
Chapter 11. Parallelism
This chapter covers
- When to use futures
- When to use promises
- Parallel operations
- Introduction to reducer/fold
Typically, parallel tasks work toward an aggregate goal; and the result of one task doesn’t affect the behavior of any other parallel task, thus maintaining determinacy. Whereas in the previous chapter we stated that concurrency was about the design of a system, parallelism is about the execution model. Although concurrency and parallelism aren’t quite the same thing, some concurrent designs are parallelizable. Recall that in the previous chapter we showed an illustration of a concurrent work queue design featuring a producer and two consumer threads (see figure 11.1).
Figure 11.1. The concurrent design with an intermediate work queue from the previous chapter is potentially parallelizable.
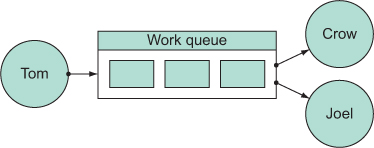
In the figure, the independent threads Tom, Crow, and Joel operate independently. For the purposes of this section, assume that Tom, Crow, and Joel are all performing independent, concurrent operations. Yet depending on the type of data placed into the work queue, this design could be parallelized by duplicating it as shown in figure 11.2.
Figure 11.2. The concurrent design can be parallelized through the use of another work queue and producer as well as two more consumers.
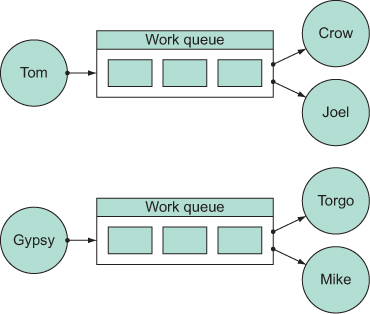
As shown, by duplicating the concurrent design, we can conceive a level of parallelism in the producer/consumer work processing. If we assume that now Tom and Gypsy are feeding subsets of related tasks into their respective queues, then the overall processing of those tasks is done in parallel. Of course, the details of how this might work are entirely application specific, but we hope the intent is clear.
In this chapter, we’ll discuss the topic of parallelism in Clojure using futures, promises, and a trio of functions: pmap, pvalues, and pcalls. We’ll end the chapter with a discussion of a way to look at parallel computations orthogonal to data structures: reducibles.
11.1. When to use futures
Clojure includes two reference types supporting parallelism: futures and promises. Futures, the subject of this section, are simple yet elegant constructs that are useful for partitioning a typically sequential operation into discrete parts. These parts can then be asynchronously processed across numerous threads that will block if the enclosed expression hasn’t finished. All subsequent dereferencing will return the calculated value. The simplest example of the use of a future that performs a task (sleeping in this case) on a thread and returns a value is shown next:
(time (let [x (future (do (Thread/sleep 5000) (+ 41 1)))] [@x @x])) ; "Elapsed time: 5001.682 msecs" ;=> [42 42]
The processing time of the do block is only experienced on the first dereference of the future x. Futures represent expressions that have yet to be computed.
11.1.1. Futures as callbacks
One nice use case for futures is in the context of a callback mechanism. Normally you might call out to a remote-procedure call (RPC), wait for it to complete, and then proceed with some task depending on the return value. But what happens if you need to make multiple RPC calls? Should you be forced to wait for them all serially? Thanks to futures, the answer is no. In this section, you’ll use futures to create an aggregate task that finds the total number of occurrences of a string in a given set of Twitter[1] feeds. This aggregate task will be split into numerous parallel subtasks via futures.
1 Twitter is online at http://twitter.com.
Counting word occurrences in a set of RSS/Atom feeds
Like many frequently updated services on the Internet, Twitter provides a feed of status messages in a digest format. One such format provided by services like Twitter is known as the Rich Site Summary version 2.0, or RSS for short. An RSS 2.0 feed is an XML document used to represent a piece of data that’s constantly changing. The layout of a Twitter RSS entry is straightforward:
<rss version="2.0">
<channel>
<title>Twitter / fogus</title>
<link>http://twitter.com/fogus</link>
<item>
<title>fogus: Thinking about #Clojure futures.</title>
<link>
http://twitter.com/fogus/statuses/12180102647/
</link>
</item>
</channel>
</rss>
Another format for providing information about site updates is known as the Atom syndication format, and it contains similar types of information. Obviously, there’s more to the content of a typical RSS or Atom feed than shown in the example Twitter timeline, but for this example you will retrieve only the title of the individual feed elements. To do this, you need to first parse the XML and put it into a convenient format. If you recall from section 8.4, you created a domain DSL to create a tree built on a simple node structure of tables with the keys :tag, :attrs, and :content. As mentioned, that structure is used in many Clojure libraries, and you’ll take advantage of this fact. Clojure provides some core functions in the clojure.xml and clojure.zip namespaces to help make sense of the feed.[2]
2 Recall from chapter 8 that the ->> macro works like the -> macro, except it inserts the pipelined arguments into the last position.
Listing 11.1. Converting an XML feed to an XML zipper

Using the function clojure.xml/parse, you can retrieve the XML for a Twitter RSS feed and convert it into the familiar tree format. That tree is then passed into a function clojure.zip/xml-zip that converts that structure into another data structure called a zipper. The form and semantics of the zipper are beyond the scope of this book (Huet 1997), but using it in this case allows you to easily navigate down from the root rss XML node to the channel node, where you then retrieve its children.
The exact form of a RSS feed versus an Atom feed is slightly different. Therefore, navigating to the feed elements requires a different sequence of zipper steps to achieve. But if you take the zipper from the xml/parse step and detect the precise feed type (RSS or Atom), you can normalize the feed elements into a common structure, as shown next.
Listing 11.2. Normalizing RSS and Atom feed entries to a common structure

The child nodes returned from feed-children contain other items besides :item and :entry nodes; but because you only care about the titles, this example glosses over a more thorough normalization.
Once you have the normalized child nodes, you then want to retrieve the title text.
Listing 11.3. Retrieving the title text from the normalized feed structure

Now that you can extract the title content of either an RSS or Atom feed, you’d like a function to count the number of occurrences of some text (case-insensitive). You can perform this task using the function count-text-task, defined next.
Listing 11.4. Function to count the number of occurrences of text

Although the example focuses on counting text occurrences in the titles of a feed, we couldn’t help but make count-text-task a bit more generic. count-text-task doesn’t care one bit what the format of a feed is. Instead it works by applying an extractor function to the feed structure to get a sequence of text strings to match over. This indirection will come in handy should you want to extend this code to count text in the body fields, or any other field for that matter.
Here we’re using count-text-task to find some text in the titles of the RSS feed for the Elixir language blog:[3]
3 Elixir (http://elixir-lang.org/) is an exciting new programming language that adds syntax and many Clojure-like features to the Erlang runtime.
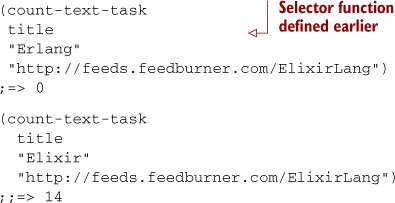
The result you’ll see is highly dependent on when you run this function, because blog feeds are ever-changing. This is fine and good, but at the moment, computing the results of count-text-task is a serial operation. What if you wanted to count the occurrences of a pieces of text for multiple feeds? Surely you wouldn’t want to wait for each and every feed retrieval/match cycle.
Instead, using the count-text-task function, you can build a set of related tasks to be performed over a sequence of RSS or Atom feeds and spread them over a number of threads for parallel processing using the following code.
Listing 11.5. Manually spreading tasks over a sequence of futures

You can use this pattern every time to build a seq of futures, each processing a portion of the feed set. Or you can create a convenience macro as-futures to build a similar bit of code, as in the following listing.
Listing 11.6. Macro to dispatch a sequence of futures

The as-futures macro implemented here names a binding corresponding to the arguments for a given action, which is then dispatched across a number of futures, after which a task is run against the futures sequence. The body of as-futures is segmented using the partition-by function so that you can clearly specify the needed parts—the action arguments, the action to be performed for each argument, and the tasks to be run against the resulting sequence of futures:
(as-futures [<arg-name> <all-args>] <actions-using-args> :as <results-name> => <actions-using-results>)
To simplify the macro implementation, you use the :as keyword and => symbol to clearly delineate its segments. The as-futures body exits only after the task body finishes—as determined by the execution of the futures. You can use as-futures to perform count-text-task with a new function occurrences, implemented in the following listing.
Listing 11.7. Counting text occurrences in feed titles fetched in parallel

The as-futures macro builds a sequence of futures named results, enclosing the call to count-text-task across the unique set of Twitter feeds provided. You then sum the counts returned from the dereferencing of the individual futures:
(occurrences title "released" "http://blog.fogus.me/feed/" "http://feeds.feedburner.com/ElixirLang" "http://www.ruby-lang.org/en/feeds/news.rss") ;=> 11
And that’s that. Using only a handful of functions and macros, plus using the built-in core facilities for XML parsing and navigation, you’ve created a simple RSS/Atom text occurrences counter. This implementation has some trade-offs made in the name of page count. First, you blindly dereference the future in occurrences when calculating the sum. If the future’s computation freezes, then the dereference will likewise freeze. Using some combination of future-done?, future-cancel, and future-cancelled? in your own programs, you can skip, retry, or eliminate ornery feeds from the calculation. Futures are only one way to perform parallel computation in Clojure, and in the next section we’ll talk about another: promises.
11.2. When to use promises
Another tool that Clojure provides for parallel computation is the promise and deliver mechanism. Promises are similar to futures, in that they represent a unit of computation to be performed on a separate thread. Likewise, the blocking semantics when dereferencing an unfinished promise are the same. Whereas futures encapsulate an arbitrary expression that caches its value in the future on completion, promises are placeholders for values whose construction is fulfilled by another thread via the deliver function. A simple example is as follows:
(def x (promise)) (def y (promise)) (def z (promise)) (dothreads! #(deliver z (+ @x @y))) (dothreads! #(do (Thread/sleep 2000) (deliver x 52))) (dothreads! #(do (Thread/sleep 4000) (deliver y 86))) (time @z) ; "Elapsed time: 3995.414 msecs" ;=> 138
What’s not shown is that if you execute @z before executing the two dothreads! calls (defined in the beginning of the previous chapter), the entire REPL will hang. The reason is that @z waits until a value has been delivered, but in our alternate scenario this could never happen because dothreads! would never have the chance to run. Each promise must be delivered once and only once for a dereference to return a value. Promises are write-once; any further attempt to deliver will throw an exception.
11.2.1. Parallel tasks with promises
You can create a macro similar to as-futures for handling promises, but because of the more advanced value semantics, the implementation is more complicated. Let’s again provide a named set of tasks, but additionally let’s name the corresponding promises so that you can then execute over the eventual results.
Listing 11.8. Dispatching a sequence of promises across threads
(defmacro with-promises [[n tasks _ as] & body]
(when as
`(let [tasks# ~tasks
n# (count tasks#)
promises# (take n# (repeatedly promise))]
(dotimes [i# n#]
(dothreads!
(fn []
(deliver (nth promises# i#)
((nth tasks# i#))))))
(let [~n tasks#
~as promises#]
~@body))))
You can then build a rudimentary parallel testing facility, dispatching tests across disparate threads and summing the results when all the tests are done.
Listing 11.9. Parallel test runner using with-promises

This unit-testing model is simplistic by design in order to illustrate parallelization using promises, not to provide a comprehensive testing framework.
11.2.2. Callback API to blocking API
Promises, much like futures, are useful for executing RPCs on separate threads. This can be useful if you need to parallelize a group of calls to an RPC service, but there’s also a converse use case. Often, RPC APIs take arguments to the service calls and also a callback function to be executed when the call completes. Using the feed-children function from the previous section, you can construct an archetypal RPC function:
(defn feed-items [k feed]
(k
(for [item (filter (comp #{:entry :item} :tag)
(feed-children feed))]
(-> item :content first :content))))
The feed-items function is a distillation of the count-text-task function from the previous section, as shown:
(feed-items count "http://blog.fogus.me/feed/") ;=> 5
The argument k to feed-items is the callback, or continuation, that’s called with the filtered RPC results. This API is fine, but there are times when a blocking call is more appropriate than a callback-based call. You can use a promise to achieve this blocking behavior:
(let [p (promise)]
(feed-items #(deliver p (count %))
"http://blog.fogus.me/feed/")
@p)
;=> 5
As you see, the call blocks until the deliver occurs. This is a fine way to transform the callback into a blocking call, but it would be good to have a way to do so generically. Fortunately, most well-written RPC APIs follow the same form for their callback functions/methods, so the following listing creates a function to wrap this up nicely.
Listing 11.10. Transforming a callback-based function to a blocking call
(defn cps->fn [f k]
(fn [& args]
(let [p (promise)]
(apply f (fn [x] (deliver p (k x))) args)
@p)))
(def count-items (cps->fn feed-items count))
(count-items "http://blog.fogus.me/feed/")
;=> 5
This is a simple solution to a common problem that you may have encountered already in your own applications.
11.2.3. Deterministic deadlocks
You can cause a deadlock in your applications by never delivering on a promise. One possibly surprising advantage of using promises is that if a promise can deadlock, it will deadlock deterministically. Because only a single thread can ever deliver on a promise, only that thread will ever cause a deadlock. You can use the following code to create a cycle in the dependencies between two promises to observe a deadlock:
(def kant (promise)) (def hume (promise)) (dothreads! #(do (println "Kant has" @kant) (deliver hume :thinking))) (dothreads! #(do (println "Hume is" @hume) (deliver kant :fork)))
The Kant thread is waiting for the delivery of the value for kant from the Hume thread, which in turn is waiting for the value for hume from the Kant thread. Attempting either @kant or @hume in the REPL will cause an immediate deadlock. Furthermore, this deadlock will happen every time; it’s deterministic rather than dependent on odd thread timings or the like. Deadlocks are never nice, but deterministic deadlocks are better than nondeterministic.[4]
4 There are experts in concurrent programming who say that naïve locking schemes are also deterministic. Our simple example is illustrative, but alas it isn’t representative of a scheme that you may devise for your own code. In complex designs where promises are created in one place and delivered in a remote locale, determining deadlock is naturally more complex. Therefore, we’d like to use this space to coin a new phrase: “Determinism is relative.”
We’ve only touched the surface of the potential that promises represent. The pieces assembled in this section represent some of the basic building blocks of data-flow (Van Roy 2004) concurrency. But any attempt to do justice to data-flow concurrency in a single section would be a futile effort. At its essence, data flow deals with the process of dynamic changes in values causing dynamic changes in dependent “formulas.” This type of processing finds a nice analogy in the way spreadsheet cells operate, some representing values and others dependent formulas that change as the former also change.
Continuing our survey of Clojure’s parallelization primitives, we’ll next discuss some of the functions provided in the core library.
11.3. Parallel operations
In the previous two sections, you built two useful macros, as-futures and with-promises, allowing you to parallelize a set of operations across numerous threads. But Clojure has functions in its core library that provide similar functionality: pvalues, pmap, and pcalls. We’ll cover them briefly in this section.
11.3.1. The pvalues macro
The pvalues macro is analogous to the as-futures macro, in that it executes an arbitrary number of expressions in parallel. Where it differs is that it returns a lazy sequence of the results of all the enclosed expressions, as shown:
(pvalues 1 2 (+ 1 2)) ;=> (1 2 3)
The important point to remember when using pvalues is that the return type is a lazy sequence, meaning your access costs might not always present themselves as expected:
(defn sleeper [s thing] (Thread/sleep (* 1000 s)) thing)
(defn pvs [] (pvalues
(sleeper 2 :1st)
(sleeper 3 :2nd)
(keyword "3rd")))
(-> (pvs) first time)
; "Elapsed time: 2000.309 msecs"
;=> :1st
The total time cost of accessing the first value in the result of pvs is only the cost of its own calculation. But accessing any subsequent element costs as much as the most expensive element before it, which you can verify by accessing the last element:
(-> (pvs) last time) ; "Elapsed time: 2999.435 msecs" ;=> :3rd
This may prove a disadvantage if you want to access the result of a relatively cheap expression that happens to be placed after a more costly expression. More accurately, all seq values in a sliding window[5] are forced, so processing time is limited by the most costly element therein.
5 Currently, the window size is N+2, where N is the number of CPU cores. But this is an implementation detail, so it’s enough to know only that the sliding window exists.
11.3.2. The pmap function
The pmap function is the parallel version of the core map function. Given a function and a set of sequences, the application of the function to each matching element happens in parallel:

The total cost of realizing the result of mapping a costly increment function is again limited by the most costly execution time in the aforementioned sliding window. Clearly, in this contrived case, using pmap provides a benefit, so why not replace every call to map in your programs with a call to pmap? Surely this would lead to faster execution times if the map functions were all applied in parallel, correct? The answer is a resounding: it depends. A definite cost is associated with keeping the resulting sequence result coordinated, and to indiscriminately use pmap might incur that cost unnecessarily, leading to a performance penalty. But if you’re certain that the cost of the function application outweighs the cost of the coordination, then pmap might help to realize performance gains. Only through experimentation can you determine whether pmap is the right choice.
11.3.3. The pcalls function
Finally, Clojure provides a pcalls function that takes an arbitrary number of functions taking no arguments and calls them in parallel, returning a lazy sequence of the results. Its use shouldn’t be a surprise by now:
(-> (pcalls
#(sleeper 2 :first)
#(sleeper 3 :second)
#(keyword "3rd"))
doall
time)
; "Elapsed time: 3001.039 msecs"
;=> (:1st :2nd :3rd)
The same benefits and trade-offs associated with pvalues and pmap also apply to pcalls and should be considered before use.
Executing costly operations in parallel can be a great boon when used properly but should by no means be considered a magic potion guaranteeing speed gains. There’s currently no magical formula for determining which parts of an application can be parallelized—the onus is on you to determine your application’s parallel potential. What Clojure provides is a set of primitives—including futures, promises, pmap, pvalues, and pcalls—that you can use as the building blocks for your own personalized parallelization needs.
In the next section, we’ll look briefly at the fold function for processing large collections in parallel.
11.4. A brief introduction to reducer/fold
Starting with version 1.5, Clojure ships with a library called clojure.core.reducers. This library was inspired in part by a talk Guy Steele gave at the International Conference on Functional Programming in 2009. In it,[6] Steele pointed out a weakness of data structures that only support sequential access, like Lisp’s cons-cell-based lists and Clojure’s lazy seq: they’re incapable of supporting efficient parallelization because you can’t get more input data without walking linearly through the data to get there. Similarly, he called out foldl (called reduce in Clojure) and foldr (which has no native Clojure counterpart) as providing ordering guarantees that thwart parallelization.
6 Guy Steele, “Organizing Functional Code for Parallel Execution; or, foldl and foldr Considered Slightly Harmful,” http://vimeo.com/6624203.
Specifically, parallelizing a workload generally involves splitting the work into small parts, doing work on all those parts simultaneously, and then combining the results of those parts to compute the single final result. But reduce can’t work this way because it promises to call the given reducing function on each input item in order, with the first parameter representing the reduction of everything that has come before it.
But many times when reduce is used, these guarantees aren’t required by the reducing function being used. For example, addition is associative, which means if you want the sum of three numbers, you’ll get the same answer whether you compute it as (+ (+ a b) c) or as (+ a (+ b c)). Clojure’s reducers library provides many of the operations you know from the sequence library, but it allows you to choose whether you require sequential processing or whether you’d rather parallelize the work.
Because Clojure’s reduce function already promises sequential operation, all that’s needed is a new function that doesn’t. This new function is called fold, and you can see its benefit in this contrived micro-benchmark:
(require '[clojure.core.reducers :as r]) (def big-vec (vec (range (* 1000 1000)))) (time (reduce + big-vec)) ; "Elapsed time: 63.050461 msecs" ;=> 499999500000 (time (r/fold + big-vec)) ; "Elapsed time: 27.389584 msecs" ;=> 499999500000
The proper use of fold in nontrivial cases depends heavily on other aspects of the reducers library that we won’t cover until chapter 15. Alas, this means further discussion of fold must also wait until then.
11.5. Summary
From the expression-centric future; to the function-centric set-once “variable” promise; to the core functions pcalls, pvalues, and pmap, Clojure gives you the raw materials for parallelizing related tasks. These reference types and operations can help to simplify the process of slicing your problem space into simultaneous executions of (possibly) related computations. But truly fostering parallelism in your programs requires a different view of how to build algorithms that can take advantage of fold. Although we only touched on this topic in this chapter, we’ll dive back into it in chapter 15 when we talk about Clojure’s reducers framework. For now, we’ll take you on a journey to explore Java interoperability.