
Plain Old Text still reigns supreme, despite the many predictions of its demise. | ||
| --Bob Foster | ||
Similar to HTML, XML is a technology that is best understood by working with it. I could go on and on for pages about the philosophical ramifications of XML, but in the end I’m sure you just want to know what you can do with it. Most of your XML work will consist of developing XML documents, which are sort of like HTML web pages, at least in terms of how the code is generally structured. Keep in mind, however, that XML documents can be used to store any kind of information. After you’ve created an XML document, you will no doubt want to see how it appears in a web browser or how it is used in a functioning application. Because there is no standard approach to viewing an XML document according to its meaning, you must either find or develop a custom application for viewing the document or use a style sheet to view the document in a web browser. This hour uses the latter approach to provide a simple view of an XML document that you create.
In this hour, you’ll learn
The basics of XML
How to select an XML editor
How to create XML documents
How to view XML documents
You learned in the previous hour that XML is a markup language used to create other markup languages. Because HTML is a markup language, it stands to reason that XML documents should in some way resemble HTML documents. In fact, you saw in the previous hour how an XML document looks a lot like an HTML document, with the obvious difference that XML documents can use custom tags. So, instead of seeing <head> and <body> you saw <pet> and <friend>. Nonetheless, if you have some experience with coding web pages in HTML, XML will be very familiar. You will find that XML isn’t nearly as lenient as HTML, so you may have to unlearn some bad habits carried over from HTML.
Of course, if you don’t have any experience with HTML you probably won’t even realize that XML is a somewhat rigid language.
Like some other markup languages, XML relies heavily on three fundamental building blocks: elements, attributes, and values. An element is used to describe or contain a piece of information; elements form the basis of all XML documents. Elements consist of two tags: an opening tag and a closing tag. Opening tags appear as words contained within angle brackets (<>), such as <pet> or <friend>. Closing tags also appear within angle brackets, but they have a forward-slash (/) just before the tag name. Examples of closing tags are </pet> and </friend>. Elements always appear as an opening tag, followed by optional data, followed by a closing tag:
<pet> </pet>
In this example, there is no data appearing between the opening and closing tags, which illustrates that the data is indeed optional. XML doesn’t care too much about how whitespace appears between tags, so it’s perfectly acceptable to place tags together on the same line:
<pet></pet>
Keep in mind that the purpose of tags is to denote pieces of information in an XML document, so it is rare to see a pair of tags with nothing between them, as the previous two examples show. Instead, tags typically contain text content or additional tags. Following is an example of how the pet element can contain additional content, which in this case is a couple of friend elements:
<pet> <friend /> <friend /> </pet>
By the Way
It’s important to note that an element is a logical unit of information in an XML document, whereas a tag is a specific piece of XML code that comprises an element. That’s why I always refer to an element by its name, such as pet, whereas tags are always referenced just as they appear in code, such as <pet> or </pet>.
You’re probably wondering why this code broke the rule requiring that every element has to consist of both an opening and a closing tag. In other words, why do the friend elements appear to involve only a single tag? The answer to this question is that XML allows you to abbreviate empty elements. An empty element is an element that doesn’t contain any content within its opening and closing tags. The earlier pet examples you saw are empty elements. Because empty elements don’t contain any content between their opening and closing tags, you can abbreviate them by using a single tag known as an empty tag. Similar to other tags, an empty tag is enclosed by angle brackets (<>), but it also includes a forward slash (/) just before the closing angle bracket. So, the empty friend element, which would normally be coded as <friend></friend> can be abbreviated as <friend />. The space before the /> isn’t necessary but is a standard style practice among XML developers.
By the Way
Any discussion of opening and closing tags wouldn’t be complete without pointing out a glaring flaw that appears in most HTML documents. I’m referring to the <p> tag, which is used to enclose a paragraph of text, and is often found in HTML documents with an opening tag but no closing tag. The p element in HTML is not an empty element, and therefore should always have a </p> closing tag, but most HTML developers make the mistake of leaving it out. This kind of freewheeling coding will get you in trouble quickly with XML!
All this talk of empty elements brings to mind the question of why you’d want to use an element that has no content. The reason for this is because you can still attach attributes to empty elements. Attributes are small pieces of information that appear within an element’s opening tag. An attribute consists of an attribute name and a corresponding attribute value, which are separated by an equal symbol (=). The value of an attribute appears to the right of the equal symbol and must appear within quotes. Following is an example of an attribute named name that is associated with the friend element:
<friend name="Augustus" />
By the Way
Attributes represent another area where HTML code is often in error, at least from the perspective of XML. HTML attributes are regularly used without quotes, which is a clear violation of XML syntax. Always quoting attribute values is another habit you’ll need to learn if you’re making the progression from free-spirited HTML designer to ruthlessly efficient XML coder.
In this example, the name attribute is used to identify the name of a friend. Attributes aren’t limited to empty elements—they are just as useful with nonempty elements. Additionally, you can use several different attributes with a single element. Following is an example of how several attributes are used to describe a pet in detail:
<pet name="Maximillian" type="pot bellied pig" age="3">
As you can see, attributes are a great way to tie small pieces of descriptive information to an element without actually affecting the element’s content.
A nonempty element is an element that contains content within its opening and closing tags. Earlier I mentioned that this content could be either text or additional elements. When elements are contained within other elements, they are known as nested elements. To understand how nested elements work, consider an apartment building. Individual apartments are contained within the building, whereas individual rooms are contained within each apartment. Within each room there may be pieces of furniture that in turn are used to store belongings. In XML terms, the belongings are nested in the furniture, which is nested in the rooms, which are nested in the apartments, which are nested in the apartment building. Listing 2.1 shows how the apartment building might be coded in XML.
Example 2.1. An Apartment Building XML Example
1: <apartmentbldg> 2: <apartment> 3: <room type="bedroom"> 4: <furniture type="armoire"> 5: <belonging type="t-shirt" color="navy" size="xl" /> 6: <belonging type="sock" color="white" /> 7: <belonging type="watch" /> 8: </furniture> 9: </room> 10: </apartment> 11: </apartmentbldg>
If you study the code, you’ll notice that the different elements are nested according to their physical locations within the building. It’s important to recognize in this example that the belonging elements are empty elements (lines 5–7), which is evident by the fact that they use the abbreviated empty tag ending in />. These elements are empty because they aren’t required to house (no pun intended!) any additional information. In other words, it is sufficient to describe the belonging elements solely through attributes.
It’s important to realize that nonempty elements aren’t just used for nesting purposes. Nonempty elements often contain text content, which appears between the opening and closing tags. Following is an example of how you might decide to expand the belonging element so that it isn’t empty:
<furniture type="desk">
<belonging type="letter">
Dear Michael,
I am pleased to announce that you may have won our sweepstakes. You are
one of the lucky finalists in your area, and if you would just purchase
five or more magazine subscriptions then you may eventually win some
money. Or not.
</belonging>
</furniture>In this example, my ticket to an early retirement appears as text within the belonging element. You can include just about any text you want in an element, with the exception of a few special symbols, which you learn about a little later in the hour.
Now that you have a feel for the XML language, it’s time to move on and learn about the specific rules that govern its usage. I’ve mentioned already that XML is a more rigid language than HTML, which basically means that you have to pay attention when coding XML documents. In reality, the exacting nature of the XML language is actually a huge benefit to XML developers—you’ll quickly get in the habit of writing much cleaner code than you might have been accustomed to writing in HTML, which will result in more accurate and reliable code. The key to XML’s accuracy lies in a few simple rules, which I’m calling XML’s five commandments:
Tag names are case sensitive.
Every opening tag must have a corresponding closing tag (unless it is abbreviated as an empty tag).
A nested tag pair cannot overlap another tag.
Attribute values must appear within quotes.
Every document must have a root element.
Admittedly, the last rule is one that I haven’t prepared you for, but the others should make sense to you. First off, rule number one states that XML is a case-sensitive language, which means that <pet>, <Pet>, and <PET> are all different tags. If you’re coming from the world of HTML, this is a very critical difference between XML and HTML. It’s not uncommon to see HTML code that alternates back and forth between tags such as <b> and <B> for bold text. In XML, this mixing of case is a clear no-no. Generally speaking, XML standards encourage developers to use either lowercase tags or mixed case tags, as opposed to the uppercase tags commonly found in HTML web pages. The same rule applies to attributes. If you’re writing XML code in a specific XML-based markup language, the language itself will dictate what case you should use for tags and attributes.
The second rule reinforces what you’ve already learned by stating that every opening tag (<pet>) must have a corresponding closing tag (</pet>). In other words, tags must always appear in pairs (<pet></pet>). Of course, the exception to this rule is the empty tag, which serves as an abbreviated form of a tag pair (<pet />). Rule three continues to nail down the relationship between tags by stating that tag pairs cannot overlap each other. This really means that a tag pair must be completely nested within another tag pair. Perhaps an example will better clarify this point:
<pets> <pet name="Maximillian" type="pot bellied pig" age="3"> </pet> <pet name="Augustus" type="goat" age="2"> </pets> </pet>
Do you see the problem with this code? The problem is that the second pet element isn’t properly nested within the pets element. The code indentation helps to make the problem more apparent but this isn’t always the case. For example, consider the following version of the same code:
<pets> <pet name="Maximillian" type="pot bellied pig" age="3"> </pet> <pet name="Augustus" type="goat" age="2"> </pets> </pet>
Remembering that whitespace doesn’t normally affect the structure of XML code, this listing is functionally no different than the previous listing but the nesting problem is much more hidden. In other words, the second pet element is still split out across the pets element, which is wrong. This code is wrong because it is no longer clear whether the second pet element is intended to be nested within the pets element or not—the relationship between the elements is ambiguous. And XML despises ambiguity! To resolve the problem you must either move the closing </pet> tag so that it is enclosed within the pets element, or move the opening <pet> tag so that it is outside of the pets element.
Getting back to the XML commandments, rule number four reiterates the earlier point regarding quoted attribute values. It simply means that all attribute values must appear in quotes. So, the following code breaks this rule because the name attribute value Maximillian doesn’t appear in quotes:
<friend name=Maximillian />
As I mentioned earlier, if you have used HTML this is one rule in particular that you will need to remember as you begin working with XML. Most web page designers are very inconsistent in their usage of quotes with attribute values. In fact, the tendency is to not use them. XML requires quotes around all attribute values, no questions asked!
The last XML commandment is the only one that I haven’t really prepared you for because it deals with an entirely new concept: the root element. The root element is the single element in an XML document that contains all other elements in the document. Every XML document must contain a root element, which means that exactly one element must be at the top level of any given XML document. In the “pets” example that you’ve seen throughout this hour and the previous hour, the pets element is the root element because it contains all the other elements in the document (the pet and friend elements). To make a quick comparison to HTML, the html element in a web page is the root element, so HTML adheres to XML rules in this regard. However, technically HTML will let you get away with having more than one root element, whereas XML will not.
There are a few special symbols in XML that must be entered differently than other text characters when appearing as content within an XML document. The reason for entering these symbols differently is because they are considered part of XML syntax by identifying parts of an XML document such as tags and attributes. The symbols to which I’m referring are the less than symbol (<), greater than symbol (>), quote symbol (“), apostrophe symbol (‘), and ampersand symbol (&). These symbols all have special meaning within the XML language, which is why you must enter them using a symbol instead of just using each character directly. So, as an example, the following code isn’t allowed in XML because the apostrophe (‘) character is used directly in the name attribute value:
<movie name="All the King's Men" />
The trick to referencing these characters is to use special predefined symbols known as entities. An entity is a symbol that identifies a resource, such as a text character or even a file. There are five predefined entities in XML that correspond to each of the special characters you just learned about. Entities in XML begin with an ampersand (&) and end with a semicolon (;), with the entity name sandwiched between. Following are the predefined entities for the special characters:
To fix the movie example code, just replace the ampersand and apostrophe characters in the attribute value with the appropriate entities:
<movie name="All the King's Men" />
Here’s another movie example, just to clarify how another of the entities is used:
<movie name="Pride & Prejudice" />
In this example, the & entity is used to help code the movie title, “Pride & Prejudice.” Admittedly, these entities make the attribute values a little tougher to read, but there is no question regarding the usage of the characters. This is a good example of how XML is willing to make a trade-off between ease of use on the developer’s part and technical clarity. Fortunately, there are only five predefined entities to deal with, so it’s pretty easy to remember them.
One final important topic to cover in this quick tour of XML is the XML declaration, which is not strictly required of all XML documents but is a good idea nonetheless. The XML declaration is a line of code at the beginning of an XML document that identifies the version of XML used by the document. Currently there are two versions of XML: 1.0 and 1.1. XML 1.1 primarily differs from XML 1.0 in how it supports characters in element and attribute names. XML 1.1’s broader character support is primarily of use for mainframe programmers, which likely explains why XML 1.1 isn’t very widely supported. Given this scenario, you should only worry about supporting XML 1.0 in your documents, at least for the foreseeable future.
By the Way
There have been some rumblings in the XML community about a possible XML 2.0 but nothing concrete has materialized as of yet.
Getting back to the XML declaration, it notifies an application or web browser of the XML version that an XML document is using, which can be very helpful in processing the document. Following is the standard XML declaration for XML 1.0:
<?xml version="1.0"?>
This code looks somewhat similar to an opening tag for an element named xml with an attribute named version. However, the code isn’t actually a tag at all. Instead, this code is known as a processing instruction, which is a special line of XML code that passes information to the application that is processing the document. In this case, the processing instruction is notifying the application that the document uses XML 1.0. Processing instructions are easily identified by the <? and ?> symbols that sandwich each instruction.
To create and edit your own XML documents, you must have an application to serve as an XML editor. Because XML documents are raw text documents, a simple text editor can serve as an XML editor. For example, if you are a Windows user you can just use the standard Windows Notepad or WordPad applications to edit XML documents. Or on a Macintosh computer you can use TextEdit. If you want XML-specific features such as the ability to edit elements and attributes visually, you’ll want to go beyond a simple text editor and use a full-blown XML editor. Before introducing you to some popular XML editors, it’s worth taking a quick step back and explaining how XML editors differ in their fundamental approaches.
There are three basic types of XML editors: WYSIWYG, WYSIWYM, and plain text. If you have any experience with web development or desktop publishing, you’re probably familiar with the term WYSIWYG, which stands for What You See Is What You Get. The idea behind WYSIWYG tools is that you edit content exactly as you want it to appear. Microsoft Word and Macromedia Dreamweaver are examples of WYSIWYG tools in that they allow you to edit word processing documents and web pages just as they will appear when printed or viewed on the Web. WYSIWYG XML editors take a similar approach by focusing on the final appearance of an XML document for display purposes, as opposed to the meaning of the XML content itself.
If you want to focus more on the meaning of XML content, you should consider using a WYSIWYM XML editor. Any guesses as to what the acronym stands for? You get two points if you said What You See Is What You Mean! A WYSIWYM XML editor focuses on the meaning of XML code as opposed to how the code is rendered for viewing. WYSIWYM editors often take into consideration specific XML languages, and offer you context-sensitive help in using tags and attributes. Most WYSIWYM editors display XML code as a tree-like structure roughly similar to the default browser view of XML that you saw in the previous chapter (Figures 1.1 and 1.2).
By the Way
WYSIWYM XML editors are also sometimes referred to as semantic editors because they focus on the semantics (meaning) of XML code, as opposed to the resulting appearance of the code.
The third type of XML editor is the plain text editor, which simply allows you to edit an XML document as plain text. The plain text approach is neither WYSIWYG or WYSIWYM because there is no clue provide regarding the eventual appearance of the code or the context of its meaning. You’re pretty much on your own if you go the plain text route, which is not entirely a bad thing, at least in terms of learning the ropes and understanding every single character of an XML document.
There are several commercial XML editors available at virtually every price range and supporting both major approaches to XML editing (WYSIWYG and WYSIWYM). Although a commercial XML editor might prove beneficial at some point, I recommend spending at least a little time with a plain text editor because it allows you to work directly at the XML code level with no frills. Figure 2.1 shows the “talltales” example XML document open in Windows Notepad.
Figure 2.1. Simple text editors such as Windows Notepad allow you to edit XML documents as plain text.
By the Way
If you use Windows WordPad or some other text editor that supports file formats in addition to standard text, you’ll want to make sure to save XML documents as plain text. This means you will need to use the Save As command instead of Save, and choose Text Only (.txt) as the file type.
As far as WYSIWYG XML editors go, one of the better editors I’ve seen is called Vex, and it is freely available for download at http://vex.sourceforge.net/. Vex presents a visual user interface generally similar to a word processor such as Microsoft Word. More importantly, Vex earns the WYSIWYG label because it hides XML tags from you, allowing you to focus solely on the appearance of your code. Vex uses CSS (Cascading Style Sheets) to render the appearance of XML code. You learn how to use CSS to style XML code in Hour 10, “Styling XML Content with CSS.” Unfortunately, Vex is a little tricky to get the hang of in terms of creating and managing XML projects, so I’d recommend sticking with a WYSIWYM or plain text for the creation of XML documents until you have more experience. Keep in mind that you can always use a web browser for a WYSIWYG view of an XML document that you create in a WYSIWYM or plain text XML editor.
Many XML documents aren’t about appearance at all, in which case you’ll want to look into using an editor that focuses on meaning as opposed to appearance. One of my favorite WYSIWYM XML editors is Butterfly XML, which is available for free download at http://www.butterflyxml.org/. Unlike Vex, Butterfly XML is geared toward editing XML content with a focus on what the content means, not what it will look like. Butterfly XML displays an XML document as both a hierarchical tree of data and context-highlighted text. In other words, you get to see both the tree-like structure of an XML document as well as how each portion of the tree is associated with plain text in the document. However, instead of entering raw text in the document, you are presented with editing aids such as a pop-up list of available tags. Figure 2.2 shows an example of how Butterfly XML allows you to edit an XML document with a focus on the meaning of the content.
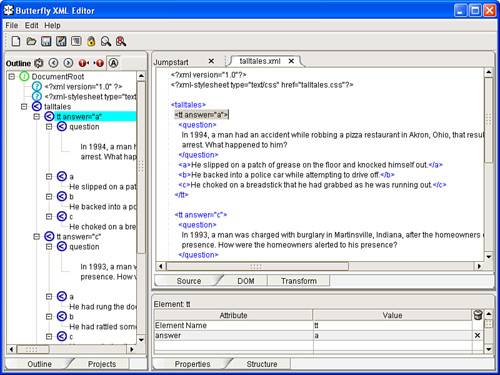
Figure 2.2. The Butterfly XML WYSIWYM XML editor gives you an opportunity to focus on the meaning of XML documents as you edit them.
By the Way
I’ve actually done a bit of foreshadowing here by showing you the talltales.xml document in Figure 2.2. You create this document as your first XML document in the next section of this hour.
In case you’re concerned that I’m being too cheap by only showing you free XML editors, there are plenty of commercial editors you can buy if you want to go that route. Many of the commercial editors allow you to edit XML documents using a combination of WYSIWYG and WYSIWYM approaches, which gives you lots of flexibility. One of the more powerful commercial XML editors I’ve run across is <oXygen/> XML Editor, which is available for Windows, Macintosh, Linux, and Eclipse. <oXygen/> isn’t free but it could very well pay for itself with its advanced XML features. To learn more about <oXygen/>, visit it on the Web at http://www.oxygenxml.com/.
Another solid XML editor is XML Spy, which is available for Windows computers. XML Spy has been around a while, and is packed with support for a wide range of XML technologies. Perhaps of more interest to you at this stage of the game, XML Spy is available for free in a special Home Edition. There is also an Enterprise Edition and a Professional Edition, both of which are not free but pack in a lot more features. You can download and try out XML Spy Home Edition at http://www.altova.com/download_spy_home.html.
You now have the basic knowledge necessary to create an XML document of your own. You may already have in mind some data that you’d like to format into an XML document, which by all means I encourage you to pursue. For now, however, I’d like to provide some data that you can use to work through the creation of a simple XML document. When I’m not writing books, I am involved with a toy and game company called Stalefish Labs, which designs and produces traditional board games, social games, toys, and even mobile software games. We released a traditional print version of a trivia game called Tall Tales a couple of years ago (http://www.talltalesgame.com/), and we’re in the process of putting together a software version of the game. It only makes sense to code the database of questions and answers in XML. The idea is to use XML documents to provide trivia questions to web and mobile versions of the game. By using XML, we’ll be able to code the content in a consistent format and easily provide updates and new content periodically.
Anyway, the point of all this game stuff is that a good example of an XML document is one that allows you to store trivia questions and answers in a structured format. My trivia game, Tall Tales, involves several different kinds of questions, but one of the main question types is called a “tall tale” in the game. It’s a multiple-choice question consisting of three possible answers. Knowing this, it stands to reason that the XML document will need a means of representing each question plus three different answers. Keep in mind, however, that in order for the answers to have any meaning, you must also provide a means of specifying the correct answer. A good place to do this is in the main element for each question/answer group.
Don’t forget that earlier in this hour you learned that every XML document must have a root element. In this case, the root element is named talltales to match the name of the game. Within the talltales element you know that there will be several questions, each of which has three possible answers. Let’s code each question with an element named question and each of the three answers with the three letters a, b, and c. It’s important to group each question with its respective answers, so you’ll need an additional element for this. Let’s call this element tt to indicate that the question type is a tall tale. The only remaining piece of information is the correct answer, which can be conveniently identified as an attribute of the tt element. Let’s call this attribute answer. Just in case I went a little too fast with this description of the Tall Tales document, let’s recap the explanation with the following list of elements that are used to describe pieces of information within the document:
In addition to these elements, an attribute named answer is used with the tt element to indicate which of the three answers (a, b, or c) is correct. Also, don’t forget that the document must begin with an XML declaration. With this information in mind, take a look at the following code for a complete tt element:
<tt answer="a">
<question>
In 1994, a man had an accident while robbing a pizza restaurant in Akron,
Ohio, that resulted in his arrest. What happened to him?
</question>
<a>He slipped on a patch of grease on the floor and knocked himself out.</a>
<b>He backed into a police car while attempting to drive off.</b>
<c>He choked on a breadstick that he had grabbed as he was running out.</c>
</tt>This code reveals how a question and its related answers are grouped within a tt element. The answer attribute indicates that the first answer (a) is the correct one.
All of the elements in this example are nonempty, which is evident by the fact that they all either contain text content or additional elements. Notice also how every opening tag has a matching closing tag and how the elements are all nested properly within each other. Now that you understand the code for a single question, check out Listing 2.2, a complete XML document that includes three trivia questions.
Example 2.2. The Tall Tales Sample XML Document
1: <?xml version="1.0"?>
2:
3: <talltales>
4: <tt answer="a">
5: <question>
6: In 1994, a man had an accident while robbing a pizza restaurant in
7: Akron, Ohio, that resulted in his arrest. What happened to him?
8: </question>
9: <a>He slipped on a patch of grease on the floor and knocked himself out.</a>
10: <b>He backed into a police car while attempting to drive off.</b>
11: <c>He choked on a breadstick that he had grabbed as he was running out.</c>
12: </tt>
13:
14: <tt answer="c">
15: <question>
16: In 1993, a man was charged with burglary in Martinsville, Indiana,
17: after the homeowners discovered his presence. How were the homeowners
18: alerted to his presence?
19: </question>
20: <a>He had rung the doorbell before entering.</a>
21: <b>He had rattled some pots and pans while making himself a waffle in
their kitchen.</b>
22: <c>He was playing their piano.</c>
23: </tt>
24:
25: <tt answer="a">
26: <question>
27: In 1994, the Nestle UK food company was fined for injuries suffered
28: by a 36 year-old employee at a plant in York, England. What happened
29: to the man?
30: </question>
31: <a>He fell in a giant mixing bowl and was whipped for over a minute.</a>
32: <b>He developed an ulcer while working as a candy bar tester.</b>
33: <c>He was hit in the head with a large piece of flying chocolate.</c>
34: </tt>
35: </talltales>Although this may appear to be a lot of code at first, upon closer inspection you’ll notice that most of the code is simply the content of the trivia questions and answers. The XML tags should all make sense to you given the earlier explanation of the Tall Tales trivia data. You now have your first complete XML document that has some pretty interesting content ready to be processed and served up for viewing. Be sure to take a look back at Figure 2.2 to see how this exact same code appears within the Butterfly XML WYSIWYM XML editor.
Short of developing a custom application from scratch, the best way to view XML documents is to use a style sheet, which is a series of formatting descriptions that determine how elements are displayed on a web page. In its most basic usage, a style sheet allows you to carefully control what the content in a web page looks like in a web browser. In the case of XML, style sheets allow you to determine exactly how to display data in an XML document. Although style sheets can improve the appearance of HTML web pages, they are especially important for XML because web browsers typically don’t understand what the custom tags mean in an XML document.
You learn a great deal about style sheets in Part III, “Formatting and Displaying XML Documents,” but for now I just want to show you a style sheet that is capable of displaying the Tall Tales trivia document that you created in the previous section. Keep in mind that the purpose of a style sheet is typically to determine the appearance of XML content. This means that you can use styles in a style sheet to control the font and color of text, for example. You can also control the positioning of content, such as where an image or paragraph of text appears on the page. Styles are always applied to specific elements. So, in the case of the trivia document, the style sheet should include styles for each of the important elements that you want displayed: tt, question, a, b, and c.
Later in the book, in Hour 16, “Parsing XML with DOM,” you learn how to incorporate interactivity to the Tall Tales example using scripting code, but right now all I want to focus on is displaying the XML data in a web browser using a style sheet. The idea is to format the data so that each question is displayed followed by each of the answers in a smaller font and different color. The code in Listing 2.3 is the talltales.css style sheet for the Tall Tales trivia XML document.
Example 2.3. A CSS Style Sheet for Displaying the Tall Tales XML Document
1: tt {
2: display: block;
3: width: 750px;
4: padding: 10px;
5: margin-bottom: 10px;
6: border: 4px double black;
7: background-color: silver;
8: }
9:
10: question {
11: display: block;
12: color: black;
13: font-family: Times, serif;
14: font-size: 16pt;
15: text-align: left;
16: }
17:
18: a, b, c {
19: display: block;
20: color: brown;
21: font-family: Times, serif;
22: font-size: 12pt;
23: text-indent: 15px;
24: text-align: left;
25: }Don’t worry if the style sheet doesn’t make too much sense. The point right now is just to notice that the different elements of the XML document are addressed in the style sheet. Even without any knowledge of CSS, if you study the code closely you should be able to figure out what many of the styles are doing. For example, the code color: black; (line 12) states that the text contained within a question element is to be displayed in black. If you create this style sheet and include it with the talltales.xml document, the document as viewed in the Mozilla Firefox browser appears as shown in Figure 2.3.
Figure 2.3. The tallltales. xml document is displayed as XML code because the style sheet hasn’t been attached to it.
The page shown in the figure probably doesn’t look like you thought it should. In fact, the style sheet isn’t even impacting this figure because it hasn’t been associated with the XML document yet. So, in the absence of a style sheet, Firefox just displays the XML code as a hierarchical tree of XML data. To attach the style sheet to the document, add the following line of code just after the XML declaration for the document:
<?xml-stylesheet type="text/css" href="talltales.css"?>
So, the start of the talltales.xml document should now look like this:
<?xml version="1.0"?>
<?xml-stylesheet type="text/css" href="talltales.css"?>
<talltales>
<tt answer="a">
...If you’ve been following along closely, you’ll recognize the new line of code as a processor instruction, which is evident by the <? and ?> symbols. This processor instruction notifies the application processing the document (the web browser) that the document is to be displayed using the style sheet talltales.css. After adding this line of code to the document, it is displayed in Firefox in a format that is much easier to read (see Figure 2.4).
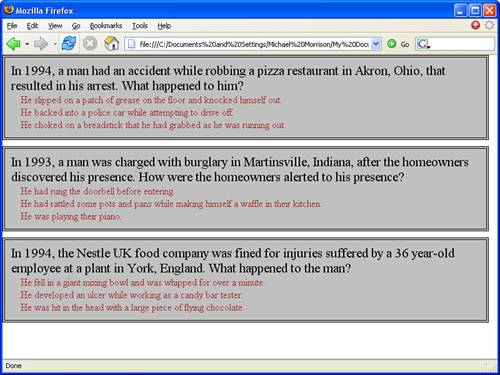
Figure 2.4. A simple style sheet provides a means of formatting the data in an XML document for convenient viewing in a web browser.
That’s a little more like it! As you can see, the style sheet does wonders for making the XML document viewable in a web browser. You’ve now successfully created your first XML document, along with a style sheet to view it in a web browser.
By the Way
If you’re concerned that I glossed over the details of style sheets in this section, please don’t be. I readily admit to glossing them over, but I just wanted to quickly show you how to view a web page in a web browser. Besides, you’ll get a heavy dose of style sheets in Part III of the book, so hang in there.
As you learned in this hour, the basic rules of XML aren’t too complicated. Although XML is admittedly more rigid than HTML, once you learn the fundamental structure of the XML language, it isn’t too difficult to create XML documents. It’s this consistency in structure that makes XML such a useful technology in representing diverse data. Just as XML itself is relatively simple, the tools required to develop XML documents can be quite simple—all you really need is a text editor such as Windows Notepad. Even so, more powerful tools can ultimately come in handy as you progress onward and develop more complex XML documents.
This hour began by teaching you the basics of XML, after which you learned how XML documents are created and edited using XML editors. After covering the fundamentals of XML, you were then guided through the creation of a complete XML document that stores information for an online trivia game. You then learned how a style sheet is used to format the XML document for viewing in a web browser.
How do I know what the latest version of XML is? | |
The latest version of XML to date is version 1.1, although it isn’t widely supported. To find out about new versions as they are released, please visit the World Wide Web Consortium (W3C) web site at http://www.w3c.org/. Keep in mind, however, that XML is a relatively stable technology, and isn’t likely to undergo version changes nearly as rapidly as more dynamic technologies such as Java or even HTML. For practical purposes, you can still consider XML 1.0 as the current version of XML in use today. | |
What happens if an XML document breaks one or more of the XML commandments? | |
Well, of course, your computer will crash immediately and erupt in a ball of flames! No, actually nothing tragic will happen unless you attempt to process the document via an automated XML tool or application. Even then, you will likely get an error message instead of any kind of fatal result. XML-based applications expect documents to follow the rules, so they will likely notify you of the errors whenever they are encountered. Fortunately, even web browsers are pretty good at reporting errors in XML documents, which is in sharp contrast to how loosely they interpret HTML web pages. | |
Are there any other approaches to using style sheets with XML documents? | |
Yes. The Tall Tales trivia example in this hour makes use of CSS (Cascading Style Sheets), which is used primarily to format HTML and XML data for display. Another style sheet technology known as XSL (eXtensible Style Language) allows you to filter, transform, and otherwise finely control exactly what information is displayed from an XML document. You learn about both style sheet technologies in Part III, “Formatting and Displaying XML Documents.” |
The Workshop is designed to help you anticipate possible questions, review what you’ve learned, and begin learning how to put your knowledge into practice. The answers to the quiz can be found following the quiz.