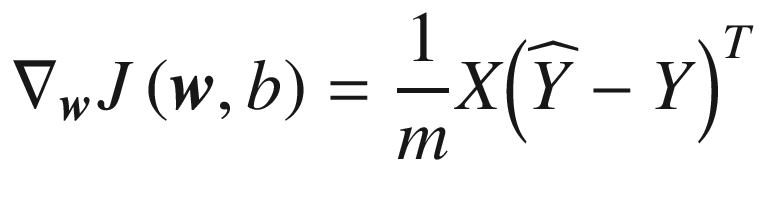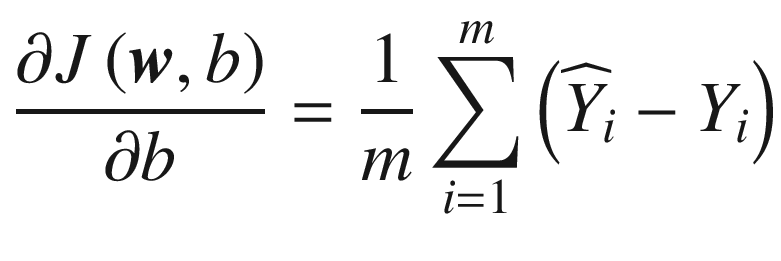In Chapter
, we developed a logistic regression model for binary classification with one neuron and applied it to two digits of the
MNIST dataset. The actual Python code
for the computational graph construction was just ten lines of code (excluding the part that performs the training of the model; review Chapter
, if you don’t remember what we did there).
X = tf.placeholder(tf.float32, [n_dim, None])
Y = tf.placeholder(tf.float32, [1, None])
learning_rate = tf.placeholder(tf.float32, shape=())
W = tf.Variable(tf.zeros([1, n_dim]))
b = tf.Variable(tf.zeros(1))
init = tf.global_variables_initializer()
y_ = tf.matmul(tf.transpose(W),X)+b
cost = tf.reduce_mean(tf.square(y_-Y))
training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
This code is very compact and very quick to write. There is really a lot going on behind the scenes that you don’t see with this Python code. TensorFlow does a lot of things in the background that you may not be aware of. It will be very instructive to try to develop this exact model completely from scratch, mathematically and in Python, without using TensorFlow, to observe what is really going on. The next sections lay out the entire mathematical formulation required, and its implementation in Python (with just numpy). The goal is to build a model that we can train for binary classification.
I will not spend too much time on the notation or the ideas behind the mathematics, because you have seen these several times in previous chapters. The discussion of dataset preparation will also be very brief, as it has already been described in Chapter .
I will not go through all the Python code
line by line, because, if you read the previous chapters, you should have quite a good grasp of the practices and ideas used here. There are no real new concepts; you have already seen almost everything. Consider this chapter as a reference, to learn how to implement a logistic model completely from scratch. I strongly suggest that you try to understand all the mathematics and implement it in Python once. It is very instructive and will teach you a lot about debugging, about how important it is to write good code, and how comfortable libraries such as TensorFlow are.
Mathematics Behind Logistic Regression
Let’s start with some notation and a reminder of what we are going to do. Our
prediction will be a variable
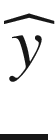
that can only be 0 or 1. (We will indicate with 0 and 1 the two classes we are trying to predict.)
What our method will give as output, or as a prediction, will be the probability of
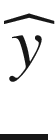
being 1, given the input case
x. Or, in a more mathematical form,
We will then define an input observation to be of class 1, if
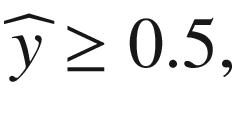
and of class 0, if
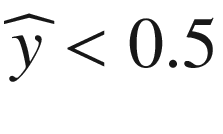
. As we have in Chapter
(see Figure
2-2), we will consider
nx inputs and one neuron with the sigmoid (indicated with
σ) activation function
. Our neuron output
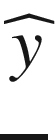
can be easily written for observation
i as
To find the best weights and bias
, we will minimize the cost function that is written here for one observation
where, with
y, we have indicated our labels. We will use the gradient descent algorithm, as described in Chapter
, so we will need the partial derivatives of our cost function with respect to the weights and the bias. You will remember that at iteration
n + 1 (we will indicate here the iteration with an index in square brackets as subscript), we will update our weights from iteration
n with the equations
where
γ is the learning rate. The derivatives
are not so complicated and can be calculated easily with the chain rule
Now, calculating the derivatives, you can verify that
When we put all this together, we get
These equations are valid only for one training case; therefore, as we have already done, let’s generalize them to many training cases, remembering that we define our cost function
J for many observations as
where, as usual, we have indicated the number of observations with
m. The bold
w is simply a vector of all the weights
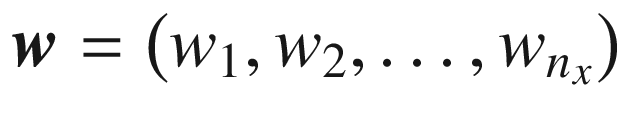
. We will also need our beloved matrix formalism here (which you have seen several times in previous chapters)
where we have indicated with
B a matrix of dimensions (1,
nx) (to make it consistent with the notation we are using now here) and with all elements equal to
b (in Python, we will not have to define it, because broadcasting will take care of it for us).
X will contain our observations
and features and have dimensions (
nx,
m) (observations on columns, features on rows), and
WT will be the transpose of the matrix containing all the weights, which, in our cases, has the dimensions (1,
nx), because it is transposed. Our neuron output in matrix form will be
where the sigmoid function acts element by element. The equations for the partial derivatives now become
These equations can be written in matrix form (where ∇
w indicates the gradient with respect to
w) as
Finally, the equation we need to implement for the
gradient descent algorithm is
At this point, you should already have gained a completely new appreciation of TensorFlow. The library does all this for you in the background, and, more important, all automatically. Remember: We are dealing here with just one neuron. You can easily see how complicated it can get when you want to calculate the same equations for networks with many layers and neurons, or for something as a convolutional or recurrent neural network.
We now have all the mathematics we need to implement logistic regression completely from scratch. Let’s move on to some Python.
Python Implementation
Let’s start importing the necessary libraries.
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
Note that we don’t import TensorFlow. We will not need it here. Let’s write a function for the sigmoid activation function
sigmoid(z).
def sigmoid(z):
s = 1.0 / (1.0 + np.exp(-z))
return s
We will also require a function to initialize the weights. In this basic case, we can simply initialize everything with zeros. Logistic regression will work anyway.
def initialize(dim):
w = np.zeros((dim,1))
b = 0
return w,b
Then we must implement
the following equations, which we have calculated in the previous section:
def derivatives_calculation(w, b, X, Y):
m = X.shape[1]
z = np.dot(w.T,X)+b
y_ = sigmoid(z)
cost = -1.0/m*np.sum(Y*np.log(y_)+(1.0-Y)*np.log(1.0-y_))
dw = 1.0/m*np.dot(X, (y_-Y).T)
db = 1.0/m*np.sum(y_-Y)
derivatives = {"dw": dw, "db":db}
return derivatives, cost
Now we need the function that will update the weights.
def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost = False):
costs = [] for i in range(num_iterations):
derivatives, cost = derivatives_calculation(w, b, X, Y)
dw = derivatives ["dw"]
db = derivatives ["db"]
w = w - learning_rate*dw
b = b - learning_rate*db
if i % 100 == 0:
costs.append(cost)
if print_cost and i % 100 == 0:
print ("Cost (iteration %i) = %f" %(i, cost))
derivatives = {"dw": dw, "db": db}
params = {"w": w, "b": b}
return params, derivatives, costs
The next function
,
predict(), creates a matrix of dimensions (1,
m) that contains the predictions of the model given the inputs
w and
b.
def predict (w, b, X):
m = X.shape[1]
Y_prediction = np.zeros((1,m))
w = w.reshape(X.shape[0],1)
A = sigmoid (np.dot(w.T, X)+b)
for i in range(A.shape[1]):
if (A[:,i] > 0.5):
Y_prediction[:, i] = 1
elif (A[:,i] <= 0.5):
Y_prediction[:, i] = 0
return Y_prediction
Finally, let’s put everything together in the model() function.
def model (X_train, Y_train, X_test, Y_test, num_iterations = 1000, learning_rate = 0.5, print_cost = False):
w, b = initialize(X_train.shape[0])
parameters, derivatives, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
w = parameters["w"]
b = parameters["b"]
Y_prediction_test = predict (w, b, X_test)
Y_prediction_train = predict (w, b, X_train)
train_accuracy = 100.0 - np.mean(np.abs(Y_prediction_train-Y_train)*100.0)
test_accuracy = 100.0 - np.mean(np.abs(Y_prediction_test-Y_test)*100.0)
d = {"costs": costs, "Y_prediction_test": Y_prediction_test, "Y_prediction_train": Y_prediction_train, "w": w, "b": b, "learning_rate": learning_rate, "num_iterations": num_iterations}
print ("Accuracy Test: ", test_accuracy)
print ("Accuracy Train: ", train_accuracy)
Test of the Model
After building the model, we must see what results it can achieve with some data. In the next section, I will first prepare the dataset we have already used in Chapter , the two digits one and two from the MNIST dataset, and then train our neuron on the dataset and check what results we get.
Dataset Preparation
As an optimizing metric, we chose accuracy, so let’s see what value we can reach with our model. We will use the same dataset as in Chapter : a subset of the MNIST dataset consisting of the digits one and two. Here, you can find the code to get the data without explanation, because we have already dissected it extensively in Chapter .
The code we require is the following:
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
X,y = mnist["data"], mnist["target"]
X_12 = X[np.any([y == 1,y == 2], axis = 0)]
y_12 = y[np.any([y == 1,y == 2], axis = 0)]
Because we loaded all images in one block, we must create a dev and a train dataset (the split being 80% train and 20% dev), as follows:
shuffle_index = np.random.permutation(X_12.shape[0])
X_12_shuffled, y_12_shuffled = X_12[shuffle_index], y_12[shuffle_index]
train_proportion = 0.8
train_dev_cut = int(len(X_12)*train_proportion)
X_train, X_dev, y_train, y_dev =
X_12_shuffled[:train_dev_cut],
X_12_shuffled[train_dev_cut:],
y_12_shuffled[:train_dev_cut],
y_12_shuffled[train_dev_cut:]
As usual, we normalize
the inputs,
X_train_normalised = X_train/255.0
X_dev_normalised = X_test/255.0
bring the matrices in the right format,
X_train_tr = X_train_normalised.transpose()
y_train_tr = y_train.reshape(1,y_train.shape[0])
X_dev_tr = X_dev_normalised.transpose()
y_dev_tr = y_dev.reshape(1,y_dev.shape[0])
and define some constants.
dim_train = X_train_tr.shape[1]
dim_dev = X_dev_tr.shape[1]
Now let’s shift our labels (remember this from Chapter
?). We have here 1 and 2, and we need 0 and 1.
y_train_shifted = y_train_tr - 1
y_test_shifted = y_test_tr - 1
Running the Test
Finally, we can test the model with the call
d = model (Xtrain, ytrain, Xtest, ytest, num_iterations = 4000, learning_rate = 0.05, print_cost = True)
Although your numbers may vary, you should get an output similar to the following, in which I have omitted a few
iterations for space reasons:
Cost (iteration 0) = 0.693147
Cost (iteration 100) = 0.109078
Cost (iteration 200) = 0.079466
Cost (iteration 300) = 0.067267
Cost (iteration 400) = 0.060286
Cost (iteration 3600) = 0.031350
Cost (iteration 3700) = 0.031148
Cost (iteration 3800) = 0.030955
Cost (iteration 3900) = 0.030769
Accuracy Test: 99.092131809
Accuracy Train: 99.1003111074
Not so bad for a result.
Conclusion
You should really try to understand all the steps I have outlined in this chapter, to understand how much is done for you by a library. Remember: We have here an incredibly simple model with just one neuron. Theoretically, you could write all the equations for more complex network architectures, but this would be very difficult and extremely error-prone. TensorFlow calculates all the derivatives for you, regardless of the complexity of the network. In case you are interested in learning what TensorFlow can do, I suggest you read the official documentation, available at
https://goo.gl/E5DpHK
.

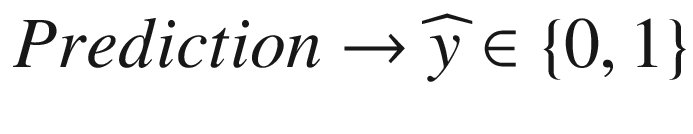
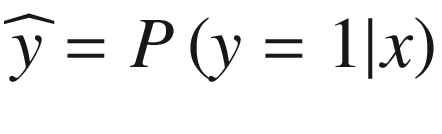
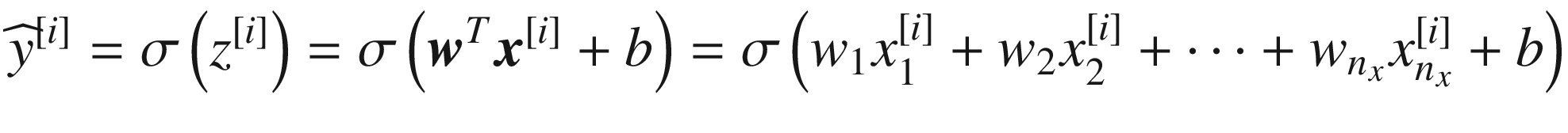
![$$ mathrm{mathcal{L}}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)=-left({y}^{left[i
ight]}log {widehat{y}}^{left[i
ight]}+left(1-{y}^{left[i
ight]}
ight)log left(1-{widehat{y}}^{left[i
ight]}
ight)
ight) $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equd.png)
![$$ {w}_{j,left[n+1
ight]}={w}_{j,left[n
ight]}-gamma frac{partial mathcal{L}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial {w}_j} $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Eque.png)
![$$ {b}_{left[n+1
ight]}={b}_{j,left[n
ight]}-gamma frac{partial mathcal{L}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial b} $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equf.png)
![$$ frac{mathrm{partial mathcal{L}}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial {w}_j}=frac{mathrm{partial mathcal{L}}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial {widehat{y}}^{left[i
ight]}}frac{d{widehat{y}}^{left[i
ight]}}{d{z}^{left[i
ight]}}frac{partial {z}^{left[i
ight]}}{partial {w}_j} $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equg.png)
![$$ frac{mathrm{partial mathcal{L}}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial b}=frac{mathrm{partial mathcal{L}}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial {widehat{y}}^{left[i
ight]}}frac{d{widehat{y}}^{left[i
ight]}}{d{z}^{left[i
ight]}}frac{partial {z}^{left[i
ight]}}{partial b} $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equh.png)
![$$ frac{mathrm{partial mathcal{L}}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial {widehat{y}}^{left[i
ight]}}=-frac{y^{left[i
ight]}}{{widehat{y}}^{left[i
ight]}}+frac{1-{y}^{left[i
ight]}}{1-{widehat{y}}^{left[i
ight]}} $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equi.png)
![$$ frac{d{widehat{y}}^{left[i
ight]}}{d{z}^{left[i
ight]}}={widehat{y}}^{left[i
ight]}left(1-{widehat{y}}^{left[i
ight]}
ight) $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equj.png)
![$$ frac{partial {z}^{left[i
ight]}}{partial {w}_j}={x}_j^{left[i
ight]} $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equk.png)
![$$ frac{partial {z}^{left[i
ight]}}{partial b}=1 $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equl.png)
![$$ {w}_{j,left[n+1
ight]}={w}_{j,left[n
ight]}-gamma frac{partial mathcal{L}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial {w}_j}={w}_{j,left[n
ight]}-gamma left(1-{widehat{y}}^{left[i
ight]}
ight){x}_j^{left[i
ight]} $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equm.png)
![$$ {b}_{left[n+1
ight]}={b}_{left[n
ight]}-gamma frac{mathrm{partial mathcal{L}}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial b}={b}_{j,left[n
ight]}-gamma left(1-{widehat{y}}^{left[i
ight]}
ight) $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equn.png)
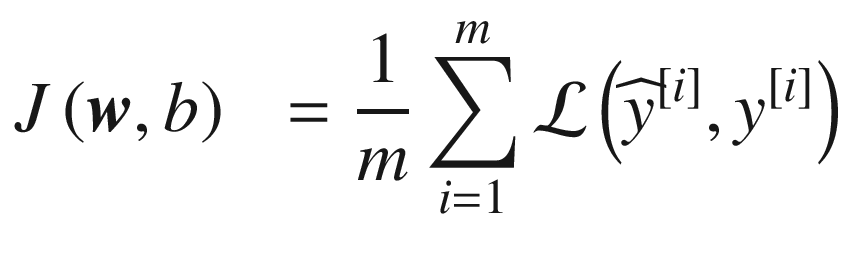
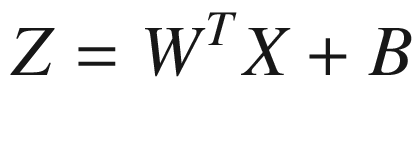
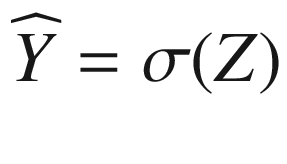
![$$ frac{partial Jleft(w,b
ight)}{partial {w}_j}=frac{1}{m}sum limits_{i=1}^mfrac{partial mathcal{L}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial {w}_j}=frac{1}{m}sum limits_{i=1}^mfrac{partial mathcal{L}left({widehat{y}}^{left[i
ight]},kern0.375em {y}^{left[i
ight]}
ight)}{partial {widehat{y}}^{left[i
ight]}}frac{d{widehat{y}}^{left[i
ight]}}{d{z}^{left[i
ight]}}frac{partial {z}^{left[i
ight]}}{partial {w}_j}=frac{1}{m}sum limits_{i=1}^mleft(1-{widehat{y}}^{left[i
ight]}
ight){x}_j^{left[i
ight]} $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equr.png)
![$$ frac{partial Jleft(w,b
ight)}{partial b}=frac{1}{m}sum limits_{i=1}^mfrac{partial mathcal{L}left({widehat{y}}^{left[i
ight]},{y}^{left[i
ight]}
ight)}{partial b}=frac{1}{m}sum limits_{i=1}^mfrac{partial mathcal{L}left({widehat{y}}^{left[i
ight]},kern0.375em {y}^{left[i
ight]}
ight)}{partial {widehat{y}}^{left[i
ight]}}frac{d{widehat{y}}^{left[i
ight]}}{d{z}^{left[i
ight]}}frac{partial {z}^{left[i
ight]}}{partial b}=frac{1}{m}sum limits_{i=1}^mleft(1-{widehat{y}}^{left[i
ight]}
ight) $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equs.png)
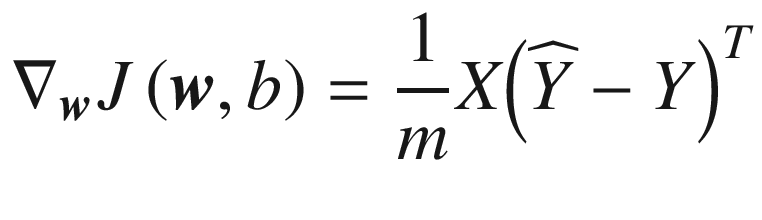
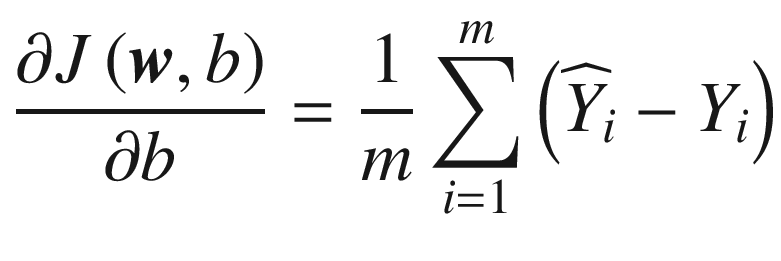
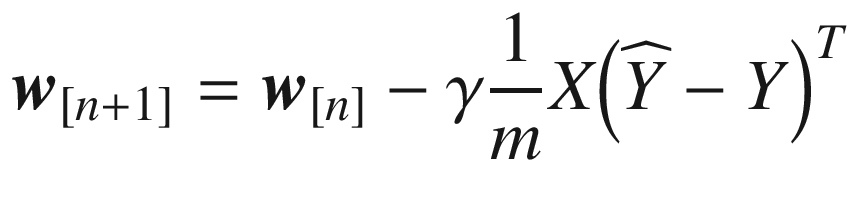
![$$ {b}_{left[n+1
ight]}={b}_{left[n
ight]}-gamma frac{1}{m}sum limits_{i=1}^mleft({widehat{Y}}_i-{Y}_i
ight) $$](http://images-20200215.ebookreading.net/10/2/2/9781484237908/9781484237908__applied-deep-learning__9781484237908__images__463356_1_En_10_Chapter__463356_1_En_10_Chapter_TeX_Equw.png)