This chapter focuses your attention in the here and now by applying the kill chain concept operationally. You’ll start by assuming that multiple attacks, each in its own different phase of its own unique kill chain, are happening right now. You’ll also assume that other systems anomalies, which might be accidents or design flaws raising their bad-news heads, are also occurring in the midst of your day by day, moment by moment watch-standing activities. You’ll make it part of your checklist-driven approach to defending your systems and the information that keeps your organization alive and flourishing. This is all about translating all of the decisions you made during risk management and mitigation planning and all of the actions you took in implementing your chosen risk and security control tactics into real-time operational use. In Chapter 3, “Risk Identification, Monitoring, and Analysis” you used the concept of the kill chain to identify high-impact risks and link them to exploitable vulnerabilities in your systems, processes, and data; you then used those insights to decide what and how to harden which high-leverage elements of those systems so that your business could stay in business in the face of risk. You saw how a single advanced persistent threat (APT) actor might go through a complex, dynamic, ever-evolving sequence of steps as they attempt to attack your systems. This led to planning, preparing, testing, assessing, and monitoring your systems so that you could defeat multiple, overlapping patterns of hostile action, from multiple APTs, one skirmish at a time.
It’s time to dive deeper into getting your organization ready to detect an information security incident, respond to it, recover from it, and continue to learn to respond better as a result of its rough teaching. In some respects, that means that the preparation portions of this chapter will seem as if they speak to you in the past tense—they offer advice and ideas about what you should have done to prepare better—while the respond and investigate portions focus more on actions you’ll need to do in real time. You’ll need to think and act in three different, overlapping time frames, as you deal with pre-event readiness, real-time hands-on response, and post-incident analysis and learning. You’ll also see how to incorporate the human elements in your information systems into real-time detection, characterization, and response.
Although there are as many incident response frameworks as there are risk management ones (as you saw in Chapter 3), let’s focus our attention here in this chapter on NIST SP 800-61 as a point of departure. Nearly all of these standards and frameworks call for organizations to create some form of an incident response team, which then acts as the focal point for real-time decision-making and action during an information security incident and its immediate aftermath. Senior leadership and management designate this team, equip it, train its people, and provide it with the visibility and connectivity it needs to detect and respond in ways that just might keep the company in business. No matter what you call it—a computer emergency response team (CERT), a computer security incident response team (CSIRT), or any other name—it’s your last clear line of defense in real time.
What do you do if your organization doesn’t have an established incident response team? Let’s jump right in, do some focused preparation, and improve your operational information security posture so that you can detect, identify, contain, eradicate, and restore after the next anomaly.
Support the Incident Lifecycle
Before diving into the lifecycle of an information security incident, let’s start by defining an incident as the occurrence of an event that the systems’ owners or users consider as both unplanned and disruptive. Incidents can be hostile, accidental, or natural in origin.
Incidents that are deliberately triggered or caused are defined as hostile events, whether the systems owners know or understand their attacker’s motives or not. Hostile events almost always involve attackers who exploit vulnerabilities in the target organization’s information systems, IT architecture, and social and administrative processes and culture.
Incidents that are caused by accident or acts of nature are not, by definition, hostile; they are still unplanned and disruptive to normal business operations.
Unmanaged systems, as Chapter 3 asserted, are the most vulnerable to exploitation or accidental disruption. You bring such systems under management using risk management frameworks, configuration management, change control, and information security controls. Each of these involves a planning process; taken together, this planning should have identified those risks that must be considered as urgent, compelling, or of sufficient potential impact that you need to know immediately when such a risk event is occurring. Thus, information risk management sets the stage for incident management and response by establishing the alarm conditions you need to watch for and respond to.
It’s important at the outset to recognize that such risk events can fall into several broad types, loosely based on how your organization needs to respond.
Ongoing attempts to penetrate, gain access, or misuse systems resources and assets have long been the principle focus of incident response concepts and frameworks. By focusing on real-time urgency of detection, characterization, and response, systems security planners and systems owners hope to limit the damage from such an event. This event response paradigm uses a triage approach to determine when and how to escalate the alarm to appropriate levels of senior leadership.
Ransom attacks of any kind are also real-time emergencies that demand an immediate response; since ransom attacks (using ransomware or built-in systems capabilities) often involve sophisticated encryption of systems resources, databases, and information assets, it’s often vitally important that the right expert talent be tasked in real time to assist.
Rude awakenings are as good a name as any to refer to those events in which you happen to discover—or are told by a third party—that your systems were breached weeks or even months ago and that your valuable and confidential or proprietary data had been exfiltrated and sold on the Dark Web or other marketplaces. In too many cases, businesses and organizations are discovering (or being informed about) such exfiltrations long after the incident itself has ended. Since it’s taking many companies over seven months to detect an intrusion into their systems, the opportunity to prevent impacts is long gone. In such events, emphasis shifts from technical responses to an incident to coping with customer claims for losses or damages, defense against litigation, or charges of criminal negligence. Anomalies can be any kind of event that occurs without much warning, such as a server crash, an internal network segment suffering from too much traffic or too little throughput, or almost any other kind of odd event. Until you’ve gathered data and analyzed or characterized them, you don’t really know if an anomaly is caused by a hardware failure, a software bug, a user error, bad data, nature, the enemy, or a combination of all of these.
It’s important to realize that events and incidents are two related yet different terms. In management and leadership terms, it may not matter much whether it was an event or an incident that caused the organization to suffer disruption, damage, or losses; as security planners, however, it’s useful to have some commonly understood terms to help deal with them when they occur. Let’s review a few key terms as they pertain to information security incidents by stepping through the sequence in which you’d see them in action as an incident unfolds. An event is something that happens; it is either a physical or logical activity. Events cause something to change state, value, or condition; they are observable, although you have to know what to look for and how to look for it to notice that an event has occurred. Events may be discrete, single occurrences, or they may be made up of many distinct events.
Many events can be safely disregarded. Events of interest are some types of events or some events that occur under certain conditions, which may be suggestive of a security-related incident in progress or that already occurred. These are worthy of further analysis, data collection, and characterization.
Precursors are events, usually occurring outside of your systems, that might be an early warning of an information security incident. Political or social unrest, gang activities, or protests against your organization, its business, or national origin might all be suggesting that your physical facilities, systems, web presence, and people might soon be under attack by various individuals or groups. Much like traveler’s security advisories or other threat condition warnings, however, most precursors are hard to translate into specific indicators you can act upon.
By contrast, an indicator is an event that more clearly signals an information security incident is happening or is about to happen.
An indicator of compromise is a signal from an event that shows your systems have been penetrated, attacked, or compromised in some way. These are (or should be) clear and unambiguous alarms to your security operations team, network operations team, or computer emergency response teams that an incident is occurring now. These alarms are often generated by your anti-malware, software whitelisting, access control, intrusion detection and prevention systems, or other systems health and status monitoring systems.
An information security incident is declared to have occurred, or is in progress, when alarm data generated via monitoring, analysis, and characterization activities strongly suggests that such is the case. You sound the alarm and start to execute your incident response plans. Note that an information security incident (often referred to just as an incident) is typically a set of multiple, related events that together can or will affect the confidentiality, integrity, availability, authenticity, or other security characteristics of your information system.
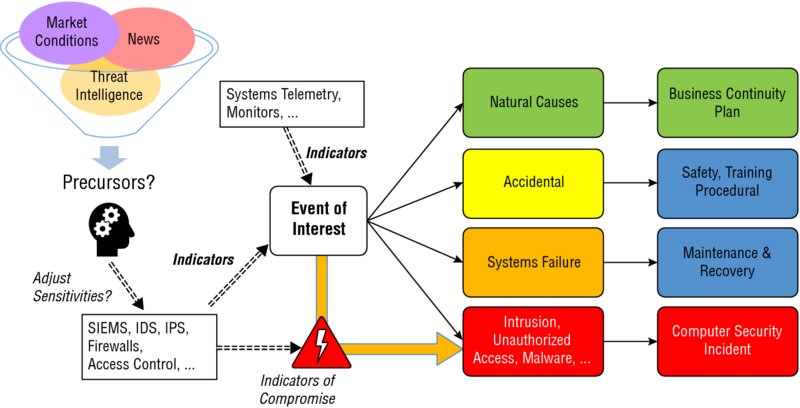
Figure 4.1 shows these ideas in the context of several key decisions that the security operations center (SOC), the network operations center (NOC), and senior management have to make. It starts with filtering a combination of open source intelligence, more focused threat intelligence, and your own observations to develop a sense of what types of precursors (if any) might be anticipated in the near term and what they might mean. At most, these might lead you to change the sensitivity settings on your various automated monitoring and detection systems or provide additional, focused guidance to your security team members. Hardware, software, and people systems will be producing a variety of indicators, as they observe events happening throughout the day; an event triage process should be used to consistently assess each event of interest, determine the first best appropriate response, and dispatch that event and the assessment findings to the right response team and process. In an ideal world, only a few of those will be indicators of compromise—but when (not if) these occur, the SOC team needs to swing into immediate action. Other events of interest may or may not be a security incident but may very well indicate a failure in other risk mitigation controls.
FIGURE 4.1 Triage: from precursors to incident response
Note that in each case, the possibility for false positive and false negative outcomes exists: your detectors, filters, and analysis tools will sound false positive alarms when nothing harmful is happening, while failing to sound the alarm when a real event of interest is in progress or already happened.
It’s also important to note that those definitions of events, precursors, indicators, and incidents are not limited to just the IT components or infrastructures your organization depends upon. It is vitally important to recognize that attackers know from experience that social engineering attacks—such as phishing and vishing—are effective, low-cost, and low-risk ways to penetrate your organization and pave the way toward having unrestricted and undetected access to your information assets. As you think about incident response, be sure to include responding to potential social engineering attacks as well! (As of this writing, only a very few organizations have any processes in place that systematically detect and assess human-to-human contacts as possible social engineering attack attempts; as late as May 2019, even the U.S. government was only starting to consider establishing capabilities to detect possible propaganda, social engineering, or “false news” influencing attacks on the nation, regardless of their source.)
Precursors might be found in a variety of sources.
Server or other logs that indicate a vulnerability scanner has been used against a system
Missing or modified systems and security logs
An announcement of a newly found vulnerability by a systems or applications vendor, information security service, or reputable vulnerabilities and exploits reporting service that might relate to your systems or platforms
Media coverage of events that put your organization’s reputation at risk (deservedly or not)
Email, phone calls, or postal mail threatening attack on your organization, your systems, your staff, or those doing business with you
Increasingly hostile or angry content in social media postings regarding customer service failures by your company
Threat intelligence you receive or a “threat temperature” reading shared with you via your participation in local information security communities of practice
Anonymous complaints in employee-facing suggestion boxes, ombudsman communications channels, or even graffiti in the restrooms or lounge areas
One of your best systems security monitoring techniques might be called vigilance by walking around. The nature of your organization and how its people and chains of command or leadership are both physically and logically arranged may make this easier or harder to do; what’s important is that SOC team members be known and recognized as trusted brokers of informal observations about the current security climate and posture and how changes in the “business normal” operations tempo might be causing changes in that security posture or indicating that something isn’t exactly normal.
It’s worth focusing a moment on accidental incidents, which are triggered by your own authorized end users. The root cause of these accidents may be inadequate or ineffective training, gaps in policies and procedures, or simply because the end user in question cannot effectively perform the required tasks despite the training you’ve provided to them. Useful statistics regarding the frequency of such accidental incidents and their impact are hard to come by, although one indicator is the estimate of lost work and productivity due to poor quality or incomplete data. In 2018, IBM estimated these losses as exceeding $3.1 trillion worldwide; clearly, some portion of that is in part due to accidental misuse of information systems by one’s own trusted employees. Your own staff can be accidentally contributing to both your false positive and false negative security alarm rates.
Think like a Responder
Take each step of this chapter from the perspective of someone working in your company’s security operations center. It doesn’t matter if your organization does not have a physically separate SOC or an officially designated set of people who are the SOC team complete with its leaders and responders. It does not matter if your “normal” IT department or team handles all of the network operations, IT security tasks, and help-desk-like anomaly investigation, response, and escalation processes. Think as if you run the SOC. Own that SOC as a mental set of resources, frameworks, and responsibilities. Take off your planner and architect’s hats and start thinking in the near real time. “Job one” of the SOC is to alert management and leadership to situations and conditions that may require urgent or immediate decisions that can keep the business operating—or ensure its survival—in the face of information security risk events.
If your organization already does have an security operations center (SOC) or has otherwise formally designated SOC-like roles and responsibilities, that’s good news! Grab a copy of their procedures, their training, and their resourcing plans, and use them as a starting point and checklist as you put this chapter to work for you.
Many organizations will formally define the team of responders who are called into action when an information systems security incident or other information systems emergency occurs. Known by names such as computer emergency response team (CERT), computer incident response team (CIRT), or computer security incident response team (CSIRT), these teams are called into action by the SOC’s alerts to management that an urgent situation is in progress. (I’ll use CSIRT throughout this chapter to refer to any such team of incident responders.) The SOC does not own either of these teams (usually), and unless the incident is small in scope and can quickly be handled by the SOC team, most incidents are turned over to the CERT or CSIRT for ongoing response activities. So again, in the spirit of putting this chapter to work for you, it’s time to think and act as if you own the CERT or CSIRT too. During an actual incident, you might be called upon to perform many tasks that start as SOC responsibilities but transition to the on-scene management, direction, and control of the CSIRT.
Physical, Logical, and Administrative Surfaces
Keep in mind that your organization and its information systems present a combined set of physical, logical, and administrative attack or hazard surfaces, places where hostile action, accident, or natural causes can attempt to inflict disruption, damage, or loss upon the organization and its objectives. By the same token, these three surfaces present you, their defender, with powerful opportunities to observe, gather data, make decisions, and respond. Events that might be security incidents in the making can and do happen at all three of these surfaces, and the more complex and pernicious attacks combine physical, logical, and administrative actions throughout their kill chain.
Think of the physical, logical, and administrative surfaces as comparable to the data plane, control plane, and management plane of your networks: each layer or plane presents opportunities to attacker and defender alike. And since you already know your own systems architectures and understand all of these views of them, you should be several steps ahead of your potential adversaries.
Incident Response: Measures of Merit
“If you can’t measure it, you can’t manage it.” This bit of commonsense management wisdom should focus our thinking on what might be the most important question this chapter can help you answer: how do you know you’re getting better at incident response?
In many information security professional circles, discussion about this question focuses on what may be the three most vitally important metrics.
Mean time to detect (MTTD)
Mean time to respond (MTTR)
Mean time to eradicate (MTTE)
The MTTD story is not an encouraging one; in 2017, research by the Ponemon Institute for IBM Security showed it had fallen from 201 days to 191 days, but since then, many sources report it is now pushing upward of 220 days to detect an intrusion. (Ponemon’s report can be found at https://www.ibm.com/downloads/cas/ZYKLN2E3.) MTTR was last reported in 2017 as 66 days; that’s nearly 10 months to detect and contain an intrusion. Industry average mean time to eradicate estimates are hard to come by; even if MTTE is in the 30- to 60-day range, you still have a serious problem on the front end of this timeline.
Note the metric that isn’t in this conversation: mean time to repair or remediate. The issue here is that depending upon the impacts of an incident, organizations might take days, months, or even years to “recover enough” to consider themselves more or less back to normal. It’s also worth considering the number of organizations that get put out of business by a serious information security incident (and what number do you put in to represent the time to repair when you go out of business?). Perhaps, too, it’s worth noting that the repairs and remediation are not usually the responsibility of the information security specialists; it’s the rest of the management and leadership team that have to make the hard choices about what to repair, and on what kind of timeline, and then get the money, people, and other resources lined up to achieve that desired remediation target.
Your job is to find ways to make the MTTD and MTTR for your organization drive toward immediate. In a 2015 summit report for SANS Institute, Christopher Petersen notes that most organizations already have, on their own networks and systems, all of the threat intelligence data that they need to provide much more timely indications and warnings of an intrusion or incident in the making. That I&W problem—finding the right indications and translating them into useful, actionable warnings—is probably where smart investments can produce high-leverage returns by reducing those metrics and by giving you more focused, actionable alarms about threats becoming incidents. (Petersen’s report can be found at https://www.sans.org/cyber-security-summit/archives/file/summit-archive-1493840823.pdf.)
The Lifecycle of a Security Incident
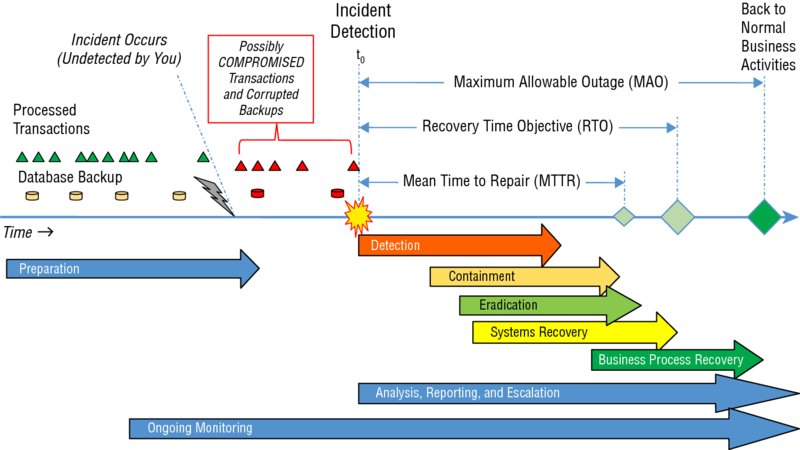
Traditionally, the incident response lifecycle consists of six major phases of activity: preparation, detection, containment, eradication, recovery, and post-incident analysis and improvement. Chapter 3 put this cycle in the context of the planning decisions that senior management must make, which start with translating risk appetite into measurements such as maximum allowable outage time limits. Figure 4.2 builds on Chapter 3’s use of quantitative risk assessment time frames to put these major phases of incident response activity in context.
It’s important to realize that, as Figure 4.2 shows, there are no hard and fast boundary points between these large phases of activity. Similarly, within each major phase of activities there’s an ebb and flow of effort, as you shift focus and effort from subtask to subtask or from issue to issue. It is during detection, for example, that you go from sifting through signals to declaring an information security incident alarm, by way of recognizing an event or series of events and subjecting them to further analysis. Notice, too, that the cyclical, backward-chaining, or iterative nature of incident response isn’t shown in gory detail on this flow. (Imagine, if you will, multiple APTs at various stages in their kill chains, as they separately attempt to reconnoiter, penetrate, take command, and exploit your systems against you. You need to detect each skirmish-level attack attempt and deal with it, capturing what that experience has taught you into your ongoing efforts to detect and respond to other activities.) Finally, too, it’s important to realize that sometimes there is a lot of just plain waiting involved, whether waiting on resources to be available, training to be completed, or (shudder!) for an incident to occur.
What’s also not explicitly shown in Figure 4.2 is the never-ending cycles of learning that the SOC team and the organization as a whole must engage with throughout. Initial assumptions are made during initial preparation and during each incident response. Those assumptions get tested (often to the breaking point) by reality; the organization either learns from watching those assumptions fail or continues to be vulnerable to repeated attacks that exploit those flawed assumptions.
Let’s get into the details using a checklist borrowed from NIST SP 800-61 rev 2 as the road map.
Which Frameworks?
If your organization is just starting out on its information risk management and incident response journey, you have a golden opportunity to pick the frameworks that best suit your needs and tailor them to the specifics of your organizational culture, business logic, markets, and customers. In doing so, you make a risk-based approach become a living, breathing part of the day-to-day and the longer-term tasks of keeping the organization alive and well.
Unless there are contractual, legal, regulatory, or other constraints on which frameworks you use and upon how you can tailor them, just keep it simple: any framework consistently used is better than none. Take the time to build experience in using the chosen framework, and carefully, prudently assess any suggestions to move to a new and different framework.
Preparation
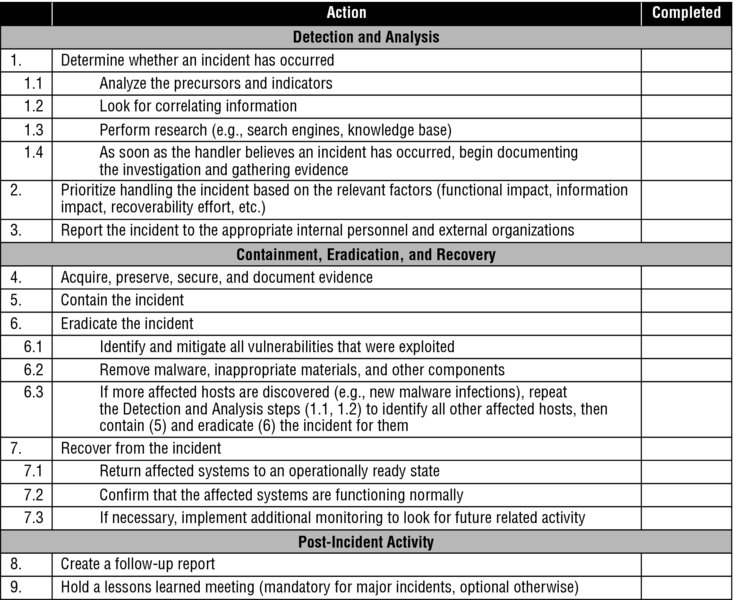
Getting prepared to respond to incidents starts with planning; then, of course, you must gain management’s commitment to provide the people, funding, tools, connectivity, and management support necessary to achieve the goals of that plan. One useful approach is to start with an incident handling checklist as your “shopping list” of milestones in that plan. NIST’s Incident Handling Checklist, shown in Figure 4.3, is a useful place to start. It is designed to be used in real time, incident by incident, reminding your watch-standers and first responders of key steps to perform, data to gather, or decisions to make, phase by phase, as they respond to an unauthorized penetration or other attack. You can use this same checklist as your template to plan and prepare with, by adding columns that prompt you (as preparation planner) to:
Estimate how long it will take to accomplish each task.
Identify needed resources, such as digital forensics workbenches, security information and event monitoring and analysis tools, workspaces, or people.
Identify key decision points, which provide management with critical insights into your readiness preparation.
Record the accomplishment of each preparation task, along with any action items or open discrepancies.
At each step in the checklist, ask these six questions: who and what do you need; where do you need it; by when; why; how are you going to get it in place, on time; and how will you measure or demonstrate that you’ve successfully completed this step in the checklist?
One key question to ask, step-by-step in the checklist, is whether an administrative control such as a policy, procedure, or guideline needs to be issued in support of that step. Written administrative documents are either directive, instructional, or advisory in nature; all are important, but the policy documents provide the best opportunity for personnel accountability. Policies set the constraints and expectations on employee behavior and direct affected employees to comply with them; they also provide the legal framework for disciplinary action, changes in job duties, or loss of a job altogether for employees who cannot or will not comply.
NIST breaks its checklist down into three broad categories; these may be useful as guideposts when you consider the current incident response capabilities and state of the practice within your organization. This checklist-focused planning process is also useful to use when auditing or assessing your current incident detection and response capabilities and practices—simply add to it, row by row, as you discover significant gaps in your end-to-end ability to prepare for, detect, contain, eradicate, recover from, and learn from incidents of all types.
The same checklist that you use to develop your preparation plan can and should be used to plan and conduct your response team initial training, as well as ongoing refresher or proficiency training. Clearly, if there’s a task on your checklist that you’ve not trained someone to do (or that you cannot identify who’s responsible for getting that task done), you’ve found a gap.
Tests and Exercises
Exercise these preparation processes throughout their planning, development, and operational deployment life. Simple tabletop exercises, either with responsible managers or “stand-ins” taking their functional place at the exercise table, are valuable and inexpensive ways to find misunderstandings and opportunities for miscommunication. As you put a response team in place and equip it with systems, tools, and procedures, include them in the scope of these exercises. The most important part of these exercises is the debrief activity, in which you invite and encourage dialogue, questions, concerns, and complaints to come forward. Resist the temptation to analyze, assess, or judge such inputs during the debrief itself—instead, make sure that exercise participants can see the value you place on their frank and open sharing with you. Analyze it all later and then develop appropriate ways to reflect the results of that analysis back to exercise participants and their managers.
Ethical penetration testing is the penultimate test and evaluation of your ongoing incident detection and response capabilities. Chapter 3 looked at this in some depth; it’s worth recalling here that in many businesses, standards or contractual obligations require ethical penetration testing, independent audit, and internal assessments as major components of an ongoing due diligence effort.
Note, too, that this preparation checklist should help you identify key performance or risk management metrics by which you can assess how well you’re doing, both with preparation and with ongoing response activities. Ideally, you should be able to link these metrics to other key performance indicators or process maturity indicators used throughout your organization. This may also offer opportunities to assess successful incident response preparation and ongoing operational capabilities in cost avoidance terms, as well as link them to other strategic and tactical goals of the organization.
Taken all at once, that looks like a lot of preparation! And it is! Yet much of what’s needed by your incident response team, if they’re going to be well prepared, comes right from the architectural assessments, your vulnerability assessments, and your risk mitigation implementation activities. Other key information comes from your overall approach to managing and maintaining configuration control over your information systems and your IT infrastructure. And you should already be carrying out good “IT hygiene” and safety and security measures, such as clock synchronization, event logging, testing, and so forth. The “new” effort is in creating the team, defining its tasks, writing them up in procedural form, and then using those procedures as an active part of your ongoing training, readiness, and operational evaluation of your overall information security posture.
One last point to keep in mind is that, as in all things, you should start small and simple. You cannot start from having zero detection and response capability and get prepared for every risk the first time around. Growing and maintaining an effective information security incident response capability should be an iterative learning experience. Start by identifying the risks that have management worried the most, and prepare to be able to detect and respond to these first. From that planning and readiness activity, learn what you can do better the next time, as you take on successively more and more of the risks identified, assessed, and prioritized in your company’s risk register. Keeping your organization’s information systems healthy and their immune system—your incident response capabilities—strong and effective is an ongoing part of business life. It stops only when the organization ceases to exist.
Incident Response Team: Roles and Structures
Unless you’re in a very small organization and as the SSCP you wear all of the hats of network and systems administration, security, and incident response, your organization will need to formally designate a team of people who have the “watch-standing” duty of a real-time incident response team. This team might be called a computer emergency response team (CERT). CERTs can also be known as computer incident response teams, as cyber incident response teams (both using the CIRT acronym), or as computer security incident response teams (CSIRTs). For ease of reference, let’s call ours a CSIRT for the remainder of this chapter. (Note that CERTs tend to have a broader charter, responding whether systems are put out of action by acts of nature, accidents, or hostile attackers. CERTs, too, tend to be more involved with broader disaster recovery efforts than a team focused primarily on security-related incidents.)
Your organization’s risk appetite and its specific CIANA needs should determine whether this CSIRT provides around-the-clock, on-site support, or supports on a rapid-response, on-call basis after business hours. These needs will also help determine whether the incident response team should be a separate and distinct group of people or be part of preexisting groups in your IT, systems, or network departments. Some organizations see strong value in segregating the day-to-day network operations jobs of the network operations center from the time-critical security and incident response tasks of a security operations center; others leave NOC and SOC functions combined within one set of responders.
Whether your organization calls them a CSIRT or a SOC, or they’re just a subset of the IT department’s staff, there are a number of key functions that this incident response team should perform. We’ll look at them in more detail in subsequent sections, but by way of introduction, they are as follows:
Serve as a Single Point of Contact for Incident Response Having a single point of contact between the incident and the organization makes incident command, control, and communication much more effective. This should include the following:
Focusing reporting and rumor control with users and managers regarding suspicious events, systems anomalies, or other security concerns
Coordinating responses and dispatching or calling in additional resources as needed
Escalating computer security incident reports to senior managers and leadership
Coordinating with other security teams (such as physical security) and with local police, fire, and rescue departments as required
Take Control of the Incident and the Scene Taking control of the incident, as an event that’s taking place in real time, is vital. Without somebody taking immediate control of the incident and where it’s taking place, you risk bad decisions placing people, property, information, or the business at greater risk of harm or loss than they already are. Taking control of the incident scene protects information about the incident, where it happened, and how it happened. This preserves physical and digital evidence that may be critical to determining how the incident began, how it progressed, and what happened as it spread. This information is vital to both problem analysis and recovery efforts and legal investigations of fault, liability, or unlawful activity.
Response procedures should specify the chain of command relationships and designate who (by position, title, or name) is the “on-scene commander,” so to speak. Incident situations can be stressful, and often you’re dealing with incomplete information. Even the simplest of decisions needs to be clearly made and communicated to those who need to carry it out; committees usually cannot do this well in real time.
Clearly defined escalation paths and procedures, with by-name contact information (and designated alternate points of contact), provide ways to keep key stakeholders informed and engaged as an incident evolves.
The scene itself and the systems, information, and even the rooms or buildings themselves represent investments that the organization has made. Due care requires that the incident response team minimize further damage to the organization’s property or the property of others that may be involved in the incident scene.
Investigate, Analyze, and Assess the Incident This is where all of your skills as a troubleshooter, an investigator, or just being good at making “informed guesses” start to pay off. Gather data; ask questions; dig for information.
Escalate, Report to, and Engage with Leadership Once they’ve determined that a security-related incident might in fact be happening, the team needs to promptly escalate this to senior leadership and management. This may involve a judgment call on the response team chief’s part, as preplanned incident checklists and procedures cannot anticipate everything that might go wrong. Experience dictates that it’s best to err on the side of caution and report or escalate to higher management and leadership.
Keep a Running Incident Response Log The incident response team should keep accurate logs of what happened, what decisions got made (and by whom), and what actions were taken. Logging should also build a time-ordered catalog of event artifacts—files, other outputs, or physical changes to systems, for example. This time history of the event, as it unfolds, is also vital to understanding the event, mitigating, or taking remedial action to prevent its reoccurrence. Logs and the catalogs of artifacts that go with them are an important part of establishing the chain of custody of evidence (digital or other) in support of any subsequent forensic investigation.
Coordinate with External Parties External parties can include systems vendors and maintainers, service bureaus or cloud-hosting service providers, outside organizations that have shared access to information systems (such as extranets or federated access privileges), and others whose own information and information systems may be put at risk by this incident as it unfolds. By acting as the organization’s focal point for coordination with external parties, the team can keep those partners properly informed, reduce risk to their systems and information, and make better use of technical, security, and other support those parties may be able to provide.
Before You Share Incident Information, Get Senior Leadership’s Buy-In
In almost all cases, you’ll need senior leadership and management to make the real-time decisions regarding what information about an incident should be shared with outside organizations. Note, too, that your internal CSIRT or SOC should not be the liaison with the news media!
Contain the Incident Prevent it from infecting, disrupting, or gaining access to any other elements of your systems or networks, as well as preventing it from using your systems as launchpads to attack other external systems.
Eradicate the Incident Remove, quarantine, or otherwise eliminate all elements of the attack from your systems.
Recover from the Incident Restore systems to their pre-attack state by resetting and reloading network systems, routers, servers, and so forth, as required. Finally, inform management that the systems should be back up and ready for operational use by end users.
Document What You’ve Learned Capture everything possible regarding systems deficiencies, vulnerabilities, or procedural errors that contributed to the incident taking place for subsequent mitigation or remediation. Review your incident response procedures for what worked and what didn’t, and update accordingly.
Incident Response Priorities
No matter how your organization breaks up the incident response management process into a series of steps or how they are assigned to different individuals or teams within the organization, the incident response team must keep firmly three basic priorities in mind.
The first one is easy: the safety of people comes first. Nothing you are going to try to accomplish is more important than protecting people from injury or death. It does not matter whether those people are your co-workers on the incident response team, other staff members at the site of the incident, or even people who might have been responsible for causing the incident, your first priority is preventing harm from coming to any of them—yourself included! Your organization should have standing policies and procedures that dictate how calls for assistance to local fire, police, or emergency medical services should be made; these should be part of your incident response procedures. Legal as well as ethical responsibilities set this as the number-one priority.
Warning
Throughout every phase of an incident response, the safety of people is always priority one. After any issues involving the safety of people have been dealt with, you can deal with the often-conflicting needs to understand what happened versus getting things back up and running quickly.
Priority number two is not so simple to identify. One of the most difficult challenges facing an organization that’s found itself in the midst of a computer security incident is whether to prioritize getting back into normal business operations or supporting a digital forensics investigation that may establish responsibility, guilt, or liability for the incident and resultant loss and damages. This is not a decision that the on-scene response team leader makes! Simply put, the longer it takes to secure the scene and gather and protect evidence (such as memory dumps, systems images, disk images, log files, etc.), the longer it takes to restore systems to their normal business configurations and get users back to doing productive work. This is not a binary, either-or decision—it is something that the incident response team and senior leaders need to keep a constant watch over throughout all phases of incident response.
Increasingly, we see that government regulators, civic watchdog groups, shareholders, and the courts are becoming impatient with senior management teams that fail in their due diligence. This impatience is translating into legal and market action that can and will bring self-inflicted damage—negligence, in other words—home to roost where it belongs. The reasonable fear of that should lead to tasking all members of the IT organization, including their information security specialists, with developing greater proficiency at being able to protect and preserve the digital evidence related to an incident, while getting the systems and business processes promptly restored to normal operations.
Detection, Analysis, and Escalation
First and foremost, remember why you’re on the SOC: to enable your organization’s senior leadership and management to make informed decisions about emergency or urgent actions to take to protect the organization from loss or impact. The SOC doesn’t unilaterally decide to activate a backup alternate operations location or halt business operations; what it must do instead is escalate the event and the need for an urgent decision to previously designated responsible managers and leaders—or to the next rung in the reporting chain in their absence. Your SOC roles and responsibilities will provide you with clear guidance on what issues to escalate and to whom; your procedures should also clearly define what you must do in real time and how to escalate the fact of taking those actions to your responsible managers and leaders.
Next, remember that you’re not only leading the technical charge to protect your organization’s information systems and get them back into action, but you’re also a vital part of protecting its legal capabilities to respond and recover. Those legal responses will in all probability depend upon evidence that points to who is responsible and in what capacity; your actions during containment, eradication, and recovery can significantly enhance your organization’s legal abilities to respond or all but erase them.
Watching for Kill Chains in Action
Let’s take a closer look at the kill chain concept shown in Figure 4.4, which was introduced in Chapter 3, and look more closely at the kinds of outputs your SOC team members need if they are to detect, characterize, and respond to a security incident or an intrusion promptly.
Any kind of surveillance, monitoring, or control system can produce a number of different types of signals, which are the observable results of an event having taken place. Table 4.1 illustrates some of these types of signals and the types of events they might be associated with.
Suggests that a security-related event might occur in the near future
Local area social/political unrest; government threat condition warnings
Low
Low
Indicator
Change of state in a designated systems element
Server successful reboot; User privilege elevation; file deletion
Moderate (can be forensically verified)
Depends upon security alert needs
Alarm
Systems element conditions out of limits, or critical events have occurred
Server halt; ISP connection fails to respond; switchover to backup power
Medium to High (usually can be cross-checked with other signals in near real time)
High: Corrective Actions may be needed immediately
Telltale
An important or hazardous event has occurred or is in progress
Server started shutdown or reboot; system updates being pushed
Medium to High (usually can be cross-checked with other signals in near real time)
High: If unexpected, may be an IOC
Indicator of Compromise
Security posture of systems or elements has occurred
Suspected malware detected; Missing or corrupt security/server logs causing server to stop; Unauthorized attempts at privilege elevation
Low to High (dependent upon monitoring technology and strategy)
High: Incident Response Procedures should be invoked
Of the five types of signals in Table 4.1, only two—precursors and indicators of compromise—are presumed to be related to some kind of information security event of interest.
Indicators, telltales, and alarms by design are calling attention to an event that someone ought to pay attention to, but it will take further investigation and analysis to determine whether the signal is crying out for a repair team, a security response, or a simple acknowledgment of its occurrence. Telltales are a case in point: such signals are generally associated with significant changes in the status, state, or health of the system or of major subsystems and elements, and they are often related to complex sequences of events. They also are generally accepted as high-confidence, unambiguous evidence that the event they are related to has happened. A scheduled push of access control data, security policy settings, or a software update might generate a telltale signal to the SOC so that the on-shift crew is aware that this event has started. Progress indicators may be sent to the SOC team as this task progresses, and a final telltale would indicate successful completion. They can then verify that this is a planned, authorized event, and if it is not, they can take appropriate action to correct it. Similarly, indicators and alarms can be calling attention to equipment or systems malfunctions regardless of their root cause.
By contrast, indicators of compromise (IOCs), which should definitely be high on your priority list of security concerns, are typically generated by specific systems-security-monitoring technologies, such as an anti-malware or an intrusion detection and prevention system. Some of these indicators may be clear, unambiguous, and irrefutable. Immediate incident response action should be taken for these types of indicators. Other IOCs may be of lower confidence, requiring additional investigation or analysis before the SOC can declare that a compromise event may in fact be taking place and invoke the incident response procedures to characterize, contain, and respond to it. Precursors may come from threat information sharing communities or even from the news media, and they generally do not convey sufficient information or confidence to act upon. Where do these signals come from? Think about the monitoring and assessment capabilities that you have set up and the data sources that drive them. Chapter 3 provided you with shopping lists of systems, servers, platforms, applications, and devices that can provide you with rich sources of status, state, health, and alarm indications data. With Figure 4.4 in mind, ask yourself: which of our systems elements might be trying to tell me that something’s gone wrong with it? Start this by focusing on the types of events that steps in an attacker’s kill chain might be trying to accomplish, such as:
Input buffer overflows that indicate attempts to inject SQL or other script commands into a web page or database server.
Antivirus software detects that a device, such as an endpoint or removable media, has a suspected infection on it.
Systems administrators, or automated search tools, notice filenames containing unusual or unprintable characters in them.
Access control systems notice a device attempting to connect, which does not have required software or malware definition updates applied to it.
A host, server, or endpoint device does an unplanned restart.
A new or unmanaged host or endpoint attempts to join the network.
A host or an endpoint device notices a change to a configuration-controlled element in its baseline configuration.
An application platform logs multiple failed login attempts, seemingly from an unfamiliar system or IP address.
Email systems and administrators notice an increase in the number of bounced, refused, or quarantined emails with suspicious content or ones with unknown addressees.
Unusual deviations in network traffic flows or systems loading are observed.
If events of those types do not correlate with administrative information—if they are not planned and approved configuration changes (that might result in restarts of systems) or are not the legitimate actions of known, authorized subjects—then you have an event of interest on your hands.
Now, step back from that set of events, and ask what indicators (or alarms) should be observable and reported to your SOC to help you recognize that a possible security incident is happening. Figure 4.4 illustrated some possible indicator events; think these through for your systems to help you determine your needs for event-specific alarms.
In some cases, your desired tell-tale sign is only going to surface from analysis, and potentially deep analysis at that. A data exfiltration attack, for instance, might be using a series of bogus or compromised accounts to initially clone copies of its desired data assets and then fragment, encrypt, and package them for transmission outside of your systems. Each of these steps could be done record by record (if the attacker is that patient); traffic pattern anomaly recognition might not find it for you in such cases. Only a thorough review, account by account, of everything it has been doing lately might find this for you.
It’s often assumed that the incident response process cannot begin until an incident is detected; the types of risk events examined at the start of this chapter highlight a potentially devastating counter-example, however, with incidents that you become aware of only when someone outside of your organization tells you about them. Even then, investigating what has happened is still quite similar to detecting that something is happening: you have to wade through a tremendous number of event-level signals to find the real indicators worth worrying about.
Let’s consider some of the near-real-time aspects of constant vigilance.
Filtering to Detect: How Many Signals?
Each day, most large organizations that have extensive web presences may see tens of millions of IP packets arrive at the front doors of their web servers or their Internet points of presence. The vast majority of these, perhaps as many as 90 percent of them, are both innocent in purpose and routine in nature: they are part of the background of traffic that is the Internet and the Web keeping itself alive, its clocks and caches synchronized, and its traffic flowing normally. Of that remaining million packets, which are the ones to worry about? Firewall, router, and IPS/IDS access control rules, behavioral anomaly rules, and other filters might further reduce that to 10,000 or so suspicious inbound events in a 24-hour day. Similar rules, tools, and filters looking at outbound traffic might produce a similar-sized set of events. Even so, 20,000+ events is far too many for human analysts to wade through.
It’s at this point that it’s worthwhile to consider what some security specialists call the two false beliefs about continuous monitoring: it is neither all data from all measurement devices nor in real time.
Monitoring every sensor in your system and capturing every measurable event that flows through a node in your network—or even just at its edges, where it interfaces with the Internet—could produce terabytes of data every day. It is impractical, if not impossible, to attempt to capture all of that data, every moment, from every node, box, interconnection point, firewall, gateway, switch, or router. Your access control system would bog down if it attempted to capture everything about every access attempt. You push the filtering, the down-selecting of data, out as far toward the edge as you can, within the capabilities of each systems element and your risk profile. The local device may keep hours, or even days of log data on it; your overall systems architecture and your assessment of your risk profile should help you choose how much log data to import from which devices, how often, and where to put it for safe keeping and later analysis. As a result, your SIEM, IDS, IPS, or other analyst workstation tools have a smaller, more manageable set of data that they can begin to correlate in time, logical space (such as a network segment), or physical space (a building, floor, or zone within your facilities, or even a geographic location). Correlations can also be done against blacklists and whitelists for IP addresses, geographic locations, URLs, or other items pertinent to your risk profile.
Monitoring results—the outputs that tell you an alarm condition has been met—are not available instantly. Analysis activities take time: time to get the data, time to analyze it, and time to interpret and assess it. If analysis is conducted continuously, it might be able to generate alarms within handfuls of seconds, or maybe a few minutes, of the occurrence of an event of interest or an indicator of compromise. On the other hand, if the analysis tasks are set to run periodically, perhaps every hour or once per day, their outcomes are naturally lagging behind the events in question. Analysis tasks that ask for distant monitoring devices to forward large log files may also be subject to additional delays.
There are some obvious, painful trade-offs that confront you as a security systems architect in all of this. Measure or monitor too small a set of indicators or log and keep too little data and both your real-time and after-action analysis efforts can be severely limited. This probably results in an increasing rate of false negative errors—and intruders being granted access to your systems. Measure too much, keep too much, and analyze too much, and your false positive error rate goes up, causing you to spend too much analysis effort and waste too much time for legitimate users who were erroneously denied access.
Again, go back to that kill chain model as a set of guideposts: if you assume that multiple attackers are attempting to get at your systems every hour of every day, with each attacker taking different actions in different phases of their own conceptual kill chain, then what no-kidding, bottom-line alarm information do you need to notice that something unauthorized is going on? You’ll then dive deeper into the data to understand that anomaly better and to characterize it as maintenance gone bad, an accident, or as an attack; you’ll also then be on more informed ground as you take your next steps in the response cycle.
Tuning your security monitoring and response systems is a never-ending challenge. Business conditions change about as often as the threats evolve. In many organizations, management does not have the confidence to shut down part of their business just because the machine learning and behavioral modeling systems in the next-generation firewalls or NIPS have signaled an indicator of compromise. As business processes become more tightly integrated and as transaction volumes increase, managers may also believe that recovering from an incident is less disruptive than shutting down a business process on the likelihood that it has been compromised. In such conditions, management will look to its SOC team for clarity. It’s up to you to convey to management why you are as confident in that IOC as you are and therefore why your recommended course of action makes the most sense.
Human Observation and Reporting
Sadly, one of the most valuable sources of information in many organizations goes under-utilized. Members of your workforce, at their endpoints and in their workspaces, see, hear, or notice things that are unusual; yet the processes we establish for them to report such problems, and your own processes for triage, correlation, and analysis of them, are often less than effective. Employees may report theft of a company-owned endpoint device, such as a laptop or smartphone, in a reasonably timely manner; loss of such a device or of an employee-owned endpoint device might not get noticed or reported for days. Phishing and vishing attack attempts are often not reported; most training programs teach employees to just delete them and go on with their work. (A few but noteworthy exceptions can be found, such as when organizations not only self-test their workers with fake phishing attacks, actively monitoring employees as their bait-spotting skills improve but also engage employees in other ways as part of the social engineering defense team.)
Leadership and management can change this; with the right set of administrative controls, they can and should create and nurture the security culture that encourages each person in the workplace to maintain a watchful but helpful presence and to take an active role in protecting everyone’s job and livelihood. Sometimes, all it takes is a simple process change to transform a painfully inadequate complaint process into a beneficial detection, data capture, and reporting opportunity.
Correlation
As in many other forms of risk management, it’s necessary to correlate data of different types, gathered by different measurement or monitoring systems, in order to determine whether an event of interest has actually occurred. A server’s system log file might show a shutdown and restart sequence; but until you correlate this with human activity logs, you won’t know if this was malware-induced, a deliberate but unauthorized human action, or part of a scheduled software maintenance activity. Traffic monitoring data might suggest that a user’s endpoint device is involved in a suspected data exfiltration activity; correlating that endpoint’s anti-malware or software whitelisting systems logs, along with outbound connection attempts, might help you separate malware-induced from insider-perpetrated events.
SIEMs, IDS, or IPS capabilities can automate a great deal of the data gathering and correlation needed to identify potential events like these; they can also be programmed to route selected subsets of such events to human analysis for further triage.
Manufacturing, robotic warehouse, or other environments heavily dependent upon industrial control systems (ICS) or other supervisory control and data acquisition (SCADA) systems present yet another layer of correlation challenges and opportunities. SCADA and ICS technologies are often implemented in companies via contracts that tie specific revision levels of hardware, operating systems, and applications together; vendors often do not support frequent updates or release patch kits, and contracts may actually void vendor support guarantees if end-user clients patch the systems themselves. While this may protect the assembly line or the process systems under control from self-inflicted disruption or downtime, it does mean that other administrative, people-intensive means may be necessary to maintain appropriate vigilance. Security analysts supporting such environments might have to translate CVE data into human-observable terms, for example; for some exploitable vulnerabilities, this might involve specific, focused training for factory floor workers, supervisors, and process control technicians as well as for security operations team members.
Organizations with significant investments in physical security measures, such as motion detectors, video monitoring, and internal foot traffic monitoring systems, may also find it challenging to correlate data between these systems and the SIEMs, IDS, and IPS that monitor their IT backbone and systems. The same is true from data taken from internal environmental control systems or from fire and other safety monitoring systems.
Security Event Triage
Another high payoff that you can achieve by applying the kill chain concept in reverse is to see that not every information security incident is an emergency but that any event could become an emergency without proper attention. The threat intelligence and modeling communities provide useful insights that suggest that certain types of attack vectors quite often correlate to different phases in the cybersecurity kill chain. This assessment is based in large part on whether such an attack vector can immediately lead to information loss or compromise or to the disruption of critical business functions. Table 4.2 summarizes the views of NIST, MITRE, AT&T Business, and others, which taken together suggest (not dictate) that some types of incidents need more of an incident response than others.
Most can be ignored, unless IP/region is suspect, and scanning is frequent and intensive
False Rejects
All Stages
Low
Gather data for longer-term analytics
Malware Infection
Delivery and Attack
Low to Medium
Contain and eradicate, scan rest of systems for signatures related to this IOC
DDOS
Exploitation and Installation
High
Immediately reconfigure web servers to protect against floods; coordinate with your ISPs or cloud provider
Unauthorized Access
Exploitation and Installation
Medium to High
Investigate; analyze access attempts; isolate/restrict access to high value data or systems
Unauthorized Privilege Escalation
Exploitation and Installation
High
Investigate; analyze access attempts; isolate/restrict access to high value data or systems
Insider Breach
System Compromise
High
Identify accounts involved; monitor; contain or control, especially for access to high-value data or systems
Destructive Attack
System Compromise
High
Contain; gather forensic information; inspect backups prior to restoring from them
Ransom or ransomware attacks illustrate the thinking behind building a severity index based on how close to “payday” the attacker is on their kill chain. These are of course potentially highly destructive attacks on your systems. If you discover that parts of your system are showing signs that a ransom attack is underway (such as files starting to be unavailable to user processes because they have been encrypted by the attacker), this calls for immediate action. Working backward along the kill chain, that ransom attacker may have had to use a malware payload as part of gaining access to your systems and to then elevate privileges as required to map out the file systems, prepare encryption scripts, and mask their intrusion into your systems. On the other hand, unless you have threat intelligence to identify IP address ranges to be wary of, you probably can’t learn anything useful about an impending attack just because your ports are being scanned. Seeing such scanning taking place is a great signal to you to verify that you’ve got proper security measures in place.
Conducting a rapid triage based on the type of event is a critical step in making a first characterization of the incident at hand. By developing such triage priority tables and procedures beforehand, you can also guide the SOC team on what additional data (if any) to gather to use as part of the assessment they’ll need to report to management.
Declaring an Incident: Alarm!
At some point during the initial evaluation of the event of interest, your watch-standers need to come to a decision: is this an information security incident that is ongoing, developing, or in the making? Is it indicative of an incident that has already occurred (and completed its dirty deeds)? Or is it just a set of interesting observations but not worthy of elevated concern or the application of emergency response capabilities?
As you prepare and plan for incident response, you should be able to identify or characterize ways in which these declarations of an alarm condition can be made in real time by the people who are on duty when it is first noticed. You may also have to simply rely on the experience and judgment of your watch-standers and their knowledge of your “business normal” conditions for your information systems.
Raising the alarm over an information security incident should be a deliberate, thoughtful, and purposeful decision, for it will quite likely lead to loss of productivity as response measures start to isolate systems, subsystems, or network segments, and as platforms and services are suspended or shut down as part of containment efforts. Senior managers, too, will have to set aside some of what they are investing their time and attention on, as they come up to speed on what your first responders or CERT team leader is reporting to them.
It should not, however, be something that is just assumed to have been communicated by the actions of members of your CERT or IT teams. It should be clear and unambiguous about what your team knows has happened and as to what they don’t yet know about the incident. A cautious warning, coupled with “still under investigation,” is appropriate. And if your existing SOC processes and procedures or your alert notification and escalation processes don’t define this clearly enough, that’s a clear sign of an opportunity to improve!
Log It!
Your SOC processes must provide for making and updating its own log files as it starts the incident response process. These logs form an important element in your situational awareness of the incident, especially if it is a complex or time-consuming one to assess, characterize, and respond to. An old-fashioned paper log book can be a great thing to use, in the event of an emergency response; keep track of each alarm, each decision, and each response; log each escalation to senior management, and of course log their contacts with the SOC as they seek information or provide direction to you. Log contacts from users or outsiders, especially from outsiders requesting information or updates about your systems status and your organization’s ability to function properly. In most cases, these calls will be from affected users, partners, or others; but other such queries might be from the news media, from government regulators, or even from the attackers themselves using an alias as they seek real-time battle damage assessment insight.
Logbooks are absolutely vital when dealing with any incident that spans a normal work shift boundary; and since almost any reasonably complete effort at post-event debrief and process or systems improvement (and further risk mitigation) will no doubt run into subsequent days, use your log books. Manually generated logs have a distinct advantage that should not be missed out on: they encourage free-format capture of the thoughts, observations, or questions that the SOC team comes up with, in a format that is easy to record and time stamp.
Tip
Logs are usually the files that are generated automatically by elements of your IT infrastructure or its security systems. A logbook, by contrast, is the contemporaneous record kept by a human being, annotating step by step each activity performed or decision taken during a security incident. Procedures can and should dictate what information to include in the logbook, as well as encouraging the human observer to think about what is going on and make note of that in the logbook.
It’s useful if multiple team members keep their own informal notes as they work through the incident response; that said, you need to ensure that there is one official team chief’s log book, with clearly defined expectations and procedures for what gets logged, by whom, and when. Reconciling different observations between individual, informal logs and the official logbook is important but may be one of those tasks that you as team chief have to postpone till after the incident response is complete.
Your meticulous record-keeping during an incident response is also a critical component of protecting the chain of custody of an information that might become evidence in any subsequent forensic investigation. This applies to your informal notes as well. Whether you take those notes with pen and paper, a smartphone, or any other device, that information pertains to the incident. It should be immediately put into custody and protected as any other potential evidence would be.
Visually Mapping an Incident
When our systems are all up and running, various dashboard displays can help SOC team members visualize the current status, state, and health of the systems in their care. When the networks go down or critical servers go offline, the team still can gain advantage from having such visualizations handy—even if they need to be done on a whiteboard or other not-so-smart technologies. Diagramming the affected systems elements and being able to quickly update each element’s status as you work through containment, eradication, and recovery can be a powerful way to keep the incident response in perspective.
Once your SIEM or other online dashboard systems come back to life and you’ve determined that they are trustworthy, they can and should help you in the ongoing analysis, characterization, containment, eradication, and recovery tasks—once you know you can rely upon them and be sure they’re not providing battle damage assessment intelligence to your attackers, of course!
Containment
Containment and eradication are the next major task areas that the CSIRT needs to take on and accomplish. As you can imagine, the nature of the specific incident or attack in question all but defines the containment and eradication tactics, techniques, and procedures you’ll need to bring to bear to keep the mess from spreading and to clean up the mess itself.
These two steps are also the ones that could have the greatest impact on the success of any subsequent forensic investigation. Take advantage of the time you have right now, while you’re not in the middle of an incident response action, to make sure that your organization has the forensic aspect of containment and eradication thoughtfully considered in its plans. Those plans should address questions such as:
How does forensic triage relate to incident severity level (or security incident triage) with respect to this incident?
How does the SOC team determine whether a system component (a server, endpoint, network device, or other) can be isolated without corrupting information in it that may be evidence the investigation needs?
Are there forensic triage procedures in place to determine which systems components must be restored to operational condition as quickly as possible and therefore need to have forensic information collected from them during the incident response? (The rest, presumably, can stay contained or idle until further forensic triage efforts can determine which ones need to be imaged and which ones can be released back to operational use.)
Are the SOC team or incident responders trained and equipped to conduct forensic triage efforts as part of containment and eradication?
More formally, containment is the process of identifying the affected or infected systems elements, whether hardware, software, communications systems, or data, and isolating them from the rest of your systems to prevent the disruption-causing agent from affecting the rest of your systems or other systems external to your own. Pay careful attention to the need not only to isolate the causal agent, be that malware or an unauthorized user ID with superuser privileges, but also to keep the damage from spreading to other systems. As an example, consider a denial-of-service (DoS) attack that’s started on your systems at one local branch office and its subnets and is using malware payloads to spread itself throughout your systems. You may be able to filter any outbound traffic from that system to keep the malware itself from spreading, but until you’ve thoroughly cleansed all hosts within that local set of subnets, each of them could be suborned into DoS attacks on other hosts inside your system or out on the Internet.
Some typical containment tactics might include the following:
Logically or physically disconnecting systems from the network or network segments from the rest of the infrastructure
Disconnecting key servers (logically or physically), such as Domain Name System (DNS), Dynamic Host Configuration Protocol (DHCP), or access control systems
Disconnecting your internal networks from your ISP at all points of presence
Disabling Wi-Fi or other wireless and remote login and access
Disabling outgoing and incoming connections to known services, applications, platforms, sites, or services
Disabling outgoing and incoming connections to all external services, services, applications, platforms, sites, or services
Disconnecting from any extranets or VPNs
Disconnecting some or all external partners and user domains from any federated access to your systems
Disabling internal users, processes, or applications, either in functional or logical groups or by physical or network locations
Take another close look at your data sources for monitoring and alarm information. Quite often, attack vectors are trying to cover their tracks by modifying, erasing, or otherwise making log files and indicator data unavailable to the SOC. As the alarms begin to sound, keeping your event data sources clean and pristine needs to be high on the SOC’s internal priority watch-and-protect lists.
A familiar term should come to mind as you read this list: quarantine. In general, that’s what containment is all about. Suspect elements of your system are quarantined off from the rest of the system, which certainly can prevent damage from spreading. It also can isolate a suspected causal agent, allowing you a somewhat safer environment in which to examine it, perhaps even identify it, and track down all of its pieces and parts. As a result, containment and eradication often blur into each other as interrelated tasks rather than remain as distinctly different phases of activity.
This gives us another term worthy of a definition: a causal agent is a software process, a data object, a hardware element, a human-performed procedure, or any combination of those that perform the actions on the targeted systems that constitute the incident, attack, or disruption. Malware payloads, their control and parameter files, and their carriers are examples of causal agents. Bogus user IDs, hardware sniffer devices, or systems on your network that have already been suborned by an attacker are examples of causal agents. As you might suspect, the more sophisticated APT kill chains may use multiple methods to get into your systems and in doing so leave multiple bits of stuff behind to help them achieve their objectives each time they come on in.
Check your SOC’s processes and procedures as to when and how you should escalate or notify management regarding containment activities. Don’t lose sight of the need to keep the organization informed and patient.
Before you conclude your containment efforts and begin eradication (or other recovery actions), make sure you’ve made protected copies of affected systems, as required, for evidence; ensure that you properly log all evidence to establish and protect its chain of custody.
Eradication
It’s sometimes difficult to separate containment from eradication, since in many cases, the tools and processes you use to contain a causal agent (such as a malware infection or an unauthorized user ID) provide a one-step contain-and-eradicate. One vital distinction is to remember the need for evidence to support any follow-on forensics investigation: containment, by itself, should not alter information that might be needed as evidence, whereas eradication certainly will! Eradication is the process of identifying and then removing every instance of the causal agent and its associated files, executables, and so forth, from all elements of your system. For example, a malware infection would require you to thoroughly scrub every CPU’s memory, as well as all file storage systems (local and in the clouds), to ensure you had found and removed all copies of the malware and any associated files, data, or code fragments. You’d also have to do this for all backup media for all of those systems to ensure you’d looked everywhere, removed the malware and its components, and clobbered or zeroized the space they were occupying in whatever storage media you found them on. Depending on the nature of the causal agent, the incident, and the storage technologies involved, you may need to do a full low-level reformat of the media and completely initialize its directory structures to ensure that eradication has been successfully completed.
Don’t Let Eradication Become a Self-Inflicted Attack
Far too many times, incident responders eradicate too much information from too many systems, servers, and endpoints. This can cause two different disastrous effects.
Eradicate too many files from too many systems or endpoint, and you may do worse damage than the attacker was trying to inflict. You delay getting business operations back to normal and may cause more data loss than the attack would have done.
Eradicate too soon or without proper containment and evidence capture, and you compromise or negate any attempts to conduct a follow-on forensic investigation of the incident.
Treat your eradication tools as if they are scalpels; use them to surgically remove just what needs to be removed.
Eradication is where two priorities potentially collide: getting back into business naturally conflicts with being able to know and prove who or what was responsible for the disruption in the first place. Eradicating malware from infected systems does, at one level, destroy evidence of the malware’s presence there. Anti-malware systems usually provide extensive logging capabilities, which may be sufficient to meet evidentiary needs. This is something that should of course have been examined and decided upon during risk management, mitigation, and incident response planning and preparation activities, but there may be incidents where this decision has to be made in real time. If that’s the case, get senior leadership or management’s concurrence first, if at all possible! The incident response team must make note of these circumstances and management’s authorization to proceed in the formal incident response team log files.
Eradication should result in a formal declaration that the system, a segment or subsystem, or a particular host, server, or communications device has been inspected and verified to be free from any remnants of the causal agent. This declaration is the signal that recovery of that element or subsystem can begin.
It’s beyond the scope of this book to get into the many different techniques your incident response team may need to use as part of containment and eradication—quite frankly, there are just far too many potential causal agents out there in the wild, and more are being created daily. It’s important to have a working sense of how detection and identification provided you the starting point for your containment, and then your eradication, of the threat. Your best bet may be to think even more like an attacker would and continue to get training, education, and experience in ethical penetration techniques, including reverse engineering of malware, as part of staying current and effective as an SSCP.
Recovery
Recovery is the process by which the organization’s IT infrastructure, applications, data, and workflows are reestablished and declared operational. In an ideal world, recovery starts when the eradication phase is complete and when the hardware, networks, and other systems elements are declared safe to restore to their required “normal” state. The ideal recovery process brings all elements of the system back to the moment in time just before the incident started to inflict damage or disruption to your systems. When recovery is complete, end users should be able to log back in and start working again, just as if they’d last logged off at the end of a normal set of work-related tasks.
It’s important to stress that every step of a recovery process must be validated as correctly performed and complete. This may need nothing more than using some simple tools to check status, state, and health information, or using preselected test suites of software and procedures to determine whether the system or element in question is behaving as it should be. It’s also worth noting that the more complex a system is, the more it may need to have a specific order in which subsystems, elements, and servers are reinitialized as part of an overall recovery and restart process.
With that in mind, let’s look at this step-by-step, in general terms:
Eradication Complete Ideally, this is a formal declaration by the CSIRT that the systems elements in question have been verified to be free of any instances of the causal agent (malware, illicit user IDs, corrupted or falsified data, etc.).
Restore from “Bare Metal” to Working OS Servers, hosts, endpoints, and many network devices should be reset to a known good set of initial software, firmware, and control parameters. In many cases, the IT department has made standard image sets that it uses to do a full initial load of new hardware of the same type. This should include setting up systems or device administrator identities, passwords, or other access control parameters. At the end of this task, the device meets your organization’s security and operational policy requirements and can now have applications, data, and end users restored to it.
Ensure All OS Updates and Patches Are Installed Correctly It’s critical to ensure that the reloaded operating systems have all the required operational, functional, and security updates and patches correctly applied to them as a part of systems recovery efforts. Some organizations build and maintain a master or golden image of each operating system for each type of device and ensure that this golden image is routinely updated in accordance with configuration management and control decisions. Reloading systems from these golden images thus brings with it all current approved updates and patches. Otherwise, you will have to restore from the last known good distribution kit or systems image and then apply all patches and updates.
A special set of system restoration assessment tests should be developed (prior to being in the midst of an incident response) and used to verify that each reloaded system does in fact have its operating system correctly and completely restored.
Restore Applications as Well as Links to Applications, Platforms, and Servers on Your Network Many endpoint devices in your systems will need locally installed applications, such as email clients, productivity tools, or even multifactor access control tools, as part of normal operations. These will need to be reinstalled from pristine distribution kits if they were not in the standard image used to reload the OS. This set of steps also includes reloading the connections to servers, services, and application platforms on your organization’s networks (including extranets). This step should also verify that all updates and patches to applications have been installed correctly.
Restore Access to Resources via Federated Access Controls and Resources Beyond Your Security Perimeter on the Internet This step may require coordination with these external resource operators, particularly if your containment activities had to temporarily disable such access.
At this point, the systems and infrastructure are ready for normal operations. Aren’t they?
Data Recovery
Remember that the IT systems and the information architecture exists because the organization’s business logic needs to gather, create, make use of, and produce information to support decisions and action. Restoring the data plane of the total IT architecture is the next step that must be taken before declaring the system “ready for business” again.
Backups: They Exist Only When You Plan for Business Continuity
When you’re in the midst of responding to an information security incident, you do not want to discover that you have no backups of the business-critical software systems, databases, or other information resources. Yes, the CSIRT is the primary customer of these backups, but somebody else had to have planned and specified how to generate them, how often to make updated backups, and how they should be stored, kept safe, and yet be available when urgently needed.
Business continuity planning is the broad functional area that should address these needs, which is covered in greater detail in the “Understand and Support Business Continuity Plan and Disaster Recovery Plan Activities” section in this chapter. As to the CSIRT, please note that your own preparation phase should have found either where the backups are kept and how to know which ones to use…or discovered that nobody’s actually making any backups in the first place!
In most cases, incident recovery will include restoring databases and storage systems content to the last known good configuration. This requires, of course, that the organization has a routine process in place for making backups of all of their operational data. Those backups might be:
Complete copies of every data item in every record in every database and file
Incremental or partial copies, which copy a subset of records or files on a regular basis
Differential, update, or change copies, which consist of records, fields, or files changed since a particular time
Transaction logs, which are chronologically ordered sets of input data
Restoring all databases and filesystems to their “ready for business as usual” state may take the combined efforts of the incident response team, database administrators, application support programmers, and others in the IT department. Key end users may also need to be part of this process, particularly as they are probably best suited to verifying that the systems and the data are all back to normal.
For example, a small wholesale distributor might use a backup strategy that takes a full copy of their databases once per week and then a differential backup at the end of every business day. Individual transactions (reflecting customer orders, payments to vendors, inventory changes, etc.) would be reflected in the transaction logs kept for their specific applications or by their end users. In the event that their database has been corrupted by an attacker (or a serious systems malfunction), they’d need to restore the last complete backup copy and then apply the daily differential backups for each day since that backup copy had been made. Finally, they’d have to step through each transaction again, either using built-in applications functions that recover transactions from saved log files or by hand.
Now, that distributor is ready to start working on new transactions, reflecting new business. Their CSIRT’s response to the incident is over, and they move on to the post-incident activities I’ll cover in just a moment.
Post-Recovery: Notification and Monitoring
One of the last tasks that the incident response team has is to ensure that end users, functional managers, and senior leaders and managers in the organization know that the recovery operations are now complete. It is important to note that the response team notifies responsible management and leadership that systems are ready for normal operational use; management and leadership then decide to move the organization from “incident response” back to normal business operations. The CSIRT does not make this decision nor own the responsibilities that go with it—the management team does!
Once the CSIRT has given this “ready to relaunch” signal to management and management decides to move in that direction, three separate communications need to take place.
Back in business: This notice gives the green light to the organization to get back into normal business operations. Each department or functional division of the organization may have a different approach to this, based on their business logic and processes. This is particularly true as to how each department addresses any work lost during the overall downtime. Synchronization of efforts across departments and between lines of business may require extensive coordination, depending upon the incident and its impacts.
Proceed with caution: Users and their managers should be extra vigilant as they start to use the systems, applications, and data once again. They may want to start with load-balancing constraints in place so that processes can be closely monitored as they start up slowly and then throttle up to the normal pace of business.
Get the word out: Senior leaders and managers should help make sure that key external stakeholders, partners, and others are properly informed about the successful recovery operation. They may also need to meet legal and regulatory obligations and keep government officials, shareholders or investors, customers, and the general public properly informed. This is also a great opportunity for leadership and management, from the top down to the first-rung supervisors, to help ensure that every member of the team can be confident in the post-recovery state of the organization.
At this point the incident response team’s real-time sense of urgency can relax; they’ve met the challenges of this latest information security incident to confront their organization. Now it’s time to take a deep breath, relax, and capture their lessons learned.
While remaining vigilant for the next incident, of course.
Lessons Learned; Implementation of New Countermeasures
Figure 4.2, you recall, suggests but does not explicitly show the web of cross-connections that are the opportunities for you and your teammates to learn from the painful lessons of the experiences you gain, moment by moment, in dealing with an information systems security incident. As the SOC team and the CSIRT focused on the details of further characterizing the incident, containing it, eradicating as necessary, and recovering all systems back to normal, those teams learned important lessons. Perhaps some procedures were found to be incomplete; tools and processes were found to be inadequate or had significant room for improvement to make them more effective and reliable to use. Logging, record-keeping, and the gathering of evidence might have shown that your chain of custody processes need improvement, if you’re going to help the organization make its bullet-proof case really bullet-proof, based on that evidence and its associated records. People-to-people communication skills, processes, or protocols might not have worked very well.
No lesson is too small to make note of, capture, and then consider as part of your continuing process of improvement. Nor should you push this lessons-learning too far off into the future. Yes, the textbook portrayals of the incident response lifecycle can suggest that it’s after the incident is over that you begin the process of debriefing the responders, capturing the ideas and problems, prioritizing which to deal with first, and getting those fixes or improvements into production. This does not need to be a “Monday-morning quarterbacking” exercise of trying to second-guess what happened in Sunday’s game. Instead, reality and experience suggest several reasons why immediately starting to implement the lessons your current response experiences are teaching you is sound practice.
Incidents may have long dwell times: APTs using a sophisticated kill chain strategy may take months to go from their first attempts to infiltrate your systems to finally departing your systems (if they leave at all); you’ll need to respond to such an attack over weeks or months as well.
Attacks by different threat actors may overlap in time and space: As you respond to one element of one APT’s kill chain, you may discover that other unwanted guests are attempting to capture your systems’ resources and capabilities to use for their own ends.
Let different teams work in parallel across the incident response lifecycle: In all but the smallest of organizations, the on-shift watch-standing SOC teams and incident response team members are not the only ones who can (or should) be working on developing, implementing, and testing new or improved information risk mitigation and security controls. Usually, too, there are subtly different skill sets needed to analyze and assess requirements, select and implement new controls, and operationalize them via administrative, procedural, and training efforts, versus those needed for on-scene incident response.
Some fixes, improvements, or changes can and should be quick and easy, so do them: You have no real reason to wait; if you’ve got the people time or other assets you need to make some of these fixes right now, while the need for them and the pertinent details are fresh in your mind, do it before the next incident arrives.
Go back to that NIST checklist in Figure 4.3; the lessons learned process, be it done after the incident response or during it, can use this same kind of checklist approach. Preparation planning identified assets that you believed would increase your chance of successfully surviving an incident and recovering from it. The reality of an incident has tested the assumptions you made regarding each of those readiness items. In light of that, re-evaluate each item; write down the list of changes, improvements, repairs, or the justification to outright replace that asset, based on what you’ve just learned in the “live-fire” testing event (the incident) you’ve just been through. Then get management and leadership to start resolving each action item on that list you’ve just created.
Third-Party Considerations
Today, with public/private hybrid environments and those that lean heavily on outsourced or third-party services, it is imperative to include them in your incident management program’s policies, plans, and procedures. Security teams should be reviewing their third parties as part of their overall risk management strategy; it is also important to make sure they align with your incident management program. This detailed coordination should start before selecting and contracting with any such third-party services provider or strategic partner, by identifying the total set of services, information exchanges, coordination, and collaboration activities required by that relationship. Your organization, after all, is totally responsible for every step, every nuance, and every detail of every process that is part of how you do business; delegating some of those responsibilities and actions to third parties does not relieve your team of their due diligence and due care burdens. Once your team has identified everything that needs a particular third-party type of support relationship, your organization can then negotiate with that third party from a more informed and confident position. After the contracts are signed, it can be extremely difficult (and expensive) to renegotiate aspects of that relationship or to attempt to add forgotten or overlooked items. You certainly do not want to be trying to negotiate for exchanges of log files or other forensic data while you’re in the middle of responding to an information security incident.
It’s important to recognize the demonstrated ability of APTs to use multiple targets of opportunity to ultimately strike at the target that supports their main objective. Along the way, these attacks—as in the Target data breach in 2013—involve using service providers that have existing business relationships with the APT’s ultimate target. Third-party considerations for information security incidents reach far beyond your cloud services providers or strategic partners that are part of your SSO-enabled federated systems. Every organization you do business with, including your customers, is a potential player in your next information security incident response. This should be carefully considered during the planning phases, as you develop both your incident response plans and procedures and identify where your third parties can and should be stronger parts of your overall shared security posture.
Real-Time Notification and Coordination: Set These Up Before the First Incident
One of the most critical service levels that must be coordinated prior to signing a service contract involves responsiveness to a suspected information security incident. Your SLA or TOR with that third party must clearly spell out how quickly each party must notify the other and what real-time communications and coordination channels, facilities, or processes must be used when either party suspects or has detected such an incident. The SLA should also address whether that notification and communication must occur regardless of whether the detecting party has probable cause to believe that the other party is at risk (or is contributing to the incident) or not.
The ideal, of course, is a real-time secure voice and data collaboration channel between your organization’s SOC points of contact and their opposite numbers within the service provider. At the other end of the spectrum are response channels that are based on submitting trouble tickets or emails to the provider, in the hope that your sense of urgency will convey to them and elicit a prompt response. Email exchanges are not, in general, effective ways to contain and resolve an information security incident involving a third-party relationship.
Timely coordination and effective collaboration with each third party can be expensive; but with the average data breach or security incident costing their targets upward of $500,000 each, at some point it’s worth paying more for the level of services your business really needs and deserves.
Coordination and collaboration continue throughout the entire lifecycle of the relationship with any third-party services provider, whether they provide cloud services, website hosting, off-site data storage and archiving, data recovery, systems maintenance, logistics support, or data and systems disposal and destruction. This covers phases such as the following:
Pre-incident
Prediction: All service provider relationships should define the real-time and near-real-time telemetry data that needs to be exchanged for both parties to be able to meaningfully detect possible information security incidents in the making. Based on each partner’s needs, this might also include behavioral information to support advanced threat detection systems or other trending and performance data. Both parties have a vested interest in improving each other’s capabilities in keeping their joint threat surface safe, secure, and useful after all.
Detection: Does the third party warn of any incidents or take actions to minimize the probability and/or impact of a security incident? This answer can depend greatly with third parties, and it is important to understand how the third party prevents breaches and how they document and provide their customers with security reviews and audits.
During the incident
Notification: Your incident response procedures must include timely notification to potentially affected third parties, especially those providing services that may be involved in the incident. Your team should also have clearly identified points of contacts to receive incident notifications from third parties (including ones that have no third party standing with you, such as someone surfing your website who detects something suspicious).
Assessment: Some incidents may be strictly internal, not involving any third-party services or information; for those that do involve one or more third-party relationships, a collaborative assessment process can bring each party’s knowledge of their own systems and data to the incident at hand.
Response: Once an incident is believed to involve third-party systems and services, coordination before action is crucial to keeping both organizations and their systems on the safest of paths to recovery. Just as you risk disrupting your own business by too aggressively attempting to contain and eradicate a threat actor’s causal agents or in disabling accounts they may be using, so too your business can be derailed if one of your third parties overreacts to an incident. You don’t want to help the attacker by cascading the damages to your systems into those of your third parties, and vice versa.
Post-incident
Recovery and reporting: Recovery timelines must be in sync with both internal and external parties as a delay from one could result in damages or fees. A hosting company that fails to recover a database or application could have severe financial impacts to the organization. It is therefore important to develop relationships with the people who receive notifications and how customers are notified. Reporting of vulnerabilities from third parties in a timely matter must take place and be incorporated with internal vulnerability management programs.
After action: The security team should work with third parties to evaluate how an incident may have happened and what steps can be taken to further prevent a reoccurrence. The security practitioner should regularly evaluate, address, and verify remediation of weaknesses and deficiencies with the third-party providers.
During a forensic investigation
At some point in an incident response process, your organization’s management and leadership may decide to institute a forensic investigation, either formally or informally. Such investigations may require that third parties be notified that an investigation is underway and that they are requested to protect all information involved with the event; or they may be served with digital discovery motions. In almost all cases, the forensic investigations teams (yours and that of your third parties) and the respective managers and legal counsel will have to take charge of coordinating this with any third parties that are a party to the incident.
The involvement of third parties, both upstream and downstream, is vitally important in incident response, as they may affect explicit and crucial aspects in the sequence of response actions.
Understand and Support Forensic Investigations
A risk event occurs, and the organization suffers its resulting impacts and losses; the organization now needs to determine how the incident occurred, who has what portion of responsibility for it, and what corrective actions to take as part of a longer-term business plan. Ideally, these decisions are based on reliable, credible evidence; that evidence is chained together in a series of logical, well-reasoned steps to argue conclusively what happened, who did it, and what should be done next. Forensics is the science of using evidence to construct logically valid arguments; forensics investigators generate hypotheses (or possible explanations) regarding the event and then look for evidence that confirms or denies each hypothesis. All of this supports the need for management and leadership to make informed, fact-based decisions regarding the incident and its aftermath. Gathered together, the body of evidence; the applicable laws, policies, regulations, or administrative controls; and the logical arguments and their conclusion are called the findings of a forensic investigation.
In the world of information systems security, there are many reasons to perform an investigation, and there are many scenarios that may require one, such as in response to a crime, a violation of policy, or a significant IT outage/incident. (An interruption of service or malfunction may indicate something beyond routine equipment failure or user error.) Organizations today are faced with an almost nonstop demand for authoritative, reliable, accurate, and complete disclosures of information, and in most cases, the penalties for making or filing false, incomplete, or deliberately misleading statements or findings can be quite severe. Some of these demands include the following:
Digital discovery motions, issued by a court, demanding disclosure of specified records to the court or to a designated recipient
Legal briefs to a court on pending or ongoing criminal or civil actions
Legal briefs and discovery disclosures to government regulators, auditors, or inspectors
Digital discovery or other legal briefs to labor tribunals, the courts, or others involved in adjudicating, arbitrating, or mediating a civil dispute involving the organization
Information filings in support of insurance claims
Compliance filings required by health, safety, or financial regulatory authorities
Information disclosure and reporting required by contracts with partners, suppliers, vendors, subcontractors, or strategically important customers
Disclosures in support of contract negotiations
Investigations to determine causes of systems failures, unsafe operational behavior, or incorrect operation
In short, every aspect of the CIANA stack of information security needs—including privacy and safety considerations—may require an unimpeachable forensic investigation to support a decision to take an urgent and compelling action in its regard.
Key to the success of any investigation is preserving the integrity of the evidence. Incident scenes are dirty; they contain some useful objects, bits of information, and clues to the event you’re investigating, all thrown against a real-world canvas that is incredibly rich with almost totally irrelevant items. The evidence that is in the scene will be incomplete; your guesswork (your hypotheses) will attempt to bridge over the gaps in the evidence, while you systematically filter out the stuff that’s not relevant and meaningful to the questions you’re investigating. Nevertheless, you must constantly preserve the evidence in exactly the condition you found it in; if you change it in any way, you really cannot rely on it as you build your argument about who did what and why. We’ll look at this in more detail in “The Chain of Custody” section.
Call in the Lawyers and the Experts
In almost all cases, a proper forensic investigation must rely on two kinds of experts: legal advisors and forensic investigators. Even the smallest of small office/home office (SOHO) organizations exists inside layer upon layer of conflicting laws, regulations, contracts, and other constraints; as the business reaches out across regional and national borders, the legal complexities that must be faced grow almost without bound. Depending upon the type of incident you’re investigating, you and the organization may need expert legal advice regarding criminal, fair employment, liability, civil tort (contract), and environmental, safety, or even munitions export laws and restrictions. This is not the time to make an educated guess! Get management to get the lawyers involved.
For all but the simplest of incidents, you may need to have expert digital forensic investigators involved to help you identify the right evidence to look for, to explain the right ways to gather it (to keep it pristine), and to take that evidence into controlled possession. If you haven’t had training in evidence handling and the chain of custody requirements that apply in your local jurisdictions, get expert, qualified help.
In many jurisdictions around the world, the law and the practice of law by officials and the courts change rapidly; not only that, in some countries you may face separate legal and court systems that enforce national, local, religious, and tribal or clan law. The good news is that most SSCPs do not need to be legal technicians as well as information security specialists. The bad news? Many organizations do not depend upon expert legal advice while preparing to respond to information security incidents; once the incident has started to occur, the best that expert legal advice may be able to do is contain or limit the legal damages.
Legal and Ethical Principles
The complexities of the law at home, much less abroad, dictate that you call in the lawyers early and often throughout your incident response lifecycle. Regardless, there are a few key legal and ethical ideas you should have a solid understanding of as you conduct all of your tasks as an information security specialist.
Chapter 2, “Security Operations and Administration,” established the broadly accepted legal and ethical principles behind CIANA, the core information security requirements of confidentiality, integrity, availability, nonrepudiation, authentication, privacy, and safety. Each of these directly links to the common business ethical requirements of due care and due diligence (which many nations have embodied in their criminal and civil laws). Chapter 2 also linked these ideas to the (ISC)2 Code of Ethics and to your professional obligations to supporting that code. Taken together, those concepts (CIANA, privacy, safety, due care, and due diligence) should be a sufficient set of foundational elements for you to build your incident response processes upon.
Most legal systems do impose constraints and duties upon everyone involved in an incident scene, whether as participants, bystanders, responders, or owners or managers of the property or location in question. Societies value being able to establish that something happened and further to show who had responsibility for what happened; they need to be able to demonstrate that laws were broken (or complied with) and be able to unemotionally assess what injuries, deaths, damage to property, or other losses resulted from an incident. In almost all societies, evidence is required to establish those conclusions; therefore, it’s in everyone’s interest that evidence at the scene be preserved and protected as best as possible. But societies do recognize that first responders may, in emergency situations, have higher priorities to attend to than the preservation of evidence. Firefighters responding to a structure fire in your data center will not, of course, be worrying about saving the digital contents of your servers or the media, documents, and files kept in your records center; their priority is ensuring the safety of life by controlling the fire, containing it, and ideally extinguishing (eradicating) it.
For the rest of us, the nonemergency and non-life-saving first responders and incident investigators, we share in the legal obligation to ensure that the incident scene be preserved as best as possible so that it can tell its own story; the evidence in that scene needs to be protected from loss, damage, or corruption (be that deliberate or accidental) so that any investigation of that incident will come to an unimpeachable and irrefutable conclusion. By controlling, preserving, and protecting the scene, we limit or prevent loss, damage, or corruption of evidence; this is due care in action. Establishing and maintaining a chain of custody for evidence related to that scene is the accountability proof that we need, as responders and investigators, to show that we fulfilled our due diligence responsibilities.
Chapter 2 also examined various legal and ethical concepts regarding the rights that individuals and organizations have against unwarranted search of their belongings (including their information and record-keeping systems) and their rights to privacy of their persons, places, and actions. These legal and ethical rights form a set of constraints on how you and an incident response team can search an incident scene, question people who are or may have been involved in the incident, and attempt to search the property under the control of such persons. They can constrain how you establish internal, perimeter, and external surveillance systems; they can also limit or dictate what you can or must do with surveillance data, such as video or audio recordings these systems collect. Different legal systems have different processes that control how you can give access to such surveillance information to others, such as to national or local government agencies, law enforcement, insurance adjusters, and investigators, or even to others in your management and leadership chain. Thus, it’s vital that you get your organization’s legal team involved as you develop these aspects of your incident response procedures; gain their approval before you put your teammates in jeopardy by tasking them to carry out those procedures.
Logistics Support to Investigations
Digital forensics is a game of large numbers: the total number of objects to examine can easily exceed one million or more when you consider every file, file header, date and time stamp, location information, and the data in the file itself. It’s imperative that the investigators use efficient forensics tool sets, often integrated as a forensic workstation, as their investigative infrastructure. When you combine this with the need to preserve and protect such evidence with a strong chain of custody procedures, you can quickly imagine that an investigative team is going to have some specific needs from your organization for facilities and administrative support.
Separate workspaces, which the investigative team can secure or lock when they are not present. These should be considered as restricted access spaces, and other organizational employees (even senior managers or leaders) must be prevented from attempting to access them without express permission from the investigators. (This supports chain of custody integrity.) Larger or more technically savvy organizations (which as lucrative targets may attract multiple attack attempts per year) may see the need to establish separate clean room facilities to support forensic investigations.
Access to your systems, information storage and documentation libraries, administrative procedures, policies, and guidelines.
Access to your networks and systems.
Access to your people.
Depending upon your organization’s physical locations, you may also need to provide routine access (such as special visitor badges), reserved parking, or otherwise expedite the ways in which the team can bring in their own forensic analysis, evidence collection, and related equipment and supplies.
It’s also wise to designate someone in the organization as the principle point of contact for investigators to come to when special support needs or issues arise. This point of contact can then broker the issues within the organization and get the right resources marshalled to resolve them; or, if need be, get the right managers and leaders to meet with the investigators to seek a common understanding and a way forward.
Evidence Handling
“Evidence collection and handling” can have a broad range of meaning, much of which is beyond the normal duties of an SSCP. Organizations need evidence to support criminal prosecution of attackers and malicious insiders. Evidence informs the choices organizations make during incident response, during recovery, and in remediation, repair, or upgrades of systems and processes after an incident. Evidence also establishes whether the organization fulfilled its due care and due diligence responsibilities in the event of an information security incident or a data breach. Evidence also aids in lawsuits brought in civil court.
There is a tendency for information systems professionals to hear “evidence” and think only about digital evidence; this is hard to understand, since as an information security professional you also have to make the right choices about physical and administrative risk mitigation and security controls, as well as logical (that is, software-implemented digital) controls. You’ll need to use a combination of physical, logical, and administrative evidence to prove to your managers that your physical access control systems, for example, are working correctly. Thus, it’s important and relevant to think about all forms of evidence when you consider the collection, protection, and use of evidence pertaining to an incident scene.
As the on-scene SSCP, you might have to assist in gathering and protecting evidence related to a security incident. This evidence could be in many forms:
Physical IT-related evidence, such as computers, USB or other media, paper documentation, cables, or other hardware devices.
Physical evidence about the scene itself, such as damaged doors on secured cabinets.
Images or descriptions of physical evidence, such as a video or photograph of a portion of the incident scene, or video recordings showing the movement of people, vehicles, or other objects in and around the scene.
Documentary evidence, which can be any log, recording, notes, or papers that describe or attest to something at the scene. A book found at the scene is a physical piece of evidence; your personal notes made during the incident response are your description or documentation of what you believe transpired.
Digital evidence, such as files, directory structures, memory dumps, disk images, packet trace histories, log files, or extracts from databases.
Testimony given by any person regarding the incident, either in direct (in person) form, as a recording, or as a transcript.
Everybody who has any role in responding to an incident will become involved with items of evidence such as these. Typical information security incidents may have actions taking place in many different physical and virtual locations, which of course complicates the whole process of identifying who is a “first responder,” which incident response teams have responsibility over which portions of this dispersed scene-of-scenes, and what it means to have one person take control of “the” scene. For starters, let’s consider a simpler scene, confined to one building, such as a data center at your company’s main operating location.
It’s useful to think about evidence collection, protection, and analysis from the organizational perspective of the end game: what does the evidence need to do for the organization, when it take its case to court or uses the findings of an investigation to take a controversial internal action? Generally speaking, the total set of evidence you put together as the findings of your investigation needs to be the following:
Be accurate: The evidence and documentation must not vary, deviate, or conflict with other evidence or contain any errors. Inaccurate evidence can be disputed or dismissed.
Be authentic: Evidence should not deviate from the truth and relevant facts. In addition to harming your side’s opportunity for a favorable court decision, inauthentic evidence may be construed as deceiving the court, which is itself a crime.
Be complete: Both sides of a court case will be allowed to review and dispute all evidence provided by the other side; you will be required to share any and all data related to the case, regardless of whether that data supports your side. Even evidence that does not demonstrate your intended outcomes must be shared with the opposing side to give the court an opportunity to make a fair, informed, and objective decision. Furthermore, as with deception, failure to disclose all evidence in a legal matter may have financial and even criminal consequences.
Be convincing: Regardless of the type of court, the purpose of the case is to determine which side’s narrative is more believable, as supported by testimony and evidence. You will try to convince the court your story is more believable, while disputing your opponent’s side; the adversary will be doing the same. The evidence you present should support your story, and your story should be reasonably demonstrated by the evidence.
Be admissible: There are many kinds of evidence that are admissible in court and only a few that aren’t; some are admissible only after a ruling by the court and discussion/review by opposing counsel (such as expert testimony). Be sure to understand the rules of evidence that are applicable in your jurisdiction to know which evidence will be admissible.
In all matters of evidence, it is absolutely imperative to consult with legal counsel to ensure your efforts are suitable for the court.
Data Cleaning at a Crime Scene?
One of the enduring myths in our industry is the belief that original content will be rendered inadmissible as evidence if it is modified in any way; this is simply not a black-and-white issue. Ideally, the evidence should be unaltered as you collect, preserve, and analyze it; this “gold standard” of evidence, when supported by an unimpeachable set of chain of custody records, is worth striving for.
What do you do when multiple pieces of evidence still do not paint a complete picture or contradict each other? In many cases, data cleaning provides an audit-proof approach to find other sources of data (such as official records databases) that can be used to fill in the gaps or resolve conflicts.
“Would you clean a crime scene?” asks Robin Farshadfar, general manager at EastNets Holdings Ltd, a financial integrity and payment solutions provider. Instead, she admonishes us to “let the data stay dirty” by building a new record or file that combines the new corrections on top of the original data—but avoids changing the original if at all possible. Keep a change log of each bit that is changed; be able to trace back to the sources you used for the new or replacement data; build your argument that each change is correct. Spare no details in doing this!
Sometimes you cannot; destructive testing, or even the nature of the evidence collection process itself, may unavoidably make changes to the evidence. As storage devices become smarter and smarter, it’s becoming harder to work around their onboard journaling and data integrity processes as you try to extract a copy of the data from the device. When this happens, take detailed notes of every step you take; build that audit trail step by step.
That chain of argument — that audit trail — and your chain of custody records for the original evidence and all of the data you use in cleaning the evidence is what your case will rest upon.
Controlling and Preserving the Scene
In his memoirs, Colin Powell remarked that the U.S. Army used to teach its young officers that when they come to a new location and they determine that they are the senior ranking person there, that they first take charge of the scene by identifying all personnel who are there (military and civilian) and inventorying all assets at the location (whether or not owned by the Army). This is still sound advice!
Treat the incident scene as if it is a physical, logical, and administrative baseline that you must bring under change management and control. First, you inventory what’s there; second, you use the authority granted to you as a first responder or incident response team lead, and your incident response procedures, to guide you in asserting change ownership over the scene and everything in it. You do this for several important reasons.
To limit further loss or damage to property, or injury to persons, from whatever cause
To control the response process so that systems, equipment, or business processes can be safely and controllably brought to a known halt, hazards (malware, smoke, or intruders) can be contained, and their damaging effects prevented from spreading
To protect and preserve the objects and information contained in the scene as possible evidence
One further benefit of controlling and preserving the scene is that you can assist senior management and leadership in balancing the conflicting needs to understand what happened, prevent it from happening again, pursue claims against responsible parties, and get back into business operations as normal. Each of those legitimate needs pushes or pulls on the responders with different senses of urgency; as the on-scene change control owner, you can to the best extent possible ensure that senior leaders make those priority calls and that people on scene act to achieve them.
As with any change control process, the record-keeping that you do as you control and preserve the scene is vitally important. Take notes. Time-tag each note, whether in your smartphone, your incident responder’s ruggedized laptop, or your paper pocket notebook; keep track of what happened, who did it, on whose authority did they do it, when they did it, and what resulted from their actions.
The Chain of Custody
In legal terms, the chain of custody is the change control process and the change control record-keeping that is used to identify, preserve, store, and control access to and use of pieces of evidence. The evidence custodian is the person (or agency) who has the responsibility and authority to protect the evidence and maintain records of any attempts to access, move, modify, delete, or destroy such evidence.
The chain of custody can easily be seen by looking at the lifecycle of a piece of evidence related to an information security incident scene. Such a lifecycle model can consist of steps such as the following:
Creation: Someone or something does something in or at the incident scene that creates something new or modifies something that is already part of the scene. This may happen well in advance of the start of the incident; other times, evidence is created or changed by the actions that take place during the incident. (A log file that was created the day before the incident and that was not modified during the incident might be useful evidence that indicates that the logging function had been bypassed or disabled.)
Recognition and identification: Someone responding to or investigating the incident determines that an object or set of information might be relevant and material evidence.
Taking possession or custody of the evidence item: This starts the chain of custody and establishes the first set of information about that piece of evidence that needs to be captured and recorded.
Cataloging: Each item of evidence is uniquely identified in an evidence log.
Protection, preservation, or control: At this step, change control is exerted; no one should be permitted to access, touch, view, change, or move the evidence item without proper authorization and without the evidence custodian (the keeper of the chain of custody records) granting permission and access to do so. The evidence item is either preserved on scene (for example, by restricting access to the scene by others) or removed from the scene and placed in secure storage. For digital evidence, this may involve making a complete or partial copy of the physical or logical media that the digital information is on.
Analysis: Many different analysis tasks might need to be performed using various pieces of evidence. Analysis tests can be broadly classified as destructive or nondestructive, based on whether the tests irreversibly alter the piece of evidence. Most digital evidence analysis tasks can and should be performed on a copy of the evidence item, rather than on the original, as a precaution.
Reporting: The analysis findings are collated and put into summary form, presenting the arguments, their step-by-step results, and the ultimate bottom-line conclusion of the investigation.
Transfer: Evidence may be transferred to other facilities, agencies, or organizations. Transfers may be directed by a court order or by other law enforcement action; the organization holding the evidence and its investigators may also determine that a more effective analysis, or better protection for the evidence, may be obtained by transferring it to another facility.
Retention: After the investigation is complete, evidence is usually retained (and protected) for a number of years, which protects the organization and all parties if appeals or counter-actions are initiated that need to re-examine an item of evidence.
Destruction or disposal: At some point, the findings of the investigation have been accepted as final, all appeals have been exhausted or their time frames have expired, and the data can be disposed of in accordance with applicable data retention and destruction policies.
The first important question that comes up about any and every piece of evidence is whether that evidence itself is credible; is it reasonable to believe that the item of evidence is what it seems to be and claims to be? (That ought to sound familiar; think about what the identity proofing and authentication steps in access control must accomplish.) That lifecycle view of a piece of evidence reveals just how many opportunities there are for someone to accidentally or deliberately change, destroy, or lose a piece of evidence. That possibility alone means that someone can impeach that piece of evidence, by claiming that the person who had custody of the evidence cannot prove that the evidence item has not been altered in any way by anyone. The chain of custody is the sequence of records kept, step-by-step, for each piece of evidence. Who gathered it? What did they do with it? How and where was it stored? Was the storage facility secure enough that no one could gain access to evidence and alter or remove it without being detected?
This chain of custody continues during the analysis process. Each analyst must sign out a piece of evidence, must record every movement of that evidence, every analysis task that is performed on it, what changes if any of that analysis made to the evidence, and what they did with the evidence at the end of their test. (It is hoped that they returned the evidence to the evidence storage facility and logged it back into custody.) Custody records must also capture the details of any copies made (digital or otherwise). Once made, a copy of an evidence item must also be subject to chain of custody record-keeping (imagine the havoc that could result from findings based on a false or altered copy of an important bit of evidence).
Evidence Collection
Your organization will most likely need to collect a variety of physical, administrative, and logical or digital evidence in the course of responding to an incident and supporting a forensic investigation into its cause. In almost all cases, the organization will be better protected if it uses trained, expert forensic investigators to conduct all aspects of evidence collection, preservation, and analysis. You should, however, become familiar with the processes such evidence collection may use and appreciate what your role might be in supporting such expert investigators. Standards such as ISO 27037, “Information technology – Security techniques – Guidelines for identification, collection, acquisition and preservation of digital evidence” (https://www.iso.org/standard/44381.html), can provide great insight into what you and your organization need to do to be prepared to call in the experts and support them to achieve your investigative needs.
During the preparation phase, the organization should identify candidate investigator teams and establish at least a preliminary working relationship with them. This can help the organization establish on-call or urgent support relationships with investigators and analysts with the proper training, expertise, and tools to perform digital forensics. These investigators can be internal employees, external contractors, or a combination of both. These decisions should take into consideration response time, data classification, and sensitivity.
The ideal forensic team should be made up of people with diverse skillsets, including knowledge of networking principles and protocols, a wide range of security products, and network-based threats and attack vectors. Skillsets should overlap between team members, and cross-training should be encouraged so that no one member is the only person with a particular skill.
Other teams within the organization should be available to support forensic activities. This should have top-down support through policy, and the forensic team should feel enabled to approach members of management, the legal team, human resources, auditors, IT, and physical security staff. Working together, the cross-functional forensic team should have a broad set of skills, capabilities, tools, techniques, and understanding of procedures.
Tools
Digital forensic analysts need an assortment of tools to collect and examine data. Different tools are necessary to be able to collect and examine both volatile and nonvolatile data; to capture information from media, software, and hardware; and to craft meaningful reports from all the data collected and created during analysis. There are, for example, many types of file viewers necessary to view files that have different formats, extensions, or compression types. Investigating systems based on Microsoft Windows technologies will benefit from a variety of third-party tools, such as registry, event log, and virtual disk analysis utilities, which provide analysts with new ways to view and navigate these complex data structures, and investigate changes made to them that might relate to the incident at hand. Debugging tools allow analysts to get more details than default reports or logs will include. Decompilers, reverse assemblers, and binary analysis tools allow analysts to look inside executable programs, at the code level, to find anomalies and malicious code. Reverse engineering tools and systems provide for complex, powerful, integrated capabilities to take executable (binary) files apart and identify in human-readable terms the patterns of instructions that they’re made of. Many of these reverse engineering suites support communities of practitioners, which allows the power of many, many pairs of eyes to help your investigators identify oddities implanted in your code or potential malware they’ve found on your system. There are also dedicated tools to extract data from a database. Analysts also use specialized tools to analyze mobile devices for file changes and to find deleted files and messages.
A drive imaging tool is critical to the forensic process. These come in different forms, such as a dedicated workstation, small appliance, or software, but the function is to make an exact copy of a drive or piece of media. Some versions require the physical removal of the drive or media and attachment to the imaging tool, which is called a dead copy. Other imaging tools can interface via transfer cables, FireWire technology, network media, and so on, to capture “live” images or copies, meaning that the image is taken while the device is running.
A write blocker is another valuable tool used in forensic investigation. It can be either an appliance or a software tool. It does just what its names says: it prevents any new data from being written to the drive or media and prevents data from being overwritten during analysis of the drive/media. This is useful to reduce the possibility of introducing unintended modifications to the original data.
It is also useful to have a hashing tool to create digests for integrity purposes. A message digest is the output of a hash function, creating a unique representation of the exact value of a given set of data. If the data changes, even in a minor way (even by one character), the entire digest changes; in this way, an investigator can be sure that the original data collected as evidence is the same data that was analyzed and is the same data provided as evidence to the court and opposing parties. Two common algorithms for creating message digests are Secure Hash Algorithm 1 (SHA-1) and Message Digest 5 (MD5). Many popular forensic tools incorporate automatic hashing/integrity checks.
Network traffic is also an important aspect of digital forensics. Capturing traffic from a sniffer, packet analysis tool, or network threat detection tool provides live session data. Log files are also a critical element of analyzing the network aspects of a forensic investigation. Log files are found in many locations, including servers, firewalls, intrusion detection systems/intrusion prevention systems, and routers and can provide significant insight into the events that transpired over networks.
Finally, a video screen capture tool can be valuable for analysis purposes. The ability to capture real-time video can be used to document the steps taken on a forensic workstation, for example. It proves that the analysts are performing the steps they claimed and performing them consistently and in accordance with the written forensic procedures. It can also help with documenting and reporting afterward.
Not all tools are created equally, and there are a wide variety of both open source and commercial tools. It is essential that the selection of tools be made in consultation with the organization’s legal counsel, who can provide guidance on which particular tools would provide admissible evidence.
Triage and Evidence?
Applying a triage process to the gathering and processing of evidence might seem a self-contradicting proposition: don’t you risk throwing away the very nugget of evidence you need to reveal the real root cause, the real threat actor, and prove your case? The problem, however, is that it’s quite likely that you and your forensic investigation team face a literal data deluge, and you won’t have the time or resources to gather and examine everything you’ll encounter at an incident scene. Terabyte-sized USB drives are commonplace; cloud infrastructures routinely deal in blobs (binary large objects) of storage that can exceed petabytes in size. The challenge to the investigator almost becomes what evidence not to capture, take custody of, catalog, and then analyze. The apparent nature of the incident, your systems architecture, and the size and complexity of your organizational structure may provide some guidance to help you and the investigators avoid needlessly copying and preserving huge amounts of data—or be too stingy in what you choose to gather as evidence and potentially throw away too many “smoking guns” without realizing it.
Forensic triage is a rapidly growing practice within the digital forensic community. As you might expect from its name, this process involves the investigative team quickly examining each computer system, other object, or other set of information at the scene and prioritizing it for further examination. If a system, object, or information asset ranks high in that triage priority, it is taken into custody; if it clearly has no material bearing on the case, it can be released to the organization for further eradication, restoration, and normal business use. Items that fall in between the urgent and the probably useless should also be taken into custody, but analysis on these may have to wait until investigative resources are available. Such triage decisions do have something of the nature of a self-fulfilling prophecy to them: if you think you’re looking for an embezzler, you’ll probably not choose to run search tools on employee or visitor laptops that might suggest they were used to exfiltrate your database, install malware, or buy and sell pornography or pirated videos. (Note, too, that in jurisdictions that require search to be specific, with or without a search warrant, you usually cannot examine a system for any evidence of any possible crime.) A variety of forensic analysis workstation products now make managing forensic triage easier. Again, your organization’s unique risk profile should be your guide; let it focus your attention to the higher-priority threats you face and then develop forensic triage strategies to help you respond to them more efficiently.
Some investigators argue that this is actually digital triage and not forensic triage, as there’s actually no real analysis of the evidence items performed as part of the prioritization process. It’s arguably true that calling it forensic triage can be appropriate only if the process adheres to all of the rules of evidence and forensic investigative process for the legal jurisdiction in question.
A variety of process models or lifecycles for digital triage have been published, and they do seem to have several important phases in common.
Planning and preparation looks to organizing, training, and equipping the investigative teams with the tools, techniques, and procedures needed to apply triage principles to an investigation. This should match the preparation activities to a selected range of incident types.
Live digital triage focuses on prioritizing the capture of volatile data, such as in-memory data, mobile device memories, or the content of control tables in networks and communications devices.
Post-mortem triage addresses the prioritization of evidence collection from nonvolatile memories or from other physical sources.
You might also consider whether your organization should prepare for digital triage and investigations based on broad categories of types of crimes or incidents. General personal crimes, for example, require a different investigative and evidence-gathering approach than high-tech corporate crimes do (one typically does not need extensive forensic accounting capabilities to investigate an employee suspected of using work-related IT assets for viewing or selling pornography). There’s a lot to learn from the ongoing debates in digital or forensic triage; while learning, focus on what your business impact analysis (BIA) has identified as the high-impact, high-priority risks or threats that face your organization, and apply a bit of winnowing—a bit of triage thinking—to how you’d prepare, respond to, and investigate such incidents.
Techniques and Procedures
The previous sections addressed the skills and tools the forensic team should have. This section discusses the techniques your team should follow. What are the goals and actions of effective analysts as they proceed through investigations?
Start with a standard process: Analysts should follow a predefined process for collecting data. For example, ISO has standards for the capture, analysis, and interpretation of digital forensic evidence; these include standards 27041, 27042, 27043, and 27050. NIST also publishes NIST SP 800-86, “Guide to Integrating Forensic Techniques into Incident Response,” which is free to download as are all NIST publications. Much has changed at the technical level since this publication came out in 2006, but its overall emphasis on process, and how incident response and forensic investigation can and should be mutually supportive, remains an important source of guidance.
Define priorities: An organization has three possible priorities when responding to an incident: returning to normal operations as fast as possible, minimizing damage, and preserving detailed information about what occurred. These priorities are, necessarily, conflicting: a fast recovery will reduce opportunities to collect evidence, taking time to collect evidence may lead to more damage, and so forth. The organization needs to determine which order to address these priorities, in both the general (what does the policy say?) and the specific (what should we do for this incident?).
Identify data sources: Before a team can begin investigating in earnest, analysts need to define what data they are looking for and all possible sources for that data. Consideration needs to be given as to the flow of certain data and all the places where it is stored and processed. Are copies made along the way? Is the data mirrored off-site or to the cloud for backup? What kind of event logs or notifications are triggered in the process? What devices will this data travel through? At this point, the analysts also need to discover the physical location of the components that store and process the data and who the administrators are for those components. Logging and monitoring are essential for analysis purposes. If logging and monitoring settings are configured at too low a verbosity, some of the important sources of data for the investigators will be missing. The correct level of detail for log collection needs to be determined long before an investigation needs to take place, if at all possible. Long-term storage requirements (and retention policies) for such log data must also be identified and be made an integral part of the organization’s overall data archiving, protection, and control plans, policies, and procedures.
Make a data collection plan: The analysts should make a plan addressing how the data will be collected, including the priority and the order in which it should be collected. This should prioritize data of higher value and volatility first to avoid the chance that a machine could be turned off or data could be overwritten.
Capture volatile data: Analysts need to be able to gather volatile data, such as data stored in RAM, which will disappear after the device is powered off, or data at high risk of being overwritten or corrupted by new data. There are risks associated with capturing live data, such as file modification during collection, or affecting the service or performance of the machine from which data is being taken. The organization needs to discuss and document in advance whether and when to accept these risks and capture live data. Analysts should be equipped with special tools for gathering live data and understand how each tool might alter the system during collection. The concept of scheduling collection actions based on possible data loss is often referred to as order of volatility; the most volatile data should be collected first.
Collect nonvolatile data: As we discussed in the preceding tools section, an imaging tool is used to copy the contents of a drive. If the image is going to be used for a criminal case or disciplinary actions, it should be a bit-level image, not a logical backup, because it includes the slack space and possible data remnants. A write blocker should be employed to protect the image or data from being changed. The method used to shut down the target machine must be discussed and decided in advance. Each operating system (OS) has multiple methods for shutdown, and they have different behaviors and effects on the data.
Capture time details: It is essential to know when files were created, accessed, or last changed. These must be preserved for the investigation. Based on the OS, the time formats and method for attributing timestamps to files will vary. Going back to the differing uses of bit-level images and logical backups, this is another aspect of digital forensics where a bit-level image must be used in important investigations. This is because bit-level imaging will not alter the timestamps, but logical backup could, for example, change the original date and time the file was created to the date and time the logical backup was performed. The analysts collecting the data need to account for and document inaccuracies in timestamps, such as if the system clock was wrong and/or not connected to a network time source or if they suspect the attacker altered the timestamps. Inaccurate timestamps can hinder the investigation and hurt the credibility of the evidence.
Preserve and verify file integrity: There are many steps and actions that can preserve and verify file integrity. We’ve already discussed some of them, such as using a write-blocker during the imaging process, calculating and comparing the message digests of drives and files, and using copies of drives or files for analysis, instead of the originals. A chain of custody should be clearly defined in advance and followed closely to preempt any claims of mishandling evidence. This includes using proper chain of custody forms and sealing evidence taken with evidence tape, evidence bags, and other tamper-proofing packaging.
Look for deleted or hidden data: Deleted, overwritten, or hidden files can provide essential clues to an investigation. Deleted files or remnants can often be recovered from slack space using dedicated recovery applications. Files can be found in hidden system folders or folders that an intruder might have created and then marked as “hidden.” Actors might also hide files “in plain sight” by changing the filename and/or changing the file extension, such as changing virusnamehere.exe to an innocuous and even boring name like warranty.txt. Because the name and extension are so easy to change, even for end users with limited permissions, analysts should inspect file headers and not take the extensions at face value.
Look at the big picture: For example, a failed attempt by an attacker to access a server might leave their digital footprints in many places. Such data might be captured in a firewall traffic log, a server OS event log, or an authentication server log, as well as by an intrusion detection system or security information and event management (SIEM) alert. If one action can leave a trail in five places, the analyst must consider this fact in reverse. If the analyst starts working from one or two log entries, are there three or four other places or other pieces of information they haven’t seen yet? Would those facts affect how they interpret the few things they currently know? They should seek the other pieces before forming conclusions. Another point to consider is that some monitoring tools operate according to simple rules, such as “event log A + event log B = incident C.” In a situation like this, the tool, such as a SIEM tool, is often correct in its conclusion. In an investigation, however, the analyst should verify this type of information. They should look at each event log separately and make their own conclusion about what those things mean together. The logs in this example are more immediate; direct information and the incident alerts from the SIEM tool are derivative and secondhand and have injected an additional layer of inference and decision-making, which may or may not be correct.
Make no leaps: Analysts should use a conservative, fact-based approach in the final analysis and reporting stages. Do not come into an incident investigation (whether an initial event assessment or a full-blown forensic process) with preconceived notions as to how it happened, who did what, and what the “final” results or outcomes of the incident are. Either there is enough data to draw a given conclusion or there is not and no conclusion can be drawn. The data cannot be “almost conclusive” or “point to” being conclusive.
Forensics in the Cloud
Managed cloud computing services pose several challenges for forensic investigation and analysis. Both the technological implementation of cloud computing and the contractual nature of managed services complicate the investigator’s ability to perform the actions and use the tools just described. It is important for the security professional to understand the unique characteristics of cloud computing that can make forensic activities difficult to accomplish.
Virtualization: Cloud computing is typified by the use of virtual machines in software containers running on various (and constantly changing) host devices. Often, it is difficult, if not impossible, to know the exact physical machine that any given virtual machine might be “on” at any given moment, and virtual machines, when “shut down,” are migrated to other devices for storage, in the form of files. This makes forensic examination and establishing a chain of custody extremely difficult. Proving the state and content of any given virtual machine (or the data on it) takes much more effort and will require a much longer set of logs (thus introducing more doubt to the evidence, and thus the case).
Access: Depending on the vendor, the service model, and the cloud deployment model, the cloud customer may have difficulty acquiring and analyzing evidence for a legal case because the customer may not own the hardware/software on which the customer’s data resides and therefore may not have administrative access to those systems and the logging data they contain. Furthermore, all the ancillary sources that often provide useful investigatory data (such as network devices, SIEM solutions, data loss prevention tools, firewalls, IDS/intrusion prevention system [IPS] tools, etc.) may also not be under the customer’s control, and access to their data may be extremely restricted.
Jurisdiction: The larger cloud vendors often have data centers geographically spread across state, regional, or international boundaries; users and customers making transactions on the cloud can be located anywhere in the world. This creates many legal and procedural challenges and may significantly affect how evidence is collected and utilized.
Tools/techniques: The technologies and ownership of managed cloud computing may hinder the use of common forensic tools; specific or customized tools may be necessary to capture and analyze digital evidence taken from/existing in the cloud.
Because there are so many variables involved in each of these aspects, it is difficult to dictate a specific approach to cloud forensics. However, some professional and governmental organizations are developing standards for this purpose. For instance, the Cloud Security Alliance (a partner of (ISC)2, the organization producing this book and the progenitor of the SSCP Common Body of Knowledge) has created instructions for how to use the ISO forensics standard (ISO 27037) in a cloud environment (https://cloudsecurityalliance.org/download/mapping-the-forensic-standard-isoiec-27037-to-cloud-computing/). They’ve also created a capability maturity model for cloud forensics (https://cloudsecurityalliance.org/download/cloud-forensics-capability-model/). Both should be on your reading list as you prepare to support forensic investigations as part of your incident response activities.
Finally, there is one principle that can be recommended regardless of all other variables and conditions in a cloud-managed services arrangement: start with what it says in the contract. The cloud vendor and customer should have already reached an explicit agreement, in writing, as to how incident investigation and evidentiary collection and analysis will be performed and executed, before the managed service commences. This contract, and the service level agreements (SLAs) or terms of reference (TORs) that are included in it by reference, forms the legally binding agreement between the organization and the cloud services provider. Be absolutely sure that you involve the organization’s legal advisors before you start any forensic investigation that might spread into such cloud services!
Understand and Support Business Continuity Plan and Disaster Recovery Plan Activities
In Chapter 3, you looked in depth at how organizations manage and mitigate risks of all kinds; as an information security professional, you may not deal with all aspects of all risks. However, you do need to be aware and perhaps involved with how your organization prepares to cope with natural disasters, local political unrest, riots, or other events that are not directly related to information security but can still severely disrupt the organization’s ongoing business operations. Here in Chapter 4, we’ve also looked at incidents in general and in greater detail at information systems security incidents along withhow to respond to them.
Let’s put the incident response concepts shown in Figure 4.1 into the larger context of the various plans and processes organizations need to develop, prepare for, and execute. Figure 4.5 shows a spectrum of disruption that faces most any organization, ranging from anomalies in systems behavior all the way up through disasters—events whose scale of disruption can literally put the business out of business. Figure 4.5 suggests a few ideas worth considering.
Failing to properly contain the impacts of an incident, recover from its impacts, or restore normal business operations can cascade into more serious incidents that can threaten the survival of the organization.
Failure of a plan, such as a BCP or DRP, does not necessary mean that the plan was poorly written or carried out—some events can still overwhelm even the best-laid plans organizations try to make.
FIGURE 4.5 The descent from anomaly to organizational death
Emergency Response Plans and Procedures
Figure 4.5 also suggests that each type of incident may need to call upon one or more type of response capability. Prudence, if not due care, suggests that organizations plan for many different types of incident response. In broad topical terms, these plans are shown in Figure 4.6. Your own organization may refer to these planning processes by different names and may even put all of this planning activity into one process; it may also split some of these task areas apart. Key to successful risk management planning (which this is all about) is that the plans are suited to the risk environment and context that your organization faces; your plans should be tailored to meet that environment, as they should also meet your risk tolerance, the culture of your organization, and its surrounding context. Each of these plans should be driven by the BIA; more to the point, due care requires that your organization be effective at this spectrum of business continuity planning. The bottom-line goal of this planning—and of all of these plans taken together—is that if your organization wants to stay in business, it has to survive if it is to thrive.
FIGURE 4.6 Continuity of operations planning and supporting planning processes
It’s safe to conclude that each of the types of plans shown in Figure 4.6 has a different set of champions within your organization, since each type of plan must draw upon knowledge and experience with different aspects of the organization’s operations, resource planning, budgeting, and decision-making. While a chief risk officer (CRO) may have overall responsibility for all of these planning processes, it’s that set of champions on each plan that will do the leadership and management work of transforming their plan into an operationally prepared capability to respond. Senior leadership, including the CRO, challenges and leads the overall effort to achieve business continuity readiness; mid-level management and knowledge workers throughout the organization both turn the plans into reality and are often the ones who execute those plans when an incident takes place.
Each of these layers of planning is (or should be) driven by the business impact analysis, which took the results of the risk assessment process to produce a prioritized approach to which risks, leading to which impacts to the organization, were the most important, urgent, or compelling to protect against. (Note that important, urgent, and compelling do address different decision criteria about responding to risks.) Let’s take a brief look in more detail at each of these planning processes and the plans they produce.
Business continuity planning considers how to keep core business logic and processes operating safely and reliably in the face of disruptive incidents; it also looks at how to restore these core processes after they have been disrupted. The business continuity plans (BCPs) that are produced are at the “high tactical” level; they use the strategic plans of the organization as context to take the prioritized core business processes (as defined by the BIA), specifying the tasks needed to recover from such a disruption. This includes all phases of incident response. BCPs do not normally go into the step-by-step operational details necessary to achieve effective preparation, response, or recovery; they rely on other, subordinate plans and procedures to do so.
Disaster recovery planning must concern itself with significant loss of life, injury to people, damage to organizational assets (or the property or assets of others), and significant disruption to normal business operations. As a result, disaster recovery plans (DRPs) look to ways to prevent a disruption from turning into panic or hysteria, while at the same time meeting the organization’s due care and due diligence responsibilities to keep both stakeholders and the community informed. DRPs, for example, often must consider that organizational cash flow will probably suffer significantly as business operations are suspended, or greatly reduced, perhaps for months.
Contingency operations planning takes business continuity considerations a few steps further by examining and selecting how to provide alternate means of getting business operations up and running again. This can embrace a variety of approaches, depending on the nature of the business logic in question.
Alternate work locations for employees to use
Alternate communications systems, internal and external, to keep employees, stakeholders, customers, or partners in touch, informed, and engaged
Information backup, archive, and restore capabilities, whether for physical backup of information and key documents or digital backups
Alternate processing capabilities
Alternate storage, support, and logistics processes
Temporary staffing, financial, and other key considerations
Critical asset protection planning looks at the protection required for strategic, high-value, or high-risk assets in order to prevent significant loss of value, utility, or availability of these assets to serve the organization’s needs. As you saw in Chapter 3, these can be people, intellectual property, databases, assembly lines, or almost anything that is hard to replace and almost impossible to carry on business without.
Physical security and safety planning focuses on preventing unauthorized physical access to the organization’s premises, property, systems, and people; it focuses on fire, environmental, or other hazards that might cause injury or death, property damage, or otherwise reduce the value of the organization and its ability to function. It works to identify safety hazards and reduce accidents.
Finally, we as SSCPs come back to the information security incident response planning processes, as shown in the “Preparation” section of this chapter. That planning process rightly focuses your attention on detecting IT and information systems events (or anomalies) that might be security incidents in the making, characterizing them, notifying appropriate organizational managers and leaders, and working through containment, eradication, and recovery tasks as you respond to such incidents.
The conclusion is inescapable: planning is what keeps you prepared so that you can respond, but your planning has to be multifaceted and allow you to look at your organization, your operations, your information architectures, and your risks across the whole spectrum of business strategic, tactical, and operational concerns and details.
It’s important to make a distinction here between plans and planning.Plans are sets of tasks, objectives, resources, constraints, schedules, and success criteria, brought together in a coherent way to show you what you need to do and how you do it to achieve a set of goals. Planning is a process—an activity that people do to gather all of that information, understand it, and put it to use. Planning is iterative; you do it over and over again, and each time through, you learn more about the objectives, the tasks, and the constraints; you learn more about what “success” (or “failure”) really means in the context of the planning you’re doing. In the worst of all worlds, plans become documents that sit on shelves; they are taken down every year, dusted off, thumbed through, and put back on the shelf with minor updates perhaps. These plans are not living documents; they are useless. Plans that people use every day become living documents through use; they stay alive, current, and real, because the people served by those plans take each step of those plans and develop detailed procedures that they then use on the job to accomplish the intent of the plan.
In a real sense, the planning you’ll do to meet the CIANA needs of your organization or business does not and should not end until that organization or business does. Ongoing, continuous planning is in touch with what the knowledge workers and knowledge-seeking workers on your team are doing, every day, in every aspect of their jobs.
Security and the Continuity Planning Process
Security professionals in your organization (like you) should be actively involved in all aspects of the continuity planning process. This can provide a consistent security focus on planning concerns and issues as they are encountered by the various planning teams, and this in turn can enable the organization to seek consistent, common approaches to providing or enhancing the security of company assets, people, facilities, and information in the event of an incident or a disaster. Read-throughs, tabletop exercises, and other test and training events can also benefit from having security’s eyes and ears open for opportunities to strengthen the loss prevention posture of the organization. (You might even suggest that a red team approach could be useful, at some points in a plan’s growth from rough draft to fully implemented. As a security professional, you should be more in tune with the ways that threat actors think and act than perhaps the other members of a planning team are.)
Interim or Alternate Processing Strategies
When disruption or disaster strikes, your organization is faced with a stark but simple choice: either activate some kind of alternate capability to conduct business processes with or have employees, customers, suppliers, and stakeholders stand around and wait until you have your original (primary) processing capabilities back in operation. Management and leadership frame this choice by setting the maximum allowable outage (MAO) time; the shorter that time period is, the greater the need for backup, alternate processing capabilities, and the greater the need for those alternate capabilities to be on “hot standby,” ready to swing into action instantly. It’s worth a moment to think about what interim and alternate generally mean in this context.
Interim processing tends to be thought of as addressing a short-term need, perhaps for less than a day; it normally does not involve the relocation of other business assets, people, or communications links; customers and suppliers are not faced with a temporary change of address or a new location to go to in order to do business with your organization.
Alternate processing tends to involve a longer-term need, such as when a fire or natural disaster makes your primary business location (or your data center) unusable for weeks or months. Customers, suppliers, employees, and critical business assets need to move to the new location and orient their interactions around it.
Translating that MAO into a processing strategy requires that you shift your thinking for a moment to the business processes that your organization uses across its full spectrum of operations. How do these fail when data, communications, processing capabilities, or other critical resources, are not available or have become corrupted or unreliable? Business continuity planning should identify these, ranked in order of their criticality to the survival and continued operation of the organization. This leads to some process-based definitions of systems failure that are most useful for planning for interim or alternate processing.
Disaster (or complete disruption): Most or all of the critical business processes needed for minimum safe operation of the business cannot function.
Interruption: One or more business processes are not able to function for a relatively short period of time.
Partial disruption: Some critical business processes cannot function, but others can continue to operate, perhaps with degraded capability or for a limited period of time.
Minor disruption: A few critical business processes cannot function, but the majority of routine functions can operate with no or minimal impact for some period of time.
Most retail sales businesses, for example, can continue to meet customer needs even though their back-office human resources, accounts payable, or strategic planning functions are disrupted. Similarly, a manufacturer can continue to operate their assembly line without those back-office business functions. Both types of business, however, will start to run into obstacles if they cannot pay their suppliers, process payments from customers, or meet payroll and tax payment obligations. Segmenting your overall business processing workloads in this way (guided of course by the logic in your BCP) should allow you to make cost-effective choices for interim or alternate processing capabilities.
The BCP should also identify which functions are tied to physical locations and which are not. This may also require separating the command, control, and management functions (the automation) from the physical systems themselves. Interim or alternate processing needs to provide some designated subset of the normal set of data acquisition, processing, storage, retrieval, computation, display, and communication services that the business processes depend upon.
Taken all together, this suggests that several strategies may be used by your organization, depending upon its business activities and overall needs for security, reliability, safety, and robustness.
Edge computing pushes the data acquisition, processing, and command and control of devices as close to the point of action as possible. For example, self-driving vehicles cannot rely on a distant command and control function because of communications latency, potential link failures or interruptions, and the volume of data acquired by the vehicle sensors and used in real time to navigate, avoid hazards, or deal with emergency conditions. Patient care, manufacturing and process control, traffic control, and many integrated logistics functions are making use of edge computing. In these cases, the endpoint systems can operate for some time without the central management system being available; and the failure of one endpoint to function does not usually cascade into failures of other endpoints.
Mirrored or parallel processing uses two nearly identical data processing systems, physically separated from each other; each transaction or operation is performed simultaneously on both systems, and both centers’ underlying databases are updated in parallel and should always be in sync with each other.
Hot backup provides for physically separated, nearly identical data processing centers as well; the backup center, however, is not mirroring every transaction or operation in real time but is refreshed with periodic incremental database updates (taken as incremental backups on the primary system). The primary system keeps a log file of transactions or operations that occur between such updates; at most, these updates (or delta transactions, as they’re sometimes called) will have to be repeated on the hot backup system before it can be fully up-to-date with the state of the business.
Cold backup provides for a minimal set of capabilities at an alternate processing location. This usually consists of having similar IT systems installed and reasonably prompt access to off-site data archival storage. It may take some time to bring operations personnel, current backups, and other critical resources to the cold backup site, start it up, and bring its databases up to date, before business operations can resume.
Warm backup refers to alternate backup processing capability that is anywhere between cold and hot in terms of responsiveness.
Note
Hot, warm, and cold backups are often said to take place at hot, warm, and cold site locations. These temperature terms have some versatility and are applied logically in a variety of ways.
Each of these strategies brings with it some hard choices, as you must trade costs, time, availability of talent, and loss of business opportunity to get different levels of availability. Each brings with it a set of choices about levels of graceful degradation that you’ll want to consider, as well as choices you’ll need to make regarding fail-safe behavior.
Fail-safe design and operation ensures that systems failures or disruptions cannot cause part or all of the system to operate in ways that can cause injury or death, or damage information, property, or the system itself. Rapidly shutting down a chemical processing facility, for example, might cause pressure vessels or pipes to overheat (or get too cold), leading to a rupture, explosion, or fire; fail safe design ensures that a pre-planned emergency shutdown operation can be performed instead.
Graceful degradation is a design and operational characteristic that allows a system to lose or shut down functions in ways that can limit the impact of a disruption. Typically, this provides users and operators with time to safely isolate activities and then use normal shutdown processes to halt those operations. Graceful degradation relies on fail safe design.
Cloud computing delivers any of these alternate or interim processing capabilities, by means of what your organization contracts with the cloud services provider to deliver. Most major cloud services providers, such as Microsoft, Amazon, or Google, can at the flip of a virtual switch provide your organization with fully mirrored backup capabilities running in data centers on different continents, or any degree of hot, warm, or cold backup. Moving business functions into the cloud does not change the overall set of strategic, tactical, and operational choices your organization must make—it only affects how much money the organization must invest up front (to buy or lease its own equipment, and hire its own people), what its recurring costs are, and how much of the technical details of managing the alternate processing capabilities it wants to outsource.
Note
Interim or alternate processing capabilities can provide significant mitigation strategies against accident, acts of nature, ransom attacks, or even malware attacks. They have little payoff, however, when it comes to data exfiltration risks, especially those involving live-off-the-land tactics. Conceivably, if you detect an intruder before they’ve started to copy, packetize, and exfiltrate data, an alternate processing capability (even a set of virtual machines) might make a suitable honeynet to isolate the intruder in while you restore systems from known intruder-free golden backups. But once you’re told that your data is for sale on the Dark Web, it may be difficult to impossible to determine when the intrusion started and therefore how far back to attempt to recover from and restore to normal.
Restoration Planning
Recovery operations bring a minimum acceptable set of capabilities back into operation and thereby deliver a minimum acceptable set of business services to the organization, its customers, and other stakeholders. Management and leadership define this minimum set of acceptable services as part of the business continuity planning process; as with all plans, the reality of any given incident may require tailoring expectations and needs to what’s practical and achievable. Restoration, by contrast, brings back the full and complete set of capabilities and services that would be considered “business normal” for the organization. These are not just IT systems–related terms. Both recovery and restoration include actions to ensure that related data, connectivity, and human procedural capabilities are also brought back to being operationally available and useful.
A third possibility exists, which applies in situations where the impact of the incident (or disaster) is significant enough that returning to “normal” business operations at that location, with the same business processes, would be too difficult, time-consuming, or exorbitantly expensive. In this case, the organization needs to build toward a new business normal, which may involve new or significantly reengineered business processes, along with the systems and infrastructures to enable and support them. A simple example would be when fire destroys the office of a small business, including its on-premises SOHO LAN system, data storage, and paper records. Migrating this business to a cloud-based platform service model might make a great deal of technical and business sense; using an application platform may require some changes to existing business processes, which might in turn catalyze the owners’ thinking in ways that reveal new business opportunities. In more extreme cases, the disaster may make it emotionally, financially, or politically difficult if not impossible to go back to the same location and restart the business at all.
The decision to return to normal operating conditions has its own set of risks that must be recognized and managed. Resuming normal operations too early, particularly at the original or primary operating location, may put people and assets at risk if containment of the causal agent(s), damages at the site, and secondary disruptions related to the incident still present hazards or risks to contend with. Conversely, a delay in returning to normal operations might incur additional unnecessary expense and maybe even additional losses. Key personnel, for example, may emotionally (not logically) react to a disaster or severe disruption by needing to seek greater job security elsewhere. Payroll obligations must be met during an outage; employment law may not allow for temporary layoffs of employees in such circumstances, and this may constrain the organization to paying its employees, or terminating them, if they cannot be put to useful work. Customers may feel the need to take their business elsewhere; investors may lose confidence in the company and its management team; share prices may start to suffer. These, of course, are management’s issues to worry about; what they’ll need from you and the rest of the information security team is the reassurance during incident response and, afterward, that the information they are getting about the organization’s systems, and the information from those systems, is reliable enough to base those decisions on.
Recovery and restoration planning are important opportunities for security professionals to advise, guide, and, if need be, lead the planning team toward effective ways to protect the organization’s information, assets, people, and reputation. Security’s viewpoints and experience should be involved as BCP and DRP policies are formulated, as those policies are turned into procedures and guidelines and as implementation programs are developed and put into action. From an information systems security perspective, you’ll be the experts to advise on the step-by-step of the recovery and restoration processes so that the right security controls are put back in place, configured, and activated at the right point in the recovery and restoration of each part of the organization’s IT infrastructure and its systems, servers, and endpoints. A significant amount of sensitive and important data is in motion during recovery and restoration operations—moving from archival and backup storage facilities and media, being reformatted, being reloaded into its proper operational places, and then validated as ready for use. Each step of that process is an opportunity for mistakes (or malfeasance) to cause more harm.
Every step of the recovery and restoration processes—in fact, every step of business continuity and disaster recovery activities, from planning to post-op—is an opportunity to learn from experience. It’s also important to learn from the experiences of other organizations as they have gone through responding to and recovering from incidents, disruptions, and disasters. This cross-fertilization of experience and ideas can be something your company pursues with its strategic partners or members of its trade or industry association; as an SSCP, you have many opportunities within (ISC)2 and beyond to do the same. Listen to the people involved with each step, seek their views and impressions, and resist the temptation to explain, solve, or seem to judge what they are saying. Take their candor at face value, go back to your workspaces, and translate those observations into the two favorite lists of the ethical hacker: findings and good findings. Findings are the observations of what didn’t work right; either the plan was not sufficient or the steps were not executed according to plan. Good findings are observations of what worked correctly and effectively. These are good news! Celebrate them with the team, and with management and leadership. No matter how small the incident was, recovering from it brought stress, worry, aggravation, and lost work with it as part of its impacts. Good findings can be a powerful and inexpensive way to help re-invigorate a tired and worn-out team.
Backup and Redundancy Implementation
Perhaps the most important element in providing for safe, secure, and reliable data backup is the process by which you manage, account for, and control the ways that backups are made, stored, validated, used, and retired. If that sounds like another lifecycle model or another configuration management and configuration control opportunity, you’re right! It’s trivially easy for the smallest of organizations to benefit from many different free or inexpensive cloud-based data backup services, such as OneDrive, Dropbox, or iDrive. Very inexpensive RAID disk systems provide multiterabyte mirroring, striping, and recovery capabilities that bring hardware redundancy to the SOHO LAN user. These same controller and software technologies, when combined with very large arrays of high performance, high-reliability disk drives, are the backbones of modern data center and cloud-hosted storage systems.
Managing the Data Backup Process
All data backup operations involve the same simple steps: first, make a copy of the files; then, move the copy to another location or device for safekeeping (sometimes called the backing store). Restoration then involves getting the copy from safe storage and reloading it onto the original target machine, its replacement, or onto another machine for parallel or shared use by another user. Keeping track of what’s been backed up, when, where the backup copy is, and knowing when and how to reload which systems from the backups is the heart of the data backup management problem. These simple concepts apply whether your operational systems and backing store are on-premises, in a public or hybrid cloud, or totally within a single cloud service provider’s system. (Just because you host your data in the cloud to begin with does not mean you don’t need to back it up. Someplace else, preferably.)
Management challenges common to all backup and restore strategies include the following:
What data was selected and scheduled for a routine backup? Was the backup performed successfully?
Are backups validated in some way to ensure that they can be reloaded onto the source system or a replacement target system?
What prevents malware or other software-induced corruption of your source system’s files from being propagated into your backup copies?
Do you have (or need) to know when backups have been partially or completely restored to a system, and if so, by whom?
What prevents unauthorized access to, copying, or other use of backup data sets?
Managing all of those backup copies, archive copies, and the media they are stored upon is an exercise in metadata management. At its heart, backup management needs to have:
Ways to define sets of files to be backed up (and possibly restored) as logical sets
A system for creating, dispatching, monitoring, controlling, and verifying backup jobs
A system for creating, dispatching, monitoring, controlling, and verifying restore jobs, either partial or complete
Error recovery capabilities (useful when backup jobs get interrupted, or when files cannot be accessed, read, or written to)
Access control and accounting commensurate with the security needs of the organization, as applied to backup data
It’s ideal that your backup management system use a catalog database to capture and keep metadata information on every file that’s part of your backup operations. This metadata should tell the full life story of the file, which at a minimum should include:
Its initial creation, including date, time, system location, and creating user ID or process ID
Data security classification, handling restrictions, or other security parameters and constraints assigned to the file at creation
Each subsequent alternation of the file, including date, time, system location, user ID or process ID
Each copy of the file, to any other media, and whether the copy was for backup, archive, or other operational use
For each archival media set (be that a tape cartridge, disk, NAS, or cloud storage blob), your catalog should also track each time the data has been downloaded (or restored) to a location.
Many backup, archive, and restore management systems provide extensive capabilities to allow systems administrators and security administrators a wide range of control over how data is backed up, shared, restored, and used throughout their organization’s information infrastructure. In many ways, the task of managing a data backup and restore capability has merged with that of managing the data in a data center.
Even the smallest of SOHO shops can benefit from a sensible data backup and restore management capability. This starts by first making decisions about what data to protect from catastrophe and outlining some simple procedures to define backup sets and backup processes. Next, choose an appropriate set of technologies, including the management dashboard or functionality that you need. Gone should be the days of backups done on seven removable disks, one per day, with six being daily incremental backups and the seventh being a complete backup, all managed by the stick-on labels on the disks themselves. Even the smallest of businesses deserves better.
One significant advantage of a cloud-based backup management system is that no matter what happens to your primary operating location and systems, all you need are your access credentials to get to the tools that you’ll use to manage the data recovery portion of your incident response plan.
Platform and Database Backup
Application platforms and most database applications have their own built-in data backup, restore, and synchronization capabilities. These are quite often used to define and manage incremental, differential, or transaction-level backup operations, as well as managing complete backups of the data involved with that platform or database. This often provides important capabilities to manage the reload of portions of the data, such as individual transactions, or to back out (logically remove) transactions that are deemed suspect for any reason. Using built-in platform and database capabilities to manage their own data backup and restore does add a layer of complexity to your overall planning, but it’s probably worth the effort in terms of data integrity.
Once you’ve solved the management problem, it’s time to consider how you want to implement what degree of redundancy in your backup operations.
Storage Redundancy
In one sense, redundancy and backup are the same concept to enhance data availability and integrity. Both use multiple storage devices (such as disk drives) to which multiple copies of a file, directory structure, or database extent are written. Redundant storage technologies, such as redundant array of independent disks (RAID), write those copies at the same time; when retrieved, all copies of the data are read back at the same time, compared (by the storage controller) to provide error checking and correcting before the data is passed to the compute task and processor that needs it. Backup operations take a file, disk image, or database that is already written to storage media and copy it to a different storage device; depending upon the nature of the backup, both the original and the copy may then be compared as part of error checking and correction.
Redundant storage using RAID technologies provides a number of different options for systems architects and security planners to consider, known as the different RAID levels.
RAID 0, block-level striping: Distributes the data across multiple drives. This increases the read and write speed (performance), but it also increases the risk of drive failure since the loss of any one of the drives will make the data unusable.
RAID 1, mirroring: Copies the data to two or more drives so that the loss of a single drive would not mean the loss of the data.
RAID 2, bit-level striping: Manages bit-level striping with error correction. This is not commercially viable because computational overhead exceeds performance benefits.
RAID 3, byte-level striping with parity bits: Stripes data across multiple drives. Parity bits are created that would allow the data to be rebuilt in the event of a single drive failure.
RAID 4, block-level striping with parity bits: Stripes data at a block level. Parity bits are created that would allow the data to be rebuilt in the event of a drive failure.
RAID 5, block-level striping with interleaved parity: Stripes data at a block level. Parity bits are created and distributed among all drives. This would allow the data to be rebuilt in the event of a drive failure.
RAID 6, block-level striping with duplicate interleaved parity: Stripes data at a block level. Parity bits are created that are distributed among all drives. This would allow the data to be rebuilt in the event multiple drives fail.
RAID 1+0 and 0+1, a combination of mirroring and striping: Mirrors the stripes or stripes the mirrored data (the order of operations is different). These are the most expensive options but the best for both performance and reliability.
Backup Protection at Rest and in Motion
Protecting your data while at rest while it is in backup or archive storage systems or location may be required to meet your organization’s full set of CIANA information security needs. This may involve using encrypting file systems, digitally signing files, folders, or other container structures. Security may also require or be enhanced by using secure links or connections to protect the data while in motion from source system to backup storage. These same security needs may dictate that any RAID storage devices or systems you use encrypt the stripes or blocks of files as they are written to physically separate disk drives. When (not if) an individual disk drive fails, it can simply be scrapped if all of the data on it, including its directory structures, were encrypted; if no encryption is used, somebody has to attempt to randomize or sanitize that drive to ensure that no exploitable information can be recovered from it. Almost all cloud hosting services encrypt each customer’s data separately and then bulk encrypt what gets written to each physical disk. They spend a little more CPU time doing encryption and decryption, but this simplifies their maintenance activities while buying them a lot of litigation insurance against a data breach or data loss affecting multiple customers. The same strategy is easy to implement, and highly recommended, for in-house data centers. Chapter 5, “Cryptography,” will go into this in more detail.
Backup technologies can involve cloud storage, network-attached storage (NAS), or removable storage devices. It’s strongly worth considering RAID technologies for any on-premises NAS or removable storage use.
Data Recovery and Restoration
Your incident response team has all the hardware, operating systems, and network elements of your IT infrastructure back up and running; you’re now about to reload data, either directly from archive or backup media or by restarting applications platforms and database systems servers and letting those software systems manage their own data reload. Several possibilities face you at this point:
Your archive and backup data exist where your backup management records say that they should, and they can be successfully read and used to reload the systems with.
Although you can find and access the backup media, parts or all of it cannot be read or loaded without errors.
You have no data backups available to load from.
The storage technologies on the systems disrupted by the impact had to be completely sanitized and reformatted as part of containment, eradication, and restoration.
Case 1 is the ideal, of course; it does not come free, and it does require both initial investment and ongoing costs to continually make backups, validate them, and manage them. Case 2 does happen, and as a worst-case situation, you may need to use data recovery tools to scan the storage devices on your systems to see whether you can identify original files, recover them, rebuild directory structures, and then get back into business. Cases 3 and 4, despite the difference in their causes, present your management with a hard choice: either the end users create a new “fresh start” in the data plane and then begin new business operations from that point forward or they exhume paper or other business records from archive, re-create the past transaction history in the systems’ data files and databases, and then build a “fresh start” on top of that foundation.
Although these may seem somewhat extreme, experience shows us that most organizations face similar data recovery choices despite their best efforts at pre-planning and arranging for data backup or archive operations.
The skills, tools, and techniques you’ll need for recovering data from a crashed or partially corrupted disk drive or storage subsystem are almost the same that you’d need when conducting a forensic analysis of it. Data carving is the name given to the art and science of scanning areas of storage to find partial files, file headers, and other data, and attempting to reassemble those pieces into logically complete files. It’s a bit like reverse engineering what’s stored on the drive(s) and is logically similar to trying to reverse engineer, decompile, or disassemble executable program files. Sometimes all that is needed is to physically mount the offending disk drive on a system running a different operating system (e.g., mount a Windows NTFS drive on a Linux machine) as a way to work around errors induced into the directory structures by the source operating system’s misbehavior during the incident. Other tools, such as RecoverMyFiles, can quickly deal with terabyte-sized disks and locate almost all recoverable files; these tools provide powerful capabilities to manage this recovery process, including extensive logging and reporting functions.
When you finally get to the happy landing of the previously described case (1) and can load backup or archive data directly into your systems, you’re just about done. Ideally, the same management tools, application platforms, or database systems you used to create and manage the backups and archive copies are being used to manage and verify the reload.
Three special considerations during data reload (whether by restoring from backups or recovering from damaged media) should come to mind at this point.
Preventing reinfection from malware: It’s a good chance that a backup copy might have a specimen of malware on it that was unknown to your anti-malware scanner when the copy was made; scan all restore media using the latest malware definition and signature files that you can get hold of to reduce this risk.
Prevent reloading of corrupted data files: Files that are malware-free but contain contradictory, illogical, or erroneous data could cause critical business processes to produce errors, hazardous outputs, or crash. Consider ways to scan or validate that all critical applications data files are logically correct before reloading them.
Intruder user IDs, device IDs, or other subject-related data: At some point in the recovery of your systems, you may have to reload data into the access control system, which conceivably could be vulnerable to having bogus user IDs, device IDs, or attribute data loaded into it as if it were trustworthy data. The access control technologies you use may determine whether this is a significant or near-zero risk and may provide ways to mitigate that risk.
The nature of your systems and your information architecture will in large part determine whether you must reload all data for all applications before you can validate that the incident response and recovery is complete or whether you can do this by location, by function, by application, or by sets of business processes. Incident response and business continuity planning should consider this and provide structured guidance, which the reality of each incident will then test. Patience is hard to hold on to at this point, unfortunately, as it can seem hard for business unit managers to separate “we’re almost there” from “we’re ready to go back to business.” Regardless, your incident response process should invoke some kind of integrity checking at this point: just because you have everything reloaded, restarted, and running, and all of the data is there, doesn’t necessarily mean it’s all working correctly. Subsets of routine operational test and evaluation (OT&E) test scenarios may offer well-understood and proven benchmarks to use at this point.
Training and Awareness
Once the business continuity and disaster recovery plans have been written, they must be communicated to the entire staff of the organization. Although some people who have specific responsibilities during a crisis will need more advanced training, everyone should be provided an awareness of the organization’s plans and how they should react in a crisis.
At high-risk locations, crisis awareness should be provided to all personnel at the time they enter the site. This will ensure that everyone on the site knows how to recognize an emergency situation and how they should respond. All personnel should be familiarized with safety and occupant evacuation plans at the time of hiring and then provided with annual reminders. These awareness sessions will advise staff on evacuation plans and procedures, specify meeting points, declare who is in charge during a crisis, and advise on how to report a crisis or suspicious activity.
Other personnel may require training in the use of tools or procedures such as chemical suits, system recovery procedures, crowd control, team management, evidence preservation, incident analysis, and damage estimation.
Since staff often change roles within the organization, it can be necessary to retrain staff and reorganize recovery teams on a periodic basis.
Personnel training for BCDR activities should be in concert with plan testing, which is discussed in the following section.
Testing and Drills
It may seem odd to have a strong focus on testing and assessment of your information security practices embedded here in a chapter on incident response; if so, think of this as boiling this chapter down to the question of what your readiness to respond actually is. Other chapters will look at security testing and assessment in the context of risk mitigation and controls (Chapter 3) and the protections put in place for your networks and communications (Chapter 6), systems applications, and data (Chapter 7, “Systems and Application Security”). Here, let’s use testing, exercises, drills, assessments, inspections, and audits as part of how confident you and your managers can be in your end-to-end incident response capabilities and the people who deliver them day in and day out.
Three different approaches can be used to build confidence in your organization’s incident response capabilities; each brings different issues to light while providing a different way to assess overall response readiness. In some organizational and systems cultures, these three words have distinct meanings; in others, they are used interchangeably. The distinctions are useful to keep in mind.
Testing validates that a system can or does deliver the functional or performance requirements allocated to it. Tests can include the operational procedures and the people who would normally use these systems during routine business operations; tests can also be performed against controlled test scenarios and be conducted by test teams.
Exercises provide controlled, safe ways for the people and procedural components of systems to use those systems in realistic scenarios that reflect portions of normal operations. Exercises are often the major component in training programs, as they can focus on building skills and proficiency through practice.
Drills are similar to exercises and tend to use a smaller set of activities in their specified scenario than an exercise might. Drills can be used to provide a simulation of reality, often without notice to end users (or building occupants).
The use of testing, assessment, exercises, and drills in information security has expanded greatly in the last decade and has borrowed many additional concepts from the world of military security and intelligence activities.
Penetration testing (more properly known as ethical penetration testing) is a broad category of activities intended to see your systems from the adversary’s point of view; the pen testers attempt to challenge the security effectiveness of your organization and its systems to help the organization uncover exploitable weaknesses.
War games can be a form of testing, exercises, drills, or penetration testing; many war games start with a given scenario or problem set (such as “Can we detect a data breach before it’s too late?”) and build the scenario to drive toward that assessment. Other war games can focus instead on personnel proficiency, which is at its heart an assessment of what people have been trained to do and how effective that training was in building knowledge and skills.
Red team/blue team exercises are a form of war gaming or ethical penetration testing. A broad set of rules of engagement (ROE), constraints, and conditions is established; the red team (the attackers) can then do anything they want within those constraints and ROE, to attempt to “capture the flag,” exfiltrate the crown jewels of your data, or otherwise achieve objectives set by the red team and the organization. The blue team (the defenders) is usually not told that such a test is taking place; these are no-notice activities, with the conscious intent of having an independent attacker realistically test the organization’s defenses.
Why Red and Blue?
Colors have long been associated with nations; and in the 1920s, U.S. Army planners, fearful of the power of Britain’s Royal Navy, developed what became known as the Color Plans. War Plan Red assumed that the United States would go to war with the British Empire (remember the red coats worn by the British Army up until World War I?). Other color plans looked at other scenarios. After the end of WW II, heightened fears of a U.S.-Soviet nuclear war led to the United States creating a series of war games called Blue Flag (with controlled scenarios, primarily to evaluate doctrine) and Red Flag (in which the aggressor squadrons modeled the best that the United States knew about Soviet military doctrine).
Americans tend, therefore, to always label the aggressors as the red team. However, I was told by the commander of the National Training Center, Fort Irwin, California, that during a visit in the late 1980s by Soviet military leaders, one of them remarked that in his country they use the red team/blue team paradigm as well. “But in our country,” he went on,” the red team are the good guys.”
I don’t know if there are any cultures in which the “black hats” are known to be the good guys; if there are, please let me know.
One further set of color schemes to keep in mind about all of these kinds of events describes the level of knowledge or awareness that participants, especially the attackers, aggressors, or pen testers, have about the organization, its systems, its security measures, and its problems.
Black-box testing, or zero-knowledge testing, denies the testers any inside knowledge of how the system works, its design, and its operational characteristics. Testers can only learn about the system under test by observing it, probing it, or interacting with it; they can also exploit open source intelligence (OSINT) by seeking publicly available knowledge about the target, such as published filings with government regulators, news coverage, employee social media postings, and the like. Black-box testing is adversarial testing in every sense of the word.
White-box testing, or full-knowledge testing, shares everything that the systems builders, operators, and owners know about their system with the testers. This is cooperative testing and is most often seen in development and acceptance testing.
Gray-box testing involves any level of sharing of information between the extremes of zero sharing and full sharing.
This brings us to one more color of testing: purple team testing is a red team/blue team test that is structured to encourage and rely upon active cooperation and communication between the aggressors and the defenders.
Tests, evaluations, exercises, and drills should all be planned events that are managed and conducted by an evaluation, test, or exercise director. Each of these activities has an objective it is trying to achieve; the test or exercise director has to be able to decide in real time if the continued conduct of the activity is on track to demonstrating or achieving that objective or if the issues discovered so far dictate that the activity be suspended or terminated. The test or exercise director must also be able to terminate the activity if other real-world business or environmental circumstances dictate the need to do so. (For example, a real severe weather warning may dictate that personnel not essential to a minimum and safe level of business operations be sent home or sent to take shelter, which would probably require terminating a test, exercise, or drill activity.) The test director is also the single face and point of contact to other organizational managers and leaders.
Tests should be part of your ongoing process to validate that your various incident response plans still provide the capabilities you require. They can measure, assess, or demonstrate that functions can be performed and that specific response or recovery actions can be accomplished within the time allotted to them. They can also provide powerful ways to develop and train staff, familiarize them with their roles in carrying out the various plans, and help them bring their role together with those of other team members. Incremental or spiral test strategies help grow team capabilities while they find flaws in the initial concepts, procedures, or processes; this also provides the opportunity for continuously improving your incident response processes.
Test Environments
Testing on your live production system is inherently risky; if something goes wrong, the test activity can interrupt your normal business processing, corrupt it, and in a worst case start a cascade of errors that damages your relationships with key customers or suppliers. Tests that involve the use of malware, such as ethical penetration testing (in any color and shade of gray) could conceivably fail in ways that spread that weaponized malware across your Internet connection to other unsuspecting systems, with concomitant legal repercussions for your organization. Despite these risks, the payoff to organizations from testing in the live environment is significant; this dictates that extraordinary precautions be taken and that the test be closely supervised by the test director, who can pull the plug and terminate the test before things go too far wrong.
Many organizations have separate software and systems test environments (which may merely be a separate set of virtual machines and containers) that they use for development and acceptance testing, operator training, and software remediation testing. These can be easily and safely adapted or replicated for security testing; in fact, it is more than prudent to first perform any test activities in a virtual sandbox environment before you take that same attack scenario into your live production settings.
Tests, exercises, and drills can also involve external players, such as emergency services providers, strategic partners, vendors, or customers, and other members of your federated systems community. Outside observers, such as independent auditors or security professionals, may also be of value to your test approach. In some cases, regulations may require that specific kinds of security-related testing be conducted by specially trained and certified independent testers or auditors; these regulations may specify whether this testing can be done in a test environment or whether it must be done in the live production systems.
At the completion of every test, a debriefing session should be held to review the results of the test and examine ways to improve the plans and mentor staff. The results of the test should be compared against the initial objectives. The examination of the plans following a test should also involve the auditors and the business units to ensure that the plans are aligned with the business priorities and strategy. Debriefing can be conducted immediately after the test in what is sometimes known as a hot debrief, when the activities of the test are still fresh in everyone’s mind, but this can also run the risk of some of the tension and stress of the test affecting a person’s response and perception. A debrief at a later date (preferably within a week) may allow the participants more time to reflect and analyze the test and thereby provide more detailed objective feedback. This can be done through a survey or a formal workshop.
A variety of test strategies and approaches should be considered, as you build your incident response capabilities and assess their effectiveness and readiness.
Read-Through or Tabletop Assessment
The most basic level of business continuity and disaster recovery testing is a simple read-through of the plan. This review should be done by the manager or liaison from each business unit and the emergency planner coordinator on (at least) an annual basis to ensure the plan is up-to-date and reflects business priorities. Each manager should be required to review and approve the plan for their department and provide updates where required.
The manager of each business unit should verify contact information, validate priorities and key personnel, and verify that all of their staff is familiar with the business continuity procedures.
The tabletop exercise accentuates the read-through. The response participants (those with roles in crisis management/response) meet together, along with a moderator, and role-play a response to a simulated contingency situation using the response plan as a guide/resource. This is the least expensive/intrusive form of test/exercise and is used to validate the utility of the plan and familiarize participants with their respective roles.
Walk-Through
A walk-through builds on the concept of the tabletop/read-through, adding the simulation of response activities at actual locations where response actions will be performed. In a tabletop exercise, a participant might say, “I go to the wire closet and flip a switch,” whereas, in a walk-through, the participant will actually go to the wire closet, point to the switch, and say, “I flip this switch.” The action, at this level of exercise, is only simulated, but the locations are mapped to the activity, and participants are familiarized with specific areas and hardware. In some cases, a test like this may be based on an actual scenario to test the response process and create a realistic setting for the test to be conducted in. A test like this may follow the actual timelines of the scenario or jump ahead to a later point in the scenario to test specific conditions or activities.
Simulation or Drill
Simulations, in general, use a predefined scenario and set of input actions to drive a limited or constrained copy or version of a system (including its human and procedural components) to make decisions and take action. Using a copy of the production system in a virtual environment and operating it with a test team is an example of a simulation. A drill, by contrast, may use the same scenario but is executing on the production system or in the actual workplace and affects the pace of activity of end users, operators, and others in the workplace. Drills can be conducted with advance notice to all parties concerned or run as no-notice events; fire drills and other disaster preparedness drills are often done both ways.
Parallel
Parallel tests are useful and usually involve fully duplicated systems or operational locations. For example, an organization that has a mirrored hot site may run that site in parallel to the primary location once a month, or an organization with a subscription to a commercial hot site may load its data onto the hot site and run its operation at that site once or twice per year. This allows the systems and operations to be tested at the recovery site without impacting normal business operations, which continue to operate at the normal or primary location. Another example is restoring data backup media in a test environment to determine whether the backup can be accessed in a specific time frame (whether the media is on-site or off-site), whether the restoration procedures are sufficiently detailed and clear, and whether the backup data is complete and accurate.
This type of test often finds errors that are not easy to find during other types of tests. Examples of this include access permissions set incorrectly, missing files, incorrect configurations, outdated or unpatched applications, and licensing issues.
Full Interruption
A full interruption test presents the highest level of risk to an organization. It is designed to test the plan or a portion of the plan in a live scenario and requires the participation of many team members. This type of test may inject an intentional failure into the process to ensure that staff and recovery systems operate correctly. An example of this is where a telecommunications company is required to demonstrate to regulators that the telephone system can continue to operate in the absence of commercial power. For this test, the telecom company has to cut over to batteries and diesel backups for several hours once per year. Such tests always introduce a level of stress and uncertainty since it is common that some part of the failover process will not operate correctly on the day of the test. It is noteworthy that these companies will do a parallel test of their power backups monthly but a full interruption only once per year. A full interruption test should be conducted only when other, less risky tests have been completed and only with the approval of senior management.
CIANA at Layer 8 and Above
Although the OSI reference model technically has only seven layers, ever since it was first being drafted, there were any number of authors (including Michael Gregg, in his 2006 classic Hack the Stack) who referred to the people-facing administrative, policy, training, and procedural stuff as layer 8. (Pundits have also pointed out additional layers, such as Money, Political, and Dogmatic, but for simplicity of analysis, SSCPs can lump those all into the “people layer.”) Layer 8 by that name probably won’t appear on any official standards document, but regardless, vulnerabilities, exploitations, and countermeasures involving how people configure, control, manage, use, misuse, mismanage, and misconfigure their IT systems no doubt will. Figure 4.7 illustrates this concept, and much like Figure 4.6, it too shows many process-focused aspects of running a business or organization that intermesh with each other. Note that just as every layer within the OSI protocol stack defines and enables interactions with the outside world, so too does every protocol or business architectural element on Figure 4.7. The surrounding layers might be immediate customers, suppliers, and clients; next comes the overall marketplace and maybe the society or dominant culture in the nation or region in which the organization does business. This layer-by-layer view of interaction can be a powerful way to look at both the power and value of information at, within, or across a layer, as well as a tool that SSCPs can use to think about threats and vulnerabilities within those higher layers of the uber-stack.
In Chapter 2, you saw that network security needs to address more than just the CIA triad of information security. As an acronym, CIA reminds you of the need to maintain the confidentiality, integrity, and availability of your information.
CIANA adds nonrepudiation and authentication to those same three attributes.
Nonrepudiation, you recall, is strongly linked to the use of the public key infrastructure and its use of asymmetric encryption. Authentication, of course, is provided by identity management and access control.
Chapters 6 and 7 present the need to add safety and privacy as separate but equal partners to these five attributes of information security, which I will write as CIANA+PS.
Collaborative workspaces are an excellent case in point of this. The design and manufacturing of the Boeing 767 aircraft family involves hundreds of design, manufacturing, and supply businesses, all working together with a dozen or more major airlines and air cargo operators, collaborating digitally to bring the ideas through design to reality and then into day-to-day sustained air transport operations. At layer 7 of the OSI stack, there were multiple application programs and platforms used to provide the IT infrastructure needed for this project. The information security rules that all players in the B767 design space had to abide by might see implementation using many physical and logical control technologies across layers 1 through 7, yet with all of the administrative controls being implemented out in “people space” and with the interorganizational contractual, business process, and cultural spaces all in layer 8.
To date, sadly, a number of IT security professionals have constrained their gaze to layer 7 and below. The results? Missed opportunities to better serve the information security needs of their organizations. One irony of this is that almost by definition, all administrative controls are instantiated, implemented, and used (and abused or ignored) beyond layer 7.
Let’s take a closer look at those next layers.
It Is a Dangerous World Out There
If we were to redraw Figure 4.7, we might be able to see that the people element of an organization makes up a great deal of its outermost threat surface. Even the digital or physical connections our businesses make with others are, in one sense, surrounded by a layer of people-facing, people-powered processes that create them, operate them, maintain them, and sometimes abuse or misuse them. You can see this reflected in the dark humor of the security services of many nations: before the computer age, they’d joke that if your guards, secretaries, or janitors owned better cars, houses, or boats than you did, you might want to look into who else is paying them and why. By the 1980s, we’d added communications and cryptologic technical and administrative people to that list of “the usual suspects.” A decade later, our sysadmins and database administrators joined this pool of people to really watch more closely. And like all apocryphal stories, these still missed seeing the real evolution of the threat actor’s approaches to social engineering.
The goal of any social engineering process is to gain access to insider information—information that is normally not made public or disclosed to outsiders, for whatever reason. With such insider information, an outsider can potentially take actions that help them gain their own objectives at greatly reduced costs to themselves, while quite likely damaging the organization, its employees, its customers, its stakeholders, or its community. In Chapter 3 you saw how one classical and useful approach to keeping insider information inside involves creating an information security classification process; the more damaging that disclosure, corruption, or loss of this information can cause to the company, the greater the need to protect it. This is a good start, but it’s only a start. Social engineering attacks have proven quite effective at sweeping up many different pieces of unclassified information, even that which is publicly available, and analyzing it to deduce the possible existence of an exploitable vulnerability.
Social engineering works because people in general want to be well regarded by other people; we want to be helpful, courteous, and friendly, because we want other people to behave in those ways toward us. (We’re wired that way inside.) But we also are wired to protect our group, be that our home and family, our clan, or any other social grouping we belong to. So, at the same time that we’re open and trusting, we are hesitant, wary, and maybe a bit untrusting or skeptical. Social engineering attacks try to establish one bit of common ground with a target, one element on which further conversation and engagement can take place; over time, the target begins to trust the attacker. The honest sales professional, the doctor, and the government inspector use such techniques to get the people they’re working with to let down their guard and be more open and more sharing with information. Parents do this with their children and teachers with their students. It’s human to do so. So, naturally, we as humans are very susceptible to being manipulated by the smooth-talking stranger with hostile intent.
Consider how phishing attacks have evolved in just the last 10 or 15 years.
Phishing attacks tended to use email spam to “shotgun blast” attractive lures into the inboxes of perhaps thousands of email users at a time; the emails either would carry malware payloads themselves or would tempt recipients to follow a URL, which would then expose their systems to hostile reconnaissance, malware, or other attacks. The other major use of phishing attacks is to identity theft or compromise; by offering to transfer an inheritance or a bank’s excess profit to the addressee, the attacker tempts the target to reveal personally identifiable information (PII), which the attacker can then sell or use as another step in an advanced persistent attack’s kill chain. The attacker can also use this PII to defraud the addressee, banks, merchants, or others by masquerading as the addressee to access bank accounts and credit information, for example.
Spear phishing attacks focused on individual email recipients or very select, targeted groups of individuals, and in true social engineering style, they’d try to suggest that some degree of affinity, identification, or relationship already existed in order to wear down the target’s natural hesitation to trusting an otherwise unknown person or organization. Spear phishing attacks often were aimed at lower-level personnel in large organizations—people who by themselves can’t or don’t do great things or wield great authority and power inside the company but who may know or have access to some little bit of information or power the attacker can make use of. The most typical spear phishing attack would be an email sent to a worker in the finance department, claiming to be from the company’s chief executive. “I’m traveling in (someplace far away), and to make this deal happen, I need you to wire some large amount of money to this name, address, bank name, account, etc.,” such phishing attacks would say. Amazingly, an embarrassingly large number of small, medium, and large companies have fallen for these attacks and lost their money in the process.
Whaling attacks, by contrast, aim at key individuals in an organization. The chief financial officer (CFO) of a company might get an email claiming to be from their chief executive officer (CEO), which says much the same thing: “If we’re going to make this special deal happen, I need you to send this payment now!” CFOs rarely write checks or make payments themselves—so they’d forward these whaling attack emails on to their financial payments clerks, who’d just do what the CFO told them to do. (One of my friends is the CEO of a small technology company, and he related the story of how such an attack was attempted against his company recently, and the low-level payments clerk in that kill chain was the only one who said, “Wait a minute, this email doesn’t look right…,” which got the CEO involved in the nick of time.)
Real World Example:
Buying a home? Best be Whale-Watching too!
Whaling attacks are beginning to target real estate purchasers, using the same “transfer the funds now or we’ll lose the deal” kind of tactic. Sadly, it’s proving quite profitable for the attackers.
Catphishing involves the creation of an entirely fictitious persona; this “person” then strikes up what seems to be a legitimate personal or professional relationship with people within its operator’s target set. Catphishing originated within the online dating communities, but we’ve seen several notorious examples so far of its use in attack strategies that do not involve romance.
This list could go on and on; we’ve already had more than enough examples of advanced persistent threat operations that create phony companies or organizations, staffed with nonexistent people, as part of their reconnaissance and attack strategies.
Notice that by shifting from phishing to more sophisticated spear phishing, whaling, or even catphishing attacks, attackers have to do far more social engineering, in more subtle ways, to gather the intelligence data about their prospective target, its people, and its internal processes. Of course, the potential payoff to the attacker often justifies the greater up-front reconnaissance efforts.
This all should suggest that if we can provide for more trustworthy interpersonal interaction and communication, we could go a long way toward establishing and maintaining a greater security posture at these additional layers of our organization’s information architecture. Much of this will depend on your organization, its decision-making culture and managerial style, its risk tolerance, and its mission or strategic sense of purpose. Similar to how we look at incident detection and its requirements for timely and far-ranging monitoring and analysis (as discussed in this chapter’s “Support the Incident Lifecycle” section), we’re looking for ways to find precursors and indicators that some kind of reconnaissance probe or attack is in the works. For example, separation of duties can be used to identify “need to know” boundaries; queries by people not directly involved in those duties, whether insiders or not, should be considered as possible precursor signals. This can aid in key asset protection, security for critical business processes, or even the protection of information about the movement or availability of key personnel. Penetration testing or exercises that focus on social engineering attack vectors might also help discover previously unknown vulnerabilities or identify important ways that improved (or different) staff education and training can help “phishing-proof” your organization.
People Power and Business Continuity
There’s a lot of great advice out there in the marketplace and on the Internet as to why organizations need to teach their people how to help protect their own jobs by protecting critical information about the company. As an SSCP, you can help the organization select or create the right education, training, and evaluation processes and tools for this. A survival tip: use the separation of duties principle to identify groups or teams of people whose job responsibilities suggest the need for specific, focused information protection skills at the people-to-people level.
That’s an important thought; this is not about multifactor identification or physical control of the movement of people throughout the business’s office spaces or work areas. This is also not trying to convert your open, honest, trusting, and helpful team members into suspicious, surly, standoffish “moat dragons” either! All you need to do is get each of them to add one key concept to their mental map of the workplace: trust, but verify. Our network engineers need to build our systems in as much of a zero-trust architectural way as the business needs and can afford, but the most flexible, responsive, surprise-tolerant, and “abnormality-detecting” link in our security chain needs to stay trusting if it’s going to deliver the agility that resilient organizations require. They just need to have routine, simple, safe, reliable, and efficient ways to verify that what somebody seemingly is asking them to do, share, or divulge is a legitimate request from a trustworthy person or organization.
Without needing to dive too deeply into organizational psychology and culture, as SSCPs we ought to be able to help our organizations set such processes in place and keep them simple, current, and useful. This won’t stop every social engineering attack—but then again, no risk control will stop every threat that’s targeted against it either. And as organizations find greater value and power in actually sharing more information about themselves with far larger sets of outsiders—even publishing it—the collection of information “crown jewels” that need to be protected may, over time, get smaller. That smaller set of valuable nuggets of information may be both easier to protect from inadvertent disclosure, but may also become much more of an attractive target.
Summary
Incident response can be summarized by using the rule of threes.
First, you’ve seen that there are three measures of merit that should dominate your thinking when it comes to information security incidents. The mean time to detect an incident can no longer remain in the over-100-day neighborhood if businesses and organizations are going to survive. SSCPs have got to find ways to bring that number down, at least into the double-digit range if not into the bounds of a single week. The mean time to respond is currently hovering around 60 days; this, too, speaks horribly about the security industry’s best practices as not being effective in characterizing an intrusion and containing it. And while there’s not much data published regarding the mean time to eradicate an intrusion (with or without its malware elements), there’s no doubt room for significant improvement on this front as well.
Second, incident responders cannot see their job as being in only one phase of the incident response lifecycle at any given day or time. While one incident is being contained, others are probably already in progress, undetected and unrecognized. Your awareness has to embrace the past, present and enable you to look into the near-term future; your ability to learn from the now has to become the most powerful edge you have over your adversaries.
Third, you’ve seen that the success or failure of your organization boils down to the people, the processes, and the technologies that are put in place to reduce the information security threats to your organization to a survivable, acceptable minimum. Lessons can and should be learned by applying process maturity models to the ways in which you help organize, train, equip, and prepare your fellow incident response team members to provide constant vigilance and on-time response. Doing so can strengthen your arguments as you seek management’s support for focused investments in new technologies, in re-engineered and improved processes, and in the people who will make or break your organization’s security posture in the long run.
Fourth (for we are not limited to three uses of the rule of threes), organizations must look at incident response from the strategic, operational, and tactical perspectives. These three different viewpoints should be harmonized continuously. It’s not just one department, such as IT security, that has the total responsibility for keeping the organization’s information safe, secure, private, and available. Marketing, public relations, budget and finance, sales, manufacturing, customer relations, the product or service development, and every other function in the organization have people whose day-to-day job tasks embody opportunities to keep critical information safe and secure…or let it leak out into the gaze of an attacker.
Incident response is where the rubber hits the road; it’s where we as SSCPs earn our stripes, earn our pay, every day.