
Promoting XML is kinda like selling illegal drugs, where the first acronym is always free. | ||
| --Jeff Lowery | ||
Unfortunately, the steady stream of XML acronyms will only continue to flow by as you progress through this book. This hour introduces you to a few more acronyms, and along the way takes a closer look at the inner workings of XML documents. You will find out that in addition to the logical structure of documents that is dictated by elements, there is also a physical structure that is very important. This physical structure of documents is determined by entities, which are units of storage that house content within documents. Closely related to entities are notations, which make it possible for XML applications to handle certain types of entities that aren’t capable of being processed. This hour tackles entities and notations along with a few other important topics related to the inner workings of XML documents. Oh, and don’t forget about those new acronyms you get to add to your rapidly growing XML vocabulary!
In this hour, you’ll learn
How to document your XML code with comments
How characters of text are encoded in XML
All about entities and how they are used
Why notations make it possible to use certain kinds of entities
It shouldn’t come as a surprise that any self-respecting XML developer would want to write clean XML code that is as easy to understand as possible. Part of the process of writing clean XML code is documenting the code whenever necessary. Comments are used in XML to add descriptions to code and include information that isn’t part of a document’s content. Comments aren’t considered part of a document’s content because XML processors ignore them.
By the Way
Technically speaking, it’s possible for an XML processor to actually pay attention to comments and not ignore them, which might make sense in an XML development tool such as a WYSIWYM editor. Such a tool might allow you to enter and modify comments through a graphical user interface, in which case it would need to process comments to some degree. Even so, the comments wouldn’t be interpreted as document content.
Comments are specified in a document between the <!-- and --> symbols. The only limitation on comments is that you can’t include double-hyphens (--) in the body of a comment because they conflict with XML’s comment syntax. Following is an example of how you could use a comment to add information to a Tall Tales question in the Tall Tales sample document that you’ve worked with in previous hours:
<!-- This question still needs to be verified. -->
<tt answer="a">
<question>
In 1994, the Nestle UK food company was fined for injuries suffered by a
36 year-old employee at a plant in York, England. What happened to the man?
</question>
<a>He fell in a giant mixing bowl and was whipped for over a minute.</a>
<b>He developed an ulcer while working as a candy bar tester.</b>
<c>He was hit in the head with a large piece of flying chocolate.</c>
</tt>The information contained within the comment isn’t considered part of the document data. The usefulness of comments will naturally vary with the type of XML documents you are creating. Some documents tend to be relatively self-explanatory, whereas others benefit from comments that make them more understandable. In this example, the comment is used to flag a question that still needs to be verified before being incorporated into the final game. In reality, an attribute might provide a better approach for flagging unverified questions but the comment still works as a simpler approach.
As you know, XML documents are made of text. More specifically, an XML document consists of characters of text that have meaning based upon XML syntax. The characters of text within an XML document can be encoded in a number of different ways to suit different human languages. All of the character-encoding schemes supported by XML are based on the Unicode text standard, which specifies the set of characters available for use in text documents. The character-encoding scheme for an XML document is determined within the XML declaration in a piece of code known as the character encoding declaration. The character encoding declaration looks like an attribute of the XML declaration, as the following code shows:
<?xml version="1.0" encoding="UTF-8"?>
The UTF-8 value assigned in the character encoding declaration specifies that the document is to use the Unicode UTF-8 character-encoding scheme, which is the default scheme for XML. All XML applications are required to support the UTF-8 and UTF-16 character encoding schemes; the difference between the two schemes is the number of bits used to represent each character of text (8 or 16). If you don’t expect your documents to be used in a scenario with multiple human languages, you can probably stick to UTF-8. Otherwise, you’ll need to go with UTF-16, which requires more memory but allows for multiple languages.
By the Way
There are other character encoding standards in addition to UTF-8 and UTF-16, such as ISO-8859-1, which is used in Western Europe. You’ll want to look into other character encoding options if you plan on developing XML documents that target languages other than English.
Regardless of the scheme you use to encode characters within an XML document, you need to know how to specify characters numerically. All characters in an encoding scheme have a numerical value associated with them that can be used as a character reference. Character references come in very handy when you’re trying to enter a character that can’t be typed on a keyboard. For example, the copyright symbol (©) is an example of a character that can only be specified using a character reference. There are two types of numeric character references:
Decimal reference (base 10)
Hexadecimal reference (base 16)
A decimal character reference relies on a decimal number (base 10) to specify a character’s numeric value. Decimal references are specified using an ampersand followed by a pound sign (&#), the character number, and a semicolon (;). So, a complete decimal character reference has the following form:
&#Num;
The decimal number in this form is represented by Num. Following is an example of a decimal character reference:
©
This character reference identifies the character associated with the decimal number 169, which just so happens to be the copyright symbol. Following is the copyright symbol character reference used within the context of other character data:
©2005 Michael Morrison
Even though the code looks a little messy with the character reference, you’re using a symbol (the copyright symbol) that would otherwise be difficult to enter in a normal text editor since there is no copyright key on your keyboard.
By the Way
The actual decimal number associated with the copyright symbol is determined by a standard that applies to both XML and HTML. To learn more about special characters that can be encoded using character references, please refer to the following web page: http://www.w3.org/TR/REC-html40/sgml/entities.html.
Table 4.1 lists some common character references you may find useful when developing XML documents of your own:
There are many more character references that you can use to code obscure or otherwise difficult-to-enter characters. This list should give you a good start on using some of the more popular character references.
Thus far you’ve focused on the first approach to specifying characters numerically in XML, which involves using decimal character references. If you’re coming from a programming background, you may opt for the second approach to specifying numeric characters: hexadecimal references. A hexadecimal reference uses a hexadecimal number (base 16) to specify a character’s numeric value. Hexadecimal references are specified similarly to decimal references, except that an x immediately precedes the number:
&#xNum;
Using this form, the copyright character with the decimal value of 169 is referenced in hexadecimal as the following:
©
Because decimal and hexadecimal references represent two equivalent solutions to the same problem (referencing characters), there is no technical reason to choose one over the other. However, most of us are much more comfortable working with decimal numbers because it’s the number system used in everyday life. It ultimately has to do with your degree of comfort with each number system; the decimal system is probably much more familiar to you.
Just as bricks serve as the building blocks of many houses, entities are special units of storage that serve as the building blocks of XML documents. Entities are typically identified with a unique name and are used to contain content within a document. To help understand the role of entities, it helps to think of elements as describing the logical structure of a document, whereas entities describe the physical structure. Entities often correspond with files that are stored on a file system, such as the file that holds an XML document. However, entities don’t have to be associated with files in any way; an entity can be associated with a database record or even a piece of memory. The significance is that entities represent a unit of storage in an XML document.
Although most entities have names, a few notable ones do not. The document entity, which is the top-level entity for a document, does not have a name. The document entity is important because it serves as a storage container for the entire document. This entity is then broken down into subentities, which are often broken down further. The breakdown of entities ends when you arrive at nothing but pure content. The other entity that goes unnamed is the external DTD (Document Type Definition), if one exists. You learned in the previous hour that a DTD is used to describe the format and structure of documents created in a specific XML-based language. For example, the DTD for HTML would specify exactly how the <img> tag is used to mark up images.
Getting back to entities, the TallTales.dtd external DTD you saw in the previous hour is an entity, as is the root document element talltales in the talltales.xml document. Following is an excerpt from the talltales.xml document that illustrates the relationship between the external DTD and the root document element:
<?xml version="1.0"?> <!DOCTYPE talltales SYSTEM "TallTales.dtd"> <talltales> <!-- Document markup --> </talltales>
In this code, the talltales root element and the TallTales.dtd external DTD are referenced in the document type declaration. To clarify how entities are storage constructs, consider the fact that the contents of the external DTD could be directly inserted in the document type declaration, in which case it would no longer be considered an entity. What makes the DTD an entity is the fact that its storage is external. A good analogy to this concept is a JPEG image on an HTML web page. The image itself is stored externally in a JPEG file, and then referenced from the web page via an <img> tag. Because the storage of the image is external to the HTML document, the image is considered an entity. The talltales.dtd schema in the previous example works in a similar way because it is referenced externally from talltales.xml.
The XML document entity is a unique entity in that it is declared in the document type declaration. Most other entities are declared in an entity declaration, which must appear before the entities can be used in the document. An entity declaration consists of a unique entity name and a piece of data that is associated with the name. Following are some examples of data that you might reference as entities:
A string of text (a boilerplate copyright notice, for example)
A section of the DTD
An external file containing text data (a list of email addresses, for example)
An external file containing binary data (a GIF or JPEG image, for example)
This list reveals that entities are extremely flexible when it comes to the types of data that can be stored in them. Although the specific data within an entity can certainly vary widely, there are two basic types of entities that are used in XML documents: parsed entities and unparsed entities. Parsed entities store data that is parsed (processed) by an XML application, which means that parsed entities can contain only text. Unparsed entities aren’t parsed and therefore can be either text or binary data. As an example, a text name would be a parsed entity whereas a JPEG image would be an unparsed entity.
Parsed entities end up being merged with the contents of a document when they are processed. In other words, parsed entities are directly inserted into documents as if they were directly part of the document to begin with. Unparsed entities cannot be handled in this manner because XML applications are unable to parse them. Going back to the JPEG image example, consider the difficulty of combining a binary JPEG image with the text content of an HTML document. Because binary data and text data don’t mix well, unparsed entities are never merged directly with a document.
If an XML application can’t process and merge an unparsed entity with the rest of a document, how does it use the entity as document data? The answer to this question lies in notations, which are XML constructs used to identify the entity type to an XML processor. In addition to identifying the type of an unparsed entity, a notation also specifies a helper application that can be used to process the entity. A good example of a helper application for an unparsed entity is an image viewer, which would be associated with a GIF or JPEG image entity or maybe a lesser-used image format such as TIFF. The point is that a notation tells an XML application how to handle an unparsed entity using a helper application.
By the Way
If you’ve ever had your web browser prompt you for a plug-in to view a special content type such as an Adobe Acrobat file (.PDF document), you understand how important helper applications can be.
You learned that parsed entities are entities containing XML data that is processed by an XML application. There are two fundamental types of parsed entities:
General entities
Parameter entities
The next couple of sections explore these types of entities in more detail.
General entities are parsed entities that are designed for use in document content. If you have a string of text that you’d like to isolate as a piece of reusable document data, a general entity is exactly what you need. A good example of such a reusable piece of text is the copyright notice for a web site, which appears the same across all pages. Before you can reference a general entity in a document, you must declare it using a general entity declaration, which takes the following form:
<!ENTITY EntityName EntityDef>
The unique name of the entity is specified in EntityName, whereas its associated text is specified in EntityDef. All entity declarations must be placed in the DTD, although you can decide whether they go in the internal or external DTD. If an entity is used only in a single document, you can place the declaration in the internal DTD; otherwise you’ll want to place it in the external DTD so it can be shared. Of course, if you’re using an existing XML language you may be forced to include your entity declarations in the internal DTD. Following is an example of a general entity declaration:
<!ENTITY copyright "Copyright ©2005 Michael Morrison.">
By the Way
Just in case you’ve already forgotten from earlier in the hour, the © character reference in the code is the copyright symbol.
You are now free to use the entity anywhere in the content of a document. General entities are referenced in document content using the entity name sandwiched between an ampersand (&) and a semicolon (;), as the following form shows:
&EntityName;
Following is an example of referencing the copyright entity:
My Life Story. ©right; My name is Michael and this is my story.
In this example, the contents of the copyright entity are replaced in the text where the reference occurs, in between the title and the sentence. The copyright entity is an example of a general entity that you declare yourself. This is how most entities are used in XML. However, there are a handful of predefined entities in XML that you can use without declaring. I’m referring to the five predefined entities that correspond to special characters, which you learned about back in Hour 2, “Creating XML Documents.” Table 4.2 lists some of the entities just in case you don’t quite remember them.
These predefined entities serve as an exception to the rule of having to declare all entities before using them; beyond these five entities, all entities must be declared before being used in a document.
The other type of parsed entity supported in XML is the parameter entity, which is a general entity that is used only within a DTD. Parameter entities are used to help modularize the structure of DTDs by allowing you to store commonly used pieces of declarations. For example, you might use a parameter entity to store a list of commonly used attributes that are shared among multiple elements. As with general entities, you must declare a parameter entity before using it in a DTD. Parameter entity declarations have the following form:
<!ENTITY % EntityName EntityDef>
Parameter entity declarations are very similar to general entity declarations, with the only difference being the presence of the percent sign (%) and the space on either side of it. The unique name of the parameter entity is specified in EntityName, whereas the entity content is specified in EntityDef. Following is an example of a parameter entity declaration:
<!ENTITY % autoelems "year, make, model">
This parameter entity describes a portion of a content model that can be referenced within elements in a DTD. Keep in mind that parameter entities apply only to DTDs. Parameter entities are referenced using the entity name sandwiched between a percent sign (%) and a semicolon (;), as the following form shows:
%EntityName;
Following is an example of referencing the autoelems parameter entity in a hypothetical automotive DTD:
<!ELEMENT car (%autoelems;)> <!ELEMENT truck (%autoelems;)> <!ELEMENT suv (%autoelems;)>
This code is equivalent to the following:
<!ELEMENT car (year, make, model)> <!ELEMENT truck (year, make, model)> <!ELEMENT suv (year, make, model)>
It’s important to note that parameter entities really come into play only when you have a large DTD with repeating declarations. Even then you should be careful how you modularize a DTD with parameter entities because it’s possible to create unnecessary complexity if you layer too many parameter entities within each other.
Unparsed entities aren’t processed by XML applications and are capable of storing text or binary data. Because it isn’t possible to embed the content of binary entities directly in a document as text, binary entities are always referenced from an external location, such as a file. Unlike parsed entities, which can be referenced from just about anywhere in the content of a document, unparsed entities must be referenced using an attribute of type ENTITY or ENTITIES. Following is an example of an unparsed entity declaration using the ENTITY attribute:
<!ELEMENT player EMPTY> <!ATTLIST player name CDATA #REQUIRED position CDATA #REQUIRED photo ENTITY #IMPLIED>
In this code, photo is specified as an attribute of type ENTITY, which means that you can assign an unparsed entity to the attribute. Following is an example of how this is carried out in document content:
<player name="Rolly Fingers" position="pitcher" photo="rfpic" />
In this code, the binary entity rfpic is assigned to the photo attribute. Even though the binary entity has been properly declared and assigned, an XML application won’t know how to handle it without a notation declaration, which you find out about a little later in the hour.
The physical location of entities is very important in determining how entities are referenced in XML documents. Thus far I’ve made the distinction between parsed and unparsed entities. Another important way to look at entities is to consider how they are stored. Internal entities are stored within the document that references them and are parsed entities out of necessity. External entities are stored outside of the document that references them and can be either parsed or unparsed.
By the Way
By definition, any entity that is not internal must be external. This means that an external entity is stored outside of the document where the entity is declared. A good example of an external entity is a binary image; images are always stored in separate files from the documents that reference them.
Unparsed external entities are often binary files such as images, which obviously cannot be parsed by an XML processor. Unparsed external entities are identified using the NDATA keyword in their entity declaration; NDATA (Not DATA) simply indicates that the entity’s content is not XML data.
External entity declarations are different than internal entity declarations because they must reference an external storage location. Files associated with external entities can be specified in one of two ways, depending on whether the file is located on the local file system or is publicly available on a network:
SYSTEM— The file is located on the local file system or on a networkPUBLIC— The file is a public-domain file located in a publicly accessible place
Watch Out!
When specifying the location of external entities, you must always use the SYSTEM keyword to identify a file on a local system or network; the PUBLIC keyword is optional and is used in addition to the SYSTEM keyword.
The file for an external entity is specified as a URI, which is very similar to the more familiar URL. You can specify files using a relative URI, which makes it a little easier than listing a full path to a file. XML expects relative URIs to be specified relative to the document within which an entity is declared. Following is an example of declaring a JPEG image entity using a relative URI:
<!ENTITY skate SYSTEM "pond.jpg" NDATA JPEG>
In this example, the pond.jpg file must be located on the local file system in the same directory as the file (document) containing the entity declaration. The NDATA keyword is used to indicate that the entity does not contain XML data. Also, the type of the external entity is specified as JPEG. Unfortunately, XML doesn’t support any built-in binary entity types such as JPEG, even though JPEG is a widely known image format. You must use notations to establish entity types for unparsed entities.
Unparsed entities are unable to be processed by XML applications, which means that applications have no way of knowing what to do with them unless you specify helper information that allows an application to rely on a helper application to process the entity. The helper application could be a browser plug-in or a standalone application that has been installed on a user’s computer. Either way, the idea is that a notation directs an XML application to a helper application so that unparsed entities can be handled in a meaningful manner. The most obvious example of this type of handling is an external binary image entity, which could be processed and displayed by an image viewer (the helper application).
Notations are used to specify helper information for an unparsed entity and are required of all unparsed entities. Following is an example of a notation that describes the JPEG image type:
<!NOTATION JPEG SYSTEM "image/jpeg">
In this example, the name of the notation is JPEG, and the helper information is image/jpeg, which is a universal type that identifies the JPEG image format. It is expected that an XML application could somehow use this helper information to query the system for the JPEG type in order to figure out how to view JPEG images. So, this information would come into play when an XML application encounters the following image entity:
<!ENTITY pond SYSTEM "pond.jpg" NDATA JPEG>
If you didn’t want to trust the XML application to figure out how to view the image on its own, you can get more specific with notations and specify an application, as follows:
<!NOTATION JPEG SYSTEM "Picasa2.exe">
This code associates Google’s popular Picasa image editing application (Picasa2.exe) with JPEG images so that an XML application can use it to view JPEG images. Following is an example of what a complete XML document looks like that contains a single image as an unparsed entity:
<?xml version="1.0" standalone="no"?> <!DOCTYPE image [ <!NOTATION JPEG SYSTEM "Picasa2.exe "> <!ENTITY pond SYSTEM "pond.jpg" NDATA JPEG> <!ELEMENT image EMPTY> <!ATTLIST image source ENTITY #REQUIRED> ]> <image source="skate" />
Although this code does all the right things in terms of providing the information necessary to process and display a JPEG image, it still doesn’t work in major web browsers because none of them support unparsed entities. In truth, web browsers know that the entities are unparsed; they just don’t know what to do with them. Hopefully this will be remedied at some point in the future. Keep in mind, however, that although web browsers may not support unparsed entities, plenty of other XML applications and tools do support them.
Just as an XML processor doesn’t process unparsed entities, you can deliberately mark content within an XML document so that it isn’t processed. This type of content is known as unparsed character data, or CDATA. CDATA in a document must be specially marked so that it is treated differently than the rest of an XML document. For this reason, the part of a document containing CDATA is known as a CDATA section. You define a section of CDATA code by enclosing it within the symbols <![CDATA[ and ]]>. Following is an example of a CDATA section, which should make the usage of these symbols a little clearer:
This is my self-portrait: <![CDATA[ ***** * @ @ * * ) * * ~~~ * ***** ]]>
In this example, the crude drawing of a face is kept intact because it isn’t processed as XML data. If it wasn’t enclosed in a CDATA section, the white space within it would be processed down to a few spaces, and the drawing would be ruined. CDATA sections are very useful any time you want to preserve the exact appearance of text. You can also place legitimate XML code in a CDATA section to temporarily disable it and keep it from being processed.
I realize that this discussion of the internals of XML documents has been mind-numbingly technical and that you haven’t really done anything practical to justify the effort. Unfortunately, this is a necessary part of your XML education. However, I want to close this hour with a practical and fun example that demonstrates the use of comments and entities in the context of an online radio. By online radio, I mean a music player you can embed in a web page that is entirely driven by XML data. The radio itself is a Flash animation called Catalist Radio that was developed by Grant Hinkson of the design studio Catalist Creative (http://www.catalistcreative.com/). Grant was kind enough to allow me to use Catalist Radio as a demonstration of how to feed XML data into a practical online application.
By the Way
If the idea of manipulating music data via XML appeals to you, you’ll be glad to know that Hour 13, “Access Your iTunes Music Library via XML,” shows you how to access and manipulate an iTunes music library with XML.
Catalist radio consists of a Flash animation that is stored in a file with a .swf extension, along with an HTML web page that contains the embedded Flash Player. The web page is set up to use the file radio.xml as the XML data source for the radio. This is the file that is of primary interest to you.
By the Way
You can download the complete code for the Catalist Radio example, along with all of the code for this book, from my web site at http://www.michaelmorrison.com/.
The idea behind Catalist Radio is that you can specify multiple radio channels along with multiple songs in each channel. You can think of each channel as a playlist very much like playlists that you might already use in media players such as Windows Media Player or iTunes. When you launch the XML Radio application by opening the radio.html page in a browser, the first channel opens and begins playing the first song in the list. You can navigate forward and back through songs in a given channel, as well as change channels. The songs themselves must be stored as MP3 files in the same folder as the other files: radio.html, radio.xml, and GH_radiov2.swf.
The radio.xml file is where the interesting stuff takes place in the Catalist Radio application. Rather than try to lay the groundwork of how this file is structured up front, I’d rather just let you dive right into it. Listing 4.1 shows the complete XML code for the Catalist Radio example, which includes several different channels of music.
Example 4.1. The XML Data File for the Catalist Radio Example
1: <?xml version="1.0" encoding="UTF-8"?> 2: 3: <radio> 4: <station name="Rock"> 5: <song> 6: <title>Ol' 55</title> 7: <composer>Tom Waits</composer> 8: <file>tomwaits_ol55.mp3</file> 9: </song> 10: <song> 11: <title>King Contrary Man</title> 12: <composer>The Cult</composer> 13: <file>thecult_kingcontraryman.mp3</file> 14: </song> 15: <song> 16: <title>Drunken Chorus</title> 17: <composer>The Trashcan Sinatras</composer> 18: <file>trashcansinatras_drunkenchorus.mp3</file> 19: </song> 20: </station> 21: <station name="Rap"> 22: <song> 23: <title>Follow the Leader</title> 24: <composer>Eric B. & Rakim</composer> 25: <file>ericbrakim_followtheleader.mp3</file> 26: </song> 27: <song> 28: <title>My Philosophy</title> 29: <composer>Boogie Down Productions</composer> 30: <file>bdp_myphilosophy.mp3</file> 31: </song> 32: <song> 33: <title>I Pioneered This</title> 34: <composer>M.C. Shan</composer> 35: <file>mcshan_ipioneeredthis.mp3</file> 36: </song> 37: </station> 38: <!-- DISABLE COUNTRY 39: <station name="Country"> 40: <song> 41: <title>Mama Tried</title> 42: <composer>Merle Haggard</composer> 43: <file>merlehaggard_mamatried.mp3</file> 44: </song> 45: <song> 46: <title>A Boy Named Sue</title> 47: <composer>Johnny Cash</composer> 48: <file>johnnycash_aboynamedsue.mp3</file> 49: </song> 50: <song> 51: <title>Big Iron</title> 52: <composer>Marty Robbins</composer> 53: <file>martyrobbins_bigiron.mp3</file> 54: </song> 55: </station> 56: --> 57: </radio>
This code isn’t quite as tricky as you might initially think given its size. What you’re seeing is three different channels that are specified via the <station> tag (lines 4, 21, and 39). Notice that the name of each station is identified using the name attribute. Within each station, songs are coded using the <song> tag. And finally, within each song element you provide the song specifics via the title, composer, and file elements.
Of particular interest in this code is how comments are used. Notice that a comment appears about two-thirds of the way down the document (line 38), and doesn’t close until near the end of the document (line 56). The effect is that the country music station is completely ignored by the Catalist Radio application, and therefore is disabled. This is a perfect example of how you can use comments in XML code to temporarily remove a section of code.
Entities are also used in the radio.xml document to handle characters in the names of song titles and song composers. For example, the apostrophe in the Tom Waits song “Ol’ 55” is specified using the ' entity (line 6). Similarly, the ampersand in the rap artist name “Eric B. & Rakim” is specified using the & entity (line 24).
You’re no doubt itching to see what this code actually does in the context of the Catalist Radio application. Figure 4.1 shows the Tom Waits song “Ol’ 55” playing using the Catalist Radio application.
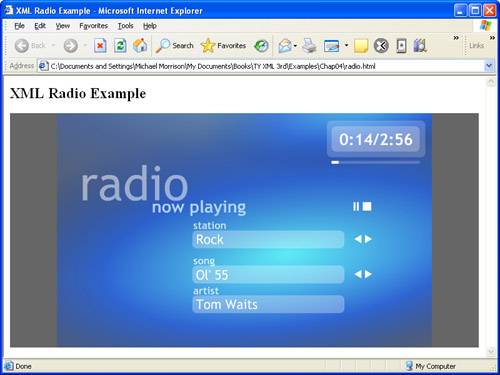
Figure 4.1. Catalist Radio provides a way to organize and play MP3 music online via an XML data feed.
Keep in mind that all you have to do create your own Catalist Radio online music player is to change the radio.xml file to reference your songs and then publish the application files and MP3 songs to the Web.
By the Way
If you download the sample code for Catalist Radio and open radio.html in a web browser, you won’t hear any music because I haven’t provided the actual MP3 files. You’ll have to modify radio.xml to use your own MP3 music. The last thing I need is the Recording Industry Association of America breathing down my neck for illegally distributing copyrighted music!
Although the code for many XML documents is somewhat self-explanatory, there are situations where it can be beneficial to provide additional information about XML code using comments or even temporarily disable XML code with comments. This hour showed you how to use comments, which allow you to make your code easier to understand. In addition to comments, you also learned how characters of text are encoded in an XML document. Although you might never change the character encoding scheme of your documents from the default setting, it is nonetheless important to understand why there are different encoding options.
After learning about comments and character encoding schemes, you spent the bulk of this hour getting acquainted with entities. You found out about parsed entities and unparsed entities, as well as the difference between internal and external entities. From there you learned the significance of notations and how they affect unparsed entities. Finally, the hour concluded with a practical XML application that allowed you to create an online radio driven by an XML document.
The Workshop is designed to help you anticipate possible questions, review what you’ve learned, and begin learning how to put your knowledge into practice.