
Single shot detection for detecting real-time flying objects for unmanned aerial vehicle
Sampurna Mandal1, Sk Md Basharat Mones1, Arshavee Das1, Valentina E. Balas2, Rabindra Nath Shaw3 and Ankush Ghosh1, 1School of Engineering and Applied Sciences, The Neotia University, Kolkata, India, 2Department and Applied Software, Aurel Vlaicu University of Arad, Arad Romania, 3Department of Electrical, Electronics & Communication Engineering, Galgotias University, Greater Noida, India
Abstract
This world of rapidly changing technology has an impact on the infrastructure of worldwide transportation systems. These changes are becoming more and more clear with time. As the field of Robotics and Artificial Intelligence is booming, every gadget is getting smarter. The concept of manual vehicles is shifting toward autonomous vehicles. For example, manual delivery is shifting toward autodelivery by autonomous drones. However, the Unmanned Aerial Vehicle (UAV) is one of the recent hot topics in research. There are various challenges that we need to overcome on the questions of safety and reliability. One such challenge for UAVs is detecting flying objects in real time. Our work focuses on detecting real-time objects using the Single Shot Detector (SSD) algorithm. The objective is to train the labeled images of flying objects with SSD and evaluate the efficiency of the algorithm in terms of confidence value and accuracy.
Keywords
Single Shot Detection (SSD); Convolutional Neural Network (CNN); deep learning (DL); machine learning (ML); artificial intelligence (AI); robotics; automation
4.1 Introduction
This world is headed toward a future where the skies are not occupied with only birds, manually driven airplanes, helicopters, and fighter planes. In the near future the sky is going to be occupied by unmanned vehicles ranging from unmanned drones to large Unmanned Aerial Vehicles (UAV). Some of the UAVs will be able to communicate among themselves without human interruption. It is extremely important to make commercial as well as military UAVs economical, safe, and reliable. One of the solutions is to use inexpensive sensors and camera devices for collision avoidance.
The latest automotive technologies have given solutions to these problems, for example, nowadays commercial products [1,2] are designed to sense the obstacles and avoid collision with other cars, pedestrians, cyclists, and other movable and immovable objects. Modern technology has already made progress on navigation and accurate position estimation with either single or multiple cameras [3–9], although there is comparatively little improvement in visual guided collision avoidance technique [10]. Basically, it is quite difficult to apply the same algorithm for pedestrian or automobile detection just by simply extending and modifying. Some challenges for flying object detection are given below:
- • The object motion is more complex due to the 3D environment.
- • There are various kinds of flying objects with diverse shapes. These flying objects can appear both on the ground and in the sky. Because of that the background also becomes more diverse and complex.
- • The UAV must detect potentially dangerous objects from a safe distance, where speed is also involved.
Fig. 4.1 shows some examples where flying objects are being detected on just a single image where even the human eye cannot clearly see them. When the sequence of frames is observed, these objects popped up and therefore were detected easily, which leads to the conclusion that motion cues play a very crucial role in detection.

But these motion cues become very difficult to target if the images are taken from a moving camera with featured backgrounds. It becomes a matter of challenge to stabilize as they are changing rapidly and are nonplanar. Moreover, since there are other moving objects, as shown in the first row of Fig. 4.1, there is a person in motion. But only motion is not sufficient, and the corresponding appearance must be taken care of.
In this chapter, our target is to detect and classify the object of interest present in the image or frame. The work for flying object detection in this chapter is divided into two steps:
- • At first, the images of flying objects taken from various sources with different shapes and diverse background are detected and classified with labeled bounding box along with a confidence score predicted by the network.
- • Then, the same network is applied to video to test the performance of the network while the motion is included along with the constantly changing background.
The primary motivation behind this work is to test the Single Shot Detection (SSD) algorithm to detect and classify flying objects such as airplanes and birds. The secondary objective for working on this chapter is to demonstrate how this algorithm is successfully applied for real-time flying object detection and classification for frames taken from a video feed during UAV operation.
4.2 Related work
There are three main categories in which the moving objects can be classified:
Let us briefly discuss the review of the incorporated processes:
4.2.1 Appearance-based methods
These types of methods rely on ML (machine learning) algorithms and the performances of these algorithms are quite good even in cluttered background or in complex light variation. They are typically based on Deformable Part Models [11], Convolutional Neural Networks (CNN) [12], or Random Forests [13]. Among these algorithms the best is Aggregate Channel Features [14].
These algorithms perform better for those kind of target objects where the objects are clearly visible in individual images. This is not the case applied for us. As an example, let’s say, there is fog or smoke in the environment. The algorithm should be able to detect a target which is a flying object even in a hazy or foggy environment. Another example is shown in Fig. 4.1, the object is quite small and is not visible with the human eye. It was only possible to detect that object because of the motion cues.
4.2.2 Motion-based methods
These types of methods can be divided further into two subsets: The first one comprises the targets that rely upon background subtraction [15–18] and this subclass determines the objects as a group of pixels that are different from the group of pixels that form the background. The second subclass includes those targets that rely on optical flow [19–21].
When the camera is in a fixed position or the motion is very small and almost negligible, the background subtraction method works best, which is not the case for an onboard camera of a fast-moving aircraft. To overcome these problems, flow-based methods are used and give satisfactory results. But flow-based methods are critical when these come to detect the small and blurry objects. To overcome this problem, some methods use the combination of the both background subtraction and flow-based methods [22,23].
In our case, the background changes as the flying objects move through 3D spaces. The same types of flying objects (e.g., birds) can appear in various shapes and sizes simultaneously depending on the variable distance between the camera and the objects. So, it is clearly seen that only motion information is not sufficient to detect flying objects with high reliability. As said earlier, there are other methods which combine both background subtraction and flow-based methods, for example, it is seen that the work done in the references [24–27] depend on optical flow critically, which is again combined with [21] and may suffer from the low quality of flow vectors. Additionally, it can be included that the assumption made by Narayana et al. [26] about the translational camera motion is again violated in aerial videos.
4.2.3 Hybrid methods
These approaches combine information related to both object appearance and motion patterns and are therefore highly reliable. This method performs well regardless of the frame background variation and motion cue. Walk et al.’s [28] work can be shown as an example here, where histograms of flow vectors are used are used as features combined with the appearance features, which are more standard, and then fed to a statistical learning method. This approach is taken in Ref. [29], where at first the patches are aligned to compensate for motion and after that the differences of the frames (both consecutive and separate frames) are used as additional features. This alignment depends on the Lucas–Kanade optical flow algorithm [20]. The resulting algorithm responds very well when it comes to pedestrian detection and performs better than the single-frame methods. The flow estimates are not reliable while detecting the smaller target objects which are harder to detect, and, like purely flow-based methods, this method becomes less effective.
The first deep learning object detection technique was Overleaf Network [30]. This technique used CNNs for classifying every part of the image along with a sliding window to detect and classify an image as object (object of interest) or nonobject (background). These earlier methods led to even more advanced techniques for object detection. In recent years, the deep learning community has proposed several object detectors, such as Faster RCNN [31], YOLO [32], R-FCN [33], SSD [34], and RetinaNet [35]. The primary focus of these algorithms was:
- • to improve the accuracy and confidence score of the algorithm in terms of map; and
- • to improve the computational complexity, so that these algorithms can be used effective for real-time object detection for embedded and mobile platforms [36].
These detection algorithms can be divided into two subclasses based on their high-level architecture: (1) single based approach and (2) two-step approach, that is, the region-based approach. The single-step approach is given more priority when the aim is to achieve faster results and high memory efficiency. Whereas the two-step approach is taken when accuracy is more important than time complexity and memory consumption.
4.2.4 Single-step detectors
Single-step detectors are simpler and faster than region-based models with reasonable accuracy. These detectors directly predict the coordinate offsets and object classes instead of predicting objects/nonobjects. SSD, YOLO, and RetinaNet are some of the examples of single-step detectors.
4.2.5 Two-step detectors/region-based detectors
This method has two stages for object detection:
R-CNN, Fast R-CNN, FPN, Faster R-CNN, and R-FCN are some of the examples of single-step detectors.
4.3 Methodology
4.3.1 Model training
Here, a pretrained model of SSD [37] “Caffe Model” [38] is used for training the dataset. The dataset contains classes of flying objects like birds and aero planes (all types of planes are labeled as aero plane). OpenCV 4 library is used here. Within this OpenCV library, a highly improved deep learning model “DNN” is present. This “DNN” module supports a deep learning framework like “Caffe.” The “Caffe” model architecture, which is used in this chapter, is shown below (Fig. 4.2):
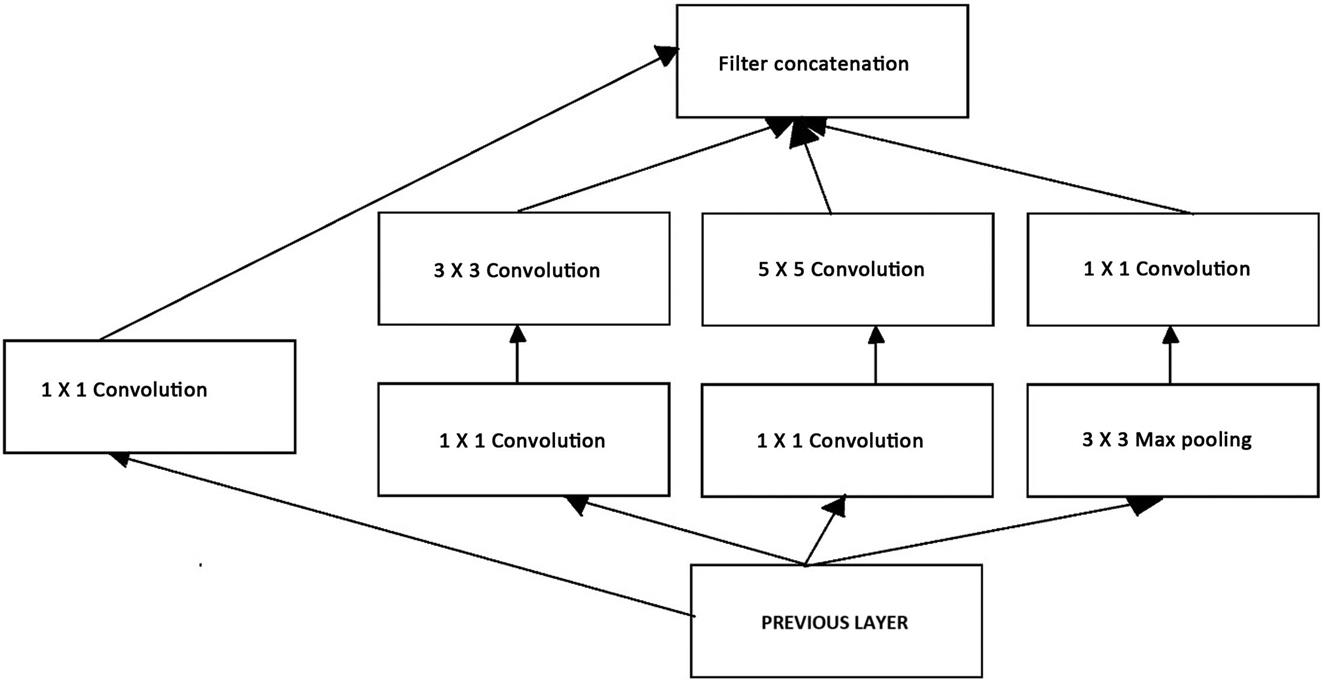
The layers of Caffe model are described as follows:
- • Vision layers:
- • Particularly operate to some region of the input and as a result, produce a corresponding region of the output.
- • Other layers ignore the spatial structure of the input. Though there are few exceptions.
- • May include convolution, pooling, Local Response Normalization layers.
- • Convolutional layers consist of a set of learnable filters which are applied over image.
- • Loss layers:
- • Activation layers:
- • Elementwise operation is performed, taking one bottom blob and producing one top blob of the same size.
- • Transforms the weighted sum of inputs that goes into artificial neurons.
- • These functions are nonlinear to encode to encode complex patterns.
- • May include ReLU or Leaky ReLU, Sigmoid, TanH/Hyperbolic Tangent, Absolute Value, etc.
- • Data layers:
- • Common layers:
4.3.2 Evaluation metric
A confidence score is calculated as an evaluation standard. This confidence score shows the probability of the image being detected correctly by the algorithm and is given as a percentage. The scores are taken on the mean average precision at different IoU (Intersection over Union) thresholds. For this work, the thresholds are set at 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, that is, if the confidence of the detected object is over 60%, 65%, 70%, 75%, 80%, 85%, and 90%, respectively, then only the label will be taken for evaluation.
Intersection over Union (IoU) [39] is measured by the magnitude of overlap between two bounding boxes of two objects. The formula for IoU is given below:
Eq. (4.1) can be expresses as:
Precision is calculated at the threshold value depending on the True Positives (TP), False Positives (FP), and False Negatives (FN) which are the result of comparing the predicted object to the ground truth object. FN is not applicable for our case. A TP is counted when the ground truth bounding box is matched with the prediction bounding box. A FP is counted when a predicted object had no association with the ground truth object. A FN is counted when a ground truth object had no association with the predicted object. The confidence score is given as the mean over all the precision scores for all thresholds. The average precision is given as:
4.4 Results and discussions
Images of the flying objects are taken with a diverse background to test if the algorithm can work properly. Figs. 4.3 and 4.4 show the output when these images are fed to the algorithm for testing purposes. The output contains bounding boxes with a label of the object and a confidence score. This open source tool is known as Bounding Box Label [12], and is used to label all the different types of birds and aeroplanes (Table 4.1).




Table 4.1
| Object | Average confidence score |
|---|---|
| Bird | 96.65 |
| Aeroplane | 97.89 |
The average confidence score was calculated as the mean of all confidence scores given (for labeled images) by the algorithm. However, for testing purposes 100 images were provided for each class. It is seen that there are some images where the algorithm was detecting birds as aeroplanes and aeroplanes as birds. For some images instead of having aeroplanes and birds in the image, the network was not able to detect all the objects. The confusion matrix for each class is given below:
Tables 4.2 and 4.3 show that 97% aeroplane images and 95% bird images were correctly detected by the algorithm. For Table 4.2, TP=97, FP=1, FN=2, True Negative (TN)=Not Applicable (NA). For Table 4.3, TP=96, FP=3, FN=1, TN=NA.
Table 4.2
| Classification | Class | Detected | |
|---|---|---|---|
| Aeroplane | Not aeroplane | ||
| Actual | Aeroplane | 97 | 2 |
| Not aeroplane | 1 | NA | |
4.4.1 For real-time flying objects from video
Figs. 4.5 and 4.6 are the screenshots taken from two videos. The first video shows the birds starting to fly and the second video is from an aeroplane takeoff.


At first, the confidence of the network was tested for different objects in multiobject scenarios. Then the same network was applied to evaluate the performance of the network from a video feed. Some snapshots were taken after testing the video with the algorithms. The results from Figs. 4.5 and 4.6 clearly show that the network is working very well even for instantaneous object detection. The SSD algorithm was able to detect and classify an object accurately in the video feed, even when the full object contours were obscured partially by another object. Based on the accuracy attained in detecting and classifying flying objects, this can be applied both for commercial and military applications. With slide modifications, many transportation-related projects can apply this approach successfully.
4.5 Conclusion
Vision-based unmanned autonomous vehicles have a wide range of operations in intelligent navigation systems. In this chapter, a framework for real-time flying object detection is presented. The flying objects were detected by the network with a very high accuracy (average 97%, for bird and aeroplane classes) as shown in the results. These results show that the network is highly reliable for detecting flying objects. Here “SSD,” which is an open source platform for object detection and classification, is based on CNN. Future work can focus on detecting more flying objects like drone, helicopters, and even skydivers and paragliders. UAVs and CNN can be used for peripheral flying objects counting as well as detection and classification. Thus SSD can be very useful for detecting real-time objects. We hope that this work will add some value to modern ongoing research work on UAVs. Though this chapter focuses mainly on flying object detection for UAVs, the modified algorithm can be applied in the transportation and civil engineering fields. It is highly recommended to test the approach with a combination of different object classes on various images and to observe how these advancements will have an impact on how UAVs implement complex task. Another application can include automated identification of roadway features. These applications have the ability to transform the infrastructure of transportation asset management in the near future.