
Chapter 8
Datacenter Design
vCenter functionality gives rise to many design possibilities, particularly the combination of vCenter and the Enterprise and Enterprise Plus licensing features. This chapter explores some of those options, such as the ability to design-in redundancy and share resources efficiently between hosts to offer a fair proportion of hardware while enforcing VM protection. Unused servers can be shut down to reduce power costs, and VMs can automatically balance among hosts in concert with rules to apply control where required.
The chapter looks at the ways in which vSphere objects are flexible enough to create designs optimized for your particular environment. You can control security permissions, collectively manage objects, and monitor and schedule tasks in your datacenters easily and effectively.
This chapter will cover the following topics:
- How objects in vCenter interact and create a hierarchy
- Why clusters are central to your vCenter design
- Resource pool settings
- Using distributed resource scheduling to load-balance, save power, and control VM placement
- How high availability recovers VMs quickly when host failures occur
- Using fault tolerance to provide maximum VM availability
vSphere Inventory Structure
The vSphere Web Client offers the same Home dashboard that is available in the Windows-based vSphere Client. This familiar vCenter hub is a collection of icons organized by function. The first functional area is Inventories, as shown in Figure 8.1.
Figure 8.1 vSphere Home dashboard
The Windows Client's inventory has four different links, along with a search option. The Web Client replaces the search option with a link to the top of the vCenter hierarchy view. In the Web Client, there is always a search field in the upper-right corner of the browser window no matter where you are. The four common inventory links are as follows:
- Hosts and Clusters
- VMs and Templates
- Storage (labeled Datastores in the Windows Client)
- Networking
These views present items from the inventory, each following the same basic structure but still capable of including its own objects. Although the object types can differ, the hierarchical elements are common to all the views.
The relationship between the elements differs depending on how you use the Client. The Windows Client can connect directly to hosts or vCenter Servers, but the Web Client can still only connect to vCenters, highlighting one of the remaining compelling reasons for an administrator to keep a copy of the Windows Client installed on a workstation. As discussed in Chapter 3, “The Management Layer,” you can also connect vCenter Servers via Linked Mode, which aggregates multiple instances.
The inventory structure creates a delineation that serves a number of purposes. It helps you organize all the elements into more manageable chunks, making them easier to find and work with. Monitoring can be arranged around the levels with associated alarms; events trigger different responses, depending on their place in the structure. You can set security permissions on hierarchical objects, meaning you can split up permissions as required for different areas and also nest and group permissions as needed. Perhaps most important, the inventory structure permits certain functionality in groups of objects, so they can work together. This chapter will discuss some of that functionality in much more depth.
The vSphere Web Client in 5.0 had fairly rudimentary options with a small tab for each of the four inventory views that could quickly help navigate from one section to another. The Web Client in 5.1 enhanced the traditional hierarchical view with Inventory Lists, as shown in Figure 8.2. The four views are still available under the Inventory Trees section, but the new Lists section provides jump-points to quickly get to a listing of any of the particular inventory objects.
Figure 8.2 vCenter Home Inventory Trees and Lists
Figure 8.3 shows the relationship of each of the Inventory Lists jump-points to the overall vCenter hierarchy. These convenient links make managing the environment quicker because objects can be found more directly. To design the most effective structure for vCenter, it's still fundamental to understand the basic relationships between and within the available objects. Figure 8.3 will help you understand the options available in your design.
Figure 8.3 Hierarchy of vCenter Inventory Lists objects
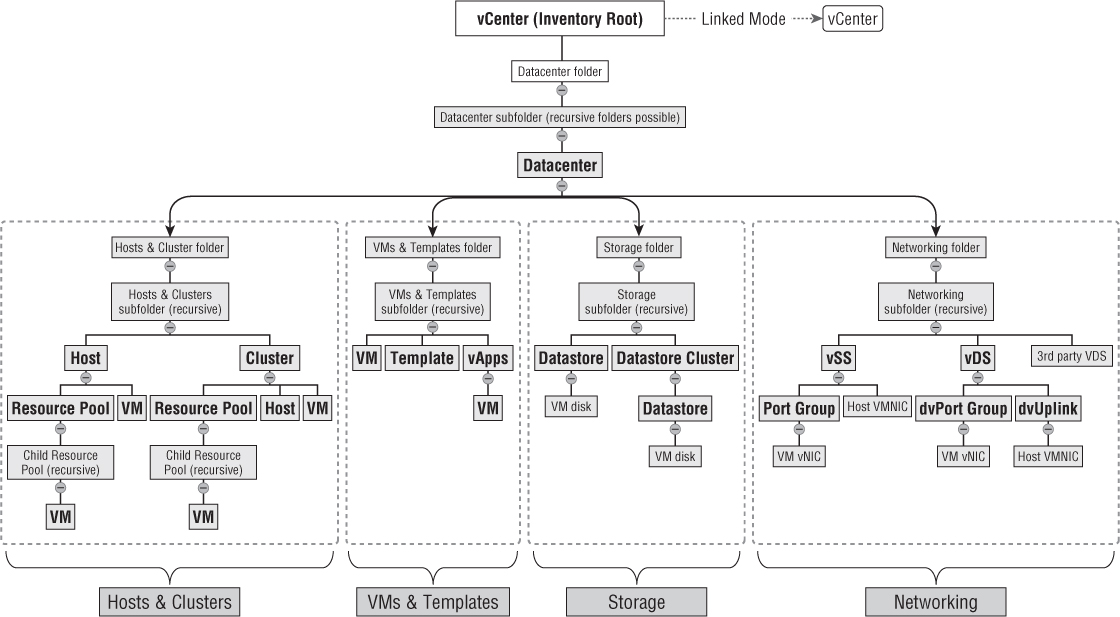
Each of the following sections describes the main vCenter structural components that are involved in the design of vCenter objects.
Inventory Root
The inventory root object is a special type of folder. It's the starting point of all objects in the Client and the top level for all permissions and alarms. Every object and function cascades from this one element, and their interrelationships can always be traced back to the root.
When the Windows Client is connected directly to a host, the inventory root is the host. When the Client is pointing to a vCenter Server, the root object is effectively the vCenter Server. If the vCenter Server is part of a Linked Mode group, you'll see several root inventory objects, one for each vCenter. The vCenter root object can contain only folders and datacenter objects.
Folders
Folders are a purely organizational element, used to structure and group other elements. They let you manage objects collectively, such as applying permissions across a group of datacenters. Folders are a vCenter feature, so they're available only when the client is connected to a vCenter Server instance. Folders can also contain child folders, to allow for more complex organization.
Folders can only contain objects of the same type; you can use them at various levels and in different views to consolidate like items. Folders can contain subfolders, datacenters, clusters, hosts, VMs, templates, datastores, or networks. Each inventory view can have its own sets of folders, so the Hosts and Clusters view can have a folder structure that's different than that of the VMs and Templates view. But folders off the root object are common to all views.
They're a very flexible way to organize vCenter items without having to adhere to the normal rules that limit other objects.
Datacenters
Datacenters are the basic building blocks of a vCenter structural design. They make up all the objects needed for virtualization and are visible in all four Inventory views. Folders are useful for organizing elements, but datacenters are always required because they directly house the hosts, clusters, and VMs.
Datacenters are a vCenter-only construct; they aren't available to stand-alone hosts and aren't visible when the Windows Client is directly connected to hosts. They're the boundary to vMotions, which means your datacenter design should consider the network and storage topology, because this is often what separates one datastore from another.
Remember that despite the moniker, a datacenter doesn't necessarily have to align with a physical datacenter or server-room location. However, network and storage connections do tend to be determined by geographical location, so it's common to see this parallel used.
Clusters
A cluster is a vCenter-only element that collects hosts together from a single datacenter to aggregate compute resources. A datacenter can contain multiple clusters. A cluster groups hosts to provide additional functionality, allowing the hosts and VMs to work together. Clusters can have hosts, resource pools, VMs, and vApps as child objects.
Cluster functionality is further described in later sections of this chapter.
Resource Pools
Resource pools can exist on vCenter instances in clusters or under hosts. They let you divide and apportion the available CPU and memory resources from a cluster or host. You can further subdivide resource pools by using subordinate resource pools. VMs draw their CPU and memory entitlements from the resource pool in which they reside.
To use resource pools on a vCenter cluster, the cluster must have distributed resource scheduling (DRS) enabled. You shouldn't use resource pools as a substitute for folders to organize VMs, but instead use folders in the VMs and Templates view.
Resource pools are examined in more detail later in this chapter.
Hosts
A host represents a physical server running the vSphere ESXi hypervisor, or potentially a pre-5.0 ESX host. Both types can coexist in a cluster, although the host's CPU determines compatibility with other hosts in the same cluster.
The host is the top-level root object when the vSphere Windows Client is logged in to a host directly. Hosts can have resource pools and VMs under them in the structure.
Virtual Machines
VMs can be seen in all four Inventory views, but VM management tends to revolve around the Hosts and Clusters view and the VMs and Templates view. The former concentrates on a VM's physical hardware location: the host, cluster, and resource pool in which it resides. The latter shows the logical groupings you create in the datacenter to organize the VMs.
Templates
A template is a special type of VM that's only displayed in the VMs and Templates view. Because templates are a vCenter-only feature, they aren't visible when the Windows Client is connected directly to a host. Templates were discussed in Chapter 7, “Virtual Machines.”
Storage
The Storage view shows all available storage for each datacenter. It collates all local host storage and shared SAN and NAS datastores, allowing common management for all types. You can organize this vCenter-only view using datastore folders to help pool all the sources into logical groupings.
vSphere 5.0 introduced datastore clusters, which were examined in depth in Chapter 6. In a similar fashion to host clusters, datastore clusters aggregate resources for VMs. Folders are still useful, providing organizational structure without the resource implications associated with datastore clusters.
Networks
In the Networking view, all the port groups and dvport groups are collected under each datacenter. As long as different hosts' port groups are named identically, this view treats them together, in the same way that vMotion understands them to be the same. This lets you manage them collectively so you can apply permissions and alarms. You can use folders in the Networking view to group and split port groups, although this view is available only through vCenter connections.
Why and How to Structure
From a design perspective, it's important to reiterate the advantages of using hierarchical structuring, especially because the vSphere 5.1 Web Client provides such convenient access to individual areas that it can seem less important:
- Enables certain functionality via the grouping of similar elements
- Aids management
- Allows granular permissions
- Lets you monitor events and tasks at different levels
- Lets you set alarms and responses based on the structure
- Lets you align scheduled tasks to the same groupings
You can organize your vCenter pieces in several ways. The most successful hierarchical designs usually closely follow the business. This makes it easy for everyone to understand the structure, to apply the appropriate importance and focus to key elements, and to provide suitable resources.
Most designs follow one or more of the following approaches:
Usually, businesses use a hybrid solution consisting of several elements from this list. The hierarchy itself is normally scaled on the size of the business's VM deployment. A small company with one or two hosts may have a practically flat structure. However, a large organization can have many tiers. For example, an enterprise may have several linked vCenters to create a hard permissions division, each with a layer of folders to group several datacenters together; more folders under each datacenter to consolidate some hosts and clusters while segregating others; and an entire tree of resource pool levels to tightly control allocation. Figure 8.4 demonstrates some of the structural elements and options you may encounter.
Figure 8.4 vCenter structural example
Clusters
vCenter clusters group hosts together for two main reasons. Clusters allow the hosts to work together, enabling the use of both high availability (HA) and DRS resource management. These two cluster functions are examined more closely in their own sections later in the chapter. But it's worth considering the cluster itself as a vehicle to support hosts and VMs.
Although this isn't a strict requirement of a cluster, the cluster's power is realized when the hosts have access to the same shared storage and networking. This allows HA and DRS to work across the cluster, and prevents VM incompatibilities that would inhibit HA or DRS from functioning effectively.
It's often advisable to zone your shared storage to the clusters, because doing so simplifies I/O and capacity resourcing as well as storage management. vMotion is possible across clusters in the same datacenter; so, to provide more flexibility, you can zone at the datastore level.
To take full advantage of DRS, you should collocate servers with the same CPU manufacturer into the same cluster. As we'll explain in the next section, Enhanced vMotion Compatibility (EVC) can assist with compatibility between different versions from the same chip manufacturer. Note that if you have a mixture of AMD and Intel, and you'll rely on any feature that uses vMotion, then you should aim to split these two manufacturers' chips into separate clusters. However, mixing AMD and Intel hosts in a single cluster is technically possible. If you have only a small, limited number of hosts, you may choose to house all of them in the same cluster to take advantage of HA coverage; just don't expect DRS to work.
You should also keep the host versions consistent in a cluster. It's always advisable to keep all host patching at the same level. Mixing ESXi hosts at different versions, and even alongside older ESX hosts, in a cluster is a viable configuration and fully supported by VMware.
There are several reasons why you may want to create a cluster to house hosts, even if you don't enable DRS or HA:
When you're considering clusters without DRS/HA enabled, note that although a stand-alone host can have resource pools, hosts in a cluster with DRS turned off can't. Adding a host to a cluster without DRS strips all the host's resource pool settings. A host without resource pools can still set shares, limits, and reservations, as discussed in Chapter 7, but they will be apportioned in relation to the host and can't be subdivided or spread across the cluster.
You can independently disable HA and DRS at any time at the cluster level. But doing so loses all the associated settings, including any advanced settings that were configured. If you need to temporarily stop a subcomponent of DRS or HA, you should disable the specific undesired function. This way, you can retain the configuration so that when the feature is re-enabled, the same settings are applied again. This is particularly important for DRS, because disabling DRS completely destroys all the resource pools.
There are two other separate cluster settings, which aren't directly related to DRS or HA functionality: EVC and default swapfile locations.
EVC
Enhanced vMotion Compatibility (EVC) is a feature that improves the ability to vMotion VMs between hosts that don't have CPUs from the same family. When you enable EVC, the cluster has to be set for either Intel or AMD chips and must have a minimum baseline level.
Chapter 7 discussed a compatibility feature that hides certain host CPU flags from the VM. Many of the CPU extensions presented by modern CPUs aren't used by VMs and can be safely hidden. EVC is a development of this, and it works by applying CPU masks across all the hosts.
Each CPU type, whether Intel or AMD, has a list of compatibility levels. You should be sure you select the lowest level required to support the oldest CPUs that will be members of the cluster. Add the oldest host first: doing so ensures that the least feature-full host will be checked against the baseline before you start creating or transferring VMs to the cluster.
The general advice is to enable EVC on all clusters. Doing so makes adding hosts easier, saves you from splitting the cluster in future, and shouldn't affect performance. EVC guarantees that each host has the same vMotion compatibility, which reduces the number of calculations the vCenter Server has to undertake. For the most part, EVC can be enabled with the VMs powered on (although to remove the EVC masking from a VM may take a power off/power on), so having the foresight to enable it from the outset isn't as important to prevent mass migrations. The only VMs that need to be shut down are those that use CPU feature sets that are greater than the EVC mode you wish to enable. If you buy all the server hardware for a cluster in one go and completely replace it at the next hardware refresh, then you probably don't need to worry about EVC being enabled. If the company is more likely to add capacity slowly as required, then turn on EVC from the outset.
Swapfile Policy
By default, a VM's swapfiles are stored along with its other files in a location that's determined by the working directory setting. The swapfile in this case isn't the guest OS's pagefile or swap partition but the file used by the hypervisor to supplement physical RAM. You can find more details about host memory in Chapter 4, “Server Hardware.”
The swapfile location is configurable on a VM-by-VM basis, but this cluster-level setting sets a default for all the VMs. You can choose to move all of these swapfiles to a location set on each host. This can be useful for a couple of reasons:
Moving swap onto another less-expensive or nonreplicated SAN LUN is practical, but moving it onto the local host disk does have implications. First, vMotions will take considerably longer, because the swapfile will need to be copied across the network every time. In addition, using local-host storage can have unexpected results for other cluster functions. You need to be sure there is sufficient space on all the hosts to hold any possible configuration needs. HA or DRS won't operate effectively if it can't rely on swap space being available on the hosts.
Cluster Sizing
There are several hard limits related to cluster sizing. First, you can have a maximum of 32 hosts per cluster, and 4,000 VMs (3,000 in vSphere 5.0). DRS and HA functions can impact the size of your clusters in their own way. Suffice it to say, just because you can have 32 hosts in a cluster doesn't mean you should plan it that way.
vSphere 5.0 has a limit of 512 VMs per host, regardless of the number of hosts in the cluster. With the limit of 3,000 VMs per cluster, if you fully populate the cluster with 32 hosts, those hosts can have only an average of up to 93 VMs (3,000/32). In reality, not many implementations have more than 93 VMs per host, except perhaps in desktop VDI solutions. But today's largest commodity servers, and an ESXi limit of 2 TB of RAM, mean that it isn't unfeasible to create massive clusters with monster servers that could be restricted by these limits.
Creating very dense clusters has its ups and downs. The benefit of larger HA clusters is that you need less host hardware to provide redundancy, because splitting the cluster in two can double the need for failover hosts. Also, DRS and distributed power management (DPM) have more hosts to load-balance and can spread resources more efficiently. However, creating very large clusters has certain impacts; some companies like to segregate their clusters into smaller silos to create hard resource limitations.
The actual cluster size depends on a number of other factors. It's likely to be designed in conjunction with HA, DRS, and possibly DPM. But the starting point usually depends on factors such as host resilience and VM criticality. For most businesses, n+1 is sufficient; but this is always a numbers game. The concept is similar to Chapters 6's discussion of the availability of storage, which explains how additional redundant pieces reduce the percentage of overall downtime—but with diminishing returns. Also, if you're contemplating an n+1 design, you may want to hold off on patching and hardware maintenance until quieter times; any time you purposefully remove a host from the cluster, you lose that failover capability. If individual VMs are considered very important, you may wish to consider the fault tolerance (FT) functionality discussed later in the chapter; but if you want to protect large proportions of your VMs more carefully, you might consider n+2. Additional hosts for pure redundancy are costly, and most businesses are likely to consider this only for their most crucial clusters.
Generally, you want to opt for larger clusters because they're more efficient, but some guest OSes and applications are licensed by the number of hardware sockets they have access to. As described later in the chapter, you may be able to restrict this with a must VM-host rule. Unfortunately, some vendors won't accept this as sufficient segregation and determine it only as the total number of sockets in the cluster. Housing this in a large cluster can cause your software fees to skyrocket.
Previously, the impact of LUN reservations caused concerns as clusters grew, but with Virtual Machine File System (VMFS) 5's optimistic locking or, preferably, vStorage APIs for Array Integration (VAAI) SAN support, this is much less likely to create performance issues. There is still a limit of 256 LUNs per host. It's regarded as good practice where possible to have all hosts in a cluster connected to all the same datacenters. This may limit the size of the cluster. The larger 64 TB VMFS-5 volumes can relieve this constraint in most instances.
Patching large clusters can take longer, but version 5 of the vCenter Update Manager (VUM) can automatically put multiple hosts into maintenance mode if there are enough spare resources. It can be a problem if you're trying to patch the entire 32-host cluster in one evening's change window—because we all keep the same level of patching on all hosts in the cluster, don't we?
Despite the argument that larger clusters are more efficient, it's interesting to think how much more efficient a 32-host cluster is over a 16-host cluster for DRS. For resource management, you probably want to reserve a certain percentage on each host for spikes and capacity growth. Reducing the ratio of redundant hosts is likely to have little impact above a point if you still want to reserve 10% or 20% spare compute power. When clusters become larger, the notion of n+1 becomes more tenuous as an appropriate measure. The reality is that if you're planning between 16 and 32 hosts in a cluster, you're probably counting on at least n+2.
If you do decide to split the clusters into more manageable chunks, consider grouping like-sized VMs. Perhaps you want a cluster just for your very large VMs so that the HA slot sizes are more appropriate, and to match your very large physical hosts with VMs with more vCPUs and/or large memory requirements. Remember the impacts of different host non-uniform memory architecture (NUMA) configurations from Chapter 4. When a VM is powered on, the guest OS sets its vNUMA based on the residing host. If the cluster has different hosts, then the VM vMotions around it will have a vNUMA setup that may not appropriately match the destination hosts.
Despite EVC, you may want to split unequal hosts because DRS doesn't take into account which hosts have better CPUs or better memory management. Some server generations are quite different from each other, such as the jump to Nehalem from Penryn. In contrast, keeping a Nehalem host and a Westmere host in the same cluster won't create such obvious mismatches.
Often there are internal political resourcing reasons why clusters have to be split up, so consider the failure domains, the levels of redundancy, and projected growth versus hardware lifecycle. From a manageability standpoint, there is definitely a sweet spot. Too many small clusters undoubtedly become more of a burden. But very large clusters have their own management issues, because keeping that many hosts identically configured and having the same networks and storage for all the VMs can become increasingly difficult. Many other aspects are likely to impose cluster-size constraints, but the guiding principles of cluster sizing remain relevant:
Resource Pools
Resource pools group VMs to allow dynamic allocation of CPU and memory resources. They can contain VMs but also child resource pools, enabling very fine-grained resource allocation. Resource pools can be found either under stand-alone hosts or as members of a DRS-enabled cluster. Because resource pools in a cluster require DRS, the cluster's hosts require a minimum of an Enterprise license.
We looked at resource allocation in some depth in Chapter 7, examining the use of shares, reservations, and limits and how they can impact other VMs. But setting these values on every VM is time-consuming, is error-prone, and doesn't scale effectively. Setting these values on a resource pool is much more efficient, and the values dynamically readjust as VMs and host resources are added and removed. VM reservations (and limits), on the other hand, are static and always impact the other VMs in cluster. However, note that HA doesn't consider resource pool reservations, only VM-level reservations for its admission control calculations. VM resource settings can also set shares and input/output operations per second (IOPS) as limits for storage; and network I/O controls can set shares and bandwidth limits for vNetwork distributed switches (vDSs). Resource pools concentrate only on CPU and memory resources.
Resource pools can have sibling pools at the same level and child pools beneath them. Each stand-alone host or DRS cluster is effectively a root resource pool, and all resource pools subsequently derive from that point. Child pools own some of their parents' resources and in turn can relinquish resources to their children.
Each DRS cluster supports resource pools up to eight hierarchal levels deep. To prevent overcomplicating the resource-entitlement calculations and ensure that the hosts' resources are allocated to the VMs in the appropriate manner, the flattest structure should be created. Often, one level of sibling pools is all that is required. Rarely are multilevel child pools desirable. Creating too many sublevels may reduce effectiveness as the environment changes.
Resource pools are very useful tools, but you shouldn't think of them as a substitute for VM folders. In the Hosts and Clusters view, folders are available at the root of the vCenter instance above datacenters, and below datacenters but above hosts and cluster items. No folder items are allowed inside the clusters themselves. For this reason, resource pools are often misappropriated as a way of grouping VMs into logical silos. However, even with the default values and no adjustment of the unlimited reservations and limits, resource pools still apply normal pool-level shares. Because they're filled with VMs, all the pools continue to have the same value despite some having more VMs than others. During periods of contention, some VMs receive more attention than others. If you create pools purely to group and organize your VMs, then this unexpected resource allocation will be undesired and unexpected. A better method of grouping VMs is to use the VMs and Templates view, which provides for grouping VMs into folders.
As a general rule, don't place individual VMs at the same level as resource pools. It's almost never appropriate. Resource allocation is always relative to items as the same level, whether they're VMs or resource pools. VMs placed alongside a resource pool will get shares relative to the collective VMs in that resource pool and compete during times of contention. All the VMs one level down could be starved by the VM above them.
Resource Pool Settings
For each resource pool, you set CPU and memory shares, reservations, expandable reservations, and limits, as shown in Figure 8.5.
Figure 8.5 Resource pool settings
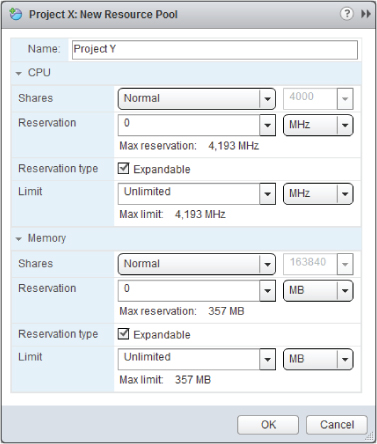
Most of these terms were discussed in Chapter 7, particularly the differences between how CPU and memory are handled. However, it's important to understand the concepts of allocation with regard to resource pools.
Shares
The CPU or memory shares are relative to any sibling resource pools or VMs. Shares are used only during periods of contention and are always bound first by any reservations or limits. They can only apportion the unreserved memory, and then only up to the limit if one has been set. But if sufficient resources are available to all VMs in the resource pool (there is no contention), then shares are never invoked.
There are no guarantees with shares, and due to their dynamic nature, they can be unpredictable. A VM's resources are relative to the pool it resides in, so as the pool expands to accommodate new VMs, the pool's allocation is spread increasingly thin. Even if you give a particular resource pool a relatively high level of shares, if it has far more VMs than a sibling pool, you may find that its VMs actually receive fewer resources than those in a less densely populated pool.
Remember, VM shares are relative to the other VMs in the same pool, but resource pool shares are relative to sibling resource pools and sibling VMs. For this reason, it's recommended that you not make resource pools and VMs siblings at the same level in the hierarchy. VMs are unlikely to have share values comparable to the resource pools, so this would result in unbalanced clusters.
Resource pool shares are often the fairest way to allocated resources, but you must check them regularly to be sure you're getting the results you want. They're fickle if neglected for long and can eventually work against you. For example, it isn't uncommon to see a split of high, normal, and low resource pools. It's only human nature that everyone wants their VM in the high resource pool. You quickly end up with an overpopulated high resource pool that performs worse than the other two when resources become oversubscribed.
Reservations
A CPU or memory reservation guarantees resources to its resource pool occupants. Any reservation set is taken from its parent's unreserved amount, even if VMs don't use it. Reservations that are set too high can prevent other resource pools and sibling VMs from being able to operate properly or even from powering on.
Setting a resource pool reservation instantly prevents other siblings or the parent from reserving this amount themselves. Reservations should set the minimum amounts that are acceptable, because leftover resources are still apportioned over and above the reservation. If the resource pool reservations commit all of the cluster's memory, this can prevent VMs from vMotioning between hosts because during the vMotion's pre-copy the equivalent memory resources must exist on the destination host as well as the source host.
Resource pool reservations are a significantly better way to reserve memory than setting it on a per-VM basis. HA ignores the resource pool reservation, so these reservations don't have such a negative affect on HA slot sizes. They allow a guarantee for the VM's memory without the greed that is associated with VM-level memory reservations.
Remember, reservations guarantee a minimum but don't limit the VM to that amount. They can receive more if it's available.
Expandable Reservations
The Expandable Reservation check box in the New Resource Pool dialog indicates whether a resource pool can steal resources from its parent resource pool to satisfy reservations defined at the VM's level. This is used during resource pool admission control, which is explained in the following section.
If powered-on VMs in a resource pool have reservations set that use the resource pool's entire reservation quota, then no more VMs are allowed to power on—that is, unless the pool has an expandable reservation, which allows it to ask upward for more resources. Using expandable reservations offers more flexibility but as a consequence offers less protection.
Limits
Just as with VM limits, resource pool limits artificially restrict the entire pool to certain amounts of CPU or memory. You can use this option to prevent a less important resource pool of VMs from impacting a more important pool. You should use this setting very sparingly; limits are hard and will take effect even if spare resources are available.
Admission Control
Admission control ensures that reservations are valid and can be met. It works at different points in your virtual infrastructure; hosts, storage DRS, HA, and resource pools are all mechanisms that have their own type of admission control. Resource pool admission control depends on whether the pool's reservations are set as expandable.
Resource pool admission control is checked whenever one of the following takes place:
- A VM in the resource pool is powered on
- A child resource pool is created
- The resource pool is reconfigured
If the reservations aren't expandable (the Expandable Reservation check box isn't selected), then admission control only checks to see whether the resource pool can guarantee the requirements. If it can't, then the VM doesn't power on, the child isn't created, or the pool isn't reconfigured.
If the reservations are expandable (the Expandable Reservation check box is selected, which is the default), then admission control can also consider the resource pool's parent. In turn, if that parent has its reservations set as expandable, then admission control can continue to look upward until the root is reached or it hits a pool without an expandable reservation.
Expandable reservations allow more VMs to be powered on but can lead to overcommitment. A child pool may reserve resources from a parent pool while some of the parent's VMs are powered off. Therefore, subordinates with expandable reservations must be trusted. This is particularly relevant if you use resource pools for permissions.
Distributed Resource Scheduling
DRS in vSphere clusters uses VM placement and the power of vMotion to optimize cluster resources. Its primary function is to load-balance VMs across hosts to provide the best resource usage possible. DRS can use special rules to control VM placement, so that certain VMs can be kept together or apart depending on your requirements. A subfunction of DRS known as distributed power management (DPM) can use vMotion to evacuate hosts and selectively power-down host servers while they aren't needed and power them back on automatically when they're required again.
Load Balancing
DRS monitors the CPU and memory load on the cluster's hosts and VMs, and tries to balance the requirements over the available resources. It can use vMotion to seamlessly move VMs when appropriate, effectively aggregating CPU and memory across the cluster.
DRS does this with two approaches. First, when VMs are powered on, it looks to see which host would be most suitable to run on. Second, while VMs are running, if DRS calculates that the resources have become unbalanced, it decides how to live-migrate VMs to minimize contention and improve performance.
When VMs in the cluster are powered on, DRS performs its own admission control to ensure that sufficient resources are present to support the VM. This is essentially recognition that the DRS cluster is itself a root resource pool and so follows the same resource checks.
DRS Requirements
For DRS to load-balance effectively, you should adhere to a number of design requirements:
vMotion Improvements in vSphere 5
vSphere 5 has had a number of improvements to vMotion that benefit DRS. Up to four 10 Gbps NICs or sixteen 1 Gbps NICs can be used (or a mixture of both) in combination to accelerate vMotions. This not only speeds up individual vMotions but is particularly helpful in fully automatic DRS clusters when evacuating a host, for example putting a host in maintenance mode and allowing DRS to clear all the VMs off to other hosts in the cluster. To use multiple NICs, all the vMotion interfaces (which are vmknics) on a host should share the same vSwitch, be set active on only one uplink (vmnics) with the other uplinks set to standby, and use the same vMotion subnet.
The improvements in vSphere 5 vMotion techniques also include a more efficient process that should cause fewer issues for guest OSes and applications that previously had problems with the prolonged stun vMotion invoked. The vMotion process now completes more quickly and with fewer interruptions. The performance of vMotions is up to 30% faster to complete, and an improved migration technique helps move those VMs with lots of changing memory whose vMotion would have otherwise failed. These improvements enable a new feature of the Enterprise and Enterprise Plus licensed hosts to do vMotions over stretched links with up to 10 ms latency. Prior to vSphere 5, and with a non-Enterprise licensed host, this is limited to 5 ms.
DRS Automation Levels
A DRS cluster has an automation level that controls how autonomous the resource allocation is. Figure 8.6 shows the settings page for DRS levels.
Figure 8.6 DRS Automation levels

As you can see in Figure 8.6, the Fully Automated setting has a slider control that allows finer control over the cluster's propensity to vMotion VMs. The most conservative setting automatically moves VMs only when a top-priority migration is required—for example, if a host has been put into maintenance mode or standby mode. The most aggressive setting takes even the least advantageous recommendations, if it thinks they can benefit the clusters' resource-allocation spread.
VM Options (DRS)
DRS has the ability to override the cluster settings for individual VMs. Figure 8.7 displays all the possible options for a VM.
Figure 8.7 VM Overrides options
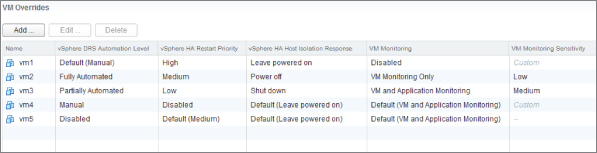
Each VM by default follows the cluster setting; but by being able to set a different level, you avoid the cluster being too prescriptive. Otherwise, the needs of a single VM can force you to lower the cluster setting. With the per-VM option, if a particular VM needs to avoid being vMotioned, this doesn't have to affect the entire cluster. A common use of this override ability occurs if your vCenter Server is itself a VM: you can pin that VM to a particular host. This makes it easy to find your vCenter VM in an emergency when it has been powered off.
If your cluster ordinarily is set as fully automated, and you want to shield a VM from this level then you have 3 options: Partially Automated, Manual or Disabled. Setting the VM to disabled or manual means you need to move the VM yourself when you place the host into maintenance mode, whereas partially automated would move it for you. Partially automated and manual VMs, unlike disabled VMs, are included in DRS recommendations and it's expected that those recommendations are followed; otherwise the cluster can become unbalanced. Disabled VMs are included in the DRS calculations, but vCenter understands that they can't move, so although no action is required to keep balancing the cluster there are still less optimal choices for the cluster. For these reasons it is advisable to keep as many VMs at the cluster's default setting as possible.
Balancing Decisions
The DRS threshold slider, shown in Figure 8.6, measures how much of an imbalance should be tolerated in the cluster. There are several reasons why the cluster should change after the initial placement of the VMs, such as changes to VM loads, affinity rules, reservations, or host availability.
DRS uses a priority rating to show the varying levels of migration recommendations. The most-recommended migrations are given a priority of 1 or 2.
The DRS summary section in the Windows Client, shown in Figure 8.8, displays the threshold settings.
Figure 8.8 DRS summary in the Windows Client
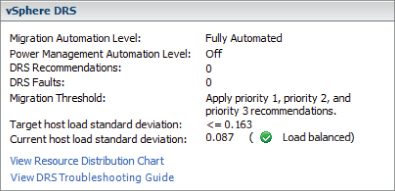
The threshold explains which priority level's recommendations are applied automatically. This threshold value, along with the amount of host resources available, determines the Target Host Load Standard Deviation. The Target is effectively a measure of how much the cluster is willing to accept a resource disparity.
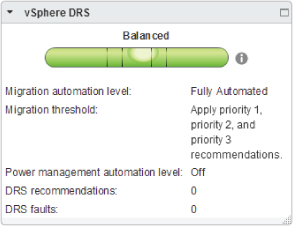
Every 5 minutes, the DRS cluster calculates the corresponding Current Host Load Standard Deviation. The Current level is compared to the Target value; if it exceeds the Target, then a recommendation needs to be made. If the cluster is set to Fully Automated, then Current should always be below Target. But if the cluster is only Partially Automated, then a Current value greater than Target shows that there are recommendations that haven't been followed. In vCenter's 5.1 Web Client, as shown in Figure 8.9, the imbalance is illustrated with a spirit level. The threshold settings shown in figure 8.8 are also available via the information link to the right of the spirit level.
Figure 8.9 DRS summary in the Web Client
If the cluster has decided that a migration needs to occur, it goes through a selection process to decide which is the next best candidate. It does this by evaluating each VM and seeing which one would make the largest improvement to the cluster. It also considers the vMotion history, and it drops VMs that have had problems migrating in the past. This is why DRS tends to move VMs that have the most vCPUs and biggest memory allocation: they're likely to have the greatest effect on the cluster's performance and reduce the number of vMotions needed to balance the hosts. DRS's main function is to distribute the CPU and memory load across the cluster, not necessarily to distribute the VMs.
DRS Efficiency
Several factors determine how well DRS is able to perform. The hosts should be as similar as possible, to maintain vMotion compatibility and avoid different CPU and memory configurations. This allows the cluster to predict performance outcomes more accurately and consequently make better migration choices.
Try to minimize excessively loading VMs, because those with significantly more vCPUs or memory will ultimately reduce DRS opportunities. Where possible, shut down or suspend VMs that aren't being used, because they consume CPU and memory resources even when not being taxed. Disconnect any unused hardware, such as CD-ROMs, floppy drives, and serial and parallel ports, because they not only use CPU cycles but also reduce the vMotion possibilities. As stated earlier, reservations shouldn't be set too high and limits shouldn't be set too low, because this also affects the DRS calculations.
All DRS hosts should be able to access the same shared storage. If some hosts can only see portions of the storage, this separates the cluster and severely constrains the options for DRS migrations.
Temporarily disabling DRS causes all the resource pool and VM option settings to be lost. To preserve these for the future, you should set the cluster setting to Manual. That way, the resource pools will remain intact, and you just need to set the level back to what it was to restore the previous settings.
DRS Fully Automated mode ensures that the cluster is as balanced as it can be, without requiring intervention. When your hosts are as uniform as possible and your VMs maintain steady resource needs, you can set the cluster threshold more aggressively.
DRS doesn't solve underlying problems when there aren't enough resources to go around. It will, however, ensure that you're using the available resources in the best way possible.
Affinity Rules
Affinity rules are an additional feature of DRS that let you specify how to place VMs. Two types of affinity rules exist. The original affinity rules, which give you control over keeping VMs together or apart, are now known as VM-VM affinity rules. These are augmented with the VM-Host affinity rules to direct the placement of VMs on the correct hosts.
Both types of rules have the basic concept of affinity or anti-affinity. As you'd expect, affinity rules try to keep objects together, whereas anti-affinity rules aim to keep them apart.
VM-VM Affinity Rules
The VM-VM affinity rules have been around since pre-vSphere days and keep VMs together either on the same host (affinity) or on separate hosts (anti-affinity).
Figure 8.10 shows the DRS affinity rules screen. As you can see, the first rule is keeping VMs together, and the second is keeping them apart.
Figure 8.10 DRS affinity rules
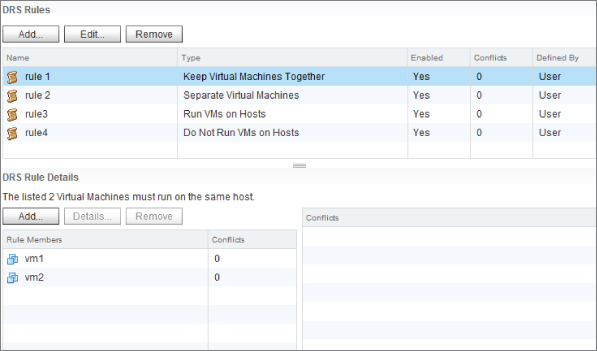
Rules can be created and not enabled. However, DRS disregards rules that aren't enabled. The vSphere Client won't let you enable VM-VM rules that conflict with each other. For example, if a rule exists that keeps two VMs together, then although you can create a second rule to keep the same two VMs apart, you can't enable the second rule. The older rule always takes precedence, and the newer rule will be disabled if the older rule is ever enabled. If you have competing affinity and anti-affinity rules, DRS first tries to apply the anti-affinity rule, then the affinity rule.
Keep VMs Together
You may wish to keep VMs together on the same host to minimize the amount of inter-host network traffic. This is useful if two VMs work closely together—for example, an application that has a web server VM and a database VM. These two VMs may benefit from the reduced latency of the network traffic flowing between them, instead of between two hosts via a physical switch.
Also, if you have an application that needs multiple VMs to work, each of them being a potential single point of failure, then you may wish to keep them together. Allowing DRS to separate them only increases the chance that a host failure will affect the application.
Arguably, you can try to keep together VMs that are extremely similar, because you know this will benefit host transparent page sharing the most and reduce memory consumption. But DRS uses very sophisticated algorithms, so such rules are more likely to constrain potential optimizations and may make things worse.
Separate VMs
Rules to separate VMs tend to be used to guarantee that the VMs are always kept on different physical hardware. Applications that can provide redundancy between VMs can be protected against a single host failure. An example is a group of Network Load Balancing (NLB) web servers.
Another reason to keep VMs apart is if you know some VMs are very resource intensive, and for performance reasons you want them on separate hardware. This is particularly relevant if the VMs are inconsistently heavy and you find DRS doesn't do a good job of spreading their load.
With VM-VM anti-affinity rules, although you can state that you want VMs kept on separate hosts, you can't dictate which hosts. For that, you need a VM-Host rule.
VM-Host Affinity Rules
VM-Host affinity rules allow you to keep VMs on or off a group of hosts. To specify the groups of VMs and the groups of hosts for each rule, you use the DRS Groups pane (see Figure 8.11). Here you can create logical groupings of VMs and hosts that you want to use in your VM-Host rules.
Figure 8.11 DRS Groups
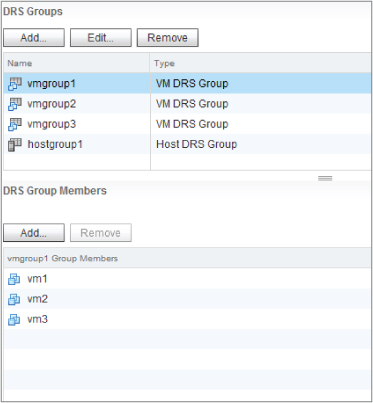
In Figure 8.10, the DRS Rules page, you can see that rules 3 and 4 use the VM groups and the hosts groups. The third rule specifies that a group of VMs should run on a group of hosts, whereas the last rule keeps the group of VMs away from the group of hosts.
In addition to the affinity and anti-affinity rules, VM-Host rules have the concept of should rules and must rules.
Should Rule
A should rule is one that DRS treats as a preference. DRS tries to adhere to the rules when it can but may violate them if other constraints are deemed more important. Should rules are always a best effort and allow DRS a certain amount of freedom. Similarly, DPM tries to conform to should rules but can break them if it needs to.
HA ignores should rules and powers on VMs in case of a failure regardless. But if DRS is set to Fully Automated, it then steps in and rebalances the cluster according to the rules.
Must Rule
A must rule is a mandatory one that can't be broken by DRS, DPM, or HA. This level of strictness constrains cluster functionality and should be used only in exceptional circumstances. DRS won't power-on or load-balance VMs in a way that would violate a must rule, DPM won't power-off hosts if doing so would break a must rule, and HA will only recover VMs onto hosts that adhere to the must rule.
Must rules make certain hosts incompatible with VMs to enforce the rules for DRS, DPM, and HA. If DRS as a whole is disabled, these rules continue to be enforced. DRS must be re-enabled if you need to disable a must rule.
Using VM-Host Rules
VM-Host affinity rules are useful in several ways. The classic must rule use case is to keep VMs tied to a group of hosts for licensing requirements. Some independent software vendors' (ISVs) licensing depends on the physical hardware—often the CPU socket count. Prior to VM-Host rules, vSphere users created a separate cluster just for this purpose. Despite the fact that the separate cluster complied with the licensing terms, it often wasted spare resources, cost more in both OPEX and CAPEX terms, reduced redundancy possibilities, and gave the regular cluster fewer DRS/DPM/HA options. Such a situation is likely to use must rules.
Another good use of VM-Host rules is to keep VMs together or apart on a blade chassis or an entire rack. For the same reasons as VM-VM affinity and anti-affinity, you may consider blade systems one piece of hardware, even though as far as vSphere is concerned, they're all separate hosts. You can use VM-Host rules to keep network traffic together on one chassis or ensure that VMs are on blade hosts that are in different chassis to provide greater physical protection. These sorts of use cases are best set as should rules.
Unfortunately, DRS has no inherent way of understanding (or being instructed) which blade servers run in which chassis, or by extension which rack servers or chassis are in which racks. To ensure that VMs are kept on separate chassis, you need to create a host group that has only one member from each chassis. This is more limiting that you'd perhaps like, because all you need is to keep them on any blade in each chassis, but by pinning them on a single blade in each chassis at least you prevent them from accidentally pooling together.
You can also use should VM-Host rules to provide soft partitioning for areas that previously you may have considered separate clusters in the same datacenters. You may have test and development environments that you want segregated from other VMs on their own hosts. You don't want the management overhead of complex resource pools and VM resource settings, but you want to keep all the VMs in the same cluster so you can take advantage of a pool of hosts that DRS and HA can optimize. Here you can use should rules to keep groups of VMs affined to hosts.
You should use mandatory must rules sparingly because they restrict the other cluster operations so much. They can divide the cluster, prevent HA from functioning properly, go against DRS optimizations, and limit DPM selection of hosts to power down. If you're considering a must rule for a purpose other than licensing, consider a should rule with an associated alarm. You can create vCenter alarms to trigger an email whenever a should rule is violated. That way, you're aware of another cluster function breaking a rule without unnecessarily constraining the entire cluster.
Applying several overlapping affinity rules can complicate troubleshooting, because it can be difficult to comprehend the resulting effects. Use affinity rules only when you need to, and avoid creating more than one rule that applies to the same VM or the same host.
Distributed Power Management
DPM is an additional feature of DRS that looks to conserve power by temporarily shutting down hosts during periods of lesser activity. It monitors the total levels of CPU and memory across the cluster and determines whether sufficient resources can be maintained while some hosts are put into standby mode. If so, it uses DRS to migrate VMs off a host to clear it, preparing it for shutdown.
When the cluster deems that additional host resources are needed again, it brings them out of standby in preparation. The cluster either determines this by observing increased CPU or memory levels, or considers historical data to predict busier periods.
By default, if both CPU and memory usage levels on all the hosts in a DPM cluster drop below 45%, then DPM selects a host to power down. It re-evaluates this every 40 minutes. At 5-minute intervals, it checks whether either CPU or memory rises over 81%, and if so, it powers on a host.
To bring the servers back online, it can use one of three different remote power-management protocols. In order, the cluster attempts to use Intelligent Platform Management Interface (IPMI), then HP's Integrated Lights Out (iLO), and finally Wake On LAN (WOL) to send the power-on command.
DPM has a preference for smaller hosts when selecting which server to shut down. It does this because the larger hosts should be more power efficient per VM and probably have better host power-management results. If all the servers are the same size, then it selects the host to power down based on what it considers the least loaded and from which it will be easiest to evacuate the VMs.
DPM Requirements
DPM has a number of requirements in order to function:
- DPM is a subfeature of DRS, which requires an Enterprise or Enterprise Plus license.
- The cluster must have DRS enabled.
- Hosts participating in the DPM set must be running vSphere 3.5 or later.
- Using the IPMI or iLO protocol requires a baseboard management controller (BMC) IP address, a MAC address, and username/password credentials.
- WOL protocol use requires the following:
- Hosts' vMotion NICs must support WOL.
- Hosts' vMotion addresses should share a single subnet.
- The switch ports that the WOL cables connect to must be set to autonegotiate.
You should test each host thoroughly to ensure that it can wake properly when required. This is often forgotten when introducing new additional hosts to an existing DPM-enabled cluster.
DPM Automation Levels
The DPM Power Management page, shown in Figure 8.12, controls the level of automation across all the cluster's hosts:
Figure 8.12 DPM Power Management

It's probably less useful in the longer term, because the most likely times for DPM recommendations are during quiet periods (for example, weekends and overnight) when administrative staff are less likely to be available to act on them. But you can use this mode for longer-term warm spares, which ordinarily can be shut down even during busier times based on these recommendations.
The DPM automation-level setting isn't the same as the DRS automation level. They act independently of each other.
DPM Host Options
When DPM is enabled on a DRS cluster, all the hosts inherit the cluster's settings. However, the Host Options settings allow you to manually override this on a per-host basis. Just as with the cluster itself, you can select Disabled, Manual, or Automatic for each host, or set Host Options to Default to use the cluster's setting.
This is particularly useful when you're introducing new hosts to the cluster and testing a host's ability to wake up when requested. Check a host's Last Time Exited Standby field to see if it was able to resume properly on the last occasion. This individual setting can also be useful if you want to maintain a minimum number of hosts left on despite any DPM recommendations, or if you want to prevent particular hosts from being shut down.
The cluster must be set to either Manual or Automatic for these options to be considered. You can't disable DPM for the entire cluster and enable it only for certain hosts in the Host Options section.
DPM Impacts
DPM takes advantage of spare cluster resources, so the more hosts that are available to it, the better. You should avoid the temptation to exclude too many hosts if they're capable of remotely waking, because the more choices the cluster has, the more potential power savings it can generate. If there are VMs that are set to override the default DRS cluster settings, then you should manually keep them to one host, or as few as possible to allow for the most efficient DPM action. VM templates are not moved off hosts for DPM, so it's a good idea to keep all the templates on one host that is excluded from DPM, unless DPM is only scheduled to run during times when provisioning VMs is unlikely.
The cluster does consider historical patterns to try to predict when there will be an impending resource requirement. However, even when the hosts wake up, performance is always reduced for several minutes. It takes a while for DRS to spread the increasing load across to the newly powered-on hosts, and then some time for the benefits of transparent page sharing (TPS) and memory compression to take effect. If you need the fastest possible time to recover into a fully performant set of hosts, don't set the DRS slider too low.
A scheduled task associated with DPM lets you set a predefined time to disable DPM on a host and therefore wake up the host. This allows you to be sure the resources are ready when you know resource demands will increase, such as when lots of employees start work at the same time. You may know about certain busy periods, such as monthly billing cycles or scheduled work on a weekend, and want the hosts ready beforehand. Just remember, you'll need another scheduled task to re-enable DPM afterward, if you aren't planning to do it manually.
If any host is passing through USB devices, you should consider disabling DPM for that host. Although vSphere can vMotion VMs with USB devices attached, if the host that has the physical connection is powered down, the VMs will obviously lose their connection. DPM can be used with a mixed cluster and supports hosts from version 3.5 onward. However, DPM can operate effectively only if the VMs are able to vMotion between all the hosts; think about VM hardware versions, EVC, attached hardware, and any other factors that will affect the VMs' ability to migrate seamlessly.
When DPM is looking to migrate VMs off hosts, it not only appraises the CPU and memory demands, but also adds the reservation levels set on the VMs and the cluster's resource pools. It does this to ensure that sufficient compute resource will remain available; it respects the reservation guarantees that are set. This demonstrates how you can use reservations to be sure a suitable number of hosts are left powered on, but also reinforces the advice that reservations have far-reaching impacts, shouldn't be set without reasonable justification, and shouldn't be set excessively.
Finally, remember that DPM also takes into consideration the cluster's HA settings. It doesn't power off all the hosts it otherwise can, if it needs to keep hosts turned on to provide sufficient failover capacity. Again, this reiterates the fact that being overly cautious and setting very conservative values in some areas will have an impact on the efficiency of other features.
When to Use DPM
When designing vSphere clusters, many people question the usefulness of DPM. It can be advantageous in environments where demand varies substantially at different times. Shutting down hosts for extended times can save power and also reduce air-conditioning requirements in a busy server room. But if resource demand is fairly static, which is common in server workloads rather than desktops, the savings are minimal.
Many companies don't pay for their own power or air-conditioning, if they're collocated in third-party datacenters. Often, stringent change-control rules don't allow for automatic host shutdowns. And many power and cooling systems are designed to run at full load, so shutting down a handful of hosts that are potentially spread out through different racks won't provide any savings. Although DPM allows you to set whether specific hosts ignore the cluster's setting, it doesn't currently let you express a preference regarding the order in which hosts should be shut down (to target a certain rack space first). In addition, all the associated storage and networking equipment must remain powered on, even if some hosts are shut down.
DPM does have potential use cases. If a site has a heavy VDI implementation, and the desktop users work predictable hours, then there is obviously scope to power down hosts overnight and on weekends. There may be longer holiday periods or designated shutdown periods when a site is mothballed.
Another possible scenario is disaster recovery (DR) sites that are predominantly required for standby purposes. In the event of a failover, such sites need lots of spare hosts that can be resumed reasonably quickly. DPM allows them to fire up automatically, when more hosts are needed; this provides an excellent solution that requires little additional intervention.
Test and lab environments also tend to vary wildly in their requirements. These can be good candidates for DPM use because they often see much quieter periods, and generally it's acceptable if the time to recover to full capacity is several minutes.
DPM is just one more useful option in a business's toolkit. As hardware manufacturers incorporate more power-saving functionality into their equipment, it will become more useful. ESXi's host power management is available on every host, and is a complementary option to reduce the overall power usage, using ACPI p-states and c-states to calculate when its CPU scaling is appropriate without detrimentally affecting performance. Chapter 4 examines host power management.
Larger cloud data providers with thousands of hosts undoubtedly will be interested in the potentially very large savings. The technology certainly has its place. However, you should remain mindful that in small environments, the savings may be minimal. Don't spend time and resources designing and testing a DPM solution if it's obvious from the outset that you won't recover enough energy savings to make it worthwhile. Or you may want to apply DPM only in specifically targeted sites, rather than across all your hosts.
High Availability and Clustering
vSphere encompasses several high-availability options. The primary technique is VMware's HA for hosts, but this is supplemented with both VM monitoring and fault tolerance (FT) capabilities.
High Availability
VMware HA is a clustering solution to detect failed physical hosts and recover VMs. It uses a software agent deployed on each host, along with network and datastore heartbeats to identify when a host is offline. If it discovers that a host is down, it quickly restarts that host's VMs on other hosts in the cluster. This is a fast and automated recovery service, rather than what most consider a true high-availability clustering solution to be.
HA uses vCenter to license the feature and deploy the necessary agent software; but after hosts are enabled for the HA cluster, the heartbeat and failure detection are completely independent of the vCenter Server. An offline vCenter won't affect ongoing HA operations, only any reconfiguration that's required, such as adding or removing new hosts.
HA primarily protects against host failures, and as such no special consideration is required for the VM's guest OS or application. There are no requirements for VM-level agents to be installed, and any new VMs in the cluster automatically inherit the HA protection. HA can also protect VM OSes and applications via the VMware Tools software, although it doesn't do this by default. It can detect when OSes aren't responding and allows applications to alert HA when critical services or processes aren't working as expected.
HA also monitors the capacity of the cluster and its ability to fail over VMs from any host. It can enforce policies to ensure that sufficient resources are available.
One common misunderstanding about HA among newcomers to the technology is that HA doesn't use vMotion to recover VMs. The VMs crash hard when the host fails, but they're restarted promptly on alternate hosts. HA uses DRS's load-balancing if it's enabled to make the best restart decisions possible. HA doesn't provide the same level of uptime as some other clustering solutions, but it's very easy to set up and maintain. Expect the VMs to be off for several minutes while they restart after a host failure.
HA Requirements
To enable HA in a vCenter cluster, you should ensure that you meet the following requirements:
- The cluster's hosts must be licensed as Essential Plus or above.
- There must be at least two hosts in the cluster.
- All hosts must be able to communicate with each via their Management Network connections (Service Console if older ESX hosts).
- The HA hosts must be able to see the same shared storage. VMs on local storage aren't protected.
- Hosts must also have access to the same VM networks. For this reason, it's important to use consistent port-group naming across hosts.
- HA's VM and application monitoring functionality needs VMware Tools to be installed in the guest OS.
- TCP/UDP port 8182 must be open between the hosts.
HA in vSphere 5
One of the biggest changes with the initial release of vSphere 5, but one of the least noticeable to users was the replacement of the old HA system with a new purpose-built, superior mechanism. This new HA, known internally as Fault Domain Manager (FDM), does away with the old primary and secondary host model used in pre-vSphere 5 versions. If you're unfamiliar with how this worked previously, see the following breakout section entitiled Pre-vSphere 5 HA where an overview is provided. This will be useful if you're still responsible for a vSphere 4 environment, want to see how much the design of an HA cluster has simplified, or are simply feeling a tad nostalgic.
The FDM version of HA instead has the concept of a master/slave relationship and no longer has the limit of five primaries that heavily impacted cluster design. This simplifies your design significantly because you no longer need to worry about which room, rack, or chassis the primaries are in. IPv6 is supported; logging is done through a single file for each host (in /var/log) with syslog shipping now possible. Reliability has improved, in no small part because HA has dropped its dependency on DNS resolution, a common cause of misconfiguration—everything is IP based. The newer host agents are dramatically faster to deploy and enable regardless of cluster size. This improves cluster reconfigurations, and the status of the master/slave status is clearly revealed in the vCenter GUI.
These HA improvements come as part of vCenter 5. So if there are pre-5 hosts, they receive the benefit of the FDM-based HA if their vCenter is upgraded or they're joined to a vCenter 5 instance. vCenter 5 can manage ESXi and ESX hosts back to and including version 3.5; their HA agents are automatically upgraded if they join an HA-enabled cluster. This is a quick way to take advantage of one of the major vSphere 5 features by upgrading a single infrastructure component.
- ESX 3.5 hosts require patch ESX350-201012401-SG PATCH.
- ESXi 3.5 hosts require patch ESXe350-201012401-I-BG PATCH.
HA now uses multiple channels for agent-to-agent communication; both network and storage fabrics are utilized. A second heartbeat via the storage subsystem in addition to the network heartbeats improves the reliability of the fault detection, helps to prevent false positives, and clarifies the root cause.
Master Host
In each HA cluster, one host is selected to run in the master role. The host that is connected to the greatest number of datastores and the greatest diversity of datastores (the most arrays) is selected as the master host. Under normal working conditions there is only one master host per cluster. The rest of the hosts are designated as slaves.
The master node is responsible for the following:
- Monitoring the slave hosts and restarting its VMs if a host fails
- Protecting all the powered-on VMs, and restarting them if a VM fails
- Maintaining a list of hosts in the cluster and a list of protected VMs
- Reporting the cluster's state to the vCenter Server
HA communicates using the hosts' management network via point-to-point secure TCP connections (elections are via UDP). It uses the datastores as a backup communications channel to detect if VMs are still alive and to assign VMs to the masters if a network partition occurs, creating multiple masters (more in this later). The datastore heartbeat also helps to determine the type of failure.
vCenter is responsible for informing the master node about which VMs should fall under the protection of HA and any changes to the cluster's configuration, but the recovery of VMs is solely the responsibility of the master. If vCenter is unavailable, the master will continue to protect the VMs; but changes to the cluster's settings, which VMs are protected, and any alarms or reporting will remain unchanged until the vCenter Server is back online.
Slave Hosts and Elections
When a cluster is first enabled for HA, the master host is selected and the remaining hosts in the clusters are designated as slave hosts. A slave in the cluster is responsible for the following:
- Monitoring the state of its own VMs and forwarding information to the master
- Participating in the election process if the master appears to fail
If the slave hosts believe that the master has failed, there is an election between the remaining active hosts to decide which is best placed to take over the master role. The process is identical to when the HA was first initialized—the host with the most datastore connections wins. The entire HA election process takes less than 20 seconds to resolve. The new master takes over all roles and responsibilities immediately.
Failed Hosts
Network heartbeats are sent between the master and each of the slaves every second. If the master doesn't receive a return acknowledgment, it uses the datastore to see if the slave is responding via its datastore file locks. If there is no response to the network or datastore heartbeats, the master tries an ICMP ping to the slave's management address. If the master can't confirm that the host is alive, it deems that the slave has failed and begins restarting its VMs on the most appropriate hosts in the cluster. At this point, the failed host may still be running in some capacity (for example it has lost network access, including IP-based storage), but the master still considers it failed and begins seizing the VMs and powering them on elsewhere.
However, if the slave is found to still be responding to its datastores, then the master assumes it has become either network-partitioned or network-isolated and leaves the slave to respond accordingly to its own VMs.
A network partition occurs when a host loses its network heartbeat to the master but is still responding to its storage and can see election traffic. A network isolation event happens when a host is in similar position but can't see election traffic. When a host can't ping its isolation address, it realizes that it won't be participating in an election, and it must be isolated.
A common scenario to explain a network partition involves hosts split between two locations but with a stretched Layer 2 network. This is often known as a stretched cluster, metro cluster, or campus cluster. If the interroom network connection fails, this can create a partitioned network with grouped hosts split on either side. Another common example of a partition is when the link to a network switch on a chassis fails.
When a partition happens, the master host can still communicate with all the slaves on the same side of the split. The hosts and VMs on that side are unaffected. The master can see that the hosts on the other side of the split are partitioned and not failed (due to the storage fabric heartbeats) and leaves them to their own recovery. In the other room, all the slaves can see the election traffic from each other, but they can't communicate with the master through the network. They hold a reelection between themselves to appoint a new master so they're protected until the partition is resolved. This is why we said “under normal conditions there is only one master per cluster,” because when a cluster becomes partitioned a master is elected in each partition.
If the slave doesn't see any election traffic on the network, it realizes that it's isolated from all the other slaves. At this point it carries out the Host Isolation response that was configured in the cluster's settings to leave the VMs running, shut them down, or power them off. The Host Isolation response options are examined further in the “Host Monitoring” section. In a properly designed network environment with appropriately redundant devices and cabling, host isolations should be a very rare occurrence.
When a cluster experiences a network partition, it isn't as worrisome as a host isolation because at least the partitioned hosts have the potential for some redundancy within themselves. Partitioned states should be fixed as soon as possible, because admission control doesn't guarantee sufficient resources for recovery. The VMs aren't fully protected, and it's very likely that some, if not all, of the partitions have lost their connection to vCenter. Until the partitioned state is resolved, the cluster isn't properly protected or managed.
Host Monitoring
After enabling HA in the cluster settings, you can begin protecting the hosts via their HA agents and heartbeats by switching on host monitoring. The check box to enable this feature is the first option in Figure 8.13.
Figure 8.13 HA settings
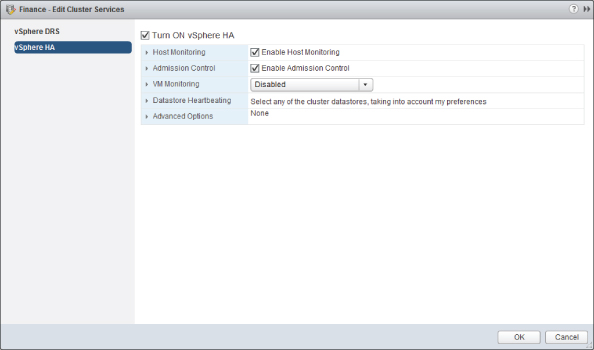
If you wish to disable HA host monitoring, you should do it with the second setting rather than disable the entire cluster for HA. That way, you keep all your advanced settings, and VM and application monitoring can continue to function.
FT requires that HA host monitoring be enabled in order for it to protect its VMs properly. vSphere keeps the FT secondary copies running if you disable host monitoring, but they may not fail over as expected. This saves the FT clones from being re-created if HA host monitoring is disabled for a short time.
VM Options (HA)
HA's Virtual Machine Options settings let you control the default restart priority and what the cluster's hosts should do if a host becomes isolated from the rest of the network. Figure 8.14 shows these settings.
Figure 8.14 HA Virtual Machine Options
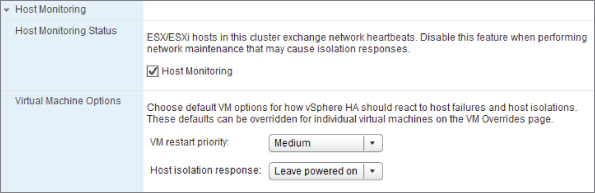
Setting the VM options gives the default actions for the cluster, but both settings can be overridden on a per-VM basis. Figure 8.14 shows how each VM can have its own restart and isolation response:
You can choose to start certain VMs first if they provide essential services, such as domain controllers and DNS servers. In addition, the order in which some VMs start is important for certain multiserver applications. For example, you may need a database server to start before its application server (as you would for a split virtual vCenter instance).
You can also disable restarting some VMs in the case of a host failure. For example, you may choose not to restart some development and test VMs if you think the extra load on fewer hosts will adversely affect your production VMs. VMs disabled here will react to the VM-monitoring feature on a host that is still up, unless it's disabled in that section as well.
If two hosts fail simultaneously or in quick succession, then the master host begins starting the VMs from whichever it determines was the first host to fail. It restarts all of that host's VMs in their restart priority and doesn't begin to restart the second host's VMs until all the VMs from the first are finished. This is the case even if there are higher-priority VMs on the second host.
Even though the VMs are still running, this is a less-than-ideal situation. There is clearly an issue with the infrastructure, and the VM's guest OSes are most likely no longer on the network.
The cluster has three possible settings for an isolation response: Leave Powered On, Shut Down, and Power Off. Shut Down attempts to use the VMware Tools to cleanly shut down the VM, thus preventing the guest OS from crashing. If after 5 minutes the VM hasn't shut down, the host powers it off hard. You can change this timing with the advanced setting das.isolationshutdowntimeout if there are VMs you know take longer to shut down cleanly.
In vSphere 5, before the isolated host shuts down or powers off each VM, it checks that the master host can lock the datastore. If it can't, then the isolated host doesn't shut down (or power off) the VM. It does this to make sure the master is in a state to be able to recover the VM. If it can't, you're better off keeping the VM running on the isolated host.
In vCenter 5 the default isolation is now Leave Powered On. This setting has changed a number of times during vCenter's lifecycle, so if you've been upgrading this server through the years, then you should check each cluster's setting. Once vCenter has been upgraded, all new clusters are created with the default setting, but existing clusters can maintain the old defaults.
Leave Powered On is the default because it's generally accepted as the safest option in most situations and prevents any false-positive worries. When should you not keep the default setting? Remember that when a host is isolated, it can see the datastore heartbeat volumes but can't connect to other hosts on the network. There are a couple of things to consider here. If the management interface of the host can't connect to the isolation address, then something is wrong with your infrastructure's networking. Depending on where the fault lies (the IP interface, a physical NIC, a cable, a switch), how likely is it that your VM's guest OSes are also offline? If you have a very redundant physical network set up, and the VM networks are physically and virtually separate from the management network, this is highly unlikely. But if you have a converged network of two 10GbE connections through one blade mezzanine card, then this is far more likely. If you're concerned that leaving the isolation response as the default may mean your VMs could stay turned on but not be on the network, then you might choose to shut them down. A second consideration is that although the isolated host can by definition see the heartbeat datastores, that doesn't mean it can definitely see all the datastores. For example, if you have a mix of array connections, and the heartbeat datastores are on the more robust arrays' connections, then there is the possibility that an isolated host could lose some of the datastores and not others (particularly if you have an IP-based array.
If you opt not to stay with the default of Leave Powered On, then you have the choice of Shut Down or Power Off. VMs can individually override the cluster isolation response setting. Shut Down is obviously the more graceful approach and results in a lower probability of a crash-consistency issue when the VM is powered up on a different host. However, selecting Shut Down over Power Off means the recovery will take longer. If you're confident that a VM won't suffer any ill effect from a sudden power off, and the shortest downtime is paramount, then you can consider dropping down to the Power Off option to provide higher availability—isn't that ironic?
Admission Control
HA admission control is similar to the admission control used by hosts, resource pools, and storage DRS. One notable difference is that HA admission control can be disabled. It's used to control oversubscribing the HA cluster. If enabled, it uses one of three methods to calculate how to reserve sufficient resources to ensure that there are enough hosts for recovery; the following subsections describe these policies. If it determines that the limit has been reached, it can prevent further VMs from being turned on in the cluster or VM reservations from being increased. HA admission control doesn't include hosts that are disconnected, in standby, or in maintenance mode in its calculations.
Without the protection of admission control, there is a greater chance that HA may not be able to power on all the VMs during a failover event. You may want to temporarily disable it if you plan to oversubscribe your cluster during testing or patching. Remember that HA admission control is used to ensure sufficient capacity during failure events. It isn't meant as a general capacity-management tool. Proper host capacity management is about making VMs run well during normal operation.
HA admission control reserves capacity for times when hosts fail. When a failure does occur, it uses that capacity, powering-on VMs that admission control would ordinarily prevent a user from starting. Admission control is driven by vCenter, but recovering from failures is left to the master host to coordinate. Admission control in and of itself doesn't prevent VMs from being powered on during a failure; but without the correct admission control a lack of resources may cause VMs not to be started.
When DRS is enabled on the cluster, it attempts to create contiguous space on hosts. This reduces the potential of the available resources being too divided across hosts and allows larger VMs to be restarted.
Figure 8.15 shows the three policy options available when host monitoring is enabled.
Figure 8.15 Admission Control policies
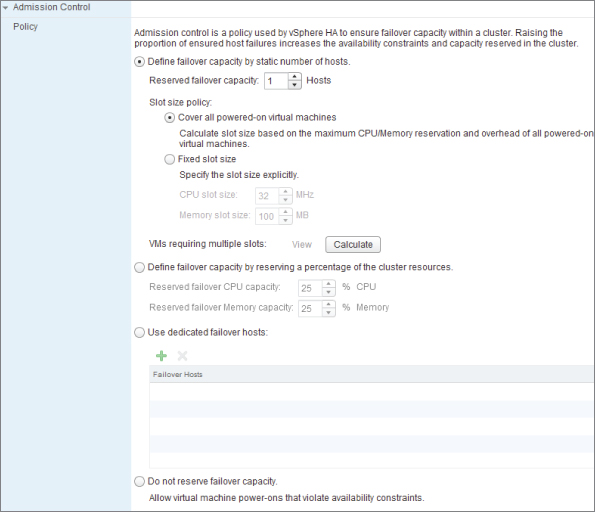
Static Number of Hosts
The first admission control policy—and the default, which for that reason is used in most clusters—is the number of host failures the cluster will tolerate. In other words, it's the amount of capacity kept spare in terms of number of hosts.
HA calculates the amount of spare capacity in terms of number of hosts via an arbitrary value called a slot size. This slot size determines how admission control is performed against the cluster:
Obviously, very large VMs with large reservations will skew this amount, highlighting the need to keep VM reservations to a minimum. Resource pool reservations don't affect HA slot sizes. In the Windows Client, you can use the advanced settings das.slotCpuInMHz and das.slotMemInMB to reduce a very high slot setting if you think something lower is appropriate, but doing so can fragment the reserved slots for the larger VMs and cause issue if resources are thinly spread across the cluster when a host fails. Although the spare resources will be available, they may not be enough on a single host to accommodate a large VM. The Web Client in vSphere 5.1 allows you to change these values in the GUI via the Fixed Slot Size radio button option. If you opt to manually reduce the slot sizes to prevent this admission control policy from being too conservative, the GUI shows you which VMs are larger than the fixed slot size chosen. (If you're using the default options for this policy, not manually changing the slot size, resource fragmentation shouldn't be a significant issue because the slot size is set for the maximum reservations.)
Setting specific slot sizes manually can also be useful in situations where VM reservations aren't used. If no reservations are set, then only the most basic slot size is determined for a cluster. This is usually based on the memory overhead for the largest VM in the cluster. However, if all the VMs are very similar in size and no one VM is significantly bigger than the rest, then only the bare minimum needed to power on VMs will be guaranteed. This is the minimum for the hosts to power them on and often not enough to get the guest OS up and running. Setting no VM reservations in this case could lead to a serious overcommitment during a failover event. Manually setting a slot size can prevent this.
Figure 8.16 HA Advanced Runtime Info
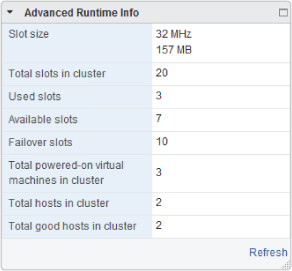
HA calculates how much CPU and memory are available for VMs on each host, after the virtualization overhead is taken into account. It does this for all connected hosts that aren't in maintenance mode and works out how many slots each host can hold. Both CPU and memory slot sizes are compared, and the smaller (more conservative) of the two is used. Starting with the smallest host, HA determines how many hosts will accommodate all the slots. Any hosts left over, which will be the larger ones to ensure that worst-case failures are considered, are totaled to give the failover capacity.
This method of admission control is useful primarily because it requires no user intervention after it's initially configured. New hosts are added to the slot size calculations automatically, to ensure that larger hosts are guaranteed protection. As long as you don't use advanced slot-size settings, this method doesn't suffer from the resource fragmentation that is possible with the percentages method discussed next.
But this type of admission control is inflexible and can be overly conservative. It works well if all the VMs have the same CPU and memory requirements; but a small number of large VMs will significantly bias the slot sizes, and you'll need extra hosts to maintain the failover capacity. If you're faced with a cluster with disproportionate VMs, carefully consider how you're using VM reservations, whether the cluster should be split, or if another policy is more appropriate.
Percentage of Cluster Resources
The Percentage of Cluster Resources admission control policy uses cluster totals compared to VM totals to calculate a percentage value of spare capacity.
This policy adds up all the powered-on VMs' CPU and memory requirements, considering their reservations. If the reservations are set to 0 (zero), then it takes 0 MB plus any overhead for memory and adds 32 MHz for CPU. It then adds together all of the hosts' available CPU and memory resources. It creates a percentage difference for both CPU and memory, and if either is less than the admission control policy states, it enforces admission control.
Using percentages for admission control is very useful because it doesn't rely on complex slot size calculations while continuing to respect any set reservations. Unlike the very conservative policy regarding a static number of host failures, the percentage policy is more adaptable. If all the hosts have similar CPU and memory, then calculating the percentages to give a one- or two-host failover capacity is simple. Although appearing reductive, 1/n×100 is commonly enough to give sufficient failover for a cluster (n+1), and its simplicity makes this easy to recalculate whenever the number of hosts in the cluster changes.
Hosts with very different capacities can lead to problems, if the percentage set is lower than the resources of the largest host. Every time a host is added or removed, you may need to recalculate the percentage each host gives to the cluster, to ensure that each is sufficiently protected. Very large VMs may have problems restarting if the spare capacity is spread thinly over the remaining hosts; so, set large VMs to have an earlier restart priority, and always watch to make sure any large VMs can still fit on each host.
This policy is well suited to clusters with a mix of VMs with different CPU and memory sizes. The Web Client in 5.1 allows you to specify different capacities for CPU and RAM if there is significant disparity. DRS does its best to defragment this and make space for VMs when required, but with the type of Admission Control policy there is always this risk.
Dedicated Failover Hosts
This policy designates a particular host or multiple hosts as the ones to fail over to, reserving entire hosts as a hot spares. When this policy is selected, no VMs can power on or migrate to the designated hosts.
This means the hosts are unavailable for use, and they need to be the most powerful hosts in the cluster to ensure that it can recover from any host failures. If you have unbalanced hosts in the cluster, with one host having a very large number of CPUs and another having much more RAM than the rest, then you may find that no particular host is suitable to specify as a single failover host. Being able to select multiple hosts with different hardware profiles can alleviate this but can obviously be costly to implement. This policy is only suitable for the most risk-averse or bureaucratic scenarios where protocols stipulate that reserved hardware has to be on standby to guarantee that no performance degradation can occur during failure.
Do Not Reserve Failover Capacity
This last option is the equivalent of disabling admission control, the nomenclature used in the Windows Client.
HA lets you power on VMs until all of the cluster's resources are allocated. This means that during a failover event, not enough resources might be available to power on all the VMs. We hope you've set the restart priority on the more critical VMs, so at least they can power on first! Needless to say, although operational needs may require you to temporarily switch to this mode, you shouldn't leave it this way for long because the VMs are potentially unprotected. Switching to this often is a result of poor capacity planning. It shouldn't be part of planned design.
VM Monitoring
VM monitoring is an additional feature of HA that watches the VMware Tools' heartbeat, looking for unresponsive guest OSes. If HA determines that the guest has stopped responding—for example, due to a Windows BSOD or a Linux kernel panic—then it reboots the VM.
With vSphere version 4.1, application monitoring was added. For an application to share heartbeat information with HA's monitoring, it relies on either the application's developers adding support via a special API available to select VMware partners, or setting them up yourself using the available SDK. If the application or specific service stops, VMware Tools can be alerted, and vSphere can restart the VM.
Figure 8.17 shows the available VM Monitoring settings. At the top, in the drop-down box, you can select VM, Application, or VM and Application Monitoring. The next section allows you to select the monitoring sensitivity, with an option to customize each setting individually. You can adjust the settings on a VM basis in the VM Overrides section of the cluster, shown previously in Figure 8.7.
Figure 8.17 VM Monitoring
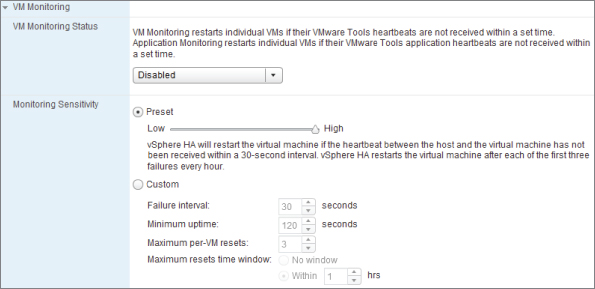
If heartbeats from the guest OS or application are lost from a VM in the Failure Interval period, disk and network I/O are checked to prevent any false results. The I/O activity interval is an advanced cluster setting, which by default is 120 seconds, but you can customize it with the das.iostatsinterval setting. HA VM monitoring has a minimum uptime value that waits a period of time after the VM is started or restarted before making monitoring failovers; this allows the VMware Tools to start. If you have a guest OS or application that is known to start very slowly, you should extend this value to be sure everything has started and the initial CPU demands have tapered off. This feature also limits the number of times a VM is reset in a certain period. This prevents a VM from being repeatedly restarted, if the same error continuously reoccurs and causes OS or application failures.
If HA decides a failure has happened after checking heartbeats and I/O, it takes a screenshot of the VM's console and stores it in the VM's working directory. The VM is then immediately restarted. This console screenshot can be very useful in troubleshooting the initial error, because it often contains kernel error messages from the guest OS.
Adjusting the monitor's sensitivity, especially with custom values, affects the monitoring responsiveness and success rate. If you set the sensitivity too high, then you may suffer unnecessary reboots, particularly if the VM is under a heavy workload or the host's resources are constrained. On the other hand, if you set the sensitivity too low, then it will take longer to respond, and critical services may be down longer than you want.
A successful implementation of VM monitoring depends on testing each OS and application. Every instance may have different sensitivity requirements. For this reason, the VM Overrides section is very useful; it lets you test each VM with its own settings before introducing it to the cluster's settings. It's advisable to have as few VMs with their own individual settings as possible, after you've determined the most appropriate cluster-wide sensitivity settings.
Datastore Heartbeating
As described in the previous sections, HA in vCenter 5 uses the datastores as an additional way to communicate between hosts and prevent false positives. This provides extra redundancy over the network agent-to-agent checking and can more accurately determine faults.
By default, vCenter selects two datastores to use for heartbeating purposes. It picks the datastores that are connected to the most hosts, if possible ones that are split across different storage arrays, with a preference for VMFS volumes over NFS volumes.
Figure 8.18 shows where you can nominate a predilection for specific datastores. You can also use an advanced setting to increase the default of two datastores up to a maximum of five.
Figure 8.18 Datastore Heartbeating
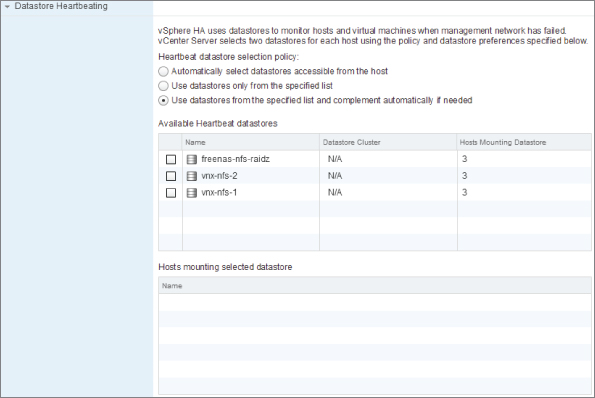
Making changes to the datastores used for heartbeating isn't usually necessary in a design because vCenter's smarts attempt to spread the choice across multiple sources and favor FC fabrics where possible. However, if you have datastores that you know are likely to provide more redundancy or resilience, this is where you can enhance the defaults.
Advanced Options
Some of the advanced options for HA have been discussed throughout this chapter. This is the section in the GUI where advanced options can be manually added for a cluster. To review all the possible HA advanced options that are currently available, refer to http://kb.vmware.com/kb/1006421.
One advanced setting worthy of note because of its absence in vSphere 5 is das.failuredetectiontime. This was a popular setting to customize in previous HA configurations because there were different VMware recommendations depending on your extenuating circumstances. This is no longer a customizable setting in vSphere 5. In vSphere 5.1, a setting called das.config.fdm.isolationpolicydelaysec was introduced to provide a somewhat similar ability, allowing you to delay the trigger of the isolation response. Ordinarily this isn't a requirement, and is not needed for additional isolation addresses. This setting has a minimum value of 30 seconds, the default isolation response time, and should only ever be increased if the network experiences drops of longer than 30 seconds, but circumstances when you know that you won't want HA to kick-in immediately.
HA Impacts
vSphere has a tight integration with its cluster components and is affected by DRS, DPM, and affinity rules. During failover, if resources are spread thinly over the cluster and HA needs to restart one very large VM, it can ask DRS to make room for it by vMotioning existing VMs around. It can also ask DPM to power-on hosts if it has shut some down, to provide additional resources.
The VM-Host affinity rules can limit the choices HA has to restart VMs after a host failure. If there is a VM-Host mandatory must rule, then HA honors it and doesn't restart a VM if doing so would violate the rule. If it's a soft should rule, then HA restarts the VM, thus breaking the rule, but creating an event that you can monitor with an appropriate alarm. Multiple VM-Host rules can also fragment the resources in a cluster, enough to prevent HA power-ons. HA asks DRS to vMotion VMs to a point where every VM can be recovered but may not be able to achieve it within the rules. As per the recommendations for VM-Host affinity rules, only use must rules if you have to, and be aware that doing so can limit HA so much that VMs may not be recovered.
For clusters that use resource pools, vSphere 5 recovers VMs to the root of the cluster but with adjusted shares relative to their allocation before the failover. This is temporary, because when DRS is also enabled on the cluster (which is required for resource pools), it moves the VMs back into the correct pools automatically.
HA Recommendations
The most crucial factor for HA to work successfully is the communication of the network and storage heartbeats. Therefore two critical design aspects related to this in HA are network redundancy and storage-path redundancy.
The most common risk to an HA cluster is an isolated host, particularly hosts that rely on IP-based storage instead of a FC fabric. You must ensure that there is complete redundancy for the management network (Service Console for ESX hosts) connection at all points through the network to every host. You can do either of the following:
- Configure more than one VMNIC on the management VMkernel's vSwitch.
- Add a second management VMkernel connection to a separate vSwitch on a separate subnet.
The management VMkernel connection must have a default gateway that all the hosts can reach. Hosts use it to decide whether they have become isolated; so, if your management VMkernel subnet doesn't have a gateway or the gateway device doesn't respond to ICMP pings, you should change the das.usedefaultisolationaddress parameter to “false” and add an alternative isolation address. To add an alternate isolation address, or if you use a second management VMkernel connection on a separate subnet and want to specify a second isolation address for the alternate subnet, add das.isolationaddress0. With the improvements to HA that allow the new default isolation response to be Leave Powered On, there should be less concern regarding false results shutting down VMs. But if you're conducting maintenance tasks on your network devices or the host's networking configuration, you should temporarily disable host monitoring to prevent any false failovers.
Try to minimize the number of network devices between hosts, because each hop causes small delays to heartbeat traffic. Enabling PortFast on the physical switches should reduce spanning-tree isolation problems. If you use active/passive policies for the management VMkernel connections, configure all the active VMkernel links from each host to the same physical switch. Doing so helps to reduce the number of hops.
If only IP-based storage is being used in the design, then you should try to split the networks as much as possible from your management networks. Completely separate fabrics would be ideal, providing physical air-gapped equipment. However, for practical reasons this isn't often possible. Perhaps you have to share the access-layer network switches. Depending on the network topology, the storage may be connected to common aggregate or core switches. If you aren't using converged 10GbE cabling, it may be feasible to allocate a pair of redundant storage-only cables to the northbound switches. If physical separation isn't an option, then at least splitting out the subnets on trunked ports gives a logical split.
A firewall port must be open between all hosts in the same cluster. When HA is enabled on the cluster, the required ports are automatically opened on the host's own firewalls. However, if there are any physical firewalls between the hosts, then TCP/UDP port 8182 needs to be configured.
If the cluster is configured for DRS, you should already have common port group names across all the hosts; otherwise, the vMotions will fail. But if you only enable HA, it's possible to misconfigure your hosts with different port group names between the hosts. Use the Networking view in vCenter of the cluster to confirm consistent naming standards.
Attempt to keep the host versions at the same version and updated to the latest build whenever possible. It's possible to have mixture of vSphere 3.5 hosts and upward, but older hosts don't support all the same features or react quite the same way. To be assured of the most efficient cluster that is as highly available as possible, update the hosts frequently.
Customize the VMs' restart policy to suit your environment. Doing so improves the chances that the more critical servers will be restarted successfully if you don't have admission control enabled or if the failover levels are insufficient. Also, the restart policy will ensure that the servers that need to start first, which subsequent servers rely on, will be ready.
Create an alarm with an associated email action to warn you if an HA failover has occurred. You'll want to check that all the necessary VMs come back online and that services are restored. Then, investigate the state of the failed host to see if it's ready to rejoin the cluster. You can also use alarms to warn you when a cluster becomes overcommitted or invalid.
- Synchronous storage replication of datastores between sites using either FC, FCoE, or iSCSI protocols. Datastores backed by NFS are not supported.
- Storage and network latency less than 5 ms between sites is required. A vSphere Enterprise Plus license includes the Metro vMotion feature which allows the network latency to be up to 10 ms.
- A minimum of 622 Mbps network bandwidth for vMotion traffic between sites. This does not include the storage replication traffic.
- Each datastore must not only be replicated, but the storage array in each room must be able to read and write to the datastore.
- It is recommended to have an equal number of (and similarly sized) hosts on both sites.
- Use the Percentage of Cluster Resources admission control policy and set this to 50% for both CPU and Memory. This ensures that during an HA recovery there will be enough resources to recover from an entire site failure. If you don't have an equal split of host resources on each site, these percentages will need to be even greater.
- Create VM-to-Host should affinity rules to group the Hosts into two sides and align the VMs with their primary datastores to prevent excess cross-site replication and network traffic.
- By default each cluster selects two datastores to act as a storage heartbeat for HA. Make sure that a datastore from each site is used, and preferably add another so there is a pair of datastores per site.
- Add a second isolation address (das.isolationaddress) so there is a network device in both sites. This help all hosts deal with a split room scenario.
- Since vSphere 5.0 update 1, two new advanced options allow us tune the hosts to respond more appropriately to Permanent Device Loss (PDL) codes from a storage array. When a host sees that a LUN has failed, but can still communicate with the array, it is able to recognize that the failure is not a temporary fault and the LUN is most likely not coming back — this is labeled a PDL. The two advanced options enable HA to restart VMs from a PDL datastore that is still available to other hosts in the cluster. The follow settings should be changed in a stretched cluster:
- disk.terminateVMonPDLDefault set to true. Allows HA to kill a VM if its home datastore is in PDL state.
- disk.maskCleanShutdownEnabed set to true. Makes an HA cluster assume a powered off VM on a PDL datastore as failed and restarts it.
Fault Tolerance
VMware FT is a clustering technology that was introduced with vSphere 4 but whose roots can be traced back to the record/replay feature first introduced in VMware workstation back in 2006. It creates an identical running copy of a VM on another host, which can step in seamlessly should the first VM's host fail.
FT records all the inputs and events that happens on the primary VM and sends them to replay on the secondary VM, in a process known as vLockstep. Both primary and secondary VMs have access to the same VM disks via shared storage, so either can access the disks for I/O.
Both VMs are kept synchronized and can initiate the same inputs and events identically on their respective hosts. Only the primary VM advertises itself on the network, so it can capture all the incoming network I/O, disk I/O, and keyboard and mouse input. These inputs and events are passed to the secondary VM via a dedicated VMkernel connection known as the FT logging link. They can then be injected into the running secondary VM at the same execution points. All the outputs from the secondary VM are suppressed by its host before being committed, so only the primary actually transmits network responses to clients and writes to disk. The outside world is oblivious to the secondary VM's existence.
The mechanism to create and maintain the secondary VM is similar to vMotion; but instead of fully transferring control to the second host, it keeps the secondary VM in a permanently asynchronous mirrored state. The initial creation of the FT VM happens over the vMotion network; then, the remaining lockstep occurs over the FT logging network. This clustering is only for host failures and doesn't protect VMs against OS or application failures, because those are replicated to the second VM. But FT does protect VMs against host failures more effectively than HA, because there is no downtime or loss of data, whereas HA needs to restart the VMs, creating a short outage and crash-consistent VMs.
The VMs need to be members of an HA cluster, to detect and restart hosts should a failure occur. Like HA, FT uses vCenter purely for the initial creation of the FT pair but isn't dependent on vCenter and isn't disrupted if it becomes unavailable. The cluster is also responsible for keeping the VMs on different hosts, so when FT is enabled on a VM, the secondary VM is created and never coexists on the same hardware as the primary.
The primary VM is continuously monitored for failures so the secondary can be promoted, be brought onto the network, and spawn a new secondary copy. Failures are detected by checking the VMs for UDP heartbeats between the servers. FT also watches the logging connection to prevent false positives, because regular guest OS timing interrupts should always create a steady stream of logging traffic. FT uses a file-locking technique, similar to vSphere 5's HA, on the shared datastore to tell if there is a split-brain networking issue instead of a host down. This prevents an isolated host from incorrectly trying to promote the secondary VM and advertise itself.
FT by itself only protects a VM from host failure, not OS or application failures. However, you can combine this with HA's VM monitoring and application monitoring. The VM monitoring detects OS problems such as kernel panics/BSODs and restarts the primary VM. This in turn causes the primary to create a new secondary copy. Remember that because the primary and secondary VMs always share the same storage, FT doesn't protect you against a SAN failure.
FT Versions
The FT feature maintains a version number between revisions of vSphere to ensure that hosts are compatible with each other and capable of mirroring VMs. When FT was introduced in vSphere 4.0 with version 1, the build number (effectively, the patching level of the host) was compared: VMs could only run on hosts with exactly the same build number. Since vSphere 4.1 (FT version 2 and above), FT isn't restricted by build numbers, but hosts must still be at the same FT version number.
Version 2 and above FT VMs have a more sophisticated version-control technique that allows the hosts to be slightly different if vCenter can tell FT would be unaffected. This makes patching the hosts considerably simpler. But upgrading hosts between major vSphere revisions still requires a minimum four-host cluster without having to disable FT for an extended period. Ensuring that all hosts in a cluster are at the same vSphere version, and therefore the same FT version, is important in maintaining the most effective environment for FT.
FT can use DRS for both initial placement and load-balancing, but the cluster must be EVC enabled. EVC improves the cluster's ability to place VMs on hosts. The secondary VM assumes the same DRS settings as its primary. If EVC is disabled in the cluster, the FT VMs are DRS disabled as they were with version 1 back in vSphere 4.0. Whenever a FT VM is powered on, it uses anti-affinity rules to ensure that the secondary copy is running on a different host. You can use VM-Host affinity rules to specify the hosts on which you want the FT VMs to run. When you set particular hosts, both the primary and secondary VMs adhere to the rule and only run on those hosts. But with a VM-VM affinity rule, this only applies to the primary, because that is the VM other VMs interact with. If the primary fails, the secondary is promoted, and DRS steps in and moves VMs as the rule requires.
As each version of vSphere, and therefore FT, is released, support for newer CPUs and guest OSes become available. For this reason, it's generally good advice to keep the FT hosts updated as newer releases become available. VMware's online compatibility guide (known as the HCL) at www.vmware.com/go/hcl shows the supported hardware and guests: select Fault Tolerant (FT) in the Features section.
vLockstep Interval
The primary VM always runs slightly ahead of the secondary VM with regard to actual physical time. However, as far as the VMs are concerned, they're both running at the same virtual time, with inputs and events occurring on the secondary at the same execution points. The lag between the two VMs in real time is affected by the amount of input being received by the primary, the bandwidth and latency of the logging link between the two, and the ability of the host running the secondary VM to keep up with the primary VM.
If a secondary VM starts to significantly lag the primary, then FT slows the primary by descheduling its CPU allocation. When the secondary has caught up, the primary's CPU share is slowly increased.
The lag between the two VMs is known as the vLockstep interval and appears in the FT summary shown in Figure 8.19. The vLockstep interval typically needs to be less than 500 ms.
Figure 8.19 FT summary
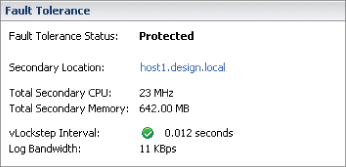
All network transmits and disk writes are held at the primary VM until the secondary acknowledges that it received all the preceding events to cause the output. Therefore, sufficiently large latency on the logging link can delay the primary, although normal LAN-style response times shouldn't cause a problem.
Requirements and Restrictions
The process of recording and replaying VMs is very complex; hence a number of strict requirements and restrictions apply to the environment.
This is a relatively new feature from VMware, and it's still evolving; as such, it has a tendency to change frequently. You should check the latest VMware documentation to make sure these restrictions still apply, because each new version works to remove the existing constraints and improve functionality.
The following lists are aimed at the version of FT that came with vSphere 5.1, but additional prior limitations or differences are highlighted:
Clusters
- At least two hosts that can access the same networks and storage that the FT-protected VMs will use. Hosts must be running a compatible FT version. Host certificate checking must be enabled on the cluster. This has been the default since vCenter 4.1, but upgraded installations may not have it enabled.
- The cluster must have HA enabled with host monitoring.
- Primary and secondary VMs can't span across multiple clusters.
- If cluster hosts are separated from each other by firewalls, FT requires ports 8100 and 8200 to be open for TCP and UDP between all hosts.
Hosts
- Enterprise or Enterprise Plus licensing.
- FT-compatible hardware (see the FT HCL for updated listings).
- FT-compatible CPUs (http://kb.vmware.com/kb/1008027).
- Hardware virtualization enabled in the BIOS (Intel VT or AMD-V).
- Access to the vMotion network via a VMkernel connection.
- Access to the FT logging network via a VMkernel connection. The FT logging network should be a separate subnet to the vMotion network. IPv6 isn't supported.
VMs
- Must be at least hardware version 7.
- Must be on shared storage.
- A few guest OSes aren't supported, and some that are supported need to be powered off to enable FT (http://kb.vmware.com/kb/1008027).
- Only a single vCPU.
- No more than 16 disks.
- Maximum 64 GB of memory.
- Can't use IPv6.
- Can't use Storage vMotion and therefore can only use the initial placement feature of Storage DRS.
- Can't use or have snapshots, which rules out the VMware Data Protection (VDP) tool and any vStorage APIs for Data Protection (VADP) based backup utilities.
- Can't use or have linked clones.
- No physical raw device mapping disks (RDMs); virtual RDMs are allowed.
- No N-Port ID virtualization (NPIV).
- No NIC or HBA passthrough (DirectPath I/O or SR-IOV).
- No 3D graphics.
- Only virtual BIOS firmware; EFI firmware isn't supported.
- VMs can't have any of the following devices attached:
- Vlance vNICs
- VMXNET 3 vNICs with FT version 1
- PVSCSI devices
- VMCI connections
- Serial ports
- Parallel ports
- CD drives
- Floppy drives
- USB passthrough devices
- Sound devices
VMware has created a freely downloadable tool called SiteSurvey (www.vmware.com/support/sitesurvey) that can connect to your vCenter instance and analyze clusters, hosts, and VMs to check whether they're suitable for FT. It highlights any deficiencies and makes recommendations.
Enabling FT
A two-step process is involved in using FT on a VM. First FT is turned on, which prepares the VM for FT. When FT is turned on for a VM, it disables the following features:
- Nested page tables (Extended Page Tables/Rapid Virtualization Indexing [EPT/RVI]). If this has been enabled, then the VM must be turned off to disable it. FT only does this per VM, so the host remains enabled, and other VMs on the host can still take advantage of this hardware optimization.
- Device hot-plugging.
- DRS is disabled on the primary and secondary unless EVC is enabled on the cluster.
Turning on FT also converts all of the VM's disks to thick-provision eager-zeroed format, removes any memory limits, and sets the VM's memory reservation to the full allocation of RAM.
The second step is known as enabling FT, which creates the secondary VM. If the VM is already powered on when you turn on FT, it's automatically enabled at the same time.
When to Use FT
FT provides excellent protection against host failures, despite not protecting VMs from OS or application faults. But some of the restrictions listed here make FT less useful for some designs.
In particular, two requirements severely limit how it's used. First, the licensing needed to enable FT on VMs is Enterprise or above, meaning that many companies can't take advantage of this feature. Second, the fact that only single-vCPU VMs can be protected really restricts its use. The sort of Enterprise customers who pay for additional licensing features are also the entities most likely to run their more critical VMs with multiple vCPUs.
With the long list of restrictions and the additional demands to run the secondary VMs, most businesses only protect their most crucial VMs with FT. Not only does the cluster need to provide the extra resources for the secondary, but enabling FT also sets the full memory reservation for the primary, and in turn the secondary, to prevent any chance of ballooning or swapping. Enabling FT on the VM prevents you from changing any CPU or memory shares, limits, or reservations.
Enabling FT can also reduce the performance of VMs by up to 10% just with the additional overhead. If the secondary VMs CPUs can't keep up with the primary, this can reduce its performance even more.
DRS also restricts the number of primary and secondary VMs per host to a default of four. You can change this value with the advanced setting das.maxftvmsperhost; if you set it to 0 (zero), the limit is ignored.
However, the higher protection afforded by FT makes it extremely useful. Most popular guest OSes are supported; and FT is unaware of the application stack running, so the best use cases tend to rely on the services that are most important to the business. Because this feature is in addition to HA, it makes sense to use it only when a quick HA failover is unacceptable. You may want to consider using FT in your design in these cases:
- For the most business-critical applications
- During periods when a particular application is more crucial to the business
- When there are no other appropriate clustering techniques for the application
Scheduled tasks are available to turn FT on and off, so VMs can be protected on demand. You can automate when FT is used, so the additional resources are consumed only during those periods when you need the protection.
FT Impacts
FT works very closely with HA and also interacts with DRS functions. You should note some of these impacts while considering your design.
As we stated earlier, VM-VM affinity rules apply only to the primary VM, because that is where all the I/O traffic is directed. FT keeps both VMs apart through its own hidden anti-affinity rule, so you can't force them together on the same host.
If the primary has an additional VM-VM affinity rule, and there is an affinity or anti-affinity between the primary and another VM, then when a failover happens a violation can occur. DRS can't move the newly promoted secondary, and its original position may be in conflict with the rule. With EVC enabled on the cluster, DRS can move the promoted secondary VM to avoid any rule violation.
The VM-Host affinity rules apply to both primary and secondary, so both are effectively kept in the same VM group and have an affinity or anti-affinity with a group of hosts. This means that even if the FT fails over to the secondary VM, it will also be in the correct group of hosts for licensing or hardware association as required.
FT reserves the full allocation of memory on the primary VM and removes any previously set limits. To assist the secondary VM with keeping pace with the primary's host, you have the option of setting a CPU reservation as well. Both these reservations can have a significant impact on HA. The likely candidates for FT protection will probably have a reasonable amount of RAM allocated to them, and setting several FT VMs in the same cluster will change the HA slot sizes and so HA's efficiency. With larger VM reservations set in the cluster, DRS finds it harder to turn on more and more VMs if strict admission control is set. HA includes both the primary and secondary FT VMs when it's calculating admission control.
Without EVC enabled, you can't use DRS for active load-balancing the FT VMs, which means DPM may not be able to evacuate a selected host to shut it down. DPM won't recommend powering off any hosts running an FT VM if it can't vMotion it.
HA is able to protect FT VMs when a host fails. If the host running the primary VM fails, then the secondary takes over and spawns a new secondary. If the host running the secondary VM fails, then the primary creates a new secondary. If multiple hosts fail, which affects both primary and secondary, then HA restarts the primary on an alternate host, which in turn automatically creates a new secondary. During an HA failover, HA can intelligently place the new primary, and FT should create the new secondary on the most suitable host.
HA's VM monitoring feature can detect if the primary VM's guest OS or a specific service fails. When it does detect this, it restarts the primary VM. Once FT sees that the sync between the primary and secondary has failed, it instantly re-creates a replacement secondary VM. In this way, FT can work alongside VM monitoring to provide a solution that can protect against host, VM, and application failures.
FT Recommendations
Along with the long list of requirements and restrictions that FT places on hosts and VMs, a number of design recommendations improve the efficiency of FT:
Clusters
- All cluster hosts should have access to same networks and shared storage. Otherwise, the hosts selected for the secondary VMs will be limited.
- It's important that all the hosts have similar performance characteristics so primary and secondary VMs can run at similar speeds. VMware recommends that host CPUs shouldn't vary more than 400 MHz.
- All cluster hosts should have the same power-management, CPU instruction sets, and HyperThreading BIOS settings.
- Enable EVC on the cluster so the FT VMs can participate in DRS.
- You can create a resource pool for all your FT VMs with excess memory, to ensure that VM overhead is accounted for. Because FT is turned on, the VM's memory reservation is set to the full amount of allocated RAM. But this doesn't account for any memory overhead.
Hosts
- You should have fully redundant network and storage connections. FT will fail over a VM if the host loses all paths to its Fiber Channel (FC) connected datastore, but this shouldn't replace redundant FC links.
- The use of active/passive links with other VMkernel traffic provides a simple way of providing logging-traffic redundancy.
- You should split the vMotion and FT logging subnets and use separate active links for each.
- You should use at least 1 GbE links for the logging network. Using jumbo frames can improve the efficiency of the logging network even further. The FT logging connection is likely to be the limiting factor on the number of FT VMs you can have on each host. If you're consolidating host traffic via 10 GbE links, you need to implement some sort of QoS for the FT logging link to prevent any bursty traffic from saturating the link. For example, vMotions can use up to 8 Gbps of bandwidth, and each host can vMotion eight VMs at once. Without control, this can flood the connections shared with FT logging.
- Adding more uplinks on the logging connection's vSwitch doesn't necessarily increase distribution of the traffic across multiple links. You can use IP-hash load-balancing with EtherChannel to provide some load-balancing across multiple links. Source port ID or source MAC address load-balancing policies won't balance logging traffic.
- Host time should be synchronized to an available Network Time Protocol (NTP) server.
- VMware advises that you run at most four primary VMs and four secondary VMs on each host. Because the logging traffic is largely asymmetric from primary to secondary, spreading them between hosts improves the use of the logging connection. Also, because all the network I/O and disk I/O is being directed to and from the primary, the primary's host has more load that can be balanced by splitting primary and secondary VMs.
- The network used for FT logging should be sufficiently secure because this traffic is unencrypted and contains network and storage I/O that could potentially carry sensitive data.
VMs
- If the secondary VM is struggling for CPU resources on its host, causing the primary to slow down, you can add a CPU reservation to the primary that will be duplicated to the secondary. This should help with CPU contention on the secondary host.
- When you initially turn on FT for a VM, the disks are converted to eager-zeroed thick, which can take time to process. You can convert the disks ahead of time, during quieter periods, to ensure that FT can be turned on more quickly.
- Turning on FT disables some performance features, such as nested page tables. Don't turn on FT unless you're going to use it.
- If you're enabling FT on VMs with more than 64 GB of memory, you can encounter issues because there may be insufficient bandwidth to transfer all the changes in the default vMotion timeout of 8 seconds. You can increase the timeout in the VM's configuration file, but doing so may lead to the VM being unresponsive longer when you enable FT or during failovers or vMotions.
- Enabling FT causes spikes in CPU and saturates the vMotion network while the secondary VM is created. Try to avoid enabling and disabling FT frequently.
- The secondary VM uses additional resources on its host: CPU and memory levels equivalent to that of the primary. So, don't enable VMs unnecessarily.
- High guest OS timer interrupts cause increased logging traffic. Some Linux OSes allow you to reduce this setting, and you may wish to consider doing so if the logging bandwidth is constrained.
- Each FT VM's guest OS should have its time synchronized to an external time source.
Summary
This chapter has looked carefully at vCenter's datacenter structures and the functionality available to protect and optimize your clusters.
A clever datacenter design allows you to manage the hosts and VMs more efficiently and more intuitively. Fortunately, many of the structural pieces can be changed and honed easily, often with little or no downtime, so retrospective design changes may be relatively painless. It's worth considering your entire vSphere environment, because the power of vCenter's permissions, events/tasks, alarms, scheduled tasks, and views can make a big difference; this central infrastructure tool is simple to manage and effective, which enables staff instead of burdening them.
There are several cluster tools to make the most of your physical resources. First, you can use resources pools to divide and allocate CPU and memory as required, ensuring that the VMs that need resources receive them fairly and as you want them apportioned. DRS is critical to resource management; it places VMs appropriately on hosts and keeps the cluster suitably balanced with vMotion. You can achieve more granular control over VM placement with affinity rules and VM-Host rules. Finally, DPM makes power savings possible by shutting down hosts that aren't required.
In addition to all the resource optimizations, you can design clusters to provide differing levels of protection for your VMs. HA can restart VMs on alternate hosts, VM monitoring watches for unresponsive guest OSes and applications, and FT maintains online stand-in copy VMs. The rewritten HA mechanism in vSphere 5 not only improves the stability and scalability of this feature but also removes many of the awkward design constraints necessary to accommodate its predecessor.
Datacenter design is very important to the overall efficiency of your vSphere environment. It can enhance the working ability of your hosts and their VMs, making the most of your CAPEX layout and reducing the accompanying OPEX overhead. It's one part of the design worth reevaluating regularly, because nothing remains static and there are usually areas that can benefit from further optimizations. When you're looking at the datacenter design, it's important to examine it as a whole, because so many of the elements interact, work together, and even constrain each other. Think of all the elements in this chapter, and apply each part to best effect.