
Chapter 17. Case Studies
“You understand these are all hypothetical scenarios,” T.J. had said. “In all these cases, the net refused to open.”
To Say Nothing of the Dog
—CONNIE WILLIS
Let’s put this all together now and examine a few scenarios. More precisely, let’s look closely at some quasi-realistic case studies: the high-level paper designs of various systems and the effects that some equally hypothetical changes in technology, needs, or operating environment can have on the system architecture and in particular on its security.
Don’t take the designs too literally. I’m presenting realistic scenarios, but I’ve often omitted important details that aren’t relevant to the exact points I’m trying to illustrate. What is most important is the thought process: How did we arrive at our answer?
17.1 A Small Medical Practice
More than almost any other small businesses, medical practices have critical needs for secure and rapid access to information, at more or less any time of day; at the same time, few outside of major hospitals have any dedicated IT staff, let alone security specialists. In other words, such practices pose a major challenge for today, let alone in the future.
While there are many variations, especially for larger practices, one common setup is a small, network of computers, usually (but not always) running Windows. Backup is to a local file server. There is probably Internet connectivity; this is used for email, electronic prescriptions (via special web sites), and the like. Someday, this link will be used to transfer electronic health records; right now, though, the various brands of systems don’t talk to each other very well, so that’s still a ways off [Pear 2015].
There are many ways that a system like this could evolve. Given the increasing complexity of the information environment in medicine, it’s far from clear that such small networks will remain economically viable. Still, let’s look at one near-term change: the need for doctors to access patient records remotely, perhaps to deal with aelectronic health records!remote access patient request or emergency at times when they’re not in the office.
There are two main constraints here. First, security is crucially important. Even in the United States, which has comparatively weak privacy laws, the Health Insurance Portability and Accountability Act (HIPAA) requires doctor’s offices to exercise great care when handling patient information.1 The technical requirements include access control, auditing, integrity mechanisms, and transmission security. The rules are so strict that some companies explicitly prohibit their customers from using their facilities for HIPAA-covered information. To give just one example, the terms of service for Pair.com’s cloud offering explicitly states that their clientele may not “[p]ost, store, publish, transmit, reproduce, or distribute individually identifiable health information or otherwise violate the USA Health Insurance Portability and Accountability Act (HIPAA) and The Patient Safety and Quality Improvement Act of 2005 (PSQIA) or the privacy protection equivalent of these USA laws adopted in any other relevant jurisdiction.”2 There’s a reason for this restriction: regardless of their technical abilities, they almost certainly do not have the procedures and processes in place to comply with the legal requirements set by HIPAA.
1. “Summary of the HIPAA Security Rule,” http://www.hhs.gov/ocr/privacy/hipaa/understanding/srsummary.html.
2. “- pair Networks,” https://www.pair.com/company/hosting-policies/paircloud_contract.html.
The second major constraint is the technical capability of the practice: they have very little. Undoubtedly, they rely on contract IT support; this in turn means that sophisticated solutions are inadvisable. Even if they worked initially, they’re likely to break in short order. In other words, we need a solution that will be robust without constant care and attention.
There are two classes of solution that are worth considering: bring the outside machine to the office network, or store the data in a secure cloud environment. Each has its advantages and disadvantages.
The first has a conceptually easy solution: set up a VPN gateway on the office network, and set up VPN software on each external client. Setting up the VPN in the first place can be contracted out; if the client software works well, there shouldn’t be many problems.
Alas, life is not that simple. Often, VPN software does not play nicely with the NAT boxes installed in hotels, hotspots, and the like. I personally have—and need—several different VPN setups, just to cope with the many different failure modes I’ve encountered. To give just one example, I sometimes connect to a VPN server running on TCP port 443, to work around networks that only want to permit web browsing. This isn’t ideal—running a TCP application on top of a TCP-based VPN can lead to very weird performance problems—but it’s (often) better than nothing. If the doctors will only be connecting from a few places that have known characteristics, for example, their homes, a VPN can work well; otherwise, they’re dicey. We thus have a solution that is secure but often not usable.
Using a secure cloud storage service can solve this problem. By “secure” I mean one where the client machines encrypt the data before uploading it and decrypt it after downloading it. The service itself does not have the decryption keys; thus, data stored there is protected even if the service itself is hacked. The only issue is configuring the various medical applications to look for their data in the directories that are shared via the cloud; generally, this is not a difficult matter.
Cloud storage services are generally simple to use. The hard part is the server, but that’s managed by the provider, not the end users. Furthermore, the client programs generally use HTTP or HTTPS to communicate; as noted earlier, those are the universal solvents that can get through most NATs.
There are two flies in the ointment for either of these solutions; both concern the client computers that doctors will use. First, are they adequately secured? A computer used for general-purpose Internet work is probably not safe; there are too many nasties floating around the Internet. There is guidance on the subject from one US government agency [Scholl et al. 2008, Appendix I], but it basically boils down to “run your computer securely.” It’s safer to use a records-only computer—and laptops are cheap enough today that it’s not an unreasonable burden. (Conversely, of course, the computers in the doctors’ offices should not be used for general work, either.)
The second issue is more problematic: are the doctors using phone apps to access patient records? In general, phones and phone apps are less configurable than desktop and laptop equivalents; it may not be possible to play cloud storage games. In that case, the VPN solution might be the only choice.
17.2 An E-Commerce Site
Let’s consider an e-commerce site of the type discussed in Chapter 11. There is a web server that is a front end for several databases; one of these databases contains user profile information, including addresses and credit card numbers. There are other important databases, including ones for billing, order tracking, and inventory.
The site now wishes to expand dramatically and act as a sales hub for other sites, much as Amazon and several other companies do. This implies links from this site, which I’ll dub VeryBigCo.com, to, say, VerySmallCo.com, a representative of its ilk. What changes should we make to VeryBigCo’s site architecture to do this safely? (Naturally, the discussion here is only about the security changes and not about things like a mismatch in database semantics.)
This isn’t the place for a complete design; there are far too many elements and messages in a real system. Still, by looking at the kinds of events that take place, we can understand the broad shape of the security issues we must address. In other words, we look at the boxes and arrows (Chapter 11) of the functional design.
The first question to ask is the usual first question one should ask when doing security: “What are you trying to protect, and against whom?” E-commerce sites live and die by the confidentiality and integrity of their databases; therefore, that’s what we need to defend most strongly. Furthermore, this is an ordinary e-commerce site, rather than one selling defense gear; we thus don’t have to worry about MI-31. Our enemies are primarily opportunistic hackers, though there may be some element of targeting.
Protecting the databases is a matter of application security, not network security. (That said, per the discussion in Section 11.3 encryption is probably a good idea but not necessarily vital.) The enclave strategy suggested in Chapter 11 is a good start, but here it is not sufficient; what’s really important here is making sure that the database operations on the intentionally shared systems are correct. In other words, protecting the database computer is not enough; we must ensure that only legitimate changes are made to the database.
Another question is which site’s security should have priority. Suppose we can’t come up with a single design that protects VeryBigCo.com and VerySmallCo.com equally. Which is more important? There are several possible ways to address this question. One is to note that that customers are dealing with VeryBigCo.com; therefore, it will be held responsible for any errors. A second approach is to assume that the larger company is more technically capable, and hence should make the decisions. That assumption, of course, is dubious; besides, a big site is more likely to be targeted. We could, of course, use the pragmatic, power-politics approach: VeryBigCo.com is bigger than VerySmallCo.com and hence can get its way.
This, however, is a technical book, so we can look at a technical security metric: which solution is simplest and hence most likely to be secure? Even with that approach, business considerations do enter into our analysis. As it turns out, the solution we’ll devise is symmetric. The larger company has more reason to deploy it, and is probably more capable of doing so, but this design is symmetric.
We start by assuming that the standard precautions—enclaves, encryption, care in parsing input messages, and so on—are already in place. What more do we need to do to protect VeryBigCo.com’s databases, and in particular to protect their contents? Phrased this way, the goal becomes clear: How do we ensure that only legitimate changes are made? This translates very directly to a design requirement: some component must assure the semantic consistency of requests from VerySmallCo.com with VeryBigCo.com’s understanding of the state of transactions. For example, there cannot be a message saying, “We have just shipped 17 widgets; please pay us €437.983¼” unless someone has actually placed such a order. How is this to be enforced?
The wrong way to do this is to add logic to VeryBigCo.com’s database systems. Those are already complicated enough; adding more complexity will hurt security. Furthermore, the last thing you want to do is to allow an untrusted party (VerySmallCo.com) that close to the crown jewels of the company. Instead, there should be a small proxy gateway that validates all transactions. This is an application firewall; it is the actual border between the two companies.
It is tempting to combine this proxy box with whatever code is necessary to translate between the different parties’ databases. Don’t do it. First, the translation is a difficult but unprivileged function. If it’s done by the firewall, there is more risk of the firewall being penetrated. Second, the translation is partner-specific, so it should be closer to the partner. (If you work for the large company you may even be able to tell your smaller partners, “Here’s what we’re sending and receiving; if your databases don’t work this way, you can do the translation, not us.”) Third, the validation logic is not partner-dependent; you want to be able to use the same module (more precisely, another instance of that module) to do the proxying for all of your partners. This is much harder to do if the validation logic is inextricably entwined with the translation logic. A corollary is that you want to do your validation on concepts that your system understands; these, of course, are actions against your type of database.
Doing the validations requires that the proxy firewall check the transactions against your side’s notion of the current state. There is an interesting tradeoff here. If the proxy queries the master database, it will learn the definitive status of all transactions; on the other hand, it means that this exposed box has to have very broad access. The alternative, having a separate transaction status database, eliminates that risk but it means that you will have the same information in two different places. This is always a dubious practice. On balance, the first alternative is likely better, since the proxy by intent has to have fairly broad access if it’s going to pass through validated commands. If, on the other hand, your database has sensitive fields that will never be used by the proxy, you may feel that the other approach is better.
There’s one more thing to consider: logging. Per Section 16.3, your proxy should log all inputs and outputs. Furthermore, its log files should be on a machine outside of the enclave; this way, they’re protected in case the proxy is penetrated.
The final architecture is shown in Figure 17.1. There is an enclave with a VPN to your partner. Inside the enclave, you have two computers: your database translation computer and your proxy. Exactly two types of outbound connections are allowed from the enclave: to the logging server and to your database. If you opt for two databases, you have to permit access to both or put the state database inside the enclave. That’s a bad idea, for reasons that should be obvious by now. (Hint: ask yourself two questions: “Who has to write to this database? What are the consequences if it’s hacked?”)
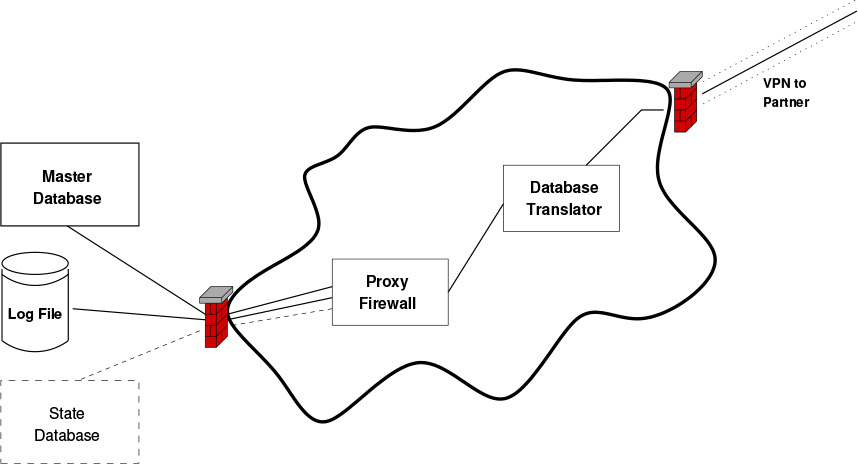
Figure 17.1: The enclave design for linked e-commerce sites.
The important thing about this design is how we arrived at it. Per Section 11.7, we drew our boxes: initially, these were just your database and the other side’s query module. We then asked, “What can happen if the other side is evil?” The answer, that your database could be corrupted, led to the need for a proxy. The protection against its failure is the log file; the need to protect it leads us to put it outside of the enclave.
17.3 A Cryptographic Weakness
It’s going to happen: no matter how sound your design, no matter how careful your users, some day you’ll read of a new security hole (e.g., Heartbleed [Bellovin 2014b; Schneier 2014]) or cryptographic weakness (e.g., the serious attack on RC4 [Vanhoef and Piessens 2015]). What do you do? What should you have done earlier?
The first step is simple: don’t panic [Adams 1980]. Many problems are not nearly as easily exploitable as the trade press would have you believe; there is no need for an emergency response. The second step, then, is to get sound technical information on the problem. Exactly what is wrong, and under exactly what conditions can an attacker use it against you? Third, consult your sysadmin database (Section 15.3) to learn which of your computers might be susceptible.
The analysis that follows should not be taken as a recommendation of what you should do right after reading this section. I’m describing how to respond to a particular attack; by the time you read this, there may be a more powerful one. Rather, take this as an example of how to do the necessary analysis when the next break comes along.
Let’s start with a cryptanalytic attack on RC4. RC4 is commonly used in two contexts, TLS and WPA-TKIP. (The Temporal Key Integrity Protocol [TKIP] is the RC4-based encryption protocol used with WPA. Wireless Protected Access [WPA] is a now-obsolete standard that replaced WEP, but could run on hardware that is too slow for the newer, AES-based WPA2 standard.) Where do you use these? Your mail and web servers probably use TLS; you may also have other software that uses it. WPA-TKIP, of course, was employed to protect Wi-Fi networks. Your system administration databases should point you to all of these; for WPA, though, you may find that your employees are using it at home.
The next part of the analysis is to consider your threat model. Wi-Fi signals have a normal range of 100 meters; even with a good antenna, it’s still likely that an attacker would have to be within a couple of kilometers. In other words, a remote attacker, no matter how skilled, can’t exploit WPA’s use of RC4. The Andromedans could probably get someone close enough to your building, and a targetier might try, but many targetiers are insiders anyway, with legitimate access to the wireless LAN. Suppose, though, that you are being targeted by MI-31. Are they likely to send someone that close, thus risking physical exposure? It can certainly happen, but one of the big advantages of Internet espionage is that you don’t have to risk sending people into dangerous environments.
Of course, there’s another place that WPA-TKIP might be used, one that probably won’t be in your databases: your employees’ home networks. For the most part, the same logic applies; there is still no remote threat. An employee’s network is somewhat more likely to be hit by an ambitious joy hacker, one who has found a clever new cryptanalytic tool. Direct traffic to your company should still be safe—you are using a VPN, right?—but there may be some risk. Per the analysis in Chapter 9, your employee’s computer is now sharing a LAN with an attacker. This might expose the machine to on-network attacks, just as in a public hotspot. Worse yet, the attacker might go after other devices on the LAN and use them to attack the employee’s machine indirectly. Imagine, for example, putting an infected executable file on a home file server. This poses more of a risk than the same technique used against an organization’s LAN, since the organization’s file server is probably run much more securely.
We see, then, that the direct risks to a company from the RC4 crack are relatively low. By all means move away from it (and yes, that may require hardware upgrades), but for most organizations it isn’t a crisis. Your database will point you at exactly which boxes need to be replaced. Home networks probably pose more of a risk, though likely only from attackers in the upper right quadrant of our chart. It is worth considering whether the company should purchase new gear for employees with insecure home networks.
Our analysis of the risk to TLS proceeds along similar lines. First, though, remember two things: in general, eavesdropping on communications links isn’t easy (Section 11.3), and very few attackers other than the Andromedans attack the crypto (page 82). To have a problem, we need a combination of two circumstances: an attacker good enough to do cryptanalysis and use of RC4 on a link that this attacker can tap.
There is little doubt that that MI-31 can tap more or less any link, even underwater cables [Sontag and Drew 1998]. Even lesser attackers can listen to the Wi-Fi traffic in a public hotspot, though, and that poses a real threat: hotspots are popular places for people to check their email. An externally available mail server, then, is at risk.
Here’s where a thorough understanding of the attack comes in. As of when I’m writing this, the best public attack on TLS with RC4 is designed for recovering web cookies, not for spying on IMAP [Vanhoef and Piessens 2015]. Furthermore, it requires injected JavaScript and 52 hours of monitored traffic. Even the most hypercaffienated employee won’t run up that much coffeeshop time overnight. In other words, although the problem is real, it’s not a critical emergency; you don’t need to turn off your webmail servers instantly. And that brings up the last point to consider: what is the cost of reacting?
If you turn off a service, people can’t use it. What is the cost to your business if employees can’t read their email? How much money will you lose if customers can’t place web orders? How many customers will you lose permanently if you disable RC4, because their browsers are ancient and don’t support anything better? Will users fall back to plaintext, thereby making monitoring trivial? Even bad crypto can be better than none; again, most attackers are stymied by any encryption.
These is the sort of analysis you need to go through when you learn of a new flaw. Ask what is at risk, from whom, under what conditions, and what the cost of responding is. Sometimes, there are emergencies, such as when new flaws are found in popular applications and exploits are loose in the wild [Goodin 2015a; Krebs 2013; Krebs 2015]. More often, though, you do have a bit of time to think.
17.4 The Internet of Things
“Things flow about so here!” she said at last in a plaintive tone, after she had spent a minute or so in vainly pursuing a large bright thing, that looked sometimes like a doll and sometimes like a work-box, and was always in the shelf next above the one she was looking at. “And this one is the most provoking of all—but I’ll tell you what—” she added, as a sudden thought struck her, “I’ll follow it up to the very top shelf of all. It’ll puzzle it to go through the ceiling, I expect!”
But even this plan failed: the “thing” went through the ceiling as quietly as possible, as if it were quite used to it.
Through the Looking-Glass, and What Alice Found There
—LEWIS CARROLL
Let’s now try to apply our methodology to something that doesn’t really exist yet in any final form, the so-called Internet of Things (IoT). The Internet of Things is the name given to a future where many objects (which I’ll just call “Things”) contain not just microprocessors but networked processors, thus allowing remote monitoring and control. We’re already seeing its start, what with Internet-enabled thermostats, fitness-tracking devices, and the like; we’re almost certainly going to see more of it. What should a security architecture look like for the IoT?
We have to start by understanding the different components. While there are many possible design choices, in the near term the design space is constrained by current technologies and current business models. All of that can and will change, of course, but for my purposes here it suffices to set out a plausible model rather than a prediction.
• Things will have very poor user interfaces, which will complicate their security setup. Many will speak via a private protocol to a home-resident hub/charger; it will speak IP for its Things.
• Because of the shortage of globally routable IP addresses, very few, if any, Things will have their own unique address. Rather, they’ll have local addresses [Rekhter et al. 1996] and live behind some NAT box such as a home router. The advent of IPv6 will eliminate this need for it but probably will not eliminate the home NAT; per the box on page 67, to some extent NATs serve as firewalls. This need will not go away in the near term. They are thus unable to be contacted directly from outside the house LAN.
• Given this, most Things will report up to and be controlled by some vendor’s (cloud) server complex. Yes, it’s possible to punch holes in NATs. Few people do it because every home router is different and most people don’t have the skill or the time. If you’re a vendor, it’s far easier to have your Things phone home frequently.
• Since these vendor-supplied servers will exist and will capture a lot of data, the temptation to monetize the data will be overwhelming for many such companies. Ignoring the privacy aspects (at least in this book), this means that a large database of personally sensitive information will exist, and hence will need to be protected.
• There will be multiple vendors, and hence multiple server complexes. They’ll need to talk to each other, at least partially as a proxy for the Things talking to each other. Some static Things in the home may try to communicate directly with each other, but other Things will be mobile and will have to go via the cloud. (“Hey, Hot Water Heater—this is Robin’s Phone. Based on her heart rate, speed, and route, she’s probably out jogging. She’ll be home and ready for a shower in 20 minutes; better heat up some water.” “Thank you, Phone, but based on the current temperature and the timing of hot water demand earlier this morning, I think I’m ok.”)
• The consequences of a Thing being hacked may or may not be very serious; it depends on the Thing. A “smart TV” generally has a microphone and camera; it can be abused to spy on people in their homes (and we know that some bad guys like to do things like that [N. Anderson 2013]). A coffee pot is much less dangerous—unless its protection against overheating is controlled by software. A hacked toy might be annoying, but if it contains a microphone that talks to cloud servers, like some dolls do [Halzack 2015], it’s also dangerous. And then there are hacked cars [Greenberg 2015b] and rifles [Greenberg 2015a]. . .
Our architecture, then, has several levels: Things, hubs, and servers. Things should speak only to the proper hub. Hubs can speak locally to other hubs or to hubless Things. All hubs communicate over the Internet with their assigned servers; these servers talk to each other. What are the security properties we need to worry about?
Let’s start by looking at a hub. A hub has to register with a server; this registration somehow has to be tied to ownership. I should be allowed to control my thermostat, but not my neighbor’s. The details of how this is done will vary, but the need to do this securely will always exist. For that matter, hubs have to be on the home’s (probably Wi-Fi) network; this means provisioning an SSID and a WPA2 password. There are some interesting usability challenges here. A compromised hub can attack other local hubs, its own Things, and the server complex to which it connects. For that matter, since it has Internet connectivity, it could be turned into a bot and even send spam.
All connections from the hub should be encrypted, with the possible exception of very short range wireless connections to its associated Things. Although the link over the Internet is hard to tap (and Andromeda is probably not interested in monitoring your laundry cycles), there will be authentication data sent over the home Wi-Fi network; any compromised computer in the home (including another hub) could grab it.
Server-to-server links should also be encrypted. Per the discussion earlier in this chapter, that’s more for authentication than confidentiality. That said, in the large mass of data from many people, there might be information of interest to MI-31, such as the location of a person of interest.
A corrupted server could attack hubs and Things. The most devastating thing it could do would be to replace the firmware on them, though just what this evil firmware could do would obviously be Thing-dependent. There are all of the other usual issues involving servers, such as compromise of its authentication database, its other personal data, and so on.
There is a delicate architectural question involving server-mediated Thing-to-Thing communication: who trusts whom? Consider the phone-to-water heater conversation presented above: how should this message be authenticated? The obvious solution—giving the phone a login on each Thing to which it may talk—doesn’t work; the administrative hassles for consumers are appalling. If the phone and the water heater both talk to the same server, perhaps there’s a trust relationship that can be assumed: the server knows that both belong to Robin. If, though, they’re homed to different companies’ cloud-resident servers, we have a problem. Communication should be allowed to take place if both Things belong to the same person, but how is that to be established? Should the servers trust each other? That might be the simplest answer, assuming suitable contracts (and suitable liability and indemnification clauses) between the IoT companies. If that doesn’t work, we need complex cryptographic protocols for hubs to use to authenticate requests, or share key pairs, or what have you. This issue—how to establish and manage trust, across the acquisition and disposal of hubs, Things, homes, and servers companies—has many possible solutions. Most of these will be quite delicate; evaluating the security of any such architecture will be a considerable challenge.
Managing access control is another issue. Permissions on Things can be complex. Parents may not want their teenagers to be able to adjust the thermostat; they may want to permit house guests to do so. They may also want the thermostat to change itself automatically when a selected set of phones come within a certain radius of the house—this ability is on the market today. As I’ve discussed, managing access control lists is hard, but it’s an essential part of the IoT, and vendors can’t ignore usability.
We may find that part of the solution is another box: a household Thing manager. The manager needs LAN access to all Things, including phones (which will have to have the proper apps). Maybe the manager is built into some hubs, and contacted by a web browser; this, of course, means that more passwords need to be set and managed.
Hubs and Things run software; this software will sometimes be buggy and will need to be updated. This means that there needs to be a bidirectional trust path; servers will have to authenticate themselves to the devices. This may conflict with some people’s desire to reprogram their own gadgetry, much like they jailbreak iPhones. How shall this be handled?
The early returns are distressing. Many current devices don’t do even rudimentary encryption [Barcena, Wueest, and Lau 2014]; my own analysis of some thermostats show similar weaknesses. The analytic methods I’ve described here seem adequate, though; they let us see the sensitivity of different elements and links, and understand where we need to put defenses.
A topology that fits these constraints is shown in Figure 17.2. Every house has a set of hubs; houses may or may not have Thing managers. Mobile Things are presumed to be associated with some hub; alternately, some may be managed directly by an associated phone, which in turn would likely maintain a quasi-permanent connection to a vendor’s server. Let’s see what happens if different components are compromised. I’ve drawn a few in “bold” to reduce ambiguity.
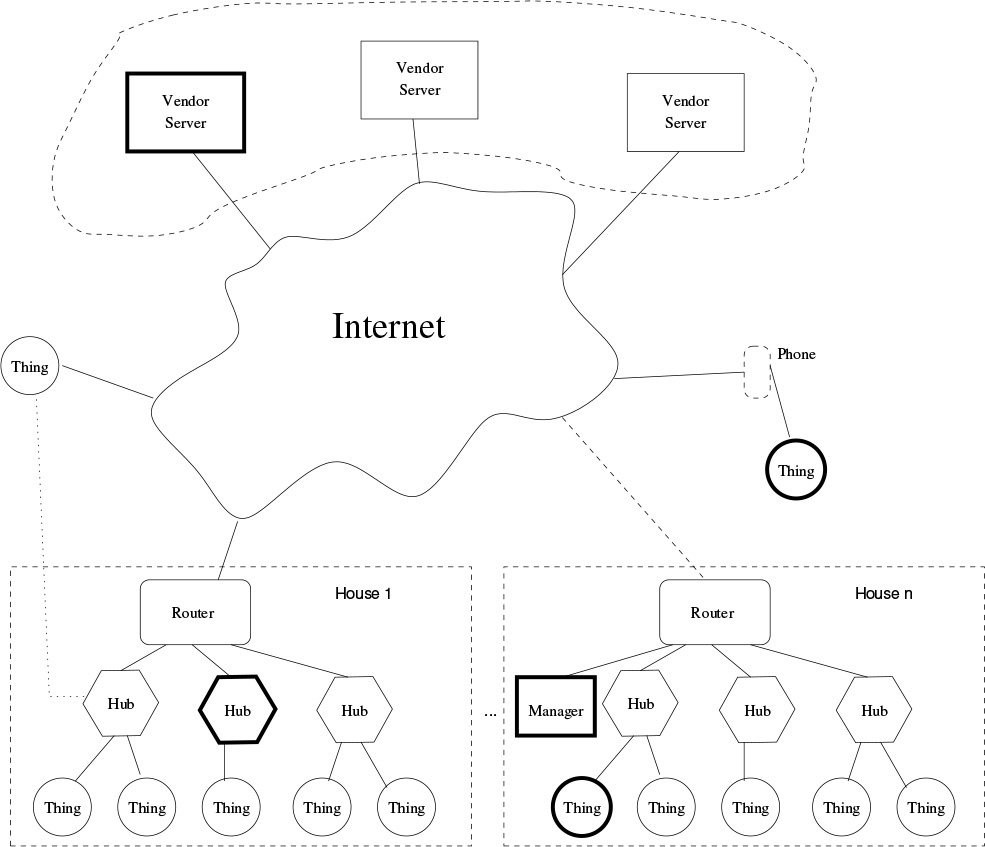
Figure 17.2: A possible IoT configuration. Objects drawn in bold may be compromised.
We will assume that all links are cryptographically protected. This prevents both eavesdropping and impersonation via the net. If the links are not encrypted, the effect is more or less the same as a compromise of one of its endpoints.
Let’s look first at defending the servers. It turns out that that’s a hard thing to do. By design, they’re talking to many customer-controlled Things; they’re also talking to other servers. They’re dealing with a very heterogeneous (and constantly growing) set of Things; this in turn implies the need for frequent updates, probably by many parties. Servers are thus quite vulnerable, much more so than, say, manufacturer development machines.
Suppose that a vendor server has been taken over. What are the implications? Per the discussion, it has several abilities: it can send malicious commands to its associated Things, it can send bad firmware to Things, and it can steal authentication data. We need defenses against each of these threats and against the server itself being compromised.
There is not much that can be done directly about bad commands; by design, Things will listen unconditionally to their servers. However, it is possible to incorporate hardwired limits that prevent dangerous behavior. The Nest thermostat, for example, has “safety temperatures”: if these values are exceeded, either because it’s too cold or too warm, the thermostat will activate the appropriate device, even if the thermostat has been turned off. At least some versions of the device will also ignore requests that seem inappropriate:
Note that your Nest Thermostat [sic] will never cool when the temperature is below 45°F/7°C or heat when the temperature is above 95°F/35°C. These limits cannot be changed.
That text appeared in an earlier version of their web site; it is unclear why the current web site does not say the same thing.3
3. “How Safety Temperatures Work,” https://web.archive.org/web/20140205203310/http://support.nest.com/article/How-do-Safety-Temperatures-work.
IoT Design Property 1 Things should reject dangerous requests. To the extent feasible, these limits should be enforced by hardware, not software.
We can do a better job of defending against nasty firmware. As noted, servers are vulnerable machines. We’re therefore better off if firmware files are digitally signed by the manufacturer. This isn’t a perfect defense: Attackers could replay older, and perhaps buggier firmware versions but they would find it very hard to make arbitrary malicious changes to the firmware if the server were the only machine compromised. Note that this is not the same as an “app store only” model. That all firmware be signed is a security requirement; which signatures should be accepted is a policy decision that is separable from this requirement.
IoT Design Property 2 All firmware must be digitally signed by the manufacturer; the signing key must not be accessible to the servers.
Finally, authentication data is at risk. This completely rules out the use of passwords for Thing-to-server authentication, if for no other reason than that we know that people will use the same, easy-to-remember passwords for all of their Things (and lots of other stuff besides). Things, however, are computers, not people; they can remember large numbers and do complex calculations. Accordingly, some form of cryptographic authentication seems best. Users will need to talk to the servers’ web interface, though; there’s not much that can be done save to follow the advice in Chapter 7. Finally, since Thing-to-Thing communication will go via the servers, authentication between them should be end to end; that way, a compromised server can’t interfere with such messages. This in turn suggests the need for a “house PKI”: issue each customer a certificate; this certificate will in turn be used to issue certificates to all of her hubs and Things.
IoT Design Property 3 Use cryptographic authentication, and in particular public key-based cryptographic authentication, to authenticate Thing-to-server and Thing-to-Thing messages.
If servers are compromised, many clients could be at risk. By putting authorization in the house—that is, at Things and hubs, rather than on vendor servers—this risk is minimized.
IoT Design Property 4 Authorization is done by Things and hubs, not by the servers.
There is one last line of defense: server complexes are professionally run; as such, they can be equipped with sophisticated intrusion-detection systems, separate authentication servers, competent sysadmins, and more. In other words, with a bit of luck and ordinary competence many breaches will be avoided, and others will be detected and remedied quickly.
Home devices, such as hubs and Things, do not have those advantages. What if a hub is compromised? It turns out that there is not much new danger here. A hub is largely a message relay; if the messages are protected end to end, a compromised hub can’t tamper with them. Hubs do have another role, though: they act as the agent for newly acquired Things and perhaps even issue them their certificates. They may also handle authorization on behalf of their Things—it makes much more sense to have a lighting controller regulate who can turn on a given lamp than to have to reconfigure access rules every time someone replaces a burned-out light bulb. For very low-powered Things, the hubs may even be the endpoint for all encryption. In other words, the Things trust them completely and don’t even have an alternate communications path over which they can yell for help.
Hubs are on the local LAN and can generally be attacked from within the house or by a compromised server. They’re generally not reachable directly from the outside, nor do they engage in risky activities such as browsing the web. The best defense, then, is intrusion detection: hubs should look for probes or nasty stuff coming at them from their servers, and alert the device owners if something appears wrong. It is possible that compromised hubs will need to be replaced; at the least, they’ll need to be reset to the factory-shipped configuration.
IoT Design Property 5 All hubs should incorporate intrusion detection. They should be able to upload and download configuration files, even across software versions.
Things themselves may be compromised. A compromised Thing could attack its hub or associated phone; it could also send attack messages through the hub to its server or to other Things. Servers, being professionally run, have to protect themselves. The hubs, though, could perform an intrusion detection function on relayed messages if they’re not encrypted end to end. However, messages must still be authenticated end to end. This demands complex key management scenarios, a possible danger point.
IoT Design Property 6 Thing-to-Thing messages should be authenticated end to end. However, they are encrypted Thing-to-hub, hub-to-hub, and hub-to-Thing, to permit intrusion detection by the Hubs. Messages to servers may or may not be encrypted end to end.
The last component of interest is the Thing manager, whether it’s a stand-alone box or a component built into a hub. Managers are controlled by users via web browsers; user computers are, of course, at great risk of compromise, which in turn puts the manager (or at least the configurations it manages) at risk. Note that the manager will have to have a way to authenticate users; this is almost certainly going to be password based and without the opportunity for external authentication servers. There is also the very thorny issue of password reset: what should be done with the configurations (including private keys; the manager is probably the house CA) and authorizations stored in the manager? It seems likely that they should be retained, since someone who sets a new password could reset all access permissions anyway, but there may be privacy issues to consider.
IoT Design Property 7 Managers are at great risk of attack from compromised user machines. The best they can do is strongly protect passwords and keys, and perhaps look for anomalous change requests—but it is hard to see whom to notify if the apparently authorized user is doing strange things.
Needless to say, a full Internet of Things design would be far more complex than this sketch. Even at this level, though, looking at each type of box lets us analyze the risks to each component and some necessary defensive measures.