
Chapter 17. Clojure changes the way you think
- Thinking in the domain
- Testing
- Invisible design patterns
- Error handling and debugging
In this final chapter, we’ll cover some tangential topics that you might already be familiar with, but perhaps not from a Clojure perspective. Our discussion will start with domain-specific languages (DSLs) and the unique way Clojure applications are built from a layering of unique application-specific DSLs. Next, you’re unlikely to be ignorant of the general push toward a test-driven development (TDD) philosophy with a special focus on unit testing. We’ll explore why Clojure is especially conducive to unit testing and why it’s often unnecessary. Next, whether you agree with the cult of design patterns or not, it’s inarguable that patterns have changed the way object-oriented software is designed and developed. The classical design patterns are often invisible and at times are outright nonexistent in Clojure code, as we’ll discuss. As we’ll then show, error handling in Clojure flows in two directions: from inner functions to outer via exceptions, and from outer functions inward via dynamic bindings. Finally, we’ll explore how having the entire language at your disposal can help change the way your debugging occurs. We hope that by the time you’ve finished this chapter, you’ll agree—Clojure changes the way you think about programming.
17.1. Thinking in the domain
Lisp is not the right language for any particular problem. Rather, Lisp encourages one to attack a new problem by implementing new languages tailored to that problem.
Harold Abelson and Gerald Jay Sussman[1]
1 “Lisp: A Language for Stratified Design” (Abelson 1988).
In chapter 8, we explored the notion of a domain-specific language for describing domains with the man-versus-monster example, and the domain macro in particular. This meta-circularity, although playful, was meant to make a subtle point: Clojure blurs, and often obliterates, the line between DSL and API. When a language is built from the same data structures that the language itself manipulates, it’s known as homoiconic (Mooers 1965). When a programming language is homoiconic, it’s simple to mold the language into a form that bridges the gap between the problem and solution domains. We hinted at this point in chapter 14 during the discussion of the defunits-of macro; the best language for solving a problem is the language of the domain itself. But with DSLs, a caveat always applies:
Just because you can create a DSL, doesn’t mean you should.
This book, right now
Creating DSLs introduces new syntax, and with new syntax comes some level of complexity, in implementation and (potentially) in use. You should think through each chance for a DSL and weigh the complexities. When designing DSLs in Clojure, it’s important to determine when the existing language facilities will suffice (Raymond 2003) and when it’s appropriate to create one from whole cloth (Ghosh 2010). In this section, we’ll do both and provide a little discussion about each.
17.1.1. A ubiquitous DSL
The declarative language SQL is among the most widespread DSLs in use today. Interestingly, Clojure provides a comprehensive library for relational algebra, on which SQL is based (Date 2009). Imagine the following dataset:
(def artists
#{{:artist "Burial" :genre-id 1}
{:artist "Magma" :genre-id 2}
{:artist "Can" :genre-id 3}
{:artist "Faust" :genre-id 3}
{:artist "Ikonika" :genre-id 1}
{:artist "Grouper"}})
(def genres
#{{:genre-id 1 :genre-name "Dubstep"}
{:genre-id 2 :genre-name "Zeuhl"}
{:genre-id 3 :genre-name "Prog"}
{:genre-id 4 :genre-name "Drone"}})
The vars artists and genres are sets of maps and can conceptually stand in for a couple of database tables. The artists data is shown in table 17.1. The genres data is laid out as in table 17.2.
Table 17.1. Artists
|
:artist |
:genre-id |
|---|---|
| Burial | 1 |
| Magma | 2 |
| Can | 3 |
| Faust | 3 |
| Ikonika | 1 |
| Grouper | 4 |
Table 17.2. Genres
|
:genre-id |
:genre-name |
|---|---|
| 1 | Dubstep |
| 2 | Zeuhl |
| 3 | Prog |
| 4 | Drone |
Laying out the data this way allows you to view the data relationally, similarly to SQL relations. You can try Clojure’s relational functions by entering the example shown in the following listing to return all the data in a table, emulating a SQL select * clause on the genres table.
Listing 17.1. select * example using Clojure’s relational algebra functions
(require '[clojure.set :as ra])
(def ALL identity)
(ra/select ALL genres)
;;=> #{{:genre-id 4, :genre-name "Drone"}
{:genre-id 3, :genre-name "Prog"}
{:genre-id 2, :genre-name "Zeuhl"}
{:genre-id 1, :genre-name "Dubstep"}}
The clojure.set/select function works by taking a function and collecting every map that, when supplied to that function, returns a truthy value. Because the ALL function is identity, all maps are collected in the result set. To filter on a given genre ID, you can use a custom function as follows:
(ra/select (fn [m] (#{1 3} (:genre-id m))) genres)
;;=> #{{:genre-id 3, :genre-name "Prog"}
{:genre-id 1, :genre-name "Dubstep"}}
You can make that code a bit more fluent by currying[2] a function named ids:
2 A curried function is one that returns a function for each of its logical arguments, executing the function logic only after each logical argument is exhausted.
(defn ids [& ids] (fn [m] ((set ids) (:genre-id m))))
Now the query reads more nicely:
(ra/select (ids 1 3) genres)
;;=> #{{:genre-id 3, :genre-name "Prog"}
{:genre-id 1, :genre-name "Dubstep"}}
SQL supports natural joins, combining tables by finding a field in one table’s rows that matches a field in a second table’s rows. When the fields that are matched have the same name in both tables, this is called a natural join.
The clojure.set namespace also provides a function named join that performs a SQL-like natural join and is used as follows:
(take 2 (ra/select ALL (ra/join artists genres)))
;;=> #{{:artist "Burial", :genre-id 1, :genre-name "Dubstep"}
{:artist "Magma", :genre-id 2, :genre-name "Zeuhl"}}
The relational functions in clojure.set are a perfect example of the way Clojure blurs the line between API and DSL. No macro tricks are involved, but through the process of functional composition, the library provides a highly expressive syntax that closely matches (Abiteboul 1995) that of SQL. You can create queries as complex as your imagination can dream up using the clojure.set offerings.
You might be tempted to create a custom query language for your own application(s), but there are times when the relational functions are exactly what you need. Although querying small datasets in Clojure sets might be appropriate for some tasks, it’s not likely to scale to meet your enterprise needs. Instead, any significantly large data will likely be stored in a database, and chances are good that it will be relational.
17.1.2. Implementing a SQL-like DSL to generate queries
The relational algebra functions in the core.set namespace are useful for ad hoc data queries on small data sets, but in reality you would probably want to use a real database coupled with a real database query language. If we were to sketch an embedded variant of SQL in a hypothetical Clojure library, it might look as follows:
(defn fantasy-query [max]
(SELECT [a b c]
(FROM X
(LEFT-JOIN Y :ON (= X.a Y.b)))
(WHERE (< a 5) AND (< b max))))
We hope some of those words look familiar to you, because this isn’t a book on SQL. Regardless, our point is that Clojure doesn’t have SQL support built in. The words SELECT, FROM, and so forth aren’t built-in forms. They also can’t be implemented as regular functions: if SELECT were, then the use of a, b, and c would be an error because they hadn’t been defined yet.
What does it take to define a DSL like this in Clojure? Well, if you’ve been paying attention so far, the answer should be readily available: macros.
The following code isn’t production-ready and doesn’t tie in to any real database servers; but with just one macro and three functions, the preceding fantasy-query function should return something like this:
(fantasy-query 5)
;;=> {:query "SELECT a, b, c FROM X LEFT JOIN Y ON (X.a = Y.b)
WHERE ((a < 5) AND (b < ?))"
:bindings [5]}
Note that some words such as FROM and ON are taken directly from the input expression, whereas others such as max and AND are treated specially. The max argument that was given the value 5 when the query was called is extracted from the literal SQL string and provided in a separate vector, perfect for use in a prepared query in a way that guards against SQL-injection attacks. To keep thing simpler in the implementation, we won’t require that the AND symbol be used as an infix operator in the macro body; but for posterity’s sake we’ll make sure it becomes infix in the generated query.
The DSL you’re creating must do three things: extract bindings, convert prefix to infix, and generate each of the more complex SQL clauses supported. These are all pieces of infrastructure the DSL implementation will need, which you’ll combine and provide access to using a nice sugary syntax.
The first thing you need is a helper named shuffle-expr that walks a Clojure-like expression and converts it from prefix notation into infix notation, building a string from the new form. You’d also like it to handle references to locals in a special way so you can supply their values later in a substitution structure. The implementation of shuffle-expr is shown next.
Listing 17.2. Shuffling SQL-like operators into infix position

The shuffle-expr function works off clojure collections and indeed returns the expression outright when not given one:
(shuffle-expr 42) ;;=> 42
But shuffle-expr treats collections that start with clojure.core/unquote specially ![]() . You can see what happens when shuffle-expr encounters this special condition:
. You can see what happens when shuffle-expr encounters this special condition:
(shuffle-expr `(unquote max)) ;;=> "?"
When an expression starts with the clojure.core/unquote function, shuffle-expr returns a simple string "?" to stand in for the value that is meant to fill its place. By using the unquote operator ~, you can build this special expression at read-time:
(read-string "~max") ;;=> (clojure.core/unquote max)
Marking value slots like this is a common technique for guarding against common SQL attacks, and we’ll show how it works soon.
First, it’s worth following through with our explanation of shuffle-expr and mentioning that when a regular collection type is encountered, its head, referring to its function, is switched into
an infix position ![]() , as shown:
, as shown:
(shuffle-expr '(= X.a Y.b)) ;;=> "(X.a = Y.b)"
The infix alignment is proper SQL, but you need to traverse the collection recursively in order to “infixify” the nested expressions
![]() :
:
(shuffle-expr '(AND (< a 5) (< b ~max))) ;;=> "((a < 5) AND (b < ?))"
This nested expansion will work up to an arbitrary depth:
(shuffle-expr '(AND (< a 5) (OR (> b 0) (< b ~max)))) ;;=> "((a < 5) AND ((b > 0) OR (b < ?)))"
You maintain the same number of parentheses, but you change them so they work to group sub-expressions.
Now that shuffle-expr is in place, you can use it to complete the last category of your DSL infrastructure: the clause-specific portions of the SQL-like DSL. Start with a function to process a WHERE clause:
(defn process-where-clause [processor expr] (str " WHERE " (processor expr)))
The implementation of process-where-clause effectively delegates down to the behavior of shuffle-expr and concatenates a "WHERE" string onto the front:
(process-where-clause shuffle-expr '(AND (< a 5) (< b ~max))) ;;=> " WHERE (((a < 5) AND (b < ?)))"
A similarly implemented clause processor process-left-join-clause does a little more work, but not much:
(defn process-left-join-clause [processor table _ expr]
(str " LEFT JOIN " table
" ON " (processor expr)))
Where process-left-join-clause differs is in the fact that it takes three arguments rather than a single expression meant for shuffling. You can see how process-left-join-clause might work, given a list of its expected features:
(apply process-left-join-clause
shuffle-expr
'(Y :ON (= X.a Y.b)))
;;=> " LEFT JOIN Y ON (X.a = Y.b)"
Providing a more fluent LEFT-JOIN clause is a simple alias away:
(let [LEFT-JOIN (partial process-left-join-clause shuffle-expr)] (LEFT-JOIN 'Y :ON '(= X.a Y.b))) ;;=> " LEFT JOIN Y ON (X.a = Y.b)"
Your SQL-like DSL is starting to shape up, but we’ll defer the topic of a fluent DSL for now and focus instead on what you’ve accomplished so far. If you’ll recall from chapter 14, we discussed the notion of “putting parentheses around the specification.” The purpose of that pithy phrase was to invoke the spirit of data and function-orientation in the development of DSLs. Clojure is especially suited to DSLs because of its inherent flexibility and default rich data types. In this section, you’ve so far built a subset of a SQL-like DSL on lists and a few simple data-processing functions. This is a surprisingly powerful way to build DSLs in general:
- Start with core data types and their syntax as the base for your DSL.
- Gradually build up to the DSL by filling in the constituent data processors.
You won’t implement a full SQL-like DSL, but we can show how you might continue building out the remaining features by implementing a few more data processors. The FROM clause meant to name a target table in a SELECT clause is fairly straightforward:
(defn process-from-clause [processor table & joins]
(apply str " FROM " table
(map processor joins)))
And now you can stitch the use of process-from-clause (with an alias) to the use of LEFT-JOIN to see how they compose:
(process-from-clause shuffle-expr 'X (process-left-join-clause shuffle-expr 'Y :ON '(= X.a Y.b))) ;;=> " FROM X LEFT JOIN Y ON (X.a = Y.b)"
You can also round off the data processors by implementing the SELECT clause as follows:
(defn process-select-clause [processor fields & clauses]
(apply str "SELECT " (str/join ", " fields)
(map processor clauses)))
Notice that the data processors have a similar form. If you really wanted to be fancy, you could build a DSL to help build the SQL-like DSL; we’ll leave that as an exercise for you. Instead, observe how the use of SELECT works to compose with the existing data processors:
(process-select-clause shuffle-expr
'[a b c]
(process-from-clause shuffle-expr 'X
(process-left-join-clause shuffle-expr 'Y :ON '(= X.a Y.b)))
(process-where-clause shuffle-expr '(AND (< a 5) (< b ~max))))
;;=> "SELECT a, b, c FROM X
;; LEFT JOIN Y ON (X.a = Y.b)
;; WHERE ((a < 5) AND (b < ?))"
Now that you have the data processors in place and operating as you expect, you can start to think about cleaning up the DSL so your users don’t need to explicitly quote the clause elements but can instead write queries in a more natural way. This is where macros come into play: now that you’ve built your DSL infrastructure on data and processors, you can use macros to provide some syntactic sugar. First, it’s not a terribly compelling DSL if it requires you to use long clauses with names of the form process-*-clause. Instead, it would be fun to define a mapping from more relevant names like SELECT and FROM. You can describe this name mapping directly to the functions that provide the data processing:
(declare apply-syntax)
(def ^:dynamic *clause-map*
{'SELECT (partial process-select-clause apply-syntax)
'FROM (partial process-from-clause apply-syntax)
'LEFT-JOIN (partial process-left-join-clause shuffle-expr)
'WHERE (partial process-where-clause shuffle-expr)})
Adding a level of indirection in the way a DSL syntax maps to the underlying processors is a powerful technique. By making such a split, we’re viewing DSLs as a way to define a language to decouple the problem from the strategies for solving it. That is, you can swap out the data-processing functions for other, more powerful and robust functions at any time to enhance the effect of the DSL while maintaining a consistent SQL-like syntax.
Because the process-select-clause and process-from-clause functions allow nested clauses, they’re partially applied with a function to look up the mapped function for their subclauses from clause-map. The function that performs the lookup is named apply-syntax.
Listing 17.3. Looking up syntax processors in the processor table
![]()
The apply-syntax function takes the first word of a clause, looks it up in *clause-map*, and calls the appropriate function to do the actual conversion from Clojure s-expression to SQL string. *clause-map* provides the specific functionality needed for each part of the SQL expression: inserting commas or other SQL syntax, and sometimes recursively calling apply-syntax when subclauses need to be converted. One of these is the WHERE clause, which handles the general conversion of prefix expressions to the infix form required by SQL by delegating to the shuffle-expr function.
Because the DSL triggers on a SELECT clause, you can implement it as a macro in the next listing so that its nested elements don’t explicitly require quoting.
Listing 17.4. Building a SQL-like SELECT statement DSL

The :query element in the returned map is generated by calling apply-syntax, which generates the converted query string; the :bindings entry is a vector of expressions marked by ~ (read-time expanded to unquote) in the input. But one interesting point is that by taking advantage of the split between the read-time and compile-time phases, you can effectively grab the values of locals for use as bindings.
The point here isn’t that this is a particularly good SQL DSL—more complete ones are available.[3] Our point is that once you have the skill to easily create a DSL like this, you’ll recognize opportunities to define your own DSLs that solve much narrower, application-specific problems than SQL does. Whether it’s a query language for a non-SQL data-store, a way to express functions in some obscure math discipline, or another application we as authors can’t imagine, having the flexibility to extend the base language like this, without losing access to any of the language’s features, is a game-changer:
3 One of note is Korma (http://sqlkorma.com).
(defn example-query [max]
(SELECT [a b c]
(FROM X
(LEFT-JOIN Y :ON (= X.a Y.b)))
(WHERE (AND (< a 5) (< b ~max)))))
(example-query 9)
;;=> {:query "SELECT a, b, c
;; FROM X LEFT JOIN Y ON (X.a = Y.b)
;; WHERE ((a < 5) AND (b < ?))"
;; :bindings [9]}
Overall, the flexibility of Clojure demonstrated in this section comes largely from the fact that macros accept code forms, such as the SQL DSL example we showed, and can treat them as data—walking trees, converting values, and more. This works not only because code can be treated as data, but also because in a Clojure program, code is data.
17.1.3. A note about Clojure’s approach to DSLs
DSLs and control structures implemented as macros in Common Lisp tend to be written in a style more conducive to macro writers. But Clojure macros such as SELECT, cond, and case are idiomatic in their minimalism; their component parts are paired and meant to be grouped through proper spacing, as shown in this example of cond:
(cond (keyword? x) "x is a keyword" :else "x is not a keyword")
This is in contrast to some LISPs, which prefer to group pairs of related clauses in another set of parentheses. Clojure macro writers should understand that the proliferation and placement of parentheses are legitimate concerns for some, and as a result you should strive to reduce the number whenever possible. Why would you explicitly group your expressions when their groupings are only a call to partition away?
Clojure Aphorism
If a project elicits a sense of being lost, begin from the bottom up.
DSLs are an important part of a Clojure programmer’s tool-set and stem from a long Lisp tradition. When Paul Graham talks about “bottom-up programming” in his perennial work On Lisp (Prentice Hall, 1993), this is what he’s referring to. In Clojure, it’s common practice to start by defining and implementing a low-level language specifically for the levels above. Creating complex software systems is hard, but using this approach, you can build the complicated parts out of smaller, simpler pieces.
Clojure changes the way that you think.
17.2. Testing
Object-oriented programs can be highly complicated beasts to test properly when they’re built on mutating state and deep class hierarchies. Programs are a vast tapestry of interweaving execution paths, and to test each path comprehensively is difficult, if not impossible. In the face of unrestrained mutation, the execution paths are overlaid with mutation paths, further adding to the chaos. Conversely, Clojure programs tend to be compositions of pure functions with isolated pools of mutation. The result of this approach helps to foster an environment conducive to unit testing. But although the layers of an application are composed of numerous functions, each individually and compositionally tested, the layers themselves and the wiring between them must also be tested.
Test-driven development (Beck 2002) has conquered the software world, and at its core it preaches that test development should drive the architecture of the overall application. Certainly TDD presents one way of writing and testing software, but it’s far from the only way. We already showed in chapter 14 how a data-driven approach to software design can facilitate powerful testing techniques like simulation and generative (property-based) testing; in this section, we’ll cover a few more interesting ways that Clojure programs are validated using contracts-programming and unit testing.
17.2.1. Some useful unit-testing techniques
We don’t want to disparage TDD, because its goals are virtuous and testing in general is essential. Clojure programs are organized using namespaces, and they’re themselves aggregations of functions, often pure, so the act of devising a unit-test suite at the namespace boundary is frequently mechanical in its directness. From a larger perspective, devising comprehensive test strategies is the subject of numerous volumes and therefore outside the scope of this book; but there are a few Clojure-specific techniques that we wish to discuss.
Using with-redefs
Stubbing (Fowler 2007) is the act of supplying an imitation implementation of a function for testing purposes. One mechanism that can perform this stubbing is the with-redefs macro introduced in Clojure 1.3.
The function feed-children from listing 11.2 parses a Twitter RSS2 feed, returning a sequence of the top-level feed elements. Testing functions that rely on feed-children is futile against live Twitter feeds, so a stubbed implementation returning a known sequence is more prudent, as shown in the following listing.
Listing 17.5. Using with-redefs to create stubs

The stubbed-feed-children function returns a sequence of canned data. Therefore, when testing the count-feed-entries function, you temporarily change the value of feed-children so that it resolves to stubbed-feed-children instead. This change is made at the root of the feed-children var and so is visible to all threads. As long as all the test calls to it are made before control leaves the with-redefs form, the stub will be invoked every time. Because occurrences doesn’t return until it collects results from all the futures it creates, it uses the redef given by with-redefs:
(with-redefs [feed-children stubbed-feed-children] (joy/occurrences joy/title "Stub" "a" "b" "c")) ;=> 3
As shown, the joy/occurrences function attempts to fetch the feeds at the (clearly nonconforming) URLs "a", "b", and "c". Even though those URLs couldn’t possibly resolve to a feed, the fact that the feed-children function is stubbed out means joy/occurrences thinks each feed has a single element, each with the title "Stub".
Another option that is sometimes suggested is to use binding in place of with-redefs. This would push a thread-local binding for feed-children, which might seem attractive in that it could allow other threads to bind the same var to a different stub function, potentially for simultaneously running different tests. Because occurrences uses futures, the bindings are conveyed to the used threads. But using binding requires that the function under test be defined as ^:dynamic. Therefore, because future isn’t the only way to spawn threads, with-redefs is still recommended for mocking out functions during tests.
clojure.test as a specification
Clojure ships with a testing library in the clojure.test namespace that you can use to create test suites that can further serve as partial system specifications. We won’t provide a comprehensive survey of the clojure.test functionality, but you should get a feel for how it works. Unit-test specifications in Clojure are declarative in nature, as shown next.
Listing 17.6. clojure.test as a partial specification
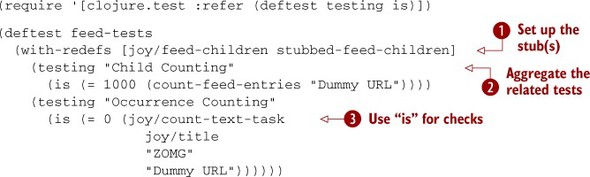
Clojure’s test library provides a DSL for describing unit test cases that interacts as you would expect with the stubbing
code we showed earlier ![]() . The testing form
. The testing form ![]() is useful for aggregating related tests, each checked by the is macro
is useful for aggregating related tests, each checked by the is macro ![]() . Notice that we added a failing test to the "Child Counting" test so that when run, the test fails as expected:
. Notice that we added a failing test to the "Child Counting" test so that when run, the test fails as expected:
(clojure.test/run-tests 'joy.unit-testing)
; Testing joy.unit-testing
;
; FAIL in (feed-tests)
; Child Counting
; expected: (= 1000 (count-feed-entries "Dummy URL"))
; actual: (not (= 1000 1))
;
; Ran 1 tests containing 2 assertions.
; 1 failures, 0 errors.
;;=> {:type :summary, :pass 1, :test 1, :error 0, :fail 1}
The tools for unit testing contained in clojure.test are more extensive than we’ve outlined here and provide support for fixtures, different assertion macros, test ordering, and customized test reports. It will be a wise investment to explore the unit-testing tools available in the core Clojure distribution; and we love the wide variety of excellent documentation available in the public domain and in existing Clojure books (Emerick 2012). Regardless of your views on software development, tests work to help ensure your software’s quality, and Clojure provides a usable and ubiquitous testing tool by default.
Although tests are a good way to find some errors, they make few guarantees that the system works properly. Planning, interaction with domain experts and potential users, and deep thinking must come before testing begins. No amount of testing can substitute for thoroughly thinking through the implications of potential designs. One interesting way to tease out the requirements and shape of a solution is to explore its fundamental expectations, as we’ll discuss next.
17.2.2. Contracts programming
Test-driven development is in many ways a heuristic affair. People tend to only test the error conditions and expectations they can conceptualize. Surely there’s no such thing as an exhaustive test suite, but in many cases test suites tend toward a local maxima. There’s a better way to define semantic expectations in applications: using Clojure pre- and postconditions.
Revisiting pre- and postconditions
In section 7.1, we explored Clojure’s pre- and postcondition facility. Function-constraint specification is a conceptually simple model for declaring the expectations for any given function. Function constraints can cover the full range of expected conditions imposed on the function’s inputs, its outputs, and their relative natures. The beauty of specifying constraints is that they can augment a testing regimen with the application of random values. This works because you can effectively throw out the values that fail the preconditions and instead focus on the values that cause errors in the postconditions. Let’s try this approach for a simple function to square a number:
(def sqr (partial
(contract sqr-contract
[n]
(require (number? n))
(ensure (pos? %)))
#(* % %)))
[(sqr 10) (sqr -9)]
;=> [100 81]
The contract for sqr is as follows: require a number, and ensure that its return is positive. Now let’s create a simple test driver[4] that throws many random values at it to see if it breaks:
4 For the sake of highlighting this technique, we’ve simplified the test driver. Testing a limited range of input values might not be an appropriate approach in all circumstances.
(doseq [n (range Short/MIN_VALUE Short/MAX_VALUE)]
(try
(sqr n)
(catch AssertionError e
(println "Error on input" n)
(throw e))))
; Error on input 0
;=> java.lang.AssertionError: Assert failed: (pos? %)
Even when adhering to the tenets of the preconditions, we’ve uncovered an error in the sqr function at the postcondition end. Postconditions should be viewed as the guarantee of the return value given that the preconditions are met. Errors like this are an indication of a disagreement between the precondition, the implementation, and the postcondition. One way to resolve the disagreement and eliminate the postcondition error is to decide that the function’s contract should specify that the number n should not be zero. By adding a check for zero (not= 0 n) in the preconditions, we can guarantee that the sqr function acts as expected. To perform this same verification using unit testing is trivial in this case, but what if the edge condition wasn’t as obvious? In such a case, the error might not be caught until it was too late. Of course, there’s no guarantee that contracts are comprehensive, but that’s why domain expertise is often critical when defining them.
Advantages of pre- and postconditions
Function constraints aren’t code. They take the form of code, but that is only a matter of representation. Instead, constraints should be viewed as a specification language describing expectations and result assurances. On the other hand, unit tests are code, and code has bugs. Contracts are essential semantic coupling, independent of any particular test case.
Another potential advantage of contracts over tests is that in some cases, tests can be generated from the contracts. Also, pre- and postconditions are amenable to being expressed as an overall description of the system, which can thus be fed into a rule base for query and verification. Both of these cases are outside the scope of this book, but you shouldn’t be surprised if they make their way into future versions of Clojure.[5] There’s tremendous potential in Clojure’s pre- and postconditions. Although they’re currently low-level constructs, they can be used to express full-blown design by contract facilities for your own applications.
5 A contrib library named core.contracts hopes to fulfill this role: www.github.com/clojure/core.contracts.
Clojure changes the way that you think.
17.3. Invisible design patterns
Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp.
Greenspun’s Tenth Rule[6]
The book Design Patterns: Elements of Reusable Object-Oriented Software (Gamma et al. 1995) was a seminal work of software design and development. You’d be hard pressed to find a software programmer in this day and age who’s not familiar with this work. The book describes 23 software practices encountered throughout the course of experience in developing software projects of varying sizes.
Design patterns have obtained a bad reputation in some circles, whereas in others they’re considered indispensable. From our perspective, design patterns are a way to express certain architectural elements found in programs written in some object-oriented programming languages, and of course to name these elements. But where design patterns fall short is that they don’t represent pure abstraction. Instead, design patterns have come to be viewed as goals in and of themselves, which is likely the source of the antagonism aimed at them. Simultaneously, they’re most often employed in languages that can’t express the patterns, so programs must repeat much or all of a pattern each time it’s used. The ability to think in abstractions is an invaluable skill for a software programmer to strengthen, and the ability to name and reuse these abstractions is an invaluable quality in a language. In this section, we’ll survey some classic design patterns (Norvig 1998) and address how in many cases Clojure provides a component that implements the pattern, and in others such a component is unnecessary because of inherent qualities of Clojure.
17.3.1. Clojure’s first-class design patterns
Most, if not all, of the patterns listed in the Design Patterns book are applicable to functional programming languages in general and to Clojure in particular. But at the book’s most pragmatic, the patterns described are aimed at patching deficiencies in popular object-oriented programming languages. This practical view of design patterns isn’t directly relevant to Clojure, because in many ways the patterns are ever present and are first-class citizens of the language. We won’t provide a comprehensive survey of the ways Clojure implements or eliminates popular design patterns but will provide enough information to make our point.
Observer pattern
Clojure’s add-watch and remove-watch functions provide the underpinnings of an observer (publisher/subscriber) capability based on reference types. You can see this through the implementation of the simple defformula macro shown in the following listing.
Listing 17.7. Creating formulas that are like spreadsheet cells

The defformula macro defines a syntactic form that builds a reference type (in this case, an agent) ![]() that depends on the value of other reference types. These constituent references on which the formula depends are given in
a binding structure as the bindings argument. This bindings vector is iterated over
that depends on the value of other reference types. These constituent references on which the formula depends are given in
a binding structure as the bindings argument. This bindings vector is iterated over ![]() , and for each reference found, a watch is added
, and for each reference found, a watch is added ![]() . An example of defformula in action is as follows.
. An example of defformula in action is as follows.
Listing 17.8. defformula to track baseball averages

Now that you have the constituent refs h and ab and the dependent formula avg in place, you can see the initial formula value:
@avg ;;=> 0.25
That avg equals 0.25 is a good sign, given that the value of 25/100 converted to a float is the same. To see a change in the formula, you can enter something like the following to trigger an automatic calculation:
(dosync (ref-set h 33)) @avg ;;=> 0.33
Changing one of the constituent refs, h, triggers a recalculation of the formula, resulting in a new value given by 33/100: 0.33. By now we hope it’s clear that the Observer pattern is satisfied by the way reference types and watchers operate in Clojure and ClojureScript. By using watchers on references, you can use defformula to provide an abstract value that changes when any of its parts change. This style of programming hints at a more general, spreadsheet-like style of operation. If you look at figure 17.1, perhaps you’ll see how the analogy applies.
Figure 17.1. Using defformula is akin to programming a spreadsheet.

Using watchers allows for a reactive style of programming triggered on value changes in references. A more traditional Lisp approach is to provide predefined hooks (Glickstein 1997) that are called at certain times in the execution cycle. To participate in a classical Observer pattern in a Java codebase, you can of course use proxy or gen-class to extend the java.util.Observable class.
Strategy pattern
Algorithm strategies selected at runtime are common practice in Clojure, and there are a number of ways to implement them. One way is via continuation-passing style, as we explored in section 7.3. A more general solution is to pass the desired function as an argument to a higher-order function, such as you’d see in the ubiquitous map, reduce, and filter functions. Further, we’ll provide a case of dynamic error functions in the next section, illustrating how Clojure’s multimethods are a more powerful substitute for the classic Strategy pattern.
Visitor pattern
The Visitor pattern is designed to describe a way to decouple operations on a structure from the structure itself. Even casual observers will see the parallel to Clojure’s multimethods, protocols, types, proxies, and reify features.
Abstract Factory pattern
The Abstract Factory pattern is used to describe a way to create related objects without having to name explicit types at the point of creation. Clojure’s types avoid the creation of explicit hierarchies (although ad hoc hierarchies can be created, as seen in section 9.2). Therefore, in Clojure this particular usage scenario is relegated to use in Java interoperability contexts. But the use of factory functions to abstract the call to the constructors of types and records is actively promoted, even in the presence of the auto-generated factory functions. For example, imagine you’re building a system that allows the creation of subsystems based on a configuration file structured as a Clojure map. Ignoring the file I/O for reading, you can create an example map corresponding to a configuration:
(ns joy.patterns.abstract-factory)
(def config
'{:systems {:pump {:type :feeder, :descr "Feeder system"}
:sim1 {:type :sim, :fidelity :low}
:sim2 {:type :sim, :fidelity :high, :threads 2}}})
The config var holds a fragment of a plausible system configuration, specifically the portion dealing with subsystem types and parameters. Before we show you how to dynamically initialize the systems described, you can create a function that creates something like a system descriptor:
(defn describe-system [name cfg] [(:type cfg) (:fidelity cfg)])
describe-system is a simple function that takes a name (that it ignores) and a configuration map and builds a vector of the :type and :fidelity values. Here’s an example descriptor:
(describe-system :pump {:type :feeder, :descr "Feeder system"})
;;=> [:feeder nil]
These kinds of descriptors can form the basis for a baseline subsystem-initialization multimethod named construct. That is, you can associate methods with construct that dispatch to specific system builders based on the descriptors. First, let’s provide a default that builds a map of a couple of key values.
Listing 17.9. Basis for an abstract factory implementation using multimethods

The multimethod construct dispatches based on the system descriptor returned from describe-system and starts with a simple default that returns a map. The function construct-subsystems builds a seq of system objects based on the return values given by calls to construct. A quick run with the defaults in place should give you a seq of three generic system maps:
(construct-subsystems (:systems config))
;;=> ({:name :pump, :type :feeder}
;; {:name :sim1, :type :sim}
;; {:name :sim2, :type :sim})
You’ve put in place a simple system for dynamically constructing a map that describes in brief a subsystem in the hypothetical system. But in reality, you would probably want more specific types for certain subsystems. To see how you can do that, start with the simple case of building a type of object other than a map for the :pump subsystem:
(defmethod construct [:feeder nil]
[_ cfg]
(:descr cfg))
(construct-subsystems (:systems config))
;;=> ("Feeder system"
;; {:name :sim1, :type :sim}
;; {:name :sim2, :type :sim})
You create another method on the construct multimethod that deals with the descriptor [:feeder null]. Although in a real system you’d probably want a more agreeable type than a string to return, this exercise shows how you can extend your abstract factory function to build instances for the two :sim types:
(defrecord LowFiSim [name]) (defrecord HiFiSim [name threads])
A complete program built using this abstract factory type of layout would probably have richer types adhering to system-like protocols, but because our goal is to show construction only, we’ve decided to keep things simple. Having said that, you can dispatch on a descriptor for each of the records to see the complete implementation.
Listing 17.10. Defining concrete factories using multimethods

The new concrete constructors dispatching from the low- and high-fidelity simulation systems work to build the precise implementations:
(construct-subsystems (:systems config))
;;=> ("Feeder system"
;; #joy.patterns.abstract_factory.LowFiSim{:name :sim1}
;; #joy.patterns.abstract_factory.HiFiSim {:name :sim2, :threads 2})
We could have used a simple case statement to implement a similar construction program, but we chose to use a multimethod-based approach because it’s more open for extension. An added advantage of a multimethod-based factory is that it allows you to add project-specific functionality to the constructor, including, but not limited to, keyword arguments, default values, and validations.
Builder pattern
The creation of complex structures from representations is central to Clojure programming, although it’s viewed differently from a similar object-oriented approach: the Builder pattern. In section 8.4, you used a simple data representation as the input to Clojure’s clojure.xml/emit function to produce an analogous XML representation. If you prefer a different output representation, you can write another conversion function. If you prefer finer control over the constituent parts, you can write functions or multimethods for each, and specialize at runtime.
Façade pattern
The use of Clojure namespaces, as discussed in section 9.1, is the most obvious way to provide a simplified façade for a more complex API. You can also use the varying levels of encapsulation (as outlined in section 2.4) for more localized façades.
Iterator pattern
Iteration in Clojure is defined through an adherence to the seq protocol, as outlined in section 5.1 and later elaborated on in section 9.3 about types and protocols.
Dependency injection in Clojure
Although not a classical pattern in the Design Patterns sense, dependency injection has become a de facto pattern for object-oriented languages that don’t allow overridable class constructors. This condition requires that separate factory methods and/or classes create concrete instances conforming to a given interface. We sowed the seeds for this discussion in the previous section about how the Abstract Factory pattern is absorbed by multimethods. Recall the following distillations of the high- and low-fidelity simulation configurations:
(ns joy.patterns.di
(:require [joy.patterns.abstract-factory :as factory]))
(def lofi {:type :sim, :descr "Lowfi sim", :fidelity :low})
(def hifi {:type :sim, :descr "Hifi sim", :fidelity :high, :threads 2})
As shown, the configurations are the focused simulation construction arguments and are useful in building instances of specific records:
(factory/construct :lofi lofi)
;;=> #joy.patterns.abstract_factory.LowFiSim{:name :lofi, ...}
Based on this code, we’re effectively right back where we were in our discussion of abstract factories. But we can extend this idea into a discussion of dependency injection and how Clojure’s core features subsume its paradigm. To start, let’s define a set of protocols used to describe system-level and simulation capabilities.
Listing 17.11. Protocols describing system-level and simulation capabilities

The protocols defined, Sys and Sim, define the set of capabilities available to higher-level system objects and specific simulation systems, respectively. If you were putting together an application to take advantage of these abstractions, you might start with a function build-system that uses the existing factory constructors to instantiate a system object and get it started.
Listing 17.12. Using abstract system construction and a system-level protocol
(defn build-system [name config]
(let [sys (factory/construct name config)]
(start! sys)
sys))
Although it’s nice that you have a system-builder function in place, you currently have nothing that adheres to the Sys protocol. You can take care of that by extending the joy.patterns.abstract_factory.LowFiSim record type to that protocol, as shown in the next listing.
Listing 17.13. Extending an existing type to the Sys and Sim protocols

As shown, the Sys protocol is implemented for the LowFiSim type as simple printouts. You also extend the LowFiSim type to Sim, for good measure. To capture the spirit of what it means to be low fidelity, you perform a calculation using a weak approximation of pi. Now, observe what happens when you call the start! function with a new instance of the LowFiSim type:
(start! (factory/construct :lofi lofi)) ;; Started a lofi simulator.
As you might have guessed, the implementation of the LowFiSim type’s start! function was called, as evinced by the proper printout. Now, if you run the proper configuration parameters through the build-system function, you should see the same thing:
(build-system :sim1 lofi)
;; Started a lofi simulator.
;;=> #joy.patterns.abstract_factory.LowFiSim{:name :sim1, ...}
And if you ask an instance of a LowFiSim type to handle a message, you should see the low-fidelity behavior:
(handle (build-system :sim1 lofi) {:weight 42})
;;=> 131.88
This is interesting because it demonstrates that you can instantiate a specific type, adhering to a specific protocol, and based solely on configuration parameters.[7] The Dependency Injection pattern is usually more interesting when more than one type is involved. So, let’s monkey with the HiFiSim type as well.
7 Not only that, but you extend an existing type to a protocol of your design, without ever changing the original type.
Listing 17.14. Extending the existing HiFiSim type to Sys and Sim

Based on the extension shown, you’ll see different behavior occurring if you change the system configuration:
(build-system :sim2 hifi)
;; Started a lofi simulator.
;;=> #joy.patterns.abstract_factory.HiFiSim{:name :sim2,...}
(handle (build-system :sim2 hifi) {:weight 42})
;; wait 5 seconds...
;;=> 131.9468914507713160154292M
Not only is the printout different from that of the previously instantiated, low-fidelity sim, but the message handler for the HiFiSim takes longer and is more precise in the number of decimal places. In simulation, you often instantiate low-fidelity and high-fidelity models for the purposes of speed, fallback, and the like. A useful pattern using both a high- and a low-fidelity model is to use the low-fidelity model as the immediate answer and then hope a high-fidelity answer eventually replaces it. The following listing shows a function that realizes this kind of usage pattern.
Listing 17.15. Calculating both a low- and a high-fidelity answer

The excellent promise is meant to store the high-fidelity answer, should it ever be delivered. In any case, the simulate function always returns a low-fidelity answer:
(simulate excellent
(build-system :sim1 lofi)
(build-system :sim2 hifi)
{:weight 42})
;;=> 131.88
The answer 131.88 is the same as before when you ran the low-fidelity calculation. Because you passed in the excellent promise, you can check to see if you have a better answer:
(realized? excellent) ;;=> false
Clojure’s realize? function is used to check whether realizable objects have a graspable representation. In the case of promises, they’re realized if a value has been delivered. Additionally, you can use realized? to check whether all the slots in a lazy seq have been calculated or whether futures and delays have calculated values inside. It’s been a few moments, so check the promise again:
;; wait a few seconds (realized? excellent) ;;=> true @excellent ;;=> 131.9468914507713160154292M
Because the excellent promise contains a high-fidelity answer, you could use it instead of the less-precise value.
Before we conclude our discussion of dependency injection, we’ll provide one more example to hammer the point home. Imagine that, for the purposes of testing, you want to create a new kind of simulation that returns canned answers and tracks certain call conditions. In testing parlance, this type of object is known as a mock, which by virtue of its tracking behavior differentiates itself from a stub. Following a similar pattern of protocol extension in listings 17.16 and 17.17, you can create a mock simulation that will stand in for either the low- or high-fidelity models.
Listing 17.16. Creating a mock of a system
(ns joy.patterns.mock
(:require [joy.patterns.abstract-factory :as factory]
[joy.patterns.di :as di]))
(defrecord MockSim [name])
(def starts (atom 0))
The starts atom is meant to contain the number of times that the times! function is called overall.[8] Extending the MockSim record type to the relevant protocols is shown.
8 If you wanted to track these calls on a per-instance basis, then you would have to structure this differently—do you see how?
Listing 17.17. Extending a mock system to existing protocols.

Whereas the LoFiSimand HiFiSim record types had default construction functions, MockSim has no such function. Instead, you can wire into the construct multimethod from afar.
Listing 17.18. Construction function for the mock system
(defmethod factory/construct [:mock nil] [nom _] (MockSim. nom))
That Clojure allows all the mock concerns to live in a single location is a powerful way to build and compose systems. We’ve often used this technique in our own code to build up applications from components adhering to well-defined protocols in a generic way. A simple system to pull this together is shown in the following listing.
Listing 17.19. Tying together a system via configuration
(ns joy.patterns.app
(require [joy.patterns.di :as di]))
(def config {:type :mock, :lib 'joy.patterns.mock})
The configuration to describe mock instances is similar to that of the high- and low-fidelity simulations, except for something new: the :lib key is mapped to a symbol corresponding to the namespace where the mock simulation code exists. This symbol helps to fully realize a system built with Clojure that allows the injection of dependencies, as shown next.
Listing 17.20. Injecting dependencies
(defn initialize [name cfg]
(let [lib (:lib cfg)]
(require lib)
(di/build-system name cfg)))
The initialize function knows nothing about the type of object being built. But by extracting the symbol held at :lib, it can dynamically require the correct namespace and therefore trigger the correct multimethod overload and protocol extensions:
(di/handle (initialize :mock-sim config) {})
;; Started a mock simulator.
;;=> 42
As shown, the initialization routine creates the correct type of object (MockSim) and delegates the start logic to the underlying machinery. Additionally, the call to handle resolves to the correct canned implementation. Now you can check to see whether the mock simulation checks for the number of calls to start!:
(initialize :mock-sim config) ;; java.lang.RuntimeException: Called start! more than once.
The mock simulation indeed checks that the correct call structure is observed. You can use this approach as the basis for a test suite and as a general-purpose way to build systems—and you have.[9]
9 Many of the principles described in this section are explored by Stuart Sierra in various talks and especially in his Component library at https://github.com/stuartsierra/component.
We could go further with this survey of design patterns, but to do so would belabor the point: most of what are known as design patterns are either invisible or trivial to implement in Clojure. But what about the Prototype pattern, you ask? You implemented the UDP in section 9.2. Decorators or chain of responsibility? Why not use a macro that returns a function built from a list of forms spliced into the -> or ->> macro? Proxies would likely be implemented as closures, and so would commands. The list goes on and on, and in the end you must face the inevitable: Clojure changes the way that you think.
17.4. Error handling and debugging
Our goal throughout this book has been to show the proper way to write Clojure code, with mostly deferral and hand-waving regarding error handling and debugging. In this section, we’ll cover these topics with what you might view as a unique twist, depending on your programming background.
17.4.1. Error handling
As we showed in figure 10.7, there are two directions for handling errors. The first, and likely most familiar, refers to the passive handling of exceptions bubbling outward from inner functions. But when using Clojure’s dynamic var binding, you can achieve a more active mode of error handling, where handlers are pushed into inner functions. In section 10.6.1, we mentioned that the binding form is used to create thread-local bindings, but its utility isn’t limited to this use case. In its purest form, dynamic scope is a structured form of a side effect (Steele 1978). You can use it to push vars down a call stack from the outer layers of a function, nesting into the inner layers: a technique that we’ll demonstrate next.
Dynamic tree traversal
In section 8.4, you built a simple tree structure for a domain model where each node was of this form:
{:tag <node form>, :attrs {}, :content [<nodes>]}
As it turns out, the traversal of a tree built from such nodes is straightforward using mundane recursion:
(defn traverse [node f]
(when node
(f node)
(doseq [child (:content node)]
(traverse child f))))
For each node in the tree, the function f is called with the node, and then each of the node’s children is traversed in turn. Observe how traverse works for a single root node:
(traverse {:tag :flower :attrs {:name "Tanpopo"} :content []}
println)
; {:tag :flower, :attrs {:name Tanpopo}, :content []}
But it’s much more interesting if you traverse trees larger than a single node. Let’s build a quick tree from an XML representation using Clojure’s clojure.:
xml/parse function:
(use '[clojure.xml :as xml])
(def DB
(-> "<zoo>
<pongo>
<animal>orangutan</animal>
</pongo>
<panthera>
<animal>Spot</animal>
<animal>lion</animal>
<animal>Lopshire</animal>
</panthera>
</zoo>"
.getBytes
(java.io.ByteArrayInputStream.)
xml/parse))
The DB var contains an animal listing for a small zoo. Note that two of the animals listed have the elements Spot and Lopshire; both are seemingly out of order for a zoo. Therefore, you can write a function to handle these nefarious intruders.
Listing 17.21. Handling nefarious tree nodes with exceptions

The default handler handle-weird-animal is set as ^:dynamic to foster something we like to call dynamic delegation. By setting up the default function this way, you can dynamically bind specialized handlers, as we’ll show soon. First, though, you need a function to make the actual delegation.
Listing 17.22. Example of dynamic delegation

The multimethod visit can be used as the input function to the traverse function; it triggers only when a node with the :tag attribute of :animal is encountered. When the method triggered on :animal is executed, the node :content is destructured and checked against the offending Spot and Lopshire values. When found, the devious node is then passed along to an error handler handle-weird-animal for reporting. By default, the handler handle-weird-animal throws an exception. This model of error reporting and handling is the inside-out model of exceptions and stops processing cold:
(traverse DB visit) ; orangutan ; java.lang.Exception: Spot must be 'dealt with'
You’ve managed to identify Spot, but the equally repugnant Lopshire escapes your grasp. It would be nice to instead use a different version of handle-weird-animal that allows you to both identify and deal with every such weird creature. You could pass handle-weird-animal along as an argument to be used as an error continuation,[10] but that would pollute the argument list of every function along the way. Likewise, you could inject catch blocks at a point further down the call chain, say in visit, but you might not be able to change the source; and if you could, it would make for more insidious pollution. Instead, using a dynamic binding is a perfect solution, because it lets you attach specific error handlers at any depth in the stack according to their appropriate context:
10 See section 7.3 for more on continuation-passing style.
(defmulti handle-weird (fn [{[name] :content}] name))
(defmethod handle-weird "Spot" [_]
(println "Transporting Spot to the circus."))
(defmethod handle-weird "Lopshire" [_]
(println "Signing Lopshire to a book deal."))
(binding [handle-weird-animal handle-weird]
(traverse DB visit))
; orangutan
; Transporting Spot to the circus.
; lion
; Signing Lopshire to a book deal.
As you might expect, this approach works across threads to allow for thread-specific handlers:
(def _ (future
(binding [handle-weird-animal #(println (:content %))]
(traverse DB visit))))
; orangutan
; [Spot]
; lion
; [Lopshire]
What we’ve outlined here is a simplistic model for a grander error-handling scheme. Using dynamic scope via binding is the preferred way to handle recoverable errors in a context-sensitive manner.
17.4.2. Debugging
The natural progression of debugging techniques as discovered by a newcomer to Clojure follows a fairly standard progression:
1. (println)
2. A macro to make (println) inclusion simpler
3. Some variation on debugging as discussed in this section
4. IDEs, monitoring, and profiling tools
Many Clojure programmers stay at step 1, because it’s simple to understand and also highly useful, but there are better ways. After all, you’re dealing with Clojure—a highly dynamic programming environment. Observe the following function:
(defn div [n d] (int (/ n d)))
The function div divides two numbers and returns an integer value. You can break div in a number of ways, but the most obvious is to call it with zero as the denominator: (div 10 0). Such an example probably wouldn’t give you cause for concern if it failed, because the conditions under which it fails are limited, well known, and easily identified. But not all errors are this simple, and the use of println is fairly limited. Instead, a better tool would likely be a generic breakpoint[11] that could be inserted at will and used to provide a debug console for the current valid execution context. It would work as follows:
11 The code in this section is based on debug-repl, which was created by the amazing George Jahad, extended by Alex Osborne, and integrated into Swank-Clojure by Hugo Duncan.
(defn div [n d] (break) (int (/ n d))) (div 10 0) debug=>
At this prompt, you can query the current lexical environment, experiment with different code, and then resume the previous execution. As it turns out, such a tool is within your grasp. Most of the behavior desired at this prompt is already provided by the standard Clojure REPL, so you can reuse that and extend it from inside a macro expansion to satisfy your particular requirements.
A breakpoint macro
We hope that by the end of this section, you’ll understand that Lisps in general, and Clojure in particular, provide an environment where the entire language truly is “always available” (Graham 1993). First, it’s interesting to note that the Clojure REPL is available and extensible via the Clojure REPL itself, via the clojure.main/repl function. By accessing the REPL implementation directly, you can customize it as you see fit for application-specific tasks.
Typing (clojure.main/repl) at the REPL seemingly does nothing, but rest assured you’ve started a sub-REPL. What use is this? To start, the repl function takes a number of named parameters, each used to customize the launched REPL in different ways. Let’s use three such hooks—:prompt, :eval, and :read—to fulfill a breakpoint functionality.
Overriding the REPL’s reader
The repl function’s :read hook takes a function of two arguments: one corresponding to a desired display prompt, and one to a desired exit form. You want the debug console to provide convenience functions—you’d like it to show all the available lexical bindings and to resume execution. It also needs to be able to read valid Clojure forms, but because that’s too complex a task, you’ll instead farm that functionality out to Clojure’s default REPL reader.
Listing 17.23. A modest debug console reader

You can begin testing the reader immediately:
(readr #(print "invisible=> ") ::exit) [1 2 3] ;; this is what you type ;=> [1 2 3] (readr #(print "invisible=> ") ::exit) ::tl ;; this is what you type ;=> :user/exit
The prompt you specified isn’t printed, and typing ::tl at the prompt does nothing because the readr function isn’t yet provided to the repl as its :read hook. But before you do that, you need to provide a function for the :eval hook. Needless to say, this is a more complex task.
Overriding the REPL’s evaluator
In order to evaluate things in context, you first need to garner the bindings in the current context. Fortunately, Clojure macros provide an implicit argument &env that’s a map of the local bindings available at macro-expansion time. You can extract from &env the values associated with the bindings and zip them up with their names into a map for the local context, as shown next.
Listing 17.24. Creating a map of the local context using &env

One interesting point is the use of the &env symbol. This special symbol holds the value of the bindings available to the macro in which it occurs. The bindings are of a special type that is opaque to your direct inspection, but by putting them into the return map you can build a Clojure data structure from them for direct use and manipulation. Observe local-context in action:
(local-context)
;=> {}
(let [a 1, b 2, c 3]
(let [b 200]
(local-context)))
;=> {a 1, b 200, c 3}
The local-context macro provides a map to the most immediate lexical bindings, which is what you want. But you want to provide a way to evaluate expressions with this contextual bindings map. Wouldn’t you know it, the contextual-eval function from section 8.1 fits the bill. Now that you have the bulk of the implementation complete, you can hook into the repl function to provide a breakpoint facility.
Putting it all together
The hard parts are done, and wiring them into a usable debugging console is relatively easy.
Listing 17.25. Implementation of a breakpoint macro
(defmacro break []
`(clojure.main/repl
:prompt #(print "debug=> ")
:read readr
:eval (partial contextual-eval (local-context))))
Using this macro, you can debug the original div function:
(defn div [n d] (break) (int (/ n d))) (div 10 0) debug=>
Querying locals to find the “problem” is simple:
debug=> n
;=> 10
debug=> d
;=> 0
debug=> (local-context)
;=> {n 10, d 0}
debug=> ::tl
; java.lang.ArithmeticException: Divide by zero
There’s the problem! You passed in a zero as the denominator. You should fix that.
Multiple breakpoints, and breakpoints in macros
What would be the point if you couldn’t set multiple breakpoints? Fortunately, you can, as shown in the following listing.
Listing 17.26. Using multiple breakpoints in the keys-apply function
(defn keys-apply [f ks m]
(break)
(let [only (select-keys m ks)]
(break)
(zipmap (keys only) (map f (vals only)))))
(keys-apply inc [:a :b] {:a 1, :b 2, :c 3})
debug=> only
; java.lang.Exception: Unable to resolve symbol: only in this context
debug=> ks
;=> [:a :b]
debug=> m
;=> {:a 1, :b 2, :c 3}
debug=> ::tl
debug=> only
;=> {:b 2, :a 1}
debug=> ::tl
;=> {:a 2, :b 3}
And you can also use breakpoints in the body of a macro (in its expansion, not its logic), as shown next.
Listing 17.27. Using a breakpoint in the awhen macro
(defmacro awhen [expr & body]
(break)
`(let [~'it ~expr]
(if ~'it
(do (break) ~@body))))
(awhen [1 2 3] (it 2))
debug=> it
; java.lang.Exception: Unable to resolve symbol: it in this context
debug=> expr
;=> [1 2 3]
debug=> body
;=> ((it 2))
debug=> ::tl
debug=> it
;=> [1 2 3]
debug=> (it 1)
;=> 2
debug=> ::tl
;=> 3
There’s much room for improvement, but we believe our point has been made. Having access to the underpinnings of the language allows you to create a powerful debugging environment with little code. We’ve run out of ideas, so we’ll say our credo only once more, and we hope by now you believe us: Clojure changes the way that you think.
17.5. Fare thee well
This book possesses many lacunae, but it’s this way by design. In many cases, we’ve skipped approaches to solving problems via a certain route to avoid presenting non-idiomatic code. In many examples, we’ve left exposed wiring. For example, the defcontract macro requires that you partially apply the contract to the function under constraint instead of providing a comprehensive contract-overlay façade. It was our goal to leave wiring exposed, because exposed wiring can be explored, tampered with, and ultimately enhanced—which we hope you’ll find the motivation to do. We’ve worked hard to provide a vast array of relevant references, should you choose to further enhance your understanding of the workings and motivations for Clojure. But it’s likely that we’ve missed some excellent resources, and we hope you can uncover them in time. Finally, this wasn’t a survey of Clojure, and many of the functions available to you weren’t used in this book. We provide some pointers in the resource list, but there’s no way we could do justice to the libraries and applications mentioned and those unmentioned. We implore you to look deeper into the functionality of not only Clojure, but also the rich ecology of libraries and applications that have sprung up in its relatively short life span.
Thank you for taking the time to read this book; we hope it was as much a pleasure to read as it was for us to write. Likewise, we hope you’ll continue your journey with Clojure. Should you choose to diverge from this path, then we hope some of what you’ve learned has helped you to view the art of programming in a new light. Clojure is an opinionated language, but it and most of its community believe these opinions can work to enhance the overall state of affairs in our software industry. The onus is on us to make our software robust, performant, and extensible. We believe the path toward these goals lies with Clojure.
Do you?
—FOGUS AND HOUSER 2014