
Chapter 4
Server Hardware
All vSphere hosts rely on the underlying hardware to provide a suitable environment to run the ESXi hypervisor and the guest virtual machines (VMs). The server hardware is the most significant factor that affects the host's capabilities, performance, and cost. A vSphere design will never be successful if the server hardware isn't fit for the task.
Often, during the initial stages of a design, hardware procurement is on the critical path, because the process of selecting, approving, and ordering hardware and having it delivered can take several weeks. However, as this chapter investigates, you must review many considerations before embarking on the right server choice.
The chapter is split into the following sections:
- The importance of hardware, and the factors that influence and constrain your choices
- How vendors differ and the options to consider when choosing among them
- Which server components are most important to a vSphere installation and why
- Scale up a design with large powerful servers, or scale out with more agile servers
- Choosing between rack servers and blade servers
- Understanding new consolidated datacenter approaches
- Alternatives to buying servers
Hardware Considerations
A host's hardware components are critical to the capabilities of your vSphere environment. Selecting the correct mix and ensuring sufficient capacity will determine how much guest consolidation is possible. Unlike most of the other chapters in this book, which discuss software options, this chapter examines hardware, which is much more difficult to change after the initial implementation. Most software choices can be reconfigured after the fact, albeit with perhaps short outages, if something doesn't work as expected or you find an improvement to the design. With hardware selection, however, it's crucial that the architecture can survive not only the proposed requirements but any likely changes.
A design that tries to plan for any eventuality will end in overkill. You can't expect to cover every possible variant. Your goal should be a design that isn't overly specific but that covers a few of the most likely contingencies. This section will help you think about what is required before you start to select individual components.
Frequently, in a vSphere project, the first item addressed is the purchase of hardware. When any project begins and new hardware is needed, a whole procurement cycle must begin. A basic design is provided, along with the justification; project managers push it forward, and managers who control budgets are involved. Often, due to the large expense associated with server hardware, several nontrivial levels of approval are required, requests for tender follow, and vendor negotiations ensue. The cycle repeats until everyone is satisfied. But that's usually only the start.
Once the servers are ordered, it's often several weeks before they're delivered. Then, the server engineers need to test and configure them. Prior to that, a pilot may be required. The hardware must be moved to the appropriate datacenter, racked, and cabled. Power, network, and storage need to be connected and configured appropriately. All this installation work is likely to involve several different teams, and possibly coordination among several companies.
This potentially drawn-out hardware procurement cycle can take months from start to finish. This is one of the reasons virtualization has become so popular. Many managers and solutions architects are beginning to forget how long and painful this process can be, thanks to the advent of virtual hardware and the subsequent almost-immediate provisioning that is now possible.
For this reason, server hardware is nearly always on the critical path of a vSphere deployment. It's important to start this process as quickly as possible to avoid delays. But so much relies on the hardware that until you make many of the other decisions covered in this book, it's impossible to correctly design the server configurations. Buying incorrectly specified server hardware is likely to cause a vSphere design to fail to meet expectations, and this issue can be very difficult to recover from. Probably more than any other factor, the server hardware must be designed properly before you rush forward.
It's possible to identify certain do's and don'ts for server hardware that reduce the likelihood of ordering the wrong equipment. The next section looks at what is likely to determine these choices in your individual circumstances.
Factors in Selecting Hardware
The physical hardware of vSphere servers plays an important role in several areas. These roles and their importance in a specific environment will shape the hardware's design. Some are hard requirements, such as particular hypervisor features that need an explicit piece of equipment or functionality in order for the feature to be available. Others are quantitative options that you can select and weigh against each other, such as the amount of RAM versus the size or speed of the hard drives.
Features
Several vSphere features have specific hardware requirements. These features may not be available or may not run as efficiently if the correct underlying hardware isn't present. It's therefore critical to review these features prior to purchasing equipment and decide whether you need any of them now or are likely to need them. Purchasing servers without the capability of running a required feature could be an expensive mistake.
These features are discussed in more depth in the subsequent chapters, but at this stage it's important for you to understand their hardware requirements:
The following VMware article lists Intel CPU compatibility:
The following VMware article lists CPUs compatible with FT:
http://kb.vmware.com/kb/1008027
Performance
The hypervisor's performance relates directly to the hardware. Other elements can have an effect, but the most significant performance enabler is derived from the hardware itself. The general premise of more and faster is better; but with other limiting constraints, you must usually choose what hardware gives the most performance bang for your buck.
In a vSphere design, the main performance bottlenecks revolve around CPU, memory, and I/O (particularly storage I/O). Therefore, in a server's hardware, the CPU and memory are critical in terms of its scalability. Most other server components are required in order to provide functionality, but they don't tend to limit the performance the same way. The CPU and memory rely on each other, so a good balance is required. The question of smaller but more numerous servers, as opposed to fewer servers that are more powerful, is examined in a later section in this chapter; but either way, the server's CPU and memory ratio should correlate unless you have a particular need for more of one.
Other elements can limit performance, but most newly purchased up-to-date servers from mainstream vendors avoid the obvious bottlenecks unless you have unusual cases that demand special attention. This chapter looks closely at both CPUs and memory.
Reliability
The vSphere server hardware is likely to be a critical infrastructure piece in the datacenter and has the potential to make up a large part of a company's compute resources. It's obvious that the server's stability is paramount. Therefore it's important when you're selecting hardware that each component be thoroughly reliable. Although it's possible to find whitebox equipment that works with ESXi, and which may even be listed on the HCL, it's important to consider the server's reliability.
Servers for a production environment should be from a reputable vendor with a proven track record. Many companies avoid the first-generation series of a new server line, even from a recognized top-tier server vendor, because this is where any stability quirks in the BIOS code or hardware agents are most likely to be found.
Additionally, with each new server, a period of testing and bedding-in is normal and is part of checking for stability issues. Common approaches are discussed later in the chapter.
Redundancy
Along with general reliability, a server's components should provide sufficient redundancy to avoid outages during hardware failures. All components, even the most reliable, will fail periodically. However, a well-designed server can mitigate many of these failures with redundant parts. You should choose servers that are designed to take redundant parts and ensure that you order them with the extra parts to make them redundant.
These are the most common server parts that should be offered with redundancy:
- Hard drives with both RAID protection and hot spares
- Power supply units (PSUs) that not only protect from a failure of the PSU but also let you split the power supply across two separate circuits
- Multiple network and storage interfaces/cards, allowing connections to separate switches
- Several fans that prevent overheating, should one fail
Upgradability and Expandability
An important element, particularly in vSphere hosts, is the ability to expand the server's hardware options at a later stage. Server hardware is often purchased with an expected life cycle of three to five years, but rapid advances in hardware and software, and continuously falling prices, often make upgrading existing servers an attractive option.
It's somewhat unrealistic to expect to upgrade a server's CPU at a later stage, because the increase in performance is likely to be minimal in comparison to the additional cost. And you're unlikely to buy a server with excess sockets that aren't filled when the server is first purchased (not to mention the difficulty of finding the exact same CPU to add to the server). However, RAM tends to drop significantly in price over time, so it's feasible that you could consider a replacement memory upgrade. Larger servers with extra drive bays offer the option for more local storage, although this is rarely used in vSphere deployments other than locations without access to any shared storage facilities.
The most likely upgrade possibilities that you may wish to consider when purchasing servers is the ability to fit extra PCI-based cards. These cards can add network or storage ports, or provide the potential to later upgrade to a faster interface such as 10GbE or converged network adapters (CNAs). This is one of the reasons some companies choose 2U-based server hardware over 1U-based rack servers. If space isn't an issue in the datacenter, these larger servers are usually priced very similarly but give you considerably more expandability than their smaller 1U counterparts.
Computing Needs
It's important to look carefully at the computing needs of the vSphere environment before you create a detailed shopping list of server parts. Although generalizations can be made about every vSphere deployment, each one will differ, and the hardware can be customized accordingly.
Hardware Compatibility List
VMware has a strict Compatibility Guide, which for hypervisor servers is colloquially known as the hardware compatibility list (HCL). It's now a web-based tool, which you can find at www.vmware.com/go/hcl. This is a list of certified hardware that VMware guarantees will work properly. Drivers are included or available, the hardware will be supported if there's an issue, and VMware has tested it as a proven platform.
Choosing hardware that isn't on the HCL doesn't necessarily mean it won't work with vSphere; but if you have issues along the way, VMware may not provide support. If a component that isn't on the HCL does work, you may find that after a patch or upgrade it stops working. Although the HCL is version-specific, if hardware has been certified as valid, then it's likely to be HCL compatible for at least all the subsequent minor releases.
For any production environment, you should use only HCL-listed hardware. Even test and development servers should be on the HCL if you expect any support and the business needs any level of reliability. If these nonproduction servers mimic their production counterparts, this has the advantage that you can test the hardware with any changes or upgrades to the vSphere environment that you plan to introduce. A disciplined strategy like this also provides warm spares in an emergency as onsite hardware replacements for your production servers.
Which Hypervisor?
Chapter 2, “The ESXi Hypervisor,” discussed the newer ESXi hypervisor and the differences from the older ESX. Despite their similarity, the hypervisor does have some impact on the hardware. ESXi is less reliant on local storage but can still use it if required. ESX and ESXi have different HCLs, so if an upgrade project is considering reusing hardware originally designed for use with ESX classic, you should check to ensure that the proposed solution is still compliant.
ESXi combines the Service Console and VMkernel network interfaces into one management network, so you may need one less NIC if you use 1GbE. ESXi also uses particular Common Information Model (CIM) providers, which allows for hardware monitoring. If you're using ESXi, you should confirm the availability of CIM providers for the hardware being used.
If you want to use ESXi Embedded, it will probably have a significant effect on your hardware selection, because vendors sell specific servers that include this. In addition, the HCL for ESXi Embedded is much smaller than the HCL for Installable/Stateless, so it may limit your choices for adding hardware.
Minimum Hardware
The minimum hardware requirements for each version of vSphere can differ, so be sure to consult the appropriate checklist. Most designed solutions are unlikely to come close to the required minimums, but occasional specific use cases may have minimal custom needs. You still need to hit VMware's minimums in order for the hypervisor to be VMware supported.
Purpose
It's worth considering the type of VMs that will run on the hypervisor. vSphere servers can be used not only to virtualize general-purpose servers but also for a variety of other roles. A server may be destined to host virtual desktops, in which case servers should be designed for very high consolidation ratios. Alternatively, the hypervisor may host only one or two very large VMs, or VMs with very specific memory or CPU requirements. Some VMs need high levels of storage or network I/O; you can fit more capable controller cards to provide for the VM's needs, with high I/O ratings or the ability to do hardware passthrough. The servers may need to host old P2Ved servers that have specific hardware requirements such as serial or parallel ports for software dongles, or to access old equipment like facsimile modems or tape backup units.
Scaling
Buying the right hardware means not only getting the right parts but also scaling properly for your capacity and performance needs. If you buy too much, then resources will lie idle and money will have been wasted. If you buy too little, then resources will be constrained and the servers won't deliver the expected levels of performance and may not provide the required level of redundancy. No one likes to waste money, but an under-resourced environment means trouble. First impressions last, and if virtualized servers are a new concept to a business, then it's important that it perform as expected, if not better.
Not every design needs its hardware requirements planned from the outset. If your company's procurement process is sufficiently flexible and expeditious, then you can add server nodes as they're demanded. This way, the quantity should always be suitable for the job. Despite the planning and testing you conduct beforehand, you're always making a best estimate with a bit added for good measure.
Hardware Consistency
If you're purchasing new servers to supplement existing equipment, it's important to ensure that certain components are sufficiently similar. This is particularly significant if the new hardware will coexist in the same cluster, because this is where VMs frequently migrate.
Consistency within the same hardware generation is also important, so wherever possible it's advisable to set a standard level of hardware across the servers. If some situations require more or less compute resources, then you may want to implement two or three tiers of hardware standards. This consistency simplifies installation, configuration, and troubleshooting, and it also means that advanced cluster functions such as DRS, high availability (HA), and DPM can work more efficiently.
Consistency within the same type of servers is beneficial, such as populating the same memory slots and the same PCI slots. You should try to use the same NICs for the same purpose and ensure that the same interface connects to the same switch. This makes managing the devices much easier and a more scalable task.
Server Constraints
In any server design, you must consider a number of constraints that limit the possible deployment. Any datacenter will be restricted primarily by three physical factors: power, cooling, and space. vSphere servers have traditionally put a strain on I/O cabling, and host licenses can restrict what server hardware is utilized.
Rack Space
The most apparent physical constraint faced in any server room is that of rack space. Even though virtualization is known to condense server numbers and may alleviate the problem, you still can't fit servers where there is no available space. Co-locating datacenters is common these days, and customers are often billed by the rack or down to the single U; even if it isn't your datacenter to manage, it still makes sense to pack in as much equipment as possible.
Aside from virtualizing, there are two common approaches to maximizing space: minimize the height of the rack servers or switch to blade servers. Rack servers are traditionally multi-U affairs, with sufficient height to stack ancillary cards vertically. But all mainstream vendors also sell 1U servers to reduce space. Many opt for blade servers as a way to fit more servers into a limited amount of rack space. A regular rack can take up to 42 1U servers; but most vendors sell 10U chassis that can fit 16 half-height blades, meaning at least 64 servers with 2U to spare. Both thin rack servers and half-height blades are normally sold only as dual-socket servers, so these methods align themselves more closely with a scale-out model. Both rack versus blade and scale-up versus scale-out are debated later in this chapter.
Power
With denser hardware configurations and virtualization increasing consolidation levels, power and cooling become even more important. Smaller, more heavily utilized servers need more power and generate more heat. Cooling is discussed separately later in this section; but be aware that increased heat from the extra power used must be dissipated with even more cooling, which in turn increases the power required. Older datacenters that weren't designed for these use cases will likely run out of power well before running out of space.
As energy prices go up and servers use more and more power, the result can be a significant operating expense (OPEX). Power supply can be limited, and server expansion programs must consider the availability of local power.
Most of the world uses high-line voltage (200–240V AC) for its regular power supply, whereas North America's and Japan's standard for AC supply is low-line voltage (100–120V AC). Most datacenter customers in North America have the option of being supplied with either low-line or high-line for server racks. Vendors normally supply servers with dual-voltage PSUs that are capable of automatically switching. High-line is considered more stable and efficient, can reduce thermal output, and allows for more capacity. However, whatever the available power supply is, you should check all server PSUs, uninterruptible power supplies (UPSs), and power distribution units (PDUs) to be sure they're compatible. Some very high-performance servers may require three-phase high-line power to operate.
The power input for each server is often referred to as its volt amperes (VA), and this is cumulatively used to calculate the power required in a rack for PDU and UPS capacity. PDUs shouldn't provide more than half of its capacity in normal operations to ensure that it can handle the excess required if one circuit fails. Also consider the number and type of sockets required on each PDU. Vertical PDUs help save rack space.
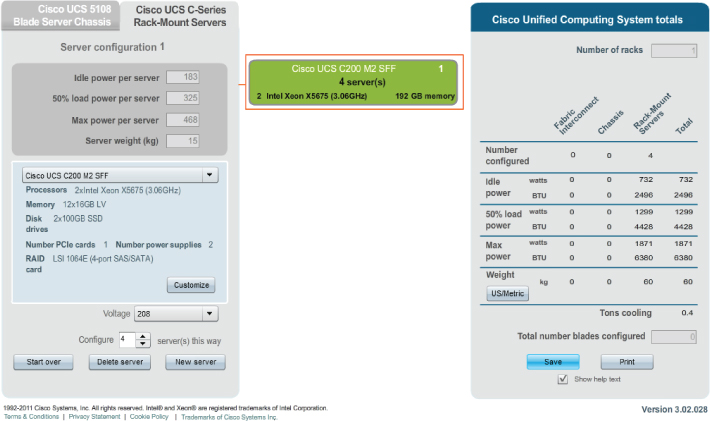
It isn't just the make and model of servers that affect the power estimate, but also how fully fitted the server is with CPUs, RAM, disks, I/O cards, and so on. The hypervisor's load affects power usage, so if you expect to run the servers at 40% or 80% utilization, that should be factored in. Most hardware manufacturers have downloadable spreadsheets or online calculators you can use to make more accurate estimates of server power and cooling requirements. Figure 4.1 shows an example of one offering, but all vendors have their own versions.
Server PSUs should come with inrush surge protection, because when power is initially applied to a server, it draws power momentarily on full load. This normally lasts only a few seconds but can use several times more current than normal. It's important to think about this with multiple servers in a cluster. Following a power outage, if all the servers in a cluster try to power back on at the same time, the result may be an inrush that can affect the whole room. When you're powering servers back on, consider waiting at least 10 seconds between servers. Most servers have power settings to automatically start up after a power failure, but look for those that can use a random time offset to help prevent inrush issues.
Power-design calculations are often made at the start of an initial deployment—for example, when a blade chassis is fitted and only semipopulated with blades. As time goes on, more blades are added. But because no extra power cables need to be fitted, the additional power requirements are forgotten. If you're fitting a blade enclosure, then for design purposes, imagine it's fully populated.
UPS
UPSs are necessary to provide a clean, continuous supply of power to vSphere host servers. Any type of power failure or minor fluctuation can cause a shutdown. UPSs are designed to bridge the gap, automatically switching over to a battery bank until power is restored. UPSs can also filter out power spikes or sags, which can not only power off servers but also damage the PSUs and internal components. Many UPS systems provide automatic monitoring and alarming and can help with power capacity planning.
UPSs should be sufficiently rated to keep the servers powered on long enough to at least allow a clean shutdown of all VMs and hosts. Unlike regular servers, which only need to shut down one OS, hypervisors can be running tens of guests, which when all instructed to shut down at the same time can take several minutes to do so. Therefore, it's important to think about how long it may take banks of vSphere servers and all their VMs to go down cleanly.
For environments where uptime is absolutely crucial, UPS systems may only need to be enough to tide things over until a backup generator starts up. You should test any UPSs and standby power supply to ensure that all the equipment is suitably balanced and will be ready when required.
Cooling
All server hardware produces a lot of heat, which must be constantly dissipated to prevent the equipment from overheating. Cooling makes up a substantial amount of the power used in a datacenter, often over half the total power bill. Making that cooling more efficient means less cooling is required. Making the server's power usage more efficient also reduces cooling needs.
When you're trying to minimize the amount of cooling that each server needs, think about the airflow through your servers from front to back. How much airflow do the rack doors allow? Is the cabling at the back impeding the flow? Are the side doors attached, servers stacked together, and blanking covers fitted to prevent hot and cold air mixing? With server cooling systems, it's important to think of the entire room, because the air isn't contained to one server or one rack. Use hot and cold aisles, and think about the placement of AC units, perforated floor tiles, and the use of overhead conduits even if you have raised floors, to split power from other cables and leave more room for cooling.
I/O Ports
In addition to the power cabling provided by PDUs, servers have a collection of cables that need to be connected. These can include Ethernet cables for both network and storage I/O, fiber optic cables, out-of-band management card connectors, and KVM cabling. Prior to fitting new servers, it's critical that you consider the amount of cabling and the number of ports required to connect each one. This means you need to know how many switch ports, patch panel ports, fibre switch ports, and KVM ports are free and usable. Remember, some of these types of equipment also need licensing on a per-port basis.
Proper capacity management also means thinking about the I/O loads on these connectors, to ensure that additional workloads won't prevent linear scaling.
vSphere Licensing
Although it isn't a physical constraint, vSphere licensing can be an important consideration. Many vSphere features are only available with higher-tier licensing, but licensing may also restrict the hardware you can use. This is in addition to the fact that larger four- or eight-way servers need more licenses. In a new vSphere deployment, this becomes a project cost; but if you're supplementing an existing environment that already has a license agreement drawn up, your existing license may reduce your options.
Differentiating among Vendors
Several vendors produce servers suitable for vSphere hypervisors. The Tier-1 companies commonly associated with ESXi servers are HP, IBM, and Dell, although Fujitsu-Siemens has a limited following in Europe. Cisco, well known for its networking equipment, burst onto the scene in 2009 with its new line of servers; it can also be considered a mainstream vendor, despite its infancy in the server market. Many other companies have products listed on VMware's HCL, but they're much less well-known and arguably less trusted.
An option for the most budget-conscious business is what is known as a whitebox server. These are computers that aren't sold by a recognized vendor and may even be configured from parts. Whitebox servers tend to lack the high-end features available from the main vendors, such as redundant parts and on-hand identical stocked replacements, and whitebox servers rarely scale beyond one or two CPUs. Such servers may appear on the HCL or meet the minimum requirements, but checking each part is left up to you.
It's difficult to recommend whitebox servers, although this approach has a popular community following and is frequently used for home test-lab type situations. A couple of excellent sites list tested whitebox equipment, although obviously VMware will only support those on its own HCL:
http://vm-help.com/esx40i/esx40_whitebox_HCL.php
http://ultimatewhitebox.com/systems
Both sites largely revolve around ESXi 4 compatibility, but the advice is still largely valid. The forum connected to the vm-help.com site has good 5.x device information.
The vast majority of vSphere installations happen on Tier-1 supplied hardware. The relative importance of hypervisor hardware in comparison to regular servers, largely in part due to its high consolidation workload, means most companies spend the extra dollars to buy trusted equipment. Another reason these vendors are so popular with vSphere is that it's still an enterprise-dominated product. Small companies that are more likely to use whitebox equipment haven't embraced hypervisors so readily. They often don't benefit as much from consolidation and lack dedicated IT staff with the skills to implement it.
In certain circumstances, you may be unable to choose a different vendor, because your organization has an approved supplier. This may be due to prenegotiated pricing, tender agreements, or a historical preference for one brand that makes continued support easier if everything remains the same. But given the opportunity to choose between vendors, beyond the raw computing power of their servers you may wish to consider the following points for hypervisor equipment. Many of them use the same underlying generic hardware, but these value-adds make them different and are particularly important for hypervisor servers, which usually have a very high criticality in a datacenter:
Support agreements vary between vendors, and often each vendor has different options available. Compare how they can offer support—telephone support, instant messaging, email, and so on—and what hours they're willing to provide support (such as business hours or 24/7). If you have multinational offices, be sure the vendor provides international support. Previous experience with a vendor will often give you a feel for the level of service you can expect. Agreements should also specify onsite support, detailing how quickly the vendor will fit replacement parts or be onsite to troubleshoot issues.
Later in the chapter, we'll consider consolidated approaches that match networking and storage options to servers to provide all-in-one packages.
- Remote console access
- Power-button access
- Virtual optical drives
- Hardware status and logging
Server Components
Servers have a multitude of options available, and almost every component can be customized for your needs. vSphere host servers have particular needs; with careful consideration of each part, you can design a server to best fit its role as hypervisor. This section looks at each component important to virtualization, the impact it has, and where your budget should concentrate.
Before we explain the function of each component, remember the basic premise of type 1 hypervisors. vSphere ESXi virtualizes the CPU, memory, disk, and network I/O to maximize throughput, making as few changes as possible so as to not impede performance. Most other hardware functions are emulated in software, because they don't play a critical role in performance and are referenced relatively little. How these four elements are shared among the hypervisor and guests is critical in overall performance, but any improvement in hardware that can improve the efficiency and speed of the CPU, memory, and I/O is crucial.
CPU
VMware vSphere 5 hosts only run on top of 64-bit CPUs. The server's CPUs are critical in the performance of the VMs. Most servers come equipped with at least two CPU sockets, although four- and eight-way models are common as companies scale up. The most recent major advance is the use of multicore CPUs and the significant performance increases they can provide. CPUs used to be measured purely in MHz, but now vendors are packing in more punch by delivering CPUs with multiple cores. 4-, 6-, 8-, and 10-core CPUs are available now, and more are delivered in each generational refresh.
Multicore CPUs and Scheduling
A multicore CPU consists of a single socket processor with multiple core units. These cores can share some of the cache levels and can also share the memory bus. Each core has near-native performance to that of a single-core CPU, so a dual core is close to two single CPUs, and a quad core is close to four single CPUs or two dual-core CPUs. Sharing the same caches and buses can reduce performance when the VMs are particularly memory intensive, but otherwise multicore CPUs offer compelling performance for their modest increase in price.
Some Intel CPUs have a feature known as HyperThreading (HT) that allows each physical core to behave as two logical cores. HT allows two different threads to run on the same core at the same time. This may speed up some operations, depending on the software running at the time. The gains are likely to be marginal and certainly not as substantial as having additional physical cores. vSphere uses HT by default, as long as it's enabled in the server's BIOS. Since Intel's Nehalem chip, HT has been referred to as simultaneous multithreading (SMT).
The VMkernel employs a complex but extremely efficient CPU scheduler. Its purpose is to equitably share CPU resources between its own needs and those of all the running VMs. With default resources allocated, a vSphere host time-slices processing power equally among all the VMs as soon as the CPU resources are overcommitted. Ordinarily, the host needs to take into account VM shares, reservations, and limits; the number of allocated vCPUs (VM CPUs); and the varying demands made by each VM. A VM should be oblivious to the fact that it's running on virtualized hardware, so the scheduler needs to give the impression to the VM that it completely owns the CPU. This becomes increasingly complicated when VMs have multiple vCPUs that expect all their processors to compute at the same time and not to have to wait on each other. This synchronous use of CPUs is maintained in the VMkernel with a technique known as co-scheduling. The co-scheduling algorithms have steadily evolved with each ESX (and ESXi) release, with continuous improvements being made to how the CPU scheduler deals with symmetric multiprocessor (SMP) VMs.
The CPU scheduler must take into account the number of physical CPUs and cores, whether HT is available, the placement of logical and physical cores in relation to the CPU caches and their cache hierarchy, and memory buses. It can make informed choices about which core each VM should run on, to ensure that the most efficient decisions are made. It dynamically moves vCPUs around cores to yield the most efficient configuration with regard to cache and bus speeds. It's possible to override the CPU scheduler on a VM basis by setting the CPU affinity in a VM's settings. This process is explained in Chapter 7, “Virtual Machines.” By pinning vCPUs to specific cores, you can optimize a VM's usage. However, the built-in CPU scheduler is incredibly efficient, and pinning vCPUs to cores can prevent simultaneous workloads from being spread among available cores. This may lead to the VM performing worse and will interfere with the host's ability to schedule CPU resources for the other VMs.
CPU Virtualization
CPUs from both Intel and AMD have continued to evolve alongside each other, mostly offering comparable features (albeit with each one pushing ahead of the other, followed by a quick period of catch-up). As each vendor's products are released, new features are added that can help to improve performance and capabilities while also potentially breaking compatibility with previous versions.
vSphere uses virtualization, rather than CPU emulation where everything runs in software and the underlying hardware is never touched. Virtualization is different in that it tries to pass as much as possible to the physical hardware underneath. This can result in significantly better performance and means VMs can take advantage of all the features the CPUs can offer. With regard to server hardware choices, the impact comes from compatibility between hosts. A VM runs on only one host at a time. However, when the host is a member of a cluster, the hosts must present similar CPUs to the guest VMs to allow vMotion. If a host exposes more (or fewer) features than another host in the cluster, you can't vMotion the VMs between them. This in turn affects other features that rely on vMotion, such as DRS.
You can configure clusters with Enhanced vMotion Compatibility (EVC) settings, which effectively dumbs down all the hosts to the lowest common denominator. This technically solves the incompatibility problems but can mask instruction sets from your new CPUs that the VMs might be able to take advantage of. If there are mixed hosts, then this is a useful technique to allow them to cohabit a cluster and prevent segmentation of compute resources. Enabling EVC is a balancing act between the flexibility and elasticity of your cluster resources, against the perhaps obscure potential to remove a performance enhancing feature that an application benefits from.
Also be aware that there is currently no compatibility between Intel hosts and AMD hosts. You should split these servers into separate clusters whenever possible. Incompatible hosts can still power on VMs moved from other hosts, so you can take advantage of HA if you have no choice but to run a mixed cluster.
FT also has specific CPU requirements, which you should account for if FT is part of your design. Chapter 8 provides more details about FT requirements and how they may affect CPU decisions.
VMware uses two types of virtualization in its vSphere 5 products:
In previous versions of vSphere, a third type of virtualization was supported, known as paravirtualization. Paravirtualization is a technique that is possible when a guest VM is aware that it's virtualized and can modify its system calls appropriately. Because paravirtualization depends on guest OS cooperation, it could only be used with certain OSes. It was enabled on a per-VM basis with a feature known as Virtual Machine Interface (VMI). Support for paravirtualization was deprecated in vSphere 5.0 due to the advent of hardware-assisted CPUs and lack of OS support.
Virtualization Enhancements
Subsequent generations of CPUs from both Intel and AMD offer virtualization-specific enhancements. The first generation supported CPU improvements, the second generation of hardware advancements adds optimizations to the overhead associated with the memory management unit (MMU), and the third generation allows VMs direct access to PCI devices:
CPU Capacity
When you're selecting CPUs for your server hardware, there are several things to consider. The overall strategy of scaling up or scaling out may dictate the spread of CPUs to memory, which will be discussed in significantly more depth in the aptly named “Scale Up vs. Scale Out” section. Because CPUs are such a significant part of a server's ability to consolidate VMs, it's important to get the most powerful processors possible.
The general premise of faster, newer, and more is reasonable and won't see you wrong; but for virtualization-specific scaling, you should look a little further. The high core count on some CPUs yields massive improvements. Get the most cores possible, because other than scaling up to more CPUs, you'll achieve the greatest improvements. Any recently purchased CPUs should have the hardware-assisted CPU and MMU additions, but this is worth checking. Paying more for incrementally faster CPUs usually won't give you the same return as additional cores.
Scaling the server to the VMs depends largely on the workload of the VMs and the number of vCPUs per VM. As an approximate guide, you should expect to get at least four vCPUs per physical core. As the number of cores per CPU increases, your vCPU consolidation may drop slightly because the cores are getting smaller proportions of the CPU bus and shared memory cache. Some workloads can comfortably fit far more vCPUs per core, so if possible test the configuration with your own environment.
RAM
In additional to CPUs, host memory is critical to the performance and scalability of the server. With the core count on most servers rising rapidly, it's increasingly important to have enough memory to balance the equation. There is little point in cramming a server full of the latest CPUs if you have so little RAM that you can only power on a few VMs.
vSphere hypervisors are incredibly efficient with memory usage and have several methods to consolidate as many VMs onto the same host as possible. In order to make the most of the limited supply, you should understand the basic ways in which guest VMs are allocated RAM.
Memory Usage
vSphere hosts need memory for both the host and the VMs:
Table 4.1 Memory overheads for common VM configurations

Memory Mapping
The hypervisor maps the host's physical memory through to each powered-on VM. Ordinarily, the memory is divided into 4 KB pages and shared out to the VMs, and its mapping data is recorded using a page table. The guest OS is unaware that the memory is being translated via the hypervisor; the OS just sees one long, contiguous memory space.
vSphere can also use large pages. Large pages are 2 MB in size, and if a guest OS is able to and enabled to use them, the hypervisor uses them by default. Large pages reduce the overhead of mapping the pages from the guest physical memory down to the host physical memory.
Hardware-Assisted Mapping
The memory mapping is stored in a shadow page table that is then available to the host's MMU, unless the host has CPUs that are capable of hardware-assisted memory mapping. Hardware-assisted MMU virtualization is possible if the host is fitted with either Intel's EPT support or AMD's RVI support (AMD's RVI is also occasionally referred to as Nested Page Tables [NPT]). Using this additional hardware feature can improve performance compared to the shadow page table technique because it reduces the associated overhead of running it in software. Only some guest OSes can use hardware-assisted MMU; vSphere uses the shadow page table for those that aren't supported.
Memory Overcommitment
vSphere has a unique set of features to overcommit its memory. This means it can potentially provide more memory to its guests than it physically has on board. It can transfer memory to guests that need more, improving the server's overall memory utilization and increasing the level of consolidation possible.
Memory overcommitment is successful largely because at any one time, not all guests are using their full entitlement of allocated RAM. If memory is sitting idle, the hypervisor may try to reclaim some of it to distribute to guests that need more. This memory overcommitment is one of the reasons virtualization can use hardware more efficiently than regular physical servers.
Techniques to Reclaim Memory
Several methods exist in vSphere to reclaim memory from VMs, enabling more efficient guest memory overcommitment. These are the five primary methods used, in order of preference by the VMkernel:
Using TPS results in less host memory being used and therefore more opportunities to consolidate more running VMs on the one host. TPS doesn't compare every last byte but instead uses a hash of each 4 KB page to identify pages that need closer inspection. Those are then compared to confirm whether they're identical. If they're found to be the same, then only one copy needs to be kept in memory. The VM is unaware that it's sharing the page.
When the VMkernel needs a guest to release memory, it inflates the balloon by telling the driver to try to consume more memory as a process in the guest. The guest OS then decides what is the least valuable to keep in memory. If the VM has plenty of free memory, it's passed to the balloon driver, and the driver can tell the hypervisor what memory pages to reclaim. If the VM doesn't have any free memory, the guest OS gets to choose which pages to swap out and begins to use its own pagefile (in the case of Windows) or swap partition/file (in the case of Linux). This means the balloon driver, and hence the hypervisor, can make full use of the guest's own memory-management techniques. It passes the host memory pressure on to the guests, which can make enlightened decisions about what pages should be kept in RAM and which should be swapped out to disk.
By default, the balloon driver only ever tries to reclaim a maximum of 65% of its configured memory. The guest must have a sufficiently large internal pagefile/swap to cover this; otherwise the guest OS can become unstable. As a minimum, you must ensure that your guests have the following available:
Pagefile/swap ≥ (configured memory – memory reservation) × 65%
We strongly recommended that ballooning not be disabled within VMs. If users are concerned about the potentially negative effect on their VMs, consider strategies other than disabling ballooning to prevent memory overcommitment. For example, applying a memory reservation will reduce the chance that any ballooning will occur (in fact, a full memory reservation means all the VM's memory is mapped to physical memory and no reclamation will ever happen).
When the VM needs the page again, it decompresses the file back into guest memory. Despite the small latency and CPU overhead incurred by compressing and decompressing, it's still a considerably more efficient technique than host swapping. By default, the memory-compression cache is limited to 10% of guest's memory, and the host doesn't allocate extra storage over and above what is given to the VMs. This prevents the compression process from consuming even more memory while under pressure. When the cache is full, it replaces compressed pages in order of their age; older pages are decompressed and subsequently swapped out, making room for newer, more frequently accessed pages to be held in the cache.
A pool of cache for all the VMs on a host is created. This isn't the same as moving all the VMs' .vswp files to a SSD datastore, because the cache doesn't need to be large enough to accommodate all the .vswp files. If host swapping is necessary, then this host cache is used first; but once it's all allocated, the host is forced to use the VM allocated .vswp files. Regardless of this host cache being available, each VM still requires its own .vswp file. However, the larger the host cache available, the less extensively the VMs' .vswp files are used.
The swap-to-host-cache feature reduces the impact of host swapping but doesn't eliminate it unless each host has more SSD space than configured vRAM (fewer memory reservations). Remember to include HA failovers and host maintenance downtime if you're sizing SSD for this purpose. This is ideal but isn't always possible for servers with large amounts of memory and a small number of drive bays—for example, high-density scale-up blades.
Host swapping leads to significant performance degradation, because the process isn't selective and will undoubtedly swap out active pages. This swapping is also detrimental to the host's performance, because it has to expend CPU cycles to process the memory swapping.
If the guest is under memory pressure at the same time as the host, there is the potential for the host to swap the page to the .vswp file, and then for the guest to swap the same page to the guest's pagefile.
Host swapping is fundamentally different than the swapping that occurs under the control of the guest OS. Ballooning can take time to achieve results and may not free up enough memory, whereas despite its impact, host swapping is an immediate and guaranteed way for the host to reclaim memory.
When Memory Is Reclaimed
Memory is only reclaimed from nonreserved memory. Each VM is configured with an amount of memory. If no memory reservation is set, then when the VM is powered on, the .vswp file is created as large as the allocated memory. Any memory reservation made reduces the size of the swap file, because reserved memory is always backed by physical host memory and is never reclaimed for overcommitment. It's guaranteed memory and so is never swapped out by the host:
Swap file (vswp) = configured memory − memory reservation
Because the host never attempts to reclaim reserved memory, that proportion of memory is never under contention. The VM's shares only apply to allocated memory over and above any reservation. How much physical memory the VM receives above its reservation depends on how much the host has free and the allocation of shares among all the VMs.
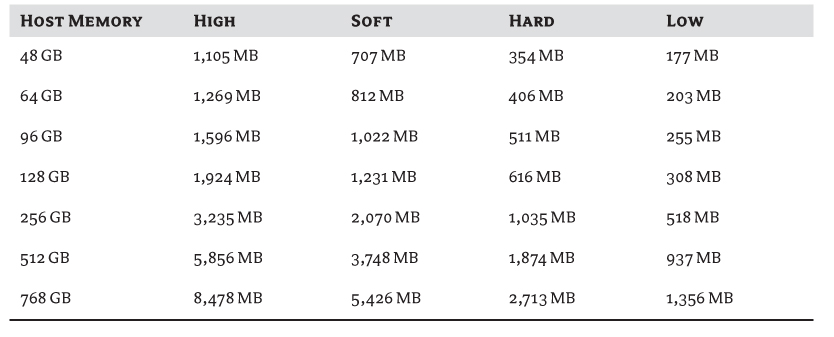
The use of the memory-reclamation techniques depends on the amount of free host memory. Some processes run all the time, and others are activated as less free memory is available. There are four defined levels of memory usage: High; Soft, which is two-thirds of High; Hard, which is one-third of High; and Low, which is one-sixth of High (the exact values are 64%, 32%, and 16% of High, respectively). Prior to vSphere 5, High was set by default at 6%, which meant Soft approximately equaled 4%, Hard 2%, and Low 1%. These levels are primarily in place to protect the VMkernel from running out of memory, but as host memory capacity has grown, the need to protect so much isn't as relatively great. For example, an ESXi 5.0 host can potentially run on hosts with 2 TB of RAM. Using these static values, the host would start reclaiming memory even when it still had over 100 GB of free memory. To set the levels more effectively, vSphere 5 adjusts the High level according to the amount of memory in the host. Assuming your host has more than 28 GB of memory installed, High is set at 900 MB plus 1% of all memory above 28 GB. Table 4.2 extrapolates the memory levels for some common server configurations.
Table 4.2 Memory reclamation levels
If the VMkernel is deemed to be in the High memory state—that is, it has more free memory than the High column in Table 4.2—it's considered not to be in contention. But when the memory state is pushed above this level, the host begins to compare VM shares to determine which VMs have priority over the remaining memory.
If the amount of free memory drops lower as VMs consume more resources, then as it reaches each predetermined threshold, more aggressive memory reclamation takes place. Each level is designed to get the host back to a free memory state:
However, TPS only scans 4 KB memory pages and not 2 MB large pages. This is because the large pages are far less likely to have identical contents, and scanning 2 MB is more expensive. The one thing it does continue to do, regardless of the host's memory state, is create hashes for the 4 KB pages in the large pages.
The other process that runs regularly is the calculation of idle memory tax (IMT). VMs' memory shares are used when the host hits levels of memory contention, to figure out which ones should have priority. However, a VM with higher levels of shares may be allocated memory that it isn't actively using. To rebalance the shares so those VMs that really need memory are more likely to get some, IMT adjusts the shares to account for the amount of unused memory. It “taxes” those VMs that have lots of idle memory. IMT is regularly calculated (every 60 seconds by default) despite the level of free memory on the host. Remember that the shares that are being adjusted are taken into account only when the host is in memory contention. IMT runs all the time but is used only when memory usage is above the High memory level.
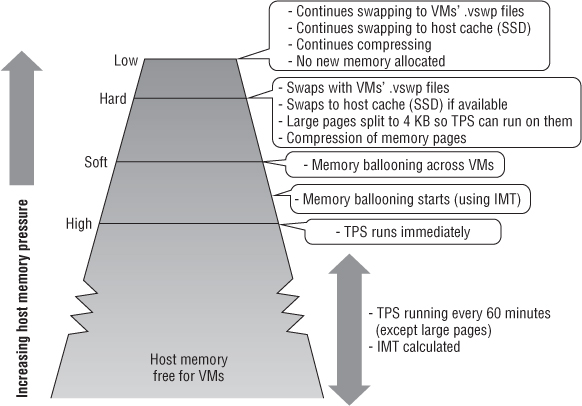
Figure 4.2 shows the levels at which the different memory-reclamation techniques kick in. As less memory is available for the VMs, the VMkernel becomes more aggressive.
Figure 4.2 How memory is reclaimed
The one exception to these memory state levels is if a VM has a memory limit set. If an artificial limit is set, then when the VM reaches it, the host begins to balloon and, if necessary, swap the VM. The host does this even if it has plenty of free memory. Chapter 7 discusses the dangers of setting VM memory limits.
Memory Capacity
vSphere hypervisor servers demand more from their memory than the average general-purpose OS. Not only do they require swaths of capacity, but they often test the hardware more rigorously than other OSes.
Achieving the right balance of CPU cores to memory is important. A general rule of thumb is to make sure you have at least 4 GB RAM per core. Many of today's memory-hungry applications tilt this ratio, so you may need more memory than 4 GB per core, although this very much depends on workload. Remember, this ratio is related to the proportion of shared and reclaimed memory to the time-sliced co-scheduling of the CPU cores. It's used to understand what a balanced amount of RAM may be for an average server with a certain CPU configuration.
As the core density in modern servers grows, it can become increasingly difficult to fit in enough memory. At the time of writing, 16 GB modules are the sweet spot for memory, being only an additional 20% premium relative to 8 GB sticks. Jumping up to 32 GB modules can quadruple the price from 16 GB. However, if you have a 4-way, 12 -core server, you need at least 192 GB to make sure you have enough memory to back all the cores. If you want to set up a greater consolation ratio of 8 GB to each core, then unless you have a server with at least 24 DIMM sockets, you'll have to pay the extra for those costly 32 GB modules.
As 32 GB modules become the norm and CPUs gain more cores, you should reevaluate this guideline for your environment. But be aware that more dense form-factor motherboards can constrain overall system performance unless more expensive memory is fitted.
Fortunately, with the abolition of vRAM, vSphere licensing is based on CPU socket count, not RAM; if you have the slots available, buying the maximum amount of memory you can afford is probably worthwhile. Arguably, memory is the number-one scalability factor in any server. Aside from capacity, the front-side bus speed on the memory is an important element of overall server performance. The speed of the bus and the attached memory often have as much impact as the CPUs driving the instructions.
NUMA
Most modern servers come with nonuniform memory access (NUMA), occasionally referred to as nonuniform memory architecture, enabled CPUs and motherboards. NUMA is available on all recent AMD and Intel CPUs, with support on current motherboard chipsets (although some vendors extol the virtues of their own specialized chipset support).
Multi-CPU servers, particularly those with multiple cores, face a bottleneck when so many processors simultaneously try to access the same memory space through a single memory bus. Although localized CPU memory caches can help, they're quickly used up. To alleviate this issue, NUMA-enabled servers' CPUs are split into nodes that have access to localized RAM modules that have much lower latency. NUMA combines CPU and memory allocation scheduling. But if VMs need access to nonlocal memory, this can actually increase latency beyond normal SMP-style architecture and degrade performance.
vSphere can use NUMA-enabled systems and has a specially tuned NUMA CPU scheduler to manage the placement of VMs. Each VM is allocated a home node and is then given memory from the same home node. The NUMA scheduler dynamically balances the home-node allocations every 2 seconds, rebalancing them as each VM's CPU and memory requirements change.
The NUMA scheduler uses TPS memory sharing on a per-node basis to prevent shared pages being matched from nonlocal memory. You can disable this feature if memory is particularly tight on the server or if many VMs are very similar and will benefit more from TPS.
One of the problems faced by the NUMA scheduler is VMs with more vCPUs than each node has cores. Also, if a VM is allocated more memory than a single node's local memory can provide, it must get some of its memory across an intersocket connection. vSphere 4.1 introduced wide NUMA scheduling to improve the placement of VMs with more vCPUs than a single node can hold, which prevents them becoming more scattered than they need to be and allocates memory as locally as possible. Of course, if you know how many vCPUs and how much RAM will be allocated to your larger VMs, you can scale your server design sufficiently to make sure that, where possible, the VMs will fit on a single NUMA node.
Often, NUMA is disabled in the BIOS. The setting Node Interleaving means the server ignores NUMA optimizations and doesn't attempt to localize the memory. To enable the use of NUMA, make sure Node Interleaving is set to Disabled. Normally, NUMA is only enabled on hosts with at least four cores across at least two NUMA nodes.
NUMA allocation is yet another reason it's advisable to have similarly specified servers in the same DRS cluster. Otherwise, VMs can vMotion between hosts where the source has one NUMA node size but there's a different node allocation on the next. The DRS mechanism is currently unaware of NUMA calculations and sizes on each host.
ESXi 5.0 introduced support for virtual NUMA (vNUMA). vNUMA presents the host's physical NUMA typology through to the guest OS and its applications, allowing them to participate in placement optimization. If a guest OS can understand the underlying NUMA structure, it can schedule its guest threads to better align with the NUMA nodes. vNUMA is enabled by default on VMs greater than eight vCPUs because those are the most likely VMs to naturally span more than one NUMA node. For a VM to be exposed to vNUMA information, the hardware compatibility must be set to ESXi 5.0 or greater (hardware version 8).
Arguably, NUMA as a feature is useful but probably not enough to make you buy servers because they include it. However, if you're deploying servers that have NUMA, various design options can take advantage of the NUMA scheduling and maximize local low-latency memory access for your VMs. If possible, it's preferable to size VMs' vCPUs as multiples of the host's NUMA node. The physical placement of RAM modules in the motherboard slots affects which CPUs use that RAM as local memory, so normally you should follow your vendor's advice and ensure that the RAM modules are spread evenly so each CPU receives an equal share.
Motherboard
The server's motherboard, sometimes known as the mainboard or system board, dictates what components can be fitted to the server and how many of each. The motherboard is designed to cope with the hardware, so it shouldn't be a bottleneck; but different vendors try to provide competing efficiencies because the motherboard is one of the few pieces particular to them.
One of the more crucial elements on the motherboard is the chipset that provides the interface between the CPU and its front-side bus (FSB) to the memory and peripheral buses. The motherboard and its chipset mandate the number and type of CPUs, RAM slots, and PCI slots. Given sufficient space in the case, how expandable the server is depends on its motherboard.
The motherboard can also be responsible for an onboard RAID solution, although it's more common to use a separate controller card in large servers. It monitors the temperature of components and can adjust the internal fans appropriately. Motherboards also provide integrated peripherals such as serial, parallel, and USB ports and usually have onboard diagnostics.
Normally, motherboards aren't marketed as options, but they're the main differentiators between a vendor's models. Choosing a particular model of server isn't just about the form factor of the case; primarily it's about the motherboard inside. From a vSphere design perspective, it dictates the expandability of the server and configuration maximums available. Generationally, newer boards allow you to connect newer hardware components. In addition to choosing the CPU family and number of sockets you need, along with the capacity to fit all the memory and cards required, you should look for designs with better bus speeds, the latest PCIe standards, and the largest system caches.
Storage
Storage in vSphere is a fundamental topic that is the basis for Chapter 6, “Storage.” From a server hardware perspective, it revolves around two different areas: the local storage that the server commonly boots from and the way in which the server connects to any shared external storage.
Local storage is most often used for the ESXi boot image. Other options exist, such as Boot from SAN or Auto Deploy images, which can negate the need for any local storage. The local storage can also be physically external to the server itself, in an expansion shelf connected via a SCSI cable.
If the local storage will be used to run VMs on a Virtual Machine File System (VMFS) partition, the performance of the disks is important. In this case, the speed of the disks, interface connector (SAS, SATA, and so on), RAID type, number of spindles in the RAID set, and RAID controller are all factors in the VM's performance, because disk I/O is important. Local VMFS storage is often used in small offices and remote office locations where shared storage may not be available. It tends to be significantly less expensive and so can be useful to store less important data, or as an emergency drop location if there are issues with shared storage.
If local storage is only used to boot the vSphere OS, performance is arguably less important. The ESXi hypervisor is loaded from disk entirely into memory, so apart from minor differences in boot speed, faster disks won't improve performance. The expense of buying faster disks is probably better spent on more CPU cores or more RAM modules. Any production server should employ some sort of RAID redundancy protection, but an extra hot spare provides an inexpensive additional level of protection.
The more common storage for VMs is shared storage where the servers connect to centralized storage. The method a server uses to connect to that shared storage is dictated by the protocol and transport used by the storage array. The common connections are Fibre Channel (FC) host bus adapters (HBAs), Fibre Channel over Ethernet (FCoE) converged network adapters (CNAs), iSCSI hardware HBAs, and Ethernet network cards for both software iSCSI and Network File System (NFS). Because the speed and resilience of these connections can be paramount to VMs, the selection of the cards, their speed rating, the redundancy of ports, and the PCI connector type are all important. Select the best PCI card connection possible on the motherboard, because the storage cards should ordinarily take priority over any other I/O cards. It's advisable to buy two single-connector cards instead of one dual-port card if the budget allows, because this will help to spread the I/O across two PCI connectors and provide redundancy if a card fails or disconnects.
Network
Network I/O is also a cardinal vSphere design topic and is explained in depth in Chapter 5, “Designing Your Network,” but several design choices with respect to server hardware are worth discussing at this juncture. First, although most servers have two or four onboard 1GbE network adapters, it isn't uncommon to see an extra two or even three four-port 1GbE PCI cards to cover all networking needs. If you're using any FC HBAs or CNAs, you should reserve the fastest PCI connections for them and then use the next available fastest PCI slots for your additional network connections.
But if there is no need for other storage bandwidth-intensive cards, or you're going to use 10GbE cards to aggregate storage and network traffic, these should be in the fastest slots possible. Although using 10GbE ports is likely to reduce the number of cables used, at the time of writing few servers come with onboard 10GbE; and like storage cards, you may choose to use two one-port cards instead of a single two-port card, so you still need at least two high-speed PCI slots. Try to get cards that support NetQueue, because it can improve 10GbE performance.
If a company has specific rules about DMZ cabling or doesn't use trunked network ports, you may need even more network cards.
PCI
PCI is a standard bus used by expansion cards to connect to a motherboard. The original PCI standard has evolved through numerous versions, including the PCI-X and PCI Express (PCIe) revisions. Table 4.3 shows the increased theoretical maximum bandwidth between the standards.
The PCI-X interface became increasingly popular with 1GbE cards because the cards couldn't saturate the bus link. Now the PCI Express standard brings bus speeds closer to the FSB speeds used by CPUs today. Most servers come with PCI Express slots, but you should check how many and of what type, because some have only one or two or may not be PCI Express version 2.0 or 3.0. Consider the number of high-speed PCI slots and the version number against your card requirements. At the time of writing, only the latest-generation servers were shipping with PCIe 3.0 sockets, and network/storage cards were not yet available.
Table 4.3 PCI bus speeds
| Bus | Max Bandwidth |
| PCI | 133 MB/s (although extended up to 533 MB/s for 64-bit at 66 MHz) |
| PCI-X | 1,064 MB/s |
| PCI Express | 250 MB/s per lane (8x is 2 GB/s, 16x is 4 GB/s, 32x is 8 GB/s) |
| PCI Express 2.0 | 500 MB/s per lane (8x is 4 GB/s, 16x is 8 GB/s, 32x is 16 GB/s) |
| PCI Express 3.0 | 1 GB/s per lane (8x is 8 GB/s, 16x is 16 GB/s, 32x is 32 GB/s) |
You should make sure your highest-speed slots are used for your highest-bandwidth I/O cards, to avoid buses being a bottleneck. Usually, storage cards—whether FC HBAs, FCoE CNAs, or 10GbE interfaces—take precedence. If you're limited on PCI Express slots, ensure that these cards are fitted first. Less bandwidth-intensive workloads such as 1GbE network adapter cards can use less-well-specified slots. For a single-port 10GbE card, aim to use at least a PCI Express 2.0 x4 slot; and for a dual-port card, use a x8 as a minimum.
One last important design consideration for host PCI slots is consistency. Ensuring that servers have the same cards in the same slots can ease installation and configuration, particularly cabling, and make troubleshooting hardware issues considerably more straightforward. This becomes increasingly important as your deployment techniques mature with greater levels of automation. If all the servers in a cluster are the same make and model, then having the same I/O cards in the same slots means that each port gets the same vmnic or vmhba number. If you have a multisite rollout, and you're able to purchase the same server hardware for more than one location, think about all the sites' storage and networking requirements before choosing which slot to use for which. For example, although you may have only a few sites with a FC SAN, with the rest using 1GbE-connected iSCSI or NFS devices, you may wish to always put the 1GbE cards into a slower slot. Even though at most sites you have one or two slots free that are very high performance, the 1GbE cards won't use the extra bandwidth, and you can keep all the servers consistent across the fleet.
- Very small number of PCIe cards supported
- Server hardware must specifically include support in the BIOS and have IOMMU enabled
- Only Red Hat Enterprise Linux (RHEL) 6.1 or Windows 2008 R2 SP1 guest OSes
- PCIe NICs can't be used as host uplinks (vmnics) when they're enabled for SR-IOV
- vMotion, Storage vMotion, DRS, or DPM
- HA protection or FT support
- Standby/hibernate or suspend and resume
- Hot adding/removing of VM hardware devices
- NetFlow or vShield support
Preparing the Server
After server hardware selection is complete, you should test the server's non-OS settings and hardware configuration prior to using them in production. You need to make several choices regarding their setup, and a good design should include a set of preproduction checks to make sure the hardware is deployed as planned. Hardware configuration and testing will affect the rollout.
Configuring the BIOS
Every server's hardware settings are primarily configured through its BIOS. Some of the default settings set by vendors are configured for general-purpose OSes and may not give you optimal performance with vSphere. To get the most from your servers, several settings should always be set:
The following are settings you may wish to consider changing:
In general, you should aim to keep as many settings as possible at the manufacturer's default. Use the server installation as a good opportunity to update the BIOS to the latest version available. Do this first, before taking the time to change any options, because re-flashing the BIOS may reset everything. Strive to have all BIOS firmware levels and settings identical across every host in a cluster.
Other Hardware Settings
In addition to the BIOS settings, remember that you should set several other settings according to the designed environment:
Burn-in
Before each server is unleashed under a production workload, you should test it extensively to ensure that any initial teething problems are identified and rectified. Most servers have a hardware diagnostic program in the BIOS, during the POST, or on a bootup CD. This utility runs a series of stress tests on each component to make sure it can cope with a full load.
For vSphere, the server's memory is the most critical thing to test thoroughly, because it's used so much more intensively than normal. A useful free tool to test memory is Memtest86+, which you can download from www.memtest.org and burn to a CD. We recommend that you boot new servers off the CD and let the utility run its memory testing for at least 72 hours before using the server in production.
Preproduction Checks
Finally, after the server's hypervisor is installed and before the server is brought into a working cluster and allowed to host VMs, you should perform several checks:
- Memory and I/O cards have been fitted to the correct slots.
- The server is racked properly, and the cabling is correctly fitted. Using cable-management arms not only helps improve airflow but also allows access to the servers without shutting them off to change hot-swap items and check diagnostic lights.
- The storage cards can see the correct datastores. If you're using NFS, the server has write access to each datastore.
- The network cards can see the correct subnets. Move a test VM onto each port group, and test connectivity.
- This is a good opportunity to make sure the hypervisor is patched.
- NTP is working properly.
- The server has the appropriate vSphere licensing.
Scale-Up vs. Scale-Out
vSphere allows administrators to spread the x86 infrastructure across multiple physical hosts, with the ability to consolidate several workloads onto each server. Each VM's hardware layer is virtualized, abstracting the underlying physical compute resources such as CPU and memory from each VM's allocation. This abstraction allows you to separate the decisions around VM scaling from those of the host servers. The process of virtualizing the guest systems gives rise to an important design decision: how much consolidation is desirable. The ever-expanding capabilities of today's hardware allows an unprecedented level of VMs to hypervisors; but as an architect of vSphere solutions it's important to understand that just because they can be larger doesn't necessarily make them the most desirable configuration for your business.
The scale-up versus scale-out argument has existed as long as computers have. Virtualized infrastructure has its own implications on the debate; and as hardware evolves, so do the goal posts of what scale-up and scale-out really mean. Essentially, a scale-up design uses a small number of large powerful servers, as opposed to a scale-out design that revolves around many smaller servers. Both aim to achieve the computing power required (and both can, if designed properly), but the way in which they scale is different.
The classic scale-up scenario was based around server CPU sockets; in general computing circles during the ESX virtualization era, this usually meant one or two sockets for scale-out and four or eight sockets for scale-up. But in the last few years, this definition has been significantly blurred, primarily due to a couple of hardware advances. First, the size of RAM modules in terms of gigabytes and the number of DIMM sockets per motherboard has increased massively. Even in relatively small servers with one or two sockets, the amount of memory that can be fitted is staggering. Smallish blade servers can take large amounts of RAM. For example, some of Cisco's UCS blade servers can handle up to 1.5 TB of RAM! Second, the number of physical sockets on a server no longer necessarily dictates the CPU processing power, because the advent of multicore CPUs means a 2-way Intel server can have 20 CPU cores, and an 8-way server can have a colossal 80 cores. At the time of writing, AMD had 16-core CPUs available, and undoubtedly these two vendors will only continue apace.
These monstrous memory and core levels rewrite the rules on scale-up and scale-out and reiterate the message that the design is no longer based only on socket numbers. But the underlying premise still holds true. Scale-up is a smaller number of more powerful servers; scale-out is about lots of smaller servers. It's just that the definitions of large and small change and are based on differing quantifiable means.
With regard to vSphere servers, the scale-up or scale-out debate normally revolves around CPU and memory. I/O is less of a performance bottleneck, and storage and networking requirements are more often an issue of function rather than scale. These things work or they don't; it isn't so much a matter of how well they work. We're talking about the server hardware, not the switches or the storage arrays themselves. Obviously, storage can be a performance bottleneck, as can the backplanes on the switches; but with regard to the server hardware, we mean the I/O cards, adapter ports, and transport links. These adapters rarely dictate a server's level of scalability. There can be clear exceptions to this, such as security-focused installations that require unusually large numbers of network ports to provide redundant links to numerous air-gapped DMZ switches, or hosts that need to connect to several older, smaller SANs for their collective storage. Create a rule, and there will always be an exception. But generally speaking, scale-up versus scale-out server design is concerned with CPU and memory loading.
As this chapter has identified, CPU and memory are both important performance characteristics of a host server. It's important to note that for the average VM workload, you need to maintain a good balance of each. Even though RAM modules are inexpensive and a two-socket server can fit a very large amount of memory, they may not help much if the VMs are CPU-constrained. Similarly, even if it's comparatively cheap to buy eight-core CPUs instead of four-core CPUs, if you can't afford the extra memory to fit alongside them, the extra cores may be wasted. The CPU and memory requirements must normally be in balance with each other to be truly effective.
A common misconception is that scaling up means rack servers and scaling out means blades. The densities that can be achieved in both form factors mean that scaling up and out decisions aren't necessarily the same discussion. To understand a business's requirements, you should examine each independently. Although there is potential for crossover in arguments, one certainly doesn't mean the other. Blades and rack servers have their own interesting architectural considerations, and we'll look at them in the next section.
Now that you understand the basic definitions of scaling up and out, we can compare each approach.
Advantages of Scaling Up
The advantages of scaling up are as follows:
Larger servers can cope with spikes in compute requirements much more effectively, whereas smaller servers have to react by using load-balancing techniques that incur significant delay.
Additionally, many businesses license their guest OS software on physical servers. You can buy Microsoft server licensing to cover unlimited guest copies per host hypervisor. The fewer hosts, the fewer licenses needed.
Advantages of Scaling Out
In comparison to larger servers, more servers that are less powerful have the following advantages:
Arguably, having twice as many servers, each with half the parts, should mean you get twice the number of failed hosts on average. But the reality is that you'll have fewer outages per VM. Hardware failures are likely to account for relatively few host failures. Server components are so reliable and are backed by so many redundant subsystems that they don't often collapse in a heap. User error is a far more likely cause of host failure these days.
Although scaling out may reduce overall VM outages per year, that's not the main point. The real importance of scaling out is the impact of a single host failure. When a host fails (and they will fail occasionally), fewer VMs will fail at once. One of the greatest worries that companies have about virtualization is that host failures can have a significant effect on services. By scaling out to many more servers, fewer VMs are affected at once.
Although HA is a great recovery mechanism, reducing the time VMs are offline, it doesn't prevent VM outages when a host fails. With fewer VMs per host, HA should recover those VMs far more quickly. In a scale-out situation, if a host fails, HA has fewer VMs to recover and also has more hosts on which to recover them. Generally, the VMs are up and running again much more quickly. After the VMs are brought back up, DRS can load-balance those VMs more effectively than if there is a much smaller pool of hosts.
Scaling Is a Matter of Perspective
The classic picture of scale-up and scale-out being one to two sockets versus four or eight isn't appropriate in many situations. It's all about the interpretation of what is large and what is small. For example, compared to six one-socket servers, three two-socket servers is scaling up. And instead of four eight-way servers, using eight four-way servers is scaling out. The same can be said of cores versus sockets or the size of the RAM modules. It's all a matter of perspective.
Whatever a business considers scaling up or out is always tempered somewhat by its VM requirements. It's often not out or up, but what is right for the business. It's unlikely that any company will only opt for two very large servers, because if it's hoping to have n+1 redundancy, it effectively needs two hosts that are so large the company could run everything from one. That means buying double the capacity the company needs. Neither is a company likely to decide that 32 hosts per cluster is a good idea, because the company will lose any efficiencies of scale, and such a solution doesn't leave any room for host growth in the cluster.
Sizing hosts appropriately depends on the work you expect. Hosts will vary if you're going to run hundreds of workstation VDI desktops or a handful of very large Tier-1 multi-vCPU workhorses. Generally, large VMs need large hosts, and lots of small VMs work best with scaled-out hosts.
Risk Assessment
The biggest fear with a scaled-up architecture is the large impact created by a single host failure. This risk is largely dependent on the business and the applications running on the hosts. Is such aggressive consolidation worth the associated risk? If the server hosts business-critical VMs, then perhaps reducing the consolidation ratio to limit the risk of an outage is justified. Some companies split their resources so that most VMs run in large, consolidated scaled-up hosts; other, more important VMs run in a cluster that is designed with smaller hosts that have consolidation ratios normally found in a scale-out approach.
You should consider the risk of a failure of a particularly heavily loaded host in the context of its likelihood. Yes, there is always the chance that a host will fail. However, think of some of your organization's other critical infrastructure pieces. For example, many businesses run all of their main datacenter's VMs from a single storage array. That one array is stacked full of redundant parts, but it's still a single infrastructure piece. Unfortunately, servers don't have the same level of redundancy. But if you manage your hosts properly, with good maintenance and change-control procedures, host failures should be very rare.
Fear still drives a lot of companies away from scale-up designs. If an application is that critical to the business, much more than server hardware redundancy and vSphere HA should be in place to protect it. With the correct level of software insurance, only the most extremely risk-averse situations should shy away from scale-up servers for fear of host outages. Many options exist, such as VMware's FT, guest OS-based clustering, and failover written into applications. These extra levels of protection should supplement the most important VMs.
It's important to think about how applications interoperate, as well. There is little point in having clustered VMs run across servers that are scaled up so much that a single server failure will apply enough pressure on the remaining nodes that the application becomes unusable. On the other hand, scaling out servers to minimize the risk to an application won't help if all the VMs need to be online for the application to work. A single host failure, however scaled out, will still bring down the entire system. This is where you can design VM affinity and anti-affinity rules, along with host sizing, to protect your VMs.
If you're less concerned with the potential risk of large hosts, it's worth considering that these days, application owners think less and less about redundancy and failover. This is largely due to the success of virtualization and improvements to hardware and guest OS stability. In the days before mainstream x86 virtualization, application owners thought carefully about hardware redundancy and what would happen if a server were to fail. But with the ease of provisioning new virtual servers, and the belief that vSphere hosts with DRS and HA features are infallible, many application designers assume that their failover needs are taken care of. They don't realize that hosts can still fail—and that when they do, their VMs will go down. This means that more and more, it's up to those designing the vSphere layer to understand the applications that run on it and the level of risk associated with an outage.
Choosing the Right Size
Getting the right scaled hosts is usually a good balance of risk versus cost efficiencies. Scaling up saves money on OPEX and licensing. Larger servers used to be prohibitively expensive, but this is no longer the case. Most costs are fairly linear. Adding more cores is now often cheaper than scaling out; and because servers have increasingly large DIMM banks, there is less need to buy very expensive RAM modules. CAPEX-wise, price your scale-up and scale-out options, because they will depend on your definition of up and out. You may be surprised to find that scaling up is no longer the more expensive option.
Another issue that used to plague scale-up solutions was rack space, because most four-socket servers were at least 3Us, and often 4Us or 5Us. Today, with such dense core packages on the processors, your scale-up option may be on a 1U server or even a blade.
Look at the VM workload and the number of VMs, and consider what you think the pain points will be. Sometimes different situations require solutions that most would consider lopsided. You may have very high CPU requirements or unusually high memory requirements. The scale-up and scale-out approaches may also differ within an organization. The company's main datacenter probably has very different compute requirements than one of its branch offices. For example, a design that chooses a scale-out approach in the datacenter may want a scale-up for its smaller sites. The fact that the scaled-out servers are larger than the remote office's scaled-up servers is a product of the situation.
When you're considering the desirable consolidation ratio for VMs on each host, it's important to remember that after a design is implemented, the ratio will very likely change naturally. Undoubtedly, more VMs will appear, and it may be some time before the hosts are scaled up or out further to accommodate the extra VMs. Consolidation ratios should be designed with the expectation that they will be stretched.
It's easy for this to become a “religious” debate, and all too often architects have strong opinions one way or the other. These preferences can often cloud the best decision for a business, because every situation is different. Remember the conceptual design behind the functional and nonfunctional requirements, and how that affected the logical design. Chapter 1, “An Introduction to Designing VMware Environments,” delved into the process of deriving the physical design from a logical design first. Each company has its own unique requirements, and only by revisiting the base differentiators can you make an objective, agnostic decision every time. It's important to remember that as hardware capabilities constantly change and evolve, this decision should be continually reviewed. Although you had a preference for scale-out last year, this year you may think differently for the same business and opt for scale-up (or vice versa).
CPU to Memory Design Ratio
One frequently debated area of host design is the ratio of CPU to memory levels. Of course, the correct answer lies in the oft-used reply it depends, which is true: it does rely on the VMs that will run on the hosts. As you'll see in the next section, sizing the hosts doesn't need to be a black art. It's a fairly straightforward process to right-size a cluster of hosts for a particular workload. However, it can be instructive to talk in generalities and understand common server workload ratios.
When looking at the ratio of CPUs to memory in a host, the CPUs are best described in terms of cores. Although HT increases the number of logical processors, they don't provide the full power of a separate core. Factors such as HT, speed in GHz, bus speed, and NUMA design affect performance, but the number of cores is the best unit for this primitive comparative analysis.
An understanding of this type of analysis is useful is because it can be applied to existing configurations. Once you compare a few clusters, particularly clusters that are starting to create performance concerns, you begin to get a feel for vCPU consolidation ratios and CPU to memory levels in your environment.
Memory levels in a host are fairly easy to understand. Memory maps through to VMs on a one-to-one basis initially. Memory-reclamation techniques such as page sharing allow for some level of overcommitment, but it's unusual to see anything more than 30% in general server VM clusters. Many enterprises strive to avoid overcommitment, using it instead as a soft limit for their capacity (not that we advocate this as a good method of capacity management). When considering failover capacity in a cluster, this further reduces the chances that the hosts are overcommitted for memory. For planning purposes, a one-to-one mapping of VM memory to host memory isn't uncommon.
CPU sizing is far less tangible. There is an expectation that you can over-allocate CPUs many times over. As opposed to memory, which a guest uses all the time, a CPU is sent instructions to process on a more intermittent basis. The level of CPU cores to vCPUs will affect the VMs' performance once the CPUs become overloaded. The old rule of thumb was that around four vCPUs to each core was reasonably safe. As CPU technology has progressed, many users see 6:1 or even 8:1 as acceptable in their environment. Obviously each circumstance is different, and just as CPU power has increased, often so has the applications' demands as SMP tasking becomes more efficient in guests. For mission-critical operations where even small amounts of CPU latency are unacceptable, 2:1 or even 1:1 may be appropriate.
In new configurations, experience can help to make design assumptions about the potentially nebulous vCPUs-to-core ratio and the CPU-to-memory balance. In an existing environment, it's possible to see whether the existing levels of consolidation are within norms. Unfortunately, the vSphere Client's CPU usage graphs for the hosts are somewhat misleading. Look at any heavily used host, and it will almost always appear that the memory usage is high and the CPU is hardly being taxed. But the CPUs could be the performance bottleneck if the vCPUs-to-core ratio is too high and there are insufficient scheduling opportunities for the VMs. A host's CPU allocation to each VM is affected by such things as the hypervisor's SMP coscheduling, time slicing, and NUMA locality. A heavily consolidated host can equate to VMs that suffer from CPU queuing. Check the host's CPU Load Average and VMs' CPU Ready figures to see if it's being affected by processor latency.
Sizing the Hosts
A possible approach to right-sizing your hosts could be as follows. Figure 4.3 shows an assessment cycle to determine the CPU and memory sizing for hosts and the number of hosts. It follows the process from VM requirements through the logical design phase, finishing in a physical design. If followed properly, the logical design is where the majority of the work is done, meaning the physical design is only a final step.
Figure 4.3 Host sizing cycle
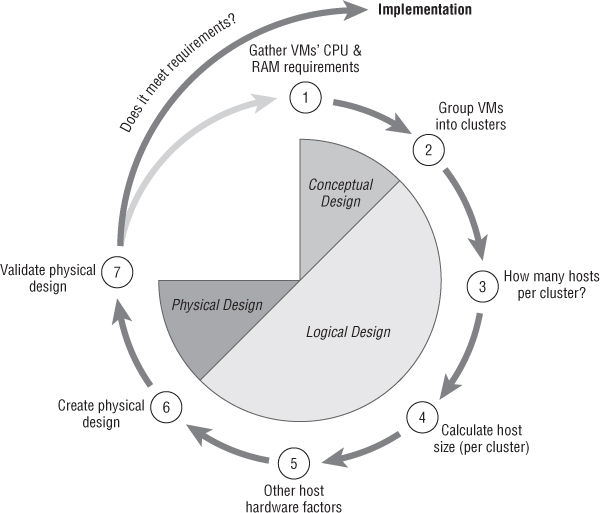
As you'll see in Chapter 8, cluster design can revolve around many factors. In an ideal world, clusters would be dictated by aligning similar VMs. Collocating VMs of approximately equal size means cluster functions such as DRS, HA, and Storage DRS work most efficiently. However, being pragmatic, clusters are often split out for other important technical and business reasons, such as connection to storage arrays, security zones, business units, projects, tenancy, application ownership, business criticality, and DR rules.
The previous sections covered the scale-up versus scale-out arguments. Clusters can only have up to 32 hosts. Consider the level of redundancy you need: the failure domain size the business is comfortable with. Most consider creating multiple general-purpose clusters smaller than five hosts a waste of redundancy resources. It's common to see clusters up to 8 or 12 hosts. Additional redundancy should be factored in. The standard n+1 is a common approach but may not be sufficient. On the other hand, some businesses are willing to accept a certain level of performance degradation or allow some test VMs to be offline during short outages.
Once you know how many hosts you'd like to have in each cluster and the VMs you hope to have in each cluster, then it's fairly simple math to add up the VMs' vCPUs and RAM. You need to make some assumptions about the vCPUs to cores and memory commitment levels (see the previous section). You can then calculate the number of cores and GB of RAM required in each host. Your calculations should take into account the expected growth of the environment during the life-cycle of the hardware.
You may find that the levels are too high or too low and that hosts don't come in those types of specifications. If that is the case, then you'll need to revise the number of hosts in each cluster or be prepared to split or consolidate the clusters.
Once you have the appropriate CPU and memory requirements for your servers, you can turn your attention to all the other hardware choices available. These include things like PCI slots, form factor (blades half-height, full-height, 1U, 2U, and so on), vendors, and any ancillaries and accoutrements.
At this point you can look at the specifics of the physical servers. These include model numbers, parts, memory modules, and PCI cards.
Once the hardware has been chosen, you should re-review all the conceptual design requirements and each of the logical design steps to validate that the final decision is appropriate. If need be, another cycle back through the circle can help to resolve outstanding issues and gives you an opportunity to finesse the physical design.
Blade Servers vs. Rack Servers
In addition to the continual debate over scaling up or out, the intertwined argument over blade or rack servers continues unabated. This is also a contentious issue, but it's slightly more quantitative. There are different opinions about what a scale-up or scale-out solution is, but a server is definitively either a blade or a rack. Each manufacturer has its own twist, but generally a rack server is a stand-alone unit that is horizontally mounted. A blade server uses a chassis or enclosure with certain shared components such as power, backplane, and I/O units. It's common to see blade servers mounted vertically with half- or full-height options.
The blade versus rack discussion used to be far more closely aligned with scale-up and scale-out solutions, because blades were always considered to be a very dense, lower-performing option. But these days, that categorization isn't as applicable. You can find blade servers in four-way configurations with the potential for several hundred gigabytes of memory. Also, some manufacturers are beginning to produce rack servers that can compete with blades in the areas of power efficiency and reduced cabling.
With that caveat understood, you can generalize about blades and take them as a scale-out option, the advantages and limitations of which we covered in the last section. Our discussion here will focus on the differences inherent in the two form factors.
Servers have also long come in tower models. Towers serve a purpose and shouldn't automatically be discounted even by large enterprises. But their large size usually prevents them from being space-efficient enough in all but the smallest deployment. Also, remember that tower servers should be specified just like any other production server with adequate hardware redundancy and quality components. Towers aren't often used in virtualization environments because they tend to be very underpowered; but if a small branch office needs a stand-alone server, and you want to consolidate its small workload on a hypervisor, a tower can prevent the cost and space requirements that come with a half-height rack installation.
Blade Servers
Both blades and racks are viable options with vSphere. Despite a blade's limitations, you can make it work well in a virtualized environment. Although rack servers are very much the predominant force in the server market, blades have always attracted those interested in hypervisors. Often, the same people who can see the distinct advantages of consolidation, energy efficiency, and modular hardware options in vSphere can see obvious synergies with blade servers as their form factor of choice.
However, those who dabbled with blades when they first arrived were often hit by first-generational teething problems: poor redundancy, lack of management tools, BIOS issues, no training, excessive heat, and so on. This has tarnished the view of many server engineers, and some are vehemently opposed to using blades. But in many situations, using blade servers offers real gains.
The Case for Blade Servers
After a blade chassis has been fitted to a rack and cabled in, adding/removing/replacing blades is trivial. It takes only minutes to fit or unrack a server and move it to new chassis. The modular design is one of its key strengths. This can be one of most obvious OPEX cost-reduction effects of using blade servers.
Their combined midplane reduces the amount of cabling, which not only reduces the OPEX but can also reduce the CAPEX resulting from cabling costs in a datacenter. Fewer power cables are required in racks and therefore fewer PDU connectors. The reduction in the number of Ethernet and FC cables going to the next hop switch cuts cabling costs and can also substantially reduce the number of ports on network and storage switching equipment.
Blade chassis can potentially allow for a reduction in rack-space usage. You can typically fit at least 50% more servers into the same area than even 1U rack servers. If you lease your rack space, this can be quite a cost saving. Most of the current generation chassis offer very advanced management tools, which can surpass those found on rack servers; and unlike the rack equivalents, which can be licensed extras, the blade's tools are usually included in the price of the chassis. These advanced management tools can provide remote management (power options and remote consoles), virtual hardware device emulation (mounting remote media), midplane configuration, BIOS management, automated provisioning, and so on.
Traditionally, blade servers have offered power-efficiency savings. By combining several servers' PSUs together, a chassis can reduce the number of PSUs well below the normal minimum of two per rack server and still provide hardware redundancy. Modern blade chassis use incredibly efficient PSUs, to try to reduce heat generation as much as possible. They can automatically step down their power consumption depending on how full the enclosure is.
With the increasing use of 10GbE in servers, storage, and networking equipment, blades become even more viable. The additional bandwidth they can provide means that much higher I/O is possible down to each server. The interconnects on many of the chassis backplanes are 10GbE, with extremely fast interserver traffic possible. This removes one of the biggest drawbacks that blades posed, particularly to virtualized workloads that needed excessive Ethernet cabling.
With the increase in CPU core density, the availability of four-way blades, and large DIMM socket density, it's possible to build very powerful blade servers. Considering that vSphere servers aren't usually built to depend heavily on local storage, blades can make excellent hypervisors. Additionally, often companies don't virtualize everything they have, and it's possible to mix non-ESX servers into chassis to spread the HA and I/O load.
The Case against Blade Servers
One of the biggest constraints with blade servers that deters many companies is the much higher initial entry cost. Before deploying your first blade server, you must buy and fit a full chassis with power supplies, network, and possibly FC switches. This can effectively make the first server very expensive. If you buy several blades at once, this cost can be absorbed. Either you need a flexible budget in which you can offset CAPEX investments for subsequent blades, or you must plan to purchase quite a few blades in the first order to make the cost more palatable. The tipping point for blade servers is usually somewhere around seven or eight per chassis, at which point you can begin to see reasonable unit costs per server. Anything less means each server will seem very expensive.
Server technology churns frequently, with new models and features arriving all the time, so you shouldn't expect to wait several years to fill each chassis—those empty slots may become useless because the new blades may need newer chassis. Make sure the chassis, all its integrated equipment, and the change in infrastructure provide a suitable ROI. The chassis are proprietary to the vendor, so you're locked into those blades and their add-on options after you buy the chassis. You're entirely reliant on the vendor's hardware plans, so in the future you may be limited to the technology roadmap the vendor chooses. If it delays moving to the next CPU architecture, doesn't offer the latest chipset options, or doesn't provide a new I/O protocol or transport, there is little you can do.
Another frequently quoted concern about blades is the chance of an entire chassis failure. Such failures are regarded as very rare, but the thought is enough to dissuade many businesses. If you've ever experienced a complete chassis outage that takes all the blades down at once, it's likely to make you think twice about purchasing blades again. People dismiss scaling up their vSphere servers to two or three times their usual size, for fear of losing all their VMs in one go. Imaging losing 16 scaled-out servers for a period of time. Although vendors describe chassis failures as extremely unlikely, there are always single points of failure involved; and if that risk is too much, this is a very real barrier to adopting blades.
This possibility of a single point of failure also influences certain aspects of your vSphere design. For example, vSphere 5 clusters still have no understanding of the physical server placement within blade chassis (or racks for that matter). Ensuring that a redundant pair of VMs do not run on the same host can be achieved with a single VM-to-Host anti-affinity rule. However keeping those two VMs in separate chassis isn't as easy to accomplish.
If you've ever stood behind several fully loaded blade chassis, then you know the tremendous amount of heat they can generate. Although high server density is an obvious advantage of using blade servers, you need to be prepared for the very high power and subsequent cooling requirements. Today's datacenters are struggling to keep up with these physical demands, and the power or cooling available to you may be limited. Although blades shouldn't produce any more heat than their rack equivalents, they allow increased concentration. If you expect to take the same amount of space and fill it with blade servers, then you'll need more power and more cooling. Think about the hot spots blades can create and how they affect your hot and cold aisle distribution. You may need additional cooling units and extractors over particular areas to account for uneven heat distribution.
When introducing blades, especially in larger environments, you may find that internal teams need to work more closely than they're accustomed to. If there are separate server, storage, and networking teams, you'll need buy-in from all parties. They may be accustomed to physical separation of equipment, but with blades chassis, the management tools and rack space are shared. You may have to change internal processes for teams that are used to being independent. Often, these teams have disparate purchasing cycles and separate budgeting models, so the financial logistics may need to change. To make this happen, a cultural shift is often required, which can be more difficult to achieve than you expect. Or, as sometimes happens, the server guys may need to come up to speed with network switches and storage equipment very quickly.
One often-overlooked aspect of using blades is training. Rack servers are a known entity, and it's fairly straightforward for an engineer to maintain a new model or even move to a new vendor's equipment. But blade servers are different beasts and need a lot of internal management that may require additional training. Even moving from one blade vendor to another can involve an uphill learning curve, because blades are much more proprietary than rack servers. A deeper understanding of network and storage switches is often needed, and non-server engineers may have to familiarize themselves with new management tools.
Blade chassis used to suffer terribly from a lack of I/O in comparison to their corresponding rack server models. 10GbE has resolved many of these issues; but unless you already have a 10GbE uplink switch to connect to, this can require expensive upgrades to your switching infrastructure. Most vendors should have 10GbE and FC mezzanine cards available, but you may not always find the 16 Gbps FC option, PCIe flash accelerator, PCoIP cards, or even a compatible connector for your requirements. Even when it comes to changing from one standard to another, you normally have to do it en masse and exchange the entire chassis's I/O options at once.
Even with 10GbE, you'll still find I/O limitations with vSphere. You'll almost certainly need to rely on VLANing to separate the traffic to reduce the broadcast domains and provide basic security segregation. vSphere's network I/O control (NIOC) feature can help provide simple quality of service (QoS) while aggregating the traffic onto a smaller number of cables and maintaining redundant links. But blade servers can never match rack servers with their full PCI slots for I/O expansion options.
Despite the fact that the blades have access to very fast interconnects, chances are that most of the traffic will still exit each blade, go out through the network cards, and hit a physical network switch where the default gateway sits. Localizing traffic in a chassis usually depends on the network cards' functionality and how capable and interested the network team is.
Blades are considerably more powerful than they used to be, with four-socket CPU configurations possible and many more DIMM slots than previously. The increase in core density has also improved the viability of blades, increasing the compute density. However, even though some 2-way blades offer up to 32 DIMM sockets, to really scale out in terms of some of the large 4-way rack servers is very expensive, because you have to use large, costly memory modules. It's difficult to fit enough memory to keep up with the number of cores now available. Even the most powerful blades can't compete with the levels of scalability possible with rack servers. For your most ambitious scale-up architectures and your most demanding Tier-1 applications, you may find that blades don't measure up.
Rack Servers
An often lauded downside of rack servers is that they consume more physical rack space. You literally can't squeeze as many of them into as small a space as you can with dense blade servers. However, if you're not space constrained, this may not be such a disadvantage. Blades tend to increase heat and power usage in certain areas in your datacenter, creating hotspots. Often, virtualization projects free up space as you remove less powerful older servers and consolidate on fewer, smaller, and often more energy-efficient servers that take up less space than their predecessors. If you have plenty of space, why not spread out a little?
One advantage of rack servers is that they can be rolled out in small numbers. Unlike blades, which need several servers to be deployed at a minimum to make them economical, rack servers can be bought individually. In small offices that need one or two vSphere servers, you wouldn't even consider a blade chassis purchase. By choosing rack servers to also use in your larger datacenters, you can standardize across your entire fleet. If you don't need to manage two different form factors, then why would you?
You can also redeploy rack servers to different locations without having to provide an accompanied chassis. They're stand-alone units, so you can more easily redistribute the equipment. Rack servers also provide opportunities for upgrading, because they're much more standardized and usually take standard PCI cards. If you need to add the latest I/O card to support new network or storage technologies, then doing so will always be easier, and probably cheaper, on a set of rack servers.
If you need to be able to scale up, then rack servers will always be the obvious choice. Although blades can scale up to respectable levels these days, they can never match the options with rack servers. Many datacenter backbones are still 1GbE, and it isn't uncommon to see vSphere host servers with the need for two quad NIC cards and a pair of FC HBA ports. In addition to the number of ports, if you have very heavy I/O loads and bandwidth is particularly important, you're likely to opt for rack servers, because blades can't offer the same level of bandwidth across the entire chassis. Most blades still come as two sockets, so even four-way servers are usually rack servers, not blades. If you need to scale up beyond four sockets, rack servers are really the only option.
Blade servers have long been admired for their cable consolidation, but with 10GbE PCI cards, you can consolidate all networking and storage demands down to similarly small numbers on rack servers as well. Even some of the advanced management features that blade chassis enjoy are starting to be pushed back up, allowing the management of rack servers in common profile configurations.
Form-Factor Conclusions
Both blades and rack-mounted servers are practical solutions in a vSphere design. Blades excel in their ability to pack compute power into datacenter space, their cable minimization, and their great management tools. But rack servers are infinitely more expandable and scalable; and they don't rely on the chassis, which makes them ultimately more flexible.
Rack servers still dominate, holding more than 85% of the worldwide server market. Blades can be useful in certain situations, particularly in large datacenters or if you're rolling out a brand-new deployment. Blades are inherently well suited to scale-out architectures, whereas rack servers can happily fit either model. Blades compromise some elements. But if you can accept their limitations and still find them a valuable proposition, they can provide an efficient and effective solution.
A reasonable approach may be to use a mixture of small rack-mounted servers in your smaller offices, have some blade chassis making up the majority of your datacenter needs, and use a few monster rack servers to virtualize your largest Tier-1 VMs. After the blade chassis are filled, the cost per VM works out to be very similar. Neither blades nor racks are usually very different in cost per vCPU and gigabyte of memory. As long as each solution can provide sufficient processing power, memory, I/O, and hardware redundancy, either form factor is acceptable. Much of the decision comes down to personal preference drawn from previous experiences and seeing what works and doesn't work in your environment.
Alternative Hardware Approaches
Before trotting down to your local vendor's corner store with a raft of well-designed servers on your shopping list, you may wish to consider a couple of alternatives: cloud computing and converged hardware. Both approaches are in their relative infancy, but momentum is starting to grow behind each one. Although neither is likely to displace the role of traditional server purchases any time soon, it's worth considering where you might benefit and look at how they could replace elements of your existing design.
Cloud Computing
Much is being made of the term cloud computing these days, but confusion often remains about its place in traditional infrastructure models. Cloud computing is really a generic term used to describe computing services provided via the Internet. Rather than buying servers, storage, and networking in-house, you work with an external company that provides a service offering. Such offerings can usually be classified into three common models:
You may be offered two different versions of IaaS. With the first, the hosting company provides you with a dedicated physical server, and you're responsible for the hypervisor, the VMs, the guest OSes, and the applications (similar to the traditional hosted model). With the second type of IaaS, you get only the virtual infrastructure. The hosting company manages the virtualization layer, and you control your VMs and templates on the provided hypervisor or transfer them from your existing infrastructure. This is what most people consider IaaS in the newer cloud-centric viewpoint, and it's the basis that third-party vCloud providers supply.
Clearly IaaS has an obvious correlation to an existing or a newly designed vSphere environment. When you're considering new hardware, it's becoming more feasible to consider external providers to provide that hardware and manage it for you. VMware's own vCloud Director is a product that gives external service providers the tools to more easily provide these IaaS services around the vSphere hypervisor. Chapter 12, “vCloud Design,” discusses vCloud Director and its design impacts. The vCloud Connector is a plug-in for vCenter that allows VMs to be moved into and out of publicly hosted cloud offerings. Amazon is the clear market leader with its Xen-based Elastic Compute Cloud (EC2) model. Some of the other prominent players in this IaaS space currently are the large web-hosting companies such as Rackspace and AT&T.
IaaS can be a boon for small business and startups, because minimal technical knowledge is needed to get going. It can be instantly deployed and accessed worldwide. It's completely self service, so users can create instances themselves. IaaS is usually pay-as-you-go, so you only have to pay for the time it's been used—you don't need to justify it through an entire hardware lifecycle. And IaaS is instantly scalable; if you need more compute power, you just add more.
The biggest concern for any company regarding these cloud computing offerings is security. Most businesses are rightfully wary of giving up all their precious data to sit in someone else's datacenter, relying on their backups and entrusting an external company with the keys.
Despite the considerable hype surrounding cloud computing and the ongoing growth in this sector, there will always be a substantial need for in-house vSphere deployments on privately owned servers. Don't worry: despite the pundits' warnings, our jobs are safe for now. However, this is an increasingly interesting market, which gives you more options when designing how to deploy VMs. You may wish to investigate external hardware IaaS solutions prior to making any large investment, to compare costs and see if IaaS is a viable option.
Converged Hardware
Most server vendors are starting to come to market with their versions of a converged solution that combines servers, virtualization, networking, and storage in various ways. This may be a combination of the vendor's own home-grown equipment, because some vendors have expanded or bought their way into diversified markets; or it may be the result of a coalition between hardware partners. The coalitions are often the outcome of coopetition, where companies in related fields such as servers, storage, and networking work together in some parts of the market where they don't directly compete but continue to vie in other areas.
For example, here are some of the more popular current examples of these converged market products:
Vblocks are predesigned systems that have a fixed hardware makeup. They're sold in tiered units, scaled for particular purposes, and come prebuilt as new equipment, racked and ready to install. They provide an easy, quick way to deploy new environments. You're literally purchasing capacity en masse.
Unlike Vblocks and other more traditional rigid converged infrastructure models, FlexPod is something you need to design and build yourself. Doing so in accordance with the FlexPod reference architecture produces a combined, supportable solution. It's more customizable; and because it isn't sold as a unit, it gives you the opportunity to reuse existing equipment. This makes the FlexPod solution more flexible but also more complex to build.
These are just some of the more popular and well-known examples of continuing converged solution sets from vendors. Buying equipment this way has the advantage of being generally a more simplified total solution that needs less design and that provides end-to-end accountability with components that are certified to work together.
A converged solution reduces the amount of homework you need to do to get something on the ground if you need to produce a more immediate solution with less risk. However, by purchasing your equipment this way, you risk the dreaded vendor lock-in, making it harder to switch out to a competitor when you want to. You have to accept the vendor's opinion regarding the correct balance of equipment. If your needs are less typical, then a preconfigured arrangement may not fit your workload. When buying converged packages, you'll always have an element of compromise: you reduce the opportunity to get the best of breed for your environment in each area. Such solutions are useful for new greenfield deployments or companies that need to scale up with a new solution very quickly.
At the end of the day, converged equipment is just another way for vendors to sell you more stuff. It can simplify the procurement process; and if you're already tied to a vendor, or you have a particularly good relationship with one (that is, they offer you a substantial discount over the others), it can make sense to explore these options as alternatives to server hardware in isolation.
Summary
Server hardware defines the capabilities, the performance, and a large proportion of the CAPEX of a vSphere implementation. It's crucial that you don't rush into the purchase, but first consider all the elements of your design. CPU, memory, and I/O requirements are fundamental to hypervisor servers, but more options exist and need to be thought out. Don't try to make the design fit the servers, but create the logical design around your needs and then figure out exactly what physical hardware is required. Some architects have very fixed opinions about scaling up or out, or blade versus rack servers, but each situation is different and demands its own solution.
If possible, standardize the hardware across your fleet. You may need to provide a tiering of two or three levels to accommodate more or less demanding roles. You may even be able to stick to one model while scaling up or down with more or fewer cores or memory modules. Try to select common I/O cards across the board and think of other ways you can simplify deployment, configuration, or management to reduce OPEX.
When comparing vendors or models, get some sample equipment and test it during any pilot phases. Most vendors will be only too happy to lend such equipment, and often you can learn a lot by spending hands-on time with it. Make sure you double-check the HCL for all server equipment you order.
Despite any preconceptions you may have with regard to hardware, try to think about your overall strategy and whether you want to generally scale up or out. Choose the approach you want for the size of servers before you even think about whether you want rack or blade servers. Your hardware needs can then influence your form-factor decision. Trying to fit your design to a prechosen vendor, form factor, or server capacity will only result in a compromise. Design first, and then choose your servers.