
Chapter 4
Process Management
4.1 Introduction to Process Management
A process is a program in execution. A process must have system resources, such as memory and the underlying CPU. The kernel supports the illusion of concurrent execution of multiple processes by scheduling system resources among the set of processes that are ready to execute. This chapter describes the composition of a process, the method that the system uses to switch between processes, and the scheduling policy that it uses to promote sharing of the CPU. Later chapters study process creation and termination, signal facilities, and process-debugging facilities.
Two months after the developers began the first implementation of the UNIX operating system, there were two processes: one for each of the terminals of the PDP-7. At age 10 months, and still on the PDP-7, UNIX had many processes, the fork operation, and something like the wait system call. A process executed a new program by reading in a new program on top of itself. The first PDP-11 system (First Edition UNIX) saw the introduction of exec. All these systems allowed only one process in memory at a time. When a PDP-11 with memory management (a KS-11) was obtained, the system was changed to permit several processes to remain in memory simultaneously, to reduce swapping. But this change did not apply to multiprogramming because disk I/O was synchronous. This state of affairs persisted into 1972 and the first PDP-11/45 system. True multiprogramming was finally introduced when the system was rewritten in C. Disk I/O for one process could then proceed while another process ran. The basic structure of process management in UNIX has not changed since that time [Ritchie, 1988].
A process operates in either user mode or kernel mode. In user mode, a process executes application code with the machine in a nonprivileged protection mode. When a process requests services from the operating system with a system call, it switches into the machine’s privileged protection mode via a protected mechanism, and then operates in kernel mode.
The resources used by a process are similarly split into two parts. The resources needed for execution in user mode are defined by the CPU architecture and typically include the CPU’s general-purpose registers, the program counter, the processor-status register, and the stack-related registers, as well as the contents of the memory segments that constitute the 4.4BSD notion of a program (the text, data, and stack segments).
Kernel-mode resources include those required by the underlying hardware—such as registers, program counter, and stack pointer—and also by the state required for the 4.4BSD kernel to provide system services for a process. This kernel state includes parameters to the current system call, the current process’s user identity, scheduling information, and so on. As described in Section 3.1, the kernel state for each process is divided into several separate data structures, with two primary structures: the process structure and the user structure.
The process structure contains information that must always remain resident in main memory, along with references to a number of other structures that remain resident; whereas the user structure contains information that needs to be resident only when the process is executing (although user structures of other processes also may be resident). User structures are allocated dynamically through the memory-management facilities. Historically, more than one-half of the process state was stored in the user structure. In 4.4BSD, the user structure is used for only the per-process kernel stack and a couple of structures that are referenced from the process structure. Process structures are allocated dynamically as part of process creation, and are freed as part of process exit.
Multiprogramming
The 4.4BSD system supports transparent multiprogramming: the illusion of concurrent execution of multiple processes or programs. It does so by context switching—that is, by switching between the execution context of processes. A mechanism is also provided for scheduling the execution of processes—that is, for deciding which one to execute next. Facilities are provided for ensuring consistent access to data structures that are shared among processes.
Context switching is a hardware-dependent operation whose implementation is influenced by the underlying hardware facilities. Some architectures provide machine instructions that save and restore the hardware-execution context of the process, including the virtual-address space. On the others, the software must collect the hardware state from various registers and save it, then load those registers with the new hardware state. All architectures must save and restore the software state used by the kernel.
Context switching is done frequently, so increasing the speed of a context switch noticeably decreases time spent in the kernel and provides more time for execution of user applications. Since most of the work of a context switch is expended in saving and restoring the operating context of a process, reducing the amount of the information required for that context is an effective way to produce faster context switches.
Scheduling
Fair scheduling of processes is an involved task that is dependent on the types of executable programs and on the goals of the scheduling policy. Programs are characterized according to the amount of computation and the amount of I/O that they do. Scheduling policies typically attempt to balance resource utilization against the time that it takes for a program to complete. A process’s priority is periodically recalculated based on various parameters, such as the amount of CPU time it has used, the amount of memory resources it holds or requires for execution, and so on. An exception to this rule is real-time scheduling, which must ensure that processes finish by a specified deadline or in a particular order; the 4.4BSD kernel does not implement real-time scheduling.
4.4BSD uses a priority-based scheduling policy that is biased to favor interactive programs, such as text editors, over long-running batch-type jobs. Interactive programs tend to exhibit short bursts of computation followed by periods of inactivity or I/O. The scheduling policy initially assigns to each process a high execution priority and allows that process to execute for a fixed time slice. Processes that execute for the duration of their slice have their priority lowered, whereas processes that give up the CPU (usually because they do I/O) are allowed to remain at their priority. Processes that are inactive have their priority raised. Thus, jobs that use large amounts of CPU time sink rapidly to a low priority, whereas interactive jobs that are mostly inactive remain at a high priority so that, when they are ready to run, they will preempt the long-running lower-priority jobs. An interactive job, such as a text editor searching for a string, may become compute bound briefly, and thus get a lower priority, but it will return to a high priority when it is inactive again while the user thinks about the result.
The system also needs a scheduling policy to deal with problems that arise from not having enough main memory to hold the execution contexts of all processes that want to execute. The major goal of this scheduling policy is to minimize thrashing—a phenomenon that occurs when memory is in such short supply that more time is spent in the system handling page faults and scheduling processes than in user mode executing application code.
The system must both detect and eliminate thrashing. It detects thrashing by observing the amount of free memory. When the system has few free memory pages and a high rate of new memory requests, it considers itself to be thrashing. The system reduces thrashing by marking the least-recently run process as not being allowed to run. This marking allows the pageout daemon to push all the pages associated with the process to backing store. On most architectures, the kernel also can push to backing store the user area of the marked process. The effect of these actions is to cause the process to be swapped out (see Section 5.12). The memory freed by blocking the process can then be distributed to the remaining processes, which usually can then proceed. If the thrashing continues, additional processes are selected for being blocked from running until enough memory becomes available for the remaining processes to run effectively. Eventually, enough processes complete and free their memory that blocked processes can resume execution. However, even if there is not enough memory, the blocked processes are allowed to resume execution after about 20 seconds. Usually, the thrashing condition will return, requiring that some other process be selected for being blocked (or that an administrative action be taken to reduce the load).
The orientation of the scheduling policy toward an interactive job mix reflects the original design of 4.4BSD for use in a time-sharing environment. Numerous papers have been written about alternative scheduling policies, such as those used in batch-processing environments or real-time systems. Usually, these policies require changes to the system in addition to alteration of the scheduling policy [Khanna et al, 1992].
4.2 Process State
The layout of process state was completely reorganized in 4.4BSD. The goal was to support multiple thread s that share an address space and other resources. Threads have also been called lightweight processes in other systems. A thread is the unit of execution of a process; it requires an address space and other resources, but it can share many of those resources with other threads. Threads sharing an address space and other resources are scheduled independently, and can all do system calls simultaneously. The reorganization of process state in 4.4BSD was designed to support threads that can select the set of resources to be shared, known as variable-weight processes [Aral et al, 1989]. Unlike some other implementations of threads, the BSD model associates a process ID with each thread, rather than with a collection of threads sharing an address space.
Figure 4.1 Process state.
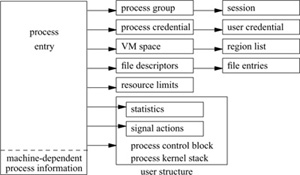
The developers did the reorganization by moving many components of process state from the process and user structures into separate substructures for each type of state information, as shown in Fig. 4.1. The process structure references all the substructures directly or indirectly. The use of global variables in the user structure was completely eliminated. Variables moved out of the user structure include the open file descriptors that may need to be shared among different threads, as well as system-call parameters and error returns. The process structure itself was also shrunk to about one-quarter of its former size. The idea is to minimize the amount of storage that must be allocated to support a thread. The 4.4BSD distribution did not have kernel-thread support enabled, primarily because the C library had not been rewritten to be able to handle multiple threads.
All the information in the substructures shown in Fig. 4.1 can be shared among threads running within the same address space, except the per-thread statistics, the signal actions, and the per-thread kernel stack. These unshared structures need to be accessible only when the thread may be scheduled, so they are allocated in the user structure so that they can be moved to secondary storage when memory resources are low. The following sections describe the portions of these structures that are relevant to process management. The VM space and its related structures are described more fully in Chapter 5.
The Process Structure
In addition to the references to the substructures, the process entry shown in Fig. 4.1 contains the following categories of information:
• Process identification. The process identifier and the parent-process identifier
• Scheduling. The process priority, user-mode scheduling priority, recent CPU utilization, and amount of time spent sleeping
• Process state. The run state of a process (runnable, sleeping, stopped); additional status flags; if the process is sleeping, the wait channel, the identity of the event for which the process is waiting (see Section 4.3), and a pointer to a string describing the event
• Signal state. Signals pending delivery, signal mask, and summary of signal actions
• Tracing. Process tracing information
• Machine state. The machine-dependent process information
• Timers. Real-time timer and CPU-utilization counters
The process substructures shown in Fig. 4.1 have the following categories of information:
• Process-group identification. The process group and the session to which the process belongs
• User credentials. The real, effective, and saved user and group identifiers
• Memory management. The structure that describes the allocation of virtual address space used by the process
• File descriptors. An array of pointers to file entries indexed by the process open file descriptors; also, the open file flags and current directory
• Resource accounting. The rusage structure that describes the utilization of the many resources provided by the system (see Section 3.8)
• Statistics. Statistics collected while the process is running that are reported when it exits and are written to the accounting file; also, includes process timers and profiling information if the latter is being collected
• Signal actions. The action to take when a signal is posted to a process
• User structure. The contents of the user structure (described later in this section)
A process’s state has a value, as shown in Table 4.1. When a process is first created with a fork system call, it is initially marked as SIDL. The state is changed to SRUN when enough resources are allocated to the process for the latter to begin execution. From that point onward, a process’s state will fluctuate among SRUN (runnable—e.g., ready to execute), SSLEEP (waiting for an event), and SSTOP (stopped by a signal or the parent process), until the process terminates. A deceased process is marked as SZOMB until its termination status is communicated to its parent process.
The system organizes process structures into two lists. Process entries are on the zombproc list if the process is in the SZOMB state; otherwise, they are on the allproc list. The two queues share the same linkage pointers in the process structure, since the lists are mutually exclusive. Segregating the dead processes from the live ones reduces the time spent both by the wait system call, which must scan the zombies for potential candidates to return, and by the scheduler and other functions that must scan all the potentially runnable processes.
Table 4.1 Process states.

Most processes, except the currently executing process, are also in one of two queues: a run queue or a sleep queue. Processes that are in a runnable state are placed on a run queue, whereas processes that are blocked awaiting an event are located on a sleep queue. Stopped processes not also awaiting an event are on neither type of queue. The two queues share the same linkage pointers in the process structure, since the lists are mutually exclusive. The run queues are organized according to process-scheduling priority, and are described in Section 4.4. The sleep queues are organized in a hashed data structure that optimizes finding of a sleeping process by the event number (wait channel) for which the process is waiting. The sleep queues are described in Section 4.3.
Every process in the system is assigned a unique identifier termed the process identifier, (PID). PIDs are the common mechanism used by applications and by the kernel to reference processes. PIDs are used by applications when the latter are sending a signal to a process and when receiving the exit status from a deceased process. Two PIDs are of special importance to each process: the PID of the process itself and the PID of the process’s parent process.
The p_pglist list and related lists (p_pptr, p_children, and p_siblings) are used in locating related processes, as shown in Fig. 4.2. When a process spawns a child process, the child process is added to its parent’s p_children list. The child process also keeps a backward link to its parent in its p_pptr field. If a process has more than one child process active at a time, the children are linked together through their p_sibling list entries. In Fig. 4.2, process B is a direct descendent of process A, whereas processes C, D, and E are descendents of process B and are siblings of one another. Process B typically would be a shell that started a pipeline (see Sections 2.4 and 2.6) including processes C, D, and E. Process A probably would be the system-initialization process init (see Section 3.1 and Section 14.6).
CPU time is made available to processes according to their scheduling priority. A process has two scheduling priorities, one for scheduling user-mode execution and one for scheduling kernel-mode execution. The p_usrpri field in the process structure contains the user-mode scheduling priority, whereas the p_priority field holds the current kernel-mode scheduling priority. The current priority may be different from the user-mode priority when the process is executing in kernel mode. Priorities range between 0 and 127, with a lower value interpreted as a higher priority (see Table 4.2). User-mode priorities range from PUSER (50) to 127; priorities less than PUSER are used only when a process is asleep—that is, awaiting an event in the kernel—and immediately after such a process is awakened. Processes in the kernel are given a higher priority because they typically hold shared kernel resources when they awaken. The system wants to run them as quickly as possible once they get a resource, so that they can use the resource and return it before another process requests it and gets blocked waiting for it.
Figure 4.2 Process-group hierarchy.

Table 4.2 Process-scheduling priorities.

Historically, a kernel process that is asleep with a priority in the range PZERO to PUSER would be awakened by a signal; that is, it might be awakened and marked runnable if a signal is posted to it. A process asleep at a priority below PZERO would never be awakened by a signal. In 4.4BSD, a kernel process will be awakened by a signal only if it sets the PCATCH flag when it sleeps. The PCATCH flag was added so that a change to a sleep priority does not inadvertently cause a change to the process’s interruptibility.
For efficiency, the sleep interface has been divided into two separate entry points: sleep() for brief, noninterruptible sleep requests, and tsleep() for longer, possibly interrupted sleep requests. The sleep() interface is short and fast, to handle the common case of a short sleep. The tsleep() interface handles all the special cases including interruptible sleeps, sleeps limited to a maximum time duration, and the processing of restartable system calls. The tsleep() interface also includes a reference to a string describing the event that the process awaits; this string is externally visible. The decision of whether to use an interruptible sleep is dependent on how long the process may be blocked. Because it is complex to be prepared to handle signals in the midst of doing some other operation, many sleep requests are not interruptible; that is, a process will not be scheduled to run until the event for which it is waiting occurs. For example, a process waiting for disk I/O will sleep at an uninterruptible priority.
For quickly occurring events, delaying to handle a signal until after they complete is imperceptible. However, requests that may cause a process to sleep for a long period, such as while a process is waiting for terminal or network input, must be prepared to have their sleep interrupted so that the posting of signals is not delayed indefinitely. Processes that sleep at interruptible priorities may abort their system call because of a signal arriving before the event for which they are waiting has occurred. To avoid holding a kernel resource permanently, these processes must check why they have been awakened. If they were awakened because of a signal, they must release any resources that they hold. They must then return the error passed back to them by tsleep(), which will be EINTR if the system call is to be aborted after the signal, or ERESTART if it is to be restarted. Occasionally, an event that is supposed to occur quickly, such as a tape I/O, will get held up because of a hardware failure. Because the process is sleeping in the kernel at an uninterruptible priority, it will be impervious to any attempts to send it a signal, even a signal that should cause it to exit unconditionally. The only solution to this problem is to change sleep()s on hardware events that may hang to be interruptible. In the remainder of this book, we shall always use sleep() when referencing the routine that puts a process to sleep, even when the tsleep() interface may be the one that is being used.
The User Structure
The user structure contains the process state that may be swapped to secondary storage. The structure was an important part of the early UNIX kernels; it stored much of the state for each process. As the system has evolved, this state has migrated to the process entry or one of its substructures, so that it can be shared. In 4.4BSD, nearly all references to the user structure have been removed. The only place that user-structure references still exist are in the fork system call, where the new process entry has pointers set up to reference the two remaining structures that are still allocated in the user structure. Other parts of the kernel that reference these structures are unaware that the latter are located in the user structure; the structures are always referenced from the pointers in the process table. Changing them to dynamically allocated structures would require code changes in only fork to allocate them, and exit to free them. The user-structure state includes
• The user- and kernel-mode execution states
• The accounting information
• The signal-disposition and signal-handling state
• Selected process information needed by the debuggers and in core dumps
• The per-process execution stack for the kernel
The current execution state of a process is encapsulated in a process control block (PCB). This structure is allocated in the user structure and is defined by the machine architecture; it includes the general-purpose registers, stack pointers, program counter, processor-status longword, and memory-management registers.
Historically, the user structure was mapped to a fixed location in the virtual address space. There were three reasons for using a fixed mapping:
1. On many architectures, the user structure could be mapped into the top of the user-process address space. Because the user structure was part of the user address space, its context would be saved as part of saving of the user-process state, with no additional effort.
2. The data structures contained in the user structure (also called the u-dot (u.) structure, because all references in C were of the form u.) could always be addressed at a fixed address.
3. When a parent forks, its run-time stack is copied for its child. Because the kernel stack is part of the u. area, the child’s kernel stack is mapped to the same addresses as its parent kernel stack. Thus, all its internal references, such as frame pointers and stack-variable references, work as expected.
On modern architectures with virtual address caches, mapping the user structure to a fixed address is slow and inconvenient. Thus, reason 1 no longer holds. Since the user structure is never referenced by most of the kernel code, reason 2 no longer holds. Only reason 3 remains as a requirement for use of a fixed mapping. Some architectures in 4.4BSD remove this final constraint, so that they no longer need to provide a fixed mapping. They do so by copying the parent stack to the child-stack location. The machine-dependent code then traverses the stack, relocating the embedded stack and frame pointers. On return to the machine-independent fork code, no further references are made to local variables; everything just returns all the way back out of the kernel.
The location of the kernel stack in the user structure simplifies context switching by localizing all a process’s kernel-mode state in a single structure. The kernel stack grows down from the top of the user structure toward the data structures allocated at the other end. This design restricts the stack to a fixed size. Because the stack traps page faults, it must be allocated and memory resident before the process can run. Thus, it is not only a fixed size, but also small; usually it is allocated only one or two pages of physical memory. Implementors must be careful when writing code that executes in the kernel to avoid using large local variables and deeply nested subroutine calls, to avoid overflowing the run-time stack. As a safety precaution, some architectures leave an invalid page between the area for the run-time stack and the page holding the other user-structure contents. Thus, overflowing the kernel stack will cause a kernel-access fault, instead of disastrously overwriting the fixed-sized portion of the user structure. On some architectures, interrupt processing takes place on a separate interrupt stack, and the size of the kernel stack in the user structure restricts only that code executed as a result of traps and system calls.
4.3 Context Switching
The kernel switches among processes in an effort to share the CPU effectively; this activity is called context switching. When a process executes for the duration of its time slice or when it blocks because it requires a resource that is currently unavailable, the kernel finds another process to run and context switches to it. The system can also interrupt the currently executing process to service an asynchronous event, such as a device interrupt. Although both scenarios involve switching the execution context of the CPU, switching between processes occurs synchronously with respect to the currently executing process, whereas servicing interrupts occurs asynchronously with respect to the current process. In addition, interprocess context switches are classified as voluntary or involuntary. A voluntary context switch occurs when a process blocks because it requires a resource that is unavailable. An involuntary context switch takes place when a process executes for the duration of its time slice or when the system identifies a higher-priority process to run.
Each type of context switching is done through a different interface. Voluntary context switching is initiated with a call to the sleep() routine, whereas an involuntary context switch is forced by direct invocation of the low-level context-switching mechanism embodied in the mi_switch () and setrunnable () routines. Asynchronous event handling is managed by the underlying hardware and is effectively transparent to the system. Our discussion will focus on how asynchronous event handling relates to synchronizing access to kernel data structures.
Process State
Context switching between processes requires that both the kernel- and user-mode context be changed; to simplify this change, the system ensures that all a process’s user-mode state is located in one data structure: the user structure (most kernel state is kept elsewhere). The following conventions apply to this localization:
• Kernel-mode hardware-execution state. Context switching can take place in only kernel mode. Thus, the kernel’s hardware-execution state is defined by the contents of the PCB that is located at the beginning of the user structure.
• User-mode hardware-execution state. When execution is in kernel mode, the user-mode state of a process (such as copies of the program counter, stack pointer, and general registers) always resides on the kernel’s execution stack that is located in the user structure. The kernel ensures this location of user-mode state by requiring that the system-call and trap handlers save the contents of the user-mode execution context each time that the kernel is entered (see Section 3.1).
• The process structure. The process structure always remains resident in memory.
• Memory resources. Memory resources of a process are effectively described by the contents of the memory-management registers located in the PCB and by the values present in the process structure. As long as the process remains in memory, these values will remain valid, and context switches can be done without the associated page tables being saved and restored. However, these values need to be recalculated when the process returns to main memory after being swapped to secondary storage.
Low-Level Context Switching
The localization of the context of a process in the latter’s user structure permits the kernel to do context switching simply by changing the notion of the current user structure and process structure, and restoring the context described by the PCB within the user structure (including the mapping of the virtual address space). Whenever a context switch is required, a call to the mi_switch () routine causes the highest-priority process to run. The mi_switch () routine first selects the appropriate process from the scheduling queues, then resumes the selected process by loading that process’s context from its PCB. Once mi_switch () has loaded the execution state of the new process, it must also check the state of the new process for a nonlocal return request (such as when a process first starts execution after a fork; see Section 4.5).
Voluntary Context Switching
A voluntary context switch occurs whenever a process must await the availability of a resource or the arrival of an event. Voluntary context switches happen frequently in normal system operation. For example, a process typically blocks each time that it requests data from an input device, such as a terminal or a disk. In 4.4BSD, voluntary context switches are initiated through the sleep() or tsleep() routines. When a process no longer needs the CPU, it invokes sleep() with a scheduling priority and a wait channel. The priority specified in a sleep() call is the priority that should be assigned to the process when that process is awakened. This priority does not affect the user-level scheduling priority.
The wait channel is typically the address of some data structure that identifies the resource or event for which the process is waiting. For example, the address of a disk buffer is used while the process is waiting for the buffer to be filled. When the buffer is filled, processes sleeping on that wait channel will be awakened. In addition to the resource addresses that are used as wait channels, there are some addresses that are used for special purposes:
• The global variable lbolt is awakened by the scheduler once per second. Processes that want to wait for up to 1 second can sleep on this global variable. For example, the terminal-output routines sleep on lbolt while waiting for output-queue space to become available. Because queue space rarely runs out, it is easier simply to check for queue space once per second during the brief periods of shortages than it is to set up a notification mechanism such as that used for managing disk buffers. Programmers can also use the lbolt wait channel as a crude watchdog timer when doing debugging.
• When a parent process does a wait system call to collect the termination status of its children, it must wait for one of those children to exit. Since it cannot know which of its children will exit first, and since it can sleep on only a single wait channel, there is a quandary as to how to wait for the next of multiple events. The solution is to have the parent sleep on its own process structure. When a child exits, it awakens its parent’s process-structure address, rather than its own. Thus, the parent doing the wait will awaken independent of which child process is the first to exit.
• When a process does a sigpause system call, it does not want to run until it receives a signal. Thus, it needs to do an interruptible sleep on a wait channel that will never be awakened. By convention, the address of the user structure is given as the wait channel.
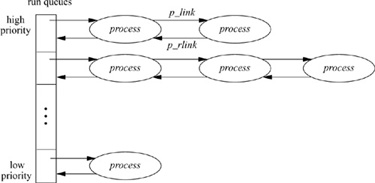
Sleeping processes are organized in an array of queues (see Fig. 4.3). The sleep() and wakeup () routines hash wait channels to calculate an index into the sleep queues. The sleep() routine takes the following steps in its operation:
1. Prevent interrupts that might cause process-state transitions by raising the hardware-processor priority level to splhigh (hardware-processor priority levels are explained in the next section).
2. Record the wait channel in the process structure, and hash the wait-channel value to locate a sleep queue for the process.
3. Set the process’s priority to the priority that the process will have when the process is awakened, and set the SSLEEP flag.
Figure 4.3 Queueing structure for sleeping processes.

4. Place the process at the end of the sleep queue selected in step 2.
5. Call mi_switch () to request that a new process be scheduled; the hardware priority level is implicitly reset as part of switching to the other process.
A sleeping process is not selected to execute until it is removed from a sleep queue and is marked runnable. This operation is done by the wakeup () routine, which is called to signal that an event has occurred or that a resource is available. Wakeup() is invoked with a wait channel, and it awakens all processes sleeping on that wait channel. All processes waiting for the resource are awakened to ensure that none are inadvertently left sleeping. If only one process were awakened, it might not request the resource on which it was sleeping, and so any other processes waiting for that resource would be left sleeping forever. A process that needs an empty disk buffer in which to write data is an example of a process that may not request the resource on which it was sleeping. Such a process can use any available buffer. If none is available, it will try to create one by requesting that a dirty buffer be written to disk and then waiting for the I/O to complete. When the I/O finishes, the process will awaken and will check for an empty buffer. If several are available, it may not use the one that it cleaned, leaving any other processes waiting for the buffer that it cleaned sleeping forever.
To avoid having excessive numbers of processes awakened, kernel programmers try to use wait channels with fine enough granularity that unrelated uses will not collide on the same resource. Thus, they put locks on each buffer in the buffer cache, rather than putting a single lock on the buffer cache as a whole. The problem of many processes awakening for a single resource is further mitigated on a uniprocessor by the latter’s inherently single-threaded operation. Although many processes will be put into the run queue at once, only one at a time can execute. Since the kernel is nonpreemptive, each process will run its system call to completion before the next one will get a chance to execute. Unless the previous user of the resource blocked in the kernel while trying to use the resource, each process waiting for the resource will be able to get and use the resource when it is next run.
A wakeup () operation processes entries on a sleep queue from front to back. For each process that needs to be awakened, wakeup ()
1. Removes the process from the sleep queue
2. Recomputes the user-mode scheduling priority if the process has been sleeping longer than 1 second
3. Makes the process runnable if it is in a SSLEEP state, and places the process on the run queue if it is not swapped out of main memory; if the process has been swapped out, the swapin process will be awakened to load it back into memory (see Section 5.12); if the process is in a SSTOP state, it is left on the queue until it is explicitly restarted by a user-level process, either by a ptrace system call or by a continue signal (see Section 4.7)
If wakeup () moved any processes to the run queue and one of them had a scheduling priority higher than that of the currently executing process, it will also request that the CPU be rescheduled as soon as possible.
The most common use of sleep() and wakeup () is in scheduling access to shared data structures; this use is described in the next section on synchronization.
Synchronization
Interprocess synchronization to a resource typically is implemented by the association with the resource of two flags; a locked flag and a wanted flag. When a process wants to access a resource, it first checks the locked flag. If the resource is not currently in use by another process, this flag should not be set, and the process can simply set the locked flag and use the resource. If the resource is in use, however, the process should set the wanted flag and call sleep() with a wait channel associated with the resource (typically the address of the data structure used to describe the resource). When a process no longer needs the resource, it clears the locked flag and, if the wanted flag is set, invokes wakeup () to awaken all the processes that called sleep() to await access to the resource.
Routines that run in the bottom half of the kernel do not have a context and consequently cannot wait for a resource to become available by calling sleep(). When the top half of the kernel accesses resources that are shared with the bottom half of the kernel, it cannot use the locked flag to ensure exclusive use. Instead, it must prevent the bottom half from running while it is using the resource. Synchronizing access with routines that execute in the bottom half of the kernel requires knowledge of when these routines may run. Although interrupt priorities are machine dependent, most implementations of 4.4BSD order them according to Table 4.3. To block interrupt routines at and below a certain priority level, a critical section must make an appropriate set-priority-level call. All the set-priority-level calls return the previous priority level. When the critical section is done, the priority is returned to its previous level using splx (). For example, when a process needs to manipulate a terminal’s data queue, the code that accesses the queue is written in the following style:
Table 4.3 Interrupt-priority assignments, ordered from lowest to highest.

s = spltty(); /* raise priority to block tty processing */
... /* manipulate tty */
splx(s); /* reset priority level to previous value */
Processes must take care to avoid deadlocks when locking multiple resources. Suppose that two processes, A and B, require exclusive access to two resources, R1 and R2, to do some operation. If process A acquires R1 and process B acquires R2, then a deadlock occurs when process A tries to acquire R2 and process B tries to acquire R1. Since a 4.4BSD process executing in kernel mode is never preempted by another process, locking of multiple resources is simple, although it must be done carefully. If a process knows that multiple resources are required to do an operation, then it can safely lock one or more of those resources in any order, as long as it never relinquishes control of the CPU. If, however, a process cannot acquire all the resources that it needs, then it must release any resources that it holds before calling sleep() to wait for the currently inaccessible resource to become available.
Alternatively, if resources can be partially ordered, it is necessary only that they be allocated in an increasing order. For example, as the namei () routine traverses the filesystem name space, it must lock the next component of a pathname before it relinquishes the current component. A partial ordering of pathname components exists from the root of the name space to the leaves. Thus, translations down the name tree can request a lock on the next component without concern for deadlock. However, when it is traversing up the name tree (i.e., following a pathname component of dot-dot (..)), the kernel must take care to avoid sleeping while holding any locks.
Raising the processor priority level to guard against interrupt activity works for a uniprocessor architecture, but not for a shared-memory multiprocessor machine. Similarly, much of the 4.4BSD kernel implicitly assumes that kernel processing will never be done concurrently. Numerous vendors—such as Sequent, OSF/1, AT&T, and Sun Microsystems—have redesigned the synchronization schemes and have eliminated the uniprocessor assumptions implicit in the standard UNIX kernel, so that UNIX will run on tightly coupled multiprocessor architectures [Schimmel, 1994].
4.4 Process Scheduling
4.4BSD uses a process-scheduling algorithm based on multilevel feedback queues. All processes that are runnable are assigned a scheduling priority that determines in which run queue they are placed. In selecting a new process to run, the system scans the run queues from highest to lowest priority and chooses the first process on the first nonempty queue. If multiple processes reside on a queue, the system runs them round robin; that is, it runs them in the order that they are found on the queue, with equal amounts of time allowed. If a process blocks, it is not put back onto any run queue. If a process uses up the time quantum (or time slice) allowed it, it is placed at the end of the queue from which it came, and the process at the front of the queue is selected to run.
The shorter the time quantum, the better the interactive response. However, longer time quanta provide higher system throughput, because the system will have less overhead from doing context switches, and processor caches will be flushed less often. The time quantum used by 4.4BSD is 0.1 second. This value was empirically found to be the longest quantum that could be used without loss of the desired response for interactive jobs such as editors. Perhaps surprisingly, the time quantum has remained unchanged over the past 15 years. Although the time quantum was originally selected on centralized timesharing systems with many users, it is still correct for decentralized workstations today. Although workstation users expect a response time faster than that anticipated by the timesharing users of 10 years ago, the shorter run queues on the typical workstation makes a shorter quantum unnecessary.
The system adjusts the priority of a process dynamically to reflect resource requirements (e.g., being blocked awaiting an event) and the amount of resources consumed by the process (e.g., CPU time). Processes are moved between run queues based on changes in their scheduling priority (hence the word feedback in the name multilevel feedback queue). When a process other than the currently running process attains a higher priority (by having that priority either assigned or given when it is awakened), the system switches to that process immediately if the current process is in user mode. Otherwise, the system switches to the higher-priority process as soon as the current process exits the kernel. The system tailors this short-term scheduling algorithm to favor interactive jobs by raising the scheduling priority of processes that are blocked waiting for I/O for 1 or more seconds, and by lowering the priority of processes that accumulate significant amounts of CPU time.
Short-term process scheduling is broken up into two parts. The next section describes when and how a process’s scheduling priority is altered; the section after describes the management of the run queues and the interaction between process scheduling and context switching.
Calculations of Process Priority
A process’s scheduling priority is determined directly by two values contained in the process structure: p_estcpu and p_nice. The value of p_estcpu provides an estimate of the recent CPU utilization of the process. The value of p_nice is a user-settable weighting factor that ranges numerically between –20 and 20. The normal value for p_nice is 0. Negative values increase a process’s priority, whereas positive values decrease its priority.
A process’s user-mode scheduling priority is calculated every four clock ticks (typically 40 milliseconds) by this equation:
Values less than PUSER are set to PUSER (see Table 4.2); values greater than 127 are set to 127. This calculation causes the priority to decrease linearly based on recent CPU utilization. The user-controllable p_nice parameter acts as a limited weighting factor. Neg ative values retard the effect of heavy CPU utilization by offsetting the additive term containing p_estcpu. Otherwise, if we ignore the second term, p_nice simply shifts the priority by a constant factor.
The CPU utilization, p_estcpu, is incremented each time that the system clock ticks and the process is found to be executing. In addition, p_estcpu is adjusted once per second via a digital decay filter. The decay causes about 90 percent of the CPU usage accumulated in a 1-second interval to be forgotten over a period of time that is dependent on the system load average. To be exact, p_estcpu is adjusted according to
![]()
where the load is a sampled average of the sum of the lengths of the run queue and of the short-term sleep queue over the previous 1-minute interval of system operation.
To understand the effect of the decay filter, we can consider the case where a single compute-bound process monopolizes the CPU. The process’s CPU utilization will accumulate clock ticks at a rate dependent on the clock frequency. The load average will be effectively 1, resulting in a decay of
p_estcpu = 0.66×p_estcpu + p_nice.
If we assume that the process accumulates Ti clock ticks over time interval i, and that p_nice is zero, then the CPU utilization for each time interval will count into the current value of p_estcpu according to
p_estcpu = 0.66×T0
p_estcpu = 0.66×(T1 + 0.66×T0) = 0.66×T1 + 0.44×T0
p_estcpu = 0.66×T2 = 0.44×T1 + 0.30×T0
p_estcpu = 0.66×T3 + ... + 0.20×T0
p_estcpu = 0.66×T4 + ... + 0.13×T0.
Thus, after five decay calculations, only 13 percent of T0 remains present in the current CPU utilization value for the process. Since the decay filter is applied once per second, we can also say that about 90 percent of the CPU utilization is forgotten after 5 seconds.
Processes that are runnable have their priority adjusted periodically as just described. However, the system ignores processes blocked awaiting an event: These processes cannot accumulate CPU usage, so an estimate of their filtered CPU usage can be calculated in one step. This optimization can significantly reduce a system’s scheduling overhead when many blocked processes are present. The system recomputes a process’s priority when that process is awakened and has been sleeping for longer than 1 second. The system maintains a value, p_slptime, that is an estimate of the time a process has spent blocked waiting for an event. The value of p_slptime is set to 0 when a process calls sleep(), and is incremented once per second while the process remains in an SSLEEP or SSTOP state. When the process is awakened, the system computes the value of p_estcpu according to
![]()
and then recalculates the scheduling priority using Eq. 4.1. This analysis ignores the influence of p_nice; also, the load used is the current load average, rather than the load average at the time that the process blocked.
Process-Priority Routines
The priority calculations used in the short-term scheduling algorithm are spread out in several areas of the system. Two routines, schedcpu () and roundrobin (), run periodically. Schedcpu () recomputes process priorities once per second, using Eq. 4.2, and updates the value of p_slptime for processes blocked by a call to sleep(). The roundrobin () routine runs 10 times per second and causes the system to reschedule the processes in the highest-priority (nonempty) queue in a round-robin fashion, which allows each process a 100-millisecond time quantum.
The CPU usage estimates are updated in the system clock-processing module, hardclock(), which executes 100 times per second. Each time that a process accumulates four ticks in its CPU usage estimate, p_estcpu, the system recalculates the priority of the process. This recalculation uses Eq. 4.1 and is done by the setpriority () routine. The decision to recalculate after four ticks is related to the management of the run queues described in the next section. In addition to issuing the call from hardclock (), each time setrunnable () places a process on a run queue, it also calls setpriority () to recompute the process’s scheduling priority. This call from wakeup () to setrunnable () operates on a process other than the currently running process. So, wakeup () invokes updatepri () to recalculate the CPU usage estimate according to Eq. 4.3 before calling setpriority (). The relationship of these functions is shown in Fig. 4.4.
Figure 4.4 Procedural interface to priority calculation.

Process Run Queues and Context Switching
The scheduling-priority calculations are used to order the set of runnable processes. The scheduling priority ranges between 0 and 127, with 0 to 49 reserved for processes executing in kernel mode, and 50 to 127 reserved for processes executing in user mode. The number of queues used to hold the collection of runnable processes affects the cost of managing the queues. If only a single (ordered) queue is maintained, then selecting the next runnable process becomes simple, but other operations become expensive. Using 128 different queues can significantly increase the cost of identifying the next process to run. The system uses 32 run queues, selecting a run queue for a process by dividing the process’s priority by 4. The processes on each queue are not further sorted by their priorities. The selection of 32 different queues was originally a compromise based mainly on the availability of certain VAX machine instructions that permitted the system to implement the lowest-level scheduling algorithm efficiently, using a 32-bit mask of the queues containing runnable processes. The compromise works well enough today that 32 queues are still used.
The run queues contain all the runnable processes in main memory except the currently running process. Figure 4.5 shows how each queue is organized as a doubly linked list of process structures. The head of each run queue is kept in an array; associated with this array is a bit vector, whichqs, that is used in identifying the nonempty run queues. Two routines, setrunqueue () and remrq (), are used to place a process at the tail of a run queue, and to take a process off the head of a run queue. The heart of the scheduling algorithm is the cpu_switch () routine. The cpu_switch () routine is responsible for selecting a new process to run; it operates as follows:
Figure 4.5 Queueing structure for runnable processes.
1. Block interrupts, then look for a nonempty run queue. Locate a nonempty queue by finding the location of the first nonzero bit in the whichqs bit vector. If whichqs is zero, there are no processes to run, so unblock interrupts and loop; this loop is the idle loop.
2. Given a nonempty run queue, remove the first process on the queue.
3. If this run queue is now empty as a result of removing the process, reset the appropriate bit in whichqs.
4. Clear the curproc pointer and the want_resched flag. The curproc pointer references the currently running process. Clear it to show that no process is currently running. The want_resched flag shows that a context switch should take place; it is described later in this section.
5. Set the new process running and unblock interrupts.
The context-switch code is broken into two parts. The machine-independent code resides in mi_switch (); the machine-dependent part resides in cpu_switch (). On most architectures, cpu_switch () is coded in assembly language for efficiency.
Given the mi_switch () routine and the process-priority calculations, the only missing piece in the scheduling facility is how the system forces an involuntary context switch. Remember that voluntary context switches occur when a process calls the sleep() routine. Sleep() can be invoked by only a runnable process, so sleep() needs only to place the process on a sleep queue and to invoke mi_switch() to schedule the next process to run. The mi_switch () routine, however, cannot be called from code that executes at interrupt level, because it must be called within the context of the running process.
An alternative mechanism must exist. This mechanism is handled by the machine-dependent need_resched () routine, which generally sets a global reschedule request flag, named want_resched, and then posts an asynchronous system trap (AST) for the current process. An AST is a trap that is delivered to a process the next time that that process returns to user mode. Some architectures support ASTs directly in hardware; other systems emulate ASTs by checking the want_resched flag at the end of every system call, trap, and interrupt of user-mode execution. When the hardware AST trap occurs or the want_resched flag is set, the mi_switch() routine is called, instead of the current process resuming execution. Rescheduling requests are made by the wakeup (), setpriority (), roundrobin (), schedcpu(), and setrunnable () routines.
Because 4.4BSD does not preempt processes executing in kernel mode, the worst-case real-time response to events is defined by the longest path through the top half of the kernel. Since the system guarantees no upper bounds on the duration of a system call, 4.4BSD is decidedly not a real-time system. Attempts to retrofit BSD with real-time process scheduling have addressed this problem in different ways [Ferrin & Langridge, 1980; Sanderson et al, 1986].
4.5 Process Creation
In 4.4BSD, new processes are created with the fork system call. There is also a vfork system call that differs from fork in how the virtual-memory resources are treated; vfork also ensures that the parent will not run until the child does either an exec or exit system call. The vfork system call is described in Section 5.6.
The process created by a fork is termed a child process of the original parent process. From a user’s point of view, the child process is an exact duplicate of the parent process, except for two values: the child PID, and the parent PID. A call to fork returns the child PID to the parent and zero to the child process. Thus, a program can identify whether it is the parent or child process after a fork by checking this return value.
A fork involves three main steps:
1. Allocating and initializing a new process structure for the child process
2. Duplicating the context of the parent (including the user structure and virtual-memory resources) for the child process
3. Scheduling the child process to run
The second step is intimately related to the operation of the memory-management facilities described in Chapter 5. Consequently, only those actions related to process management will be described here.
The kernel begins by allocating memory for the new process entry (see Fig. 4.1). The process entry is initialized in three steps: part is copied from the parent’s process structure, part is zeroed, and the rest is explicitly initialized. The zeroed fields include recent CPU utilization, wait channel, swap and sleep time, timers, tracing, and pending-signal information. The copied portions include all the privileges and limitations inherited from the parent, including
• The process group and session
• The signal state (ignored, caught and blocked signal masks)
• The p_nice scheduling parameter
• A reference to the parent’s credential
• A reference to the parent’s set of open files
• A reference to the parent’s limits
The explicitly set information includes
• Entry onto the list of all processes
• Entry onto the child list of the parent and the back pointer to the parent
• Entry onto the parent’s process-group list
• Entry onto the hash structure that allows the process to be looked up by its PID
• A pointer to the process’s statistics structure, allocated in its user structure
• A pointer to the process’s signal-actions structure, allocated in its user structure
• A new PID for the process
The new PID must be unique among all processes. Early versions of BSD verified the uniqueness of a PID by performing a linear search of the process table. This search became infeasible on large systems with many processes. 4.4BSD maintains a range of unallocated PIDs between nextpid and pidchecked. It allocates a new PID by using the value of nextpid, and nextpid is then incremented. When nextpid reaches pidchecked, the system calculates a new range of unused PIDs by making a single scan of all existing processes (not just the active ones are scanned—zombie and swapped processes also are checked).
The final step is to copy the parent’s address space. To duplicate a process’s image, the kernel invokes the memory-management facilities through a call to vm_fork(). The vm_fork () routine is passed a pointer to the initialized process structure for the child process and is expected to allocate all the resources that the child will need to execute. The call to vm_fork () returns a value of 1 in the child process and of 0 in the parent process.
Now that the child process is fully built, it is made known to the scheduler by being placed on the run queue. The return value from vm_fork () is passed back to indicate whether the process is returning in the parent or child process, and determines the return value of the fork system call.
4.6 Process Termination
Processes terminate either voluntarily through an exit system call, or involuntarily as the result of a signal. In either case, process termination causes a status code to be returned to the parent of the terminating process (if the parent still exists). This termination status is returned through the wait4 system call. The wait4 call permits an application to request the status of both stopped and terminated processes. The wait4 request can wait for any direct child of the parent, or it can wait selectively for a single child process, or for only its children in a particular process group. Wait4 can also request statistics describing the resource utilization of a terminated child process. Finally, the wait4 interface allows a process to request status codes without blocking.
Within the kernel, a process terminates by calling the exit () routine. Exit () first cleans up the process’s kernel-mode execution state by
• Canceling any pending timers
• Releasing virtual-memory resources
• Closing open descriptors
• Handling stopped or traced child processes
With the kernel-mode state reset, the process is then removed from the list of active processes—the allproc list—and is placed on the list of zombie processes pointed to by zombproc. The process state is changed, and the global flag curproc is marked to show that no process is currently running. The exit () routine then
• Records the termination status in the p_xstat field of the process structure
• Bundles up a copy of the process’s accumulated resource usage (for accounting purposes) and hangs this structure from the p_ru field of the process structure
• Notifies the deceased process’s parent
Finally, after the parent has been notified, the cpu_exit () routine frees any machine-dependent process resources, and arranges for a final context switch from the process.
The wait4 call works by searching a process’s descendant processes for processes that have terminated. If a process in SZOMB state is found that matches the wait criterion, the system will copy the termination status from the deceased process. The process entry then is taken off the zombie list and is freed. Note that resources used by children of a process are accumulated only as a result of a wait4 system call. When users are trying to analyze the behavior of a long-running program, they would find it useful to be able to obtain this resource usage information before the termination of a process. Although the information is available inside the kernel and within the context of that program, there is no interface to request it outside of that context until process termination.
4.7 Signals
UNIX defines a set of signals for software and hardware conditions that may arise during the normal execution of a program; these signals are listed in Table 4.4. Signals may be delivered to a process through application-specified signal handlers, or may result in default actions, such as process termination, carried out by the system. 4.4BSD signals are designed to be software equivalents of hardware interrupts or traps.
Table 4.4 Signals defined in 4.4BSD.

Each signal has an associated action that defines how it should be handled when it is delivered to a process. If a process has not specified an action for a signal, it is given a default action that may be any one of
• Terminating the process
• Terminating the process after generating a core file that contains the process’s execution state at the time the signal was delivered
• Stopping the process
• Resuming the execution of the process
An application program can use the sigaction system call to specify an action for a signal, including
• Taking the default action
• Ignoring the signal
• Catching the signal with a handler
A signal handler is a user-mode routine that the system will invoke when the signal is received by the process. The handler is said to catch the signal. The two signals SIGSTOP and SIGKILL cannot be ignored or caught; this restriction ensures that a software mechanism exists for stopping and killing runaway processes. It is not possible for a user process to decide which signals would cause the creation of a core file by default, but it is possible for a process to prevent the creation of such a file by ignoring, blocking, or catching the signal.
Signals are posted to a process by the system when it detects a hardware event, such as an illegal instruction, or a software event, such as a stop request from the terminal. A signal may also be posted by another process through the kill system call. A sending process may post signals to only those receiving processes that have the same effective user identifier (unless the sender is the superuser). A single exception to this rule is the continue signal, SIGCONT, which always can be sent to any descendent of the sending process. The reason for this exception is to allow users to restart a setuid program that they have stopped from their keyboard.
Like hardware interrupts, the delivery of signals may be masked by a process. The execution state of each process contains a set of signals currently masked from delivery. If a signal posted to a process is being masked, the signal is recorded in the process’s set of pending signals, but no action is taken until the signal is unmasked. The sigprocmask system call modifies a set of masked signals for a process. It can add to the set of masked signals, delete from the set of masked signals, or replace the set of masked signals.
The system does not allow the SIGKILL or SIGSTOP signals to be masked. Although the delivery of the SIGCONT signal to the signal handler of a process may be masked, the action of resuming that stopped process is not masked.
Two other signal-related system calls are sigsuspend and sigaltstack. The sig-suspend call permits a process to relinquish the processor until that process receives a signal. This facility is similar to the system’s sleep() routine. The sigaltstack call allows a process to specify a run-time stack to use in signal delivery. By default, the system will deliver signals to a process on the latter’s normal run-time stack. In some applications, however, this default is unacceptable. For example, if an application is running on a stack that the system does not expand automatically, and the stack overflows, then the signal handler must execute on an alternate stack. This facility is similar to the interrupt-stack mechanism used by the kernel.
The final signal-related facility is the sigreturn system call. Sigreturn is the equivalent of a user-level load-processor-context operation. A pointer to a (machine-dependent) context block that describes the user-level execution state of a process is passed to the kernel. The sigreturn system call is used to restore state and to resume execution after a normal return from a user’s signal handler.
Comparison with POSIX Signals
Signals were originally designed to model exceptional events, such as an attempt by a user to kill a runaway program. They were not intended to be used as a general interprocess-communication mechanism, and thus no attempt was made to make them reliable. In earlier systems, whenever a signal was caught, its action was reset to the default action. The introduction of job control brought much more frequent use of signals, and made more visible a problem that faster processors also exacerbated: If two signals were sent rapidly, the second could cause the process to die, even though a signal handler had been set up to catch the first signal. Thus, reliability became desirable, so the developers designed a new framework that contained the old capabilities as a subset while accommodating new mechanisms.
The signal facilities found in 4.4BSD are designed around a virtual-machine model, in which system calls are considered to be the parallel of machine’s hardware instruction set. Signals are the software equivalent of traps or interrupts, and signal-handling routines perform the equivalent function of interrupt or trap service routines. Just as machines provide a mechanism for blocking hardware interrupts so that consistent access to data structures can be ensured, the signal facilities allow software signals to be masked. Finally, because complex run-time stack environments may be required, signals, like interrupts, may be handled on an alternate runtime stack. These machine models are summarized in Table 4.5 (on page 104).
The 4.4BSD signal model was adopted by POSIX, although several significant changes were made.
• In POSIX, system calls interrupted by a signal cause the call to be terminated prematurely and an “interrupted system call” error to be returned. In 4.4BSD, the sigaction system call can be passed a flag that requests that system calls interrupted by a signal be restarted automatically whenever possible and reasonable. Automatic restarting of system calls permits programs to service signals without having to check the return code from each system call to determine whether the call should be restarted. If this flag is not given, the POSIX semantics apply. Most applications use the C-library routine signal () to set up their signal handlers. In 4.4BSD, the signal () routine calls sigaction with the flag that requests that system calls be restarted. Thus, applications running on 4.4BSD and setting up signal handlers with signal () continue to work as expected, even though the sigaction interface conforms to the POSIX specification.
Table 4.5 Comparison of hardware-machine operations and the corresponding software virtual-machine operations.

• In POSIX, signals are always delivered on the normal run-time stack of a process. In 4.4BSD, an alternate stack may be specified for delivering signals with the sigaltstack system call. Signal stacks permit programs that manage fixed-sized run-time stacks to handle signals reliably.
• POSIX added a new system call sigpending; this routine determines what signals have been posted but have not yet been delivered. Although it appears in 4.4BSD, it had no equivalent in earlier BSD systems because there were no applications that wanted to make use of pending-signal information.
Posting of a Signal
The implementation of signals is broken up into two parts: posting a signal to a process, and recognizing the signal and delivering it to the target process. Signals may be posted by any process or by code that executes at interrupt level. Signal delivery normally takes place within the context of the receiving process. But when a signal forces a process to be stopped, the action can be carried out when the signal is posted.
A signal is posted to a single process with the psignal () routine or to a group of processes with the gsignal () routine. The gsignal () routine invokes psignal () for each process in the specified process group. The actions associated with posting a signal are straightforward, but the details are messy. In theory, posting a signal to a process simply causes the appropriate signal to be added to the set of pending signals for the process, and the process is then set to run (or is awakened if it was sleeping at an interruptible priority level). The CURSIG macro calculates the next signal, if any, that should be delivered to a process. It determines the next signal by inspecting the p_siglist field that contains the set of signals pending delivery to a process. Each time that a process returns from a call to sleep() (with the PCATCH flag set) or prepares to exit the system after processing a system call or trap, it checks to see whether a signal is pending delivery. If a signal is pending and must be delivered in the process’s context, it is removed from the pending set, and the process invokes the postsig () routine to take the appropriate action.
The work of psignal () is a patchwork of special cases required by the process-debugging and job-control facilities, and by intrinsic properties associated with signals. The steps involved in posting a signal are as follows:
1. Determine the action that the receiving process will take when the signal is delivered. This information is kept in the p_sigignore, p_sigmask, and p_sig-catch fields of the process’s process structure. If a process is not ignoring, masking, or catching a signal, the default action is presumed to apply. If a process is being traced by its parent—that is, by a debugger—the parent process is always permitted to intercede before the signal is delivered. If the process is ignoring the signal, psignal ()’s work is done and the routine can return.
2. Given an action, psignal () adds the signal to the set of pending signals, p_siglist, and then does any implicit actions specific to that signal. For example, if the signal is a continue signal, SIGCONT, any pending signals that would normally cause the process to stop, such as SIGTTOU, are removed.
3. Next, psignal () checks whether the signal is being masked. If the process is currently masking delivery of the signal, psignal ()’s work is complete and it may return.
4. If, however, the signal is not being masked, psignal () must either do the action directly, or arrange for the process to execute so that the process will take the action associated with the signal. To get the process running, psignal () must interrogate the state of the process, which is one of the following:
The implementation of psignal () is complicated, mostly because psignal () controls the process-state transitions that are part of the job-control facilities and because it interacts strongly with process-debugging facilities.
Delivering a Signal
Most actions associated with delivering a signal to a process are carried out within the context of that process. A process checks its process structure for pending signals at least once each time that it enters the system, by calling the CURSIG macro.
If CURSIG determines that there are any unmasked signals in p_siglist, it calls issignal() to find the first unmasked signal in the list. If delivering the signal causes a signal handler to be invoked or a core dump to be made, the caller is notified that a signal is pending, and actual delivery is done by a call to postsig (). That is,
if (sig = CURSIG(p))
postsig(sig);
Otherwise, the action associated with the signal is done within issignal () (these actions mimic the actions carried out by psignal ()).
The postsig () routine has two cases to handle:
1. Producing a core dump
2. Invoking a signal handler
The former task is done by the coredump () routine and is always followed by a call to exit () to force process termination. To invoke a signal handler, postsig () first calculates a set of masked signals and installs that set in p_sigmask. This set normally includes the signal being delivered, so that the signal handler will not be invoked recursively by the same signal. Any signals specified in the sigaction system call at the time the handler was installed also will be included. Postsig () then calls the sendsig () routine to arrange for the signal handler to execute immediately after the process returns to user mode. Finally, the signal in p_cursig is cleared and postsig () returns, presumably to be followed by a return to user mode.
Figure 4.6 Delivery of a signal to a process.
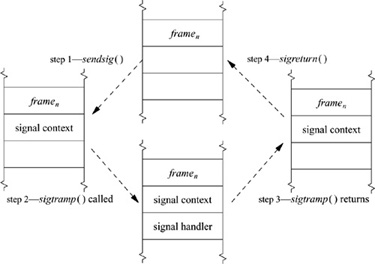
The implementation of the sendsig () routine is machine dependent. Figure 4.6 shows the flow of control associated with signal delivery. If an alternate stack has been requested, the user’s stack pointer is switched to point at that stack. An argument list and the process’s current user-mode execution context are stored on the (possibly new) stack. The state of the process is manipulated so that, on return to user mode, a call will be made immediately to a body of code termed the signal-trampoline code. This code invokes the signal handler with the appropriate argument list, and, if the handler returns, makes a sigreturn system call to reset the process’s signal state to the state that existed before the signal.
4.8 Process Groups and Sessions
A process group is a collection of related processes, such as a shell pipeline, all of which have been assigned the same process-group identifier. The process-group identifier is the same as the PID of the process group’s initial member; thus process-group identifiers share the name space of process identifiers. When a new process group is created, the kernel allocates a process-group structure to be associated with it. This process-group structure is entered into a process-group hash table so that it can be found quickly.
A process is always a member of a single process group. When it is created, each process is placed into the process group of its parent process. Programs such as shells create new process groups, usually placing related child processes into a group. A process can change its own process group or that of a child process by creating a new process group or by moving a process into an existing process group using the setpgid system call. For example, when a shell wants to set up a new pipeline, it wants to put the processes in the pipeline into a process group different from its own, so that the pipeline can be controlled independently of the shell. The shell starts by creating the first process in the pipeline, which initially has the same process-group identifier as the shell. Before executing the target program, the first process does a setpgid to set its process-group identifier to the same value as its PID. This system call creates a new process group, with the child process as the process-group leader of the process group. As the shell starts each additional process for the pipeline, each child process uses setpgid to join the existing process group.
In our example of a shell creating a new pipeline, there is a race. As the additional processes in the pipeline are spawned by the shell, each is placed in the process group created by the first process in the pipeline. These conventions are enforced by the setpgid system call. It restricts the set of process-group identifiers to which a process may be set to either a value equal its own PID or a value of another process-group identifier in its session. Unfortunately, if a pipeline process other than the process-group leader is created before the process-group leader has completed its setpgid call, the setpgid call to join the process group will fail. As the setpgid call permits parents to set the process group of their children (within some limits imposed by security concerns), the shell can avoid this race by making the setpgid call to change the child’s process group both in the newly created child and in the parent shell. This algorithm guarantees that, no matter which process runs first, the process group will exist with the correct process-group leader. The shell can also avoid the race by using the vfork variant of the fork system call that forces the parent process to wait until the child process either has done an exec system call or has exited. In addition, if the initial members of the process group exit before all the pipeline members have joined the group—for example if the process-group leader exits before the second process joins the group, the setpgid call could fail. The shell can avoid this race by ensuring that all child processes are placed into the process group without calling the wait system call, usually by blocking the SIGCHLD signal so that the shell will not be notified yet if a child exits. As long as a process-group member exists, even as a zombie process, additional processes can join the process group.
There are additional restrictions on the setpgid system call. A process may join process groups only within its current session (discussed in the next section), and it cannot have done an exec system call. The latter restriction is intended to avoid unexpected behavior if a process is moved into a different process group after it has begun execution. Therefore, when a shell calls setpgid in both parent and child processes after a fork, the call made by the parent will fail if the child has already made an exec call. However, the child will already have joined the process group successfully, and the failure is innocuous.
Sessions
Just as a set of related processes are collected into a process group, a set of process groups are collected into a session. A session is a set of one or more process groups and may be associated with a terminal device. The main uses for sessions are to collect together a user’s login shell and the jobs that it spawns, and to create an isolated environment for a daemon process and its children. Any process that is not already a process-group leader may create a session using the setsid system call, becoming the session leader and the only member of the session. Creating a session also creates a new process group, where the process-group ID is the PID of the process creating the session, and the process is the process-group leader. By definition, all members of a process group are members of the same session.
A session may have an associated controlling terminal that is used by default for communicating with the user. Only the session leader may allocate a controlling terminal for the session, becoming a controlling process when it does so. A device can be the controlling terminal for only one session at a time. The terminal I/O system (described in Chapter 10) synchronizes access to a terminal by permitting only a single process group to be the foreground process group for a controlling terminal at any time. Some terminal operations are allowed by only members of the session. A session can have at most one controlling terminal. When a session is created, the session leader is dissociated from its controlling terminal if it had one.
A login session is created by a program that prepares a terminal for a user to log into the system. That process normally executes a shell for the user, and thus the shell is created as the controlling process. An example of a typical login session is shown in Fig. 4.7 (on page 110).
The data structures used to support sessions and process groups in 4.4BSD are shown in Fig. 4.8. This figure parallels the process layout shown in Fig. 4.7. The pg_members field of a process-group structure heads the list of member processes; these processes are linked together through the p_pglist list entry in the process structure. In addition, each process has a reference to its process-group structure in the p_pgrp field of the process structure. Each process-group structure has a pointer to its enclosing session. The session structure tracks per-login information, including the process that created and controls the session, the controlling terminal for the session, and the login name associated with the session. Two processes wanting to determine whether they are in the same session can traverse their p_pgrp pointers to find their process-group structures, and then compare the pg_session pointers to see whether the latter are the same.
Figure 4.7 A session and its processes. In this example, process 3 is the initial member of the session—the session leader—and is referred to as the controlling process if it has a controlling terminal. It is contained in its own process group, 3. Process 3 has spawned two jobs: one is a pipeline composed of processes 4 and 5, grouped together in process group 4, and the other one is process 8, which is in its own process group, 8. No process-group leader can create a new session; thus, processes 3, 4, or 8 could not start their own session, but process 5 would be allowed to do so.

Job Control
Job control is a facility first provided by the C shell [Joy, 1994], and today provided by most shells. It permits a user to control the operation of groups of processes termed jobs. The most important facilities provided by job control are the abilities to suspend and restart jobs and to do the multiplexing of access to the user’s terminal. Only one job at a time is given control of the terminal and is able to read from and write to the terminal. This facility provides some of the advantages of window systems, although job control is sufficiently different that it is often used in combination with window systems on those systems that have the latter. Job control is implemented on top of the process group, session, and signal facilities.
Each job is a process group. Outside the kernel, a shell manipulates a job by sending signals to the job’s process group with the killpg system call, which delivers a signal to all the processes in a process group. Within the system, the two main users of process groups are the terminal handler (Chapter 10) and the interprocess-communication facilities (Chapter 11). Both facilities record process-group identifiers in private data structures and use them in delivering signals. The terminal handler, in addition, uses process groups to multiplex access to the controlling terminal.
For example, special characters typed at the keyboard of the terminal (e.g., control-C or control-) result in a signal being sent to all processes in one job in the session; that job is in the foreground, whereas all other jobs in the session are in the background. A shell may change the foreground job by using the tcsetpgrp () function, implemented by the TIOCSPGRP ioctl on the controlling terminal. Background jobs will be sent the SIGTTIN signal if they attempt to read from the terminal, normally stopping the job. The SIGTTOU signal is sent to background jobs that attempt an ioctl system call that would alter the state of the terminal, and, if the TOSTOP option is set for the terminal, if they attempt to write to the terminal.
Figure 4.8 Process-group organization.
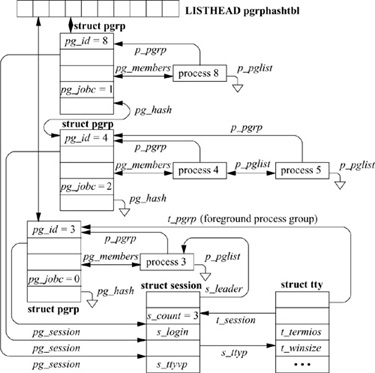
The foreground process group for a session is stored in the t_pgrp field of the session’s controlling terminaltty structure (see Chapter 10). All other process groups within the session are in the background. In Fig. 4.8, the session leader has set the foreground process group for its controlling terminal to be its own process group. Thus, its two jobs are in background, and the terminal input and output will be controlled by the session-leader shell. Job control is limited to processes contained within the same session and to the terminal associated with the session. Only the members of the session are permitted to reassign the controlling terminal among the process groups within the session.
If a controlling process exits, the system revokes further access to the controlling terminal and sends a SIGHUP signal to the foreground process group. If a process such as a job-control shell exits, each process group that it created will become an orphaned process group : a process group in which no member has a parent that is a member of the same session but of a different process group. Such a parent would normally be a job-control shell capable of resuming stopped child processes. The pg_jobc field in Fig. 4.8 counts the number of processes within the process group that have the controlling process as a parent; when that count goes to zero, the process group is orphaned. If no action were taken by the system, any orphaned process groups that were stopped at the time that they became orphaned would be unlikely ever to resume. Historically, the system dealt harshly with such stopped processes: They were killed. In POSIX and 4.4BSD, an orphaned process group is sent a hangup and a continue signal if any of its members are stopped when it becomes orphaned by the exit of a parent process. If processes choose to catch or ignore the hangup signal, they can continue running after becoming orphaned. The system keeps a count of processes in each process group that have a parent process in another process group of the same session. When a process exits, this count is adjusted for the process groups of all child processes. If the count reaches zero, the process group has become orphaned. Note that a process can be a member of an orphaned process group even if its original parent process is still alive. For example, if a shell starts a job as a single process A, that process then forks to create process B, and the parent shell exits, then process B is a member of an orphaned process group but is not an orphaned process.
To avoid stopping members of orphaned process groups if they try to read or write to their controlling terminal, the kernel does not send them SIGTTIN and SIGTTOU signals, and prevents them from stopping in response to those signals. Instead, attempts to read or write to the terminal produce an error.
4.9 Process Debugging
4.4BSD provides a simplistic facility for controlling and debugging the execution of a process. This facility, accessed through the ptrace system call, permits a parent process to control a child process’s execution by manipulating user- and kernel-mode execution state. In particular, with ptrace, a parent process can do the following operations on a child process:
• Read and write address space and registers
• Intercept signals posted to the process
• Single step and continue the execution of the process
• Terminate the execution of the process
The ptrace call is used almost exclusively by program debuggers, such as gdb.
When a process is being traced, any signals posted to that process cause it to enter the SSTOP state. The parent process is notified with a SIGCHLD signal and may interrogate the status of the child with the wait4 system call. On most machines, trace traps, generated when a process is single stepped, and breakpoint faults, caused by a process executing a breakpoint instruction, are translated by 4.4BSD into SIGTRAP signals. Because signals posted to a traced process cause it to stop and result in the parent being notified, a program’s execution can be controlled easily.
To start a program that is to be debugged, the debugger first creates a child process with a fork system call. After the fork, the child process uses a ptrace call that causes the process to be flagged as traced by setting the P_TRACED bit in the p_flag field of the process structure. The child process then sets the trace trap bit in the process’s processor status word and calls execve to load the image of the program that is to be debugged. Setting this bit ensures that the first instruction executed by the child process after the new image is loaded will result in a hardware trace trap, which is translated by the system into a SIGTRAP signal. Because the parent process is notified about all signals to the child, it can intercept the signal and gain control over the program before it executes a single instruction.
All the operations provided by ptrace are carried out in the context of the process being traced. When a parent process wants to do an operation, it places the parameters associated with the operation into a data structure named ipc and sleeps on the address of ipc. The next time that the child process encounters a signal (immediately if it is currently stopped by a signal), it retrieves the parameters from the ipc structure and does the requested operation. The child process then places a return result in the ipc structure and does a wakeup () call with the address of ipc as the wait channel. This approach minimizes the amount of extra code needed in the kernel to support debugging. Because the child makes the changes to its own address space, any pages that it tries to access that are not resident in memory are brought into memory by the existing page-fault mechanisms. If the parent tried to manipulate the child’s address space, it would need special code to find and load any pages that it wanted to access that were not resident in memory.
The ptrace facility is inefficient for three reasons. First, ptrace uses a single global data structure for passing information back and forth between all the parent and child processes in the system. Because there is only one structure, it must be interlocked to ensure that only one parent–child process pair will use it at a time. Second, because the data structure has a small, fixed size, the parent process is limited to reading or writing 32 bits at a time. Finally, since each request by a parent process must be done in the context of the child process, two context switches need to be done for each request—one from the parent to the child to send the request, and one from the child to the parent to return the result of the operation.
To address these problems, 4.4BSD added a /proc filesystem, similar to the one found in UNIX Eighth Edition [Killian, 1984]. In the /proc system, the address space of another process can be accessed with read and write system calls, which allows a debugger to access a process being debugged with much greater efficiency. The page (or pages) of interest in the child process is mapped into the kernel address space. The requested data can then be copied directly from the kernel to the parent address space. This technique avoids the need to have a data structure to pass messages back and forth between processes, and avoids the context switches between the parent and child processes. Because the ipc mechanism was derived from the original UNIX code, it was not included in the freely redistributable 4.4BSD-Lite release. Most reimplementations simply converted the ptrace requests into calls on /proc, or map the process pages directly into the kernel memory. The result is a much simpler and faster implementation of ptrace.
Exercises
4.1 What are three implications of not having the user structure mapped at a fixed virtual address in the kernel’s address space?
4.2 Why is the performance of the context-switching mechanism critical to the performance of a highly multiprogrammed system?
4.3 What effect would increasing the time quantum have on the system’s interactive response and total throughput?
4.4 What effect would reducing the number of run queues from 32 to 16 have on the scheduling overhead and on system performance?
4.5 Give three reasons for the system to select a new process to run.
4.6 What type of scheduling policy does 4.4BSD use? What type of jobs does the policy favor? Propose an algorithm for identifying these favored jobs.
4.7 Is job control still a useful facility, now that window systems are widely available? Explain your answer.
4.8 When and how does process scheduling interact with the memory-management facilities?
4.9 After a process has exited, it may enter the state of being a zombie, SZOMB, before disappearing from the system entirely. What is the purpose of the SZOMB state? What event causes a process to exit from SZOMB?
4.10 Suppose that the data structures shown in Fig. 4.2 do not exist. Instead assume that each process entry has only its own PID and the PID of its parent. Compare the costs in space and time to support each of the following operations:
a. Creation of a new process
b. Lookup of the process’s parent
c. Lookup of all a process’s siblings
d. Lookup of all a process’s descendents
e. Destruction of a process
4.11 The system raises the hardware priority to splhigh in the sleep() routine before altering the contents of a process’s process structure. Why does it do so?
4.12 A process blocked with a priority less than PZERO may never be awakened by a signal. Describe two problems a noninterruptible sleep may cause if a disk becomes unavailable while the system is running.
4.13 For each state listed in Table 4.1, list the system queues on which a process in that state might be found.
*4.14 Define three properties of a real-time system. Give two reasons why 4.4BSD is not a real-time system.
*4.15 In 4.4BSD, the signal SIGTSTP is delivered to a process when a user types a “suspend character.” Why would a process want to catch this signal before it is stopped?
*4.16 Before the 4.4BSD signal mechanism was added, signal handlers to catch the SIGTSTP signal were written as
catchstop()
{
prepare to stop;
signal(SIGTSTP, SIG_DFL);
kill(getpid(), SIGTSTP);
signal(SIGTSTP, catchstop);
}
This code causes an infinite loop in 4.4BSD. Why does it do so? How should the code be rewritten?
*4.17 The process-priority calculations and accounting statistics are all based on sampled data. Describe hardware support that would permit more accurate statistics and priority calculations.
*4.18 What are the implications of adding a fixed-priority scheduling algorithm to 4.4BSD?
*4.19 Why are signals a poor interprocess-communication facility?
**4.20 A kernel-stack-invalid trap occurs when an invalid value for the kernel-mode stack pointer is detected by the hardware. Assume that this trap is received on an interrupt stack in kernel mode. How might the system terminate gracefully a process that receives such a trap while executing on the kernel’s run-time stack contained in the user structure?
**4.21 Describe a synchronization scheme that would work in a tightly coupled multiprocessor hardware environment. Assume that the hardware supports a test-and-set instruction.
**4.22 Describe alternatives to the test-and-set instruction that would allow you to build a synchronization mechanism for a multiprocessor 4.4BSD system.
**4.23 A lightweight process is a thread of execution that operates within the context of a normal 4.4BSD process. Multiple lightweight processes may exist in a single 4.4BSD process and share memory, but each is able to do blocking operations, such as system calls. Describe how lightweight processes might be implemented entirely in user mode.
References
Aral et al, 1989.
Z. Aral, J. Bloom, T. Doeppner, I. Gertner, A. Langerman, & G. Schaffer, “Variable Weight Processes with Flexible Shared Resources,” USENIX Association Conference Proceedings, p. 405–412, January 1989.
Ferrin & Langridge, 1980.
T. E. Ferrin & R. Langridge, “Interactive Computer Graphics with the UNIX Time-Sharing System,” Computer Graphics, vol. 13, p. 320–331, 1980.
Joy, 1994.
W. N. Joy, “An Introduction to the C Shell,” in 4.4BSD User’s Supplementary Documents, p. 4:1–46, O’Reilly & Associates, Inc., Sebastopol, CA, 1994.
Khanna et al, 1992.
S. Khanna, M. Sebree, & J. Zolnowsky, “Realtime Scheduling in SunOS 5.0,” USENIX Association Conference Proceedings, p. 375–390, January 1992.
Killian, 1984.
T. J. Killian, “Processes as Files,” USENIX Association Conference Proceedings, p. 203–207, June 1984.
Ritchie, 1988.
D. M. Ritchie, “Multi-Processor UNIX,” private communication, April 25, 1988.
Sanderson et al, 1986.
T. Sanderson, S. Ho, N. Heijden, E. Jabs, & J. L. Green, “Near-Realtime Data Transmission During the ICE-Comet Giacobini-Zinner Encounter,” ESA Bulletin, vol. 45, no. 21, 1986.
Schimmel, 1994.
C. Schimmel, UNIX Systems for Modern Architectures, Symmetric Multiprocessing, and Caching for Kernel Programmers, Addison-Wesley, Reading, MA, 1994.