute it. That being the case, how can you protect yourself from an SQL injection attack? The only surefire way is to validate every input that you accept and revalidate it every step along the way from the client to the database. Don’t depend on checks at the client end to protect you. An attacker skillful enough to bypass your client will have a field day in your unprotected back end.
Check every input to ensure the following:
- The input is of the expected type (text, numeric, and so on).
- Values fall within the expected range.
- The number of characters falls within the expected range.
- Only allowed (whitelisted) characters are present.
Comparing input against a whitelist of allowed entries is safer than comparing it against a blacklist of nonallowed entries. If you leave a vulnerability off your blacklist, you’re wide open to exploitation. On the other hand, if you leave a valid entry off your whitelist, you may hear some complaining from your users, but nothing terrible will happen. All you need to do to remedy the situation is add the forgotten entry to your whitelist and move on.
Test the adequacy of your checks by violating them and noting what happens. Error messages should be returned to the user, but those messages shouldn’t be too helpful. Overly helpful error messages end up giving clues to attackers on how to penetrate your defenses.
MISHANDLING TYPES
An attacker doesn’t need a mishandled escape character to gain control of a database. Whereas character strings use the single-quote character as a delimiter, numeric data has no such delimiter. Suppose that you want to allow users to view the information you have on file for them in your USERINFO table. They can access their information by entering their UserID, which is a number, in a numeric variable named NumVar. You could accept their input in the following SQL statement:
userinfo := "SELECT * FROM USERINFO
WHERE UserID = " + NumVar + ";"
The expectation, of course, is that the user will enter a valid UserID number. What if a malicious user entered the following instead?
1; DROP TABLE USERINFO;
This entry would generate the following SQL statements:
SELECT * FROM USERINFO WHERE UserID = 1; DROP TABLE USERINFO;
After reading the contents of a record in the table, the attacker can destroy the entire table.
You can protect yourself from a data-type-based attack the same way that you protect yourself from an escape-character attack: by validating the input. If you expect the variable NumVar to be a number, check it to make sure that it is a number, with nothing extra added.
THE DANGER OF PUTTING USER INPUT DIRECTLY IN A DYNAMIC SQL STATEMENT
Some applications really do require dynamic SQL. Sometimes, you want to retrieve data from a table that didn’t even exist when you wrote your application. If you use GET without validation to place user input directly in the dynamic SQL statement that you’re building, you are wide open to exploitation. Consider an example in which a new table is created every month to hold records of transactions during that month. You want authorized users to be able to display the data in selected columns for all the records in this table, but not necessarily the contents of any other tables in the database. A mishandled escape character is one way that attackers can become authorized users. What more could they do, beyond seeing what’s in the transaction table?
They can do a lot. They could hijack the dynamic SQL statement you’re building, for example, and use it to penetrate a table that you don’t want them to see.
Take a look at the following PHP and MySQL code, which builds a dynamic SQL statement to display the transaction number and dollar amount from the transactions table for last month:
// Build statement to pull transaction amounts from table for specified month
$SQL = "SELECT $_GET["ColumnA"], $_GET["ColumnB"] FROM $_GET["MonthlyTrans"];
// Execute statement
$result = mysql_query($SQL);
// Count rows returned
$rowcount = mysql_num_rows($result);
// Display each record
$row = 1
while ($db_field = mysql_fetch_assoc($result)) {
if ($row <= $rowcount) {
print $db_field[$row] . "<BR>";
$row++;
}
}
You expect the user to make reasonable inputs, such as a customer name (which is the first column), transaction amount (which is the second column), and TransFor022019 (which is the table name for the month desired). That’s not what an attacker will do, however.
Taking user input and placing it directly in a dynamic SQL statement is like sending formal invitations to thieves to come visit your house while you’re away on vacation. Instead of entering a customer name and transaction amount for the TransFor022019 table, an attacker might enter a user and password for the USERS table, thereby gaining access to anything that any user, including the system administrator, can access.
The solution to this problem is (again) quite simple: Validate user input before incorporating it into a dynamic SQL statement. You’d be surprised to see how many developers don’t do this.
GIVING TOO MUCH AWAY IN ERROR MESSAGES
Error messages are important parts of any computer program. Legitimate users sometimes make mistakes or get confused about the right way to interact with the system. Error messages are designed to give helpful hints to users when they get off track. That’s good. Those messages can also give helpful hints to attackers. That’s not so good.
One way to help attackers penetrate a database application is to tell them which DBMS you are using. SQL Server has a lot of standard names for things that differ from those of Oracle, MySQL, or PostgreSQL. Often, an attacker can gain a critical piece of information just by entering illegal characters in a text box and noting what the error message says.
Microsoft SQL Server is particularly “helpful” in this regard. Consider a dynamic SQL query in the AdventureWorks database. The application expects a user who wants to know about sales to customer number 1 to enter 1 in a text box onscreen. This entry would generate the following SQL statement:
SELECT * FROM Sales.Customer WHERE CustomerID=1;
An attacker, however, instead of entering 1, enters the following:
1 and 1 in (SELECT AccountNumber) --
This creates the following erroneous SQL statement:
SELECT * FROM Sales.Customer WHERE CustomerID=1 and 1 in (SELECT version) --
Instead of returning all the information about Customer 1, SQL Server 2017 returns the following error message:
Msg 207, Level 16, State 1, Line 1
Invalid column name 'version'.
Thankfully, this does not reveal too much to a hacker. However, if you are using an earlier version of SQL Server than SQL Server 2017, the hacker might be a lot luckier. Take note of what SQL Server 2008 R2 returned for this same input.
Msg 245, Level 16, State 1, Line 1
Conversion failed when converting the nvarchar value 'Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600.1 (X64)
Apr 2 2010 15:48:46
Copyright (c) Microsoft Corporation
Web Edition (64-bit) on Windows NT 6.0 <X64> (Build 6002: Service Pack 2)
' to data type int.
Talk about giving away the store! SQL Server helpfully provided full details on the version of DBMS that was running. I suspect Microsoft read my coverage of this issue in an earlier edition of this book and performed a major overhaul of their error messages as a result. With the older error message, the attacker knows exactly what dialect of SQL to use, as well as what helpful functions are available, which will aid her in prying more secrets from the database.
DEPENDING ON NORMAL FLOW OF EXECUTION
There is a tendency for a software developer to follow a logical path in code development and to expect the user to follow a similar logical path. The expectation is that the user will make entries in form 1 and move on to form 2, finally interacting with form 3. Based on that flow, the developer will validate an input made in form 1 and not bother to revalidate it in the code behind form 2. That’s logical. If the input is validated in the code of form 1 and assigned to a parameter, surely there’s no point in validating it again when it’s used by the code of form 2.
Don’t count on it. An attacker could bypass form 1, along with all its validation checks, jumping directly to form 2. As a result, malicious code can enter the system. The bottom line is that any data derived from user input should be validated every time it crosses a trust boundary, such as the boundary between the code behind form 1 and the code behind form 2.
Recognizing unsafe configurations
If the code you have behind your data-entry screens doesn’t have adequate validation checks for everything that’s entered, your database could be taken over by an attacker co-opting your SQL statements. Even if your data-entry screens do have validation checks, the very error messages that these checks produce could give the attacker the information he needs to complete a penetration. When the attacker has broken through, your database and everything in it is laid bare.
The most popular DBMS products have some pretty serious vulnerabilities after you do a default installation. These vulnerabilities have to do with highly privileged user accounts. If an attacker can gain access to one of these accounts, she can operate without restriction on everything on your server. Nothing is safe.
Microsoft SQL Server comes with a system administrator account named sa. Clearly, somebody needs to have system administrator privileges, but it would be wise for a new system’s system administrator to log in as sa but then immediately create a new system administrator account under a different name and then delete the sa account. That will at least cause the attacker to work a little harder to take over your system.
Other products have similar vulnerabilities. MySQL’s root account, for example, is highly privileged and created by default. Oracle has several highly privileged default accounts, preconfigured with well-known passwords, including SYS, SYSTEM, DBSNMP, and OUTLN. In the case of Oracle running under Windows, at least, you cannot summarily delete these accounts, because doing so can prevent Oracle from running at all.
The best precaution is to create each user account with the minimum privileges needed for the user to do his or her job. This way, if an account is compromised, the damage done will be the minimum possible.
Finding vulnerabilities on your site
SQL injection vulnerabilities are relatively easy to spot when you can examine the source code of an application. Look for cases in which the code places user input directly or indirectly in dynamic SQL statements. Often, however, you don’t have access to the source code of a web-based application that you’re testing for such vulnerabilities. In such cases, you must infer the presence of a vulnerability from the responses you get from inputs that you send to the application. This is exactly what an attacker does. To test for vulnerabilities, you would approach a site the same way that an attacker would.
TESTING BY INFERENCE
From the way that a database application responds to inputs, you can infer things about the details of that application. Based on these inferences, you can try additional inputs that may enable you to penetrate the system.
The first order of business is discovering which inputs the system considers to be legal. You can determine this by making reasonable entries, such as numbers in a numeric field and character strings in a text field. Assuming that you don’t hit the jackpot by making an actual valid entry, the system should return a generic error message. When you know the normal response to a legal but incorrect entry, you can probe further by making entries that are illegal and unexpected. If you receive an error message for one of these entries that’s different from the message you received for a legal but incorrect input, you’ve made progress. Often, you can infer what to do next, based on how one error message differs from another.
USING VULNERABILITY TESTING TOOLS
Some developers try to protect their sites from SQL injection attacks by using a drop-down menu to restrict data entry to legal values. Others place size limits on what can be entered in a data-entry field. These measures prevent a legitimate user from accidentally entering invalid data but don’t inconvenience an attacker. This client-side functionality can be bypassed easily, and you can send what you want to the database back end. Readily available tools can even assist you in this endeavor, such as add-ons to the Mozilla Firefox browser that expand its capabilities. Many tools are available to help you scan your site for vulnerabilities. Here are a few of these tools:
- Web Developer: Web Developer is a Firefox add-on that you can download from
https://addons.mozilla.org/en-US/firefox/addon/60. This add-on has a lot of functionality that doesn’t relate directly to website security. You can display the contents of all the cookies that the site being tested has set, for example. You can display the contents of the associated cascading style sheet and even edit it. More helpful to both website testers and attackers, you can view the source code behind a form, display details on entry fields, display hidden fields, show passwords, convertGETtoPOSTorPOSTtoGET, and remove the maximum length restriction on a data-entry field. You can also change a drop-down list to a field in which you can enter what you want. - Tamper Data: Tamper Data, another Firefox add-on, was so dangerous that it was withdrawn from the Firefox site. It is doubtless still available from less reputable sources. With it, you can view and modify headers and
POSTparameters on HTTP and HTTPS requests. It also gives you information about the server responding to your requests. SQL Inject Me: The SQL Inject Me Firefox add-on has also been withdrawn from the Firefox site. It actually makes injection attacks on the active page in your browser.
Be careful when using this tool, because there are severe criminal penalties for computer crime, which your actions could be construed to be.If you have permission to test a site for vulnerabilities, however — preferably in writing — you can use SQL Inject Me to discover weaknesses in a site. When you use this add-on with Web Developer and Tamper Data, you can get a clear idea of a site’s weaknesses.
SQL Inject Me hammers a website with a barrage of illegal inputs that have been known to compromise susceptible applications. Each such input constitutes a test. Out of several tens of thousands of tests, if even one fails, the application has a problem that could be exploited by a bad actor. It would be a good idea to address this issue now rather than after the proverbial horse has trotted out of the barn door.
HP WebInspect: Whereas the Firefox add-ons described in this list are available for free download, you can buy commercial products to test your websites for vulnerabilities. HP WebInspect is one such product. It scans a website and provides more extensive information about vulnerabilities than SQL Inject Me does — and appears to find more of them, too. You can generate a variety of reports giving the results of a scan, explanations of the vulnerabilities, and suggestions for eliminating those vulnerabilities.
Figure 1-2 shows the HP WebInspect screen after a scan has finished. The website shown is a sample site that deliberately displays a variety of vulnerabilities. Contact Hewlett-Packard at
www.hp.comfor prices for HP WebInspect.- IBM Security AppScan: IBM provides a family of security products to accommodate the needs of organizations of different sizes. These products come with 12 months of support and consequently are pretty spendy. In addition to identifying SQL injection attacks, IBM Rational AppScan discovers and identifies problems such as cross-site scripting and even predictable login credentials — “weak” logins that are too easily predicted by hackers. Figure 1-3 shows the result of a scan of a test site deliberately salted with vulnerabilities.
- HP Scrawlr: HP Scrawlr is a free scan tool from Hewlett-Packard that does only a cursory scan of a website. It catches only a small fraction of the vulnerabilities revealed by its “big brother” product HP WebInspect or by IBM Rational AppScan. However, if it does detect a vulnerability in your site, you would be wise to address it immediately.
FIGURE 1-2: HP WebInspect scan result.
FIGURE 1-3: IBM Security AppScan scan result.
Much more can be said about SQL injection attacks than I have room to cover here. My objective with this brief overview is to alert you to the potential damage to your organization from a successful attack. As with other types of malware, you have defenses against SQL injection attacks. Make sure, however, that your site is created and maintained by experienced and security-conscious web database developers. Testing for vulnerabilities is a must for anything that will be exposed to the world on the web. A lot of people can build database applications that function well, but not nearly as many know how to protect those applications well. Many programmers have never even heard of SQL injection attacks. These attacks generally aren’t covered in computer science classes.
Phishing scams
Experienced fisherfolk will get a bite sooner or later, if they cast their lures into a lake enough times. Phishing is like fishing, but in this case, the victims are people rather than fish. Scammers send out emails to thousands or even millions of people, purporting to be from a legitimate bank or business such as eBay, saying that your account has shown unusual activity and you must update your information. These messages can look very legitimate. After you enter your financial information, the scammer has access to your bank or business account and can transfer your funds to his offshore account in a country that doesn’t monitor financial transactions. The next time you access your account, you receive an unpleasant surprise.
The best defense against a phishing attack is to never respond to an email with sensitive information. Even though the email sends you to a site that looks for all the world like the official website of your bank, it’s a fake, specifically designed to induce you to surrender your account information and, along with it, all the money in the account.
Zombie spambots
Zombie spambots are similar to the worms that engage in denial-of-service attacks, but instead of launching an attack on a single website, they spew unsolicited advertising messages to lists of email addresses that the spammers have acquired. Instead of being from a single, relatively easy-to-trace source, the spam is produced by thousands of computers that have been taken over by worms to mindlessly pump out spam to their address lists. If you happen to be one of the people whose computer has been taken over, you see an unexplained drop in performance, as a significant fraction of your computational capacity and Internet bandwidth is dedicated to sending spam to unlucky recipients around the world. Such distributed spam attacks are devilishly difficult to trace to their source.
Installing Layers of Protection
The creators of viruses, worms, and bots have become increasingly sophisticated and are perpetually one or two steps ahead of the guys in the white hats who are trying to stamp them out. As a user, you should do everything you can to protect your computers and the sensitive information they contain. Because no one type of protection is totally effective, your best hope is to put several layers of protection between your valuable files and programs and the outside world.
Network-layer firewalls
Communication on the Internet consists of packets of data that conform to the TCP/IP protocol. A network-layer firewall is a packet filter, operating on a low level, that resides on a computer situated between the Internet and a local area network (LAN), in what is called the DMZ (demilitarized zone). The computer that’s running the firewall in the DMZ doesn’t contain any sensitive information. Its sole purpose is to protect the LAN. Rules set up by the network administrator (or default values) determine which packets are allowed to pass from the Internet to the LAN and which are rejected.
Application-layer firewalls
An application-layer firewall operates at a higher (more abstract) level than the network-layer firewall. It can inspect the contents of network traffic and block traffic that the firewall administrator deems to be inappropriate, such as traffic from known-malicious websites, recognized viruses, or attempts to exploit known vulnerabilities in software running on the LAN.
Antivirus software
Considering the hundreds of viruses and worms circulating in the wild, up-to-date antivirus software is a necessity for any computer directly or indirectly connected to the Internet. Even computers that aren’t connected to the Internet are susceptible to infection if they can receive software from CD-ROMs, DVDs, or flash (thumb) drives. Be sure to buy a subscription to one of the popular antivirus programs, such as McAfee or Norton, and then keep the subscription current with regular downloads of updates.
Vulnerabilities, exploits, and patches
Antivirus software can protect you from viruses, worms, and other malware that crackers have created to serve their own nefarious purposes. Such software, however, can’t protect you from malware that hasn’t yet been released into the wild and detected by the antivirus software vendors.
Existing software may have vulnerabilities that haven’t yet been exploited by malware developers. New software is almost certain to contain vulnerabilities just waiting to be exploited. When exploits for these vulnerabilities appear, all computers are at risk until the vulnerabilities have been patched.
Sometimes, exploits (called zero-day exploits) are released into the wild on the same day that the vulnerability becomes known. In such cases, the time between the release of the exploit and the release of the patch that shuts it down is a period during which there is no effective defense against the exploit.
When a patch does become available, install it immediately on all susceptible machines. An ongoing problem is the huge number of naive users who are unaware of either the danger (and the associated patch) or who don’t realize the importance of hardening their systems against attack. By remaining vulnerable, they endanger not only their own systems, but also others that could be attacked if their machine is compromised.
Education
One of the best defenses against malicious attacks on your systems is for all users to be educated about the threats and the countermeasures available to eliminate those threats. Regular training on security should be part of every organization’s defensive arsenal.
Alertness
If you ever sit down at your computer and see something that just strikes you as odd, beware. You could be seeing evidence that your computer has been compromised. Run some checks. If you don’t know what checks to run, ask someone who does know for help. The problem could be nothing, but then again, maybe a stranger is sucking value out of your system. It doesn’t hurt to be a little paranoid.