
10
Speech Recognition Solutions for Wireless Devices
10.1 Introduction
Access to wireless data services such as e-mail, news, stock quotes, flight schedules, weather forecasts, etc. is already a reality for cellular phone and pager users. However, the user interface of these services leaves much to be desired. Users still have to navigate menus with scroll buttons or “type in” information using a small keypad. Further, users have to put up with small, hard-to-read phone/pager displays to get the results of their information access. Not only is this inconvenient, but also can be downright hazardous if one has to take their eyes off the road while driving. As far as input goes, speaking the information (e.g. menu choices, company names or flight numbers) is a hands-free and eyes-free operation and would be much more convenient, especially if the user is driving. Similarly, listening to the information (spoken back) is a much better option than having to read it. In other words, speech is a much safer and natural input/output modality for interacting with wireless phones or other handheld devices.
For the past few years, Texas Instruments has been focusing on the development of DSP based speech recognition solutions designed for the wireless platform. In this chapter, we describe our DSP based speech recognition technology and highlight the important features of some of our speech-enabled system prototypes, developed specifically for wireless phones and other handheld devices.
10.2 DSP Based Speech Recognition Technology
Continuous speech recognition is a resource-intensive algorithm. For example, commercial dictation software requires more than 100 MB of disk space for installation and 32 MB for execution. A typical embedded system, however, has constraints of low power, small memory size and little to no disk storage. Therefore, speech recognition algorithms designed for embedded systems (such as wireless phones and other handheld devices) need to minimize resource usage (memory, CPU, battery life) while providing acceptable recognition performance.
10.2.1 Problem: Handling Dynamic Vocabulary
DSPs, by design, are well suited for intensive numerical computations that are characteristic of signal processing algorithms (e.g. FFT, log-likelihood computation). This fact, coupled with their low-power consumption, makes them ideal candidates for running embedded speech recognition systems. For an application where the number of recognition contexts is limited and vocabulary is known in advance, different sets of models can be pre-compiled and stored in inexpensive flash memory or ROM. The recognizer can then load different models as needed. In this scenario, a recognizer running just on the DSP is sufficient. It is even possible to use the recognizer to support several applications with known vocabularies by simply pre-compiling and storing their respective models, and swapping them as the application changes. However, if the vocabulary is unknown or there are too many recognition contexts, pre-compiling and storing models might not be efficient or even feasible. For example, there are an increasing number of handheld devices that support web browsing. In order to facilitate voice-activated web browsing, the speech recognition system must dynamically create recognition models from the text extracted from each web page. Even though the vocabulary for each page might be small enough for a DSP based speech recognizer, the number of recognition contexts is potentially unlimited. Another example is speech-enabled stock quote retrieval. Dynamic portfolio updates require new recognition models to be generated on the fly. Although speaker-dependent enrollment (where the person trains the system with a few exemplars of each new word) can be used to add and delete models when necessary, it is a tedious process and a turn-off for most users. It would be more efficient (and user-friendly) if the speech recognizer could automatically create models for new words. Such dynamic vocabulary changes require an online pronunciation dictionary and the entire database of phonetic model acoustic vectors for a language. For English, a typical dictionary contains tens of thousands of entries, and thousands of acoustic vectors are needed to achieve adequate recognition accuracy. Since a 16-bit DSP does not provide such a large amount of storage, a 32-bit General-Purpose Processor (GPP) is required. The grammar algorithms, dictionary look-up, and acoustic model construction are handled by the GPP, while the DSP concentrates on the signal processing and recognition search.
10.2.2 Solution: DSP-GPP Split
Our target platform is a 16-bit fixed-point DSP (e.g. TI TMS320C54x or TMS320C55x DSPs) and a 32-bit GPP (e.g. ARM™). These two-chip architectures are very popular for 3G wireless and other handheld devices. Texas Instruments' OMAP™ platform is an excellent example [1]. To implement a dynamic vocabulary speech recognizer, the computation-intensive, small-footprint recognizer engine runs on the DSP; and the computation non-intensive, larger footprint grammar, dictionary, and acoustic model components reside on the GPP. The recognition models are prepared on the GPP and transferred to the DSP; the interaction among the application, model generation, and recognition modules is minimal. The result is a speech recognition server implemented in a DSP-GPP embedded system. The recognition server can dynamically create flexible vocabularies to suit different recognition contexts, giving the perception of an unlimited vocabulary system. This design breaks down the barrier between dynamic vocabulary speech recognition and a low cost platform.
10.3 Overview of Texas Instruments DSP Based Speech Recognizers
Before we launch into a description of our portfolio of speech recognizers, it is pertinent to outline the different recognition algorithms supported by them and to discuss, in some detail, the one key ingredient in the development of a good speech recognizer: speech training data.
10.3.1 Speech Recognition Algorithms Supported
Some of our recognizers can handle more than one recognition algorithm. The recognition algorithms covered include:
- Speaker-Independent (SI) isolated digit recognition. An SI speech recognizer does not need to be retrained on new speakers. Isolated digits imply that the speaker inserts pauses between the individual digits.
- Speaker-Dependent (SD) name dialing. An SD speech recognizer requires a new user to train it by providing samples of his/her voice. Once trained, the recognizer will work only on that person's voice. For an application like name dialing, where you do not need others to access a person's call list, an SD system is ideal. A new user goes through an enrollment process (training the SD recognizer) after which the recognizer works best only on that user's voice.
- SI continuous speech recognition. Continuous speech implies no forced pauses between words.
- Speaker and noise adaptation to improve SI recognition performance. Adapting SI models to individual speakers and to the background noise significantly improves recognition performance.
- Speaker recognition – useful for security purposes as well as improving speech recognition (if the system can identify the speaker automatically, it can use speech models specific to the speaker).
10.3.2 Speech Databases Used
The speech databases used to train a speech recognizer play a crucial role in its performance and applicability for a given task and operating environment. For example, a recognizer trained on clean speech in a quiet sound room will not perform well in noisy in-car conditions. Similarly, a recognizer trained on just one or a few ( < 5) speakers will not generalize well to speech from new speakers, as it has not been exposed to enough speaker variability. Our speech recognizers were trained on speech from the Wall Street Journal [2], TIDIGITS [3] and TI-WAVES databases. The Wall Street Journal database was used only for training our clean speech models. The TIDIGITS and TI-WAVES corpora were collected and developed in-house and merit further description.
10.3.2.1 TIDIGITS
The TIDIGITS database is a publicly available, clean speech database of 17,323 utterances from 225 speakers (111 male, 114 female), collected by TI for research in digit recognition [3]. The utterances consist of 1–5- and 7-digit strings recorded in a sound room under quiet conditions. The training set consists of 8623 utterances from 112 speakers (55 male; 57 female), while the test set consists of 8700 utterances from a different set of 113 speakers (56 male; 57 female). The fact that the training and test set speakers do not overlap allows us to do speaker-independent recognition experiments. This database provides a good resource for testing digit recognition performance on clean speech.
10.3.2.2 TI-WAVES
The TI-WAVES database is an internal TI database consisting of digit-strings, commands and names from 20 speakers (ten male, ten female). The utterances were recorded under three different noise conditions in a mid-size American sedan, using both a handheld and a hands-free (visor-mounted, noise-canceling) microphone. Therefore, each utterance in the database is effectively recorded under six different conditions. The three noise conditions were (i) parked (ii) stop-and-go traffic, and (iii) highway traffic. For each condition, the windows of the car were all closed and there was no fan or radio noise. However, the highway traffic condition generated considerable road and wind noise, making it the most challenging portion of the database. Table 10.1 lists the Signal-To-Noise Ratio (SNR) of the utterances for the different conditions.
The digit utterances consisted of 4-, 7- and 10-digit strings, the commands were 40 call and list management commands (e.g. “return call”, “cancel”, “review directory”) and the names were chosen from a set of 1325 first and last name pairs. Each speaker spoke 50 first and last names. Of these, ten name pairs were common across all speakers, while 40 name pairs were unique to each speaker. This database provides an excellent resource to train and test speech recognition algorithms designed for real-world noise conditions. The reader is directed to Refs. [9] and [17] for details on recent recognition experiments with the TI-WAVES database.
Table 10.1 SNR (in dB) for the TI-WAVES speech database

10.3.3 Speech Recognition Portfolio
Texas Instruments has developed three DSP based recognizers. These recognizers were designed with different applications in mind and therefore incorporate different sets of cost-performance trade-offs. We present recognition results on several different tasks to compare and contrast the recognizers.
10.3.3.1 Min_HMM
Min_HMM (short for MINimal Hidden Markov Model) is the generic name for a family of simple speech recognizers that have been implemented on multiple DSP platforms. Min_HMM recognizers are isolated word recognizers, using low amounts of program and data memory space with modest CPU requirements on fixed-point DSPs.
Some of the ideas incorporated in Min_HMM to minimize resources include:
- No traceback capability, combined with efficient processing, so that scoring memory is fixed at just one 16-bit word for each state of each model.
- Fixed transitions and probabilities, incorporated in the algorithm instead of the data structures.
- Ten principal components of LPC based filter-bank values used for acoustic Euclidean distance.
- Memory can be further decreased, at the expense of some additional CPU cycles, by updating autocorrelation sums on a sample-by-sample basis rather than buffering a frame of samples.
Min_HMM was first implemented as a speaker-independent recognition algorithm on a DSP using a TI TMS320C5x EVM, limited to the C2xx dialect of the assembly language. It was later implemented in C54x assembly language by TI-France and ported to the TI GSM chipset. This version also has speaker-dependent enrollment and update for name dialing.
Table 10.2 shows the specifics of different versions of Min_HMM. Results are expressed in % Word Error Rate (WER), the percentage of words mis-recognized (each digit is treated as a word. Results on the TI-WAVES database are averaged over the three conditions (parked, stop-and-go and highway). Note that the number of MIPS increases dramatically with noisier speech on the same task (SD Name Dialing).
Table 10.2 Min_HMM on the C54x platform (ROM and RAM figures are in 16-bit words)

10.3.3.2 IG
The Integrated Grammar (IG) recognizer differs from Min_HMM in that it supports continuous speech recognition and allows flexible vocabularies. Like Min_HMM, it is also implemented on a 16-bit fixed-point DSP with no more than 64K words of memory. It supports the following recognition algorithms:
- Continuous speech recognition on speaker-independent models, such as digits and commands.
- Speaker-dependent enrollment, such as name dialing.
- Adaptation (training) of speaker-independent models to improve performance.
IG has been implemented on the TI TMS320C541, TMS320C5410 and TMS320C5402 DSPs. Table 10.3 shows the resource requirements and recognition performance on the TIDIGITS and TI-WAVES (handheld) speech databases. Experiments with IG are described in greater detail in Refs. [4–6].
Table 10.3 IG on the TI C54x platform (ROM and RAM figures are in 16-bit words)

10.3.3.3 TIESR
The Texas Instruments Embedded Speech Recognizer (TIESR) provides speaker-independent continuous speech recognition robust to noisy background, with optional speaker-adaptation for enhanced performance. TIESR has all of the features of IG, but is also designed for operation in adverse conditions such as in a vehicle on a highway with a hands-free microphone. The performance of most recognizers that work well in an office environment degrades under background noise, microphone differences and speaker accents. TIESR includes TI's recent advances in handling such situations, such as:
- On-line compensation for noisy background, for good recognition at low SNR.
- Noise-dependent rejection capability, for reliable out-of-vocabulary speech rejection.
- Speech signal periodicity-based utterance detection, to reduce false speech decision triggering.
- Speaker-adaptation using name-dialing enrollment data, for improved recognition without reading adaptation sentences.
- Speaker identification, for improved performance on groups of users.
TIESR has been implemented on the TI TMS320C55x DSP core-based OMAP1510 platform. The salient features of TIESR and its resource requirements will be discussed in greater detail in the next section. Table 10.4 shows the speaker-independent recognition results (with no adaptation) obtained with TIESR on the C55x DSP. The results on the TI-WAVES database include %WER on each of the three conditions (parked, stop-and-go, and highway). Note the perfect recognition (0% WER) on the SD Name Dialing task in the ‘parked’ condition. Also, the model size, RAM and MIPS increase on the noisier TI-WAVES digit data (not surprisingly), compared to the clean TIDIGITS data. The RAM and MIPS figures for the other TI-WAVES task are not yet available.
Table 10.4 TIESR on C55x DSP (RAM and ROM figures are in 16-bit words)

10.4 TIESR Details
In this section, we describe two distinctive features of TIESR in some detail, noise robustness and speaker adaptation. Also, we highlight the implementation details of the grammar parsing and model creation module (on the GPP) and discuss the issues involved in porting TIESR to the TI C55x DSP.
10.4.1 Distinctive Features
10.4.1.1 Noise Robustness
Channel distortion and background noise are the two of the main causes of recognition errors in any speech recognizer [11]. Channel distortion is caused by the different frequency responses of the microphone and A/D. It is also called convolutional noise because it manifests itself as an impulse response that “convolves” with the original signal. The net effect is a non-uniform frequency response multiplied with the signal's linear spectrum (i.e. additive in the log spectral domain). Cepstral Mean Normalization (CMN) is a very effective technique [12] to deal with it because the distortion is modeled as a constant additive component in the cepstral domain and can be removed by subtracting a running mean computed over a 2–5 second window.
Background noise can be any sound other than the intended speech, such as wind or engine noise in a car. This is called additive noise because it can be modeled as an additive component in the linear spectral domain. Two methods can be used to combat this problem: spectral subtraction [14] and Parallel Model Combination (PMC) [13]. Both algorithms estimate a running noise energy profile, and then subtract it from the input signal's spectrum or add it to the spectrum of all the models. Spectral subtraction requires less computation because it needs to modify only one spectrum of the speech input. PMC requires a lot more computation because it needs to modify the spectra of all the models; the larger the model, the more computation required. However, we find that PMC is more effective than spectral subtraction.
CMN and PMC cannot be easily combined in tandem because they operate in different domains, the log and linear spectra, respectively. Therefore, we use a novel joint compensation algorithm, called Joint Additive and Convolutional (JAC) noise compensation, that can compensate both the linear domain correction and log domain correction simultaneously [15]. This JAC algorithm achieves large error rate reduction across various channel and noise conditions.
10.4.1.2 Speaker Adaptation
To achieve good speaker-independent performance, we need large models to model different accents and speaking styles. However, embedded systems cannot accommodate large models, due to storage resource constraints. Adaptation thus becomes very important. Mobile phones and PDAs are “personal” devices and can therefore be adapted for the user's voice. Most embedded recognizers do not allow adaptation of models (other than enrollment) because training software is usually too large to fit into an embedded system. TIESR, on the other hand, incorporates training capability into the recognizer itself. It supports supervision alignment and trace output (where each input speech frame is mapped to a model). This capability enables us to do Maximum Likelihood Linear Regression (MLLR) phonetic class adaptation [16,17,19]. After adaptation, the recognition accuracy usually improves significantly, because the models effectively take channel distortion and speaker characteristics into account.
10.4.2 Grammar Parsing and Model Creation
As described in Section 10.2, in order to support flexible recognition context switching, a speech recognizer needs to create grammar and models on demand. This requires two major information components: an online pronunciation dictionary and decision tree acoustics. Because of the large sizes of these components, a 32-bit GPP is a natural choice.
10.4.2.1 Pronunciation Dictionary
The size and complexity of the pronunciation dictionary varies widely for different languages. For a language with more regular pronunciation, such as Spanish, a few hundred rules are enough to convert text to phone accurately. On the other hand, for a language with more irregular pronunciation, such as English, a comprehensive online pronunciation dictionary is required. We used a typical English pronunciation dictionary (COMLEX) with 70,955 entries; it required 1,826,302 bytes of storage in ASCII form. We used an efficient way to represent this dictionary using only 367,599 bytes, a 5:1 compression. Our compression technique was such that there was no need to decompress the dictionary to do a look-up, and there was no extra data structure required for the look-up either; it was directly computable in low-cost ROM. We also used a rule-based word-to-phone algorithm to generate a phonetic decomposition for any word not found in the dictionary. Details of our dictionary compression algorithm are given in Ref. [8].
10.4.2.2 Decision Tree Acoustics
A decision tree algorithm is an important component in a medium or large vocabulary speech recognition system [7,18]. It is used to generate context-dependent phonetic acoustics to build recognition models. A typical decision tree system consists of hundreds of classification trees, used to classify a phone based on its left and right contexts. It is very expensive to store these trees on disk and create searchable trees in memory (due to their large sizes). We devised a mechanism to store the tree in binary form and create one tree at a time during search. The tree file was reduced from 788 KB in ASCII form to 32 KB in binary form (ROM), a 25:1 reduction. The searchable tree was created and destroyed one at a time, bringing the memory usage down to only 2.5 KB (RAM). The decision tree serves as an index mechanism for acoustic vectors. A typical 10K-vector set requires 300 KB to store in ROM. A larger vector set will provide better performance. It can be easily scaled depending on the available ROM size. Details of our decision tree acoustics compression are given in Ref. [8].
10.4.2.3 Resource Requirements
Table 10.5 shows the resource requirements for the grammar parsing and model creation module running on the ARM9 core. The MIPS numbers represent averages over several utterances for the digit grammars specified.
Table 10.5 Resource requirements on the ARM9 core for grammar creation and model generation

10.4.3 Fixed-Point Implementation Issues
In addition to making the system small (low memory) and efficient (low MIPS), we need to deal with fixed-point issues. In a floating-point processor, all numbers are normalized into a format with sign bit, exponent, and mantissa. For example, the IEEE standard for float has one sign bit, an 8–bit exponent, and a 23-bit mantissa. The exponent provides a large dynamic range: 2128 ~ = 1038. The mantissa provides a fixed level of precision. Because every float number is individually normalized into this format, it always maintains a 23-bit precision as long as it is within the 1038 dynamic range. Such good precision covering a large dynamic range frees the algorithm designer from worrying about scaling problems. However, it comes at the cost of more power, larger silicon, and higher cost. In a 16-bit fixed-point processor, on the other hand, the only format is a 16-bit integer, ranging from 0 to 65535 (unsigned) or −32768 to +32767 (signed). The numerical behavior of the algorithm has to be carefully normalized to be within the dynamic range of a 16-bit integer at every stage of the computation.
In addition to the data format limitation, another issue is that some operations can be done efficiently, while others cannot. A fixed-point DSP processor usually incorporates a hardware multiplier so that addition and multiplication can be completed in one CPU cycle. However, there is no hardware for division and it takes more than 20 cycles to do it by a routine. To avoid division, we want to pre-compute the inverted data. For example, we can pre-compute and store 1/σ2 instead of σ2 for the Gaussian probability computation. Other than the explicit divisions, there are also implicit divisions hidden in other operations. For example, pointer arithmetic is used heavily in the memory management in the search algorithm. Pointer subtraction actually incurs a division. Division can be approximated by multiplication and shift. However, pointer arithmetic cannot tolerate any errors. Algorithm design has to take this into consideration and make sure it is accurate under all possible running conditions.
We found that 16-bit resolution was not a problem for our speech recognition algorithms [10]. With careful scaling, we were able to convert computations such as Mel-Frequency Cepstral Coefficients (MFCC) used in our speech front-end and Parallel Model Combination (PMC) used in our noise compensation, to fixed-point precision with no performance degradation.
10.4.4 Software Design Issues
In an embedded system, resources are scarce and their usage needs to be optimized. Many seemingly innocent function calls actually use a lot of resources. For example, string operation and memory allocation are both very expensive. Calling one string function will cause the entire string library to be included, and malloc() is not efficient in allocating memory. We did the following optimizations to our code:
- Replace all string operations with efficient integer operations.
- Remove all malloc() and free(). Design algorithms to do memory management and garbage collection. The algorithms are tailored for efficient utilization of memory.
- Local variables consume stack size. We examine the allocation of local and global variables to balance memory efficiency and program modularity. This is especially important for recursive routines.
- Streamline data structures so that all model data are stored efficiently and designed for computability, as opposed to using one format for disk storage and another for computation.
10.5 Speech-Enabled Wireless Application Prototypes
Figure 10.1 shows the schematic block diagram of a speech-enabled application designed for a dual-processor wireless architecture (like the OMAP1510). The application runs on the GPP, while the entire speech recognizer and portions of the Text-To-Speech (TTS) system run on the DSP. The application interacts with the speech recognizer and TTS via a speech API that encapsulates the DSP-GPP communication details. In addition, the grammar parsing and model creation software runs on the GPP and interacts with the DSP recognizer, as described in Section 10.2.2.

Figure 10.1 Speech-enabled application schematic using the DSP-GPP architecture
The TTS system shown in Figure 10.1 is assumed to be a concatenative TTS system (similar to the one described in Ref. [20]). The text analysis and linguistic processing modules of the TTS system are resource-intensive and require large databases. As such, they are best suited to run on the GPP. The waveform generation component of the TTS system runs on the DSP. Note that the TTS system and the Grammar Parsing modules are shown sharing a common pronunciation dictionary. While this may not be true of some TTS systems in existence today, it is indeed possible and is the preferred scenario, in order to conserve storage on the ARM™. The “Other TTS Data” box refers to the point-of-speech lexicon, trigram language models, letter-to-sound rules and binary trees used by the Text Analysis and Linguistic Processing modules.
10.5.1 Hierarchical Organization of APIs
The Speech API module in Figure 10.1 merits further description. The application on the ARM™ interacts with the speech recognizer and TTS system using a hierarchy of progressively finer-grained APIs. This is shown in Figure 10.2. The application talks to the Speech API layer, which could be either the Java Speech API (JSAPI) [26] or a variant of Microsoft's SAPI [27]. JSAPI and SAPI are two of the most commonly used standard speech APIs. This API layer is implemented in terms of a set of basic speech functions, called Speech Primitives (SP). The SP layer contains functions to start and stop a recognizer, pause and resume audio, load grammars, return results, start and stop the TTS, set the TTS speech rate, select the TTS ‘speaker’, etc. in a format dictated by the speech recognizer and the TTS system. The SP layer in turn is implemented in terms of the DSP/BIOS Bridge API. The DSP/BIOS Bridge API takes care of the low-level ARM-DSP communication and the transfer of data between the application and the recognizer and TTS system. This hierarchical API architecture has the following advantages:
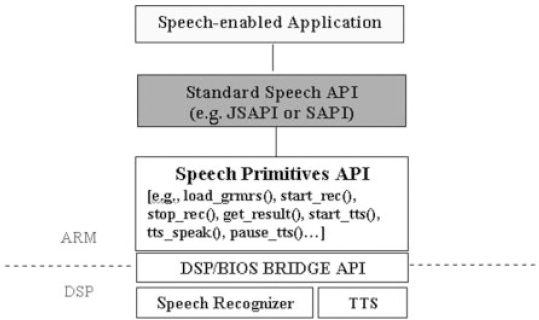
Figure 10.2 Hierarchical organization of APIs
- The application and the standard API layers (JSAPI and SAPI) are totally independent of the implementation details of the lower-level APIs. This encapsulation makes it easier to incorporate changes into the lower-level APIs, without having to rework the higher-level APIs.
- The existence of the SP layer reduces the amount of development needed to implement the mutually incompatible JSAPI and SAPI standards, as they are implemented in terms of a common set of functions/methods in the SP layer.
With this architecture in mind, we have developed several application prototypes that are specifically designed for the wireless domain. In the following sections, we describe four system prototypes for:
- Internet information retrieval (InfoPhone);
- Voice e-mail;
- Voice navigation; and
- Voice-enabled web browsing.
The first three systems, designed primarily for hands-busy, eyes-busy conditions, use speaker-independent speech recognizers, and can be used with a restricted display or no display at all. These systems use a client–server architecture with the client designed to be resident on a GPP-DSP combination on the phone or other handheld device. The fourth prototype for web browsing, called VoiceVoyager, was originally developed for desktop browsers (Netscape and Microsoft IE). We are currently in the process of modifying it for a client–server, wireless platform with a wireless microbrowser. Of the four systems, the InfoPhone prototype is the first one to be ported to a GPP-DSP platform; we have versions using both IG (on TIC541) and TIESR (TI C55x DSP; on OMAP1510). Work is underway to port the other three applications to a DSP-GPP platform as well.
10.5.2 InfoPhone
InfoPhone is a speech-enabled Java application that is best described as a 3G wireless data service prototype. It allows speech-enabled retrieval of useful information such as stock quotes, flight schedules and weather forecasts. Users can choose one of flights, stocks and weather from a top-level menu and interact with each “service” by speech commands. “Keypad” (non-speech) input is also available as a back-up. The application incorporates separate grammars for company names (for stocks), flight numbers and city names (for weather). We have developed versions of this demo using both IG (on C541) and TIESR (C5510; OMAP™). In this section, we will be describing the OMAP-enabled version that runs on the pre-OMAP™ EVM (ARM925 and TI C5510 DSP).
The application runs on the ARM925 under Symbian OS (previously known as EPOC) Release 5 [21] and communicates with the TIESR recognizer running on the C5510 under OSE [22], via the TI JSP Speech API. The JSP API is a Java API, developed in-house, that handles all of the GPP-DSP communication and allows any Java application to be speech-enabled with a DSP based speech recognizer. Figure 10.3 shows the block diagram of the system architecture.
Speech input to the application is processed by TIESR and the information request is sent to an InfoServer application running on a remote server that accesses the appropriate website, retrieves the HTML page, extracts just the essential information and transmits it to the application. The results of the information retrieval are displayed on the 320 × 240 LCD screen that is part of the pre-OMAP™ EVM. We are in the process of incorporating a TTS system on the ARM™ and the C5510. Once this is done, then the information retrieved will be played back by the TTS system, resulting in true eyes-free, hands-free operation.
Users can switch between the three “services” dynamically. Keypad input is always active and users can switch back and forth between voice and tactile input at any time.
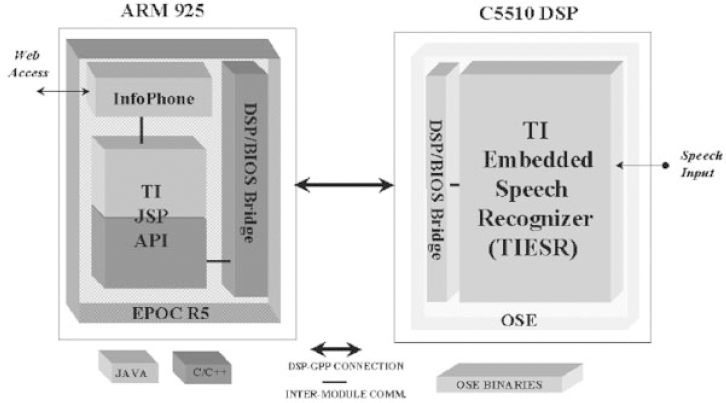
Figure 10.3 OMAP™-enabled InfoPhone architecture.
10.5.3 Voice E-mail
Over the past several years, the cellular telephone has become an important mobile communication tool. The use of voice-mail has also increased over the same time period. It would be convenient if a mobile user could use a single device (such as a cellular phone) to access both his e-mail and voice-mail. This eliminates the hassle of dealing with multiple devices and also allows multimodal messaging; a user can call up the sender of an e-mail message to respond verbally to his e-mail, or send e-mail in response to a voice-mail message. TI has developed a Voice E-mail (VE) system prototype that addresses these issues.
10.5.3.1 System Overview
The VE system has a client–server architecture and is completely voice-driven. Users talk to the system and listen to messages and prompts played back by the speech synthesizer. The system has a minimal display (for status messages) and is designed to operate primarily in a “displayless” mode, where the user can effectively interact with the system without looking at a display. The current system is an extension of previous collaborative work with MIT [23] and handles reading, filtering, categorization and navigation of e-mail messages. It also has the capability to “compose” and send e-mail using speech-based form filling. Work is underway to incorporate voice-mail send and receive (using caller ID information).
An important aspect of the displayless user interface is that the user should, at all times, know exactly what to do, or should be able to find out easily. To this end, we have incorporated an elaborate context-dependent help feature. If the user gets lost, he also has the ability to reset all changes and start over from the beginning. An optional display can be incorporated into the VE system to provide visual feedback as well.
10.5.3.2 Client–Server Architecture
The VE server handles all of the e-mail/voice-mail functions. It accesses the e-mail and voice-mail servers and handles the receiving, sending and storage of the messages. It communicates with the client via sockets. The VE server is implemented as a Java application. We use Microsoft Exchange Server as the mail server. The VE server uses MAPI (Microsoft's Mail API) to directly access and interact with mail objects such as message stores, messages, sender lists, etc.
The client provides the user interface and handles the reading, navigation, categorization, and filtering of e-mail and voice-mail messages. It is completely agnostic about the type of mail server used by the VE server. This feature ensures that the VE client is not specific to a single mail system and can be used with any mail server as long as the interface between the VE server and client is maintained. The VE client has both speech recognition and TTS capabilities, and is designed to not maintain constant connection to the server (to reduce connection time charges). It connects to the server only to initiate or end a session, check for new mail or to send a message. It also has an extensive help feature that provides guidance to beginners of the system and on request. The client is implemented as a Java applet.
10.5.3.3 User Interface
The user can speak to the system in a natural, continuous speaking style. Several alternates to each phrase are allowed (for example, “any messages from John Smith?” and “is there a message from John Smith?”). There is also a rejection feature that handles incorrect speech input; it prompts the user for more information if the recognition score falls below an empirically determined threshold. To minimize fatigue, the error prompts in case of a rejection are randomized. Further, if more than three consecutive rejections occur, the system initiates context-dependent help to guide the user. The TTS system operates in e-mail mode; that is, it can correctly speak out the e-mail headers.
10.5.4 Voice Navigation
Car navigation systems have been available for some time, but they have received only limited use. We can partly attribute this to the user interface available for such systems: often unnatural, sometimes clumsy, and potentially unsafe. Some systems use a touch screen while others use a rotating knob to enter destination addresses one alpha-numeric character at a time. We have developed a system to obtain maps and/or directions for different places in a city as naturally as possible, by voice I/O only. It could be incorporated into either a built-in device in a car or a cellular phone. This navigation system is primarily aimed at hands-busy, eyes-busy conditions such as automobile driving. An optional display is provided for situations where the user may safely look at the screen, when the car is parked. All textual information is played back to the user via a TTS system. A dialog manager is used to handle all interactions with the user.
10.5.4.1 Client–Server Architecture
The car navigation device acts as a client. The user interacts with the client which in turn communicates with a remote server to process user utterances. A Global Positioning System (GPS) connected to the client tracks the location of the user at any point in time. A web-based map service on the server provides maps and directions. We currently use the MapQuest™ website as our map server (www.mapquest.com). Further, a yellow pages server is used to find businesses near the user's current location. We use the GTE SuperPages™ website as our yellow pages server (www.superpages.com).1 Our speech recognizer processes the user's utterances and passes the result to the dialog manager, which then interprets these utterances in context. If the appropriate information needed to issue a query has been given, the dialog manager will query the appropriate server to get a response. Otherwise, it may interact further with the user. For example, if the user says “Where is the DoubleTree Hotel?” and the system has knowledge of multiple hotels of the same name, it will first interact with the user to resolve this ambiguity before querying the map server.
The navigation application has been designed so that the user may query the system using natural speech. The speech interface provides a natural way for users to specify the destination, while the presence of a dialog manager ensures that users can have their queries satisfied even in the presence of missing, ambiguous, inconsistent, or erroneous information. The dialog manager also assists in constraining the grammars for the speech recognizer and in providing context-sensitive help. This dialog manager has been described in greater detail in Ref. [24]. In case of any errors on the part of the user or the system, the user may say “Go back” at any time to undo the effect of the previous utterance. It also supports a rejection feature that requests the user to repeat something if the system does not have enough confidence in its recognition.
10.5.4.2 Navigation Scenarios
This application covers different scenarios in which a user may need directions to some place. In some cases, the user may know the exact address or cross streets of the destination and might query the system for directions to these locations (for example, “How do I get to 8330 LBJ Freeway in Dallas?”). In addition, the system has knowledge of a list of common points of interest for the current city. These may include hotels, hospitals, airports, malls, universities, sports arenas, etc. and the user can get directions to any of these by referring to them by name (for example, “I need to go to the Dallas Museum of Art”). Finally, there are often instances where a user is interested in locating some business near his/her current location. For example, the user may just say “Find a movie theater around here”. In such situations, the system needs to access the yellow pages server to find the list of movie theaters, interact with the user to identify the one of interest, and then query the map server for maps and/or directions. The phone number of the identified business can also be provided to the user on demand.
10.5.5 Voice-Enabled Web Browsing
We have developed an interface to the Web, called VoiceVoyager that allows convenient voice access to information [25]. VoiceVoyager uses a speaker-independent, continuous speech, arbitrary vocabulary recognition system that has the following specific features for interacting with the Web:
- Customizable speakable commands for simple browser control;
- Speakable bookmarks to retrieve pages by random access using customized phrases;
- Speakable links to select any hypertext link by simply speaking it; and
- Smart pages for natural spoken queries specific to pages.
To support these features, VoiceVoyager has the ability to incorporate new grammars and vocabularies “on the fly”. The ability to handle a flexible vocabulary, coupled with the ability to dynamically modify and create new grammars in the recognizer (as described in Section 10.2.1), is crucial to VoiceVoyager's ability to speech-enable arbitrary web pages, including those that the user has never visited before.
Since VoiceVoyager was originally developed as a PC desktop tool, the following discussion uses terms such as Hypertext Mark-up Language (HTML) and “pages”, concepts that are somewhat specific to desktop-based web browsers. For a WAP [28] microbrowser, the corresponding analogues would be Wireless Markup Language (WML) and “cards” (or “decks”), respectively. A deck is a set of WML cards (or pages). It is to be noted that the features of VoiceVoyager described below are not specific to the PC domain, they apply just as well to wireless microbrowsers, be they WAP or i-Mode or any other type.
10.5.5.1 Speakable Commands
To control the browser, VoiceVoyager provides spoken commands to display help pages, scroll up or down, go back or forward, display the speakable commands and bookmarks, add a page to the speakable bookmarks, and edit phrases for the speakable bookmarks. Voice-Voyager has default phrases for these commands, but the user may change them, if desired, to more convenient ones.
10.5.5.2 Speakable Bookmarks
To reach frequently accessed pages, users may add pages to their speakable bookmarks. When adding a page currently displayed in the browser, VoiceVoyager uses the title of the page to construct a grammar for subsequent access by voice. The initial grammar includes likely alternatives to allow, for example, either “NIST's” or “N.I.S.T's” in a page entitled “NIST's Home Page”. The user may then add additional phrases to make access to the information more convenient or easier to remember. The speakable bookmarks remain active at all times giving users instant access to important information.
10.5.5.3 Speakable Links
Every time VoiceVoyager encounters a page on the Web, it parses HTML content to determine the links and the Uniform Resource Locators (URLs) associated with them. VoiceVoyager then transforms the string of words into a grammar that allows likely alternatives as mentioned above. It checks several phonetic dictionaries for pronunciations and uses a text-to-phone mapping if these fail. We currently use a proper name dictionary, an abbreviation/acronym dictionary, and a 250,000 entry general English dictionary. The text-to-phone mapping proves necessary in many cases, including, for example, pages that include invented words (for example, “Yahooligans” on the Yahoo page).
10.5.5.4 Smart Pages
On some occasions, the point-and-click paradigm associated with links falls short. For a more flexible voice-input paradigm, we developed a mechanism called smart pages. Smart pages are simply web pages that contain a link to a grammar appropriate for a page or set of pages. When a smart page is downloaded onto a client browser, the grammar(s) associated with that page are also downloaded and dynamically incorporated into the speech recognizer. Using standard web conventions, web page authors may specify what users can say and interpret the recognized words appropriately for the context.
10.6 Summary and Conclusions
Unlike desktop speech recognition systems, embedded speech recognizers have to contend with constraints of limited memory, low power and little to no disk storage. Combining its expertise in speech recognition technology and its leadership in DSP platforms, TI has developed several speech recognizers for the C54x and C55x platforms. Despite conforming to low-cost, low-memory constraints of DSPs, these recognizers handle a variety of useful recognition tasks, including isolated and continuous digits, speaker-dependent name-dialing, speaker-independent continuous speech recognition under adverse noise conditions (using both handheld and hands-free in-car microphones). Table 10.6 summarizes our portfolio of recognizers.
Table 10.6 Summary of Texas Instruments' DSP based speech recognizers

The four system prototypes (InfoPhone, Voice E-mail, Voice Navigation and VoiceVoyager) demonstrate the speech capabilities of a DSP-GPP platform. They are a significant step towards providing GPP-DSP-based speech recognition solutions for 3G wireless platforms.
References
[1] Chaoui, J., Cyr, K., Giacalone, J.-P., de Gregorio, S., Masse, Y., Muthusamy, Y., Spits, T., Budagavi, M. and Webb, J., ‘Open Multimedia Application Platform: Enabling Multimedia Applications in Third Generation Wireless Terminals”, Texas Instruments Technical Journal, October–December 2000.
[2] Paul, D.B. and Baker, J.M., ‘The Design for the Wall Street Journal Based CSR Corpus”, Proceedings of ICSLP 1992.
[3] Leonard, R.G., ‘A Database for Speaker-Independent Digit Recognition”, Proceedings of ICASSP 1984.
[4] Kao, Y.H. ‘A Multi-Lingual, Speaker-Independent, Continuous Speech Recognizer on TMS320C5x Fixed-Point DSP”, Proceedings of ICSPAT 1997.
[5] Kao, Y.H., ‘Minimization of Search Network in Speech Recognition”, Proceedings of ICSPAT 1998.
[6] Kao, Y.H., ‘N-Best Search Algorithm for Continuous Speech Recognition”, Proceedings of ICSPAT 1998.
[7] Kao, Y.H., ‘Building Phonetic Models for Low Cost Implementation Using Acoustic Decision Tree Algorithm”, Proceedings of ICSPAT 1999.
[8] Kao, Y.H. and Rajasekaran, P.K., ‘Designing a Low Cost Dynamic Vocabulary Speech Recognizer on a GPP-DSP System”, Proceedings of ICASSP 2000.
[9] Ramalingam, C.S., Gong, Y., Netsch, L.P., Anderson, W.W., Godfrey, J.J. and Kao, Y.H., ‘Speaker-Dependent Name-Dialing in a Car Environment with Out-of-Vocabulary Rejection’, Proceedings of ICASSP 1999.
[10] Kao, Y.H., Gong, Y., ‘Implementing a High Accuracy Continuous Speech Recognizer on a Fixed-Point DSP’, Proceedings of ICASSP 2000.
[11] Gong, Y., ‘Speech Recognition in Noisy Environments: A Survey’, Speech Communications, Vol. 16, No. 3, 1995, pp. 261–291.
[12] Atal, B., ‘Effectiveness of Linear Prediction Characteristics of the Speech Wave for Automatic Speaker Identification and Verification’, Journal of the Acoustical Society of America, Vol. 55, 1974, pp. 1304–1312.
[13] Gale, M.J.F. and Young, S., ‘An Improved Approach to the Hidden Markov Model Decomposition of Speech and Noise’, Proceedings of ICASSP 1992.
[14] Boll, S.F., ‘Suppression of Acoustic Noise in Speech Using Spectral Subtraction’, Acoustics, Speech and Signal Processing (ASSP) Journal, Vol. ASSP-27, No. 2, 1979, pp. 113–120.
[15] Gong, Y., ‘A Robust Continuous Speech Recognition System for Mobile Information Devices’, Proceedings of Workshop on Hands-Free Speech Communication, Kyoto, Japan, April 2001.
[16] Leggetter, C.J. and Woodland, P.C., ‘Maximum Likelihood Linear Regression for Speaker Adaptation of Continuous Density HMMs’, Computer Speech and Language, Vol. 9, No. 2, 1995, pp. 171–185.
[17] Gong, Y. and Godfrey, J.J., ‘Transforming HMMs for Speaker-Independent Hands-Free Speech Recognition in the Car’, Proceedings of ICASSP 1999.
[18] Bahl, L.R., de Souza, P.V., Gopalakrishnan, P. and Picheny, M., ‘Decision Trees for Phonological Rules in Continuous Speech’, Proceedings of ICASSP 1991.
[19] Gong, Y., ‘Source Normalization Training for HMM Applied to Noisy Telephone Speech Recognition’, Proceedings of Eurospeech 1997, Rhodes, Greece, September 1997, pp. 1555–1558.
[20] Black, A.W. and Taylor, P., ‘Festival Speech Synthesis System: System Documentation Edition 1.1 (for Festival Version 1.1.1)’. Human Communication Research Centre Technical Report HCRC/TR-83, University of Edinburgh, 1997.
[21] The Symbian Platform. http://www.epocworld.com.
[22] Enea OSE Systems. http://www.enea.com.
[23] Marx, M., ‘Towards Effective Conversational Messaging’, MS Thesis, MIT, June 1995.
[24] Agarwal, R., ‘Towards a PURE Spoken Dialogue System for Information Access’, Proceedings of the ACL/EACL Workshop on Interactive Spoken Dialog Systems, 1997.
[25] Hemphill, C.T. and Thrift, P.R., ‘Surfing the Web by Voice’, Proceedings of Multimedia 1995, San Francisco, CA, November 1995.
[26] Java Speech Application Programming Interface. http://java.sun.com/products/java-media/speech.
[27] Microsoft Speech Application Programming Interface version 5.0. http://www.microsoft.com/speech/technical/SAPIOverview.asp.
[28] The Wireless Application Protocol Forum. http://www.wapforum.org.
1 Our prototypes access these websites programmatically and post-process the complete HTML page(s) retrieved from them to extract just the information needed. This information is passed onto the TTS system and the client display.