
8
A Flexible Distributed Java Environment for Wireless PDA Architectures Based on DSP Technology
Gilbert Cabillic, Jean-Philippe Lesot, Frédéric Parain, Michel Banâtre, Valérie Issarny, Teresa Higuera, Gérard Chauvel, Serge Lasserre and Dominique D'Inverno
8.1 Introduction
Java offers several benefits that could facilitate the use of wireless Personal Digital Assistants (WPDAs) for the user. First, Java is portable, and that means that it is independent of the hardware platform it runs on, which is very important for reducing the cost of application development. As Java can be run anywhere, the development of applications can be done on a desktop without the need of a real hardware platform. Second, Java supports dynamic loading of applications and can significantly contribute to extend the use of WPDA.
Nevertheless, even if Java has a very good potential, one of its main drawbacks is the need of resources for running a Java application. By resources, we mean memory volume, execution time and energy consumption, which are the resources examined for embedded system trade-off conception. It is clear that the success of Java is conditioned by the availability of a Java execution environment that will manage efficiently these resources.
Our goal is to offer a Java execution environment for WPDA architectures that enables a good trade-off between performance, energy and memory usage. This chapter is composed of three different parts. As energy consumption is very important for WPDAs, we first pose the problem of Java and energy. We propose a classification of opcodes depending on energy features, and then, using a set of representative WPDA applications, we analyze what the Java opcodes are that will influence significantly the energy consumption. In the second part we present our approach to construct a Java execution environment that is based on a modular decomposition. Using modularity it is possible to specialize some parts of the Java Virtual Machine (Jvm) for one specific processor (for example to exploit low power features of the DSP). At last, as WPDA architectures are based on shared memory heterogeneous multiprocessors such as the Omap platform [25], we present in the third part our ongoing work carried out around a distributed Jvm1 in the context of multimedia applications. This distributed Jvm first permits the use of a DSP to a Java application and second exploits the energy consumption features of the DSP to minimize the overall energy consumption of the WPDA.
8.2 Java and Energy: Analyzing the Challenge
Let's first examine the energy aspects related to Java opcodes. Then let's give some approaches (hardware and software) to minimizing the energy consumption of opcodes.
8.2.1 Analysis of Java Opcodes
To understand the energetic problem connected with a Java execution, we describe in this section the hardware and software resources involved for a Java program, and in what way these resources affect the energy consumption. We propose a classification according to hardware and software components needed to realize them; the complexity of opcode's realization and energy consumption aspects.
Java code is composed of opcodes defined in the Java Virtual Machine Specification [14]. There are four different memory areas. The constant pool contains all the data constants needed to run the application (signature of methods, arithmetic or string constants, etc.). The object heap is the memory used by the Jvm to allocate objects. With each method there is associated a stack and a local variable memory space. For a method, local variables are the input parameters and the private data of the method. The stack is used to store variables needed to realize the opcodes (for example, an arithmetic addition opcode iadd implies the realization of two pops, an addition, and the push of the result on the stack), and to store the resulting parameters after an invocation of a method. Note that at the end and at the beginning of a method the stack is empty. At last, associated with the memory areas, a Pointer Counter (PC) identifies the next opcode to execute in the Java method.
8.2.1.1 Classification
There are 201 opcodes supported by a Jvm. We propose the following classification:
Arithmetic
Java offers three categories of arithmetic opcodes: integer arithmetic opcodes with low (integer, coded on 32 bits) and high (long, coded on 64 bits) representation, floating point arithmetic opcodes with simple precision (float, coded on 32 bits) and double precision (double, coded on 64 bits), and logic arithmetic (shift and back forwards, and elementary logic operations).
These opcodes involve the use of the processor's arithmetic unit and, if available, the floating-point unit coprocessor. All 64-bit based opcodes will take more energy than the others because more pop and push on the stack are required for the opcode realization. Moreover, floating point opcodes require more energy than for other arithmetic opcodes.
PC
This category concerns Java opcodes that are used to realize a conditional jump, a direct jump, or an execution of a subroutine. Other opcodes (tableswitch and lookupswitch) realize multiple conditional jumps. All these opcodes manipulate the PC of the method. The penalty on energy here is linked to the cache architecture of the processor. For example a jump can possibly generate a cache miss to load the new byte-code sequence the execution of which will take a lot of energy.
Stack
The opcodes related to the stack realize quite simple operations: popping out one (pop) or two stack entries (pop2); duplicating one (dup) or two entries (dup2) (note that it is possible to insert a value before duplicating the entries using dup*_x* opcodes); or swapping the two first data on the stack (swap). The energy connected to these opcodes depends on the memory transfers on the stack memory area.
Load-Store
We group in this category opcodes that make memory transfers between the stack, the local variables, the constant pool (by pushing a constant on the heap) and the object heap (by setting or getting a value for an object field, static or not). Opcodes between the stack and the local variables are very simple to implement and take less energy than other ones. Constant pool opcodes are also quite simple to realize, but require more tests to identify the constant value. The realization complexity for opcodes involving the stack and the object heap is complex, principally due on one hand to the huge number of tests needed to verify that the method has the right to modify or access a protected object field, and on the other hand due to the identification of the memory position of the object. It is important to see that this memory is not necessary in the cache, and solving the memory access can introduce an important penalty on the energy. At last, in Java, an array is a specific object and is allocated in the object heap. An array is composed of a fixed number either of object references, or either of basic Java types (boolean, byte, short, char, integer, long, float, and double). Every load-store of an array requires a dynamic born check of the array (to see if the index is valid). This is why array opcodes need more tests than other load-store heap opcodes.
Object Management
In this category, we group opcodes related to object management as: method invocation, creation of an object, throw of an exception, monitor management (used for mutual exclusion), and opcodes needed for type inclusion tests. All these opcodes require a lot of energy because they are very complex to realize and involve lots of Jvm steps (in fact, the invocation is the most complex). For example, the invocation of a method requires at least the creation of a local variable memory zone and a stack space, to identify the method and then to execute the method entry point.
8.2.2 Analyzing Application Behavior
The goal of our experiments is to understand precisely the opcodes that significantly influence the energy consumption. To achieve this goal, we first chose a set of representative applications that cover the range of use of a wireless PDA (multimedia and interactivity based applications):
- Mpeg I Player is a port of a free video Mpeg I stream player [9]. This application builds a graphic window, opens the video stream, and decodes the video stream until the end. We used an Mpeg I layer II video stream that generates 8 min of video in a 160 × 140 window.
- Wave Player is a wave riff file player. We built from scratch this application and we decomposed it into two parts: a sound player decodes the wave streams and generates the sound, and a video plug-in shows the frequency histogram of played sounds. We used a 16-bit stereo wave file that generates approximately 5 min of sound.
- Gif89a Player reads a gif89a stream and eternally loops until a user exit action. We built from scratch this application. Instead of decoding all the bitmap images included in a gif89a file once, we preferred to realize the decoding of each image on the fly (indexation and decompression) to introduce more computations. Moreover, this solution requires less memory than the first one (because we don't have to allocate an important number of bitmaps). We used a gif89 file that generates 78 successive 160 × 140 sized images, and we ran the application for 5 min.
- Jmpg123 Player is a Mpeg I sound player [11]. We adapted the original player to integrate it on the supported APIs of our Java Virtual machine. This player doesn't use graphics. For our results, we played an mp3 file at 128 Kb/s, for approximately 6 min.
- Mine Sweeper is a game using graphic APIs. This application characterized for us a general application using text and graphics management, and also user interactivity. We adapted the application from an existing one freely available [12]. We played for 30 min with this game.
We integrated these applications on our Jvm (see Section 8.3.2.5) and its supported APIs to be able to run them. Then we extended our Jvm to count for each Java opcode, the number of times it is executed by each application in order to have statistics on the opcode distribution. We used the categorization introduced in the previous section to present the results. Moreover, to understand the application behavior better, we will present and analyze in detail a sub-distribution for each category.
To precisely evaluate which opcodes influence the energy, we need a real estimation of energy consumption for each opcode to compare the several categories.
8.2.2.1 Global Distribution
Table 8.1 presents the results for the global opcode distribution. As we can see, load-store takes the major part of the execution (63.93% for all applications). It is important to note that this number is high for all the applications. Due to the complexity of decoding, Jmpg123 and Mpeg I players have the most important use of arithmetic opcodes. We also can see, for these two applications, that the use of stack opcodes is important due to the arithmetic algorithm used for the decoding. Wave and Gif89a players and Mine Sweeper, have the highest proportion of object opcodes, due to their fine-grained class decomposition. At last, Mine Sweeper which is a very user interacted application implies the most important use of PC opcodes. That is due to the graphic use which generates a huge number of conditional jumps.
Table 8.1 Global distribution of opcodes

8.2.2.2 Sub-Distribution Analysis
Arithmetic
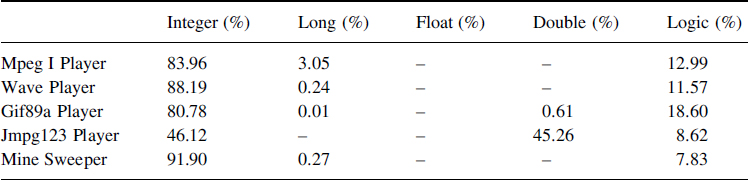
Table 8.2 presents a detailed distribution of arithmetic opcodes. First, only Jmpg123 uses intensively floating arithmetic double precision. It is important because floating point arithmetic needs more energy than integer or logic arithmetic. After analyzing the source code of Jmpg123, the decoder algorithm uses a lot of floating points. We think that it is possible to avoid the use of floating points for the decoding using a long representation in order to have the required precision, but the application's code has to be transformed. Gif89, Wave and Mpeg I Player use a lot of logic opcodes. In fact, these applications use lots of ‘or’ and ‘and’ operations to manage the screen bitmaps.
Table 8.2 Distribution of arithmetic opcodes
PC
Table 8.3 presents the distribution of PC opcodes. Numbers show that the conditional jump opcodes are the most executed. We can also see that no subroutines are used. So, for this category, the energetic optimization of conditional jump is important.
Stack
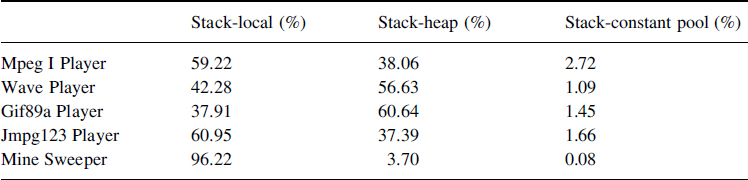
Table 8.4 presents the distribution of stack based opcodes. We can remark that the dup is the most numbered except for Jmpg123 Player where the use of double precision floats gives a huge number of dup2 (used to duplicate one double precision value on the stack). Moreover, no pop2, swap, tableswitch or lookupswitch are done (column 5). At last, Mine Sweeper makes a lot of pop opcodes. This is due to the unused return parameters of graphic API methods. As these parameters are on the stack, pop opcodes are generated to release them.
Table 8.3 Distribution of PC manipulation opcodes

Table 8.4 Distribution of stack opcodes
Load-Store
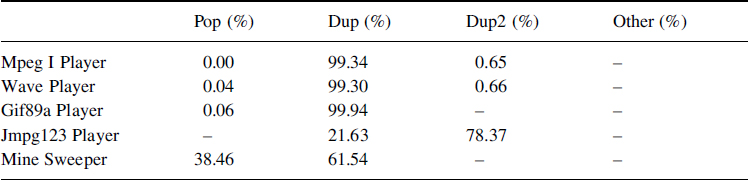
As we said previously, this category represent opcodes making memory transfers between the method's stack and the method's local variables, between the method's stack and the object heap, and between the constant pool and the stack. Table 8.5 presents the global distribution for these three sub-categories. Results indicate that Mpeg layers and Mine Sweeper use more local variable data than object data. For the Wave and Gif89a players, as we already mentioned previously, when we designed the applications, we decomposed them into many classes. This is why, according to the object decomposition, the number of accesses to the object heap is higher than the other applications. For Mpeg I Player, accesses to the constant pool corresponds to many constants.
Table 8.5 Distribution between stack-local and stack-heap
We calculated the distribution for each sub-category according to read (load) and write (store) opcodes. Moreover in Java, some opcode exists to push constants that are intensively used (for example, the opcode iconst_1 puts the integer value 1 on the stack). These opcodes are simple and require less energy than other load-store opcodes. This is why we also distinguish them in the distribution.
Table 8.6 Detailed distribution of load-store between stack and local variables
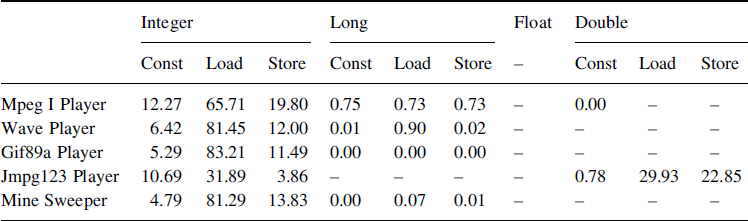
Table 8.6 presents the results for the load-store between the stack and the local variables of methods. Loads are more important that store opcodes.
Results of the memory transfers between the stack and the heap are shown in Table 8.7. We can see, except for Mine Sweeper, that applications significantly use arrays. Moreover, as shown in Table 8.6, load operations are the most important. So, the load opcodes are going to drive the overall energetic consumption. For Jmpg123, field opcodes are important and are used to access data constants.
Table 8.7 Detailed distribution of load-store between stack and object heap

Objects
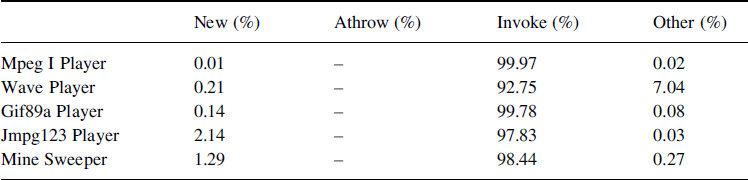
Table 8.8 presents evaluation done for object opcodes. Results show that the invocation opcode should influence significantly (97.75% for all applications) the energy consumption. Table 8.8 shows that no athrow opcode occur (exception mechanism) and few new opcodes occur. It is clear that depending on the way the applications are coded, the proportion of these opcodes could be more important, but the invocation will be that of the majority executed opcode.
8.2.3 Analysis
We have shown that load-store opcodes, are the most executed opcodes, which is counter intuitive. Arithmetic opcodes are next.
Table 8.8 Distribution of objects opcodes
A real evaluation of the energy consumption for each opcode is needed to totally understand the problem. We group into three categories the approaches that could bring minimization of energy consumption in the context of Java:
8.2.3.1 Java Compilers
Existing compilation techniques could be adapted to Java compilers to minimize the energy consumption (by the use of less greedy energetic opcodes). An extension to these techniques could also permit the optimization of the number of load-store opcodes, or minimize the number of invocations. Moreover, the transformation of a floating-point based Java code into an integer based Java code will minimize the energy consumption. At last, the use of the switch jump opcode has to be preferred to a sequence of several conditional jumps opcode.
8.2.3.2 Opcode Realization
The most important work has to be done on Jvm opcode realization. An important Jvm flexibility is required in order to explore and quantify the energy consumption gain according to a specific energetic optimization. For example, the use of compilation techniques [1,2] that have energetic optimization features could improve the overall energy consumption of the Jvm. A careful management of memory areas [3] will also permit the optimization of the energy consumption of load-store opcodes. For example, the use of locked cache line techniques or private memories could bring a significant improvement of energy consumption by minimizing the number of electric signals needed to access the data. Moreover, some processor features need to be exploited. For example, for a DSP processor [10], the Jvm could create for a method the local variable memory area and the stack inside the local RAM of the DSP. In this way, accesses are going to be less greedy in energy consumption, but also more efficient due to the DSP possibility to access simultaneously different memory areas. Just-in-time compilers could generate during the execution a binary code requiring less energy. For example, on object opcodes, the amount of invocation opcodes can be reduced by in-lining of methods [16]. Nevertheless, at this moment these compilers generate an important memory volume making their use inappropriate in the WPDA context. Another way to improve performance is to accelerate type inclusion tests [8]. And last, but not least, hardware Java co-processors [5,6,7] could also permit the reduction of the energy for arithmetic opcodes. Moreover, due to the number of load-store opcodes, the memory hierarchy architecture should also influence the energy consumption.
8.2.3.3 Operating System
As the Jvm relies on an operating system (thread management, memory allocation and network), an energetic optimization of the operating system is complementary to these previous works. A power analysis of a real-time operating systems, as presented in [4] will permit the system to adapt the way the Jvm uses the operating system to decrease the energy consumption.
8.3 A Modular Java Virtual Machine
A flexible Java environment is required in order to work on the trade-off between memory, energy and performance. In order to be flexible, we designed a modular Java environment named Scratchy. Using modularity, it is possible to specialize some parts of the Jvm for one specific processor (for example to exploit low power features of the DSP). Moreover, as WPDA architecture orientation is to be shared memory heterogeneous multiprocessor based [25] support for managing the heterogeneity of data allocation schemes has been introduced.
In this section we first describe the several Java environment implantation possibilities; we then introduce our modular methodology and development environment; and then we present Scratchy, our modular Jvm.
8.3.1 Java Implantation Possibilities
8.3.1.1 Hardware Dependent Implantation
A Jvm permits the total abstraction of the embedded system from the application programmer's point of view. Nevertheless, for the Jvm developer, the good trade-off is critical because performance relies principally on the Jvm. For the developer, an embedded system is composed of, among other things, one or several core processors, memory architecture and some energy awareness features. This section characterizes these three categories and gives one simple example of the implementation of a Jvm part.
Core Processor
Each processor defines its own data representation capabilities from 8-bit up to 128-bit. To be efficient, the Jvm must realize a bytecode manipulation adapted to the data representation. Note that Ref. [13] reports that 5 billion out of 8 billion manufactured in 2000 were 8-bit microprocessors. The availability of a floating-point support (32- or 64-bit) in a processor could also be used by the Jvm to treat the float or double Java types. Regarding the available registers, the use of a subset of those can be exploited to optimize Java stack performance. One register can be used to represent the Java stack pointer. Memory alignment (constant, proportional to size with or without threshold, etc.) and memory access cost have to be taken into account to efficiently arrange object fields. In a multiprocessor case, homogeneous or heterogeneous data representation (little/big endian), data size and alignment have to be managed to correctly share Java objects or internal Jvm data structures between processors.
Memory
The diversity of memories (RAM, DRAM, flash, local RAM, etc.) has to be considered depending on their performance and their sizes. For example, local variable sets can be stored in a local RAM, and class files in flash. Finally, on a shared memory multiprocessor, the Jvm must manage homogeneous or heterogeneous address space to correctly share Java objects or Jvm internal structures. Moreover, regarding the cache architecture (level one or two, type of flush, etc.), it must be used to implement Java synchronized and volatile attributes of an object field.
Energy
The use by the Jvm of energetic aware instruction set for the realization of the bytecode to minimize system energy consumption is a possibility. As well, considering the number of memory transfers is a big deal for the Jvm, as mentioned in the first part of this chapter.
8.3.1.2 Example
To illustrate the several possibilities of implementation, we describe in this section some experiments done with the interpreter engine of our Jvm on two different processors, Intel Pentium II and TI TMS320C55x DSP. To understand the following experiments we briefly describe (i) hardware features and tool chain characteristics of the TMS320C55x, (ii) the interpreter engine role, and (iii) two different possible implementations.
TI DSP TMS320C55x
The TMS320C55x family of Texas Instruments is a low power DSP. Its data space is only word – addressable. Its tool chain has an ANSI C compiler, an assembler and a linker. The C compiler has uncommon data types like char of 16-bit, and function pointer of 24-bit. The reader should refer to Ref. [10] for more details.
The Interpreter Engine
The interpreter engine of a Jvm is in charge of decoding the bytecode to call the appropriate function to perform the opcode operation. To implement the engine, the first solution is to use a classical loop to fetch one opcode, to decode it with a C switch statement (or similar statements in other languages) and to branch to the right piece of code. The second solution, called threaded code [17], is to translate, before execution, the original bytecode by a sequence of addresses which point directly to opcode implementations. At the end of each opcode implementation, a branch to the next address is performed and so on. This solution avoids the decoding phase of the switch solution but causes an expansion of code.
Experiments
We carried out experiments on these two solutions. We first coded a switched interpreter with ANSI C, and a threaded interpreter with gnu C (this implementation requires the gnu C's label as a values feature). We experimented with both versions on the 32-bit Intel Pentium II. We then compiled the switched interpreter on the TI DSP TMS320C55x. Due to the absence of gnu C features on the TI tool chain, we added assembler statements to enable the threaded interpreter to thus become a TMS320C55x specific one.
Table 8.9 shows the number of cycles used to execute one loop of a Java class-file to compute Fibonacci numbers and the number of memory bytes to store the bytecode (translated or not).
On the Intel Pentium II, the threaded interpreter saves 19% of cycles, whereas on the TI DSP TMS320C55x, it saves 62% of cycles. The difference of speed-up due to the same optimization is very important: more than three times on the TI DSP TMS320C55x.
Table 8.9 Example of different interpreter implementation
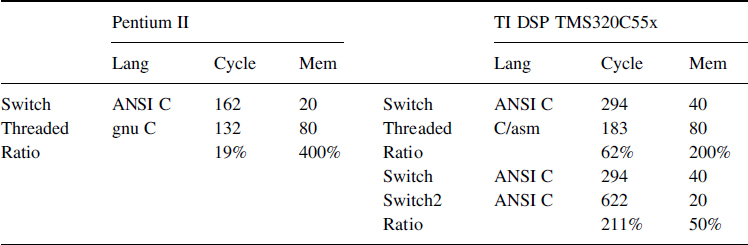
On the other hand, on the Pentium II, there is a memory overhead of 400% between the threaded motor and the switched interpreter. This is because of the representation of one opcode by 1 byte in the first case and by one pointer in the last case. On the TI DSP TMS320C55x, the memory overhead is only 200% because of the representation of one opcode by 2 bytes (due to the 16-bit char type). Thus, we added a modified switched interpreter specific to the TMS320C55x (“switch 2”) without memory overhead. It takes the high or low byte of one word depending of the program counter parity. This interpreter takes more than double the cycles of a classic switched one.
In conclusion, for this simple example, we obtained four interpreter implementations, two processor specifics, one C compiler specific and one generic. All have different performance and memory expansion behavior. This illustrates the difficulties involved in reaching the desired trade-off especially with respect to complex software like Jvm.
8.3.2 Approach: a Modular Java Environment
8.3.2.1 Objective: Resource Management Tradeoff Study
We believe that for one WPDA, a specific resource management trade-off has to be found to deal with the user choice. We consider that the trade-off can be abstracted through three criteria: Mem for memory allocation size, Cpu for efficiency of treatments and Energy for energy consumption. The less these criteria are, more optimum is the associated resource management. For example, a small Mem means that the memory is compacted. If Cpu is high that means that the Java environment is inefficient and if Energy is small that the Java environment takes care of energy consumption.
It is clear that, depending on the architecture of a WPDA, this trade-off has to be changed depending on the user needs. For example, if the user prefers to have an efficient Java environment, the trade-off has to minimize Cpu criterion, without taking care of Energy and Mem resources. As all these criteria depend on the architecture features, we believe that to one dedicated WPDA architecture is connected several strategies of trade-off that can be proposed to the user.
But focusing on this trade-off on a monolithic Java programmed environment is difficult and introduces an expensive cost. Due to the huge compactness of source code, it's very difficult to change at many levels the way to manage the hardware resources without rewriting the Jvm from scratch for each platform.
Our approach to reach the possibility to adapt our resource management for a WPDAs Java environment consists of splitting up the source code of the Java environment into software independent modules. In this way, we want to break with problems introduced by a monolithic design. Like this, it is possible to work on a particular module to obtain one trade-off between performance, memory and energy for that module by designing new resource management strategies. At the end, it is easier to reach the trade-off for all modules (so for the complete Jvm).
In this way, the usage of a resource can be redesign with a minimal cost of time. Moreover, the resource management strategies can be more open than a monolithic approach because the resource management in one module is isolated, but contributes to the global trade-off. We also believe that the experimentation of strategies is necessary to design new ones, compare with existing ones and choose the best one. Modularity is a way to realize these choices.
8.3.2.2 Modularity Related Works
Object-based solutions like corba [20] or com [18] are not suitable because the linking is too dynamic and introduces a high overhead for an embedded software. To reach the desired trade-off, it is necessary to introduce the minimum overhead in terms of Cpu, memory and energy.
Introduction of modularity using compilers like a generic package in Modula-3 [21] or Ada95 [19] is not a practical solution because it is uncommon to have compilers other than C or native assembler with embedded hardware. It is also uncommon to have source code of the compiler to add features.
The approach taken by Knit [24] for use with the OSKit is very interesting and quite close to our solution. It is a tool, with its own language to describe linking requirements. But it is too limited for our goals because it only addresses problems at the linking level, so Knit manages only function calls, and not data types. Management of data type is useful to optimize memory consumption and data access performance especially on shared memory multiprocessor hardware.
8.3.2.3 Scratchy Development Environment Principle
We designed the “Scratchy Development Environment” (SDE) to achieve modularity for a Java environment. This tool is designed to introduce no time or memory overhead on module merging and to be the most language and compiler independent as possible. SDE takes four inputs:
- A global specification file describes services (functions) and data types by using an Interface Definition Language (IDL);
- A set of modules implements services and data types in one of the supported language mappings;
- An implementation file inside each module describes the link between specification and implementation;
- Alignment descriptions indicate alignment constrains with their respective access cost for each processor in the targeted hardware.
SDE chooses a subset of modules, generates stubs for services, sets structures of data types, generates functions to dynamically allocate and access data types, etc. SDE works at source level, so it is the responsibility of compilers or preprocessors (through in-lining for example) to optimize a source which has potentially no overhead.
8.3.2.4 Modularity Perspectives
A modular environment classically allows replacing, completing, composing and intercepting functions. On top of that, for a specific hardware, SDE could be used to compensate the lack of features, to optimize an implementation or to exploit a hardware support:
- There is no direct use of compiler basic types. It is possible to easily implement missing types (e.g. 64-bit integer support);
- Structures are not managed by the compiler but by SDE. Therefore, it is possible to generate well-aligned structures compatible at the same time with several core processors as well as rearrange structure organization to minimize memory consumption. It is also possible to manage the trade-off between CPU, memory and energy. For example, due to the high frequency of object structure access, the access cost to objects is very important to optimize;
- SDE provides developers with mechanisms to access data. Therefore, a module in SDE could intercept data access to convert data between heterogeneous processors, and heterogeneous address space for example.
8.3.2.5 Scratchy Modular Java Virtual Machine
Scratchy is our Jvm that has been designed using the modular approach. To achieve the modular design, we wrote Scratchy totally “from scratch”. It is composed of 23 independent modules.
From the application's point of view, we fully support CLDC [15] specification. However, Scratchy is closer to CDC than CLDC because we also support floating-point operations and we want to authorize classloader execution to permit the downloading of applications through the network.
Most modules are written in ANSI C compiler, few with the gnu C features and others with TI DSP TMS320C55x assembler statements. We have also designed some module implementations with ARM/DSP assembler language and with DSP optimized C compiler (to increase the efficiency of bytecode execution).
Considering the operating system, we designed a module named “middleware” to make the link with an operating system. This module supports a Posix general operating system (Linux, Windows Professional/98/2000) but also a real-time operating system with Posix compatibility (VxWorks).
8.3.3 Comparison with Existing Java Environments
In this section, we compare our approach to two different Jvms designed for embedded systems: JWorks from WindRiver Systems, and Kvm, the Jvm of J2m from Sun microsystems.
- JWorks is a port of Personal Java Jvm distribution on the VxWorks real-time operating system. Because VxWorks is designed to integrate a large range of hardware platforms and because JWorks is (from the operating system's point of view) an application respecting VxWorks APIs, JWorks could be executed on a large range of hardware platforms. Nevertheless, the integration of JWorks on a new embedded system is limited to VxWorks porting, without any reconsideration of the Jvm. A Jvm must take care of many different aspects. That way, JWorks cannot achieve the desired trade-off explained previously whereas Scratchy does, thanks to modularity.
- J2me is a Sun Java platform for small embedded devices. Kvm is one possible Jvm of J2me. It supports 16- and 32-bit cisc and risc processors, engenders a small memory footprint and keeps the code in an area of 128 KB. It is written for an ANSI C Compiler, with the size of basic types well defined (e.g. char on 8-bit, long on 32-bit). Regarding data alignment, an optional alignment can only be obtained for 64-bit data. The C compiler handles other alignments. Moreover, there is no possibility of managing a heterogeneous multiprocessor without rewriting C structures (due to data representation conversion). In fact, Kvm is one of six Jvms written by Sun more or less from scratch: HotSpot, Standard Jvm, Kvm, Cvm, ExactVm and Cardvm (it is a Java Card Vm but it indubitably has common mechanisms with a Jvm). That proves that it is impossible to tune a trade-off between CPU, memory and energy without rewriting all the parts of the Jvm.
8.4 Ongoing Work on Scratchy
Our main ongoing work is to design a Distributed Jvm (DJVM) in order to integrate an Omap shared memory heterogeneous multiprocessor [25]. Scratchy Jvm (presented in Section 8.3.2.5) is the base of our DJVM software implementation. Figure 8.1 presents an overview of our DJVM. The main objective of this approach is first to permit the use of the DSP as another processor to execute Java code and secondly to exploit the DSP low power features to minimize the overall energy consumption for Java applications. Using our DJVM it is the way to open the use of the DSP that is at this moment used for very specific jobs.
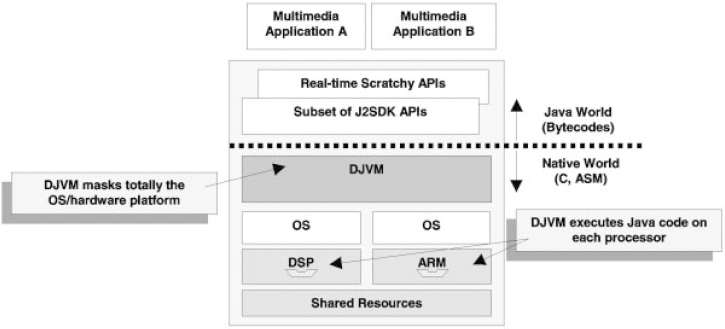
Figure 8.1 Distributed JVM overview
We briefly describe ongoing works we are carrying out on the DJVM in the context of multimedia applications:
8.4.1 Multi-Application Management
As a WPDA has a small memory, we introduce in the DJVM a support to execute several applications at the same time. In this way, only one Jvm process is necessary and the memory needed for the execution of Java applications can be reduced.
8.4.2 Managing the Processor's Heterogeneity and Architecture
We want each object to be shared by all the processors through the shared memory and accessed through the putField and getField opcodes. This is why we are designing modules to realize on the fly data representation conversion to take into account the plurality of data representations. Note that the heterogeneous allocation scheme of one object according to the specific object size of each processor is solved using our SDE development environment (see Section 8.3.2.3). At last, multiprocessor architectures dispose of multiple ways to allocate memory and to communicate between the processors. It is also an ongoing work to choose the best strategy that will result in a good performance.
8.4.3 Distribution of Tasks and Management of Soft Real-Time Constraints
Regarding the execution, our basic approach is to design a distribution rule that will transparently distribute the tasks among the multiprocessor. We consider a multimedia application as a soft real-time application (application deadlines are not guarantied but are just indicators for the scheduler). Thus, the distribution rules will take into account the efficiency of each processor to distribute the treatments in the best way. Moreover, a Java environment needs to provide a garbage collection process that will identify and free the unused objects. Due to soft real-time constraints of applications, the garbage collector strategy has to be designed in such a way that it does not disturb the application's execution [22].
8.4.4 Energy Management
Many works have been done on energy consumption reduction. We introduce [23] a new way to manage the energy in the context of a heterogeneous shared memory multiprocessor. The basic idea is to distribute treatments according to their respective energy consumption. In the case of the OMAP™ platform, the use of the DSP results in a decrease in the energy consumption for all DSP-based treatments.
8.5 Conclusion
In this chapter we first presented the energy problem connected with Java in the context of WPDAs. We showed by experimentation made on a representative set of applications, that load-store opcodes and then arithmetic opcodes have the most important proportion (81.88% for all these opcodes). We secondly described our methodology to design and implement a Jvm on WPDA architectures. We presented our Jvm named Scratchy, which follows our modular methodology. This methodology is based on modularity specification and implementation. The flexibility introduced by modularity opens the possibilities of design, with regard to one module without reconsidering the implementation of all the other ones. It permits also the exploitation of specific features of processors such as the low-power instruction set of a DSP. Lastly, we presented our ongoing works on the distributed Jvm and presented some of our future extensions that are going to be integrated soon in Scratchy Distributed Java Virtual Machine.
To conclude, we think that achieving energy, memory and performance trade-off is a real challenge for Java on WPDA architectures. With a strong cooperation between hardware and software through a flexible Jvm, this challenge could be solved.
References
[1] Simunic, T., Benini, L. and De Micheli, G., ‘Energy-Efficient Design of Battery-Powered Embedded Systems’, In: Proceedings of International Symposium on Low Power Electronics and Design, 1999.
[2] Simunic, T., Benini, L. and De Micheli, G., ‘Cycle-Accurate Emulation of Energy Consumption in Embedded Systems’, In: Proceedings of the Design Automation Conference, 1999, pp. 867–872.
[3] Da Silva, J.L., Catthoor, F., Verkest, D. and De Man, H., ‘Power Exploration for Dynamic Data Types Through Virtual Memory Management Refinement’, In: Proceedings of International Symposium on Low Power Electronics and Design, 1998.
[4] Dick, R.P., Lakshminarayana, G., Raghunathan, A. and Hja, N.K., ‘Power Analysis of Embedded Operating Systems’, In: Proceedings of Design Automation Conference, 2000.
[5] Shiffman, H., ‘JSTAR: Practical Java Acceleration For Information Appliances’, Technical White Paper, JEDI Technologies, October 2000.
[6] Ajile, ‘Overview of Ajile Java Processors’, Technical White Paper, Ajile (http://www.ajile.com), 2000.
[7] Imsys, ‘Overview of Cjip Processor’, Technical White Paper, Imsys (http://www.imsys.se), 2001.
[8] Vitek, J., Horspool, R. and Krall, A., ‘Efficient Type Inclusion Test’. In: Proceedings of ACM Conference on Object Oriented Programming Systems, Languages and Applications (OOPSLA), 1997.
[9] Anders, J., Mpeg I Java Video Decoder. TU-Chemnitz, http://www.rnvs.informatik.tu/chemnitz.de/~jan/MPEG/MPEG_Play.html, 2000.
[10] Texas Instruments, TMS320C5x User's Guide. http://www-s.ti.com/sc/psheets/spru056d/spru056d.pdf, 2000.
[11] Hipp, M., Jmpg123: a Java Mpeg I Layer III. OODesign, http://www.mpg123.org/, 2000.
[12] Bialach, R., A Mine Sweeper Java Game, Knowledge Grove Inc., http://www.microjava.com/, 2000.
[13] Kopetz, H., ‘Fundamental R&D Issues in Real-Time Distributed Computing’, In: Proceedings of the 3rd IEEE International Symposium on Object-oriented Real-time Distributed Computing (ISORC), 2000.
[14] Sun Microsystems, The Java Virtual Machine Specification, Second Edition, 1999.
[15] Sun Microsystems, CLDC and the K Virtual Machine (KVM), http://java.sun.com/products/cldc/, 2000.
[16] Sun Microsystems, ‘The Java Hotspot Performance Engine Architecture’, White Paper, 1999.
[17] Bell, J.R., ‘Threaded Code’, Communication of the ACM 16(6), 1973, pp. 370–372.
[18] Microsoft Corporation and Digital Equipment Corporation, Component Object Model Specification, October 1995.
[19] International Organization for Standardization, The Language, Ada 95 Reference Manual, January 1995.
[20] Object Management Group, The Common Object Request Broker: Architecture and Specification, Revision 2.3, June 1999.
[21] Harbison, S.P., Modula-3, Prentice Hall, Englewood Cliffs, NJ, 1991.
[22] Higuera, T., Issarny, V., Cabillic, G., Parain, F., Lesot, J.P. and Banâtre, M., ‘-based Memory Management for Real-time Java’, In: Proceedings of the 4th IEEE International Symposium on Object-oriented Real-time Distributed Computing (ISORC), 2001.
[23] Parain, F., Cabillic, G., Lesot, J.P., Higuera, T., Issarny, V., Banâtre, M., ‘Increasing Appliance Autonomy using Energy-Aware Scheduling of Java Multimedia Applications’, In: Proceedings of the 9th ACM SIGOPS European Workshop – Beyond the PC: New Challenges, 2000.
[24] Reid, A., Flatt, M., Soller, L., Lepreau, J. and Eide, E., ‘Knit: Component Composition for System Software’. In: Proceedings of the 4th Symposium on Operating Systems Design and Implementation (OSDI), San Diego, CA, October 2000, pp. 347–360.
[25] http://www.ti.com/sc/docs/apps/omap/overview.htm
1 See http://www.irisa.fr/solidor/work/scracthy.html for more details.