
Chapter 2. Processing Transactions and Analytics in a Single Database
Historically, businesses have separated operations from analytics both conceptually and practically. Although every large company likely employs one or more “operations analysts,” generally these individuals produce reports and recommendations to be implemented by others, in future weeks and months, to optimize business operations. For instance, an analyst at a shipping company might detect trends correlating to departure time and total travel times. The analyst might offer the recommendation that the business should shift its delivery schedule forward by an hour to avoid traffic. To borrow a term from computer science, this kind of analysis occurs asynchronously relative to day-to-day operations. If the analyst calls in sick one day before finishing her report, the trucks still hit the road and the deliveries still happen at the normal time. What happens in the warehouses and on the roads that day is not tied to the outcome of any predictive model. It is not until someone reads the analyst’s report and issues a company-wide memo that deliveries are to start one hour earlier that the results of the analysis trickle down to day-to-day operations.
Legacy data processing paradigms further entrench this separation between operations and analytics. Historically, limitations in both software and hardware necessitated the separation of transaction processing (INSERTs, UPDATEs, and DELETEs) from analytical data processing (queries that return some interpretable result without changing the underlying data). As the rest of this chapter will discuss, modern data processing frameworks take advantage of distributed architectures and in-memory storage to enable the convergence of transactions and analytics.
To further motivate this discussion, envision a shipping network in which the schedules and routes are determined programmatically by using predictive models. The models might take weather and traffic data and combine them with past shipping logs to predict the time and route that will result in the most efficient delivery. In this case, day-to-day operations are contingent on the results of analytic predictive models. This kind of on-the-fly automated optimization is not possible when transactions and analytics happen in separate siloes.
Hybrid Data Processing Requirements
For a database management system to meet the requirements for converged transactional and analytical processing, the following criteria must be met:
- Memory optimized
-
Storing data in memory allows reads and writes to occur at real-time speeds, which is especially valuable for concurrent transactional and analytical workloads. In-memory operation is also necessary for converged data processing because no purely disk-based system can deliver the input/output (I/O) required for real-time operations.
- Access to real-time and historical data
-
Converging OLTP and OLAP systems requires the ability to compare real-time data to statistical models and aggregations of historical data. To do so, our database must accommodate two types of workloads: high-throughput operational transactions, and fast analytical queries.
- Compiled query execution plans
-
By eliminating disk I/O, queries execute so rapidly that dynamic SQL interpretation can become a bottleneck. To tackle this, some databases use a caching layer on top of their Relational Database Management System (RDBMS). However, this leads to cache invalidation issues that result in minimal, if any, performance benefit. Executing a query directly in memory is a better approach because it maintains query performance (see Figure 2-1).
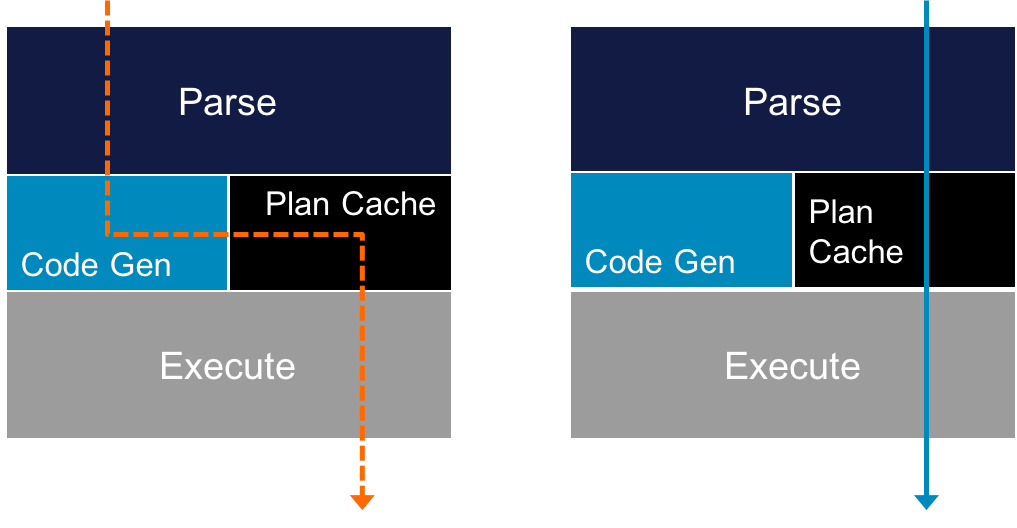
Figure 2-1. Compiled query execution plans
- Multiversion concurrency control
-
Reaching the high-throughput necessary for a hybrid, real-time engine can be achieved through lock-free data structures and multiversion concurrency control (MVCC). MVCC enables data to be accessed simultaneously, avoiding locking on both reads and writes.
- Fault tolerance and ACID compliance
-
Fault tolerance and Atomicity, Consistency, Isolation, Durability (ACID) compliance are prerequisites for any converged data system because datastores cannot lose data. A database should support redundancy in the cluster and cross-datacenter replication for disaster recovery to ensure that data is never lost.
With each of the aforementioned technology requirements in place, transactions and analytics can be consolidated into a single system built for real-time performance. Moving to a hybrid database architecture opens doors to untapped insights and new business opportunities.
Benefits of a Hybrid Data System
For data-centric organizations, a single engine to process transactions and analytics results in new sources of revenue and a simplified computing structure that reduces costs and administrative overhead.
New Sources of Revenue
Achieving true “real-time” analytics is very different from incrementally faster response times. Analytics that capture the value of data before it reaches a specified time threshold—often a fraction of a second—and can have a huge impact on top-line revenue.
An example of this can be illustrated in the financial services sector. Financial investors and analyst must be able to respond to market volatility in an instant. Any delay is money out of their pockets. Limitations with OLTP to OLAP batch processing do not allow financial organizations to respond to fluctuating market conditions as they happen. A single database approach provides more value to investors every second because they can respond to market swings in an instant.
Reducing Administrative and Development Overhead
By converging transactions and analytics, data no longer needs to move from an operational database to a siloed data warehouse to deliver insights. This gives data analysts and administrators more time to concentrate efforts on business strategy, as ETL often takes hours to days.
When speaking of in-memory computing, questions of data persistence and high availability always arise. The upcoming section dives into the details of in-memory, distributed, relational database systems and how they can be designed to guarantee data durability and high availability.
Data Persistence and Availability
By definition an operational database must have the ability to store information durably with resistance to unexpected machine failures. More specifically, an operational database must do the following:
-
Save all of its information to disk storage for durability
-
Ensure that the data is highly available by maintaining a readily accessible second copy of all data, and automatically fail-over without downtime in case of server crashes
These steps are illustrated in Figure 2-2.
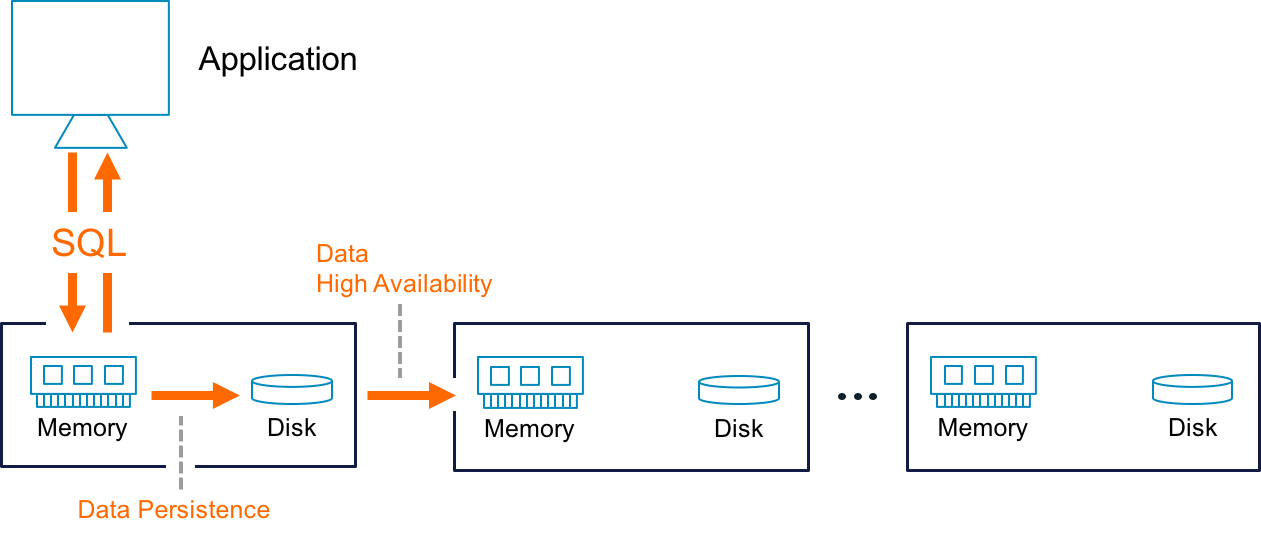
Figure 2-2. In-memory database persistence and high availability
Data Durability
For data storage to be durable, it must survive any server failures. After a failure, data should also be recoverable into a transactionally consistent state without loss or corruption to data.
Any well-designed in-memory database will guarantee durability by periodically flushing snapshots from the in-memory store into a durable disk-based copy. Upon a server restart, an in-memory database should also maintain transaction logs and replay snapshot and transaction logs.
This is illustrated through the following scenario:
Suppose that an application inserts a new record into a database. The following events will occur as soon as a commit is issued:
-
The inserted record will be written to the datastore in-memory.
-
A log of the transaction will be stored in a transaction log buffer in memory.
-
When the transaction log buffer is filled, its contents are flushed to disk.
The size of the transaction log buffer is configurable, so if it is set to 0, the transaction log will be flushed to disk after each committed transaction.
-
Periodically, full snapshots of the database are taken and written to disk.
The number of snapshots to keep on disk and the size of the transaction log at which a snapshot is taken are configurable. Reasonable defaults are typically set.
An ideal database engine will include numerous settings to control data persistence, and will allow a user the flexibility to configure the engine to support full persistence to disk or no durability at all.
Data Availability
For the most part, in a multimachine system, it’s acceptable for data to be lost in one machine, as long as data is persisted elsewhere in the system. Upon querying the data, it should still return a transactionally consistent result. This is where high availability enters the equation. For data to be highly available, it must be queryable from a system regardless of failures from some machines within a system.
This is better illustrated by using an example from a distributed system, in which any number of machines can fail. If failure occurs, the following should happen:
-
The machine is marked as failed throughout the system.
-
A second copy of data in the failed machine, already existing in another machine, is promoted to be the “master” copy of data.
-
The entire system fails over to the new “master” data copy, removing any system reliance on data present in the failed system.
-
The system remains online (i.e., queryable) throughout the machine failure and data failover times.
-
If the failed machine recovers, the machine is integrated back into the system.
A distributed database system that guarantees high availability must also have mechanisms for maintaining at least two copies of data at all times. Distributed systems should also be robust, so that failures of different components are mostly recoverable, and machines are reintroduced efficiently and without loss of service. Finally, distributed systems should facilitate cross-datacenter replication, allowing for data replication across wide distances, often times to a disaster recovery center offsite.
Data Backup
In addition to durability and high availability, an in-memory database system should also provide ways to create backups for the database. This is typically done by issuing a command to create on-disk copies of the current state of the database. Such backups can also be restored into both existing and new database instances in the future for historical analysis and long-term storage.