
3
Dispelling Common Myths about TDD
Test-driven development (TDD) brings many benefits to developers and the business. However, it is not always used in real projects. This is something I find surprising. TDD has been demonstrated to improve internal and external code quality in different industrial settings. It works for frontend and backend code. It works across verticals. I have experienced it working in embedded systems, web conferencing products, desktop applications, and microservice fleets.
To better understand how perceptions have gone wrong, let’s review the common objections to TDD, then explore how we can overcome them. By understanding the perceived difficulties, we can equip ourselves to be TDD advocates and help our colleagues reframe their thinking. We will examine six popular myths that surround TDD and form constructive responses to them.
In this chapter, we’re going to cover the following myths:
- “Writing tests slows me down”
- “Tests cannot prevent every bug”
- “How do you know the tests are right”
- “TDD guarantees good code”
- “Our code is too complex to test”
- “I don’t know what to test until I write the code”
Writing tests slows me down
Writing tests slowing development down is a popular complaint about TDD. This criticism has some merit. Personally, I have only ever felt that TDD has made me faster, but academic research disagrees. A meta-analysis of 18 primary studies by the Association for Computing Machinery showed that TDD did improve productivity in academic settings but added extra time in industrial contexts. However, that’s not the full story.
Understanding the benefits of slowing down
The aforementioned research indicates that the payback for taking extra time with TDD is a reduction in the number of defects that go live in the software. With TDD, these defects are identified and eliminated far sooner than with other approaches. By resolving issues before manual quality assurance (QA), deployment, and release, and before potentially facing a bug report from an end user, TDD allows us to cut out a large chunk of that wasted effort.
We can see the difference in the amount of work to be done in this figure:
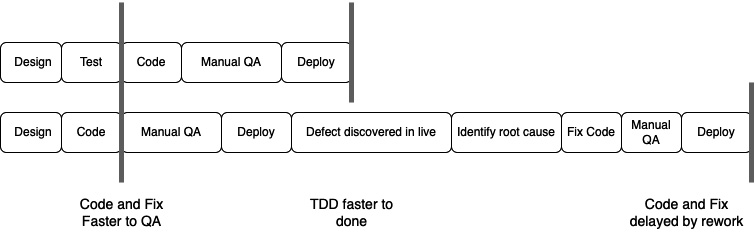
Figure 3.1 – Not using TDD slows us down due to rework
The top row represents developing a feature using TDD, where we have sufficient tests to prevent any defects from going into production. The bottom row represents developing the same feature in a code-and-fix style, without TDD, and finding that a defect has gone live in production. Without TDD, we discover faults very late, annoy the user, and pay a heavy time penalty in rework. Note that the code-and-fix solution looks like it gets us into the QA stage faster, until we consider all the rework caused by undiscovered defects. The rework is what isn’t taken into account in this myth.
Using TDD, we simply make all our design and testing thinking explicit and upfront. We capture and document it using executable tests. Whether we write tests or not, we still spend that same thinking time considering what the specifics that our code needs to cover are. It turns out that the mechanical writing of the test code takes very little time. You can measure that yourself when we write our first test in Chapter 5, Writing Our First Test. The total time spent writing a piece of code is the time to design it, plus the time to write the code, plus the time to test it. Even without writing automated tests, the design and coding time remain constant and dominant factors.
The other area conveniently ignored through all this is the time taken to manually test. Without a doubt, our code will be tested. The only question is when and by who. If we write a test first, it is by us, the developers. It happens before any faulty code gets checked into our system. If we leave testing to a manual testing colleague, then we slow down the whole development process. We need to spend time helping our colleague understand what the success criteria are for our code. They must then devise a manual test plan, which often must be written up, reviewed, and accepted into documentation.
Executing manual tests is very time-consuming. Generally, the whole system must be built and deployed to a test environment. Databases must be manually set up to contain known data. The user interface (UI) must be clicked through to get to a suitable screen where our new code might be exercised. The output must be manually inspected and a decision made on its correctness. These steps must be manually performed every time we make a change.
Worse still, the later we leave it to test, the greater the chance is that we will have built on top of any faulty code that exists. We cannot know we are doing that, as we haven’t tested our code yet. This often becomes difficult to unpick. In some projects, we get so far out of step with the main code branch that developers start emailing patch files to each other. This means we start building on top of this faulty code, making it even harder to remove. These are bad practices but they do occur in real projects.
The contrast to writing a TDD test first could not be greater. With TDD, the setup is automated, the steps are captured and automated, and the result checking is automated. We are talking timescale reductions of minutes for a manual test down to milliseconds using a TDD unit test. This time saving is made every single time we need to run that test.
While manual testing is not as efficient as TDD, there is still one far worse option: no testing at all. Having a defect released to production means that we leave it to our users to test the code. Here, there may be financial considerations and the risk of reputation damage. At the very least, this is a very slow way to discover a fault. Isolating the defective lines of code from production logs and databases is extraordinarily time-consuming. It is also usually frustrating, in my experience.
It’s funny how a project that can never find time to write unit tests can always find time to trawl production logs, roll back released code, issue marketing communications, and stop all other work to do a Priority 1 (P1) fix. Sometimes, it feels like days are easier to find than minutes for some management approaches.
TDD certainly places a time cost up front in writing a test, but in return, we gain fewer faults to rectify in production – with a huge saving in overall cost, time, and reputation compared to multiple rework cycles with defects occurring in live code.
Overcoming objections to tests slowing us down
Build a case that tracks the time spent on undiscovered defects in manual QA and failed deployments. Find some rough figures for the time taken for the most recent live issue to be fixed. Work out which missing unit test could have prevented it. Now work out how long that would have taken to write. Present these figures to stakeholders. It can be even more effective to work out the cost of all that engineering time and any lost revenue.
Knowing that tests do have an overall benefit in terms of fewer defects, let’s examine another common objection that tests are of no value, as they cannot prevent every bug.
Tests cannot prevent every bug
A very old objection to testing of any kind is this one: you cannot catch every bug. While this is certainly true, if anything, it means that we need more and better testing, not less. Let’s understand the motivations behind this one to prepare an appropriate response.
Understanding why people say tests cannot catch every bug
Straight away, we can agree with this statement. Tests cannot catch every bug. More precisely, it has been proven that testing in software systems can only reveal the presence of defects. It can never prove that no defects exist. We can have many passing tests, and defects can still hide in the places we haven’t tested.
This seems to apply in other fields as well. Medical scans will not always reveal problems that are too faint to notice. Wind tunnel tests for aircraft will not always reveal problems under specific flight conditions. Batch sampling in a chocolate factory will not catch every substandard sweet.
Just because we cannot catch every bug, does not mean this invalidates our testing. Every test we write that catches one defect results in one less defect running through our workflow. TDD gives us a process to help us think in terms of testing as we develop, but there are still areas where our tests will not be effective:
- Tests you have not thought to write
- Defects that arise due to system-level interactions
Tests that we have not written are a real problem. Even when writing tests first in TDD, we must be disciplined enough to write a test for every scenario that we want to function. It is easy to write a test and then write the code to make it pass. The temptation is to then just keep adding code because we are on a roll. It is easy to miss an edge case and so not write a test for it. If we have a missing test, we open up the possibility of a defect existing and being found later.
The problem with system-level interactions here refers to the behavior that emerges when you take tested units of software and join them. The interactions between units can sometimes be more complex than anticipated. Basically, if we join up two well-tested things, the new combination itself is still not yet tested. Some interactions have faults that only show up in these interactions, even though the units that they are made up of passed all tests.
These two problems are real and valid. Testing will never cover every possible fault, but this misses the main value of testing. Every test we do write will reduce one defect.
By not testing anything, we will never spot anything wrong. We will not prevent any defects. If we test, no matter how little, then we will improve the quality of our code. Every defect that these tests can detect will be prevented. We can see the straw-man nature of this argument: just because we cannot cover every eventuality, it does not mean we should not do what we can.
Overcoming objections to not catching every bug
The way to reframe this is for us to have confidence that TDD prevents many classes of errors from happening. Not all kinds of errors, certainly, but a bank of thousands of tests is going to make a noticeable improvement to the quality of our applications.
To explain this to our colleagues, we can draw on familiar analogies: just because a strong password cannot prevent every hacker, this does not mean we should not use passwords and leave ourselves vulnerable to any and every hacker. Staying healthy will not prevent every kind of medical problem but it will prevent many kinds of serious problems.
Ultimately, this is a question of balance. Zero testing is clearly not enough – every single defect will end up going live in this case. We know that testing can never eliminate defects. So, where should we stop? What constitutes enough? We can argue that TDD helps us decide on this balance at the best possible time: while we are thinking about writing code. The automated TDD tests we create will save us manual QA time. It’s manual work that no longer needs to be done. These time and cost savings compound, repaying us in every single iteration of code.
Now that we understand why testing as much as possible always beats not testing at all, we can look into the next common objection: how do we know the tests themselves were written correctly?
How do you know the tests are right?
This is an objection that has merit, so we need to deeply understand the logic behind it. This is a common objection from people unfamiliar with writing automated tests, as they misunderstand how we avoid incorrect tests. By helping them see the safeguards we put in place, we can help them reframe their thinking.
Understanding the concerns behind writing broken tests
One objection you will hear is, “How do we know the tests are right if the tests themselves don’t have tests?” This objection was raised the first time I introduced unit tests to a team. It was polarizing. Some of the team understood the value right away. Others were indifferent, but some were actively hostile. They saw this new practice as suggesting they were somehow deficient. It was perceived as a threat. Against that background, one developer pointed out a flaw in the logic I had explained.
I told the team that we could not trust our visual reading of production code. Yes, we are all skilled at reading code, but we are humans, so we miss things. Unit tests would help us avoid missing things. One bright developer asked a great question: if visual inspection does not work for production code, why are we saying that it does work for test code? What’s the difference between the two?
The right illustration for this came after I needed to test some XML output (which was in 2005, I remember). The code I had written for checking the XML output was truly complex. The criticism was correct. There was no way I could visually inspect that test code and honestly say it was without defects.
So, I applied TDD to the problem. I used TDD to write a utility class that could compare two XML strings and report either that they were the same or what the first difference was. It could be configured to ignore the order of XML elements. I extracted this complex code out of my original test and replaced it with a call to this new utility class. I knew the utility class did not have any defects, as it passed every TDD test that I had written for it. There were many tests, covering every happy path and every edge case I cared about. The original test that had been criticized now became very short and direct.
I asked my colleague who had raised the point to review the code. They agreed that in this new, simpler form, they were happy to agree that the test was correct, visually. They added the caveat “if the utility class works right.” Of course, we had the confidence that it passed every TDD test we had written it against. We were certain that it did all the things we specifically wanted it to do, as proven by tests for these things.
Providing reassurance that we test our tests
The essence of this argument is that short, simple code can be visually inspected. To ensure this, we keep most of our unit tests simple and short enough to reason about. Where tests get too complex, we extract that complexity into its own code unit. We develop that using TDD and end up making both the original test code simple enough to inspect and the test utility simple enough for its tests to inspect, a classic example of divide and conquer.
Practically, we invite our colleagues to point out where they feel our test code is too complex to trust. We refactor it to use simple utility classes, these themselves written using simple TDD. This approach helps us build trust, respects the valid concerns of our colleagues, and shows how we can find ways to reduce all TDD tests to simple, reviewable code blocks.
Now that we have addressed knowing our tests are right, another common objection involves having overconfidence in TDD: that simply following the TDD process will therefore guarantee good code. Can that be true? Let’s examine the arguments.
TDD guarantees good code
Just as there are often overly pessimistic objections to TDD, here is an opposite view: TDD guarantees good code. As TDD is a process, and it claims to improve code, it is quite reasonable to assume that using TDD is all you need to guarantee good code. Unfortunately, that is not at all correct. TDD helps developers write good code and it helps as feedback to show us where we have made mistakes in design and logic. It cannot guarantee good code, however.
Understanding problem-inflated expectations
The issue here is a misunderstanding. TDD is not a set of techniques that directly affect your design decisions. It is a set of techniques that help you specify what you expect a piece of code to do, when, under what conditions, and given a particular design. It leaves you free to choose that design, what you expect it to do, and how you are going to implement that code.
TDD has no suggestions regarding choosing a long variable name over a short one. It does not tell you whether you should choose an interface or an abstract class. Should you choose to split a feature over two classes or five? TDD has no advice there. Should you eliminate duplicated code? Invert a dependency? Connect to a database? Only you can decide. TDD offers no advice. It is not intelligent. It cannot replace you and your expertise. It is a simple process, enabling you to validate your assumptions and ideas.
Managing your expectations of TDD
TDD is hugely beneficial in my view but we must regard it in context. It provides instant feedback on our decisions but leaves every important software design decision to us.
Using TDD, we are free to write code using the SOLID principles (which will be covered in Chapter 7, Driving Design — TDD and SOLID, of this book) or we can use a procedural approach, an object-oriented approach, or a functional approach. TDD allows us to choose our algorithm as we see fit. It enables us to change our minds about how something should be implemented. TDD works across every programming language. It works across every vertical.
Helping our colleagues see past this objection helps them realize that TDD is not some magic system that replaces the intelligence and skill of the programmer. It harnesses this skill by providing instant feedback on our decisions. While this may disappoint colleagues who hoped it would allow perfect code to come from imperfect thinking, we can point out that TDD gives us time to think. The advantage is that it puts thinking and design up front and central. By writing a failing test before writing the production code that makes the test pass, we have ensured that we have thought about what that code should do and how it should be used. That’s a great advantage.
Given that we understand that TDD does not design our code for us, yet is still a developer’s friend, how can we approach testing complex code?
Our code is too complex to test
Professional developers routinely deal with highly complex code. That’s just a fact of life. It leads to one valid objection: our code is too difficult to write unit tests for. The code we work on might be highly valuable, trusted legacy code that brings in significant top-line revenue. This code may be complex. But is it too complex to test? Is it true to say that every piece of complex code simply cannot be tested?
Understanding the causes of untestable code
The answer lies in the three ways that code becomes complex and hard to test:
- Accidental complexity: We chose a hard way over a simpler way by accident
- External systems cannot be controlled to set up for our tests
- The code is so entangled that we no longer understand it
Accidental complexity makes code hard to read and hard to test. The best way to think about this is to know that any given problem has many valid solutions. Say we want to add a total of five numbers. We could write a loop. We could create five concurrent tasks that take each number, then report that number to another concurrent task that computes the total (bear with me, please… I’ve seen this happen). We could have a complex design pattern-based system that has each number trigger an observer, which places each one in a collection, which triggers an observer to add to the total, which triggers an observer every 10 seconds after the last input.
Yes, I know some of those are silly. I just made them up. But let’s be honest – what kinds of silly designs have you worked on before? I know I have written code that was more complex than it needed to be.
The key point of the addition of five numbers example is that it really should use a simple loop. Anything else is accidental complexity, neither necessary nor intentional. Why would we do that? There are many reasons. There may be some project constraints, a management directive, or simply a personal preference that steers our decision. However it happened, a simpler solution was possible, yet we did not take it.
Testing more complex solutions generally requires more complex tests. Sometimes, our team thinks it is not worth spending time on that. The code is complex, it will be hard to write tests for, and we think it works already. We think it is best not to touch it.
External systems cause problems in testing. Suppose our code talks to a third-party web service. It is hard to write a repeatable test for that. Our code consumes the external service and the data it sends to us is different each time. We cannot write a test and verify what the service sent us, as we do not know what the service should be sending to us. If we could replace that external service with some dummy service that we could control, then we could fix this problem easily. But if our code does not permit that, then we are stuck.
Entangled code is a further development of this. To write a test, we need to understand what that code does to an input condition: what do we expect the outputs to be? If we have a body of code that we simply do not understand, then we cannot write a test for it.
While these three problems are real, there is one underlying cause to them all: we allowed our software to get into this state. We could have arranged it to only use simple algorithms and data structures. We could have isolated external systems so that we could test the rest of the code without them. We could have modularized our code so that it was not overly entangled.
However, how can we persuade our teams with these ideas?
Reframing the relationship between good design and simple tests
All the preceding problems relate to making software that works yet does not follow good design practices. The most effective way to change this, in my experience, is pair programming – working together on the same piece of code and helping each other find these better design ideas. If pair programming is not an option, then code reviews also provide a checkpoint to introduce better designs. Pairing is better as by the time you get to code review, it can be too late to make major changes. It’s cheaper, better, and faster to prevent poor design than it is to correct it.
Managing legacy code without tests
We will encounter legacy code without tests that we need to maintain. Often, this code has grown to be quite unmanageable and ideally needs replacing, except that nobody knows what it does anymore. There may be no written documentation or specification to help us understand it. Whatever written material there is may be completely outdated and unhelpful. The original authors of the code may have moved on to a different team or different company.
The best advice here is to simply leave this code alone if possible. Sometimes though, we need to add features that require that code to be changed. Given that we have no existing tests, it is quite likely we will find that adding a new test is all but impossible. The code simply is not split up in a way that gives us access points to hang a test off.
In this case, we can use the Characterization Test technique. We can describe this in three steps:
- Run the legacy code, supplying it with every possible combination of inputs.
- Record all the outputs that result from each one of these input runs. This output is traditionally called the Golden Master.
- Write a Characterization Test that runs the code with all inputs again. Compare every output against the captured Golden Master. The test fails if any are different.
This automated test compares any changes that we have made to the code against what the original code did. This will guide us as we refactor the legacy code. We can use standard refactoring techniques combined with TDD. By preserving the defective outputs in the Golden Master, we ensure that we are purely refactoring in this step. We avoid the trap of restructuring the code at the same time as fixing the bugs. When bugs are present in the original code, we work in two distinct phases: first, refactor the code without changing observable behavior. Afterwards, fix the defects as a separate task. We never fix bugs and refactor together. The Characterization Test ensures we do not accidentally conflate the two tasks.
We’ve seen how TDD helps tackle accidental complexity and the difficulty of changing legacy code. Surely writing a test before production code means we need to know what the code looks like before we test it though? Let’s review this common objection next.
I don’t know what to test until I write the code
A great frustration for TDD learners is knowing what to test without having written the production code beforehand. This is another criticism that has merit. In this case, once we understand the issue that developers face, we can see that the solution is a technique we can apply to our workflow, not a reframing of thinking.
Understanding the difficulty of starting with testing
To an extent, it’s natural to think about how we implement code. It’s how we learn, after all. We write System.out.println("Hello, World!"); instead of thinking up some structure to place around the famous line. Small programs and utilities work just fine when we write them as linear code, similar to a shopping list of instructions.
We begin to face difficulties as programs get larger. We need help organizing the code into understandable chunks. These chunks need to be easy to understand. We want them to be self-documenting and it to be easy for us to know how to call them. The larger the code gets, the less interesting the insides of these chunks are, and the more important the external structure of these chunks – the outsides – becomes.
As an example, let’s say we are writing a TextEditorWidget class, and we want to check the spelling on the fly. We find a library with a SpellCheck class in it. We don’t care that much about how the SpellCheck class works. We only care about how we can use this class to check the spelling. We want to know how to create an object of that class, what methods we need to call to get it to do its spellchecking job, and how we can access the output.
This kind of thinking is the definition of software design – how components fit together. It is critical that we emphasize design as code bases grow if we want to maintain them. We use encapsulation to hide the details of data structures and algorithms inside our functions and classes. We provide a simple-to-use programming interface.
Overcoming the need to write production code first
TDD scaffolds design decisions. By writing the test before the production code, we are defining how we want the code under test to be created, called, and used. This helps us see very quickly how well our decisions are working out. If the test shows that creating our object is hard, that shows us that our design should simplify the creation step. The same applies if the object is difficult to use; we should simplify our programming interface as a result.
However, how do we cope with the times when we simply do not yet know what a reasonable design should be? This situation is common when we either use a new library, integrate with some new code from the rest of our team, or tackle a large user story.
To solve this, we use a spike, a short section of code that is sufficient to prove the shape of a design. We don’t aim for the cleanest code at this stage. We do not cover many edge cases or error conditions. We have the specific and limited goal of exploring a possible arrangement of objects and functions to make a credible design. As soon as we have that, we sketch out some notes on the design and then delete it. Now that we know what a reasonable design looks like, we are better placed to know what tests to write. We can now use normal TDD to drive our design.
Interestingly, when we start over in this way, we often end up driving out a better design than our spike. The feedback loop of TDD helps us spot new approaches and improvements.
We’ve seen how natural it is to want to start implementing code before tests, and how we can use TDD and spikes to create a better process. We make decisions at the last responsible moment – the latest possible time to decide before we are knowingly making an irreversible, inferior decision. When in doubt, we can learn more about the solution space by using a spike – a short piece of experimental code designed to learn from and then throw away.
Summary
In this chapter, we’ve learned six common myths that prevent teams from using TDD and discussed the right approach to reframing those conversations. TDD really deserves a much wider application in modern software development than it has now. It’s not that the techniques don’t work. TDD simply has an image problem, often among people who haven’t experienced its true power.
In the second part of this book, we will start to put the various rhythms and techniques of TDD into practice and build out a small web application. In the next chapter, we will start our TDD journey with the basics of writing a unit test with the Arrange-Act-Assert (AAA) pattern.
Questions and answers
- Why is it believed that TDD slows developers down?
When we don’t write a test, we save the time spent writing the test. What this fails to consider is the extra time costs of finding, reproducing, and fixing a defect in production.
- Does TDD eliminate human design contributions?
No. Quite the opposite. We still design our code using every design technique at our disposal. What TDD gives us is a fast feedback loop on whether our design choices have resulted in easy-to-use, correct code.
- Why doesn’t my project team use TDD?
What a fantastic question to ask them! Seriously. See whether any of their objections have been covered by this chapter. If so, you can gently lead the conversation using the ideas presented.
Further reading
More detail on the Characterization Test technique, where we capture the output of an existing software module exactly as-is, with a view to restructuring the code without changing any of its behavior. This is especially valuable in older code where the original requirements have become unclear, or that has evolved over the years to contain defects that other systems now rely on.
An in-depth look at what deciding at the last responsible moment means for software design.