
Chapter 6. Cryptography and VPNs
He unlocked his desk, opened the drawer-safe, and withdrew the Executive’s Code Book, restricted to the executive heads of the firms listed quadruple A-1-* by Lloyds.
The Demolished Man
—ALFRED BESTER
6.1 Cryptography, the Wonder Drug
Some years ago, shortly after Firewalls and Internet Security [1994] was first published, a friend who wasn’t fond of firewalls remarked that someday, he was going to write a book on how to do Internet security “correctly.” I asked him what that entailed; he replied, “Use Kerberos or other forms of cryptography.” Now, Kerberos [Bryant 1988; S. P. Miller et al. 1987; Neuman et al. 2005; Steiner, Neuman, and Schiller 1988] is a perfectly fine system; in Firewalls, we called it “extremely useful.” But to call it or any form of cryptography the “correct” way to do Internet security is to misunderstand both the security problem and what cryptography can and cannot do for you.
Although theoreticians have come up with many interesting cryptographic tricks (and some are even in commercial use), the two most common uses of cryptography are to prove identity and to hide data from prying eyes. It can do these things very well, but at a price. The most obvious is that keys have to be protected. To quote another friend of mine, “Insecurity is like entropy: it can’t be destroyed, but it can be moved around. With cryptography, we substitute the insecurity of the key for the insecurity of the data, because we think we can protect the keys better.”
A second major price is the difficulty of devising proper cryptographic mechanisms. Cryptography is a very difficult and subtle branch of applied mathematics; remarkably few people are qualified to practice it. Never use a proprietary encryption algorithm, especially if you’re told that it’s more secure because it’s secret. The same applies to cryptographic protocols; they’re also quite hard to get right. I’ll give just one example. SSL 3.0 was devised for Netscape in 1996. It was devised by one world-famous cryptographer, analyzed by two others [Wagner and Schneier 1996], and served as the basis for the Internet Engineering Task Force’s (IETF) Transport Layer Security (TLS) protocol [Dierks and Rescorla 2008], which itself received a lot of scrutiny from members of the IETF’s TLS working group. In 2011, a new flaw was found [Rescorla 2011], present in the most commonly deployed versions of TLS; other new problems have been found since then. [Sheffer, Holz, and Saint-Andre 2015] lists attacks known through February, 2015, but at least one more has been found since then [Adrian et al. 2015]. Don’t try it at home, kids; even trained professionals have trouble getting protocols right.
The third issue to be aware of is the difficulty of retrofitting cryptography to existing systems, especially if there are complex communication patterns or requirements. A simple reliable transport channel between two nodes that know and trust each other can easily be secured with TLS. Multiparty communications with complex trust patterns are considerably more difficult and may require the inclusion of additional, mutually trusted parties. Ideally, the cryptographic mechanisms should be designed together with the system. Unfortunately, “green field” architectures are very rare; most of the time, we have to deal with legacy requirements, legacy systems, and legacy code, and aspects that are not just difficult to encrypt but downright hostile to encryption. You might very well need a custom protocol—which, of course, is a bad idea for other reasons.
What happens if you get the cryptography wrong? Is there a real threat? Thus far, the many cryptographic weaknesses that have been found in deployed systems have only rarely been exploited, at least as far as the public knows. None of the more complex protocol attacks have been reported in the wild, with the arguable exception of Flame [Goodin 2012b; Zetter 2014]. Those exploits do take a fair amount of skill and often need specific types of access. More to the point, such attacks haven’t been necessary; there always seem to be easier ways in. However. . .
Flaws of this type are very hard to fix. The problem is in the protocol itself, not a particular piece of code; very likely, all implementations will be vulnerable. (Implementing cryptography correctly is itself a Herculean task; it’s even harder to get right than ordinary code.) It’s often impossible to fix just one end at a time; both ends (or all endpoints) may need to be upgraded simultaneously. (Think how many hundreds of millions of endpoints need patching to upgrade to TLS 1.2, which is immune to the known flaws!) And even though designers try to build in negotiation mechanisms to allow for an orderly transition, they don’t always get it right [Bellovin and Rescorla 2006].
Finally, there’s one class of attacker—the advanced persistent threat—where cryptographic weaknesses are a very real problem. MI-31 knows a lot about the subject, and if that’s the easiest way in they’ll use it.
6.2 Key Distribution
Where do long-term keys come from? How does one party know the other’s keys or enough about them to trust them? These questions are at the heart of the key distribution problem.
For a small number of nodes, especially if they’re in reasonable geographic proximity, manual distribution can work. The problem, though, lies in the word “small”: it’s an O(n2) process. The usual solutions are key distribution centers and public key cryptography, often in the form of certificates.
A key distribution center (KDC) is a special computer, trusted by all parties, that hands out keys. Every other computer shares a key with it; this key is used to protect and authenticate traffic between it and the KDC. When some computer wants to talk to another, it asks the KDC for a session key to the other machine. Somehow—I’ll omit the details; see any good cryptography text or the Kerberos documentation [Bryant 1988; S. P. Miller et al. 1987; Neuman et al. 2005; Steiner, Neuman, and Schiller 1988] for how to do it—the other computer learns the session key, too, in a message protected by its long-term key.
There are three crucial points to notice. First, the key provisioning problem is reduced to O(n); for even modest-sized n, this is important. Second, the KDC plays a crucial security role, and hence is an important target for any sophisticated adversary. Suppose, for example, that MI-31 has intercepted traffic between computers A and B. This traffic is protected by some random session key KA,B generated by the KDC and distributed to those nodes. But that distribution takes place under long-term keys KA,KDC and KB,KDC, which are both known to the KDC. An attacker who breaks into the KDC, even very much later, can obtain those keys and read all recorded traffic; the only caveat is that the key set-up messages must be recorded, too. Finally, although the provisioning problem is now O(n), it must be done via a secure process that preserves both confidentiality and authenticity; there is by definition no existing key to protect the traffic between a new machine and the KDC.
The latter two problems are frequently handled by use of public key technology. A new node can generate its own key pair and send only the public key to the KDC; this changes a confidentiality and authenticity problem into just an authenticity problem, which is often much easier to solve. Furthermore, the KDC no longer shares any long-term secrets with individual nodes; it knows only public keys. When it generates a session key, it encrypts it with the two computers’ public keys; it never sees the corresponding private keys, and thus cannot read what it itself has written. There is thus no threat to past traffic if a public key-based KDC is compromised, though there is of course a threat to keys handed out before a compromise is detected and remediated.
The final step is for the KDC or some other mutually trusted party to sign each computer’s ![]() name, publickey
name, publickey![]() pair. This is known as a certificate; certificates are discussed in great and gory detail in Chapter 8.
pair. This is known as a certificate; certificates are discussed in great and gory detail in Chapter 8.
6.3 Transport Encryption
There are two primary ways encryption is employed: for transport encryption, where a real-time connection is being protected, and for object encryption, where a sequence of bytes must be protected across an arbitrary number of hops amongst arbitrary parties. We’ll deal with each of them in turn.
Transport encryption is the easiest (not easy, merely easiest) cryptographic problem to solve. Fundamentally, two parties wish to talk. At least one, and often both, have keying material. How do you set up a “secure” connection?
The first phase is key setup, during which the two parties somehow agree on a common session key. (Resist the temptation to preprovision static keys to use as session keys [Bellovin and Housley 2005]; at best, you lose certain abilities, and at worst it’s a complete security disaster, where the enemy can read, modify, create, etc., all traffic.) Some key setup schemes include authentication—often, bilateral authentication—whereas in others, the application must do it itself if necessary. Beyond that, there are three requirements for key setup: that the two parties agree on the same key, that no one else can obtain those keys, and that the keys be fresh, that is, new for this session and not old keys being reused. This last requirement helps protect against the various sorts of nastiness that an enemy can engage in by replaying old traffic into the current session.
An optional key setup property is forward secrecy. Forward secrecy means that if an endpoint is compromised after the session is over, the keys for that session cannot be recovered. The more competent your attackers, the more important this is. In particular, if you’re worried about the Andromedans, you should use it; they’re just the sort of folks who will record your traffic and later, when they find they can’t cryptanalyze it, they will hack in to try to get the keys another way.
The second phase, of course, is the actual data transport. It, too, has certain important properties. You should always use authentication with encryption; there are too many nasty games an attacker can play if you don’t, by judiciously modifying or combining various pieces of ciphertext [Bellovin 1996]. Some textbooks will say that you only need to use authentication when using stream ciphers. They’re wrong. Authentication is vital with stream ciphers, but it’s almost always extremely important. (There are a few—a very few—situations where one can omit it. As usual when dealing with materia cryptographica, that’s a call that should only be made by qualified experts, and many of them will get it wrong. In 1978, in the very first paper on key distribution protocols, Needham and Schroeder said it very well [1978]:
Finally, protocols such as those developed here are prone to extremely subtle errors that are unlikely to be detected in normal operation. The need for techniques to verify the correctness of such protocols is great, and we encourage those interested in such problems to consider this area.
They were remarkably prescient; indeed, their own designs had several flaws [Denning and Sacco 1981; Lowe 1996; Needham and Schroeder 1987].) There are some newer modes of operation that combine encryption with authentication in a single pass; this is the preferred way to proceed.
Another important property of the transport phase is replay protection. Just as keys must be fresh, so, too, must messages. Don’t make the mistake of assuming that just because the IP and UDP service models permit reordering, duplication, damage, replay, etc., that they’re benign when done by a clever attacker. Again, there are rare exceptions, but this decision should be left to qualified experts.
Different sorts of encryption need to be used for UDP and TCP. The former is a datagram protocol; accordingly, use of a stream cipher is almost certain to be disastrous. (That is one of the flaws in WEP; see the box on page 177.)
The last phase is tear-down. It seems trivial, but you want to ensure that your conversation hasn’t been truncated. Accordingly, the “goodbye” signaling should be cryptographically protected, too. One last thing: when you’re done, destroy the session key; even if you’re not using forward secrecy, there’s no point to making life too easy for the attackers.
Transport encryption can be applied at different layers of the stack. What protection is obtained depends on the choice; all have their uses.
Link-layer protection, such as assorted Wi-Fi encryption schemes (Chapter 9), has two primary uses: it limits access to a LAN to authorized users, and it protects against eavesdropping and traffic analysis, especially on particularly vulnerable links. Wi-Fi nets are the most obvious choice, but it is used as well on things like international satellite links: a satellite has a large signal footprint, and many unauthorized recipients can pick up transmissions [Goodin 2015b]. In the past, when there was a lot less undersea fiber, many companies used link encryptors for all international connections, even fiber or copper, because they might be rerouted to a satellite circuit in case of an outage. In some cases, there was suspicion that outages were not accidental—some countries seemed to have a very large number of very clumsy fishing trawlers. But that’s the sort of attack frequently launched by the Andromedans, which means that link encryption can’t be your only layer of defense if you’re the actual target: a typical connection traverses many hops and hence many links.
On certain kinds of connection and against certain enemies, link encryption has a very powerful property: an eavesdropper can’t even tell that a message has been sent. The NSA realized this more than fifty years ago [Farley and Schorreck 1982]:
Mostly we were aiming for online equipment and, in fact, eventually generated the notion that we had a circuit and there was something going on the circuit twenty-four hours a day. If you had a message to send you just cut in and sent your message. But an enemy intercepting that link would simply see a continuous stream of off/on signals which when you examine them all looked random and you can’t tell when or where a message was inserted along in there. That was the aim, the goal.
Network-layer encryption can be end to end, end to gateway, or gateway to gateway; it is most commonly used for virtual private networks (VPNs), discussed below (Section 6.5). The chief advantages of network encryption is that it can protect multiple hops and all traffic. A crucial limitation is that the granularity of protection is typically per machine (or per destination pair), which may not be what is desired, especially for servers or other multiuser computers. (The IPsec standards do permit finer-grained keying; this is difficult to do and rarely implemented.)
Transport-level cryptographic protocols have been defined (see, for example, [Bittau et al. 2010]), but are rarely used in practice. They require kernel modifications, which makes them hard to deploy, and they offer limited advantages compared with application-level encryption. Unlike network-layer encryption, it’s easy to do fine-grained keying; in addition, transport encryptors can protect the TCP header [Postel 1981] against malicious modifications. Users are thus protected against session-hijacking attacks [Joncheray 1995]. However, network-layer has often been good enough; the utility of fine-grained keying for typical VPN scenarios is not obvious.
The most common layer at which encryption is done is the application layer; in particular, TLS and its older sibling SSL are heavily used for web transmission security. TLS has two tremendous advantages: it’s relatively easy to add it to more or less any two-party, TCP-based application, on more or less any operating system; in addition, configuration is quite straightforward compared to, say, IPsec. There’s even a UDP version of it now, DTLS [Rescorla and Modadugu 2006]. TLS doesn’t do everything; that’s probably one of the secrets to its success. All that said, there are caveats—important ones—that implementers and system administrators should heed; see Chapter 8.
At what layer should you encrypt? Not surprisingly, there’s no one answer; it depends on what your goals are. There have been times when I have used four layered encryption mechanisms, each of which serves a different purpose:
• WPA2, to limit access to the LAN to authorized users (Unknown to me at the time, there may also have been cryptographic protection of some of the telephony links; see [Malis and Simpson 1999] for a definition of a point-to-point link-layer encryption protocol.)
• A VPN, to protect my traffic from the local network operator
• SSH [Ylönen 1996] to a remote site I control, used to tunnel my web traffic to my HTTP proxy, to protect my traffic from the remote network—my VPN is to a university network that has experienced serious attacks (page 172)
• HTTPS to a remote web site, for end-to-end protection of credit card or login information
The combination of SSH and the VPN is unusual (and arguably unnecessary), but one of those two is quite important and neither is redundant with WPA2 or HTTPS.
I’ve spoken here about two-party conversations. Multiparty secure communications are possible, too, but the actual mechanisms are considerably more complex and are well beyond the scope of this book. That said, if you’re trying to protect all traffic between a pair of computers, or you’re trying to protect all traffic between two groups of machines (including the case where one group is just a single machine), you should consider using a VPN instead (Section 6.5).
6.4 Object Encryption
Object encryption is much harder than transport encryption because by definition you’re not talking to the other party when you encrypt something. Accordingly, you can’t negotiate things like cipher algorithms; you have to know in advance what the other party supports. You don’t know whether your key setup has succeeded; you have to encrypt and pray. With long-lived objects (such as email messages), you may want to read or verify them long after you’ve lost or deleted the relevant keys. In a multihop protocol, you may not know what portions of the data are deemed modifiable by some hop or other. Worse yet, you might know and find yourself unable to do anything about it, especially if you’re trying to bolt the crypto on to an existing design—secure email and DNSSEC come to mind. Replay detection is harder; detection of message deletion is much harder because each object is effectively a datagram.
Here, too, there are phases: key acquisition, message canonicalization, encryption and/or signing, and transport encoding, though in some situations some of these steps may be omitted.
Key acquisition is exactly what it sounds like: getting the keys for the other parties. As with transport encryption, it can be preprovisioned, though in the more common case you’ll be using certificates (see Chapter 8). If you’re only trying to authenticate the object, rather than encrypt it—a scenario that is possible for transport, too, though rather less common—you need to ensure that the receivers have your key as well. If you’re using certificates, you can just include the certificate in the message. If you’re not using certificates, the recipients either know your key or have the difficult problem of verifying the authenticity of any included keys, so there’s no point to putting them in the message.
One special case of key acquisition is when it’s your own key; more accurately, it’s the key you’re going to want to use at some arbitrary time in the future to decrypt the object. This is especially serious for things like encrypted archival backups, since you may not ever need them, but if you do you’ll need the key as well. The issue, then, is not acquiring the key per se but rather figuring out how you’re going to preserve it while still keeping it safe from prying eyes.
Message canonicalization is a problem that applies to signed, unencrypted objects. When objects are moved from system to system, transformations such as adding or deleting white space, expanding tabs, and changes in the end-of-line character—a simple line feed on Unix-derived systems; a carriage return/line feed sequence on Windows—are commonplace. XML objects can be embedded in other objects, which in turn might induce a change in indentation. A digital signature verification will not survive such changes. Accordingly, a canonical representation is often defined; the signature and verification calculations are performed over it, rather than over any given real instantiation.
Transport encoding is an optional phase. It is necessary if some channels over which the object is likely to be transported cannot handle arbitrary byte sequences. Arguably, one could say that this isn’t really part of the encryption process—one can represent any byte sequence as a series of hexadecimal digits—but if some channel is especially likely to be used its properties should be taken into account. The S/MIME standards (partially based on the earlier PEM design) for signed and/or encrypted email are one case in point; many email systems can’t handle binary values, so a base-64 encoding [Josefsson 2006; Linn 1989] was specified. Another interesting case is DNSSEC, the extension to the DNS for digitally signed records [Arends et al. 2005a; Arends et al. 2005b; Arends et al. 2005c]: DNS packets over UDP were limited to 512 bytes by [Mockapetris 1987], which is not enough to accommodate both the actual response and a digital signature. Accordingly, the DNSSEC standards had to mandate the use of the EDNS0 extension [Vixie 1999]. (DNSSEC is actually a case study in the difficulty of retrofitting object security to an existing protocol. The advanced student of such matters would be well advised to compare today’s standards with the predecessor [Eastlake 1999]: many of the changes were needed because of subtle protocol and operational aspects.)
The temporal aspects of object security raise some interesting philosophical issues. Certificates expire; they can also be revoked if the private key is compromised or if there’s reason to fear that the certificate might be fraudulent (Chapter 8). What does it mean to check the signature on signed email, if the certificate was revoked? Can you still read an encrypted email message, if your certificate has expired since then? What if you have a digitally signed program? Can you install it after the expiration date? Should you run it after certificate revocation? There may be a timestamp in the file saying when it was signed, but of course an enemy can change the system clock before signing some malware. Should software vendors re-sign their software when the certificates roll over? What about copies on CDs? How do you validate the code if you’re installing something such as a network device driver on an offline machine? This is discussed at great length in Section 8.4.
Storage encryption raises other issues, especially because the popular mythology often conflates the notions of “encrypted disk” and “information security.” To put it briefly, encryption is useful if and only if your threat model includes attacks that do not go through the operating system; most notably, this includes someone with physical access. Good places to use storage encryption are USB flash drives (they’re regularly lost), laptops (judging from how many of them seem to walk away, one can only conclude that laptops have feet), off-site backup media, and the like. Bad places for it are most desktops and virtually all servers, unless your threat model includes targeted burglaries aimed at the information on your drives rather than the hardware’s resale value, or perhaps seizures by the police. (Of course, you can’t count on drive encryption defeating the police, since they now have technology to keep your machine powered up while they cart it away to their lab.1) There’s one more physical security threat that many people overlook: what happens to the disk drive when you discard your computer? Most people do not remember to wipe their disk first [S. L. Garfinkel and Shelat 2003].
1. “HotPlug: Transport a live computer without shutting it down,” http://www.wiebetech.com/products/HotPlug.php.
Why not encrypt other disks? The main reason is that it generally doesn’t do any good. Suppose the enemy doesn’t have root or Administrator privileges on the machine? In that case, ordinary file permissions will keep the data safe. On the other hand, if the attacker has gained elevated privileges, he or she can impersonate the legitimate users, replace software, steal keys, and so on. In other words, it doesn’t do much good; it just increases system overhead, though that’s often quite low these days. You might, of course, want to encrypt your drives to protect yourself against random burglaries and the discarded drive problem. That’s not bad reasoning, but remember that it won’t protect against electronic intrusions that are more likely to target your information. The threats are very different, and a single defense does not address both.
Supplying keys for encrypted storage objects poses another problem. For interactive use—inserting a flash drive, booting a laptop, etc.—it’s not a big deal; the user can just type in the passphrase at the right time. But what about server keys? Most servers run in lights-out computer rooms; there’s no one present to type in the key at boot time.
6.5 VPNs
“What do you think happens if you open a gateway for an ancient evil to infest our departmental LAN?”
Bob Howard in The Jennifer Morgue
—CHARLES STROSS
Virtual private networks (VPNs) are intended to provide seamless, secure communications between a host and a network or two or more networks. While there are many types in use, we’ll focus on encrypted ones—this is, after all, the cryptography chapter in a security book. The big advantage of VPNs is that they provide fire-and-forget crypto: once you turn one on, all of your traffic is protected.
Although many VPN topologies are possible, only two are common: connecting multiple locations of a single organization, and connecting road warriors’ laptops (and often other toys) back to the mothership. For the most part, they use similar technologies. Let’s look at the road warrior case first.
A virtual private network is intended to seem and operate like a real network, with one crucial difference: some of the “wires” are in fact encrypted network connections that may pass through many other networks and routers. These links—tunnels—are often treated like any other network links. This has several implications for VPN configuration. First, packets are routed to the virtual interface, including using the usual longest prefix match [Fuller and T. Li 2006]. This makes triangle routing—sending all traffic through the VPN gateway—straightforward, by pointing the default route at the tunnel interface; typically, it also permits direct connection to resources on directly connected LANs, since they have a longer prefix than 0/0. This is often necessary—how else will packets reach the real network’s default gateway?—but carries certain risks; in particular, you are sometimes not shielded from attacks originating on-LAN. This is a particular concern when on untrusted networks, such as coffee shop hotspots. The alternative, adding prefixes only for the organizational LAN to the tunnel link, is known as split tunneling; see Figure 6.1.
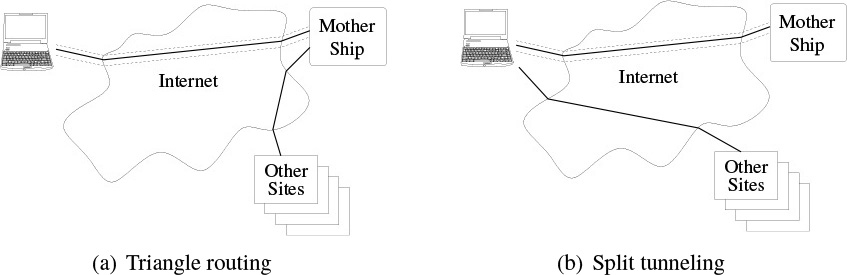
Figure 6.1: VPN routing configurations. The dotted lines show the encrypted link back to the home organization.
It’s important to remember that a road warrior VPN is connecting some machine to your network and giving it essentially unfettered access. Is that machine trustworthy? More or less by definition, it lives outside your firewall some of the time—has it been infected? Perhaps more to the point, it is often used outside of the social milieu of an office; what are euphemistically termed “adult sites” are notorious malware purveyors [Wondracek et al. 2010]. Such sites sometimes label themselves not safe for work (NSFW). Their concern is what your coworkers or boss might see, but there’s a security aspect as well. Has that laptop connecting via the VPN been infected?
Viewing virtual network links strictly like any other network link, and hence using them in accordance with the routing table, has another, more subtle limitation: it’s impossible to pass only certain ports over the VPN, as opposed to certain destination hosts and networks [Bellovin 2009a]. While in principle routing by port number can be done [Zhao and Bellovin 2009; Zhao, Chau, and Bellovin 2008], I know of no production operating systems that support it.
The use of triangle routing raises some complex issues. It certainly hurts performance, in that all traffic has to be routed to the home network before heading to its proper destination. On the other hand, it provides two types of protection: it lets road warriors reap the benefits (whatever they may be) of the enterprise firewall; perhaps more importantly, it ensures that plaintext traffic to assorted web sites is shielded from others on the same, untrusted LAN. (A lot of the plaintext traffic, and in particular much web traffic, is unencrypted; this in turn can expose people to sidejacking attacks [Krebs 2007], where web authentication cookies are stolen from unencrypted sessions after login.)
From a security perspective, then, it would seem that triangle routing should always be used, with the VPN activated immediately at boot time. Unfortunately, there are some complications. First, many hotspots use boxes that intercept the first web request and pop up a box with the usual login, advertising, terms of service, liability waiver, and so on. If even initial web traffic is routed towards the VPN, the interception can’t occur, in which case the user can’t log in and the network path isn’t unblocked for use. The fact that the VPN can’t be set up is a minor inconvenience compared with not being able to talk at all. Perhaps users could take advantage of the local net exception to the VPN’s routing and try to connect to some hypothetical on-LAN web server; however, most normal people neither know nor care what IP address their laptop has at any given time. Besides, some of the resources necessary to complete some of these web logins are off-LAN and hence would be caught by the VPN.
The second issue is a little odder. On some systems—Macs are notorious for this—some applications wake up and try to transmit as soon as a network connection appears. Depending on timing and VPN design, they may start sending as soon as the network is unblocked, before the VPN can finish its setup.
On top of that, of course, there are performance issues: the possible overloading of the official gateway’s link (fixable by spending more money on a faster link), and the latency from the user to that gateway, which is often a matter of geography and hence is fixable only by finding applied physicists who don’t think that the speed of light is really that stringent an upper bound on signal propagation times.
Picking what VPN technology to use is harder than deciding that you need one; VPNs are the poster child for the saying that the nice thing about standards is that there are so many to choose from.2 There are at least five obvious choices: IPsec [S. T. Kent and Seo 2005]; Microsoft’s Point-to-Point Tunneling Protocol (PPTP) [Hamzeh et al. 1999]; the Layer 2 Tunneling Protocol (L2TP) [Townsley et al. 1999], the IETFication of PPTP which needs to run over IPsec to be secure; OpenVPN [Feilner 2006]; and a plethora of so-called “TLS VPN” products [Frankel et al. 2008].
2. “How Standards Proliferate,” http://xkcd.com/927/.
IPsec probably has the cleanest architectural vision. It is available on virtually all platforms, supports a wide range of authentication methods, and can secure more or less anything layered on top of it. Unfortunately, its adoption has been hindered by too much complexity in the base specification (e.g., per-user keying of port-specific IPsec connections), plus about ![]() 0 different options [Srivatsan, M. Johnson, and Bellovin 2010]. The key management protocol, Internet Key Exchange (IKE) [Kaufman 2005], has even more options than that. IPsec also has trouble with NATs [Srisuresh and Egevang 2001]; it seems it does too good a job of protecting the IP and TCP headers [Aboba and Dixon 2004]. There is a mechanism in IKE to negotiate NAT traversal [Kivinen et al. 2005]; naturally, this involves another option, rather than it being standard for all IPsec configurations. Worse yet, according to various reports, different implementations don’t interoperate very well; they’re a fine choice for single-vendor shops but can often be problematic otherwise.
0 different options [Srivatsan, M. Johnson, and Bellovin 2010]. The key management protocol, Internet Key Exchange (IKE) [Kaufman 2005], has even more options than that. IPsec also has trouble with NATs [Srisuresh and Egevang 2001]; it seems it does too good a job of protecting the IP and TCP headers [Aboba and Dixon 2004]. There is a mechanism in IKE to negotiate NAT traversal [Kivinen et al. 2005]; naturally, this involves another option, rather than it being standard for all IPsec configurations. Worse yet, according to various reports, different implementations don’t interoperate very well; they’re a fine choice for single-vendor shops but can often be problematic otherwise.
PPTP is a Microsoft invention. It’s basically a LAN extension protocol—remote machines appear to be on the same LAN, and things like broadcast messages are supposed to work—with its own built-in encryption mechanisms. In some environments, the LAN orientation can cause trouble because remote machines have different timing characteristics, especially if they’re reached by slow links; talking to them is not cheap, and broadcast messages carry a notable cost. Still, the ubiquity of Windows means that almost any machine you have will support PPTP. There are two significant limitations, though, that should be considered. First, PPTP uses Generic Routing Encapsulation (GRE) [Hanks et al. 1994] for transport. GRE is blocked by many packet filters; reconfiguration may be necessary to support it. Second, the authentication protocol has serious flaws [Marlinspike and Hulton 2012; Schneier and Mudge 1999].
L2TP is, as noted, the IETF’s version of PPTP. Because the security comes from IPsec, if you want to use it you have to deal with both the LAN orientation of PPTP and the configuration complexity of IPsec. It does exist, it is supported, and it is used, but it’s hard to identify a compelling unique niche for it unless you’re already running IPsec for other reasons. L2TP uses UDP for transport, which means that it passes easily through most rational NAT boxes. Unfortunately, “rational NAT box” is often an oxymoron.
OpenVPN is the open source community’s response to the problems people have experienced with IPsec, PPTP, and L2TP. OpenVPN runs on most platforms of interest, can communicate through NATs, and supports both triangle routing and direct routing. The disadvantage is that it’s virtually always add-on software, no matter what OS you’re using.
The last option is the TLS (or SSL) VPN. The key differentiator here is the use of TLS to provide the protected transport; it in turn builds on the many years of easy interoperability of web browsers and servers. In fact, they do more than build on TLS, they actually use web browsers. This is both the benefit and the limitation of the technology.
In TLS portal VPNs, the server is just a glorified web server: after the usual process, the user is presented with a web page customized to show links to the resources he or she is allowed to access. Crucially, though, when the links are clicked on, the browser itself does not contact another machine directly; instead, the TLS VPN server acts as a proxy, contacting the internal server on the client’s behalf and forwarding data in both directions. This in turn exposes the two crucial limitations of portal VPNs. First and most obviously, only specific services can be reached. Second, the encryption from the browser is not end to end. Apart from the fact that the VPN gateway itself becomes a very tempting target, since a lot of traffic will be in the clear on it, it also rules out authentication methods like client-side certificates (Section 7.8).
TLS tunnel VPNs support other applications, but in a curious way: the browser downloads some active content (Java, JavaScript, ActiveX, what have you) that acts as a more conventional VPN. That is, the active content is the VPN endpoint for an IPsec-like VPN, but only for connections from that machine.
Although TLS VPNs are relatively simple to configure and operate, they have some unique limitations. First, because there are no standards there is little interoperability. This is not a serious issue for portal VPNs; it is very serious for tunnel VPNs. A related issue is that the necessary active content modules may not exist for all client platforms of interest.
There’s a more subtle limitation as well: more than any other type of VPN, TLS VPNs rely on the user to do the right thing. Any way to trick the user into disclosing login credentials (e.g., phishing) will work against a TLS VPN, since the client is, after all, a browser. Furthermore, portal VPNs require the user to consent to the installation of some active content. This an extremely dangerous habit to teach people. (Aside: there was once a web-based corporate expense vouchering system written in Java. Employees who used it—more precisely, who were required to use it—would visit this page, at which point the Java applet would be downloaded. This applet required more access rights than the standard Java sandbox permitted; accordingly, there was a pop-up box asking user permission to do this. The real security experts complained that this was teaching bad habits; the answer that came back from On High said that the vendor had been thoroughly checked by the corporate security group and that the applet was safe. That response, of course, missed the point completely, which if nothing else shows that even corporate security groups are very fallible.)
6.6 Protocol, Algorithm, and Key Size Recommendations
Given all this, what protocols, algorithms, etc., should you use? For standard situations, this is generally a relatively easy question to answer. With cryptography, though, in addition to the usual questions about threat model, there are two more things to think about: work factor and time.
Unlike most security situations, in cryptography we often have a quantitative upper bound on the effort an adversary must expend. When using a symmetric cipher with an n-bit key, the enemy’s work factor is bounded at 2n: that number of trial decryptions is guaranteed to find the key. (I’m ignoring the question of how they can recognize when they’ve gotten the right answer. It’s generally not too hard; see [Bellovin 1997] and its references for some discussion of the topic.) If we can estimate the enemy’s resources, we can determine whether that upper bound is sufficient.
That’s the good news. The bad news is the time dimension: encrypted data often must be protected for a long time, and it’s quite imponderable how much cryptanalysis will improve over the years. There’s an NSA saying that Bruce Schneier is fond of quoting: “attacks always get better; they never get worse.” We can calculate a lower bound on the attacker’s economic improvement by assuming that Moore’s Law will continue to hold. Assume that you’ve determined that an m-bit key is adequate today, given your estimate of your enemy’s resources. The data you’re encrypting must remain secret for 30 years. By Moore’s Law, we know that there will be approximately 20 halvings of the price-performance of a given amount of CPU power. Accordingly, you should use a cipher with a keylength of at least n + 20 bits.
We can approach the question from another angle: the attacker’s maximum possible resource commitment. Assume that the enemy has 107 processors, each of which can try 109 keys per second. (107 nodes is a large but not preposterously large botnet. 109 decryptions/second is too high by a factor of at least 10 and probably 100 for a general-purpose processor or GPU core.) There are about 3.15·107 seconds in a year, which yields 3.15 · 1023 guesses per year, which in turn corresponds to a keylength of about 78 bits. Adding 20 bits for a 30-year margin and another 20 bits to reduce the odds of a lucky guess early in the effort gives a keylength of 118 bits. In other words, using a standard 128-bit key is more than ample. (It’s also worth noting that even a very powerful enemy who can manage 1016 trial decryptions per second is unlikely to devote all that to one single problem, such as your data, for 30 years. A few years ago, I told a friend with spooky connections about a new paper on cryptanalytic hardware. The design would cost many millions to build and would take a year for each solution. He laughed, thinking of the political fights that would ensue: which intercepts would be worth solving on such slow, expensive hardware?)
There’s one more aspect to take into account: advances in cryptanalysis. Can someone, such as the Andromedans, crack a modern cipher? While this can’t be ruled out—though no one ever knowingly uses a cipher that their enemies can break, the history books are full of examples of world-changing cryptanalytic feats—it’s important to realize what a solution would look like. Ciphers today don’t shatter; it is all but impossible to imagine a solution where one plugs in some ciphertext, presses a button, and an answer pops out immediately. Rather, there’s a work factor associated with a solution, often a considerable work factor. Consider the Data Encryption Standard (DES), a now-obsolete 56-bit cipher endorsed at the time by the NSA. The best attack on it ever published, linear cryptanalysis [Matsui 1994], requires 243 known plaintexts. As it turns out, for completely different reasons, encrypting more than 232 DES blocks with the same key is a bad idea; no one will encrypt 2,048 times more data. In other words, the attacker almost certainly cannot collect enough ciphertext, let alone the corresponding plaintext, to launch the attack. If a modern 128-bit cipher is cracked, it’s likely that the work factor is reduced to something that is still preposterously large, but not up to the nominal 2128 standard. There’s still plenty of safety margin.
An interesting statement appeared in the press recently. James Bamford, probably the foremost NSA watcher, wrote: [2012]:
According to another top official also involved with the program, the NSA made an enormous breakthrough several years ago in its ability to cryptanalyze, or break, unfathomably complex encryption systems employed by not only governments around the world but also many average computer users in the United States. The upshot, according to this official: ‘Everybody’s a target; everybody with communication is a target.’
Is that statement accurate? If so, what work factor is still needed? The context of the statement was a description of a massive new NSA datacenter.
It is worth stressing that this analysis has primarily focused on the upper bound, the one given by key size. A cipher can be much weaker than that! A monoalphabetic substitution cipher on the 26-letter English alphabet has 26! possible keys, or a key size of about 88 bits. It is nevertheless simple enough to solve that there are puzzles based on it in daily newspapers. However, the amount of cryptanalytic review that today’s public ciphers undergo is a reasonable guarantee that they’re nowhere near that weak.
There’s one more way to look at the problem: an appeal to authority. In 2009, the NSA published a remarkable document, their so-called Suite B Cryptography specifications.3 In it, they state that 128-bit Advanced Encryption Standard (AES) encryption is strong enough for Secret data, and 256-bit AES is good enough for Top Secret data. Assuming that this isn’t disinformation (and I don’t think that it is), the NSA is saying that a 128-bit cipher is good enough for most national security data. (Of course, given Bamford’s statement, perhaps it is disinformation.)
3. “NSA Suite B Cryptography,” http://www.nsa.gov/ia/programs/suiteb_cryptography/.
Should you go to 256 bits? After all, that’s what they recommend for Top Secret data. Your cryptography is rarely the weakest point. The NSA itself says, “Creating secure cryptographic components, products and solutions involves much more than simply implementing a specific cryptographic protocol or suite of cryptographic algorithms.” Unless your computers and practices are in line with NSA’s own habits—and they’re almost certainly not—your algorithms and key sizes are not your weak link. And the NSA itself? From what I’ve heard, they want 256-bit keys to guard against the possibility of massively parallel quantum computers being developed; such a computer could crack a 128-bit key in O(264) time. Their enemies may not be your enemies, though, and their requirements are stringent; I’ve seen redactions they ordered in a document more than 65 years old. That said, newer versions of their Suite B document do suggest planning for quantum-resistant algorithms and key lengths.
I conclude that 128-bit keys are adequate for almost all purposes and against all enemies short of MI-31. You can use longer keys if it doesn’t cost you anything (256-bit RC4 runs at the same speed as 128-bit RC4), but it rarely makes much security sense.
Stream ciphers are harder to employ properly than are block ciphers, but they do have their uses. RC4 has been the most popular choice, and it is extremely fast; that said, it has a number of serious cryptanalytic weaknesses [Golić 1997; Knudsen et al. 1998; Vanhoef and Piessens 2015]. Don’t use it for new applications; instead, use AES in counter mode. In fact, do your best to eliminate all uses of RC4 within your infrastructure. (The history of RC4 is too tangled to explain here; the Wikipedia article is a good starting point. The best source for a description of the algorithm itself is an expired Internet draft.4)
4. “A Stream Cipher Encryption Algorithm ‘Arcfour’,” http://tools.ietf.org/id/draft-kaukonen-cipher-arcfour-03.txt.
If we’re going to use 128-bit keys for our symmetric ciphers, what size modulus should be used for RSA or Diffie-Hellman moduli for equivalent strength? There have been analytic efforts based on how many operations are required to factor large numbers; two of the best-known analyses are by the National Institute of Standards and Technology (NIST) [Barker et al. 2012] and the IETF [Orman and Hoffman 2004]; a comprehensive survey of recommendations can be found at http://www.keylength.com/. The calculations are complex and I won’t repeat them here, but they don’t completely agree. That said, both agree that a 3,072-bit modulus is adequate for 128-bit ciphers, and 2,048-bit moduli are sufficient for 112-bit ciphers. Although the 3,072-bit size is probably more mathematically accurate, it is considerably more expensive in CPU time, especially on low-end devices. Unless you feel that you really need 128 bits of security (as opposed to key size, since AES doesn’t support 112-bit keys), 2,048-bit moduli are adequate. Again, if the Andromedans are after you, a more conservative choice may be indicated; even the NSA says so. 1,024-bit moduli are too small; research results suggest that MI-31 or its competitors can break them [Adrian et al. 2015].
The situation for elliptic curve algorithms is more complex, since deployment has been hindered by confusion about their patent status (but see [McGrew, Igoe, and Salter 2011]). That said, most of the analyses, including the NSA’s, concur that a 256-bit modulus is suitable for 128-bit ciphers. The problem is that using elliptic curve cryptography requires picking a curve; it’s not entirely clear which are the safest.
One choice is the set of curves standardized by NIST [NIST 2013]. In years gone by, that would have been uncontroversial; NIST standards have generally been seen as strong. However, one of the Snowden revelations was that the NSA tampered with the design of a NIST standard random number generator used for cryptography [Checkoway et al. 2014; Green 2013; Perlroth, Larson, and Shane 2013]; since then, many people have come to distrust all NIST standards. The NIST curves do include some mysterious constants; might they have been selected to produce a curve that the NSA can break? Some people prefer the Brainpool curves [Lochter and Merkle 2010], but there is concern that those curves could have been manipulated, too [Bernstein et al. 2014]. Others have opted for Bernstein’s Curve25519 [2006], which is very fast; however, there are some technical issues with its point representation that pose some compatibility issues. If you don’t trust NIST and the NSA, the latter two choices are arguably safer, but which of the two is best is not yet completely obvious.
By contrast, the proper hash function output size is very strongly and clearly related to cipher key length: it should be double to avoid birthday paradox attacks. In other words, if you’re using a 128-bit cipher, use a hash function with 256-bit output.
My size recommendations are summarized in Table 6.1.

Table 6.1: Size Recommendations for Cryptographic Primitives
For protocols, the IETF made a series of recommendations in 2003 that have held up pretty well [Bellovin, Schiller, and Kaufman 2003]. Some of the protocols described there (e.g., IPsec and TLS) have newer versions, but in general the advice given there is worth following. Table 6.3 summarizes it and adds some newer items.
Recommendations for the cryptographic algorithms themselves (Table 6.2) are a bit more problematic. RSA, Diffie-Hellman, and elliptic curve are all considered secure when used with proper modulus sizes, per Table 6.1. Elliptic curve is often preferred because it requires less CPU and produces smaller output; however (and especially in the wake of the Snowden revelations), there is concern over which curves to use.

Table 6.2: Recommended Cryptographic Algorithms

Table 6.3: Recommended IETF Cryptographic Protocols
Considerations of cryptanalytic strength and output size both rule out the MD5 and SHA-1 algorithms as hash functions. The 256-, 384-, and 512-bit variations of SHA-2 [Eastlake and T. Hansen 2011; NIST 2015b] all look quite strong. NIST has selected an algorithm known as Keccak as SHA-3 [NIST 2015a], but a NIST cryptographer has recently stated that “cryptanalysis since 2005 has actually eased our concerns about SHA-2.”5 The significance of SHA-3 is that it is based on fundamentally different design principles than MD5, SHA-1, and SHA-2; a new cryptanalytic attack on one is unlikely to affect the other. At this point, both seem like excellent choices.
5. “IETF 83 Proceedings, Security Area Open Meeting,” http://www.ietf.org/proceedings/83/slides/slides-83-saag-0.pdf.
A somewhat troublesome part is the block cipher algorithm. AES is standardized, endorsed by the NSA, and has been the subject of a lot of academic study. That said, and even discounting Bamford’s comments because he didn’t say what algorithms are vulnerable (and for all we know was himself the victim of disinformation), there is a modest amount of uneasiness about it; it doesn’t seem to have the safety margins one would like. There have been attacks on weakened versions of AES with 256-bit keys [Biryukov, Dunkelman, et al. 2010], and attacks only marginally better than brute force [Bogdanov, Khovratovich, and Rechberger 2011], but some cryptographers feel that these attacks are still stronger than one would like. Others feel that there’s no problem [Landau 2004]. Thus far, there are no results that pose any credible threat—the attacks on 256-bit AES were related-key attacks, which shouldn’t be an issue for properly designed protocols—but it bears watching. It’s even harder to decide what to recommend in its place. One obvious thing to do is to increase the number of rounds in AES (at a modest cost in performance) and/or improve the key scheduling algorithm, especially for the 192- and 256-bit variants; those algorithms were criticized while the algorithm was still being considered for standardization. Ferguson et al. [2000] wrote, “Compared to the cipher itself, the Rijndael key schedule appears to be more of an ad hoc design. It has a much slower diffusion structure than the cipher, and contains relatively few non-linear elements.” Of course, doing that means that you have a non-standard cipher, with all that that implies for compatibility. Camellia [Matsui, Nakajima, and Moriai 2004], a Japanese standard, has gained some adherents and should be a drop-in replacement for AES. Still, it has not received as much analysis because AES is the 800-kilogram gorilla in the crypto world.
On the other hand, is AES really weak? Some years ago, Biham et al. found a marginally more efficient attack than brute force on a slightly weakened version of the NSA-designed algorithm Skipjack [Biham, Biryukov, and Shamir 1999]. I marveled aloud about it to a very knowledgeable friend, noting that taking away just one round made such a difference. His reply: “You call it a weakness; I call it good engineering.” Maybe the NSA really has that deep an understanding of cipher design—or maybe the safety margin is low. We’ll know for sure in a few decades; for now, I do recommend AES’s use.
6.7 Analysis
As long as we stay with today’s standard models of interaction—client/server, for simple transmission or object security—I don’t expect significant changes in protocols. The important cases are handled reasonably well; the difficult problems, such as preserving access to the key used to encrypt a backup tape, are inherent in the problem statement. One can’t rule out breakthroughs, of course—prior to Diffie and Hellman’s work [1976], no one in the civilian world had even conceived of the concept of public key cryptography—but such insights occur once in a generation at most.
An interesting question is what will happen with different interaction models, such as inherently 3-way or 4-way sessions with no one universally trusted party. (No, I don’t know what sort of really popular application would require that; if I did, I might find myself a venture capitalist.) The key management protocol might be a bit tricky, but lots of other things get complicated with more than two parties.
My very strong statement that people should stick with well-understood, standardized protocols is extremely likely to stand. Remember the quote from Needham and Schroeder discussed earlier. It goes down as one of the more prescient statements in a technical paper; indeed, it took 18 years for what in retrospect was an obvious flaw in one of their own schemes to be discovered [Lowe 1996].
A place I hope we’ll see improvements is the usability of cryptographic technology. A certain amount of over-the-wire flexibility is mandatory, if only to permit migration to different algorithms over time. Unfortunately, this protocol flexibility generally manifests itself as more buttons, knobs, and sliders for the poor, benighted users, who neither know nor care about, say, the rationale for using what is essentially SHA-2-256 truncated to 224-bit output [Housley 2004] to better match triple-DES; all they know is that they’re presented with yet another incomprehensible option. Couple that with the inherent issues of trust management—who really owns a given key?—and you end up with applications that very few people can actually use successfully [Clark et al. 2011; S. L. Garfinkel and R. C. Miller 2005; Whitten and Tygar 1999]. Thus far, cryptography has succeeded where users weren’t given any decisions to make; if it’s all hidden away under the hood, people accept it and feel better for having used it.
Given the concerns I expressed in the last section, do I think that the algorithm recommendations in the previous section will change soon? It’s important to note the assumptions behind my suggestions. First, I’m assuming no drastic improvements in the price/performance of hardware. Even if I’m off by a factor of 100—about 7 bits of keylength—it probably doesn’t matter. If Moore’s Law runs into a brick wall within the desired secrecy lifetime (it will at some point; it seems extremely unlikely that we can produce gates smaller than an atom), the situation is better yet for the defender. I’m also assuming no unforeseen cryptanalytic results. The algorithms and protocols discussed are all well studied, but breakthroughs happen. Again, it is unlikely that a modern algorithm will suddenly shatter, so there will still most likely be a large work factor required—but that’s a prediction, not a promise.
Large-scale quantum computers, should they ever become real, will change things significantly. In particular, there are efficient quantum factoring algorithms [Shor 1994]; that will probably rule out all of today’s public key algorithms. However, it’s still unclear whether such computers are possible.
Finally, remember Shamir’s advice in 1995: “Don’t use cryptographic overkill. Even bad crypto is usually the strong part of the system.”6
6. “Notes on ‘Cryptography—Myths and Realities,’ a talk by Adi Shamir, CRYPTO ‘95,” http://www.ieee-security.org/Cipher/ConfReports/conf-rep-Crypto95.html.
Given all that, where should cryptography be used? The security advantages of universal encryption are clear enough that I won’t bother reviewing them; the disadvantages are not always obvious beyond the problem of “what do I do if lose my key?” That latter is especially serious (albeit obvious) for object encryption, enough so to merit a blanket statement: do not encrypt stored objects unless the risk is very great; if you do, take adequate precautions to preserve keys at least as carefully. If you’re encrypting backup media, stage regular practice drills in retrieving files (a good idea in any event, if only to test the quality of the backups and your operational procedures for using them) and keys.
There are other disadvantages as well. The difficulty in network operations has long been recognized: it’s impossible to see the contents of an encrypted message, even if you need to understand why it’s causing trouble. This can also cause problems for security folk; network intrusion detection systems can’t peer inside, either. It would be nice if we had some sort of magic cryptanalysis box that could only look at packets with the evil bit set [Bellovin 2003]; thus far, no one has developed a suitable one.
There’s a more subtle issue, though. Obviously, protecting cryptographic keys is extremely vital. A key that doesn’t exist on a machine can’t be stolen from it; a key that is there but itself strongly encrypted is likewise effectively immune to compromise. This poses a dilemma: the best way to keep a key safe is to avoid using it. Of course, if we never use it, it’s rather pointless to have it. Nevertheless, we can draw an important conclusion: high-value keys should be employed as sparingly as possible and removed from machines when they’re no longer necessary. Given the rate of host compromise, a long-term key in constant use—say, for routinely signing all outbound email—is at great risk; a recipient should therefore attach a lot less value to the signature than one produced by a key that is rarely used and well protected at other times. In the absence of strong key storage (and general-purpose hosts rarely have such facilities), strong overall security therefore requires different keys for different sensitivity levels, suitable (and suitably usable) software to let users manage such complexity, plus a lot of user education and training on how to behave.