
In Chapter 12, we discussed how interactive products should be designed to behave like considerate and intelligent people. One of the ways in which products are least capable in this regard is when the user is required to enter data. Some unfortunate artifacts of implementation-model thinking prevent people from working in the way they find most natural. In this chapter, we’ll discuss problems with existing ways of dealing with data entry and some possible strategies for making this process more focused on human needs and less focused on the needs of the database.
One of the most critical requirements for properly functioning software is clean data. As the aphorism says, “garbage in, garbage out.” As a result, programmers typically operate according to a simple imperative regarding data entry and data processing: Never allow tainted, unclean data to touch an application. Programmers, thus, erect barriers in user interfaces so that bad data can never enter the system and compromise the pure internal state that is commonly called data integrity.
The imperative of data integrity posits that there is a world of chaotic information out there, and before any of it gets inside the computer it must be filtered and cleaned up. The software must maintain a vigilant watch for bad data, like a customs official at a border crossing. All data is validated at its point of entry. Anything on the outside is assumed to be suspect, and after it has run the gauntlet and been allowed inside, it is assumed to be pristine. The advantage is that once data is inside the database, the code doesn’t have to bother with successive, repetitive checks on its validity or appropriateness.
The problem with this approach is that it places the needs of the database before those of its users, subjecting them to the equivalent of a shakedown every time they enter a scrap of data into the system. You don’t come across this problem often with most personal productivity software: PowerPoint doesn’t know or care if you’ve formatted your presentation correctly. But as soon as you deal with a large corporation — whether you are a clerk performing data entry for an enterprise management system or a Web surfer buying DVDs online — you come face to face with the border patrol.
People who fill out lots of forms every day as part of their jobs know that data isn’t typically provided to them in the pristine form that their software demands. It is often incomplete, and sometimes wrong. Furthermore, they may break from the strict demands of a form to expedite processing of this data to make their customers happy. But when confronted with a system that is entirely inflexible in such matters, these people must either grind to a halt or find some way to subvert the system to get things done. If, however, the software recognized these facts of human existence and addressed them directly with an appropriate user interface, everyone would benefit.
Efficiency aside, there is a more insidious aspect to this problem: When software shakes down data at the point of entry, it makes a very clear statement that the user is insignificant and the application is omnipotent — that the user works for the good of the application and not vice versa. Clearly, this is not the kind of world we want to create with our technological inventions. We want people to feel empowered, and make it clear that computers work for us. We must return to the ideal division of digital labor: The computer does the work, while the human makes the decisions.
Happily, there’s more than one way to protect software from bad data. Instead of keeping it out of the system, the programmer needs to make the system immune to inconsistencies and gaps in the information. This method involves creating much smarter, more sophisticated applications that can handle all permutations of data, giving the application a kind of data immunity.
To implement this concept of data immunity, our applications must be built to look before they leap and to ask for help when they need it. Most software blindly performs arithmetic on numbers without actually examining them first. The application assumes that a number field must contain a number — data integrity tells it so. If a user enters the word “nine” instead of the number “9,” the application will barf, but a human reading the form wouldn’t even blink. If the application simply looked at the data before it acted, it would see that a simple math function wouldn’t do the trick.
We must design our applications to believe that a user will enter what he means to enter, and if a user wants to correct things, he will do so without paranoid insistence. But applications can look elsewhere in the computer for assistance. Is there a module that knows how to make numeric sense of alphabetic text? Is there a history of corrections that might shed some light on a user’s intent?
If all else fails, an application must add annotations to the data so that when — and if — a user comes to examine the problem, he finds accurate and complete notes that describe what happened and what steps the application took.
Yes, if a user enters “asdf” instead of “9.38” the application won’t be able to arrive at satisfactory results. But stopping the application to resolve this right now is not satisfactory either; the entry process is just as important as the end report. If a user interface is designed correctly, the application provides visual feedback when a user enters “asdf,” so the likelihood of a user entering hundreds of bad records is very low. Generally, users act stupidly only when applications treat them stupidly.
When a user enters incorrect data, it is often close to being correct; applications should be designed to provide as much assistance in correcting the situation as possible. For example, if a user erroneously enters “TZ” for a two-letter state code, and also enters “Dallas” for a city name, it doesn’t take a lot of intelligence or computational resources to figure out how to correct the problem.
It is clearly counter to the goals of users — and to the utility of the system — if crucial data is omitted. The data-entry clerk who fails to key in something as important as an invoice amount creates a real problem. However, it isn’t necessarily appropriate for the application to stop the clerk and point out this failure. Think about your application like a car. Your users won’t take kindly to having the steering wheel lock up because the car discovered it was low on windshield-washer fluid.
Instead, applications should provide more flexibility. Users may not immediately have access to data for all the required fields, and their workflow may be such that they first enter all the information they have on hand and then return when they have the information needed to fill in the other fields. Of course, we still want our users to be aware of any required fields that are missing information, but we can communicate this to them through rich modeless feedback, rather than stopping everything to let them know something they may be well aware of.
Take the example of a purchasing clerk keying invoices into a system. Our clerk does this for a living and has spent thousands of hours using the application. He has a sixth sense for what is happening on the screen and wants to know if he has entered bad data. He will be most effective if the application notifies him of data-entry errors by using subtle visual and audible cues.
The application should also help him out: Data items, such as part numbers, that must be valid shouldn’t be entered through free text fields, but instead should be entered via type-ahead (auto-completion) fields or bounded controls such as drop-downs. Addresses and phone numbers should be entered more naturally into smart text fields that can parse the data. The application should provide unobtrusive modeless feedback on the status of his work. This will enable our clerk to take control of the situation, and will ultimately require less policing by the application.
Most of our information-processing systems are tolerant of missing information. A missing name, code, number, or price can almost always be reconstructed from other data in the record. If not, the data can always be reconstructed by asking the various parties involved in the transaction. The cost is high, but not as high as the cost of lost productivity or technical support centers. Our information-processing systems can work just fine with missing data. Some of the programmers who develop these systems may not like all the extra work involved in dealing with missing data, so they invoke data integrity as an unbreakable law. As a result, thousands of clerks must interact with rigid, overbearing software under the false rubric of keeping databases from crashing.
It is obviously counterproductive to treat workers like idiots to protect against those few who are. It lowers everyone’s productivity, encourages rapid, expensive, and error-causing turnover, and decreases morale, which increases the unintentional error rate of the clerks who want to do well. It is a self-fulfilling prophecy to assume that your information workers are untrustworthy.
The stereotypical role of the data-entry clerk mindlessly keypunching from stacks of paper forms while sitting in a boiler room among hundreds of identical clerks doing identical jobs is rapidly evaporating. The task of data entry is becoming less a mass-production job and more of a productivity job: a job performed by intelligent, capable professionals and, with the popularization of e-commerce, directly by customers. In other words, the population interacting with data-entry software is increasingly less tolerant of being treated like unambitious, uneducated, unintelligent peons.
Users won’t tolerate stupid software that insults them, not when they can push a button and surf for another few seconds until they find another vendor who presents an interface that treats them with respect.
If a system is too rigid, it can’t model real-world behaviors. A system that rejects the reality of its users is not helpful, even if the net result is that all its fields are valid. Which is more important, the database or the business it is trying to support? The people who manage the database and create the data-entry applications that feed it are often serving only the CPU. This is a significant conflict of interest that good interaction design can help resolve.
Fudgeability can be difficult to build into a computer system because it demands a considerably more capable interface. Our clerk cannot move a document to the top of the queue unless the queue, the document, and its position in the queue can be easily seen. The tools for pulling a document out of the electronic stack and placing it on the top must also be present and obvious in their functions. Fudgeability also requires facilities to hold records in suspense, but an Undo facility has similar requirements. A more significant problem is that fudging admits the potential for abuse.
The best strategy to avoid abuse is using the computer’s ability to record a user’s actions for later examination, if warranted. The principle is simple: Let users do what they want, but keep very detailed records of those actions so that full accountability is possible.
Many programmers believe it is their duty to inform users when they make errors entering data. It is certainly an application’s duty to inform other applications when they make an error, but this rule shouldn’t extend to users. The customer is always right, so an application must accept what a user tells it, regardless of what it does or doesn’t know. This is similar to the concept of data immunity because whatever a user enters should be acceptable, regardless of how incorrect the application believes it to be.
This doesn’t mean that the application can wipe its hands and say, “All right, he doesn’t want a life preserver, so I’ll just let him drown.” Just because the application must act as though a user is always right, doesn’t mean that a user actually is always right. Humans are always making mistakes, and your users are no exception. User errors may not be your application’s fault, but they are its responsibility. How are you going to fix them?

Applications can provide warnings — as long as they don’t stop the proceedings with idiocy — but if a user chooses to do something suspect, the application can do nothing but accept the fact and work to protect that user from harm. Like a faithful guide, it must follow its client into the jungle, making sure to bring along a rope and plenty of water.
Warnings should clearly and modelessly inform users of what they have done, much as the speedometer silently reports our speed violations. It is not reasonable, however, for the application to stop the proceedings, just as it is not right for the speedometer to cut the gas when we edge above 65 miles per hour. Instead of an error dialog, for example, data-entry fields can highlight any user input the application evaluates as suspect.
When a user does something that the application thinks is wrong, the best way to protect him (unless real disaster is imminent) is to make it clear that there may be a problem, but to do this in an unobtrusive way that ultimately relies on the user’s intelligence to figure out the best solution. If the application jumps in and tries to fix it, it may be wrong and end up subverting the user’s intent. Further, this approach fails to give the user the benefit of learning from the situation, ultimately compromising his ability to avoid the situation in the future. Our applications should, however, remember each of the user’s actions, and ensure that each action can be cleanly reversed, that no collateral information is lost, and that a user can figure out where the application thinks the problems might be. Essentially, we maintain a clear audit trail of his actions. Thus the principle: Audit, don’t edit.
Microsoft Word has an excellent example of auditing, as well as a nasty counterexample. This excellent example is the way it handles real-time spell checking: As you type, red wavy underlines identify words that the application doesn’t recognize (see Figure 18-1). Right-clicking on these words pops up a menu of alternatives you can choose from — but you don’t have to change anything, and you are not interrupted by dialogs or other forms of modal idiocy.
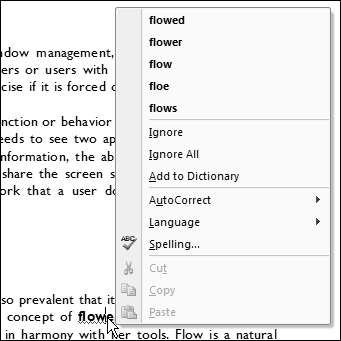
Word’s AutoCorrect feature, on the other hand, can be a little bit disturbing at first. As you type, it silently changes words it thinks are misspelled. It turns out that this feature is incredibly useful for fixing minor typos as you go. However, the corrections leave no obvious audit trail, so a user has no idea that what he typed has been changed. It would be better if Word could provide some kind of mark that indicates it has made a correction on the off chance that it has miscorrected something (which becomes much more likely if you are, for instance, writing a technical paper heavy in specialized terminology and acronyms).
More frightening is Word’s AutoFormat feature, which tries to interpret user behaviors like use of asterisks and numbers in text to automatically format numbered lists and other paragraph formats. When this works, it seems magical, but frequently the application does the wrong thing, and once it does so, there is not always a straightforward way to undo the action. AutoFormat is trying to be just a bit too smart; it should really leave the thinking to the human. Luckily, this feature can be turned off (though it’s hard to determine how). Also, more recent versions of Word provide a special in-place menu that allows users to adjust AutoFormat assumptions.
In the real world, humans accept partially and incorrectly filled-in documents from each other all the time. We make a note to fix the problems later, and we usually do. If we forget, we fix it when we eventually discover the omission. Even if we never fix it, we somehow survive. It’s certainly reasonable to use software to improve the efficiency of our data collection efforts, and in many cases it is consistent with human goals to do so. (No one wants to enter the wrong shipping address for an expensive online purchase.) However, our applications can be designed to better accommodate the way humans think about such things — the technical goal of data integrity should not be our users’ problem to solve.