
6 Test Control
The previous chapters explained how test activities are designed and planned. This chapter explains how test managers control test activities during testing to ensure that the test schedule is implemented according to plan. Finally, some hints and tips for an adequate reporting system are given.
The best plan is only as good as its implementation. In the same way a project manager is judged by the final results of his project, a test manager is judged by how well he has performed in actually implementing the strategic specifications of the test plan and the operative specifications of the test project plan.
To do so, the test manager must actively control the test activities. Test control comprises the identification and implementation of all measures necessary to ensure that test activities are performed according to plan during the test cycle and that all test objectives are achieved. This requires timely initiation of the test task, continuous monitoring of the test progress, and adequate response to test results and sometimes to changed circumstances. Based on gained insights, the test manager must then be able to judge if the test process may be completed.
Control test activities actively
Test results and information about the test activities are to be communicated in the test report. Each run through the test cycle usually results in defect correction or change requests for development. When defects are corrected or changes have been implemented, a new software version is created that again must be tested. For this, the test process typically runs through several cycles. Furthermore, the test process runs (perhaps in parallel) at each of the different test levels. Depending on project size, each test level may have its own test manager (see chapter 5).
The following sections explain a test manager’s different management tasks from the sometimes simplified perspective of one individual test cycle. In practice, the iterative nature and potentially parallel execution of the test process at several test levels require additional management and control.
6.1 Initiating the Test Tasks
Tasks planned in the test schedule must be initiated, which means the test manager must ensure that planned tasks are assigned to testers, that testers understand the tasks assigned to them, and that they begin performing their tasks in due course.
Assign test tasks clearly.
It would be naive to assume that all task assignments have been effectively communicated to those in charge simply because they have been listed in the plan. In principle, when allocating test tasks to testers, the test manager may choose between two strategies:
![]() Definite assignment of specific functional or application-specific test topics to individual testers: For instance, one tester can be in charge of the specialist topic “VSR contract management” during the entire test period; i.e., specification and possibly automation and execution of the corresponding test cases are performed by the same tester. The advantage of this strategy is that the tester can and will delve deeply into the test object and gain profound knowledge about the system that he can use in testing. This strategy, however, only works with comprehensively trained testers. Besides, there is a risk that not only the test specification but also the test results could become dependant on individual testers with possibly negative effects on test repeatability and completeness.
Definite assignment of specific functional or application-specific test topics to individual testers: For instance, one tester can be in charge of the specialist topic “VSR contract management” during the entire test period; i.e., specification and possibly automation and execution of the corresponding test cases are performed by the same tester. The advantage of this strategy is that the tester can and will delve deeply into the test object and gain profound knowledge about the system that he can use in testing. This strategy, however, only works with comprehensively trained testers. Besides, there is a risk that not only the test specification but also the test results could become dependant on individual testers with possibly negative effects on test repeatability and completeness.
![]() Assignment of testers based on test phases or roles: Test designers specify the test cases, test automaters implement test automation, and testers are in charge of test execution and the creation of incident reports. For this reason, tests must be tester independent and specified with sufficient accuracy and detail. This approach ensures a very high reproducibility and regression test capability. If the expected behavior of the test object is unclear, if the test object changes considerably, or if there is extreme time pressure, it may be difficult or too time consuming to create accurate test specifications. In this case, assigning personal tasks as described above may be more advisable.
Assignment of testers based on test phases or roles: Test designers specify the test cases, test automaters implement test automation, and testers are in charge of test execution and the creation of incident reports. For this reason, tests must be tester independent and specified with sufficient accuracy and detail. This approach ensures a very high reproducibility and regression test capability. If the expected behavior of the test object is unclear, if the test object changes considerably, or if there is extreme time pressure, it may be difficult or too time consuming to create accurate test specifications. In this case, assigning personal tasks as described above may be more advisable.
In practice, both strategies are used. Dedicated testers, for instance, are employed for technically sophisticated and risky topics, while in order to gain efficiency, general testing is done concurrently using phase- or role-oriented task assignment.
Assigning a task in the plan by no means ensures that the tester is aware of the assignment. The test manager must ensure that each tester understands the task assigned to him, that he accepts it, and that he starts testing in due course. In some cases, a brief phone call will suffice; in others, it will be expedient to arrange for an initiation plan. Perhaps it may be necessary to provide a “free desk” or to remove other organizational hurdles to allow the tester to work productively. Such organizational issues will not be discussed any further in this book; nevertheless, a great deal of the test manager’s time will be “eaten up” by this kind of organizational activity. The test manager must allow for this when planning his own work packages.
Ensure that test tasks are undertaken.
6.2 Monitoring the Test Progress
Monitoring the test progress must start as soon as the first draft version of the test schedule becomes available. It is not only a matter of monitoring test execution alone; all test preparation tasks, too, will have to be monitored. Test cases, for instance, must be specified in time (including those that are planned for later versions of the test objects). Test automation for tests that are to run automatically at some later time must be set up early. And last but not least, it must be ensured that the test objects are delivered to test and installed in the test environment.
It is therefore not enough to pay attention to test execution only, since delays in test specification or test automation will inevitably lead to delays in later test cycles. Questions concerning three task categories must be answered:
Test progress versus test schedule
![]() How many of the test cases contained in the plan have already been specified? How many and which are still awaiting specification? How long is it expected to take ? Will work be completed in time?
How many of the test cases contained in the plan have already been specified? How many and which are still awaiting specification? How long is it expected to take ? Will work be completed in time?
![]() Which tests are fully automated? Is automation still adequate for the current test object version or will it have to be adjusted? Which other fully specified tests are suitable for automation? Does the automation effort pay off? When must the extended automation be available?
Which tests are fully automated? Is automation still adequate for the current test object version or will it have to be adjusted? Which other fully specified tests are suitable for automation? Does the automation effort pay off? When must the extended automation be available?
![]() Which tests (automated or manual) have already been completed? Which tests are still open, delayed, or blocked?
Which tests (automated or manual) have already been completed? Which tests are still open, delayed, or blocked?
We should be able at any time to answer each of these questions for each individual test case. To this end, the team must keep the processing status of each test case in the test project plan up-to-date. It is obvious that this is only possible if a well-structured and up-to-date test project plan is available.
For smaller projects (up to approximately five testers), a spreadsheet may be sufficient. A test plan template is available for download under [URL: Templates].
Test schedule template
In larger projects, however, where many testers work in parallel according to the test project plan, technical constraints alone mean that the project will be unmanageable without a database test management tool. An up-to-date test project plan allows a large variety of analyses about the test progress and makes it possible to find answers to questions such as these: What is the percentage of test cases that have reached a particular status (e.g., “completed”)? Is work progressing according to plan? If not, to what degree does progress deviate from the plan? How much work is there still left for the team to complete?
Example: Tracking test progress in the VSR project
In his test report, the VSR project test manager presents the test progress statistics of the past three test cycles. Each test cycle lasts three weeks whereby a maximum of 250 test cases per week can be performed with the available test team. The evaluation documents the following test progress (see figure 6-1):
Figure 6–1 Test progress across three test cycles
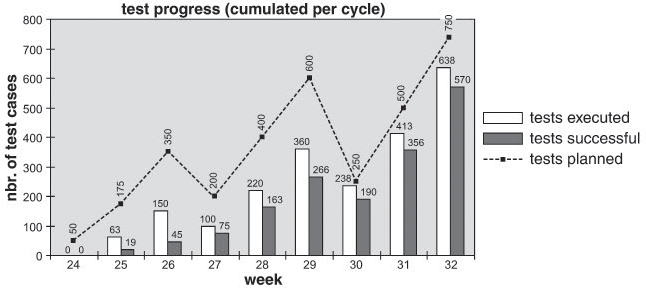
For the first cycle (KW 24–26), the set target was to complete 350 test cases. Certain start-up problems were allowed for in the plan. Due to the functionally incomplete and still very immature test object, only 150 test cases could be completed. Only 45 test cases ran bug free.
The second cycle started in week 27 with an intensively reworked and extended test object. Out of the now 200 planned cases per week, 50% – 70% could actually be completed. The proportion of passed test cases was at almost 75%. In sum, 266 of the planned 600 test cases—that is, 44%—could be completed successfully.
In week 30, cycle 3 received a corrected, stable test object. At the beginning, testing proceeded almost on schedule. Because one of the testers fell ill in week 31, test progress fell below target. In sum, 638 of the planned 750 test cases (85%) could be completed. Thus, 76% of the planned tests ran bug free.
The tracking of the test progress described above refers exclusively to test project plan content (test-schedule-oriented test coverage). One hundred percent test progress thus means that “all planned tests are completed.” However, this does not suffice. How do we ensure that all necessary tests are planned and contained in the test project plan? One hundred percent test progress in terms of test schedule does not necessarily mean that the test object has been sufficiently tested.
Test coverage concepts
For this reason, additional, suitable test coverage metrics are required that measure the test progress compared to the product or test object scope (test-object-oriented test coverage). Chapter 11 suggests some corresponding metrics.
Test progress compared to product size
Product size can be considered and measured at different abstraction levels. It is important that the selected metric corresponds with the abstraction level at which the respective test levels are working (compare chapter 3). Thus, the preferred metrics in component testing are code coverage measurements. Architecture-related measurements are particularly suitable for integration testing, whereas in system and acceptance testing, requirements coverage is predominantly measured. If there are any requirements without assigned test cases, it is obvious that tests are missing in the test schedule. However, if test cases exist that cannot be assigned to any requirement (or perhaps only at a level of very vaguely defined requirements), then requirements are missing. In this case, testers have obviously identified use cases to which the person asking for the requirement (e.g., customer or system designer) has not given any thought.
The test-object-oriented coverage can be evaluated analogous to test-schedule-oriented coverage; for instance, to answer one of the following questions:
What is the percentage of the reference units (lines of code, architecture components, requirements) that were covered by the test cases? Is this in accordance with the plan? If not, what is the degree of deviation from the plan? How much work is there still left for the team to complete?
Measurement and evaluation are here more difficult because reference value and test cases must be seen as closely tied up with each other. Modern test management tools, however, will be able to do this.
As mentioned at the beginning, test-object-oriented coverage metrics help in determining if test cases are missing. The test manager should not only check if coverage increases sufficiently with test progress but he should also check all poorly covered software parts to see whether there are any test cases missing in the test design specification. If the latter turns out to be the case, the test design specification must be completed and all added test cases need to be executed.
If this turns out to be true, it must be completed and the added tests must be made up. The “test design verification” metric is helpful in this respect (see chapter 11).
Besides the question of how to determine and present test progress, there is the question of timing. The following recommendations can be given:
Timing test progress control
![]() The test-schedule-oriented test progress should be evaluated frequently-for instance, on a weekly basis, or in hot test phases, even daily. Delays that become apparent are mostly caused by immature test objects or coordination problems in the test team requiring quick reaction.
The test-schedule-oriented test progress should be evaluated frequently-for instance, on a weekly basis, or in hot test phases, even daily. Delays that become apparent are mostly caused by immature test objects or coordination problems in the test team requiring quick reaction.
![]() Test-object-oriented coverage metrics should be analyzed at the end of the test cycle. If all planned test cases in the test cycle have been executed and coverage proves to be insufficient, test cases must be added. Either these will then be executed in the subsequent test cycle or the current cycle will be extended accordingly.
Test-object-oriented coverage metrics should be analyzed at the end of the test cycle. If all planned test cases in the test cycle have been executed and coverage proves to be insufficient, test cases must be added. Either these will then be executed in the subsequent test cycle or the current cycle will be extended accordingly.
Example: Measurement and evaluation of requirements coverage
The VSR project test plan requires that the achieved requirements coverage is measured and tracked for each test cycle. In order to implement this requirement, the test management tool TestBench [URL: TestBench] is used, providing an interface to the requirements management tool. The test manager imports the requirements list into the test management tool. In order to be able to indicate which test cases validate which requirements, the test designer assigns one or more requirements to each test case.
Figure 6-2 illustrates this in the example of test case “2.1.1. Calculate total price without discount”. Four requirements are associated with this test case. Three requirements are already marked “completed,” which means that these requirements are actually validated by test case 2.1.1. The fourth requirement is also supposed to be validated by test case 2.1.1. For this to be done, however, test case 2.1.1. still needs to be revised and extended. Thus, the status of the assignment is “not completed”.
Figure 6–2 Linking requirements to test cases
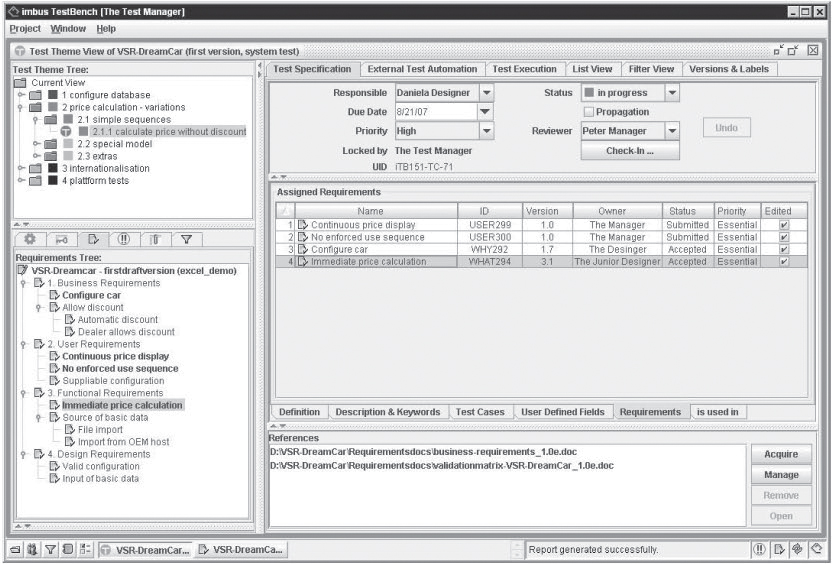
If requirements change or new ones are added, the test manager can synchronize the test schedule with the latest version of the requirements list (baseline). Using a filter query, TestBench shows which test cases have been impacted by changed requirements or which requirements have not yet been assigned to a test case. This is a quick way for test designers to find out which test cases need to be changed or extended. Based on these associations between requirements and test cases or test specifications, the test manager determines after each test cycle which requirements were actually tested and with which result.
Figure 6-3 shows the tool-generated evaluation of the achieved requirements coverage. For example, the table shows that requirement 301 is to be tested by three associated test cases but that one of the three test cases failed. This is not enough to consider the requirement “validated.”
Figure 6–3 Evaluation of requirements coverage
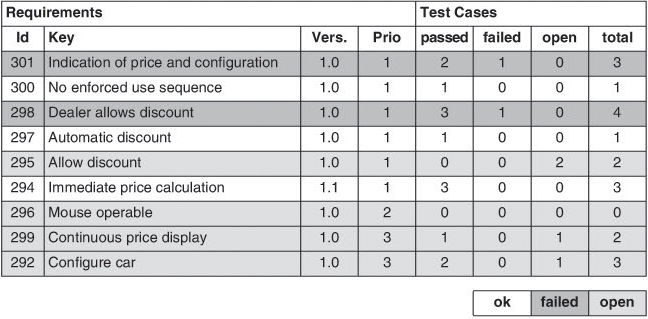
The tools used in the VSR project support bidirectional exchange of data between the requirements management and the test management tool, allowing the test manager to transfer the validation status of each requirement after each test run back into the requirements management tool. This way, everyone involved in the project outside test receives feedback about the test progress achieved in the project.
6.3 Reacting to Test Results
Based on insights gained during progress tracking, test managers may have to initiate specific and appropriate correction measures. For example, if test execution is behind schedule, it needs to be determined how many test cases and which testers are affected. From this a test manager can deduce whether or not tests can be shifted to other testers. If work shifting is not enough, sufficient resources must be provided.
The actual demand on resources can be proven by the data and thus can be explained to management. If neither work shifting nor redistribution are possible, rescheduling of the test cases, new prioritization, or even cancellation of the tests is inevitable.
In any case, it is important to ascertain traceability of and the reasons for changes in the plan in order to learn from these situations through subsequent analysis—for instance, in project reviews or metrics-based evaluations—and to improve planning accuracy in subsequent projects.
For quick allocation or redistribution of tasks, using a tabular view of test schedule data is a suitable option. The test manager may, for instance, filter the plan by the test status “not executed” for tests relating to “contract management”. By reassigning the list of test cases thus generated to the tester and by entering new due dates (if necessary), replanning will not cause much effort or many errors.
Task assignment via test schedule tables
Affected testers subsequently receive their new tasks list in the form of a printout, e-mail, or personal spreadsheet in the test management tool.
The identification and evaluation of the test progress based on the test project plan or based on coverage metrics is only one aspect. Since it is the declared target of testing to detect as many defects in the test object as possible, the “quality” of the test objects, i.e., the concrete test execution results, may by no means be neglected. Whoever follows the test schedule regardless of test results and without readjusting the schedule in view of such results will not be able to achieve this goal. In addition to evaluating the data on test progress, the test manager must evaluate test results and use them as control values.
Several defect-based metrics are available on this issue: number of defects detected, number of defects discovered over time or at a given test intensity (defect trend), number of defects based on test object size (→defect density), number of defects based on criticality (defect severity), number of defects per status (progress of defect correction), and others. Chapter 11 discusses these metrics in more detail.
Defect-based metrics
Fundamental to defect-based evaluation and control is the prompt and systematic recording of found defects necessitating a defect or incident management system (incident database). Chapter 8 provides more details. To gain useful evaluations, it must be ensured that all incident reports—irrespective of the author—are classified according to comparable evaluation standards. Only then it does make sense to compare, for instance, the average defect severity in different components and to draw conclusions from them.
In order to ensure comparability, we need, on the one hand, to use practicable methods for defect classification. Chapter 8 describes the IEEE 1044 standard classification for software anomalies. The test manager, on the other hand, is supposed to minimize different author-dependent classifications by post-classifying each report (done either by himself or by an authorized tester). That way, classification outliers can be detected and corrected.
Ensure comparability of incident reports.
In addition, it also makes sense to discuss incident reports with the test team at the start and end of a test cycle to work toward a common evaluation standard.
How can test results or defect data be used for test control? We may postulate three theses:
React to test results.
![]() Where you find defects, there will be even more: If in certain places in the test object (methods, components, and so on) or in relation to certain test topics we find that there is an accumulation of defects, it is very likely that we shall find further defects in the test object’s environment. Perhaps this burst of defects could even be a symptom of completely misunderstood requirements. The test manager’s reaction may go in two directions:
Where you find defects, there will be even more: If in certain places in the test object (methods, components, and so on) or in relation to certain test topics we find that there is an accumulation of defects, it is very likely that we shall find further defects in the test object’s environment. Perhaps this burst of defects could even be a symptom of completely misunderstood requirements. The test manager’s reaction may go in two directions:
• Intensive tests of error-prone parts. The following questions need to be answered: What did the developer understand incorrectly? What is it that he may have implemented incorrectly because of that? Suitable test cases are added that may support or refute these assumptions. The tests are executed on the current test object version and in the defect retest; that is, after the correction of previously found defects. If no further failures are detected, the priority of these additional test cases may again be lowered; however, such test cases should not be thrown away so they do not have to be created again unnecessarily in a similar situation in later project phases.
• Terminate testing of error-prone parts. If too may defects pile up, if many “trivial” or similar defects are found, or if further testing is blocked, it may be reasonable to simply return the test object. Instead of putting more effort into continued testing, we should try to get to the root cause of the problem by using intermediary quality assurance measures such as reviews on entry documents or program code.
![]() Where there are no defects, there are no test cases: When we consider defect distribution across the test object, we need to look at regions with a defect density below average.
Where there are no defects, there are no test cases: When we consider defect distribution across the test object, we need to look at regions with a defect density below average.
• Perhaps it is not a good product that we see but just a bad test. In order to find that out, we need to look at all associated test cases and talk to the testers in charge. Do they consider the tests useful and sufficient in this position? Which test cases need to be added?
• Of course, the change history of test objects must be taken into account. If the component in question was not changed in the previous version cycle, “no defect” may be good news. In such cases, the controlling reaction could be to lower the priority of all or many test cases associated with this component or to remove them altogether from subsequent test cycles.
![]() The defect trend curve indicates test completion: In his evaluation of the defect detection intensity, the test manager must always look at which testing intensity was applied in each case. The absence of an experienced tester on holiday may have a serious effect on the number of defects found during that period. The same applies to weeks with public holidays or to overtime work or weekend shifts. The test manager is therefore advised to deduct from his data variations in test intensity that are caused by resource or workload fluctuations and to establish a normalized trend curve. If the normalized trend curve also shows that with constant test intensity there is a decrease in the number of newly detected defects, it may be taken as a sure sign that the test object is now “stable.” If coverage of the test objects is considered sufficient and progress is achieved according to schedule, testing can be stopped.
The defect trend curve indicates test completion: In his evaluation of the defect detection intensity, the test manager must always look at which testing intensity was applied in each case. The absence of an experienced tester on holiday may have a serious effect on the number of defects found during that period. The same applies to weeks with public holidays or to overtime work or weekend shifts. The test manager is therefore advised to deduct from his data variations in test intensity that are caused by resource or workload fluctuations and to establish a normalized trend curve. If the normalized trend curve also shows that with constant test intensity there is a decrease in the number of newly detected defects, it may be taken as a sure sign that the test object is now “stable.” If coverage of the test objects is considered sufficient and progress is achieved according to schedule, testing can be stopped.
Example: Evaluation of the defect density per component
The different components of the VSR system are designed and developed by different development groups. To be able to compare the maturity and quality of the components, the affected components are noted in the incident reports using the reporting attribute “component.” Based on the component thus noted, the incident management system automatically enters the associated development group into the report.
If during defect analysis it turns out that the cause of the defect is located in another component, the analyzing developer adds a corresponding comment and corrects the “component” attribute. With this he has passes the report on to the development team that in his opinion is now responsible.
Project and test manager can see the number and status of incident reports for each development group at any time. Furthermore, in order to see which group might have to cope with an above average defect occurrence, the size of the components must be taken into account. This is done by measuring the current code size (e.g., in “lines of code”) whenever a new build or release is compiled. The test manager is then able to determine the number of defects associated with each component in relation to its respective code size.
Of course, the “lines of code” metric is only a rough measure, yet at least it provides the test manager with a useful indicator to judge the relative stability and maturity of the components.
Even if test plan, incident database, and metrics ensure perfect formal communication within the test team, the test manager ought to talk to testers frequently. He should “look over their shoulders”, so to speak, at what they are doing and ask them for their subjective opinion on test progress and product quality. He should also sit down once in a while in front of the PC and carry out or repeat some test cases on the test object to gain a personal impression of the quality of the test object and tests. This rather selective but personal observation will put the test manager into a better position to evaluate and interpret abstract “measurement data” and test statistics.
6.4 Reacting to Changed Circumstances
The measures concerning test control that we discussed in the previous sections are based on the circumstances and conditions agreed upon in the test plan. They assume that during the test period, the test manager has a designated amount of human resources, suitable system-technical resources (test environment, test workplace, test tools, etc.), and perhaps further financial resources (e.g., for employing external test consultants) at his disposal. Within this context, the test strategy and test schedule were set up in such a way as to achieve an optimal test process.
Circumstances may of course change—unfortunately, for the worse. The first disillusionment may come even before testing starts because it may turn out that the agreed-upon resources can actually not be made available. The test schedule must then be set up in the light of the actual circumstances and not based on the ideal conception set out in the test plan. Realistically speaking, the test plan, too, must be adapted to these circumstances. This could mean that because of unresolvable resource shortages, test objectives and test exit criteria might have to be redefined.
Circumstances change.
The test manager must be very open in his reports about the degree by which project and product risks increase as a result of the unexpected cutbacks in test.
In later project phases, too, there may be as many incidences as you like that may lead to worsening circumstances. Test team members may fall ill, be transferred to different departments, or hand in their notice.
Perhaps some testers turn out to be less talented or qualified than expected. The test environment may cause problems. Test tools might not meet expectations, they might be unstable, or maybe they cannot be handled properly. Test automation is not ready in time or is not as stable as it should be.
Hopefully, the test manager has already identified many of these issues in his risk assessment (see chapter 9) at the beginning of the project and has designed some compensatory measures.
Often full compensation (at least for a transition period) will not be possible. The only alternative left is to revise the test project plan, reprioritize test cases, or drop them altogether. This carries the inevitable risk that product defects will be missed. These changes in circumstances, the enforced changes to plans, and the resulting increases in risk must be unequivocally stated in the project reports (see section 6.6).
Risk management
One very essential determining factor has so far not been addressed at all: the release1 or build plan. The test schedule is always based on a forecast or assumption regarding the number and delivery dates of the test object releases (test object versions planned for internal or external release). From the testing point of view this prediction is often too optimistic. On the one hand, delivery of builds from development to test is often delayed, while on the other hand, test often shifts the release schedule on the grounds that the delivered test objects are not as fit for testing as expected, thus prolonging the time needed for test. And because of the detected defects, more and more work-intensive defect corrections than expected are necessary. In the end, there are more builds or releases than originally planned.
The release plan is a determining factor.
At first glance, this is a comfortable situation for the test manager because the test team wins time. The time left till the delayed release date can, for instance, be used to develop additional tests or to complete test automation. Additional releases and hence additional test cycles can be used to increase (cumulated) test coverage. All this, however, presupposes that test resources must be available for longer than originally planned. Despite the “gained” time, it is precisely this that is often lacking at the end because, in most cases, the external delivery date is kept fixed despite internal delays.
Whenever expensive hardware or software resources need to be shared with other test groups or development, it may only be possible to compensate for shifts in the schedule by working night shifts or weekends.
Risk when sharing resources
Due to schedule shifts, it may happen that key people will no longer be available for testing. Often application experts can only be borrowed from their respective departments for a limited period to work as expert testers. A delayed or extended release plan means these experts will have been withdrawn before final tests are completed. Vacations, too, may thin out testing. For example, if development was originally scheduled to be completed before the summer or seasonal holidays, delays in coding may shift test cycles into precisely these periods.
The lessons to be learned for the test manager are to account for release delays (for example, by including a buffer in the test schedule), provide sufficient time when allocating human resources, and assign a stand-in for each tester. Consider each shared resource (staff, parts of the test environment) as a risk factor in risk management. Beyond all planning, sound improvisation is also necessary.
Example: Compatibility test for an operating system patch
A large manufacturer of operating systems releases a comprehensive security patch at short notice on a Friday. A little later, the VSR hotline receives the first inquiries about whether the DreamCar component is “compatible” with this patch and whether or not customers may install it. Support asks the VSR test manager to have the situation checked by the test group before Monday morning. For many testers, such emergency actions at short notice are nothing out of the ordinary.
That very Friday afternoon, the VSR test manager manages to motivate one of his testers to give up his weekend and together they manage to arrange for an experienced system administrator to be on call by telephone in case system specific questions arise while loading the patch.
The action is successful and on Monday morning support can give the green light to the customers. Of course, “regular” testing continues normally on Monday despite the weekend action and the patch must immediately be considered in the test schedule and test environment as an additional system environment variant.
6.5 Evaluating Test Completion
At the end of each test cycle, the question of test completion arises: Have we tested enough? Has the quality of the test objects been achieved as required or have we missed any serious defects?
Since testing is a spot-check technique that can show the presence of defects but cannot prove that no defects remain in the test object, it is difficult to answer these questions. Even if after complete execution of the test plan no further defects are encountered, it cannot assumed that there are no defects left in the tested software.
Nevertheless, the test manager must decide or at least voice a recommendation as to whether or not the test process may be terminated.
At this juncture, the test manager finds himself in a dilemma: If he stops testing too early, he increases the risk of delivering a product that is (too) defective. If he continues testing and finishes later than would perhaps be acceptable, he prolongs testing, makes it more expensive, and ultimately delays product release. In both instances, customer satisfaction and market opportunities may suffer severely.
Dilemma
In order to arrive at a well-founded and comprehensible decision, so-called “test exit criteria” are being used. Usually, one test exit criterion is a combination of different test metrics, including defined objectives to be achieved per measure. The test exit criteria and the objectives are defined ex ante in the test plan. Reaching or exceeding the objectives (during or at the end of a test cycle) then signalizes the end of the test activities. To satisfy a sound test completion, evaluation of the test exit criteria must cover the following aspects:
Test exit criteria
![]() Evaluation of the achieved test progress based on the test schedule and based on the achieved test object coverage.
Evaluation of the achieved test progress based on the test schedule and based on the achieved test object coverage.
![]() Evaluation of available test results, with subsequent (informal) conclusions drawn on product quality.
Evaluation of available test results, with subsequent (informal) conclusions drawn on product quality.
![]() Estimation of residual risks. A certain number of defects will remain in the system even after testing, either because these defects have not yet been detected or because they (deliberately) have not been corrected. The risks arising from these so-called residual defects have a decisive effect on whether testing can be terminated or not. Based on known data about “test progress” and “test results” the residual error probability can be either informally evaluated by means of test effectiveness metrics such as “Defect Detection Percentage” or analytically, using statistical methods (compare chapter 11).
Estimation of residual risks. A certain number of defects will remain in the system even after testing, either because these defects have not yet been detected or because they (deliberately) have not been corrected. The risks arising from these so-called residual defects have a decisive effect on whether testing can be terminated or not. Based on known data about “test progress” and “test results” the residual error probability can be either informally evaluated by means of test effectiveness metrics such as “Defect Detection Percentage” or analytically, using statistical methods (compare chapter 11).
![]() Economic circumstances: The achieved quality and the (feared) residual risk must be weighed against the available resources, the further development or release plan, the market opportunities, and expected customer reactions. Ultimately, the decision to complete testing is a management decision.
Economic circumstances: The achieved quality and the (feared) residual risk must be weighed against the available resources, the further development or release plan, the market opportunities, and expected customer reactions. Ultimately, the decision to complete testing is a management decision.
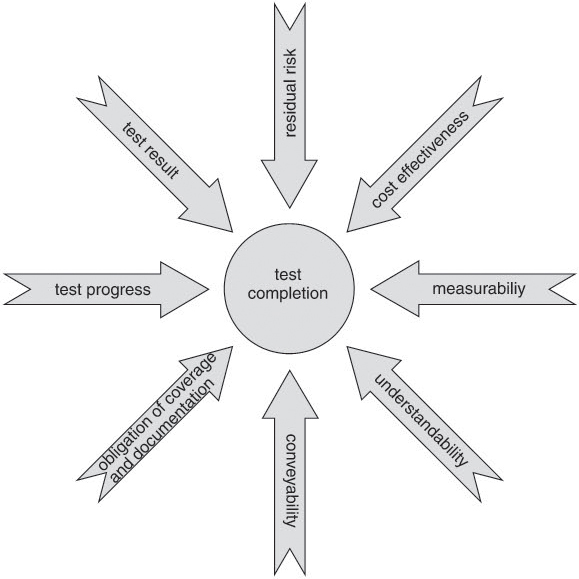
The test manager’s contribution is to provide advice and solid decision supporting data. In practice, additional influencing factors play a role, too: the practical measurability, understanding, and conveyability of the criteria, obligations of accountability resulting from standards, and others (see figure 6-4).
Figure 6–4 Influencing factors on test completion evaluation
Typically, test exit criteria are not defined and evaluated globally but rather specifically for each test level. The metrics used are the same as those used for monitoring test progress at the particular test level (see section 6.2). Instead of giving any additional advantage, the use of other metrics will only waste effort. The trick is to combine the metrics in a goal-oriented way and to provide reasonable objectives per metric.
Specific test exit criteria for each test level
![]() In component testing, test-object-based and structure-oriented metrics are useful if combined with a metric on test scope per component. For example, the achievement of 100% instruction coverage in “uncritical” components and 100% branch coverage for all components classed “critical” could be a useful test completion criterion.
In component testing, test-object-based and structure-oriented metrics are useful if combined with a metric on test scope per component. For example, the achievement of 100% instruction coverage in “uncritical” components and 100% branch coverage for all components classed “critical” could be a useful test completion criterion.
![]() In integration testing, structure-oriented metrics are the most interesting ones. For each interface, for instance, one could request at least one “positive” (transmission of an allowed data value/data record) and one “negative” (data value outside the interface specification) test case.
In integration testing, structure-oriented metrics are the most interesting ones. For each interface, for instance, one could request at least one “positive” (transmission of an allowed data value/data record) and one “negative” (data value outside the interface specification) test case.
![]() In system test or acceptance testing, the emphasis is on test-schedule-based, defect-based, and requirements-based metrics. One exit criterion could be 100% requirements coverage and zero defects in priority 1 test cases.
In system test or acceptance testing, the emphasis is on test-schedule-based, defect-based, and requirements-based metrics. One exit criterion could be 100% requirements coverage and zero defects in priority 1 test cases.
In the case of test exit criteria, it is true that, as a rule, no simple yes/no decisions can be made but the metrics used provide an acceptance range (see figure 6-5, acceptance range according to [ISO 9126] and [ISO 14598-4]). This results from the fact that data based on insecure knowledge is to be evaluated.
Figure 6–5 Test completion indicator and acceptance range
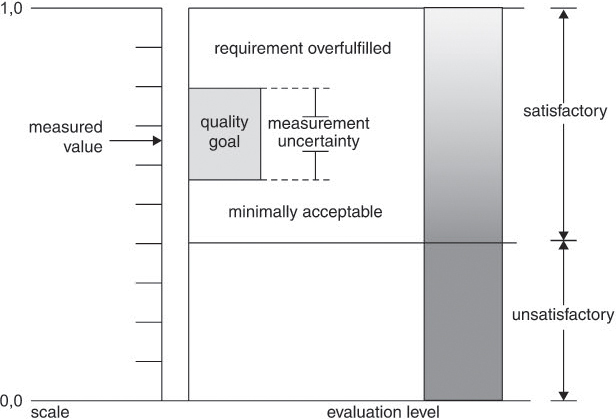
Test exit criteria are indicators. At test completion, evaluation derived from these indicators is always risky. However, without clear test exit criteria, we always run the risk that testing will be arbitrarily terminated due to time pressure or lack of resources.
This way, the test objective, which is to secure a certain minimum product quality, cannot be achieved. After test completion has been declared, the release of the test object does not automatically follow. The decision on when to “release” the tested products is a separate second step not made by the test manager but by project or product management. This decision is again based on objective release and acceptance criteria defined in the test plan (see section 5.2.7).
Distinguish between test completion and product release.
Example: Evaluation of test completion in the VSR project
During the system test of the VSR project, the decision on test completion is made based on the two criteria: test progress and test result. Evaluation of data (already shown in parts in previous examples) by the test manager yields the following overall picture:
![]() Test progress versus test schedule: 112 test cases not yet performed, some of which are priority 1. The test completion criterion requires that “100% of prio-1 tests must be completed”.
Test progress versus test schedule: 112 test cases not yet performed, some of which are priority 1. The test completion criterion requires that “100% of prio-1 tests must be completed”.
![]() Test progress versus test object coverage: If all high-priority requirements are validated by at least one test case, sufficient coverage of all test object areas “important” to the user is assumed. Thus, the analysis of the requirements coverage provides an informal and implicit evaluation of the residual risk. The actually achieved requirements coverage (see figure 6-3), however, shows that this test completion criterion also has not yet been met because some requirements remain untested or associated tests were unsuccessful.
Test progress versus test object coverage: If all high-priority requirements are validated by at least one test case, sufficient coverage of all test object areas “important” to the user is assumed. Thus, the analysis of the requirements coverage provides an informal and implicit evaluation of the residual risk. The actually achieved requirements coverage (see figure 6-3), however, shows that this test completion criterion also has not yet been met because some requirements remain untested or associated tests were unsuccessful.
![]() Test result: performed tests generated “critical” incident reports showing, for instance, crashes during contract storage or price calculation errors. However, the test completion criterion specifies “zero critical defects”. As a result, the test manager decides in agreement with the project leader to continue testing in a further test cycle after defect correction.
Test result: performed tests generated “critical” incident reports showing, for instance, crashes during contract storage or price calculation errors. However, the test completion criterion specifies “zero critical defects”. As a result, the test manager decides in agreement with the project leader to continue testing in a further test cycle after defect correction.
6.6 Test Report
The test manager must communicate information regarding test progress, product quality, and controlling actions not only within his own team but also within his own line organization (e.g., to test managers of other test levels). To do so he needs to regularly create test reports2 (also called test progress report or test status report).
The test report should not be confused with the test protocol, which is created during test execution (often automated) and records the results of each individual test case. It can also record additional data and test object reactions to provide testers with detailed information about test object behavior during the test run. The test protocol documents actual behavior of the tested software, whereas the test report provides an evaluation of the tests. The test report as defined by the [IEEE 829] standard combines the test activities and test results and assesses the quality of the test objects based on the test exit criteria.
Do not confuse test report with test protocol.
It concentrates and interprets the findings of a whole range of executed test cases, evaluated test protocols, and analyzed incident reports. It is advisable to create and distribute a test report at the end of each test cycle but often it is also useful to create (shorter) weekly or monthly progress reports. Often, after test completion or at product release, a more detailed general report is issued. The reporting frequency and distribution list is in each case to be defined in the test plan.
The test report is to contain the following information in concise form:
Content of the test report
![]() Context: project, test object, author, distribution list, reporting period, etc.
Context: project, test object, author, distribution list, reporting period, etc.
![]() Test progress: summary of past test activities; if required, information about the particular focus of the past test cycle (e.g., test cycle with focus on “load test”); the most important indicators and data (test schedule and test object related) pertaining to the actual test progress, ideally supported by charts; the test manager’s (subjective, informal) assessment
Test progress: summary of past test activities; if required, information about the particular focus of the past test cycle (e.g., test cycle with focus on “load test”); the most important indicators and data (test schedule and test object related) pertaining to the actual test progress, ideally supported by charts; the test manager’s (subjective, informal) assessment
![]() Product quality: number and severity of detected defects, in particular, the number of new defects detected during the reporting period; progress or problems during defect removal; defect trend and product stability; the test manager’s (subjective, informal) assessment or quality estimation; perhaps a statement concerning product release
Product quality: number and severity of detected defects, in particular, the number of new defects detected during the reporting period; progress or problems during defect removal; defect trend and product stability; the test manager’s (subjective, informal) assessment or quality estimation; perhaps a statement concerning product release
![]() Resources/measures: resource workload, correction measures and reasons for them (e.g., the requirement of additional resources), perhaps a recommendation to external groups (e.g., development) concerning correction measures
Resources/measures: resource workload, correction measures and reasons for them (e.g., the requirement of additional resources), perhaps a recommendation to external groups (e.g., development) concerning correction measures
![]() Budget: Overview on spent and still available money and time budget; if required, request of additional means
Budget: Overview on spent and still available money and time budget; if required, request of additional means
![]() Risks: Perceived/impending (project) risks (e.g., product release delays), other particular incidents.
Risks: Perceived/impending (project) risks (e.g., product release delays), other particular incidents.
![]() Further planning: upcoming tasks and outlook on the next test cycle (e.g., focus of the next test cycle), potential changes in the plan (to address newly identified risks), perhaps recommendations regarding test completion
Further planning: upcoming tasks and outlook on the next test cycle (e.g., focus of the next test cycle), potential changes in the plan (to address newly identified risks), perhaps recommendations regarding test completion
The scope of the report may vary depending on the target audience. A report to other test groups will be more detailed and also refer to incident reports and test schedules or contain excerpts from them. A report to management will focus on issues such as budget, risks and release maturity.
The structure or form of a report should remain stable and not change from report to report. Metrics presentation, i.e., the way they are presented graphically, should not change. Easy comparison of reports is necessary because most test metrics are significant or only make sense when compared to metrics in previous test cycles. A stable reporting structure makes it easier for the reader to recognize trends in data. A test report template is available for download under [URL: Templates].
Ensure comparability of reports.
Data captured for test control provides many possibilities for person-related assessments. It is relatively easy to use the incident management system to identify the “proportion of defect occurrence” per developer. The incident management system also allows easy access to productivity-related data per individual tester (e.g., “performed test cases per week,” “number of rejected incident reports,” etc.). Such assessments fall under the category “assessment of person-related data” and “human performance assessment”.
The problem with person-related assessments
In many countries, there are laws ruling the extent to which such data may be collected, stored, and used. The test manager has to be aware of such regulations and respect the employees right to informational self-determination.
Right to informational self-determination
Prior to setting up or even communicating person-related assessments, test managers should familiarize themselves with labor regulations and discuss the issue with affected persons, superiors, and, where applicable, staff association. Unproblematic under data privacy laws are anonymized assessments that cannot be traced back to any individuals. Of course, this does not mean that the unsatisfactory or below-average performance of a coworker needs to be tolerated.
Anonymized assessments are unproblematic.
To address this issue, a personal talk is surely better than a report circulating around the whole department. What is more, test managers must never forget to seek personal and informal communication with their staff, especially before preparing their formal report.
6.7 Summary
![]() The test schedule does not “implement itself.” The test manager must actively see to it that planned tasks are assigned to people and that tasks are completed in time. Test progress must be regularly monitored, including all preparatory tasks related to test. Test progress can be tracked in relation to the test schedule and in relation to the test object or product scope.
The test schedule does not “implement itself.” The test manager must actively see to it that planned tasks are assigned to people and that tasks are completed in time. Test progress must be regularly monitored, including all preparatory tasks related to test. Test progress can be tracked in relation to the test schedule and in relation to the test object or product scope.
![]() During the test cycle, the test manager must assess test progress and test results and use them as control values. Should test progress turn out to be unsatisfactory, additional testers or other resources may have to employed. Depending on the number and criticality of detected defects, the focus of the test may need to be changed.
During the test cycle, the test manager must assess test progress and test results and use them as control values. Should test progress turn out to be unsatisfactory, additional testers or other resources may have to employed. Depending on the number and criticality of detected defects, the focus of the test may need to be changed.
![]() If circumstances change fundamentally, the test plan and further course of action in test must be adapted to these changes. The test manager must be very open in his reports about the degree by which project and product risks increase as a result.
If circumstances change fundamentally, the test plan and further course of action in test must be adapted to these changes. The test manager must be very open in his reports about the degree by which project and product risks increase as a result.
![]() Due to the spot-check character of testing, the decision on test completion is always accompanied by uncertainty. Test exit criteria provide indicators by means of which the decision may be supported.
Due to the spot-check character of testing, the decision on test completion is always accompanied by uncertainty. Test exit criteria provide indicators by means of which the decision may be supported.
![]() The test manager must regularly use the test report to communicate information on test progress, product quality, and control measures initiated by him.
The test manager must regularly use the test report to communicate information on test progress, product quality, and control measures initiated by him.