Cryptography is the art and science of “secret writing” and has been used for thousands of years to provide its users with some degree of protection for their messages, documents, and other information. Today, it is the backbone of our e-business e-society—without pervasive, nonstop use of cryptography as an infrastructure, online banking, international business, personal communications, defense, and national security would be far more difficult (and far less profitable!) to conduct. Cryptography provides powerful ways to prove that a document or a file is what it claims to be and keep it secret and safe. It authenticates people and organizations as well. The transparency, reliability, and integrity of information are all enhanced by smart use of cryptographic systems and techniques. Criminals, too, make use of it; there was no practical way to keep cryptography secret and make it the province of princes and presidents only. In fact, the only thing you can keep secret about your cryptographic systems are your keys, and they don’t stay secret for long either!
This chapter takes you through the hands-on details of the building blocks of modern cryptographic systems; these systems are a fascinating hybrid of classical techniques and cutting-edge algorithms and technologies. You’ll gain an appreciation for the “hard” math that drives cryptosystem designs and the somewhat easier math of how the basics of encryption work. So much of modern encryption comes together in our public key infrastructure, and this chapter will help you bring all these threads together in practical ways that you can apply in your business, professional, or personal quests for CIANA+TAPS—confidentiality, integrity, availability, nonrepudiation, authentication, transparency, auditability, privacy, and safety, as aspects of your information security needs.
There’s an oversimplification that many information systems users, and their managers, often fall prey to—the belief that if you just “sprinkle a little crypto dust” over your systems, you can almost magically make them totally secure. It’s natural perhaps to think this way, since cryptography seems to be pervasive; it’s everywhere we look. Following this approach can be expensive and probably won’t work very well. You’ll see in this chapter that there are some high-leverage applications of cryptography that are well understood and should be part of your systems architecture today. The heart of these applications are the secure protocols, such as public key encryption, that make up the bulwark of our information security defenses today.
Understand Fundamental Concepts of Cryptography
In simple terms, cryptography embraces everything involved with protecting the meaning (or contents) of a message or a file by means of manipulations performed on that meaning. Some cryptographic techniques transform that meaning—that plaintext input—into something that is as meaningless as possible to someone else; only those people or processes that can unlock (decrypt) that ciphertext can recover its original meaning and intent. Other cryptographic techniques produce a unique ciphertext that cannot be decrypted to reveal its associated meaning; these one-way hash functions prove incredibly useful in digital signatures, file or message integrity and authenticity verification, and many other security-enhancing ways. Cryptographic techniques can be applied to digital signals as well as to analog signals. In many respects the math is the same: an algorithm is used to define how to transform plaintext into ciphertext; that algorithm uses a key, and some control variables, to make the output ciphertext unique. An inverse of that algorithm, along with a key and the control variables, allow the recovery of plaintext from the ciphertext. (We call it text whether the signal being encrypted and decrypted is an analog or digital one.) We won’t look at analog cryptography any further, as it’s beyond the jobs that most SSCPs perform; just be aware that up until the 1980s it was the backbone of many secure communications systems for national security systems, including secure voice telephony and radio links, and still has important uses today.
The math of digital encryption is either simple or far more complicated depending upon the security needed. Symmetric encryption uses simple transformation and substitution to encrypt and decrypt. Symmetric encryption is fast; it’s a workhorse of our systems, but its real weakness is its use of the same key to encrypt and decrypt. Asymmetric algorithms, by contrast, use complex algebraic functions to combine plaintext, key, and control variables to produce the ciphertext, and an inverse and equally complex algorithm to decrypt the plaintext. These algorithms use different keys for encryption and decryption, and it’s considered computationally infeasible to compute the decryption key from the encryption key alone. Asymmetric encryption is compute-intensive, using tremendous numbers of CPU cycles to encrypt or decrypt a message; but, it’s incredibly secure. If you’re wondering which to use and when, the answer most likely is a mix of both.
Properly used, cryptography brings many capabilities to the information systems designer, builder, user, and owner.
Confidentiality: Protect the meaning of information and restrict its use to authorized users.
Utility: Map very large sets of possible messages, values, or data items to much smaller, more useful sets.
Uniqueness: Generate and manage identifiers for use in access control and privilege management systems.
Identity: Validate that a person or process is who and what they claim to be (also known as authentication).
Privacy: Ensure that information related to the identity of a person or process is kept confidential, and its integrity is maintained throughout.
Nonrepudiation: Provide ways to sign messages, documents, and even software executables so that recipients can be assured of their authenticity.
Integrity: Ensure that the content of the information has not been changed in any way except by authorized, trustworthy processes.
Authorization: Validate that messages, data, subjects, processes, or objects have been granted the privileges or rights to perform the actions they are attempting to execute.
Privacy and Confidentiality
Separating privacy and confidentiality has become much more important in recent years, particularly with the increased emphasis on protecting data related to personal identity. (Some standards, such as the Trust Service Principles used extensively by the financial industry, also distinguish between personally identifying information [PII] and nonpublic information [NPI]; you’d best check if this distinction applies or should apply in your industry or organization’s marketplaces.) Increasingly, business and government have to address privacy in the aggregate, when large data sets containing PII or NPI on millions of individuals are merged, processed together, or used as collateral sources for data quality and verification purposes. Such aggregation of data runs the risk of compromises in one element of the aggregate cross-contaminating or cross-compromising data in another, even if individual customer or personal records in their original places remain unchanged.
Cryptographic techniques can be used to protect data at rest, in motion, and in use; in doing so, they also can protect data through time, by providing ways to protect data in long-term storage from being exposed to decryption and compromise. Whether this forward secrecy is perfect or imperfect depends primarily upon the choice of algorithms and keys, as you’ll see in this chapter. Because of its powerful capabilities to ensure the integrity of information while enforcing access control policies and privileges regarding that data, cryptographic systems can make significant improvements in the reliability, availability, resilience, and safe operation of almost any information system.
Plaintext or Cleartext?
Depending upon where you look, these terms can either mean the same thing or have different meanings.
Plaintext is the original, unencrypted form of the data, in a form where its meaning or value is readily apparent. Whether it is human-readable characters or binary object code, plaintext is the data that we ultimately use. (This meaning will be used throughout this chapter.)
Cleartext can either mean (a) plaintext or (b) data that is never intended to be transmitted, stored, or used in anything but an unencrypted form with its meaning and value available to anyone to read.
This distinction between data that we must protect and data that is always “in the clear” is important. For example, the name of a business (like IBM or Microsoft) would always be cleartext (able to be read and recognized) on websites.
Note that you’ll often see these terms—and many other information security terms—written in hyphenated form, as single words, or as compound nouns. This minor inconsistency can show up across many different documentation products in your organization. Don’t let it throw you.
As an SSCP, be aware of how the other information security team members in your organization may use these terms…with or without a hyphen.
Building Blocks of Digital Cryptographic Systems
Let’s first take a closer look at some of these fundamental concepts of cryptography in action; then, in subsequent sections, we can look at the details you’ll need to be aware of, or make use of, as you incorporate such cryptographic techniques into systems you’re trying to keep secure.
Digital systems represent all information as a series of numbers (and these numbers are ultimately a series of binary digits, 1s and 0s); by contrast, analog systems represent information as a continuously variable physical value. When you make a voice-over-IP (VoIP) call, the sender’s speech (and background sounds) must be transformed from the digital form sent over the Internet into acoustic waves in the air that your ears can detect and process; the signal fed into that acoustic device (the headphone) is an analog electrical wave. (Protecting your VoIP conversations requires that you consider protecting the digital data in motion, at rest in recorded versions such as .mp3 files, and in use, by protecting both the digital and analog presentation of the call.) There are many ways to encrypt and decrypt analog signals which we won’t go into here, since they’re beyond what most of us in computing and networking ever encounter.
Cryptographic Algorithms: The Basics
A cryptographic algorithm defines or specifies a series of steps—some mathematical, some logical, some grouping or ungrouping of symbols, or other kinds of operations—that must be applied, in the specified sequence, to achieve the required operation of the system. Think of the algorithm as the total set of “swap rules” that you need to use, and the correct order to apply those rules in, to make the cryptographic system work properly. (Note, too, that I sometimes use cryptographic algorithm and encryption algorithm as interchangeable terms, even though a decryption algorithm is part of the same system too.) We mentioned before that the basic processes of substitution and permutation (also called transposition) can be repetitively or iteratively applied in a given cryptographic process. The number of rounds that an algorithm iterates over is a measure of this repetition. A combination of hardware and software features can implement this repetition. In many cases, these algorithms require a set of control parameters, such as seeds, salts, keys, block size, and cycle or chain (iteration) values. Both sender and (intended) receiver must agree to use a mutually consistent set of algorithms and control parameters if they are to successfully use cryptographic processes to send and receive information.
Encryption and decryption processes can suffer from what we call a collision, which can render them unusable. This can occur if one of the following happens:
Two different plaintext phrases should not map (encrypt) to the same ciphertext phrase; otherwise, you lose the difference in meaning between the two plaintext inputs.
Two different ciphertext phrases should not map (decrypt) to the same plaintext phrase; otherwise, you have no idea which plaintext meaning was intended.
Substitution and permutation are done in a series of steps to help make the encryption harder to break. Different cryptographic algorithms define these operations in unique ways and then go on to specify the order in which these combinations of substitutions and permutations is to be performed. Two broad classes of encryption algorithms, symmetric and asymmetric, make up the backbone of our cryptographic infrastructures.
Symmetric vs. Asymmetric Encryption
Both symmetric and asymmetric algorithms depend heavily on advanced mathematical concepts drawn from set theory, group theory, and number theory. These algorithms treat their input plaintext as a set of numbers—not as characters, phrases in a human language, images, or even executable machine language. As a result, the same algorithm, when used with the same keys and cryptovariable settings, will demonstrate the same cryptographic strength regardless of the type of data used as input plaintext.
Cryptovariables Are Not Keys
Nearly all cryptographic systems consist of an algorithm plus a variety of processes that are used to initialize the system, break the input plaintext down into groups of symbols, manage the flow of plaintext and ciphertext through the systems, and control other operational aspects of the system overall. Example cryptovariables might be the seed or salt values, block size, or what bytes to use in padding blocks out to their required length.
These control parameters are not the encryption or decryption keys themselves, although in some cryptosystems, the values of these cryptovariables are considered part of the total set of keying materials that are distributed by the key distribution and management processes used with that system.
Symmetric algorithms were the first to find extensive use in electronic and electromechanical form, notably in the cipher machines used throughout the first half of the 20th century. These algorithms perform relatively simple operations on each element of the plaintext input (bit, byte, or block), but they do a substantial number of them in combination and iteration to achieve some surprisingly powerful encryption results. By arranging the plaintext into blocks, and those blocks into two-dimensional matrices, permutation can swap rows, columns, or both in various blocks of an input plaintext. Substitution can also use these rows or columns (or whole blocks) as input values to functions that further obscure the meaning of the plaintext. Symmetric algorithms use the same key for encryption and decryption, or a simple transformation of one into the other. Symmetric algorithms usually must work on fixed-length blocks, and thus the last block will be padded to the block length specified by the controlling cryptovariables.
In addition to overall cryptographic strength (measured by resistance to attacks or the work factor or time required for a successful brute-force attack), the speed of processing is a major requirement for an effective symmetric algorithm. As a result, many hardware and software implementations will take the explicit iteration expressed as loops in the algorithm’s design and implement them in sequentially repeated blocks of code, hardware, or both. Symmetric encryption provides straightforward ways to protect large sets of data, whether in motion, at rest, or in use. However, this protection fundamentally rests upon the strategy used to choose and manage the encryption keys used with the chosen algorithm.
Asymmetric encryption does not use the same key for encryption and decryption; in fact, its cryptographic strength and utility derives from the fact that it is almost impossible to determine the decryption key from the algorithm alone, the encryption key itself, and the ciphertext it produces. It relies on so-called trapdoor functions that are relatively easy and straightforward to compute in one direction (for encryption), but their logical inverse is difficult if not impossible to compute in the other direction.
Asymmetric encryption came into practical use as a way of addressing three inherent problems with the widespread use of symmetric encryption: key distribution and management, improved security, and the management of trust relationships. These three sets of concepts are so interrelated that in many respects, it’s hard to explain one of these big sets of ideas without using the other two to do so!
Figure 5.1 summarizes the modern families of cryptographic algorithms by types, mathematical algorithms, and use. It also gives a quick round-up of the various protocols used in the public key infrastructure and in key management in general. As an SSCP, you’re going to need to be on a first-name basis with most if not all of the items shown on this “family tree.” Throughout this chapter we’ll use members of each branch of this tree to demonstrate important concepts and provide relevant details.
Cryptographic keys are a set of data that the encryption algorithm combines with the input plaintext to produce the encrypted, protected output—the ciphertext. Many different processes have been used over the centuries to produce encryption and decryption keys for use with a particular encryption algorithm or process.
Published books, such as a specific edition of Shakespeare’s Romeo and Juliet, Caesar’s Commentaries, or even holy scriptures can provide a lookup table for either substitution or permutation operations. Bob, for example, could use such a book to encrypt a message by starting on a pre-agreed page, substituting the first letter in his plaintext for the first letter of the first line on the page. Carol would decrypt his message by using the same print edition of the book and go to the same pre-agreed page.
One-time pads are a variation of using published books (and predate the invention of movable type). The key generator writes out a series of key words or phrases, one per sheet of paper, and makes only one copy of this set of sheets. Carol encrypts her message using the first sheet in the one-time pad and then destroys that sheet. Alice decrypts the ciphertext she receives from Carol using that same sheet and then destroys that sheet.
Pseudorandom numbers of various length are also commonly used as keys. Senders and recipients each have a copy of the same pseudorandom number generator algorithm, which uses a seed value to start with. A sequence of pseudorandom numbers from such an algorithm provides either a one-time pad of encryption keys or a keystream for stream cipher use.
Hardware random and pseudorandom number generators, combined with software functions, can also generate keys or keystreams. The latest of these use quantum computing technologies to generate unique keystreams.
In theory and in practice, the one-time pad encryption process is the only truly unbreakable system—when it is used correctly. Well-designed and properly used one-time systems have still resisted attempts to crack them, decades later. In fact, there are products available today that use quantum effects to generate gigabit-length key streams as one-time pads, burned into read-once memory devices, which are distributed to the two parties via bonded, trusted couriers. Once all the bits of that key have been used, the parties must buy new keys. Attempts to read the key values consumes them. Session keys are a form of one-time key system, but they aren’t a one-time pad key distribution approach.
If the algorithm is known to our adversaries (and probably published in an information security, mathematics, or cryptography journal anyway), how is it that the key provides us the security we need? Cryptologic key strength is a way to measure or estimate how much effort would be required to break (that is, illicitly decrypt) a cleartext message encrypted by a given algorithm using such a key. In most cases, this is directly related to the key size, defined as how many bits make up a key. Another way to think of this is that the key strength determines the size of the key space—the total number of values that such a key can take on. Thus, an 8-bit key can represent the decimal numbers 0 through 255, which means that an 8-bit key space has 256 unique values in it. Secure Socket Layer (SSL) protocol, for example, uses a 256-bit key as its session key (to encrypt and decrypt all exchanges of information during a session), which would mean that someone trying to brute-force crack your session would need to try 2256 possible values (that’s a 78-digit base-10 number) of a key to decrypt packets they’ve sniffed from your session. With one million zombie botnet computers each trying a million key values per second, that still needs 1059years to go through all values. (If you’re thinking of precomputing all such values, how many petabytes might such a “rainbow table” take up?)
Key distribution and management become the biggest challenges in running almost any cryptographic system. Keying material is a term that collectively refers to all materials and information that govern how keys are generated and distributed to users in a cryptographic system and how those users validate that the keys are legitimate. Key management processes govern how long a key can be used and what users and systems managers must do if a key has been compromised (by falling into the wrong hands or by a published cryptanalysis demonstrating how easily such keys can be guessed). Key distribution describes how newly generated keys are issued to each legitimate user, along with any updates to the rules for their period of use and their safe disposal.
Key distribution follows the same topological considerations as networks do; point-to-point, star, and full-mesh models express how many users of a cryptographic system need to share keys if they are to communicate with each other and under what rules for sharing of protected information. Consider these three typical topologies from a key distribution and management perspective. The simple one-time pad system connects only two users; only one pair of pads is needed. Most real-world needs for secure communication require much larger sets of users, however. For a given set of n users, the star topology requires n pairs of keys to keep traffic between each user and the central site secure and private—from all other users as well as from outsiders. A full-mesh system requires [n × (n – 1)] sets of keys to provide unique and secure communication for each pair of users on this mesh.
Exploitable vulnerabilities will exist in whatever choices you make regarding key generation, distribution, management, and use. Examining these vulnerabilities can also reveal ways that you as the security architect can mitigate the risks that they raise; this is covered in some detail later in this section by addressing cryptanalysis attacks and other attacks on the encryption elements of your information security posture. You’ll also look closely at a number of countermeasures you can use to mitigate these risks.
“The Enemy Knows Your System!”
Mathematician and information theorist Claude Shannon’s maxim rather bluntly restates Dutch cryptographer Auguste Kerckhoffs’s principle from 1883. Whether by burglary, spies, analysis, or just dumb luck, Kerckhoffs first summed up the growing sense of mathematicians and cryptographers by saying that the secrecy of the messages—the real secrets you want to protect—cannot depend on keeping your cryptographic system and its algorithms and protocols secret. The one thing that determines whether your secrets are safe is the cryptographic key that you use and its strength and secrecy. If this key can be guessed, reversed-engineered from analysis of your ciphertext, stolen, or otherwise compromised, your secrets become known to the attacker.
Shannon’s maxim dictates that key management provides the highest return on our investments in keeping our secrets safe and secure; and the problems and pitfalls of key management lead us just as inexorably to using the right mix of hybrid encryption systems.
Protocols and Modules
The term cryptographic protocols can refer to two different sets of processes and techniques. The first is the use of cryptography itself in the operation of a cryptographic system, which typically can refer to key management and key distribution techniques. The second usage refers to the use of cryptographic systems and techniques to solve a particular problem. Secure email, for example, can be achieved in a variety of ways using different protocols, each of which uses different cryptographic techniques. We’ll look at these more closely later in this chapter.
A cryptographic module, according to Federal Information Processing Standards (FIPS) publication 140, is any combination of hardware, firmware, or software that implements cryptographic functions. What’s interesting about FIPS 140 is that it directly addresses the security of an information systems supply chain with respect to the underlying supply chain of its cryptographic elements. To earn certification as a cryptographic module, vendors must submit their works to the Cryptographic Module Validation Program (CMVP) for testing.
Notice that a vital element of encryption and decryption is that the original meaning of the plaintext message is returned to us—encrypting, transmitting, and then decrypting it did not change its meaning or content. The ciphertext version of information can be used as a signature of sorts—a separate verification of the authenticity or validity of the plaintext version of the message. Digital signatures use encryption techniques to provide this separate validation of the content of the message, file, or information they are associated with.
This brings us to a cryptographic system, which is the sum total of all the elements we need to make a specific application of cryptography be part of our information systems. It includes the algorithm for encrypting and decrypting our information; the control parameters, keys, and procedural information necessary to use the algorithm correctly; and any other specialized support hardware, software, or procedures necessary to make a complete solution.
Sets and Functions
The simple concepts of sets and functions make cryptography the powerful concept that it is. As an SSCP, you should have a solid, intuitive grasp of both. The good news? As a human being, your brain is already 90 percent of the way to where you need to go!
Sets provide for grouping of objects or items based on characteristics that they have in common. It’s quite common to represent sets as Venn diagrams, using nested or overlapping shapes (they don’t always have to be circles). In the following figure, part (a) shows an example of proper subsets—one set is entirely contained within the one “outside” it—and of subsets, where not all members of one set are part of another (they simply overlap). Part (b) of the figure shows a group of people who’ve earned one or more computer security-related certifications; many only hold one, some hold two, and a few hold all three, as shown in the overlapping regions. If a subset contains all elements of another subset, it is called an improper subset.
Functions are mathematical constructs that apply a given set of operations to a set of input values, producing an output value as the result. We write this as:
f(x) = y or f(x) → y
The second form, written as a production function, shows that by applying the function f to the value x, we produce the value y.
Note that for any given value of x there can be only one y as a result.
For example, a simple cryptographic substation might be written as f(x) = mod(xor(x,keypart),b), where b is the number base for the modulo function, x is the input plaintext, and key is the portion of the key to exclusive-or with x. Cryptographic permutation might be written as f(x1x2x3….x8) = x8…x3x2x1, which transposes an 8-symbol input plaintext into its reverse order as ciphertext.
One powerful application of functions is to consider them as mapping one set to another. The previous function says that the set of all values of x is mapped to the set y. This is shown in part (c) of the figure, which shows how a list of out-of-limit conditions is mapped to a list of alarms. (This looks like a table lookup function.) If you wanted any of a set of conditions to trigger the same alarm, you wouldn’t use a function; you’d end up with something like the “check engine” light in automobiles, which loses more meaning than it conveys!
Not all mappings have to map every element of the source set into the destination set, nor do they use every element in the destination; some of these pairs (x,y) are just undefined. For example, the division function f(x) = y/x is undefined when x = 0 but not when y = 0.
Cryptography, Cryptology, or ?
There are many different names for very different aspects of how we study, think about, use, and try to crack “secret writing” systems. Some caution is advised, and as an SSCP you need to understand the context you’re in to make sure you’re using the right terms for the right sets of ideas.
For example, as Wikipedia and many others point out, many people, agencies, and academics use the terms cryptography and cryptology interchangeably, as if they mean the same things. Within the U.S. military and intelligence communities and those of many NATO nations, however, these terms have definite meanings.
Cryptography refers specifically to the use and practice of cryptographic techniques.
Cryptanalysis refers to the study of vulnerabilities (theoretical or practical) in cryptographic algorithms and systems and the use of exploits against those vulnerabilities to break such systems.
Cryptology refers to the combined study of cryptography (the secret writing) and cryptanalysis (trying to break other people’s secret writing systems or find weaknesses in your own).
Cryptolinguistics, however, refers to translating between human languages to produce useful information, insight, or actionable intelligence (and has little to do with cryptography).
You may also find that other ways of hiding messages in plain sight, such as steganography, are sometimes included in discussions of cryptography or cryptology.
Note, though, that cryptograms are not part of this field of study or practice—they are games, like logic puzzles, which present ciphers as challenges to those who want something more than a crossword puzzle to play with.
Black hats, gray hats, and white hats alike conduct all of these various kinds of cryptography-related activities.
Hashing
Hashing is considered a form of one-way cryptography: you can hash a plaintext value into its hash value form, but you cannot “de-hash” the hash value to derive the original plaintext value, no matter what math you try to use. This provides a way to take a very large set of expressions (such as messages, names, or values) and map them down to a much smaller set of values. Hash algorithms transform the original input plaintext, sometimes called the long key, into a hash value, hash key, or short key, where the long keys can be drawn from some arbitrarily large set of values (such as personal names) and the short key or hash key needs to fit within a more constrained space. The hash key, also called the hash, the hash value, the hash sum, or other term, is then used in place of the long key as a pointer value, an index, or an identifier.
Two main properties of hash functions are similar to those of a good encryption function.
The hash function must be one way: there should be no computationally feasible way to take a hash value and back-compute or derive the long key from which it was produced.
The hash function must produce unique values for all possible inputs; it should be computationally infeasible to have two valid long keys as input that produce the same hash value as a result of applying the hash function.
Compare these two requirements with the two main requirements for any kind of encryption system, as shown in Figure 5.2. Hashing and encryption must be one-to-one mappings or functions—no two input values can produce the same output value. But encryption must be able to decrypt the ciphertext back into one and only one plaintext (the identical one you started with!); if it can’t, you’re hashing, aren’t you?
FIGURE 5.2 Comparing hashing and encryption as functions
As with encryption algorithms, hash algorithms need to deal with collisions (situations where two different long key inputs can hash to the same hash value). These are typically addressed with additional processing stages to detect and resolve the collision.
Some of the most powerful uses of hashing include the following:
Anonymization of user (subject) IDs and credentials: This is often done locally on the client, with the hash value being transmitted to the server, where hashed values are stored for comparison and authentication. User ID, password, and other factor information is typically hashed as separate values.
Error detection and integrity checking for files, messages, or data blocks: The hash is computed when the file is stored and travels with the file. Each time the file is used, a user function recomputes the hash and compares; a change of even a single bit in the file will produce a mismatching hash value. These are sometimes called digital fingerprints or checksums when used to detect (and possibly correct) errors in file storage or transmission.
Efficient table (or database) lookup: Compressing or collapsing a large, sparse set of possible values (such as personal names) into a smaller but unique set of lookup key values makes the search space much smaller. Personal names, for example, might be written with any of the 26 Latin alphabet characters and a handful of punctuation marks and could be as long as 50 or 60 characters; they may have culturally or ethically dependent letter frequencies (vowels in Polynesian names versus certain consonants in Eastern European ones). One practical hash might produce an 8-byte hash value to compress this space. As each name is encountered, it is hashed, and the table is searched to see if it already has been entered into the table; if not, it’s entered in. Indexing schemes used for files, databases, and other applications often make use of hashes this way.
Secure message digests or hashes: These provide ways to authenticate both the contents of a file and its originator’s identity.
A number of published standards define secure hash functions for use in various kinds of information security systems. The SHA series of Secure Hash Algorithms, published by the NSA, is one such series; the original SHA-0 and SHA-1 standards have been shown to be vulnerable to collision attacks and are being disbanded for use with SSL and its successor TLS.
Hashes used for indexing and lookup functions may not need to be as secure as those used in secure message digests, digital signatures, or other high-integrity applications. The greater the need for a secure hash, the more important it is to have a reliable source of random or pseudorandom numbers to seed or salt that hash algorithm with.
Pseudorandom and Determinism
The science of probability gives us a strong definition of what we mean by “random.” A random event is one whose outcome cannot be determined in advance with 100 percent certainty. Flipping a “perfect” coin or rolling a “perfect” pair of dice is a good example—in which “perfect” means that no one has tampered with the coin or the dice and the way that they are flipped, rolled, or tossed offers no means of controlling where they land and come to rest with the desired outcome showing. One hundred perfect tosses of a perfect coin will produce 100 random outcomes (“heads” or “tails”) for that sequence of 100 events. But despite our intuition as gamblers and humans, the fact that 100 “heads” have been flipped in a row has no bearing whatsoever on what the outcome of the next flip will be as long as we are perfectly flipping a perfect coin. So, the sequence of outcomes is said to have a random distribution of values—any one value has the same likelihood of occurring at any place in the sequence.
In computing, it is difficult to compute purely random numbers via software alone. Specialized hardware can, for example, trigger a signal when a cosmic ray hits a detector, and these natural events are pretty close to being perfectly randomly distributed over time. The beauty of computing is that once you write an algorithm, it is deterministic—given the same input and series of events, it always produces the same result. (Think what it would mean if computers were not deterministic!)
If we look at a very large set of numbers, we can calculate the degree of statistical randomness that set represents. There are lots of ways to do this, which are (blissfully!) well beyond the scope of what SSCPs need in the day-to-day of their jobs. If we use a deterministic algorithm to produce this set of numbers, using a seed value as a key input, we call such sets of numbers pseudorandom: the set as a whole exhibits statistical randomness, but given the nth value of the sequence and knowing the algorithm and the seed, the next element of the sequence—the (n + 1)th value—can be determined. (You can visualize this by imagining what happens when you drop a family-sized container of popcorn across your dark blue living room carpet. It’s incredibly difficult to precompute and predict where each bit of popcorn will end up; but look at the patterns. A spray pattern would reveal that you threw the container across the room while standing in one location; other patterns might indicate a stiff breeze was coming in through the windows or the doorway or that you lofted the container upward rather than waved it about in a side-to-side way. A purely random popcorn spill would not have any patterns you could detect.)
Modern operating systems use such pseudorandom number generators for many purposes, some of which involve the encryption of identity and access control information. In 2007, it was shown that the CryptGenRandom function in Windows 2000 was not so random after all, which led to exploitable vulnerabilities in a lot of services (such as Secure Sockets Layer) when supported by Windows 2000. The math behind this claim is challenging, but the same pseudorandom number generator was part of Windows XP and Vista.
Entropy is a measure of the randomness of a system; this term comes from thermodynamics and has crossed over into software engineering, computer science, and of course cryptography. A simple web search on entropy and cryptography will give you a taste of how rich this vein of ideas is.
Salting
One exploitable weakness of hashing is that the stored hash value tables are vulnerable to an attacker precomputing such values themselves; such a rainbow table can then be used in a brute-force (all values) or selectively focused attack to attempt to force a match leading to a false positive authentication, for example. Let’s look at password protection via hashing as an example. The goals of such protection, as they apply to the use of hashing, would be that:
An attacker is unlikely to be able to determine the original password from the hashed value.
An attacker is unlikely to be able to generate a random string of characters that will hash to the same value as the original password (known as a collision).
However, simply hashing the password down into a shorter hash value creates an exploitable vulnerability if the password has been reused, is used by another user, or consists of common words. Simple comparisons with captured hash tables or hash values intercepted via packet sniffing could provide a sufficient set of samples that would facilitate such an attack. This is particularly true if the hash function in question is one that has widespread use on many systems (as most hash functions do).
By using a secret salt value added to the input long key to initialize the calculations, the defenders in effect increase the attacker’s rainbow tables to impractical sizes. The salt value is typically a random (well, pseudorandom) value that is included with the input long key; if the hash algorithm is dealing with a 256-byte long key, a two-byte salt value effectively has the algorithm work on long keys that are 258 bytes long. That two bytes may not sound like much, but it is a 65,535-fold increase (216) of the number of rainbow table values that the attacker must precompute and compare.
You can see why combining a random salt with lengthy pass phrases can be a significant security improvement. Using and storing different salt values for each protected credential and determining when and how to change salt values are some of the tricks that defenders can do to make it harder for attackers to find, scrape, harvest, guess, or otherwise work around the salt.
Note that brute-force attacks, such as credential replay ones, have a strong possibility of gaining knowledge of the salt. Once the attacker takes the salt and tries different possible passwords in an attempt to obtain a match, it’s more likely the attacker will succeed with matching to hash tables. If the user has chosen a simple or short password, then it matters little which hashing algorithm the security architect has chosen. But if the password is reasonably complex, then the security of the hash will depend on how computationally difficult the hashing algorithm is. For example, Microsoft used an overly simple hashing algorithm in NT LAN Manager (NTLM), and it was possible, using multiple GPU boards, to generate 350 billion password hashes per second, enabling an attacker to try every possible eight-character password in less than seven hours. LinkedIn used a more secure algorithm, SHA-1, to secure its users’ passwords, but when its password database was breached, high-powered password-cracking machines using multiple GPUs were able to break 90 percent of the 6.5 million passwords leaked.
Such multiple GPU systems are approaching, if not exceeding, the processing power of many commercial supercomputers, if only for a narrow niche of applications. (Supercomputers still have the massive edge over the GPU clusters in terms of overall data throughput and are still required for manipulating massive data sets.) The costs of ownership of such GPU systems continue to plummet, making them more affordable to a much larger number of black-hat cryptanalysts. As a result, and at the risk of oversimplifying, it makes it quite feasible to precompute massive rainbow tables for a given algorithm, against which one captured hashed password can be checked; a match indicates a corresponding password or passphrase. Jeremi Gosney’s research, published in 2012, suggests for example that such an NTLM rainbow table might be able to help crack a given password hash in six hours of run time, whereas a hash generated with a different algorithm such as bcrypt might take 3,300 years to crack. There’s also been a phenomenal (but predictable) growth in the number of online forums and resources that share both precomputed rainbow tables and services that exploit them.
The rapidly declining cost of cloud computing, particularly with functional or serverless computing models, continues to challenge our thinking about how infeasible and unaffordable such offline back-computation attacks against hash functions and encryption algorithms actually will be in the very near future. Thus, key sizes need to keep increasing and algorithms need to keep improving if we are to continue to enjoy strong but affordable cryptographic hashing for the masses.
The question then becomes: what is an appropriate cryptographic hash function? Appropriate sources of current information on cryptographic algorithms, key and salt lengths, and iteration counts (for password hashing) include the Password Hashing Competition (https://password-hashing.net/) and the U.S. National Institute of Standards and Technology (NIST).
Symmetric Block and Stream Ciphers
Let’s start with how our cryptographic systems process units of plaintext, whether that unit be a bit, byte, character, block, file, or even an entire storage volume. Early character cipher systems took each character of plaintext and applied substitutions to it, transposed it with other characters, and then repeated these processes in a number of rounds of processing, all based on the algorithm and its controlling cryptovariables. This gave rise to two additional cipher systems, block and stream, which are the two types of symmetric encryption algorithms in common use, which we’ll look at in some depth. The extensive development of block and stream cipher algorithms, systems, and technologies predate the birth of asymmetric algorithms by almost a hundred years, and for many very good reasons symmetric block and stream cipher systems are the backbone of our secure information systems today.
Stream vs. Streaming
Be careful to keep stream ciphers and streaming services separate and distinct in your mind and in your security planning. Streaming services provide large data volumes, such as multimedia, at normal real-time playback rates for users to enjoy and may or may not use flow control, error correction, retransmission, or other features normally associated with file transfers. A variety of protocols are used in supporting these, as you’ll see in Chapter 6, “Network and Communications Security.” Some streaming services even use block ciphers. Stream ciphers are used in ways that are often associated with streaming services, but the two do not have to go hand in hand.
Block Cipher Basics
Block ciphers take the input plaintext and break it into a fixed-length series of symbols (a block) and then encrypt and decrypt the block as if it was a single symbol. A block of 64 bits (8 eight-bit bytes) can be thought of as a 64-digit binary number, which is what the encryption algorithm would then work on. Block ciphers typically need to pad the last block of a fixed-length plaintext message (such as a file or an email) so that each block has the required length. Block ciphers are used both with symmetric and asymmetric encryption algorithms and keys; in the asymmetric case, the entire padded block is treated as a number, which then has some algebraic function applied to it, such as raising it to a power, to produce the resultant ciphertext.
As cryptographic engineers began building more and more complex systems, they modularized different functions into easily replicated hardware and software elements. Substitution is implemented in S-boxes, for example, while P-boxes perform permutation. Figure 5.3 shows a notional substitution operation (an S-box that does a table lookup), while Figure 5.4 shows a P-box that implements one particular transposition of its eight different input lines.
Many algorithms will split the input to each round of processing into pieces, such as a left half and a right half, and process them separately and recombine at the end of each round. Note that different algorithms will have their own unique definitions of what its S-boxes or P-boxes must perform (XOR, at least, is still an XOR). The Data Encryption Standard (DES) algorithm, which uses a 16-round Feistel network, is an example of rounds of S-Boxes and P-Boxes layered together. Figure 5.5 shows a notional Feistel network being used in encryption and decryption, and as you follow the flow through both processes, you’ll get a clearer sense of what cryptographers mean when they talk about iterating the permutations and substitutions.
FIGURE 5.5 Feistel encryption and decryption (notional)
Feistel networks or Feistel ciphers are named after Horst Feistel, a German-born cryptographer who designed block ciphers for the U.S. Air Force and IBM. Feistel’s passion was developing a cipher with repeating iterations or rounds. The use of S-boxes and P-boxes to create a repeating, often reversible structure, makes for a more easily wired or coded implementation that can be used to process a stream of text. DES is one example of a Feistel cipher construction. (AES, by contrast, is not a Feistel network.) Learn more about how the Feistel cipher process works during encryption and decryption at: https://www.tutorialspoint.com/cryptography/feistel_block_cipher.htm.
Block ciphers present some interesting problems and opportunities worth examining for a moment—padding, chaining and feedback, and optimization strategies such as the Electronic Code Book approach.
Padding and Block Ciphers
All block ciphers work on fixed-length blocks of plaintext (on one block at a time, of course), and these blocks must be padded out to the fixed block size that the algorithm is designed to use. This can be done by adding bytes (or bits) to the end of the short blocks, along with a counter value that indicates how much padding was used. Note how during decryption the last byte of the message block is examined to determine how many padding bytes have been added. If the plaintext is a multiple of the block size, then a final block that just contains padding must have been added. The padding bytes that have been added will thus need to be removed. Padding is not without its own risks, such as the Padding Oracle Attack described later in the “Side-Channel Attacks” section.
Cipher Block and Feedback Chaining
With Cipher Block Chaining (CBC), the first block of data is XORed with a block of random data called the initialization vector (IV). Every subsequent block of plaintext is XORed with the previous block of ciphertext before being encrypted. (See Figure 5.6.)
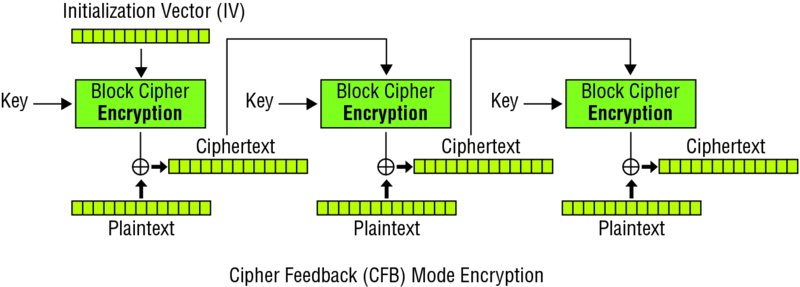
With Cipher Feedback (CFB) mode, the IV is encrypted and then XORed with the first block of the plaintext, producing the first block of ciphertext. Then that block of ciphertext is encrypted, and the result is XORed with the next block of plaintext, producing the next block of ciphertext. (See Figure 5.7.)
Because with both CBC and CFB the encryption of block Pn+1 depends on the encryption of block Pn, neither mode is amenable to the parallel encryption of data. Both modes can, however, be decrypted in parallel.
The main differences between CBC and CFB are as follows:
With CBC, a one-bit change in the IV will result in the same change in the same bit in the first block of decrypted ciphertext. Depending on the application, this could permit an attacker who can tamper with the IV to introduce changes to the first block of the message. This means with CBC it is necessary to ensure the integrity of the IV.
With CFB, a one-bit change in the IV will result in random errors in the decrypted message and thus is not a method of effectively tampering with the message.
With CBC, the decryption of messages requires the use of the block cipher in decryption mode. With CFB, the block cipher is used in the encryption mode for both encryption and decryption, which can result in a simpler implementation. Their benefit comes from being structured in a way that is reversible or nearly reversible. For a mathematical view on how the reversibility trait is achieved, read this technical walk-through: http://cryptowiki.net/index.php?title=Generalized_Feistel_networks. For a presented discussion of an eight-round Feistel cipher, this video is recommended: https://www.youtube.com/watch?v=3kr6DbulIVc.
The problem with both modes is that encryption cannot be parallelized, which affects speed and throughput, and random access is complicated by the need to decrypt block Cn-1 before one can decrypt the desired block Cn.
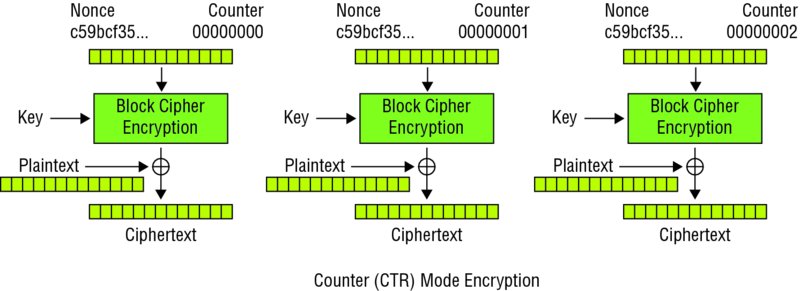
Another mode called counter or CTR mode addresses this problem by not using previous blocks of the plaintext (CBC) or ciphertext (CFB) in producing the ciphertext. (See Figure 5.8.) By using an IV combined with a counter value, one can both parallelize the encryption process as well as decrypt a single block of the ciphertext. You’ll note that Figure 5.8 includes a nonce value. That unique, randomly generated value is inserted into each block cipher encryption round. Similar to how a random “salt” value is used to ensure different hash values (to prevent comparing to rainbow tables), a nonce is unique and is intended to prevent replay attacks.
With all of the modes other than ECB, you need an initialization vector (IV), which either must be communicated to the receiver, or the message must be prefixed by a throw-away block of data (since decryption of an CBC or CFB stream of data without knowing the IV will only cause problems for the first block).
The IV need not be secret (it can be transmitted in plaintext along with the ciphertext), but it must be unpredictable. If an attacker can predict the next IV that will be used and is able to launch a chosen plaintext attack, then that may enable launching a dictionary attack on the ciphertext.
Electronic Code Book
Once the message has been padded to be an exact multiple of the cipher’s block size, it can be encrypted. The easiest, obvious, and least secure method (for longer messages) is the Electronic Code Book (ECB) mode of operation. In this mode, each block of plaintext is processed independently by the cipher. And each block is processed or encrypted using the same key.
Using the same key to encrypt each block brings both a significant advantage and disadvantage. Using the same key greatly simplifies the process. The disadvantage is, while it may be adequate for messages that are no greater than the block size, a serious weakness develops for longer messages as identical blocks of plaintext will produce identical blocks of ciphertext. An example of this weakness can be seen in Figure 5.9, where the graphic is encrypted using ECB, using a comparatively small block size. While each block is adequately encrypted, the process is repeated so often to encrypt the entire graphic that the overall picture is actually recognizable.
FIGURE 5.9 ECB with small block size weaknesses showing
Even in situations in which the data to be encrypted is the same or smaller than the block size (e.g., a numeric field in a database), use of ECB may be ill-advised if revealing that different rows of the table have the same value might compromise confidentiality. As a trivial example, if one were to use ECB to encrypt the birthdate field, then one could easily determine all the people in the database born on the same day, and if one could determine the birthdate of one of those individuals, you would know the birthdate of all (with the same encrypted birthdate).
The advantage of ECB, apart from its simplicity, is that encryption can be done in parallel (i.e., divided up across multiple processors), and so can decryption. Consequently, an error in one block does not affect subsequent blocks.
Block Ciphers: Symmetric and Asymmetric?
Don’t get confused—just because many of the standard, widely accepted block cipher algorithms such as AES use symmetric encryption does not mean that all block encryption is done symmetrically. Many asymmetric encryption algorithms use padded blocks, with sizes specified by their cryptovariables, as their unit of encryption.
Table 5.1 provides a quick overview of some of the block ciphers you’ll frequently encounter or hear about. It indicates the type, block sizes, key sizes, and number of rounds (or iterations) that the algorithm defines.
Prior to the 1970s, there were no publicly available encryption systems of any market significance. In fact, U.S. law at the time still reflected post World War I sentiment that only the government should be able to transmit messages in codes. Building on a seminal paper published by Claude Shannon in 1949, commercial, government, and academic researchers around the globe began developing the next generation of complex, powerful block encryption algorithms. The explosive growth of computing in the 1960s and 1970s, the shift of public telephony to digital technologies, and even the birth of the hacking and hobbyist communities came together to make the demand for commercially available encryption systems seem like too good a business opportunity to pass up. Thus was born the first public competition for a new encryption standard.
Data Encryption Standard and Triple
The Data Encryption Standard (DES) was, and still is, quite controversial. It was the first published and open competition by the U.S. government for a new symmetric-key block encryption algorithm. Some reviewers alleged that NSA had inserted elements into the design (its “S-box” circuits) to allow DES-encrypted traffic to be decrypted by NSA without needing the original encryption key; others, in turn, insisted these S-boxes were there to defeat still other backdoors built into DES. To date, no one has been able to convincingly confirm or deny these fears, and the disclosure of many NSA secrets by Edward Snowden only reheated this simmering controversy. There were many arguments about the key length as well; IBM originally proposed using 64-bit keys, which were downsized at NSA’s insistence to 56 bits. (The key actually remains 64 bits in length, but since 8 bits are used for parity checking, the effective key length is still 56 bits.) DES was made a U.S. Federal Information Processing Standard in 1977, despite much outcry within the community that it was insecure right from the start.
DES used 16 rounds of processing, and its design reflects the capabilities of 1970s-era hardware. (This was the era of the first 8-bit microprocessors, and most minicomputer architectures had only a 16-bit address space.)
Although many people argued whether DES was in fact secure or insecure, the Electronic Frontier Foundation (EFF) spent $250,000 to build a custom “DES Cracking Machine” to prove their point. Its 29 circuit boards hosted 64 custom application-specific integrated circuit chips (ASICs), with the whole assemblage controlled by a single personal computer. At more than 90 billion key tests per second, it would take about nine days to brute-force test the entire 56-bit DES key space, with typical cracks happening in one to two days. At about the same time, another machine, the Cost Optimized Parallel COdeBreaker or COPACABANA, hit comparable cracking speeds but at substantially lower cost.
Significant work was done to try to tighten up DES, including the Triple DES standard published in 1999, which in effect applied three super-iterations of the basic DES algorithm. But it remained unsecure, and DES in all forms was finally withdrawn as a U.S. government standard in 2002 when it was superseded by AES.
DES remains important, not because it is no longer secure but because in the opinion of academics, industry, and government experts it stimulated the explosive growth in the study of cryptography by those who had no connections at all to the military and intelligence communities and their cryptographers. Even today it is still worth studying as you begin to understand cryptography, cryptanalysis, and common attack strategies.
Advanced Encryption Standard
Throughout the 1980s and 1990s work continued to find a replacement for DES, and in November 2001 the U.S. government published FIPS 197 describing the Advanced Encryption Standard (AES). AES is also a symmetric block encryption algorithm but one that is much more secure in design and implementation than DES or 3DES proved to be. The open competition that NSA had sponsored reviewed a number of promising designs, and the Rijndael (pronounced “rhine-dahl”) algorithm by Vincent Rijmen and Joan Daeman was the clear winner. It is the first and still the only publicly available cipher that is approved by NSA for use on government classified information up through Top Secret, when it is used as part of an NSA-approved cryptographic module.
AES uses a fixed block size of 128 bits and provided a number of possible key sizes, which were directly related to the number of rounds of processing used, as shown in Table 5.1. AES follows the design principles of a substitution-permutation network, which in some respects looks like a pretty straightforward application of substitutions, permutations, XORs, and matrix manipulations. AES is not, however, a Feistel network (which is also a permutation-substitution design concept). AES uses the principles of finite field arithmetic to manipulate its arrays of bytes, known as the state of the algorithm. (These states can have a varying number of columns but are always four rows of bytes.) Yet despite this apparent simplicity, it has withstood a number of very ambitious attacks and is still a primary standard of choice by security architects and savvy users.
Internally, the AES algorithm goes through four major phases of processing:
Key expansion, in which keys for a given round of processing are derived from the cipher key using the Rijndael key schedule, which uses a set of round constants to generate a unique 128-bit round key block for each round (along with one extra round key block).
Initial round key addition, which does a bitwise XOR of the state and the round key.
An additional set of 9, 11, or 13 rounds, depending upon key length, which combine byte substitution, row shifting, and column mixing, culminating in another XOR of the final state and the round key.
A final round consisting of byte substitution, row shifting, and round key addition.
A number of optimization techniques are included in the basic AES design, which allow implementation decisions to trade memory space for processing time, for example.
Until May 2009, the only known successful attacks on AES were side-channel attacks, which rely on observing possible data leaks that reveal internal characteristics of the implemented cryptosystem (such as heat, vibration, power fluctuations, or noise on signal or power connections), rather than attacks on the mathematics of the cipher itself. As of the Snowden disclosures in 2013, there were still no known practical attacks against a properly implemented AES system using 256-bit keys.
Blowfish and Twofish
These algorithms were both developed by Bruce Schneier as part of his work to find a stronger replacement for DES. Twofish, derived from Blowfish’s design, was one of the five finalist designs in the AES competition; when that competition chose the Rijndael algorithm, Schneier placed the reference implementation of the designs of Blowfish and Twofish into the public domain. They’ve been widely incorporated into a wide variety of commercial and open source cryptographic systems and products, with Twofish being one of the few ciphers included in the OpenPGP standard (RFC 4880) by the Internet Engineering Task Force. They both are Feistel substitution-permutation designs, and thus far, the only successful attack has been the SWEET32 or “birthday attack,” in an HTTPS context, which was able to recover plaintext from ciphertext for ciphers using a 64-bit block size. As a result, the GnuPG project recommended that so long as Blowfish is not used on files larger than 4 GB in size, it should still be secure.
OpenPGP and GnuPG are both part of what can only be called the public service aspect of the white hat cryptographic community of researchers, designers, and users. This community firmly believes that all of us need alternatives to the systems provided to us by governments or large multinational corporations. The intersection of very big business interests and governments’ natural drives for control can, this community warns us, have us becoming too dependent upon systems that only are secure against us. (As an international banker acquaintance of mine puts it, the Bank Secrecy Acts of various nations are about one-way secrets: banks keeping secrets from their customers.) The commercial and open source successes of GnuPG, OpenPGP, PGP, and GPG are in part a testament to the credibility of these warnings.
International Data Encryption Algorithm
The International Data Encryption Algorithm (IDEA) was first proposed by James Massey and Xuijia Lai in 1991 and was at that time intended as a proposed replacement for DES. It is a symmetric block cipher using a 64-bit block size and 128-bit keys. It consists of eight rounds of bitwise XORs, addition module 216, and multiplication modulo 216 + 1; a “half-round” provides an output transformation and swap. Thus far there have been no published linear or algebraic weaknesses demonstrated in the IDEA design, and the only successful attacks thus far (in 2012) demonstrated an effective reduction in cryptographic strength of about two bits (roughly equivalent to reducing the key from 128 to 126 bits, or roughly from 3.4 × 1038 to 8.5 × 1037 as a measure of the time required to crack it). Practically speaking, this does not reduce the security of the IDEA algorithm in use, if properly implemented.
Part of that concern about proper implementation regards what are called weak keys, that is, keys that have long repeating stretches of 0 or 1 bits. While there’s still debate in cryptologist circles as to the real risks of weak keys, there are a number of practical mitigations—including using IDEA as part of a hybrid system that co-generates a one-time session key.
Although originally protected by a number of patents, IDEA became freely available as a reference design in 2011. MediaCrypt AG, in Zurich, Switzerland, has been working to make commercial versions of it, notably IDEA NXT, available and has been positioning it as the successor to IDEA. IDEA NXT supports block sizes of 64 or 128 bits and key sizes of 128 or 256 bits.
CAST
Carlisle Adams and Stafford Tavares created the CAST family of ciphers, with CAST-128 first made available in 1996. (Bruce Schneier has reported that although the name represents its creators’ initials, they meant it to “conjure up images of randomness,”as in the casting of the dice.) These are Feistel networks with large S-boxes that make use of what are called bent functions (the name suggests functions that are different from all others in Boolean logic), along with a mix of key-dependent rotations, modular arithmetic, and XOR operations. Entrust, Inc., of Dallas, Texas, holds patents on the CAST design procedure, but CAST-128 itself is available worldwide on a royalty-free basis for both commercial and noncommercial use. CAST-256 (also called CAST6) was published in 1998. As of 2012, the last published results show a theoretical cryptanalysis attack against a 28-round CAST-256 design, which would take 2246.9 in time to complete; to date, no known successful attacks against CAST-256 have taken place.
PGP, OpenPGP, and GnuPG
These three cryptographic systems—for they are more than just an algorithm or a protocol—have their origins in the social and legal debate over whether private citizens should have both legal and ethical rights to use strong encryption in their private lives. The security services of national governments have long fought against this concept, as you can see in the history of many encryption algorithms and protocols to date. This social agenda is still felt by many to be vitally important today, when many national governments are using cloud-hosted data mining systems combined with mass surveillance to pursue their own agendas. Whether you agree with those agendas in whole or in part is not the issue; the underlying operational security needs and issues are.
The “PGP family” (if I can call these three related but separate systems that) implement an alternative to the hierarchy of trust that the Public Key Infrastructure (PKI) has provided us all. PKI and its certificate authentication system is a monoculture, a single ecosystem, the PGP family advocates rightly point out. As the mass market backbone of trust, it is all that we have. If it fails—if it can be corrupted or subverted by anyone—we are all at risk. An alternative is necessary for survival, these advocates claim. The PGP family implements nonhierarchical ways of asserting trust, managing public key exchanges, and providing for user storage and protection of their private keys. (See the “Web of Trust” section later in this chapter for more on these concepts.)
The good news about PGP et al. is that when used correctly it provides comparable levels of security to that provided by traditional PKI and its algorithms. The encryption algorithms used in PGP and its follow-on systems have proven exceptionally difficult to break; notorious examples include attempts by various law enforcement agencies to break PGP-encrypted emails and files. While some successful cracks by law enforcement have been reported, there seems to be some question as to whether they broke the encryption algorithms per se, brute-forced a weak password, or used side-channel attacks on the device in question (such as a BlackBerry or other smartphone) itself.
This gets to what may be the heart of the controversy. Opponents of PGP, OpenPGP, and GnuPGP state that these systems are technically challenging to use; they simply do not scale well into consumer-friendly products and service offerings. While PGP plugins are readily available for most email systems, this sidesteps the issues of certificate generation and management, certificate revocation, and user protection and use of private keys. Bruce Schneier referred to this as “Giving Up on PGP” in 20161 ; Thaddeus T. Grugq expresses this by proclaiming “I am here to liberate you from PGP” with its emphasis on knowing many “arcane obscure weird commands” in order to use it safely and effectively.2 A more reasoned approach is posted at AT&T Security’s Alienvault site, in which the author (CryptoCypher, a student and intern no less) points out that if you do not understand your own operational security needs first, you may actually complicate your own risk posture by diving into PGP use.3 This advice no doubt applies equally to using mainstream encryption products and services.
While many in industry and research are advising users to “dump PGP,” there are also a growing number of voices to the contrary. It is clear that some elements in the marketplace recognize the risk of having all of one’s security eggs placed in one basket. Some are also looking at blockchain technologies as a smarter way to make webs of trust more scalable and useful. Some of these voices view the mainstream product offerings as focused too intensely on scaling into the corporate and enterprise user base, with little concern for how individual netizens need to ensure their own information security needs are met. Many of these netizens do see the CIANA+PS model in very different terms than the monoculture does after all.
Watch this space. There are good reasons why PGP, OpenPGP, and GPG haven’t gone away yet, in which case they may represent opportunities to be understood and seized.
Stream Ciphers
Stream ciphers are symmetric encryption processes that work on a single byte (sometimes even a single bit) of plaintext at a time, but they use a pseudorandom string (or keystream) of cipher digits to encrypt the input plaintext with. Stream ciphers typically use simple operations, such as exclusive-or, to encrypt each bit or byte. (Exclusive-or, written as xor and using the symbol ⊕, is true if either input is true but not both; think of it as binary 1+1= 0, and ignore the carry to the 2’s place.) These operations run very fast (perhaps each encryption taking a few nanoseconds). Figure 5.10 shows the basic concept of a stream cipher, where the plaintext flows through the cipher function as a stream, is encrypted byte by byte (or bit by bit) with a corresponding piece of the keystream, producing the resulting stream of ciphertext. Decryption, using the same key, is the reverse of this process.
The classical one-time pad cipher, which had its random keys written one per page on a pad of paper, has been proven by experience and mathematical analysis to be the only truly unbreakable cipher system; this approach loosely inspired the design of stream cipher systems. However, using a stream cipher to protect any potentially unlimited-length plaintext input requires that the keystream be truly random across its entire use with that plaintext, which makes it somewhat impractical to exchange and keep the keystreams secret. Instead, special hardware or software keystream generators take a fixed-length key, typically 128 bits in length, and use it as an input, along with other cryptovariables, to continuously generate the keystream. As a symmetric cipher, the same 128-bit key is used for encryption and decryption; key distribution and management, as with any symmetric cipher, become the most important elements in preserving the security of the overall system. In most implementations, keystream generators produce pseudorandom keystreams, as opposed to truly random ones. Thus, it is quite possible for a stream cipher system to become insecure with use. Figure 5.10 shows how the RC4 stream cipher does this; note the key k and the initialization vector IV are actually combined outside of the RC4 algorithm box itself. (More on this in a moment.)
Stream ciphers by design can work on any length of input plaintext. The keystream generator is a function (implemented in hardware, software, or both) that uses a seed value (the encryption key itself) as input, producing encryption values to be combined with each bit or byte of the input plaintext. Stream ciphers like RC4 found widespread use in mobile communications systems such as cell phones, Wi-Fi™ and others, in which the plaintext input is often of unbounded length and is quite bursty in nature (that is, it is produced in sets of data of unpredictable size separated by unpredictably short or long periods of no signal on the link). Both of these characteristics argued against block encryption approaches with their need to pad blocks (and possibly pad larger groups of blocks) for efficient encryption and decryption. Such bursty communications systems have many applications that call for encryption to provide security, as we’ll see in Chapter 6. These all call for fast encryption using little CPU processing power, or the use of dedicated hardware such as field programmable gate arrays (FPGAs).
Practical stream ciphers use a fixed-length key to encrypt messages of variable length. Some ciphers can be broken if the attacker comes into possession of enough ciphertexts that have been encrypted with the same key. Changing the key periodically so that the amount of ciphertext produced with each unique key is limited can increase the security of the cipher.
Stream ciphers are divided into two types: synchronous and self-synchronizing.
Synchronous ciphers require the sender and receiver to remain in perfect synchronization in order to decrypt the stream. Should characters (bits) be added or dropped from the stream, the decryption will fail from that point on. The receiver needs to be able to detect the loss of synchronization and either try various offsets to resynchronize or wait for a distinctive marker inserted by the sender to enable the receiver to resync.
Self-synchronizing stream ciphers, as the name implies, have the property that after at most N characters (N being a property of the particular self-synchronizing stream cipher), the receiver will automatically recover from dropped or added characters in the ciphertext stream. While an obvious advantage in situations in which data can be dropped or added to the ciphertext stream, self-synchronizing ciphers suffer from the problem that should a character be corrupted, the error will propagate, affecting up to the next N characters. With a synchronous cipher, a single-character error in the ciphertext will result in only a single-character error in the decrypted plaintext.
Other key aspects of stream cipher designs include a mix of linear-feedback shift registers, nonlinear combining functions, clock-controlled generators, and filter generators.
As with any cipher, its strengths and weaknesses both derive from and affect how you use it. It is impractical to have a keystream that never repeats itself; otherwise, previously transmitted portions of your cipherstream could be subjected to cryptanalysis to identify repeating patterns, which might lead to a potential decryption. Suppose, instead, that you specify a repeat period of 232 bits; this sounds like a lot, but it’s a keystream of 4 GB in size. If you’re transmitting at a reasonable rate of 8MBPS (which would provide acceptable streaming video or audio, such as from a UAV back to its base station), then that keystream needs to be repeated every half hour. Depending upon your operational security needs, this may or may not be acceptable.
Key to the operation of many stream ciphers is their use of an initialization vector (IV), which is used along with the encryption key to start up the keystream generator function in some algorithms. RC4, one of the more widely used streaming ciphers, does not use an initialization vector; if applications demand such an IV, then it must be combined with the encryption key externally to the RC4 module itself. (Initialization vectors do seem quite similar to the concept of a session key, which is used in asymmetric encryption systems to generate a nonce, a value used only once, as the symmetric encryption and decryption key.) RC4 had other design flaws, which many implementations such as WEP failed to bridge around, making them easy to break.
Table 5.2 summarizes important stream ciphers and provides a peek at the evolution and use of these ciphers.
It is interesting to compare the controversies around the development of different stream ciphers with the DES history. In both cases, U.S. government perspectives on national security and encryption attempted to make early algorithms—DES or A5/1, A5/2, and RC4—easily breakable by government. Acrimonious disagreement with some NATO allies, such as Germany, pointed out that the closer one was to the Iron Curtain, the stronger one needs to protect one’s own communications. As with DES, compromises on design and key length were finally reached; in the meantime, cryptanalysis capabilities outpaced the supposedly secure compromise designs in short order.
As we look at the short history of stream cipher applications, one might be tempted to think that the stream cipher is dead. In many demanding use cases, block ciphers that are part of hybrid systems seem to be replacing them; in others, the stream cipher depends upon a block cipher as a vital part of its keystream generation process. It is true that either basic cell phone service is not encrypted at all, or it is provided with bare-bones and not terribly secure encryption as a basic service in many locations around the world. However, it’s prudent to withhold judgment on this question, at least until after putting both stream and block ciphers into the context of secure protocols and the use cases they support. It’s also prudent to keep in mind that the onboard processing power, speed, and memory capacity of cell phone chip designs have grown almost astronomically in the short time since GSM2 services were becoming widespread. That processing power and speed enables devices to host far more effective encryption algorithms. This will be explored further in this chapter and in Chapter 6.
Let’s take a closer look at a few of these stream ciphers.
A5/1, A5/2
A5/1 and its deliberately weakened stepchild A5/2 were developed in the late 1980s when some Western nations believed that their dominance of cell phone communications markets would remain unchanged for some time. The Berlin Wall had not fallen, yet, and worries about the Soviet Union still dominated government and international business thinking alike. The GSM cell phone system was becoming more widely used in Western Europe but was not considered for use outside of that marketplace at that point in time.
In that context, the arguments reported by security researcher Ross Anderson in 1994 make sense. NATO signals intelligence officials, according to Anderson, argued over whether GSM calls ought to be deliberately made easy to decrypt to plaintext voice or not. One outcome of this was the deliberate weakening of the A5/1 algorithm to produce A5/2 and then later A5/3 variants.
Without getting too much into the cryptanalytic details, it’s important to note that this family of ciphers has suffered many different types of attacks. Some of these, such as the Universities of Bochum and Kiel’s COPACABANA field programmable gate array (FPGA) cryptographic accelerator, or Karsten Nohl’s and Sascha Krißler’s use of 12 Nvidia GeForce graphics processors, are reminiscent of EFF’s hardware-based attacks on DES some years earlier.
Finally, you do have to consider that documents released to the public by Edward Snowden in 2013 show that the NSA can easily decrypt cell phone traffic encrypted with A5/1.
RC4
Rivest Cipher 4, developed by Ron Rivest of RSA Security in 1987, was initially protected as a trade secret by RSA Security; but in 1994 it was leaked anonymously to the Cipherpunks mailing list and soon became known widely across the Internet cryptanalysis communities (black hat and white). It was originally designed to support wireless encryption, applications in which its efficient, small implementation (hardware or software) and speed made it an ideal solution. It was an important element of the Wired Equivalent Privacy (WEP) algorithm for IEEE 802.11 wireless networking and then later in Wi-Fi™ Protected Access (WPA). Its use in SSL and then later in TLS ended in 2015, when its inherent weaknesses no longer allowed these protocols to be secure in any real sense. RC4 proved vulnerable to a number of attacks, many of which were enabled by lack of attention to detail by various implementations (such as those that did not use a strong message authentication code or tag).
RC4 is no longer recommended for use.
Salsa20/ChaCha20
These two closely related ciphers, designed by Daniel J. Bernstein, are proving remarkably secure and popular in hardware and software implementations. Not protected by patent, Bernstein has also released several different implementations optimized for common architectures to the public domain. Salsa20 was selected as a finalist in the EU’s ECRYPT competition, which is discussed later in the “EU ECRYPT” section. ChaCha20 has been adopted by Google, along with another of Bernstein’s ciphers (the Poly1305 message authentication code) as a replacement for RC4 in TLS; this strengthens Google’s port of Chrome, for example, into its Android operating systems for mobile devices. ChaCha20 has also been adopted as part of the arc4random random number generator, used in the NetBSD, OpenBSD, and FreeBSD implementations of Unix. Dragonfly BSD also uses ChaCha20, and from version 8.4 onward, the Linux kernel uses it as part of the /dev/urandom device.
In May 2015, the IETF published an implementation reference for ChaCha20 in RFC 7539, which did include some modifications to Bernstein’s original design. The RFC does point out these modifications may limit effectively secure use to a maximum message length of 256 GB (which we used to think was incredibly large!) and suggests that the original Bernstein design be used if this is insufficient, such as for full disk volume encryption. The IEFT has also proposed, in RFC 7634, the use of ChaCha20 as a standard for Internet Key Exchange (IKE) use and IPsec.
EU ECRYPT
In 2004, the European Union launched its ECRYPT initiative. This European Network of Excellence in Cryptology was a four-year effort to stimulate collaboration across the EU cryptologic communities and to encourage research in five core areas. These “virtual laboratories,” as the core areas were also known, and their EU-designated acronyms or monikers were as follows:
Symmetric key algorithms (STVL)
Public key algorithms (AZTEC)
Protocols (PROVILAB)
Secure and efficient implementations (VAMPIRE)
Digital watermarking (WAVILA)
Many different collaborative projects were started as part of the ECRYPT effort, and some useful results were achieved. eSTREAM, for example, was part of the STVL portfolio and was in fact a follow-on to the earlier NESSIE project, which failed to find any useful and secure new stream ciphers. Disappointed but not defeated, the EU’s researchers reorganized and relaunched eSTREAM, which has indeed surfaced some strong contenders (such as Salsa20) for a next generation of secure stream ciphers. The New European Initiative for Signatures, Integrity, and Encryption (NESSIE) ran from 2000 to 2003. It embraced block and stream ciphers, public key encryption, message authentication, hashing, digital signatures, and identification schemes.
The EU maintains archive pages on both eCRYPT and NESSIE, and you’ll find reviews, discussions, and analyses of their work throughout the online cryptographic communities.
Asymmetric Encryption
It’s hard to speak of asymmetric encryption without also speaking about shared key generation as well as key management and distribution issues. After all, the original work that led to our modern public key infrastructure was created as if in one burst of interrelated ideas, all inspired by the need to eliminate or mitigate a bundle of known risks:
Eliminate the need to precompute, distribute, and manage keys, and you eliminate much of the risk in any cryptographic system.
Eliminate the need for sender and recipient to trust a third party—the key manager—or trust each other, and you can eliminate other significant risks to secure communication.
Eliminate the ability to back-compute a decryption key (that is, find the same symmetric encryption key) associated with a set of ciphertext, and you start to provide real forward secrecy.
As if by flashes of insight, the same set of mathematical ideas applies to eliminating or mitigating all of these risks. They also brought with them powerful capabilities to provide strong nonrepudiation (or message authentication). As a result, from the first published paper, asymmetric cryptography has been associated with terms such as public key, private key, generator, shared key generation, and session key.
At this point, we’ll separate out the details of some of the more well-known asymmetric algorithms; then, in the upcoming sections, at the protocols that make use of them. The “Understand Public Key Infrastructure Systems” section of this chapter will bring all of this together in the context of key management.
Asymmetric encryption refers to the use of different algorithms for encryption and decryption, which each use different keys. Both will use the same cryptovariables, which might include a seed value or parameter that both encryption and decryption algorithms need. What makes this asymmetry so powerfully secure—and what delivers an asymmetric advantage to the security architect and users of it—is that if those algorithms are chosen correctly, the iron laws of mathematics dictate that it is highly unlikely that an attacker can decrypt the ciphertext encrypted by an asymmetric algorithm, even if they have the encryption key itself, and all of the other cryptovariables. The only way that such a ciphertext can be decrypted is if the recipient (or interceptor) has the corresponding decryption key. This mathematical limit is known in cryptanalysis circles as the computational infeasibility of reversing the encryption to solve for the decryption key in any practical amount of time. The first publications about these functions and their use in cryptography referred to them as trapdoor functions, since it is easy to fall down through an open trap door but rather challenging to fall up through it.
Forward Secrecy
By itself, any form of symmetric encryption by itself has always been vulnerable to revealing the content of encrypted messages or files once an attacker had broken the key. This would often force users to hope that when (not if) their keys were compromised or broken, they had already fully enjoyed the value of the secrets protected in their encrypted files or messages; those secrets could then be made publicly available at little or no harm or loss to their originators and users. More often than not, such hope was folly. On the other hand, if those messages had been encrypted with a true one-time pad and that pad was destroyed after use, then only the holder of the other copy of the pad could decrypt those messages, even if that was not until years later. Session keys, generated and used in hybrid encryption systems, provide such forward secrecy, so long as the session keys are destroyed immediately upon the end of the session. (Recall that if I send you a file via such an encrypted process and you store it—but don’t decrypt it—you can decrypt it later only if you still have that session key handy. The pseudorandom nature of the way in which good session keys get generated should prevent you or anyone else from decrypting the file without it.) Since a well-designed hybrid system distributes the session key using asymmetric encryption, then by definition there is nothing an eavesdropper can glean from intercepted traffic that can lead to being able to decrypt intercepted ciphertext, even if the originally used keys are later compromised.
A variation on forward secrecy known as weak forward secrecy describes the situation where the sender and recipient private keys are compromised. This does not affect the secrecy of the previously generated session keys, but it might allow an attacker to masquerade as the party whose keys have been compromised.
As with any cryptosystem, it takes a set of protocols to make the most of this asymmetric advantage, and we’ll look at these in the upcoming sections. First, however, let’s look at the basic math (and keep it somewhat basic as we do so). Then let’s look at some of the asymmetric algorithms in widespread use, in chronological order rather than any other.
Note the difficulty of using asymmetric encryption systems to protect archival copies of data at rest: at some point in this process, you have to separately store the session keys used in that encryption, or you’ll never be able to retrieve the data from the archive. To date, the best approach to this is investing in a hardware security module (HSM) and wisely using its multifactor, shared-secrets architecture to enforce your backup and restore teams to segregate their duties.
Discrete Logarithm Problems
The first broad category of trapdoor functions and the ones first described in the paper by Whitfield Diffie and Martin Hellman (who based their work on concepts developed by Ralph Merkle) capitalized on the problem of computing discrete logarithms. For any given number base b (such as 2, e, or 10), the logarithm is the value of the exponent that b must be raised to in order to produce the required result a. Functionally, that’s written as:
logb(a) = x such that bx = a
Except for a few examples, it is computationally difficult to compute discrete logarithms for any particular value a, when a is a member of a particular type of group or set. The details of how you choose such a set of values for a, b, and x, and how you put them to work in a cryptographic system, are all part of each protocol’s unique approach.
Diffie-Hellman-Merkle, Elliptical Curve, ElGamal, and the Digital Signature Algorithm are all examples of discrete logarithm-based trapdoor functions at work.
Factoring Problems
The second broad category of asymmetric algorithms involves factoring extremely large semiprime numbers. A semiprime number is the product of two prime numbers: 5 and 7 are prime, so 35 is a semi-prime; 3 and 3 are primes, so 9 is a semi-prime; and so on. Calculating a semiprime from two times is a simple, single multiplication. But given a large number such as 33,782, it takes a lot more CPU time and a more complex algorithm to determine whether it is a semiprime or not and, if it is, what its two prime factors are. (It’s not, by the way. But its nearest neighbor, 33,783, is.) When such candidate semiprime numbers have hundreds of digits, the amount of computer time necessary to test it (regardless of how efficient your numerical approach) can become astronomical; even with rooms full of today’s GPU-based bitcoin cryptocurrency mining systems, it can be no better than brute force or dumb luck to determine which two prime factors produce a given result. (In 2009, it was reported that factoring a 232-digit number required 1,500 processor years to complete; the large semiprimes in use today typically have in excess of 600 digits.) Thus, the two prime factors and the semiprime that results from them become elements in our encryption and decryption system.
Rivest-Shamir-Adleman (RSA) and LUC are examples of trapdoor algorithms based on factoring very large numbers involving semiprimes.
Diffie-Hellman-Merkle
It’s difficult to focus on Diffie-Hellman (or Diffie-Hellman-Merkle, to be precise) as an algorithm without putting it in the context of shared key generation, particularly between two parties who have no shared prior knowledge of each other nor any basis upon which to trust in a shared communications process with each other. Each party must somehow prove their identity—that is, demonstrate that they are who they assert that they are—before they can jointly authorize each other to participate in the session that’s about to take place. One important distinction must be recognized at the start: key exchange is not about exchanging secret information between the parties; rather, it is about creating a shared key to use for subsequent encrypted sharing of secrets. Furthermore, it’s important to realize that the “public” part of public key exchange is that you can quite literally publish parts of that key exchange without compromising the security of the encryption it supports. Whitfield Diffie and Martin Hellman, in a 1976 article published in IEEE Transactions on Information Theory, first showed that public key exchange requires the use of what they called trapdoor functions—a class of mathematical problems that are easy to do in one direction (like falling through the trapdoor in the floor) but extremely difficult if not impossible to do in the other direction. Their work leaned heavily on concepts developed by their friend Ralph Merkle, who was not a co-author on their paper; later, in 2002, Hellman suggested that their work be referred to using all three of their names. Twenty-one years later, the Government Communications Headquarters (GCHQ), the British counterpart to the National Security Agency in the United States, revealed that in 1969, three of their employees had developed similar concepts demonstrating the practicality of a public key cryptographic system. U.S. Patent 4,200,770 was issued in 1977, citing Diffie, Hellman, and Merkle as inventors, and describing the reference implementation of their algorithm and approach; it is now expired.
Diffie, Hellman, and Merkle described their system using what’s known as a multiplicative group of integers, modulo p, where the modulus p is a large prime number, and g, the generator value, is also another large prime. Choosing these values appropriately allows for a resulting shared secret (later known as the session key) to be in the range between 1 and p - 1. P and g are both publicly available. What happens next depends upon the two (or more) parties choosing other values, which will be used as exponents in computing the shared secret value.
Let’s start with a simple illustration. Suppose Bob and Carol want to establish their own encrypted Internet connection with each other. Here’s what happens:
Bob and Carol choose a suitable trapdoor function; they choose the key parameters that they will use. What they agree on can be shared in open, unsecured email with each other.
Carol chooses her private key and keeps it secret; she uses the trapdoor function to calculate her public key, which she sends to Bob. (Anyone can see her public key. More on this in a moment.) Bob, too, chooses a private key and uses the same trapdoor function to calculate his public key and sends that to Carol.
Carol applies the trapdoor function to Bob’s public key, using her own private key; call the result the session key. Carol keeps this secret; she doesn’t have to send it to Bob, and she shouldn’t!
Bob applies the same trapdoor function to Carol’s public key, using his own private key. This produces the same session key by the magic of the mathematics of the chosen trapdoor function. (The proof is left to the mathematically inclined reader.)
Carol and Bob now share a new secret, the session key. This key can be used with an appropriate (and agreed to) symmetric encryption algorithm so that Bob and Carol can exchange information with each other and keep others from being able to read it.
This is shown with small values for all numbers in Figure 5.11.
What about Eve, sitting along the sidelines of this conversation? Suppose Eve is, well, eavesdropping on Bob and Carol’s key exchange; she somehow is trapping packets going back and forth and recognizes that they’ve agreed to an algorithm and its control parameters; she recognizes the exchange of Bob’s and Carol’s public keys for what they are. As long as Eve does not have a secret key that participated in the computation of the session key, she does not have anything that lets her read the traffic that Bob and Carol encrypt with the session key. Eve is left to using brute-force, side channel, or other attacks to attempt to break the session encryption.
Ted, on the other hand, is someone Bob and Carol want to include in a three-way secure conversation (still keeping Eve out in the cold, of course). The process previously shown in steps 1 through 5 can easily be expanded to include three or more parties who share the choices about algorithms and parameters, who then compute their own public keys and share them; they then use everybody else’s public keys to compute their own copy of the session key.
Obviously, this simplified description of the Diffie-Hellman key exchange process has some vulnerabilities. It doesn’t actually authenticate that Bob is Bob, or Carol is Carol, thus tempting Ted to be the “man in the middle” who masquerades to be the other party from the initial handshake and key generation through to the end of the session. The choice of trapdoor function, and the control values for it, can also present exploitable vulnerabilities. But in its simplest form, this is where the public key infrastructure (PKI) got its start.
Building a public key infrastructure starts with the algorithms used to generate the shared secret keys used to establish trustworthy communications. Those algorithms have to be implemented in some combination of software and hardware, which are then made available to users to incorporate into their systems or use as standalone messaging apps. These apps themselves and the software and hardware distribution channels (wholesale, retail, original equipment manufacturer (OEM), or other) all have to be part of a network of trust relationships if two end users are going to trust in such apps to protect their communication with each other. Thus, the problem of building a public key infrastructure must also embrace the problem of trusted software (and hardware) distribution and update. This will be explored further in the “Understand Public Key Infrastructure Systems” section of this chapter.
RSA
Immediately after Diffie and Hellman published their article in 1976, two MIT computer scientists, Ron Rivest and Adi Shamir, teamed with MIT mathematician Leonard Adleman and set out to create a suitable trapdoor or one-way function for use in a public key exchange process. These three focused on both an algorithm (based on modular exponentiation) as well as on a process by which users could authenticate themselves, hence eliminating the risk of the man-in-the-middle attack. As is typical in the scientific and technical literature, they named the algorithm after themselves (thus the acronym RSA). The three authors founded RSA Security, Inc., in 1982, and MIT was granted a U.S. Patent in 1983 that used the RSA algorithm. Prior publication in 1973 by Clifford Cocks in the United Kingdom of very similar concepts precluded patenting RSA in other countries, and had that publication by Cocks been known, it would have invalidated even the U.S. patent (it was not disclosed by GCHQ until 1997). RSA later released the algorithm into the public domain in September 2000.
Like Diffie-Hellman, RSA uses the properties of modulo arithmetic applied to exponentiation of very large integers, where the modulus is also a very large prime number. Prior to the 1990s, the compute power needed to perform such operations (just to create the keys) was substantial, and the compute power necessary to break such algorithms was thought to be unaffordable by even the security services of major nation-states.
The founders of RSA did spend most of the 1980s and 1990s in what can only be called a pitched battle with the NSA and the White House. As this was during the heart of the Cold War and the Reagan-Bush defense buildup, it’s not surprising that the government saw any widespread use of powerful encryption by anybody as a threat to national security. (They still see that threat, particularly since “anybody” can be a terrorist, while in the same breath they know how our modern digital economy cannot function without widespread public use of highly secure encryption.) This history in and of itself is worth your time and study, as an SSCP and as a citizen, but it is beyond the scope of this book.
ElGamal
First described by Taher ElGamal in 1985, this asymmetric encryption algorithm is based on the mathematical theory of cyclic groups and the inherent difficulties in computing discrete logarithms in such groups. Borrowing from Diffie-Hellman-Merkle key exchange concepts, ElGamal provides for asymmetric encryption of keys previously used in symmetric encryption schemes. ElGamal also proposed a digital signature mechanism that allows third parties to confirm the authenticity of a message signed with it; this signature mechanism is not widely used today, but it did lead the NSA to develop its Digital Signature Algorithm (DSA) as part of the Digital Signature Standard (DSS). DSS was adopted as FIPS 186 in 1996, and it has undergone four revisions since then. (Don’t confuse DSA with ElGamal signature schemes.)
Some hybrid encryption systems use ElGamal to encrypt the symmetric keys used to encrypt message content. It is vulnerable to the chosen-ciphertext attack, in which the attacker somehow tricks or spoofs a legitimate user (an oracle) into decrypting an arbitrary message block and then sharing those results with the attacker. (Variations on this kind of attack were first known as lunchtime attacks since the user’s machine was assumed to be available while they were at lunch.) ElGamal does provide padding and other means to limit this vulnerability.
ElGamal encryption is used in the GNU Privacy Guard system, which we’ll look at in concert with PGP in the “Pretty Good Privacy” section.
Quantum Cryptography
Quantum mechanics has been a field of study and argument since 1905, when Albert Einstein published his now-famous paper on the photoelectric effect. One of the outcomes of that paper and the next few decades of incredible theoretical and practical research that flowed on from it was what some physicists called the “spooky side effects” of a universe made up of indivisible, small quanta or packets of force—packets that also behaved as if they were waves. Two of those side effects are at the heart of what may be the next revolution in computing and cryptography, based on quantum computing.
The first is what’s known as the observer effect, which means that many of the properties of a quantum (such as its position, velocity, spin, etc.) cannot be known unless you observe it, and since observation is a kind of interaction, your observation changes the state of the quantum. (This is similar to our definition in Chapter 4 of an event in your information system: if something has changed its value or state, that’s an indication that an event has occurred. The change of state is the relevant observation, whether you notice it or not.) Prior to observing such a quantum, or a system of quanta, its state is defined as being a set of probable outcomes all superimposed on each other. Observing the system collapses all of those probabilities into the right-now result. Quantum computing looks to have each of those probable outcomes be the outcome of a branch in a calculation; reading out that qubit (quantum bit) forces it to collapse into one result. Quantum computing may provide significant reductions in run time for massively parallel algorithms, which could give advantage both in computing new public and private keys, performing encryption and decryption, and in attacks against encryption systems.
The other spooky side effect is known as entanglement. Two particles created together are entangled, which means if you move one of them someplace else and then observe it, both it and its entangled twin will instantly take on the same state (the same spin, for example). Note that “instantly”—this change of state happens without any known message, energy, or force traveling the distance between the entangled twins. While that suggests science-fictional ideas such as faster-than-light communication, what it practically demonstrates is that an entangled quantum communications link is a tamper-proof way to ensure that no one has observed the content of your message or file once it was encrypted. In 2017, the Peoples’ Republic of China launched its Micius satellite, which demonstrated this and other “action at a distance” effects across its 1,200-kilometer space-to-ground links.
Quantum key distribution is, at this writing, the only use of these spooky side effects in practical cryptologic systems. These systems generate large quantities of entangled particle pairs that are stored in some fashion and used as a keystream or one-time pad. Any attempts to interrogate the stored copy of the keystream would invalidate it. A variety of commercial products provide such one-time pads, and several different protocols based on these quantum effects are in use. Some of these are positioned at the executive communications market, for example, as they arguably provide greater than normal communications confidentiality and integrity protection. https://en.wikipedia.org/wiki/Quantum_key_distribution provides a useful summary of work to date in this field.
In the meantime, researchers are working to develop algorithms that should be more resistant to quantum computing attacks. NIST plans to have proposals for post-quantum cryptography standards ready by 2025, and current estimates are that quantum computers capable of compromising today’s algorithms will not become available until 2030 at the earliest. The European Union is also doing work in this direction with its PQCRYPTO project, which interestingly enough asserts (on its home page) that while RSA and similar uses of discrete logarithms, finite fields, or elliptic curves offer rich alternatives now, “these systems are all broken as soon as large quantum computers are built…[and] society needs to be prepared for the consequences, including cryptographic attacks accelerated by these computers.” You might find “Post-quantum cryptography and dealing with the fallout of physics success,” by Daniel Bernstein and Tanja Lange, 2017, an illuminating read; it’s available at https://eprint.iacr.org/2017/314.pdf.
As costs come down through early adoption, and as hardware and systems capabilities continue to improve, you may find yourself dealing with spooky side effects on the job sooner than you might think. Watch this space…well, that space, please.
Hybrid Cryptosystems
Hybrid cryptosystems use multiple approaches to encrypt and decrypt the plaintext they are protecting. The most common hybrid systems are ones that combine asymmetric and symmetric algorithms. In most if not all of these systems, the cryptologic strength of the asymmetric algorithms are used to overcome potentially exploitable weaknesses in symmetric algorithms by means of computing a one-time session key, nonce, initialization vector, or other set of data that allows the far faster but weaker symmetric encryption process to handle the throughput needs of the systems’ users. Marrying the two provides two new approaches you’ll need to be familiar with.
Key encapsulation processes, which are typically built with public key infrastructures (PKIs) to handle key exchange
Data (or payload) encapsulation processes, which use more runtime-efficient symmetric-key algorithms
Most of the protocols we’ll look at use some variation of this approach. As we examine these, keep the OSI protocol stack in mind. Somewhere in that stack, the user, an application, or a lower-level service must be able to initiate a secure exchange with a host, negotiate with that host, control the secure session’s exchange of information, and then cleanly terminate the session. The protocols we’ll examine in some detail support these tasks.
Elliptical Curve Cryptography
ECC seeks to find discrete logarithm problems that are even more difficult to work backward than those used by RSA or Diffie-Hellman-Merkle; these can be thought of as either providing far, far greater security for the same range of key sizes or equivalent security for smaller keys that require far less computation time to encrypt and decrypt messages via ECC.
There are two approaches to understanding and appreciating elliptical curve cryptography (ECC). One gets graphical and mathematical very quickly, and you’ll find articles such as https://arstechnica.com/information-technology/2013/10/ a-relatively-easy-to-understand-primer-on-elliptic-curve-cryptography/ quite helpful in explaining things without too much math. (The ArsTechnica article also animates this math, which is appealingly useful.) The other is to set the mathematics aside and look at the practicalities of EEC in action.
Applying ECC in a practical system is becoming easier all the time. It’s become incredibly popular and is part of the TOR project (The Onion Relay, an anonymizing virtual private network, created by the U.S. Office of Naval Research in part to facilitate free speech and journalism); it’s part of proof of ownership of BitCoins and is in Apple’s iMessage Service. The Domain Name System uses it as part of DNSCurve to secure DNS information and is becoming a preferred member of cryptographic suites on many websites because it seems to provide perfect forward secrecy. You’ll probably find it as a member of the encryption suites on your endpoints already.
There are some unknowns, or at least some things believed to be true but not proven so. In 2007, NSA released its Dual Elliptic Curve Deterministic Random Bit Generator, known as Dual_EC_DBRG. Despite some initial criticism and skepticism (users and cryptanalysts either trust or don’t trust the NSA), it was one of the algorithms included in NIST’s SP 800-90A standard. Researchers began to demonstrate the potential for such a backdoor, and documents that the New York Times had but never published appeared to demonstrate that NSA had in fact inserted such a backdoor into Dual_EC_DBRG. Supposedly, members of the American National Standards Institute group reviewing all of this had information that described how to disable such a backdoor if it existed but chose to do nothing with it. By 2014, after more details revealed by Edward Snowden, NIST withdrew its draft guidance supporting the use of Dual_EC_DBRG, recommending that users transition to other approved algorithms quickly. In addition, a presidential advisory panel confirmed that NSA had been spending $250 million per year to insert backdoors into software and hardware elements of encryption systems. RSA Security and others chose to withdraw certain products that had standardized on the use of this ill-fated random bit generator.
While none of this calls into question the underlying mathematical validity or power of ECC, it does shed quite an unfavorable light on the standards and review processes used to establish good working implementations of new encryption algorithms and technologies. Advocates of open source and alternative approaches, such as GnuPG, OpenPGP, and PGP/GPG, point to the Dual_EC_DBRG fracas as a case in point.
The Modulus (Mod)
If math has never been your strong suit and you find this talk of using a modulus (mod) confusing, for the purposes of understanding the Diffie-Hellman Key Exchange, the concepts really aren’t too difficult. Before jumping into why Diffie-Hellman works, let’s first explain a few terms like exponent, prime, and modulus.
First, the exponent, which is written as a superscript value above another value. For example, in the formula K = Ab mod p, the exponent is the “b.” When reading this, we say “A to the power of b.”
Using an exponent creates a large number quickly. For example, we know that 7 * 7 = 49. Using exponents, you could write 7 * 7 also as 72, which is to say “7 to the power of 2.“ So far, so good? Let’s try 73 or 7 * 7 * 7. That is the same as 49 * 7, or 343, Last exponent example: how big is 77? That is 7*7*7*7*7*7*7, which comes to 823,543. Yes, with exponents, numbers get large very quickly.
On to prime numbers. Being prime is a trait of any whole number that can be divided only by itself, or 1, and get a whole number as a result. For example, the number 4 can be divisible by 4 (which equals 1) and by 2 (which equals 2). The number 49 is not a prime number, because it can divided by 7. But the number 7 is a prime because it is only divisible by itself and 1. Since there are so many ways to multiply any number of primes together to generate a non-prime, prime numbers become fewer and farther between as you look at larger and larger numbers. The Diffie-Hellmann Key Exchange makes use of this as it relies on using very large prime numbers as factors in its cogeneration of the session key.
Now onto the idea of modulus. The modulo operation divides any number by another number to get the remainder. It sounds complicated, but it really is as simple as getting the remainder after dividing. For example, if you divide 7 by 3, you get 2 plus 1 remaining. If you divide 21 by 4, then you get 5, plus 1 remaining. In both examples, the 1 remaining is called the modulus.
Remember the complicated-looking formula when Alice computed the key value K? The formula was K = Ba mod p. If you read that right, you take a number “B” to the power of “a” and then divide it by “p.” Whatever remains as the remainder is now Alice’s key value K. That’s all there is to it..
Bob does something similar. Both have used large prime numbers in their calculations.
After walking through all this math, I imagine you’re coming to a conclusion about the Diffie-Hellmann Key Exchange. It’s not an exchange of keys at all, but rather two users mutually generating their key, together but separate. This way, no one could intercept the key being transmitted between them.
For a deeper explanation or answers to questions such as, “Why can’t someone just derive the same secret key, knowing all the values?” or “How can Alice and Bob compute such large numbers?” take a look at:
You often need to be able to thwart any attempts to deny that somebody took an action, sent a message, or agreed to something in a document. Virtually every transaction in business and many interpersonal transactions depend on being able to prove that both parties to the transaction actually participated in it. (Imagine trying to buy a house and having the seller claim that they never agreed to the signed offer and acceptance contract!) Nonrepudiation provides all the confidence that, having reached an agreement, one party or another cannot back away from the agreement by claiming that they never agreed to it. In most cases, this requires building a set of evidence that attests to the transaction or the agreement, the identity of the parties involved, and even the process they went through to reach agreement. In many nations, business and government agreements are literally bound up with special colored ribbons, riveted fasteners, and seals so that visibly and physically the agreement and all of its supporting evidence is in one package. This package can be audited, placed in protected storage (such as an official records office), and used as evidence if the parties have to seek enforcement or relief in a court of law.
Generalizing this, you can see that nonrepudiation requires that:
The identity of all parties has been authenticated.
All parties have proven that they have the authority or privilege to participate in the transaction.
The terms and conditions of the transaction exist in a form that can be recorded.
All of this information can be collectively or separately verified and validated to be true and correct, free from any attempts to tamper with or alter it.
Nonrepudiation and integrity of information are strongly linked. We believe that the bank notes or coins we spend are legal tender, able to be lawfully used to pay for goods and services, because we believe both in the integrity of the coins and paper notes themselves and that the issuing government won’t turn around and say “Those are no longer valid.”
Registered Email
Let’s consider one of the most common examples of the failure to provide reliable nonrepudiation—the use of typical email systems. Although email protocols provide ways for senders and recipients to exchange delivery and read receipts, these fail in nearly all circumstances to provide any proof that what one party claims was sent in an email was received and opened by the intended recipients. Within an organization (that is, when on a single, unified email server), delivery and read receipts are somewhat reliable, but no one relies on them as legally acceptable evidence or proof. It’s also trivially easy for senders or recipients to edit the email after it’s been sent or received, falsifying address, delivery, or content information in the process. Recipients can easily claim that they never received the email in question, and this lack of verified receipt and viewing of an email can give rise to deception or fraud.
Postal mail systems have long used registered and certified mail delivery processes to provide legally acceptable proof that a letter or package sent by one party to another was in fact delivered to the recipient and received by them. These processes require proof of identification of sender and recipient, and in the case of certified mail they record every step along the delivery path. Courts of law have long recognized that these processes, and similar ones offered by private document or package courier companies, provide acceptable evidence of delivery and receipt. Of course, the U.S. Postal Service cannot prove that the envelope containing the letter was opened or that the letter was read or understood by the addressee—but by denying the opportunity to claim “I never received that letter,” many contract disputes or simple misunderstandings can be quickly resolved.
There are several examples of commercial service providers who offer something conceptually similar to registered mail for email and e-documents. Many national postal authorities around the world have started to offer these “registered email” services to their individual, business, and government customers. The European Union set standards in place via the European Electronic Commerce Directive 2000/31/EC, for example, which specifies the technical standards such proof of receipt systems must meet so as to provide legally acceptable evidence of delivery and receipt. One of these systems, provided by RPost, uses multiple cryptographic techniques (many of which are patented) to provide these capabilities. The U.S. Department of Defense and other NATO nations have long used proprietary or closed government systems to ensure that when electronic messages are sent by one command to another, or to a subordinate unit, the recipient cannot ignore that message simply by claiming that “we never got that order.” These systems, too, make extensive use of cryptographic techniques. Key to these systems is that strong identity verification, authentication, and information integrity protection measures must work together.
Digital Signatures and Nonrepudiation
Digital signatures use cryptographic techniques to authenticate the identity of the file, its contents, its originator or sender, or any combination of these assertions. Several important elements of a digital signature infrastructure are needed in order to be able to make these assertions hold true over time.
Authentication: Some process must be able to validate that the person or entity signing the file, document, or message is who the signature is associated with.
Integrity: Some process must be able to confirm that the file, document, or message has not been altered—in any way—from the state it was in at the moment it was signed.
Nonrepudiation: Once signed, some process must exist that can defeat any claim by the signer that they did not actually sign the file, message, or document; the system must deny the possibility of a forged signature being affixed to a document, file, or message. This is a one-way declaration of nonrepudiation by the originator; it does not specifically bind an instance of the message, document, or file, to the identity of a specific recipient.
Note that digital signatures, by themselves, are not responsible for assuring the confidentiality of the content of the message, document, or file, nor of the identity of the person or entity that signed it. Privacy, too, is not protected (for either the sender/originator or the recipient).
From a practical perspective, such a digital signature system should be scalable; it should not require significant effort to add new signatories to it or for recipients of files or messages to validate the signatures attached to them. As with key management, there should also be mechanisms to expire a signature in ways that do not invalidate documents signed prior to that expiration date. In many respects this is building an infrastructure of trust, by providing the mechanisms to assert trust between two parties, extend it from them to a third, and so on.
With the publication of Diffie-Hellman and the RSA algorithms, efforts accelerated to develop a workable infrastructure concept to support digital signatures.
The basic digital signature process involves the use of a highly secure hash function and asymmetric encryption in the following way. Suppose our friend Carol wants to send a message to Bob, but in doing so, she needs to prove to Bob that the message is inarguably from her and not from some imposter. Carol and Bob agree to use the following digital signature protocol:
Carol produces a strong hash of the message content. This is known as the secure message digest.
Carol “decrypts” that hash value, using the trapdoor function and her private key. This new value is her digital signature.
Carol sends the message and her digital signature to Bob.
Bob “encrypts” Carol’s digital signature, using the same trapdoor algorithm and Carol’s public signature, to produce the signed hash value.
Bob uses the same hash function to produce a comparison hash of the message he received (not including the signature). If this matches the value he computed in step 4, he has proven that Carol (who is the only one who knows her private key) is the only one who could have sent that message.
Again, please note that signing the message does not require Carol to encrypt its content, nor Bob to decrypt it. They can, of course, agree to use an encryption process (ideally a hybrid one relying upon their public and private keys) if so required. Note, too, that if a hostile third party such as Ted or Alice attempts to spoof Carol’s digital signature, they can succeed only if they already have Carol’s private key—or have hacked it via a brute force, burglary, or other attack mechanism. Note, too, that digitally signing a file for storage provides the same mix of integrity, authentication, and nonrepudiation protection. (Digitally signing an entire storage backup medium or file set, for example, provides a powerful assertion that the backup content is what the signature block asserts it to be.)
In many ways this process is independent of the algorithms used for producing the message hash, public and private keys, or the encryption and decryption used in this process. The root of this all, of course, is in how and where those public and private keys come from, and that bit of the infrastructure became associated with digital certificates as the vehicles by which trust is bestowed, recognized, distributed, and managed.
Digital signatures have widespread application in almost every area of systems integrity, availability, safety, and overall trustworthiness. Digital signatures are used in validating that a software update package or distribution kit is authentic or that a database backup set is from the system, date, and time it claims to be. Systems health checks, configuration management and control, and other change control processes can also digitally sign a system (at the level of a file directory or a whole disk volume) at the time the approved change is completed and routinely check by computing the digest value and comparing it to the signature to detect any changes.
All of this, of course, relies upon the sender or originator keeping their secret key secret and that there is some process as described in this section that can authenticate the validity of that originator’s public (and therefore their private) key.
Hashed Message Authentication Codes
Message authentication codes have long been used as a way of asserting that a particular message did in fact come from a properly authorized originator. Some messaging systems would sequentially number each message as part of formatting it for transmission, which when combined with sending date, time, originator ID, and other information, gave a reasonably unique and verifiable way to prevent attempts by third parties to spoof traffic into the system. Hashed message authentication codes (HMACs) perform this same function and were originally generated by noncryptographic hash functions. In use, HMACs are similar to generating a digital signature for the message contents. Senders and recipients then need to agree to a protocol for the exchange of an HMAC and its associated message content in ways that preserve message integrity and sender authenticity.
Depending upon the hash used to produce a digital signature, there may be exploitable weaknesses that leave the system open to attack. Replacing a standard hash with a cryptographic hash, using a strong cryptographic key, and using the HMAC algorithm allows systems to verify both the integrity of the message data and authenticate the sender of the message (or signer of the digital signature). HMAC first breaks the key into two halves (the inner and outer keys), then hashes the message first with the inner key, and then hashes that result with the outer key. This double-hash, using two different keys, leads to HMAC having greater immunity against length-extension attacks, which systems with only one pass through the hash function can be susceptible to. Similar to SHA-256 and other hash functions, HMAC breaks the message (or file) into fixed-length blocks and iteratively applies a compression function to them. It does not encrypt the message; as with all digital signature processes, the original version of the file or message used to generate the signature must accompany the signature so that the recipient (or later reader) can repeat the signature generation process and compare results to demonstrate authenticity.
Bellare, Canetti, and Krawczyk first published HMAC in a 1996 paper, and then in 1997 wrote RFC 2104 to bring it into the Internet community. It can make use of most any iterative hash function and is part of IPsec, TLS, and JSON Web Tokens. It was later included in FIPS 198 and in its later version FIPS 198-1, which specify the use of cryptographic hash functions to generate reliable message authentication codes for authenticating the information in the message.
Digital Signature Algorithm
The Digital Signature Algorithm (DSA) was first proposed by NIST in August 1991 as part of its Digital Signatures Standard (DSS) proposal. Although many software companies complained (having made significant investments in their own digital signature systems, many based on RSA’s cryptosystem), NIST moved ahead with its efforts and adopted DSA as Federal Information Processing Standard 186 in 1994. As of this writing there have been four revisions to DSA, the latest in 2013. DSA was patented by the U.S. government, which has made it available royalty-free worldwide.
DSA uses a combination of modular exponentiation and discrete logarithms to generate a digital signature given a public and private key pair. It supports full verification of authentic signatures and thus provides authentication, integrity, and nonrepudiation. DSA uses a four-step process.
Key generation, which consists of parameter generation and then computation of a per-user pair of public and private keys based on those parameters
Key distribution
Signing
Signature verification
The algorithm has demonstrated extreme sensitivity to the entropy, secrecy, and uniqueness of the random signature value k that is used during the signing process. Violating any one of these three cryptologic requirements, even by revealing just a few bits of k, can end up revealing the entire private key to an attacker. Experience with and analysis of DSA shows that typical cryptologic hygiene functions—not reusing a key value or a portion of one, for example—must be followed to keep the system secure. This vulnerability is also present in ECDSA, the elliptic curve variant of DSA, and was famously exploited in 2010 by the overflow group’s attack on Sony, which had been using ECDSA to sign software for its PlayStation 3 console. (Sony had failed to generate a new k for each pair of keys.)
DSA has been incorporated into multiple cryptographic libraries, such as Botan, Bouncy Castle, OpenSSL, and wolfCrypt.
Digital Certificates
Digital signatures—and the whole system of public key encryption—require some kind of authority, broker, or other function that can generate the public and private keys, authoritatively bind them to an identity, issue the keys to their owners, authenticate a public key as valid upon request (that is, that it is in fact associated with the identity as claimed), and manage key revocation and expiration. These issues gave rise to the need for special forms of digital signatures known as digital certificates. These are intrinsically bound up with public key infrastructures, webs and hierarchies of trust, and other related concepts, which will all be explored together in the “Understand Public Key Infrastructure Systems” section of this chapter.
Digital certificates are one of the lynch pins that hold the public key infrastructure together. It’s best to think of these certificates as the result of the following process:
Private key generation: A user requests that a server generate a private key for them. This can be a built-in service in the endpoint device’s operating system, an additional server layered on top of that OS, or an application-provided service. The server does this private key generation in accordance with the standards that apply for the type of key needed. (Most keys and digital certificates comply with the X.509 Certificate standard.) The private key never leaves the server, unless the requesting user exports it (for archival purposes in an HSM, perhaps).
Public key generation: The server also generates the corresponding public key for this user. (It’s not published yet, of course.)
Certificate signing request (CSR): The server issues a request to a complaint certificate authority selected by the user, containing required identification fields as well as the user-generated public key. The certificate signing request is digitally signed using the requestor’s private key. The private key is not part of the CSR. (Note that these are sometimes referred to as SSL CSRs, even though SSL has largely been replaced by TLS if not completely retired by the time you read this.)
Certificate enrollment: The server registers the identity information, public key, and digital signature in its records, and issues the certificate to the user.
The results of this process are a publicly registered, cryptographically secure binding or association of an identity and a public key; the strength of that binding, that is, its acceptability by the marketplace of users, is fundamentally tied to the trustworthiness of the certificate authority. The certificate authority (CA) is the one that issues certificates, sets their expiration dates, revokes them upon indications of compromise or for other legitimate reasons, and thereby facilitates the use of public-private key cryptography. (This is true whether the CA serves the general public or is a private CA internal to an organization.)
Public CAs include companies such as Comodo, Geotrust, Digicert, Thawte, Entrust, and many others. Symantec had been a major player in the public CA marketplace, but in 2018, Google had issues with Symantec over the latter’s issuing of free certificates in an attempt to stimulate small and startup business use. These were quickly gobbled up by fraudsters and exploited in a number of ways. One result of this was that Symantec sold its CA business line to Digicert.
Various circumstances might invalidate a certificate, such as the following:
Change of the subject’s name (does not always invalidate the certificate, depending on policy and the implementing technology)
Change of association between the subject and the certificate authority (such as when the subject is an employee leaving the company that acts as the certificate authority)
Compromise of the private key that corresponds to the public key included in the certificate
In these circumstances, the CA must revoke the certificate. One common way is to put that certificate’s serial number on a certificate revocation list (CRL) maintained and made public, perhaps on a website, by the CA.
Checking that a certificate you have received has not been revoked is an important step in verifying it. You can either download the latest CRL from the CA or check directly with the CA in real time using the Online Certificate Status Protocol (OCSP). If the certificate has not been revoked, the digital signature of the certificate authority is authentic, and you trust that CA, then the chain of logic is complete.
Once you have verified a certificate, you may consider the data contained in it as authentic. That choice, like others in our field, is a risk to be balanced. Because digital certificates are such an important part of modern security, it comes as no surprise that attackers have worked hard—and have often succeeded—at discovering and exploiting vulnerabilities associated with certificates. Dozens of flaws with digital certificates have been uncovered over the years.
Some attackers have focused their efforts on certificate authorities. One approach seeks to exploit weaknesses in the domain validation schemes a CA employs to authenticate the applicant for a new certificate. Another is to directly compromise the databases maintained by a certificate authority to cause the issuance of rogue certificates.
The potential use of rogue certificates has afflicted more than one mobile banking application, weakening their defense against man-in-the-middle (MITM) attacks. The MITM risk is that an attacker may intercept an encrypted connection, pose to each side as the other participant, copy the user’s banking credentials, and steal their money. Recently, a defensive tactic known as pinning—associating a particular host with their expected certificate—has become popular. Pinning, however, fails to solve the problem if the application does not check to see whether it is connected to a trusted source (that is, authenticate the hostname) before using the certificate.
Critics have long pointed to cryptographic issues with digital certificates, as well. To make certificates more difficult to subvert, the hash function must provide unique values. The ability to generate two different files with identical hash values makes possible a so-called “collision attack,” diluting the value of the digital signatures used in certificates. The National Institute of Standards and Technology warned in 2015 that advances in processing speed had rendered unsafe the use of the popular SHA-1 cryptographic algorithm, and in 2017 Google researchers demonstrated a hash collision attack against SHA-1.
Pure implementation issues not directly due to cryptographic issues have plagued certificate-based security in recent years as well, as the infamous “HeartBleed” and “POODLE” vulnerabilities of 2014 illustrated only too well.
Many of these certificate-based vulnerabilities have been addressed, over the years, with new designs and new implementation versions. Yet as long as clever attackers seek to undermine complex authentication systems, you can never be absolutely certain that a certificate is trustworthy.
The responsible management of digital certificates is so important because they are critical to modern authentication methods. Certificates have so many uses!
For example, a software developer may use a credential scheme to allow their application to log into a database without having to hard code the username and password into the source code. It is also possible to digitally sign software and patches upon release with credentials so that any tampering with the executable file can be detected. IPsec, a framework of open standards helping to secure communications over the Internet, relies on digital certificates, as do almost all virtual private network (VPN) technologies. Digital certificates also make possible the Secure/Multipurpose Internet Mail Extension (S/MIME) capabilities that can be used to encrypt electronic mail.
The place where the everyday user interacts with digital certificates most often, without question, is when they visit a “secure” website—that is, one with a URL that begins with “HTTPS” and not “HTTP.”
When you connect to a website with an address that begins with “HTTPS,” you are specifying that you want the browser session to use Transport Layer Security (TLS), a cryptographic protocol that provides communications security between computer networks. (TLS has largely supplanted the earlier protocol Secure Sockets Layer, which introduced this capability.)
TLS uses digital certificates. A peek at the National Institute for Standards and Technology guidance gives you a sense of the complexity of the configuration possibilities:
The TLS server shall be configured with one or more public key certificates and the associated private keys. TLS server implementations should support multiple server certificates with their associated private keys to support algorithm and key size agility.
There are six options for TLS server certificates that can satisfy the requirement for Approved cryptography: an RSA key encipherment certificate; an RSA signature certificate; an Elliptic Curve Digital Signature Algorithm (ECDSA) signature certificate; a Digital Signature Algorithm (DSA) signature certificate; a Diffie-Hellman certificate; and an ECDH certificate…
TLS servers shall be configured with certificates issued by a CA, rather than self-signed certificates. Furthermore, TLS server certificates shall be issued by a CA that publishes revocation information in either a Certificate Revocation List (CRL) [RFC5280] or in Online Certificate Status Protocol (OCSP) [RFC6960] responses.
NIST Special Publication 800-52, Guidelines for the Selection, Configuration and Use of Transport Layer Security (TLS) Implementations, April 2014 (https://doi.org/10.6028/NIST.SP.800-52r1)
The full details, which extend for several additional pages, are beyond the scope of this chapter. The key concept is that your web browser and the website server use certificates to be sure of the identity of the other side of the transaction.
The most popular design for the content and format of digital certificates is defined by the standard X.509, provided by the Standardization sector of the International Telecommunications Union (ITU-T). Version 1 was defined in 1988, version 2 in 1993, and version 3 (the current version) in 1996.
An X.509 certificate consists of three required fields: tbscertificate, signatureAlgorithm, and signatureValue. Here is a quick look at the contents of each.
Inside the tbscertificate field, you will find the names of the subject and the issuer. This field also contains the public key associated with the subject and the “validity period” specifying the notBefore and notAfter times. The certificate authority generates and inserts a unique serialNumber for the certificate, too.
The signatureAlgorithm field contains an identifier for the cryptographic algorithm used by the certificate authority to sign the certificate.
The signatureValue field contains a digital signature computed for this certificate, encoded as a bit string.
Note
For more information about the X.509 certificate and its required fields, see RFC 5280, “Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile,” from the Internet Engineering Task Force (https://doi.org/10.17487/RFC5280).
In addition to specifying the content of X.509 certificates, the standard lays out a certification path validation algorithm. Digital certificates build and rely upon a chain of trust, and a certificate chain carefully lists for examination each CA in the chain, conveying credence to the certificate.
A certificate can in fact be self-signed by the subject. Properly constructed self-signed certificates adhere to the format and satisfy the standard, leaving it up to the recipient to evaluate whether they are trustworthy. Self-certification limits, naturally, the sum of conveyed trust to the subject alone. On the other hand, self-signed certificates do eliminate the potential risk of third parties that may improperly sign certificates or have themselves been compromised by an attack.
Before leaving the subject of digital certificates, we must tackle the difference between a certificate and a blockchain. Blockchains have made cryptocurrencies possible (and increasingly popular) in recent years. They are based on a cryptographic message integrity scheme. A blockchain is a decentralized public record of transactions calculated by distributed computing systems across the Internet. The blockchain uses cryptographic encryption to ensure that any tampering with that record can be detected.
Briefly, the blocks keep batches of valid transactions that are hashed and encoded into something called a Merkel tree. Each block holds the cryptographic hash of the previous block. Hence, they are chained together, in a set of continuous links, all the way back to a genesis block. This distributed public chain of verifiable blocks ensures the integrity of the blockchain transaction records.
Encryption Algorithms
Cryptographic algorithms describe the process by which plaintext is encrypted and ciphertext decrypted back to its original plaintext. Those algorithms have to meet a number of mathematical and logical conditions if they are going to provide reliable, collision-free mapping of plaintext to ciphertext (for encryption or hashing) and then from ciphertext back to plaintext (in the case of decryption). Collisions would mean that any two plaintext strings could produce the same hash, which would invalidate any attempt to use hashes for digital signatures or message authentication codes. Collisions during encryption would also render any attempt to protect or obscure the meaning of plaintext for storage or transmission impossible, since upon decryption, there would be no reliable way to know which of the meanings had been intended.
Cryptographic algorithms also have to be sufficiently robust that they do not provide any easy mathematical or logical attacks that can defeat their protections; the section “Cryptographic Attacks, Cryptanalysis, and Countermeasures” goes into some of these attacks in further detail. Perhaps the most successful strategy to defeat a target’s use of encryption is not to attack it head-on, but to go around it via a side-channel attack, which attempts to find and exploit weaknesses in the operational procedures the target uses to implement cryptographic security. Mismanaged keys, passwords that are allowed to be of trivial length or complexity, vulnerability to social engineering, and even sufficiently poor physical security can make it laughably easy for an attacker to obtain information about keys that are in use.
It is difficult to separate algorithms from protocols, and protocols from systems. Public key encryption is a case in point. While almost any asymmetric algorithm can be used as part of session key generation and use, the notion that private keys and public keys depend upon an infrastructure of certificates being generated and distributed (either by a hierarchy or web of trust) ties two infrastructures to the algorithms. It is also difficult—and perhaps meaningless—to attempt to separate cryptographic systems and techniques from the operational processes by which you or any organization puts them to use, audits conformance to standards and procedures, maintains them, and updates, refreshes, or renews keys and other keying materials. Cryptographic hygiene offers a mental model or framework that can encourage a commonsense, disciplined approach to reducing these risks.
Key Strength
Cryptographic key strength was introduced in the first section of this chapter as being strongly related to the number of bits in the encryption key used by a given encryption algorithm. This bit depth actually defines the size of the search space that a brute-force attack would have to go through, checking each possible value, until it found one that matched the hash value or ciphertext being attacked. Such brute-force attacks can, of course, get lucky and strike a match on one of the first few attempts…or have to run almost forever until a winner turns up. Computer scientists refer to this as a halting problem, in that while you know the maximum number of iterations the search loop must perform, you have no way of knowing whether it will take one iteration, a handful, or a full 2n times around the loop for an n-bit key. This search space size was the first practical way to estimate the work factor associated with cracking a particular cipher. Cryptanalysts could then estimate the number of CPU (or GPU) instruction cycles needed for each iteration, translate that into seconds (or microseconds), and then multiply to estimate the length of how long one’s secrets might remain safe from an attacker in terms of hours, days, or weeks.
The search space argument regarding cryptographic strength started to fall apart as the cost of high-performance graphic processing units (GPUs) fell while their processing power soared. (Think about how many complex vector calculations have to be done each second to take a streaming HD video, uncompress it, render it into clusters of pixels of the right color and intensity, provide those pixels to the video driver circuits, and then send the information out to the display. One frame of video is about 6.221 MB of data; at 60 frames per second, one second of video involves about 374 MB of data total, all the result of parallel processing streams inside the GPU.) Software systems for designing massively parallel task streams, dispatching workloads to processors, and coordinating their efforts to produce a finished result have become far more commonplace and more powerful; the hypervisor contained in most modern desktop or laptop computers has many of these capabilities built right in. These factors all compound together to give cryptanalysts—black hat and white alike—entirely new and affordable ways to bring thousands or tens of thousands of CPUs (and GPUs) to a code-breaking task. Attempts have been made by cryptanalysts to express cryptographic strength in “MIP-years,” that is, the number of millions of instructions per second a CPU executes, across a whole year, but this has proven challenging to translate across dissimilar architectures of GPUs, CPUs, and such.
Sometimes 256 May Not Be Greater Than 128
The search space argument suggests that it’s reasonable to expect a longer key will be more secure than a shorter one. All else being equal, the longer the key, the larger the key space and therefore the longer it will take to brute-force a key. But with AES, it turns out that all else is not equal. Owing to problems with the design of AES-256, Alex Biryukov, Orr Dunkelman, Nathan Keller, Dmitry Khovratovich, and Adi Shamir reported in 2009 that there is an attack on AES-256 that requires only 2119 time (compared with 2128 time for AES-128, or the 2256 time one would expect from AES-256). Practically, this does not matter as a 2119 time attack is still completely infeasible using any technology available or likely to be available within the next decade or two. (Work that out in MIP-years to see why it’s infeasible for the moment.) The attacks analyzed by Biryukov et al. are of a type known as related-key attacks that are impractical in properly implemented systems. Biryukov et al. also found a weakness in AES-192, but that attack takes 2176, not 2192 as it ought to, if AES-192 had no flaws, but that’s still much better than AES-128.
These and similar cryptanalyst findings demonstrate that as cryptographic algorithms become more complex, a measure of their strength (or weakness) needs to consider other factors than processing needs alone. The size of a data space associated with part of an algorithm, the number of rounds used, or other parameters may have a marked effect on the strength of an algorithm.
Cryptographic Safety Factor
Other cryptanalysts have also struggled with the difficulty in making a meaningful estimate of the strength of a cryptographic algorithm. One approach was taken in the selection process for the algorithm that became the Advanced Encryption Standard; for this, cryptographer Eli Biham introduced the concept of a safety factor.
Biham’s safety factor notes that all modern ciphers are built as a series of rounds, each using a subkey derived from the main key. Cryptographers typically attempt to break ciphers by first attacking a simplified version of the cipher with a reduced number of rounds. For example, early cryptographic attacks on DES (before it fell to simple brute-force) revealed an attack on eight rounds (the full DES has 16 rounds). With AES-256, there is an attack that works on a simplified version of 10 rounds (the full AES has 14 rounds). This was developed after attacks on six-, seven-, and nine-round versions.
Biham’s safety factor is the ratio of the number of rounds in the cipher, divided by the largest number of rounds that have been successfully attacked so far. While obviously dependent on the level of effort expended by cryptographers trying to undermine a cipher, it is still a useful metric, at least when comparing ciphers that have received sufficient attention from cryptographers.
Using this measure, AES-256 currently has a safety factor of 1.4. Other ciphers, such as Twofish, have greater safety factors, and it was for this reason that the team that developed the Twofish algorithm argued that it ought to have been selected as the Advanced Encryption Standard instead of the algorithm (Rijndael) that was selected.
In a somewhat tongue-in-cheek fashion, Lenstra, Kleinjung and Thomé have suggested that another, and possibly more useful, approach, would be to estimate the amount of energy (as heat) that each such attack process needs. In their paper titled “Universal Security, from bits and mips to pools, lakes, and beyond,” they focus on how difficult it really is to usefully predict (or model) the strength of an encryption process in terms that are comparable to non-encryption-based ideas of work and time. For more food for thought you can head to https://eprint.iacr.org/2013/635.pdf.
The sad news is, however, that no matter what algorithm you choose and no matter how carefully you choose its cryptovariables, you are still in a race against time. Processing power in the hands of the attackers will continue to increase, especially as they become more adept at sharing the load around in their dark web bastion areas. You can stay a few steps ahead of them, however, if you are diligent in keeping your systems and their cryptologic components properly maintained and updated and operate them in ways that do not inadvertently lead to compromising them.
Cryptographic Attacks, Cryptanalysis, and Countermeasures
As American cryptologist Bruce Schneier famously stated, “All cryptography can eventually be broken—the only question is how much effort is required.” Many cryptographers, black hats and white hats alike, read these words and think that this is a two-variable inequality: what’s the value to me (defender or attacker) of the information, and what’s the value to me of the effort required to successfully attack that information asset (or protect it from compromise, damage, or loss)? This oversimplifies the time element of the problem and the inherent asymmetry in the way that attacker and defender view the time value of information and effort.
The defenders and their organization have invested substantially in obtaining, creating, and using their information assets to gain a temporary competitive advantage. They are also usually constrained by the ways that financial markets work—if they incur huge costs in the immediate term because of an incident, they may have to finance or carry those costs for years to come. Thus, the future value of their losses can be far greater than the actual costs incurred during an incident. As a security professional, you may already be accustomed to justifying investments in better information security systems, technologies, procedures, and workforce training on the basis of the time value of the costs you can avoid versus the revenues you can protect. You may also face one of those tipping points at which the long-term strategic value of a decision or action—and thereby the information assets that support that course of action—are just too significant to ignore; and yet, that tipping point won’t last forever.
The attacker may or may not face similar time value propositions, depending upon their own agendas, goals, or objectives. Their objectives may be immediate profit from reselling the data that they exfiltrate, or they may see their attacks on your systems, facilitated by cracking their way past your cryptographic defenses, as just one step in a longer and more complex kill chain. Then, too, the attackers might view stealing (or disrupting) your information assets as an action that produces immediate competitive advantage for them, in ways we have no way to recognize.
You’re in a race against time with all of your current and potential adversaries “out there” in the wild. You cannot stand still; your defensive cryptographic systems get weaker with time as your adversaries’ abilities to analyze, assess, and circumvent them get stronger and stronger (and cheaper and cheaper to buy, build, rent, or use). That’s the bad news regarding your cryptologic risk situation; it should also be a wake-up call.
It’s also some good news for your proactive defense strategy, tactics, and operations. You need to gather and exploit the threat intelligence you have available to you and tune that to help you assess your current state of cryptologic hygiene.
Cryptologic Hygiene as Countermeasures
Cryptologic hygiene is an operational attitude and approach that takes planned, managed, and proactive steps to assess your cryptologic systems, and your use of them, across the entire face of your systems’ cryptologic attack surfaces. This requires you to examine the following:
Algorithm and protocol selection, such as in cryptologic suites.
Algorithm and protocol implementation.
Operational use of cryptographic systems as part of routine end user activities.
Systems administration of cryptologic systems.
Continuous vulnerability assessment, including CVE information regarding the systems, algorithms, cipher suites, and cryptologic management tools in use in your organization. This should include attending to CVE information regarding cryptographic-related vulnerabilities in applications or other systems elements in your architecture.
Key generation, management, and use.
Identity, digital signature, and digital certificate management and use.
Business continuity and disaster recovery cryptologic processes.
End user education and training regarding cryptographic defenses.
Education, training, and expectation management for all levels of management, leadership, and other stakeholders.
Your organization’s unique risk situation and context, and its information security needs, may dictate that other cryptology-oriented elements be included in your cryptologic hygiene plans.
Each of these topic areas (and others you might need to add) may present a determined attacker with exploitable vulnerabilities. Many have been identified by the cryptanalyst communities and are written about in journals, blog posts, or other publications. Some are reported as Common Vulnerabilities and Exposures; others appear in white papers and conference proceedings posted on the websites of security systems vendors, information security associations such as (ISC)2, ISACA, and the IEEE CS, to name a few.
Cryptologic hygiene is a subset of your overall security hygiene and posture, but it’s also the same attitude and mind-set at work. It asks you to address the fundamental issues of the quality and maturity of your processes for using, managing, controlling, protecting, assessing, improving, and restoring your cryptographic defenses. It asks to be a subset of your overall information security process maturity modeling and measurement.
A Starter Set of Crypto-Hygiene Practices
Let’s take a look at some starting points for putting a cryptologic hygiene program into action. There are any number of standards documents that address aspects of this hygiene process, many of which address information security processes across the board. Others are very intensely focused on what might be called the high-capacity, high-demand cryptologic user base, such as what you’d expect in a major financial institution, a credit card payment processor, or even at a certificate authority. The following rules of thumb should give you a simpler place to start, which may be enough to address the needs of a small office/home office (SOHO) or small to medium-sized organization infrastructure.
DIY Need Not ApplyAn important rule in cryptographic hygiene is to never invent your own cryptographic algorithm, process, or system, even if you think it’s absolutely necessary to do so. Although technology professionals are generally smart people, it is entirely too common that we become overconfident in our abilities. In 1864, famed cryptographer Charles Babbage wrote, “One of the most singular characteristics of the art of deciphering is the strong conviction possessed by every person, even moderately acquainted with it, that he is able to construct a cipher which nobody else can decipher.” This leads to a false sense of security. Simply because you have invented a system that you cannot defeat does not mean it cannot (or will not) be defeated by someone else.
Know Your Baselines and How to Maintain ThemYou need to know what you’ve already got and how to use it. Your systems will no doubt already have significant cryptologic components in them. Anything with a modern web browser installed on it, for example, already brings you the capabilities to manage the use of encryption suites, digital certificates, digital signatures, and other encryption-based security measures. As with any aspect of your baseline, start with a very detailed inventory; discover and catalog every element. Then make sure you have current vendor-supplied operational and maintenance information on hand, or at least know where to get it. Systems vendors, platform providers, and even your browser provider offer substantial libraries of how-to information—from simple procedures through in-depth knowledge base articles—which you should be familiar with. Use these support pages to identify active community support boards; join in the learning by joining the conversation.
Manage Your BaselinesYou also need to put your cryptographic infrastructure under solid configuration management and control. Plan and schedule changes, whether those are certificate renewals, minor patches and updates, or major upgrades. Identify the human elements associated with each cryptographic configuration item (CCI, to coin an acronym); these are opportunities to keep end users engaged with security by building their awareness and their skills.
Stay SharpIt is crucial to stay current. Knowing and managing your baselines should point you to the communities of practice that directly apply to the systems and technologies your organization depends upon. Find the places you need to frequent to stay informed about new exploits or attacks or cryptanalysis results that suggest a vulnerability might exist in your systems.
Protect Across the Life CycleIt is also essential to practice good housekeeping. Your systems’ baseline and configuration management processes should identify components of your systems that need special end-of-life treatment, so as not to compromise your cryptographic defenses. You may have little or no direct involvement in key management or the destruction of expired, revoked, or compromised keying materials, if you’re like the majority of business and nonprofit organizations and are totally dependent upon commodity product systems, such as servers, workstations, and endpoints, and their built-in hybrid encryption systems. Nonetheless, it’s good to have your hardware, software, firmware, and data baselines clearly identify cryptographically sensitive items that may need special protection while in use, when undergoing repairs, or when being disposed of.
If You Can’t Update, Increase Your WatchfulnessThink about the CVE process and overlay its timeline onto the kill chain conceptual model. Chances are that many exploiters in the wild will learn about that vulnerability the same way you will, by means of notifications from the CVE database operators. Three time windows start clocking out starting on “zero day”—the time to develop a fix or patch, the time for you to validate that you can safely install the fix without causing more disruption to business processes, and the time for attackers to take advantage of that vulnerability and get into your systems. It’s not hard to guess which one of those time windows runs out the fastest.
Prudent software and systems management dictates that you test and evaluate any change to your systems before putting it into production or operational use, no matter how urgent and compelling the need to update may seem to be. Security hygiene—and therefore cryptologic hygiene—dictates that between the time you have the fix in hand and the time you’ve finished testing it and declaring it the “new normal” that you increase your watchfulness. The larger your deployed architecture and the greater the mix of systems, versions, and endpoint technologies employed with it, the harder it becomes to baseline it and manage to that baseline. You should be doing this alone: the IT departments and the formal configuration management and control teams in your organization own the lion’s share of this burden. Your role should focus on the cryptologic aspects of that architecture, particularly the procedural ones, to make sure that someone else’s major change package doesn’t demolish the crypto-walls that are relied upon today.
Your first response to seeing a new CVE announcement should be to ask yourself, “How would I spot that new exploit in action against my systems?” Think like the adversary; red team your current surveillance and monitoring processes and see whether you can detect this new exploit in action. Any new exploits you cannot detect, which might remotely allow an intruder into your systems, are crying out for changing something in your monitoring, analysis, detection, and reporting operations.
As you continue to apply a cryptographic hygiene mindset, you’ll probably discover more rules to put into your cryptographic process maturity handbook. One way to do that is to look at common attack patterns; along the way, let’s also look at some “famous fails” when it comes to design, implementation, and use cases gone wrong.
Cryptography Is Not a Standalone Answer
This may be a blinding flash of the obvious, but it’s part of counteracting the “sprinkle a little crypto dust” fallacy, so you may have to keep this rule handy and use it often. For example, consider the private keys on your client endpoint systems. Where are they kept? How do you keep them safe and secure?
If you’re working in a SOHO system or any systems infrastructure where you do not buy and manage your own certificates (and thereby generate and manage your users’ private and public keys on your own), then you are vitally dependent upon the access control systems and policies on your in-house file servers, database servers, web servers, network control systems, and each and every one of your client endpoint devices. That means that anybody with superuser or systems administrative privileges, who has physical or logical access to any of these machines, has access to where its host operating system stores its certificates, public keys, private keys, and the tables that OS uses to associate each user identity with its keys (and possibly the password salts, hashed passwords, and other encryption-related parameters). Because we need systems that are easy to administer, it’s easy for such a user to call up the right built-in utility functions and export those files.
So how do you stop a lunchtime attack from purloining a copy of those key caches?
Administratively, you teach your users what the risks might be and how each of them is a vital component in the overall security system. You motivate them to become true believers in the idle-lock settings; you work with them to eliminate the yellow stickies with the password cribs. You get them to be suspicious of the pizza delivery man wandering the hallways (one of my favorite force protection drills, after I received an unordered pizza box with a “boom!” note inside it).
Physically, you identify the right mix of protection mechanisms that keep both your on-site and your mobile devices protected; this may include mobile device managers and their capabilities to lock or brick such a device if it wanders off site.
Logically, you thoroughly understand what you need in the way of access control capabilities; use what’s built into your OS and servers for all that it’s worth. Understand what to log, and what to look for in those logs, as it might relate to attempted attacks on your key stores and caches.
Without every other trick in your information security playbook working like clockwork for you, you cannot protect the number-one set of secret ingredients in your competitive advantage: your users’ and your company’s private keys, and the cryptovariables, seeds, and salts that go with them.
The “Understand Public Key Infrastructure Systems” section in this chapter will go into more depth and detail on key and certificate management and the cryptologic hygiene measures to consider. This is enough, for now, to get you seeing your systems from the black hats’ perspective, cryptologically speaking.
Common Attack Patterns and Methods
It’s now time to look outside of your cryptologic attack surface and think about the ways in which an attacker might attempt to circumvent your defenses. Start from the assumption that your attacker will know your system; the only thing that they won’t know (right away) are the specifics about the user IDs, credentials, and keys that provide the real strength that your defenses need.
Along the way, we’ll mention some attack-specific countermeasures for you to consider as part of the ways in which your organization chooses, installs, uses, and maintains its cryptologic defenses. Since you’re not developing your own encryption or hashing algorithms, we won’t address countermeasures that designers should take. These are, of course, in addition to all the normal, customary, and usual cryptographic hygiene elements regarding keeping systems up-to-date, under control, and protected. Keeping yourself “fully patched” and your knowledge up to date as well is, of course, part of that expected set of proactive measures.
Attacks Against the Human Element
The people in your organization are perhaps its greatest strength and its greatest opportunity for exploitation by a determined adversary. Too many businesses have suffered when an insider becomes susceptible to coercion, blackmail, or other “undue influences,” as they say. Some have had employees kidnapped and pressured or otherwise influenced into revealing information that allows an attacker to defeat otherwise impregnable information defenses. Technical exploitation of lost or stolen endpoint devices is becoming commonplace. Burglary and other clandestine means of entering a facility to gain information are risks that should not be ignored.
You’ve addressed those risks to your organization with various physical, logical, and administrative mitigations and security controls. Be sure to extend that to the cryptologic elements of your systems. You may be safe in relying on system and data archives protected by encryption, if you’ve used strong hybrid systems to provide you assurances of the forward secrecy of those archives; but to read and use those archives when you need them, you’ve got to have those session keys somewhere. How do you protect them against the exploitable vulnerabilities in the human elements of your systems?
Algorithm Attacks
These are attack patterns that depend upon intercepting and collecting quantities of ciphertext and plaintext and then analyzing them to look for patterns. Traffic between multiple senders and recipients may reveal coincidental changes in message length or frequency when correlated to other observable activities, for example. Four main types of attack fall into this category.
Ciphertext-only attacks occur when the attacker has access only to the encrypted traffic (ciphertext). In many cases, some information about the plaintext can be guessed (such as the language of the message, which can lead to knowledge of the character probability distribution or the format of the message, which can give clues to parts of the plaintext). Wired Equivalent Privacy (WEP), the original security algorithm for Wi-Fi™, is vulnerable to a number of ciphertext-only attacks. By capturing a sufficient number of packets (which typically can be gathered within minutes on a busy network), it is possible to derive the key used in the RC4 stream cipher. It is thought that the 45 million credit cards purloined from the American retail giant T.J. Maxx were obtained by exploiting WEP.
Known-plaintext attacks can happen when the attacker knows some or all of the plaintext of one or more messages (as well as the ciphertext). This frequently happens when parts of the message tend to be fixed (such as protocol headers or other relatively invariant parts of the messages being communicated). An example of a known-plaintext attack is the famous German Enigma cipher machine, which was cracked in large part by relying upon known plaintexts. Many messages contained the same word in the same place or contained the same text (e.g., “Nothing to report.”), making deciphering the messages possible.
Chosen-plaintext attacks see the attacker is able to inject any plaintext the attacker chooses into the target’s communications systems (or a copy of them) and thereby obtain the corresponding ciphertext. The classic example of a chosen-plaintext attack occurred during WWII when the United States intercepted messages indicating the Japanese were planning an attack on a location known as “AF” in code. The United States suspected this might be Midway Island, and to confirm their hypothesis, the United States arranged for a plaintext message to be sent from Midway Island indicating that the island’s water purification plant had broken down. When the Japanese intercepted the message and then transmitted a coded message referring to AF, the United States had the confirmation they needed.
Chosen-ciphertext attacks occur when the attacker is able to inject any ciphertext into the target’s communications systems (or a copy of them) and thereby obtain the corresponding plaintext. An example of this was the attack on SSL 3.0 developed by Bleichenbacher of Bell Labs that could obtain the RSA private key of a website after trying between 300,000 and 2 million chosen ciphertexts.
As you might expect, different cryptographic systems and their algorithms have differing levels of vulnerability to these types of attacks.
Heartbleed—An Implementation Flaw Case Study
Heartbleed was an implementation flaw in the implementation of the TLS protocol used to secure web traffic (HTTPS). Part of the protocol defined a “heartbeat” packet that contains a text message and a length field. The computer receiving the message is simply to send the message back. The defect was that the size of the message sent back was not based on the actual size of the received heartbeat packet, but on the length parameter sent by the requester. So, a malicious actor could send a heartbeat packet containing the message “Hello, world!” but with a length field of, say, 64,000. The reply would contain “Hello, world!” plus the next 63,987 bytes of whatever happened to be in memory beyond that message. That memory could contain the private key used to secure the website, or copies of previous messages containing confidential information. Access to a web server’s private keys would enable an attacker to decrypt past and future web traffic, as well as spoof the identity of the website, enabling phishing attacks.
The flaw existed in the widely used library for two years before being reported and patched. At least half a million secure websites were estimated to have been affected, not to mention the hundreds of thousands of devices with an embedded web server used to manage the device. In one example, a curious computing science student used the flaw to exfiltrate 900 social insurance numbers from the Canada Revenue Agency, earning an 18-month conditional sentence to prison for his efforts. Cybersecurity columnist Joseph Steinberg wrote in Forbes: “Some might argue that Heartbleed is the worst vulnerability found (at least in terms of its potential impact) since commercial traffic began to flow on the Internet.”
A brute-force attack is one that simply steps through all possible values until one of them works (requiring little thought, planning, reconnaissance, or analysis). Typically, this involves building (or mathematically generating) a search space of all possible values, such as 264 binary numbers for a 64-bit key space. If luck is with you (the defender), your key or hash value won’t match in the first few (days or weeks) of an attacker’s search of that space. Then again, luck may favor the attacker. Brute-force attacks against password hashes, ciphertext, digital signatures, or almost any element of your systems are possible. Brute-force attacks are commonly targeted against intercepted individual passwords or against exfiltrated password hash tables. Cryptanalytic attacks may also resort to brute-force attacks against ciphertext.
WEP, as a case study, reveals the value of a well-placed brute-force attack. Wired Equivalent Privacy (WEP) was the first approach to encryption used for Wi-Fi™ networks. One of its major design flaws was its reliance on the RC4 encryption algorithm, which was quickly shown to be susceptible to brute-force attacks. RC4 did not have an initialization vector built into its algorithm, so the WEP designers chose to use a 24-bit IV combined with the symmetric encryption key to feed to the keystream generator. Such a short IV repeats far too quickly; in typical usage, less than three minutes of Wi-Fi™ packet sniffing would provide more than enough samples to use to attack and break WEP’s encryption as a result. (As a result, WEP should not be used, especially when the stronger WPA and WPA-2 are available.)
Modified or optimized brute-force attacks are ones in which a little knowledge on the attacker’s part is used to drastically reduce their search time. This can involve any number of techniques, such as precomputing a dictionary or rainbow table.
Countermeasures to brute-force attacks include strong password and passphrase hygiene, using properly updated cryptographic hash, encryption and decryption suites, and effective, operational security procedures.
Man-in-the-Middle Attack
Man-in-the-middle (MiTM) attacks show up at almost every layer of the OSI protocol stack—including layer 8, the human-to-human layer. When they involve the attacker (imposter) attempting to sidestep, subvert, or otherwise attack the cryptographic processes used by the parties, it’s worth considering them as a cryptologic attack. For example, a MiTM attacker (Mallory, let’s say) attempts to insert herself into a conversation between Bob and Carol, who are using HTTPS as part of their processes. Bob and Carol are relying upon the digital certificates each provides to the other (via their browsers’ use of them and their built-in encryption suites) to confirm Bob’s assertion that he is in fact Bob, and Carol’s that she actually is Carol. However, if one or more of these certificates were issues by a compromised certificate authority (such as the Dutch CA DigiNotar, which was compromised in 2011), Bob and Carol might believe they are talking to each other, when in fact they are talking through Mallory. (The DigiNotar compromise affected more than 300,000 Gmail users.)
Side-Channel Attacks
Side-channel attacks involve measuring observable characteristics of the cryptographic process to deduce information to assist with compromising encrypted information. This usually requires the attacker to have a copy of the system being attacked and the ability to open it up, capture internal or intermediate data, make measurements, or even take infrared high-speed images to observe changes in heat signatures. These can include the following:
Timing
Cache access
Power consumption
Electromagnetic emanations
Error information
The time taken to encrypt or decrypt a block of data can vary depending on the key or plaintext, and a careful analysis of the time taken to encrypt or decrypt the data can reveal information. The time to perform a cryptographic operation can vary for a number of reasons.
Conditional branches within the code, which can change the time of execution depending on the branches taken, which in turn depend on the value of the key or plaintext
CPU instructions that take variable time to complete depending on the operands (e.g., multiplication and division)
Memory access, which can vary depending on where the data is located (type of memory) or the access history (thus affecting the cache and thus the speed of memory access)
Cache attacks typically involve processes running on different virtual machines on the same physical processor. As the VM performing the encryption is time-sliced with the VM running the attacker’s processes, the attacker can probe the processor’s cache to deduce information about the plaintext and the key and thus compromise the encryption process. A cache-timing attack was at the heart of the Spectre and Meltdown attacks revealed in 2018 as methods of extracting data from protected regions of a processor’s memory (e.g., keys or plaintext messages).
The power consumed by the device performing the cryptographic operation may vary depending on the instructions executed, which in turn depend on the key and data being encrypted. By carefully monitoring the power consumed by the device, it can sometimes be possible to extract information about the key or plaintext. This type of attack has been most successfully demonstrated against smartcards because of the relative ease with which the device’s power consumption can be monitored, but the attack mechanism has wide applicability.
All electronic systems emit electromagnetic radiation, and it is possible to capture this, sometimes at some distance from the device. These radio signals can sometimes be analyzed to reveal information about the data being processed by the device. Early examples of this type of attack involved analyzing the emanations of cryptographic devices that printed the decrypted message on teletypewriters to determine which characters were being printed.
Error information provided (or leaked) by decryption software can provide useful information for attackers. In the Padding Oracle Attack, a system that can be sent any number of test messages and that generates a distinctive error for encrypted messages that are not properly padded can be used to decrypt messages without knowing the key. The defense is to report generic errors and not to distinguish between padding errors and other errors.
Countermeasures exist, but in some cases, they can be difficult to implement or can exact a considerable performance penalty. In the case of timing attacks, it is necessary to modify the algorithm so that it is isochronous, which is to say runs in constant time regardless of the key and data being processed.
The difficulty of implementing a secure algorithm that is secure against side-channel attacks is another reason for the “DIY need not apply” edict. Do not attempt to d write your own cryptographic implementation—use a tested and widely used cryptographic library instead.
Differential Fault Analysis
Differential fault analysis is a cryptographic attack in which faults are induced in the circuitry performing the cryptographic operation in the expectation that the device can be forced to reveal information on its internal state that can be used to deduce the key.
For example, in 2004 Christophe Giraud published an attack on AES-128 implemented on a smart card. By using a Xenon strobe and removing the cover of the smart card processor, his team was able to induce faults in the execution of the algorithm that enabled them, after multiple induced faults, to derive enough information to determine the full key value.
Birthday Attack
A birthday attack is a method of compromising cryptographic hashes, such as those used for digital signatures. The name is derived from the observation that while the odds that anyone in a group of 23 people has a specific date as their birthday is 23 out of 365, or 6 percent, the odds that there are two people in the group of 23 with the same birthday are 50 percent. Thus, any seemingly rare event might not be so rare when considering multiple possible occurrences.
A birthday attack against a digitally signed document would attempt to create a bogus document that somehow generates the same hash value as the original does, which would be a hash collision. Cryptographic hash functions are required to be free from collisions, and algorithm designers go to great length to design to prevent this and then test to verify their success. A birthday attack might attempt to have any type of file (a document or an executable binary) be mistaken as genuine.
The choice of a provably collision-free cryptographic hash is your best countermeasure for such attacks.
Related-Key Attack
A related-key attack is a form of known-ciphertext attack in which the attacker is able to observe the encryption of the same block of data using two keys, neither of which is known to the attacker but that have a known mathematical relationship.
While it is rare that the attacker can arrange for two mathematically related keys to be used, poor implementations of cryptography can lead to keys being generated that have a known relationship that can be exploited by the attacker. Short, poorly chosen keys can make it easier for attackers to identify possible related-key pairs; this was another means of successfully attacking WEP, for example.
Meet-in-the-Middle Attack
A meet-in-the-middle is a known-plaintext attack against block ciphers that perform two or more rounds of encryption. One might think double (or triple) encryption would increase the security in proportion to the combined length of the keys. However, the math behind this doesn’t support the increased complexity.
By creating separate lookup tables that capture the intermediate result (that is, after each round of encryption) of the possible combinations of both plaintext and ciphertext, it is possible to find matches between values that will limit the possible keys that must be tested in order to find the correct key. This attack, which first came to prominence when it was used to defeat the 2DES algorithm, can be applied to a broad range of ciphers.
Unfortunately, chaining together cryptography algorithms by running them multiple times does not add as much additional security as one might think. With 2DES, the total impact of the second run was to increase complexity from 256 to 257. This has a small overall impact compared to the work done.
Effective countermeasures may include choosing a stronger algorithm that uses longer keys and of course choosing those keys wisely. If this is not an option, your current algorithms may produce somewhat greater security by increasing the number of rounds they execute. 3DES, for example, does not get you all the way to a 168-bit key strength—but its 112-bit equivalent strength is much greater than that provided by 56-bit “single” DES.
Replay Attack
A replay attack is one in which the attacker does not decrypt the message. Instead, the attacker merely sends the same encrypted message. The attacker hopes that the receiving system will assume that the message originated with the authorized party because the information was encrypted.
Replay attacks can involve user or subject access request credentials, transaction replay, or almost any step or series of steps in one of your business processes. (A rather stealthy replay is the invoice replay, in which a “vendor” repeatedly bills a larger firm for the same small purchase, with the purchase amount carefully chosen to not trigger human authorizations.) Most of these are not cryptographic attacks, per se, but might need to bypass or sidestep parts of your cryptographic defenses. Replay attacks are also possible against systems that require multiple-factor authentication, such as online banking systems that require a separate authentication step as part of some transaction requests.
Most countermeasures to replay attacks via encrypted traffic involve using session keys, cryptographic nonces, timestamps, block sequence identifiers, or other means to prevent any two blocks or messages from being bit-for-bit identical to each other within the same session. (Since a different session key should be used for each session, the replay of blocks from one session should be rejected by a subsequent session.) Each of these tactics, of course, will have its own false positive and false negative error rates to contend with.
Cryptanalytic Attacks
These types of attacks tend to be more theoretical in nature, as they often require more knowledge and skill with the underlying mathematics used by the algorithms and systems being analyzed. In most cases, there are few countermeasures available to end users or administrators, other than selection of a different algorithm or process.
Linear Cryptanalysis
Linear cryptanalysis was first described by Mitsuru Matsui in 1992. It is a known-plaintext attack that involves a statistical analysis of the operation of the cipher to create linear equations that relate bits in the plaintext, key, and ciphertext.
For example, an examination of the cipher might suggest a linear equation that says the second bit of the plaintext XORed with the fourth and seventh bits of the ciphertext equals the fifth bit of the key.
P2 ⊕ C4 ⊕ C7 = K5
With a perfect cipher, this equation would be true only half of the time. If there is a significant bias (i.e., the equation is true significantly more, or significantly less, than half of the time), then this fact can be used to guess, with probability better than 50 percent, the values of some or all of the bits of the key.
By combining a series of such equations, it becomes possible to come up with guesses for the key that are far more likely to be correct than simple random guessing, with the result that finding the key is orders of magnitude faster than a simple exhaustive search.
Differential Cryptanalysis
Differential cryptanalysis is a chosen-plaintext attack that was originally developed by Eli Biham and Adi Shamir in the late 1980s and involves comparing the effect of changing bits in the plaintext on the ciphertext output. By submitting carefully chosen pairs of plaintext and comparing the differences between the plaintext pairs with the differences between the resulting ciphertext pairs, one can make probabilistic statements about the bits in the key, leading to a key search space that can be (for a cipher vulnerable to differential analysis) far smaller than an exhaustive search.
Since the development of these two methods, all newly proposed ciphers are tested exhaustively for resistance to these attacks before being approved for use. The Advanced Encryption Standard has been demonstrated to be resistant to such forms of analysis.
Quantum Cryptanalysis
With recent developments in quantum computing, there has been great interest in the ability of quantum computers to break ciphers considered highly resistant to traditional computing methods.
Symmetric ciphers are relatively resistant to quantum cryptanalysis, with the best algorithm able to reduce the key search for a 128-bit key from 2128 to 264, and a 256-bit key from 2256 to 2128. While a 264 key search is within the realm of current technology, 2128 is not and is not likely to be for decades to come, so the solution to defending against quantum cryptography for symmetric ciphers is merely to double the key length.
For asymmetric (i.e., public key ciphers), the problem is much more difficult. Asymmetric ciphers depend on difficult mathematical problems such as factoring very large integers. Unfortunately, these problems are hard only for classical computers. Using quantum computers, integer factorization becomes much easier.
That said, quantum computers have a long way to go before they can compromise currently used public key algorithms. Consider that as of 2018, the largest integer factored by a quantum computer was 291311 (e.g., six digits). The integers used in RSA public key systems are recommended to be 2,048 bits in length, or more than 600 integer digits.
Secure Cryptoprocessors, Hardware Security Modules, and Trusted Platform Modules
The challenge with standard microprocessors is that code running with the highest privilege can access any device and any memory location, meaning that the security of the system depends entirely on the security of all of the software operating at that privilege level. If that software is defective or can be compromised, then the fundamental security of everything done on that processor becomes suspect.
To address this problem, hardware modules called secure cryptoprocessors have been developed that are resistant to hardware tampering and that have a very limited interface (i.e., attack surface), making it easier to verify the integrity and secure operation of the (limited) code running on the cryptoprocessor.
Cryptoprocessors are used to provide services such as the following:
Hardware-based true random number generators (TRNGs)
Secure generation of keys using the embedded TRNG
Secure storage of keys that are not externally accessible
Encryption and digital signing using internally secured keys
High-speed encryption, offloading the main processor from the computational burden of cryptographic operations
Features of cryptoprocessors that enhance their security over standard microprocessors (that could provide most of these services in software) can include the following:
Tamper detection with automatic destruction of storage in the event of tampering, and a design that makes it difficult to tamper with the device without leaving obvious traces of the physical compromise. These protections can range from anti-tamper stickers that clearly show attempts to access the device’s internal components to secure enclosures that detect unauthorized attempts to open the device and automatically erase or destroy sensitive key material.
Chip design features such as shield layers to prevent eavesdropping on internal signals using ion probes or other microscopic devices
A hardware-based cryptographic accelerator (i.e., specialized instructions or logic to increase the performance of standard cryptographic algorithms such as AES, SHA, RSA, ECC, DSA, ECDSA, etc.)
A trusted boot process that validates the initial boot firmware and operating system load
There are many types of secure cryptoprocessors.
Proprietary, such as Apple’s Secure Enclave Processor (SEP), found in newer iPhones
Open standard, such as the Trusted Platform Module as specified by ISO/IEC 11889 standard and used in some laptops and servers
Standalone (e.g., separate standalone device with external communications ports)
Smart cards
Trusted Platform Module
A Trusted Platform Module (TPM) is a separate processor that provides secure storage and cryptographic services as specified by ISO/IEC 11889. A TPM can be used by the operating system, processor BIOS, or application (if the OS provides access to the TPM) to provide a number of cryptographic and security services.
Generate private/public key pairs such that the private key never leaves the TPM in plaintext, substantially increasing the security related to the private key. (Public/private keys are discussed later in this chapter.)
Digitally sign data using a private key that is stored on the TPM and that never leaves the confines of the TPM, significantly decreasing the possibility that the key can become known by an attacker and used to forge identities and launch man-in-the-middle attacks. (Digital signatures are discussed later in this chapter.)
Encrypt data such that it can only be decrypted using the same TPM.
Verify the state of the machine the TPM is installed on to detect certain forms of tampering (i.e., with the BIOS).
The Private Endorsement Key is a fundamental component of a TPM’s security. This key is generated by the TPM manufacturer and burned into the TPM hardware during the manufacturing process. Because of this, the user/system owner depends upon the security of the TPM manufacturer to ensure that the PEK remains confidential.
We also depend on the quality of the TPM manufacturer’s processes. In 2017 it was revealed that a defect in the software library used by Infineon for its line of smartcards and TPMs contained a flaw that made it possible to deduce the private key stored internally. As a result, there were millions of cryptographic keys made unreliable and vulnerable. Attackers were able to calculate the private portion of an account holder’s key from having access to only the public portion. What happened, unfortunately, is that hackers impersonated legitimate users with the assurance and nonrepudiation provided by having their private keys.
Cryptographic Module
A cryptographic module is typically a hardware device that implements key generation and other cryptographic functions and is embedded in a larger system.
The advantages of using a cryptographic module as opposed to obtaining the equivalent functionality from a cryptographic software library include the following:
By performing critical cryptographic functions on a separate device that is dedicated to that purpose, it is much harder for malware or other software-based attacks to compromise the security of the cryptographic operation.
By isolating security-sensitive functionality in an isolated device with limited interfaces and attack surfaces, it is easier to provide assurances about the secure operation of the device. It also makes it easier to provide secure functions to larger systems by embedding a cryptographic module within the larger system.
Increased availability of noncryptographic dedicated resources.
Most secure cryptographic modules contain physical security protections including tamper resistance and tamper detection, making it difficult to compromise the security of the device even if the device has been physically compromised.
Some cryptographic modules can enforce separation of duties so that certain sensitive operations such as manipulating key storage can be done only with the cooperation of two different individuals who authenticate to the cryptographic module separately.
Some government organizations have issued standards related to the security of cryptographic modules and have established evaluation and certification processes so that manufacturers can have the security of their devices validated by an independent third party and users can have confidence in the security that using the module will provide their larger system.
For example, the U.S. government’s FIPS 140-2, “Security Requirements for Cryptographic Modules,” specifies the requirements for cryptographic hardware and software to meet four different levels of security. It also provides for certification of products to validate they meet the requirements.
Internationally, the “Common Criteria for Information Technology Security Evaluation,” documented in the ISO/IEC 15408 standard, provides an alternate set of requirements and certification processes to validate information security products.
Hardware Security Module
A hardware security module is a physically separate device used to safely store and protect various sets of information, which may be cryptographic keys or other highly sensitive mission-critical data. They are typically designed to be tamper-resistant and visibly show (or alarm) if tampering has been attempted. Data centers, especially those serving financial institutions, may have HSMs clustered or racked together with redundant, separately serviceable power, cooling, and network access. HSMs can perform a variety of services via APIs to other network systems, such as:
Onboard secure cryptographic key generation.
Onboard secure cryptographic key storage, especially for highest-level or master keys.
Key management.
Encryption and digital signature services.
Transparent Data Encryption (TDE) key generation and management. TDE is a database encryption technology used by Oracle, Microsoft, IBM, and others for protecting data at rest, at the file level.
HSMs can also offload asymmetric encryption and decryption from application servers; when specialized for this role, they may be referred to as cryptographic accelerators. While they may not achieve throughput rates that can match dedicated hardware encryption and decryption systems, they have been able to perform as many as 10,000 1024-bit RSA signs per second. To help meet NIST’s recommendation, in 2010, to move to 2,048-bit keys for RSA use, there has been increasing emphasis in the HSM market to provide greater performance capability, as well as providing elliptic curve cryptographic support.
Some HSMs have the capability to host a full operating system, hypervisor, and suite of virtual machines within their physically and logically protected enclosure. This provides an enhanced degree of protection for an entire applications stack (the set of all components from the operating system on up through all layers of applications logic). Use cases that require this, particularly ones requiring a simple and reliable means to validate full stack integrity, can make use of HSM-provided remote attestation features.
Certificate authorities and registration authorities make extensive use of HSMs to have reliable, secure, high-performance capabilities to generate, store, manage, and control distribution of asymmetric key pairs and certificates. These applications call for HSMs to have very strong physical and logical security protection built in, quite often involving multipart user authentication such as the Blakley-Shamir secret sharing schema. Full audit and logging of all activities and secure key backup and recovery capabilities are must-have features in this application.
Banking applications often use specialized HSMs, using a nonstandard API, to support specific security requirements in the payment card industry. Protocols and processes involved with verifying a user’s PINs, controlling ATMs and point of sales terminals, verifying card transaction attempts, generating and validating card magnetic stripe data and other card-related security codes, and supporting smart card transactions are some of the unique needs that HSMs need to support.
Domain name registrars are making increasing use of HSMs to store and protect information, such as to store key material used to sign zonefiles. The OpenDNSSEC suite supports the use of an HSM in this.
On a smaller note, HSMs are also available as a hardware cryptocurrency wallet.
Understand the Reasons and Requirements for Cryptography
From a functional and performance requirements perspective, cryptography provides the security systems architect with a significant set of capabilities to address many different information security needs. Chapter 2, “Security Operations and Administration,” examined these different information security needs in some depth; you’ll recall CIANA, which embraces confidentiality, integrity, availability, nonrepudiation, and authentication. You’ll also recall the growing demand, internationally as well as domestically, for organizations to provide greater degrees of transparency, auditability, safety, and privacy protection for the information entrusted to their care. We might call this CIANA+TAPS.
As part of your ongoing security assessments, you should be able to start with your organization’s information classification guide in one hand and your systems architectural baselines in the other and demonstrate how each element of the set of CIANA+TAPS requirements set. Not every element of information in your organization must be kept confidential; in fact, much of it is finally published in customer-facing or public-facing documents (but the internal drafts of the next updated version of that information probably needs to enjoy confidentiality, as part of protecting your firm’s competitive advantage).
Systems analysts would refer to what we’re about to do as a requirements-to-design decomposition. Such an exercise may show you that some of your toolkit items—your basic capabilities—are much more important to your overall mission than you realized they were. These are things you have just got to get right and keep them working safely, efficiently, and correctly! They may also be opportunities for capacity or capability improvements. Another bucket of requirements may appear for which you have no immediately recognized technical capabilities that address them. These may be functional requirements that need further analysis and maybe a restatement (or negotiation if possible); failing that, get shopping and get creative!
When your systems already exist, you are not designing but tracing requirements down to the components of the system that deliver what that requirement needs. Traceability exercises can provide valuable insight into your currently deployed systems, especially when you need to demonstrate to management and leadership that their investment in cryptographic technologies and systems meets or exceeds the organization’s information security needs.
With that in mind, let’s start flowing and tracing!
Confidentiality
Confidentiality is the requirement to restrict access to information to only those people, organizations, systems, and processes that have been previously authorized to have such access. Confidentiality may selectively restrict the reading or viewing of that data, loading it into memory (as data or as an executable), copying it, viewing metadata about that information asset, or viewing a transaction history that reveals accesses to that data. Confidentiality can also place restrictions on accesses to previous versions of the data.
As Chapter 2 made clear, confidentiality as a concept broadly embraces the needs to control access to or disclosure of company proprietary data, intellectual property, trade secrets, preliminary business plans, concepts, or designs, and any other data that has been shared with the organization under an expectation that such data will not be disclosed to others without agreement or due process of law.
Declaring a piece of information as having any confidentiality restrictions splits the world into two populations: those who have your permission to read, view, or use that information, and those who do not. (We traditionally refer to these groups as those who are “cleared” or “not cleared” to handle that category of information.) This is fundamentally an access control and privilege management issue for data at rest and in use; by causing data to move from storage areas to processing or display endpoints (or to transit the Internet to other users or servers), it’s also a data communications security issue. Fundamentally, confidentiality requirements invoke the no-write-down problem, as discussed in Chapter 1, “Access Controls,” your systems cannot allow a process (paper, person-to-person, or computerized) that is cleared for that data to pass it to a process that is at a lower security level (one that is not cleared to handle that data).
Access control depends upon strong ways to authenticate subjects and authorize their specific access requests; most of this requires provably secure cryptographic hashing of credentials, protection of hashed credentials stored in the access control system, and strictly enforced privilege restrictions on those subjects which can modify the security parameters of other subjects or objects in the system.
Protection of the confidentiality of information at rest and in motion is done with a combination of the right storage and communications protocols, which (no doubt) make use of appropriate encryption technologies.
A growing number of applications and systems are now able to process sets of encrypted data without needing to decrypt them, doing so without revealing confidential information. These pervasive encryption architectures are making extensive use of homomorphic encryption, which is based on the theory of groups.
Integrity and Authenticity
Integrity asserts that a data set is whole, complete, and intact; further, it asserts that the life history of that data is fully known so that we can be confident that the data is exactly what we say it is, no more and no less. This is comparable to the chain of custody process and mind-set for evidence pertaining to an incident. Information integrity demands that we build an audit trail that clearly shows that the only people, processes, programs, or hardware that had access to that data were on our list of trusted, cleared, and verified subjects. This is an access control issue and one that must also enforce restrictions that prevent read-down, or the attempt by a cleared and trusted process operating at a higher security level to read data from a lower-level domain, process, or source, and thus potentially contaminate a higher-level data asset with unverified, unaudited, or otherwise potentially hazardous data. Downloading and installing executable files is an example of a read-down process, since in nearly all cases, you’d consider your systems as worthy of more protection than the great uncontrolled wilderness of the Internet.
In the context of data or systems integrity, authenticity refers to the sources from which we gathered or drew the data. The credit risk data for a customer, for example, typically consists of data from third-party commercial credit scoring agencies, from news and social media reporting, from interviews with the customer conducted by your organization’s employees, and from documents, applications, and correspondence sent to your organization by that customer. Each of those data sources has a different degree of authenticity: the interview notes taken by your staff and the original applications submitted by the customer are principally taken at their face value (prima fascia) as authentic. Third-party credit scoring reports come from trusted sources, but you have no real insight into the sources of data they have used to develop their score.
Both the integrity and authenticity of your data are protected using cryptographic techniques in much the same ways that you’ve assured their confidentiality. Access control protects which subjects can access the data and what privileges they can exercise in doing so. Encrypted hash techniques provide for secure message or file digests, which when combined with digital signatures and encryption at rest (and in motion) protect the data from being tampered with (or a spoofed set of data substituted for it). These same techniques provide for continued assertion that a data set that claims to have come to one process from another one has, in fact, come along that auditable trail of events.
In other cases, you may need to use Hash-based Message Authentication Codes (HMAC) as part of the process by which one part of your system asserts the authenticity of a message (or file) to another. HMAC concatenates a secret key (which has been XORed with a string to pad it to a fixed length) and hashes that. It then takes that hash, combines it with the key again, and hashes it a second time producing the HMAC value. If an attacker (or malfunctioning process) attempts to change the message but it does not know the secret key K, the HMAC value will not match. This enables the recipient to verify both the integrity and origin (e.g., authentication or nonrepudiation) of the message. Among other uses, HMAC functions are found within the IPsec and TLS protocols. HMAC is a less complex method of ensuring message integrity and authentication but with the overhead of sharing a symmetric cipher key. Digital signatures eliminate the need to share a secret, but it requires the overhead of a shared key infrastructure such as PKI or IKE.
Systems integrity, and therefore the integrity of your information assets themselves, is also in part assured by the techniques you employ to protect and preserve event data, such as systems and applications logs, alarms, systems health telemetry, traffic monitoring data, and other information. In the event of an information security incident, these data sets not only help you determine what went wrong and how it happened; they can also be critical to your attempts to prove that your recovery and restoration of the systems to their required state is complete and correct. Without protected transaction logs, for example, you’d have no way to know if your database reflects reality or a morphed and incomplete view of it. The same cryptographic techniques you use to protect the integrity of your business information should also be applied to protect the information that keeps your systems infrastructure safely and reliably operating.
Data Sensitivity
Data sensitivity is the business world’s way of describing what the military and government systems communities refer to as the security classification of information. Based on an overall risk assessment, organizations must categorize (or classify) information into related groups that reflect the types of harm that could come to the organization, its stakeholders, its people, or its constituents as a result of compromise, loss of integrity, misuse, or simply the failure to have it be available as and when it is needed. Such classifications might reflect the needs to protect:
Safety-critical information, whose compromise, loss of integrity, or availability could lead systems to operate in ways that damage property, injure people, or cause death and destruction
Emergency notification information, which may have far more urgent or demanding availability needs than other “routine” business information might
Private information pertaining to individuals, such as personally identifying information, whether published or not
Proprietary information, which would include anything the business did not want to disclose to competitors or others in the marketplace
Trade secrets
Other information requiring special protection, dictated by compliance regimes, regulations, contracts, or law
This last category—the compliance-driven information sensitivity classification—is taking on a far greater role in driving the design, operation, audit, verification, testing, and ongoing use of virtually every aspect of information security. Increasingly, legislatures and courts around the world are holding individual executive officers as well as division or line managers personally and sometimes criminally liable for the damages of a data breach or other information security incident.
Chapter 2 looks in greater depth and provides further guidance on information security classification processes and guidelines. Even the smallest, most local of businesses or nonprofit organizations needs to dedicate senior leader, manager, and security analyst time and effort to translate their overall risk posture into an effective information security classification process. Then, of course, leadership and management need to make sure that the organization uses that classification process.
Availability
Imagine a world without cryptography.
It’s not customary to think of cryptography as having a strong role to play in systems or information availability; perhaps it’s time to turn that paradigm on its head. Without extensive use of strong encryption, your access control systems cannot function reliably. You cannot authenticate incoming data or messages as being from recognized, legitimate sources. You have little way to validate that software updates and distribution kits are in fact from the vendor, or are complete and correct, with no malware snuck into them. Many of the handshakes that are necessary at the session, presentation, and application layers cannot effectively function, or if they do, they cannot provide automatic and prompt assurance of a trustworthy connection.
At a minimum, your business processes run slower, as if you’ve jumped back in time to the early days of the personal computer revolution. There is no HTTPS. You spend more time validating information and inspecting, checking, and reassuring yourself that no malware has taken over your machine.
When your systems crash or when you detect an intruder in your midst, you’ve got few options but to trust that the backups you made earlier have not already been tampered with. This may require that you reload with them anyway and spend more time manually validating that what you think should be the state of your systems and your data is, in fact, what you’ve reloaded and reinitialized them to be.
Access control; digital signatures; secure message and file digests; integrity-protecting, confidentiality-assuring storage encryption; automatic and auditable secure transaction processing—each of these encryption-powered processes and more set the pace by which your business or organization uses its information assets to get business done.
That’s availability.
Nonrepudiation
For many reasons, organizations and individuals need to be able to prove that a message was originated and sent to them by the person or organization identified in that message. Nonrepudiation can work both ways, though.
Recipients can disprove a sender’s claim that they were the one who originated the message.
Senders can disprove a recipient’s claim that the message was never received or opened by the addressee.
The EU has established some fairly stringent requirements in the European Electronic Commerce Directive 2000/31/EC for messaging systems to meet in order to provide legally acceptable evidence that attests to sending, receiving, opening, and displaying a message. (Thus far, no one has any ideas about how to prove that the recipient actually read and understood the message, of course!) In the U.S. marketplaces, various U.S. Federal District Courts have established precedent law that lines up with the EU on this; many U.S. government agencies, large corporations, and industry vertical associations and channels are switching their fax, email, file exchange, and even paper-based correspondence, order processing, and non-real-time process control flows over to systems that provide such bidirectional nonrepudiation.
A variety of cryptographic techniques are used by the different commercial products that provide these services; as there are contentious patent infringement cases in the works on several of these, it’s inappropriate to delve too deeply into their technical details. Suffice it to say that combinations of cryptographically secure message digests, digital signatures, full PKI-supported encryption of contents and attachments, and other means all track the flow of a message: from the sender hitting Send through the system; to the recipients’ mail servers; from those servers to the recipient; and finally the actions taken by the recipient to open, delete, forward, or move the email or any of its attachments. In some systems, such as RMail and RSign, senders can validate that a cryptographically generated receipt itself and the files and message text it references have not been altered any time after it was originally sent. This proves to be vital in establishing a chain of custody argument for the content of such a message.
This may be another instance where the build-versus-buy decision can be greatly simplified for an organization. Many of these services are available from providers with field-proven APIs, and contracts for use of these services can be much cheaper than typical first-class letter postage rates in the West. This can transform paper-based, manually-intensive information tasks into smooth, automated, and more auditable processes while enhancing other aspects of information security in the bargain.
Another cryptographic approach to achieving nonrepudiation involves using blockchain technologies, which could provide a significant advantage when a sequence of transactions between multiple parties adds value and information to a file, message, or ledger. Blockchains (described in more detail later in the “Blockchains” section) cryptographically hash a new block of data in a chain using the hashes and content of previous blocks; thus, even a single bit changed in any one block invalidates the blockchain’s end-to-end hash. Since a blockchain depends upon a loosely coupled, distributed web of trust, which does not have one central trust authority acting like a root CA, it would take a significant amount of collusion across the thousands of blockchain processing nodes and their owner/operators to convincingly fake a spoof blockchain instance.
All of these technologies, of course, rest on the trustworthiness and integrity of the public key infrastructure and the certificate authorities that enable it. For the vast majority of transactions and use cases, this trust is justified. However, constant vigilance is still necessary, not only because of events such as the DigiNotar compromise that affected more than 300,000 Gmail users but also 2017’s reports that Symantec’s issuance of more than 30,000 compromised HTTPS certificates, some of which were abused as part of phishing attacks.
Authentication
We commonly talk about authentication in CIANA-like terms to assert that the user, process, or node that has taken some action—such as sending a message or using an information asset—did in fact have proper authority to do so, at that date and time, and for the stated purpose. It refers to the back-and-forth loops of challenge and confirmation that are often needed so that both parties in a conversation can be 100.0000 percent certain that the right parties have had the right conversation and its meaning has been clearly and unambiguously understood. (This gets its roots in the weapons release authentication disciplines used by military forces, which all strive to remove any risk of misunderstanding before lethal force shoots down an unknown aircraft or sinks a ship, for example.) CIANA’s use of authentication invokes nonrepudiation, but it also goes to the heart of the identity of the sender and recipient, as well as to the integrity of the content of the message or the file in question.
The first line of defense in a rock-solid authentication system is access control, and cryptographic technologies are essential to nearly every access control system in use today.
Access control systems use a two-part process to allow subjects (such as users, processes, or nodes on a network) to access and use objects (such as datafiles, storage subsystems, CPUs, or areas in memory). As you saw in Chapter 1, the first step is to authenticate that the subject is in fact the person, process, or node that it claims to be; it makes that claim by submitting a set of credentials, such as a user ID or process ID, along with other factors that attest to its authenticity. The access control service must then compare these submitted credentials with previously proofed credentials to validate that the claimed subject is who or what they claim to be.
Cryptographic techniques protect (or should protect) every step in this process. Identity proofing and provisioning stores cryptographically hashed versions of the credentials for each subject ID, thus protecting the credential information itself from compromise or alteration. Subjects should submit cryptographically hashed versions of their credentials, and it is these hashed forms that are compared.
The second step is to authorize what the now-authenticated subject wants to do to a specific object. This comparison of requested privileges versus previously approved privileges may involve significant constraint checking that involves the subject’s role, current and temporary conditions, or other factors that support the organization’s security needs. Once authorized, the subject can now make use of the object, perhaps by writing to a file or data set.
Protecting the data that drives the access control system requires the use of multiple cryptographic techniques (in effect, its host operating system’s access control, file management and identity systems are “plussed up” with additional application-specific hashes, message or file digests, etc., to meet the CIANA needs of your access control system).
Privacy
Privacy borrows heavily from our concepts of confidentiality, but it adds a significant portion of integrity to its mix. Unlike confidential data, which we believe will spend its life within its classification level (unless an authorized process down-writes it to a lower level), private data will usually need to change hands in controlled, auditable, and transparent ways. You give your bank PII about you when you apply for an account; their systems combine that with other data about you, which they’ve received from other trusted members of their community or marketplace to create a combination of PII and NPI. They use that in all of their decisions about what banking services to offer to you and how closely to manage your use of them. Government regulators and others will require various disclosures that may need elements from your PII and NPI. Those disclosures do not “publish” your NPI or make your PII lose its required privacy protection; rather, they require keeping a detailed chain of custody-style audit trail that ensures that your data, plus data from other sources, have only been accessed, used, shared, modified, retired, archived, or deleted by controlled and authorized use of trusted processes by trusted users.
Personal and private healthcare information is sometimes referred to as protected health information (PHI). Typically this information is focused on a specific individual person and includes PII or NPI along with information detailing current or historical medical treatment, care providers involved in such treatment, diagnoses, outcomes, prescriptions or other medical supplies and devices used in that treatment or after-care, and of course anything and everything associated with costs, billing, insurance coverages, and outstanding balances due by the patient.
Other sets of private information might include educational data, residential address history, employment history, and voter registration and voting history (which ideally only contains what elections you voted in and at what polling place and not how you voted on candidates or ballot initiatives!). Even your usage of public services, such as which books you’ve checked out at the county library, are potentially parts of records afforded some degree of privacy protection by law or by custom.
Most nations have separate and distinct legal regimes for defining, regulating, and enforcing the protection of each of these different sets of information. And as you might expect, each of those regulatory systems probably has different specific requirements as to how that data protection must be accomplished by you and be auditable and verifiable by the regulators.
Every step of such processes involves access control; each step benefits from high-integrity processes that log any attempts to access the data, tracks the nature of authorized actions taken with it, and even makes note of who viewed such logs.
Safety
Information systems safety requires that no harm is done by the actions taken as a result of the decisions made by our use of our information systems. The systems design must preclude, to the greatest extent possible, any failure modes of the system that might lead to such harmful actions being taken. These failure modes should include incorrect behavior on the part of the system’s human operators as well as failures of the hardware, software, communications, or data elements.
Unsafe operation—the “do no harm” criterion—is something that each organization must evaluate, for each business process. Incorrectly transferring money out of a customer’s account, for example, harms that customer; incorrectly crediting a customer’s account as paid in full when in fact no payment has been received, accepted, and processed harms the business and its stakeholders. Harm does not have to strictly be interpreted as bodily injury, death, or physical damage to property, although these types of harm are of course your first priority to avoid.
(Note that many systems must, by their nature, take harmful actions; military weapons systems are perhaps the obvious case, but there are many others in daily use around the world. Safe operational use of such systems requires that collateral damage, or harm caused unintentionally, be minimized or avoided wherever possible. Deliberate misuse of such systems should also be prevented by appropriate safety interlocks, whether physical, logical, or administrative.)
Once a potentially harmful business process has been identified (as part of risk assessment) and the vulnerabilities in that process that could cause it to do harm in unauthorized ways have been identified, safety engineering principles can and should guide the process designers to include authorization checks, interlocks, fail-safe logic, redundancies, or other controls to mitigate the risk of deliberate but unauthorized action, component failure, or accidental misuse from causing harm.
Each of those high-risk steps ought to sound like something that needs the best access control, data integrity, and accountability processes that you can provide. As with other aspects of CIANA, that will mean that cryptographic hashes, secure message and file digests, digital signatures, and encrypted data in motion, at rest, and in use, all play a part in assuring you—and innocent bystanders—that your systems can only operate in safe ways, even when they are failing or used incorrectly.
Regulatory
Legal and regulatory requirements can directly specify that certain cryptologic standards of performance be met by your information systems, by citing a specific FIPS or ISO standard, for example. They can also implicitly require you to meet such standards as a result of their data protection, privacy, safety, transparency, or auditability requirements themselves. For example, any business involved in handling credit or debit card payments must make sure that those elements of their systems meet the security requirements of the Payment Card Industry Security Standards Council; failure to do so can result in a business being blocked from processing card payments. Depending upon the volume of your payment card business activities, you may even be required to implement a hardware security module (HSM) as part of attaining and maintaining compliance.
As part of baselining your cryptographic systems technology infrastructure, you should identify all the standards or specifications that your systems are required to meet as a result of such laws, regulations, or your organization’s contractual obligations.
Transparency and Auditability
The legal and ethical requirements of due care and due diligence drive all organizations, public or private, to meet minimum acceptable standards of transparency and auditability.
Transparency provides stakeholders with appropriate oversight of the decisions that the organization’s leaders, managers, and workers have made in the conduct of business activities. (Those stakeholders can be the organization’s owners, investors, employees, customers, suppliers, others in its local business community, and of course bystanders who have no business relationship with the organization but are impacted by its activities.) Government regulators, tax authorities, law enforcement, health inspectors, and many other official functions also have legal and ethical responsibilities that require them to have some degree of oversight as well. In many societies, there is an expectation that the news media will exercise a degree of oversight over both public and private affairs as well.
Oversight includes insight. Insight grants you visibility of the data; you can see what led the managers to make certain decisions, such as by reading the minutes of their meetings or their internal communications, if you are authorized the right level (or depth) of insight. Oversight requires you to reach conclusions or make judgments as to the legal or ethical correctness of the decision or whether the decision process—including the gathering and processing of any information that informed that process—meets the generally accepted standards for that kind of decision, in that kind of business, for due care and due diligence.
Obviously, achieving transparency may require you to publish or otherwise disclose information that might otherwise have been kept confidential or private.
Almost every information system in use is subject to some kind of audit requirements (even your personal computer at home is subject to audit, by your nation’s income tax or revenue agencies, for example). Audit requirements exist for financial, inventory, human resources, hazardous materials, systems safety, and information safety and security needs, to name just a few examples. Most audit requirements that organizations must adhere to also require that data that is subject to audit be suitably protected from unauthorized changes and that full records be kept of all authorized changes to that information. Confidentiality requirements may also be levied by audit requirements.
Transparency and auditability, therefore, boil down to access control, access accounting, data integrity, nonrepudiation, confidentiality, and privacy, all of which are difficult if not impossible to achieve without a solid cryptologic capability.
Competitive Edge
Increasingly, businesses, nonprofit organizations, and even government activities are finding that their marketplace of customers, suppliers, constituents, and stakeholders is demanding better information stewardship from them. These stakeholders all want to see visible, tangible evidence that your team takes your CIANA+TAPS responsibilities seriously and that you carry them to completion with due care and due diligence.
In some marketplaces, this is only a growing sense of expectation or a “mark of quality” that customers or other stakeholders will perceive as being associated with your business. In other markets, potential customers will just not do business with you if they cannot clearly see that you know how to keep information about that business with them safe, secure, private, and intact.
Either way you look at it, your organization’s investments in more effective use of cryptography—and thereby better, stronger information security—makes a solid contribution to your overall reputation in your marketplace.
Understand and Support Secure Protocols
Cryptographic protocols package one or more algorithms with a set of process descriptions and instructions that structure the use of those algorithms to get specific types of work done. Secure email, for example, is a class of protocols; S/MIME, DKIM, and other approaches are protocols that support organizational and individual email users in attaining some or all of their email-related information security needs.
Certain sets of protocols become so pervasive and important to information security that they’ve been designated as infrastructures. You can think of an infrastructure as the bedrock layer of support and capability; certain protocols layer onto that to build foundations. On top of those foundations, you build business processes that address the specific needs of your organization, and those business processes probably use many other protocols that are widely used throughout the digital and business worlds. In these terms, we might think of TCP/IP as a bedrock infrastructure, onto which key management (via IPsec, PKI, or other approaches) provides a secure infrastructure. That infrastructure supports identity management and access control (as sets of protocols, systems, and services); it also supports secure email, secure web browsing, virtual private networks, and just about everything else we need. That layer of protocols provides generic services to every user and organization; you choose implementations of them, as particular sets of hardware, software, and procedures, to meet the sweet spot of risk mitigation, cost, and regulatory and legal compliance needs.
This may suggest that there’s an accepted, formal distinction between an infrastructure and a protocol—but there is not. It’s really in the eyes of the users and the use cases that capture their needs for form, fit, function, and security. (It might also bring to mind the OSI model and the need to think beyond the Application Layer into the human and organizational layers.)
Let’s first look at some of these services and protocols and then some common use cases. Then we’ll wrap this section up with a look at some practical limitations and common vulnerabilities to keep in mind.
Services and Protocols
As with the difference between protocols and infrastructures, there’s no real hard and fast rules as to whether a set of capabilities, data formats, processes, and procedures is a service, a protocol, or both at the same time. Arguably, IPsec, as a set of protocols and mechanisms, could be considered as a service; blockchain, by contrast, is a set of protocols on its way to becoming an infrastructure. PGP and the set of capabilities wrapped around it or springing from it represent an alternative set of capabilities to those whose design is dominated by major multinational corporations and the American national security state; even if you’re not a believer in the more extreme conspiracy theories, being able to operate in an alternate set of protocols and services (and the infrastructures they use and provide) may be prudent.
One thing that’s worth mentioning at an overview level is the negotiation processes that go on when using any of these protocols. It’s similar to what happens at the Physical layer of the OSI 7-Layer or TCP/IP protocol stack: each party uses an established protocol of handshakes to signal what capabilities they want to use for the session, whether that is baud rate on a communications circuit or encryption algorithm and corresponding cryptovariables. Each party strives to push this negotiation to the highest quality settings that it can (since this will make service provision and use more effective and efficient); after some give and take, the two parties either agree and the session setup continues, or the connection attempt is dropped by one or both sides. (This can give the attacker the opportunity to force the negotiation to a lower-quality standard—or lower-grade encryption suite—if they believe their target has a vulnerability at that lower level that they can exploit.)
Please note that the encryption suites and algorithms discussed in the following sections as supported by a protocol or service are provided as illustrative only and are subject to change, as vulnerabilities are found by cryptanalysis, hostile exploitation, or white-hat testing.
IPsec
Internet Protocol Security (IPsec) makes extensive use of asymmetric encryption algorithms (packaged as encryption suites), key exchange infrastructures, digital certificates, and bulk encryption protocols to deliver the security services that the original Internet Protocol could not. It was developed during the late 1980s and early 1990s to provide Internet layer (level 3) security functions, specifically the authentication and encryption of packets as they are transferred around the Internet. It needed to provide a variety of security benefits: peer authentication, sender (data origination) authentication, data integrity and confidentiality, and protection against replay attacks. IPsec can provide these services automatically, without needing application layer interaction or setup. IPsec introduced several new protocols to support these services.
Authentication headers (AH) achieve connectionless data integrity for IP datagrams and support data origin authentication. These allow recipients to validate that messages have not been altered in transit and provides a degree of protection against replay attacks.
Encapsulating security payloads (ESP) also provide a partial sequence integrity mechanism, which also adds to anti-replay protection. This also provides a limited degree of traffic flow confidentiality, while protecting the confidentiality and integrity of datagram content.
Internet Security Association and Key Management Protocol (ISAKAMP) offers an overall process and framework for key exchange and authentication of parties. Keying material itself can be provided by manually configuring pre-shared keys or using the Internet Key Exchange protocols (IKE and IKEv2). Kerberized Internet Negotiation of Keys (KINK) or the IPSECKEY DNS record can also be used as ways for parties to exchange and manage keys.
IPsec also provides the mechanisms to form security associations (SA) that are created and used by two (or more) cooperating systems agreeing to sets of encryption suites, encryption and authentication keys, and all of the cryptovariables that go with that (such as key lifetimes). This allows those internetworked systems to then implement AH, ESP, or both, to meet their agreed-to needs. Implementing AH and ESP would require multiple SAs be created so that the sequence of steps be clearly established and well-regulated to provide the required security.
As you might expect, the list of current cryptographic algorithm suites that are supported by IPsec or recommended for use with it changes as new exploits or cryptanalytic attacks make such changes advisable.
IPsec provides two methods of operation, known as transport mode and tunnel mode.
Transport mode encrypts only the payload (data content) of the IP packets being sent, which leaves all of the routing information intact. However, when transport mode uses the IPsec authentication header, services like NAT cannot operate because this will invalidate the hash value associated with the header and the routing information in it.
Tunnel mode encrypts the entire IP packet, routing headers and all; it then encapsulates that encrypted payload into a new IP packet, with a new header. This can be used to build virtual private networks (VPNs) and can also be used for private host-to-host chat functions. Since the “as-built” packets from the sending system are encrypted and encapsulated for actual transmission through the network, any packet-centric services such as NAT can function correctly.
IPsec can be implemented in three different ways. It’s normally built right into the operating system by including its functions within the IP stack (the set of operating systems service routines that implement the Internet Protocol in that environment). When such modification of the operating system is not desired, IPsec can be implemented as a separate set of functions that sit (in effect) between the device drivers and the operating system’s IP stack, earning it the name bump-in-the-stack. If external cryptoprocessors are used (that is, not under the direct, integrated control of the operating system), it’s also possible to do what’s called a bump-in-the-wire implementation.
Originally developed for IPv4, work is in process to fully port IPsec over to IPv6.
TLS
Transport Layer Security (TLS) provides for secure connections, but it’s hard to say exactly where in the TCP/IP or OSI protocol stacks it actually sits. It runs on top of the transport layer, and yet it is treated by many applications as if it is the transport layer. But applications that use TLS must actively take steps to initiate and control its use. It’s also further confusing, since the presentation layer is normally thought to provide encryption services for higher layers (such as the application layer in the OSI model). Perhaps it’s best to think of it as providing services at the transport layer and above, as required, and leave it at that. It has largely replaced its predecessor, Secure Sockets Layer, which was found to be vulnerable to attacks on SSL’s block cipher algorithms. (SSL also had this “identity problem” in terms of which layer of the protocol stack it did or didn’t belong to.) Nonetheless, many in the industry still talk of “SSL encryption certificates” when the actual protocol using them is TLS.
The TLS handshake dictates the process by which a secure session is established:
The handshake starts when the client requests a TLS connection to a server, typically on port 443, or uses a specific protocol like STARTTLS when using mail or news protocols.
Client and server negotiate what cipher suite (cryptographic algorithms and hash functions) will be used for the session.
The server authenticates its identity, usually by using a digital certificate (which identifies the server, the CA that authenticates that certificate), and provides the client with the server’s public encryption key.
The client confirms the certificate’s validity.
Session keys are generated, either by the client encrypting a random number or by using the Diffie-Hellman key exchange to securely generate and exchange this random number.
If any of these steps fail, the secure connection is not created.
The session key is used to symmetrically encrypt and decrypt all subsequent data exchanges during this session, until the client or server signals the end of the session.
The TLS cipher suite is the set of cryptographic algorithms used within TLS across its four major operational phases of key exchange and agreement, authentication, block and stream encryption, and message authentication. This suite is updated as older algorithms are shown to be too vulnerable and as new algorithms become adopted by the Internet Engineering Task Force (IETF) and the web community. As with all algorithms and protocols involving security, the two versions of TLS cipher suite now in common use, V1 and V1.2, are coming to their end of life. On June 30, 2018, SSL, TLS 1.1, and TLS 1.2 were declared obsolete by the IETF. The major browsers, such as Firefox, Chrome, and Bing, have been phasing them out in favor of their replacements. Be sure to check to see if your organization is using them anywhere else. Note that the Payment Card Industry Data Security Standard (PCI DSS) requires use of the new versions, so any credit, debit, or payment processing systems you support may need to be double-checked as well.
TLS has gone through two revisions since its first introduction, and in creating TLS 1.3, RFC 8446 in August 2018 added significant improvements to TLS. One key set of changes involved strengthening forward secrecy of TLS sessions. Forward secrecy (also known as perfect forward secrecy) provides for the protection of past sessions in the event that the server’s private key has been compromised. This protection is ensured by requiring a unique session key for every session a client initiates; in doing so, it offers protection against the Heartbleed exploit that affected SSL and OpenSSL, first reported in 2014. TLS 1.3 also removes support for other cryptographic and hash functions that have proven weak.
TLS 1.3 implements the concept of ephemeral key exchange, supported by many algorithms and cryptographic suites. “Traditional” Diffie-Hellman-Merkle, for example, dictates mathematically that unless one of the parties changes their private key (or they agree to changing some other cryptovariable), then the same session key will result. Numerous workarounds have been attempted to avoid the risks that this introduces. How each key exchange generates this one-moment-in-time (that is, ephemeral) shared key is not germane to us right now; what is important to consider is that this can mean that Diffie-Hellman Ephemeral (DHE), Elliptic Curve D-H Ephemeral (ECDHE), and others weaken the authentication mechanism: if the key is different every time, so is the digital signature. Some other authentication process, such as RSA, PSK, or ECDHA, must then be used to complete the process.
However, TLS 1.3 also added some potential pitfalls that you should be aware of. TLS in its initial versions required at least two round-trip cycles to perform its initialization handshake, which involved using asymmetric encryption. This slowed down the loading of web pages, which impacts customer satisfaction and the business bottom line. TLS 1.3 cut this down to one round-trip time (RTT) and added a capability to allow servers to “remember” a previous session’s handshakes and pick up, in effect, where the session left off. If that sounds to you like reusing a one-time session key, you’d be right to think so. This “zero RTT” option is fast, of course, but it opens the door to replay attacks. Some organizations are already planning on turning this feature off as they migrate to TLS 1.3.
Pretty Good Privacy
In much the same timeframe in which Rivest, Shamir and Adleman were battling with the U.S. government over making powerful encryption available to private citizens, businesses, and others, another battle started to rage over a software package called Pretty Good Privacy. PGP had been created by Phil Zimmerman, a long-time anti-nuclear activist, in 1991; he released it into the wild via a friend who posted it in Usenet and on Peacenet, which was an ISP that focused on supporting various grass-roots political and social movements around the world. Almost immediately, the government realized that PGP’s use of 128-bit (and larger) encryption keys violated the 40-bit limit established for export of munitions as defined in the Militarily Critical Technologies List; the government began a criminal investigation of Zimmerman, his associates, and PGP. Zimmerman then published the source code of PGP and its underlying symmetric encryption algorithm (the Bassomatic) in book form (via MIT Press), which was protected as free speech under the First Amendment of the U.S. Constitution. By 1996, the government backed down and did not bring criminal charges against Zimmerman.
PGP uses a web of trust concept but does embody a concept of key servers that can act as a decentralized mesh of repositories and clearinghouses. Its design provides not only for encryption of data in motion but also for data at rest.
Initially, PGP as a software product allowed end users to encrypt any content, whether that was a file or the body of an email message. Various distributions used different encryption algorithms, such as ElGamal, DSA, and CAST-128. The designs and source code of PGP have moved through a variety of commercial products, including the z/OS encryption facility for the IBM z mainframe computer family.
PGP is described by some as being “as the closest you’re likely to get to military-grade encryption.” As of this writing, there do not seem to be known methods, computational or cryptographic, for breaking PGP encryption. Wikipedia and other sources cite a 2006 case in which U.S. Customs agents could not break PGP-encrypted content, suspected to be child pornography, on a laptop they had seized. A bug in certain implementations of PGP was discovered in May 2018, which under certain circumstances could lead to disclosing the plaintext associated with a given ciphertext of emails encrypted by these email variants.
Since inception, PGP has evolved in several directions. It still is available in various free software and open source distributions; it’s also available in a variety of commercial product forms.
OpenPGP
A variety of efforts are underway to bring PGP and its use of different algorithms into an Internet set of standards. Some of these standards support the use of PGP by email clients; others look to specify the encryption suites used by PGP in different implementations. RFC 4880 is the main vehicle for change within the IETF for bringing PGP into the formally accepted Internet baseline. There is also work ongoing to develop a PGP-compliant open source library of JavaScript routines for use in web applications that want to use PGP when supported by browsers running the app.
GNU Privacy Guard GNU Privacy Guard (GPG) is part of the GNU project, which aims to provide users with what the project calls the four essential freedoms that software users should have and enjoy. GPG provides a free and open source implementation of the OpenPGP standard, consistent with RFC 4800. It provides key management and access modules, support for S/MIME and SSH, and tools for easy integration into a variety of applications. It’s also available as Gpg4win, which provides GPG capabilities for Microsoft Windows systems, including a plugin for Outlook email.
GPG comes as a preinstalled component on many Linux distribution kits and is available in freeware, shareware, and commercial product forms for the Mac and for Windows platforms as well.
“Free,” in the context of “free software, should be thought of in the same way as “free speech,” rather than “free beer,” as explained on https://www.gnu.org/home.en.html. Free software advocates assert that this conflux of corporate and government interests is far too willing to sacrifice individual freedom of choice, including the freedom to speak or to keep something private. Without freely available source code for important infrastructure elements such as GPG and the GNU variant of Linux, they argue, individuals have no real way to know what software to trust or what information and communications they can rely upon. Whether you agree or disagree with their politics, GPG and other free software systems are increasingly becoming common elements in the IT architectures that SSCPs need to support and defend.
It is interesting to note that the German government initially donated 250,000 Deutschmarks (about $132,000) to the development and support of GPG.
Hypertext Transfer Protocol Secure
Hypertext Transfer Protocol Secure (or HTTPS) is an application layer protocol in TCP/IP and the OSI model; it is simply Hypertext Transfer Protocol (HTTP) using TLS (now that SSL is deprecated) to provide secure, encrypted interactions between clients and servers using hypertext. HTTPS is commonly used by web browser applications programs. HTTPS provides important benefits to clients and servers alike.
Authentication of identity, especially of the server’s identity to the client
Privacy and integrity of the data transferred during the session
Protection against man-in-the-middle attacks that could attempt to hijack an HTTP session
Simplicity
By building directly on TLS, HTTPS provides for strong encryption of the entire HTTPS session’s data content or payload, using the CAs that were preinstalled in the browser by the browser application developer (Mozilla, Microsoft, DuckDuckGo, Apple, etc.). This leads to a hierarchy of trust, in which the end user should trust the security of the session only if the following conditions hold true:
The browser software correctly implements HTTPS.
Certificates are correctly installed in the browser.
The CA vouches only for legitimate websites.
The certificate correctly identifies the website.
The negotiated encryption sufficiently protects the user’s data.
Users should be aware that HTTPS use alone cannot protect everything about the user’s web browsing activities. HTTPS still needs resolvable IP addresses at both ends of the session; even if the content of the session is kept safe, traffic analysis of captured packets may still reveal more than some users want. Metadata about individual page viewings may also be available for others to sniff and inspect.
Secure Multipurpose Internet Mail Extensions
Secure Multipurpose Internet Mail Extensions (S/MIME) provides presentation-layer authentication, message integrity, nonrepudiation, privacy, and data security benefits to users. Using PKI, it requires the user to obtain and install their own certificate, which is then used in forming a digital signature. It provides end-to-end encryption of the email payload and thus makes it difficult for organizations to implement outgoing and incoming email inspection for malware or other contraband without performing this inspection on each end-user workstation after receipt and decryption.
As an end-to-end security solution, S/MIME defeats—or complicates—attempts to have enterprise-wide or server-hosted antimalware scanning (or scanning for other banned content), since S/MIME has encrypted such malware or banned content by encrypting the message content and its attachments. S/MIME may also be difficult, or at least not well suited, to use with a webmail client, if the user’s private key is not accessible from the webmail server. Workarounds, such as those used by PGP Desktop and some versions of GnuPG, will implement the signature process via the client system’s clipboard, which does offer better protection of the private key.
SMIME has other issues, which may mean it is limited in the security it can offer to users of organizational email systems. Its signatures are “detached”—that is, they are not tied to the content of the message itself, so all that they authenticate is the sender’s identity and not that the sender sent the message in question. In May 2018, the EFF announced that there were critical vulnerabilities in S/MIME, particularly when forms of OpenPGP are used. EFAIL, as this vulnerability is called, can allow attackers to hide unknown plaintext within the original message (using various HTML tags). EFAIL affects many email systems, and as such, it will require much coordination between vendors to fix.
DomainKeys Identified Mail
DomainKeys Identified Mail (DKIM) provides an infrastructure for authenticating that an email came from the domain its address information claims it did and was thus (presumably) authorized by that domain operator or owner. It can prevent or limit the vulnerability of an organization’s email system to phishing and email spam attacks. It works by attaching a digital signature to the email message, and the receiving email service validates that signature. This confirms that the email itself (and possibly some of the attachments to it) was not tampered with during transmission, providing a degree of data integrity protection. As an infrastructure service, DKIM is not normally visible to the end users (senders or recipients), which means it does not function as an end-to-end email authentication service.
DKIM can provide some support to spam filtering, acting as an anti-phishing defense as well. Using the domain-based message authentication, reporting, and conformance (DMARC) protocol, mailing services that use DKIM can protect their domain from being spoofed as part of a phishing operation. Based on DNS records and a header field added to them by RFC 5322, DMARC and DKIM together offer a degree of nonrepudiation. This has proven useful to journalists investigating claims regarding the legitimacy of emails leaked during recent political campaigns, such as during the U.S. Presidential Election in 2016. This use of DNS records also makes DKIM compatible with S/MIME and OpenPGP for example; it is compatible with DNSSEC and with the Sender Policy Framework (SPF) as well.
Note that the use of cryptographic checksums by DKIM does impose a computational overhead not usually associated with sending email. Time will tell whether this burden will make bulk spamming too expensive or not.
Both the original RFC that proposed DKIM and work since then have identified a number of possible attack vectors and weaknesses. Some of these are related to the use of short (weak) encryption keys that can easily fall prey to a brute-force attack; others relate to ways that clever spammers can spoof, misroute, forward, or otherwise misuse the email infrastructure in ways DKIM cannot help secure. Note, too, that while DKIM use may help in authentication of senders, this is not the same as offering protection against arbitrary forwarding of emails (bulk or not). A malicious sender within a reputable domain could conceivably compose a bad message, have it DKIM-signed, and send it to themselves at some mailbox from which they can retrieve it as a file. From there, they can resend it to targets who will have no effective way to determine it is fraudulent. Including an expiration time on signatures or even periodically revoking a public key or doing so upon notice of an incident involving such emails remain as options for the domain owners. Filtering outgoing email from the domain may be of limited utility as well, without having clear rules to differentiate emails potentially being misused by spammers from legitimate outgoing ones.
Ongoing work in the IETF Standards Track is adding elliptic curve cryptography to the RSA, which should facilitate making more secure use of shorter keys, which are easier to publish via DNS. There are also some concerns with DKIM and content modification, in that centralized (enterprise) antivirus systems may break the DKIM signature process; workarounds to this may add incompatibilities with MIME messages. Attempts were made to initiate author domain signing practices (ADSP), but by 2013 these were declared historic, as no significant deployment or use took place. (If you have signs of ADSP lingering in your email systems, they may be worth a closer look as candidates for upgrade or replacement.)
Blockchain
Think about the message digest process; it produces a hash value of a message (or file) that demonstrates that the content of that message has not been changed since the message digest was computed. A blockchain is nothing more than a series of messages, each with its own message digest, that taken together represent a transaction history about an item of interest; the message digest for the first block is computed normally, and then this is used as an input into the message digest for the next block, and so on. Thus, any attempt to make a change to the content of a block will invalidate all subsequent block-level message digests.
Blockchain technology is poised to turn much of our digital world sideways, if not completely onto its head. It does this by transforming the way we think about data. Traditionally, data is created (written), read, updated, tweaked, made into “old” and “updated” versions, updated again, deleted, restored; in many real-world practical situations this endless life cycle of change causes more trouble than we recognize. Blockchain treats all data as write-once, read-forever. And it never throws data away.
Blockchain also encourages (if not enforces) a fully distributed data model: every user of any data set has a full and complete copy of it; as new blocks (records) are added to that set, all registered users receive the update, and when the majority have agreed it was a legitimate update, it gets posted to this fully distributed ledger. In fact, referring to a blockchain as a ledger reveals that it views data sets as something that just keep growing, one record or transaction or event at a time. Mistakes in data are dealt with in blockchains by leaving the original data as it was created and then adding additional records as required to reverse the effect of the mistake. This provides a full audit trail of such corrections; and since blockchains are a distributed ledger, all parties to the blockchain must approve such changes for them to take effect.
In its simplest form, a blockchain starts with that first transaction (sometimes called the genesis block) and digitally signs it. Adding on the next block means that it is appended to the first block plus the digital signature attached to it, and then this whole aggregate block is digitally signed by its originator. Clearly, no changes can be made to the data in either block without it invalidating the second digest. As each processing node (or holder of this distributed data set) receives it, it generates a separate secure message digest and compares it with the arriving signature. Figure 5.13 provides a somewhat simplified sketch of this concept in action.
There are a lot more details to it than this simple sketch reveals. The basic concept, however, can be implemented using PKI, PGP/GPG, or a proprietary public/private key infrastructure. The contents of each block can be encrypted for storage, transmission, and use. Individual pairs or sets of users can and do use their own asymmetric encryption to keep their transactions private from others who are sharing the same ledger.
Bitcoin and many cryptocurrencies do something similar. Every Bitcoin user has the entire Bitcoin transaction history, for every Bitcoin ever mined, all in their individual copy of the database. But the only transactions they can read, and thereby extract data from and use in other ways, are the transactions (or blocks) that they can decrypt. The rest are as protected as anything else in this digital age is when it is using properly managed asymmetric encryption supported by a strong, trustworthy digital certificate infrastructure.
Note that blockchains are unforgiving of errors. If I authorize my Bitcoin wallet to pay you 378,456,223 Satoshis (or 3.78 Bitcoins), then as soon as I hit Send, those Satoshis are yours. If what I meant to do is send you only 2.0 Bitcoins, then I have to depend upon your goodwill (or other contractual arrangements that bind us together) to get you to send the difference back to me.
By providing strong nonrepudiation and data integrity for the transactions contained in the individual blocks, blockchains can implement digital provenance systems.
Chain of custody control, auditing, and record-keeping for cyberforensics could use blockchains to irrefutably record who touched the evidence, when, how, and what they did to it.
Parts or document provenance systems can prove the authenticity of the underlying data to help prove that safety-critical components (physical hardware, computer or network hardware, software, or firmware) are in fact what they claim to be.
Representations of any kind of value can be made extremely difficult to counterfeit.
It is this last that explains the dramatic rise in the use of cryptocurrencies—the use of blockchains to represent money and to record and attest to the transactions done with that money.
The cryptocurrency “miner” uses significant computing power to generate a new unique cryptocurrency identifier (similar to printing a new piece of paper currency with a unique combination of serial numbers, paper security markings, etc.). This “cryptodollar” is represented by a blockchain and is stored in the mining company’s wallet.
Bob buys that cryptodollar from the miner, and the underlying blockchain transfers to Bob’s wallet; the new message digest reflects this transfer into Bob’s wallet. The blockchain in the miner’s wallet is updated to show this transaction.
Later, Bob uses that cryptodollar to buy something from Ted’s online store; the blockchain that is Bob’s wallet is updated to reflect the “sell,” and the blockchain that is Ted’s wallet is updated to reflect the “buy.”
If all we do is use strong message digest functions in the blockchain, we provide some very powerful nonrepudiation and data integrity to our cryptocurrency users. We must combine this with a suitable exchange of public and private keys to be able to protect the confidentiality of the data and to ensure that only people or processes Bob authorizes (for example) can see into Bob’s wallet, read the transaction history that is there, or initiate a new transaction.
Finally, cryptocurrency systems need to address the issue of authority: who is it, exactly, that we trust as a “miner” of a cryptodollar? Bitcoin, for example, solves this problem by being a completely decentralized system with no “central bank” or authority involved. The “miners” are in fact the maintainers of copies of the total Bitcoin ledger, which records every Bitcoin owner’s wallet information and its balance; voting algorithms provide for each distributed copy of the ledger to synchronize with the most correct copy. This maintenance function is computationally intensive, typically requiring many high-performance workstations running in parallel, so the Bitcoin system rewards or incentivizes its miners by letting them earn a fraction of a Bitcoin as they maintain the system’s ledger.
One irony of the rise in popularity and widespread adoption of blockchains and cryptocurrencies is the false perception that since many money launderers, drug smugglers, and organized crime use these technologies, therefore anyone using them must also be a criminal. Of course, nearly all criminals use money, but that does not mean that all users of money are criminals!
Common Use Cases
Data at rest, in motion, and in use: that triplet defines our fundamental information security set of needs and is rapidly being addressed by encryption at rest, in motion, and in use. We’re not quite yet at the point where the total life cycle of a data set is spent in encrypted form (although advocates of blockchain technologies suggest we are heading in that direction and for some very good reasons). That said, let’s look at some common organizational uses of cryptographically powered information security.
Virtual Private Networks Virtual private networks (discussed in more detail in Chapter 6, “Network and Communications Security”) can be and have been built in unencrypted forms; their first use was as logical tunneling under the Internetworking layer to provide ways to logically combine network segments that weren’t physically in the same place. Nowadays, virtually every VPN implementation operates using PKI-enabled encryption processes.
A typical organization might unfortunately find itself hosting innumerable VPN connections and systems, if it cannot carefully manage what its end users can do at their endpoints. Some platform systems bring their own VPN capabilities built into them; others strongly encourage the use of a VPN to manage end-user connections to and use of the platform. Some of these may be needed for legitimate business purposes; others may not. Note that in many collaborative, creative environments, gamification has become a powerful way to engage team members in a complex, creative set of tasks, by associating symbolic “wins” with successfully accomplishing tasks or steps; such game platforms (such as the Panoply cybersecurity game engine at University of Texas at San Antonio’s Center for Infrastructure Assurance and Security) could have important returns on investment that justify their use in your organization.
VPNs are also widely used by people to enjoy access to media sites in other geographic regions, whether to avoid copyright and marketing restrictions (such as sports broadcast blackouts) or to access news and information using what looks like a local area IP address to the content providing website. Anonymous browsing or connections via TOR, for example, may be required by some of your business processes. It’s also worth considering that depending upon the nature of your business and applicable employment law, your organization may be somewhat constrained from preventing employees from using anonymous or secure connections for personal communications via employer-provided IT systems. Legitimately, an employee might need to communicate various forms of protected data, such as identity, health, education, with various other parties; whistleblower protection laws may also apply. While case law in this area is minimal as of this writing, caution—and good legal counsel—is advised.
It’s possible, then, that any particular set of users could have multiple VPNs that they’re using, only some of which might be directly in support of work-related tasks. Some of these VPNs might conflict with each other or with application platform settings or expectations (Microsoft Office 365 is known, for example, to sometimes need split tunneling setups to help better manage network bandwidth and traffic to avoid bottlenecks).
Proxy settings can also play hob with your ability to keep network services working effectively, with and without VPNs in action.
Federated Systems
Extending access to your IT infrastructure outside of your organization—and inviting outsiders to enjoy (hopefully limited) access to your systems and information assets—is made simpler and easier to manage and keep safe via a variety of federated access control strategies and mechanisms; Chapter 1 looks at these in some detail, including the use of mechanisms like Security Assertions Markup Language (SAML) to help automate and regulate such connections. Underneath all of these mechanisms is the encryption infrastructure that provides strong hash functions, point-to-point data integrity, confidentiality, and nonrepudiation, to name but a few. Your chosen access control systems should be your first port of call to understand how they negotiate the use of encryption with other systems in establishing connections such as single sign-on (SSO).
It’s possible that in a fairly diverse federated environment, one of the partner organizations is far less adept and skillful at keeping its cryptographic systems up to date; it may also have inherent, systemic issues in the ways in which it manages its users, its keys, digital certificates, and everything else. Part of your threat-hunting skepticism might be to see if your systems can report on any connections that routinely negotiate to the weakest choices in your installed base of acceptable encryption suites and algorithms. (And you should certainly be hunting out and locking down any such connections that keep trying to use SSL, for example!)
Transaction and Workflow Processing
Many business processes—not just financial ones—are based on a transaction processing model. Inventory systems, for example, will receive a transaction from an assembly line system each time it allocates a part or subassembly to the flow at a workstation and thus reduce the number of such parts on hand. Students enrolling in a university course generate transactions that “sell” a seat in a particular class. Workflow processing systems build up sets of information related to a set of tasks and pass that information from workstation to workstation to control the actual work itself, model it, and provide a structure and framework to measure and assess it with. Patient care systems quite often model the flow of the patient from initial intake through post-discharge follow-up care by means of a workflow model.
Workflows depend upon data integrity; many also must protect the confidentiality and privacy of the data that they collect, process, route, and use. In many respects, this is a role-based access control problem that the workflow management system needs to help you solve. Depending upon the chosen platform, it may or may not integrate seamlessly with your existing access control system; lack of good integration means that each time a workflow is changed and worker roles are redefined, you may have to update your access control lists independently; similarly, as employees change jobs or depart the organization, you could have multiple systems to update. This is discussed in Chapter 1 as well.
Underneath that, your transaction and workflow processing systems may or may not be using their own encryption technologies to deliver on their promises of data protection and systems integrity. Some large database systems (which are underneath some of these applications platforms) do use encryption to implement record-level or even field-level access control capabilities. Whether these systems turn to the underlying server for encryption infrastructure support, or have their own baked-in encryption systems, may be an issue you need to investigate.
Many industries are beginning to adopt vertical applications systems that integrate transaction and workflow processing with email and communications management. Several vendors, such as Adobe and RPost, provide such capabilities. Adobe’s approach tends to be focused around documents that flow between people and organizational units; RPost’s does that too, but by replacing email and fax traffic as steps in transaction processing, it is showing interesting application in integrated logistics and process control environments. Blockchain technologies are being applied in this use case area quite successfully.
Regulatory and compliance requirements are driving organizations to have reliable nonrepudiation, safety, auditability, and transparency with respect to the fine-grained details of how products are assembled, how acceptance testing gets accomplished, and how customer orders are handled. These capabilities fundamentally depend upon the underlying cryptographic infrastructures and the cryptographic technologies your organization is using.
Integrated Logistics Support
Integrated logistics support (ILS) takes supply chain management several steps further by finding the most cost-effective ways to use information to improve and mature the organization’s value chain. ILS extends that value chain far beyond the walls of the company or organization itself, by reaching as deep into the systems and information flows of its vendors, shippers, service providers, customers, and even their customers’ customers, as there is value to be had in doing so.
From an information security perspective, that means that an ILS system crosses many organizational boundaries; it must meld together many different cultural perspectives on privacy, auditability, compliance, data and systems integrity, information quality, and protection. As an ILS may reach across many national borders, it must also face multiple legal, regulatory, and other compliance regimes. This is a federated systems problem writ large; this is transaction and workflow management taken across time zones, human languages and dialects, and organizational imperatives. This is also another problem domain that blockchain technologies are being put to use in, and they are already achieving some significant results.
One vexing question in ILS security is raised when the many different organizations in an extended ILS value chain do not have the same information security needs in common or if they have wildly different interpretations of what “confidentiality” means, for example. Your own organization might also find that some of its other customers or suppliers have their own unique perspectives on the risks that some of your value chains’ members potentially expose their information and their systems to.
Keeping an ILS system safe and secure relies on much the same technical and managerial approaches to providing and maintaining the underlying cryptographic systems that support it.
Secure Collaboration
Collaboration suites and platforms are becoming essential in many businesses large and small. They provide much of the human-to-human activity that knits together complex project management teams, while being layer 8 of the integrated logistics support systems as well. They rely on the underlying access control systems, including SSO connections, to function effectively. Some collaboration platforms may provide separate encryption capabilities which users can invoke on a per-session basis or as part of their default settings. They may also provide the option to produce encrypted or plaintext recordings of sessions. Your organization may need to understand these capabilities if their use presents a data classification and management concern or if other compliance issues are associated with recordings of such collaboration sessions.
IoT, UAS, and ICS: The Untended Endpoints
These three different systems domains have two characteristics in common: they all have endpoint devices that generally are not directly tended to by people, and their technologies do not usually come with encrypted, secure links for data, commands, device health, and status information.
Internet of Things (IoT) devices can range from the simplest of control devices, such as a home heating thermostat, to complex, semi-autonomous and mobile devices. Mobile freight and package handling devices used in warehouse and order fulfillment processing in warehouse operations, such as at Amazon, are but one example.
Industrial process control systems (ICSs) interact directly on one side with physical manufacturing systems—furnaces, pumps, heavy machinery, or industrial robots—and an ICS-specific set of network protocols on the other.
Untended or uncrewed aerial systems (UASs), and their cousins that move on land, water, or underwater, also have unique interfaces to the systems that control them.
UAS tend to have more complex mission management, dispatch, navigation planning, and safety requirements than the other two categories sometimes do. The UAS device itself may also have a “fail-safe” mission mode that causes the device to navigate to a predetermined safe point and come to rest, in the event of a protracted communications link failure or other conditions.
Many of these types of devices, in all three of these systems domains, tend to have limited onboard capacity to support sophisticated encryption of their uplinks and downlinks. Even if they do, the protocols used on those links may not always be compatible with TCP/IP-based protocols and services that the rest of your organization’s networks and systems are using.
You may be lucky and find out that the IoT, UAS, ICS, or other robotics types of systems your organization is using or wants to begin using are directly supportable by your existing cryptographic systems and technologies. You may find that their systems, links, and operating procedures can hold to the same standards for key strength, key management, and use that you already have in place; they may also be compatible with your existing access control systems to the degree that this is an issue for your use of these untended endpoints. Then again, you may find that your organization has to either accept the potential for security compromise or plan to upgrade these systems and their interfaces to be more compatible with the rest of your cryptographic infrastructure.
Deploying Cryptography: Some Challenging Scenarios
Thinking about those use cases as a starter set, let’s superimpose them as a bundle across the sliding scale of organizational complexity and the IT architectures that result from (and often exacerbate) that complexity of interconnectedness.
Trusting SOHO
Taken altogether, small businesses (of less than 20 people) comprise the largest aggregate employer in most nations. This is the marketplace for small office/home office (SOHO) systems built with consumer-grade equipment and software and firmware installed and managed by the original equipment manufacturer (OEM) on their own schedule. It’s the marketplace of little in-house cryptographic expertise (if any), and it’s the never-ending consulting opportunity for the freelance or moonlighting security professional.
Such environments are anything but server-free, of course. Their router (typically provided by their ISP) provides DHCP services at a minimum; each endpoint has multiple servers built into it, and any network-attached storage devices provide even more. These environments are also prone to using many cloud-based storage solutions, particularly in the free end of the spectrum. Some of their uses may have set these up with encryption on some files, on some folders, or on a whole storage volume.
Many organizations in such circumstances do not get their own digital certificates; if they have a website, they may unknowingly rely on its hosting service (which might be WordPress or similar easy-entry web page development and hosting solutions) for HTTPS session support. User IDs, passwords, authorized devices (for MAC address filtering on routers), and even the use of built-in access controls can be unmanaged and disorganized. Document e-signing services may be used to provide digital signatures as part of some business processes, but the organization may not have any formal management process to control their use, maintain them, expire, or revoke them (as faces change at the company).
In such environments, some standard cryptographic hygiene measures are desperately needed. These organizations may have little or no procedural grasp of what to do when an employee quits, becomes disgruntled, or compromised. Dealing with lost or forgotten passwords or encryption keys can be a traumatic case study in learning on the fly every time it happens.
On-Premises Data Center
Once an organization has migrated to more of a structured data center as the power behind its IT infrastructure, it’s also making the step toward more formalized information security measures. Greater awareness of compliance and regulatory demands for tighter security, even the use of encryption to protect sensitive information and restrict access to sensitive processes, may also be more common in such a setting. Most server systems come with certificate generation and management capabilities built right in; even consumer-grade NAS solutions often have these features although few SOHO architectures ever see them put into effective use. At this point, systems administrators can now generate and issue certificates, and the organization can digitally sign files, documents, archive copies of data sets, and so on.
Key management becomes an issue at this point; including HSM solutions as part of their IT architecture may be prudent.
Investment in a data center can be the tipping point at which management starts to seriously worry about data exfiltration, ransom attacks, and other high-impact threats to the company’s survival and success. This brings two encryption-based worry beads to the table.
Weaponized and encrypted inbound content: Their architecture’s threat surface exposes them to many possible ways that weaponized content can make it into their systems, and if the connection being used by that attack vector has its encryption managed independently of the organization’s control, there’s no useful way to detect it or prevent it. Other means, such as tighter control of endpoint activities, software and even process-based whitelisting, endpoint and host-based intrusion detection and prevention, and behavior modeling and analysis can help but may not be enough.
Encrypted “east-west” internal traffic: Almost every business process supported by your systems and architectures will move data internally, as different servers, operational locations, departments, and human beings get involved in the end-to-end of the business of doing business. This has to happen efficiently and reliably, of course. Some of those processes may have information security needs that dictate encryption be used to protect the data while in transit internally. How can you tell whether a particular stream of encrypted packets on your internal network is legitimate, is an exfiltration in process, or is some other part of an attacker’s kill chain in action? Inspecting the unencrypted content of every packet might help, but doing this requires you to be your own MITM attacker. You have to ensure that every internal encrypted data flow path potentially carrying highly sensitive information must route itself through an encryption proxy service that provides you with opportunities for (automated) inspection, analysis, and logging. This has throughput performance penalties that can seriously affect your competitive advantage. It may also end up putting all of your most sensitive information into one high-value point of potential exploitation (the so-called “all eggs in one basket” problem).
Note
You’ll find issues such as these explored in (ISC)2’s various series of webinars, free to members and associates; this discussion of inspection of encrypted internal and inbound traffic, for example, was one of several related topics in a three-part webinar series in May and June 2019 presented by Druce MacFarlane, director of security products for Gigamon.
High-Compliance Architectures
As an organization extends its business activities into areas that must meet stringent regulatory and other compliance requirements for data protection, safety, and reliability, the needs for encryption-based security solutions increase. By one count, more than 83 different types of business activities, from healthcare through gambling and from banking through medical care are subject to compliance regimes that dictate such architectures be put in place, managed effectively, used consistently, and be subject to verification testing, audit, inspection, and ongoing security assessment. All of the issues looked at throughout this chapter, and then some, require that the organization have some seriously capable in-house cryptologic talent—or trust its fate to its vendors and consultants.
These types of environments and architectures need powerful capabilities for monitoring the use of encryption by applications; this may require extensive analysis of behavioral norms to identify acceptable use versus usage worthy of further inspection and analysis. They also need to have a similar capability to monitor cloud-hosted service usage, in particular the ebb and flow of encrypted traffic and data via cloud-based application platforms, in order to be able to spot anomalous patterns of activity. These monitoring capabilities should be in-house, directly coupled to organizational management and leadership, to strengthen the sense that the “watchers” and the managers and leaders jointly own the challenges that maintaining such vigilance entails.
Limitations and Vulnerabilities
Probably the first real limitation I have to acknowledge is the flip side of the greatest strength we have going for us.
Common to almost all of the protocols and services discussed in this chapter is the fundamental assertion that the way our “crypto industry” works is effective at keeping our systems safe and secure. We depend upon its underlying business model for establishing encryption and decryption algorithms, choosing effective keys, and managing algorithms, keys, and protocols to stay a few steps ahead of well-funded attackers. We depend upon that community effort to grant us ways to stay months ahead of the attackers, perhaps even a few years ahead of them; we operate in that window of safety in time because we rely upon that white-hat community of cryptographic practice. This community, as you know, is an incredibly large and complex system of individuals and organizations, including security agencies such as NSA or GCHQ; standards bodies like NIST, ISO, and the IEEE; the Internet engineering community (IETF and everyone who works with it); and the millions of white-hat cryptanalysts, hackers, ethical penetration testers, and end-user systems and security administrators. This system includes the CVE databases and the reporting channels, as well as the academic literature, blog sites, and conferences of all kinds.
We depend upon this human system to keep our window of security open for as many months as we can. We know it’s a question of when, not if a particular key strength will fail to be sufficient. We know that all algorithms, processes, protocols, and systems will have vulnerabilities discovered in them.
In some respects, each of us in our end-user organizations can’t do much to remedy the shortcomings of that white-hat community of practice. But we can and should recognize that it’s not perfect. We cannot count on it to watch our backs; it only provides us the tools and techniques and shares common alarms with us when it finds them.
At a lower level of abstraction, there are some common limitations and vulnerabilities we can and should take ownership of.
Weak keys continue to be a source of vulnerabilities for almost every cryptologic process, procedure, protocol, or service. For example, consider the known vulnerability of IPsec to man-in-the-middle attacks when weak preshared keys are used. IKE in its original implementation and in IKEv1 had some flaws that might allow this to occur, which could then let an attacker capture and decrypt VPN traffic. When discovered, vendors such as Cisco Systems quickly developed and released patches to eliminate this vulnerability. Each end-user organization, however, had to correctly apply the patch and then correct other deficiencies (probably in their procedures) that were allowing weak keys to be generated and used in the first place. Somewhat later, IKEv2 was shown to be vulnerable to another variant on a MiTM attack that allowed session keys to be stolen; once in possession of these, the session is wide open to the attacker. This time, Bleichenbacher Oracles, a chosen-ciphertext attack against RSA, first published by Daniel Bleichenbacher in 1998, was the attack method of choice. The next section in this chapter will look at the overall key management problem, and some solutions to it, in more depth; but keep in mind that even the strongest key management process is held hostage by its algorithms and its end users.
Password vulnerability is also a never-ending issue. Complex passwords were thought to be the fix; those are out of favor, with longer, more user-friendly passphrases being today’s preferred solution. It’s not hard to believe that these, too, will fall prey to concerted GPU cluster attack machines that draw support from a Dark Web community of malpractice, long before quantum computing becomes commonplace and affordable.
Spurious content injection has also shown to be an Achilles’ heel of a number of protocols, such as the EFAIL exploits found in S/MIME, which also seems to have affected PGP/GPG email systems. Carnegie Mellon University’s CERT recommendations included performing email decryption outside of the email client, disabling HTML rendering for email (as a way of blocking most exfiltration channels from being set up), and disabling remote content loading by email clients. (Do you disable these for your organization’s email clients?)
The protocols and the services your organization depends upon may be rock solid in their design; however, common errors in their implementation into hardware, software, and procedures still reach up and bite the end users when attackers find and exploit such weaknesses. Buffer overflows continue to plague the industry, for example (one wonders how, these days, a product can get through design and testing and still have such classic flaws in it). Virtually every one of the algorithms and protocols discussed is available to you in many different implementation forms, from many different vendors or supply chain channels. Different implementations expose different vulnerabilities to exploitation than others do. This is as true for your cryptographic infrastructure as it is for the rest of your IT architecture and installed base of systems. We’ll look more at these issues of IT supply chain security in Chapter 7, “Systems and Application Security.”
Understand Public Key Infrastructure Systems
Prior to the 1990s, the management of cryptologic keys, keying materials, and everything associated with encryption and decryption was monopolized by governments. A few commercial encryption systems, similar to the electromechanical rotor systems such as the Enigma, were in use before World War II, but these were the rare exception. The public competition that brought us the Data Encryption Standard in 1977 was driven in part by businesses that had started thinking about how and why they needed to start using encryption. By 1991, according to a NIST planning report published a decade later, the worldwide market for cryptographic business products had grown to an estimated $695 million USD (or about $1.3 billion, given inflation, in 2019). The market value of just the financial data protected by such use of DES was estimated to be between one and two trillion dollars in 1991, according to that same NIST Planning Report 01-2 published in 2001. (By 2018, the volume of funds transferred on Fedwire exceeded $716 trillion dollars, all of it protected by AES and other encryption technologies, of course.) Clearly, by 1991, quite a number of private businesses as well as the federal electronic funds clearinghouse system (or Fedwire) had learned much about the fine art of safely and securely managing cryptologic systems and their keys.
The principle challenges remain the same. Only the keys you are using right now to encrypt something are a secret that you can and should protect. You must share that key with the recipients or end users of the messages or data you encrypt it with. How you manage that sharing, without compromising that key, is the challenge. We’ve looked at that challenge earlier in this chapter in a number of ways. Let’s review it all by way of leading up to a final look at key management in a public key world and how that problem boils down to how we create, maintain, and manage millions of trust relationships. In doing so, we’ll look at the principle tasks that taken together comprise cryptologic key management as a discipline.
Key generation, including determining the key size and key strength necessary to meet your information security requirements
Key distribution, including trust relationships between key generator, distributor, and users
Key expiration and revocation
Scheduling and managing periodic key changes or key rotations across a network of subscribers or users
Lost key recovery and key escrow to meet users’ information security needs
Key escrow and recovery to meet the needs of law enforcement or digital discovery
Destruction or safe disposal of keys, keying materials, cryptovariables, and devices
Coping with data remanence issues
Again, it’s worth remembering that these tasks exist whether you’re using purely symmetric encryption, purely asymmetric encryption, or a hybrid system, and whether you’re using block ciphers, stream ciphers, or a mix of both technologies. We’ll also see that many concepts from risk mitigation and control, such as separation of duties and shared responsibilities, have their place in the world of key management.
Fundamental Key Management Concepts
You’ll recall that encryption systems consist of algorithms for encryption and decryption; the keys and control variables (or cryptovariables) that are used by those algorithms; and then the software, hardware, communications interfaces, and procedures that make that set of math-based manipulation of symbols into a working, useful cryptographic system. By definition:
Symmetric encryption uses the same key for encryption and decryption (or in some cases a simple transformation of one key into the other). The encryption and decryption algorithms are logical inverses of each other. Symmetric encryption also implies that if an attacker can work out the decryption key (from intercepted ciphertext, or from known-plaintext attacks), then he can easily determine the corresponding encryption key, and vice versa. Symmetric encryption tends to be very efficient, in terms of CPU processing power or number of logic gates used in hardware encryption and decryption systems.
Asymmetric encryption uses encryption algorithms that are fundamentally different from their corresponding decryption algorithms; the encryption and decryption keys themselves are also very different from each other, and the decryption key cannot readily be computed or estimated from the encryption key itself. The nature of the mathematics chosen for key generation, and the algorithms themselves, make it computationally infeasible to be able to reverse calculate the decryption key from the ciphertext and the encryption key. Asymmetric encryption and decryption use significantly more CPU cycles, hardware elements, or both to perform their operations, but this runtime performance penalty buys users a significantly greater degree of resulting resistance to attack.
This leads us to revisit three important types of cryptographic keys:
A session key is used for encrypting a single session of data exchange or data encryption. That unit of work can be a message, a file, an entire disk drive or storage system image; it can be an HTTPS connection to a web page, a client-server connection of any kind, or any other set of information required. Once that session’s worth of data has been encrypted, the session key is never used again. Furthermore, any future session keys generated by that system should not be easy to predict or precalculate by an attacker. For symmetric encryption, the same session key is used by the recipient to decrypt the session’s information (be it a file or a stream of packets or bits); when through, the recipient must also not reuse the session key.
A public key is part of an associated pair of keys that a user needs to operate an asymmetric cryptographic system. As its name implies, it can be and usually is made public. Unlike the session key (or a symmetric encryption key), it is not used in the encryption process directly; instead, it is used by the sender (its owner) and the recipient to co-generate a shared, secret session key. So long as sender and recipient obey the rules of session keys (and never reuse it, destroy it when no longer needed, and protect it while it is in use), the ciphertext cannot be decrypted using the public key alone.
A private key is the other part of that associated pair; it is known to the originator (the owner of the identity associated with the public and private key pair), and the originator never shares it with anybody or any other system. It is used by the sender, along with his public key, in a process of shared key cogeneration with the recipient.
You’ll also hear two other terms associated with keys when various cryptographic encapsulation techniques are used:
Key encryption keys (KEK), sometimes called key wrapping keys, are used when a cryptographic key itself must be protected by a surrounding wrapper or layer of encryption. For example, once a hybrid encryption system has successfully cogenerated a session key, it is usually put in a packet that is further encrypted using such a KEK.
Data encryption keys (DEK) are the keys used to encrypt payload data only; session keys might also be called DEKs in some systems.
Key Strength and Key Generation
Key strength is the result of two principle factors: the size of the key itself (expressed as the number of bits to represent it) and the randomness associated with the key value and its generation process. Your choices about both of these factors should always be driven by your particular information security requirements, especially the time period over which you need the data you’re about to encrypt to be kept safe from prying eyes or corrupting fingers.
Key SizeGenerally, the longer the key, the more difficult it is to attack encrypted messages; it determines the search space, the set of all possible numeric values that fit within the number of bits in the key that a brute-force attack must attempt in order to find a match. What constitutes a secure key length changes with time as computer power increases and cryptanalysis techniques become more sophisticated. In 1977, the U.S. government selected a symmetric block cipher they dubbed the Data Encryption Standard (DES), which was considered secure for nonclassified use, with the intent that banking systems and other commercial business users could start to use it to protect their data. But by 1999, multiple cryptanalysts demonstrated that DES could be cracked in as little as 24 hours using large arrays of processors such as the EFF’s DES Cracking Machine, for a cost of only $250,000. Governments’ monopoly on powerful code-breaking hardware had crumbled with the birth and explosive growth of the personal computer market, especially its appetite for higher-performance single-chip CPUs, math co-processors, and graphics processors.
As DES was replaced with AES, key sizes grew from 56 bits (DES) to 128, then 192, and then 256 bits. A brute-force attack on a 128-bit key, using a single CPU, would take something on the order of 14 billion years of CPU time to try every possible value. Of course, the attacker could be lucky on their first handful of attempts. Any clues that the attacker can use to reduce the size of that search space, bit by bit, raises their chance of success. AES, for example, was described in a 1999 paper to be vulnerable to attack by precomputing intermediate values (the Bleichenbacher Oracles attack mentioned earlier). Such intelligent guesswork can cut the effective key size (and resultant search space) down to a much more manageable size, perhaps back to the DES 56-bit window of vulnerability. Various organizations such as NIST in the United States, ANSSI in France, or the BSI in the United Kingdom provide concrete recommendations such as disallowing the use of 80-bit symmetric keys after 2012, and 112-bit keys after 2030. A strong key should be random enough to make it unlikely that an attacker can predict any of the bits of the key. If the mechanism used to generate keys is even somewhat predictable, then the system becomes easier to crack.
The choice of algorithm has a profound effect on the strength of a given size key as well. By comparing the estimated run time or work factor necessary to backward solve the decryption algorithm without the decryption key, it’s been shown for example that ECC demonstrates the same level of key strength at about one-fourth the key size of the RSA algorithm.
RandomnessThe strength of a symmetric key also depends on its being unpredictable (both “unguessable” in the human sense and resistant to mathematical attempts to generate the next key in a sequence, given one such key). Even if only some of the bits can be guessed, that can significantly reduce the strength of the cipher. Using a mechanism that will generate high-quality (i.e., cryptographically secure) random numbers is essential for key generation. The best method is to use hardware-based true random number generators (HRNGs) that use very low-level physical phenomena, such as thermal noise, to generate sequences of numbers as outputs that are statistically highly random. Such devices are embedded in various cryptographic hardware devices such as Trusted Platform Modules and Hardware Security Modules, discussed earlier, as well as in some microprocessors themselves.
Software-based RNGs are very hard to get right. For example, from 2006 until 2008, a defect introduced into the OpenSSL package in the Debian and Ubuntu Linux distributions caused all keys generated to be weak because of a bug in the random number generator (CVE-2008-0166).
Key GenerationKeys should be generated in a manner appropriate for the cryptographic algorithm being used. The proper method to generate a symmetric key is different from a public/private key pair. NIST SP800-133, “Recommendation for Cryptographic Key Generation,” provides specific guidance. The best approach for generating asymmetric keys, however, is to use a trusted digital certificate provider, which will generate a public/private key pair bound to a specific identity. At some point, however, your organization’s need for multiple public/private key pairs will dictate that you become your own certificate authority and take on the management burden and expense of generating and issuing key pairs to users within the organization. (At this point, investing in an HSM as a secure storage and processing part of your CA capabilities makes sense.) Generating your own certificates should not be confused with self-signing certificates. Self-signing certificates actually authenticate nothing but the certificate itself; they are quite useful in software and systems test environments, where a working, fully functional certificate, private key, and public key might be needed but are not required to provide security. Do not attempt to use self-signing certificates to protect anything!
Secure Key Storage and Use
Once you have generated a nice long and random key, how do you keep it secret? Obviously the first step is to encrypt your data encryption key (DEK) with another key, the key encryption key (KEK). That solves the problem but creates another: how do you secure your KEK? This depends on the sensitivity of the underlying data being encrypted and the mechanisms that are appropriate for the system you are designing.
A hardware security module (HSM) is specifically designed to securely generate and store KEKs and is among the more secure method of protecting keys. HSMs also provide for secure ways of replicating the KEKs between redundant HSMs and for enforcing controls so that no one individual can use the KEK to decrypt a data encryption key.
For systems that are deployed in the public cloud, the major cloud providers offer cloud implementations of HSM technology. Numerous hardware security module as a service (HSMaaS) vendors are available in the marketplace, often as a service offering in conjunction with other cryptographic functionality such as key escrow and cryptographic acceleration.
For less demanding applications, the approach must be tailored to the specific requirements and risks. This might permit storage of master keys in a: hardware-encrypted USB key, a password management app, or a secrets management package. Another factor to consider is how your keys are (securely) backed up. Losing access to your keys can cause you to lose access to significant amounts of other data (and backups of that data).
Key Distribution, Exchange, and Trust
Even the smallest of systems using encryption—two nodes or even one node that writes encrypted data to storage to retrieve, decrypt, and use it later—has the issue of getting the keys from the generation function to each point of use. In the more general case of a network of multiple users, all of whom are cleared to the same level of information security classification and all of whom need to communicate with each other, the key generation function has to distribute a copy of the key (and any other required cryptovariables) to each node that will participate in a multiway sharing of information. For n users in a system, that’s n different sets of messages going back and forth to send the key and verify its receipt. On the other hand, for systems that require each pair of those n users to have their own separate key so that pair-wise communication and data sharing remains secret from the others on the network that’s n(n - 1), or roughly n2 key exchanges that need to be managed, confirmed, and kept track of. (Keeping track of which user nodes or systems have which key at what time is a major part of what keeps the encryption system synchronized across those users; it’s also necessary to investigate lost or possibly compromised keys, and it’s a major component in providing nonrepudiation of messages sent through the system as well.)
Three different trust relationships exist in a key distribution system:
The key distributor has to trust that the recipients are who they claim they are (which requires that they are still using the same identities they had the last time keys were sent to them) and that their facility, local key storage, systems, and users have not been compromised without it being reported to the key distributor.
The recipients have to trust that the key distributor has not been compromised without their knowledge.
Individual user recipients have to trust that no other users on the network (whether they share keys with them or not) have been compromised without their knowledge.
The net effect of these trust relationships is that all parties can trust that the keys they’ve just been issued will provide the level of security protection that the system, with proper keys, is supposed to provide. The ultimate organizational owners of the network may be the anchor of all of these trust relationships (that is, the one whose assertions of trust the other nodes can depend upon), or it may be the key distributor that does this. (We’ll look at this in more detail in the “Hierarchies of Trust” and “Web of Trust” sections.)
Keys are sent from the distributor to user nodes in one of two ways.
In-band distribution uses the same communications channels and protocols that the parties use for normal message or data traffic between them.
Out-of-band distribution uses a physically, electrically, logically, and administratively separate and distinct channel for key distribution and management. This may be a physical channel, such as a courier, a different VPN, or a dedicated circuit used solely for key distribution.
Part of the trust that all parties must repose in each other includes the fact that they share the protection responsibility for that distribution system, whether it is in-band or out-of-band.
Key exchange, which is used with hybrid encryption systems as part of a public key encryption infrastructure, is different than key distribution. It may still use in-band or out-of-band communication channels to support the exchange process; but by its nature, it does not depend upon the parties in the key exchange having a previously established trust relationship with each other.
Distribution, Exchange, or Infrastructure?
It’s important to keep the distinction between key distribution and key exchange clearly in mind and then add the “secret sauce” that scales an exchange or distribution process up into an infrastructure.
Classical cryptographic systems depend upon key distribution systems to ensure that all known, authenticated, and trustworthy parties on the system have current encryption keys. Key distribution is the passing of secret information—the keys—from the key originator and controller to the parties who will use it.
Key exchange systems start with the presumption that parties do not know each other and thus have no a priori reason to trust each other. They achieve this trust, and therefore can share in a secure, encrypted conversation, by generating their session key together and keeping that session key secret to themselves.
In both cases, the underlying key infrastructure is the collection of systems, communications pathways, protocols, algorithms, and processes (people-facing or built into software and hardware) that make key distribution or exchange work effectively and reliability.
Key Rotation, Expiration, and Revocation
As with everything in information security, your cryptographic keys are part of your race against time with your attacker. The longer you use any given key—the more packets, messages, or files you use it to encrypt—the greater the opportunity you give your attackers to possibly succeed in attacking your encryption processes. One time-tested countermeasure is to change your keys, early and often. Ideally, you’d use a new key every byte (which sounds like an infinitely long one-time pad key being put to use). Practically, you’ve got to find the balance between the costs and efforts involved in changing keys versus the risk that adversaries can break your encryption and get at your data or systems as a result.
Many organizations establish a key rotation schedule, by which they plan for the routine replacement of keys currently in use with newly minted keys. NIST, ISO, and the Payment Card Industry Security Standards Council recommend that keys be changed at least annually, and this includes public/private key pairs as well as symmetric keys generated with them and used to encrypt archival data backups. Other industries may require keys to be changed more frequently.
In practice, the keys used to encrypt new data are changed each year, and all of the previously encrypted data is decrypted using the retired keys and then re-encrypted using the new key within the year following the key rotation. Thus, by the end of a year after the key rotation, there is no data encrypted using the retired key, at which time it can be destroyed. In cases in which backups must be maintained for longer than one year, either a process for securely archiving retired keys must be instituted or backups will have to also be re-encrypted with the new key.
Key revocation is the process of formally notifying key users, and users of data encrypted with a key, that the key has been compromised or its safety and security is in doubt. If there is evidence or even suspicion that a key has been compromised, it ought to be rotated (that is, replaced) as soon as feasible. Best practice also dictates that keys be replaced when essential personnel with access to cryptographic material leave their position.
Key rotation, expiration, and revocation all reduce the likelihood that an attacker can break your encryption systems, or otherwise circumvent them, and then have unrestricted access to your information and information systems. By smartly rotating and expiring keys, you can also manage the amount of archival or backup data that is protected by any particular set of keys. (Think of this as limiting your exposure to losing that data, in the event the key is compromised without your knowledge.)
“Rotate” Does Not Mean “Reuse”
Rotating your keys is not like rotating your tires: you do not take a key at the end of its scheduled usage lifetime for one application or pair of users and then assign it to another and continue using it. Early encryption systems did this, believing that their adversaries could not surreptitiously gather enough ciphertext messages between enough nodes in the system to make the system vulnerable to attack. This was a dangerous assumption to make, and experience usually proved it a foolish one as well.
Rotate by destroying the old keys and then generate and distribute a new key to take its place.
Key Destruction
Once a key has been retired and it has been determined that there is no data that has been encrypted using that key that will need to be decrypted, then it must be securely destroyed. This involves locating every copy of the key and deleting it in a manner appropriate for the media on which it was stored to ensure that it cannot be recovered.
Depending on the media and the risk of it becoming accessible to unauthorized individuals, this may require overwriting the storage, degaussing of the media, or physical destruction of the media or device containing the media.
Records must be kept documenting the locations of the destroyed keys and the means used to ensure secure destruction. In many regulatory and compliance regimes, these records are subject to audit.
Key Management Vulnerabilities
There are a number of vulnerabilities that can be introduced through the incorrect use, storage, and management of cryptographic keys.
There are potential trust concerns when dealing with some agencies. While NIST is highly regarded as operating with virtues in line with most cryptography users, agencies such as the NSA also possess both the expertise and responsibility to monitor electronic communications, and therefore it cannot be assumed that they will always prioritize protecting privacy over intelligence. They’ve also repeatedly stated that their national security duties require them to attempt to find ways to build in backdoors or otherwise weaken encryption processes, whether they acknowledge that they’ve done so or not. “Don’t worry if your system crashes, because NSA has a backup copy of it” may be an apocryphal bit of black humor, but if the thought of NSA having a copy of your communications or data makes you or your company uncomfortable, consider using an alternative such as a PGP-based system that’s outside of the NSA/NIST nexus of the white-hat community.
Symmetric and private keys depend upon confidentiality to be effective. This means great care must be taken with how the keys are stored to reduce the possibility of their becoming known to unauthorized entities. There are a number of approaches to secure key storage, from key management software to key management services provided by cloud service providers to dedicated hardware devices that keep the keys stored internally in a tamper-resistant secure device.
Keys that have reached the end of their lifetime (and all properly managed keys should have a defined lifetime) must be securely destroyed to prevent their misuse in the future. Keys should not be reused and should be rotated (replaced) periodically to ensure that the amount of data encrypted using a single key is limited and that the lifetime of data encrypted using a given key is likewise limited.
Another vulnerability can arise from insider threats. A rogue employee with access to key material can use that access to defeat the security of encrypted material (or enable another to do the same). Dual control or segregation of duties can be employed to ensure that at least two people must be actively involved before any key management operation that might compromise the security of the system can be completed. Another popular method to mitigate the risk of a rogue employee exposing cryptographic material is to use a third party to safeguard keys. A key escrow agent is a trusted external party that ensures the cryptographic keys are safe from unintended abuse or leaks. As an analogy, this is similar to how an escrow agreement is used to safeguard a large sum of money when purchasing a home.
The final leg of the CIA triad must also be considered: availability. If the key management system cannot provide access to the key material to authorized processes when required, then access to the encrypted material will be denied, even if the encrypted data is readily accessible.
Key operations must be logged in a manner that ensures accountability and traceability, providing the forensic evidence essential to analysis of a suspected possible compromise, intrusion, or data breach.
Finally, where possible, key management functions ought to be automated. Manual processes are more prone to error (either by commission or omission), leading to weaknesses in the system that depends upon the keys for security.
Escrow and Key Recovery
During the 1980s and 1990s, the U.S. government (and some of its NATO allies) pushed hard to get legislative support for a concept they called key escrow. Key escrow would require any private person (corporate or individual) who created a cryptographic key to place a copy of it on deposit with the government, who would have to have legal authority, such as a search or surveillance (wiretap) warrant from a court before they could take the key out of escrow and use it to decrypt intercepted files or messages involving that party. Needless to say, the outcry across many communities was substantial. This was also still at a time when the U.S. government believed it could systematically restrict export of encryption technologies, and only allow downgraded, more easily breakable versions of American-made encryption products to be exported. Market economics quickly demonstrated that foreign systems vendors would dominate the world market, which would leave American technology and software firms with nothing but a domestic market. Eventually, key escrow as a government agenda item lost what luster it might have had. But it’s not dead yet; periodically, governments protest that they need the ability to break everybody’s encryption, just in case they find the nuggets of information they need to thwart a terrorist attack. Key escrow, alas, cannot force the criminal or terrorist—or a foreign intelligence agent—to submit their keys to a government escrow agency.
Lost Key InsuranceAs the use of password managers, hardware security modules, and other such systems has grown, business and personal users are finding legitimate reasons to want some form of “lost or forgotten key insurance,” so to speak. Key escrow and key recovery are often discussed as options to mitigate the risk of lost, corrupted, or forgotten keys and digital certificates.
Internally, key escrow processes can be useful, and solutions such as hardware security modules (or even HSMaaS approaches) may be worth considering. When an organization takes on the task of being its own CA and issues certificates (and therefore public-private key pairs) to users, it may want to look further at its needs for internal key escrow. There are also legitimate business continuity needs to identify ways to safely escrow (or archive) certificates and keys and then be able to quickly reinstall them as part of recovering from an incident or disaster. In most cases, recovering a private key associated with a digital certificate issued by a public-facing CA is not possible.
Hacking Back a Lost KeyKey recovery has become the collective, polite term for any capabilities, efforts, or attempts to reverse engineer or hack back the decryption keys associated with a set of ciphertext, such as account passwords, digital signatures, encrypted files or disk drives, smartphones, network traffic, or messages of any kind, for the purpose of making the key-protected content available and useful to its owners again. Presumably, these attacks are carried out by ethical hackers, whose actions are constrained and authorized by a suitable contract with the owners of the systems or accounts in question.
There are two difficulties with such concepts, one technical and the other legal.
The legal difficulty is that for any activity involving a U.S. person, the U.S. government can serve anyone even remotely involved with that person with a National Security Letter (NSL). An NSL is a warrant issued by the U.S. Foreign Intelligence Surveillance Court, and it requires the person it is served on to surrender or make available any information the NSL asks for, without informing anyone, even their attorney, about the NSL. Presumably, LastPass, Mozilla, Google, Microsoft, or any firm making a password manager service available could be served with such an NSL; they would have no legal recourse but to comply. If your password manager can reveal or recover your master password to you, it can do so when compelled by an NSL (or even a much weaker search warrant or subpoena. (The penalties for not complying are quite painful, as spelled out in the Uniting and Strengthening America by Providing Appropriate Tools Required to Intercept and Obstruct Terrorism Act of 2001, known as the USA PATRIOT Act.)
The technical difficulty goes to the heart of our widely held assumption that our whole public cryptography infrastructure, when used with strong keys and with proper cryptographic hygiene measures in place, will really keep our information and systems safe, secure, and reliable. If the encryption keys and algorithms used are as strong as we all hope they are, any attempts at key recovery should be expensive, time-consuming, and impossible to guarantee to be completed in any specific or reasonable amount of time. Such brute-force key recovery, aided by guesses, fragmentary memory, or other information provided by the owner to the key recovery service, may help speed the process up; but at the end of the day, either all of our secrets are safe and key recovery is a pipe dream or key recovery is real, affordable, and practical, and nothing is as safe as we hope and need it to be.
Separation of Duties, Dual Control, and Split Knowledge
It’s fundamental to risk management and mitigation that any business process that involves a high-impact risk should be designed, implemented, monitored, and managed in such a way that no one person or system element has the opportunity to corrupt that process on their own. We add redundancy to such high-impact risk control processes in a variety of ways.
Majority voting: Redundant, parallel processing elements (people or systems) each execute separately on the same inputs and previous system state; the results are compared, and differences beyond a tolerance value are flagged to supervisory functions for investigation and resolution. (Blockchain systems and other distributed, high-reliability systems use this technique.)
Split (or shared) knowledge: Critical process knowledge is not granted to a sole individual person, node, or component; instead, multiple such people or nodes must bring their knowledge together to a trusted system component that combines them, and validates that result, before allowing the process to continue. This is similar to multifactor authentication; some hardware security modules use physically separate and distinct additional factors for each human interacting with the HSM, all of which (or a set majority of which) must be present in order to allow HSM critical maintenance or management functions to be performed. Using asymmetric encryption in a key exchange process to generate a session key is an example of a split knowledge process.
Dual (or multiple) control: The process is designed with layers or sequences of approval and authorization steps, each of which is performed by a unique individual person or systems component; all process steps must be correctly completed in the proper sequence for the results to be valid. High-value financial transactions often require two or three different company officers to authorize before a check can be issued or an electronic payment can be processed. This can also include process steps where all parties must execute their part of the step simultaneously, if not also at the same location. Such locations are sometimes known as no lone zones, since policy and process design prohibit one person being in the area and attempting to perform the process task by themselves.
Each of these control techniques can play a part in applying a separation of duties control strategy. Separation of duties reduces the risk that one employee can take an action that can cause harm to the organization, its information, its systems, or its customers, without that action being detected and possibly prevented or remedied in a timely fashion. Separation of duties also protects the employees from potentially being falsely accused of negligence or willfully taking harmful action by helping to isolate where in the chain of business processes an error, misstep, or improper action actually took place.
Protecting your cryptographic systems, keying material, keys, and even the data remaining in the devices or system after an encryption session is completed may very well require some form of dual control or separation of duties. Compliance requirements in many business areas may also require that your systems have no “lone zones” or one-person tasks or functions in critical process flows.
Hierarchies of Trust
We’ve now got some of the major building blocks to provide for trustworthy distribution of the software (and hardware) elements of a public encryption system. Before we can start building an infrastructure with them, we first need to look more closely at what trustworthy means and how we establish, share and encourage strangers to trust each other—or at least, trust enough to communicate with them.
We first must recognize that a trust relationship between two parties is actually the sum of two one-way trust relationships: Bob confers his trust upon Carol, and Carol confers her trust upon Bob, which we observe by saying “Bob and Carol trust each other.” (If you think that looks like a grant of privilege from Bob to Carol, you’re right!) A transitive trust relationship occurs when Carol trusts Alice,and because Bob trusts Carol, he therefore also trusts Alice. And since Alice trusts Ted, Bob and Carol each trust Ted. Thus, a transitive chain of trust is created. (If Ted trusts Alice but chooses not to trust Bob, you can see that the web or mesh of trust relationships can get…murky.) Strictly speaking, these are peer-to-peer trust relationships, as no one person in this group is the designated or accepted authority regarding trustworthiness.
Conversationally, we talk about chains of trust, webs of trust, and hierarchies of trust. Implicit in each of these ideas is the notion that those trust architectures have some “coin of the realm,” some agreed-to set of ideas, messages, data, or other things that are both the token of that trust and what is being exchanged in a trustworthy fashion. Money, for example, is exchanged both as a token (a representation) of value and of trust.
In information and communications systems terms, the foremost token of trust is a certificate that asserts that the identity of the certificate holder and the public key associated with that certificate are linked or bound with each other. This gives rise to two different concepts of how trust conferred by one node upon another can be scaled up to larger numbers of nodes.
A hierarchy of trust exists when a single node is recognized as the authority for asserting or conferring trust. This conferring of trust can be delegated downward (made transitive) by that trust authority conferring a special status to a set of intermediate nodes, each of which can act as a trust authority for other intermediary nodes or end user nodes (recipients of trust), which (in tree structure terms) are the leaf nodes. The trust anchor is the trust authority, as the root of this tree of trust, conferring trust downward through any number of intermediaries, to the leaf nodes. Hierarchies of trust resemble forests of trees (in data structure terms!), with one root branching out to start many subtrees, which may further branch, until finally we reach the leaf nodes at the very tip of each twig.
A certificate authority is the anchor node of a hierarchy of trust, issuing the certificates that bind individual identities with their corresponding public keys.
A web of trust has no designated or accepted single authority for trust, and acts in peer-to-peer fashion to establish chains of trust.
Note
In nature, of course, trees grow from their roots upward; information systems designers, out of habit, start drawing trees by putting the anchor node at the top of the page and thus grow their digital trees downward.
In both hierarchies of trust and webs of trust, any given node can be a member of one or more trust relationships and therefore be a member of one or more chains or webs of trust.
In hierarchies of trust, end users, seeking to validate the trustworthiness of a certificate, infer that a certificate from a trusted end (leaf) node is trustworthy if the intermediary who issued it is, on up to the anchor. Webs of trust, by contrast, involve peer-to-peer trust relationships that do not rely on central certificate authorities as the anchors. Hierarchies of trust are much more scalable (to billions of certificates in use) than webs of trust. Both systems have drawbacks and issues, particularly with respect to certificate revocation, expiration, or the failure of a node to maintain trustworthiness. (The details of those issues are beyond the scope of this chapter, but you do need to be aware that these issues exist and are not straightforward.)
TLS and secure HTTP (HTTPS) require the use of a certificate, granted by a certificate authority. SSL and TLS established what was called the chain of trust, shown in Figure 5.14. The chain of trust starts with the CA itself generating a self-signed certificate, called a root certificate, which anchors the chain of trust. This root certificate can be used to generate and authenticate any number of intermediate certificates, which can also be used to authenticate (sign) other intermediate certificates. The end-entity, or end-user certificate, is the distant end of the chain of trust; it authenticates the end user’s identity and is signed by an intermediate certificate issuer (or, hypothetically, it could be signed by the root authority). End-entity or “leaf” certificates (borrowing from tree structure terminology) are terminal—they cannot be used to sign other certificates of any kind.
Certificates of this kind allow browsers or other client-side programs to use a certification path validation algorithm, which has to validate that (a) the subject of the certificate matches the host name being connected to, and (b) the certificate is signed by a trusted authority, has not been revoked, and has not expired. Figure 5.15 shows this in simplified form.
In 2008, the IETF published updated versions of the X.509 standard, which defines these certificates and the protocols for their use.
As it turns out, anyone can become a self-authenticating certificate authority. This could be helpful if your organization requires an isolated LAN in which certificate-based services are necessary, but all use of those services stays within that LAN, for example. To become part of the world-spanning infrastructure, however, those wanting to become CAs must have their certificate implementations adopted by the major web browsers, which means getting their certificates bundled in with Edge, Firefox, Chrome, Safari, or Opera, for example. In fact, one of the key elements of these major vendor root certificate programs is that by becoming a root certificate member with them, your company adds significant value to that vendor’s user community, while at the same time potentially holding that vendor’s value hostage to the authenticity of your certificates and their use. CA applicants then have to go through rigorous technical demonstrations of their domains and their services. Each of those vendors has its own standards and processes to ensure that as a would-be CA, your company is not about to harm their reputation or the reputations or interests of their customers, partners, clients, and users worldwide.
What this all boils down to is that if you want to be an anchor of many trust chains, we, the rest of the Internet-using world, require that you prove your trustworthiness, your reliability, and your integrity to us. This may be why the four CAs with the largest market share between them are IdenTrust, Comodo, DigiCert, and GoDaddy, according to W3Techs surveys. In 2017, Google and Mozilla rejected Symantec’s certificates from their browser bundles, citing numerous repeated violations of trust—including incorrect or unjustified issuance of more than 30,000 HTTPS certificates. Some of this involved issuing free “domain-validated” certificates, thought to be a great way to stimulate further small business development; in reality, it made it trivially easy for malicious sites to spring into action, typically with phishing attacks on unsuspecting targets. Prior to this, Symantec had been the market leader; that same year, DigiCert acquired Symantec.
The certificate validation process also demonstrates another important aspect of cybersecurity and cryptography that SSCPs must deal with every day: every system your organization uses is the result of an information technology supply chain, a chain that runs from designers and developers, through subsystems vendors and parts suppliers to end-user sales and service and finally to your own organization’s technology support staff. Every step of that process is a potential opportunity for threats to find vulnerabilities and exploit them. In fact, one definition of an advance persistent threat is that it is an organization or entity that looks at as much of the IT supply chain as it possibly can, seeking points of entry or influence.
Web of Trust
In the world of public key cryptography, a web of trust is a network of trust relationships built and maintained by the users or members of that network. It exists without needing a central, single root certificate authority or one single anchor for all trust chains. In human terms, it’s how our relationships work; we look to someone we already trust as the source of transitive trust when they introduce us to someone else. Supply chains and business relationships work this way. Small webs of trust can be quite powerful protection to those who participate in them, since almost no participant would want to risk being ejected from the web (via a revocation of trust) because they have vouched for an unreliable and untrustworthy person as a candidate for membership and participation in that web.
The original advocates of a web of trust concept, such as Phil Zimmerman, believed that the hierarchy of trust concept places far too much dependence upon the root CA process and the government, industrial, and business processes that authenticate CAs as trustworthy. All human organizations make mistakes in judgment; some of those mistakes can put an organization out of business or cause a government to fall. Then, too, governments have legitimate motivations regarding the survival of their own societies and institutions that naturally conflict with just the idea of allowing individual people, businesses, and organizations to have too many secrets that governments are not privy to.
The problem with web of trust architectures is that they still depend upon some kind of authentication of trustworthiness. In the current PGP web of trust, this has notably been performed by having certificate-signing parties, which as social occasions bring together many people who are willing to attest to the validity of the certificate in question. A software developer might host such a party (with or without cocktails and hors d’oeuvres), inviting key customers, wholesalers, resellers, and OEMs to join in a web-based assertion of authenticity. Practically speaking, it’s not likely that a software giant could depend upon certificate-signing parties so that it has an authenticated certificate it can digitally sign its next release with. It’s also hard to see how a major wholesaler and distributor, such as Ingram Micro, could do business in such a fashion.
Hierarchies of trust and webs of trust have one structural aspect in common, and that is the need to facilitate the flow of trust across subtrees or subnets in their hierarchies or webs. In the hierarchy model, the one root node CA delegates authority to issue certificates in its name to tiers of intermediate nodes, many of whom may also delegate downward. Users underneath one intermediate node who need to verify a certificate issued by some other intermediate node, in another subtree, need to depend upon the hierarchy’s navigation features as their verification request flows up the forest, then back down to the right issuing node to be verified. Webs of trust have the same need to pass a verification request along until some node, somewhere, can verify it. These same subtree and subnet challenges make revocation of trust a management challenge as well.
One measure of the success or uptake of the web of trust concept is the size of the set of users who have connectivity with each other; that is, all users of this set participate in trust relationships with all other users. This strong set as it is called numbered about 55,000 people as of 2015. That’s not a lot. There have been some analyses published as to why PGP and the web of trust failed to come into more widespread use, and their arguments may be relevant to whether your organization should consider web of trust concepts in its own operations (and use of cryptographic security solutions).
Cryptocurrencies demonstrate a blend of both trust concepts. Their reliance on widespread PKI reflects their reliance on the hierarchy of CAs to establish trustworthy digital signatures and the public/private key pairs that those require; but their very nature as a fully distributed ledger embodies and establishes a web of trust among their subscribers and users. It is this duality, in part, that leads some blockchain enthusiasts, advocates, researchers, and practitioners to suggest that perhaps we are on the edge of another change in the way the digital social compact works. We’ve seen one such change as what might be called the PKI revolution built onto the computer revolution, which brought personal information security powered by pervasive encryption to billions of users worldwide. Blockchain technologies arguably present a comparable disruption to the ways in which we assert and verify trustworthiness. “A Declaration of Independence: Toward a New Social Contract for the Digital Economy,” by Don Tapscott, cofounder of the Blockchain Research Institute, may help inform your thinking as you help not only secure your organization against the next wave of disruptive ideas and technologies but help secure their readiness to take advantage of them; it can be found at https://www.blockchainresearchinstitute.org/socialcontract/.
Summary
You’ll probably need to be more of a systems engineer, and less of a mathematician, to successfully apply cryptography as part of your overall approach to meeting your organization’s information security needs. You’ll need to have a firm grasp on the procedural aspects of encrypting and decrypting data to protect your data while it’s in storage, in transit, and in use; you’ll need to pay especially close attention to the step-by-step of keeping that data secure as it sees greater use in collaborative business processes involving partners and other outside organizations. Getting to know the algorithms and their important characteristics, even on just a by-name basis, starts to help you know which of these cryptographic tools to reach for as you look to solve real problems or address real needs.
As with so many other aspects of information security, how you manage and maintain your cryptographic infrastructure is as important as how you’ve selected and installed those cryptosystems for your end users to make use of. Cryptographic hygiene, as a subset of more overall information security hygiene, can focus your attention on these management challenges and may give you some leverage in strengthening and maturing your organization’s current cryptographic management processes.
Cryptography can give your organization a competitive advantage; it can help you stay a few steps ahead of the adversaries that might otherwise find your systems easy to penetrate and easy to take advantage of. It provides a comprehensive suite of capabilities, each of which has many significant roles to play in improving the efficiency, reliability, integrity, and safety of your organization’s business processes. It’s becoming a mandatory part of many of these business processes, as a growing body of law, regulation, and compliance requirements demonstrates. It is not the answer to every information security challenge.
One final thought about cryptography: it can also be the edge you need to keep your company from becoming another infamous “crypto-fail” case study, where your organization ends up being the subject of blogs, articles, and government inquiry reports for years to come.
Cryptography: it’s more than just a growth industry. It’s gone from being the stuff of secrets and spies to one of the fundamental drivers of change in our modern world.
And that modern world needs more people like you who can successfully apply it, as part of keeping their organization’s information, systems, and processes safe.