
Chapter 4. Clusters and High Availability
This chapter covers the following topics:
• Distributed Resources Scheduler (DRS)
• vSphere High Availability (HA)
• Other Resource Management and Availability Features
This chapter contains information related to VMware 2V0-21.20 exam objectives 1.6, 1.6.1, 1.6.2, 1.6.3, 1.6.4, 1.6.4.1, 4.5, 4.6, 5.1, 5.1.1, 5.2, 7.5, 7.11.5
This chapter introduces vSphere 6.7, describes its major components, and identifies its requirements.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should study this entire chapter or move quickly to the “Exam Preparation Tasks” section. Regardless, the authors recommend that you read the entire chapter at least once. Table 4-1 outlines the major headings in this chapter and the corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.”
Table 4-1 “Do I Know This Already?” Section-to-Question Mapping

Caution
The goal of self-assessment is to gauge your mastery of the topics in this chapter. If you do not know the answer to a question or are only partially sure of the answer, you should mark that question as wrong for purposes of the self-assessment. Giving yourself credit for an answer you correctly guess skews your self-assessment results and might provide you with a false sense of security.
1. You are configuring EVC mode in a vSphere cluster that uses Intel hardware. Which of the following values should you choose to set the EVC mode to the lowest level that includes the SSE4.2 instruction set?
a. Merom
b. Penryn
c. Nehalem
d. Westmere
2. In vSphere 7.0, you want to configure the DRS Migration Threshold such that it is at the minimum level at which the virtual machine happiness is considered. Which of the following values should you choose?
a. Level 1
b. Level 2
c. Level 3
d. Level 4
e. Level 5
3. Which of the following is not a good use for Resource Pools in DRS?
a. To delegate control and management
b. To impact the use of network resources
c. To impact the use of CPU resources
d. To impact the use of memory resources
4. You need your resource pool to use a two-pass algorithm to divvy reservations. In the second pass, excess pool reservation is divvied proportionally to virtual machines (limited by virtual machine size). Which step should you take?
a. Ensure vSphere 6.7 or higher is used
b. Ensure vSphere 7.0 or higher is used
c. Enable scalable shares
d. Enable expandable reservations
5. You are configuring vSphere HA in a cluster. You want to configure the cluster to use a specific host as a target for failovers. Which setting should you use?
a. Host failures cluster tolerates
b. Define host failover capacity by > Cluster resource percentage
c. Define host failover capacity by > Slot Policy (powered-on VMs)
d. Define host failover capacity by > Dedicated failover hosts
e. Define host failover capacity by > Disabled
6. You are enabling VM Monitoring in your vSphere HA cluster. You want to set the monitoring level such that its failure interval is 60 seconds. Which of the following options should you choose?
a. High
b. Medium
c. Low
d. Normal
7. You are configuring Virtual Machine Component Protection (VMCP) in a vSphere HA cluster. Which of the following statements are true?
a. For PDL and APD failures, you can control the restart policy for virtual machines, by setting it to conservative or aggressive.
b. For PDL failures, you can control the restart policy for virtual machines, by setting it to conservative or aggressive.
c. For APD failures, you can control the restart policy for virtual machines, by setting it to conservative or aggressive.
d. For PDL and APD failures, you cannot control the restart policy for virtual machines
8. You want to use Predictive DRS. What is the minimum vSphere Version you need?
a. vSphere 6.0
b. vSphere 6.5
c. vSphere 6.7
d. vSphere 7.0
9. You are configuring vSphere Fault Tolerance (FT) in your vSphere 7.0 environment. What it the maximum number for virtual CPUs you can use with FT-protected virtual machine?
a. 1
b. 2
c. 4
d. 8
10. You are concerned about service availability for your vCenter Server. Which of the following statements are true?
a. If a vCenter service fails, VMware Service Lifecycle Manager restarts it.
b. If a vCenter service fails, VMware Lifecycle Manager restarts it.
c. If a vCenter service fails, vCenter Server HA restarts it.
d. VMware Service Lifecycle Manager is a part of the PSC.
Foundation Topics
Cluster Concepts and Overview
A vSphere cluster is a set of ESXi hosts that are intended to work together as a unit. When you add a host to a cluster, the host’s resources become part of the cluster’s resources. vCenter Server manages the resources of all hosts in a cluster as one unit. In addition to creating a cluster, assigning a name, and adding ESXi objects, you can enable and configure features on a cluster, such as vSphere Distributed Resource Scheduler (DRS), VMware Enhanced vMotion Compatibility (EVC), Distributed Power Management (DPM), vSphere High Availability (HA), and vSAN.
In the vSphere Client, you can manage and monitor the resources in a cluster as a single object. You can easily monitor and manage the hosts and virtual machines in the DRS cluster.
If you enable VMware EVC on a cluster, you can ensure that migrations with vMotion do not fail because of CPU compatibility errors. If you enable vSphere DRS on a cluster, you can allow automatic resource balancing using the pooled host resources in the cluster. If you enable vSphere HA on a cluster, you can allow rapid virtual machine recovery from host hardware failures using the cluster’s available host resource capacity. If you enable DPM on a cluster, you can provide automated power management in the cluster. If you enable vSAN on a cluster, you utilize a logical SAN that is built upon a pool of drives attached locally to the ESXi hosts in the cluster.
You can use the Quickstart workflow in the vSphere Client to create a configure a cluster. The Quickstart page provides three cards, Cluster Basics, Add Hosts, and Configure Cluster. For an existing cluster, you can use Cluster Basics to change the cluster name and enable cluster services, such as DRS and vSphere HA. You can use the Add Hosts card to add hosts to the cluster. You can use the Configure Cluster card to configure networking and other settings on the hosts in in the cluster.
Additionally, in vSphere 7.0 you can configure a few general settings for the cluster. For example, when you create a cluster you, even if you do not enable DRS, vSphere,HA or vSAN, you can choose an option to manage all hosts in the cluster with a single image. With this option, all hosts in a cluster inherit the same image, which reduces variability between hosts, improves your ability to ensure hardware compatibility, and simplifies upgrades. This feature requires hosts to already be ESXi 7.0 or above. It replaces baselines. Once enabled, baselines cannot be used in this cluster.
Note
Do not confuse a vSphere cluster with a datastore cluster. In vSphere, datastore clusters and vSphere (host) clusters are separate objects. Although you can directly enable a vSphere cluster for vSAN, DRS and vSphere HA, you cannot directly enable it for datastore clustering. You create datastore clusters separately. See Chapter 2, “Storage Infrastructure,” for details on datastore clusters.
Enhanced vMotion Compatibility (EVC)
Enhanced vMotion Compatibility (EVC) is a cluster setting that can improve CPU compatibility between hosts for supporting vMotion. vMotion migrations are live migrations that require compatible instruction sets for source and target processors used by the virtual machine. The source and target processors must come from the same vendor class (AMD or Intel) to be vMotion compatible. Clock speed, cache size, and number of cores can differ between source and target processors. When you start a vMotion migration, or a migration of a suspended virtual machine, the wizard checks the destination host for compatibility and displays an error message if problems exist. Using EVC, you can allow vMotion between some processors that would normally be incompatible.
The CPU instruction set that is available to virtual machine guest OS is determined when the virtual machine is powered on. This CPU feature set is based on the following items:
• Host CPU family and model
• Settings in the BIOS that might disable CPU features
• ESX/ESXi version running on the host
• The virtual machine's compatibility setting
• The virtual machine's guest operating system
EVC ensures that all hosts in a cluster present the same CPU feature set to virtual machines, even if the actual CPUs on the hosts differ. EVC is a cluster setting that you can enable and configure the EVC Mode with a baseline CPU feature set. EVC ensures that hosts in cluster uses the baseline feature set when presenting an instruction set to a guest OS. EVC uses AMD-V Extended Migration technology (for AMD hosts) and Intel FlexMigration technology (for Intel hosts) to mask processor features, allowing hosts to present the feature set of an earlier generation of processor. You should configure the EVC mode to accommodate the host with the smallest feature set in the cluster.
The EVC requirements for hosts include the following.
• ESXi 6.5 or later
• Hosts must be attached to a vCenter Server
• CPUs must be from a single vendor, either Intel or AMD.
• If the AMD-V, Intel-VT, AMD NX, or Intel XD features are available in the BIOS, enable them.
• Supported CPUs for EVC Mode per the VMware Compatibility Guide.
Note
You can apply a custom CPU compatibility mask to hide host CPU features from a virtual machine, but this is not recommended by VMware.
You can configure the EVC settings using the Quickstart > Configure Cluster workflow in the vSphere Client. You can also configure EVC directly in the cluster settings. The options for VMware EVC are Disable EVC, Enable EVC for AMD Hosts, and Enable EVC for Intel Hosts.
If you choose Enable EVC for Intel Hosts, then you can set the EVC Mode to one of the options described in Table 4-2.
Table 4-2 EVC Modes for Intel

If you choose Enable EVC for AMD Hosts, then you can set the EVC Mode to one of the options described in Table 4-3.
Table 4-3 EVC Modes for AMD
vSAN Services
You can enable DRS, vSphere HA, and vSAN at the cluster level. The following sections provide details on DRS and vSphere HA. For details on vSAN, see Chapter 2.
Distributed Resource Scheduler (DRS)
Distributed Resource Scheduler (DRS) distributes compute workload in a cluster, by strategically placing virtual machines during power on operations and live migrating (vMotion) virtual machines (VMs) when necessary. DRS provides many features and settings that enable you to control its behavior.
You can set the DRS Automation Mode for a cluster to one of the following.
• Manual: DRS does not automatically place or migrate virtual machines. It only makes recommendations.
• Partially Automated: DRS automatically places virtual machines as they power on. It makes recommendations for virtual machine migrations.
• Fully Automated: DRS not automatically places and migrates virtual machines.
You can override the automation mode at the virtual machine level.
Recent DRS Enhancements
Beginning in vSphere 6.5, VMware has added many improvements to DRS. For example, in vSphere 7.0, DRS runs once every minute rather than every 5 minutes in older DRS versions. The new DRS tends to recommend smaller (memory) virtual machines for migration to facilitate faster vMotion migrations, where the old DRS tends to recommend large virtual machines to minimize the number of migrations. The old DRS uses an imbalance metric that is derived form the standard deviation of load across the hosts in the cluster. The new DRS focuses on virtual machine happiness. The new DRS is much lighter and faster that the old DRS.
The new DRS recognizes vMotion has an expensive operation and accounts for it in its recommendations. In a cluster where virtual machines are frequently powered on the workload is volatile, avoids continuously migrating virtual machines. To this, DRS calculates the gain duration for live migrating a virtual machine and considers the gain duration when making recommendations.
The following sections provide details on other recent DRS enhancements.
Network-Aware DRS
![]()
In vSphere 6.5, DRS considers the utilization of host network adapters during initial placements and load balancing, but it does not balance the network load. Instead, its goal is to ensure that the target host has sufficient available network resources. It works by eliminating hosts with saturated networks form from the list of possible migration hosts. The threshold used by DRS for network saturation in 80% by default. When DRS cannot migrate VMs due to network saturation, the result may be an imbalanced cluster.
In vSphere 7.0, DRS uses a new cost modeling algorithm, which is flexible and now balances network bandwidth along with CPU and memory usage.
Virtual Machine Distribution
Starting in vSphere 6.5, you can enable an option to distribute a more even number of virtual machines across hosts. The main use case is to improve availability. The primary goal of DRS remains unchanged, which is to ensure that all VMs are getting the resources they need and that the load is balanced in the cluster. But with this new option enabled, DRS will also try to ensure that the number of virtual machines per host is balanced in the cluster.
Memory Metric for Load Balancing
Historically, vSphere uses the Active Memory metric for load balancing decisions. In vSphere 6.5 and 6.7, you have the option to set DRS to load balance based on Consumed Memory. In vSphere 7.0, the Granted Memory metric is used for load balancing and no cluster option is available to change the behavior.
Virtual Machine Initial Placement
Starting with vSphere 6.5, DRS uses a new initial placement algorithm that is faster, lighter, and more effective than the previous algorithm. In earlier versions, DRS takes a snapshot of the cluster state when making virtual machine placement recommendations. In the algorithm, DRS does not snapshot the cluster state, allowing faster and more accurate recommendations. With the new algorithm, DRS powers on virtual machines much faster. In vSphere 6.5, the new placement feature is not supported for the following configurations.
• Clusters where DPM, Proactive HA, or HA Admission Control is enabled
• Clusters with DRS configured in manual mode
• Virtual machines with manual DRS override setting
• Virtual machines that are FT-enabled
• Virtual machines that are part of a vApp
In vSphere 6.7, the new placement is available for all configurations.
Enhancements to the Evacuation Workflow
Prior to vSphere 6.5, when evacuating a host that is entering maintenance mode, DRS waited to migrate templates and powered-off virtual machines until after the completion of vMotion migrations, leaving those objects unavailable for use for a long time. Starting in vSphere 6.5, DRS prioritizes the migration of virtual machine templates and powered-off virtual machines over powered-on virtual machines, making those objects available for use without waiting on vMotion migrations.
Prior to vSphere 6.5, the evacuation of powered off virtual machines was inefficient. Starting in vSphere 6.5, these evacuations occur in parallel, making use of up to 100 re-register threads per vCenter Server. This means that you may see only a small difference when evacuating up to 100 virtual machines.
Starting in vSphere 6.7, DRS is more efficient in evacuating powered-on virtual machines from a host that is entering maintenance mode. Instead of simultaneously initiating vMotion for all the powered-on VMs on the host as in previous versions, DRS initiates vMotion migrations in batches of 8 at a time. Each vMotion batch of vMotion is issued after the previous batch completes. The vMotion batching makes the entire workflow more controlled and predictable.
DRS Support for NVM
Starting in vSphere 6.7, DRS supports virtual machines running on next generation persistent memory devices, known as Non-Volatile Memory (NVM) devices. NVM is exposed as a datastore that is local to the host. Virtual machines can use the datastore as an NVM device exposed to the guest (Virtual Persistent Memory or vPMem) or as a location for a virtual machine disk (Virtual Persistent Memory Disk or vPMemDisk). DRS is aware of the NVM devices used by virtual mahcines and guarantees the destination ESXi host has enough free persistent memory to accommodate placements and migrations.
How DRS scores VMs
![]()
Historically, DRS balanced the workload in a cluster based on host compute resource usage. In vSphere 7.0, DRS balances the workload based on virtual machine happiness. A virtual machine’s DRS score is a measure of its happiness, which is a measure of the resources available for consumption by the virtual machine. The higher the DRS score for a VM, the better its resource availability. DRS moves virtual machines to improve their DRS scores. DRS also calculates a DRS score for the cluster, which is a weighted sum of the DRS scores of all the cluster’s virtual machines.
In Sphere 7.0, DRS calculates the core for each virtual machine on each ESXi host in the cluster every minute. Simply put, DRS logic computes an ideal throughput (demand) and an actual throughput (goodness) for each resource (CPU, memory, and network) for each virtual machine. The virtual machine’s efficiency for a particular resource is ratio of the goodness over the demand. A virtual machine’s DRS score (total efficiency) is the product of its CPU, memory, and network efficiencies.
When calculating the efficiency, DRS applies resource costs. For CPU resources, DRS includes costs for CPU cache, CPU ready, and CPU tax. For memory resources, DRS includes costs for memory burstiness, memory reclamation, and memory tax. For network resources, DRS includes a network utilization cost.
DRS compares a virtual machine’s DRS score for the current host on which it runs. DRS determines if another host can provide a better DRS score for the virtual machine. If so, DRS calculates the cost for migrating the virtual machine to the host and factors that score into its load balancing decision.
DRS Rules
You can configure rules to control the behavior of DRS.
A VM-Host affinity rule specifies whether the members of a selected virtual machine DRS group can run on the members of a specific host DRS group. Unlike a virtual machine to virtual machine affinity rule, which specifies affinity (or anti-affinity) between individual virtual machines, a VM-Host affinity rule specifies an affinity relationship between a group of virtual machines and a group of hosts. There are required rules (designated by “must”) and preferential rules (designated by “should”.)
A VM-Host affinity rule includes the following components.
• One virtual machine DRS group.
• One host DRS group.
• A designation of whether the rule is a requirement (“must”) or a preference (“should”) and whether it is affinity (“run on”) or anti-affinity (“not run on”).
A VM-VM affinity rule specifies whether selected individual virtual machines should run on the same host or be kept on separate hosts. This type of rule is used to create affinity or anti-affinity between individual virtual machines. When an affinity rule is created, DRS tries to keep the specified virtual machines together on the same host. You might want to do this, for example, for performance reasons.
With an anti-affinity rule, DRS tries to keep the specified virtual machines apart. You could use such a rule if you want to guarantee that certain virtual machines are always on different physical hosts. In that case, if a problem occurs with one host, not all virtual machines would be at risk. You can create VM-VM affinity rules to specify whether selected individual virtual machines should run on the same host or be kept on separate hosts.
VM-VM Affinity Rule Conflicts can occur when you use multiple VM-VM affinity and VM-VM anti-affinity rules. If two VM-VM affinity rules are in conflict, you cannot enable both. For example, if one rule keeps two virtual machines together and another rule keeps the same two virtual machines apart, you cannot enable both rules. Select one of the rules to apply and disable or remove the conflicting rule. When two VM-VM affinity rules conflict, the older one takes precedence and the newer rule is disabled. DRS only tries to satisfy enabled rules and disabled rules are ignored. DRS gives higher precedence to preventing violations of anti-affinity rules than violations of affinity rules.
Note
A VM-VM rule does not allow the “should” qualifier. You should consider these as “must” rules.
DRS Migration Sensitivity
Prior to vSphere 7.0, DRS used a Migration Threshold to determine when virtual machines should be migrated to balance the cluster workload. In vSphere 7.0, DRS does not consider cluster standard deviation for load balancing. Instead, it is designed to be more virtual machine centric and workload centric, rather than cluster centric. You can set the DRS Migration Sensitivity to one of the following values.
![]()
• Level 1 –DRS only makes recommendations to fix rule violations or to facilitate a host entering maintenance mode.
• Level 2 - DRS expands on Level 1 by making recommends in situations that are at, or close to, resource contention. It does not make recommendations just to improve virtual machine happiness or cluster load distribution.
• Level 3 – (Default Level) DRS expands on Level 2 by making recommendations to improve VM happiness and cluster load distribution.
• Level 4 - DRS expands on Level 3 by making recommendations for occasional bursts in the workload and reacts to the sudden load changes.
• Level 5 - DRS expands on Level 4 by making recommendations dynamic, greatly varying workloads. DRS reacts to the workload changes every time.
Resource Pools
Resource pools are container objects in the vSphere inventory that are used to compartmentalize the CPU and memory resources of a host, a cluster, or a parent resource pool. Virtual machines run in and draw resources from resource pools. You can create multiple resource pools as direct children of a standalone host or a DRS cluster. You cannot create child resource pools on host that has been added to a cluster or on a cluster that is not enabled for DRS.
You can use resource pools much like a folder to organize virtual machines. You can delegate control over each resource pool to specific individuals and groups. You can monitor resources and set alarms on resource pools. If you need a container just for organization and permission purposes, consider using a folder. If you also need resource management, then consider using a resource pool. You can assign resource settings, such as shares, reservations, and limits to resource pools.
Use Cases
You can use resource pools to compartmentalize a cluster’s resources and then use the resource pools to delegate control to individuals or organizations. Table 4-4 provides some use cases for resource pools.
Table 4-4 Resource Pool Use Cases

Shares, Limits, and Reservations
You can configure CPU and Memory shares, reservations, and limits on resource pools, as explained in Table 4-5.
Table 4-5 Shares, Limits, and Reservations


Table 4-6 provides the CPU and memory share values for virtual machines when using the High, Normal, and Low settings. The corresponding share values for a resource pool are equivalent to a virtual machine with four vCPUs and 16 GB memory.
Table 4-6 Virtual Machine Shares

Note
For example, the share values for a resource pool configured with Normal CPU Shares and High Memory Shares are (4 x 1000) 4000 CPU shares and (16 * 1024 * 20) 327,680 Memory shares
Note
The relative priority represented by each share changes with the addition and removal of virtual machines in a resource pool or cluster. It also changes as you increase or decrease the Shares on a specific virtual machine or resource pool.
Enhanced Resource Pool Reservation
Starting in vSphere 6.7, DRS uses a new two-pass algorithm to divvy resource reservations to its children. In the old divvying model will not reserve more resources than the current demand, even when the resource pool is configured with a higher reservation. When a spike in virtual machine demand occurs after resource divvying is completed, DRS does not make the remaining pool reservation available to the virtual machine, until the next divvying operation occurs. As a result, a virtual machine’s performance may be temporarily impacted. In the new divvying model, each divvying operation uses two passes. In the first pass, the resource pool reservation is divvied based on virtual machine demand. In the second pass, excess pool reservation is divvied proportionally, limited by the virtual machine’s configured size, which reduces the performance impact due to virtual machine spikes.
Scalable Shares
![]()
Another new DRS feature in vSphere 7.0 is scalable shares. Its main use case is the scenario where you want to use shares to give high priority resource access to a set of virtual machines in a resource pool, without concern for the relative number of objects in the pool compared to other pools. With standard shares, each pool in a cluster competes for resource allocation with its siblings based on the share ratio. With scalable shares, the allocation for each pool factors in the number of objects in the pool.
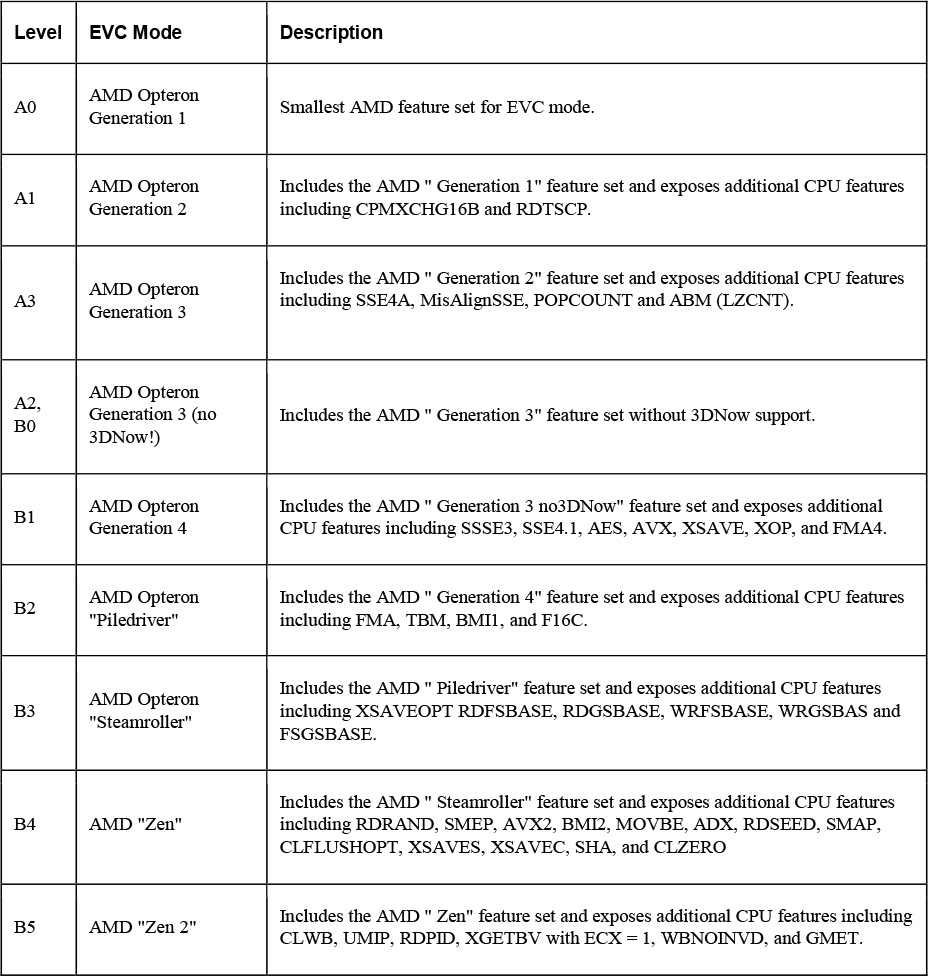
For example, consider a scenario where a cluster with 100 GHz CPU capacity has High Priority resource pool and a Low Priority resource pool with CPU Shares set to High and Normal, respectively as shown in Figure 4-1. This means that the share ratio between the pools is 2:1, so the High Priority pool is effectively allocated twice the CPU resources as the Low Priority pool, whenever CPU contention exists in the cluster. The High Priority Pool is allocated 66.7 GHz and the Low Priority Pool is effectively allocated 33.3 GHz. 40 virtual machines of equal size are running in the cluster, with 32 in the High Priority pool and 8 in the Low Priority pool. The virtual machines are all demanding CPU resources causing CPU contention in the cluster. In the High Priority pool, each virtual machine is allocated 2.1 GHz. In the Low Priority pool, each virtual machine is allocated 4.2 GHz.
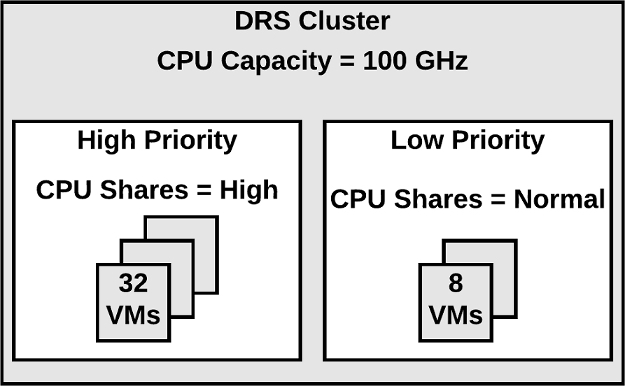
Figure 4-1 Scalable Shares Example
If you want to change the resource allocation such that each virtual machine in the High Priority pool is effectively allocated more resource than the virtual machines in the Low Priority Pool, then you can use scalable shares. If you enable scalable shares in the cluster, then DRS effectively allocates resources to the pools based on the Shares settings and the number of virtual machines in the pool. In this example, the CPU Shares for the pools provide a 2:1 ratio. Factoring this with the number of virtual machines in each pool, the allocation ratio between the High Priority pool and Low Priority pool is 2 times 32 to 1 times 8, or simply 8:1, respectively. The High Priority Pool is allocated 88.9 GHz and the Low Priority pool is allocated 11.1 GHz. Each virtual machine in the High Priority pool is allocated 2.8 GHz. Each virtual machine in the Low Priority pool is allocated 1.4GHz.
vSphere High Availability (HA)
vSphere HA is a cluster service that provides high availability for the virtual machines running in the cluster. You can enable vSphere High Availability (HA) on a vSphere cluster to provide rapid recovery from outages and cost-effective high availability for applications running in virtual machines. vSphere HA provide application availability in the following ways:
• It protects against a server failure by restarting the virtual machines on other hosts within the cluster when a host failure is detected, as illustrated in Figure 4-2.
• It protects against application failure by continuously monitoring a virtual machine and resetting it if a failure is detected.
• It protects against datastore accessibility failures by restarting affected virtual machines on other hosts which still have access to their datastores.
• It protects virtual machines against network isolation by restarting them if their host becomes isolated on the management or vSAN network. This protection is provided even if the network has become partitioned.
Figure 4-2 vSphere HA Host Failover
Benefits of vSphere HA over traditional failover solutions include:
• Minimal configuration
• Reduced hardware cost
• Increased application availability
• DRS and vMotion integration
vSphere HA can detect the following types of host issues.
• Failure: A host stops functioning
• Isolation: A host cannot communicate with any other hosts in the cluster.
• Partition: A host loses network connectivity with the master host.
When you enable vSphere HA on a cluster, the cluster elects one of the hosts to act as the master host. The master host communicates with vCenter Server to report cluster health. It monitors the state of all protected virtual machines and subordinate hosts. It uses network and datastore heartbeating to detect failed hosts, isolation, and network partitions. vSphere HA takes appropriate actions to respond to host failures, host isolation, and network partitions. For host failures, the typical reaction is to restart the failed virtual machines on surviving hosts in the cluster. If a network partition occurs, a master is elected in each partition. If a specific host is isolated, vSphere HA takes the predefined host isolation action, which may be to shut down or power down the host’s virtual machines. If the master fails, the surviving hosts elect a new master. You can configure vSphere to monitor and respond to virtual machine failures, such as guest OS failures, by monitoring heartbeats from VMware Tools.
Note
Although vCenter Server is required to implement vSphere HA, the health of the HA cluster is not dependent on vCenter Server. If vCenter Server fails, vSphere HA still functions. If vCenter Server is offline when a host fails, vSphere HA can failover the impacted virtual machines.
vSphere HA Requirements
![]()
• The cluster must have at least two hosts, licensed for vSphere HA.
• Hosts must use static IP addresses, or guarantee that IP addresses assigned by DHCP persist across host reboots.
• Each host must have at least one, preferably two, management networks in common.
• To ensure that virtual machines can run any host in the cluster, the hosts must access the networks and datastores.
• To use VM Monitoring, install VMware Tools in each virtual machine.
• IPv4 or IPv6 can be used.
Note
The Virtual Machine Startup and Shutdown (automatic startup) feature is disabled and unsupported for all virtual machines residing in a vSphere HA cluster.
vSphere HA Response to Failures
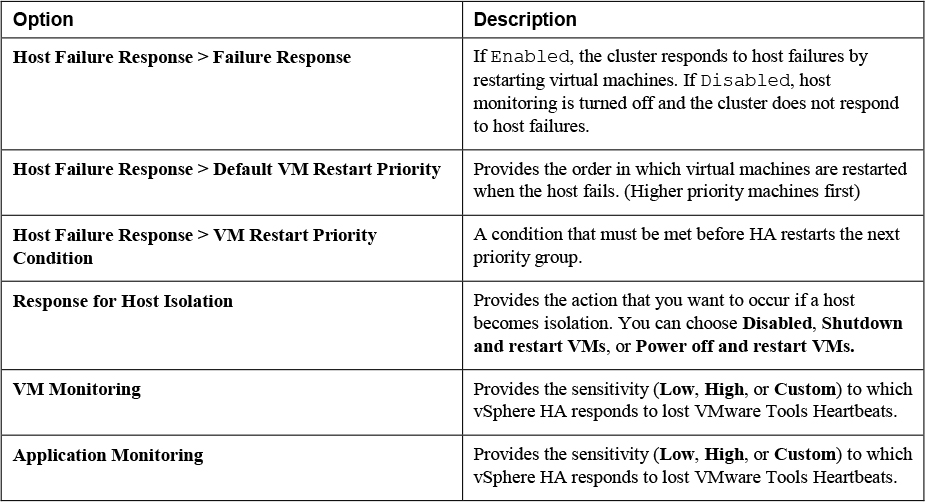
You can configure how a vSphere HA cluster should respond to different types of failures, as described in Table 4-7.
![]()
Table 4-7 vSphere HA Response to Failure Settings
Note
If multiple hosts fail, the virtual machines one failed host migrate first in order of priority, followed by virtual machines from the next host.
Heartbeats
The master host and subordinate hosts exchange network heartbeats every second. When the master host stops receiving these heartbeats from a subordinate host, it checks for ping responses or the presences of datastore heartbeats from the subordinate host. If the master host does not receive a response after checking for a subordinate host’s network heartbeat, ping, or datastore heartbeats, it declares that the subordinate host has failed. If the master host detects datastore heartbeats for a subordinate host, but no network heartbeats or ping responses, it assumes the subordinate host is isolated or in a network partition.
If any host is running, but no longer observes network heartbeats, it attempts to ping the set of cluster isolation addresses. If those pings also fail, the host declares itself to be isolated from the network.
vSphere HA Admission Control
Admission control is used by vSphere when you power on a virtual machine. It checks the amount of unreserved compute resources and determines whether it can guarantee any reservation that is configured for the virtual machine is configured. If so, it allows the virtual machine to power on. Otherwise, it generates an Insufficient Resources warning.
vSphere HA Admission Control is a setting that you can use to specify whether virtual machines can be started if they violate availability constraints. The cluster reserves resources so that failover can occur for all running virtual machines on the specified number of hosts. When you configure vSphere HA Admission Control, you can set options described in Table 4-8.
Table 4-8 vSphere HA Admission Control Options

If you disable vSphere HA Admission control, then you enable the cluster to allow virtual machines to power on regardless of whether they violate availability constraints. In the event of a host failover, you may discover that vSphere HA cannot start some virtual machines.
In vSphere 6.5, the default admission control setting is changed to Cluster Resource Percentage, which reserves a percentage of the total available CPU and memory resources in the cluster. For simplicity, the percentage is now calculated automatically by defining the number of host failures to tolerate (FTT). The percentage is dynamically changed as hosts are added or removed from the cluster. Another new enhancement is the Performance Degradation VMs Tolerate setting, which controls the amount of performance reduction that is tolerated after a failure. A value of 0% indicates that no performance degradation is tolerated.
With the slot policy option, vSphere HA admission control ensures that a specified number of hosts can fail, leaving sufficient resources in the cluster to accommodate the failover of the impacted virtual machines. Using the slot policy, when you perform certain operations, such as powering on a virtual machine, vSphere HA applies admission control in the following manner
• HA calculates the slot size, which is a logical representation of memory and CPU resources. By default, it is sized to satisfy the requirements for any powered-on virtual machine in the cluster. For example, it is sized to accommodate the virtual machine with the greatest CPU reservation and the virtual machine with the greatest memory reservation.
• HA determines how many slots each host in the cluster can hold.
• HA determines the Current Failover Capacity of the cluster, which is the number of hosts that can fail and still leave enough slots to satisfy all the powered-on virtual machines.
• HA determines whether the Current Failover Capacity is less than the Configured Failover Capacity (provided by the user).
• If it is, admission control disallows the operation.
If your cluster has a few virtual machines with much larger reservations than the others, they will distort slot size calculation. To remediate this, you can specify an upper bound for the CPU or memory component of the slot size by using advanced options. You can also set a specific slot size (CPU size and memory size). See the next section for advanced options that impact the slot size.
vSphere HA Advanced Options
You can set vSphere HA advanced options using the vSphere Client or in the fdm.cfg file on the hosts. Table 4-9 provides some of the available vSphere HA advanced options.
Table 4-9 vSphere HA Advanced Options
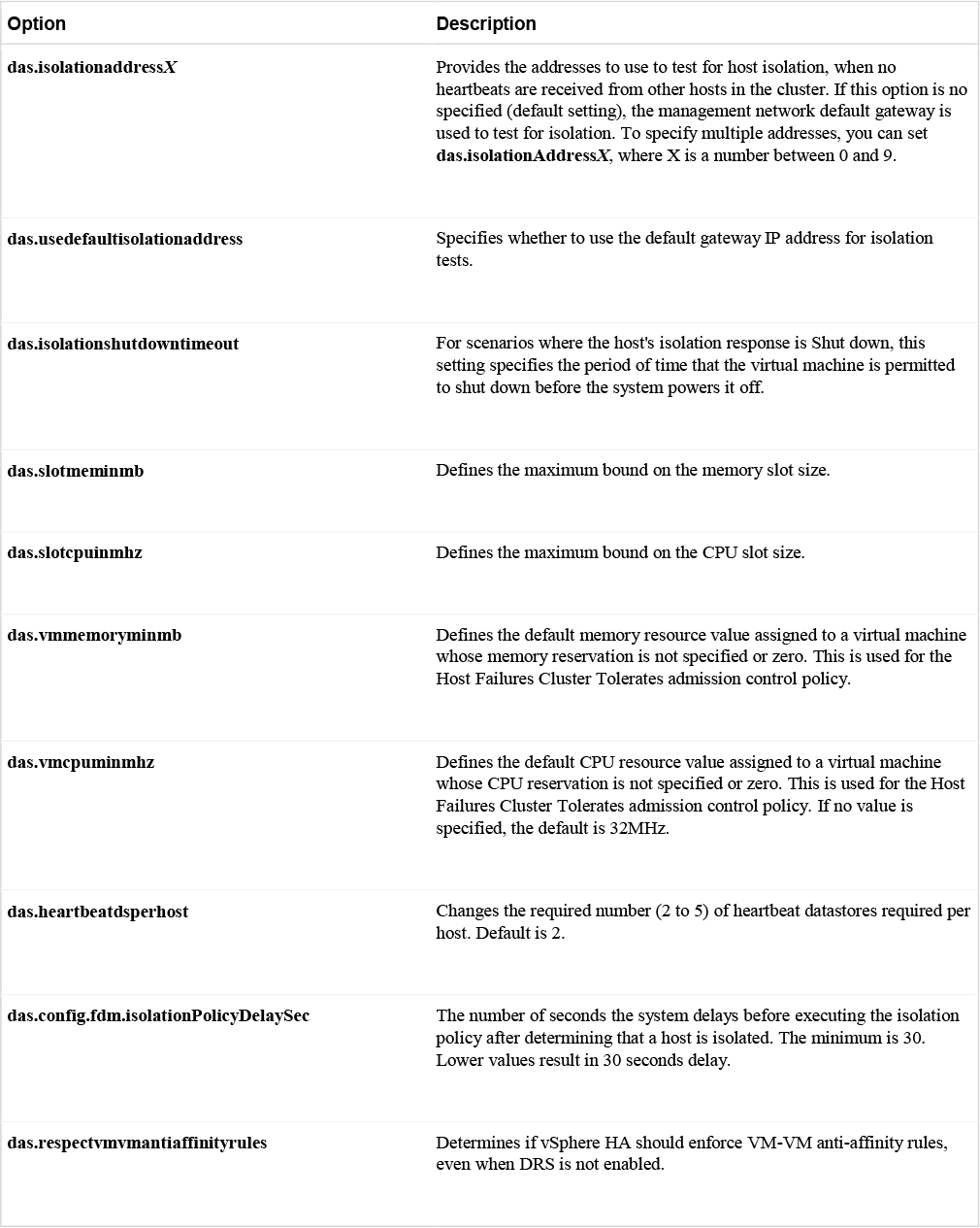
Virtual Machine Settings
To use the Host Isolation Response > Shutdown and restart VMs setting, you must install VMware Tools in the virtual machine. If a guest OS fails to shutdown 300 seconds (or value specified by das.isolationshutdowntimeout), the virtual machine is powered off.
You can override the cluster’s settings for Restart Priority and Isolation Response per virtual machine. For example, you may want to prioritize virtual machines providing infrastructure services like DNS or DHCP.
At the cluster level, you can create dependencies between groups of virtual machines. You can create VM groups, Host Groups, and dependency rules between the groups. In the rules, you can specify that one VM group cannot be restarted another specific VM group is started.
VM Component Protection (VMCP)
Virtual Machine Component Protection (VMCP) is a vSphere HA feature that can detect datastore accessibility issues and provide remediation for impacted virtual machines. When a failure occurs, such that a host can no longer access the storage path for a specific datastore, vSphere HA can respond by taking actions such as creating event alarms or restarting virtual machine on other hosts. The main requirements are that vSphere HA is enabled in the cluster and that ESX 6.0 or later is used on all hosts in the cluster.
The types of failure detected by VMCP are Permanent Device Loss (PDL) and All Paths Down (APD). PDL is an unrecoverable loss of accessibility to the storage device that cannot be fixed without powering down the virtual machines. APD is a transient accessibility loss or other issue that is recoverable.
For PDL and APD failures, you can set VMCP to either issue event alerts or to power off and restart virtual machines. For APD failures only, you can additionally control the restart policy for virtual machines, by setting it to conservative or aggressive. With the conservative setting, the virtual machine will only be powered off if HA determines that it can be restarted on another host.
Virtual Machine and Application Monitoring
VM Monitoring restarts specific virtual machines if their VMware Tools heartbeats are not received within a specified time. Likewise, Application Monitoring can restart a virtual machine if the heartbeats from a specific application in the virtual machine are not received. If you enable these features, you can configure the monitoring settings to control the failure interval and reset period. The settings are described in Table 4-10.
Table 4-10 VM Monitoring Settings
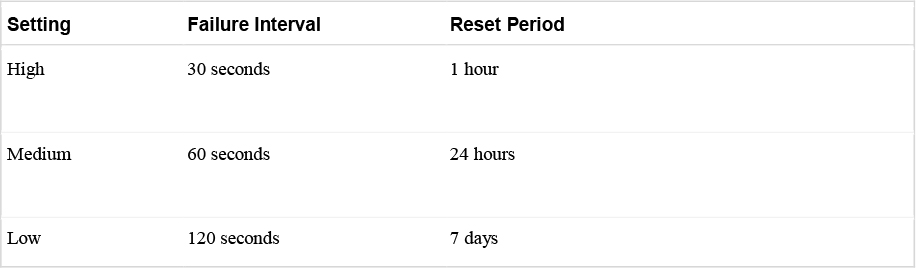
The Maximum per-VM resets setting can be used to configure the maximum number of times vSphere HA will attempt to restart a specific failing virtual machine within the reset period.
vSphere HA Best Practices
You should provide network path redundancy between cluster nodes. To do so, you can use NIC Teaming for the virtual switch. You can also create a second management network connection using a separate virtual switch.
When performing disruptive network maintenance operations on the network used by clustered ESXi host, you should suspend the Host Monitoring feature to ensure vSphere HA does not falsely detect network isolation or host failures. You can re-enable host monitoring after completing the work.
To keep vSphere HA agent traffic on specified network, you should ensure the VMkernel virtual network adapters used for HA heartbeats (enabled for Management traffic) do not share the same subnet as VMkernel adapters used for vMotion and other purposes.
Use the das.isolationaddressX advanced option to add an isolation addresses for each management network.
Proactive HA
Proactive HA integrates with select hardware partners to detect degraded components and evacuate VMs from affected vSphere hosts before an incident causes a service interruption. Hardware partners offer a vCenter Server plug-in to provide the health status of the system memory, local storage, power supplies, cooling fans, and network adapters. As hardware components become degraded, Proactive HA determines which hosts are at risk and places them into either Quarantine or Maintenance mode. When a host enters Maintenance mode, DRS evacuates its virtual machines to healthy hosts and the host is not used to run virtual machines. When a host enters Quarantine mode, DRS leaves the current virtual machines running on the host but avoids placing or migrating virtual machines to the host. If you prefer that Proactive HA simply makes evacuation recommendations rather than automatic migrations, you can set the Automation Level to Manual.
The vendor provided health providers read sensor data in the server and provide the health state to vCenter Server. The health states are Healthy, Moderate Degradation, Severe Degradation, and Unknown.
Other Resource Management and Availability Features
Predictive DRS
Since vSphere 6.5, Predictive DRS is a feature that leverages the predictive analytics of vRealize Operations (vROps) Manager and vSphere DRS. Together, these two products can provide workload balancing prior to the occurrence of resource utilization spikes and resource contention. Nightly, vROps calculates dynamic thresholds, which are used to create forecasted metrics for the future utilization of virtual machines. vROps passes the predictive metrics to vSphere DRS to determine the best placement and balance of virtual machines before resource utilization spikes occur. Predictive DRS helps prevent resource contention on hosts that run virtual machines with predictable utilization patterns.
Prerequisites include the following:
• vCenter Server 6.5 or later.
• Predictive DRS must be configured and enabled in both vCenter Server and vROps.
• The vCenter Server and vROps clocks must be synchronized.
Distributed Power Management (DPM)
The vSphere Distributed Power Management (DPM) feature enables a DRS cluster to reduce its power consumption by powering hosts on and off, as needed, based on cluster resource utilization. DPM monitors the cumulative virtual machine demand for memory and CPU resources in the cluster and compares this to the available resources in the cluster. If sufficient excess capacity is found, vSphere DPM directs the host to enter standby mode. When DRS detects a host is entering standby mode, it evacuates the virtual machines. Once the host is evacuated, DPM powers if off and the host is in standby mode. When DPM determines that capacity is inadequate to meet the resource demand, DPM brings a host out of standby mode by powering it on. Once the host exits standby mode, DRS migrates virtual machines to it.
To power on a host, DPM can use one of three power management protocols, which are Intelligent Platform Management Interface (IPMI), Hewlett-Packard Integrated Lights-Out (iLO), or Wake-On-LAN (WOL). If a host supports multiple protocols, they are used in the following order: IPMI, iLO, WOL. If a host does not support one of these protocols, then DPM cannot automatically bring a host out of standby mode.
DPM is very configurable. Like DRS, you can set its automation to be manual or automatic.
Note
Do not disconnect a host in standby mode or remove it from the DRS cluster without first powering it on. Otherwise, vCenter Server is not able to power the host back on.
To configure IPMI or iLO settings for a host, you can edit the host’s Power Management settings. You should provide credentials for the BMC account, the IP address of the appropriate NIC, and the MAC address of the NIC.
To use WOL with DPM, you must meet the following prerequisites.
• ESXi 3.5 or later
• vMotion is configured
• The vMotion NIC must support WOL
• The physical switch port must be set to auto negotiate the link speed.
Before enabling DPM, use the vSphere Client to request the host to enter Standby Mode. After the host powers down, right-click the host and attempt to power on. If this is successful, you can allow the host to participate in DPM. Otherwise, you should disable the power management for the host.
You can enable DPM in the DRS Cluster’s settings. You can set its Automation Level to Off, Manual or Automatic. When set to off, DPM is disabled. When set to manual, DPM makes recommendations only. When set to automatic, DPM automatically performs host power operations as needed.
Much like DRS you can control the aggressiveness of DPM (DPM threshold) with a slider bar in the vSphere Client. The DRS threshold and the DPM threshold are independent. You can override automation settings per host. For example, for a 16 host cluster, perhaps you would feel more comfortable if you set DPM Automation to Automatic on only 8 of the hosts.
Fault Tolerance (FT)
If you have virtual machines that require continuous availability as opposed to high availability, you can consider protecting the virtual machines with vSphere Fault Tolerance (FT). FT provides continuous availability for a virtual machine (the Primary VM) by ensuring that the state of a Secondary VM is identical at any point in the instruction execution of the virtual machine.
If the host running the Primary VM fails, an immediate and transparent failover occurs. The Secondary VM becomes the Primary VM host without losing network connections or in-progress transactions. With transparent failover, there is no data loss and network connections are maintained. The failover is fully automated and occurs even if vCenter Server is unavailable. Following the failover, FT spawns a new Secondary VM is and re-establishes redundancy and protection, assuming that a host with sufficient resources is available in the cluster. Likewise, if the host running the Secondary VM fails, a new Secondary VM is deployed. vSphere Fault Tolerance can accommodate symmetric multiprocessor (SMP) virtual machines with up to 8 vCPUs.
Use cases for FT include the following.
• Applications that require continuous availability, especially those with long-lasting client connections that need to be maintained during hardware failure.
• Custom applications that have no other way of being clustering.
• Cases where other clustering solutions are available but are too complicated or expensive to configure and maintain.
Before implementing FT, consider the following requirements.
![]()
• CPUs must be vMotion compatible
• CPUs support Hardware MMU virtualization.
• Low latency, 10 Gbps network for FT logging
• VMware recommends a minimum of two physical NICs.
• Virtual machine files, other than VMDK files, must be stored on shared storage
• vSphere Standard License for FT protection of virtual machines with up to two virtual CPUs
• vSphere Enterprise Plus License for FT protection of virtual machines with up to eight virtual CPUs
• Hardware Virtualization (HV) must be enabled in the host BIOS.
• Hosts must be certified for FT.
• VMware recommends that the host BIOS power management settings are set to “Maximum performance” or “OS-managed performance”.
• The virtual memory reservation should be set to match the memory size
• You should have at 3 hosts in the cluster to accommodate a new Secondary VM following a failover.
• vSphere HA must be enabled on the cluster
• SSL certificate checking must be enabled in the vCenter Server settings.
• The hosts must use ESXi 6.x or later
The following vSphere features are not supported for FT protected virtual machines.
• Snapshots. (Exception: Disk-only snapshots created for vStorage APIs - Data Protection (VADP) backups are supported for FT, but not for legacy FT)
• Storage vMotion.
• Linked clones.
• Virtual Volume datastores.
• Storage-based policy management. (Exception: vSAN storage policies are supported.)
• I/O filters.
• Disk encryption.
• Trusted Platform Module (TPM).
• Virtual Based Security (VBS) enabled VMs.
• Universal Point in Time snapshots (a NextGen feature for vSAN)
• Physical Raw Device Mappings (RDMs) (Note: virtual RDMs are supported for legacy FT)
• Virtual CD-ROM for floppy drive backed by physical device.
• USB, sound devices, serial ports, parallel ports.
• N_Port ID Virtualization (NPIV)
• Network adapter passthrough
• Hot plugging devices (Note: the hot plug feature is automatically disabled when you enable FT on a virtual machine.)
• Changing the network where a virtual NIC is connected.
• Virtual Machine Communication Interface (VMCI)
• Virtual disk files larger than 2 TB.
• Video device with 3D enabled.
You should apply the following best practices for FT.
• Use similar CPU frequencies in the hosts.
• Use active / standby NIC teaming settings.
• Ensure the FT Logging network is secure (FT data is not encrypted).
• Enable jumbo frames and 10 GBps for the FT network. Optionally, configure multiple NICs for FT Logging.
• Place ISO files on shared storage.
• You can use vSAN for Primary or Secondary VMs, but do not also connect those virtual machines to other storage types. Also, place the Primary and Secondary VMs in separate vSAN fault domains.
• Keep vSAN and FT Logging on separate networks.
In vSphere 6.5, FT is supported with DRS only when EVC is enabled. You can assign a DRS automation to the Primary VM and let the Secondary VM assume the same setting. If you enable FT for a virtual machine in a cluster where EVC is disabled, the virtual machine DRS automation level is automatically set to disabled. Starting in vSphere 6.7, EVC is not required for FT to support DRS.
To enable FT, you first create a VMkernel virtual network adapter on each host and connect to the FT logging network. You should enable vMotion on a separate VMkernel adapter and network.
When you enable FT protection for a virtual machine, the following events occur.
• If the Primary VM is powered on, validation tests occur. If validation is passed, then the entire state of the Primary VM is copied and used to create the Secondary VM on a separate host. The Secondary VM is powered on. The virtual machine’s FT status is Protected.
• If the Primary VM is powered off, the Secondary VM is created and registered to a host in the cluster, but not powered on. The virtual machine FT Status is Not Protected, VM not Running. When power on the Primary VM, the validation checks occur and Secondary VM is powered on. Then the FT Status changes to Protected.
Legacy FT VMs can exist only on ESXi hosts running on vSphere versions earlier than 6.5. If you require Legacy FT, you should configure a separate vSphere 6.0 cluster.
vCenter Server High Availability
vCenter Server High Availability (vCenter HA) is described in Chapter 1, “vSphere Overview, Components, and Requirements,”. vCenter HA implementation is covered in Chapter 8, “vSphere Installation,”. vCenter HA management is covered in Chapter 13, “Manage vSphere and vCenter Server.”
VMware Service Lifecyle Manager
If a vCenter service fails, VMware Service Lifecycle Manager restarts it. VMware Service Lifecycle Manager is a service running in vCenter server that monitors the health of services and takes preconfigured remediation action when it detects a failure. If multiple attempts to restart a service fails, then the service is considered failed.
Note
Do not confuse VMware Service Lifecyle Manager with VMware vSphere Lifecycle Manager, which provides simple, centralized lifecycle management for ESXi hosts through the use of images and baselines.
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have a couple of choices for exam preparation: the exercises here, Chapter 15, “Final Preparation,” and the exam simulation questions on the CD-ROM.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 4-11 lists a reference of these key topics and the page numbers on which each is found.
Table 4-11 Key Topics for Chapter 4

Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
VMware Service Lifecycle Manager
Virtual Machine Component Protection (VMCP)
Review Questions
1. You are configuring EVC. Which of the following is not a requirement?
a. A vSphere Cluster
b. A DRS cluster
c. CPUs in the same family
d. CPUs with the same base instruction set
2. In vSphere 7.0, you want to configure the DRS Migration Threshold such that it is at the maximum level at which resource contention is considered, but not virtual machine happiness. Which of the following values should you choose?
a. Level 1
b. Level 2
c. Level 3
d. Level 4
e. Level 5
3. In a vSphere Cluster, which of the following statements is true, if the master host detects datastore heartbeats for a subordinate host, but no network heartbeats or ping responses?
a. The master host declares the subordinate host is isolated
b. The master host assumes the subordinate host is isolated or in a network partition
c. The master host takes the host isolation response action
d. The master host restarts the virtual machines on the failed subordinate host.
4. You want to configure vSphere HA. Which of the following is a requirement?
a. Use IPv4 for all host management interfaces
b. Enable vMotion on each host
c. Ensure the Virtual Machine Startup and Shutdown (automatic startup) feature is enabled on each virtual machine.
d. Host IP addresses must persist across reboots.
5. You are configuring vSphere Distributed Power Management (DPM) in your vSphere 7.0 environment. Which of the following is not a requirement for using Wake on LAN (WOL) in DPM?
a. The management NIC must support WOL
b. vMotion is configured
c. The vMotion NIC must support WOL
d. The physical switch port must be set to auto negotiate the link speed