
10.8. Summary of Confidence Building Tests
This chapter has introduced a variety of tests that can help build confidence in models. The tests fall into the three broad categories shown in Figure 10.22. There are tests of behaviour, tests of structure and tests of learning. None of these tests proves that a model is valid in the sense of being the best possible representation of the problem situation. But taken in combination, they demonstrate to modellers and clients that a given model is fit for purpose and of adequate quality.
Figure 10.22. Opportunities for building confidence in models
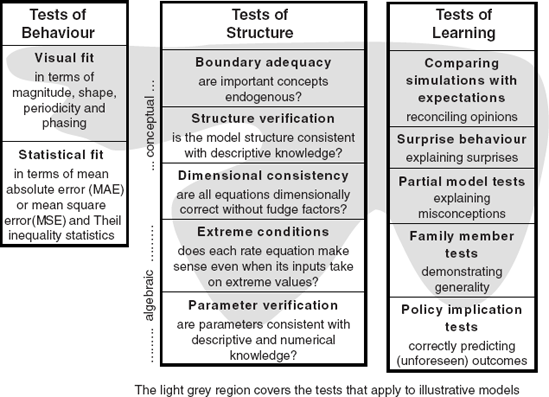
Tests of behaviour include the visual fit between simulated and actual data in terms of the magnitude, shape, periodicity and phasing of trajectories. Good visual fit is a common and effective way to build confidence in a model because it is a criterion people readily understand, even if they are not modellers. Statistical fit is a similar but more formal test where goodness-of-fit is measured numerically in terms of mean absolute error (MAE), mean square error (MSE) and the Theil inequality statistics. Of course, fit alone does not prove a model is 'correct', it simply shows the model is capable of replicating behaviour from the real world.
Tests of structure evaluate the quality of a model according to criteria that experienced modellers recognise and follow. The tests are like those a craftsman might apply to a piece of furniture or a musical instrument. Is the device well designed and carefully constructed with good materials? Design is a property mainly of the conceptual model, and two tests apply. Boundary adequacy is a test of whether important concepts are endogenous and if the model has a clear closed-loop feedback structure. This is an important criterion for system dynamics models because, in a well-conceptualised model, the dynamic behaviour of interest should arise endogenously from interacting feedback loops (Meadows, 1980). Structure verification is another test of design that requires that the assumptions underlying model structure are consistent with descriptive knowledge. Quality of construction is a property mainly of the algebraic model, and three tests apply. The most widely used is dimensional consistency to check that equations are dimensionally correct, so the units on the left of the equation balance the units on the right without the use of fudge factors. Extreme condition tests investigate whether each rate equation makes sense and delivers a plausible output when its inputs take on extreme values. This is a powerful test that brings to bear common-sense checks on the formulation of individual equations. For example, in a fisheries model, if the fish population were to fall to zero then logically the catch rate should also fall to zero – no matter how large the fleet size that normally determines the catch when fish are plentiful. Parameter verification provides yet another test of quality of construction. Are parameters consistent with descriptive and numerical knowledge?
Tests of learning are very different to tests of behaviour or structure as they apply to the interaction between the formal model and people's mental models rather than to the fidelity or quality of the formal model itself. There are five tests listed. The most common test of learning is to compare simulations with expectations as a means of reconciling, through dialogue, conflicting opinions about likely outcomes. Notice this comparison is quite different than visual fit, since the comparator is people's expectations (from their mental models) rather than time series (from the real world). Surprise behaviour is a test often applied by modellers themselves who form their own expectations about likely model behaviour (Mass, 1991). Every so often, a model produces totally unexpected behaviour for reasons that, on close inspection, turn out to be entirely plausible. In such cases, both the modeller and the project team learn something new from the simulator. Next on the list are partial model tests that help to explain people's misconceptions about dynamic behaviour. They build confidence in the model by simulating a deliberately simplified version whose behaviour coincides with outcomes people were expecting. Complex or counterintuitive behaviour of the full model is more understandable if it can be shown to arise from partial model behaviour that is intuitively obvious. Family member tests demonstrate the generality of a given model by showing that its structure and feedback loops, when parameterised differently, can be applied to a broad class of related situations. Finally, policy implication tests are simulations that correctly predict the outcome of policy changes prior to implementation. They are a good way to build confidence in models because they clearly demonstrate that modelling improves foresight, particularly if a correctly predicted policy outcome was unforeseen by those responsible for the policy.
Modellers do not apply all the tests exhaustively. Instead, they use just enough tests to convince the client (and themselves) that the model is adequate for its purpose and provides a reliable basis for understanding and action. Some tests such as statistical fit or parameter verification best apply to relatively detailed models such as the soap industry model. Other tests such as boundary adequacy, dimensional consistency and extreme conditions apply to models of all sizes. Tests of learning such as comparing simulations with expectations or surprise behaviour also apply to all models but are particularly useful for small illustrative models such as the market growth model in Chapter 7 or the simple factory model in Chapter 5 when objective comparisons with time series data are impossible.
A guide to the applicability of tests is shown in Figure 10.22. The light grey region covers the tests most appropriate for illustrative models whose purpose is to capture the essence of feedback structure without necessarily being accurately calibrated to a particular case situation. For example, tests of behaviour on the simple factory model in Chapter 5 are confined to visual fit in terms of shape, periodicity and phasing. Statistical fit is meaningless for such a model and so is visual fit in terms of magnitude since the model's scaling is arbitrary. The most appropriate tests of structure on illustrative models are boundary adequacy, dimensional consistency and extreme conditions. Only a limited amount of structure and parameter verification is possible since there are few opportunities to compare the assumptions of an illustrative model with descriptive and numerical knowledge from the real world. Tests of learning apply particularly well to illustrative models because they are small and transparent enough to promote improved understanding, which is at the heart of learning. By design, illustrative models pass the family member test as their feedback structure is intended to be generalisable. Illustrative models also lend themselves to tests that explain surprises and misconceptions.