
CHAPTER 3
Risk Identification, Monitoring, and Analysis
Information security is about controlling and managing risk to information, information systems, and the people, processes, and technologies that support them and make use of them. Most information security risks involve events that can disrupt the smooth functioning of the business processes used by a company, an organization, or even an individual person. Since all systems are imperfect, and all organizations never have enough time or resources to fix every problem, risk management processes are used to identify risks, select and prioritize those that must be dealt with soonest, and implement risk mitigations that control or limit the possibility of the risk event’s occurrence and the damage it can inflict when (not if) it occurs. Risk management also requires ongoing monitoring and assessment of both the real-world context of risks that the organization operates in, and the success or failure of the risk mitigations that management has chosen to implement. Information risk management operationalizes the information security needs of the organization, expressed in terms of the need to preserve the confidentiality, integrity, availability, nonrepudiation, authentication, privacy, and safety aspects of the information and the organizational decisions that make use of it. It does this by using a variety of assessment strategies and processes to relate risks to vulnerabilities, and vulnerabilities to effective control or mitigation approaches. At the heart of information security risk management is the prompt detection, characterization, and response to a potential security event. Setting the right alarm thresholds is as important as identifying the people who will receive those alarms and respond to them, as well as equipping those people with the tools and resources they’ll need to contain the incident and restore the organization’s IT systems back to working order. Those resources include timely senior leadership and management decisions to support the response, escalating it if need be. It’s often been said that the attackers have to get lucky only once, whereas the defenders have to be lucky every moment of every day. When it comes to advanced persistent threats (APTs), which pose potentially the most damaging attacks to our information systems, another, more operationally useful rule applies. Recall that APTs are threat actors who spend months, maybe even years, in their efforts to exploit target systems and organizations in the pursuit of the threat actors’ goals and objectives. APTs quite often use low and slow attack patterns that avoid detection by many network and systems security sensor technologies; once they gain access, they often live off the land and use the built-in capabilities of the target system’s OS and applications to achieve their purposes. APTs often subcontract out much of their work to other players to do for them, both as a layer of protection for their own identity and as a way of gaining additional attack capabilities. This means that APTs plan and conduct their attacks using what’s called a robust kill chain, the sequence of steps they go through as they discover, reconnoiter, characterize, infiltrate, gain control, and further identify resources to attack within the system; make their “target kill” by copying, exfiltrating, or destroying the data and systems of their choice; and then cover their tracks and leave. The bad news is that it’s more than likely that your organization or business is already under the baleful gaze of more than just one APT bad actor; you might also be subject to open source intelligence gathering, active reconnaissance probes, or social engineering attempts being conducted by some of the agents and subtier players in the threat space that APTS often use (much like subcontractors) to carry out steps in an APT’s kill chain. Crowded, busy marketplaces provide many targets for APTs; so, naturally, many such threat actors are probably considering some of the same targets as their next opportunities to strike. For you and your company, this means that on any given day, you’re probably in the crosshairs of multiple APTs and their teammates in various stages of their own unique kill chains, each pursuing their own, probably different, objectives. Taken together, there may be thousands, if not hundreds of thousands, of APTs out there in the wild, each seeking its own dominance, power, and gain. The millions of information systems owned and operated by businesses and organizations worldwide are their hunting grounds. Yours included. The good news is that there are many field-proven information risk management and mitigation strategies and tactics that you can use to help your company or organization adapt and survive in the face of such hostile action and continue to flourish despite the worst the APTs can do to you. These frameworks and the specific risk mitigation controls should be tailored to the confidentiality, integrity, availability, nonrepudiation, and authentication (CIANA) needs of your specific organization. With them, you can first deter, prevent, and avoid attacks. Then you can detect the ones that get past that first set of barriers and characterize them in terms of real-time risks to your systems. You then take steps to contain the damage they’re capable of causing and help the organization recover from the attack and get back up on its feet. You probably will not do battle with an APT directly; you and your team won’t have the luxury (if we can call it that!) of trying to design to defend against a particular APT and thwart their attempts to seek their objectives at your expense. Instead, you’ll wage your defensive campaign one skirmish at a time, never knowing who the ultimate attacker is or what their objectives are vis-à-vis your systems and your information. You’ll deflect or defeat one scouting party as you strengthen one perimeter; you’ll detect and block a probe from somewhere else that is attempting to gain entry into and persistent access to your systems. You’ll find where an illicit user ID has made itself part of your system, and you’ll contain it, quarantine it, and ultimately block its attempts to expand its presence inside your operations. As you continually work with your systems’ designers and maintainers, you’ll help them find ways to tighten down a barrier here or mitigate a vulnerability there. Step by step, you strengthen your information security posture—and, if you’re lucky, all without knowing that one or many APTs have had you in their sights. But in order to have such good luck, you’ve got to have a layered, integrated, and proactive information systems defense in place and operating; and your best approach for establishing such a security posture is to consciously choose which information and decision risks to manage, which ones to mitigate, and what to do when a risk starts to become an event. That’s what this chapter is all about. Since 2011, energy production and distribution systems in North America and Western Europe have been under attack from what can only be described as a large, sophisticated, advanced persistent threat actor team. Known as Dragonfly 2.0, this attack depended heavily on fraudulent IDs and misuse of legitimate IDs created in systems owned and operated by utility companies, engineering and machinery support contractors, and the fuels industries that provide the feedstocks for the nuclear, petroleum, coal, and gas-fired generation of electricity. The Dragonfly 2.0 team wove a complex web of attacks against multiple private and public organizations as they gathered information, obtained access, and created fake IDs as precursor steps to gaining more access and control. For example, reports issued by NIST and Symantec make mention of “hostile email campaigns” that attempted to lure legitimate email subscribers in these organizations to respond to fictitious holiday parties. Blackouts and brownouts in various energy distribution systems, such as those suffered in Ukraine in 2015 and 2016, have been traced to cyberattacks linked to Dragonfly 2.0 and its teams of attackers. Data losses to various companies and organizations in the energy sector are still being assessed. You can read Symantec’s report at www.symantec.com/blogs/threat-intelligence/dragonfly-energy-sector-cyber-attacks. Why should security practitioners put so much emphasis on APTs and their use of the kill chain? In virtually every major data breach in the past decade, the attack pattern was low and slow: sequences of small-scale efforts designed not to cause alarm, each of which gathered information or enabled the attacker to take control of a target system. More low and slow attacks launched from that first target against other target systems. This springboard or stepping-stone attack pattern is both a deliberate strategy to further obscure the ultimate source of the attack and an opportunistic effort to find more exploitable, useful information assets along the way. They continually conduct reconnaissance efforts and continually grow their sense of the exploitable nature of their chosen targets. Then they gain access, typically creating false identities in the target systems. Finally, with all command, control, and hacking capabilities in place, the attack begins in earnest to exfiltrate sensitive, private, or otherwise valuable data out of the target’s systems. This same pattern of events shows itself, with many variations, in ransom attacks, in sabotage, and in disruption of business systems. It’s a part of attacks seen in late 2018 and early 2019 against newspaper publishers and nickel ore refining and processing industries. In any of these attacks, detecting, disrupting, or blocking any step along the attacker’s kill chain might very well have been enough to derail that kill chain and motivate the attacker to move on to another, less well-protected and potentially more lucrative target. Preparation and planning are your keys to survival; without them, you cannot operationally defeat your attacker’s kill chain. Previous chapters examined the day-to-day operational details of information security operations and administration; now, let’s step back and see how to organize, plan, and implement risk management and mitigation programs that deliver what your people need day-to-day to keep their information and information systems safe, secure, reliable, and resilient. We’ll also look in some depth at what information to gather and analyze so as to inform management and leadership when critical, urgent decisions about information security must be made, especially if indicators of an incident must be escalated for immediate, business-saving actions to take place. Many businesses, nonprofits, and even government agencies use the concept of the value chain, which models how they create value in the products or services they provide to their customers (whether internal or external). The value chain brings together the sequence of major activities, the infrastructures that support them, and the key resources that those activities need to transform each input into an output. The value chain focuses the attention of process designers, managers, and workers alike on the outputs and the outcomes that result from each activity. Critical to thinking about the value chain is that each major step provides the organization with a chance to improve the end-to-end experience by reducing costs, reducing waste, scrap, or rework, and by improving the quality of each output and outcome along the way. Value chains extend well beyond the walls of the organization itself, as they take in the efforts of suppliers, vendors, partners, and even the actions and intentions of regulators and other government activities. Even when a company’s value chain is extended beyond its own boundaries, the company owns that value chain—in the sense that they are completely responsible for the outcomes of the decisions they make and the actions they take. The company has end-to-end due care and due diligence responsibility for each value chain they operate. They have to appreciate that every step along each of their value chains is an opportunity for something to go wrong, as much as it is an opportunity to achieve greatness. A key input could be delayed or fail to meet the required specifications for quality or quantity. Skilled labor might not be available when we need it; critical information might be missing, incomplete, or inaccurate. Ten years ago, you didn’t hear too many information systems security practitioners talking about the kill chain. In 2014, the U.S. Congress was briefed on the kill chain involved in the Target data breach of 2013, which you can (and should!) read about at https://www.commerce.senate.gov/public/_cache/files/24d3c229-4f2f-405d-b8db-a3a67f183883/23E30AA955B5C00FE57CFD709621592C.2014-0325-target-kill-chain-analysis.pdf. Today, it’s almost a survival necessity that you know about kill chains, how they function, and what you can do about them. Whether we’re talking about military action or cybersecurity, the “kill chain” as a plan of action is in effect choosing to be the sum total of all of those things that can go wrong in the target’s value chain systems. Using a kill chain does not defeat the target with overwhelming force. Instead, the attacker out-thinks the target by meticulously studying the target as a system of systems and by spotting its inherent vulnerabilities and its critical dependencies on inputs or intermediate results; then it finds the shortest, simplest, lowest-cost pathway to triggering those vulnerabilities and letting them help defeat the target. Much like any military planner, an APT plans their attack with an eye to defeating, degrading, distracting, or denying the effectiveness of the target’s intrusion deterrence, prevention, detection, and containment systems. They’ve further got to plan to apply those same “four Ds” to get around, over, or through any other security features, procedures, and policies that the target is counting on as part of its defenses. The cybersecurity defensive value chain must effectively combine physical, logical, and administrative security and vulnerability mitigation controls; in similar fashion, the APT actor considers which of these controls must be sidestepped, misdirected, spoofed, or ignored, as they pursue their plans to gain entry, attain the command and control of portions of the target’s systems that will serve their needs, and carry out their attack. (In that regard, it might be said that APT actors and security professionals are both following a similar risk management framework.) Figure 3.1 shows a generalized model of an APT’s kill chain, which is derived in part from the previously mentioned Senate committee report. FIGURE 3.1 Kill chain conceptual model One important distinction should be obvious: as a defender, you help own, operate, and protect your value chains, while all of those would-be attackers own their kill chains. With that as a starting point, you can see that an information systems kill chain is the total set of actions, plans, tasks, and resources used by an advanced persistent threat to do the following:
How do APTs apply this kill chain in practice? In broad general terms, APT actors may take many actions as part of their kill chains, as they:
The more complex, pernicious APTs will use multiple target systems as proxies in their kill chains, using one target’s systems to become a platform from which they can run reconnaissance and exploitation against other targets. In the Target breach, the attackers entered Target’s payment processing systems utilizing a maintenance back door left in place by Target’s heating, ventilation, and air conditioning (HVAC) contractors, as shown in Figure 3.2, which is from the previously mentioned Senate report. Defeating an APT’s kill chain requires you to think about breaking each step in the process, in as many ways as you can—and in ways that you can continually monitor, detect, and recognize as being part of an attack in progress. (Target’s information security team, by contrast, failed to heed and understand the alarms that their own network security systems were generating; and Target’s mid-level managers also failed to escalate these alarms to senior management, thus further delaying their ability to respond.) FIGURE 3.2 Target 2013 data breach kill chain APTs can be almost any kind of organized effort to achieve some set of objectives by means of extracting value from your information systems. That value might come from the information they can access, exfiltrate, and sell or trade to other threat actors, or it might come from disrupting your business processes or the work of key people on your team. APTs have been seen as parts of campaigns waged by organized crime, terrorist organizations, political and social activist campaigners, national governments, and even private businesses. The APT threat actors, or the people whom they work with or for, have motives that range from purely mercenary to ideological, from seeking power to seeking revenge. APT threat actors and the campaigns that they attempt to run may be of almost any size, scale, and complexity. And they’re quite willing to use any system, no matter how small, personal or business, if it can be a stepping-stone to completing a step in their kill chain. Including yours. A typical business information system, such as a corporate data center and the networks that make it available to authorized users, might suffer millions of hits each day from unknown and unauthorized Internet addresses. Some of these are merely events—something routine that has happened, such as an innocent ping or ICMP packet attempting to make contact. Others might be part of information security incidents. You obviously cannot spend human security analyst time on each of those events; you’ve got to filter it down to perhaps a few dozen or more each day that might be something worthy of further analysis and investigation. This brings us to define an event of interest as something that happens that might be an indicator (or a precursor) of one or more events that might impact your information’s systems security. An event of interest may or may not be a warning of a computer security incident in the making, or even the first stages of such an incident. But what is a computer security incident? Several definitions by NIST, ITIL, and the IETF1 suggest that computer security incidents are events involving a target information system in ways that:
The unplanned shutdown of your on-premises mail server, as an example, might have been caused by a thunderstorm-induced electrical power transient or by an accidental unplugging of its power supply and conditioning equipment. Your vulnerability assessment might have discovered these vulnerabilities and made recommendations as to how to reduce their potential for disruption. But if neither weather nor hardware-level accident caused the shutdown, you have to determine whether it was a software or systems design problem that caused the crash or a vulnerability that was exploited by a person or persons unknown. Another challenge that is becoming more acute is to differentiate phishing attacks from innocent requests for information. An individual caller to your main business phone number, seeking contact information in your IT team, might be an honest and innocent inquiry (perhaps from an SSCP looking for a job!). However, if a number of such innocent inquiries across many days have attempted to map out your entire organization’s structure, complete with individual names, phone numbers, and email addresses, it’s quite likely that your organization is the object of some hostile party’s reconnaissance efforts. It’s at this point that you realize that you need some information systems risk management. Risk is about a possible occurrence of an event that leads to loss, harm, or disruption. Individuals and organizations face risk and are confronted by its possibilities of impact, in four basic ways, as Figure 3.2 illustrates. Three observations are important here—so important that they are worth considering as rules in and of themselves.
One of the difficulties we face as information systems security professionals is that simple terms, such as risk, have so many different “official” definitions, which seem to vary in degree more than they do in substance. For example:
NIST’s Computer Security Resource Center online glossary offers 29 different definitions of risk, many of which have significant overlap with each other, while pointing at various other NIST, ISO, IEC, and FIPS publications as their sources. It’s worthwhile to note the unique contributions of some of these definitions. Much like the debate over C-I-A versus CIANA, there is probably only one way to decide which definition of risk is right for you: what works best for your organization, its objectives, and its tolerance for disruption? As you might imagine, risk management has at least as many hotly debated definitions as does risk itself. For our purposes, let’s focus on the common denominator and define risk management as the set of decision processes used to identify and assess risks; make plans to treat, control, or mitigate risks; and exercise continuous due care and due diligence over the chosen risk treatment, control, and mitigation approaches. This definition attempts to embrace all risks facing modern organizations—not just IT infrastructure risks—and focuses on how you monitor, measure, or assess how good (or bad) a job you’re doing at dealing with the risks you’ve identified. As a definition, it goes well with our working definition of risk as the possibility of a disruptive event’s occurrence and the expected measure of the impacts that event could have upon you if the event in question actually takes place. For almost all organizations, the most senior leaders and managers are the ones who have full responsibility for all risk management and risk mitigation plans, programs, and activities that the organization carries out. These people have the ultimate due care and due diligence responsibility. In law and in practice, they can be held liable for damages and may even be found criminally negligent or in violation of the law, and face personal consequences for the mistakes in information security that happened on their watch. Clearly, those senior leaders (be they board members or C-suite office holders) need the technically sound, business-based insights, analysis, and advice from everyone in the organization. Organizations depend upon their chains of supervision, control, and management to provide a broad base of support to important decisions, such as those involving risk management. But it is these senior leaders who make the final decisions. Your organization will have its own culture and practices for delegating responsibility and authority, which may change over time. As an information security professional, you may have some of that delegated to you. Nonetheless, it’s not until you’re sitting in one of those “chief’s” offices—as the chief risk manager, chief information security officer, or chief information officer—that you have the responsibility to lead and direct risk management for the organization. Risk management consists of a number of overlapping and mutually reinforcing processes, which can and should be iteratively and continuously applied. We’ll look at each of these in greater detail throughout this chapter. It’s worth noting that because of the iterative, cross-fertilizing, and mutually supportive nature of every aspect of risk management, mitigation, monitoring, and assessment, there’s probably no one right best order to do these steps in. Risk management frameworks (see the “Risk Management Frameworks” section) do offer some great “clean-slate” ways to start your organization’s journey toward robust and effective management of its information and decision risks, and sometimes a clean start (or restart) of such planning and management activities makes sense. You’re just as likely to find that bits and pieces of your organization already have some individual risk management projects underway; if so, don’t sweat getting things done in the right order. Just go find these islands of risk management, get to know the people working on them, and help orchestrate their efforts into greater harmony and greater security. Fortunately, you and your organization are not alone in this. National governments, international agencies, industry associations, and academic and research institutes have developed considerable reference libraries regarding observed vulnerabilities, exploits against them, and defensive techniques. Many local or regional areas or specific marketplaces have a variety of communities of practitioners who share insight, advice, and current threat intelligence. Public-private partnership groups, such as InfraGard (https://infragard.org) and the Electronic Crimes Task Force (ECTF), provide “safe harbor” meeting venues for private industry, law enforcement, and national security to learn with each other. (In the United States, InfraGard is sponsored by the Federal Bureau of Investigation, and the U.S. Secret Service hosts the ECTF; multinational ECTF chapters, such as the European ECTF, operate in similar ways.) Let’s look in some detail at the various processes involved in risk management; then you’ll see how different risk management frameworks can give your organization an overall policy, process, and accountability structure to make risk manageable. In any risk management situation, risks need to be visible to analysts and managers in order to make them manageable. This means that as the process of risk and vulnerability assessment identifies a risk, characterizes it, and assesses it, all of this information about the risk is made available in useful, actionable ways. As risks are identified (or demonstrated to exist because a security incident or compromise occurs), the right levels of management need to be informed. Incident response procedures are put into action because of such risk reporting. Risk reporting mechanisms must provide an accountable, verifiable set of procedures and channels by which the right information about risks is provided to the right people, inside and outside of the organization, as a part of making management and mitigation decisions about it. Risk reporting to those outside of the organization is usually confined to trusted channels and is anonymized to a significant degree. Businesses have long shared information about workplace health and safety risks—and their associated risk reduction and hazard control practices—with their insurers and with industry or trade associations so that others in that group can learn from the shared experience, without disclosing to the world that any given company is exposed to a specific vulnerability. In the same vein, companies share information pertaining to known or suspected threats and threat actors. Businesses that operate in high-risk neighborhoods or regions, for example, share threat and risk insights with local law enforcement, with other government agencies, and of course with their insurance carriers. Such information sharing helps all parties take more informed actions to cope with potential or ongoing threat activities from organized crime, gang activities, or civil unrest. These threats could manifest themselves in physical or Internet-based attempts to intrude into business operations, to disrupt IT systems, or as concerted social engineering and propaganda campaigns. Let’s look at each of these processes in some detail. Every organization or business needs to be building a risk register, a central repository or knowledge bank of the risks that have been identified in their business and business process systems. This register should be a living document, constantly refreshed as the company moves from risk identification through mitigation to the “new normal” of operations after instituting risk controls or countermeasures. It should be routinely updated with each newly discovered risk or vulnerability and certainly as part of the lessons-learned process after an incident response. For each risk in your risk register, it can be valuable to keep track of information regarding the following:
Your organization’s risk register should be treated as a highly confidential, closely held, or proprietary set of information. In the wrong hands, it provides a ready-made targeting plan that an APT or other hacker can use to intrude into your systems, disrupt your operations, hold your data for ransom, or exfiltrate it and sell it on to others. Even your more unscrupulous business competitors (or a disgruntled employee) could use it to cripple or kill your business, or at least drive it out of their marketplaces. As you grow the risk register by linking vulnerabilities, root-cause analyses, CVE data, and risk mitigation plans together, your need to protect this information becomes even more acute. There are probably as many formats and structures for a risk register as there are organizations creating them. Numerous spreadsheet templates can be found on the Internet, some of which attempt to guide users in meeting the expectations of various national, state, or local government risk management frameworks, standards, or best practices. If your organization doesn’t have a risk register now, start creating one! You can always add more fields to each risk (more columns to the spreadsheet) as your understanding of your systems and their risks grows in both breadth and depth. It’s also a matter of experience and judgment to decide how deeply to decompose higher-level risks into finer and finer detail. One rule of thumb might be that if an entry in your risk register doesn’t tell you how to fix it, prevent it, or control it, maybe it’s in need of further analysis. The risk register is an example of making tacit knowledge explicit; it captures in tangible form the observations your team members and other co-workers make during the discovery of or confrontation with a risk. It can be a significant effort to gather this knowledge and transform it into an explicit, reusable form, whether before, during, or after an information security incident. Failing to do so leaves your organization held hostage to human memory. Sadly, any number of organizations fail to document these painful lessons learned in any practical, useful way, and as a result, they keep re-learning them with each new incident. Threat intelligence is both a set of information and the processes by which that information is obtained. Threat intelligence describes the nature of a particular category or instance of a threat actor and characterizes its potential capabilities, motives, and means while assessing the likelihood of action by the threat in the near term. Current threat intelligence, focused on your organization and the marketplaces it operates in, should play an important part in your efforts to keep the organization and its information systems safe and secure. Information security threat intelligence is gathered by national security and law enforcement agencies, by cybersecurity and information security researchers, and by countless practitioners around the world. In most cases, the data that is gathered is reported and shared in a variety of databases, websites, journals, blogs, conferences, and symposia. (Obviously, data gathered during an investigation that may lead to criminal prosecution or national security actions is kept secret for as long as necessary.) As the nature of advanced persistent threat actors continues to evolve, much of the intelligence data we have available to us comes from efforts to explore sanctuary areas, such as the Dark Web, in which these actors can share information, find resources, contract with others to perform services, and profit from their activities. These websites and servers are in areas of the IP address space not indexed by search engines and usually available on an invitation-only basis, depending upon referrals from others already known in these spaces. For most of us cyber-defenders, it’s too great a personal and professional risk to enter into these areas and seek intelligence information; it usually requires purchasing contraband or agreeing to provide illegal services to gain entry. However, many law enforcement, national security, and researchers recognized by such authorities do surf these dark pages. They share what they can in a variety of channels, such as InfraGard and ECTF meetings; it gets digested and made available to the rest of us in various blogs, postings, symposia, and conference workshops. Another great resource is the Computer Society of the Institute of Electrical and Electronics Engineers, which sponsors many activities, such as their Center for Secure Design. See https://cybersecurity.ieee.org/center-for-secure-design/ for ideas and information that might help your business or organization. Many local universities and community colleges work hand in hand with government and industry to achieve excellence in cybersecurity education and training for people of all ages, backgrounds, and professions. Threat intelligence regarding your local community (physically local or virtually/Internet local) is often available in these or similar communities of practice, focused or drawing upon companies and like-minded groups working in those areas. Be advised, too, that a growing number of social activist groups have been adding elements of hacking and related means to their bags of disruptive tactics. You might not be able to imagine how their cause might be furthered by penetrating into the systems you defend; others in your local threat and vulnerability intelligence sharing community of practice, however, might offer you some tangible, actionable insights. Most newly discovered vulnerabilities in operating systems, firmware, applications, or networking and communications systems are quickly but confidentially reported to the vendors or manufacturers of such systems; they are reported to various national and international vulnerabilities and exposures database systems after the vendors or manufacturers have had an opportunity to resolve them or patch around them. Systems such as Mitre’s common vulnerabilities and exposures (CVE) system or NIST’s National Vulnerability Database are valuable, publicly available resources that you can draw upon as you assess the vulnerabilities in your organization’s systems and processes. Many of these make use of the Common Vulnerability Scoring System (CVSS), which is an open industry standard for assessing a wide variety of vulnerabilities in information and communications systems. CVSS makes use of the CIA triad of security needs by providing guidelines for making quantitative assessments of a particular vulnerability’s overall score. (Its data model does not directly reflect nonrepudiation, authentication, privacy, or safety.) Scores run from 0 to 10, with 10 being the most severe of the CVSS scores. Although the details are beyond the scope of this book, it’s good to be familiar with the approach CVSS uses—you may find it useful in planning and conducting your own vulnerability assessments. As you can see at https://nvd.nist.gov/vuln-metrics/cvss, CVSS consists of three areas of concern.
Each of these uses a simple scoring process—impact assessment, for example, defines four values from Low to High (and “not applicable or not defined”). Using CVSS is as simple as making these assessments and totaling up the values. Many nations conduct or sponsor similar efforts to collect and publish information about system vulnerabilities that are commonly found in commercial-off-the-shelf (COTS) IT systems and elements or that result from common design or system production weaknesses. In the United Kingdom, common vulnerabilities information and reporting are provided by the Government Communications Headquarters (GCHQ, which is roughly equivalent to the U.S. National Security Agency); find this and more at the National Cyber Security Centre at www.ncsc.gov.uk. Note that during reconnaissance, hostile threat actors use CVE and CVSS information to help them find, characterize, and then plan their attacks. (And there is growing evidence that the black hats exploit this public domain, open source treasure trove of information to a far greater extent than we white hats do.) The benefits we gain as a community of practice by sharing such information outweighs the risks that threat actors can be successful in exploiting it against our systems if we do the rest of our jobs with due care and due diligence. That said, do not add insult to injury by not looking at CVE or CVSS data as part of your own vulnerability efforts! Given the incredible number of new businesses and organizations that start operating each year, it’s probably no surprise that many of them open their doors, their Internet connection, and their web presence without first having done a thorough information security analysis and vulnerabilities assessment. In this case, the chances are good that their information architecture grows and changes almost daily. Starting with CVE data for the commercial off-the-shelf systems they’re using may be a prudent risk mitigation first step. One risk in this strategy (or, perhaps, more fairly a lack of a strategy) is that the organization can get complacent; it can grow to ignore the vulnerabilities it has already built into its business logic and processes, particularly via its locally grown glueware or people-centric processes. As another risk, that may encourage putting off any real data quality analysis efforts, which increase the likelihood of a self-inflicted garbage-in, garbage-out series of wasted efforts, lost work, and lost opportunities. It’s also worth reminding the owner-operators of a startup business that CVE data cannot protect them against the zero-day exploit; making extra effort to institute more effective access control using multifactor authentication and a data classification guide for its people to use is worth doing early and reviewing often. If you’re part of a larger, more established organization that does not have a solid information security risk management and mitigation posture, starting with the CVE data and hardening what you can find is still a prudent thing to do—while you’re also gathering the data and the management and leadership support to a proper information security risk assessment. Risk management is a decision-making process that must fit within the culture and context of the organization. The context includes the realities of the marketplaces that the business operates in, as well as the legal, regulatory, and financial constraints and characteristics of those marketplaces. Context also includes the perceptions that senior leaders and decision-makers in the organization may hold about those realities; as in all things human, perception is often more powerful and more real than on-the-ground reality. The culture of the organization includes its formal and informal decision-making styles, lines of communication, and lines of power and influence. Culture is often determined by the personalities and preferences of the organization’s founders or its current key stakeholders. While much of the context is written down in tangible form, that is not true of the cultural setting for risk management. Both culture and context determine the risk tolerance or risk appetite of the organization, which attempts to express or sum up the degree of willingness of the organization to maintain business operations in the face of certain types of risks. One organization might have near-zero tolerance for politically or ethically corrupt situations or for operating in jurisdictions where worker health and safety protections are nonexistent or ineffective; another, competing organization, might believe that the business gains are worth the risk to their reputation or that by being a part of such a marketplace they can exert effort to improve these conditions. Perhaps a simpler example of risk tolerance is seen in many small businesses whose stakeholders simply do not believe that their company or their information systems offer an attractive target to any serious hackers—much less to advanced persistent threats, organized crime, or terrorists. With such beliefs in place, management might have a low tolerance for business disruptions caused by power outages or unreliable systems but be totally accepting (or willing to completely ignore) the risks of intrusion, data breach, ransom attacks, or of their own systems being hijacked and used as stepping-stones in attacks on other target systems. In such circumstances, you may have to translate those loftier-sounding, international security–related threat cases into more local, tangible terms—such as the threat of a disgruntled employee or dissatisfied customer—to make a cost-effective argument to invest in additional information security measures. As the on-site information security specialist, you may often have the opportunity to help make the business case for an increased investment in information security systems, risk controls, training, or other process improvements. This can sometimes be an uphill battle. In many businesses, there’s an old-fashioned idea about viewing departments, processes, and activities as either cost centers or profit centers—either they add value to the company’s bottom line, via its products and services, or they add costs. As an example, consider insurance policies (you have them on your car, perhaps your home or furnishings, and maybe even upon your life), which cost you a pre-established premium each year while paying off in case an insured risk event occurs. Information security investments are often viewed as an insurance-like cost activity—they don’t return any value each day or each month, right? Let’s challenge that assertion. Information security investments, I assert, add value to the company (or the nonprofit organization) in many ways, no matter what sector your business operates in, its size, or its maturity as an organization. They bring a net positive return on their investment, when you consider how they enhance revenues, strengthen reputation, and avoid, contain, or eliminate losses. First, let’s consider how good information security hygiene and practice adds value during routine, ongoing business operations.
That list (which is not complete) shows just some of the positive contributions that effective information security programs and systems can make, as they enhance ongoing revenues and reduce or avoid ongoing costs. Information security adds value. Over time it pays its own way. If your organization cannot see it as a profit center, it’s at least a cost containment center. Next, think about the unthinkable: What happens if a major information security incident occurs? What are the worst-case outcomes that can happen if your customers’ data is stolen and sold on the Dark Web or your proprietary business process and intellectual property information is leaked? What happens if ransom attacks freeze your ongoing manufacturing, materials management, sales, and service processes, and your company is dead in the water until you pay up?
In short, a major information security incident can completely reverse the cost savings and value enhancements shown in that first list. Security professionals often have problems persuading mid-level and senior management to increase spending on information security—and this uphill battle is halfway lost by calling it spending, rather than cost avoidance. Nobody expects an information security department to show a profit; after all, it has no direct revenues of its own to offset its expenses. Even in nonprofit or government organizations, having your work unit or department characterized as a cost center frames your work as a necessary evil—it’s unavoidable, like paying taxes, but should be kept to an absolute minimum. You need to turn this business paradigm around by showing how your risk mitigation recommendations defer or avoid costs. For example, take all of your quantitative risk assessment information and project a five-year budget of losses incurred if all of those risks occur at their worst-case frequency of occurrence. That total impact is the cost that your mitigation efforts, your investments in safeguards, needs to whittle down to a tolerable size. Putting the organization’s information security needs into business terms is crucial to gaining the leadership’s understanding and support of them. Next, let’s consider what happens when the stakeholders or shareholders want to sell the business (perhaps to fund their retirement or to provide the cash to pursue other goals). Strong market value and the systems that protect and enhance it reduce the merger and acquisition risk, the risk that prospective buyers of the company will perceive it as having fragile, risky processes or systems or that its assets are in much worse shape than the owners claim they are. Due diligence is fundamentally about protecting and enhancing the value of the organization, which has a tangible or book value component and an intangible or good will component. Book value reflects the organization’s assets (including its intellectual property), its market share and position, its revenues, its costs, and its portfolio of risks and risk management processes. The intangible components of value reflect all of the many elements that go into reputation, which can range from credit scores, compliance audit reports, and perceptions in the marketplace. The maturity of its business logic and processes also plays an important part in this valuation of the organization (these may show up in both the tangible and intangible valuations). If you’re working in a small business, its creator and owner may already be working toward an exit strategy, their plan for how they reap their ultimate reward for many years of work, sweat, toil, and tears; or, they might be working just to make this month’s bottom line better and better and have no time or energy to worry about the future of the business. Either way, the owner’s duties of due care and due diligence—and your own—demand that you work to protect and enhance the value of the company, its business processes, and its business relationships, by means of the money, time, and effort you invest in sound information security practices. Many of the ways that we look at risk are conditioned by other business or personal choices that have already been made. Financially, we’re preconditioned to think about what we spend or invest as we purchase, lease, or create an asset, such as an assembly line, a data center, or a data warehouse full of customer transactions, product sales, marketing, and related information. Operationally, we think in terms of processes that we use to accomplish work-related tasks. Strategically, we think in terms of goals and objectives we want to achieve—but ideally we remember the reasons that we thought those goals and objectives were worth attaining, which means we think about the outcomes we achieve by accomplishing a goal. (When you’re up to your armpits in alligators, as the old saying goes, do you remember why draining the swamp was an important thing to do?) And if we are cybersecurity professionals or insurance providers or risk managers, we think about the dangers or risks that threaten to disrupt our plans, reduce the effectiveness (and value) of our assets, and derail our best-laid processes; in other words, we think about the threats to our business or the places our business is vulnerable to attack or accident. These four perspectives, based on assets, processes, outcomes, or vulnerabilities and threats, are all correct and useful; no one is the best to use in addressing your risk management and risk mitigation needs. Some textbooks, risk management frameworks, and organizations emphasize one over the others (and may even not realize that the others exist); don’t let this deceive you. As a risk management professional, you need to be comfortable perceiving the risks to your organization and its systems from all four perspectives. Note, too, that on the one hand, these are perspectives or points of view; on the other hand, they each can be the basis of estimate, the foundation or starting point of a chain of decisions and calculations about the value of an asset. All quantitative estimates of risk or value have to start somewhere, as a simple example will illustrate. Suppose your company decides to purchase a new engineering workstation computer for your product designer to use. The purchase price, including all accessories, shipping, installation, and so on, establishes its initial acquisition cost to the company; that is its basis in accounting terms. This number can be the starting point for spreading the cost of the asset over its economically useful life (that is, depreciating it) or as part of break-even calculations. Incidentally, accountants and risk managers pronounce bases, the plural of basis, as “bay-seez,” with both vowels long, rather than “bay-sez,” short “e,” as in “the bases are loaded” in baseball. All estimates are predictions about the various possible outcomes resulting from a set of choices. In the previous example, the purchase price of that computer established its cost basis; now, you’ve got to start making assumptions about the future choices that could affect its economically useful life. You’ll have to make assumptions about how intensely it is used throughout a typical day, across each week; you’ll estimate (that is, guess) how frequently power surges or other environmental changes might contribute to wear and tear and about how well (or how poorly) it will be maintained. Sometimes, modeling all of these possible decisions on a decision tree, with each branch weighted with your guesses of the likelihood (or probability) of choosing that path, provides a way of calculating a probability-weighted expected value. This, too, is just another prediction. But as long as you make similar predictions, using similar weighting factors and rules about how to choose probabilities among various outcomes, your overall estimates will be comparable with each other. That’s no guarantee that they are more correct, just that you’ve been fair and consistent in making these estimates. (Many organizations look to standardized cost modeling rules, which may vary industry by industry, as a way of applying one simple set of factors to a class of assets: All office computers might be assumed to have a three-year useful life, with their cost basis declining to zero at the end of that three years. That’s neither more right nor more wrong than any other set of assumptions to use when making such estimates; it’s just different.) One way to consider these four perspectives on risk is to build up an Ishikawa or fishbone diagram, which shows the journey from start to desired finish as supported by the assets, processes, resources, or systems needed for that journey, and how risks, threats, or problems can disrupt your use of those vital inputs or degrade their contributions to that journey. Figure 3.3 illustrates this concept. FIGURE 3.3 Four bases of risk, viewed together Let’s look in more detail at each of these perspectives or bases of risk. This perspective on risk focuses on the overarching objective—the purpose or intent behind the actions that organizations take. Outcomes are the goal-serving conditions that are created or maintained as a result of accomplishing a series of tasks to fulfill those objectives. Your income tax return, along with all of the payments that you might owe your government, is a set of outputs produced by you and your tax accountant; the act of filing it and paying on time achieves an outcome, a goal that is important or valuable to you in fulfilling an objective. This might at a minimum be because it will keep you from being investigated or prosecuted for tax evasion; it might also be because you believe in doing your civic duty, which includes paying your taxes. The alarms generated by your intrusion detection or prevention systems (IDSs or IPSs) are the outputs of these systems; your decision to escalate to management and activate the incident response procedures is an outcome that logically followed from that set of outputs (and many other preceding outputs that in part preconditioned and prepared you to interpret the IDS and IPS alarms and make your decision). Outcomes-based risk assessment looks at the ultimate value to be gained by the organization when it achieves that outcome. Investing in a new product line to be sold in a newly developed market has, as its outcome, an estimated financial return on investment (or RIO). Risks associated with the plans for developing that product, promoting and positioning it within that market, selling it, and providing after-sales customer service and support are all factors that inject uncertainty into that estimate—risks decrease the anticipated ROI, in effect multiplying it by a decreased probability of success. Organizations with strongly held senses of purpose, mission, or goals, or that have invested significant time, money, and effort in attempting to achieve new objectives, may prefer to use outcomes-based risk assessment. Organizations describe, model, and control the ways they get work done by defining their business logic as sequences of tasks, including conditional logic that enforces constraints, chooses options, or carries out other decision-making actions based on all of the factors specified by that business logic. Many organizations model this business logic in data models and data dictionaries and use systems such as workflow control and management or enterprise resource management (ERP) to implement and manage the use of that business logic. Individually and collectively these sequences or sets of business processes are what transform inputs—materials, information, labor, and energy—into outputs such as products, subassemblies, proposals, or software source code files. Business processes usually are instrumented to produce auxiliary outputs, such as key performance indicators, alarms, or other measurements, which users and managers can use to confirm correct operation of the process or to identify and resolve problems that arise. The absence of required inputs or the failure of a process step along a critical path within the overall process can cause the whole process to fail; this failure can cascade throughout the organization, and in the absence of appropriate backups, safeguards or fail-safes, the entire organization can grind to a halt. Organizations that focus on continually refining and improving their business processes, perhaps even by using a capabilities maturity modeling methodology, may emphasize the use of process-based risk assessment. The failure of critical processes to achieve overall levels of product quality, for example, might be the reason that customers are no longer staying with the organization. While this negative outcome (and the associated outcome of declining revenues and profits) is of course important, the process-oriented focus can more immediately associate cause with effect in decision-makers’ minds. Broadly speaking, an asset is anything that the organization (or the individual) has, owns, uses, or produces as part of its efforts to achieve some of its goals and objectives. Buildings, machinery, or money on deposit in a bank are examples of hard, tangible assets. The people in your organization (including you!) are also tangible assets (you can be counted, touched, moved, or even fired). The knowledge that is recorded in the business logic of your business processes, your reputation in the marketplace, the intellectual property that you own as patents or trade secrets, and every bit of information that you own or use are examples of soft, intangible assets. (Intellectual property is the idea, not the paper it is written on.) Assets are the tools you use to perform the steps in your business processes; without these tools, without assets, the best business logic by itself cannot accomplish anything. It needs a place to work, inputs to work on, and people, energy, and information to achieve its required outputs. Many textbooks on information risk management start with information assets—the information you gather, process and use, and the business logic or systems you use in doing that—and information technology assets—the computers, networks, servers, and cloud services in which that information moves, resides, and is used. The unstated assumption is that if the information asset or IT asset exists, it must therefore be important to the company or organization, and therefore, the possibility of loss or damage to that asset is a risk worth managing. This assumption may or may not still hold true. Assets also lose value over time, reflecting their decreasing usefulness, ongoing wear and tear, obsolescence, or increasing costs of maintenance and ownership. A good example of an obsolete IT asset would be a mainframe computer purchased by a university in the early 1970s for its campus computer center, perhaps at a cost of over a million dollars. By the 1990s, the growth in personal computing and network capabilities meant that students, faculty, and staff needed far more capabilities than that mainframe computer center could provide, and by 2015, it was probably far outpaced by the capabilities in a single smartphone connected to the World Wide Web and its cloud-based service provider systems. Similarly, an obsolete information asset might be the paper records of business transactions regarding products the company no longer sells, services, or supports. At some point, the law of diminishing returns says that it costs more to keep it and use it than the value you receive or generate in doing so. It’s also worth noting that many risk management frameworks seem to favor using information assets or IT assets as the basis of risk assessment; look carefully, and you may find that they actually suggest that this is just one important and useful way to manage information systems risk, but not the only one. Assets, after all, should be kept and protected because they are useful, not just because you’ve spent a lot of money to acquire and keep them. These are two sides of the same coin really. Threat actors (natural or human) are things that can cause damage, disruption, and lead to loss. Vulnerabilities are weaknesses within systems, processes, assets, and so forth, that are points of potential failure. When (not if) they fail, they result in damage, disruption, and loss. Typically, threats or threat actors exploit (make use of) vulnerabilities. Threats can be natural (such as storms or earthquakes), accidental (failures of processes or systems due to unintentional actions or normal wear and tear, causing a component to fail), or deliberate actions taken by humans or instigated by humans. Such intentional attackers have purposes, goals, or objectives they seek to accomplish; Mother Nature or a careless worker do not intend to cause disruption, damage, or loss. Ransom attacks are an important, urgent, and compelling case in point. Unlike ransomware attacks, which require injection of malware into the target system to install and activate software to encrypt files or entire storage subsystems, a ransom attack “lives off the land” by taking advantage of inherent system weaknesses to gain access; the attacker then uses built-in systems capabilities to schedule the encryption of files or storage subsystems, all without the use of any malware. This threat is real, and it’s a rare organization that can prove it is invulnerable to it. Prudent threat-based risk assessment, therefore, starts with this attack plan and assesses how your systems are configured, managed, used, and monitored as part of determining just how exposed your company is to this risk. It’s perhaps natural to combine the threat-based and vulnerability-based views into one perspective, since they both end up looking at vulnerabilities to see what impacts can disrupt an organization’s information systems. The key question that the threat-based perspective asks, at least for human threat actors, is why. What is the motive? What’s the possible advantage the attacker can gain if they exploit this vulnerability? What overall gains might an attacker achieve by an attack on our information systems at all? Many small businesses (and some quite large ones) do not realize that a successful incursion into their systems by an attacker may only be a step in that attacker’s larger plan for disruption, damage, or harm to others. By thinking for a moment like the attacker, you might identify critical assets that the attacker might really be seeking to attack; or, you might identify critical outcomes that an attacker might want to disrupt for ideological, political, emotional, or business reasons. Note that whether you call this a threat-based or vulnerability-based approach or perspective, you end up taking much the same action: You identify the vulnerabilities on the critical path to your high-priority objectives and then decide what to do about them in the face of a possible threat becoming a reality and turning into an incident. Your organization will make choices as to whether to pursue an outcomes-based, asset-based, process-based, or threat-based assessment process, or to blend them all together in one way or another. Some of these choices might already have been made if your organization has chosen (and perhaps tailored) a formal risk management framework to guide its processes with. (You’ll look at these in greater depth in the “Risk Management Frameworks” section.) The priorities of what to examine for potential impact, and in what order, should be set for you by senior leadership and management, which is expressed in the business impact analysis (BIA). One more choice remains, and that is whether to do a quantitative assessment, a qualitative assessment, or a mix of both. Impact assessments for information systems must be guided by some kind of information security classification guide, something that associates broad categories of information types with an expectation of the degree of damage the organization would suffer if that information’s confidentiality, integrity, or availability were compromised. For some types or categories of information, the other CIANA attributes of nonrepudiation and authentication are also part of establishing the security classification (the specific information as to how payments on invoices are approved, and which officials use what processes to approve high-value or special invoices or payments, is an example of the need to protect authentication-related information. False invoicing scams, by the way, are amounting to billions of dollars in losses to businesses worldwide, as of 2018). The process of making an impact assessment seems simple enough.
Now you have a better picture of what can be lost or damaged because of the occurrence of a risk event. This might mean that critical decision support information is destroyed, degraded, or delayed, or that a competitive advantage is degraded or lost because of disclosure of proprietary data. It might mean that a process or system is rendered inoperable and that repairs or other actions are needed to get it back into normal operating condition. Risk analysis is a complex undertaking and often involves trying to sort out what can cause a risk (which is a statement of probability about an event) to become an incident. Root-cause analysis looks to find what the underlying vulnerability or mechanism of failure is that leads to the incident. By contrast, proximate cause analysis asks, “What was the last thing that happened that caused the risk to occur?” (This is sometimes called the “last clear opportunity to prevent” the incident, a term that insurance underwriters and their lawyers often use.) Proximate cause can reveal opportunities to put in back-stops or safety controls, which are additional features that reduce the impact of the risk from spreading to other downstream elements in the chain of processes. Commercial airlines, for example, scrupulously check passenger manifests and baggage check-in manifests; they will remove baggage from the aircraft if they cannot validate that the passenger who checked it in actually boarded, and is still on board, the aircraft, as a last clear opportunity to thwart an attempt to place a bomb onboard the aircraft. Multifactor user authentication and repeated authorization checks on actions that users attempt to take demonstrate the same layered implementation of last clear opportunity to prevent. You’ve learned about a number of examples of risks becoming incidents; for each you’ve identified an outcome of that risk, which describes what might happen. This forms part of the basis of estimate with which you can make two kinds of risk assessments: quantitative and qualitative. Quantitative assessments use simple techniques (such as counting possible occurrences or estimating how often they might occur) along with estimates of the typical cost of each loss.
Other numbers associated with risk assessment relate to how the business or organization deals with time when its systems, processes, and people are not available to do business. This “downtime” can often be expressed as a mean (or average) allowable downtime or a maximum downtime. Times to repair or restore minimum functionality and times to get everything back to normal are also some of the numbers the SSCP will need to deal with. Other commonly used quantitative assessments are:
These types of quantitative assessments help the organization understand what a risk can do when it occurs (and becomes an incident) and what it will take to get back to normal operations and clean up the mess it caused. One more important question remains: How long to repair and restore is too long? Two more “magic numbers” shed light on this question.
Figure 3.4 illustrates a typical risk event occurrence. It shows how the ebb and flow of normal work can get corrupted, then lost completely, and then must be re-accomplished, as you detect and recover from an incident. You’ll note that it shows an undetermined time period elapsing between the actual damage inflicted by an incident—the intruder has started exfiltrating data, corrupting transactions, or introducing false data into your systems, possibly installing more trapdoors—and the time you actually detect the incident has occurred or is still ongoing. The major stages of risk response are shown as overlapping processes. Note that MTTR, RTO, and MAO are not necessarily equal. (They’d hardly ever be in the real world.) FIGURE 3.4 Risk timeline Where is the RPO? Take a look “left of bang,” left of the incident detection time (sometimes called t0, or the reference time from which you measure durations), and look at the database update and transaction in the “possible data recovery points” group. Management needs to determine how far back to go to reload an incremental database update, then reaccomplish known good transactions, and then reaccomplish suspect transactions from independent, verifiably good transaction logs. This logic establishes the RPO. The further back in time you have to fall back, the more work you reaccomplish. It used to be that we thought that RPO times close to the incident reference time were sufficient; and for non-APT-induced incidents, such as systems crashes, power outages, etc., this may be sound reasoning. But if that intruder has been in your systems for weeks or months, you’ll probably need a different strategy to approach your RPO. Chapter 4, “Incident Response and Recovery,” goes into greater depth on the end-to-end process of business continuity planning. It’s important that you realize these numbers play three critical roles in your integrated, proactive information defense efforts. All of these quantitative assessments (plus the qualitative ones as well) help you:
One final thought about the “magic numbers” is worth considering. The organization’s leadership has its stakeholders’ personal and professional fortunes and futures in their hands. Exercising due diligence requires that management and leadership be able to show, by the numbers, that they’ve fulfilled that obligation and brought it back from the brink of irreparable harm when disaster strikes. Those stakeholders—the organization’s investors, customers, neighbors, and workers—need to trust in the leadership and management team’s ability to meet the bottom line every day. Solid, well-substantiated numbers like these help the stakeholders trust, but verify, that their team is doing their job. Qualitative assessments focus on an inherent quality, aspect, or characteristic of the risk as it relates to the outcome(s) of a risk occurrence. “Loss of business” could be losing a few customers, losing many customers, or closing the doors and going out of business entirely! So, which assessment strategy works best? The answer is both. Some risk situations may present us with things we can count, measure, or make educated guesses about in numerical terms, but many do not. Some situations clearly identify existential threats to the organization (the occurrence of the threat puts the organization completely out of business); again, many situations are not as clear-cut. Senior leadership and organizational stakeholders find both qualitative and quantitative assessments useful and revealing. Qualitative assessment of information is most often used as the basis of an information classification system, which labels broad categories of data to indicate the range of possible harm or impact. Most of us are familiar with such systems through their use by military and national security communities. Such simple hierarchical information classification systems often start with “Unclassified” and move up through “For Official Use Only,” “Confidential,” “Secret,” and “Top Secret” as their way of broadly outlining how severely the nation would be impacted if the information was disclosed, stolen, or otherwise compromised. Yet even these cannot stay simple for long. Business and the military have another aspect of data categorization in common: the concept of need to know. Need to know limits who has access to read, use, or modify data based on whether their job functions require them to do so. Thus, a school’s purchasing department staff members have a need to know about suppliers, prices, specific purchases, and so forth, but they do not need to know any of the PII pertaining to students, faculty, or other staff members. Need-to-know leads to compartmentalization of information approaches, which create procedural boundaries (administrative controls) around such sets of information. Threat modeling provides an overall process and management approach organizations can use as they identify possible threats, categorize them in various ways, and analyze and assess both these categories and specific threats. This analysis should shed light on the nature and severity of the threat; the systems, assets, processes, or outcomes it endangers; and offer insights into ways to deter, detect, defeat, or degrade the effectiveness of the threat. While primarily focused on the IT infrastructure and information systems aspects of overall risk management, it has great potential payoff for all aspects of threat-based risk assessment and management. Its roots, in fact, can be found in centuries of physical systems and architecture design practices developed to protect physical plant, high-value assets, and personnel from loss, harm, or injury due to deliberate actions (which are still very much a part of overall risk management today!). Threat modeling can be proactive or reactive; it can be done as a key part of the analysis and design phase of a new systems project’s lifecycle, or it can be done (long) after the systems, products, or infrastructures are in place and have become central to an organization’s business logic and life. Since it’s impossible to identify all threats and vulnerabilities early in the lifecycle of a new system, threat modeling is (or should be) a major component of ongoing systems security support. As the nature, pervasiveness and impact of the APT threat continues to evolve, many organizations are finding that their initial focus on confidentiality, integrity, and availability may not go far enough to meet their business risk management needs. Increasingly, they are placing greater importance on their needs for nonrepudiation, authentication, and privacy as part of their information security posture. Data quality, too, is becoming much more important, as businesses come to grips with the near-runaway costs of rework, lost opportunity, and compliance failures caused by poor data quality control. Your organization should always tailor its use of frameworks and methodologies, such as threat modeling, with its overall and current information security needs in mind. In recent years, greater emphasis has been placed on the need for an overall secure software development lifecycle approach; many of these methodologies integrate threat modeling and risk mitigation controls into different aspects of their end-to-end approach. Additionally, specific industries are paying greater attention to threat modeling in specific and overall secure systems development methodologies in general. If your organization operates in one of these markets, these may have a bearing on how your organization can benefit from (or must use) threat modeling as a part of its risk management and mitigation processes. Chapter 7, “Systems and Application Security” will look at secure software development lifecycle approaches in greater depth; for now, let’s focus on the three main threat modeling approaches commonly in use.
It’s possible that the greatest risk that small and medium-sized businesses and nonprofit organizations face, as they attempt to apply threat modeling to their information architectures, is that of the failure of imagination. It can be quite hard for people in such organizations to imagine that their data or business processes are worthy of an attacker’s time or attention; it’s hard for them to see what an attacker might have to gain by copying or corrupting their data. It’s at this point that your awareness of many different attack methodologies may help inform (and inspire) the threat modeling process. There are many different threat modeling methodologies. Some of the most widely used are SDL, STRIDE, NIST 800-154, PASTA, and OCTAVE, each of which is explored next. Over the years, Microsoft has evolved its thinking and its processes for developing software in ways that make for more secure, reliable, and resilient applications and systems by design, rather than being overly dependent upon seemingly never-ending “testing” being done by customers, users, and hackers after the product has been deployed. Various methodologies, such as STRIDE and SD3+C, have been published by Microsoft as their concepts have grown. Although the names have changed, the original motto of “secure by design, secure by default, and secure in deployment and communication” (SD3+C) continue to be the unifying strategies in Microsoft’s approach and methods. STRIDE, or spoofing, tampering, repudiation, information disclosure, denial of service, and elevation of privilege, provides a checklist and a set of touchpoints by which security analysts can characterize threats and vulnerabilities. As a methodology, it can be applied to applications, operating systems, networks and communications systems, and even human-intensive business processes. These are still at the core of Microsoft’s current secure development lifecycle (SDL) thinking, but it must be noted that SDL focuses intensely on the roles of managers and decision-makers in planning, supporting, and carrying out an end-to-end secure software and systems development and deployment lifecycle, rather than just considering specific classes of threats or controls. Check out https://www.microsoft.com/en-us/securityengineering/sdl/practices for current information, ideas, and tools on SDL. In 2016, NIST placed for public comment a threat modeling approach centered on protecting high-value data. This approach is known as NIST 800-154, “Data-Centric Threat Modeling.” It explicitly rejects that best-practice approaches are sufficient to protect sensitive information, as best practice is too general and would overlook controls specifically tailored to meet the protection of the sensitive asset. In this model, the analysis of the risk proceeds through four major steps.
The Process for Attack Simulation and Threat Analysis (PASTA), as the full name implies, is an attacker-centric modeling approach, but the outputs of the model are focused on protecting the organization’s assets. Its seven-step process aligns business objectives, technical requirements, and compliance expectations to identify threats and attack patterns. These are then prioritized through a scoring system. The results can then be analyzed to determine which security controls can be applied to reduce the risk to an acceptable level. Advocates for this approach argue that the integration of business concerns in the process takes the threat modeling activity from a technical exercise to a process more suited to assessing business risk. Operationally Critical Threat, Asset, and Vulnerability Evaluation (OCTAVE) is an approach for managing information security risks developed at the Software Engineering Institute (SEI). While the overall OCTAVE approach encompasses more than threat modeling, asset-based threat modeling is at the core of the process. In its current form, OCTAVE Allegro breaks down into a set of four phases.
As compared with previous versions of OCTAVE, Allegro simplifies the collection of data, improves focus on risk mitigation strategies, and provides a simple quantitative model (as opposed to the qualitative approaches previously emphasized). Proponents argue this makes the model easier to understand and use, simplifying training and increasing the likelihood that the approach will be consistently adopted as a risk method inside organizations. Other threat modeling methodologies include the following: The business impact analysis (BIA, also sometimes called the business impact assessment) should start with the prioritized strategic objectives and goals of the organization, linking the potential impacts of risks to these prioritized objectives. The BIA is the way in which senior management and leadership document their decisions about which categories of risks to deal with first and which ones can wait to be mitigated; it lays out commitments to spend money, time, talent, and management attention and direction on specific sets of risks. The BIA is thus part of the strategic and high tactical risk management process and a vitally important output product of that risk management process. Note that prioritizing the risks is not as simple as ranking them in total expected dollar loss to the organization, even though common sense and experience may suggest these often go hand in hand. Consider the plight of Volkswagen America, which has suffered significant loss in market share and damage to its reputation after it was discovered that key decision-makers approved the falsifying of data that it had to report to regulators in the United States and the European Union. It might be exceedingly hard to quantify another reputational risk that the company might face, while at the same time the company (and its parent) might be facing other risks in the Asian markets that can be quantified. Which is the greater risk, the (hypothetical) millions of dollars involved in the Asian markets or another major reputational risk in the EU and North American markets? That decision belongs to senior management and leadership; the BIA and the plans built upon it should reflect that decision and direct efforts to carry it out. We might think that laws, regulations, and contractual terms are non-negotiable burdens that organizations and their leadership and management teams must comply with. After all, in many cases, the penalties for not complying with them can be quite severe! Take note, however: One commonly held viewpoint says that laws, regulations, and even contract terms are risks that confront the company, and like all risks, managers should choose which terms or constraints to accept, transfer to others, treat (that is, implement effective responses to the constraint), avoid, or ignore. An insurance claims processing company, for example, might choose to cut corners on protecting patient and care provider data, which public law (HIPAA in the United States, GDPR and others in the European Union) requires be protected. The risk of a data breach, they argue, is transferred (along with its impacts and losses) to the individual patients or care providers; at most, any fines the company receives are passed along in higher costs to the insurance carriers, clinicians, and patients. The (ISC)2 Code of Ethics would consider this unethical; legally speaking, it’s probably up to the judge and jury to determine. But it illustrates one type of risk management strategy, and if you see something like this in action where you’re working, you’ve possibly got an ethical problem to deal with. There is no one right, best format for a BIA; instead, each organization must determine what its BIA needs to capture and how it has to present it to achieve a mix of purposes.
You must recognize one more important requirement at this point: to be effective, a BIA must be kept up to date. The BIA must reflect today’s set of concerns, priorities, assets, and processes; it must reflect today’s understanding of threats and vulnerabilities. Outdated information in a BIA could at best lead to wasted expenditures and efforts on risk mitigation; at worst, it could lead to failures to mitigate, prevent, or contain risks that could lead to serious damage, injury, or death, or possibly put the organization out of business completely. Gone should be the days when an annual, routine review and update cycle of the BIA is considered sufficient. At its heart, making a BIA is pretty simple: You identify what’s important, estimate how often it might fail, and estimate the costs to you of those failures. You then rank those possible impacts in terms of which basis for risk best suits your organization, be that outcomes, processes, assets, or vulnerabilities. For all but the simplest and smallest of organizations, however, the amount of information that has to be gathered, analyzed, organized, assessed, and then brought together in the BIA can be overwhelming. The BIA is one of the most critical steps in the information risk management process; it’s also perhaps the most iterative, the most open to reconsideration as things change, and the most in need of being kept alive, current, and useful. A risk management framework (RMF) is a set of concepts, tools, processes, and techniques that help you organize information about risk. As you’re no doubt aware, the job of managing risks to your information is a set of many jobs, layered together. More than that, it’s a set of jobs that changes and evolves with time as the organization, its mission, and the threats it faces evolve. Let’s start by taking a quick look at NIST Special Publication 800-37 Rev. 2, “Risk Management Framework for Information Systems and Organizations: A System Life Cycle Approach for Security and Privacy.” Published in late 2018, this RMF establishes a broad, overarching perspective on what it calls the fundamentals of information systems risk management. Organizational leadership and management must address these areas of concern: You can see that there’s an expressed top-down priority or sequence here. It makes little sense to worry about your IT supply chain (which might be a source of malware-infested hardware, software, and services) if leadership and stakeholders have not first come to a consensus about risks and risk management at the broader, strategic level. (You should also note that in NIST’s eyes, the big-to-little picture goes from strategic, through operational, and then to tactical, which is how many in government and the military think of these levels. Business around the world, though, sees it as strategic, to tactical, to day-to-day operations.) The RMF goes on by specifying seven major phases (which it calls steps) of activities for information risk management:
It is tempting to think of these as step-by-step sets of activities—for example, once all risks have been categorized, you then start selecting which are the most urgent and compelling to make mitigation decisions about. Real-world experience shows us, though, that each step in the process reveals things that may challenge the assumptions we just finished making, causing us to reevaluate what we thought we knew or decided in that previous step. It is perhaps more useful to think of these steps as overlapping sets of attitudes and outlooks that frame and guide how overlapping sets of people within the organization do the data gathering, inspection, analysis, problem-solving, and then implementation of the chosen risk controls. Although NIST publications are directive in nature for U.S. government systems and indirectly provide strong guidance to the IT security market in the United States and elsewhere, many other information risk management frameworks are in widespread use around the world. For example, the International Organization for Standardization publishes ISO Standard 31000:2018, “Risk Management Guidelines,” in which the same concepts are arranged in a slightly different fashion. First, it suggests that three main tasks must be done (and in broad terms, done in the order shown):
Three additional, broader functions support or surround these central risk mitigation tasks.
As you can see in Figure 3.5, the ISO RMF also conveys a sense that, on the one hand, there is a sequence of major activities, but on the other hand, these major steps or phases are closely overlapping. FIGURE 3.5 ISO 31000 RMF ISO Standard 31000:2018 is based on a set of eight principles that drive the development of a risk framework. That framework, in turn, structures the processes for implementing risk management. Continual process improvement is an essential component of the ISO 31000 process. The ISO 31000 principles characterize an effective risk management framework that creates and protects organizational value through structured processes. To assist organizations in implementing the ISO 31000 standard, ISO 31004, “Risk Management-Guidance for the Implementation of ISO 31000,” was published to provide a structured approach to transition their existing risk management practices to be consistent with ISO 31000 and consistent with the individual characteristics and demands of the implementing organization. While the 31000-series addresses general risk, information security practices are addressed in the ISO 27000 series. The use of the ISO/IEC Guide 73 allows for a common language, but ISO/IEC 27005:2011, “Information technology – Security techniques – Information Security Risk Management,” gives detail and structure to the information security risks by defining the context for information security risk decision-making. This context includes definition of the organization’s risk tolerance, compliance expectations, and the preferred approaches for assessment and treatment of risk. ISO 27005 does not directly provide a risk assessment process. Rather, it provides inputs to, and gets outputs from, the risk assessment practice used by the organization. In this framework, the assessment process may be performed in either a quantitative or qualitative manner but done consistently so that prioritization can be performed. ISO 27005 further emphasizes the need for communication with stakeholders and for processes that continuously monitor for changes in the risk environment. The ISO standards have seen broad adoption, in part because of the broad international process in the development of the standards. Further, the standards themselves, while constantly under review, connect to other standards managed within the ISO. This enables organizations to adopt those standards that are appropriate for their business and provides a more holistic view of organizations’ compliance activities. It’s wise to bear in mind that each major section of these RMFs gives rise to more detailed guidance, instruction, and “lessons-learned” advice. For example, NIST Special Publication 800-61 Rev. 2, “Computer Security Incident Handling Guide,” looks more in-depth at what happens when an information risk actually occurs and becomes an incident. Its phases of Preparation, Detection, Analysis, Containment, Eradication, Recovery, and Post-Incident Activities parallel those found in the RMF, which looks at the larger picture of information risk management. A number of other frameworks have been developed to identify and evaluate risk, suited to the unique needs of different industries and processes. Individually, these frameworks address assessment, control, monitoring, and audit of information systems in different ways, but all strive to provide internal controls to bring risk to an acceptable level. Regardless of the framework, to effectively address risk in an organization, standard processes to evaluate the risks of operation of information systems must take into account the changing threat environment, the potential and actual vulnerabilities of systems, the likelihood that the risk will occur, and the consequence to the organization should that risk become manifest. From a governance perspective, the selection of a framework should create a controls environment that is as follows: There are dozens of different risk management frameworks. While many of the frameworks address specific industry or organizational requirements, the information security professional should be aware of the broad characteristics of the more common frameworks. Many frameworks have been developed to address risk in different contexts. Many of these are general in nature, while others are limited to a single industry or business practice. Organizations use comprehensive frameworks to take advantage of the consistency and breadth offered by the framework. This simplifies a wide range of challenges, including a consistent evaluation of performance, the conduct of audits for compliance, and the standardization of training the workforce in the activities and processes of a particular methodology. NIST also publishes the Federal Information Processing Standards (FIPS), which are mandated for all federal computer systems, with the exception of certain national security systems that are governed by a different set of standards. Authorized under a series of related laws, the FIPS addresses a range of interoperability and security practices for which there are no acceptable industry standards or solutions. Two standards are critical to the Risk Management Framework. FIPS 199, “Standards for Security Categorization of Federal Information and Information Systems,” requires agencies to categorize all of their information systems based on the potential impact to the agency of the loss of confidentiality, integrity, or availability. Implied in this process is that the agencies must have a comprehensive inventory of systems to apply the categorization standard. Once security categorization has been performed, a baseline set of controls must be selected in accordance with FIPS 200, “Minimum Security Requirements for Federal Information and Information Systems.” Using a “high watermark” approach, the security controls are selected, consistent with the categorization of impact developed under FIPS 199. FIPS 200 identifies 17 security-related areas of control, but the details of which specific control is to be applied is found in NIST Special Publication 800-53, “Recommended Security Controls for Federal Information Systems.” Once the system has been categorized and baseline controls are selected, the controls must be implemented and monitored to ensure they “are implemented correctly, operating as intended, and producing the desired outcome with respect to meeting the security requirements for the system.” This will produce a set of documents certifying the technical application of the controls. The organizational leadership then makes a formal decision whether to authorize the use of the system. This decision is based on the ability of the controls to operate the system within the organization’s risk tolerance. Finally, the organization will monitor the effectiveness of the controls over time against the security environment to ensure the continued operation of the system takes place within the organization’s risk tolerance. While focused on the computing activities of the U.S. government, the NIST standards and guidelines have had a pervasive effect on the security community because of their broad scope, their availability in the public domain, and the inclusion of industry, academic, and other standards organizations in the development of the standards. Further, the NIST standards often set the expectations for security practice that are placed on regulated industries. This is most clearly shown in the Health Information Privacy and Portability legislation, where healthcare organizations must demonstrate their controls align with the NIST security practice. The Committee of Sponsoring Organizations of the Treadway Commission (known as COSO) is a U.S. private organization created in 1985 to help combat corporate fraud. It provides a comprehensive, organizational-level view of risk management. Its framework, “Enterprise Risk Management—Integrating with Strategy and Performance,” recognizes that the pursuit of any organizational objectives incurs some level of risk, and good governance must accompany risk decisions. Based on five components, the framework captures the responsibilities of governance to provide risk oversight and set an appropriate tone for ethical, responsible conduct. The complementary “Internal Control—Integrated Framework” extends the COSO practice to the organization’s internal control environment. The three objectives (operations, reporting, and compliance) are evaluated against five components: control environment, risk assessment, control activities, information and communication, and monitoring activities. The objectives and the components are further evaluated within the context of the organizational structure. Ultimately, the system of internal control requires that each of these components be present and operating together to bring the risk of operations to an acceptable level. In short, the framework provides a high-level set of tools to establish consistency in the process in the identification and management of risks to acceptable levels. The COSO organization originally came about to address weaknesses in the financial reporting environment that allowed fraud and other criminal activities to occur without detection, exposing financial organizations to considerable risk. While the framework evolved out of the need for better internal control in the financial services industry, the framework is now broadly applied to corporations operating in a wide variety of industries. As a result, it is not designed to address industry-specific issues. Further, the breadth of the framework requires management at all levels to apply considerable judgment in its implementation. ITIL, formerly known as the IT Infrastructure Library, was developed over the course of 30 years to address the service delivery challenges with information technology. Emphasizing continuous process improvement, ITIL provides a service management framework, of which risk management is an integrated element. The ITIL framework is organized into five volumes that define 26 processes.
The ITIL Framework has been substantially incorporated into other standards, notably ISO 20000, “Information technology – Service management,” and has strongly influenced the development of ISACA’s COBIT framework and others. ITIL does not directly address risk management as a separate process. However, its emphasis on continuous improvement, which consists of leveraging metrics to identify out-of-specification activities and processes to address information security management systems, availability, and incident and event management, clearly incorporates the concepts of an enterprise risk management process. Indeed, if the goal of risk management is to reduce uncertainty, the ITIL framework emphasizes the importance of predictability in the processes. In the late 1990s the audit community in the United States and Canada recognized there was a significant gap between information technology governance and the larger organizational management structures. Consequently, information technology activities were often misaligned with corporate goals, and risks were not comprehensively addressed by the control structure’s risk or consistently reflected in financial reporting. To address this gap, the Information Systems Audit and Control Association (ISACA) developed a framework through which the information technology activities of an organization could be assessed. The Control Objectives for Information and Related Technologies (COBIT) framework differentiates processes into either Governance of Enterprise IT (five processes) or Management of Enterprise IT (32 processes). Each process has a set of objectives, inputs, key activities and outputs, and measures to evaluate performance against the objectives. As the framework is closely aligned with other management frameworks and tools (ISO20000, ISO27001, ITIL, Prince 2, SOX, TOGAF), it has gained wide acceptance as an encompassing framework for managing the delivery of information technology. Based on the ISACA COBIT IT governance framework, the RiskIT framework provides a structure for the identification, evaluation, and monitoring of information technology risk. This simplifies the integration of IT risk into the larger organization enterprise risk management (ERM) activities. Unlike the more generic risk management frameworks of COSO and ISO 31000 and the industry-specific risk structures of PCI-DSS or HITRUST, RiskIT fills the middle ground of generic IT risk. The framework consists of three domains—risk governance, risk evaluation, and risk response—each of which has three processes. The framework then details the key activities within each process and identifies organizational responsibilities, information flows between processes, and process performance management activities. Additional detail on how to implement the framework and link it to other organizational management practices is contained in the RiskIT Practitioner Guide. Many industries have unique compliance expectations. This may be the result of requirements to meet the security expectations from multiple different regulatory entities or because of unique business processes. Some of these industry-specific frameworks are described next. The Health Information Trust Alliance Common Security Framework (HITRUST CSF) was developed to address the overlapping regulatory environment in which many healthcare providers operate. Taking into account both risk-based and compliance-based considerations, the HITRUST CSF normalizes the many requirements while providing an auditable framework for the evaluation of the security environment. In many ways, the HITRUST CSF is a “framework of frameworks.” The responsibility for protecting the electrical power grid in North America falls on the individual bulk electrical system (BES) operators. However, as the systems are interconnected, a failure of one operator to secure their environment may leave weaknesses that could affect the delivery of power throughout the continent. Over the past two decades, the North American Electric Reliability Corporation Critical Infrastructure Protection (NERC CIP) published a set of standards designed to enforce good cybersecurity practice and provide an auditable framework for compliance. This framework has been influenced by the NIST standard but is a standalone framework specific to the power industry. The International Society of Automation has developed a series of standards to address the unique needs of the industrial process control environment. Organized into four groups, 13 different standards provide a policy, operational, and technical framework to increase the resilience of the industrial controls environment. Industrial process control applications provide clear examples of the competing interests at work in the application of the CIA Triad to systems which, if they fail, might endanger thousands of lives and destroy assets worth millions of dollars. Availability – seen as the continued safe functioning of the manufacturing or other physical process – directly impacted the bottom line of the company; safety considerations were often seen as injecting costs, and often were not added unless dictated by regulators or insurers. Protecting the confidentiality of information used in these systems was usually not a concern but protecting the integrity and availability of the information was. One of the major motivations in the development of the ISA/IEC 62443 body of standards for industrial automation and control systems was to provide an appropriate emphasis on all aspects of the security challenge. The PCI Security Standards Council (PCI SSC) developed the PCI-DSS standard to define a set of minimum controls to protect payment card transactions. Developed in response to increasing levels of credit card fraud, the PCI-DSS standard has undergone several modifications to increase the level of protection offered to customers. The current version of the standard, 3.2.1, identifies six goals with 12 high-level requirements that merchants are contractually obligated to meet. Figure 3.6 illustrates these goals and their respective PCI DSS requirements. The level of compliance is dependent on the volume of transactions processed by the merchant. Failing to meet the requirements can result in fines levied by the credit card processor.
FIGURE 3.6 PCI-DSS goals and requirements The PCI SSC also has published standards for PIN entry devices, point-to-point encryption (P2PE), token service providers, and software applications (PA-DSS). Having identified, characterized, and assessed the possible impacts of a particular risk, it’s time to make some strategic, tactical, and operational choices regarding what if anything to do about it. Strategic choices stem directly from senior leadership’s risk appetite or risk tolerance and in many cases reflect the external context the organization is in. These choices are whether to accept, transfer, remediate or mitigate, avoid, eliminate, or ignore the risk. Ethical or political considerations, for example, may dictate that a particular risk simply must be avoided, even if that means choosing to not operate where that risk is present. Existing systems may prove to be too costly to mitigate (repair or remediate) the vulnerabilities related to the risk, while completely replacing those systems with new ones that do not face that risk will no doubt take time to achieve; this may lead to temporarily accepting the risk as a fact of business life. Risks, you recall, can be strategic, tactical, or operational in terms of their impacts to the organization. It’s tempting to conclude, therefore, that the strategic risks should be owned (be decided about) by senior leadership and management, with tactical risks (that affect the near-term planning horizons) managed by mid-level management. The remaining day-to-day operational risks may rightly be owned and managed by line-level managers and supervisors. Be careful this delegation decision should be made explicitly, by senior leadership and management, and directed in the organization’s approved risk management plan. To do otherwise could degenerate into risk management by assuming that somebody else has got that particular risk under control. Let’s look more closely at each of these choices. This risk treatment strategy means you simply decide to do nothing about the risk. You recognize it is there, but you make a conscious decision to do nothing differently to reduce the likelihood of occurrence or the prospects of negative impact. This is also known as being self-insuring—you assume that what you save on paying risk treatment costs (or insurance premiums) will exceed the annual loss expectancy over the number of years you choose to self-insure or accept this risk. It can also be the case when facing a risk, the impacts of which could conceivably kill the organization or put it out of business completely; but the best estimates available suggest that there are no practical or affordable ways to contain, mitigate, or avoid this risk. So, senior leaders must grit their teeth and carry on with business as usual, thus accepting the risk but choosing to do nothing about it. Other risks quite commonly accepted without much analysis are ones that involve negligible damages, very low probabilities of occurrence, or both. As a result, it’s just not prudent to spend money, time, and effort to do anything about such risks, including over-analyzing them. Note that accepting a risk is not “taking a gamble” or betting that the risks won’t ever materialize. That would be ignoring the risk. For many years, most businesses, nonprofit organizations, and government offices throughout the United States and Europe, for example, blithely ignored the risk that an “active shooter” incident could occur on their premises; and in many respects, they may have been right to do so. Recent experience, alas, has motivated many organizations to gather the data, do the analysis, and make a more informed decision as to how to manage this risk to meet their needs. Many early adopters of IoT devices were ignorant of the lack of even minimal security features in these systems and have only recently started to understand the technologies, identify the risks inherent in their use, and begin to formulate risk management and mitigation strategies. Note also the need to distinguish between accepting a risk and accepting the use of a compensating control to address the risk. The first is a choice to do nothing; the second is to choose to do something else to control or contain the risk, rather than use the control strategy recommended or required by standards, regulations, or contractual agreements. Transferring a risk means that rather than spend our own money, time, and effort to reduce, contain, or eliminate the risk, and to recover from its impacts, we assign the risk to someone else; they then carry the responsibility of repairing or restoring our systems and processes, and perhaps reimburse us for lost business, in exchange for our payment to them of some kind of premium. This sounds like a typical insurance policy, such as you might have on your home or automobile, but risk transfer does not always have to be done by means of insurance. A large data center operations facility, for example, might transfer its risks of having its customers’ business operations disrupted in a number of ways.
In almost all cases, transferring a risk is about transforming the risk into something somebody else can deal with for you. You save the money, time, and effort you might have spent to deal with the risk yourself and instead pay others to assume the risk and deal with it for you; they also reimburse you (partially or completely) for consequential losses you suffer because of the risk. Simply put, this means you find and fix the vulnerabilities to the best degree that you can; failing that, you put in place other processes that shield, protect, augment, or bridge around the vulnerabilities. Most of the time this is remedial action—you are repairing something that either wore out during normal use, was not designed and built to be used the way you’ve been using it, or was designed and built incorrectly in the first place. You are applying a remedy, either total or partial, for something that went wrong. Do not confuse taking remedial action to mitigate or treat a risk with making the repairs to a failed system itself. Mitigating the risk is something you aim to do before a failure occurs, not after! Such remediation or mitigation measures might therefore include the following: It’s useful to distinguish between fixing the vulnerable element in your systems and adding a possibly redundant safeguard or alternate capability. Updating a software package to the latest revision level brings a reasonable assurance that the security fixes contained in that revision have been dealt with; those vulnerabilities have been eliminated or reduced to negligible residual risks. Providing uninterruptible power supplies or power conditioning equipment may eliminate or greatly reduce the intermittent outages that plague some network, communications, and computing systems, but they do so by making up for shortcomings in the quality and reliability of the commercial power system or the overall power distribution and conditioning systems in your facility. Either approach can be cost-effective, based on your specific risk situation and security needs. Common sense might dictate simple solutions such as physical locks on the doors to the server room or installing uninterruptible power supplies on critical systems. However, common sense usually cannot tell you the performance criteria that you should use to choose those locks or how much you should spend on those UPSs. Those numbers come from having first done the analysis to determine what the real needs are and then estimating the costs to purchase, install, verify, operate, and maintain the risk mitigation controls. The written information security requirements documents, such as your BIA and the risk assessment that flows from it, should capture what you need to know in order to decide whether your chosen risk control is cost-effective. It’s important to distinguish between these two related ways of treating risks. Risk avoidance usually requires that you abandon a vulnerable business process, activity, or location, so that the risk no longer applies to your ongoing operations. You eliminate a risk by replacing, repairing, or reengineering the vulnerable process and the systems and components it depends upon. You’re still achieving the outputs and outcomes that were originally exposed to the risk. Risk purists might argue that eliminating a risk in this way is the same as remediating it; the net result is the same. In either case, you achieve zero residual risk by spending money, time, and effort (either the costs incurred to abandon the risk-prone process, activity, or location, or the costs incurred to eliminate the risk). Most risk treatments won’t deal with 100 percent of a given risk; there will be some residual risk left over. You recast the risk by writing a new description of the residual risks, in the context of the systems or elements affected by them. This gives management and leadership a clearer picture of what the current risk posture (that is, the posture after you’ve implemented and verified the chosen risk mitigations and controls) really is. This recast statement of the risk should be reflected in updates to the BIA and the risk register so that subsequent assessments and mitigation planning have the most current and complete baseline to work from. This is the risk that’s left over, unmitigated, after you have applied a selected risk treatment or control. For example, consider the risk of data exfiltration from a system. Improving the access control system to require multifactor authentication may significantly reduce the risk of an unauthorized user (an intruder) being able to access the data, copy it, prepare it for extraction, and extract the copies from your system. This will not prevent an insider from performing an exfiltration, so this remains as a residual data exfiltration risk. Improved attribute-based access control, along with more frequent privilege review, may reduce the insider threat risk further. Protecting the data at rest and in motion via encryption may reduce it as well. Adding administrative and logical controls to prevent or tightly control the use of live data in software testing, or even using recent backups of the production database in software testing, might also reduce the risk of exfiltration. (This also illustrates how oftentimes you must decompose an overall risk into the separate possible root causes that could allow it to occur and deal with those one by one to achieve a balance of risk and cost.) As you saw in Chapter 2, “Security Operations and Administration,” risk treatments or controls are often categorized as to whether they are primarily physical, logical, or administrative in their essence. Since almost everything we do in modern organizations requires an audit trail, almost every control will have some administrative elements associated with it. But a guard dog is fundamentally a physical security control, even if its handler should be following written procedures and guidelines in putting that dog to work. Physical locks on doors need the paperwork (or e-records) that authorize their initial keying, while accounting for keys issued to and retrieved from staff members. Despite that bit of complexity, let’s take a closer look. Getting value for money invested in each of these classes of controls means choosing the right control for the right job, installing or otherwise putting it into operational use, and then ensuring that they’re being properly used, maintained, and monitored, as you saw in previous chapters. Physical controls are combinations of hardware, software, electrical, and electronic mechanisms that, taken together, prevent, delay, or deter somebody or something from physically crossing the threat surface around a set of system components we need to protect. Large-scale architectural features, such as the design of buildings, their location in an overall facility, surrounding roads, driveways, fences, perimeter lighting, and so forth, are visible, real, and largely static elements of our physical control systems. You must also consider where within the building to put high-value assets, such as server rooms, wiring closets, network and communication provider points of presence, routers and Wi-Fi hotspots, library and file rooms, and so on. Layers of physical control barriers, suitably equipped with detection and control systems, can both detect unauthorized access attempts and block their further progress into our “safe spaces” within the threat surface. Network and communications wiring, cables, and fibers are also physical system components that need some degree of physical protection. Some organizations require them to be run through steel pipes that are installed in such a way as to make it impractical or nearly impossible to uncouple a section of pipe to surreptitiously tap into the cables or fibers. Segmenting communications, network, and even power distribution systems also provides a physical degree of isolation and redundancy, which may be important to an organization’s CIANA needs. Note the important link here to other kinds of controls. Physical locks require physical keys; multifactor authentication requires logical and physical systems; both require “people power” to create and then run the policies and procedures (the administrative controls) that glue it all together and keep all of the parts safe, secure, and yet available when needed. Here is where we use software and the parameter files or databases that direct that software to implement and enforce policies and procedures that we’ve administratively decided are important and necessary. It can be a bit confusing that a “policy” can be both a human-facing set of rules, guidelines, or instructions, and a set of software features and their related control settings. Many modern operating systems, and identity-as-a-service provisioning systems, refer to these internal implementations of rules and features as policy objects, for example. So we write our administrative “acceptable use” policy document and use it to train our users so that they know what is proper and what is not; our systems administrators then “teach” it to the operating system by setting parameters and invoking features that implement the software side of that human-facing policy. In general terms, anything that human organizations write, state, say, or imply that dictates how the humans in that organization should do business (and also what they should not do) can be considered an administrative control. As you saw in Chapter 2, administrative controls such as policy documents, procedures, process instructions, training materials, and many other forms of information all are intended to guide, inform, shape, and control the way that people act on the job (and to some extent, too, how they behave off the job!). Administrative controls are typically the easiest to create—but sometimes, because they require the sign-off of very senior leadership, they can be ironically the most difficult to update in some organizational cultures. It usually requires a strong sense of the underlying business logic to create good administrative controls. Administrative controls can cover a wide range of intentions, from informing people about news and useful information to offering advice and from defining the recommended process or procedure to dictating the one accepted way of doing a task or achieving an objective. For any particular risk mitigation need, an organization may face a bewildering variety of competing alternative solutions, methods, and choices. Do we build the new software fix in-house or get a vendor to provide it? Is there a turn-key hardware/software system that will address a lot of our needs, or are we better off doing it internally one risk at a time? What’s the right mix of physical, logical, and administrative controls to apply? It’s beyond the scope of this book to get into the fine-grained detail of how to compare and contrast different risk mitigation control technologies, products, systems, or approaches. The technologies, too, are constantly changing. As you gain more experience as an SSCP, you’ll have the opportunity to become more involved in specifying, selecting, and implementing risk mitigation controls. Selecting and implementing risk controls must include new or modified end-user awareness and training. Far too many simple systems upgrades have gone wrong because the designers, builders, and testers failed to consider what the changes would mean to the people who need to use the new system effectively to get work done. Addressing end-user needs for new awareness, refresher training, or new training regarding new or modified security controls can be a double win for the organization. The first payoff is that it gets them engaged with the ideas behind the change; when users understand the purpose and intent, they can better relate it to their own jobs and their own particular needs. Building upon this, working with the end users to develop new teaching and training materials and then helping users become familiar with the changes leads to their being comfortable and competent with their use. This can greatly increase the chances of this change being successfully adopted. One important example is that of defending your organization against phishing attacks (of all kinds), which becomes more urgent and compelling with each new headline about a data breach or systems intrusion. All employees have important roles to play in making this defense effective and seamless. Initial user training can create awareness; specific job-related task training can highlight possible ways that the new user’s position and duties are exposed to the threat and familiarize them with required or recommended ways of dealing with it. “Phishing tests,” which you conduct that directly target members of your workforce, can reinforce specific elements of that training, while sharpening users’ abilities to spot the bait and not rise to it. (These tests also generate useful metrics for you.) Adding additional risk controls, which simplify the ways that employees report phishing attempts (or vishing attempts via telephone or voicemail), both engage users as part of the solution while providing you with additional threat intelligence. The key to keeping users engaged with risk management and risk mitigation controls is simple: Align their own, individual interests with the interests the controls are supporting, protecting, or securing. Help them see, day by day, that their work is more meaningful, more productive, and more valued by management and leadership, because each of them is a valued part of protecting everybody’s effort. Share the integrity. Security assessment is both a broad, categorical term that encompasses many tasks, and a specific, detailed type of activity itself. These activities include the following:
Risk assessments are often updated, or completely redone, as part of security assessments. This is particularly true when the perceived changes in the external threat environment suggest that it’s time to challenge the assumptions underneath the existing security and risk mitigation controls and systems. Do not confuse these assessments with ongoing monitoring of your systems. Monitoring involves the routine inspection, review, and analysis of data that systems diagnostics, error and alarm indicators, and log files are making available to your security team, network administrators, systems administrators, and IT support staff. Monitoring is the day-to-day exercise of due diligence; it is the constant vigilance component of your security posture. Detection of a possible security incident, or a precursor, indicator, or indicator of compromise, is part of monitoring your systems and reporting what that monitoring tells you to responsible managers and leaders in the organization. Security assessment, by contrast, is intended to answer a structured set of questions that reveal whether your systems, your security posture, your procedures, and your people are doing what’s required to meet or exceed your organization’s overall information security and risk mitigation needs. Depending upon the size and complexity of your organization, its activities, and its information systems, you may find that formal assessment, testing, and audit activities are planned throughout the year. Two facts drawn from current experience argue for a busy, frequent, and dynamic assessment schedule.
Some sources suggest that as of early 2019, organized crime spends as much as 80 percent more on cyber-attack technologies than businesses, on average, spend on cyber defense. Since the birth of the cybercrime era, the black hats have been thoroughly exploiting the same common vulnerability data and using the same scanning and analysis tools that the white hats should be using but often fail to take advantage of. It’s not enough to know your enemy; you need to know what your enemy can know about you. Many organizations use a security assessment workflow process to identify, schedule, manage, and integrate all of their formal and informal testing, auditing, assessment, analysis, and reporting tasks. Additionally, organizations that adopt a vulnerability-focused security management approach also benefit from instituting workflow processes that plan, schedule, and account for activities involved in vulnerability management. Workflow management systems, in general, eliminate or greatly reduce the risk that high-value processes might be left to ad hoc activities, taken on because they sound like “good ideas.” Many times, these ad hoc collections of processes become inextricably bound up with one or two key people, and no one else in the organization—including managers and senior leaders—understands why they’re worth spending time and resources on. As with any other risk reduction effort, security assessment must be managed, if it is to be accountable. Unmanaged security activities, especially assessments, can achieve proper levels of due care and due diligence only by means of blind luck. (An unmanaged exercise in accountability ought to sound like a contradiction in terms. It is.) Your organization’s security assessment workflow management ought to integrate or harmonize with several other workflow management processes (and their plans and schedules).
The information security team does not own all of those schedules, of course; having a greater awareness of what the business or the organization is doing and how the contexts and markets it is part of are changing should be part of your security assessment workflow thinking. The bottom line of your security assessment workflow management process should be that you can clearly identify:
Many security information and event management systems use a variety of dashboards to present this workflow information in summary form; drill-down capabilities then let security operations and analysis staff, or senior management, learn more about which particular systems, network segments, or parts of the overall organization are most affected by outstanding vulnerabilities. Your ongoing security assessments should always take the opportunity to assess the entire set of information risk controls—be they physical, logical, or administrative in nature. Security testing is a set of evaluation activities that attempt to validate that the system under test meets or exceeds all (or a designated subset) of the functional and nonfunctional security requirements allocated to that system. This testing and evaluation can be driven in two basic ways.
Requirements-driven testing is often part of a systems development acceptance process—it measures how well the developer met the requirements as specified in their contract, statement of work, or system requirements specifications. It is usually conducted by the developer, although end users quite often are active participants in test planning, have roles within test teams, and are part of post-test analysis activities. OT&E, by contrast, usually involves the as-deployed system, including the end-user organization’s own people, the procedures that they use as part of their business processes, and their tacit knowledge about the business logic, the system, and the rest of the larger context of their work. All testing involves several different sets of people, each of whom may or may not have the same breadth and depth of knowledge about the system under test. In the case of OT&E, recall that the system under test includes the normal crew of end users, operators, and their supervisors and managers. This gives rise to three definitions about testing (based on traditional use of these terms in the physical sciences and philosophy):
When conducting most forms of OT&E, and particularly when conducting ethical penetration and other security testing activities, these monochromatic terms also refer to just how much knowledge the system under test, including its people and managers, have with regards to the planned or ongoing test activities.
A common example of white-box operational testing is when network or security administrators conduct probes, port scans, or network mapping activities against their own systems and networks. As a routine, periodic (but ideally not regularly scheduled) assessment activity, these can be invaluable in discovering unauthorized changes that might reveal an intruder’s presence in your systems. It may seem a fine line to draw, but there is a line between testing and assessing. Examining the log files from systems, packets that you’ve set sniffers to capture, or reviewing the AAA data from your access control systems is not attempting to inject data into or interact with the systems you’re observing. Testing, by contrast, involves your taking actions that attempt to change the behavior of the system so that you can observe whether it behaves properly or not. In black- or gray-box security testing, it is vital to have key processes in place and people identified within the organization who can act as “cutouts” or backstops when issues arise. Ethical penetration testers often are required to attempt to enter the physical workplace as part of test activities, but you don’t want them placed under arrest if employees happen to identify them as an intruder. You also don’t want other suspicious or unusual events, not caused by the security testing, to be ignored or dismissed as if they are just part of the ongoing testing. All of these issues, and others, need to be thoroughly examined and brought under management control as a part of the test planning process. Part of your routine assessment of your systems security posture should include the same kinds of scanning techniques your attackers will use as they seek vulnerabilities to exploit against you. Vulnerability scanning should be an automated set of tasks, which generate alerts to the security team when out-of-limits conditions are detected, so as to focus your inspection and analysis to the most likely exploitable vulnerabilities. Four main categories of scanning should be part of your approach.
By definition, a zero-day exploit is one that hasn’t been reported to a vulnerability and exposures sharing and reporting system; as a result, automated vulnerability scanners of any kind really cannot find them in your system. Other techniques, such as code inspection, penetration testing, or security-focused software testing, may help you find them before the attackers do. Operational testing and evaluation (OT&E) verifies or assesses that an as-built system, including its operational procedures and external interfaces, provides the capabilities that end users need to be able to accomplish everyday work (including successful handling of contingencies, special cases, and errors, so long as these were part of the use cases that drove the design and development). It is not acceptance testing—it does not check off each functional and nonfunctional requirement as satisfied or deficient; instead, OT&E is based on scenarios that have varying levels of operational realism in their flow of activities, test input data, and the conditions to be verified upon completion. OT&E evaluates, or at least provides insight about, the readiness of the people elements of the system under test as much as it does the hardware, software, data, and communications capabilities. Quite often, OT&E discovers that the tacit knowledge of the end users and operators is not effectively captured in the system specifications or operational procedures; this can also reflect that business needs and the real world have moved on from the time the requirements were specified and design and development began. OT&E events usually run in separate test environments, with some degree of isolation from production systems and data, and can run from hours to days in nonstop duration. This same lag between what the requirements asked the systems to do and what its users know (tacitly) that they actually do with the system can be a mixed blessing when you look to include OT&E activities as part of security assessment and testing. It’s quite likely, too, that your security team’s knowledge of the threats and vulnerabilities has also continued to evolve. For everyone, OT&E activities can and should be a great learning (and knowledge management) experience. OT&E provides a great opportunity to look for ways to operationally assess specific security concerns in a realistic setting. It is white-box testing primarily; the test team, planners, users, and security personnel are all aware of the test and have as perfect knowledge about the system and the scenarios as possible. Ethical penetration testing involves running attacks against your own systems; you (or, more correctly, your organization) contractually spell out what tests to accomplish, what objectives to attempt to achieve, and what limitations, constraints, and special conditions apply to every aspect of the ethical penetration testing process. Emphasis must be placed on that first word—ethical—because the people planning, conducting, and reporting on these tests work for your organization, either as direct employees or via contracts. Their loyalties must be with your organization; they have to be your “white hats for hire” because you are trusting them with your most vital business secrets: knowledge of the vulnerabilities in your security posture. Ethical penetration testing, therefore, depends upon the trust relationship between testers and the target organization; it depends upon the integrity of those testers, including their absolute adherence to contract terms or statements of work regarding your need to have them protect the confidentiality of all information about your systems and your processes that they gather, observe, learn, or evaluate as part of the testing. Ethical penetration testing also depends upon a legally binding written agreement that grants specific permissions to the test team to attempt to penetrate your facilities, your systems, attempt deceptions (such as social engineering), plant false data, malware, or take actions that change the state of your systems. In most jurisdictions around the world, it is illegal to perform such actions without the express consent of the owners or responsible managers of the systems in question—so this contract or agreement is all that keeps your ethical penetration testers out of jail for doing what you’ve asked them to do! (This is not a good time to save some money by hiring convicted former hackers simply because they seem to know their technical stuff without some very powerful and enforceable legal assurances that your testers will turn over all copies of all data about your systems and retain absolutely nothing about them once testing and reporting is completed.) Even with such contracts in place or detailed, written permission in hand, things can always go wrong during any kind of testing, especially during penetration testing. Such tests are attempting to do what an advanced persistent threat would do if it was attacking your systems. Test activities could inadvertently crash your systems, corrupt data, degrade throughput, or otherwise disrupt your normal business operations; if things go horribly wrong, the actions the penetration testers are taking could jump from your systems out into the wild and in effect springboard their attack onto some third party systems—whose owners or managers no doubt have not signed your penetration test plan and contract. It’s beyond the scope of this book to delve further into ethical penetration testing. One good resource is Chapter 6 of Grey Hat Hacking, 5th Edition,2 which provides an excellent overview of penetration testing from the insider’s perspective. It also makes the point that penetration testing, as with other security assessments, should confirm what is working properly as much as it should find vulnerabilities that need correction (whether you knew about them before but hadn’t done anything about them yet or not). We normally think of the ethical in ethical penetration testing as describing the pen tester’s honesty, integrity, and ultimately their professional dedication to their client. Pen testing by its nature is trying to break your systems; it’s trying to find exploitable weaknesses, and oftentimes this involves placing your people under the microscope of the pen test. For the test results to be meaningful, you need your people to act as if everything is normal; they should respond to strange events (which might be test injects) as they have been trained to. The testing is evaluating the effectiveness of that training and how well it really equips your end users to do their bit in keeping your systems secure. Security testing of any kind can quickly lose its value to your organization, if the workforce perceives it as nothing more than a tool to weed out workers who need to be moved to less sensitive jobs or out of the organization completely. Security testing is a legitimate and necessary means to assess training effectiveness, people effectiveness, and systems functionality, as they all contribute to organizational security and success. These must be harmonized with keeping your workforce engaged with security and avoid having them see it as a thinly disguised reduction in staffing levels. Whether your assessment results indicate findings (of problems to fix) or good findings (celebrating the things the organization is doing well), each set of assessment results is an opportunity to improve the effectiveness of the human element in your information security system of systems. Problems or recommendations for corrective actions are typically exploited as opportunities to identify the procedural elements that could be improved, as well as possibly identifying the need for refresher training, deeper skills development training, or a more effective engagement strategy with some or all of your end users. The good news—the good findings—are the gold that you share with your end users. It’s the opportunity to share with them the “wins” over the various security threats that the total organization team has achieved; it’s a time to celebrate their wins over the APTs, offer meaningful appreciation, and seek their input on other ways to improve the overall security posture. Sadly, many organizations are so focused on threat and risk avoidance that they fail to reap the additional benefits of sharing successes with the workforce that made it possible. (It does require that assessment analysts make the effort to identify these good findings in their overall assessment reports; one might argue that this is an ethical burden that these analysts share with management.) Post-assessment debriefs to your end-user groups that were affected by or involved with the assessment can be both revealing and motivating. Questions and discussions can identify potential areas of misunderstanding about security needs, policies, and controls, or highlight opportunities to better prepare, inform, and train users in their use of these controls. Each such bit of dialogue, along with more informal conversations that you and your other team members have with end users, is an opportunity to further empower your end users as teammates; it can help them to be more intentional and more purposeful in their own security hygiene efforts. Be sure to invite end users to post-assessment debriefs and discuss both findings and good findings with them. Projects require creating a methodology and scope for the project, and security assessment and audit efforts are no different. Management must determine the scope and targets of the assessment, including what systems, services, policies, procedures, and practices will be reviewed, and what standard, framework, or methodology the organization will select or create as the foundation of the assessment. Commonly used industry frameworks include the following:
Although NIST standards may appear U.S.-centric at first glance, they are used as a reference for organizations throughout the world if there is not another national, international, or contractual standard those organizations must meet. In addition to these broad standards, specific standards like the ISA/IEC 62443 series of standards for industrial automation and control systems may be used where appropriate. Using a standard methodology or framework allows consistency between assessments, allowing comparisons over time and between groups or divisions. In many cases, organizations will conduct their own internal assessments using industry standards as part of their security operations efforts, and by doing so, they are prepared for third-party or internal audits that are based on those standards. In addition to choosing the standard and methodology, it is important to understand that audits can be conducted as internal audits using the organization’s own staff or as external audits using third-party auditors. In addition, audits of third parties like cloud service providers can be conducted. Third-party audits most often use external auditors, rather than your organization’s own staff. Once the high-level goals and scope have been set and the assessment standard and methodology have been determined, assessors need to determine further details of what they will examine. Detailed scoping questions may include the following:
Other aspects of security are also important. A complete assessment should include answers to these questions:
Budget and time constraints can make it impossible to test everything, so management must determine what will be included while balancing their assessment needs against their available resources. Once the goals, scope, and methodology have been determined, the assessment team must be selected. The team may consist of the company’s own staff, or external personnel may be retained. Factors that can aid in determining which option to select can include industry regulations and requirements, budget, goals, scope, and the expertise required for the assessment. With the team selected, a plan should be created to identify how to meet the assessment’s goals in a timely manner and within the budget constraints set forth by management. With the plan in place, the assessment can be conducted. This phase should generate significant documentation on how the assessment target complies or fails to comply with expectations. Any exceptions and noncompliance must be documented. Once the assessment activities are completed, the results can be compiled and reported to management. Upon receipt of the completed report, management can create an action plan to address the issues found during the audit. For instance, a timeframe can be set for installing missing patches and updates on hosts, or a training plan can be created to address process issues identified during the assessment. Your security assessment workflow doesn’t stop when the tests are done and the scans are complete. In many respects, this is when the hardest task begins: analyzing and assessing what those tests and scans have told you and trying to determine what they mean with respect to your security posture, a particular set of security or risk controls, or a potential threat. NIST 800-115 provides succinct but potent guidance on this subject when it says that (in the context of security assessment and testing) the purpose of analysis is to identify false positives, identify and categorize vulnerabilities, and determine (if possible) the underlying cause(s) of the vulnerabilities that have been detected. Once that analysis is complete, you can then make informed judgments as to whether each vulnerability represents a risk to avoid, accept, transfer, or treat. You’re also in a more informed position to recommend risk treatment approaches, some of which may need further analysis and study to determine costs, implementation strategies, and anticipated payback periods. Root-cause analysis (RCA) is a simple but powerful technique to apply here, as you’re struggling to reduce e-mountains of test data into actionable intelligence and reporting for your senior managers and leaders. RCA is essentially asking “why?” over and over again, until you’ve chased back through proximate causes and contributing factors to find the essential best opportunity to resolve the problem. NIST 800-115 identifies a variety of categories of root or contributing (proximate) causes of vulnerabilities.3
As you do your analysis, characterize your conclusions into two broad sets: findings and good findings. On the one hand, findings are the recommendations you’re making for corrective action; they identify problems, deficiencies, hazards, or vulnerabilities that need prompt attention. Your analysis may or may not provide enough insight to recommend a particular approach to resolving the finding, but that’s not immediately important. Getting management’s attention on the findings should be the priority. On the other hand, good findings are the positive acknowledgment that previously instituted security controls and procedures are working properly and that the investment of time, money, and people power in creating, installing, using, maintaining, and monitoring these controls is paying off. Management and leadership need to hear this as well. (Ethical penetration testers often make good use of this analysis and reporting tactic; it helps keep things in perspective.) So, you found a risk or a vulnerability, and you decided to fix it; you’ve put some kind of control in place that in theory or by design is supposed to eliminate the risk or reduce it to a more acceptable level. Perhaps part of that remediation includes improving the affected component’s ability to detect and generate alarms concerning precursors or indicators of possible attempts to attack the component. Common sense dictates that before turning that risk control and the new versions of the affected systems or applications over to end users, some type of regression testing and acceptance testing must be carried out. Two formal test processes, often conducted together, are used to validate that risk remediation actions do what is required without introducing other disruptions into the system. Security acceptance testing validates that the risk control effectively does what is required by the risk mitigation plan and that any residual risks are less than or equal to what was anticipated (and approved by management) in that plan. Regression testing establishes confidence that the changes to the component (the fix to the identified problem or vulnerability) did not break other required functions; the fix didn’t introduce other errors into the system. Unfortunately, it’s all too common to discover that security acceptance testing (or regression testing) has identified additional items of risk or levels of residual risk that go beyond what was anticipated when the decision was made to apply the particular mitigation technique in question. At this point, the appropriate levels of management and leadership need to be engaged; it is their responsibility to decide whether to accept this changed risk posture and migrate the control into production systems for operational use or to continue to accept the risk as originally understood while “going back to the drawing board” for a better fix to the vulnerability and its root cause. In almost all cases, audit findings present your organization with a set of deficiencies that must be resolved within a specified period of time. Depending upon the nature and severity of the findings and the audit standards themselves, your business might be disbarred (blocked) from continuing to engage in those types of business operations until you can prove that the deficiencies have been remediated successfully. This might require the offending systems and procedures be subjected to a follow-on audit or third-party inspection. Less severe audit findings might allow your organization to provisionally continue to operate the affected systems but perhaps with additional temporary safeguards (such as increased monitoring and inspection) or other types of compensating controls until the remediation can be successfully demonstrated. Naturally, this suggests that finishing the problem-solving analysis regarding each audit finding, identifying and scoping the cost-effective remediation options, and successfully implementing management’s chosen risk control are key to staying in the good graces of your auditors and the regulatory authorities they represent. As with any other risk control, your implementation planning for controls related to audit findings should contain a healthy dose of regression and acceptance testing. It should also have clearly defined decision points for management and leadership to sign off on the as-tested fix and commit to having it moved into production systems and use. The final audit findings closure report package should also contain the relevant configuration management and change control records pertaining to the systems elements affected by the finding and its remediation; don’t forget to include operational procedures in this too! Think back to how much work it was to discover, understand, and document the information architecture that the organization uses and then the IT architectures that support that business logic and data. Chances are that during your discovery phase, you realized that a lot of elements of both architectures could be changed or replaced by local work unit managers, group leaders, or division directors, all with very little if any coordination with any other departments. If that’s the case, you and the IT director, or the chief information security officer and the CIO, may have an uphill battle on your hands as you try to convince everyone that proper stewardship does require more central, coordinated change management and control than the company is accustomed to. The definitions of these three management processes are important to keep in mind:
As a member of your company’s information security team, consider asking (or looking yourself for the answers to!) the following kinds of questions:
This list should remind you of the list of NIST 800-115’s list of root causes of vulnerabilities that you examined in the “Interpretation and Reporting of Scanning and Testing Results” section. If you’re unable to get good answers to any of these kinds of questions, from policy and procedural directives, from your managers, or from your own investigations, you may be working in an environment that is ripe for disaster. To be effective, any management system or process must collect and record the data used to make decisions about changes to the systems being managed; they must also include ways to audit those records against reality. For most business systems, you need to consider three different kinds of baselines: recently archived, current operational, and ongoing development. Audits against these baselines should be able to verify that:
Audits of configuration management and control systems should be able to verify that the requirements and design documentation, source code files, builds and control systems files, and all other data sets necessary to build, test, and deploy the baseline contain authorized content and changes only. This was covered in more depth in Chapter 2. Traditional approaches to security process data collection involved solution-specific logging and data capture, sometimes paired with a central SIEM or other security management device. As organizational IT infrastructure and systems have become more complex, security process data has also increased in complexity and scope. As the pace of change of your systems, your business needs, and the threat environment continue to accelerate, this piecemeal approach to monitoring applications, systems, infrastructures, and endpoints is no longer workable. Information security continuous monitoring (ISCM) is a holistic strategy to improve and address security. ISCM is designed to align facets of the organization including the people, the processes, and the technologies that make up the IT infrastructure, networks, systems, core applications, and endpoints. As with any security initiative, it begins with senior management buy-in. The most effective security programs consistently have upper management support. This creates an environment where the policies, the budget, and the vision for the company all include security as a cornerstone of the company’s success. Implementing a continuous information security monitoring capability should improve your ability to do the following: A number of NIST publications, and others, provide planning and implementation guidance for bringing ISCM into action within your organization. Even if you’re not in the U.S. Federal systems marketplace, you may find these provide a good place to start:
Most of these show a similar set of tasks that organizations must accomplish as they plan for, implement, and reap the benefits of an effective ISCM strategy.
Don’t confuse the overall tasks you need to get done with the marketing copy describing a tool you may want to consider using. Security incident and event management (SIEM) systems have become increasingly popular over the last few years; be cautious, however, as you consider them for a place in your overall security toolkit. Your best bet is to focus first on what jobs the organization needs to get done and how those jobs need to be managed, scheduled, and coordinated, as well as how the people doing them need to be held accountable for producing on-time, on-target results. Once you understand that flow of work and the metrics such as key performance indicators (KPIs) or key risk indicators (KRIs) that you’ll manage it all with, you’ll be better able to shop for vendor-supplied security information management and analysis tools. It’s prudent to approach an ISCM project in a step-by-step fashion; each step along the way, as that task list suggests, offers the opportunity for the organization to learn much more about its information systems architectures and the types of data their systems can generate. With experience, your strategies for applying continuous monitoring as a vital part of your overall information security posture will continue to evolve. ICSM has become increasingly complex as organizations spread their operations into hosted and cloud environments and as they need to integrate third parties into their data-gathering processes. Successful ICSM now needs to provide methods to interconnect legacy ICSM processes with third-party systems and data feeds. Be mindful, too, that compliance regimes (and their auditors) are becoming increasingly more aware of the benefits of a sound ICSM strategy and will be looking to see how your organization is putting one into practice. Let’s take a closer look at elements of an ICSM program; you may already have many of these in place (as part of “traditional” or legacy monitoring strategies). Broadly speaking, an event of interest is something that happens (or is still ongoing) that may have a possible information systems security implication or impact to it. It does not have to be an ongoing attack in and of itself to be “of interest” to your security operations center or other IT security team members. Vulnerability assessments, threat assessments, and operational experience with your IT infrastructures, systems, and applications should help you identify the categories of events that you want to have humans (or machine learning systems) spend more time and effort analyzing to determine if they are a warning sign of an impending attack or an attack in progress. Root-cause analysis should help you track back to the triggering events that may lead to a series of other events that culminate in the event of interest that you want to be alarmed about. (Recall that by definition an event changes something in your system.) Let’s start with the three broad categories of events or indicators that you’ll need to deal with. Think of each as a step in a triage process: the further along this list you go, the greater the likelihood that your systems are in fact under attack and that you need to take immediate action. First, let’s look at precursor events. A precursor is a signal or observable characteristic of the occurrence of an event; the event itself is not an attack but might indicate that an attack could happen in the future. Let’s look at a few common examples to illustrate this concept:
Genuine precursors—ones that give you actionable intelligence—are quite rare. They are often akin to the “travel security advisory codes” used by many national governments. They rarely provide enough insight that something specific is about to take place. The best you can do when you see such potential precursors is to pay closer attention to your indicators and warnings systems, perhaps by opening up the filters a bit more. In doing so, you’re willing to accept more false positive alarms and spend more time and effort to assess them as the price to pay that a false negative (a genuine attack spoofing its way into your systems) is overlooked. You might also consider altering your security posture in ways that might increase protection for critical systems, perhaps at the cost of reduced throughput due to additional access control processing. An indicator is a sign, signal, or observable characteristic of the occurrence of an event that an information security incident may have occurred or may be occurring right now. Common examples of indicators include:
One type of indicator worth special attention is called an indicator of compromise (IOC), which is an observable artifact with high confidence signals that an information system has been compromised or is in the process of being compromised. Such artifacts might include recognizable malware signatures, attempts to access IP addresses or URLs known or suspected to be of hostile or compromising intent, or domain names associated with known or suspected botnet control servers. The information security community is working to standardize the format and structure of IOC information to aid in rapid dissemination and automated use by security systems. As you’ll see in Chapter 4, the fact that detection is a war of numbers is both a blessing and a curse; in many cases, even the first few “low and slow” steps in an attack may create dozens or hundreds of indicators, each of which may, if you’re lucky, contain information that correlates them all into a suspicious pattern. Of course, you’re probably dealing with millions of events to correlate, assess, screen, filter, and dig through to find those few needles in that field of haystacks. There’s strong value in also characterizing events of interest in terms of whether they are anomalies, intrusions, unauthorized changes, or event types you are doing extra monitoring of to meet compliance needs. Let’s take a closer look. In general terms, an anomaly is any event that is out of the ordinary, irregular, or not quite normal. Endpoint systems that freeze for a few seconds and then seem to come back to life with no harm done are anomalies. Timeouts, or time synchronization mismatches between devices on your network, may also be anomalies. Failures of disk drives to respond correctly to read, write, or positioning commands may be indicators of incipient hardware failures, or of contention for that device from multiple process threads. In short, until you know something odd has occurred and that its “oddness” has passed your filter and you’ve decided it’s worth investigating, you probably won’t know the anomaly occurred or whether it was significant (as an event of interest) until you gather up all of the log data for the affected systems and analyze it. There are some anomalous events that ought to be considered as suspicious, perhaps even triggering immediate alarms to security analysts and watch officers. Unscheduled systems reboots or restarts, or re-initializations of modems, routers, switches, or servers, usually indicate either that there’s an unmanaged software or firmware update process going on, that a hung application has tempted a user into a reboot as a workaround, or that an intruder is trying to cover their tracks. It’s not that our systems are so bug-free that they never hang, never need a user-initiated reboot, or never crash and restart themselves; it’s that each time this happens, your security monitoring systems should know about it in a timely manner, and if conditions warrant, send up an alarm to your human security analysts. Intrusions occur because something happens that allows an intruder to bypass either the access control systems you’ve put in place or your expectations for how well those systems are defending you against an intrusion. Let’s recap some of the ways intruders can gain access to your systems:
Other chapters in this book offer ways to harden these entry points into your systems; when those hardening techniques fail, and they will, what do you do to detect an intrusion while it is taking place, rather than waiting until a third party (such as law enforcement) informs you that you’ve been the victim of a data breach? Your organization’s security needs should dictate how strenuously you need to work to detect intrusions (which by definition are an unauthorized and unacceptable entry by a subject, in access control terms, into any aspect of your systems); detection and response will be covered in Chapter 4. Configuration management and configuration control must be a high priority for your organization. Let’s face it: If your organization does not use any type of formalized configuration management and change control, it’s difficult if not impossible to spot a change to your systems, hardware, networks, applications, or data in the first place, much less decide that it is an unauthorized change. Security policy is your next line of defense: administrative policies should establish acceptable use; set limits or establish procedures for controlling user-provided software, data, device, and infrastructure use; and establish programs to monitor and ensure compliance. Automated and semi-automated tools and utilities can help significantly in detecting and isolating unauthorized changes:
It may be that some or all of your information systems elements are not under effective configuration management and control (or may even be operating with minimal access control protections). This can happen during mergers and acquisitions or when acquiring or setting up interfaces with special-purpose (but perhaps outdated) systems. Techniques and approaches covered in other chapters, notably Chapter 2, should be considered as input to your plan to bring such potentially hazardous systems under control and then into your overall IT architecture. Two types of events can be considered as compliance monitoring events by their nature: those that directly trace to a compliance standard and thus need to be accounted for when they occur, and events artificially triggered (that is, not as part of routine business operations nor as part of a hostile intrusion) as part of compliance demonstrations. Many compliance standards and regulations are becoming much more specific in terms of the types of events that have to be logged, analyzed, and reported on as part of their compliance regime. This has led to the development of a growing number of systems and services that provide what is sometimes called real-time compliance monitoring. These typically use a data mart or data warehouse infrastructure into which all relevant systems, applications, and device logs are updated in real time or near real time. Analysis tools, including but not limited to machine learning tools, examine this data to detect whether events have occurred that exceed predefined limits or constraint conditions. Many of these systems try to bridge the conceptual gap between externally imposed compliance regimes (imposed by law, regulation, contract, or standards) and the detail-level physical, logical, and administrative implementation of those compliance requirements. Quite often, organizations have found that more senior, policy-focused individuals are responsible for translating contracts, standards, or regulations into organizational administrative plans, programs, and policies, while more technically focused IT experts are implementing controls and monitoring their use. The other type of compliance events might be seen when compliance standards require the use of deliberately crafted events, data injects, or other activities as part of verification and validation that the system meets the compliance requirements. Two types of these you might encounter are synthetic transactions and real user monitoring events. Monitoring frequently needs to involve more than simple log reviews and analysis to provide a comprehensive view of infrastructure and systems. The ability to determine whether a system or application is responding properly to actual transactions, regardless of whether they are simulated or performed by real users, is an important part of a monitoring infrastructure. Understanding how a system or application performs and how that performance impacts users as well as underlying infrastructure components is critical to management of systems for organizations that want a view that goes deeper than whether their systems are up or down or under a high or low load. Two major types of transaction monitoring are performed to do this: synthetic transactions and real user monitoring. Synthetic transactions are actions run against monitored objects to see how the system responds. The transaction may emulate a client connecting to a website and submitting a form or viewing the catalog of items on a web page, which pulls the information from a database. Synthetic transactions can confirm the system is working as expected and that alerts and monitoring are functioning properly. Synthetic transactions are commonly used with databases, websites, and applications. They can be automated, which reduces the workload carried by administrators. For instance, synthetic transactions can ensure that the web servers are working properly and responding to client requests. If an error is returned during the transaction, an alert can be generated that notifies responsible personnel. Therefore, instead of a customer complaining that the site is down, IT can proactively respond to the alert and remedy the issue, while impacting fewer customers. Synthetic transactions can also measure response times to issues, allowing staff to proactively respond and remediate slowdowns or mimic user behavior when evaluating newly deployed services, prior to deploying the service to production. Synthetic transactions can be used for several functions, including the following:
Real user monitoring (RUM) is another method to monitor the environment. Instead of creating automated transactions and interactions with an application, the developer or analyst monitors actual users interacting with the application, gathering information based on actual user activity. Real user monitoring is superior to synthetic transactions when actual user activity is desired. Real people will interact with an application in a variety of ways that synthetic transactions cannot emulate because real user interactions are harder to anticipate. However, RUM can also generate much more information for analysis, much of which is spurious since it will not be specifically targeted at what the monitoring process is intended to review. This can slow down the analysis process or make it difficult to isolate the cause of performance problems or other issues. In addition, RUM can be a source of privacy concerns because of the collection of user data that may include personally identifiable information, usage patterns, or other details. Synthetic transactions can emulate certain behaviors on a scheduled basis, including actions that a real user may not perform regularly or predictably. If a rarely used element of an application needs testing and observation, a synthetic transaction is an excellent option, whereas the developer or analyst may have to wait for an extended amount of time to view the transaction when using RUM. By using a blend of synthetic transactions and real user monitoring, the effectiveness of an organization’s testing and monitoring strategy can be significantly improved. Downtime can be reduced because staff is alerted more quickly when issues arise. Application availability can be monitored around the clock without human intervention. Compliance with service level agreements can also be accurately determined. The benefits of using both types of monitoring merits consideration. Logs are generated by most systems, devices, applications, and other elements of an organization’s infrastructure. They can be used to track changes, actions taken by users, service states and performance, and a host of other purposes. These events can indicate security issues and highlight the effectiveness of security controls that are in place. Assessments and audits rely on log artifacts to provide data about past events and changes and to indicate whether there are ongoing security issues, misconfigurations, or abuse issues. Security control testing also relies on logs including those from security devices and security management systems. The wide variety of logs, as well as the volume of log entries that can be generated by even a simple infrastructure, means that logs can be challenging to manage. Logs can capture a significant amount of information and can quickly become overwhelming in volume. They should be configured with industry best practices in mind, including implementing centralized collection, validation using hashing tools, and automated analysis of logs. Distinct log aggregation systems provide a secure second copy, while allowing centralization and analysis. In many organizations, a properly configured security information and event management (SIEM) system is particularly useful as part of both assessment and audit processes and can help make assessment efforts easier by allowing reporting and searches. Even when centralized logging and log management systems are deployed, security practitioners must strike a balance between capturing useful information and capturing too much information. Maintaining log integrity is a critical part of an organization’s logging practice. If logs cannot be trusted, then auditing, incident response, and even day-to-day operations are all at risk since log data is often used in each of those tasks. Thus, organizations need to assess the integrity of their logs as well as their existence, content, and relevance to their purpose. Logs should have proper permissions set on them, they should be hashed to ensure that they are not changed, a secure copy should be available in a separate secure location if the logs are important or require a high level of integrity, and of course any changes that impact the logs themselves should be logged! Assessing log integrity involves validating that the logs are being properly captured, that they cannot be changed by unauthorized individuals or accounts, and that changes to the logs are properly recorded and alerted on as appropriate. This means that auditors and security assessors cannot simply stop when they see a log file that contains the information they expect it to. Instead, technical and administrative procedures around the logs themselves need to be validated as part of a complete assessment process. Assessments and audits need to look at more than just whether logs are captured and their content. In fact, assessments that consider log reviews look at items including the following:
Policies and procedures for log management should be documented and aligned to standards. ISO 27001 and ISO27002 both provide basic guidance on logging, and NIST provides SP 800-92, “Guide to Computer Security Log Management.” Since logging is driven by business needs, infrastructure and system design, and the organization’s functional and security requirements, specific organizational practices and standards need to be created and their implementation regularly assessed. On the one hand, nearly every device, software package, application, and platform or service that is part of your systems should be considered as a data source for your continuous monitoring and analysis efforts. But without some logical structure or sense of purpose to your gathering of sources, you’re liable to drown in petabytes of data and not learn much in the process. On the other hand, it might be tempting to argue that you should use a prioritized approach, starting with your highest-valued information assets or your highest-priority business processes and the platforms, systems, and other elements that support them. Note the danger in such a viewpoint: It assumes that your attackers will use your most important “crown jewels” of your systems as their entry points and the places from which they’ll execute their attack. In many respects, you have to face this as an “all-risks” approach, as insurance underwriters refer to it. There is some benefit in applying a purposeful or intentional perspective as you look at your laundry list of possible data sources. If you’re trying to define an “operational normal” and establish a security baseline for anomaly detection, for example, you might need to tailor what you log on which devices or systems differently, than if you’re trying to look at dealing with specific categories of risk events. No matter how you look at it, you’re talking large volumes of data, which require smart filtering and analysis tools to help you make sense of it quickly enough to make risk containment decisions before it’s too late. In some IT circles, people are known to say that disk space is cheap as a way of saying that the alternatives tend to be far, far more costly in the long run. A Dell EMC survey, reported by Johnny Wu at Searchdatabackup.techtarget.com in March 2019, suggests that the average impact to businesses of 20 hours of downtime can exceed half a million dollars; losing 2.13 TB of data can double that average impact. Compare that with the budget you’d need to capture all log and event data and have sufficiently high-throughput analysis capabilities to make sense of it in near real time, and you’ve got the makings of your business case argument for greater IT security investment. At some point, treating your security logging from all sources begins to suggest that write-once, read-many storage technologies might be the standard and simplest approach to take. Capture the original data created by the source; never alter it, but link it via analysis platforms hosted in data mart or data warehouse systems, as you continually mine that data for evidence of foul play or mere malfunction. For all data sources, be they hardware, software, or firmware, part of your infrastructure or a guest endpoint, you should strongly consider making current health and status data something that you request, capture, and log. This data would nominally reflect the current identity and version of the hardware, software, and firmware, showing in particular the latest (or a complete list) of the patches applied. It would include antimalware, access control rule sets, or other security-specific dataset versions and update histories. Get this data every time a subject connects to your systems; consider turning on health and status-related access control features like quarantines or remediation servers, to prevent out-of-date and out-of-touch endpoints from possibly contaminating your infrastructures. And of course, log everything about such accesses! In doing this, and in routinely checking on this health information periodically throughout the day, you’re looking for any indicators of compromise that signal that one of your otherwise trusted subjects has been possibly corrupted by malware. Depending upon the security needs of your organization, you may need to approach the continuous monitoring, log data analysis, and reporting set of problems with the same sensibilities you might apply to investigating an incident or crime scene. The data you can gather from an incident or crime scene is dirty; it is incomplete, or it may have been inadvertently or deliberately corrupted by people and events at the scene or by first responders. So, you focus first on what looks to be a known signature of an event of interest and then look for multiple pieces of corroborating evidence. Your strongest corroboration comes from evidence gathered by dissimilar processes or from different systems (or elements of the incident scene); thus, it’s got to walk, talk, and swim like a duck, rather than just be seen to walk by three different people, for you to sound the alarm that a duck has intruded into your systems. Let’s look at the obvious lists in a bit more detail; note that a given device or software element may fit in more than one category. Almost all server systems available today have a significant number of logging features built in, both as troubleshooting aids and as part of providing accountability for access control and other security features. Services are engaged by users via applications (such as Windows Explorer or their web browser), which use applications program interfaces or systems interfaces to make service requests to the operating system and server routines; more often than not, these require a temporary elevation of privilege for that execution thread. All of those transactions—requests, acknowledge or rejection, service performance, completion, or error conditions encountered—can generate log entries; many can be set to generate other events that route alarm signals to designated process IDs or other destinations. Key logs to look for include the following: What started out decades ago as a great troubleshooting and diagnostic capability has come of age, as most applications programs and integrated platform solutions provide extensive logging features as part of ensuring auditable security for the apps themselves and for user data stored by or managed by the app. Many apps and platforms also do their own localized versions of access control and accounting, which supports change management and control, advanced collaboration features such as co-authoring and revision management, and of course security auditing and control. Some things to look for include the following: Your organization may have migrated or originally hosted much of its business logic in cloud-hosted solutions, using a variety of cloud service models. Unless these have been done “on the cheap,” there should be extensive event logging information available about these services, the identities of subjects (users or processes) making access attempts to them, and other information. If you’re using an integrated security continuous monitoring (ISCM) product or system, you should explore how to best automate the transfer of such data from your cloud systems provider into your ISCM system (which, for many good reasons based on reliability, availability, and integrity, may very well be cloud hosted itself). Other services that might provide rich security data sources and logs, nominally external to your in-house infrastructure and not directly owned or managed by your team, might include:
All endpoint devices that are allowed to have any type of access arrangements into your systems should, by definition and by policy, be considered as part of your systems; thus, they should be subject to some degree of your security management, supervision, and control. You’ll look at endpoint security in greater detail in Chapter 7, and endpoint device access control will be addressed in Chapter 6. That said, consider gathering up the following kinds of data from each endpoint every time it connects:
All of the modems, routers, switches, gateways, firewalls, IDS or IPS, and other network security devices and systems that make up your networks and communications infrastructures should be as smart as possible and should be logging what happens to them and through them.
Some of these classes of data, and others not in this list, may be found in the services and servers that provide the support (such as managing certificates, identities, or encryption services). The first generations of Internet of Things (IoT) devices have not been known to have much in the way of security features, even to the level of an ability to change the factory-default username, password, or IP address. If your company is allowing such “artificial stupidity” to connect to your systems, this could be a significant hazard and is worthy of extra effort to control the risks these could be exposing the organization to. (See Chapter 7 for more information.) If your IoT or other robot devices can provide any of the types of security-related log or event information such as what you’d require for other types of endpoints, by all means include them as data sources for analysis and monitoring. Chapter 2 highlighted many of the significant changes in international and national laws that dictate information security requirements upon organizations that operate within their jurisdictions. And for all but the most local of organizations, most businesses and nonprofits find themselves operating within multiple jurisdictions: Their actions and information, as well as their customers and suppliers, cross multiple frontiers. As a result, you may find that multiple sets of laws and regulations establish constraints on your ability to monitor your information systems, collect specific information on user activities, and share that data (and with whom) as you store, collate, analyze, and assess it. There is often a sense of damned-if-you-do to all of this: You may violate a compliance requirement if you do collect and exploit such information in the pursuit of better systems security, but you may violate another constraint if you do not. Almost all audit processes require that critical findings be supported by an audit trail that supports the pedigree (or life history) of each piece of information that is pertinent to that finding. This requires that data cleansing efforts, for example, cannot lose sight of the original form of the data, errors and omissions included, as it was originally introduced into your systems (and from whence it came). Auditors must be able to walk back each step in the data processing, transformation, use, and cleansing processes that have seen, touched, or modified that data. In short, audit standards dictate very much the same type of chain of custody of information—of all kinds—that forensics investigations require. From one point of view, the information systems industries and their customers have brought this upon themselves. They’ve produced and use systems that roughly two out of three senior leaders and managers do not trust, according to surveys in 2016 by CapGemini and EMC, and in 2018 by KPMG International; they produce systems that seemingly cannot keep private data private nor prevent intruders from enjoying nearly seven months of undetected freedom to explore, exploit, exfiltrate, and sometimes destructively disrupt businesses that depend upon them. At the same time, organized crime continues to increase its use of cybercrime to pursue its various agendas. Governments and regulators, insurers and financial services providers, and shareholders have responded to these many threats by imposing increasingly stringent compliance regimes upon public and private organizations and their use of information systems. Yet seemingly across the board, senior leadership and management in many businesses consider that the fines imposed by regulators or the courts are just another risk of doing business; their costs are passed on to customers, shareholders, or perhaps to workers if the company must downsize. Regulators and legislatures are beginning to say “enough is enough,” and we are seeing increasing efforts by these officials to respond to data breaches and information security incidents by imposing penalties and jail time on the highest-ranking individual decision-makers found to be negligent in their duties of due care and due diligence. It’s beyond the scope of this book to attempt to summarize the many legal and regulatory regimes you might need to be familiar with. Your organization’s operating locations and where your customers, partners, and suppliers are will also make the legal compliance picture more complex. Translating the legal, regulatory, and public policy complexities into organizational policies takes some considerable education and expertise, along with sound legal advice. As the on-scene information security practitioner, be sure to ask the organization’s legal and compliance officers what compliance, regulatory, or other limitations and requirements constrain or limit your ability to monitor, assess, and report on information security-related events of interest affecting your systems. Let the organization’s attorneys and compliance officers or experts chart your course through this minefield for you. As a practicing information security professional, you have so many good reasons for keeping your own logbook or journal of activity. Take notes about key decisions you’ve made and how you reached them. Log when you’ve been given directions (even if veiled as suggestions or requests) to make changes to the security posture of the systems and information that you protect. These files can provide important clues to assist in a forensic investigation, as well as capture key insights vital to responding to and cleaning up after a security incident. You create them with the same discipline you’d use in establishing a chain of custody for important evidence or the pedigree or audit trail of a set of important data. All of these contribute to achieving a transparent, auditable, and accountable security climate in your organization. Ongoing and continuous monitoring should be seen as fulfilling two very important roles. First, it’s part of your real-time systems security alarm system; the combination of controls, filters, and reporting processes are providing your on-shift watch standers in your security or network operations centers with tipoffs to possible events of interest. These positive signals (that is, an alarm condition has been detected) may be true indications of a security incident or false positives; either way, they need analytic and investigative attention to determine what type of response if any is required. The second function that the analysis of monitoring data should fulfill is the hunt for the false negative—the events in which an intruder spoofed your systems with falsified credentials or found an exploitable vulnerability in your access control system’s logic and control settings. In either case, analysis of monitoring data can provide important insight into potential vulnerabilities within your systems. And it all starts with knowing your baselines. The term baseline can refer to any of three different concepts when we use it in an IT or information security context. An architectural baseline is an inventory or configuration management list of all of the subsystems, elements, procedures, or components that make up a particular system. From most abstract to most detailed, these are: We typically see asset-based risk management needing to focus on the IT architecture as the foundational level; but even an asset purist has to link each asset back up with the organizational priorities and objectives, and these are often captured in process-oriented or outcomes-oriented terms—which the other two baselines capture and make meaningful. Chapter 2 examined the tailored application of a standard, or a set of required or desired performance characteristics, as a baseline. As a subset of baselines, security baselines express the minimum set of security controls necessary to safeguard the information security requirements and properties for a particular configuration. Scoping guidance is often published as part of a baseline, defining the range of deviation from the baseline that is acceptable for a particular baseline. This scoping guidance should interact with configuration management and control processes to ensure that the directed set of security performance characteristics are in fact properly installed and configured in the physical, logical, and administrative controls that support them. The third use of baselines in information security contexts refers to a behavioral baseline, which combines a description of a required set of activities with the observable characteristics that the supporting systems should demonstrate; these characteristics act as confirmation that the system is performing the required activities correctly. Many times, these are expressed as confirmation-based checklists: You prepare to land an aircraft by following a checklist that dictates flap, engine power, landing gear, landing lights, and other aircraft configuration settings, and you verify readiness to land by checking the indicators associated with each of these devices (and many more). The next section will explore how you can put these concepts to work to enhance your information security posture. NIST and others continue to emphasize the need for information security professionals to get smarter, faster, and better at anomaly detection. Behavioral anomaly detection is emphasized, for example, in the November 2018 draft of NISTIR 8219, “Securing Manufacturing Industrial Control Systems: Behavioral Anomaly Detection.” The 24th Annual Anti-Money Laundering and Counter-Terrorist Financing Conference, in April 2019, heard speakers from the United States, the United Kingdom, Canada, and the European Union stress the need for better behavioral anomaly detection applied to the international legal regimes for financial risk management, combating organized crime, and combating the financing of terrorism. This requires the information systems used by banks, financial regulators, and law enforcement to meet even more stringent standards for safety, security, and resilience, including behavioral anomaly detection. Machine learning and advanced data analytics vendors are already on this bandwagon; if you aren’t a master of these technologies yet, Coursera, Khan Academy, and other free online learning sources can get you started. In the meantime, read Stan Skwarlo’s blog at https://10dsecurity.com/cyber-security-baselines-anomaly-detection/, which provides an excellent overview of this topic. In this chapter, the “Source Systems” and “Security Baselines and Anomalies” sections draw extensively on Skwarlo’s work, NIST 800-53, NISTIR 8219, and other sources. As you saw in the “Source Systems” section, you’ve got many rich veins of data to mine that can give you near-real time descriptions of the behavior of your IT systems and infrastructures. Assuming these IT systems and infrastructures are properly described, documented, and under effective configuration management and configuration control, you’re ready for the next step: identifying the desired baseline behavior sets and gathering the measurements and signatures data that your systems throw off when they’re acting properly within a given behavioral baseline. Let’s use as an illustration a hypothetical industrial process control environment, such as a natural gas-fired electric power generation and distribution system. Furthermore, let’s look at just one critical subsystem in that environment: the real-time pricing system that networks with many different electric power wholesale distributor networks, using a bid-ask-sell system (as any commodity exchange does) to determine how much electricity to generate and sell to which distributor. This process is the real business backbone of national and regional electric power grids, such as the North American or European grid system. Enron’s manipulation of demand and pricing information, via the network of real-time bid-ask-sell systems used by public utilities across North America, led to the brownouts and rolling blackouts that affected customers in California in 2000 and 2001. Nothing went wrong with the power generation and distribution systems—just the marketplaces that bought and sold power in bulk. Accidents of data configuration caused a similar cascade of brownouts in Australia in the mid-1990s; it is rumored that Russian interference caused similar problems for Estonia in 2007. This bid-ask-buy system might be modeled as having the following major behavioral conditions or states:
This list isn’t comprehensive. Many permutations exist for various circumstances. For each of those behavioral sets, analysts who know the systems inside and out need to go through the architectures and identify what they would expect to see in observable terms for key elements of the system. The bulk price of electricity (dollars per megawatt-hour [mwh] in North America, Euros per mwh in Europe) would be a gross level indicator of how the overall system is behaving, but it’s not fine-grained enough to tell you why the system is misbehaving. For each of those behavioral states (and many, many more), picture a set of “test points” that you could clip a logic probe, a protocol sniffer, or a special-purpose diagnostic indicator to, and make lots of measurements over time. If the system behaved “normally” while you gathered all of those measurements, then you have a behavioral fingerprint of the system for that mode of operational use. Behavioral baselines can be tightly localized in scope, such as at the individual customer or individual end user level. Attribute-based access control, for example, is based on the premise that an organization can sufficiently characterize the work style, movement patterns, and other behaviors of its chief financial officer, as a way of protecting itself from that CFO being a target of a whaling attack. Your systems, the tools you’re using, and your ability to manage and exploit all of this data will shape your strategies and implementation choices. It’s beyond our scope here to go into much detail about this, save to say that something has got to merge all of that data, each stream of which is probably in a different format, together into a useful data mart or data warehouse that you can mine and analyze. You’ll no doubt want to apply various filters, data smoothing and cleansing, and verification tools, as you preprocess this data. Be mindful of the fact that you’re dealing with primary source evidence as you do this; protect that audit trail or the chain of custody as you carry out these manipulations, and preserve your ability to walk back and show who authorized and performed which data transformations where, when, and why. Successful detection and response to an incident, and survival of the post-response litigation that might follow, may depend upon this bit of pedigree protection. Think about your systems environments, within your organization, as they exist right now, today. Some obvious candidates for anomalies to look for in your data should come to mind.
Some of those anomalies might be useful precursors to pay attention to; others, such as changes in traffic and loading, are probably high-priority emergency alarm signals! Start with that list; peel that behavioral onion down further, layer by layer, and identify other possible anomalies to look for. By its very name, behavioral anomaly detection begs this question. Either you’ve got to define the “normal” well enough that you can use it as a whitelist (and thus raise an alarm for anything not normal-seeming) or you’ve got to develop and maintain behavioral models that probably represent undesired, suspect, or unwanted activities. So, you probably have to combine behavioral whitelisting and blacklisting in your overall strategy. If the abiding purpose of doing analysis is to inform and shape decisions, then the format and manner of how you present your findings and support those findings with your data is critical to success. This is especially true when you look at visualizations, dashboards, and other aggregate representations of security-related data, especially when you’re using single-value metrics as your measures of merit, fit, or safety. Consider for a moment a typical security dashboard metric that displays the percentage of endpoint systems that have been updated with a critical security patch during the last 48 hours. A midsize organization of 5,000 employees scattered across four countries might have 10,000 to 15,000 endpoint devices in use, either company-owned and managed, employee-owned and managed, or any combination thereof. Even if your “green” reporting threshold is as high as 99 percent, that means that as many as 150 endpoint devices are still providing a welcome mat to an exploit that the patch was supposed to lock down. Seen that way, a key risk indicator might not be as meaningful on a dashboard as you might think. Dashboard-style indicators are well suited to comparing a metric that changes over time against a required or desired trend line for that metric. Color, blink animations, or other visual cues are also useful when a clip level for the metric can be set to transform the metric into an alarm indicator. Geolocating indicators on a dashboard (including what we might call logical net-location or workspace-location, to show health and status or alarm indicators plotted on a logical network segment map or within or across physical facilities) can also help orient troubleshooters, responders, and managers to an evolving situation. Rolling timeline displays that can show a selected set of measurements as they change over time can also be quite useful; sometimes the human brain’s ability to correlate how different systems characteristics change over the same time period can trigger a sense that something might be going wrong. Industrial process control environments have had to cope with these problems for over a century; many innovative and highly effective data representation, visualization, and analysis techniques have been developed to keep physical systems working safely and effectively. Much of what we see in information security dashboards borrows from this tradition. Of course, there are some compliance requirements that dictate certain metrics, data, and other information be displayed together, correlated in certain ways, or trended in other ways. It may take some quiet contemplation to ferret out what key questions these required formats are actually trying to answer; that might be worth the effort, especially if your management and leadership keep asking for better explanations of the compliance reporting. Let’s get purposeful and intentional here: why do you need to analyze all of this data? You need to do it to help people make decisions in real time—decisions about incipient incidents, about incidents that have already happened that we’ve just found out about, or about what to do to prevent the next incident from happening, or at least reduce its impacts. That’s the only reason you gather event or anomaly or other data and analyze it every which way you can: to inform and shape decision-making. Combine that for a moment with the survey findings mentioned earlier—that roughly two out of three senior executives and managers do not trust the data from their own systems, and you begin to see the real analysis challenge. Simply put: What questions are you trying to answer? If your organization does not already have a well-developed set of plans, policies, and procedures that strongly and closely couple analysis with information security–related decision-making, then filling that void might be a good place to start. Try a thought experiment or two: Put yourself in each decision-maker’s shoes, and write down the key decision that has to be made—one that you know is necessary and logical and must be made soon. Focus on action-related decisions, such as “call in the police,” “notify the government that we’ve suffered a major data breach,” or “scrap our current security information and event management system and replace it with something better.” Another good set of decision points to ponder might be the escalation check points or triage levels in your incident response procedures, which require you to determine how severe an incident seems to be, or might become, as a litmus test for how far up the management chain to escalate and notify key decision-makers. For each of those decisions, analyze it; write down four or five questions that you’d need the answers to, to make that decision yourself. Do your analysis plans, programs, procedures, and tools help you answer those questions? If they do, test and assess those analysis processes using real data and decisions. If not, sanity check the questions and decisions with others in your team (such as your supervisor or team chief) or with others in the organization that you have a good working relationship with. If after that the questions still seem relevant to the decision that has to be made, it may be time to reexamine the analysis processes and their expressed or implied assumptions about what data to collect, how often, and what to do with it. This is a good time to go back to your security testing, assessment, and analysis workflow and the management systems you use with it. Are those processes set up to support you in getting the answers that decision-makers need? Or are they “merely” responding to compliance reporting requirements? While you’re doing that, keep thinking up security-related questions that you think are important, urgent, and compelling—the sort of questions that you would ask if you were running the company. The more of those you find that don’t quite seem to fit with your workflows and analysis procedures, the more that either your intuition is faulty or the workflows and procedures need help urgently. Other sections in this chapter have already looked at aspects of the overall analysis of security information and event-related data, which I won’t go through again here. There are three basic use cases for how and why you report findings based on your monitoring, surveillance, testing, assessment, and observations that you gather as a security professional “just by walking around.” The first is the ad hoc query, the question from a manager, leader, or a co-worker, which may or may not have a bearing you’re aware of on a decision that needs to be urgently made. As with the question itself, the format and content of your reply may be very ad hoc and informal. The second use case is that of the routine and required reporting of information, results, observations, conclusions, and recommendations. Formats, expected content, and even the decision logic you use in coming to required conclusions and recommendations may be well structured for you in advance, although there’s probably more room for you to think outside of the box on those conclusions and recommendations than you might believe. Those first two use cases don’t really involve escalation, which is defined as the urgent notification to higher levels of management, leadership, or command that something has been observed or is happening that may require their urgent attention. Escalation procedures may require a link-by-link climb up the chain of command, or it may require directly engaging with designated officials at higher levels when appropriate. Escalation separates this third data analysis and reporting use case from the previous two: When analysis results dictate that a decision needs to be made now, or at least very quickly, escalation is in order. Kipling’s six wise men4 can be helpful to you in formulating the report, finding, or recommendation that you’re about to launch up to higher headquarters. What has happened? Where did it happen, and which systems or elements of your organization are involved in it? Why do you believe this to be the case? When did it happen (or is it still happening now)? How did it happen? Who or what in your organization or your objectives is endangered, is impacted, may be harmed, or likely won’t be able to conduct normal operations because of this? And what do you recommend we do, and how quickly, in response to this news flash? Your organization’s escalation procedures should detail those sorts of essential elements of information that your target audience needs to know; if they don’t, write your own checklist-style format guide that prompts you in addressing each key point. If you’re not in a real-time escalation firefight, take the time to get a second opinion, or a sanity check from your boss, and include those views into your checklist. Share it with other team members, just in case they have to use it in real time. By this point you’ve seen three vitally important concepts come together to shape, if not dictate, what you must achieve with your risk management and risk mitigation plans, programs, and actions. The first is that your organization faces a unique set of risks and challenges, and given its own goals, objectives, and appetite for risk, it must choose its own set of risk management and mitigation strategies, tactics, and operational measures and controls. The second is that the advanced persistent threat actors you face probably know your systems better than you do and are spending more effort and resources in learning to exploit vulnerabilities in your systems than you’re able to spend in finding and fixing them. The third painful lesson of this chapter is that you’ll need more data and more analysis tools, which you’ll use nonstop, 24/7, to maintain constant vigilance as you seek precursors and indicators of behavioral anomalies that might suggest that your systems are under attack. Or have already been attacked. You’ve got a lot of opportunity to improve, as one sad statistic indicates. Each year, the cybersecurity industry average for how long it takes for businesses to notice that an intruder is in their e-midst keeps going up; as of April 2019, that number stands at more than 220 days.Defeating the Kill Chain One Skirmish at a Time
![]() Real World Example:
Real World Example:Identity Theft as an APT Tactical Weapon
Kill Chains: Reviewing the Basics
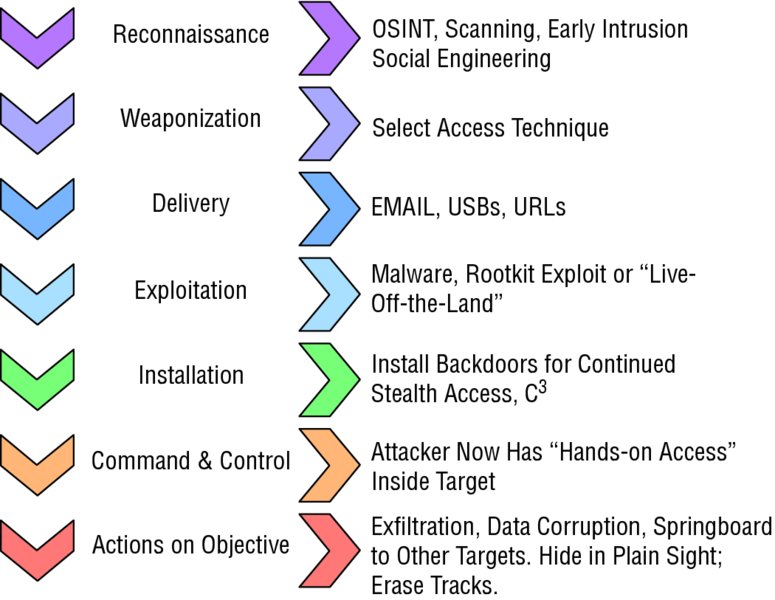
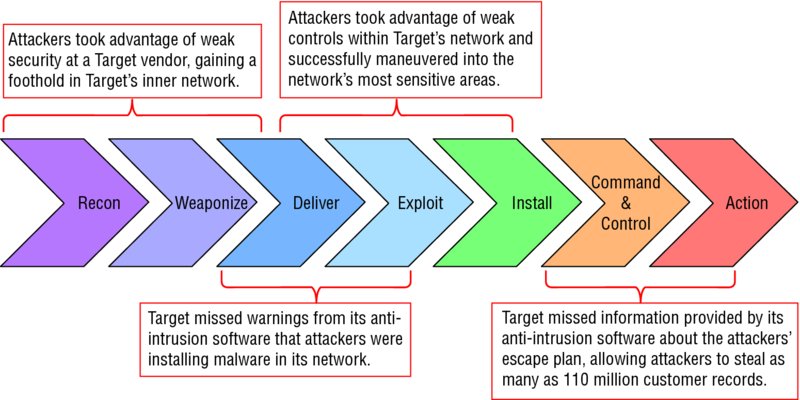
![]() Avoid Stereotyping the APTs
Avoid Stereotyping the APTsEvents vs. Incidents
Understand the Risk Management Process
![]() Who Owns Risk Management?
Who Owns Risk Management?
Risk Visibility and Reporting
Risk Register
Threat Intelligence Sharing
CVSS: Sharing Vulnerability and Risk Insight
![]() Start with the CVE?
Start with the CVE?Risk Management Concepts
Information Security: Cost Center or Profit Center?
![]() Paybacks via Cost Avoidance
Paybacks via Cost AvoidanceHow Do We Look at Risk?
Note
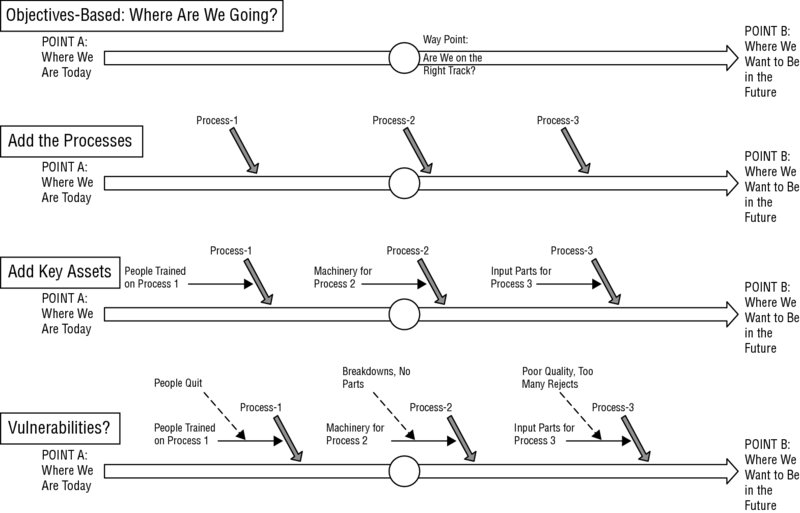
Outcomes-Based Risk
Process-Based Risk
Asset-Based Risk
Threat-Based (or Vulnerability-Based) Risk
Impact Assessments
Quantitative Risk Assessment: Risk by the Numbers

Qualitative Risk Assessment
Threat Modeling
Secure Development Lifecycle and STRIDE
NIST 800-154 Data-Centric Threat Modeling
PASTA
OCTAVE
Other Models
Business Impact Analysis
![]() Compliance as a Risk to Manage?
Compliance as a Risk to Manage?
Risk Management Frameworks

Comprehensive Frameworks
U.S. Federal Information Processing Standards
Committee of Sponsoring Organizations
ITIL
COBIT and RiskIT
Industry-Specific Risk Frameworks
Health Information Trust Alliance Common Security Framework
North American Electric Reliability Corporation Critical Infrastructure Protection
ISA-99 and ISA/IEC 62443
Payment Card Industry Data Security Standard
Risk Treatment
Accept
Transfer
Remediate or Mitigate (also Known as Reduce or Treat)
![]() When in Doubt, What’s the Requirement Say?
When in Doubt, What’s the Requirement Say?Avoid or Eliminate
Recast
Residual Risk
Risk Treatment Controls
Physical Controls
Logical (or Technical) Controls
Administrative Controls
Choosing a Control
Build and Maintain User Engagement with Risk Controls
Perform Security Assessment Activities
![]() The Black Hats Are Outspending You on Their Assessments!
The Black Hats Are Outspending You on Their Assessments!Security Assessment Workflow Management
Tip
Participate in Security Testing
Black-Box, White-Box, or Gray-Box Testing
Look or Touch?
Vulnerability Scanning
![]() Scanners Can’t Protect You Against Zero-Day Exploits
Scanners Can’t Protect You Against Zero-Day ExploitsAdding a Security Emphasis to OT&E
Ethical Penetration Testing
![]() Pen Testing and Moral Hazards
Pen Testing and Moral HazardsAssessment-Driven Training
Design and Validate Assessment, Test, and Audit Strategies
Interpretation and Reporting of Scanning and Testing Results
Remediation Validation
Audit Finding Remediation
Manage the Architectures: Asset Management and Configuration Control
What’s at Risk with Uncontrolled and Unmanaged Baselines?
Auditing Controlled Baselines
Operate and Maintain Monitoring Systems
![]() ISCM Is a Strategy; SIEM Is Just One Tool
ISCM Is a Strategy; SIEM Is Just One ToolEvents of Interest
Anomalies
Intrusions
Unauthorized Changes
Compliance Monitoring Events
Synthetic Transactions
Real User Monitoring
Logging
![]() CIANA Applies to Log Files Too!
CIANA Applies to Log Files Too!
Source Systems
![]() Data Collection and Processing: Probably Cheaper Than Disaster Recovery
Data Collection and Processing: Probably Cheaper Than Disaster RecoveryOn-Premises Servers and Services
Applications and Platforms
External Servers and Services
Workstations and Endpoints
Network Infrastructure Devices
IoT Devices
Legal and Regulatory Concerns
![]() Your Logbooks as Your Lifeline
Your Logbooks as Your LifelineAnalyze Monitoring Results
![]() Anomaly Detection: The Emerging Trend
Anomaly Detection: The Emerging TrendSecurity Baselines and Anomalies
Note
Define the Behavioral Baselines
Finding the Anomalies
Do You Blacklist or Whitelist Behaviors?
Visualizations, Metrics, and Trends
Event Data Analysis
Document and Communicate Findings
Summary
Notes