
Chapter 7
Local Filesystems
7.1 Hierarchical Filesystem Management
The operations defined for local filesystems are divided into two parts. Common to all local filesystems are hierarchical naming, locking, quotas, attribute management, and protection. These features, which are independent of how data are stored, are provided by the UFS code described in this chapter. The other part of the local filesystem is concerned with the organization and management of the data on the storage media. Storage is managed by the datastore filesystem operations described in Chapter 8.
The vnode operations defined for doing hierarchical filesystem operations are shown in Table 7.1. The most complex of these operations is that for doing a lookup. The filesystem-independent part of the lookup was described in Section 6.5. The algorithm used to look up a pathname component in a directory is described in Section 7.3.
Table 7.1 Hierarchical filesystem operations.

There are five operators for creating names. The operator used depends on the type of object being created. The create operator creates regular files and also is used by the networking code to create AF_LOCAL domain sockets. The link operator creates additional names for existing objects. The symlink operator creates a symbolic link (see Section 7.3 for a discussion of symbolic links). The mknod operator creates block and character special devices; it is also used to create FIFOs. The mkdir operator creates directories.
There are three operators for changing or deleting existing names. The rename operator deletes a name for an object in one location and creates a new name for the object in another location. The implementation of this operator is complex when the kernel is dealing with the movement of a directory from one part of the filesystem tree to another. The remove operator removes a name. If the removed name is the final reference to the object, the space associated with the underlying object is reclaimed. The remove operator operates on all object types except directories; they are removed using the rmdir operator.
Three operators are supplied for object attributes. The kernel retrieves attributes from an object using the getattr operator; it stores them using the setattr operator. Access checks for a given user are provided by the access operator.
Five operators are provided for interpreting objects. The open and close operators have only peripheral use for regular files, but, when used on special devices, are used to notify the appropriate device driver of device activation or shutdown. The readdir operator converts the filesystem-specific format of a directory to the standard list of directory entries expected by an application. Note that the interpretation of the contents of a directory is provided by the hierarchical filesystem-management layer; the filestore code considers a directory as just another object holding data. The readlink operator returns the contents of a symbolic link. As it does directories, the filestore code considers a symbolic link as just another object holding data. The mmap operator prepares an object to be mapped into the address space of a process.
Three operators are provided to allow process control over objects. The select operator allows a process to find out whether an object is ready to be read or written. The ioctl operator passes control requests to a special device. The advlock operator allows a process to acquire or release an advisory lock on an object. None of these operators modifies the object in the filestore. They are simply using the object for naming or directing the desired operation.
There are five operations for management of the objects. The inactive and reclaim operators were described in Section 6.6. The lock and unlock operators allow the callers of the vnode interface to provide hints to the code that implement operations on the underlying objects. Stateless filesystems such as NFS ignore these hints. Stateful filesystems, however, can use hints to avoid doing extra work. For example, an open system call requesting that a new file be created requires two steps. First, a lookup call is done to see if the file already exists. Before the lookup is started, a lock request is made on the directory being searched. While scanning through the directory checking for the name, the lookup code also identifies a location within the directory that contains enough space to hold the new name. If the lookup returns successfully (meaning that the name does not already exist), the open code verifies that the user has permission to create the file. If the user is not eligible to create the new file, then the abortop operator is called to release any resources held in reserve. Otherwise, the create operation is called. If the filesystem is stateful and has been able to lock the directory, then it can simply create the name in the previously identified space, because it knows that no other processes will have had access to the directory. Once the name is created, an unlock request is made on the directory. If the filesystem is stateless, then it cannot lock the directory, so the create operator must rescan the directory to find space and to verify that the name has not been created since the lookup.
7.2 Structure of an Inode
To allow files to be allocated concurrently and random access within files, 4.4BSD uses the concept of an index node, or inode. The inode contains information about the contents of the file, as shown in Fig. 7.1. This information includes
Figure 7.1 The structure of an inode.
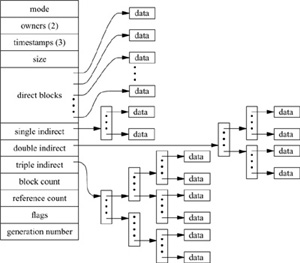
• The type and access mode for the file
• The file’s owner
• The group-access identifier
• The time that the file was most recently read and written
• The time that the inode was most recently updated by the system
• The size of the file in bytes
• The number of physical blocks used by the file (including blocks used to hold indirect pointers)
• The number of references to the file
• The flags that describe characteristics of the file
• The generation number of the file (a unique number selected to be the approximate creation time of the file and assigned to the inode each time that the latter is allocated to a new file; the generation number is used by NFS to detect references to deleted files)
Notably missing in the inode is the filename. Filenames are maintained in directories, rather than in inodes, because a file may have many names, or links, and the name of a file may be large (up to 255 bytes in length). Directories are described in Section 7.3.
To create a new name for a file, the system increments the count of the number of names referring to that inode. Then, the new name is entered in a directory, along with the number of the inode. Conversely, when a name is deleted, the entry is deleted from a directory, and the name count for the inode is then decremented. When the name count reaches zero, the system deallocates the inode by putting all the inode’s blocks back on a list of free blocks and by putting the inode back on a list of unused inodes.
The inode also contains an array of pointers to the blocks in the file. The system can convert from a logical block number to a physical sector number by indexing into the array using the logical block number. A null array entry shows that no block has been allocated and will cause a block of zeros to be returned on a read. On a write of such an entry, a new block is allocated, the array entry is updated with the new block number, and the data are written to the disk.
Inodes are statically allocated and most files are small, so the array of pointers must be small for efficient use of space. The first 12 array entries are allocated in the inode itself. For typical filesystems, this allows the first 48 or 96 Kbyte of data to be located directly via a simple indexed lookup.
For somewhat larger files, Fig. 7.1 shows that the inode contains a single indirect pointer that points to a single indirect block of pointers to data blocks. To find the one-hundredth logical block of a file, the system first fetches the block identified by the indirect pointer, then indexes into the eighty-eighth block (100 minus 12 direct pointers), and fetches that data block.
For files that are bigger than a few Mbyte, the single indirect block is eventually exhausted; these files must resort to using a double indirect block, which is a pointer to a block of pointers to pointers to data blocks. For files of multiple Gbyte, the system uses a triple indirect block, which contains three levels of pointer before reaching the data block.
Although indirect blocks appear to increase the number of disk accesses required to get a block of data, the overhead of the transfer is typically much lower. In Section 6.6, we discussed the management of the filesystem cache that holds recently used disk blocks. The first time that a block of indirect pointers is needed, it is brought into the filesystem cache. Further accesses to the indirect pointers find the block already resident in memory; thus, they require only a single disk access to get the data.
Inode Management
Most of the activity in the local filesystem revolves around inodes. As described in Section 6.6, the kernel keeps a list of active and recently accessed vnodes. The decisions regarding how many and which files should be cached are made by the vnode layer based on information about activity across all filesystems. Each local filesystem will have a subset of the system vnodes to manage. Each uses an inode supplemented with some additional information to identify and locate the set of files for which it is responsible. Figure 7.2 shows the location of the inodes within the system.
Reviewing the material in Section 6.4, each process has a process open-file table that has slots for up to a system-imposed limit of file descriptors; this table is maintained as part of the process state. When a user process opens a file (or socket), an unused slot is located in the process’s open-file table; the small integer file descriptor that is returned on a successful open is an index value into this table.
The per-process file-table entry points to a system open-file entry, which contains information about the underlying file or socket represented by the descriptor. For files, the file table points to the vnode representing the open file. For the local filesystem, the vnode references an inode. It is the inode that identifies the file itself.
Figure 7.2 Layout of kernel tables.
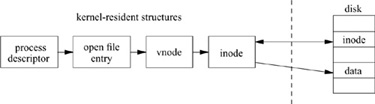
Figure 7.3 Structure of the inode table.

The first step in opening a file is to find the file’s associated vnode. The lookup request is given to the filesystem associated with the directory currently being searched. When the local filesystem finds the name in the directory, it gets the inode number of the associated file. First, the filesystem searches its collection of inodes to see whether the requested inode is already in memory. To avoid doing a linear scan of all its entries, the system keeps a set of hash chains keyed on inode number and filesystem identifier, as shown in Fig. 7.3. If the inode is not in the table, such as the first time a file is opened, the filesystem must request a new vnode. When a new vnode is allocated to the local filesystem, a new structure to hold the inode is allocated.
The next step is to locate the disk block containing the inode and to read that block into a buffer in system memory. When the disk I/O completes, the inode is copied from the disk buffer into the newly allocated inode entry. In addition to the information contained in the disk portion of the inode, the inode table itself maintains supplemental information while the inode is in memory. This information includes the hash chains described previously, as well as flags showing the inode’s status, reference counts on its use, and information to manage locks. The information also contains pointers to other kernel data structures of frequent interest, such as the superblock for the filesystem containing the inode.
When the last reference to a file is closed, the local filesystem is notified that the file has become inactive. When it is inactivated, the inode times will be updated, and the inode may be written to disk. However, it remains on the hash list so that it can be found if it is reopened. After being inactive for a period determined by the vnode layer based on demand for vnodes in all the filesystems, the vnode will be reclaimed. When a vnode for a local file is reclaimed, the inode is removed from the previous filesystem’s hash chain and, if the inode is dirty, its contents are written back to disk. The space for the inode is then deallocated, so that the vnode will be ready for use by a new filesystem client.
7.3 Naming
Filesystems contain files, most of which contain ordinary data. Certain files are distinguished as directories and contain pointers to files that may themselves be directories. This hierarchy of directories and files is organized into a tree structure; Fig. 7.4 shows a small filesystem tree. Each of the circles in the figure represents an inode with its corresponding inode number inside. Each of the arrows represents a name in a directory. For example, inode 4 is the /usr directory with entry ., which points to itself, and entry .., which points to its parent, inode 2, the root of the filesystem. It also contains the name bin, which references directory inode 7, and the name foo, which references file inode 6.
Directories
Directories are allocated in units called chunks; Fig. 7.5 (on page 248) shows a typical directory chunk. The size of a chunk is chosen such that each allocation can be transferred to disk in a single operation; the ability to change a directory in a single operation makes directory updates atomic. Chunks are broken up into variable-length directory entries to allow filenames to be of nearly arbitrary length. No directory entry can span multiple chunks. The first four fields of a directory entry are of fixed length and contain
1. An index into a table of on-disk inode structures; the selected entry describes the file (inodes were described in Section 7.2)
Figure 7.4 A small filesystem tree.
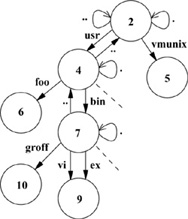
Figure 7.5 Format of directory chunks.
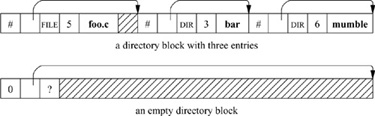
2. The size of the entry in bytes
3. The type of the entry
4. The length of the filename contained in the entry in bytes
The remainder of an entry is of variable length and contains a null-terminated file-name, padded to a 4-byte boundary. The maximum length of a filename in a directory is 255 characters.
The filesystem records free space in a directory by having entries accumulate the free space in their size fields. Thus, some directory entries are larger than required to hold the entry name plus fixed-length fields. Space allocated to a directory should always be accounted for completely by the total of the sizes of the directory’s entries. When an entry is deleted from a directory, the system coalesces the entry’s space into the previous entry in the same directory chunk by increasing the size of the previous entry by the size of the deleted entry. If the first entry of a directory chunk is free, then the pointer to the entry’s inode is set to zero to show that the entry is unallocated.
Applications obtain chunks of directories from the kernel by using the getdirentries system call. For the local filesystem, the on-disk format of directories is identical to that expected by the application, so the chunks are returned uninterpreted. When directories are read over the network or from non-BSD filesystems such as MS-DOS, the getdirentries system call has to convert the on-disk representation of the directory to that described.
Normally, programs want to read directories one entry at a time. This interface is provided by the directory-access routines. The opendir() function returns a structure pointer that is used by readdir() to get chunks of directories using getdirentries; readdir() returns the next entry from the chunk on each call. The closedir() function deallocates space allocated by opendir() and closes the directory. In addition, there is the re winddir() function to reset the read position to the beginning, the telldir() function that returns a structure describing the current directory position, and the seekdir() function that returns to a position previously obtained with telldir().
Finding of Names in Directories
A common request to the filesystem is to look up a specific name in a directory. The kernel usually does the lookup by starting at the beginning of the directory and going through, comparing each entry in turn. First, the length of the sought-after name is compared with the length of the name being checked. If the lengths are identical, a string comparison of the name being sought and the directory entry is made. If they match, the search is complete; if they fail, either in the length or in the string comparison, the search continues with the next entry. Whenever a name is found, its name and containing directory are entered into the systemwide name cache described in Section 6.6. Whenever a search is unsuccessful, an entry is made in the cache showing that the name does not exist in the particular directory. Before starting a directory scan, the kernel looks for the name in the cache. If either a positive or negative entry is found, the directory scan can be avoided.
Another common operation is to look up all the entries in a directory. For example, many programs do a stat system call on each name in a directory in the order that the names appear in the directory. To improve performance for these programs, the kernel maintains the directory offset of the last successful lookup for each directory. Each time that a lookup is done in that directory, the search is started from the offset at which the previous name was found (instead of from the beginning of the directory). For programs that step sequentially through a directory with n files, search time decreases from Order (n2)to Order (n).
One quick benchmark that demonstrates the maximum effectiveness of the cache is running the ls –l command on a directory containing 600 files. On a system that retains the most recent directory offset, the amount of system time for this test is reduced by 85 percent on a directory containing 600 files. Unfortunately, the maximum effectiveness is much greater than the average effectiveness. Although the cache is 90-percent effective when hit, it is applicable to only about 25 percent of the names being looked up. Despite the amount of time spent in the lookup routine itself decreasing substantially, the improvement is diminished because more time is spent in the routines that that routine calls. Each cache miss causes a directory to be accessed twice—once to search from the middle to the end, and once to search from the beginning to the middle.
Pathname Translation
We are now ready to describe how the filesystem looks up a pathname. The small filesystem introduced in Fig. 7.4 is expanded to show its internal structure in Fig. 7.6 (on page 250). Each of the files in Fig. 7.4 is shown expanded into its constituent inode and data blocks. As an example of how these data structures work, consider how the system finds the file /usr/bin/vi. It must first search the root directory of the filesystem to find the directory usr. It first finds the inode that describes the root directory. By convention, inode 2 is always reserved for the root directory of a filesystem; therefore, the system finds and brings inode 2 into memory. This inode shows where the data blocks are for the root directory; these data blocks must also be brought into memory so that they can be searched for the entry usr. Having found the entry for usr, the system knows that the contents of usr are described by inode 4. Returning once again to the disk, the system fetches inode 4 to find where the data blocks for usr are located. Searching these blocks, it finds the entry for bin. The bin entry points to inode 7. Next, the system brings in inode 7 and its associated data blocks from the disk, to search for the entry for vi. Having found that vi is described by inode 9, the system can fetch this inode and the blocks that contain the vi binary.
Figure 7.6 Internal structure of a small filesystem.

Links
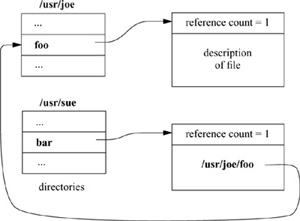
Each file has a single inode, but multiple directory entries in the same filesystem may reference that inode (i.e., the inode may have multiple names). Each directory entry creates a hard link of a filename to the inode that describes the file’s contents. The link concept is fundamental; inodes do not reside in directories, but rather exist separately and are referenced by links. When all the links to an inode are removed, the inode is deallocated. If one link to a file is removed and the file-name is recreated with new contents, the other links will continue to point to the old inode. Figure 7.7 shows two different directory entries, foo and bar, that reference the same file; thus, the inode for the file shows a reference count of 2.
The system also supports a symbolic link, or soft link. A symbolic link is implemented as a file that contains a pathname. When the system encounters a symbolic link while looking up a component of a pathname, the contents of the symbolic link are prepended to the rest of the pathname; the lookup continues with the resulting pathname. If a symbolic link contains an absolute pathname, that absolute pathname is used; otherwise, the contents of the symbolic link are evaluated relative to the location of the link in the file hierarchy (not relative to the current working directory of the calling process).
An example symbolic link is shown in Fig. 7.8 (on page 252). Here, there is a hard link, foo, that points to the file. The other reference, bar, points to a different inode whose contents are a pathname of the referenced file. When a process opens bar, the system interprets the contents of the symbolic link as a pathname to find the file the link references. Symbolic links are treated like data files by the system, rather than as part of the filesystem structure; thus, they can point at directories or files on other filesystems. If a filename is removed and replaced, any symbolic links that point to it will access the new file. Finally, if the filename is not replaced, the symbolic link will point at nothing, and any attempt to access it will be an error.
Figure 7.7 Hard links to a file.

Figure 7.8 Symbolic link to a file.
When open is applied to a symbolic link, it returns a file descriptor for the file pointed to, not for the link itself. Otherwise, it would be necessary to use indirection to access the file pointed to—and that file, rather than the link, is what is usually wanted. For the same reason, most other system calls that take pathname arguments also follow symbolic links. Sometimes, it is useful to be able to detect a symbolic link when traversing a filesystem or when making an archive tape. So, the lstat system call is available to get the status of a symbolic link, instead of the object at which that link points.
A symbolic link has several advantages over a hard link. Since a symbolic link is maintained as a pathname, it can refer to a directory or to a file on a different filesystem. So that loops in the filesystem hierarchy are prevented, unprivileged users are not permitted to create hard links (other than . and ..) that refer to a directory. The implementation of hard links prevents hard links from referring to files on a different filesystem.
There are several interesting implications of symbolic links. Consider a process that has current working directory /usr/keith and does cd src, where src is a symbolic link to directory /usr/src. If the process then does a cd .., then the current working directory for the process will be in /usr instead of in /usr/keith, as it would have been if src was a normal directory instead of a symbolic link. The kernel could be changed to keep track of the symbolic links that a process has traversed, and to interpret .. differently if the directory has been reached through a symbolic link. There are two problems with this implementation. First, the kernel would have to maintain a potentially unbounded amount of information. Second, no program could depend on being able to use .., since it could not be sure how the name would be interpreted.
Many shells keep track of symbolic-link traversals. When the user changes directory through .. from a directory that was entered through a symbolic link, the shell returns the user to the directory from which they came. Although the shell might have to maintain an unbounded amount of information, the worst that will happen is that the shell will run out of memory. Having the shell fail will affect only the user silly enough to traverse endlessly through symbolic links. Tracking of symbolic links affects only change-directory commands in the shell; programs can continue to depend on .. referencing its true parent. Thus, tracking symbolic links outside of the kernel in a shell is reasonable.
Since symbolic links may cause loops in the filesystem, the kernel prevents looping by allowing at most eight symbolic link traversals in a single pathname translation. If the limit is reached, the kernel produces an error (ELOOP).
7.4 Quotas
Resource sharing always has been a design goal for the BSD system. By default, any single user can allocate all the available space in the filesystem. In certain environments, uncontrolled use of disk space is unacceptable. Consequently, 4.4BSD includes a quota mechanism to restrict the amount of filesystem resources that a user or members of a group can obtain. The quota mechanism sets limits on both the number of files and the number of disk blocks that a user or members of a group may allocate. Quotas can be set separately for each user and group on each filesystem.
Quotas support both hard and soft limits. When a process exceeds its soft limit, a warning is printed on the user’s terminal; the offending process is not prevented from allocating space unless it exceeds its hard limit. The idea is that users should stay below their soft limit between login sessions, but may use more resources while they are active. If a user fails to correct the problem for longer than a grace period, the soft limit starts to be enforced as the hard limit. The grace period is set by the system administrator and is 7 days by default. These quotas are derived from a larger resource-limit package that was developed at the University of Melbourne in Australia by Robert Elz [Elz, 1984].
Quotas connect into the system primarily as an adjunct to the allocation routines. When a new block is requested from the allocation routines, the request is first validated by the quota system with the following steps:
1. If there is a user quota associated with the file, the quota system consults the quota associated with the owner of the file. If the owner has reached or exceeded their limit, the request is denied.
2. If there is a group quota associated with the file, the quota system consults the quota associated with the group of the file. If the group has reached or exceeded its limit, the request is denied.
3. If the quota tests pass, the request is permitted and is added to the usage statistics for the file.
When either a user or group quota would be exceeded, the allocator returns a failure as though the filesystem were full. The kernel propagates this error up to the process doing the write system call.
Quotas are assigned to a filesystem after it has been mounted. A system call associates a file containing the quotas with the mounted filesystem. By convention, the file with user quotas is named quota.user, and the file with group quotas is named quota.group. These files typically reside either in the root of the mounted filesystem or in the /var/quotas directory. For each quota to be imposed, the system opens the appropriate quota file and holds a reference to it in the mount-table entry associated with the mounted filesystem. Figure 7.9 shows the mount-table reference. Here, the root filesystem has a quota on users, but has none on groups. The /usr filesystem has quotas imposed on both users and groups. As quotas for different users or groups are needed, they are taken from the appropriate quota file.
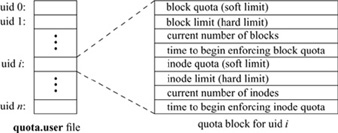
Quota files are maintained as an array of quota records indexed by user or group identifiers; Fig. 7.10 shows a typical record in a user quota file. To find the quota for user identifier i, the system seeks to location i X sizeof (quota structure) in the quota file and reads the quota structure at that location. Each quota structure contains the limits imposed on the user for the associated filesystem. These limits include the hard and soft limits on the number of blocks and inodes that the user may have, the number of blocks and inodes that the user currently has allocated, and the amount of time that the user has remaining before the soft limit is enforced as the hard limit. The group quota file works in the same way, except that it is indexed by group identifier.
Figure 7.9 References to quota files.
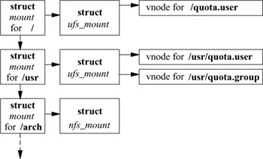
Figure 7.10 Contents of a quota record.
Active quotas are held in system memory in a data structure known as a dquot entry; Fig. 7.11 shows two typical entries. In addition to the quota limits and usage extracted from the quota file, the dquot entry maintains information about the quota while the quota is in use. This information includes fields to allow fast access and identification. Quotas are checked by the chkdq() routine. Since quotas may have to be updated on every write to a file, chkdq() must be able to find and manipulate them quickly. Thus, the task of finding the dquot structure associated with a file is done when the file is first opened for writing. When an access check is done to check for writing, the system checks to see whether there is either a user or a group quota associated with the file. If one or more quotas exist, the inode is set up to hold a reference to the appropriate dquot structures for as long as the inode is resident. The chkdq() routine can determine that a file has a quota simply by checking whether the dquot pointer is nonnull; if it is, all the necessary information can be accessed directly. If a user or a group has multiple files open on the same filesystem, all inodes describing those files point to the same dquot entry. Thus, the number of blocks allocated to a particular user or a group can always be known easily and consistently.
Figure 7.11 Dquot entries.

The number of dquot entries in the system can grow large. To avoid doing a linear scan of all the dquot entries, the system keeps a set of hash chains keyed on the filesystem and on the user or group identifier. Even with hundreds of dquot entries, the kernel needs to inspect only about five entries to determine whether a requested dquot entry is memory resident. If the dquot entry is not resident, such as the first time a file is opened for writing, the system must reallocate a dquot entry and read in the quota from disk. The dquot entry is reallocated from the least recently used dquot entry. So that it can find the oldest dquot entry quickly, the system keeps unused dquot entries linked together in an LRU chain. When the reference count on a dquot structure drops to zero, the system puts that dquot onto the end of the LRU chain. The dquot structure is not removed from its hash chain, so if the structure is needed again soon, it can still be located. Only when a dquot structure is recycled with a new quota record is it removed and relinked into the hash chain. The dquot entry on the front of the LRU chain yields the least recently used dquot entry. Frequently used dquot entries are reclaimed from the middle of the LRU chain and are relinked at the end after use.
The hashing structure allows dquot structures to be found quickly. However, it does not solve the problem of how to discover that a user has no quota on a particular filesystem. If a user has no quota, a lookup for the quota will fail. The cost of going to disk and reading the quota file to discover that the user has no quota imposed would be prohibitive. To avoid doing this work each time that a new file is accessed for writing, the system maintains nonquota dquot entries. When an inode owned by a user or group that does not already have a dquot entry is first accessed, a dummy dquot entry is created that has infinite values filled in for the quota limits. When the chkdq() routine encounters such an entry, it will update the usage fields, but will not impose any limits. When the user later writes other files, the same dquot entry will be found, thus avoiding additional access to the on-disk quota file. Ensuring that a file will always have a dquot entry improves the performance of the writing data, since chkdq() can assume that the dquot pointer is always valid, rather than having to check the pointer before every use.
Quotas are written back to the disk when they fall out of the cache, whenever the filesystem does a sync, or when the filesystem is unmounted. If the system crashes, leaving the quotas in an inconsistent state, the system administrator must run the quotacheck program to rebuild the usage information in the quota files.
7.5 File Locking
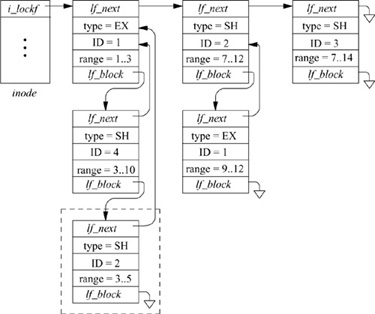
Locks may be placed on any arbitrary range of bytes within a file. These semantics are supported in 4.4BSD by a list of locks, each of which describes a lock of a specified byte range. An example of a file containing several range locks is shown in Fig. 7.12. The list of currently held or active locks appears across the top of the figure, headed by the i_lockf field in the inode, and linked together through the lf_next field of the lock structures. Each lock structure identifies the type of the lock (exclusive or shared), the byte range over which the lock applies, and the identity of the lock holder. A lock may be identified either by a pointer to a process entry or by a pointer to a file entry. A process pointer is used for POSIX-style range locks; a file-entry pointer is used for BSD-style whole file locks. The examples in this section show the identity as a pointer to a process entry. In this example, there are three active locks: an exclusive lock held by process 1 on bytes 1 to 3, a shared lock held by process 2 on bytes 7 to 12, and a shared lock held by process 3 on bytes 7 to 14.
In addition to the active locks, there are other processes that are sleeping waiting to get a lock applied. Pending locks are headed by the lf_block field of the active lock that prevents them from being applied. If there are multiple pending locks, they are linked through their lf_block fields. New lock requests are placed at the end of the list; thus, processes tend to be granted locks in the order that they requested the locks. Each pending lock uses its lf_next field to identify the active lock that currently blocks it. In the example in Fig. 7.12, the first active lock has two other locks pending. There is also a pending request for the range 9 to 12 that is currently linked onto the second active entry. It could equally well have been linked onto the third active entry, since the third entry also blocks it. When an active lock is released, all pending entries for that lock are awakened, so that they can retry their request. If the second active lock were released, the result would be that its currently pending request would move over to the blocked list for the last active entry.
Figure 7.12 A set of range locks on a file.
A problem that must be handled by the locking implementation is the detection of potential deadlocks. To see how deadlock is detected, consider the addition of the lock request by process 2 outlined in the dashed box in Fig. 7.12. Since the request is blocked by an active lock, process 2 must sleep waiting for the active lock on range 1 to 3 to clear. We follow the lf_next pointer from the requesting lock (the one in the dashed box), to identify the active lock for the 1-to-3 range as being held by process 1. The wait channel for process 1 shows that that process too is sleeping, waiting for a lock to clear, and identifies the pending lock structure as the pending lock (range 9 to 12) hanging off the lf_block field of the second active lock (range 7 to 12). We follow the lf_next field of this pending lock structure (range 9 to 12) to the second active lock (range 7 to 12) that is held by the lock requester, process 2. Thus, the lock request is denied, as it would lead to a deadlock between processes 1 and 2. This algorithm works on cycles of locks and processes of arbitrary size.
As we note, the pending request for the range 9 to 12 could equally well have been hung off the third active lock for the range 7 to 14. Had it been, the request for adding the lock in the dashed box would have succeeded, since the third active lock is held by process 3, rather than by process 2. If the next lock request on this file were to release the third active lock, then deadlock detection would occur when process 1’s pending lock got shifted to the second active lock (range 7 to 12). The difference is that process 1, instead of process 2, would get the deadlock error.
When a new lock request is made, it must first be checked to see whether it is blocked by existing locks held by other processes. If it is not blocked by other processes, it must then be checked to see whether it overlaps any existing locks already held by the process making the request. There are five possible overlap cases that must be considered; these possibilities are shown in Fig. 7.13. The assumption in the figure is that the new request is of a type different from that of the existing lock (i.e., an exclusive request against a shared lock, or vice versa); if the existing lock and the request are of the same type, the analysis is a bit simpler. The five cases are as follows:
Figure 7.13 Five types of overlap considered by the kernel when a range lock is added.
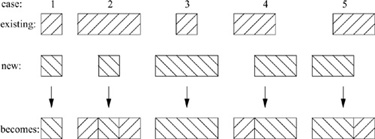
1. The new request exactly overlaps the existing lock. The new request replaces the existing lock. If the new request downgrades from exclusive to shared, all requests pending on the old lock are awakened.
2. The new request is a subset of the existing lock. The existing lock is broken into three pieces (two if the new lock begins at the beginning or ends at the end of the existing lock). If the type of the new request differs from that of the existing lock, all requests pending on the old lock are awakened, so that they can be reassigned to the correct new piece, blocked on a lock held by some other process, or granted.
3. The new request is a superset of an existing lock. The new request replaces the existing lock. If the new request downgrades from exclusive to shared, all requests pending on the old lock are awakened.
4. The new request extends past the end of an existing lock. The existing lock is shortened, and its overlapped piece is replaced by the new request. All requests pending on the existing lock are awakened, so that they can be reassigned to the correct new piece, blocked on a lock held by some other process, or granted.
5. The new request extends into the beginning of an existing lock. The existing lock is shortened, and its overlapped piece is replaced by the new request. All requests pending on the existing lock are awakened, so that they can be reassigned to the correct new piece, blocked on a lock held by some other process, or granted.
In addition to the five basic types of overlap outlined, a request may span several existing locks. Specifically, a new request may be composed of zero or one of type 4, zero or more of type 3, and zero or one of type 5.
To understand how the overlap is handled, we can consider the example shown in Fig. 7.14. This figure shows a file that has all its active range locks held by process 1, plus a pending lock for process 2.
Now consider a request by process 1 for an exclusive lock on the range 3 to 13. This request does not conflict with any active locks (because all the active locks are already held by process 1). The request does overlap all three active locks, so the three active locks represent a type 4, type 3, and type 5 overlap respectively. The result of processing the lock request is shown in Fig. 7.15. The first and third active locks are trimmed back to the edge of the new request, and the second lock is replaced entirely. The request that had been held pending on the first lock is awakened. It is no longer blocked by the first lock, but is blocked by the newly installed lock. So, it now hangs off the blocked list for the second lock. The first and second locks could have been merged, because they are of the same type and are held by the same process. However, the current implementation makes no effort to do such merges, because range locks are normally released over the same range that they were created. If the merger were done, it would probably have to be split again when the release was requested.
Lock-removal requests are simpler than addition requests; they need only to consider existing locks held by the requesting process. Figure 7.16 shows the five possible ways that a removal request can overlap the locks of the requesting process:
1. The unlock request exactly overlaps an existing lock. The existing lock is deleted, and any lock requests that were pending on that lock are awakened.
2. The unlock request is a subset of an existing lock. The existing lock is broken into two pieces (one if the unlock request begins at the beginning or ends at the end of the existing lock). Any locks that were pending on that lock are aw akened, so that they can be reassigned to the correct new piece, blocked on a lock held by some other process, or granted.
Figure 7.14 Locks before addition of exclusive-lock request by process 1 on range 3..13.

Figure 7.15 Locks after addition of exclusive-lock request by process 1 on range 3..13.

3. The unlock request is a superset of an existing lock. The existing lock is deleted, and any locks that were pending on that lock are awakened.
4. The unlock request extends past the end of an existing lock. The end of the existing lock is shortened. Any locks that were pending on that lock are awakened, so that they can be reassigned to the shorter lock, blocked on a lock held by some other process, or granted.
5. The unlock request extends into the beginning of an existing lock. The beginning of the existing lock is shortened. Any locks that were pending on that lock are awakened, so that they can be reassigned to the shorter lock, blocked on a lock held by some other process, or granted.
Figure 7.16 Five types of overlap considered by the kernel when a range lock is deleted.
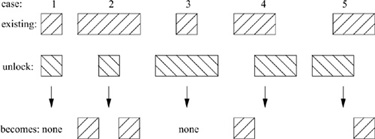
In addition to the five basic types of overlap outlined, an unlock request may span several existing locks. Specifically, a new request may be composed of zero or one of type 4, zero or more of type 3, and zero or one of type 5.
7.6 Other Filesystem Semantics
Two major new filesystem features were introduced in 4.4BSD. The first of these features was support for much larger file sizes. The second was the introduction of file metadata.
Large File Sizes
Traditionally, UNIX systems supported a maximum file and filesystem size of 231 bytes. When the filesystem was rewritten in 4.2BSD, the inodes were defined to allow 64-bit file sizes. However, the interface to the filesystem was still limited to 31-bit sizes. With the advent of ever-larger disks, the developers decided to expand the 4.4BSD interface to allow larger files. Export of 64-bit file sizes from the filesystem requires that the defined type off_t be a 64-bit integer (referred to as long long or quad in most compilers).
The number of affected system calls is surprisingly low:
• lseek has to be able to specify 64-bit offsets
• stat, fstat, and lstat have to return 64-bit sizes
• truncate and ftruncate have to set 64-bit sizes
• mmap needs to start a mapping at any 64-bit point in the file
• getrlimit and setrlimit need to get and set 64-bit filesize limits
Changing these interfaces did cause applications to break. No trouble was encountered with the stat family of system calls returning larger data values; recompiling with the redefined stat structure caused applications to use the new larger values. The other system calls are all changing one of their parameters to be a 64-bit value. Applications that fail to cast the 64-bit argument to off_t may get an incorrect parameter list. Except for lseek, most applications do not use these system calls, so they are not affected by their change. However, many applications use lseek and cast the seek value explicitly to type long. So that there is no need to make changes to many applications, a prototype for lseek is placed in the commonly included header file <sys/types.h>. After this change was made, most applications recompiled and ran without difficulty.
For completeness, the type of size_t also should have been changed to be a 64-bit integer. This change was not made because it would have affected too many system calls. Also, on 32-bit address-space machines, an application cannot read more than can be stored in a 32-bit integer. Finally, it is important to minimize the use of 64-bit arithmetic that is slow on 32-bit processors.
File Flags
4.4BSD added two new system calls, chflags and fchflags, that set a 32-bit flags word in the inode. The flags are included in the stat structure so that they can be inspected.
The owner of the file or the superuser can set the low 16 bits. Currently, there are flags defined to mark a file as append-only, immutable, and not needing to be dumped. An immutable file may not be changed, moved, or deleted. An append-only file is immutable except that data may be appended to it. The user append-only and immutable flags may be changed by the owner of the file or the superuser.
Only the superuser can set the high 16 bits. Currently, there are flags defined to mark a file as append-only and immutable. Once set, the append-only and immutable flags in the top 16 bits cannot be cleared when the system is secure.
The kernel runs with four different levels of security. Any superuser process can raise the security level, but only the init process can lower that level (the init program is described in Section 14.6). Security levels are defined as follows:
–1. Permanently insecure mode : Always run system in level 0 mode (must be compiled into the kernel).
0. Insecure mode : Immutable and append-only flags may be turned off. All devices can be read or written, subject to their permissions.
1. Secure mode : The superuser-settable immutable and append-only flags cannot be cleared; disks for mounted filesystems and kernel memory (/dev/mem and /dev/kmem) are read-only.
2. Highly secure mode : This mode is the same as secure mode, except that disks are always read-only whether mounted or not. This level precludes even a superuser process from tampering with filesystems by unmounting them, but also inhibits formatting of new filesystems.
Normally, the system runs with level 0 security while in single-user mode, and with level 1 security while in multiuser mode. If level 2 security is desired while the system is running in multiuser mode, it should be set in the /etc/rc startup script (the /etc/rc script is described in Section 14.6).
Files marked immutable by the superuser cannot be changed, except by someone with physical access to either the machine or the system console. Files marked immutable include those that are frequently the subject of attack by intruders (e.g., login and su). The append-only flag is typically used for critical system logs. If an intruder breaks in, he will be unable to cover his tracks. Although simple in concept, these two features improve the security of a system dramatically.
Exercises
7.1 What are the seven classes of operations handled by the hierarchical filesystem?
7.2 What is the purpose of the inode data structure?
7.3 How does the system select an inode for replacement when a new inode must be brought in from disk?
7.4 Why are directory entries not allowed to span chunks?
7.5 Describe the steps involved in looking up a pathname component.
7.6 Why are hard links not permitted to span filesystems?
7.7 Describe how the interpretation of a symbolic link containing an absolute pathname is different from that of a symbolic link containing a relative pathname.
7.8 Explain why unprivileged users are not permitted to make hard links to directories, but are permitted to make symbolic links to directories.
7.9 How can hard links be used to gain access to files that could not be accessed if a symbolic link were used instead?
7.10 How does the system recognize loops caused by symbolic links? Suggest an alternative scheme for doing loop detection.
7.11 How do quotas differ from the file-size resource limits described in Section 3.8?
7.12 How does the kernel determine whether a file has an associated quota?
7.13 Draw a picture showing the effect of processing an exclusive-lock request by process 1 on bytes 7 to 10 to the lock list shown in Fig. 7.14. Which of the overlap cases of Fig. 7.13 apply to this example?
*7.14 Give an example where the file-locking implementation is unable to detect a potential deadlock.
**7.15 Design a system that allows the security level of the system to be lowered while the system is still running in multiuser mode.
References
Elz, 1984.
K. R. Elz, “Resource Controls, Privileges, and Other MUSH,” USENIX Association Conference Proceedings, p. 183–191, June 1984.