
Initially, large-scale algorithms were used to run on huge machines called supercomputers. These supercomputers shared the same memory space. The resources were all local—physically placed in the same machine. It means that the communications between the various processors were very fast and they were able to share the same variable through the common memory space. As the systems evolved and the need to run large-scale algorithms grew, the supercomputers evolved into Distributed Shared Memory (DSM) where each processing node used to own a portion of the physical memory. Eventually, clusters were developed, which are loosely coupled and rely on message passing among processing nodes. For large-scale algorithms, we need to find more than one execution engines running in parallel to solve a complex problem:
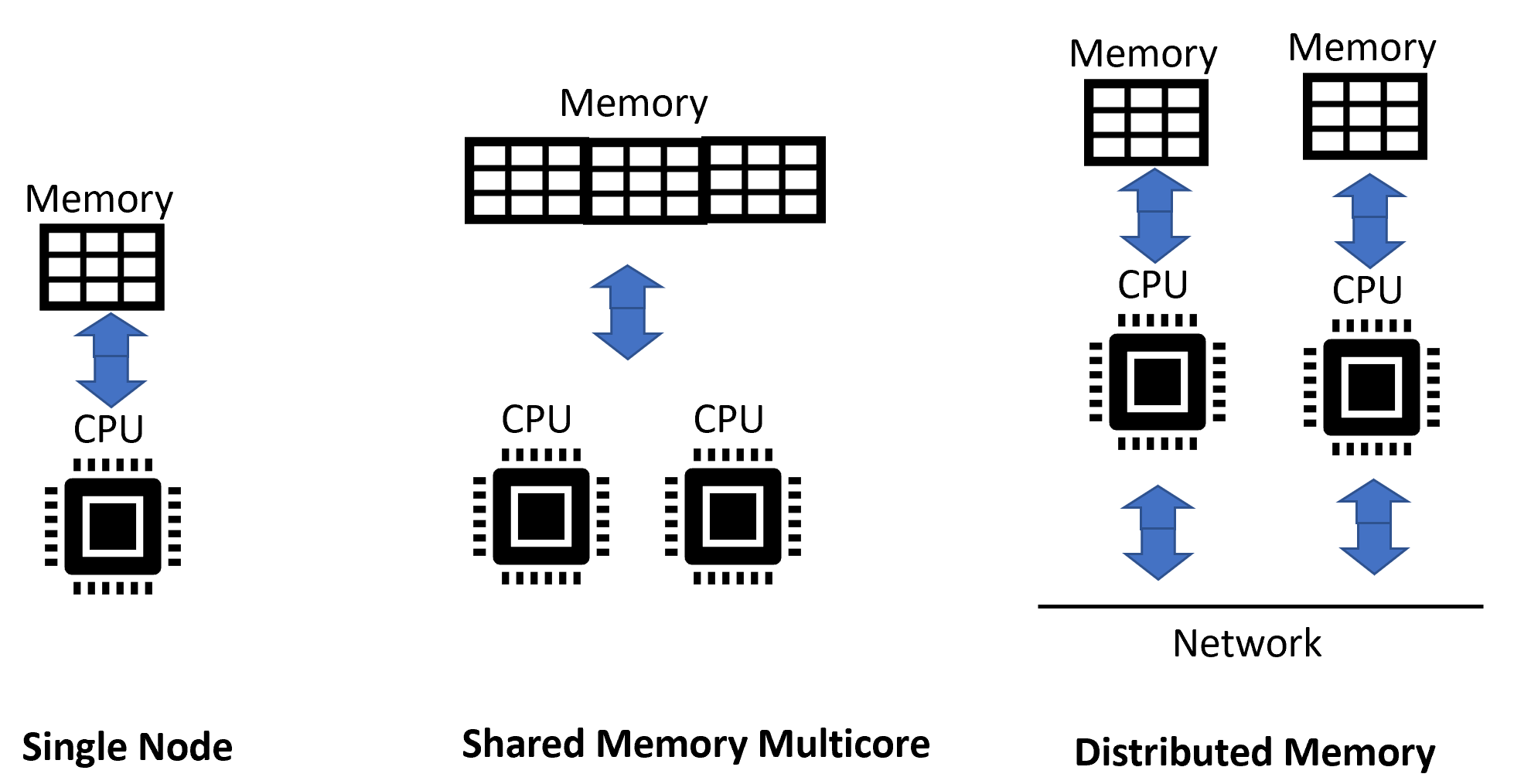
There are three strategies to have more than one execution engine:
- Look within: Exploit the resources already on the computer. Use the hundreds of cores of the GPU to run a large-scale algorithm.
- Look outside: Use distributed computing to find more computing resources that can be collectively used to solve the large-scale problem at hand.
- Hybrid strategy: Use distributed computing and, on each of the nodes, use the GPU or an array of GPUs to expedite the running of the algorithm.