
7
Driving Design – TDD and SOLID
So far, we’ve created some basic unit tests that have driven out a simple design for a couple of classes. We’ve experienced how test-driven development (TDD) makes decision-making about design choices central. In order to build out to a larger application, we are going to need to be able to handle designs of greater complexity. To do this, we are going to apply some recommended approaches to assessing what makes one design preferable to another.
The SOLID principles are five design guidelines that steer designs toward being more flexible and modular. The word SOLID is an acronym, where each letter represents one of five principles whose names begin with that letter. These principles existed long before they were known by this name. They have proven helpful in my experience, and it is worth understanding the benefits each one brings and how we can apply them to our code. To do this, we will use a running code example in this chapter. It is a simple program that draws shapes of various kinds using simple American Standard Code for Information Interchange (ASCII) art on a console.
Before we start, let’s think about the best order to learn these five principles. The acronym SOLID is easy to say, but it isn’t the easiest way to learn the principles. Some principles build on others. Experience shows that some are used more than others, especially when doing TDD. For this reason, we’re going to review the principles in the order SDLOI. It doesn’t sound as good, as I’m sure you will agree, but it makes a better order of learning.
Originally, the SOLID principles were conceived as patterns that applied to classes in object-oriented programming (OOP), but they are more general-purpose than that. They equally apply to individual methods in a class as well as the class itself. They also apply to the design of microservice interconnections and function design in functional programming. We will be seeing examples applied at both the class level and the method level in this chapter.
In this chapter, we’re going to cover the following main topics:
- Test guide–we drive the design
- Single Responsibility Principle (SRP)–simple building blocks
- Dependency Inversion Principle (DIP)–hiding irrelevant details
- Liskov Substitution Principle (LSP)–swappable objects
- Open-Closed Principle (OCP)–extensible design
- Interface Segregation Principle (ISP)–effective interfaces
Technical requirements
The code for this chapter can be found at https://github.com/PacktPublishing/Test-Driven-Development-with-Java/tree/main/chapter07. A running example of code that draws shapes using all five SOLID principles is provided.
Test guide – we drive the design
In Chapter 5, Writing Our First Test, we wrote our first test. To do that, we ran through a number of design decisions. Let’s review that initial test code and list all the design decisions we had to make, as follows:
@Test
public void oneIncorrectLetter() {
var word = new Word("A");
var score = word.guess("Z");
assertThat( score.letter(0) ).isEqualTo(Letter.INCORRECT);
}We decided on the following:
- What to test
- What to call the test
- What to call the method under test
- Which class to put that method on
- The signature of that method
- The constructor signature of the class
- Which other objects should collaborate
- The method signatures involved in that collaboration
- What form the output of this method will take
- How to access that output and assert that it worked
These are all design decisions that our human minds must make. TDD leaves us very much hands-on when it comes to designing our code and deciding how it should be implemented. To be honest, I am happy about that. Designing is rewarding and TDD provides helpful scaffolding rather than a prescriptive approach. TDD acts as a guide to remind us to make these design decisions early. It also provides a way to document these decisions as test code. Nothing more, but equally, nothing less.
It can be helpful to use techniques such as pair programming or mobbing (also known as ensemble programming) as we make these decisions—then, we add more experience and more ideas to our solution. Working alone, we simply have to take the best decisions we can, based on our own experience.
The critical point to get across here is that TDD does not and cannot make these decisions for us. We must make them. As such, it is useful to have some guidelines to steer us toward better designs. A set of five design principles known as the SOLID principles are helpful. SOLID is an acronym for the following five principles:
- SRP
- OCP
- LSP
- ISP
- DIP
In the following sections, we will learn what these principles are and how they help us write well-engineered code and tests. We will start with SRP, which is arguably the most foundational principle of any style of program design.
SRP – simple building blocks
In this section, we will examine the first principle, known as SRP. We will use a single code example throughout all sections. This will clarify how each principle is applied to an object-oriented (OO) design. We’re going to look at a classic example of OO design: drawing shapes. The following diagram is an overview of the design in Unified Modeling Language (UML), describing the code presented in the chapter:
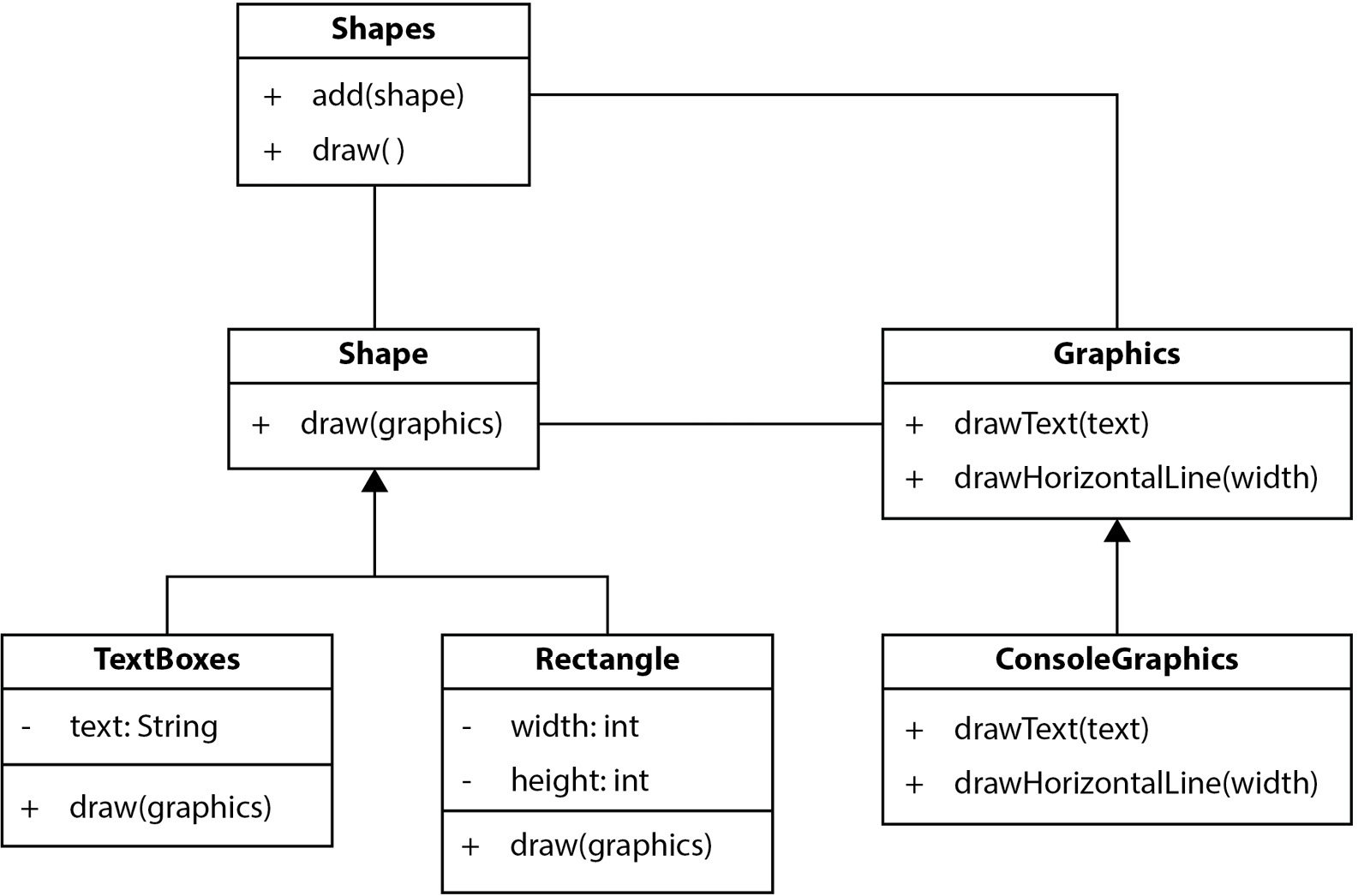
Figure 7.1 – UML diagram for shapes code
This diagram shows an overview of the Java code available in the GitHub folder for this chapter. We’ll be using specific parts of the code to illustrate how each of the SOLID principles has been used to create this design.
UML diagrams
UML was created in 1995 by Grady Booch, Ivar Jacobson, and James Rumbaugh. UML is a way of visualizing OO designs at a high level. The preceding diagram is a UML class diagram. UML offers many other kinds of useful diagrams. You can learn more at https://www.packtpub.com/product/uml-2-0-in-action-a-project-based-tutorial/9781904811558.
SRP guides us to break code down into pieces that encapsulate a single aspect of our solution. Maybe that is a technical aspect in nature—such as reading a database table—or maybe it is a business rule. Either way, we split different aspects into different pieces of code. Each piece of code is responsible for a single detail, which is where the name SRP comes from. Another way of looking at this is that a piece of code should only ever have one reason to change. Let’s examine why this is an advantage in the following sections.
Too many responsibilities make code harder to work with
A common programming mistake is to combine too many responsibilities into a single piece of code. If we have a class that can generate Hypertext Markup Language (HTML), execute a business rule, and fetch data from a database table, that class will have three reasons to change. Any time a change in one of these areas is necessary, we will risk making a code change that breaks the other two aspects. The technical term for this is that the code is highly coupled. This leads to changes in one area rippling out and affecting other areas.
We can visualize this as code block A in the following diagram:
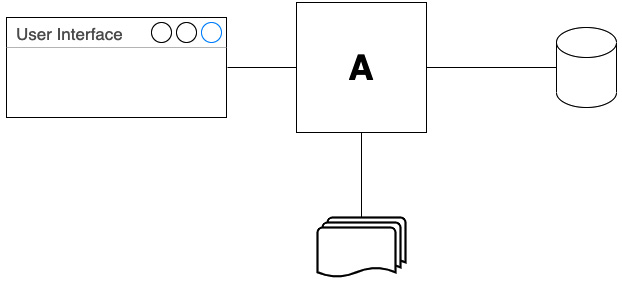
Figure 7.2 – Single component: multiple reasons to change
Block A deals with three things, so a change to any of them implies a change in A. To improve this, we apply SRP and separate out the code responsible for creating HTML, applying business rules, and accessing the database. Each of those three code blocks—A, B, and C—now only has one reason to change. Changing any single code block should not result in changes rippling out to the other blocks.
We can visualize this in the following diagram:
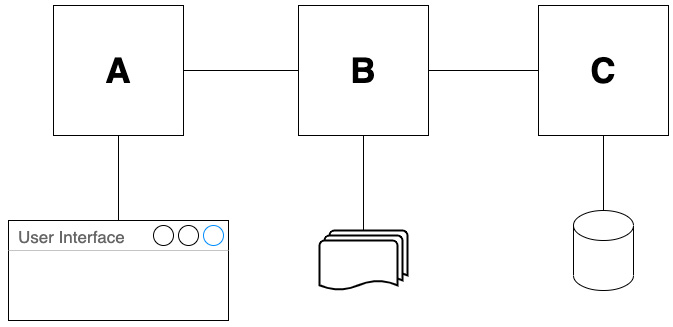
Figure 7.3 – Multiple components: one reason to change
Each code block deals with one thing and has only one reason to change. We can see that SRP works to limit the scope of future code changes. It also makes it easier to find code in a large code base, as it is logically organized.
Applying SRP gives other benefits, as follows:
- Ability to reuse code
- Simplified future maintenance
Ability to reuse code
Reusing code has been a goal of software engineering for a long time. Creating software from scratch takes time, costs money, and prevents a software engineer from doing something else. It makes sense that if we create something that is generally useful, we use it again wherever possible. The barrier to this happens when we have created large, application-specific pieces of software. The fact that they are highly specialized means they can only be used in their original context.
By creating smaller, more general-purpose software components, we will be able to use those again in different contexts. The smaller the scope of what the component aims to do, the more likely it is that we can reuse it without modification. If we have a small function or class that does one thing, it becomes easy to reuse that across our code base. It may even end up as part of a framework or library that we can reuse across multiple projects.
SRP does not guarantee that code will be reusable, but it does aim to reduce the scope of what any piece of code does. This way of thinking about code as a series of building blocks where each one does a small part of the overall task is more likely to result in reusable components.
Simplified future maintenance
As we write code, we’re aware that we are not just writing to solve a problem now, but also writing code that might be revisited in the future. This might be done by other people in the team or maybe by ourselves. We want to make this future work as simple as possible. To achieve this, we need to keep our code well-engineered—making it safe and easy to work with later.
Duplicated code is a problem for maintenance—it complicates future code changes. If we copy and paste a section of code three times, let’s say, it seems quite obvious to us at the time what we are doing. We have one concept that needs to happen three times, so we paste it three times. But when it comes time to read the code again, that thought process has been lost. It just reads as three unrelated pieces of code. We lose engineering information by copy and paste. We will need to reverse-engineer that code to work out that there are three places where we need to change it.
Counter-example – shapes code that violates SRP
To see the value of applying SRP, let’s consider a piece of code that doesn’t use it. The following code snippet has a list of shapes that all get drawn when we call the draw() method:
public class Shapes {
private final List<Shape> allShapes = new ArrayList<>();
public void add(Shape s) {
allShapes.add(s);
}
public void draw(Graphics g) {
for (Shape s : allShapes) {
switch (s.getType()) {
case "textbox":
var t = (TextBox) s;
g.drawText(t.getText());
break;
case "rectangle":
var r = (Rectangle) s;
for (int row = 0;
row < r.getHeight();
row++) {
g.drawLine(0, r.getWidth());
}
}
}
}
}We can see that this code has four responsibilities, as follows:
- Managing the list of shapes with the add() method
- Drawing all the shapes in the list with the draw() method
- Knowing every type of shape in the switch statement
- Has implementation details for drawing each shape type in the case statements
If we want to add a new type of shape—triangle, for example—then we’ll need to change this code. This will make it longer, as we need to add details about how to draw the shape inside a new case statement. This makes the code harder to read. The class will also have to have new tests.
Can we change this code to make adding a new type of shape easier? Certainly. Let’s apply SRP and refactor.
Applying SRP to simplify future maintenance
We will refactor this code to apply SRP, taking small steps. The first thing to do is to move that knowledge of how to draw each type of shape out of this class, as follows:
package shapes;
import java.util.ArrayList;
import java.util.List;
public class Shapes {
private final List<Shape> allShapes = new ArrayList<>();
public void add(Shape s) {
allShapes.add(s);
}
public void draw(Graphics g) {
for (Shape s : allShapes) {
switch (s.getType()) {
case "textbox":
var t = (TextBox) s;
t.draw(g);
break;
case "rectangle":
var r = (Rectangle) s;
r.draw(g);
}
}
}
}The code that used to be in the case statement blocks has been moved into the shape classes. Let’s look at the changes in the Rectangle class as one example—you can see what’s changed in the following code snippet:
public class Rectangle {
private final int width;
private final int height;
public Rectangle(int width, int height){
this.width = width;
this.height = height;
}
public void draw(Graphics g) {
for (int row=0; row < height; row++) {
g.drawHorizontalLine(width);
}
}
}We can see how the Rectangle class now has the single responsibility of knowing how to draw a rectangle. It does nothing else. The one and only reason it will have to change is if we need to change how a rectangle is drawn. This is unlikely, meaning that we now have a stable abstraction. In other words, the Rectangle class is a building block we can rely on. It is unlikely to change.
If we examine our refactored Shapes class, we see that it too has improved. It has one responsibility less because we moved that out into the TextBox and Rectangle classes. It is simpler to read already, and simpler to test.
SRP
Do one thing and do it well. Have only one reason for a code block to change.
More improvements can be made. We see that the Shapes class retains its switch statement and that every case statement looks duplicated. They all do the same thing, which is to call a draw() method on a shape class. We can improve this by replacing the switch statement entirely—but that will have to wait until the next section, where we introduce the DIP.
Before we do that, let’s think about how SRP applies to our test code itself.
Organizing tests to have a single responsibility
SRP also helps us to organize our tests. Each test should test only one thing. Perhaps this would be a single happy path or a single boundary condition. This makes it simpler to localize any faults. We find the test that failed, and because it concerns only a single aspect of our code, it is easy to find the code where the defect must be. The recommendation to only have a single assertion for each test flows naturally from this.
Separating tests with different configurations
Sometimes, a group of objects can be arranged to collaborate in multiple different ways. The tests for this group are often better if we write a single test per configuration. We end up with multiple smaller tests that are easier to work with.
This is an example of applying SRP to each configuration of that group of objects and capturing that by writing one test for each specific configuration.
We’ve seen how SRP helps us create simple building blocks for our code that are simpler to test and easier to work with. The next powerful SOLID principle to look at is DIP. This is a very powerful tool for managing complexity.
DIP – hiding irrelevant details
In this section, we will learn how the DIP allows us to split code into separate components that can change independently of each other. We will then see how this naturally leads to the OCP part of SOLID.
Dependency inversion (DI) means that we write code to depend on abstractions, not details. The opposite of this is having two code blocks, one that depends on the detailed implementation of the other. Changes to one block will cause changes to another. To see what this problem looks like in practice, let’s review a counter-example. The following code snippet begins where we left off with the Shapes class after applying SRP to it:
package shapes;
import java.util.ArrayList;
import java.util.List;
public class Shapes {
private final List<Shape> allShapes = new ArrayList<>();
public void add(Shape s) {
allShapes.add(s);
}
public void draw(Graphics g) {
for (Shape s : allShapes) {
switch (s.getType()) {
case "textbox":
var t = (TextBox) s;
t.draw(g);
break;
case "rectangle":
var r = (Rectangle) s;
r.draw(g);
}
}
}
}This code does work well to maintain a list of Shape objects and draw them. The problem is that it knows too much about the types of shapes it is supposed to draw. The draw() method features a switch-on-type of object that you can see. That means that if anything changes about which types of shapes should be drawn, then this code must also change. If we want to add a new Shape to the system, then we have to modify this switch statement and the associated TDD test code.
The technical term for one class knowing about another is that a dependency exists between them. The Shapes class depends on the TextBox and Rectangle classes. We can represent that visually in the following UML class diagram:
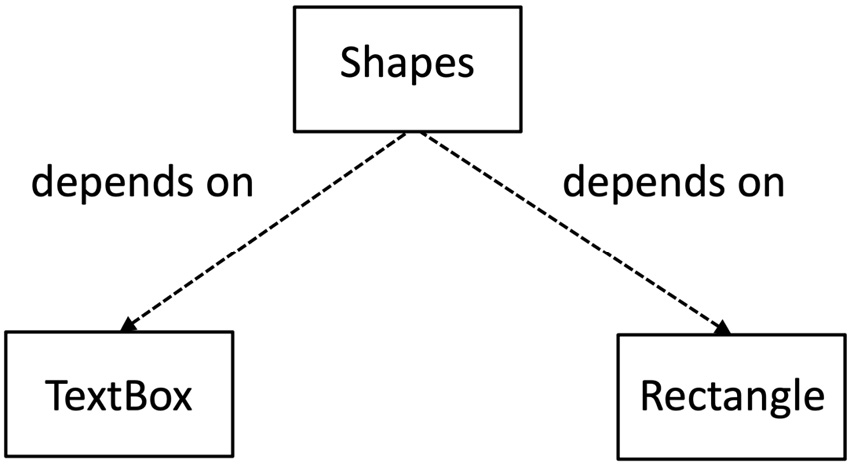
Figure 7.4 – Depending on the details
We can see that the Shapes class depends directly on the detail of the Rectangle and TextBox classes. This is shown by the direction of the arrows in the UML class diagram. Having these dependencies makes working with the Shapes class more difficult for the following reasons:
- We have to change the Shapes class to add a new kind of shape
- Any changes in the concrete classes such as Rectangle will cause this code to change
- The Shapes class will get longer and less easy to read
- We will end up with more test cases
- Each test case will be coupled to concrete classes such as Rectangle
This is a very procedural approach to creating a class that deals with multiple kinds of shapes. It violates SRP by doing too much and knowing too much detail about each kind of shape object. The Shapes class depends on the details of concrete classes such as Rectangle and TextBox, which directly causes the aforementioned problems.
Thankfully, there is a better way. We can use the power of an interface to improve this, by making it so that the Shapes class does not depend on those details. This is called DI. Let’s see what that looks like next.
Applying DI to the shapes code
We can improve the shapes code by applying the Dependency Inversion Principle (DIP) described in the previous chapter. Let’s add a draw() method to our Shape interface, as follows:
package shapes;
public interface Shape {
void draw(Graphics g);
}This interface is our abstraction of the single responsibility that each shape has. Each shape must know how to draw itself when we call the draw() method. The next step is to make our concrete shape classes implement this interface.
Let’s take the Rectangle class as an example. You can see this here:
public class Rectangle implements Shape {
private final int width;
private final int height;
public Rectangle(int width, int height){
this.width = width;
this.height = height;
}
@Override
public void draw(Graphics g) {
for (int row=0; row < height; row++) {
g.drawHorizontalLine(width);
}
}
}We’ve now introduced the OO concept of polymorphism into our shape classes. This breaks the dependency that the Shapes class has on knowing about the Rectangle and TextBox classes. All that the Shapes class now depends on is the Shape interface. It no longer needs to know the type of each shape.
We can refactor the Shapes class to look like this:
public class Shapes {
private final List<Shape> all = new ArrayList<>();
public void add(Shape s) {
all.add(s);
}
public void draw(Graphics graphics) {
all.forEach(shape->shape.draw(graphics));
}
}This refactoring has completely removed the switch statement and the getType() method, making the code much simpler to understand and test. If we add a new kind of shape, the Shapes class no longer needs to change. We have broken that dependency on knowing the details of shape classes.
One minor refactor moves the Graphics parameter we pass into the draw() method into a field, initialized in the constructor, as illustrated in the following code snippet:
public class Shapes {
private final List<Shape> all = new ArrayList<>();
private final Graphics graphics;
public Shapes(Graphics graphics) {
this.graphics = graphics;
}
public void add(Shape s) {
all.add(s);
}
public void draw() {
all.forEach(shape->shape.draw(graphics));
}
}This is DIP at work. We’ve created an abstraction in the Shape interface. The Shapes class is a consumer of this abstraction. The classes implementing that interface are providers. Both sets of classes depend only on the abstraction; they do not depend on details inside each other. There are no references to the Rectangle class in the Shapes class, and there are no references to the Shapes inside the Rectangle class. We can see this inversion of dependencies visualized in the following UML class diagram—see how the direction of the dependency arrows has changed compared to Figure 7.4:
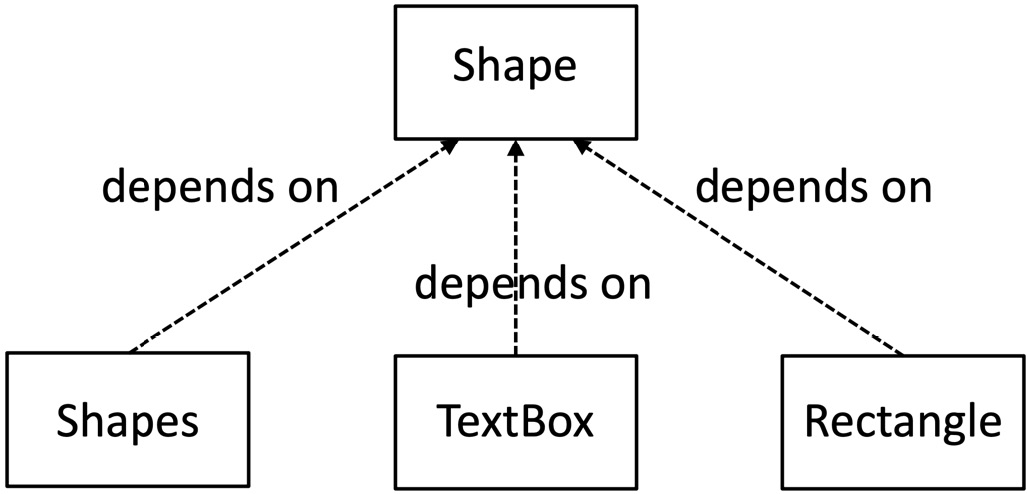
Figure 7.5 – Inverting dependencies
In this version of the UML diagram, the arrows describing the dependencies between classes point the opposite way. The dependencies have been inverted—hence, the name of this principle. Our Shapes class now depends on our abstraction, the Shape interface. So do all the Rectangle class and TextBox class concrete implementations. We have inverted the dependency graph and turned the arrows upside down. DI fully decouples classes from each other and, as such, is very powerful. We will see how this leads to a key technique for TDD testing when we look at Chapter 8, Test Doubles – Stubs and Mocks.
DIP
Make code depend on abstractions and not on details.
We’ve seen how DIP is a major tool we can use to simplify our code. It allows us to write code that deals with an interface, and then use that code with any concrete class that implements that interface. This begs a question: can we write a class that implements an interface but will not work correctly? That’s the subject of our next section.
LSP – swappable objects
Turing Award winner Barbara Liskov is the creator of a rule concerning inheritance that is now commonly known as LSP. It was brought about by a question in OOP: if we can extend a class and use it in place of the class we extended, how can we be sure the new class will not break things?
We’ve seen in the previous section on DIP how we can use any class that implements an interface in place of the interface itself. We also saw how those classes can provide any implementation they like for that method. The interface itself provides no guarantees at all about what might lurk inside that implementation code.
There is, of course, a bad side to this—which LSP aims to avoid. Let’s explain this by looking at a counter-example in code. Suppose we made a new class that implemented interface Shape, such as this one (Warning: Do NOT run the code that follows in the MaliciousShape class!):
public class MaliciousShape implements Shape {
@Override
public void draw(Graphics g) {
try {
String[] deleteEverything = {"rm", "-Rf", "*"};
Runtime.getRuntime().exec(deleteEverything,null);
g.drawText("Nothing to see here...");
} catch (Exception ex) {
// No action
}
}
}Notice anything a little odd about that new class? It contains a Unix command to remove all our files! This is not what we are expecting when we call the draw() method on a shape object. Due to permissions failures, it might not be able to delete anything, but it’s an example of what can go wrong.
An interface in Java can only protect the syntax of method calls we expect. It cannot enforce any semantics. The problem with the preceding MaliciousShape class is that it does not respect the intent behind the interface.
LSP guides us to avoid this error. In other words, LSP states that any class that implements an interface or extends another class must handle all the input combinations that the original class/interface could. It must provide the expected outputs, it must not ignore valid inputs, and it must not produce completely unexpected and undesired behavior. Classes written like this are safe to use through a reference to their interface. The problem with our MaliciousShape class is that it was not compatible with LSP—it added some extra totally unexpected and unwanted behavior.
LSP formal definition
American computer scientist Barbara Liskov came up with a formal definition: If p(x) is a property provable about objects x of type T, then p(y) should be true for objects y of type S where S is a subtype of T.
Reviewing LSP usage in the shapes code
The classes that implement Shape all conform to LSP. This is clear in the TextBox class, as we can see here:
public class TextBox implements Shape {
private final String text;
public TextBox(String text) {
this.text = text;
}
@Override
public void draw(Graphics g) {
g.drawText(text);
}
}The preceding code clearly can handle drawing any valid text provided to its constructor. It also provides no surprises. It draws the text, using primitives from the Graphics class, and does nothing else.
Other examples of LSP compliance can be seen in the following classes:
- Rectangle
- Triangle
LSP
A code block can be safely swapped for another if it can handle the full range of inputs and provide (at least) all expected outputs, with no undesired side effects.
There are some surprising violations of LSP. Perhaps the classic one for the shapes code example is about adding a Square class. In mathematics, a square is a kind of rectangle, with the extra constraint that its height and width are equal. In Java code, should we make the Square class extend the Rectangle class? How about the Rectangle class extending Square?
Let’s apply LSP to decide. We will imagine some code that expects a Rectangle class so that it can change its height, but not its width. If we passed a Square class to that code, would it work properly? The answer is no. You would then have a square with unequal width and height. This fails LSP.
The point of LSP is about making classes properly conform to interfaces. In the next section, we’ll look at OCP, which is closely related to DI.
OCP – extensible design
In this section, we’ll see how OCP helps us write code that we can add new features to, without changing the code itself. This does sound like an impossibility at first, but it flows naturally from DIP combined with LSP.
OCP results in code that is open to extension but closed to modification. We saw this idea at work when we looked at DIP. Let’s review the code refactoring we did in the light of OCP.
Let’s start with the original code for the Shapes class, as follows:
public class Shapes {
private final List<Shape> allShapes = new ArrayList<>();
public void add(Shape s) {
allShapes.add(s);
}
public void draw(Graphics g) {
for (Shape s : allShapes) {
switch (s.getType()) {
case "textbox":
var t = (TextBox) s;
g.drawText(t.getText());
break;
case "rectangle":
var r = (Rectangle) s;
for (int row = 0;
row < r.getHeight();
row++) {
g.drawLine(0, r.getWidth());
}
}
}
}
}Adding a new type of shape requires modification of the code inside the draw() method. We will be adding a new case statement in to support our new shape.
Modifying existing code has several disadvantages, as set out here:
- We invalidate prior testing. This is now different code than we had tested.
- We might introduce an error that breaks some of the existing support for shapes.
- The code will become longer and more difficult to read.
- We might have several developers add shapes at the same time and get a merge conflict when we combine their work.
By applying DIP and refactoring the code, we ended up with this:
public class Shapes {
private final List<Shape> all = new ArrayList<>();
private final Graphics graphics;
public Shapes(Graphics graphics) {
this.graphics = graphics;
}
public void add(Shape s) {
all.add(s);
}
public void draw() {
all.forEach(shape->shape.draw(graphics));
}
}We can now see that adding a new type of shape does not need modification to this code. This is an example of OCP at work. The Shapes class is open to having new kinds of shapes defined, but it is closed against the need for modification when that new shape is added. This also means that any tests relating to the Shapes class will remain unchanged, as there is no difference in behavior for this class. That is a powerful advantage.
OCP relies on DI to work. It is more or less a restatement of a consequence of applying DIP. It also provides us with a technique to support swappable behavior. We can use DIP and OCP to create plugin systems.
Adding a new type of shape
To see how this works in practice, let’s create a new type of shape, the RightArrow class, as follows:
public class RightArrow implements Shape {
public void draw(Graphics g) {
g.drawText( " " );
g.drawText( "-----" );
g.drawText( " /" );
}
}The RightArrow class implements the Shape interface and defines a draw() method. To demonstrate that nothing in the Shapes class needs to change in order to use this, let’s review some code that uses both the Shapes and our new class, RightArrow, as follows:
package shapes;
public class ShapesExample {
public static void main(String[] args) {
new ShapesExample().run();
}
private void run() {
Graphics console = new ConsoleGraphics();
var shapes = new Shapes(console);
shapes.add(new TextBox("Hello!"));
shapes.add(new Rectangle(32,1));
shapes.add(new RightArrow());
shapes.draw();
}
}We see that the Shapes class is being used in a completely normal way, without change. In fact, the only change needed to use our new RightArrow class is to create an object instance and pass it to the add() method of shapes.
OCP
Make code open for new behaviors, but closed for modifications.
The power of OCP should now be clear. We can extend the capabilities of our code and keep changes limited. We greatly reduce the risk of breaking code that is already working, as we no longer need to change that code. OCP is a great way to manage complexity. In the next section, we’ll look at the remaining SOLID principle: ISP.
ISP – effective interfaces
In this section, we will look at a principle that helps us write effective interfaces. It is known as ISP.
ISP advises us to keep our interfaces small and dedicated to achieving a single responsibility. By small interfaces, we mean having as few methods as possible on any single interface. These methods should all relate to some common theme.
We can see that this principle is really just SRP in another form. We are saying that an effective interface should describe a single responsibility. It should cover one abstraction, not several. The methods on the interface should strongly relate to each other and also to that single abstraction.
If we need more abstractions, then we use more interfaces. We keep each abstraction in its own separate interface, which is where the term interface segregation comes from —we keep different abstractions apart.
The related code smell to this is a large interface that covers several different topics in one. We could imagine an interface having hundreds of methods in little groups—some relating to file management, some about editing documents, and some about printing documents. Such interfaces quickly become difficult to work with. ISP suggests that we improve this by splitting the interface into several smaller ones. This split would preserve the groups of methods—so, you might see interfaces for file management, editing, and printing, with relevant methods under each. We have made our code simpler to understand by splitting apart these separate abstractions.
Reviewing ISP usage in the shapes code
The most noticeable use of ISP is in the Shape interface, as illustrated here:
interface Shape {
void draw(Graphics g);
}This interface clearly has a single focus. It is an interface with a very narrow focus, so much so that only one method needs to be specified: draw(). There is no confusion arising from other mixed-in concepts here and no unnecessary methods. That single method is both necessary and sufficient. The other major example is in the Graphics interface, as shown here:
public interface Graphics {
void drawText(String text);
void drawHorizontalLine(int width);
}The Graphics interface contains only methods related to drawing graphics primitives on screen. It has two methods—drawText to display a text string, and drawHorizontalLine to draw a line in a horizontal direction. As these methods are strongly related—known technically as exhibiting high cohesion—and few in number, ISP is satisfied. This is an effective abstraction over the graphics drawing subsystem, tailored to our purposes.
For completeness, we can implement this interface in a number of ways. The example in GitHub uses a simple text console implementation:
public class ConsoleGraphics implements Graphics {
@Override
public void drawText(String text) {
print(text);
}
@Override
public void drawHorizontalLine(int width) {
var rowText = new StringBuilder();
for (int i = 0; i < width; i++) {
rowText.append('X');
}
print(rowText.toString());
}
private void print(String text) {
System.out.println(text);
}
}That implementation is also LSP-compliant—it can be used wherever the Graphics interface is expected.
ISP
Keep interfaces small and strongly related to a single idea.
We’ve now covered all five of the SOLID principles and shown how they have been applied to the shapes code. They have guided the design toward compact code, having a well-engineered structure to assist future maintainers. We know how to incorporate these principles into our own code to gain similar benefits.
Summary
In this chapter, we’ve looked at simple explanations of how the SOLID principles help us design both our production code and our tests. We’ve worked through an example design that uses all five SOLID principles. In future work, we can apply SRP to help us understand our design and limit the rework involved in future changes. We can apply DIP to split up our code into independent small pieces, leaving each piece to hide some of the details of our overall program, creating a divide-and-conquer effect. Using LSP, we can create objects that can be safely and easily swapped. OCP helps us design software that is simple to add functionality to. ISP will keep our interfaces small and easy to understand.
The next chapter puts these principles to use to solve a problem in testing—how do we test the collaborations between our objects?
Questions and answers
- Do the SOLID principles only apply to OO code?
No. Although originally applied to an OO context, they have uses in both functional programming and microservice design. SRP is almost universally useful—sticking to one main focus is helpful for anything, even paragraphs of documentation. SRP thinking also helps us write a pure function that does only one thing and a test that does only one thing. DIP and OCP are easily done in functional contexts by passing in the dependency as a pure function, as we do with Java lambdas. SOLID as a whole gives a set of goals for managing coupling and cohesion among any kind of software components.
- Do we have to use SOLID principles with TDD?
No. TDD works by defining the outcomes and public interface of a software component. How we implement that component is irrelevant to a TDD test, but using principles such as SRP and DIP makes it much easier to write tests against that code by giving us the test access points we need.
- Are SOLID principles the only ones we should use?
No. We should use every technique at our disposal.
The SOLID principles make a great starting point in shaping your code and we should take advantage of them, but there are many other valid techniques to design software. The whole catalog of design patterns, the excellent system of General Responsibility Assignment Software Patterns (GRASP) by Craig Larman, the idea of information hiding by David L. Parnas, and the ideas of coupling and cohesion all apply. We should use any and every technique we know—or can learn about—to serve our goal of making software that is easy to read and safe to change.
- If we do not use the SOLID principles, can we still do TDD?
Yes—very much so. TDD concerns itself with testing the behavior of code, not the details of how it is implemented. SOLID principles simply help us create OO designs that are robust and simpler to test.
- How does SRP relate to ISP?
ISP guides us to prefer many shorter interfaces over one large interface. Each of the shorter interfaces should relate to one single aspect of what a class should provide. This is usually some kind of role, or perhaps a subsystem. ISP can be thought of as making sure our interfaces each apply the SRP and do only one thing—well.
- How does OCP relate to DIP and LSP?
OCP guides us to create software components that can have new capabilities added without changing the component itself. This is done by using a plugin design. The component will allow separate classes to be plugged in providing the new capabilities. The way to do this is to create an abstraction of what a plugin should do in an interface—DIP. Then, create concrete plugin implementations of this conforming to LSP. After that, we can inject these new plugins into our component. OCP relies on DIP and LSP to work.