
Chapter 7. Preparing Data Pipelines for Predictive Analytics and Machine Learning
Advances in data processing technology have changed the way we think about pipelines and what you can accomplish in real time. These advances also apply to machine learning—in many cases, making a predictive analytics application real-time is a question of infrastructure. Although certain techniques are better suited to real-time analytics and tight training or scoring latency requirements, the challenges preventing adoption are largely related to infrastructure rather than machine learning theory. And even though many topics in machine learning are areas of active research, there are also many useful techniques that are already well understood and can immediately provide major business impacts when implemented correctly.
Figure 7-1 shows a machine learning pipeline applied to a real-time business problem. The top row of the diagram represents the operational component of the application; this is where the model is applied to automate real-time decision making. For instance, a user accesses a web page, and the application must choose a targeted advertisement to display in the time it takes the page to load. When applied to real-time business problems, the operational component of the application always has restrictive latency requirement.
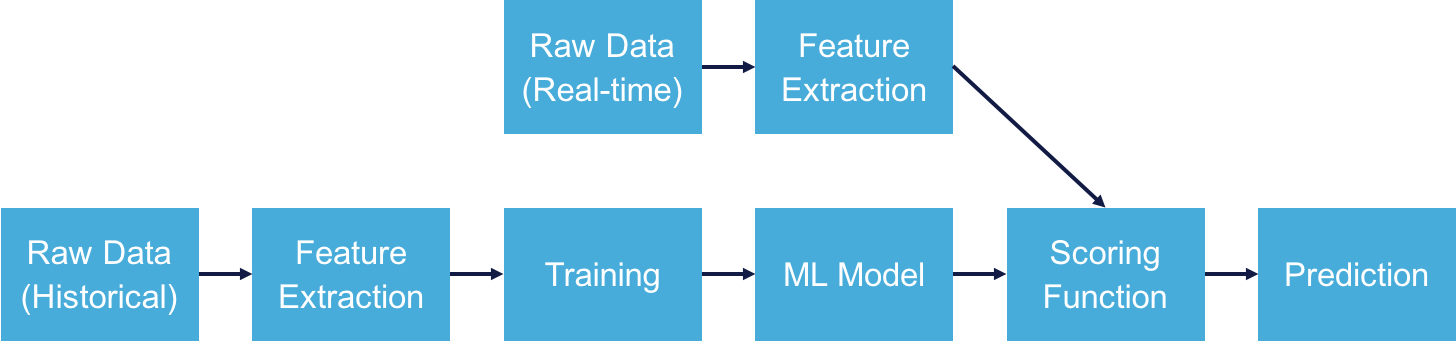
Figure 7-1. A typical machine learning pipeline powering a real-time application
The bottom row in Figure 7-1 represents the learning component of the application. It creates the model that the operational component will apply to make decisions. Depending on the application, the training component might have less stringent latency requirements—training is a one-time cost because scoring multiple data points does not require retraining. That said, many applications can benefit from reduced training latency by enabling more frequent retraining as dynamics of the underlying system change.
Real-Time Feature Extraction
Many businesses have the opportunity to dramatically improve their data intake systems. In the legacy data processing mindset, Extract, Transform, and Load (ETL) is an offline operation. We owe this assumption to the increasingly outdated convention of separating stream processing from transaction processing, and separating analytics from both. These separations were motivated largely by the latency that comes with disk-based, single-machine systems. The emergence of in-memory and distributed data processing systems has changed the way we think about datastores. See Figure 7-2 for an example of real-time pipelines.
Modern stream processing and database systems speed up and simplify the process of annotating data with, for example, additional features or labels for supervised learning.
Use a stream processing engine to add (or remove) features before committing data to a database. Although you can certainly “capture now, analyze later,” there are clear advantages to preprocessing data so that it can be analyzed as soon as it arrives in the datastore. Often, it is valuable to add metadata like timestamps, location information, or other information that is not contained in the original record.
Use a real-time database to update records as more information becomes available. Although append-only databases (no updates or deletes) enjoyed some popularity in years past, this approach creates multiple records corresponding to a single entity. Even though this is not inherently flawed, this approach will require more time-consuming queries to retrieve information.
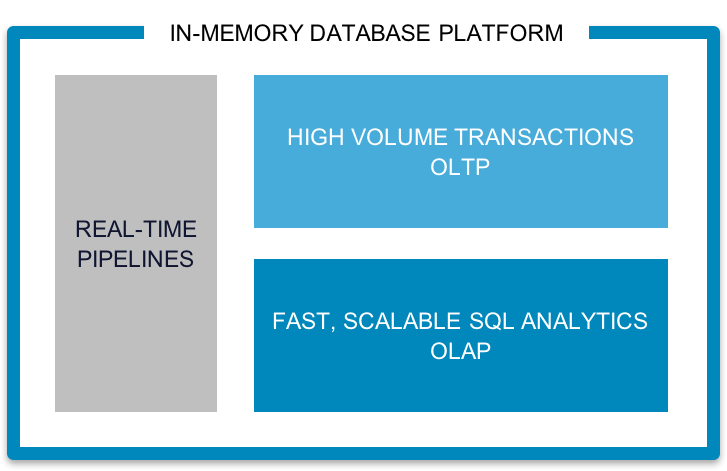
Figure 7-2. Real-time pipelines—OLTP and OLAP
Deciding when to annotate real-time data touches on issues relating to data normalization and when to store versus when to compute a particular value.
Minimizing Data Movement
The key to implementing real-time predictive analytics applications is minimizing the number of systems involved and the amount of data movement between them. Even if you carefully optimize your application code, real-time applications do not have time for unnecessary data movement. What constitutes “unnecessary” varies from case to case, but the naive solution usually falls under this category.
When first building a model, you begin with a large dataset and perform tasks like feature selection, which is the process of choosing features of the available data that will be used to train the model. For subsequent retrainings, there is no need to operate on the entire dataset. Pushing computation to the database reduces the amount of data transferred between systems. VIEWs provide a convenient abstraction for limiting data transfer. Although traditionally associated with data warehousing workloads, VIEWs into a real-time database can perform data transformations on the fly, dramatically speeding up model training time. Advances in query performance, specifically the emergence of just-in-time compiled query plans, further expand the real-time possibilities for on-the-fly data preprocessing with VIEWs.
Scoring with supervised learning models presents another opportunity to push computation to a real-time database. Whereas it might be tempting to perform scoring in the same interactive environment where you developed the model, in most cases this will not satisfy the latency requirements of real-time use cases. Depending on the type of model, often the scoring function can be implemented in pure SQL. Then, instead of using separate systems for scoring and transaction processing, you do both in the database.
Dimensionality Reduction
Dimensionality reduction is an array of technique for reducing and simplifying the input space for a model. This can include simple feature selection, which simply removes some features because they are uncorrelated (i.e., superfluous) or otherwise impede training. Dimensionality reduction is also used for underdetermined systems for which there are more variables than there are equations defining their relationships to one another. Even if all of the features are potentially “useful” for modeling, finding a unique solution to the system requires reducing the number of variables (features) to be no more than the number of equations.
There are many dimensionality reduction techniques with different applications and various levels of complexity. The most widely used technique is Principal Component Analysis (PCA), which linearly maps the data into a lower dimensional space that preserves as much total variance as possible while removing features that contribute less variance. PCA transforms the “most important” features into a lower-dimension representation called principal components. The final result is an overdetermined system of equations (i.e., there is a unique solution) in a lower-dimension space with minimal information loss.
There are many other dimensionality reduction techniques including Linear Discriminant Analysis (LDA), Canonical Correlation Analysis (CCA), and Singular Value Decomposition (SVD). Each of the techniques mentioned so far transforms data linearly into the lower-dimensional space. There are also many nonlinear methods including a nonlinear generalization of PCA. These nonlinear techniques are also referred to as “manifold learning.” Other common nonlinear techniques include Sammon Mapping, Diffusion Mapping, and Kernel PCA.