
Chapter 10. From Machine Learning to Artificial Intelligence
Statistics at the Start
Machine-learning methods have changed rapidly in the past several years, but a larger trend began about a decade ago. Specifically, the field of data science emerged and we experienced an evolution from statisticians to computer engineers and algorithms (see Figure 10-1).
Figure 10-1. The evolution from statisticians to computer engineers and algorithms
Classical statistics was the domain of mathematics and normal distributions. Modern data science is infinitely flexible on the method or properties, as long as it uncovers a predictable outcome. The classical approach involved a unique way to solve a problem. But new approaches vary drastically, with multiple solution paths.
To set context, let’s review a standard analytics and split a dataset into two parts, one for building the model, and one for testing it, aiming for a model without overfitting the data. Overfitting can occur when assumptions from the build set do not apply in general.
For example, as a paint company seeking homeowners that might be getting ready to repaint their houses, the test set may indicate the following:
| Name | Painted house within 12 months |
|---|---|
| Sam | Yes |
| Ian | No |
Understandably, you cannot generalize on this property. But you could look at income pattern, data regarding the house purchase, and recently filed renovation permits to create a far more generalizable model. This kernel of an approach spawned the transition of an industry from statistics to machine learning.
The “Sample Data” Explosion
Just one generation ago, data was extremely expensive. There could be cases in which 100 data points was the basis of a statistical model. Today, at web-scale properties like Facebook and Google, there are hundreds of millions to billions of records captured daily.
At the same time, compute resources continue to increase in power and decline in cost. Coupled with the advent of distributed computing and cloud deployments, the resources supporting a computer driven approach became plentiful.
The statisticians will say that new approaches are not perfect, but for that matter, statistics are not, either. But what sets machine learning apart is the ability to invest and discover algorithms to cluster observations, and to do so iteratively.
An Iterative Machine Process
Where machine learning stepped ahead of the statistics pack was this ability to generate iterative tests. Examples include Random Forest, an approach that uses rules to create an ensemble of decision trees and test various branches. Random Forest is one way to reduce overfitting to the training set that is common with simpler decision tree methods.
Modern algorithms in general use more sophisticated techniques than Ordinary Least Squares (OLS) regression models.
Keep in mind that regression has a mathematical solution. You can put it into a matrix and compute the result. This is often referred to as a closed-form approach.
The matrix algebra is typically (X’X)–1X’Y, which leads to a declarative set of steps to derive a fixed result. Here it is in more simple terms:
If X + 4 = 7, what is X?
You can solve this type of problem in a prescribed step and you do not need to try over and over again. At the same time, for far more complex data patterns, you can begin to see how an iterative approach can benefit.
Digging into Deep Learning
Deep learning takes machine learning one step further by applying the idea of neural networks. Here we are also experiencing an iterative game, but one that takes calculations and combinations as far as they can go.
The progression from machine learning to deep learning centers on two axes:
Far more complex transfer functions, and many of them, happening at the same time. For example, take the sng(x) to the 10th power, compare the result, and then recalibrate.
Functions in combinations and in layers. As you seek parameters that get you closest to the desired result, you can nest functions. The ability to introduce complexity is enormous. But life and data about life is inherently complex, and the more you can model, the better chance you have to drive positive results.
For example, a distribution for a certain disease might be frequency at a very young or very old age, as depicted in Figure 10-2.
Classical statistics struggled with this type of problem-solving because the root of statistical science was based heavily in normal distributions such as the example shown in Figure 10-3.
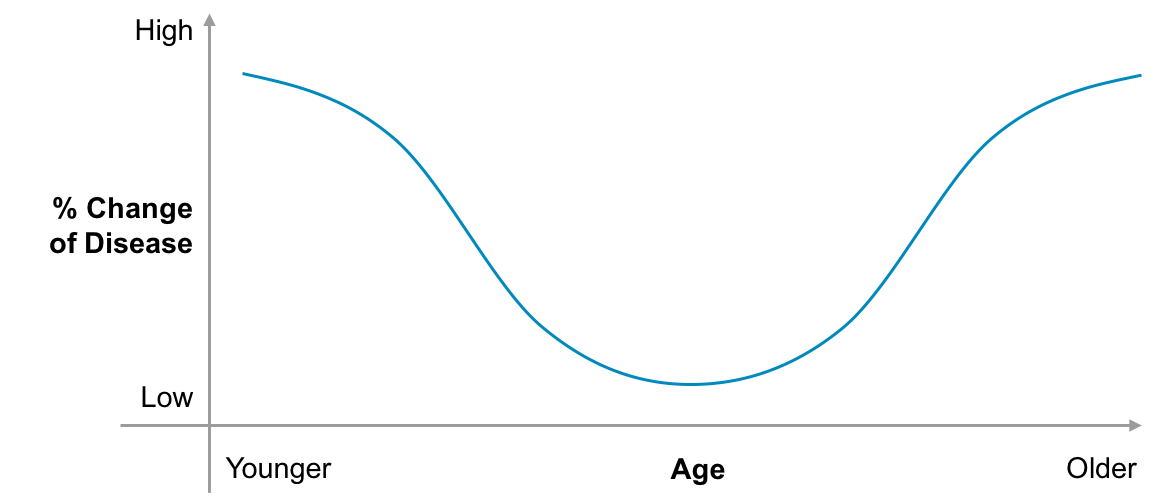
Figure 10-2. Sample distribution of disease prevalent at young and old age
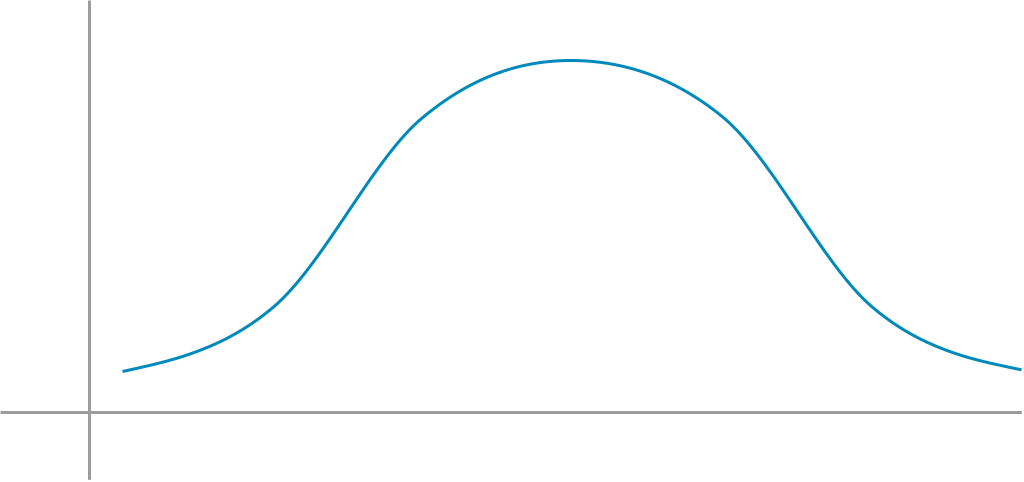
Figure 10-3. Sample normal distribution
Iterative machine learning models do far better at solving for a variety of distributions as well as handling the volume of data and the available computing capacity.
For years, machine learning methods were not possible due to excessive computing costs. This was exacerbated by the fact that analytics is an iterative exercise in and of itself, and the time and computing resources to pursue machine learning made it unreasonable, and closed form approaches reigned.
Resource Management for Deep Learning
Though compute resources are more plentiful today, they are not yet unlimited. So, models still need to be implementable to sustain and support production data workflows. The benefit of a fixed-type or closed-loop regression is that you can quickly calculate the compute time and resources needed to solve it.
This could extend to some nonlinear models, but with a specific approach to solving them mathematically. LOGIT and PROBIT models, often used for applications like credit scoring, are one example of models that return a rank between 0 and 1 and operate in a closed-loop regression.
With machine and deep learning, computer resources are far more uncertain. Deep learning models can create thousands of lines of code to execute, which, without a powerful datastore, can be complex and time consuming to implement. Credit scoring models, on the other hand, can often be solved with 10 lines of queries shareable within an email.
So, resource management and the ability to implement models in production remains a critical step for broad adoption of deep learning. Take the following example:
Nested JSON objects coming from S3 into a queryable datastore
30–50 billion observations per month
300–500 million users
Query user profiles
Identify people who fit a set of criteria
Or, people who are near this retail store
Although a workload like this can certainly be built with some exploratory tools like Hadoop and Spark, it is less clear that this is an ongoing sustainable configuration for production deployments with required SLAs. A datastore that uses a declarative language like SQL might be better suited to meeting operational requirements.
Talent Evolution and Language Resurgence
The mix of computer engineering and algorithms favored those fluent in these trends as well as statistical methods. These data scientists program algorithms at scale, and deal with raw data in large volumes, such as data ending up in Hadoop.
This last skill is not always common among statisticians and is one of the reasons driving the popularity of SQL as a programming layer for data. Deep learning is new, and most companies will have to bridge this gap from classical approaches. This is just one of the reasons why SQL has experienced such a resurgence as it brings a well-known approach to solving data challenges.
The Move to Artificial Intelligence
The move from machine learning to broader artificial intelligence will happen. We are already seeing the accessibility with open source machine learning libraries and widespread sharing of models.
But although computers are able to tokenize sentences, semantic meaning is not quite there. Alexa, Amazon’s popular voice assistant, is looking up keywords to help you find what you seek. It does not grasp the meaning, but the machine can easily recognize directional keywords like weather, news, or music to help you.
Today, the results in Google are largely based on keywords. It is not as if the Google search engine understands exactly what we were trying to do, but it gets better all the time.
So, no Turing test yet—we speak of the well-regarded criteria to indicate that a human cannot differentiate from a human or a computer when posing a set of questions.
Therefore, complex problems are still not likely solvable in the near future, as common sense and human intuition are difficult to replicate. But our analytics and systems are continuously improving opening several opportunities.
The Intelligent Chatbot
With the power of machine learning, we are likely to see rapid innovation with intelligent chatbots in customer service industries. For example, when customer service agents are cutting and pasting scripts into chat windows, how far is that from AI? As voice recognition improves, the days of “Press 1 for X and 2 for Y” are not likely to last long.
For example, chat is popular within the auto industry as a frequent question is, “is this car on the lot?”
Wouldn’t it be wonderful to receive an instant response to such questions instead of waiting on hold?
Similarly, industry watchers anticipate that more complex tasks like trip planning and personal assistants are ready for machine-driven advancements.
Broader Artificial Intelligence Functions
The path to richer artificial intelligence includes a set of capabilities broken into the following categories:
Reasoning and logical deductions to help solve puzzles
Knowledge about the world to provide context
Planning and setting goals to measure actions and results
Learning and automatic improvement to refine accuracy
Natural-language processing to communicate
Perception from sensor inputs to experience
Motion and robotics, social intelligence, creativity to get closer to simulating intelligence
Each of these categories has spawned companies and often industries, for example natural language processing has become a contest of legacy titans such as Nuance along with newer entrants like Google (Google Now), Apple (Siri), and Microsoft (Cortana). Sensors and the growth of the Internet of Things has set off a race to connect every device possible. And robotics is quickly working its way into more areas of our lives, from the automatic vacuum cleaner to autonomous vehicles.
The Long Road Ahead
For all of the advancements, there are still long roads ahead. Why is it that we celebrate click through rates online of just 1 percent? In the financial markets, why is it that we can’t get it consistently right? Getting philosophical for a moment, why do we have so much uncertainty in the world?
The answers might still be unknown, but more advanced techniques to get there are becoming familiar. And, if used appropriately, we might find ourselves one step closer to finding those answers.