
I generally avoid temptation unless I can’t resist it. | ||
| --Mae West | ||
One form of temptation many web developers have been unable to resist is that of hacking together web pages with poorly coded HTML. Fortunately, XML is well on its way to adding some much needed structure to the Web by ushering in a new version of HTML called XHTML, which represents a merger of XML and HTML. Considering that there is a lot of confusion surrounding the relationship between XML and HTML, XHTML often serves only to muddy the water in terms of how people perceive XML. XHTML is ultimately quite simple in that it is a version of HTML reformulated to meet the strict structural and syntax requirements of XML. XHTML makes use of the same elements and attributes as HTML, but it enforces XML rules, such as quoting all attribute values and requiring empty elements to end with />. It still isn’t clear if, how, or when the Web will officially transition from HTML to XHTML, but it is a likely prospect given the benefits of XML. This hour introduces you to XHTML and examines some of the consequences of migrating web pages from HTML to XHTML.
In this hour, you’ll learn
What XHTML is and why it was created
About the differences between XHTML and HTML
How to create and validate XHTML documents
How to convert existing HTML documents to XHTML
XHTML is an XML-based markup language that carries out the functionality of HTML in the spirit of XML. As you hopefully know by now, HTML is not a descendent of XML; this would be tricky considering that XML was created after HTML. HTML is actually a descendent of an older markup language technology known as SGML (Standard Generalized Markup Language), which is considerably more complex than XML. XML in many ways represents a simplified reformulation of SGML, which makes XML more compact than SGML, as well as much easier to learn and process. So, XML is beneficial from the perspective of both application developers and document developers. But what exactly does this have to do with HTML? Or, to pose the question more generally, why exactly do we need XHTML?
To answer the “Why XHTML?” question, you have to first take stock of the Web and some of the problems surrounding it. Much of the Web is a jumbled mess of hacked HTML code that has very little structure. Poor coding, browser leniency, and proprietary browser extensions have all combined to create a web of HTML documents that are extremely unstructured, which is a bad thing. Don’t get me wrong, things have improved since the early days of the Web but we still have a long way to go. Web browser vendors have had to create HTML processors that are capable of reading and displaying even the most horrendous HTML code so that web users never have to witness the underlying bad code in many web pages. Although this is good in terms of the web experience, it makes it very difficult to glean information from web pages in an automated manner because their structure is so inconsistent.
You know that XML documents can’t suffer from bad coding because XML simply won’t allow it. Knowing this, a logical answer to the HTML problem is to convert web pages to XML documents and then use stylesheets to render them. It would also be nice to have peace on earth, tasty fat-free foods, and lower taxes, but life just doesn’t work that way. What I’m getting at is that HTML will likely always have a place on the Web simply because it is too deeply ingrained to replace. Besides, even though XML paired with CSS/XSLT has huge structural benefits over a purely presentational HTML web page, it involves more work and a bit more planning. There are certainly situations where it doesn’t matter too much if content is separated from how it is displayed, in which case HTML represents a simpler, more efficient solution.
The point I’m trying to make is that plain HTML, in one form or another, is likely here to stay. The solution to the problem then shifts to improving HTML in some way. The most logical improvement to solve the structural problems of HTML is to express HTML as an XML language (XHTML), which allows us to reap many of the benefits of XML without turning the Web on its ear. The primary benefit of XHTML is obviously structure, which would finally force browser vendors and web developers alike to play by the rules. Browsers could strictly enforce an XHTML schema to ensure that documents are both well formed and valid. Just requiring XHTML documents to be well formed would be a significant step in the right direction; checking them for validity would be the icing on the cake.
By the Way
Although XHTML 2.0 is in the works, the latest supported version of XHTML is version 1.1. You can learn more about XHTML 1.1 by visiting the W3C web site at http://www.w3.org/MarkUp/#xhtml11.
Even as XHTML catches on and web developers migrate their HTML code to it, web browsers still have to support the old, unstructured versions of HTML for the foreseeable future. However, over time these legacy HTML documents could eventually be supplanted by valid, well-formed XHTML documents with plenty of structure. One thing that is already making the migration to XHTML smoother is the fact that a great deal of web page development is carried out with visual authoring tools that automatically generate XHTML code. This makes it virtually painless for developers to make the move to XHTML.
By the Way
You might not realize it, but another compelling reason to move the Web toward XHTML is so that new types of compact browsers with limited processing capabilities can avoid the hassles of trying to process unstructured HTML code. These browsers are becoming prevalent on devices such as mobile phones and handheld computers, and would benefit from highly structured XHTML documents to minimize processing overhead. In Hour 23, “Going Wireless with WML and XHTML Mobile,” you learn about WML and XHTML Mobile, which are used to develop web pages for mobile devices.
You probably know that the latest version of HTML is version 4.0 (4.01 to be exact), which is in wide use across the Web. XHTML is a reformulated version of HTML 4.0 that plays by the more rigid rules of XML. Fortunately, most of the differences between XHTML and HTML 4.0 are syntactic, which means that they don’t dramatically impact the overall structure of HTML documents. Migrating an HTML 4.0 document to XHTML is more a matter of cleaning and tightening up the code than converting it to a new language. If you have any web pages that were developed using HTML 4.0, you’ll find that they can be migrated to XHTML with relative ease. You learn how to do this later in the hour in the section titled, “Migrating HTML to XHTML.”
Even though XHTML supports the same elements and attributes as HTML 4.0, there are some significant differences that are due to the fact that XHTML is an XML-based language. Given your knowledge of XML, you may already have a pretty good idea regarding some of these differences, but the following list will help you to understand exactly how XHTML documents differ from HTML documents:
XHTML documents must be well formed.
Element and attribute names in XHTML must be in lowercase.
End tags in XHTML are required for nonempty elements.
Empty elements in XHTML must consist of a start-tag/end-tag pair or an empty element.
Attributes in XHTML cannot be used without a value.
Attribute values in XHTML must always be quoted.
An XHTML namespace must be declared in the root
htmlelement.The
headandbodyelements cannot be omitted in XHTML.The
titleelement in XHTML must be the first element in theheadelement.In XHTML, all script and style elements must be enclosed within
CDATAsections.
These differences between XHTML and HTML 4.0 shouldn’t come as too much of a surprise. Fortunately, none of them are too difficult to find and fix in HTML documents, which makes the move from HTML 4.0 to XHTML relatively straightforward. However, web pages developed with versions of HTML prior to 4.0 typically require more dramatic changes. This primarily has to do with the fact that HTML 4.0 does away with some previously popular formatting attributes such as background and instead promotes the usage of style sheets. Because XHTML doesn’t support these formatting attributes, it is necessary first to convert legacy HTML (prior to 4.0) documents to HTML 4.0, which quite often involves replacing formatting attributes with CSS equivalents. Once you get a web page up to par with HTML 4.0, the move to XHTML is pretty straightforward.
Because XHTML is an XML-based markup language, creating XHTML documents is very much like creating any other kind of XML document. You must first learn the XHTML language, after which you use a text editor or other XML development tool to construct a document using XHTML elements and attributes. If you’ve always created web pages using visual authoring tools, such as FrontPage or Dreamweaver, the concept of assembling a web page in a text editor might be new. On the other hand, if you aren’t a seasoned web developer and your only experience with markup languages is XML, you’ll feel right at home. The next few sections explore the basics of creating and validating XHTML documents.
By the Way
Many visual web development tools support XHTML, which means that you can certainly create XHTML web pages without having to rely on a simple text editor. However, if you really want to learn how XHTML works as a language, you have to get dirty and explore XHTML code. Fortunately, many web development tools include a code view that allows you to view the underlying code for a page. If your development tool offers such a view, you can forego using a simple text editor. Such code viewers also offer editing features such as context-sensitive color highlighting and automatic tag matching, which can assist you in writing valid XHTML code.
Just as it is beneficial to validate other kinds of XML documents, it is also important to validate XHTML documents to ensure that they adhere to the XHTML language. As you know, validation is carried out through a schema, which can be either a DTD or an XSD. Both kinds of schemas are available for use with XHTML. I’ll focus on the usage of an XHTML DTD to validate XHTML documents because DTDs are still more widely supported than XSDs. Before getting into the specifics of using a DTD to validate XHTML documents, it’s necessary to clarify the different versions of XHTML and how they impact XHTML document validation.
The first version of XHTML was version 1.0, which focused on a direct interpretation of HTML 4.0 as an XML-based markup language. Because HTML 4.0 is a fairly large and complex markup language, the W3C decided to offer XHTML 1.0 in three different flavors, which vary in their support of HTML 4.0 features:
These different strains of XHTML are listed in order of increasing functionality, which means that the Frameset feature set is richer and therefore more complex than the Strict feature set. These three different strains of XHTML 1.0 are realized by three different DTDs that describe the elements and attributes for each feature set. The idea is that you can use a more minimal XHTML DTD if you don’t need to use certain XHTML language features, or you can use a more thorough DTD if you need additional features, such as frames.
The Strict DTD is a minimal DTD that is used to create very clean XHTML documents without any presentation markup. Documents created from this DTD require style sheets in order to be formatted for display because they don’t contain any presentation markup. The Transitional DTD builds on the Strict DTD by adding support for presentation markup elements. This DTD is useful in performing a quick conversion of HTML documents to XHTML when you don’t want to take the time to develop style sheets. The Frameset DTD is the broadest of the three DTDs and adds support for creating documents with frames.
The three DTDs associated with XHTML 1.0 can certainly be used to validate XHTML documents, but there is a newer version of XHTML known as XHMTL 1.1 that includes a DTD of its own. The XHTML 1.1 DTD is a reformulation of the XHTML 1.0 Strict DTD that is designed for modularity. The idea behind the XHTML 1.1 DTD is to provide a means of expanding XHTML to support other XML-based languages, such as MathML for mathematical content. Because the XHTML 1.1 DTD is based upon the Strict XHTML 1.0 DTD, it doesn’t include support for presentation elements or framesets. The XHTML 1.1 DTD is therefore designed for pure XHTML documents that adhere to the XML adage of separating content from how it is formatted and displayed.
Regardless of which XHTML DTD you decide to use to validate XHTML documents, there are a few other validity requirements to which all XHTML documents must adhere:
There must be a document type declaration (
DOCTYPE) in the document that appears prior to the root elementThe document must validate against the DTD declared in the document type declaration; this DTD must be one of the three XHTML 1.0 DTDs or the XHTML 1.1 DTD
The root element of the document must be
htmlThe root element of the document must designate an XHTML namespace using the
xmlnsattribute
You must declare the DTD for all XHTML documents in a document type declaration at the top of the document. A Formal Public Identifier (FPI) is used in the document type declaration to reference one of the standard XHTML DTDs. Following is an example of how to declare the Strict XHTML 1.0 DTD in a document type declaration:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "DTD/xhtml1-strict.dtd">
It isn’t terribly important that you understand the details of the FPI in this code. The main point is that it identifies the Strict XHTML 1.0 DTD and therefore is suitable for XHTML documents that don’t require formatting or frameset features. The XHTML 1.0 Transitional DTD is specified using similar code, as the following example reveals:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "DTD/xhtml1-transitional.dtd">
The XHTML 1.0 Frameset DTD is also specified with similar code, as in the following example:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "DTD/xhtml1-frameset.dtd">
Finally, the XHTML 1.1 DTD is specified with a document type declaration that is a little different from the others:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
The decision regarding which XHTML DTD to use really comes down to what features your documents require. If you can get by without the presentation or frameset features, then the XHTML 1.0 Strict DTD or the XHTML 1.1 DTD are your best bet. Between the two, it’s better to go with the newer XHTML 1.1 DTD because it represents the future direction of XHTML. If your documents require some presentation features, the XHTML 1.0 Transitional DTD is the one for you. And finally, if you need the whole gamut of XHTML features, including framesets, the XHTML 1.0 Frameset DTD is the way to go.
By the Way
If you truly want to create XML documents that are geared toward the future of the Web, you should target the XHTML 1.1 DTD.
In addition to declaring an appropriate DTD in the document type declaration, a valid XHTML document must also declare the XHTML namespace in the root html element, and it must declare the language. Following is an example of declaring the standard XHTML namespace and the English language in the html element for an XHTML document:
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
XHTML documents are created in much the same way as any other XML document, or any HTML document for that matter. As long as you keep in mind the differences between XHTML and HTML, you can develop XHTML web pages just as you would create HTML web pages, assuming you don’t mind creating web pages by hand. To give you a better idea as to how an XHTML document comes together, check out the code for a skeletal XHTML document in Listing 21.1.
Example 21.1. A Skeletal XHTML Document
1: <?xml version="1.0" encoding="UTF-8"?> 2: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" 3: "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd"> 4: 5: <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> 6: <head> 7: <title>Skeletal XHTML Document</title> 8: </head> 9: 10: <body> 11: <p> 12: This is a skeletal XHTML document. 13: </p> 14: </body> 15: </html>
The skeleton.xhtml document admittedly doesn’t do much in terms of being a useful web page, but it does demonstrate how to create a legal XHTML document. In other words, the skeletal document declares an XHTML DTD and namespace and adheres to all of the structural and syntax rules of XML. It can also be viewed directly in a web browser. The main significance of the skeletal XHTML document is that it serves as a great template for creating other XHTML documents.
As with any XML document, it’s very important to be able to validate XHTML documents. You’ve already learned about the DTDs that factor into XHTML validation, but you haven’t learned exactly when XHTML documents are validated. Keep in mind that it takes processing time for any XML document to be validated, and in the case of XHTML, this could hinder the speed at which web pages are served and displayed. The ideal scenario in terms of performance is for developers to validate XHTML documents before making them publicly available, which alleviates the need for browsers to perform any validation. On the other hand, there currently is a lot of HTML code generated on the fly by scripting languages and other interactive technologies, in which case it might be necessary for a browser to sometimes validate XHTML documents.
Although there are no rules governing the appropriate time for XHTML documents to be validated, it’s generally a good idea for you to take the initiative to validate your own documents before taking them live. Fortunately, the W3C provides a free online validation service known as the W3C Validator that can be used to validate XHTML documents. This validation service is available online at http://validator.w3.org/ and is shown in Figure 21.1.
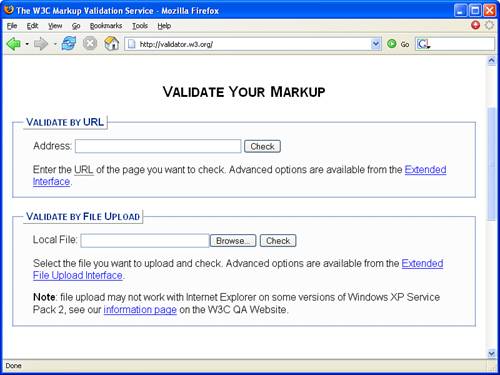
Figure 21.1. The W3C Validator service is capable of validating XHTML documents as well as HTML documents.
You can see in the figure that the W3C Validator is used by entering the URI of an XHTML document. Of course, web pages are typically developed offline, which means you may not have published them to an accessible URI online. In this case, you can simply choose the File Upload option on the W3C Validator page, which allows you to browse your computer for an XHTML document file. If you want to exercise more control over the validation of XHTML documents that you upload, you may want to consider using the Extended File Upload Interface, which is available via a text link just below the Validate by File Upload option (see Figure 21.1).
Figure 21.2 shows the results of validating the skeleton.xhtml document using the W3C Validator.
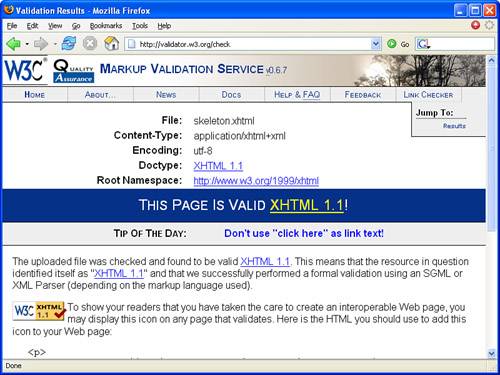
As the figure reveals, the skeletal document passed the W3C Validator with flying colors, which isn’t too much of a surprise. This is a handy service to have around when creating XHTML documents, especially when you consider that it is always up to date with the latest standards set forth by the W3C.
Throughout the hour thus far I’ve focused on the concept of creating XHTML documents from scratch. This sounds great in theory, but the reality is that there are gazillions of HTML-based web pages in existence that could benefit from being migrated to XHTML. Fortunately, it isn’t too terribly difficult to bring HTML 4.0 documents up to par with the XHTML specification. You’ve already learned about the ways in which XHTML documents differ from HTML 4.0 documents; these differences are your guide to converting HTML to XHTML. There are two fundamental approaches available for converting HTML documents to XHTML documents:
Convert the documents by hand (more work, more accurate)
Convert the documents using an automated conversion tool (less work, less accurate)
The former approach requires some serious elbow grease, but it yields the best results because you’re carrying out the migration process with considerable attention to detail. On the other hand, the latter approach has the obvious benefit of automating the conversion process and saving you a lot of tedious work. However, as in any automated process, the conversion from HTML to XHTML doesn’t always go perfectly smooth. That’s why the first approach is the more accurate of the two, even though it requires much more effort. A middle ground hybrid approach involves first using an automated conversion tool and then making fine-tuned adjustments by hand.
Converting HTML documents to XHTML can be a tedious process, but if you have a strategy for the conversion process it can make things go much more smoothly. In fact, it helps to have a checklist to use as a guide while hand-coding the conversion. Follow these steps to convert HTML code to XHTML code:
Add (or modify) a document type declaration that declares an appropriate XHTML DTD.
Declare the XHTML namespace in the
htmlelement.Convert all element and attribute names to lowercase.
Match every start tag with an end tag.
Replace
>with/>at the end of all empty tags.Make sure all required attributes are set.
Make sure all attributes have values assigned to them.
Enclose all attribute values in quotes (
"").Make sure all elements and attributes are defined in the XHTML DTD used by the document.
If you carry out each of these steps, you should be able to arrive at a valid XHTML document without too much difficulty. A simple example will help explain the relevance of these steps a little better. Listing 21.2 contains the code for an HTML document that describes a web page chronicling the construction of a vegetable filter for a water garden. Figure 21.3 shows the veggie filter web page as viewed in Firefox.
Example 21.2. The Veggie Filter Sample HTML Document
1: <HTML> 2: <HEAD> 3: <TITLE>Constructing a Veggie Filter</TITLE> 4: </HEAD> 5: 6: <BODY STYLE=background-image:url(water.jpg)> 7: <H2>Constructing a Veggie Filter</H2> 8: <P> 9: A vegetable filter is a welcome addition to any water garden, as it 10: provides a natural biofiltration mechanism above and beyond any other filter 11: systems already employed. The concept behind a vegetable filter is that you 12: simply pump water through the root system of aquatic plants, allowing them 13: to absorb nutrients from the water and thereby assist in purifying the 14: water. Below are pictures of the construction of a veggie filter that sits 15: atop the pond it is helping to keep 16: clean. 17: <P> 18: <A HREF=filter01_lg.jpg><IMG SRC=filter01.jpg STYLE=align:left BORDER=0></A> 19: <A HREF=filter02_lg.jpg><IMG SRC=filter02.jpg STYLE=align:left BORDER=0></A> 20: <A HREF=filter03_lg.jpg><IMG SRC=filter03.jpg STYLE=align:left BORDER=0></A> 21: <A HREF=filter04_lg.jpg><IMG SRC=filter04.jpg STYLE=align:left BORDER=0></A> 22: <A HREF=filter05_lg.jpg><IMG SRC=filter05.jpg STYLE=align:left BORDER=0></A> 23: <A HREF=filter06_lg.jpg><IMG SRC=filter06.jpg STYLE=align:left BORDER=0></A> 24: <P> 25: In these photos, you see the veggie filter come together as the sand bottom 26: is put into place, followed by protective felt, a leveled top, a pond liner, 27: and plumbing for the pump outlets. 28: <P> 29: If you'd like to learn more about water gardening, contact my friends at 30: Green and Hagstrom through their Web site at 31: <A HREF=http://www.greenandhagstrom.com/>Green & Hagstrom Aquatic Nursery 32: and Water Garden Supply</A> 33: </BODY> 34: </HTML>
If you study the code for the veggie filter sample HTML document, you’ll notice that it doesn’t meet the high standards of XHTML in terms of structure and syntax. Granted, the code is cleanly organized but it definitely doesn’t qualify as a valid or even well-formed document under the rules of XHTML. Following are the major problems with this code that need to be resolved in order for the document to comply with XHTML rules:
There is no document type declaration.
The XHTML namespace isn’t declared.
The elements and attributes are all in uppercase.
Not every start-tag (
<P>) has an end tag (lines 8 and 17, among others).Empty elements (
IMG) don’t end with/>(lines 18 through 23).Some elements (
IMG) are missing required attributes (ALT).Attribute values aren’t enclosed in quotes (lines 6, 18, 19, and so on).
You might be thinking that this list of problems is uncannily similar to the list of HTML to XHTML conversion steps I mentioned earlier in the hour. This is not mere coincidence—I arrived at the list of conversion steps by addressing the most common HTML coding problems that conflict with XHTML. If you go through the document and fix all of these problems, the resulting XHTML code will look like the code shown in Listing 21.3.
Example 21.3. The Veggie Filter Sample XHTML Document That Was Converted by Hand
1: <?xml version="1.0" encoding="UTF-8"?> 2: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" 3: "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd"> 4: 5: <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> 6: <head> 7: <title>Constructing a Veggie Filter</title> 8: </head> 9: 10: <body style="background-image:url(water.jpg)"> 11: <h2>Constructing a Veggie Filter</h2> 12: <p> 13: A vegetable filter is a welcome addition to any water garden, as it 14: provides a natural biofiltration mechanism above and beyond any other filter 15: systems already employed. The concept behind a vegetable filter is that you 16: simply pump water through the root system of aquatic plants, allowing them 17: to absorb nutrients from the water and thereby assist in purifying the 18: water. Below are pictures of the construction of a veggie filter that sits 19: atop the pond it is helping to keep clean. 20: </p> 21: <p> 22: <a href="filter01_lg.jpg"><img src="filter01.jpg" alt="Step 1: Build the 23: rock support walls" style="align: left; border-width: 0px"/></a> 24: <a href="filter02_lg.jpg"><img src="filter02.jpg" alt="Step 2: Lay the 25: sand base" style="align: left; border-width: 0px"/></a> 26: <a href="filter03_lg.jpg"><img src="filter03.jpg" alt="Step 3: Protect the 27: walls with felt underlayment" style="align: left; border-width: 0px"/></a> 28: <a href="filter04_lg.jpg"><img src="filter04.jpg" alt="Step 4: Level the top 29: edges" style="align: left; border-width: 0px"/></a> 30: <a href="filter05_lg.jpg"><img src="filter05.jpg" alt="Step 5: Insert and 31: trim the liner" style="align: left; border-width: 0px"/></a> 32: <a href="filter06_lg.jpg"><img src="filter06.jpg" alt="Step 6: Assemble and 33: place the pump plumbing" style="align: left; border-width: 0px"/></a> 34: </p> 35: <p> 36: In these photos, you see the veggie filter come together as the sand bottom 37: is put into place, followed by protective felt, a leveled top, a pond liner, 38: and plumbing for the pump outlets. 39: </p> 40: <p> 41: If you'd like to learn more about water gardening, contact my friends at 42: Green and Hagstrom through their Web site at 43: <a href="http://www.greenandhagstrom.com/">Green & Hagstrom Aquatic 44: Nursery and Water Garden Supply</a> 45: </p> 46: </body> 47: </html>
If you study this document carefully, you’ll see that it meets all of the requirements of a valid XHTML document. For example, the <p> tags all have matching </p> closing tags (lines 12, 21, 35, and 40). If you’re a skeptic and want to make sure that the document is really valid, you can run it through the W3C Validator just to make sure. Actually, I already did it for you and the document checked out fine, which means that it is a bona fide XHTML document.
If you don’t like getting your hands dirty, you might consider an automated approach to converting HTML documents to XHTML. Or you might decide to go for a hybrid conversion approach that involves using an automated tool and then a little hand coding to smooth out the results. Either way, there are a few tools out there that automate the HTML to XHTML conversion process. One such tool is HTML Tidy, which was developed by Dave Raggett, an engineer at Hewlett Packard’s UK Laboratories.
HTML Tidy is a command-line tool that was originally designed to clean up sloppy HTML code, but it also supports converting HTML code to XHTML code. When you think about it, converting HTML to XHTML really is nothing more than cleaning up sloppy code, which is why HTML Tidy works so well. The HTML Tidy tool is available for free download from the HTML Tidy web site at http://www.w3.org/People/Raggett/tidy/. There are also a few graphical HTML applications that serve as front ends for HTML Tidy just in case you aren’t comfortable using command-line applications.
By the Way
Dave Raggett is also the developer is HTML Slidy, which is an XHTML-based slide show tool that allows you to create PowerPoint-style slide show presentations using nothing more than XHTML code. To learn more about HTML Slidy, visit the HTML Slidy web page at http://www.w3.org/2005/03/slideshow.html.
If you run HTML Tidy without any command-line options, it will process an HTML document and clean it up. However, the resulting document won’t be an XHTML document. In order for HTML Tidy to generate an XHTML document, you must specify the -asxhtml command-line option, which indicates that HTML Tidy is to convert the HTML document to an XHTML document. Additionally, the -indent option helps to clean up the formatting of the output so that the resulting XHTML code is indented and easier to understand. The output of HTML Tidy defaults to standard output, which is usually just your command-line window. Although this works if you just want to see what a converted document looks like, it doesn’t help you in terms of generating a converted document file. You must specify that you want the output to be in XHTML format by using the -output option and specifying the output file. Following is an example command that converts the vegfilter.html veggie filter HTML document to XHTML using HTML Tidy:
tidy -asxhtml -indent -output vegfilter_t.xhtml vegfilter.html
This command directs the output of the HTML Tidy application to the file vegfilter_t.xhtml. Aside from it being a little more compressed in terms of how the content is arranged, the resulting code from HTML Tidy is very similar to the hand-coded conversion of the XHTML document. The document type is changed to XHTML 1.0 Transitional, as opposed to XHTML 1.1. Other major changes include all element and attribute types being converted to lowercase, as well as empty img elements fixed with a trailing />. Also, all attribute values are quoted.
There is still an important aspect of the generated XHTML document that must be modified by hand. I’m referring to the img elements, none of which provide alt attributes. The alt attribute is a required attribute of the img element in HTML 4.0 and XHTML, so you must specify values for them in all images in order to make the document a valid XHTML document. Fortunately, the HTML Tidy tool caught this problem and output an error message indicating that the change needed to be made by hand (see Figure 21.4). Another required change that you’ll notice in the figure is the ampersand (&) in the text Green & Hagstrom, which needs to be changed to the & entity.
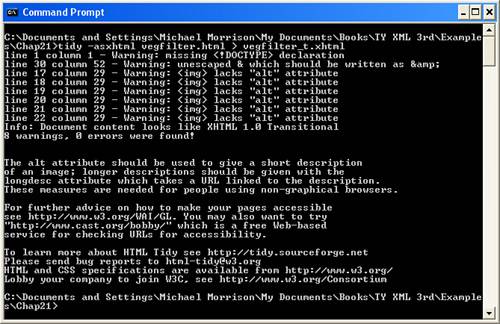
Figure 21.4. HTML Tidy was able to detect conversion errors in the veggie filter sample HTML document so that you can repair them by hand.
Finalizing the conversion of the veggie filter example document involves changing the document type to XHTML 1.1 (if desired), adding alt attributes to the img elements, and adding an entity reference. Once that’s done, the new XHTML document is good to go. The HTML Tidy tool significantly improves the HTML to XHTML conversion process, leaving you with relatively minor changes to make by hand.
HTML has served its purpose well by allowing people to build web pages with relative ease, but its lack of structure is limiting when it comes to intelligently processing web content. For this reason, the architects of the Web focused significant efforts on charting the future of the Web with a more structured markup language for creating web pages. This markup language is XHTML, which is a reformulated version of HTML that meets the high structural and organizational standards of XML. XHTML is still in many ways a future technology in terms of becoming a standard used by all web developers, but it is nonetheless important to XML developers and HTML developers alike.
This hour introduced you to XHTML and then explored the relationship between HTML and XHTML. You learned about the origins of both languages and why XHTML has long-term benefits that make it an ideal successor to HTML. The hour shifted gears toward the practical by showing you how to create and validate XHTML documents. You then finished up the hour by learning how to migrate legacy HTML documents to XHTML.
The Workshop is designed to help you anticipate possible questions, review what you’ve learned, and begin learning how to put your knowledge into practice.