

I dedicate this book to my daughter, Caterina, and my wife, Francesca. Thank you for the inspiration, the motivation, and the happiness you bring to my life every day. Without you, this would not have been possible.
Why another book on applied deep learning? That is the question I asked myself before starting to write this volume. After all, do a Google search on the subject, and you will be overwhelmed by the huge number of results. The problem I encountered, however, is that I found material only to implement very basic models on very simple datasets. Over and over again, the same problems, the same hints, and the same tips are offered. If you want to learn how to classify the Modified National Institute of Standards and Technology (MNIST) dataset of ten handwritten digits, you are in luck. (Almost everyone with a blog has done that, mostly copying the code available on the TensorFlow web site). Searching for something else to learn how logistic regression works? Not so easy. How to prepare a dataset to perform an interesting binary classification? Even more difficult. I felt there was a need to fill this gap. I spent hours trying to debug models for reasons as silly as having the labels wrong. For example, instead of 0 and 1, I had 1 and 2, but no blog warned me about that. It is important to conduct a proper metric analysis when developing models, but no one teaches you how (at least not in material that is easily accessible). This gap needed to be filled. I find that covering more complex examples, from data preparation to error analysis, is a very efficient and fun way to learn the right techniques. In this book, I have always tried to cover complete and complex examples to explain concepts that are not so easy to understand in any other way. It is not possible to understand why it is important to choose the right learning rate if you don’t see what can happen when you select the wrong value. Therefore, I always explain concepts with real examples and with fully fledged and tested Python code that you can reuse. Note that the goal of this book is not to make you a Python or TensorFlow expert, or someone who can develop new complex algorithms. Python and TensorFlow are simply tools that are very well suited to develop models and get results quickly. Therefore, I use them. I could have used other tools, but those are the ones most often used by practitioners, so it makes sense to choose them. If you must learn, better that it be something you can use in your own projects and for your own career.
The goal of this book is to let you see more advanced material with new eyes. I cover the mathematical background as much as I can, because I feel that it is necessary for a complete understanding of the difficulties and reasoning behind many concepts. You cannot comprehend why a large learning rate will make your model (strictly speaking, the cost function) diverge, if you don’t know how the gradient descent algorithm works mathematically. In all real-life projects, you will not have to calculate partial derivatives or complex sums, but you will have to understand them to be able to evaluate what can work and what cannot (and especially why). Appreciating why a library such as TensorFlow makes your life easier is only possible if you try to develop a trivial model with one neuron from scratch. It is a very instructive thing to do, and I will show you how in Chapter 10 . Once you have done it once, you will remember it forever, and you will really appreciate libraries such as TensorFlow.
I suggest that you really try to understand the mathematical underpinnings (although this is not strictly necessary to profit from the book), because they will allow you to fully understand many concepts that otherwise cannot be understood completely. Machine learning is a very complicated subject, and it is utopic to think that it is possible to understand it thoroughly without a good grasp of mathematics or Python. In each chapter, I highlight important tips to develop things efficiently in Python. There is no statement in this book that is not backed up by concrete examples and reproducible code. I will not discuss anything without offering related real-life examples. In this way, everything will make sense immediately, and you will remember it.
Take the time to study the code that you find in this book and try it for yourself. As every good teacher knows, learning works best when students try to resolve problems themselves. Try, make mistakes, and learn. Read a chapter, type in the code, and try to modify it. For example, in Chapter 2 , I will show you how to perform binary classification recognition between two handwritten digits: 1 and 2. Take the code and try two different digits. Play with the code and have fun.
By design, the code that you will find in this book is written as simply as possible. It is not optimized, and I know that it is possible to write much better-performing code, but by doing so, I would have sacrificed clarity and readability. The goal of this book is not to teach you to write highly optimized Python code; it is to let you understand the fundamental concepts of the algorithms and their limitations and give you a solid basis with which to continue your learning in this field. Regardless, I will, of course, point out important Python implementation details, such as, for example, how you should avoid standard Python loops as much as possible.
All the code in this book is written to support the learning goals I have set for each chapter. Libraries such as NumPy and TensorFlow have been recommended because they allow mathematical formulations to be translated directly into Python. I am aware of other software libraries, such as TensorFlow Lite, Keras, and many more that may make your life easier, but those are merely tools. The significant difference lies in your ability to understand the concepts behind the methods. If you get them right, you can choose whatever tool you want, and you will be able to achieve a good implementation. If you don’t understand how the algorithms work, no matter the tool, you will not be able to undertake a proper implementation or a proper error analysis. I am a fierce opponent of the concept of data science for everyone. Data science and machine learning are difficult and complex subjects that require a deep understanding of the mathematics and subtelties behind them.
I hope that you will have fun reading this book (I surely had a lot in writing it) and that you will find the examples and the code useful. I hope, too, that you will have many Eureka! moments, wherein you will finally understand why something works the way you expect it to (or why it does not). I hope you will find the complete examples both interesting and useful. If I help you to understand only one concept that was unclear to you before, I will be happy.
There are a few chapters of this book that are more mathematically advanced. In Chapter 2 , for example, I calculate partial derivatives. But don’t worry, if you don’t understand them, you can simply skip the equations. I have made sure that the main concepts are understandable without most of the mathematical details. However, you should really know what a matrix is, how to multiply matrices, what a transpose of a matrix is, and so on. Basically, you need a good grasp of linear algebra. If you don’t have one, I suggest you review a basic linear algebra book before reading this one. If you have a solid linear algebra and calculus background, I strongly advise you not to skip the mathematical parts. They can really help in understanding why we do things in specific ways. For example, it will help you immensely in understanding the quirks of the learning rate, or how the gradient descent algorithm works. You should also not be scared by a more complex mathematical notation and feel confident with an equation as complex as the following (this is the mean square error we will use for the linear regression algorithm and will be explained in detail later, so don’t worry if you don’t know what the symbols mean at this point):
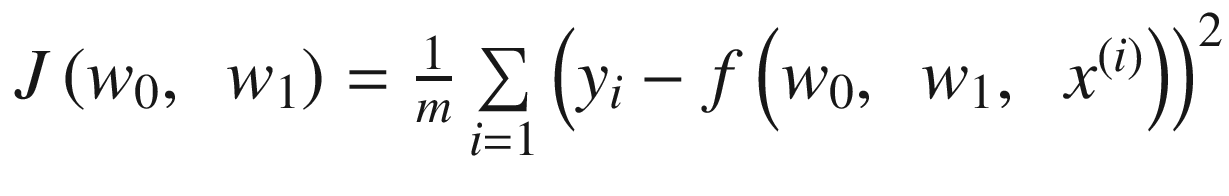
You should understand and feel confident with such concepts as a sum or a mathematical series. If you feel unsure about these, review them before starting the book; otherwise, you will miss some important concepts that you must have a firm grasp on to proceed in your deep-learning career. The goal of this book is not to give you a mathematical foundation. I assume you have one. Deep learning and neural networks (in general, machine learning) are complex, and whoever tries to convince you otherwise is lying or doesn’t understand them.
I will not spend time in justifying or deriving algorithms or equations. You will have to trust me there. Additionally, I will not discuss the applicability of specific equations. For those of you with a good understanding of calculus, for example, I will not discuss the problem of the differentiability of functions for which we calculate derivatives. Simply assume that you can apply the formulas I give you. Many years of practical implementations have shown the deep-learning community that those methods and equations work as expected and can be used in practice. The kind of advanced topics mentioned would require a separate book.
In Chapter 1 , you will learn how to set up your Python environment and what computational graphs are. I will discuss some basic examples of mathematical calculations performed using TensorFlow. In Chapter 2 , we will look at what you can do with a single neuron. I will cover what an activation function is and what the most used types, such as sigmoid, ReLU, or tanh, are. I will show you how gradient descent works and how to implement logistic and linear regression with a single neuron and TensorFlow. In Chapter 3 , we will look at fully connected networks. I will discuss matrix dimensions, what overfitting is, and introduce you to the Zalando dataset. We will then build our first real network with TensorFlow and start looking at more complex variations of gradient descent algorithms, such as mini-batch gradient descent. We will also look at different ways of weight initialization and how to compare different network architectures. In Chapter 4 , we will look at dynamic learning rate decay algorithms, such as staircase, step, or exponential decay, then I will discuss advanced optimizers, such as Momentum, RMSProp, and Adam. I will also give you some hints on how to develop custom optimizers with TensorFlow. In Chapter 5 , I will discuss regularization, including such well-known methods as l 1 , l 2 , dropout, and early stopping. We will look at the mathematics behind these methods and how to implement them in TensorFlow. In Chapter 6 , we will look at such concepts as human-level performance and Bayes error. Next, I will introduce a metric analysis workflow that will allow you to identify problems having to do with your dataset. Additionally, we will look at k-fold cross-validation as a tool to validate your results. In Chapter 7 , we will look at the black box class of problems and what hyperparameter tuning is. We will look at such algorithms as grid and random search and at which is more efficient and why. Then we will look at some tricks, such as coarse-to-fine optimization. I have dedicated most of the chapter to Bayesian optimization—how to use it and what an acquisition function is. I will offer a few tips, such as how to tune hyperparameters on a logarithmic scale, and then we will perform hyperparameter tuning on the Zalando dataset, to show you how it may work. In Chapter 8 , we will look at convolutional and recurrent neural networks. I will show you what it means to perform convolution and pooling, and I will show you a basic TensorFlow implementation of both architectures. In Chapter 9 , I will give you an insight into a real-life research project that I am working on with the Zurich University of Applied Sciences, Winterthur, and how deep learning can be used in a less standard way. Finally, in Chapter 10 , I will show you how to perform logistic regression with a single neuron in Python—without using TensorFlow—entirely from scratch.
I hope you enjoy this book and have fun with it.
It would be unfair if I did not thank all the people who helped me with this book. While writing, I discovered that I did not know anything about book publishing, and I also discovered that even when you think you know something well, putting it on paper is a completely different story. It is unbelievable how one’s supposedly clear mind becomes garbled when putting thoughts on paper. It was one of the most difficult things I have done, but it was also one of the most rewarding experiences of my life.
First, I must thank my beloved wife, Francesca Venturini, who spent countless hours at night and on weekends reading the text. Without her, the book would not be as clear as it is. I must also thank Celestin Suresh John, who believed in my idea and gave me the opportunity to write this book. Aditee Mirashi is the most patient editor I have ever met. She was always there to answer all my questions, and I had quite a few, and not all of them good. I particularly would like to thank Matthew Moodie, who had the patience of reading every single chapter. I have never met anyone able to offer so many good suggestions. Thanks, Matt; I own you one. Jojo Moolayil had the patience to test every single line of code and check the correctness of every explanation. And when I mean every, I really mean every. No, really, I mean it. Thank you, Jojo, for your feedback and your encouragement. It really meant a lot to me.
Finally, I am infinitely grateful to my beloved daughter, Caterina, for her patience when I was writing and for reminding me every day how important it is to follow your dreams. And of course I have to thank my parents, that have always supported my decisions, whatever they were.
Table of Contents
About the Author and About the Technical Reviewer
About the Author

currently works in innovation and artificial intelligence (AI) at the leading health insurance company in Switzerland. He leads several strategic initiatives related to AI, new technologies, machine learning, and research collaborations with universities. Formerly, he worked as a data scientist and lead modeler for several large projects in health care and has had extensive hands-on experience in programming and algorithm design. He managed projects in business intelligence and data warehousing, enabling data-driven solutions to be implemented in complicated production environments. More recently, Umberto has worked extensively with neural networks and has applied deep learning to several problems linked to insurance, client behavior (such as customer churning), and sensor science. He studied theoretical physics in Italy, the United States, and in Germany, where he also worked as a researcher. He also undertook higher education in the UK. He presents scientific results at conferences regularly and publishes research papers in peer-reviewed journals.
About the Technical Reviewer

is an Artificial Intelligence, Deep Learning, Machine Learning & Decision Science professional with over 5 years of industrial experience and published author of the book - Smarter Decisions – The Intersection of IoT and Decision Science . He has worked with several industry leaders on high impact and critical data science and machine learning projects across multiple verticals. He is currently associated with General Electric , the pioneer and leader in data science for Industrial IoT and lives in Bengaluru—the silicon-valley of India.
He was born and raised in Pune, India and graduated from the University of Pune with a major in Information Technology Engineering. He started his career with Mu Sigma Inc., the world’s largest pure-play analytics provider and worked with the leaders of many Fortune 50 clients. One of the early enthusiasts to venture into IoT analytics, he converged his learnings from decision science to bring the problem-solving frameworks and his learnings from data and decision science to IoT Analytics.
To cement his foundations in data science for industrial IoT and scale the impact of the problem-solving experiments, he joined a fast-growing IoT Analytics startup called Flutura based in Bangalore and headquartered in the valley. After a short stint with Flutura, Jojo moved on to work with the leaders of Industrial IoT - General Electric, in Bangalore, where he focused on solving decision science problems for Industrial IoT use cases. As a part of his role in GE, Jojo also focuses on developing data science and decision science products and platforms for Industrial IoT.
Apart from authoring books on Decision Science and IoT, Jojo has also been Technical Reviewer for various books on Machine Learning, Deep Learning and Business Analytics with Apress and Packt publications. He is an active Data Science tutor and maintains a blog at http://www.jojomoolayil.com/web/blog/ .
I would like to thank my family, friends and mentors.
— Jojo Moolayil