
Adaptation and Learning Over Networks for Nonlinear System Modeling
Simone Scardapane⁎; Jie Chen†; Cédric Richard‡ ⁎Sapienza University of Rome, Rome, Italy
†Northwestern Polytechnical University, Xi'an, School of Marine Science and Technology, Xi'an, China
‡Université Côte d'Azur, Laboratoire Lagrange (UMR CNRS 7293), Nice, France
Abstract
In this chapter, we analyze nonlinear filtering problems in distributed environments, e.g., sensor networks or peer-to-peer protocols. In these scenarios, the agents in the environment receive measurements in a streaming fashion, and they are required to estimate a common (nonlinear) model by alternating local computations and communications with their neighbors. We focus on the important distinction between single-task problems, where the underlying model is common to all agents, and multitask problems, where each agent might converge to a different model due to, e.g., spatial dependencies. Currently, most of the literature on distributed learning in the nonlinear case has focused on the single-task case, which may be a strong limitation in real-world scenarios. After introducing the problem and reviewing the existing approaches, we describe a simple kernel-based algorithm tailored for the multitask case. We evaluate the proposal on a simulated benchmark task, and we conclude by detailing currently open problems and lines of research.
Keywords
Nonlinear system identification; Distributed systems; Adaptive methods; Reproducing kernel Hilbert spaces; Diffusion algorithms
Chapter Points
- • We introduce the problem of distributed filtering over networks of communicating agents, such as sensors in a wireless network.
- • We summarize the state-of-the-art research on nonlinear distributed filtering.
- • We introduce a novel kernel approach to perform nonlinear distributed filtering in multitask scenarios.
- • We validate our proposal on an experimental benchmark problem.
Acknowledgements
The work of Simone Scardapane was supported in part by Italian MIUR, “Progetti di Ricerca di Rilevante Interesse Nazionale”, GAUChO project, under Grant 2015YPXH4W_004. The work of Jie Chen was supported in part by the National Natural Science Foundation of China (NSFC grant 61671382).
10.1 Introduction
Adaptive filters have been at the heart of digital signal processing over the last century, thanks to their capability of rapidly adapting to streams of incoming data. At the same time, classical filtering approaches have not been satisfactory to handle the challenges posed by large-scale, unstructured big data scenarios that are common today. This has fostered the recent development of techniques to deal with such problems, allowing signal processing to scale to truly massive datasets [1] and to work with less structured data types, such as graphs [2,3]. In this chapter, we look at one peculiar aspect unifying several big data problems, namely, their distributed nature, where the data are naturally generated and aggregated at different locations with possibly poor or expensive network connectivity. Examples of problems in this category abound and include (but are not limited to) wireless sensor networks (WSNs) [4], distributed databases, robotic swarms and fog computing platforms. In all these scenarios, the agents in the network can be severely limited in their capabilities, in terms of either energy constraints (e.g., low-power devices in WSNs), connectivity, privacy, or other aspects. As a consequence, any solution devised for learning and inference over networks needs to be aware of these constraints, making this a challenging problem with wide applications.
Distributed learning can be cast as a decentralized optimization problem, which has a long history in the optimization field [5] and in artificial intelligence. In recent years, this problem has gained a renewed interest from the machine learning community, with the development of a number of learning protocols for a variety of models, including boosting [6], support vector machines [7,8], kernel regression [4] and sparse linear models [9,10], to cite a few. Several of these were also applied in signal processing problems, most notably in order to provide distributed inference capabilities in WSNs [4]. A large majority of them, however, is only applicable in batch situations, where each agent is allowed to manipulate its entire (local) dataset at each iteration. Distributed filtering algorithms, on the contrary, require the development of online solutions, where the data are received and processed, sequentially, by the agents.
In the filtering literature, a recent series of works was initiated by the development of the so-called ‘diffusion filtering’ (DF) algorithms, starting from the diffusion LMS [11] and the diffusion RLS [12], up to their more general formulation in terms of generic convex cost functions [13–15], which are considered here. DF algorithms are characterized by interleaving local updates in parallel (mimicking classical filters), with communication steps, during which the agents exchange information on their current estimate with their neighbors. Following the development of the main theory, in the subsequent years, several authors have extended classical linear filters to the distributed case (e.g., sparse LMS [10] and group LMS [16]), while others have focused on nonlinear filters, as we review further on in the chapter. For the interested reader, we refer to the guest editorial in [17] and references therein for a recent overview of the literature.
All the works mentioned up to now assume that the agents are identifying a common model. This is a reasonable assumption in several contexts, particularly when the statistics of the data do not depend on the spatial locations of the agents, making it very common in distributed machine learning problems [7,15]. In general, however, the agents could be interested in different identification problems, which are similar in some quantifiable sense. As an example, consider the setup illustrated in Fig. 10.1. If the agents are sensors deployed over an environment, trying to predict some quantity of interest (e.g., some pollutant concentration), the model might be different among groups (clusters) of agents, possibly due to the spatial conformation of the ground (e.g., sensors deployed over a mountain vs. sensors deployed in a valley). Nonetheless, since they are all trying to predict the same quantity of interest, communication between agents belonging to different clusters can be beneficial.

The first DF solution to this problem, which is termed multitask network, was analyzed in [18]. Following this, a range of algorithms was proposed in the linear case. Most notably, Chen et al. [19] and Zhao and Sayed [20] investigated the possibility of unsupervised learning of the clusters structure when it is not available a priori. Additional developments include the extension to asynchronous networks where, e.g., links may fail or agents might disconnect [21]; proximal updates for nondifferentiable regularization terms [22]; total least squares approaches [23]; and, finally, multitask learning over (linear) latent subspaces [24,25]. Almost no work, however, has addressed the problem of learning in a multitask network with nonlinear models.
Based on the previous discussion, this chapter has three separate aims. First, we introduce the fundamental concept of DF in Section 10.2, which serves as a very general introduction to the topic. Next, we summarize recent works on nonlinear DF algorithms in Section 10.3, with an emphasis on three classes of solutions. In order to motivate research on multitask learning with nonlinear models, in Section 10.4 we propose a multitask kernel algorithm based on a functional formulation of DF. Finally, we validate the algorithm on an experimental benchmark in Section 10.5, before making some final remarks in Section 10.6.
10.2 Mathematical Formulation of the Problem
This section is intended to familiarize the reader with some basic theoretical elements underlying most distributed learning scenarios. We start by providing a setup for the problem in Section 10.2.1. Next, we describe a general class of algorithms based on diffusion protocols in Section 10.2.2. In Section 10.2.3, we show how these algorithms can be customized to address multitask scenarios. For conciseness, we only focus on a selection of key items, without providing a comprehensive treatment of these thematics. We refer the interested reader to [14,15] for introductory references.
10.2.1 Problem Setup
Let us consider a generic network of N agents (e.g., sensors in a WSN) as the one depicted in Fig. 10.1. We assume that time is slotted and, at every time instant n, each agent receives a new observation ![]() , where
, where ![]() is the model input vector at agent k (e.g., a buffer of the last M samples) and
is the model input vector at agent k (e.g., a buffer of the last M samples) and ![]() the corresponding desired response. For simplicity, we assume that
the corresponding desired response. For simplicity, we assume that ![]() is a scalar. For the rest of the chapter, we shall use the subscript k to denote a quantity specific to one of the agents.
is a scalar. For the rest of the chapter, we shall use the subscript k to denote a quantity specific to one of the agents.
Following the standard supervised learning approach, the desired input/output relation can be modeled by choosing a function f in some hypothesis space ![]() . For simplicity, in this section we suppose that each function is parameterized by a vector of tunable parameters
. For simplicity, in this section we suppose that each function is parameterized by a vector of tunable parameters ![]() , e.g., a linear predictor.1 With this setting, each agent is interested in finding a set of parameters
, e.g., a linear predictor.1 With this setting, each agent is interested in finding a set of parameters ![]() which minimizes some local cost function
which minimizes some local cost function ![]() defined over the hypothesis space from streaming data. Specifically, for most estimation problems in practice, these local cost functions are defined as the expectation of some error function
defined over the hypothesis space from streaming data. Specifically, for most estimation problems in practice, these local cost functions are defined as the expectation of some error function ![]() with respect to the statistics of the local stream of data,
with respect to the statistics of the local stream of data,
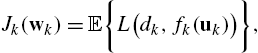
where we use the shorthand ![]() . The global optimization problem to be solved at the network level is then given by the sum of the local cost functions,
. The global optimization problem to be solved at the network level is then given by the sum of the local cost functions,
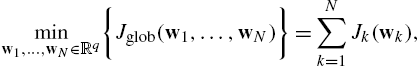
where ![]() is the estimate at the kth agent. If we assume that no relation holds between the local cost functions, then (10.2) reduces to a set of N optimization problems that can be solved in parallel by every agent, independently of all the others. A more interesting formulation arises by assuming some form of relation among the cost functions (detailed below). In this case, the information gathered by one agent during its optimization process can potentially be used by the other agents to speed up their convergence, or even converge to a better solution using some shared information.
is the estimate at the kth agent. If we assume that no relation holds between the local cost functions, then (10.2) reduces to a set of N optimization problems that can be solved in parallel by every agent, independently of all the others. A more interesting formulation arises by assuming some form of relation among the cost functions (detailed below). In this case, the information gathered by one agent during its optimization process can potentially be used by the other agents to speed up their convergence, or even converge to a better solution using some shared information.
The difficulty arises from the fact that each agent has direct access to its local cost function, but it has no access to the local cost functions of the other agents for all the reasons mentioned in the introduction. Depending on the relation between cost functions, we can distinguish between three classes of distributed problems:
- • Single-task problems: in this case,
 , i.e., all the cost functions have the same minimizer which must be attained by all agents. This is the scenario which has drawn most attention in the literature, being particularly useful in distributed machine learning problems [7], where it is common to assume that the data of interest are generated by a single underlying distribution.
, i.e., all the cost functions have the same minimizer which must be attained by all agents. This is the scenario which has drawn most attention in the literature, being particularly useful in distributed machine learning problems [7], where it is common to assume that the data of interest are generated by a single underlying distribution. - • Multitask problems: in this scenario, each local cost function has possibly a different minimizer
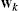 .2 In order to make the problem interesting, we assume that these minimizers are ‘similar’ (in some sense to be properly defined) among pairs of neighboring agents, so that communicating can increase their speed of convergence and possibly counter noisy environments.
.2 In order to make the problem interesting, we assume that these minimizers are ‘similar’ (in some sense to be properly defined) among pairs of neighboring agents, so that communicating can increase their speed of convergence and possibly counter noisy environments. - • Clustered multitask problems: in this intermediate case, each agent belongs to one of T different groups (clusters), such that all agents belonging to the same cluster have the same minimizer and vice versa, as shown in Fig. 10.1. Clearly, both single-task and multitask problems can be derived as extreme cases of this class of problems, by setting
 and
and  .
.
Multitask problems can be further subdivided, depending on whether the similarity between tasks is known a priori, or whether it must be inferred from the data. An example of the former case is the algorithm in [18], while examples of the latter case can be found in [19,20]. Inferring knowledge about the groups might require the inclusion of some decentralized clustering procedure in the learning process, which is an interesting problem in its own right [29]. For simplicity, in this chapter we will focus on the multitask formulation, but we underline that almost all multitask algorithms can be generalized to handle the clustered multitask case; e.g., see [18].
10.2.2 Diffusion-Based Algorithms
In order to describe a family of algorithms to solve the previous problem, we first need to define a model of communication between the different agents. Most of the literature focuses on the case where the communication links form a static, undirected, connected graph ![]() . At each time step, the kth agent is allowed to communicate with its set of direct neighbors
. At each time step, the kth agent is allowed to communicate with its set of direct neighbors ![]() , while it cannot send messages to agents to which it is not directly linked.3 Nonetheless, the overall connectedness of the graph ensures that information can flow throughout the entire network. In this scenario, connectivity can be described by a symmetric, real-valued matrix
, while it cannot send messages to agents to which it is not directly linked.3 Nonetheless, the overall connectedness of the graph ensures that information can flow throughout the entire network. In this scenario, connectivity can be described by a symmetric, real-valued matrix ![]() such that
such that ![]() only if agents k and l are connected and
only if agents k and l are connected and
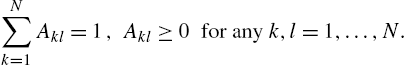
These weights are used by the agents to scale and combine information received by their neighbors. The previous condition ensures that each row of the matrix defines a convex combination, so that the range of the information to be combined is always preserved (formally, the condition requires that A be left stochastic). There are several strategies allowing agents to build such matrices, as we show later. This formulation can also be extended in several ways, most notably with the use of asynchronous formulations [30] (thus avoiding the need for a common clock throughout the network) and mixing matrices that do not respect double stochasticity [31]. Nonetheless, since this chapter is only intended as an introduction, we will focus on the simpler case detailed before.
In the case of a single agent, (10.2) could be solved by a simple gradient descent algorithm. In order to counteract the lack of global information, the basic idea of diffusion algorithms is to interleave local optimization steps with communication steps, where each agent combines its own estimate with those of its neighbors. In the filtering literature, this strategy is generally denoted as adapt-then-combine (ATC):

where ![]() is a (possibly time-dependent) step size and, similarly to before, we use a double subscript
is a (possibly time-dependent) step size and, similarly to before, we use a double subscript ![]() to denote the estimate of agent k at time n. Practically, the gradient term in (10.4) can be replaced with a noisy version, for example using an instantaneous approximation computed from the current data sample. A diffusion step example is given in Fig. 10.2.
to denote the estimate of agent k at time n. Practically, the gradient term in (10.4) can be replaced with a noisy version, for example using an instantaneous approximation computed from the current data sample. A diffusion step example is given in Fig. 10.2.
These algorithms are particularly suitable in single-task scenarios, where their convergence properties in the convex case have been analyzed extensively [14,15]. Interestingly, they can still have good convergence properties in the multitask case, as shown in [19]. However, they provide a building block for all other formulations, as we show in Section 10.2.3. Before that, we describe an example of diffusion algorithm for nonlinear learning with a distributed logistic regression model.
10.2.2.1 An Example: Logistic Regression Over Networks
Consider a binary classification problem where ![]() , i.e., each output is a single bit representing whether the corresponding input belongs to a certain class or not. We approximate the underlying relation using a logistic predictor
, i.e., each output is a single bit representing whether the corresponding input belongs to a certain class or not. We approximate the underlying relation using a logistic predictor ![]() , where
, where ![]() is the sigmoid function, as follows:
is the sigmoid function, as follows:

ensuring that the outputs of the model are properly scaled as valid probabilities. Each agent wishes to minimize the (regularized) expected cross-entropy over its stream of data:
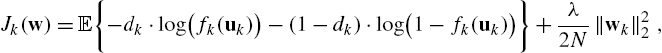
where the factor ![]() in the regularization term ensures that the total penalization in (10.2), when summed over all agents, is equal to
in the regularization term ensures that the total penalization in (10.2), when summed over all agents, is equal to ![]() . By taking instantaneous approximations to the gradient, simple algebra manipulations show that the update steps in (10.4) are given by
. By taking instantaneous approximations to the gradient, simple algebra manipulations show that the update steps in (10.4) are given by
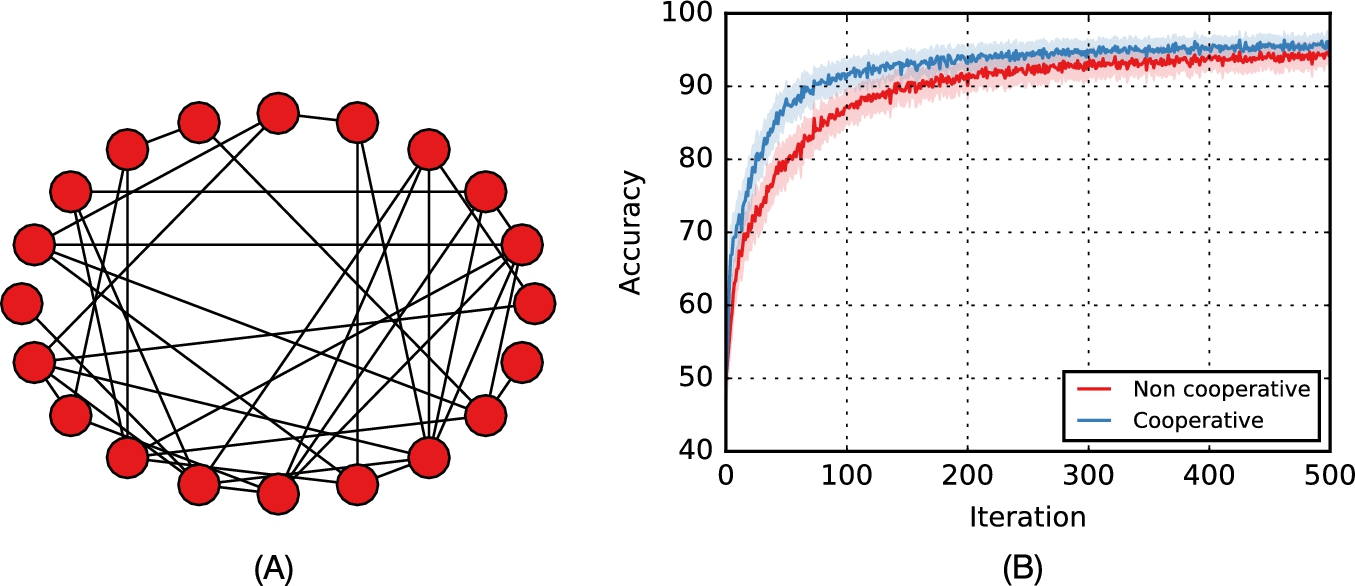
In order to show the speedup obtained by such procedure, in Fig. 10.3 we plot the average accuracy (see below) obtained with a network of 20 agents, whose connectivity is generated randomly, where at every iteration each agent receives a randomly chosen example taken from the well-known Wisconsin Breast Cancer Database (WBCD).4 The accuracy is defined as 1 if the agent makes a correct prediction (i.e., the sign of ![]() agrees with d), 0 otherwise. It is computed before the adaptation step, and it is averaged with respect to the different agents and the different simulations.
agrees with d), 0 otherwise. It is computed before the adaptation step, and it is averaged with respect to the different agents and the different simulations.
10.2.3 Extension to Multitask Learning
The general ideas exposed in Section 10.2.2 can be easily extended in order to be more efficient in the multitask scenario. Here, we detail a simple extension originally proposed in [18] to show one example of such extensions. We refer to the large number of works cited in the introduction for more recent proposals.
Suppose that, given two agents k and l, we have a way to quantify the similarity among their respective minimizers. In order to leverage this information, we can augment the original cost function in (10.2) with a regularization term forcing the similarity among minimizers, in terms of their Euclidean distance, as follows:
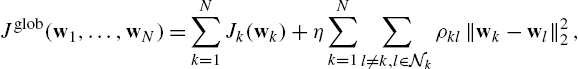
where η is a regularization factor and the nonnegative coefficients ![]() quantify our a priori knowledge about the similarities. We assume that, for each agent, the weights are positive and sum to one. We have
quantify our a priori knowledge about the similarities. We assume that, for each agent, the weights are positive and sum to one. We have
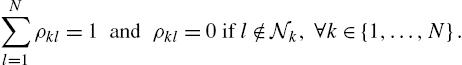
As a consequence of their definition, these regularization factors mirror the communication network of the agents. Due to this, taking a local optimization step with respect to the estimate of the kth agent immediately requires a diffusion step. We have
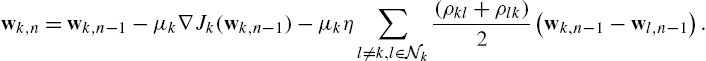
Since the estimates are already exchanged, the previous update step can be implemented without the need for additional combination steps like in Section 10.2.2. As an example, by considering a simple linear predictor ![]() and instantaneous approximations to the gradient, we obtain the following update rule for the multitask diffusion LMS, presented in [18]:
and instantaneous approximations to the gradient, we obtain the following update rule for the multitask diffusion LMS, presented in [18]:

If we assume that the mixing weights are symmetric, ![]() simplifies to
simplifies to ![]() . It is possible to obtain asymmetric regularization terms by considering a game-theoretical formulation of the optimization problem; see the discussion in [18].
. It is possible to obtain asymmetric regularization terms by considering a game-theoretical formulation of the optimization problem; see the discussion in [18].
10.3 Existing Approaches to Nonlinear Distributed Filtering
In this section we describe three approaches to extend the previous formulation to nonlinear models in an efficient way. We underline that all these algorithms have been devised mostly for the case of single-task networks. Further extensions to the multitask scenario are the topic of Section 10.4.
10.3.1 Expansion Over Random Bases
One immediate idea is to project the original input vector u to a high-dimensional space via some fixed function ![]() before using it with a linear predictor, where d is the dimensionality of the input vector u and B is a parameter which (in general) can be chosen by the user. In the distributed case, this requires only a small communication overhead in the beginning for the agents to agree on a specific projection function. Any distributed linear algorithm, such as the diffusion LMS or the diffusion RLS, can then be used.
before using it with a linear predictor, where d is the dimensionality of the input vector u and B is a parameter which (in general) can be chosen by the user. In the distributed case, this requires only a small communication overhead in the beginning for the agents to agree on a specific projection function. Any distributed linear algorithm, such as the diffusion LMS or the diffusion RLS, can then be used.
Generally speaking, deterministic mappings (such as those mentioned in Chapters 2 and 4) are not efficient, because their size might grow exponentially with respect to M. A different idea is to use basis functions whose parameters are assigned stochastically, e.g., a parameterized sigmoid,
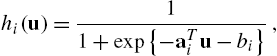
where ![]() and
and ![]() might be extracted randomly from some uniform distribution (whose range is generally chosen in order to provide a good accuracy; see the discussion in [32]). Interestingly, it is possible to show that the resulting estimator (called a random vector functional-link network) is a universal approximator over compact functions provided that B is chosen large enough [33]. It is also possible to interpret it as a degenerate case of the echo state network described in Chapter 12, where connections between different nodes have been removed. The idea of using RVFL networks in a distributed context was proposed in [34] for the batch case and in [35] for the online case with DF algorithms.
might be extracted randomly from some uniform distribution (whose range is generally chosen in order to provide a good accuracy; see the discussion in [32]). Interestingly, it is possible to show that the resulting estimator (called a random vector functional-link network) is a universal approximator over compact functions provided that B is chosen large enough [33]. It is also possible to interpret it as a degenerate case of the echo state network described in Chapter 12, where connections between different nodes have been removed. The idea of using RVFL networks in a distributed context was proposed in [34] for the batch case and in [35] for the online case with DF algorithms.
A different approach is to design a feature mapping ![]() approximating a specific kernel
approximating a specific kernel ![]() function5 chosen by the user:
function5 chosen by the user:
This idea was popularized by [36] for approximating shift-invariant kernels (e.g., the Gaussian kernel) in large-scale applications of kernel methods. In particular, it is possible to show that this class of kernels can be easily approximated with very simple stochastic mappings. The work [37] was the first to apply this idea explicitly to kernel filters, and similar algorithms were independently reintroduced in [38]. Since Chapter 7 is entirely devoted to this idea, we will not go further into it. We refer the interested reader to [32] for a recent overview on random feature methods.
10.3.2 Distributed Kernel Filters
An alternative line of research is devoted to distributed strategies for kernel filters, working directly on some reproducing kernel Hilbert space (RKHS), instead of approximating the kernel function as in Section 10.3.1. As we stated in the introduction, several distributed algorithms for kernel ridge regression were devised in the context of WSNs [4], followed by algorithms for the distributed optimization of SVMs [39,7]. Any approach to dealing with kernels faces the challenge of working with a kernel-based model that depends explicitly on all the data in the training set. A naive distributed implementation would thus require to exchange all the local datasets between the agents, which can become infeasible.
In an online context, this is made worse by the growing nature of the kernel model [40]. This is a fundamental drawback underlying any kernel filter algorithm [41–43]. An initial investigation in developing a fully distributed version of the kernel LMS (KLMS) was made in [44], where the basic idea is to consider diffusion algorithms directly in a functional form. In particular, let us assume that the data received from the kth agent satisfies a model of the following form:
where ![]() belongs to an RKHS
belongs to an RKHS ![]() , while
, while ![]() is a zero mean white noise with variance
is a zero mean white noise with variance ![]() . Restricting our attention to a generic single-task network, we have
. Restricting our attention to a generic single-task network, we have
Considering the classical squared error function, the gradient of the local cost functions can now be computed in terms of their Fréchet derivatives as6
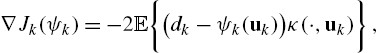
where κ is the kernel function associated to the RKHS. Considering instantaneous approximations for the expectation as was done earlier, we arrive at a functional equivalent of the ATC diffusion framework,
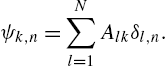
Although this formulation is extremely general, one has still to solve the problem of the growing structure of the kernel functions. The idea pursued in [44] is to assume some shared dictionary ![]() among nodes, whose selection is (at the moment) an open research question. Using this approximation, we can rewrite the desired function as
among nodes, whose selection is (at the moment) an open research question. Using this approximation, we can rewrite the desired function as
where ![]() is the vector of kernel values computed between the current input vector
is the vector of kernel values computed between the current input vector ![]() and the shared dictionary
and the shared dictionary ![]() . Each function
. Each function ![]() is now parameterized by the set of linear coefficients
is now parameterized by the set of linear coefficients ![]() . The previous algorithm can be rewritten as7
. The previous algorithm can be rewritten as7
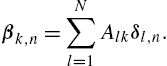
The idea of preselecting a dictionary is not new in the kernel literature. In fact, one of the earliest algorithms for distributed SVMs [39] exploited a similar idea, which is termed semiparametric SVM. In [47], a fixed dictionary is used to analyze the convergence behavior of the KLMS algorithm. A derivation of the functional diffusion KLMS algorithm when removing the fixed dictionary constraint is given in [48]. Another extension is presented in [49], where a set of consensus constraints is included in the problem to ensure convergence and speed up the algorithm.
10.3.3 Diffusion Spline Filters
Another possibility for nonlinear learning over networks is given by considering spline adaptive filters (SAFs).8 The idea of using SAFs in a distributed environment was recently introduced in [50]. In the following we briefly describe the distributed algorithm. The interested readers can refer to [51,52] for introductory material on the SAF model.
Let us assume that the data are generated according to a restricted Wiener model given by
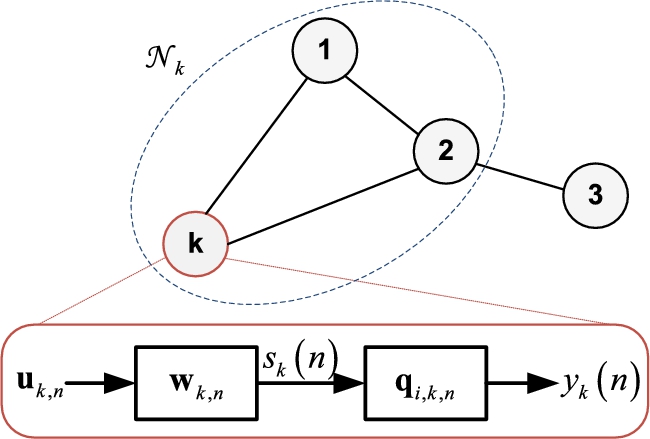
where ![]() is any smooth nonlinear function and
is any smooth nonlinear function and ![]() is a noise term. A SAF mimics this architecture, where the nonlinear term is approximated via spline interpolation over a set of Q fixed control points that are adapted during learning. Hence, in a distributed scenario each agent has estimates of the local part of the filter,
is a noise term. A SAF mimics this architecture, where the nonlinear term is approximated via spline interpolation over a set of Q fixed control points that are adapted during learning. Hence, in a distributed scenario each agent has estimates of the local part of the filter, ![]() , and of the aforementioned control points,
, and of the aforementioned control points, ![]() , as shown schematically in Fig. 10.4.
, as shown schematically in Fig. 10.4.
Consider a single-task scenario, where each agent tries to minimize the expected squared loss. Following [50], we consider a combine-then-adapt (CTA) scheme, where the combination is performed before the adaptation. The two steps are applied to both sets of parameters ![]() and
and ![]() simultaneously. However, by exploiting the SAF structure we can avoid exchanging the full weight vector
simultaneously. However, by exploiting the SAF structure we can avoid exchanging the full weight vector ![]() , as described in the following.
, as described in the following.
The combination step starts with the agents exchanging their current estimates of the linear weights as
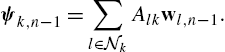
The new weights are used to compute the output of the linear part of the filter, denoted as ![]() . We use i to denote the index of the closest control point to
. We use i to denote the index of the closest control point to ![]() in our set of fixed control points. As described in Chapter 3, the final output of a Wiener SAF depends only on the ith control point and its P right neighbors, with P being the order of interpolation. Let us denote by
in our set of fixed control points. As described in Chapter 3, the final output of a Wiener SAF depends only on the ith control point and its P right neighbors, with P being the order of interpolation. Let us denote by ![]() the set of such ‘active’ control points for agent k, which are called the ‘span’ of the filter (see Chapter 3 for more details). We use a third subscript to denote dependence with respect to the span. The second combination step is performed only with respect to the current span:
the set of such ‘active’ control points for agent k, which are called the ‘span’ of the filter (see Chapter 3 for more details). We use a third subscript to denote dependence with respect to the span. The second combination step is performed only with respect to the current span:
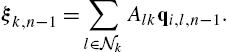
In the case of cubic interpolation, each ![]() has dimensionality 4, making its exchange extremely efficient, with only a fixed overhead with respect to a classical diffusion LMS. Practically, every agent sends its current span index i to its neighbors and receives back the vectors
has dimensionality 4, making its exchange extremely efficient, with only a fixed overhead with respect to a classical diffusion LMS. Practically, every agent sends its current span index i to its neighbors and receives back the vectors ![]() . For simplicity, the mixing weights
. For simplicity, the mixing weights ![]() in the two diffusion steps are assumed identical.
in the two diffusion steps are assumed identical.
Next, we proceed to the adaptation step. The complete SAF output given the new span is obtained (again following the general rules of Chapter 5) as
where the vector u is constructed by taking powers up to a fixed order of the normalized value ![]() , where Δx is the sampling precision of the spline, and B is the spline matrix, e.g., the Catmull-Rom spline given by
, where Δx is the sampling precision of the spline, and B is the spline matrix, e.g., the Catmull-Rom spline given by
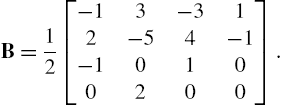
Adaptation is carried out by performing two parallel gradient descent steps:
where ![]() is the instantaneous local error and
is the instantaneous local error and ![]() is the spline derivative with respect to the linear weights. Note that the diffusion LMS can be obtained as a special case, where each node initializes its nonlinearity as the identity, and the step size of the nonlinear part is set to zero.
is the spline derivative with respect to the linear weights. Note that the diffusion LMS can be obtained as a special case, where each node initializes its nonlinearity as the identity, and the step size of the nonlinear part is set to zero.
10.4 A Distributed Kernel Filter for Multitask Problems
As we saw in Section 10.2.3, several ideas have been proposed to model nonlinear systems in a distributed fashion, but almost none is framed for the multitask scenario. As a first step towards this line of research, in this section we briefly combine some of the previous ideas to devise an efficient kernel-based diffusion algorithm for multitask networks. In a nutshell, we combine the multitask diffusion LMS presented in Section 10.2.3 with the functional diffusion KLMS of Section 10.3.2. To this end, consider again the data model in (10.14), where we assumed that all the minimizers are the same across the agents. More generally, we can consider the case where two functions ![]() and
and ![]() are assumed to be ‘close’ in the sense of the norm
are assumed to be ‘close’ in the sense of the norm ![]() of the RKHS, whenever the corresponding agents are spatial neighbors. We have
of the RKHS, whenever the corresponding agents are spatial neighbors. We have
where ![]() denotes the set of neighbors of k and ∼ denotes similarity. To recover the unknown functions and leveraging over the basic idea described in Section 10.2.3, we aim at minimizing the following global cost function in a decentralized fashion:
denotes the set of neighbors of k and ∼ denotes similarity. To recover the unknown functions and leveraging over the basic idea described in Section 10.2.3, we aim at minimizing the following global cost function in a decentralized fashion:

where ![]() is a regularization factor and the nonnegative coefficients
is a regularization factor and the nonnegative coefficients ![]() weight the similarity between different functions. Once again, we assume that, for each agent, the weights are positive and sum to one, so we have
weight the similarity between different functions. Once again, we assume that, for each agent, the weights are positive and sum to one, so we have
Thus, each agent is interested in minimizing the local expected mean squared error, under suitable proximity constraints on its function and the functions of its neighbors. The previous problem decomposes as a sum of local cost functions defined as
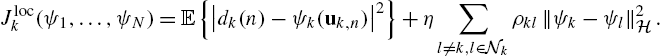
Each local cost function is independent of the estimate of agents which are not in its immediate neighborhood. Taking the Fréchet derivative of (10.31) gives us
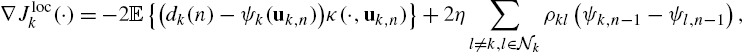
where ![]() is the reproducing kernel associated with
is the reproducing kernel associated with ![]() . For simplicity, we assume that the mixing weights
. For simplicity, we assume that the mixing weights ![]() are symmetrical (see the discussion at the end of Section 10.2.3). Making an instantaneous approximation for the expectation gives us the following local update rule in functional form at time instant n:
are symmetrical (see the discussion at the end of Section 10.2.3). Making an instantaneous approximation for the expectation gives us the following local update rule in functional form at time instant n:

where the factor 2 has been included in the step size ![]() . Considering
. Considering ![]() as the space of linear predictors over
as the space of linear predictors over ![]() , (10.33) reduces to the diffusion LMS for multitask networks presented earlier. In order to have a feasible implementation, once again we assume a shared dictionary
, (10.33) reduces to the diffusion LMS for multitask networks presented earlier. In order to have a feasible implementation, once again we assume a shared dictionary ![]() among agents. Eq. (10.33) reduces to
among agents. Eq. (10.33) reduces to
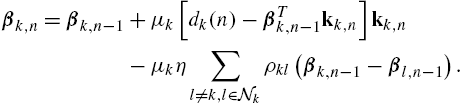
10.5 Experimental Evaluation
10.5.1 Experiment Setup
In this section, we evaluate the proposed method on a simulated multitask nonlinear problem. The output at each agent is given by the following equation:
which is composed of a common nonlinear part ![]() , a common linear term with weight vector
, a common linear term with weight vector ![]() , a local linear part
, a local linear part ![]() and a local noise of variance
and a local noise of variance ![]() . In particular, we considered a three dimensional input vector
. In particular, we considered a three dimensional input vector ![]() , with the following nonlinearity:
, with the following nonlinearity:
where a and b were generated from a normal distribution, similarly to the local and shared coefficient vectors ![]() . Noise variances were generated uniformly for each agent in the interval
. Noise variances were generated uniformly for each agent in the interval ![]() . We added an additional level of diversity over the network by randomly assigning the learning rates to the agents from the uniform distribution over the interval
. We added an additional level of diversity over the network by randomly assigning the learning rates to the agents from the uniform distribution over the interval ![]() . We considered a network of 9 agents, whose connectivity was randomly assigned such that each agent is connected in average with one-fifth of the other agents, with the requirement that the overall graph is connected. The resulting network connectivity, an example of desired output and a plot of the noise variances and learning rates are all shown in Fig. 10.5.
. We considered a network of 9 agents, whose connectivity was randomly assigned such that each agent is connected in average with one-fifth of the other agents, with the requirement that the overall graph is connected. The resulting network connectivity, an example of desired output and a plot of the noise variances and learning rates are all shown in Fig. 10.5.
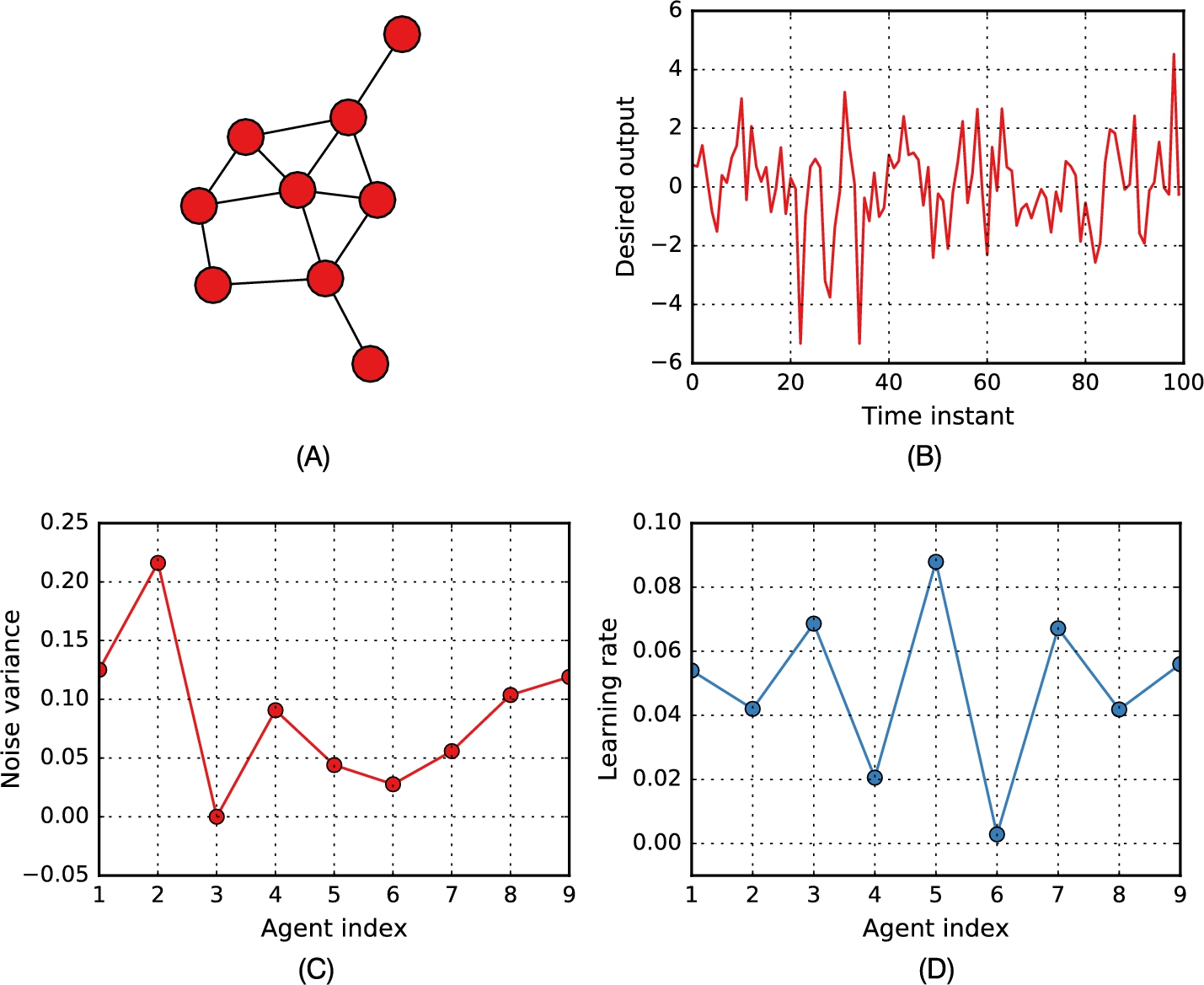
We trained the network over a sequence of 1000 time instants, with white Gaussian inputs with zero mean and unitary variance. The mixing matrix was chosen according to the max-degree heuristic:

where ![]() is the degree of node k and
is the degree of node k and ![]() is the maximum degree of the network.9 Each experiment was averaged over 500 different runs, by keeping fixed the assignments shown in Fig. 10.5.
is the maximum degree of the network.9 Each experiment was averaged over 500 different runs, by keeping fixed the assignments shown in Fig. 10.5.
10.5.2 Results and Discussion
We compared the performance of a standard diffusion LMS (D-LMS), a multitask D-LMS as described in Section 10.2.3 (D-MT-LMS), the diffusion KLMS described in Section 10.3.2 and the proposed multitask D-KLMS introduced in Section 10.4 (D-MT-KLMS). For the kernel algorithms, we used a Gaussian kernel,
where γ was chosen as the inverse of the dimensionality of u, which was found to provide a good accuracy. For the multitask algorithms, the regularization coefficients were selected uniformly as
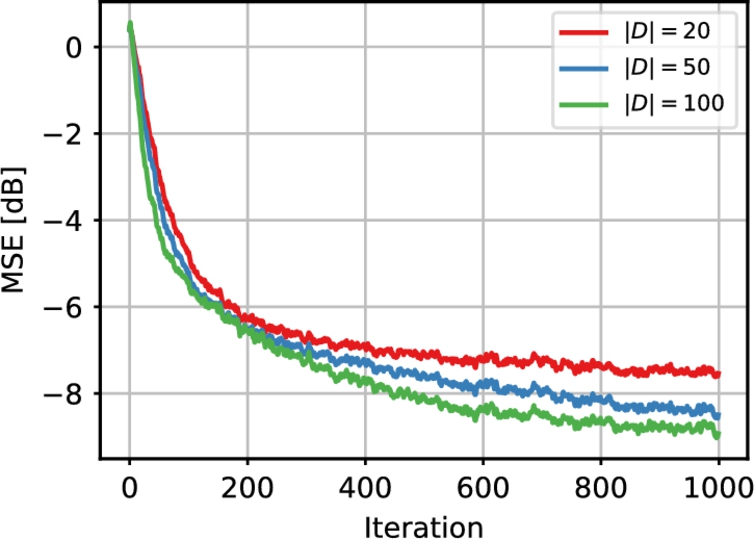
while the regularization factor was set to ![]() . For the kernel algorithms, we fixed a priori a dataset of size 100 with randomly extracted elements. The average MSE in dB across all runs is shown in Fig. 10.6.
. For the kernel algorithms, we fixed a priori a dataset of size 100 with randomly extracted elements. The average MSE in dB across all runs is shown in Fig. 10.6.
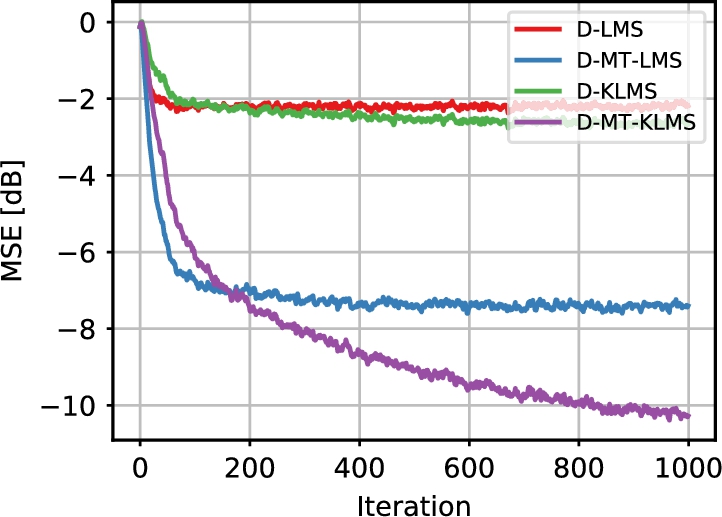
As expected, the D-LMS was the poorest performing algorithm, due to the doubly incorrect assumptions that the agents share the same minimizer and that the underlying function is linear. By relaxing one of the two assumptions, D-MT-LMS performed better, with an accuracy that is slightly inferior to D-KLMS. Clearly, D-MT-KLMS was the best algorithm in this case, showing that it can be an effective solution for nonlinear multitask problems.
In Fig. 10.7 we show the MSE evolution for three representative agents. As expected, their performance is different depending on the selected learning rate and amount of noise, but the multitask algorithm is able to effectively combine the learning curves to obtain the average behavior as in the purple (darkest gray in print version) line of Fig. 10.6. Finally, in Fig. 10.8 we show the average MSE evolution when varying the size of the dictionary. Increasing the size improves the accuracy (up to a given upper bound), at the cost of a larger computational burden.

10.6 Discussion and Open Problems
Distributed inference is a fundamental tool from the perspective of today's technological trends. In the adaptive filtering community, many classical algorithms can be readily extended to the distributed scenario by exploiting diffusion principles, where local adaptation steps are interleaved with communication steps between neighbors. The resulting algorithms are both computationally efficient and deployable over a large set of scenarios. In this chapter, we reviewed the basic tools of this field, and we briefly surveyed some of the nonlinear extensions that have been proposed.
An important distinction can be made between single-task problems, where all agents share the same minimizer, and multitask problems, where the minimizers can be different, but it is known that they share some similarities. We underlined how little work has been done on the nonlinear multitask case, and we proposed a simple kernel-based diffusion algorithm to this end. Many extensions to the basic setup of this chapter are possible, most notably a way to remove the assumption of a shared dictionary, an adaptive way to build the regularization coefficients, a theoretical analysis of the algorithm, or additional extensions towards asynchronous networks. Finally, we can consider mixing multitask networks with multiobjective algorithms [53], such that each agent is interested in minimizing multiple objectives simultaneously.