
Chapter 20. AI Ethics, Fairness, and Privacy
In this book you’ve taken a programmer’s tour of the APIs available in the TensorFlow ecosystem to train models for a variety of tasks and deploy those models to a number of different surfaces. It’s this methodology of training models using labeled data instead of explicitly programming logic yourself that is at the heart of the machine learning and, by extension, artificial intelligence revolution.
In Chapter 1, we condensed the changes this involves for a programmer into a diagram, shown in Figure 20-1.
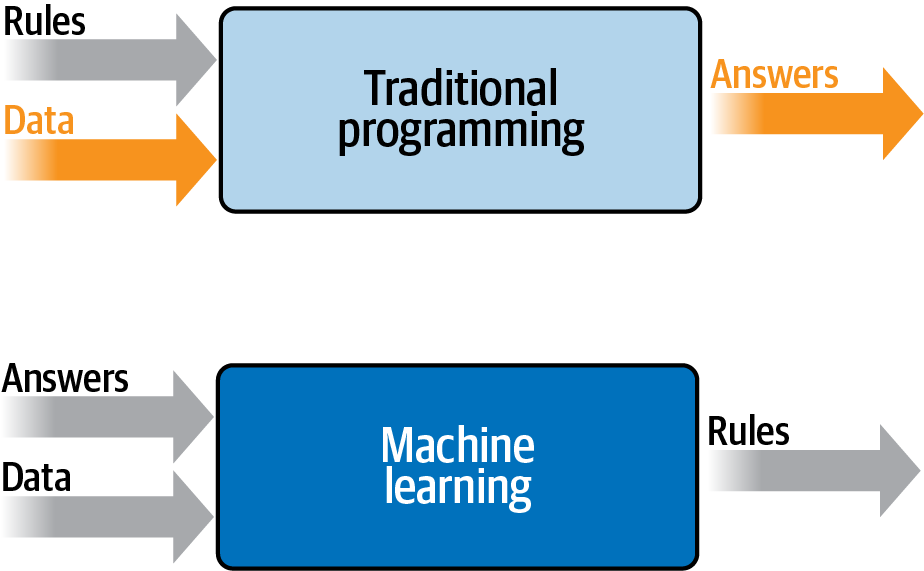
Figure 20-1. Traditional programming versus machine learning
This leads to a new challenge. With source code, it’s possible to inspect how a system works by stepping through and exploring the code. But when you build a model, even a simple one, the outcome is a binary file consisting of the learned parameters within the model. These can be weights, biases, learned filters, and more. As a result, they can be quite obscure, leading to difficulty in interpreting what they do and how they work.
And if we, as a society, begin to depend on trained models to help us with computing tasks, it’s important for us to have some level of transparency regarding how the models work—so it’s important for you, as an AI engineer, to understand building for ethics, fairness, and privacy. There’s enough to learn to fill several books, so in this chapter we’ll really only be scraping the surface, but I hope it’s a good introduction to helping you learn what you need to know.
Most importantly, building systems with a view to being fair to users isn’t a new thing, nor is it a virtue signaling of political correctness. Regardless of anybody’s feelings about the importance of engineering for overall fairness, there’s one indisputable fact that I aim to demonstrate in this chapter: that building systems with a view to being both fair and ethical is the right thing to do from an engineering perspective and will help you avoid future technical debt.
Fairness in Programming
While recent advances in machine learning and AI have brought the concepts of ethics and fairness into the spotlight, it’s important to note that disparity and unfairness have always been topics of concern in computer systems. In my career, I have seen many examples where a system has been engineered for one scenario without considering the overall impact with regard to fairness and bias.
Consider this example: your company has a database of its customers and wants to target a marketing campaign to get more customers in a particular zip code where it has identified a growth opportunity. To do so, the company will send discount coupons to people in that zip code whom it has connected with, but who haven’t yet purchased anything. You could write SQL like this to identify these potential customers:
SELECT * from Customers WHERE ZIP=target_zip AND PURCHASES=0
This might seem to be perfectly sensible code. But consider the demographics at that zip code. What if the majority of people who live there are of a particular race or age? Instead of growing your customer base evenly, you could be overtargeting one segment of the population, or worse, discriminating against another by offering discounts to people of one race but not another. Over time, continually targeting like this could result in a customer base that is skewed against the demographics of society, ultimately painting your company into a corner of primarily serving one segment.
Here’s another example—and this one really happened to me! Back in Chapter 1, I used a few emoji to demonstrate the concept of machine learning for activity detection (see Figure 20-2).

Figure 20-2. Emoji to demonstrate machine learning
There’s a story behind these that started several years ago. I was fortunate enough to visit Tokyo, and at the time I was beginning to learn how to run. A good friend of mine in the city invited me to run around the Imperial Palace. She sent a text with a couple of emoji in it that looked like Figure 20-3.

Figure 20-3. Text containing emoji
The text contained two emoji, a woman running and a man running. I wanted to reply and send the same emoji, but was doing it from a desktop chat application, which didn’t have the modern ability to pick an emoji from a list. If you wanted an emoji, you had to type a shortcode.
When I typed the shortcode (running), I would get the male emoji. But if I wanted the female emoji, there seemed to be no way of doing it. After a bit of Googling, I found that I could get the female emoji by typing (running)+♀. Then the question became, how do you type ♀?
It depends on the operating system, but for example on Windows you have to hold Alt and type 12 on the numeric keypad. On Linux you have to press Left Ctrl-Shift-U and then type the Unicode for the symbol, which is 2640.
That’s a lot of work to get a female emoji, not to mention that the implicit declaration of a female emoji is a male one that gets modified to make it female with the addition of ♀. This is not inclusive programming. But how did it arise?
Consider the history of emoji. When they were first used, they were simply characters in text that were typed with a sideways view, like :) for smiling or ;) for winking, or my personal favorite *:) which looks like Ernie from Sesame Street. They’re inherently genderless because they’re so low-resolution. As emoji (or emoticons) evolved from characters to graphics, they were typically monochrome “stick man”–type illustrations. The clue is in the name—stick man. As graphics became better, particularly on mobile devices, the emoji then became clearer. For example, in the original iPhone OS (2.2), the running emoji (renamed “Person Running”) looked like this: ,![]() .
.
As graphics improved further and screen pixel densities increased, the emoji continued to evolve, and by iOS 13.3 it looked like Figure 20-4.

Figure 20-4. Person Running emoji from iOS 13.3
When it comes to engineering, as well as improving the graphics, it’s important to maintain backward compatibility—so if earlier versions of your software used the shortcode (running) to indicate a stick man running, later versions with richer graphics can give you a graphic like this one, which is now very clearly a man running.
Consider what this would look like in pseudocode:
if shortcode.contains("(running)"){ showGraphic(personRunning) }
This is well-engineered code, because it maintains backward compatibility as the graphic changes. You never need to update your code for new screens and new graphics; you just change the personRunning resource. But the effect changes for your end users, so you then identify that you also need to have a Woman Running emoji to be fair.
You can’t use the same shortcode, however, and you don’t want to break backward compatibility, so you have to amend your code, maybe to something like this:
if shortcode.contains("(running)"){ if(shortcode.contains("+♀")){ showGraphic(womanRunning); } else { showGraphic(personRunning); } }
From a coding perspective, this makes sense. You can provide the additional functionality without breaking backward compatibility, and it’s easy to remember—if you want a female runner you use a female Venus symbol. But life isn’t just from a coding perspective, as this example shows. Engineering like this led to a runtime environment that adds excess friction to the use cases of a significant portion of the population.
The technical debt incurred from the beginning, when gender equality wasn’t considered when creating emoji, still lingers to this day in workarounds like this. Check the Woman Running page on Emojipedia, and you’ll see that this emoji is defined as a zero-width joiner (ZWJ) sequence that combines Person Running, a ZWJ, and a Venus symbol. The only way to try to give end users the proper experience of having a female running emoji is to implement a workaround.
Fortunately, as many apps that offer emoji now use a selector where you choose it from a menu, as opposed to typing a shortcode, the issue has become somewhat hidden. But it’s still there under the surface, and while this example is rather trivial, I hope it demonstrates how past decisions that didn’t consider fairness or bias can have ramifications further down the line. Don’t sacrifice your future to save your present!
So, back to AI and machine learning. As we’re at the dawn of a new age of application types, it’s vitally important for you to consider all aspects of the use of your application. You want to ensure that fairness is built in as much as possible. You also want to ensure that bias is avoided as much as possible. It’s the right thing to do, and it can help avoid the technical debt of future workarounds.
Fairness in Machine Learning
Machine learning systems are data-driven, not code-driven, so identifying biases and other problematic areas becomes an issue of understanding your data. It requires tooling to help you both explore your data and see how it flows through a model. Even if you have excellent data, a poorly engineered system could lead to issues. The following are some tips to consider when building ML systems that can help you avoid such issues:
- Determine if ML is actually necessary
It might go without saying, but, as new trends hit the technology market, there’s always pressure to implement them. There’s often a push from investors, or from sales channels or elsewhere, to show that you are cutting-edge and using the latest and greatest. As such, you may be given the requirement to incorporate machine learning into your product. But what if it isn’t necessary? What if, in order to hit this nonfunctional requirement, you paint yourself into a corner because ML isn’t suited to the task, or because while it might be useful in the future, you don’t have adequate data coverage right now?
I once attended a student competition where the participants took on the challenge of image generation using generative adversarial networks (GANs) to predict what the lower half of a face looks like based on the upper half of the face. It was flu season in Japan, and many people wear face masks. The idea was to see if one could predict the face below the mask. For this task they needed access to facial data, so they used the IMDb dataset of face images with age and gender labels. The problem? Given that the source is IMDb, the vast majority of the faces in this dataset are not Japanese. As such, their model did a great job of predicting my face, but not their own. In the rush to produce an ML solution when there wasn’t adequate data coverage, the students produced a biased solution. This was just a show-and-tell competition, and their work was brilliant, but it was a great reminder that rushing to market with an ML product when one isn’t necessarily needed, or when there isn’t sufficient data to build a proper model, can lead you down the road of building biased models and incurring heavy future technical debt.
- Design and implement metrics from day one
- Or maybe that should read from day zero, as we’re all programmers here. In particular, if you are amending or upgrading a non-ML system to add ML, you should do as much as you can to track how your system is currently being used. Consider the emoji story from earlier, as an example. If people had identified early on that, given there are as many female runners as male runners, having a Person Running emoji be a man is a user experience mistake, the problem could have been solved sooner—or might even never have arisen in the way it did. You should always try to understand your users’ needs, so that as you design a data-oriented architecture for ML you can ensure that you have adequate coverage to meet these needs, and possibly predict future trends and get ahead of them.
- Build a minimum viable model and iterate
- You should experiment with building a minimum viable model before you set any expectations about deploying ML models into your system. ML and AI are not a magic dust solution for everything. Given the data at hand, build a minimum viable product (MVP) that gets you on the road to having ML in your system. Does it do the job? Do you have a pathway to gathering more of the data needed to extend the system while keeping it fair for all users? Once you have your MVP, iterate, prototype, and continue to test before rushing something to production.
- Ensure your infrastructure supports rapid redeployment
- Whether you are deploying your model to a server with TensorFlow Serving, to mobile devices with TensorFlow Lite, or to browsers with TensorFlow.js, it’s important to keep an eye on how you can redeploy the model if needed. If you hit a scenario where it is failing (for any reason, not just bias), it’s good to have the ability to rapidly deploy a new model without breaking your end users’ experience. Using a configuration file with TensorFlow Serving, for example, allows you to define multiple models with named values that you can use to rapidly switch between them. With TensorFlow Lite, your model is deployed as an asset, so instead of hardcoding that into your app, you might want the app to check the internet for updated versions of the model and update if it detects one. In addition, abstracting the code that runs inference with a model—avoiding hardcoded labels, for example—can help you to avoid regression errors when you redeploy.
Tools for Fairness
There’s a growing market for tooling for understanding the data used to train models, the models themselves, and the inference output of the models. We’ll explore a few of the currently available options here.
The What-If Tool
One of my favorites is the What-If Tool from Google. Its aim is to let you inspect an ML model with minimal coding required. With this tool, you can inspect the data and the output of the model for that data together. It has a walkthrough that uses a model based on about 30,000 records from the 1994 US Census dataset that is trained to predict what a person’s income might be. Imagine, for example, that this is used by a mortgage company to determine whether a person may be able to pay back a loan, and thus to determine whether or not to grant them the loan.
One part of the tool allows you to select an inference value and see the data points from the dataset that led to that inference. For example, consider Figure 20-5.
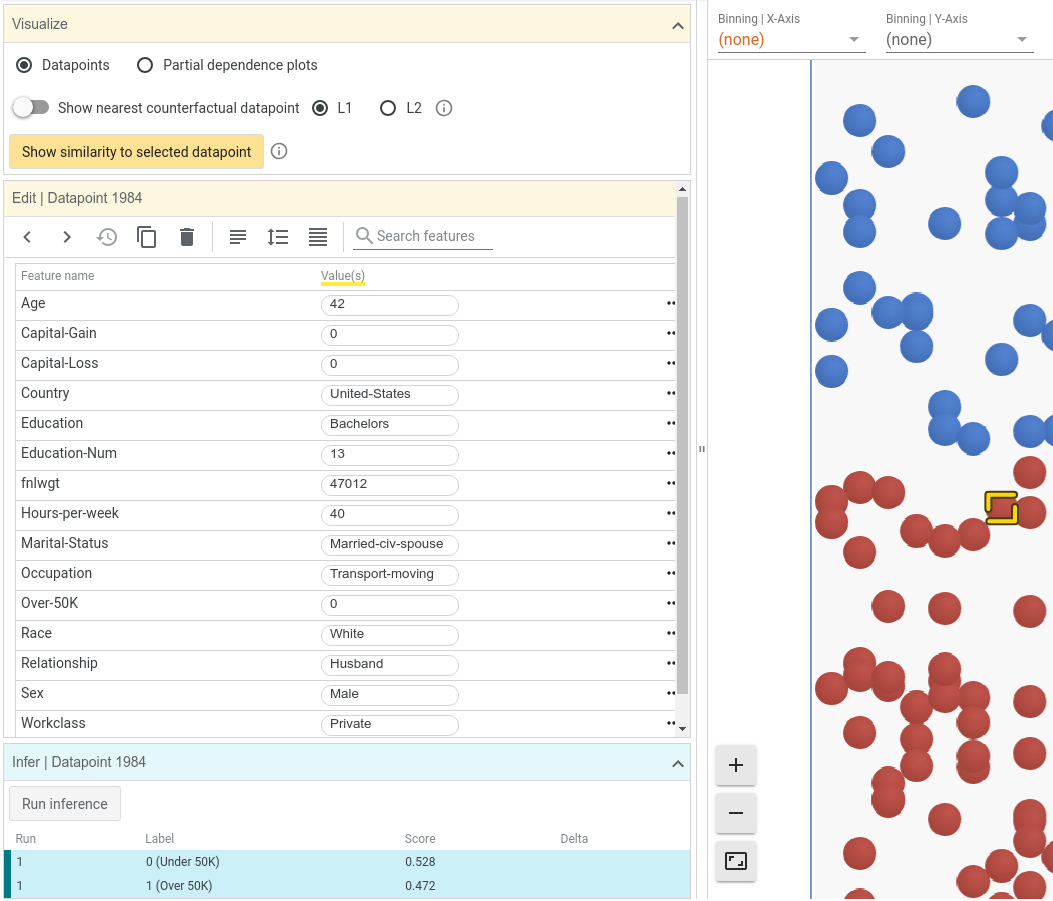
Figure 20-5. Using the What-If Tool
This model returns a probability of low income from 0 to 1, with values below 0.5 indicating high income and others low. This user had a score of 0.528, and in our hypothetical mortgage application scenario could be rejected as having too low an income. With the tool, you can actually change some of the user’s data—for example, their age—and see what the effect on the inference would be. In the case of this person, changing their age from 42 to 48 gave them a score on the other side of the 0.5 threshold, and as a result changed them from being a “reject” on the loan application to an “accept.” Note that nothing else about the user was changed—just their age. This gives a strong signal that there’s a potential age bias in the model.
The What-If Tool allows you to experiment with various signals like this, including details like gender, race, and more. To prevent a one-off situation being the tail that wags the dog, causing you to change your entire model to prevent an issue that lies with one customer and not the model itself, the tool includes the ability to find the nearest counterfactuals—that is, it finds the closest set of data that results in a different inference so you can start to dive into your data (or model architecture) in order to find biases.
I’m just touching the surface of what the What-If Tool can do here, but I’d strongly recommend checking it out. There are lots of examples of what you can do with it on the site. At its core—as the name suggests—it gives you tools to test “what if” scenarios before you deploy. As such, I believe it can be an essential part of your ML toolbox.
Facets
Facets is a tool that can work in complement to the What-If Tool to give you a deep dive into your data through visualizations. The goal of Facets is to help you understand the distribution of values across features in your dataset. It’s particularly useful if your data is split into multiple subsets for training, testing, validation, or other uses. In such cases, you can easily end up in a situation where data in one split is skewed in favor of a particular feature, leading you to having a faulty model. This tool can help you determine whether you have sufficient coverage of each feature for each split.
For example, using the same US Census dataset as in the previous example with the What-If Tool, a little examination shows that the training/test splits are very good, but use of the capital gain and capital loss features might have a skewing effect on the training. Note in Figure 20-6, when inspecting quantiles, that the large crosses are very well balanced across all of the features except these two. This indicates that the majority of the data points for these values are zeros, but there are a few values in the dataset that are much higher. In the case of capital gain, you can see that 91.67% of the training set is zeros, with the other values being close to 100k. This might skew your training, and can be seen as a debugging signal. This could introduce a bias in favor of a very small part of your population.
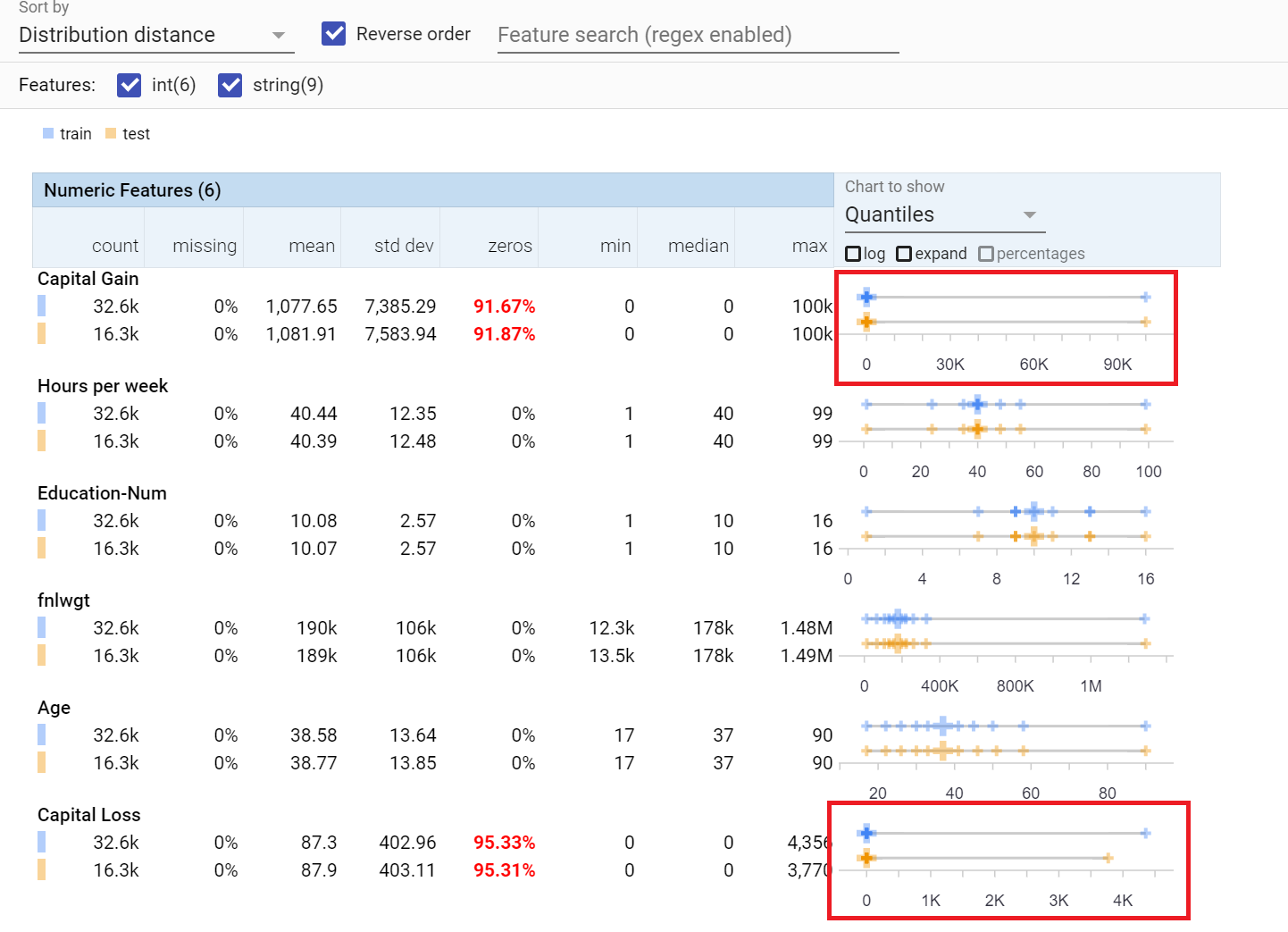
Figure 20-6. Using Facets to explore a dataset
Facets also includes a tool called Facets Dive that lets you visualize the contents of your dataset according to a number of axes. It can help identify errors in your dataset, or even preexisting biases that exist in it so you know how to handle them. For example, consider Figure 20-7, where I split the dataset by target, education level, and gender.
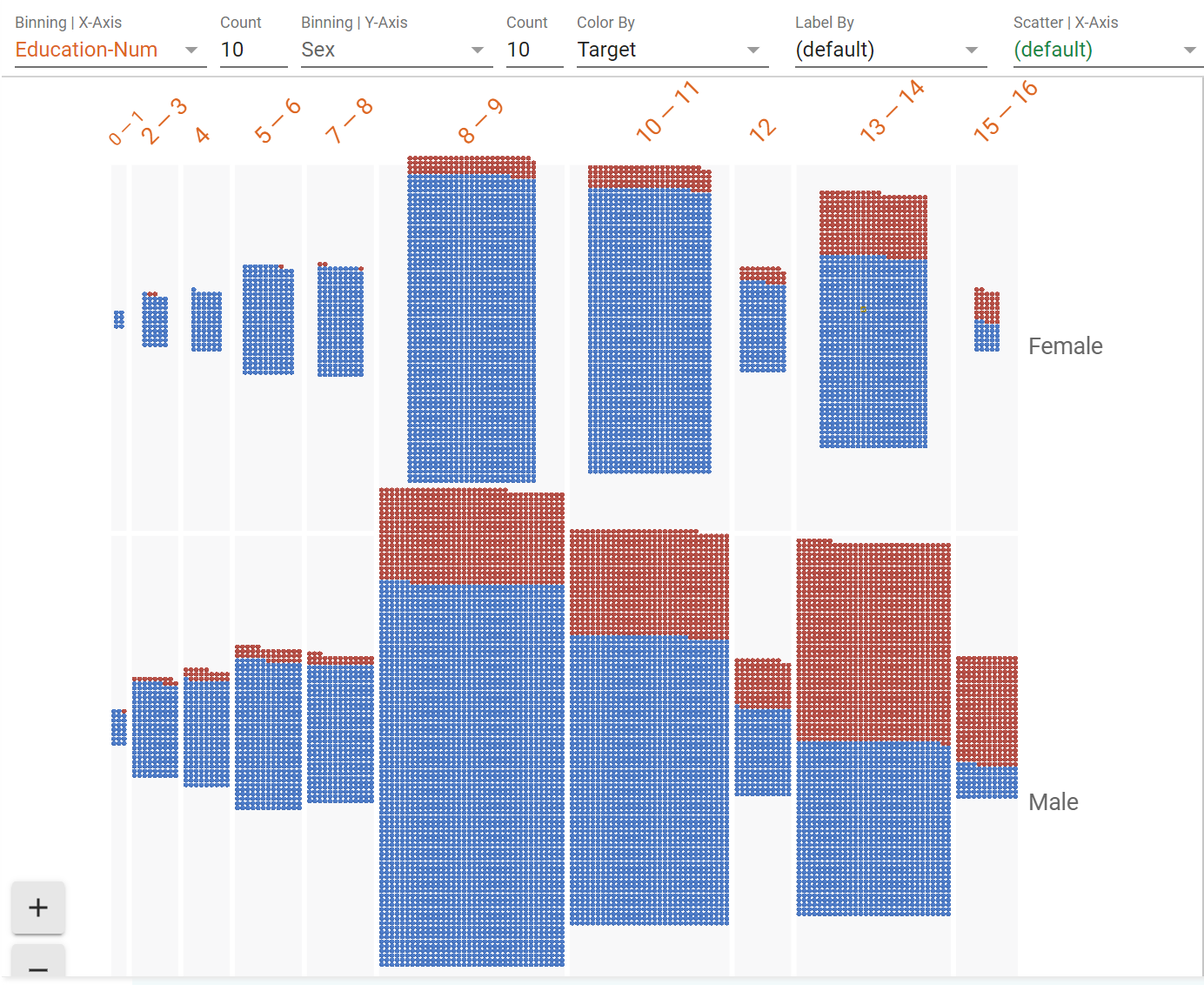
Figure 20-7. A deep dive with Facets
Red means “high income predicted,” and left to right are levels of education. In almost every case the probability of a male having a high income is greater than a female, and in particular with higher levels of education the contrast becomes stark. Look for example at the 13–14 column (which is the equivalent of a bachelor’s degree): the data shows a far higher percentage of men being high earners than women with the same education level. While there are many other factors in the model to determine earning level, having such a disparity for highly educated people is a likely indicator of bias in the model.
To help you identify features such as these, along with the What-If Tool, I strongly recommend using Facets to explore your data and your model’s output.
Both of these tools come from the People + AI Research (PAIR) team at Google. I’d recommend you bookmark their site to keep an eye on the latest releases, as well as the People + AI Guidebook to help you follow a human-centered approach to AI.
Federated Learning
After your models are deployed and distributed, there’s a huge opportunity for them to be continually improved based on how they are used by your entire user base. On-device keyboards with predictive text, for example, must learn from every user in order to be effective. But there’s a catch—in order for a model to learn, the data needs to be collected, and gathering data from end users to train a model, particularly without their consent, can be a massive invasion of privacy. It’s not right for every word your end users type to be used to improve keyboard predictions, because then the contents of every email, every text, every message would be known to an outside third party. So, to allow for this type of learning, a technique to maintain the user’s privacy while also sharing the valuable parts of the data needs to be used. This is commonly called federated learning, and we’ll explore it in this section.
The core idea behind federated learning is that user data is never sent to a central server. Instead, a procedure like the one outlined in the following sections is used.
Step 1. Identify Available Devices for Training
First of all, you’ll need to identify a set of your users that are suitable for performing training work. As the training will be done on the device (more about this later), you don’t want to break the user experience if they’re already doing something, so devices that are not currently in use and are plugged in would make a good set of “available” ones (see Figure 20-8).
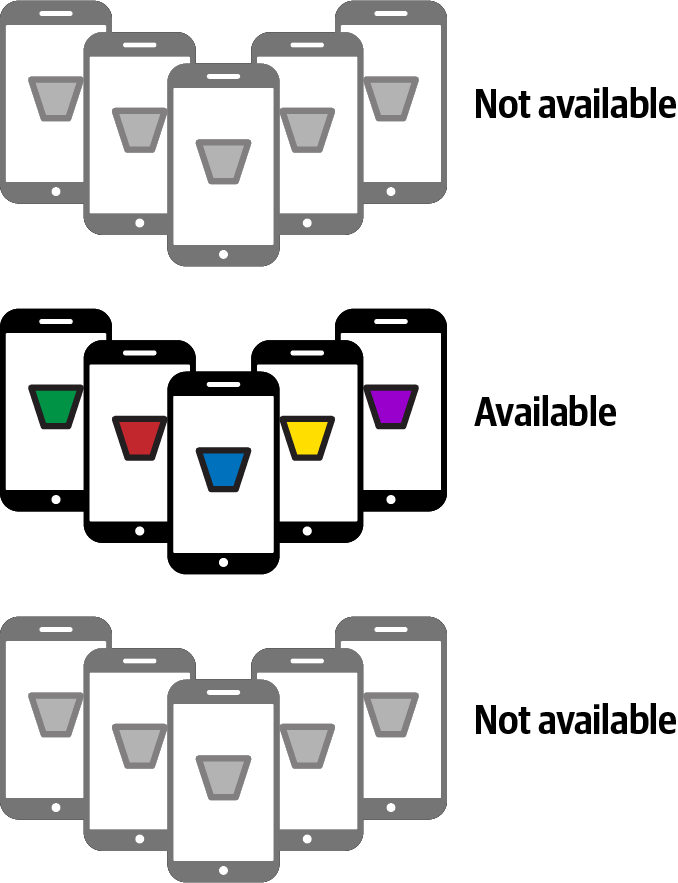
Figure 20-8. Identifying available devices
Step 2. Identify Suitable Available Devices for Training
Of the available ones, not all will be suitable. They may not have sufficient data, they may not have been used recently, etc. There are a number of factors that could determine suitability, based on your training criteria. Based on these, you’ll have to filter the available devices down into a set of suitable available devices (Figure 20-9).
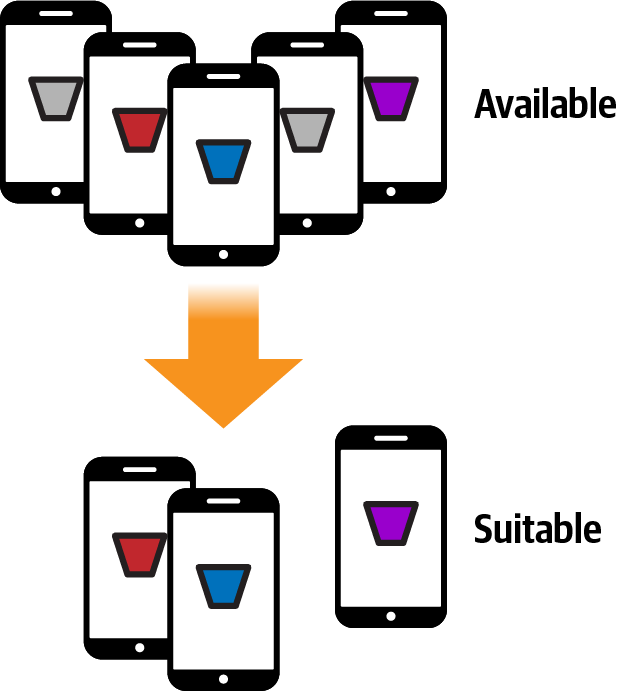
Figure 20-9. Choosing suitable available devices
Step 3. Deploy a Trainable Model to Your Training Set
Now that you’ve identified a set of suitable available devices, you can deploy a model to them (Figure 20-10). The model will be trained on the devices, which is why devices that are not currently in use and are plugged in (to avoid draining the battery) are the suitable family to use. Note that there is no public API to do on-device training with TensorFlow at this time. You can test this environment in Colab, but there’s no Android/iOS equivalent at the time of writing.
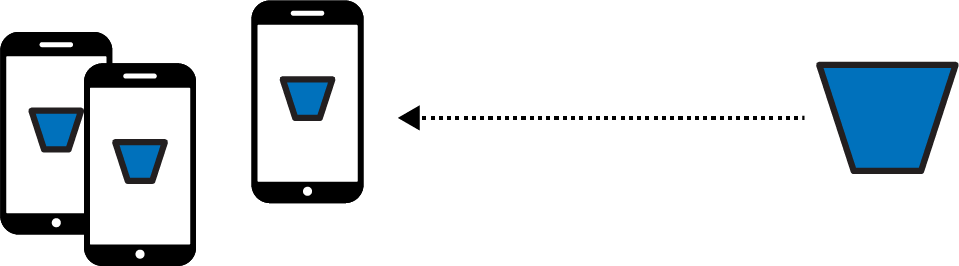
Figure 20-10. Deploying a new training model to the devices
Step 4. Return the Results of the Training to the Server
Note that the data used to train the model on the individual’s device never leaves the device. However weights, biases, and other parameters learned by the model can leave the device. Another level of security and privacy can be added here (discussed in “Secure Aggregation with Federated Learning”). In this case, the values learned by each of the devices can be passed to the server, which can then aggregate them back into the master model, effectively creating a new version of the model with the distributed learning of each of the clients (Figure 20-11).
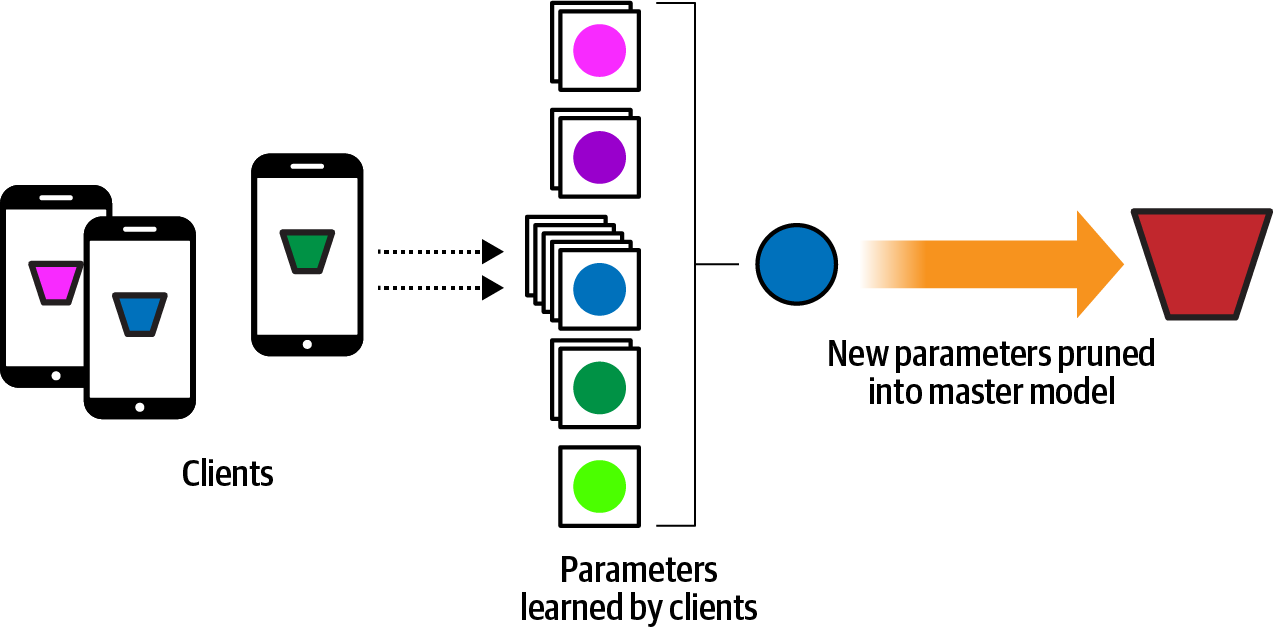
Figure 20-11. Creating a new master model from the learnings of the clients
Step 5. Deploy the New Master Model to the Clients
Then, as clients become available to receive the new master model, it can get deployed to them, so everyone can access the new functionality (Figure 20-12).
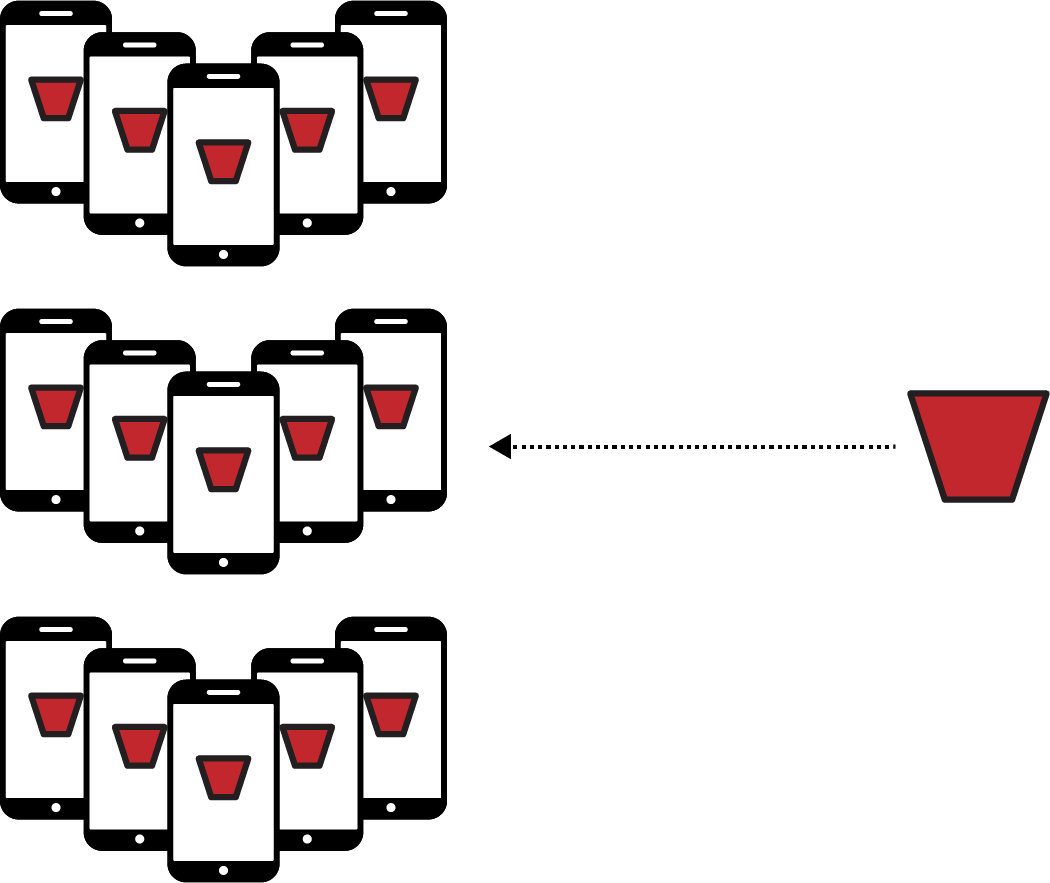
Figure 20-12. The new master model gets deployed to all of the clients
Following this pattern will allow you to have a conceptual framework where you have a centralized model that can be trained from the experiences of all of your users, without violating their privacy by sending data to your server. Instead, a subset of the training is done directly on their devices, and the results of that training are all that ever leaves the device. As described next, a method called secure aggregation can be used to provide an additional layer of privacy through obfuscation.
Secure Aggregation with Federated Learning
The previous walkthrough demonstrated the conceptual framework of federated learning. This can be combined with the concept of secure aggregation to further obfuscate the learned weights and biases while in transit from the client to the server. The idea behind it is simple. The server pairs up devices with others in a buddy system. For example, consider Figure 20-13, where there are a number of devices, each of which is given two buddies. Each buddy pair is sent the same random value to be used as a multiplier to obfuscate the data it sends.
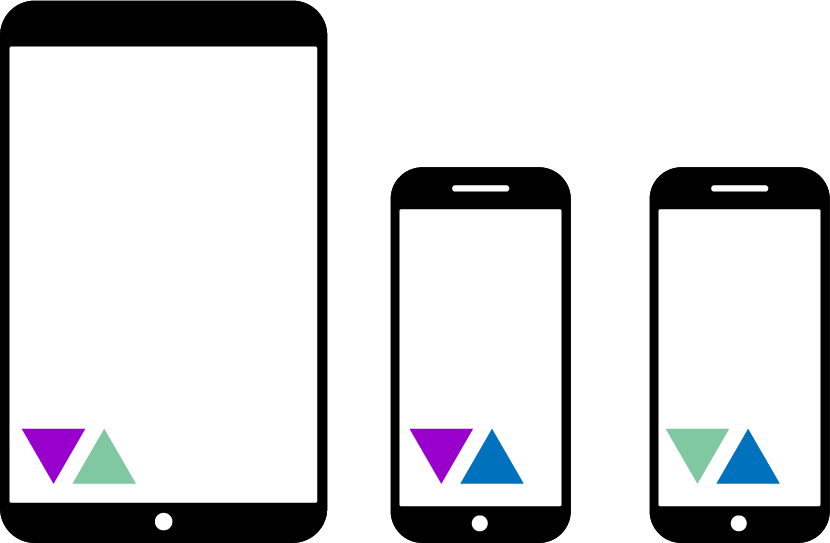
Figure 20-13. Buddy devices
Here, the first device is buddied with the second, as indicated by the dark triangles. These are values that, when combined, will cancel each other out: so, the dark “down” triangle could be 2.0, and the dark “up” could be 0.5. When multiplied together they give 1. Similarly, the first device is paired with the third device. Every device has two “buddies,” where the number on that device has a counterpart on the other.
The data from a particular device, represented by a circle in Figure 20-14, can then be combined with the random factors before being sent to the server.
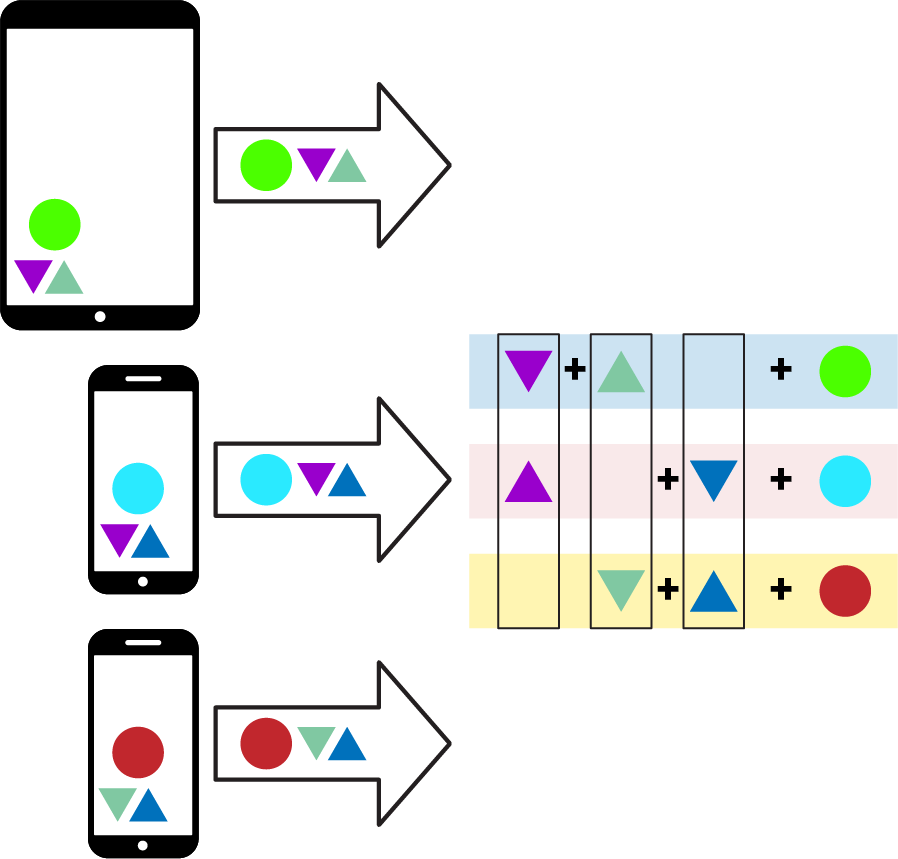
Figure 20-14. Sending values to the server with secure aggregation
The server, knowing the values sent to the buddies, can cancel them out and just get the payload. While the data is in transit to the server it is obfuscated by the keys.
Federated Learning with TensorFlow Federated
TensorFlow Federated (TFF) is an open source framework that gives you federated learning functionality in a simulated server environment. At the time of writing it’s still experimental, but it’s worth looking into. TFF is designed with two core APIs. The first is the Federated Learning API, which gives you a set of interfaces that add federated learning and evaluation capabilities to your existing models. It allows you to, for example, define distributed variables that are impacted by learned values from distributed clients. The second is the Federated Core API, which implements the federated communication operations within a functional programming environment. It’s the foundation for existing deployed scenarios such as the Google keyboard, Gboard.
I won’t go into detail on how to use TensorFlow Federated in this chapter as it’s still in its early stages, but I encourage you to check it out to prepare for the day that on-device federated learning libraries become available!
Google’s AI Principles
TensorFlow was created by Google’s engineers as an outcropping of many existing projects built by the company for its products and internal systems. After it was open sourced, many new avenues for machine learning were discovered, and the pace of innovation in the fields of ML and AI is staggering. With this in mind, Google decided to put out a public statement outlining its principles with regard to how AI should be created and used. They’re a great guideline for responsible adoption, and worth exploring. In summary, the principles are:
- Be socially beneficial
- Advances in AI are transformative, and as that change happens the goal is to take into account all social and economic factors, proceeding only where the overall likely benefits outstrip the foreseeable risks and downsides.
- Avoid creating or reinforcing unfair bias
- As discussed in this chapter, bias can easily creep into any system. AI—particularly in cases where it transforms industry—presents an opportunity to remove existing biases, as well as to ensure that new biases don’t arise. One should be mindful of this.
- Be built and tested for safety
- Google continues to develop strong safety and security practices to avoid unintended harm from AI. This includes developing AI technologies in constrained environments and continually monitoring their operation after deployment.
- Be accountable to people
- The goal is to build AI systems that are subject to appropriate human direction and control. This means that appropriate opportunities for feedback, appeal, and relevant explanations must always be provided. Tooling to enable this will be a vital part of the ecosystem.
- Incorporate privacy design principles
- AI systems must incorporate safeguards that ensure adequate privacy and inform users of how their data will be used. Opportunities for notice and consent should be obvious.
- Uphold high standards of scientific excellence
- Technological innovation is at its best when it is done with scientific rigor and a commitment to open enquiry and collaboration. If AI is to help unlock knowledge in critical scientific domains, it should aspire to the high standards of scientific excellence that are expected in those areas.
- Be made available for uses that accord with these principles
- While this point might seem a little meta, it’s important to reinforce that the principles don’t stand alone, nor are they just for the people building systems. They’re also intended to give guidelines for how the systems you build can be used. It’s good to be mindful of how someone might use your systems in a way you didn’t intend, and as such good to have a set of principles for your users too!
Summary
And that brings us to the end of this book. It’s been an amazing and fun journey for me to write it, and I hope you’ve found value in reading it! You’ve come a long way, from the “Hello World” of machine learning through building your first computer vision, natural language processing, and sequence modeling systems and more. You’ve practiced deploying models everywhere from on mobile devices to the web and the browser, and in this chapter we wrapped up with a glimpse into the bigger world of how and why you should use your models in a mindful and beneficial way. You saw how bias is a problem in computing, and potentially a huge one in AI, but also how there is an opportunity now, with the field in its infancy, to be at the forefront of eliminating it as much as possible. We explored some of the tooling available to help you in this task, and you got an introduction to federated learning and how it might be the future of mobile application development in particular.
Thank you so much for sharing this journey with me! I look forward to hearing your feedback and answering whatever questions I can.