
Chapter 6. Being lazy and set in your ways
- Immutability
- Designing a persistent toy
- Laziness
- A lazy quicksort
We mentioned in section 1.3 that the definitions of functional programming are widely disparate, and unfortunately this book won’t work to unify them. Instead, we’ll start in this chapter to build a basis for Clojure’s style of functional programming by digging into its core supporting maxims: immutable data and laziness. In addition, this chapter covers in greater depth the parts of Clojure’s composite types that we’ve only touched on. It will conclude with a sorting function that uses both maxims in a way we find to be mentally invigorating.
6.1. On immutability: being set in your ways
We’ve touched on immutability throughout this book, but we’ve avoided discussing why Clojure has chosen it as a cornerstone principle. Although it’s no panacea, fostering immutability at the language level solves many difficult problems right out of the box while simplifying many others. If you’re coming from a language background where mutability interwoven with imperative programming methods reign, it often requires a significant conceptual leap to twist your mind to accept and utilize immutability and functional programming. In this section, we’ll build a conceptual basis for immutability as it relates to Clojure’s underlying philosophy, as well as why you should work to foster immutability even when outside the warming confines of Clojure proper.
6.1.1. What is immutability?
In many cases, when talking specifically about Clojure’s immutable data structures, we could be talking about the broader category of immutable objects without loss of meaning. But we should probably set down some conditions defining what’s meant by immutability.
Every day is like Sunday
An entire branch of philosophy named predestination is devoted to exploring the notion that there’s no such thing as free will, but that instead, everything that we are or ever will be is determined beforehand. Although this possibility for our own lives may seem bleak, the notion does nicely encapsulate the first principle of immutability: all the possible properties of immutable objects are defined at the time of their construction and can’t be changed thereafter.
Immutability through convention
Computer systems are in many ways open systems, providing the keys to the vault if you’re so inclined to grab them. But in order to foster an air of immutability in your own systems, it’s important to create a facade of immutability. Creating immutable classes in Java requires a few steps (Goetz 2006). First, a class itself and all of its fields should be labeled as final. Next, in no way should an object’s this reference escape during construction. And finally, any internal mutable objects should originate, either whole-cloth or through a copy, in the class itself and never escape. Obviously we’re simplifying, because there are finer details to this recipe for Java immutability. Our point is that by observing convention, even an inherently mutable language such as Java can be made immutable. Clojure directly supports immutability as a language feature[1] with its core data structures. By providing immutable data structures as a primary language feature, Clojure separates (Braithwaite 2007) the complexity of working with immutable structures from the complexities of their implementation. By providing immutability, either as a core language feature or through convention, you can reap enormous benefits.
1 We’re intentionally glossing over Clojure’s features that support mutability, such as reference types and transients, in order to keep this section focused. Read chapters 10 and 11 for more details on such matters.
6.1.2. What is immutability for?
Clojure’s immutable data structures aren’t bolted onto the language as an afterthought. Instead, their inclusion in the language runs deep to its philosophical core.
Invariants
Invariant-based programming involves the definition of constraints on classes and functions in order to provide assurances that if instances enter into certain states, assertion errors will arise. Providing invariants in a mutable system requires a fair amount of assertion weaving in the methods of any given class. But by observing a practice of immutability, invariants are defined solely within the construction mechanism and can never be violated thereafter.
Reasoning
Because the life of an immutable object is one of predestiny, the matter of reasoning about its possible states is simplified. It follows that the act of testing such a system is simplified, in that the set of possible states and transitions is constrained.
Equality has meaning
Equality in the presence of mutability has no meaning. Equality in the face of mutability and concurrency is utter lunacy. If any two objects resolve as being equal now, then there’s no guarantee that they will a moment from now. And if two objects aren’t equal forever, then they’re technically never equal (Baker 1993). Providing immutable objects once again assigns meaning to equality, in that if two objects are equal now, they’ll always be so.
Sharing is cheap
If you’re certain that an object will never change, then sharing said object becomes a simple matter of providing a reference to it. In Java, to do so often requires a lot of defensive copying. Along this vein, because you can freely share references for immutable objects, you can likewise intern them for free.
Flattening the levels of indirection
There’s a marked difference between a mutable object and a mutable reference. The default in Java is that there are references that might point to mutable data. But in Clojure, there are only mutable references. This may seem like a minor detail, but it certainly works to reduce unnecessary complexities.
Immutability fosters concurrent programming
Immutable objects are always thread safe.
Brian Goetz[2]
2 Java Concurrency in Practice (Addison-Wesley Professional, 2006).
If an object can’t change, it can be shared freely between different threads of execution without fear of concurrent modification errors. There can be little debate about this particular point, but that fact doesn’t answer the question of how mutation occurs. Without delving into the specifics, you likely already know that Clojure isolates mutation to its reference types while the data wrapped with them is left unchanged. We’ll leave this alone for now, because we’ll devote chapter 10 to this and related topics.
6.2. Structural sharing: a persistent toy
We won’t go into terrible detail about the internals of Clojure’s persistent data structures—we’ll leave that to others (Krukow 2009). But we do want to explore the notion of structural sharing. Our example will be highly simplified compared to Clojure’s implementations, but it should help clarify some of the techniques used.
The simplest shared-structure type is the list. Two different items can be added to the front of the same list, producing two new lists that share their next parts. Let’s try this by creating a base list and then two new lists from that same base:
(def baselist (list :barnabas :adam)) (def lst1 (cons :willie baselist)) (def lst2 (cons :phoenix baselist)) lst1 ;=> (:willie :barnabas :adam) lst2 ;=> (:phoenix :barnabas :adam)
You can think of baselist as a historical version of both lst1 and lst2. But it’s also the shared part of both lists. More than being equal, the next parts of both lists are identical—the same instance:

That’s not too complicated, right? But the features supported by lists are also limited. Clojure’s vectors and maps also provide structural sharing, while allowing you to change values anywhere in the collection, not just on one end. The key is the structure each of these datatypes uses internally. You’ll now build a simple tree to help demonstrate how a tree can allow interior changes and maintain shared structure at the same time.
Each node of your tree will have three fields: a value, a left branch, and a right branch. You’ll put them in a map, like this:
{:val 5, :L nil, :R nil}
That’s the simplest possible tree—a single node holding the value 5, with empty left and right branches. This is exactly the kind of tree you want to return when a single item is added to an empty tree. To represent an empty tree, you’ll use nil. With the structure decision made, you can write your own conj function, xconj, to build up your tree, starting with the code for this initial case:

Hey, it works! Not too impressive yet, though, so you need to handle the case where an item is being added to a nonempty tree. Keep the tree in order by putting values less than a node’s :val in the left branch, and other values in the right branch. That means you need a test like this:
(< v (:val t))
When that’s true, you need the new value v to go into the left branch, (:L t). If this were a mutable tree, you’d change the value of :L to be the new node. Instead, you should build a new node, copying in the parts of the old node that don’t need to change. Something like this:
{:val (:val t),
:L (insert-new-val-here),
:R (:R t)}
A point of deep significance in understanding the fragment using :val and :R in the function position is how Clojure uses keywords as functions. In section 4.3.1, we said that keywords, when placed in a function call position, work as functions taking a map that then look up themselves (as keywords) in said map. Therefore, the snippet (:val t) states that the keyword :val takes the map t and looks itself up in the map. This is functionally equivalent to (get t :val). Although we prefer the keyword-as-function approach used in xconj, you’ll sometimes be faced with a decision and may instead choose to use get. Either choice is fine, and your decision is stylistic. A nice rule of thumb to follow is that if a keyword is stored in a local or var, using get is often clearer in its “lookup” intent:
(let [some-local :a-key]
(get {:a-key 42} :a-key))
;;=> 42
That is, the preceding is more clear than (some-local a-map).
This map will be the new root node. Now you need to figure out what to put for insert-new-val-here. If the old value of :L is nil, you need a new single-node tree—you even have code for that already, so you could use (xconj nil v). But what if :L isn’t nil? In that case, you want to insert v in its proper place in whatever tree :L is pointing to—so (:L t) instead of nil:
(defn xconj [t v]
(cond
(nil? t) {:val v, :L nil, :R nil}
(< v (:val t)) {:val (:val t),
:L (xconj (:L t) v),
:R (:R t)}))
(def tree1 (xconj nil 5))
tree1
;=> {:val 5, :L nil, :R nil}
(def tree1 (xconj tree1 3))
tree1
;=> {:val 5, :L {:val 3, :L nil, :R nil}, :R nil}
(def tree1 (xconj tree1 2))
tree1
;=> {:val 5, :L {:val 3, :L {:val 2, :L nil, :R nil}, :R nil}, :R nil}
There, it’s working. At least it seems to be—there’s a lot of noise in that output, making it difficult to read. Here’s a function to traverse the tree in sorted order, converting it to a seq that will print more succinctly:
(defn xseq [t]
(when t
(concat (xseq (:L t)) [(:val t)] (xseq (:R t)))))
(xseq tree1)
;=> (2 3 5)
Now you need a final condition for handling the insertion of values that are not less than the node value:

Now that you have the thing built, we hope you understand well enough how it’s put together that this demonstration of the shared structure is unsurprising:
(def tree2 (xconj tree1 7)) (xseq tree2) ;=> (2 3 5 7) (identical? (:L tree1) (:L tree2)) ;=> true
Both tree1 and tree2 share a common structure, which is more easily visualized in figure 6.1.
Figure 6.1. Shared structure tree: no matter how big the left side of a tree’s root node is, something can be inserted on the right side without copying, changing, or even examining the left side. All those values will be included in the new tree, along with the inserted value.
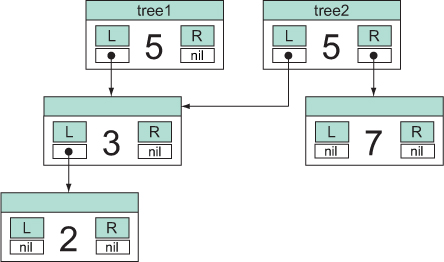
This example demonstrates several features that it has in common with all of Clojure’s persistent collections:
- Every “change” creates at least a new root node, plus new nodes as needed in the path through the tree to where the new value is being inserted.
- Values and unchanged branches are never copied, but references to them are copied from nodes in the old tree to nodes in the new one.
- This implementation is completely thread-safe in a way that’s easy to check—no object that existed before a call to xconj is changed in any way, and newly created nodes are in their final state before being returned. There’s no way for any other thread, or even any other functions in the same thread, to see anything in an inconsistent state.
The example fails, though, when compared to Clojure’s production-quality code:
- It’s a binary tree.[3]
3 Clojure’s sorted collections are binary trees, but its hash maps, hash sets, and vectors all have up to 32 branches per node. This results in dramatically shallower trees and, therefore, faster lookups and updates.
- It can only store numbers.
- It’ll overflow the stack if the tree gets too deep.
- It produces (via xseq) a non-lazy seq that will contain an entire copy of the tree.
- It can create unbalanced trees that have worst-case algorithmic complexity.[4]
4 Clojure’s sorted map and sorted set do use a binary tree internally, but they implement red-black trees to keep the left and right sides nicely balanced.
Although structural sharing as described using xconj as a basis example can reduce the memory footprint of persistent data structures, it alone is insufficient. Instead, Clojure leans heavily on the notion of lazy sequences to further reduce its memory footprint, as we’ll explore further in the next section.
6.3. Laziness
Through all the windows I only see infinity.
Mark Z. Danielewski[5]
5 House of Leaves (Pantheon, 2000).
Clojure is partially a lazy language. This isn’t to say that Clojure vectors lie around the house every day after school playing video games and refusing to get a job. Instead, Clojure is lazy in the way it handles its sequence types—but what does that mean? First, we’ll start by defining what it means for a language to be eager, or, in other words, not lazy. Many programming languages are eager in that arguments to functions are immediately evaluated when passed, and Clojure in most cases follows this pattern as well. Observe the following:
(- 13 (+ 2 2)) ;=> 9
The expression (+ 2 2) is eagerly evaluated, in that its result 4 is passed on to the subtraction function during the actual call and not at the point of need. But a lazy programming language such as Haskell (Hudak 2000) will evaluate a function argument only if that argument is needed in an overarching computation.
In this section, we’ll discuss how you can use laziness to avoid nontermination, unnecessary calculations, and even combinatorially exploding computations. We’ll also discuss the matter of utilizing infinite sequences, a surprisingly powerful technique. Finally, you’ll use Clojure’s delay and force to build a simple lazy structure. First, we’ll start with a simple example of laziness that you may be familiar with from Java.
6.3.1. Familiar laziness with logical-and
Laziness isn’t limited to the case of the evaluation of function arguments; a common example can be found even in eager programming languages. Take the case of Java’s logical-and operator &&. Java implementations, by dictate of the specification, optimize this particular operator to avoid performing unnecessary operations should an early subexpression evaluate to false. This lazy evaluation in Java allows the following idiom:
if (obj != null && obj.isWhatiz()) {
...
}
For those of you unfamiliar with Java, the preceding code says, “If the object obj isn’t null, then call the method isWhatiz.” Without a short-circuiting (or lazy, if you will) && operator, the preceding operation would always throw a java.lang.NullPointer-Exception whenever obj was set to null. Although this simple example doesn’t qualify Java as a lazy language, it does illustrate the first advantage of lazy evaluation: laziness allows the avoidance of errors in the evaluation of compound structures.
Clojure’s and operator also works this way, as do a number of other operators, but we won’t discuss this type of short-circuiting laziness too deeply. The following listing illustrates what we mean, using the case of a series of nested if expressions.
Listing 6.1. Short-circuiting if expression
(defn if-chain [x y z]
(if x
(if y
(if z
(do
(println "Made it!")
:all-truthy)))))
(if-chain () 42 true)
; Made it!
;=> :all-truthy
(if-chain true true false)
;=> nil
The call to println is evaluated only in the case of three truthy arguments. But you can perform the equivalent action given only the and macro:
(defn and-chain [x y z] (and x y z (do (println "Made it!") :all-truthy))) (and-chain () 42 true) ; Made it! ;=> :all-truthy (and-chain true false true) ;=> false
You may see tricks like this from time to time, but they’re not often found in Clojure code. Regardless, we’ve presented them as a launching point for the rest of the discussion in the section. We’ll now proceed to discuss how your own Clojure programs can be made more generally lazy by following an important recipe.
6.3.2. Understanding the lazy-seq recipe
Here’s a seemingly simple function, steps, that takes a sequence and makes a deeply nested structure from it:
(steps [1 2 3 4]) ;=> [1 [2 [3 [4 []]]]]
Seems simple enough, no? Your first instinct might be to tackle this problem recursively, as suggested by the form of the desired result:
(defn rec-step [[x & xs]]
(if x
[x (rec-step xs)]
[]))
(rec-step [1 2 3 4])
;=> [1 [2 [3 [4 []]]]]
Things look beautiful at this point; you’ve created a simple solution to a simple problem. But therein bugbears lurk. What would happen if you ran this same function on a large set?
(rec-step (range 200000)) ;=> java.lang.StackOverflowError
Observing the example, running the same function over a sequence of 200,000 elements[6] causes a stack overflow. How can you fix this problem? Perhaps it’s fine to say that you’ll never encounter such a large input set in your own programs; such trade-offs are made all the time. But Clojure provides lazy sequences to help tackle such problems without significantly complicating your source code. Additionally, your code should strive to deal with, and produce, lazy sequences.
6 On our machines, 200,000 elements are enough to cause a stack overflow, but your machine may require more or fewer depending on your JVM configuration.
Stepping back a bit, let’s examine the lazy-seq recipe for applying laziness to your own functions:
1. Use the lazy-seq macro at the outermost level of your lazy sequence–producing expression(s).
2. If you happen to be consuming another sequence during your operations, then use rest instead of next.
3. Prefer higher-order functions when processing sequences.
4. Don’t hold on to your head.
These rules of thumb are simple, but they take some practice to utilize to their fullest. For example, #4 is especially subtle in that the trivial case is easy to conceptualize, but it’s more complex to implement in large cases. For now we’ll gloss over #3, because we’ll talk about that approach separately in section 7.1.
So how can you use these rules of thumb to ensure laziness?
What happens when you create a potentially infinite sequence of integers using iterate, printing a dot each time you generate a new value, and then use either rest or next to return the first three values of the sequence? The difference between rest and next can be seen in the following example:
(def very-lazy (-> (iterate #(do (print .) (inc %)) 1)
rest rest rest))
;=> ..#'user/very-lazy
(def less-lazy (-> (iterate #(do (print .) (inc %)) 1)
next next next))
;=> ...#'user/less-lazy
As shown, the next version printed three dots, whereas the rest version printed only two. When building a lazy seq from another, rest doesn’t cause the calculation of (or realize) any more elements than it needs to; next does. In order to determine whether a seq is empty, next needs to check whether there’s at least one thing in it, thus potentially causing one extra realization. Here’s an example:
(println (first very-lazy)) ; .4 (println (first less-lazy)) ; 4
Grabbing the first element in a lazy seq built with rest causes a realization as expected. But the same doesn’t happen for a seq built with next because it’s already been previously realized. Using next causes a lazy seq to be one element less lazy, which might not be desired if the cost of realization is expensive. In general, we recommend that you use next unless you’re specifically trying to write code to be as lazy as possible.
Using lazy-seq and rest
In order to be a proper lazy citizen, you should produce lazy sequences using the lazy-seq macro. Here’s a lazy version of rec-step that addresses the problems with the previous implementation.
Listing 6.2. Using lazy-seq to avoid stack overflows

There are a few points of note for this new implementation. As we mentioned in our rules of thumb, when consuming a sequence in the body of a lazy-seq, you want to use rest, as in lz-rec-step. Second, you’re no longer producing nested vectors as the output of the function, but instead a lazy sequence LazySeq, which is the byproduct of the lazy-seq macro.
With only minor adjustments, you’ve created a lazy version of the step function while also maintaining simplicity. The first two rules of the lazy-sequence recipe can be used in all cases when producing lazy sequences. Note them in the previous example—the use of lazy-seq as the outermost form in the function and the use of rest. You’ll see this pattern over and over in Clojure code found in the wild.
If what’s going on here still doesn’t quite make sense to you, consider this even simpler example:
(defn simple-range [i limit]
(lazy-seq
(when (< i limit)
(cons i (simple-range (inc i) limit)))))
This behaves similarly to Clojure’s built-in function range, but it’s simpler in that it doesn’t accept a step argument and has no support for producing chunked seqs:[7]
7 Chunked seqs are a technique for improving performance that we cover in chapter 15.
(simple-range 0 9) ;=> (0 1 2 3 4 5 6 7 8)
Note that it follows all the lazy-seq recipe rules you’ve seen so far. Figure 6.2 is a representation of what’s in memory when the REPL has printed the first two items in a simple-range seq but hasn’t yet printed any more than that.
Figure 6.2. Each step of a lazy seq may be in one of two states. If the step is unrealized, it contains a function or closure of no arguments that can be called later to realize the step. When this happens, the thunk’s return value is cached instead, and the thunk itself is released as pictured in the first two lazy seq boxes, transitioning the step to the realized state. Note that although not shown here, a realized lazy seq may contain nothing at all, called nil, indicating the end of the seq.
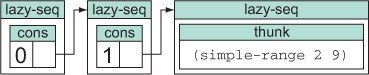
Complications may arise if you accidentally hold on to the head of a lazy sequence. This is addressed by the fourth rule of lazy sequences.
6.3.3. Losing your head
The primary advantage of laziness in Clojure is that it prevents the full realization of interim results during a calculation. If you manage to hold on to the head of a sequence somewhere within a function, then that sequence will be prevented from being garbage collected. The simplest way to retain the head of a sequence is to bind it to a local. This condition can occur with any type of value bind, be it to a reference type or through the usage of let or binding:[8]
8 When running this code, our laptop got very hot. Be warned that your lap may get toasty—please don’t sue us.
(let [r (range 1e9)] (first r) (last r)) ;=> 999999999 (let [r (range 1e9)] (last r) (first r)) ; java.lang.OutOfMemoryError: GC overhead limit exceeded
Clojure’s compiler can deduce that in the first example, the retention of r is no longer needed when the computation of (last r) occurs, and therefore Clojure aggressively clears it. But in the second example, the head is needed later in the overall computation and can no longer be safely cleared. Of course, the compiler could perform some rearranging with the order of operations for this case, but it doesn’t because in order to do so safely it would have to guarantee that all the composite functions were pure. It’s OK if you’re not clear on what a pure function is right now—we’ll cover it in section 7.1. In a nutshell, take to heart that Clojure can’t rearrange operations, because there’s no way to guarantee that order is unimportant. This is one area where a purely functional lazy language such as Haskell (Thompson 1999) shines by comparison.
6.3.4. Employing infinite sequences
Because Clojure’s sequences are lazy, they have the potential to be infinitely long. Clojure provides a number of functions for generating and working with infinite sequences:
; Run at your own risk (iterate (fn [n] (/ n 2)) 1) ;=> (1 1/2 1/4 1/8 ...)
It sure is a nice trick (although you might not think so had you chosen to ignore our warning), but what could you possibly use infinite sequences for? Working with infinite sequences often fosters more declarative solutions. Take a simple example as a start. Imagine that you have a function that calculates a triangle number[9] for a given integer:
9 If you’ve ever gone bowling, you may know what a triangle number is without realizing it. The game has 10 pins arranged in a triangular formation, where the first row has one pin and the last row has four. Therefore, the triangle number of four is 10 (1 + 2 + 3 + 4 = 10).
(defn triangle [n] (/ (* n (+ n 1)) 2)) (triangle 10) ;=> 55
The function triangle can then be used to build a sequence of the first 10 triangle numbers:
(map triangle (range 1 11)) ;=> (1 3 6 10 15 21 28 36 45 55)
There’s nothing wrong with the preceding solution, but it suffers from a lack of flexibility in that it does what it does and that’s all. By defining a sequence of all the triangle numbers, as in the following listing, you can perform more interesting “queries” in order to retrieve the desired elements.
Listing 6.3. Infinite sequences fostering declarative solutions

The queries use three ubiquitous Clojure functions: map, reduce, and filter. The map function applies a function to each element in a sequence and returns the resulting sequence. The reduce function applies a function to each value in the sequence and the running result to accumulate a final value. Finally, the filter function applies a function to each element in a sequence and returns a new sequence of those elements where said function returned a truthy value. All three of these functions retain the laziness of a given sequence.
Defining the infinite sequence of triangle numbers allows you to take elements from it as needed, only calculating those particular items.
6.3.5. The delay and force macros
Although Clojure sequences are largely lazy, Clojure itself isn’t. In most cases, expressions in Clojure are evaluated once prior to their being passed into a function rather than at the time of need. But Clojure does provide mechanisms for implementing what are known as call-by-need semantics. The most obvious of these mechanisms is its macro facilities, but we’ll defer that discussion until chapter 8. The other mechanism for providing what we’ll call explicit laziness uses Clojure’s delay and force. In short, the delay macro is used to defer the evaluation of an expression until explicitly forced using the force function. Using these laziness primitives, you can wrap an expression in a call to delay and use it only if necessary on the callee’s side:[10]
10 See the sidebar at the top of the next page for a description of if-let.

You can simulate this behavior with the use of anonymous functions, where delay is replaced by (fn [] expr) and force by (delayed-fn), but using delay/force lets you explicitly check for delayed computations using delay?. Additionally, delay caches its calculation, therefore allowing its wrapped expression to be calculated only once. Of course, you could simulate the same behavior using memoization,[11] but why would you in this case when delay and force solve the problem more succinctly?
11 We’ll cover memoization in chapter 14.
The if-let and when-let macros are useful when you’d like to bind the results of an expression based on whether it returns a truthy value. This helps to avoid the need to nest if/when and let as shown:
(if :truthy-thing (let [res :truthy-thing] (println res))) ; :truthy-thing (if-let [res :truthy-thing] (println res)) ; :truthy-thing
The latter is much more succinct.
There are more complicated usage patterns for delay and force besides the simple scheme outlined previously. For example, you can implement a version of the lazy sequence of triangular numbers from a few sections prior using delay and force:
(defn inf-triangles [n]
{:head (triangle n)
:tail (delay (inf-triangles (inc n)))})
(defn head [l] (:head l))
(defn tail [l] (force (:tail l)))
The function inf-triangles creates a lazy linked list of nodes. Each node is a map containing a value mapped to :head and a link to the remainder of the list keyed as :tail. The head of the list is the result of applying the function triangle to the incrementing counter passed recursively within the body of delay. As you can imagine, the head of a node is always calculated as you walk down the linked list, even if it’s never accessed. This type of lazy structure is known as head strict but differs from Clojure’s lazy-seq, which delays both the head and tail and then realizes them at the same time.
You can now create a structure similar to the original tri-nums and start getting at its contained elements:
(def tri-nums (inf-triangles 1)) (head tri-nums) ;=> 1 (head (tail tri-nums)) ;=> 3 (head (tail (tail tri-nums))) ;=> 6
One thing to note about the preceding code is that accessing the values 3 and 6 involves deferred calculations that occur only on demand. The structure of the example is shown in figure 6.3.
Figure 6.3. Lazy linked-list example. Each node of this linked list contains a value (the head) and a delay (the tail). The creation of the next part is forced by a call to tail—it doesn’t exist until then.

Although you can navigate the entire chain of triangular numbers using only head and tail, it’s probably a better idea[12] to use them as primitives for more complicated functions:
12 And as we’ll cover in section 9.3, participating in the ISeq protocol is even better.
(defn taker [n l]
(loop [t n, src l, ret []]
(if (zero? t)
ret
(recur (dec t) (tail src) (conj ret (head src))))))
(defn nthr [l n]
(if (zero? n)
(head l)
(recur (tail l) (dec n))))
(taker 10 tri-nums)
;=> [1 3 6 10 15 21 28 36 45 55]
(nthr tri-nums 99)
;=> 5050
Of course, writing programs using delay and force is an onerous way to go about the problem of laziness, and you’d be better served by using Clojure’s lazy sequences to full effect rather than building your own from these basic blocks. But the preceding code, in addition to being simple to understand, harkens back to chapter 5 and the entire sequence “protocol” being built entirely on the functions first and rest. Pretty cool, right?
6.4. Putting it all together: a lazy quicksort
In a time when the landscape is rife with new programming languages and pregnant with more, it seems inconceivable that the world would need another quicksort implementation. Inconceivable or not, we won’t be deterred from adding yet another to the rich ecosystem of pet problems. This implementation of quicksort differs from many in a few key ways. First, you’ll implement a lazy, tail-recursive version. Second, you’ll split the problem such that it can be executed incrementally. Only the calculations required to obtain the part of a sequence desired will be calculated. This will illustrate the fundamental reason for laziness in Clojure: the avoidance of full realization of interim results.
6.4.1. The implementation
Without further ado, we present our quicksort implementation, starting with a simple function named rand-ints that generates a seq of pseudo-random integers sized according to its given argument n with numbers ranging from zero to n, inclusive:
(ns joy.q) (defn rand-ints [n] (take n (repeatedly #(rand-int n))))
The rand-ints function works as you might expect:
(rand-ints 10) ;;=> (0 1 5 7 3 5 6 4 9 0)
The bulk of this lazy quicksort implementation[13] is as shown in the following listing.
13 This listing uses the list* function, which for some reason is rarely seen. In cases like this, though, it’s exactly what you need. list* is like list except it expects its last argument to be a list on which to prepend its other arguments. You’ll use it again in chapter 8.
Listing 6.4. Lazy, tail-recursive, incremental quicksort

The key detail in the preceding code is that sort-parts works not on a plain sequence of elements but on a carefully constructed list that alternates between lazy seqs and pivots. Every element before each pivot is guaranteed to be less than the pivot, and everything after will be greater, but the sequences between the pivots are as yet unsorted. When qsort is given an input sequence of numbers to sort, it creates a new work list consisting of just that input sequence and passes this work to sort-parts. The loop inside sort-parts pulls apart the work, always assuming that the first item, which it binds to part, is an unsorted sequence. It also assumes that if there is a second item, which will be at the head of parts, then that item is a pivot. It recurs on the sequence at the head of work, splitting out pivots and lazy seqs until the sequence of items less than the most recent pivot is empty, in which case the if-let test is false, and that most recent pivot is returned as the first item in the sorted seq. The rest of the built-up list of work is held by the returned lazy sequence to be passed into sort-parts again when subsequent sorted items are needed.
You can see a snapshot of the work list for the function call (qsort [2 1 4 3]) in figure 6.4, at an intermediate point in its process.
Figure 6.4. The qsort function shown earlier uses a structure like this for its work list when sorting the vector [2 1 4 3]. Note that all the parts described by a standard quicksort implementation are represented here.

The figure includes the characteristics of a standard quicksort implementation, which you can finalize with another function that starts sort-parts running properly:
(defn qsort [xs] (sort-parts (list xs)))
You can run qsort as follows to sort a given sequence:
(qsort [2 1 4 3]) ;=> (1 2 3 4) (qsort (rand-ints 20)) ;=> (0 2 3 5 6 7 7 8 9 10 11 11 11 12 12 13 14 16 17 19)
The implementation of the sort-parts function works to provide an incremental solution for a lazy quicksort. This incremental approach stands in opposition to a monolithic approach (Okasaki 1996) defined by its performance of the entire calculation when any segment of the sequence is accessed. For example, grabbing the first element in a lazy sequence returned from qsort performs only the necessary calculations required to get that first item:
(first (qsort (rand-ints 100))) ;=> 1
Of course, the number returned here will likely be different in your REPL, but the underlying structure of the lazy sequence used internally by sort-parts will be similar to that shown in figure 6.5.
Figure 6.5. Internal structure of qsort. Each filter and remove lazily returns items from its parent sequence only as required. So, to return the first two items of the seq returned by qsort, no remove steps are required from either level A or level B. To generate the sequence (4), a single remove step at level B is needed to eliminate everything less than 3. As more items are forced from the seq returned by qsort, more of the internal filter and remove steps are run.

The lazy qsort can gather the first element because it takes only some small subset of comparisons to gather the numbers into left-side smaller and right-side larger partitions and sort those smaller pieces only. The characteristic of the quicksort algorithm is especially conducive to laziness, because it’s fairly cheap to make and shuffle partitions where those with a smaller magnitude can be shuffled first. What then are the benefits of a lazy, tail-recursive, incremental quicksort? The answer is that you can take sorted portions of a large sequence without having to pay the cost of sorting its entirety, as the following command hints:
(take 10 (qsort (rand-ints 10000))) ;=> (0 0 0 4 4 7 7 8 9 9)
On our machines, this command required roughly 11,000 comparisons, which for all intents and purposes is an O(n) operation—an order of magnitude less than the quicksorts’s best case. Bear in mind that as the take value gets closer to the actual number of elements, this difference in asymptotic complexity will shrink. But it’s a reasonably efficient way to determine the smallest n values in a large unsorted (Knuth 1997) sequence, especially given that it doesn’t sort its elements in place.
6.5. Summary
We’ve covered the topics of immutability, persistence, and laziness in this chapter. Clojure’s core composite data types are all immutable and persistent by default, and although this fact might presuppose fundamental inefficiencies, we’ve shown how Clojure addresses them. The implementation of a persistent sorted binary tree demonstrated how structural sharing eliminated the need for full copy on write. But structural sharing isn’t enough to guarantee memory efficiency, and that’s where the benefits of laziness come into the fold. The implementation of a lazy, tail-recursive quicksort demonstrates that laziness guarantees that sequences aren’t fully realized in memory at any given step.
In the next chapter, we’ll dive into Clojure’s notion of functional programming. Along the way, you’ll notice that much of the shape of functional implementations in Clojure is influenced by the topics discussed in this chapter.