
18
Transactional Memory
18.1 Introduction
We now turn our attention from devising data structures and algorithms to critiquing the tools we use to solve these problems. These tools are the synchronization primitives provided by today’s architectures, encompassing various kinds of locking, both spinning and blocking, and atomic operations such as compareAndSet() and its relatives. They have mostly served us well. We, the community of multiprocessor programmers, have been able to construct many useful and elegant data structures. Nevertheless, everyone knows that the tools are flawed. In this chapter, we review and analyze the strengths and weaknesses of the standard synchronization primitives, and describe some emerging alternatives that are likely to extend, and perhaps even to displace many of today’s standard primitives.
18.1.1 What is Wrong with Locking?
Locking, as a synchronization discipline, has many pitfalls for the inexperienced programmer. Priority inversion occurs when a lower-priority thread is preempted while holding a lock needed by higher-priority threads. Convoying occurs when a thread holding a lock is descheduled, perhaps by exhausting its scheduling quantum by a page fault, or by some other kind of interrupt. While the thread holding the lock is inactive, other threads that require that lock will queue up, unable to progress. Even after the lock is released, it may take some time to drain the queue, in much the same way that an accident can slow traffic even after the debris has been cleared away. Deadlock can occur if threads attempt to lock the same objects in different orders. Deadlock avoidance can be awkward if threads must lock many objects, particularly if the set of objects is not known in advance. In the past, when highly scalable applications were rare and valuable, these hazards were avoided by deploying teams of dedicated expert programmers. Today, when highly scalable applications are becoming commonplace, the conventional approach is just too expensive.
The heart of the problem is that no one really knows how to organize and maintain large systems that rely on locking. The association between locks and data is established mostly by convention. Ultimately, it exists only in the mind of the programmer, and may be documented only in comments. Fig. 18.1 shows a typical comment from a Linux header file1 describing the conventions governing the use of a particular kind of buffer. Over time, interpreting and observing many such conventions spelled out in this way may complicate code maintenance.

Figure 18.1 Synchronization by convention: a typical comment from the Linux kernel.
18.1.2 What is Wrong with compareAndSet()?
One way to bypass the problems of locking is to rely on atomic primitives like compareAndSet(). Algorithms that use compareAndSet() and its relatives are often hard to devise, and sometimes, though not always, have a high overhead. The principal difficulty is that nearly all synchronization primitives, whether reading, writing, or applying an atomic compareAndSet(), operate only on a single word. This restriction often forces a complex and unnatural structure on algorithms.
Let us review the lock-free queue of Chapter 10 (reproduced in Fig. 18.2), this time with an eye toward the underlying synchronization primitives.

Figure 18.2 The LockFreeQueue class: the enq() method.
A complication arises between Lines 12 and 13. The enq() method calls compareAndSet() to change both the tail node’s next field and the tail field itself to the new node. Ideally, we would like to atomically combine both compareAndSet() calls, but because these calls occur one-at-a-time both enq() and deq() must be prepared to encounter a half-finished enq() (Line 12). One way to address this problem is to introduce a multiCompareAndSet() primitive, as shown in Fig. 18.3. This method takes as arguments an array of AtomicReference<T> objects, an array of expected T values, and an array of T-values used for updates. It performs a simultaneous compareAndSet() on all array elements, and if any one fails, they all do. In more detail: if, for all i, the value of target[i] is expected[i], then set target[i]’s value to update[i] and return true. Otherwise leave target[i] unchanged, and return false.

Figure 18.3 Pseudocode for multiCompareAndSet(). This code is executed atomically.
Note that there is no obvious way to implement multiCompareAndSet() on conventional architectures. If there were, comparing the LockFreeQueue implementations in Figs. 18.2 and 18.4 illustrates how multiCompareAndSet() simplifies concurrent data structures. The complex logic of Lines 11–12 is replaced by a call to a single multiCompareAndSet() call.

Figure 18.4 The LockFreeQueue class: simplified enq() method with multiCompareAndSet().
While multi-word extensions such as multiCompareAndSet() might be useful, they do not help with another serious flaw, discussed in Section 18.1.3.
18.1.3 What is Wrong with Compositionality?
All the synchronization mechanisms we have considered so far, with or without locks, have a major drawback: they cannot easily be composed. Let us imagine that we want to dequeue an item x from queue q0 and enqueue it at another, q1. The transfer must be atomic: no concurrent thread should observe either that x has vanished, or that it is present in both queues. In Queue implementations based on monitors, each method acquires the lock internally, so it is essentially impossible to combine two method calls in this way.
Failure to compose is not restricted to mutual exclusion. Let us consider a bounded queue class whose deq() method blocks as long as the queue is empty (using either wait/notify or explicit condition objects). We imagine that we have two such queues, and we want to dequeue an item from either queue. If both queues are empty, then we want to block until an item shows up in either one. In Queue implementations based on monitors, each method provides its own conditional waiting, so it is essentially impossible to wait on two conditions in this way.
Naturally, there are always ad hoc solutions. For the atomic transfer, we could introduce a lock to be acquired by any thread attempting an atomic modification to both q0 and q1. But such a lock would be a concurrency bottleneck (no concurrent transfers) and it requires knowing in advance the identities of the two queues. Or, the queues themselves might export their synchronization state, (say, via lock() and unlock() methods), and rely on the caller to manage multi-object synchronization. Exposing synchronization state in this way would have a devastating effect on modularity, complicating interfaces, and relying on callers to follow complicated conventions. Also, this approach simply would not work for nonblocking queue implementations.
18.1.4 What can We Do about It?
We can summarize the problems with conventional synchronization primitives as follows.
![]() Locks are hard to manage effectively, especially in large systems.
Locks are hard to manage effectively, especially in large systems.
![]() Atomic primitives such as compareAndSet() operate on only one word at a time, resulting in complex algorithms.
Atomic primitives such as compareAndSet() operate on only one word at a time, resulting in complex algorithms.
![]() It is difficult to compose multiple calls to multiple objects into atomic units.
It is difficult to compose multiple calls to multiple objects into atomic units.
In Section 18.2, we introduce transactional memory, an emerging programming model that proposes a solution to each of these problems.
18.2 Transactions and Atomicity
A transaction is a sequence of steps executed by a single thread. Transactions must be serializable, meaning that they appear to execute sequentially, in a one-at-a-time order. Serializability is a kind of coarse-grained version of linearizability. Linearizability defined atomicity of individual objects by requiring that each method call of a given object appear to take effect instantaneously between its invocation and response, Serializability, on the other hand, defines atomicity for entire transactions, that is, blocks of code that may include calls to multiple objects. It ensures that a transaction appears to take effect between the invocation of its first call and the response to its last call.2 Properly implemented, transactions do not deadlock or livelock.
We now describe some simple programming language extensions to Java that support a transactional model of synchronization. These extensions are not currently part of Java, but they illustrate the model. The features described here are a kind of average of features provided by contemporary transactional memory systems. Not all systems provide all these features: some provide weaker guarantees, some stronger. Nevertheless, understanding these features will go a long way toward understanding modern transactional memory models.
The atomic keyword delimits a transaction in much the same way the synchronized keyword delimits a critical section. While synchronized blocks acquire a specific lock, and are atomic only with respect to other synchronized blocks that acquire the same lock, an atomic block is atomic with respect to all other atomic blocks. Nested synchronized blocks can deadlock if they acquire locks in opposite orders, while nested atomic blocks cannot.
Because transactions allow atomic updates to multiple locations, they eliminate the need for multiCompareAndSet(). Fig. 18.5 shows the enq() method for a transactional queue. Let us compare this code with the lock-free code of Fig. 18.2: there is no need for AtomicReference fields, compareAndSet() calls, or retry loops. Here, the code is essentially sequential code bracketed by atomic blocks.

Figure 18.5 An unbounded transactional queue: the enq() method.
To explain how transactions are used to write concurrent programs, it is convenient to say something about how they are implemented. Transactions are executed speculatively: as a transaction executes, it makes tentative changes to objects. If it completes without encountering a synchronization conflict, then it commits (the tentative changes become permanent) or it aborts (the tentative changes are discarded).
Transactions can be nested. Transactions must be nested for simple modularity: one method should be able to start a transaction and then call another method without caring whether the nested call starts a transaction. Nested transactions are especially useful if a nested transaction can abort without aborting its parent. This property will be important when we discuss conditional synchronization later on.
Recall that atomically transferring an item from one queue to another was essentially impossible with objects that use internal monitor locks. With transactions, composing such atomic method calls is almost trivial. Fig. 18.7 shows how to compose a deq() call that dequeues an item x from a queue q0 and an enq(x) call that enqueues that item to another queue q1.

Figure 18.6 A bounded transactional queue: the enq() method with retry.

Figure 18.7 Composing atomic method calls.
What about conditional synchronization? Fig. 18.6 shows the enq() method for a bounded buffer. The method enters an atomic block (Line 2), and tests whether the buffer is full (Line 3). If so, it calls retry (Line 4), which rolls back the enclosing transaction, pauses it, and restarts it when the object state has changed. Conditional synchronization is one reason it may be convenient to roll back a nested transaction without rolling back the parent. Unlike the wait() method or explicit condition variables, retry does not easily lend itself to lost wake-up bugs.
Recall that waiting for one of several conditions to become true was impossible using objects with internal monitor condition variables. A novel aspect of retry is that such composition becomes easy. Fig. 18.8 shows a code snippet illustrating the orElse statement, which joins two or more code blocks. Here, the thread executes the first block (Line 2). If that block calls retry, then that subtransaction is rolled back, and the thread executes the second block (Line 4). If that block also calls retry, then the orElse as a whole pauses, and later reruns each of the blocks (when something changes) until one completes.

Figure 18.8 The orElse statement: waiting on multiple conditions.
In the rest of this chapter, we examine techniques for implementing transactional memory. Transactional synchronization can be implemented in hardware (HTM), in software (STM), or both. In the following sections, we examine STM implementations.
18.3 Software Transactional Memory
Unfortunately, the language support sketched in Section 18.2 is not currently available. Instead, this section describes how to support transactional synchronization using a software library. We present TinyTM, a simple Software Transactional Memory package that could be the target of the language extensions described in Section 18.2. For brevity, we ignore such important issues as nested transactions, retry, and orElse. There are two elements to a software transactional memory construction: the threads that run the transactions, and the objects that they access.
We illustrate these concepts by walking though part of a concurrent SkipList implementation, like those found in Chapter 14. This class uses a skiplist to implement a set providing the usual methods: add(x) adds x to the set, remove(x) removes x from the set, and contains(x) returns true if, and only if x is in the set.
Recall that a skiplist is a collection of linked lists. Each node in the list contains an item field (an element of the set), a key field (the item’s hash code), and a next field, which is an array of references to successor nodes in the list. Array slot zero refers to the very next node in the list, and higher-numbered slots refer to successively later successors. To find a given key, search first though higher levels, moving to a lower level each time a search overshoots. In this way, one can find an item in time logarithmic in the length of the list. (Refer to Chapter 14 for a more complete description of skiplists.)
Using TinyTM, threads communicate via shared atomic objects, which provide synchronization, ensuring that transactions cannot see one another’s uncommitted effects, and recovery, undoing the effects of aborted transactions. Fields of atomic objects are not directly accessible. Instead, they are accessed indirectly through getter and setter methods. For example, the getter method for the key field has the form
int getKey();
while the matching setter method has the form
void setKey(int value);
Accessing fields through getters and setters provides the ability to interpose transactional synchronization and recovery on each field access. Fig. 18.9 shows the complete SkipNode interface.

Figure 18.9 The SkipNode interface.
In a similar vein, the transactional SkipList implementation cannot use a standard array, because TinyTM cannot intercept access to the array. Instead, TinyTM provides an AtomicArray<T> class that serves the same functionality as a regular array.
Fig. 18.10 shows the fields and constructor for the SkipListSet class, and Fig. 18.11 shows the code for the add() method. Except for the syntactic clutter caused by the getters and setters, this code is almost identical to that of a sequential implementation. (The getter and setter calls could be generated by a compiler or preprocessor, but here we will make the calls explicit.) In Line 21 we create a new TSkipNode (transactional skip node) implementing the SkipNode interface. We will examine this class later on.

Figure 18.10 The SkipListSet class: fields and constructor.

Figure 18.11 The SkipListSet class: the add() method.
A transaction that returns a value of type T is implemented by a Callable<T> object (see Chapter 16) where the code to be executed is encapsulated in the object’s call() method.
A transactional thread (class TThread) is a thread capable of running transactions. A TThread (Fig. 18.12) runs a transaction by calling the doIt() method with the Callable<T> object as an argument. Fig. 18.13 shows a code snippet in which a transactional thread inserts a sequence of values into a skiplist tree. The list variable is a skiplist shared by multiple transactional threads. Here, the argument to doIt() is an anonymous inner class, a Java construct that allows short-lived classes to be declared in-line. The result variable is a Boolean indicating whether the value was already present in the list.

Figure 18.12 The TThread class.

Figure 18.13 Adding items to an integer list.
We now describe the TinyTM implementation in detail. In Section 18.3.1, we describe the transactional thread implementation, and then we describe how to implement transactional atomic objects.
18.3.1 Transactions and Transactional Threads
A transaction’s status is encapsulated in a thread-local Transaction object (Fig. 18.14) which can assume one of three states: ACTIVE, ABORTED, or COMMITTED (Line 2). When a transaction is created, its default status is ACTIVE (Line 11). It is convenient to define a constant Transaction. COMMITTED transaction object for threads that are not currently executing within a transaction (Line 3). The Transaction class also keeps track of each thread’s current transaction through a thread-local field local (Lines 5–8).

Figure 18.14 The Transaction class.
The commit() method tries to change the transaction state from ACTIVE to COMMITTED (Line 19), and the abort() method from ACTIVE to ABORTED(Line 22). A thread can test its current transaction state by calling getStatus() (Line 16). If a thread discovers that its current transaction has been aborted, it throws AbortedException. A thread can get and set its current transaction by calling static getLocal() or setLocal() methods.
The TThread (transactional thread) class is a subclass of the standard Java Thread class. Each transactional thread has several associated handlers. The onCommit and onAbort handlers are called when a transaction commits or aborts, and the validation handler is called when a transaction is about to commit. It returns a Boolean indicating whether the thread’s current transaction should try to commit. These handlers can be defined at run-time. Later, we will see how these handlers can be used to implement different techniques for transaction synchronization and recovery.
The doIt() method (Line 5 of Fig. 18.12) takes a Callable<T> object and executes its call() method as a transaction. It creates a new ACTIVE transaction (Line 8), and calls the transaction’s call() method. If that method throws AbortedException (Line 12), then the doIt() method simply retries the loop. Any other exception means the application has made an error (Line 13), and (for simplicity) the method throws PanicException, which prints an error message and shuts down everything. If the transaction returns, then doIt() calls the validation handler to test whether to commit (Line 16), and if the validation succeeds, then it tries to commit the transaction (Line 17). If the commit succeeds, then it runs the commit hander and returns (Line 18). Otherwise, if validation fails, it explicitly aborts the transaction. If commit fails for any reason, it runs the abort handler before retrying (Line 22).
18.3.2 Zombies and Consistency
Synchronization conflicts cause transactions to abort, but it is not always possible to halt a transaction’s thread immediately after the conflict occurs. Instead, such zombie3 transactions may continue to run even after it has become impossible for them to commit. This prospect raises another important design issue: how to prevent zombie transactions from seeing inconsistent states.
Here is how an inconsistent state could arise. An object has two fields x and y, initially 1 and 2. Each transaction preserves the invariant that y is always equal to 2x. Transaction Z reads y, and sees value 2. Transaction A changes x and y to 2 and 4, respectively, and commits. Z is now a zombie, since it keeps running, but will never commit. Z later reads x, and sees the value 2, which is inconsistent with the value it read for y.
One approach is to deny that inconsistent states are a problem. Since zombie transactions must eventually abort, their updates will be discarded, so why should we care what they observe? Unfortunately, a zombie can cause problems, even if its updates never take effect. In the scenario described earlier, where y = 2x in every consistent state, but Z has read the inconsistent value 2 for both x and y, if Z evaluates the expression
1/(x-y)
it will throw an “impossible” divide-by-zero exception, halting the thread, and possibly crashing the application. For the same reason, if Z now executes the loop
int i = x + 1; // i is 3
while (i++ != y) { // y is actually 2, should be 4
…
}
it would never terminate.
There is no practical way to avoid “impossible” exceptions and infinite loops in a programming model where invariants cannot be relied on. As a result, TinyTM guarantees that all transactions, even zombies, see consistent states.
18.3.3 Atomic Objects
As mentioned earlier, concurrent transactions communicate through shared atomic objects. As we have seen (Fig. 18.9), access to an atomic object is provided by a stylized interface that provides a set of matching getter and setter methods. The AtomicObject interface appears in Fig. 18.15.

Figure 18.15 The AtomicObject<T> abstract class.
We will need to construct two classes that implement this interface: a sequential implementation that provides no synchronization or recovery, and a transactional implementation that does. Here too, these classes could easily be generated by a compiler, but we will do these constructions by hand.
The sequential implementation is straightforward. For each matching getter–setter pair, for example:
T getItem();
void setItem(T value);
the sequential implementation defines a private field item of type T. We also require the sequential implementation to satisfy a simple Copyable<T> interface that provides a copyTo() method that copies the fields of one object to another (Fig. 18.16). As a technical matter, we also require the type to provide a no-argument constructor. For brevity, we use the term version to refer to an instance of a sequential, Copyable<T> implementation of an atomic object interface.
![]()
Figure 18.16 The Copyable<T> interface.
Fig. 18.17 shows the SSkipNode class, a sequential implementation of the SkipNode interface. This class has three parts. The class must provide a no-argument constructor for use by atomic object implementations (as described later), and may provide any other constructors convenient to the class. Second, it provides the getters and setters defined by the interface, where each getter or setter simply reads or writes its associated field. Finally, the class also implements the Copyable interface, which provides a copyTo() method that initializes one object’s fields from another’s. This method is needed to make back-up copies of the sequential object.

Figure 18.17 The SSkipNode class: a sequential SkipNode implementation.
18.3.4 Dependent or Independent Progress?
One goal of transactional memory is to free the programmer from worrying about starvation, deadlock, and “the thousand natural shocks” that locking is heir to. Nevertheless, those who implement STMs must decide which progress condition to meet.
We recall from Chapter 3 that implementations that meet strong independent progress conditions such as wait-freedom or lock-freedom guarantee that a thread always makes progress. While it is possible to design wait-free or lock-free STM systems, no one knows how to make them efficient enough to be practical.
Instead, research on nonblocking STMs has focused on weaker dependent progress conditions. There are two approaches that promise good performance: nonblocking STMs that are obstruction-free, and blocking, lock-based STMs that are deadlock-free. Like the other nonblocking conditions, obstruction-freedom ensures that not all threads can be blocked by delays or failures of other threads. This property is weaker than lock-free synchronization, because it does not guarantee progress when two or more conflicting threads are executing concurrently.
The deadlock-free property does not guarantee progress if threads halt in critical sections. Fortunately, as with many of the lock-based data structures we saw earlier, scheduling in modern operating systems can minimize the possibility of threads getting swapped out in the middle of a transaction. Like obstruction-freedom, deadlock-freedom does not guarantee progress when two or more conflicting threads are executing concurrently.
For both the nonblocking obstruction-free and blocking deadlock-free STMs, progress for conflicting transactions is guaranteed by a contention manager, a mechanism that decides when to delay contending threads, through spinning or yielding, so that some thread can always make progress.
18.3.5 Contention Managers
In TinyTM, as in many other STMs, a transaction can detect when it is about to cause a synchronization conflict. The requester transaction then consults a contention manager. The contention manager serves as an oracle,4 advising the transaction whether to abort the other transaction immediately, or stall to allow the other a chance to complete. Naturally, no transaction should stall forever waiting for another.
Fig. 18.18 shows a simplified base class for contention managers. It provides a single method, resolve() (Line 12), that takes two transactions, the requester’s and the other’s, and either pauses the requester, or aborts the other. It also keeps track of each thread’s local contention manager (Line 2), accessible by getLocal() and setLocal() methods (Lines 16 and 13).

Figure 18.18 Contention manager base class.
The ContentionManager class is abstract because it does not implement any conflict resolution policy. Here are some possible contention manager policies. Suppose transaction A is about to conflict with transaction B.
![]() Backoff: A repeatedly backs off for a random duration, doubling the expected time up to some limit. When that limit is reached, it aborts B.
Backoff: A repeatedly backs off for a random duration, doubling the expected time up to some limit. When that limit is reached, it aborts B.
![]() Priority: Each transaction takes a timestamp when it starts. If A has an older timestamp than B, it aborts B, and otherwise it waits. A transaction that restarts after an abort keeps its old timestamp, ensuring that every transaction eventually completes.
Priority: Each transaction takes a timestamp when it starts. If A has an older timestamp than B, it aborts B, and otherwise it waits. A transaction that restarts after an abort keeps its old timestamp, ensuring that every transaction eventually completes.
![]() Greedy: Each transaction takes a timestamp when it starts. A aborts B if either A has an older timestamp than B, or B is waiting for another transaction. This strategy eliminates chains of waiting transactions. As in the priority policy, every transaction eventually completes.
Greedy: Each transaction takes a timestamp when it starts. A aborts B if either A has an older timestamp than B, or B is waiting for another transaction. This strategy eliminates chains of waiting transactions. As in the priority policy, every transaction eventually completes.
![]() Karma: Each transaction keeps track of how much work it has accomplished, and the transaction that has accomplished more has priority.
Karma: Each transaction keeps track of how much work it has accomplished, and the transaction that has accomplished more has priority.
Fig. 18.19 shows a contention manager implementation that uses the back-off policy. The manager imposes minimum and maximum delays (Lines 2–3). The resolve() method checks whether this is the first time it has encountered the other thread (Line 8). If so, it resets its delay to the minimum, and otherwise it uses its current delay. If the current delay is less than the maximum, the thread sleeps for a random duration bounded by the delay (Line 13), and doubles the next delay. If the current delay exceeds the maximum, the caller aborts the other transaction (Line 16).

Figure 18.19 A simple contention manager implementation.
18.3.6 Implementing Atomic Objects
Linearizability requires that individual method calls appear to take place atomically. We now consider how to guarantee serializability: that multiple atomic calls have the same property.
A transactional implementation of an atomic object must provide getter and setter methods that invoke transactional synchronization and recovery. We review two alternative approaches to synchronization and recovery: the FreeObject class is obstruction-free, while the LockObject class uses locking for synchronization. These alternatives are implementations of the abstract AtomicObject class, shown in Fig. 18.15. The init() method takes the atomic object’s class as argument and records it for later use. The openRead() method returns a version suitable for reading (that is, one can call its getter methods only), while the openWrite() method returns a version that may be written (that is, one can call both getters and setters).
The validate() method returns true if and only if the value to be returned is guaranteed to be consistent. It is necessary to call validate() before returning any information extracted from an atomic object. The openRead(), openWrite(), and validate() methods are all abstract.
Fig. 18.20 shows the TSkipNode class a transactional SkipNode implementation. This class uses the LockObject atomic object implementation for synchronization and recovery (Line 8).

Figure 18.20 The TSkipNode class: a transactional SkipNode implementation.
This class has a single AtomicObject<SSkipNode> field. The constructor takes as argument values to initialize the AtomicObject<SSkipNode> field. Each getter performs the following sequence of steps.
1. It calls openRead() to extract a version.
2. It calls the version’s getter to extract the field value, which it stores in a local variable.
3. It calls validate() to ensure the value read is consistent.
The last step is needed to ensure that the object did not change between the first and second step, and that the value recorded in the second step is consistent with all the other values observed by that transaction.
Setters are implemented in a symmetric way, calling the setter in the second step.
We now have two alternative atomic object implementations. The implementations will be relatively unoptimized to simplify the presentation.
18.3.7 An Obstruction-Free Atomic Object
Recall that an algorithm is obstruction-free if any thread that runs by itself for long enough makes progress. In practice, this condition means that a thread makes progress if it runs for long enough without a synchronization conflict from a concurrent thread. Here, we describe an obstruction-free implementation of AtomicObject.
Bird’s-Eye View
Each object has three logical fields: an owner field, an old version, and a new version. (We call them logical fields because they may not be implemented as fields.) The owner is the last transaction to access the object. The old version is the object state before that transaction arrived, and the new version reflects that transaction’s updates, if any. If owner is COMMITTED, then the new version is the current object state, while if it is ABORTED, then the old version is current. If the owner is ACTIVE, there is no current version, and the future current version depends on whether the owner commits or aborts.
When a transaction starts, it creates a Transaction object to hold the transaction’s status, initially ACTIVE. If that transaction commits, it sets the status to COMMITTED, and if it is aborted by another transaction, the other transaction sets the status to ABORTED.
Each time transaction A accesses an object it first opens that object, possibly resetting the owner, old value, and new value fields. Let B be the object’s prior owner.
1. If B was COMMITTED, then the new version is current. A installs itself as the object’s current owner, sets the old version to the prior new version, and the new version to a copy of the prior new version (if the call is a setter), or to the new version itself (if the call is a getter).
2. Symmetrically, if B was ABORTED, then the old version is current. A installs itself as the object’s current owner, sets the old version to the prior old version, and the new version to a copy of the prior old version (if the call is a setter), or to the old version itself (if the call is a getter).
3. If B is still ACTIVE, then A and B conflict, so A consults the contention manager for advice whether to abort B, or to pause, giving B a chance to finish. One transaction aborts another by successfully calling compareAndSet() to change the victim’s status to ABORTED.
We leave it to the readers to extend this algorithm to allow concurrent readers.
After opening the object, the getter reads the version’s field into a local variable. Before returning that value, it calls validate() to check that the calling transaction has not been aborted. If all is well, it returns the field value to the caller. (Setters work symmetrically).
When it is time for A to commit, it calls compareAndSet() to change its status to COMMITTED. If it succeeds, the commit is complete. The next transaction to access an object owned by A will observe that A has committed, and will treat the object’s new version (the one installed by A) as current. If it fails, it has been aborted by another transaction. The next transaction to access an object updated by A will observe that A has been aborted, and will treat the object’s old version (the one prior to A) as current. Fig. 18.21 shows an example execution.

Figure 18.21 The FreeObject class: an obstruction-free atomic object implementation. Thread A has completed the writing of one object and is in the process of switching a copy of the second object that was last written by thread B. It prepares a new locator with a fresh new copy of the object and an old object field that refers to the new field of thread B’s locator. It then uses a compareAndSet() to switch the object to refer to the newly created locator.
Why It Works
Here is why every transaction observes a consistent state. When a transaction A calls a getter method to read an object field, it opens the object, installing itself as the object’s owner. If the object already had an active owner, B, then A aborts B. A then reads the field value into a local variable. Before the getter returns that value to the application, however, it calls validate() to check that the value is consistent. If another transaction C displaced A as owner of any object, then C aborted A, and A’s validation fails. It follows that if a setter returns a value, that value is consistent.
Here is why transactions are serializable. If a transaction A successfully changes its status from ACTIVE to COMMITTED, then it must still be owner of all the objects it accessed, because any transaction that usurps A’s ownership must abort A first. It follows that none of the objects it read or wrote have changed since A accessed them, so A is effectively updating a snapshot of the objects it accessed.
In Detail
Opening an object requires changing multiple fields atomically, modifying the owner, old version, and new version fields. Without locks, the only way to accomplish this atomic multi-field update is to introduce a level of indirection. As shown in Fig. 18.22, the FreeObject class has a single field, start, that is an AtomicReference to a Locator object (Line 3), which holds the object’s current transaction, old version, and new version (Lines 5–7).

Figure 18.22 The FreeObject class: the inner Locator class.
Recall that an object field is modified in the following steps: (1) call openWrite() to acquire an object version, (2) tentatively modify that version, and (3) call validate() to ensure the version is still good. Fig. 18.23 shows the FreeObject class’s openWrite() method. First, the thread tests its own transactional state (Line 14). If that state is committed, then the thread is not running in a transaction, and updates the object directly (Line 15). If that state is aborted, then the thread immediately throws an AbortedException exception (Line 16). Finally, if the transaction is active, then the thread reads the current locator and checks whether it has already opened this object for writing, returning immediately if so (Line 19). Otherwise, it enters a loop (Line 22) where it repeatedly initializes and tries to install a new locator. To determine the object’s current value, the thread checks the status of the last transaction to write the object (Line 25), using the new version if the owner is committed (Line 27) and the old version if it is ABORTED (Line 30). If the owner is still active (Line 30), there there is a synchronization conflict, and the thread calls the contention manager module to resolve the conflict. In the absence of conflict, the thread creates and initializes a new version (Lines 37–39). Finally, the thread calls compareAndSet() to replace the old locator with the new, returning if it succeeds, and retrying if it fails.

Figure 18.23 The FreeObject class: the openWrite() method.
The openRead() method (not shown) works in the same way, except that it does not need to make a copy of the old version.
The FreeObject class’s validate() method (not shown) simply checks that current thread’s transaction status is ACTIVE.
18.3.8 A Lock-Based Atomic Object
The obstruction-free implementation is somewhat inefficient because writes continually allocate locators and versions and reads must go through two levels of indirection (two references) to reach the actual data to be read. In this section, we present a more efficient atomic object implementation that uses short critical sections to eliminate the need for a locator and to remove a level of indirection.
A lock-based STM could lock each object as it is read or written. Many applications, however, follow the 80/20 rule: roughly 80% of accesses are reads and roughly 20% are writes. Locking an object is expensive, since it requires a compareAndSet() call, which seems excessive when read/write conflicts are expected to be infrequent. Is it really necessary to lock objects for reading? The answer is no.
Bird’s-Eye View
The lock-based atomic object implementation reads objects optimistically, and later checks for conflicts. It detects conflicts using a global version clock, a counter shared by all transactions and incremented each time a transaction commits. When a transaction starts, it records the current version clock value in a thread-local read stamp.
Each object has the following fields: the stamp field is the read stamp of the last transaction to write to that object, the version field is an instance of the sequential object, and the lock field is a lock. As explained earlier, the sequential type must implement the Copyable interface, and provide a no-argument constructor.
The transaction virtually executes a sequence of read and write accesses to objects. By “virtually”, we mean that no objects are actually modified. Instead, the transaction uses a thread-local read set to keep track of the objects it has read, and a thread-local write set to keep track of the objects it intends to modify, and their tentative new versions.
When a transaction calls a getter to return a field value, the LockObject’s openRead() method first checks whether the object already appears in the write set. If so, it returns the tentative new version. Otherwise, it checks whether the object is locked. If so, there is a synchronization conflict, and the transaction aborts. If not, openRead() adds the object to the read set and returns its version.
The openWrite() method is similar. If the object is not found in the write set, the method creates a new, tentative version, adds the tentative version to the write set, and returns that version.
The validate() method checks that the object’s stamp is not greater than the transaction’s read stamp. If so, a conflict exists, and the transaction aborts. If not, the getter returns the value read in the previous step.
It is important to understand that the LockObject’s validate() method guarantees only that the value is consistent. It does not guarantee that the caller is not a zombie transaction. Instead, a transaction must take the following steps to commit.
1. It locks each of the objects in its write set, in any convenient order, using timeouts to avoid deadlock.
2. It uses compareAndSet() to increment the global version clock, storing the result in a thread-local write stamp. If the transaction commits, this is the point where it is serialized.
3. The transaction checks that each object in its read set is not locked by another thread, and that each object’s stamp is not greater than the transaction’s read stamp. If this validation succeeds, the transaction commits. (In the special case where the transaction’s write stamp is one more than its read stamp, there is no need to validate the read set, because no concurrent modification could have happened.)
4. The transaction updates the stamp field of each object in its write set. Once the stamps are updated, the transaction releases its locks.
If any of these tests fails, the transaction aborts, discards its read and write sets, and releases any locks it is holding.
Fig. 18.24 shows an example execution.
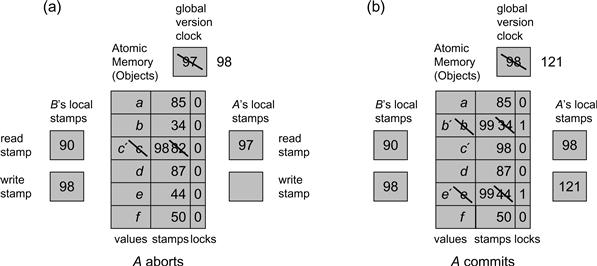
Figure 18.24 The LockObject class: A lock-based transactional memory implementation. In Part (a) thread A starts its transaction, setting its read stamp rs to 97, the global version clock value. Before A starts reading and writing objects, thread B commits: it increments the global version clock to 98, records 98 in its local write stamp ws field, and after a successful validation writes a new value c′ with stamp 98. (B’s acquisition and release of the object locks is not shown.) When A reads the object with stamp 98, it detects thread B’s modification because its read stamp is less than 98, so A aborts. In Part (b) on the other hand, A starts its transaction after B completed, and reads a read stamp value of 98, and does not abort when reading c′. A creates read–write sets, and increments the global version clock. (Notice that other threads have incremented the clock to 120.). It locks the objects it intends to modify, and successfully validates. It then updates the values and stamps of these objects based on the write stamp value. In the figure, we do not show A’s final release of the locks on the written objects.
Why It Works
Transactions are serializable in the order they increment the global version clock. Here is why every transaction observes a consistent state. If A, with read stamp r, observes that the object is not locked, then this version will have the latest stamp not exceeding r. Any transaction that modifies the object at a later time locks the object, increments the global version clock, and sets that object’s stamp to the new version clock value, which exceeds r. If A observes the object is not locked, then A cannot miss an update with a stamp less than or equal to r. A also checks that the object’s stamp does not exceed r by reading and testing the stamp after it reads the field.
Here is why transactions are serializable. We claim that if A reads x and A later commits, then x could not have changed between the time A first reads x and the time A increments the global version clock. As noted earlier, if A with read stamp r observes x is unlocked at time t, then any subsequent modifications to x will give x a stamp larger than r. If a transaction B commits before A, and modifies an object read by A, then A’s validation handler will either observe that x is locked by B, or that x’s stamp is greater than r, and will abort either way.
In Detail
Before we describe the algorithm, we describe the basic data structures. Fig. 18.25 shows the WriteSet class used by the locking implementation. This class is essentially a map from objects to versions, sending each object written by the transaction to its tentative new version. In addition to the get() and set() methods, the class also includes methods to lock and unlock each object in the table. The ReadSet class (not shown) is just a set of objects.

Figure 18.25 The LockObject class: the inner WriteSet class.
Fig. 18.26 shows the version clock. All fields and methods are static. The class manages a singe global version counter, and a set of thread-local read stamps. The getWriteStamp() method returns the current global version and setWriteStamp() advances it by one. The getReadStamp() method returns the caller’s thread-local read stamp, and setReadStamp() sets the thread-local read stamp to the current global clock value.

Figure 18.26 The VersionClock class.
The LockObject class (Fig. 18.27) has three fields: the object’s lock, its read stamp, and the object’s actual data. Fig. 18.28 shows how to open an object for reading. If a copy of the object is not already in the transaction’s write set (Line 13), then it places the object in the transaction’s read set. If, however, the object is locked, then it is in the middle of an update by a concurrent transaction, and the reader aborts (Line 15). If the object has a tentative version in the write set, it returns that version (Line 19).

Figure 18.27 The LockObject class: fields.

Figure 18.28 The LockObject class: the openRead() method.
Fig. 18.29 shows the LockObject class’s openWrite() method. If the call occurs outside a transaction (Line 31), it simply returns the object’s current version. If the transaction is active (Line 33), it tests whether the object is in its write set (Line 35). If so, it returns that version. If not, the caller aborts if the object is locked (Line 37). Otherwise it creates a new, tentative version using the type’s no-argument constructor (Line 39), initializes it by copying the old version (Line 40), puts it in the write set (Line 41), and returns the tentative version.

Figure 18.29 The LockObject class: the openWrite() method.
The validate() method simply checks whether the object’s read stamp is less than or equal to the transaction’s read stamp (Line 56).

Figure 18.30 The LockObject class: the validate() method.
We now look at how a transaction commits. Recall that TinyTM allows users to register handlers to be executed on validation, commit, and abort. Fig. 18.31 shows how the locking TM validates transactions. It first locks each object in the write set (Line 66). If the lock acquisition times out, there may be a deadlock, so the method returns false, meaning the transaction should not commit. It then validates the read set. For each object, it checks that it is not locked by another transaction (Line 70) and that the object’s stamp does not exceed the transaction’s read stamp (Line 72).

Figure 18.31 The LockObject class: the onValidate() hander.
If validation succeeds, the transaction may now commit. Fig. 18.32 shows the onCommit() handler. It increments the version clock (Line 83), copies the tentative versions from the write set back to the original objects (Lines 86–89) and sets each object’s stamp to the newly incremented version clock value (Line 90). Finally, it releases the locks, and clears the thread-local read–write sets for the next transaction.

Figure 18.32 The LockObject class: the onCommit() handler.
What have we learned so far? We have seen how a single transactional memory framework can support two substantially different kinds of synchronization mechanisms: one obstruction-free, and one employing short-lived locking. Each of these implementations, by itself, provides weak progress guarantees, so we rely on a separate contention manager to ensure progress.
18.4 Hardware Transactional Memory
We now describe how a standard hardware architecture can be augmented to support short, small transactions directly in hardware. The HTM design presented here is high-level and simplified, but it covers the principal aspects of HTM design. Readers unfamiliar with cache coherence protocols may consult Appendix B.
The basic idea behind HTM is that modern cache-coherence protocols already do most of what we need to do to implement transactions. They already detect and resolve synchronization conflicts between writers, and between readers and writers, and they already buffer tentative changes instead of updating memory directly. We need change only a few details.
18.4.1 Cache Coherence
In most modern multiprocessors, each processor has an attached cache, a small, high-speed memory used to avoid communicating with large and slow main memory. Each cache entry holds a group of neighboring words called a line, and has some way of mapping addresses to lines. Consider a simple architecture in which processors and memory communicate over a shared broadcast medium called a bus. Each cache line has a tag, which encodes state information. We start with the standard MESI protocol, in which each cache line is marked with one of the following states:
![]() Modified: the line in the cache has been modified, and must eventually be written back to memory. No other processor has this line cached.
Modified: the line in the cache has been modified, and must eventually be written back to memory. No other processor has this line cached.
![]() Exclusive: the line has not been modified, but no other processor has this line cached. (A line is typically loaded in exclusive mode before being modified.)
Exclusive: the line has not been modified, but no other processor has this line cached. (A line is typically loaded in exclusive mode before being modified.)
![]() Shared: the line has not been modified, and other processors may have this line cached.
Shared: the line has not been modified, and other processors may have this line cached.
The cache coherence protocol detects synchronization conflicts among individual loads and stores, and ensures that different processors agree on the state of the shared memory. When a processor loads or stores a memory address a, it broadcasts the request on the bus, and the other processors and memory listen in (sometimes called snooping).
A full description of a cache coherence protocol can be complex, but here are the principal transitions of interest to us.
![]() When a processor requests to load a line in exclusive mode, the other processors invalidate any copies of that line. Any processor with a modified copy of that line must write the line back to memory before the load can be fulfilled.
When a processor requests to load a line in exclusive mode, the other processors invalidate any copies of that line. Any processor with a modified copy of that line must write the line back to memory before the load can be fulfilled.
![]() When a processor requests to load a line into its cache in shared mode, any processor with an exclusive copy must change its state to shared, and any processor with a modified copy must write that line back to memory before the load can be fulfilled.
When a processor requests to load a line into its cache in shared mode, any processor with an exclusive copy must change its state to shared, and any processor with a modified copy must write that line back to memory before the load can be fulfilled.
![]() If the cache becomes full, it may be necessary to evict a line. If the line is shared or exclusive, it can simply be discarded, but if it is modified, it must be written back to memory.
If the cache becomes full, it may be necessary to evict a line. If the line is shared or exclusive, it can simply be discarded, but if it is modified, it must be written back to memory.
We now show how to adapt this protocol to support transactions.
18.4.2 Transactional Cache Coherence
We keep the same MESI protocol as before, except that we add a transactional bit to each cache line’s tag. Normally, this bit is unset. When a value is placed in the cache line on behalf of a transaction, this bit is set, and we say the entry is transactional. We only need to ensure that modified transactional lines cannot be written back to memory, and that invalidating a transactional line aborts the transaction.
Here are the rules in more detail.
![]() If the MESI protocol invalidates a transactional entry, then that transaction is aborted. Such an invalidation represents a synchronization conflict, either between two stores, or a load and a store.
If the MESI protocol invalidates a transactional entry, then that transaction is aborted. Such an invalidation represents a synchronization conflict, either between two stores, or a load and a store.
![]() If a modified transactional line is invalidated or evicted, its value is discarded instead of being written to memory. Because any transactionally written value is tentative, we cannot let it “escape” while the transaction is active. Instead, we must abort the transaction.
If a modified transactional line is invalidated or evicted, its value is discarded instead of being written to memory. Because any transactionally written value is tentative, we cannot let it “escape” while the transaction is active. Instead, we must abort the transaction.
![]() If the cache evicts a transactional line, then that transaction must be aborted, because once the line is no longer in the cache, then the cache-coherence protocol cannot detect synchronization conflicts.
If the cache evicts a transactional line, then that transaction must be aborted, because once the line is no longer in the cache, then the cache-coherence protocol cannot detect synchronization conflicts.
If, when a transaction finishes, none of its transactional lines have been invalidated or evicted, then it can commit, clearing the transactional bits in its cache lines. If an invalidation or eviction causes the transaction to abort, its transactional cache lines are invalidated. These rules ensure that commit and abort are processor-local steps.
18.4.3 Enhancements
Although the scheme correctly implements a transactional memory in hardware, it has a number of flaws and limitations. One limitation, common to nearly all HTM proposals, is that the size of the transaction is limited by the size of the cache. Most operating systems clean out the cache when a thread is descheduled, so the duration of the transaction may be limited by the length of the platform’s scheduling quantum. It follows that HTM is best suited for short, small transactions. Applications that need longer transactions should use STM, or a combination of HTM and STM. When a transaction aborts, however, it is important that the hardware return a condition code indicating whether the abort was due to a synchronization conflict (so the transaction should be retried), or whether it was due to resource exhaustion (so there is no point in retrying the transaction).
This particular design, however, has some additional drawbacks. Many caches are direct-mapped, meaning that an address a maps to exactly one cache line. Any transaction that accesses two addresses that map to the same cache line is doomed to fail, because the second access will evict the first, aborting the transaction. Some caches are set-associative, mapping each address to a set of k lines. Any transaction that accesses k + 1 addresses that map to the same set is doomed to fail. Few caches are fully-associative, mapping each address to any line in the cache.
There are several ways to alleviate this problem by splitting the cache. One is to split the cache into a large, direct-mapped main cache and a small fully associated victim cache used to hold entries that overflow from the main cache. Another is to split the cache into a large set-associated non-transactional cache, and a small fully-associative transactional cache for transactional lines. Either way, the cache coherence protocol must be adapted to handle coherence between the split caches.
Another flaw is the absence of contention management, which means that transactions can starve one another. Transaction A loads address a in exclusive mode, then transaction B loads a in exclusive mode, aborting A. A immediately restarts, aborting B, and so on. This problem could be addressed at the level of the coherence protocol, allowing a processor to refuse or delay an invalidation request, or it could be addressed at the software level, perhaps by having aborted transactions execute exponential backoff in software.
Readers interested in addressing these issues in depth may consult the chapter notes.
18.5 Chapter Notes
Maurice Herlihy and Eliot Moss [67] were the first to propose hardware transactional memory as a general-purpose programming model for multiprocessors. Nir Shavit and Dan Touitou [142] proposed the first software transactional memory. The retry and orElse constructs are credited to Tim Harris, Simon Marlowe, Simon Peyton-Jones, and Maurice Herlihy [54]. Many papers, both earlier and later, have contributed to this area. Larus and Rajwar [97] provide the authoritative survey of both the technical issues and the literature.
The Karma contention manager is taken from William Scherer and Michael Scott [137], and the Greedy contention manager from Rachid Guerraoui, Maurice Herlihy, and Bastian Pochon [49]. The obstruction-free STM is based on the Dynamic Software Transactional Memory algorithm of Maurice Herlihy, Victor Luchangco, Mark Moir, and Bill Scherer [66]. The lock-based STM is based on the Transactional Locking 2 algorithm of Dave Dice, Ori Shalev, and Nir Shavit [32].
Exercise 211. Implement the Priority, Greedy, and Karma contention managers.
Exercise 212. Describe the meaning of orElse without mentioning transaction roll-back.
Exercise 213. In TinyTM, implement the openRead() method of the FreeObject class. Notice that the order in which the Locator fields are read is important. Argue why your implementation provides a serializable read of an object.
Exercise 214. Invent a way to reduce the contention on the global version clock in TinyTM.
Exercise 215. Extend the LockObject class to support concurrent readers.
Exercise 216. In TinyTM, the LockObject class’s onCommit() handler first checks whether the object is locked by another transaction, and then whether its stamp is less than or equal to the transaction’s read stamp.
![]() Give an example showing why it is necessary to check whether the object is locked.
Give an example showing why it is necessary to check whether the object is locked.
![]() Is it possible that the object could be locked by the committing transaction?
Is it possible that the object could be locked by the committing transaction?
![]() Give an example showing why it is necessary to check whether the object is locked before checking the version number.
Give an example showing why it is necessary to check whether the object is locked before checking the version number.
Exercise 217. Design an AtomicArray<T> implementation optimized for small arrays such as used in a skiplist.
Exercise 218. Design an AtomicArray<T> implementation optimized for large arrays in which transactions access disjoint regions within the array.
1 Kernel v2.4.19 /fs/buffer.c
2 Some definitions of serializability in the literature do not require transactions to be serialized in an order compatible with their real-time precedence order.
3 A zombie is a reanimated human corpse. Stories of zombies originated in the Afro-Caribbean spiritual belief system of Vodou.
4 Dating back to 1400 BC, Pythia, the Oracle of Delphi, provided advice and predictions about crops and wars.