
C H A P T E R 11
Putting It All Together
Writing software has some interesting similarities to building a skyscraper. The architecture of a building defines its style, aesthetics, structure, and mechanics. Software architecture includes the same things; there’s a definite flow and texture to it. There’s an art to both, and software can be just as beautiful.
With a good architecture, the pieces fit together smoothly. The relationships between building blocks are clear. The system can be more easily developed, maintained, deployed, expanded, and managed. You can tell you’re working with a good architecture during the development phase because the hiccups tend to be small; forward progress tends to be consistent, you can fix bugs readily when you find them, and there are no big surprises.
A good architecture is a key prerequisite for an ultra-fast web site. You might be able to make a few fast pages without one, in the same way that you might be able to build a few rooms of a skyscraper without one. However, in order to build a large site, you need a cohesive plan.
This chapter covers the following:
- Where to start
- How to choose and tune your software development process
- How to establish a rough sense of the target performance of your site (your league) and how to use that to establish some architectural guidelines
- Tools to aid the development process
- How to approach your architectural design
- Detailed checklists that summarize recommendations from earlier chapters
Where to Start
Although every project has unique requirements, I can offer some guidelines that I’ve found helpful in kicking off new projects that incorporate the ultra-fast principles:
- Establish the software development process that you’re going to use. In my experience, choosing the wrong process, or not having a formal process at all, is one of the most common reasons projects get off track.
- Define your project’s requirements in detail, and determine your league. This process helps establish the foundation and motivation for many aspects of the project.
- Establish a solid infrastructure to support your development, including software tools and build, test, and staging environments.
- Define your system architecture. Start with a high–level block diagram, and work down to functional building blocks. Spend more time in this phase than you think you need.
- The design phase is a key part of your development process. However, be careful not to over–design. One of the most important insights about software development that I’ve gained in my 30+ years in the business is this: the software is the design. In other words, the only way to specify a software design completely is to actually build it.
- Software development projects are driven by cost, features, schedule, and quality (performance and security are aspects of quality). With careful planning, you can choose which three of those four attributes you want to constrain. Although trade–offs are possible, you can’t constrain all of them at the same time. It reminds me of the Heisenberg Uncertainty Principle in physics, which says that you can determine either position or momentum to arbitrary precision, but that the more accurately you know one, the less accurately you know the other. Most projects start out with trying to control cost. Features are next, because that’s what managers think they are paying for. Then, the projects inevitably have business requirements that force delivery by a certain date. With cost, features, and schedule heavily constrained, quality often ends up being sacrificed. When the quality is found to be unacceptable, managers lose control of cost and schedule, and the results are huge cost overruns and delays. The solution is straightforward: let features be the aspect that you allow to change; maintain the cost, schedule, and quality constraints, and cut features if you must.
- Project staffing is of course a crucial element. Good people are at the heart of any successful project. However, it’s also true that having too many people, or people with the wrong skills, can significantly delay your project.
Development Process
As I mentioned, using the right development process is an important cornerstone to the success of any complex software project. Surprisingly, most companies I’ve worked with use an ad hoc process that is often based around what they’re comfortable with or an approach they find to be intuitive, rather than on what the industry has found to be effective.
I am keenly aware that the choice of development process is often a near–religious one and that there is no one–size–fits–all solution. However, given the importance of choosing and using a good process to building an ultra–fast site, let’s review one way of doing things in detail.
After working with dozens of companies that create software, some as the core of their business and others because they are forced into it out of necessity, I’ve seen just about every different type of software development process you can imagine. My experience also includes working at Microsoft for several years on a development team. In addition, I’ve done considerable development in my own company, where I’ve been able to choose and customize the process.
The conclusion I’ve reached is that the process Microsoft uses is an excellent starting point. The company’s ability to deliver regularly such a broad array of immensely complex products is a testament to its success.
For example, the Developer Division at Microsoft employs more than two thousand people. They create more than 30 different products for software developers, including Visual Studio, the .NET Framework, and Team Foundation. Their code base consists of more than 8 million lines of code, and they are able to regularly release substantial new versions and feature enhancements that are used by tens of thousands of developers all over the world.
Microsoft used its internal experience as the foundation for the MSF Agile process, which it has incorporated into Team Foundation. I have an ultra–fast spin on this approach, which includes several additional techniques that can improve team effectiveness even more, particularly when it comes to quality and performance.
Organization
The team at Microsoft that builds an individual software product is called a Product Group. Table 11-1 shows the number of people in each role in a typical medium–sized Product Group of 40 people.
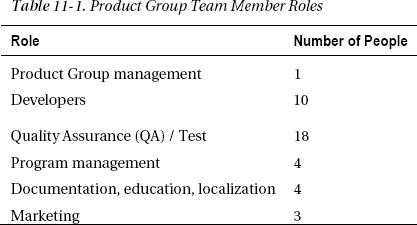
![]() Note There are almost twice as many people working on QA and Test as on Development.
Note There are almost twice as many people working on QA and Test as on Development.
Program managers drive features. They own the customer experience and are responsible for managing the Product Group and for helping team members make decisions regarding priorities. They are also responsible for writing a design specification for each feature.
Project Phases and Milestones
Microsoft breaks a project down into phases, with a milestone or deliverable at the end of each phase, as indicated in Table 11-2.

All milestones include quality–based exit criteria. Each phase is finished only when the milestones are complete. Features that don’t meet the exit criteria on time can be dropped. There may be additional beta test and release candidate phases if they are needed.
In the planning phase, most of the developers, testers, and documentation or localization staff aren’t yet involved. The marketing team gathers requirements based on product concepts provided by upper management.
Marketing then works with engineering and program management to create a vision statement along with an initial schedule, including estimates of which features will go into which release, and their priorities. The vision statement adds details to the initial concept and requirements and becomes the input to the system architecture design. Coding for new features is typically broken down into eight– to ten–week periods, with continuous integration.
The M2 and beta–test phases end with a milestone called zero bug bounce (ZBB). The idea is to help ensure application stability by delaying exit from the project phase until there are no bugs more than 48 hours old. Features that are still generating new bugs at the end of the project phase may be cut or deferred to the next release to help ensure quality.
Project escrow is typically a 48–hour period at the end of the project, just prior to final release, which is used to help ensure that the product is stable. The team holds the software without making any changes, while continuing testing. If any blocking bugs turn up during that period, then the bugs are fixed and the escrow starts over again.
After the end of M2, the team no longer starts development on any new features. Instead, they focus all remaining time on testing, fixing bugs, and improving stability and quality.
Coding
In addition to the code for the features they’re working on, developers are also responsible for writing unit tests. The tests should exercise the new feature with a goal of at least 70 percent code coverage. All unit tests must run correctly before a developer checks in their changes.
After check–in, other team members are notified about the nature of the changes, either by e-mail or through the source control system or a central management web site.
Using an automated build system, the full product is built after every check–in, and released every evening. The QA team deploys the nightly releases to a dedicated staging environment the next day, where they run tests on the previous day’s changes.
Testing
The QA team is responsible for writing and executing test plans and for building and maintaining test–specific infrastructure, as well as performing tests and reporting the results.
Testing includes functional, performance, load (scalability), deployment, operations, monitoring, and regression tests. It is the testing team’s responsibility to make sure the software is ready both for end users and for deployment and operations.
To give you an idea of the scale of testing that goes into an enterprise–class product, Visual Studio has more than 10 million functional test cases. Microsoft uses about nine thousand servers to run the tests, and a full test pass takes about three weeks to run. That’s more than one test case per line of code and roughly one test server for every thousand test cases.
Bug Tracking
Program managers triage bugs and assign them a priority from zero to four. Priority zero (P0) means developers should stop whatever else they were doing and fix the bug immediately. That may happen if the production site is having urgent problems or if the developer broke the build somehow. P1 and P2 bugs are for the most important features. P3 bugs are “if you have time,” and P4 bugs are “if you feel like it.”
Bugs are tracked in a central location that’s integrated with the source control system, such as Team Foundation Server (TFS), which facilitates reporting and change–history tracking. The tool that Microsoft used internally (and that some teams are still using) for many years to track bugs, called Product Studio, inspired the bug–tracking part of TFS.
When team members check in a fix for a bug, they mark the bug resolved. The person who submitted the original bug report is then responsible for verifying the fix before they close it.
After the project gets to the feature–complete milestone at the end of M2, all development efforts focus on testing and bug fixing. The goal is either to fix bugs or to defer them (and possibly the related feature) to the next release. By the time they release the product, there should be no bugs outstanding that they haven’t consciously deferred.
Beginning in the Beta 2 phase, the team locks down the design, more and more as the release date approaches. The bug triage team establishes a priority and importance threshold, or bug bar, to decide between bugs that will be fixed in the current release and bugs that will be deferred. They then raise the bar as time goes on. The goal is to maximize stability by minimizing changes. With a good architecture and a sound software development process, the number of must–fix showstopper bugs drops to zero as the ship date approaches (a process that sometimes requires considerable effort).
After bugs stop coming in, the build goes into escrow for a few days to be sure the system remains stable while testing continues. If everything is still OK after that, the build is released to manufacturing or to an operations team and the Web.
User Feedback
User feedback, including the response to beta tests and release candidates, forms an important pillar of the development process. From a performance perspective, you should confirm that your users think the parts of the site which interest them are fast. You should also provide an easy way for them to let you know if they have problems.
Microsoft solicits feedback from many different sources, including its Connect web site, forums, newsgroups, the Technical Assistance Program (TAP), and Community Technology Previews (CTPs). The company analyzes that feedback continuously and uses it to drive product features and priorities.
The Ultra–Fast Spin
Here are a few variations on Microsoft’s process that I’ve found can further reduce risk and help to deliver a scalable, high–performance, high–quality site.
Depth–First Development
The most powerful technique is something I call depth–first development (DFD). The idea flows from an additional project requirement, which is that instead of trying to target specific delivery dates, you should build your site in such a way that you could deploy it into production at almost any time in the development process, not just at the very end. Projects that use DFD are never late.
Implementing DFD involves building the software infrastructure that you need to deploy and operate your site before building more user–visible features. That includes things such as how you handle software or configuration updates in production, custom performance counters, logging, capacity planning, using data access and business logic layers, caching, deployment, and so on.
With this approach, I’ve found that although developing the first few pages on a site goes very slowly, things are also dramatically easier as the site grows.
With a more conventional approach, the “deep” aspects of your system, such as deployment and operations, are often left to the end as developers focus on features. In many companies, the features are what earn pats on the back from management, so they naturally receive first priority. The deep components are also sometimes forgotten in the original development plan and schedule, because they relate to all features rather than to one particular feature. What’s often missed is the fact that those components aid development, too. You can use the same system to find and fix problems during development that your operations team will later use to identify bugs quickly after the site goes live.
Imagine building a race car. When the car is in a race, you know you will need to be able to fill it with fuel and change tires quickly. However, you will also be testing the car a lot before the race. Think about how much time you could save at the test track if you had the ability to do those things early on.
DFD also helps you iron out deployment and operations issues early, when they are usually orders of magnitude less expensive to fix. For a large site, it allows the hardware or VM infrastructure to be built up incrementally, alongside the software.
You might think of DFD as narrow but deep: build everything you need, but only what you need, and nothing more. The idea is to focus on what the site could use immediately if it was in production, rather than what it might need many months from now, which can be very difficult to predict accurately.
DFD helps minimize code rework by establishing important patterns early. If you don’t add things like logging to your system early, then when you do add them, they end up touching nearly your entire system. A large number of changes like that can easily introduce instabilities, as well as being costly and time–consuming. It’s much better to establish the coding patterns early and then use them as you go.
Unit Testing
Another area where I like to do things a little differently involves unit tests. First, I appreciate the concept behind test–driven development (TDD) very much, and I’ve used it at length. Unfortunately, I can’t endorse its use in real–world environments. My experience has been that it doesn’t produce better code or reduce development time compared to other alternatives. However, unit tests are extremely important.
In addition to developers coding their own tests, I also like to have developers write unit tests for each other’s code. In some shops, having QA write unit tests can also be useful. The idea is that developers (myself included) sometimes become stuck thinking about their code in a certain way, and they miss code paths and test cases that others may see. Having developers write tests for each other’s code is a wonderful prelude to code reviews.
I also like to include performance and security–specific unit tests that verify not just functionality but also quality. Those tests can help to identify regressions. If someone introduces a change that slows down another part of the system, it’s much better to catch it when the change is first made than after the code is running in production.
Unit tests should include your stored procedures as well as your .NET code. You can use a data generator to create a realistic number of rows for your tests. Some editions of Visual Studio include support for auto-generating unit test stubs for stored procedures. You can also easily add checks to ensure that the calls execute within a certain amount of time. Combined with the data generator, that provides a great way to help avoid performance surprises when your code goes into production.
Other Tips
Here are a few more tips.
- Establish formal coding standards. The larger your team is, the more important it becomes for everyone to use a consistent style. Humans are very good at processing familiar patterns. An experienced developer can quickly tell a lot about how code works just by how it looks when it’s formatted in a consistent and familiar way. I suggest starting with the Visual Studio standard code–formatting rules, because that makes it easy for everyone on the team to be consistent. Then, add rules concerning comments, order of objects within a file, mapping between file names and their contents, object naming, and so on. The whole thing shouldn’t be more than a couple of pages long.
- Store your schema definitions and other database scripts and code in source code control along with the rest of your site. It’s a good idea for the same reason that using source control for the rest of your site is. To make it easier to track changes, separate your scripts at the database object level (tables, stored procedures, and so on) rather than having a single do–all file.
- Use a source control system that’s tightly coupled with your bug–tracking system. Doing so provides a valuable synergy that allows you to see not only what changed in your system from one check–in to another, but why.
- Schedule regular code reviews to look at the code your team is developing. In addition to checking the code for functional accuracy, also look at it from a quality perspective, including maintainability, performance, security, and so on. I’ve also found regular brown bag talks to be useful, where team members give a presentation about the details of their design and implementation, typically over lunch.
- Refactor your code frequently. Make sure it’s readable, remove dead code, make sure names adhere to your coding standards, improve the code’s maintainability, factor out duplicate code, refine your class design, and so on. I’m not saying to focus on refactoring to the point of distraction, but if you see something that’s not structured correctly that you can fix easily at a tactical level, you should fix it. Similarly, if you make changes that render other code no longer necessary or that introduce redundant code, it’s better to fix those issues sooner than later. Good unit tests will help you avoid undue disruption from refactoring.
- Leverage static code analysis to help identify code patterns that can be a problem. The Premium and Ultimate editions of Visual Studio include support for code analysis (see the Analyze menu), with rules that look at things like library design, globalization, naming conventions, performance, interoperability, maintainability, mobility, portability, reliability, security, and usage. Another option is
FxCop, which has similar functionality and is available as a free download from Microsoft.
League
To help focus your efforts on the tasks that are most likely to improve the performance and scalability of your site, I’ve found that it’s useful to establish a rough sense of your site’s target performance and scalability.
I’ve never seen a formal partitioning along these lines, so I came up with my own system that I call leagues. See Table 11-3.

These definitions don’t include secondary hardware or software that may be attached to your system, nor do they say anything about how big your servers are, whether they are virtual machines, or even how much traffic they serve.
Knowing the league you’re playing in helps simplify many decisions during your site development process. Certain architectural options may be reasonable for one league that would be very unreasonable at another. For example, even though I don’t recommend in–proc session state, if you’re targeting LG-1, where your site is always on a hosted server, then it may be an option for you because it works in a single–server environment. On the other hand, if you’re targeting LG-4, you can quickly rule out in–proc session state, because it doesn’t work correctly in a true load–balanced environment.
Similar decisions and analysis are possible across many dimensions of web site development. For example, the requirements for logging, staging environments, monitoring, and deployment vary from one league to another.
Establish your league by determining where your site will be within three to five years. Keep in mind that higher leagues cost more to build and operate. Overestimating your league will result in unnecessary costs; underestimating will result in rework down the road and potential performance and operations issues in the meantime.
When you know your league, use it as a focal point in your architectural analysis and decision making. For example, in LG-5, adding a high–availability database also means that having a Windows domain in your production environment would be a good idea to help manage the cluster. With that in mind, you may need to allocate additional resources for primary and secondary domain controllers.
Tools
Using good tools can make a huge difference in both developer productivity and code quality. I’m always shocked when I see companies with large software teams and poor tools. The time saved with good tools invariably reduces labor costs through productivity improvements, which allows smaller teams. Then costs decline even more because smaller teams are more efficient and because high–quality code doesn’t take as much effort to maintain.
Imagine a carpenter with hand tools compared to power tools, or carrying firewood in your backpack instead of in the back of a truck, or making changes to a book you’ve written with pencil and paper instead of a word processor. It’s the same idea for software development.
Of course, exactly which tools to use is often a matter of debate. Visual Studio is at the heart of ASP.NET development, and I’m partial to the Microsoft tools because they are seamlessly integrated. There are also a few open source options and third–party vendors of well–integrated tools that can be very useful. I find the overhead of using development tools that aren’t integrated into Visual Studio to often be time–consuming and error–prone.
When you have the tools, it’s important to know how to use them well, so a little training can go a long way—even if it’s just a web cast or two. Visual Studio includes a number of productivity–enhancing features, some of which aren’t very visible unless you know they’re there (things like code snippets).
Some of the more important tools that ultra–fast developers should have available include the following:
Architecture
Whether you’re working on a new site or modifying an existing one, it’s a good idea to spend some time putting together an architectural block diagram. It may sound simple and obvious, but it’s a useful exercise. Figure 11-1 shows an example architectural diagram for a high–end LG-6 system.
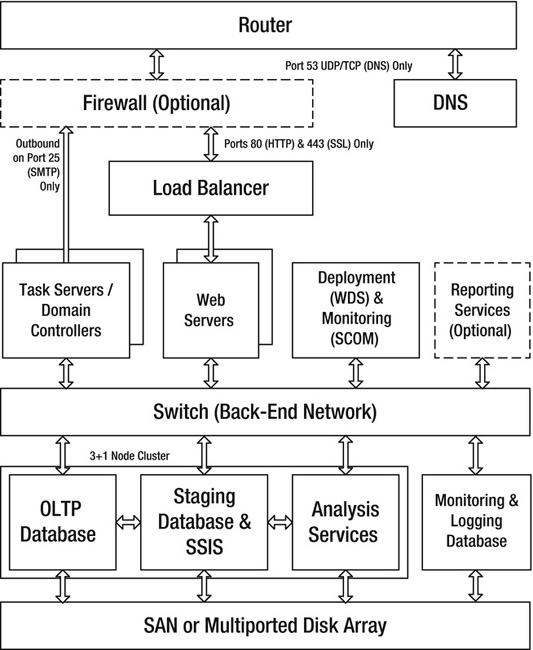
Figure 11-1. Example architectural block diagram
Include all the main components of your system, and break them out both logically and physically. Include third–party resources on which your site relies.
With a draft diagram in hand (or, even better, on a whiteboard), think about the issues discussed earlier in the book: minimizing round trips, minimizing latency, caching, deployment, monitoring, upgrading, partitioning, AppPools, minimizing the number of different server types, and so on. You may find that a slight reorganization of your production environment can result in significant improvements.
Something else to consider in the area of architecture is the number of tiers in your system. By tiers, I mean software layers that are separated by out–of–process calls, such as web services or database calls (a data access layer or a business logic layer is not a tier). Keeping the core principles in mind, it should come as no surprise that I favor flat architectures, because they tend to minimize round trips. In general, a two–tier server architecture, where your web tier talks directly to your data tier, can perform much better than systems with three or more tiers.
Architects often introduce additional tiers as a way to reduce the load on the database. However, as I discussed at length earlier in the book, you can usually do better by offloading the database in other ways, such as by caching, partitioning, read–only databases, Service Broker, and SSAS.
Allowing the web tier to connect directly to the database also facilitates SqlDependency type caching, where SQL Server can send notifications to the web tier when the results of a prior query have changed.
Another goal of additional middle tiers is often to provide a larger cache of some kind. However, recall from the earlier discussion that the way SQL Server uses memory means it can become a large cache itself. Because SQL Server can process queries very quickly when the data it needs is already in memory, it is often difficult to improve that performance by just adding more cache in another tier. The reverse is often true: the additional latency introduced by a middle tier can have an adverse impact on performance and scalability.
Checklists
Here are a few checklists that summarize recommendations from earlier chapters.
Principles and Method (Chapter 1)
- Focus on perceived performance.
- Minimize blocking calls.
- Reduce round trips.
- Cache at all tiers.
- Optimize disk I/O management.
Client Performance (Chapter 2)
- Put one or more requests for resources in the first 500 bytes of your HTML.
- Move requests for resources from the
<head>section into the<body>of your HTML, subject to rendering restrictions.- Make the position of objects on the page independent of download order, with early– and late–loading techniques (load large objects as late as you can).
- Use lowercase for all your URLs.
- Use a single, consistent URL for each resource, with matched case and a single domain name.
- Use two or three subdomains to optimize parallel loading of your static files.
- Minimize the number of different script files you’re using. If you can’t avoid having multiple files, combine them into the minimum possible number of files on the server.
- If you need multiple script files because they call
document.write(), useinnerHTMLor direct DOM manipulation instead.- If you can’t avoid
document.write(), use absolute positioning to invoke the script late in the file or use the hidden<div>technique.- Use the page
onloadhandler (directly or via jQuery) to request objects that aren’t needed until after everything else on the page, such as rollover images or images below the fold.- Replace spacer GIFs and text images with CSS.
- Bundle multiple CSS files into one.
- Hide, remove, or filter comments from your HTML, CSS, and JavaScript.
- Use lowercase HTML tags and property names.
- Consider using CSS instead of images for transparency, borders, color, and so on.
- Consider varying CSS transparency instead of using separate rollover images.
- Use image tiling when appropriate to help minimize image sizes, such as for backgrounds.
- Crop or resize images to the minimum size.
- Use the smaller of GIF or PNG format for lossless images, and use JPEG for complex images without sharp edges in them (such as photos).
- Enable progressive rendering on large PNG and JPEG images, to improve perceived performance.
- Increase the level of compression on JPEG images to the maximum that’s reasonable for your application.
- Use the lowest bit depth on your images that you can (8-bit images are smaller than 24-bit images).
- Consider using image slicing to improve the perceived performance of large images.
- Consider using image maps instead of multiple images for things like menus (although a text and CSS–based menu is even better).
- Specify an image’s native size or larger in an
<img>tag. If you need to use a size that’s smaller than native, you should resize the source image instead.- Instead of modifying image sizes to adjust fill and spacing on a page, use CSS.
- Set a relatively near–term expiration date on your
favicon.icofile (such as 30 days).- Consider running your HTML and CSS through an optimizer, such as the one available in Expression Web.
- Remove unused JavaScript.
- Move
styledefinitions from your HTML into a CSS include file.- Consider generating inline CSS the first time a user requests a page on your site, followed by precaching the CSS file to reduce the load time for subsequent pages.
- Validate form fields on the client before submitting them to the server.
- Don’t enable submit buttons until all form fields are valid.
- Use script to avoid or delay submitting a form if the new parameters are the same as the ones that were used to generate the current page.
- Use script to generate repetitive HTML, which reduces HTML size.
- Use script to add repetitive strings to property values in your HTML.
- Minimize the total size of your cookies by using short names and optimized encoding, merging multiple cookies into one, and so on.
- Set an explicit
pathfor all cookies, and avoid using the root path (/) as much as possible.- Group pages and other content that need cookies into a common folder hierarchy, to help optimize the cookie
pathsetting.- Reference your static content from subdomains that never use cookies.
- Optimize your CSS by merging and sharing class definitions, leveraging property inheritance, eliminating whitespace, using short specifiers and property cascading, remove unused and duplicate CSS classes, and so on.
- Combine multiple images used on one page into a single file, and use CSS image sprites to display them.
- Use JavaScript to avoid a server round trip for things like showing and hiding part of the page, updating the current time, changing fonts and colors, and event–based actions.
- Use Ajax to make partial–page updates.
- Prefer CSS to
<table>.- When you can’t avoid
<table>, consider using<col>, and make sure to set the size properties of any images the<table>contains.- Include a
<!DOCTYPE>tag at the top of your HTML.- If you can anticipate the next page that a user will request, use script to precache the content and DNS entries that page will use.
- Optimize the performance of your JavaScript.
Caching (Chapter 3)
- Enable
Cache-Control: max-agefor your static content, with a default far–future expiration date.- Review all pages of your dynamic content, and establish an appropriate caching location and duration for them: client–only, proxies, server–side, cache disabled, and so on.
- Use cache profiles in
web.configto help ensure consistent policies.- Disable
ViewStateby default, on a per–page basis. Only enable it on pages that post back and where you explicitly need the functionality it provides.- Create and use a custom template in Visual Studio that disables
ViewState, disablesAutoEventWireup, and sets a base class for your page, if you’re using one.- Use
ViewStateorControlStateto cache page–specific state.- Prefer using cookies, web storage, or Silverlight isolated storage to cache state that’s referenced by multiple pages, subject to size and security constraints.
- Send a privacy policy HTTP header (
P3P) whenever you set cookies.- Use
Cache.VaryByHeaders()for pages that vary their content based on HTTP headers such asAccept-Language.- Consider using a CDN to offload some of your static file traffic.
- Change the name of your static files (or the folders they’re in) when you version them, instead of using query strings, so that they remain cacheable by
http.sys.- Enable output caching for your user controls, where appropriate.
- If you have pages that you can’t configure to use the output cache, consider either moving some of the code on the pages into a cacheable user control or using substitution caching.
- Avoid caching content that is unique per user.
- Avoid caching content that is accessed infrequently.
- Configure cached pages that depend on certain database queries to drop themselves from the cache based on a notification that the data has changed.
- Use the
VaryByCustomfunction to cache multiple versions of a page based on customizable aspects of the request such as cookies, role, theme, browser, and so on.- Use a cache validation callback if you need to determine programmatically whether a cached page is still valid.
- Use
HttpApplicationState,Cache, andContext.Itemsto cache objects that have permanent, temporary, and per–request lifetimes, respectively.- Associate data that you store in
Cachewith a dependency object to receive a notification that flushes the cache entry if the source data changes.- Consider using a
WeakReferenceobject to cache objects temporarily in a lightweight way compared to theCacheobject, but with less control over cache lifetime and related events.- Use the 64-bit versions of Windows Server and SQL Server.
- Make sure your database server has plenty of RAM, which can help improve caching.
- Consider precaching SQL Server data pages into RAM by issuing appropriate queries from a background thread when you can anticipate the user’s next request.
- For dynamic content that changes frequently, consider using a short cache–expiration time rather than disabling caching.
IIS 7.5 (Chapter 5)
- Partition your application into one or more AppPools, using the Integrated pipeline mode.
- Configure AppPool recycling to happen at a specific time each day when your servers aren’t busy.
- Consider using a web garden (particularly if your site is LG-3+ but you are temporarily using LG-2).
- If you’re using multiple AppPools, consider using WSRM to help ensure optimal resource allocation between them when your system is under load.
- Use Log Parser to check your IIS logs for HTTP
404 Not Founderrors and other similar errors that may be wasting server resources.- Configure IIS to remove the
X-Powered-ByHTTP header.- Install an
HttpModuleto remove theServerandETagHTTP headers.- Modify your
web.configto remove theX-Aspnet-VersionHTTP header.- Enable site–wide static file compression.
- Add support for the
deflatecompression option toapplicationHost.config.- Specify
staticCompressionLevel="10"anddynamicCompressionLevel="3"inapplicationHost.config.- Turn off the feature that disables compression if the server’s CPU use exceeds a certain threshold.
- Use the
<urlCompression>tag inweb.configto selectively enable dynamic compression.- Keep your URLs short and your folder hierarchies flat, rather than deep.
- Consider using virtual directories to help flatten existing hierarchies.
- Consider using URL rewriting to help shorten URLs and make them more meaningful for search engines.
- Use Failed Request Tracing to validate caching behavior and to find pages that fail or run too slowly.
- Consider using IIS bandwidth throttling to help smooth the load on your servers, particularly during peak periods.
ASP.NET Threads and Sessions (Chapter 5)
- Use asynchronous pages for all pages that do I/O, including accessing the database, web service calls, filesystem access, and so on.
- Modify the
<applicationPool>section in yourAspnet.configfile to reflect the load you anticipate on your servers.- Use code rather than the runtime to enforce concurrency limits where the load on a remote system is an issue, such as with some web services.
- If you have an existing site that uses synchronous calls, you’re seeing low CPU use and high request latencies, and your code is compatible with load balancing, consider temporarily using multiple worker processes while you migrate to async pages.
- Add a background worker thread to your application, and use it for tasks that don’t have to be executed in–line with page requests, such as logging.
- Avoid session state if you can; use cookies, web storage, or Silverlight isolated storage instead whenever possible.
- If you do need session state, configure the runtime to store it in SQL Server.
- When using session state, disable it by default in
web.config, and enable it only on the pages that need it.- Configure
ReadOnlysession state for pages that don’t need to write it.- If your site makes heavy use of session state, maximize the performance of the supporting hardware, and consider using partitioning for added scalability.
- When you choose which objects to store in the
Sessiondictionary, prefer basic data types to custom objects.
Using ASP.NET to Implement and Manage Optimization Techniques (Chapter 6)
- Use master pages as a dynamic page template system.
- Use custom user controls to factor out code that you use on several different pages.
- Consider applying output caching to your user controls.
- Use short strings for control IDs, because the strings can appear in your HTML.
- Use IDs only when you need to reference an object from your code–behind.
- Use ASP.NET themes to help group and manage your style–related assets. Prefer
styleSheetThemesto standard themes.- Use ASP.NET skins to help define default or often–used user control properties.
- Use the runtime’s bundling and minification features to reduce the number and size of your CSS and JavaScript files.
- Use an optimized
GetVaryByCustomString()to limit the number of different versions of browser–specific pages or controls that the runtime caches.- Consider using control adapters to help optimize generated HTML.
- Consider generating CSS and JavaScript dynamically, particularly for things like browser dependencies.
- Use custom user controls or control adapters to automatically assign your static files to multiple subdomains and to implement other techniques from Chapter 2.
- If you have many images that are larger on the server than the client needs them to be, consider using a dynamic image–resizing control that resizes and caches them on the server before sending the smaller files to the client.
Managing ASP.NET Application Policies (Chapter 7)
- Consider using one or more custom
HttpModules to enforce things like site–wide cookie policies, centralized monitoring and logging, custom session handling, and custom authorization and authentication.- Because
HttpModules run in–line with every request, try to offload long–running tasks (such as logging to a database) onto a background worker thread when you can.- Consider using a custom
HttpHandlerfor dynamic content that doesn’t include a markup file, such as dynamic images and charts.- Use an async
HttpModuleorHttpHandlerif your code needs to access the database or do any other I/O.- Create a page base class, and use it with all your pages.
- Disable
AutoEventWireupin thePagedirective, and override theOnLoad()style methods instead of using the defaultPage_Load()style.- Consider using a page adapter to implement site–wide page–specific policies, such as custom
ViewStatehandling.- Identify client requests that are page refreshes, and limit or minimize the processing to create a new page when appropriate.
- Consider using URL routing or programmatic URL rewriting to help shorten the URLs of your dynamic content.
- Consider using tag transforms in cases where you like to replace the class for one control with another class everywhere it’s used in your application.
- Minimize the use of redirects. Use
Server.Transfer()instead when you can.- When you use redirects, be sure to end page processing after issuing the redirect.
- Regularly review the HTTP requests and responses that your pages make, using the Fiddler debugging proxy.
- For pages with long–running tasks and where Ajax wouldn’t be appropriate, consider flushing the response buffer early to help improve perceived page–load time.
- Use whitespace filtering to minimize the size of your HTML.
- Check
Page.IsPostBackto see whether you can avoid repeating work that is already reflected on the page or stored inViewState.- Before performing any time–consuming operations on a page, check the
Response.IsClientConnectedflag to make sure the client still has an active network connection.- Disable debug mode for the version of your site that runs in production.
SQL Server Relational Database (Chapter 8)
- Make sure your database data and log files are on separate disks from one another.
- Make sure you have enough RAM (helps improve caching and read performance).
- Use stored procedures as your primary interface to the database.
- Use dynamic SQL, triggers, or cursors only when there is no other way to solve a particular problem.
- When you have to use dynamic SQL, always use it with parameterized queries.
- Structure your stored procedures to help minimize database round trips.
- Use command batching, table–valued parameters, and multiple result sets to help minimize database round trips.
- Group multiple
INSERT,UPDATE, andDELETEoperations into transactions to help minimize database log I/O pressure.- Optimize the data types you choose for your tables, and prefer narrow, always–increasing keys to wide or randomly ordered ones.
- Optimize the indexes for your tables, including clustered vs. nonclustered indexes and including extra columns to allow the indexes to cover queries.
- Try to structure your queries and indexes to avoid table and index scans.
- Make frequent use of SQL Profiler to observe the activity on your database.
- To prevent deadlocks, ensure that you access lockable database objects consistently in the same order.
- Use
SET NOCOUNT ONat the top of your stored procedures, except in cases where the results are associated withSqlDependency.- Use data paging to retrieve only the rows you need to use for a particular page.
- Prefer ADO.NET to ORM systems such as LINQ to SQL and the Entity Framework or NHibernate, particularly for large projects, due to its support for native async commands, command batching, multiple result sets, and table–valued parameters. ORM systems may be acceptable for LG-1 or LG-2 sites or for rapid prototyping that won’t evolve into production code.
- Consider using XML columns as an alternative to having many sparse columns when you have properties that are difficult to represent in relational form, when you have XML documents that you need to query, as an alternative to adding new columns dynamically to your tables, or as an alternative to many–to–many mappings.
- Avoid using wildcards in your XML queries.
- For sites that require consistent performance and 24/7 uptime, consider using table partitioning to ease ongoing maintenance issues; doing so requires SQL Server Enterprise (LG-5+).
- Prefer full–text search to wildcard searches using the T-SQL
LIKEclause.- Enable Service Broker in your database.
- Use Service Broker to offload or time–shift long–running tasks to a background thread (LG-1 to LG-3) or to a Windows Service (LG-3+).
- Use Service Broker to queue requests to send e-mails, rather than sending them in–line.
- Associate
SqlDependencyorSqlCacheDependencyobjects with database queries that return cacheable results (requires Service Broker).- Use Resource Governor to help maintain the relative priorities of certain types of database traffic, such as low–priority logging compared to commands generated by your VIP users or purchase transactions; this requires SQL Server Enterprise (LG-5+).
- Prefer scaling up your database servers first, before scaling out.
- For read–heavy workloads, consider using several load–balanced read–only database servers (LG-6+).
- Monitor the relevant Windows and SQL Server performance counters to help identify bottlenecks early and for long–term trend analysis and capacity planning.
- Be sure to take into account the time for a failover to happen when designing your high–availability architecture. In general, prefer clustering when a fail–over time of 30 seconds or more is acceptable, and prefer mirroring when a shorter time is required (LG-5+).
- Set a large enough file size for your database data and log files that they should never have to autogrow.
- Don’t shrink or autoshrink your database files.
- Minimize the number of different databases you need.
- Consider SQL CLR for functions, types, or stored procedures that contain a large amount of procedural code, or to share constants or code between your web and data tiers.
SQL Server Analysis Services (Chapter 9)
- Avoid using the relational database for aggregation queries such as sums and counts; whenever possible, prefer SSAS for that instead (LG-2+).
- Download and install ADOMD.NET so that you can query your cubes from your web site (LG-2+).
- Use SSMS to test your MDX queries.
- Use both Visual Studio and Excel to peruse your cube and to make sure the data is organized as you intended.
- As with relational queries, be sure to cache the results of MDX queries when it makes sense to do so. Keep in mind that cubes are updated less often than your tables.
- For sites with SQL Server Standard, use SSIS and SQL Agent to automate the process of updating your cubes (LG-2+).
- For sites with SQL Server Enterprise, configure proactive caching to update your cubes when the relational data changes (LG-5+).
- Consider using a staging database in between your OLTP database and SSAS. Populate the staging database with SSIS, and allow it to be used for certain types of read–only queries (LG-6+).
Infrastructure and Operations (Chapter 10)
- Use custom performance counters to instrument and monitor your application.
- Minimize the different types of web and application servers that you use in your production environment. If necessary, use WSRM to help balance the load among different AppPools.
- Test your servers to determine how they behave under heavy load, including determining their maximum CPU use. Use that information in your capacity planning analysis.
- Optimize your disk subsystem by using disks with a high rotation speed, narrow partitions, and an appropriate RAID type; matching controller capacities with the achievable throughput; having enough drives; using a battery–backed write cache; and so on.
- Minimize NTFS fragmentation by putting your database files on fresh file systems by themselves.
- For filesystems where you add and delete files regularly, periodically run a disk or file defragmentation tool and use a cluster size that reflects your average file size.
- Prefer SAS or SCSI drives to SATA when maximizing throughput or data reliability are important.
- Consider using SSD drives. Although they have a cost premium, they are much faster than rotating disks.
- Consider using a SAN in environments where building and maintaining your own disk arrays aren’t practical, or where data reliability is paramount.
- Use a high–speed back–end network: at least 1Gbps, and 10Gbps if you can (LG-3+).
- Configure the network that connects your web tier with your data tier to use jumbo frames (LG-3+).
- Configure the network from your database servers to the local switch to use link aggregation (LACP) (LG-4+).
- Enable Windows Firewall on all your servers.
- For LG-1 to LG-3 sites where users can upload files onto your web server, consider using server–side antivirus software as an alternative to a hardware firewall (LG-4+ sites shouldn’t store any uploaded files on the web servers, except perhaps as a temporary cache).
- If you have access to your router, configure it to do port filtering and to protect against things like SYN floods and other DDOS attacks (LG-4+).
- For sites with up to eight web servers, consider using NLB for load balancing. For more than eight servers, use a hardware load balancer (LG-4+).
- Consider running your own DNS server or subscribing to a commercial service that provides high–speed DNS.
- Prefer DNS
Arecords toCNAMErecords whenever possible.- If you aren’t using DNS as part of a failover scheme (LG-7), set your default TTL to around 24 hours.
- Establish staging environments for testing both in development and in preproduction.
- Establish a deployment procedure that allows you to complete deployments quickly. It may be manual for smaller sites or automated using WDS for larger sites.
- Establish a procedure for upgrading your data tier.
- Deploy your web site in precompiled form.
- Create an
app_offline.htmfile in the top–level folder of your web site to take it offline temporarily, such as while performing upgrades.- Warm up the cache after a restart on both your web and database servers.
- Consider deploying a system to monitor your servers proactively, such as System Center Operations Manager (LG-4+).
Summary
In this chapter, I covered the following:
- The steps to follow to kick off a new project that incorporates ultra–fast principles, as well as the importance of developing a good architecture
- An overview of Microsoft’s internal software development process
- The ultra–fast spin on the software development process, including how you can use Depth-first Development to improve the quality and predictability of your project
- The importance of unit testing, including testing for quality–oriented metrics such as execution time
- How determining the league of your system can help provide a focal point for many architectural decisions
- The importance of good software tools, as well as a list of the more important ones to have available
- An example architectural block diagram
- Why two–tier server architectures are generally preferable to three–tier or N–tier
- Detailed checklists with recommendations from earlier chapters