
Chapter 3
Kernel Services
3.1 Kernel Organization
The 4.4BSD kernel can be viewed as a service provider to user processes. Processes usually access these services through system calls. Some services, such as process scheduling and memory management, are implemented as processes that execute in kernel mode or as routines that execute periodically within the kernel. In this chapter, we describe how kernel services are provided to user processes, and what some of the ancillary processing performed by the kernel is. Then, we describe the basic kernel services provided by 4.4BSD, and provide details of their implementation.
System Processes
All 4.4BSD processes originate from a single process that is crafted by the kernel at startup. Three processes are created immediately and exist always. Two of them are kernel processes, and function wholly within the kernel. (Kernel processes execute code that is compiled into the kernel’s load image and operate with the kernel’s privileged execution mode.) The third is the first process to execute a program in user mode; it serves as the parent process for all subsequent processes.
The two kernel processes are the swapper and the pagedaemon. The swap-per—historically, process 0—is responsible for scheduling the transfer of whole processes between main memory and secondary storage when system resources are low. The pagedaemon—historically, process 2—is responsible for writing parts of the address space of a process to secondary storage in support of the paging facilities of the virtual-memory system. The third process is the init process—historically, process 1. This process performs administrative tasks, such as spawning getty processes for each terminal on a machine and handling the orderly shutdown of a system from multiuser to single-user operation. The init process is a user-mode process, running outside the kernel (see Section 14.6).
System Entry
Entrances into the kernel can be categorized according to the event or action that initiates it;
• Hardware interrupt
• Hardware trap
• Software-initiated trap
Hardware interrupts arise from external events, such as an I/O device needing attention or a clock reporting the passage of time. (For example, the kernel depends on the presence of a real-time clock or interval timer to maintain the current time of day, to drive process scheduling, and to initiate the execution of system timeout functions.) Hardware interrupts occur asynchronously and may not relate to the context of the currently executing process.
Hardware traps may be either synchronous or asynchronous, but are related to the current executing process. Examples of hardware traps are those generated as a result of an illegal arithmetic operation, such as divide by zero.
Software-initiated traps are used by the system to force the scheduling of an event such as process rescheduling or network processing, as soon as is possible. For most uses of software-initiated traps, it is an implementation detail whether they are implemented as a hardware-generated interrupt, or as a flag that is checked whenever the priority level drops (e.g., on every exit from the kernel). An example of hardware support for software-initiated traps is the asynchronous system trap (AST) provided by the VAX architecture. An AST is posted by the kernel. Then, when a return-from-interrupt instruction drops the interrupt-priority level below a threshold, an AST interrupt will be delivered. Most architectures today do not have hardware support for ASTs, so they must implement ASTs in software.
System calls are a special case of a software-initiated trap—the machine instruction used to initiate a system call typically causes a hardware trap that is handled specially by the kernel.
Run-Time Organization
The kernel can be logically divided into a top half and a bottom half, as shown in Fig. 3.1. The top half of the kernel provides services to processes in response to system calls or traps. This software can be thought of as a library of routines shared by all processes. The top half of the kernel executes in a privileged execution mode, in which it has access both to kernel data structures and to the context of user-level processes. The context of each process is contained in two areas of memory reserved for process-specific information. The first of these areas is the process structure, which has historically contained the information that is necessary even if the process has been swapped out. In 4.4BSD, this information includes the identifiers associated with the process, the process’s rights and privileges, its descriptors, its memory map, pending external events and associated actions, maximum and current resource utilization, and many other things. The second is the user structure, which has historically contained the information that is not necessary when the process is swapped out. In 4.4BSD, the user-structure information of each process includes the hardware process control block (PCB), process accounting and statistics, and minor additional information for debugging and creating a core dump. Deciding what was to be stored in the process structure and the user structure was far more important in previous systems than it was in 4.4BSD. As memory became a less limited resource, most of the user structure was merged into the process structure for convenience; see Section 4.2.
Figure 3.1 Run-time structure of the kernel.
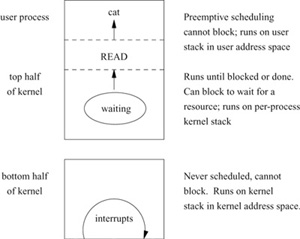
The bottom half of the kernel comprises routines that are invoked to handle hardware interrupts. The kernel requires that hardware facilities be available to block the delivery of interrupts. Improved performance is available if the hardware facilities allow interrupts to be defined in order of priority. Whereas the HP300 provides distinct hardware priority levels for different kinds of interrupts, UNIX also runs on architectures such as the Perkin Elmer, where interrupts are all at the same priority, or the ELXSI, where there are no interrupts in the traditional sense.
Activities in the bottom half of the kernel are asynchronous, with respect to the top half, and the software cannot depend on having a specific (or any) process running when an interrupt occurs. Thus, the state information for the process that initiated the activity is not available. (Activities in the bottom half of the kernel are synchronous with respect to the interrupt source.) The top and bottom halves of the kernel communicate through data structures, generally organized around work queues.
The 4.4BSD kernel is never preempted to run another process while executing in the top half of the kernel—for example, while executing a system call—although it will explicitly give up the processor if it must wait for an event or for a shared resource. Its execution may be interrupted, however, by interrupts for the bottom half of the kernel. The bottom half always begins running at a specific priority level. Therefore, the top half can block these interrupts by setting the processor priority level to an appropriate value. The value is chosen based on the priority level of the device that shares the data structures that the top half is about to modify. This mechanism ensures the consistency of the work queues and other data structures shared between the top and bottom halves.
Processes cooperate in the sharing of system resources, such as the CPU. The top and bottom halves of the kernel also work together in implementing certain system operations, such as I/O. Typically, the top half will start an I/O operation, then relinquish the processor; then the requesting process will sleep, awaiting notification from the bottom half that the I/O request has completed.
Entry to the Kernel
When a process enters the kernel through a trap or an interrupt, the kernel must save the current machine state before it begins to service the event. For the HP300, the machine state that must be saved includes the program counter, the user stack pointer, the general-purpose registers and the processor status longword. The HP300 trap instruction saves the program counter and the processor status long-word as part of the exception stack frame; the user stack pointer and registers must be saved by the software trap handler. If the machine state were not fully saved, the kernel could change values in the currently executing program in improper ways. Since interrupts may occur between any two user-level instructions (and, on some architectures, between parts of a single instruction), and because they may be completely unrelated to the currently executing process, an incompletely saved state could cause correct programs to fail in mysterious and not easily reproduceable ways.
The exact sequence of events required to save the process state is completely machine dependent, although the HP300 provides a good example of the general procedure. A trap or system call will trigger the following events:
• The hardware switches into kernel (supervisor) mode, so that memory-access checks are made with kernel privileges, references to the stack pointer use the kernel’s stack pointer, and privileged instructions can be executed.
• The hardware pushes onto the per-process kernel stack the program counter, processor status longword, and information describing the type of trap. (On architectures other than the HP300, this information can include the system-call number and general-purpose registers as well.)
• An assembly-language routine saves all state information not saved by the hardware. On the HP300, this information includes the general-purpose registers and the user stack pointer, also saved onto the per-process kernel stack.
After this preliminary state saving, the kernel calls a C routine that can freely use the general-purpose registers as any other C routine would, without concern about changing the unsuspecting process’s state.
There are three major kinds of handlers, corresponding to particular kernel entries:
1. Syscall () for a system call
2. Trap () for hardware traps and for software-initiated traps other than system calls
3. The appropriate device-driver interrupt handler for a hardware interrupt
Each type of handler takes its own specific set of parameters. For a system call, they are the system-call number and an exception frame. For a trap, they are the type of trap, the relevant floating-point and virtual-address information related to the trap, and an exception frame. (The exception-frame arguments for the trap and system call are not the same. The HP300 hardware saves different information based on different types of traps.) For a hardware interrupt, the only parameter is a unit (or board) number.
Return from the Kernel
When the handling of the system entry is completed, the user-process state is restored, and the kernel returns to the user process. Returning to the user process reverses the process of entering the kernel.
• An assembly-language routine restores the general-purpose registers and user-stack pointer previously pushed onto the stack.
• The hardware restores the program counter and program status longword, and switches to user mode, so that future references to the stack pointer use the user’s stack pointer, privileged instructions cannot be executed, and memory-access checks are done with user-level privileges.
Execution then resumes at the next instruction in the user’s process.
3.2 System Calls
The most frequent trap into the kernel (after clock processing) is a request to do a system call. System performance requires that the kernel minimize the overhead in fielding and dispatching a system call. The system-call handler must do the following work:
• Verify that the parameters to the system call are located at a valid user address, and copy them from the user’s address space into the kernel
• Call a kernel routine that implements the system call
Result Handling
Eventually, the system call returns to the calling process, either successfully or unsuccessfully. On the HP300 architecture, success or failure is returned as the carry bit in the user process’s program status longword: If it is zero, the return was successful; otherwise, it was unsuccessful. On the HP300 and many other machines, return values of C functions are passed back through a general-purpose register (for the HP300, data register 0). The routines in the kernel that implement system calls return the values that are normally associated with the global variable errno. After a system call, the kernel system-call handler leaves this value in the register. If the system call failed, a C library routine moves that value into errno, and sets the return register to –1. The calling process is expected to notice the value of the return register, and then to examine errno. The mechanism involving the carry bit and the global variable errno exists for historical reasons derived from the PDP-11.
There are two kinds of unsuccessful returns from a system call: those where kernel routines discover an error, and those where a system call is interrupted. The most common case is a system call that is interrupted when it has relinquished the processor to wait for an event that may not occur for a long time (such as terminal input), and a signal arrives in the interim. When signal handlers are initialized by a process, they specify whether system calls that they interrupt should be restarted, or whether the system call should return with an interrupted system call (EINTR) error.
When a system call is interrupted, the signal is delivered to the process. If the process has requested that the signal abort the system call, the handler then returns an error, as described previously. If the system call is to be restarted, however, the handler resets the process’s program counter to the machine instruction that caused the system-call trap into the kernel. (This calculation is necessary because the program-counter value that was saved when the system-call trap was done is for the instruction after the trap-causing instruction.) The handler replaces the saved program-counter value with this address. When the process returns from the signal handler, it resumes at the program-counter value that the handler provided, and reexecutes the same system call.
Restarting a system call by resetting the program counter has certain implications. First, the kernel must not modify any of the input parameters in the process address space (it can modify the kernel copy of the parameters that it makes). Second, it must ensure that the system call has not performed any actions that cannot be repeated. For example, in the current system, if any characters have been read from the terminal, the read must return with a short count. Otherwise, if the call were to be restarted, the already-read bytes would be lost.
Returning from a System Call
While the system call is running, a signal may be posted to the process, or another process may attain a higher scheduling priority. After the system call completes, the handler checks to see whether either event has occurred.
The handler first checks for a posted signal. Such signals include signals that interrupted the system call, as well as signals that arrived while a system call was in progress, but were held pending until the system call completed. Signals that are ignored, by default or by explicit programmatic request, are never posted to the process. Signals with a default action have that action taken before the process runs again (i.e., the process may be stopped or terminated as appropriate). If a signal is to be caught (and is not currently blocked), the handler arranges to have the appropriate signal handler called, rather than to have the process return directly from the system call. After the handler returns, the process will resume execution at system-call return (or system-call execution, if the system call is being restarted).
After checking for posted signals, the handler checks to see whether any process has a priority higher than that of the currently running one. If such a process exists, the handler calls the context-switch routine to cause the higher-priority process to run. At a later time, the current process will again have the highest priority, and will resume execution by returning from the system call to the user process.
If a process has requested that the system do profiling, the handler also calculates the amount of time that has been spent in the system call, i.e., the system time accounted to the process between the latter’s entry into and exit from the handler. This time is charged to the routine in the user’s process that made the system call.
3.3 Traps and Interrupts
Traps
Traps, like system calls, occur synchronously for a process. Traps normally occur because of unintentional errors, such as division by zero or indirection through an invalid pointer. The process becomes aware of the problem either by catching a signal or by being terminated. Traps can also occur because of a page fault, in which case the system makes the page available and restarts the process without the process being aware that the fault occurred.
The trap handler is invoked like the system-call handler. First, the process state is saved. Next, the trap handler determines the trap type, then arranges to post a signal or to cause a pagein as appropriate. Finally, it checks for pending signals and higher-priority processes, and exits identically to the system-call handler.
I/O Device Interrupts
Interrupts from I/O and other devices are handled by interrupt routines that are loaded as part of the kernel’s address space. These routines handle the console terminal interface, one or more clocks, and several software-initiated interrupts used by the system for low-priority clock processing and for networking facilities.
Unlike traps and system calls, device interrupts occur asynchronously. The process that requested the service is unlikely to be the currently running process, and may no longer exist! The process that started the operation will be notified that the operation has finished when that process runs again. As occurs with traps and system calls, the entire machine state must be saved, since any changes could cause errors in the currently running process.
Device-interrupt handlers run only on demand, and are never scheduled by the kernel. Unlike system calls, interrupt handlers do not have a per-process context. Interrupt handlers cannot use any of the context of the currently running process (e.g., the process’s user structure). The stack normally used by the kernel is part of a process context. On some systems (e.g., the HP300), the interrupts are caught on the per-process kernel stack of whichever process happens to be running. This approach requires that all the per-process kernel stacks be large enough to handle the deepest possible nesting caused by a system call and one or more interrupts, and that a per-process kernel stack always be available, even when a process is not running. Other architectures (e.g., the VAX), provide a systemwide interrupt stack that is used solely for device interrupts. This architecture allows the per-process kernel stacks to be sized based on only the requirements for handling a synchronous trap or system call. Regardless of the implementation, when an interrupt occurs, the system must switch to the correct stack (either explicitly, or as part of the hardware exception handling) before it begins to handle the interrupt.
The interrupt handler can never use the stack to save state between invocations. An interrupt handler must get all the information that it needs from the data structures that it shares with the top half of the kernel—generally, its global work queue. Similarly, all information provided to the top half of the kernel by the interrupt handler must be communicated the same way. In addition, because 4.4BSD requires a per-process context for a thread of control to sleep, an interrupt handler cannot relinquish the processor to wait for resources, but rather must always run to completion.
Software Interrupts
Many events in the kernel are driven by hardware interrupts. For high-speed devices such as network controllers, these interrupts occur at a high priority. A network controller must quickly acknowledge receipt of a packet and reenable the controller to accept more packets to avoid losing closely spaced packets. However, the further processing of passing the packet to the receiving process, although time consuming, does not need to be done quickly. Thus, a lower priority is possible for the further processing, so critical operations will not be blocked from executing longer than necessary.
The mechanism for doing lower-priority processing is called a software interrupt. Typically, a high-priority interrupt creates a queue of work to be done at a lower-priority level. After queueing of the work request, the high-priority interrupt arranges for the processing of the request to be run at a lower-priority level. When the machine priority drops below that lower priority, an interrupt is generated that calls the requested function. If a higher-priority interrupt comes in during request processing, that processing will be preempted like any other low-priority task. On some architectures, the interrupts are true hardware traps caused by software instructions. Other architectures implement the same functionality by monitoring flags set by the interrupt handler at appropriate times and calling the request-processing functions directly.
The delivery of network packets to destination processes is handled by a packet-processing function that runs at low priority. As packets come in, they are put onto a work queue, and the controller is immediately reenabled. Between packet arrivals, the packet-processing function works to deliver the packets. Thus, the controller can accept new packets without having to wait for the previous packet to be delivered. In addition to network processing, software interrupts are used to handle time-related events and process rescheduling.
3.4 Clock Interrupts
The system is driven by a clock that interrupts at regular intervals. Each interrupt is referred to as a tick. On the HP300, the clock ticks 100 times per second. At each tick, the system updates the current time of day as well as user-process and system timers.
Interrupts for clock ticks are posted at a high hardware-interrupt priority. After the process state has been saved, the hardclock () routine is called. It is important that the hardclock () routine finish its job quickly:
• If hardclock () runs for more than one tick, it will miss the next clock interrupt. Since hardclock () maintains the time of day for the system, a missed interrupt will cause the system to lose time.
• Because of hardclock ()s high interrupt priority, nearly all other activity in the system is blocked while hardclock () is running. This blocking can cause network controllers to miss packets, or a disk controller to miss the transfer of a sector coming under a disk drive’s head.
So that the time spent in hardclock () is minimized, less critical time-related processing is handled by a lower-priority software-interrupt handler called soft-clock (). In addition, if multiple clocks are available, some time-related processing can be handled by other routines supported by alternate clocks.
The work done by hardclock () is as follows:
• Increment the current time of day.
• If the currently running process has a virtual or profiling interval timer (see Section 3.6), decrement the timer and deliver a signal if the timer has expired.
• If the system does not have a separate clock for statistics gathering, the hard-clock () routine does the operations normally done by statclock (), as described in the next section.
• If softclock () needs to be called, and the current interrupt-priority level is low, call softclock () directly.
Statistics and Process Scheduling
On historic 4BSD systems, the hardclock () routine collected resource-utilization statistics about what was happening when the clock interrupted. These statistics were used to do accounting, to monitor what the system was doing, and to determine future scheduling priorities. In addition, hardclock () forced context switches so that all processes would get a share of the CPU.
This approach has weaknesses because the clock supporting hardclock () interrupts on a regular basis. Processes can become synchronized with the system clock, resulting in inaccurate measurements of resource utilization (especially CPU) and inaccurate profiling [McCanne & Torek, 1993]. It is also possible to write programs that deliberately synchronize with the system clock to outwit the scheduler.
On architectures with multiple high-precision, programmable clocks, such as the HP300, randomizing the interrupt period of a clock can improve the system resource-usage measurements significantly. One clock is set to interrupt at a fixed rate; the other interrupts at a random interval chosen from times distributed uniformly over a bounded range.
To allow the collection of more accurate profiling information, 4.4BSD supports profiling clocks. When a profiling clock is available, it is set to run at a tick rate that is relatively prime to the main system clock (five times as often as the system clock, on the HP300).
The statclock () routine is supported by a separate clock if one is available, and is responsible for accumulating resource usage to processes. The work done by statclock () includes
• Charge the currently running process with a tick; if the process has accumulated four ticks, recalculate its priority. If the new priority is less than the current priority, arrange for the process to be rescheduled.
• Collect statistics on what the system was doing at the time of the tick (sitting idle, executing in user mode, or executing in system mode). Include basic information on system I/O, such as which disk drives are currently active.
Timeouts
The remaining time-related processing involves processing timeout requests and periodically reprioritizing processes that are ready to run. These functions are handled by the softclock () routine.
When hardclock () completes, if there were any softclock () functions to be done, hardclock () schedules a softclock interrupt, or sets a flag that will cause softclock() to be called. As an optimization, if the state of the processor is such that the softclock () execution will occur as soon as the hardclock interrupt returns, hardclock() simply lowers the processor priority and calls softclock () directly, avoiding the cost of returning from one interrupt only to reenter another. The savings can be substantial over time, because interrupts are expensive and these interrupts occur so frequently.
The primary task of the softclock () routine is to arrange for the execution of periodic events, such as
• Process real-time timer (see Section 3.6)
• Retransmission of dropped network packets
• Watchdog timers on peripherals that require monitoring
• System process-rescheduling events
An important event is the scheduling that periodically raises or lowers the CPU priority for each process in the system based on that process’s recent CPU usage (see Section 4.4). The rescheduling calculation is done once per second. The scheduler is started at boot time, and each time that it runs, it requests that it be invoked again 1 second in the future.
On a heavily loaded system with many processes, the scheduler may take a long time to complete its job. Posting its next invocation 1 second after each completion may cause scheduling to occur less frequently than once per second. However, as the scheduler is not responsible for any time-critical functions, such as maintaining the time of day, scheduling less frequently than once a second is normally not a problem.
The data structure that describes waiting events is called the callout queue. Figure 3.2 shows an example of the callout queue. When a process schedules an event, it specifies a function to be called, a pointer to be passed as an argument to the function, and the number of clock ticks until the event should occur.
The queue is sorted in time order, with the events that are to occur soonest at the front, and the most distant events at the end. The time for each event is kept as a difference from the time of the previous event on the queue. Thus, the hard-clock () routine needs only to check the time to expire of the first element to determine whether softclock () needs to run. In addition, decrementing the time to expire of the first element decrements the time for all events. The softclock () routine executes events from the front of the queue whose time has decremented to zero until it finds an event with a still-future (positive) time. New events are added to the queue much less frequently than the queue is checked to see whether any events are to occur. So, it is more efficient to identify the proper location to place an event when that event is added to the queue than to scan the entire queue to determine which events should occur at any single time.
Figure 3.2 Timer events in the callout queue.

The single argument is provided for the callout-queue function that is called, so that one function can be used by multiple processes. For example, there is a single real-time timer function that sends a signal to a process when a timer expires. Every process that has a real-time timer running posts a timeout request for this function; the argument that is passed to the function is a pointer to the process structure for the process. This argument enables the timeout function to deliver the signal to the correct process.
Timeout processing is more efficient when the timeouts are specified in ticks. Time updates require only an integer decrement, and checks for timer expiration require only a comparison against zero. If the timers contained time values, decrementing and comparisons would be more complex. If the number of events to be managed were large, the cost of the linear search to insert new events correctly could dominate the simple linear queue used in 4.4BSD. Other possible approaches include maintaining a heap with the next-occurring event at the top [Barkley & Lee, 1988], or maintaining separate queues of short-, medium- and long-term events [Varghese & Lauck, 1987].
3.5 Memory-Management Services
The memory organization and layout associated with a 4.4BSD process is shown in Fig. 3.3. Each process begins execution with three memory segments, called text, data, and stack. The data segment is divided into initialized data and uninitialized data (also known as bss). The text is read-only and is normally shared by all processes executing the file, whereas the data and stack areas can be written by, and are private to, each process. The text and initialized data for the process are read from the executable file.
An executable file is distinguished by its being a plain file (rather than a directory, special file, or symbolic link) and by its having 1 or more of its execute bits set. In the traditional a.out executable format, the first few bytes of the file contain a magic number that specifies what type of executable file that file is. Executable files fall into two major classes:
1. Files that must be read by an interpreter
2. Files that are directly executable
In the first class, the first 2 bytes of the file are the two-character sequence #! followed by the pathname of the interpreter to be used. (This pathname is currently limited by a compile-time constant to 30 characters.) For example, #!/bin/sh refers to the Bourne shell. The kernel executes the named interpreter, passing the name of the file that is to be interpreted as an argument. To prevent loops, 4.4BSD allows only one level of interpretation, and a file’s interpreter may not itself be interpreted.
Figure 3.3 Layout of a UNIX process in memory and on disk.
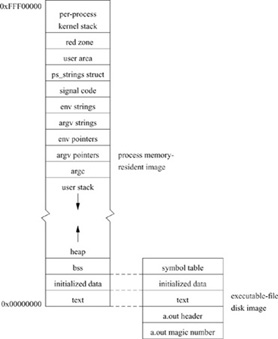
For performance reasons, most files are directly executable. Each directly executable file has a magic number that specifies whether that file can be paged and whether the text part of the file can be shared among multiple processes. Following the magic number is an exec header that specifies the sizes of text, initialized data, uninitialized data, and additional information for debugging. (The debugging information is not used by the kernel or by the executing program.) Following the header is an image of the text, followed by an image of the initialized data. Uninitialized data are not contained in the executable file because they can be created on demand using zero-filled memory.
To begin execution, the kernel arranges to have the text portion of the file mapped into the low part of the process address space. The initialized data portion of the file is mapped into the address space following the text. An area equal to the uninitialized data region is created with zero-filled memory after the initialized data region. The stack is also created from zero-filled memory. Although the stack should not need to be zero filled, early UNIX systems made it so. In an attempt to save some startup time, the developers modified the kernel to not zero fill the stack, leaving the random previous contents of the page instead. Numerous programs stopped working because they depended on the local variables in their main procedure being initialized to zero. Consequently, the zero filling of the stack was restored.
Copying into memory the entire text and initialized data portion of a large program causes a long startup latency. 4.4BSD avoids this startup time by demand paging the program into memory, rather than preloading the program. In demand paging, the program is loaded in small pieces (pages) as it is needed, rather than all at once before it begins execution. The system does demand paging by dividing up the address space into equal-sized areas called pages. For each page, the kernel records the offset into the executable file of the corresponding data. The first access to an address on each page causes a page-fault trap in the kernel. The page-fault handler reads the correct page of the executable file into the process memory. Thus, the kernel loads only those parts of the executable file that are needed. Chapter 5 explains paging details.
The uninitialized data area can be extended with zero-filled pages using the system call sbrk, although most user processes use the library routine malloc (), a more programmer-friendly interface to sbrk. This allocated memory, which grows from the top of the original data segment, is called the heap. On the HP300, the stack grows down from the top of memory, whereas the heap grows up from the bottom of memory.
Above the user stack are areas of memory that are created by the system when the process is started. Directly above the user stack is the number of arguments (argc), the argument vector (argv), and the process environment vector (envp) set up when the program was executed. Above them are the argument and environment strings themselves. Above them is the signal code, used when the system delivers signals to the process; above that is the struct ps_strings structure, used by ps to locate the argv of the process. At the top of user memory is the user area (u.), the red zone, and the per-process kernel stack. The red zone may or may not be present in a port to an architecture. If present, it is implemented as a page of read-only memory immediately below the per-process kernel stack. Any attempt to allocate below the fixed-size kernel stack will result in a memory fault, protecting the user area from being overwritten. On some architectures, it is not possible to mark these pages as read-only, or having the kernel stack attempt to write a write protected page would result in unrecoverable system failure. In these cases, other approaches can be taken—for example, checking during each clock interrupt to see whether the current kernel stack has grown too large.
In addition to the information maintained in the user area, a process usually requires the use of some global system resources. The kernel maintains a linked list of processes, called the process table, which has an entry for each process in the system. Among other data, the process entries record information on scheduling and on virtual-memory allocation. Because the entire process address space, including the user area, may be swapped out of main memory, the process entry must record enough information to be able to locate the process and to bring that process back into memory. In addition, information needed while the process is swapped out (e.g., scheduling information) must be maintained in the process entry, rather than in the user area, to avoid the kernel swapping in the process only to decide that it is not at a high-enough priority to be run.
Other global resources associated with a process include space to record information about descriptors and page tables that record information about physical-memory utilization.
3.6 Timing Services
The kernel provides several different timing services to processes. These services include timers that run in real time and timers that run only while a process is executing.
Real Time
The system’s time offset since January 1, 1970, Universal Coordinated Time (UTC), also known as the Epoch, is returned by the system call gettimeofday. Most modern processors (including the HP300 processors) maintain a battery-backup time-of-day register. This clock continues to run even if the processor is turned off. When the system boots, it consults the processor’s time-of-day register to find out the current time. The system’s time is then maintained by the clock interrupts. At each interrupt, the system increments its global time variable by an amount equal to the number of microseconds per tick. For the HP300, running at 100 ticks per second, each tick represents 10,000 microseconds.
Adjustment of the Time
Often, it is desirable to maintain the same time on all the machines on a network. It is also possible to keep more accurate time than that available from the basic processor clock. For example, hardware is readily available that listens to the set of radio stations that broadcast UTC synchronization signals in the United States. When processes on different machines agree on a common time, they will wish to change the clock on their host processor to agree with the networkwide time value. One possibility is to change the system time to the network time using the settimeofday system call. Unfortunately, the settimeofday system call will result in time running backward on machines whose clocks were fast. Time running backward can confuse user programs (such as make) that expect time to invariably increase. To avoid this problem, the system provides the adjtime system call [Gusella et al, 1994]. The adjtime system call takes a time delta (either positive or negative) and changes the rate at which time advances by 10 percent, faster or slower, until the time has been corrected. The operating system does the speedup by incrementing the global time by 11,000 microseconds for each tick, and does the slowdown by incrementing the global time by 9,000 microseconds for each tick. Regardless, time increases monotonically, and user processes depending on the ordering of file-modification times are not affected. However, time changes that take tens of seconds to adjust will affect programs that are measuring time intervals by using repeated calls to gettimeofday.
External Representation
Time is always exported from the system as microseconds, rather than as clock ticks, to provide a resolution-independent format. Internally, the kernel is free to select whatever tick rate best trades off clock-interrupt–handling overhead with timer resolution. As the tick rate per second increases, the resolution of the system timers improves, but the time spent dealing with hardclock interrupts increases. As processors become faster, the tick rate can be increased to provide finer resolution without adversely affecting user applications.
All filesystem (and other) timestamps are maintained in UTC offsets from the Epoch. Conversion to local time, including adjustment for daylight-savings time, is handled externally to the system in the C library.
Interval Time
The system provides each process with three interval timers. The real timer decrements in real time. An example of use for this timer is a library routine maintaining a wakeup-service queue. A SIGALRM signal is delivered to the process when this timer expires. The real-time timer is run from the timeout queue maintained by the softclock () routine (see Section 3.4).
The profiling timer decrements both in process virtual time (when running in user mode) and when the system is running on behalf of the process. It is designed to be used by processes to profile their execution statistically. A SIGPROF signal is delivered to the process when this timer expires. The profiling timer is implemented by the hardclock () routine. Each time that hardclock () runs, it checks to see whether the currently running process has requested a profiling timer; if it has, hardclock () decrements the timer, and sends the process a signal when zero is reached.
The virtual timer decrements in process virtual time. It runs only when the process is executing in user mode. A SIGVTALRM signal is delivered to the process when this timer expires. The virtual timer is also implemented in hardclock () as the profiling timer is, except that it decrements the timer for the current process only if it is executing in user mode, and not if it is running in the kernel.
3.7 User, Group, and Other Identifiers
One important responsibility of an operating system is to implement access-control mechanisms. Most of these access-control mechanisms are based on the notions of individual users and of groups of users. Users are named by a 32-bit number called a user identifier (UID). UIDs are not assigned by the kernel—they are assigned by an outside administrative authority. UIDs are the basis for accounting, for restricting access to privileged kernel operations, (such as the request used to reboot a running system), for deciding to what processes a signal may be sent, and as a basis for filesystem access and disk-space allocation. A single user, termed the superuser (also known by the user name root), is trusted by the system and is permitted to do any supported kernel operation. The superuser is identified not by any specific name, such as root, but instead by a UID of zero.
Users are organized into groups. Groups are named by a 32-bit number called a group identifier (GID). GIDs, like UIDs, are used in the filesystem access-control facilities and in disk-space allocation.
The state of every 4.4BSD process includes a UID and a set of GIDs. A process’s filesystem-access privileges are defined by the UID and GIDs of the process (for the filesystem hierarchy beginning at the process’s root directory). Normally, these identifiers are inherited automatically from the parent process when a new process is created. Only the superuser is permitted to alter the UID or GID of a process. This scheme enforces a strict compartmentalization of privileges, and ensures that no user other than the superuser can gain privileges.
Each file has three sets of permission bits, for read, write, or execute permission for each of owner, group, and other. These permission bits are checked in the following order:
1. If the UID of the file is the same as the UID of the process, only the owner permissions apply; the group and other permissions are not checked.
2. If the UIDs do not match, but the GID of the file matches one of the GIDs of the process, only the group permissions apply; the owner and other permissions are not checked.
3. Only if the UID and GIDs of the process fail to match those of the file are the permissions for all others checked. If these permissions do not allow the requested operation, it will fail.
The UID and GIDs for a process are inherited from its parent. When a user logs in, the login program (see Section 14.6) sets the UID and GIDs before doing the exec system call to run the user’s login shell; thus, all subsequent processes will inherit the appropriate identifiers.
Often, it is desirable to grant a user limited additional privileges. For example, a user who wants to send mail must be able to append the mail to another user’s mailbox. Making the target mailbox writable by all users would permit a user other than its owner to modify messages in it (whether maliciously or unintentionally). To solve this problem, the kernel allows the creation of programs that are granted additional privileges while they are running. Programs that run with a different UID are called set-user-identifier (setuid) programs; programs that run with an additional group privilege are called set-group-identifier (setgid) programs [Ritchie, 1979]. When a setuid program is executed, the permissions of the process are augmented to include those of the UID associated with the program. The UID of the program is termed the effective UID of the process, whereas the original UID of the process is termed the real UID. Similarly, executing a setgid program augments a process’s permissions with those of the program’s GID, and the effective GID and real GID are defined accordingly.
Systems can use setuid and setgid programs to provide controlled access to files or services. For example, the program that adds mail to the users’ mailbox runs with the privileges of the superuser, which allow it to write to any file in the system. Thus, users do not need permission to write other users’ mailboxes, but can still do so by running this program. Naturally, such programs must be written carefully to have only a limited set of functionality!
The UID and GIDs are maintained in the per-process area. Historically, GIDs were implemented as one distinguished GID (the effective GID) and a supplementary array of GIDs, which was logically treated as one set of GIDs. In 4.4BSD, the distinguished GID has been made the first entry in the array of GIDs. The supplementary array is of a fixed size (16 in 4.4BSD), but may be changed by recompiling the kernel.
4.4BSD implements the setgid capability by setting the zeroth element of the supplementary groups array of the process that executed the setgid program to the group of the file. Permissions can then be checked as it is for a normal process. Because of the additional group, the setgid program may be able to access more files than can a user process that runs a program without the special privilege. The login program duplicates the zeroth array element into the first array element when initializing the user’s supplementary group array, so that, when a setgid program is run and modifies the zeroth element, the user does not lose any privileges.
The setuid capability is implemented by the effective UID of the process being changed from that of the user to that of the program being executed. As it will with setgid, the protection mechanism will now permit access without any change or special knowledge that the program is running setuid. Since a process can have only a single UID at a time, it is possible to lose some privileges while running setuid. The previous real UID is still maintained as the real UID when the new effective UID is installed. The real UID, however, is not used for any validation checking.
A setuid process may wish to revoke its special privilege temporarily while it is running. For example, it may need its special privilege to access a restricted file at only the start and end of its execution. During the rest of its execution, it should have only the real user’s privileges. In 4.3BSD, revocation of privilege was done by switching of the real and effective UIDs. Since only the effective UID is used for access control, this approach provided the desired semantics and provided a place to hide the special privilege. The drawback to this approach was that the real and effective UIDs could easily become confused.
In 4.4BSD, an additional identifier, the saved UID, was introduced to record the identity of setuid programs. When a program is exec’ed, its effective UID is copied to its saved UID. The first line of Table 3.1 shows an unprivileged program for which the real, effective, and saved UIDs are all those of the real user. The second line of Table 3.1 show a setuid program being run that causes the effective UID to be set to its associated special-privilege UID. The special-privilege UID has also been copied to the saved UID.
Also added to 4.4BSD was the new seteuid system call that sets only the effective UID; it does not affect the real or saved UIDs. The seteuid system call is permitted to set the effective UID to the value of either the real or the saved UID. Lines 3 and 4 of Table 3.1 show how a setuid program can give up and then reclaim its special privilege while continuously retaining its correct real UID. Lines 5 and 6 show how a setuid program can run a subprocess without granting the latter the special privilege. First, it sets its effective UID to the real UID. Then, when it exec’s the subprocess, the effective UID is copied to the saved UID, and all access to the special-privilege UID is lost.
A similar saved GID mechanism permits processes to switch between the real GID and the initial effective GID.
Host Identifiers
An additional identifier is defined by the kernel for use on machines operating in a networked environment. A string (of up to 256 characters) specifying the host’s name is maintained by the kernel. This value is intended to be defined uniquely for each machine in a network. In addition, in the Internet domain-name system, each machine is given a unique 32-bit number. Use of these identifiers permits applications to use networkwide unique identifiers for objects such as processes, files, and users, which is useful in the construction of distributed applications [Gifford, 1981]. The host identifiers for a machine are administered outside the kernel.
Table 3.1 Actions affecting the real, effective, and saved UIDs. R—real user identifier; S—special-privilege user identifier.

The 32-bit host identifier found in 4.3BSD has been deprecated in 4.4BSD, and is supported only if the system is compiled for 4.3BSD compatibility.
Process Groups and Sessions
Each process in the system is associated with a process group. The group of processes in a process group is sometimes referred to as a job, and manipulated as a single entity by processes such as the shell. Some signals (e.g., SIGINT) are delivered to all members of a process group, causing the group as a whole to suspend or resume execution, or to be interrupted or terminated.
Sessions were designed by the IEEE POSIX.1003.1 Working Group with the intent of fixing a long-standing security problem in UNIX—namely, that processes could modify the state of terminals that were trusted by another user’s processes. A session is a collection of process groups, and all members of a process group are members of the same session. In 4.4BSD, when a user first logs onto the system, they are entered into a new session. Each session has a controlling process, which is normally the user’s login shell. All subsequent processes created by the user are part of process groups within this session, unless they explicitly create a new session. Each session also has an associated login name, which is usually the user’s login name. This name can be changed by only the superuser.
Each session is associated with a terminal, known as its controlling terminal. Each controlling terminal has a process group associated with it. Normally, only processes that are in the terminal’s current process group read from or write to the terminal, allowing arbitration of a terminal between several different jobs. When the controlling process exits, access to the terminal is taken away from any remaining processes within the session.
Newly created processes are assigned process IDs distinct from all already-existing processes and process groups, and are placed in the same process group and session as their parent. Any process may set its process group equal to its process ID (thus creating a new process group) or to the value of any process group within its session. In addition, any process may create a new session, as long as it is not already a process-group leader. Sessions, process groups, and associated topics are discussed further in Section 4.8 and in Section 10.5.
3.8 Resource Services
All systems have limits imposed by their hardware architecture and configuration to ensure reasonable operation and to keep users from accidentally (or maliciously) creating resource shortages. At a minimum, the hardware limits must be imposed on processes that run on the system. It is usually desirable to limit processes further, below these hardware-imposed limits. The system measures resource utilization, and allows limits to be imposed on consumption either at or below the hardware-imposed limits.
Process Priorities
The 4.4BSD system gives CPU scheduling priority to processes that have not used CPU time recently. This priority scheme tends to favor processes that execute for only short periods of time—for example, interactive processes. The priority selected for each process is maintained internally by the kernel. The calculation of the priority is affected by the per-process nice variable. Positive nice values mean that the process is willing to receive less than its share of the processor. Negative values of nice mean that the process wants more than its share of the processor. Most processes run with the default nice value of zero, asking neither higher nor lower access to the processor. It is possible to determine or change the nice currently assigned to a process, to a process group, or to the processes of a specified user. Many factors other than nice affect scheduling, including the amount of CPU time that the process has used recently, the amount of memory that the process has used recently, and the current load on the system. The exact algorithms that are used are described in Section 4.4.
Resource Utilization
As a process executes, it uses system resources, such as the CPU and memory. The kernel tracks the resources used by each process and compiles statistics describing this usage. The statistics managed by the kernel are available to a process while the latter is executing. When a process terminates, the statistics are made available to its parent via the wait family of system calls.
The resources used by a process are returned by the system call getrusage. The resources used by the current process, or by all the terminated children of the current process, may be requested. This information includes
• The amount of user and system time used by the process
• The memory utilization of the process
• The paging and disk I/O activity of the process
• The number of voluntary and involuntary context switches taken by the process
• The amount of interprocess communication done by the process
The resource-usage information is collected at locations throughout the kernel. The CPU time is collected by the statclock () function, which is called either by the system clock in hardclock (), or, if an alternate clock is available, by the alternate-clock interrupt routine. The kernel scheduler calculates memory utilization by sampling the amount of memory that an active process is using at the same time that it is recomputing process priorities. The vm_fault () routine recalculates the paging activity each time that it starts a disk transfer to fulfill a paging request (see Section 5.11). The I/O activity statistics are collected each time that the process has to start a transfer to fulfill a file or device I/O request, as well as when the general system statistics are calculated. The IPC communication activity is updated each time that information is sent or received.
Resource Limits
The kernel also supports limiting of certain per-process resources. These resources include
• The maximum amount of CPU time that can be accumulated
• The maximum bytes that a process can request be locked into memory
• The maximum size of a file that can be created by a process
• The maximum size of a process’s data segment
• The maximum size of a process’s stack segment
• The maximum size of a core file that can be created by a process
• The maximum number of simultaneous processes allowed to a user
• The maximum number of simultaneous open files for a process
• The maximum amount of physical memory that a process may use at any giv en moment
For each resource controlled by the kernel, two limits are maintained: a soft limit and a hard limit. All users can alter the soft limit within the range of 0 to the corresponding hard limit. All users can (irreversibly) lower the hard limit, but only the superuser can raise the hard limit. If a process exceeds certain soft limits, a signal is delivered to the process to notify it that a resource limit has been exceeded. Normally, this signal causes the process to terminate, but the process may either catch or ignore the signal. If the process ignores the signal and fails to release resources that it already holds, further attempts to obtain more resources will result in errors.
Resource limits are generally enforced at or near the locations that the resource statistics are collected. The CPU time limit is enforced in the process context-switching function. The stack and data-segment limits are enforced by a return of allocation failure once those limits have been reached. The file-size limit is enforced by the filesystem.
Filesystem Quotas
In addition to limits on the size of individual files, the kernel optionally enforces limits on the total amount of space that a user or group can use on a filesystem. Our discussion of the implementation of these limits is deferred to Section 7.4.
3.9 System-Operation Services
There are several operational functions having to do with system startup and shutdown. The bootstrapping operations are described in Section 14.2. System shutdown is described in Section 14.7.
Accounting
The system supports a simple form of resource accounting. As each process terminates, an accounting record describing the resources used by that process is written to a systemwide accounting file. The information supplied by the system comprises
• The name of the command that ran
• The amount of user and system CPU time that was used
• The elapsed time the command ran
• The average amount of memory used
• The number of disk I/O operations done
• The UID and GID of the process
• The terminal from which the process was started
The information in the accounting record is drawn from the run-time statistics that were described in Section 3.8. The granularity of the time fields is in sixty-fourths of a second. To conserve space in the accounting file, the times are stored in a 16-bit word as a floating-point number using 3 bits as a base-8 exponent, and the other 13 bits as the fractional part. For historic reasons, the same floatingpoint–conversion routine processes the count of disk operations, so the number of disk operations must be multiplied by 64 before it is converted to the floating-point representation.
There are also flags that describe how the process terminated, whether it ever had superuser privileges, and whether it did an exec after a fork.
The superuser requests accounting by passing the name of the file to be used for accounting to the kernel. As part of a process exiting, the kernel appends an accounting record to the accounting file. The kernel makes no use of the accounting records; the records’ summaries and use are entirely the domain of user-level accounting programs. As a guard against a filesystem running out of space because of unchecked growth of the accounting file, the system suspends accounting when the filesystem is reduced to only 2 percent remaining free space. Accounting resumes when the filesystem has at least 4 percent free space.
The accounting information has certain limitations. The information on run time and memory usage is only approximate because it is gathered statistically. Accounting information is written only when a process exits, so processes that are still running when a system is shut down unexpectedly do not show up in the accounting file. (Obviously, long-lived system daemons are among such processes.) Finally, the accounting records fail to include much information needed to do accurate billing, including usage of other resources, such as tape drives and printers.
Exercises
3.1 Describe three types of system activity.
3.2 When can a routine executing in the top half of the kernel be preempted? When can it be interrupted?
3.3 Why are routines executing in the bottom half of the kernel precluded from using information located in the user area?
3.4 Why does the system defer as much work as possible from high-priority interrupts to lower-priority software-interrupt processes?
3.5 What determines the shortest (nonzero) time period that a user process can request when setting a timer?
3.6 How does the kernel determine the system call for which it has been invoked?
3.7 How are initialized data represented in an executable file? How are uninitialized data represented in an executable file? Why are the representations different?
3.8 Describe how the “#!” mechanism can be used to make programs that require emulation appear as though they were normal executables.
3.9 Is it possible for a file to have permissions set such that its owner cannot read it, even though a group can? Is this situation possible if the owner is a member of the group that can read the file? Explain your answers.
*3.10 Describe the security implications of not zero filling the stack region at program startup.
*3.11 Why is the conversion from UTC to local time done by user processes, rather than in the kernel?
*3.12 What is the advantage of having the kernel, rather than an application, restart an interrupted system call?
*3.13 Describe a scenario in which the sorted-difference algorithm used for the callout queue does not work well. Suggest an alternative data structure that runs more quickly than does the sorted-difference algorithm for your scenario.
*3.14 The SIGPROF profiling timer was originally intended to replace the profil system call to collect a statistical sampling of a program’s program counter. Give two reasons why the profil facility had to be retained.
**3.15 What weakness in the process-accounting mechanism makes the latter unsuitable for use in a commercial environment?
References
Barkley & Lee, 1988.
R. E. Barkley & T. P. Lee, “A Heap-Based Callout Implementation to Meet Real-Time Needs,” USENIX Association Conference Proceedings, p. 213–222, June 1988.
Gifford, 1981.
D. Gifford, “Information Storage in a Decentralized Computer System,” PhD Thesis, Electrical Engineering Department, Stanford University, Stanford, CA, 1981.
Gusella et al, 1994.
R. Gusella, S. Zatti, & J. M. Bloom, “The Berkeley UNIX Time Synchronization Protocol,” in 4.4BSD System Manager’s Manual, p. 12:1–10, O’Reilly & Associates, Inc., Sebastopol, CA, 1994.
McCanne & Torek, 1993.
S. McCanne & C. Torek, “A Randomized Sampling Clock for CPU Utilization Estimation and Code Profiling,” USENIX Association Conference Proceedings, p. 387–394, January 1993.
Ritchie, 1979.
D. M. Ritchie, “Protection of Data File Contents,” United States Patent, no. 4,135,240, United States Patent Office, Washington, D.C., January 16, 1979. Assignee: Bell Telephone Laboratories, Inc., Murray Hill, NJ, Appl. No.: 377,591, Filed: Jul. 9, 1973.
Varghese & Lauck, 1987.
G. Varghese & T. Lauck, “Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facility,” Proceedings of the Eleventh Symposium on Operating Systems Principles, p. 25–38, November 1987.