
Recent trends in pedestrian detection for robotic vision using deep learning techniques
Sarthak Mishra and Suraiya Jabin, Department of Computer Science, Faculty of Natural Sciences, Jamia Millia Islamia, New Delhi, India
Abstract
Pedestrian detection has become more and more important in the field of robotic vision, having applications in autonomous driving, automated surveillance, smart homes, as well as mobile robots (or mobot). With the help of smart cameras, mobile robots have been able to detect, localize, and recognize pedestrians in a scene. In recent years, researchers from all around the world have developed robust deep learning-based systems for detecting pedestrians with subpar results. In this chapter, we have presented a review of the most superior deep learning techniques used by robotic vision systems in recent years and how well they have performed on different benchmark datasets available all around the world. All the techniques differ in two major respects, firstly the architecture of the system, and secondly the preprocessing, where input data is used in different capacities. The field of robotic vision is still under constant development and the day isn’t far when full automation will be a reality.
Keywords
Pedestrian detection; deep learning; robotic vision; reidentification; occlusion; crowd monitoring
10.1 Introduction
A crowd comprises groups of individuals in an open or closed space. Behavior of the individuals in a crowd as a single entity and with each other defines the collective behavior of the crowd. Monitoring crowd through CCTV cameras has been a tedious task in analyzing crowd behavior and identifying anomalous behavior that may lead to harm. A number of challenges exist in crowd behavior analysis, one of which is detecting pedestrians with absolute accuracy in the high density crowded scenes, individually as well as collectively.
Robotic vision is a branch of computer vision that specializes in evolving human-aware navigation (HAN), autonomous driving, smart camera-based surveillance, etc. Deep learning techniques are now being fully used to develop vision-based robots for these purposes. The development of smart homes and cities has been constantly on the rise with the development of surveillance systems based on Deep Neural Networks.
A Deep Neural Network is designed by keeping in mind the problem domain, a feature extractor extracts the relevant features from the data, and the classifier classifies the data into an appropriate category. With the boom of Computer Vision in 2012, Convolutional Neural Networks (CNNs) have since been used to solve some of the complicated computer vision problems which appeared impossible two decades ago. This has given rise to deep learning as a new tool for solving the problems of automated crowd analysis and monitoring. Deep Neural Networks have tackled some of the major challenges in the past few years, like classification of images, localization of classified objects in images, object recognition, semantic, and instance segmentation. The devised deep learning techniques have also been able to achieve state-of-the art results on these robotic vision problems. Fig. 10.1 shows an overview of a crowd monitoring system.
The unprecedented growth of the population has demanded the immediate need of advanced surveillance and crowd monitoring systems that will provide unequivocal contributions to the field of computer vision. Advancement of deep learning, with efficient applications, tools, and techniques being developed frequently, has eased the task to make computer vision comparable to human vision, now not a distant reality. Deep learning models have become more robust and accurate in automating the process of pedestrian detection (PD), tracking, and reidentification in high-density occluded crowded scenes.
10.2 Datasets and artificial intelligence enabled platforms
A number of datasets are publicly available for PD, tracking, and identification. Here we list some of the widely used benchmark datasets in recent years.
- • CityPersons [1]: contains 5k images with more than 35k annotations. It has on average seven pedestrians per image.
- • NightOwls [2]: contains more than 279K annotations from three different countries. It is a night-time dataset.
- • Caltech [3]: contains 10 hours of video from a vehicle driving in an urban scene having more than 42K training and 4K testing images.
- • ETH [4]: contains three video sequences with more than 1.8K images.
- • KAIST [5]: contains more than 95K images with 100K+ annotations and 1182 pedestrian instances.
- • INRIA [6]: contains 614 positive and 1218 negative images for training and 288 for testing.
- • PETS [7]: contains video sequences from multiple cameras (eight).
- • UMN [8]: contains 11 video sequences with three different scenes with more than 7K frames.
Here are some of the artificial intelligence (AI)-enabled platforms that offer surveillance and other detection capabilities.
- • Ella from ICRealtime [9]: uses google cloud to process CCTV footage from any camera. It is a real-time open source platform that integrates deep learning tools for detection, recognition, and can be integrated with any number of cameras.
- • AnyConnect [10]: provides smarter surveillance tools for CCTV footage using IP cameras. It fuses deep learning, robotic vision, and sensor information over a wireless network for bodycams and security cameras.
- • Icetana [11]: offers surveillance through video anomaly detection by identifying abnormal behavior. It is a real-time monitoring platform that automatically learns normal patterns and recognizes anomaly.
- • Hikvision [12]: offers facial recognition and vehicle identification management tools. Offers security with the help of multiple tools under the safe city program to monitor surveillance footage, alarm systems, and so on.
10.3 AI-based robotic vision
Robotic vision systems are being developed for HAN, human machine interaction, unmanned aerial vehicle (UAV), and autonomous driving. Such systems need an efficient vision system for object detection and localization. Deep learning techniques have improved the capabilities of robotic vision applications, such as automated surveillance, autonomous driving, drones, smart cities, etc. Such systems are highly complex and can’t be easily developed with limited resources, but the advantages gained by developing such systems have a crucial role in improving the way of life for humans.
Kyrkou [13] designed a system to achieve a good trade-off between accuracy and speed for a deep learning-based PD system using smart cameras. The proposed system uses separable convolutions and integrates connections across layers to improve representational capability. The authors also suggest a new loss function to improve localization of detection. Mandal et al. [14] designed a real-time robotic vision system for multiobject tracking and detection in complex scenes using RGB and depth information. The spatiotemporal object representation combines a color model with the texture classifier that is based on the Bayesian framework for particle filtering.
Detection of pedestrians from cameras at varying altitudes is a complex issue. UAVs or drones are now being designed with robotic vision system for better trajectory planning. Jiang et al. [15] proposes a unique technique for PD to be employed in UAVs for efficient PD. The system is trained with Adaptive Boosting and cascade classifiers, based on Local Binary Patterns, with Meanshift algorithm for detection. Aguilar et al. [16] designed an extension of Jiang et al.’s work [15] where Saliency Maps algorithm is used instead of Meanshift. The dataset provided by the authors is suitable for use in UAV systems. The images are captured from surveillance cameras at different angles as well as altitudes.
For developing a mobile robot (or Mobot), robotic vision is one of the most important aspects. It is important for the Mobot to be aware of obstacles and which of them are people. An efficient mobile robot is supposed to have a robust vision system that can detect and localize pedestrians as well as plan and predict the trajectory of motion. Hence PD becomes an important aspect of robotic vision in terms of HAN. Mateus et al. [17] addressed the problem of HAN for a robot in a social aspect. This author proposed a deep learning-based person tracking system, where a cascade of aggregate channel features (ACF) detector with a deep convolutional neural network (DCNN) is used to achieve fast and accurate PD. Human-aware constraints associated with robots' motion were reformulated using a mixture of asymmetric Gaussian functions, for determining the cost functions related to each constraint. Aguilar et al. [18] applied the real-time deep learning techniques on human-aware robot navigation. The CNN is combined with Aggregate ACF detector that generates region proposals to save computational cost. The generated proposals are then classified by CNN. The suggested pedestrian detector is then integrated with the navigation system of a robot for evaluation. Riberio et al. [19] proposed a novel 3DOF pedestrian trajectory prediction method for autonomous mobile service robots. Range-finder sensors were used to learn and predict 3DOF pose trajectories. T-Pose-LSTM was trained to learn context-dependent human tasks and was able to predict precisely both position and orientation. The proposed approach can perform on-the-fly prediction in real time.
10.4 Applications of robotic vision toward pedestrian detection
In this section some of the major applications of PD using robotic vision are described. Fig. 10.2 shows these applications.
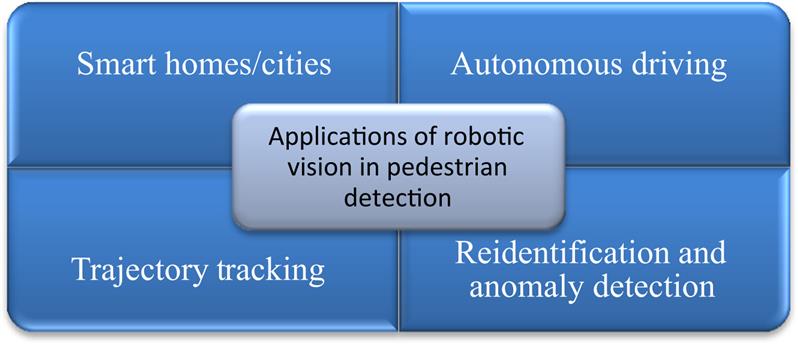
10.4.1 Smart homes and cities
In the smart home, town or cities, robotic vision is gaining pace in order to accommodate the growing demands of fully automated systems. These systems are supposed to detect and localize any object or person and can make decisions based on those detections. For example, a person enters a room, the system should be able to identify if it’s one of the residents or an intruder and can raise the alarm. In smart towns or cities, detecting a pedestrian can be a first step toward a robust surveillance system that can identify any wanted person or detect any suspicious activity. Garcia et al. [20] presented the basic idea of using an IP camera to automate the process of person detection in smart homes, smart towns, and smart cities. The authors have used MIDGAR architecture which is a popular IOT platform and integrated it with a computer vision module to analyze images from the IP cameras. The real-time monitoring system developed can be used to define actions owing to the presence of a person in an area. Ibrahim et al. [21] designs a framework using Deep Convolutional Neural Network for detecting pedestrians in an urban scene, and also mapping slums and transport modes among other things. The Urban-I architecture comprises three parts. One of which is used for identifying pedestrians using the CNN and Single Shot Detector technique. The framework is useful in smart cities as it serves multiple purposes. Othman et al. [22] combined the IOT system and computer vision module like Garcia et al. [20] to detect people. Using the PIR sensor on a Raspberry 3 card, motion is detected in an area and an image is captured. The computer vision module is then used to detect the position of the pedestrian in that image. The resultant image is sent to a smartphone along with a notification. The proposed system is useful in maintaining security in a smart home. For detecting pedestrians at distance and to improve the resolution of input images, Dinakaran et al. [23] made use of Generative Adversarial Networks (GANs) in combination with a cascaded Single Shot Detector. GAN is helpful in image reconstruction to discriminate features of objects present in the image. This discriminative feature of the proposed system is helpful in differentiating vehicles and pedestrians from a street surveillance camera to make it suitable for smart cities applications. Lwowski et al. [24] proposes a fast and reliable regional detection system integrated with deep convolutional networks for real-time PD. This study has its application in robotics, surveillance, and driving. The proposed study used rg-chromaticity to extract relevant red, green, blue (RGB) channels features and a further sliding window algorithm was utilized for the detection of feature points for classification purposes.
10.4.2 Autonomous driving
Designing an autonomous vehicle or mobile robots crucially requires a robust and accurate PD system. Khalifa et al. [25] propose a dynamic approach to detect moving pedestrians using a moving camera placed on top of a car’s windshield. This framework models the motion of the background using several consecutive frames then differentiates between the background and foreground, then checks for the presence of pedestrians in the scene. The main idea by Wang [26] is to develop a system of PD based on panoramic vision of the vehicle. Center and Scale Prediction, which is a two-stage process of feature extraction and detection, has been designed. Resnet-101 is used as base model which is used for feature extraction using multiple channels. In the detection stage, small-sized convolutions are used to predict the center, scale, and offsets. Pop et al. [27] proposes PD along with activity recognition and time estimation to cross the road for driver assistance systems in order to increase road safety. PD is done using RetinaNet, which is based on ResNet50, using the JAAD dataset for training that is annotated to derive the pedestrian actions before crossing the streets. The actions are classified into four categories: pedestrian is preparing to cross the street (PPC), pedestrian is crossing the street (PC), pedestrian is about to cross the street (PAC), and pedestrian intention is ambiguous (PA).
10.4.3 Tracking
For the purpose of crowd surveillance, it is important to detect pedestrians in a crowded scene, it is also important to track the pedestrians in a scene. The trajectory of pedestrian’s movement is crucial in understanding the flow of the crowd, analysis of crowd behavior, and detection of anomalous behavior in crowd. Mateus et al. [17] proposes a PD and tracking mechanism using multicamera sensors. Detection is done by combining ACF detectors along with Deep Convolutional Neural Network. HAN for a robot in a social context is handled using Gaussian as the cost function for different constraints. In Chen et al. [28] a pedestrian detector is developed using a faster region based convolutional neural networks (R-CNN) and then a tracker is designed using a target matching mechanism by utilizing a color histogram in combination with scale invariant feature transformed into a Fully Convolutional Network to extract pedestrian information. It is also shown to reduce background noise in a much more efficient manner and works well in occluded conditions. Zhong et al. [29] presents a novel technique for estimating the trajectory of pedestrians’ motion in 3D space rather than 2D space. A stereo camera is used to detect and estimate a human pose using the Hourglass Network. For predicting trajectory, SocialGAN is extended from 2D to 3D. The detection of the CNN can be improved by enhancing the representational ability. Yu et al. [30] proposes fusing extracted features such as color, texture, and semantics using different channels of the CNN by emphasizing the correlations among them via learning mechanisms. Yang et al. [31] proposes a pedestrian trajectory extraction technique using a single camera that doesn’t acquire any blind space. A Deep CNN in combination with Kalman filter and Hungarian algorithm to detect pedestrian heads are used to obtain the coordinates of the trajectory points using a novel height estimation technique.
10.4.4 Reidentification
Reidentifying pedestrians is a challenging task. It involves tracking a pedestrian across multiple cameras/scenes as well distinguishing different people at the same time. A number of factors come into play like similarity in appearances, varying camera angles, pedestrian pose, and so on. Fu et al. [32] proposes a two-stream network based on ResNet50 that uses spatial segmentation and identifies global as well as local features. One of the two branches in the network learns global spatial features using adaptive average pooling, whereas the other branch learns the local features using horizontal average pooling to depict the pose of the pedestrians. Qu et al. [33] proposes a Deep Convolutional Neural Network that identifies differences in the local features between the two input images. The DCNN extracts feature vectors from the input images then utilize Euclidean distance to calculate the similarity. For training, the focal loss is used to handle the class imbalance problem in the dataset, thus improving the recognition accuracy of the overall system.
10.4.5 Anomaly detection
Anomaly in terms of surveillance refers to any suspicious activity that is different from the activities occurring in the scene. A dual channel CNN [34] enables identification of suspicious crowd behavior by integrating motion and scene-related information of the crowd extracted from input video frames. This highlights the significance of raw frames along with feature descriptors in identifying an anomaly in crowded scenes. Fully Convolutional Neural Networks (FCN) have also been used recently for detecting abnormal crowd behaviors. These networks can be used in combination with temporal data to detect and localize abnormalities in crowded scenes [35]. Transfer Learning (pretrained CNN) can be adapted to an FCN (by removing the Fully Connected Layers). This FCN-based structure extracts distinctive features of input regions and verifies them with the help of a special-design classifier. Ganokratanaa et al. [36] attempted to detect anomalies and localize them using a deep spatiotemporal translation network based on GAN. Using normal activities framed as a training set, the authors train a system to generate dense optical flow as temporal features of normal events. For application, the input videos are fed into the system and any event that was not in the training set is categorized as anomaly.
10.5 Major challenges in pedestrian detection
In this section, we list the most pertinent issues faced in the area of state-of-the-art PD and remedies suggested by various researchers. Fig. 10.3 shows the major challenges faced by PD.
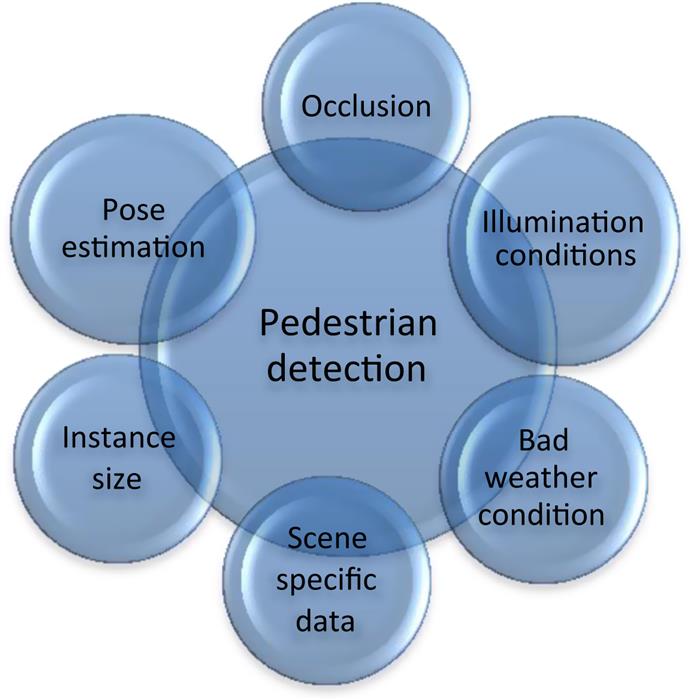
10.5.1 Illumination conditions
Illumination conditions play the most crucial role in accurate PD. Several factors can contribute to bad lightening conditions, such as bad weather, nighttime, or insufficient light in an indoor scene.
Researchers [37] designed a multispectral PD system which consists of two subnetworks designed using region-based FCN, by combining color and thermal image information. The model fuses the color and thermal images, and nonmaximum suppression is used to fuse the detection results of the two subnetworks. Researchers [38] proposed a multispectral Deep Convolutional Neural Network that combines the visible and infrared images using a two-branch network which is merged together using three different fusion techniques at different convolutional stages. Color and thermal images and their correlation can also be used as a measure to detect pedestrians in nighttime videos. This illumination measure [39] can be used as a facilitator in the detection process or can be used to design a CNN for the same. CNN fusion architectures have also proved useful in detecting pedestrian in images with illumination problem. Vanilla architectures have been used to obtain and combine the detection results of the fusion architectures. In outdoor scenarios, weather plays an important role as visibility is totally dependent on it. Tumas et al. [40] focused on detecting pedestrians in adverse weather conditions. A new dataset named ZUT captured during severe weather conditions (cloudy, rainy, foggy, etc.) was used to train a system trained using You Only Look Once (YOLO) v3 detector. The detector performs well in varying lighting conditions and under motion blur as well.
10.5.2 Instance size
Position of the camera that captures a scene can have positive as well as negative effects on how a system detects pedestrians in that scene. For example, pedestrians that are closer to the camera can be easily identified but the small instances can even be missed by a human eye. When Deep Neural Networks process these scenes, there is a possibility that they may miss the small instances.
A Scale Aware Fast R-CNN synthesizes two subnetworks into a single framework [41], and detects pedestrians in outdoor scenes where different pedestrian instances possess different spatial scales. The framework takes the location of people (proposal) and the feature map of the scene as inputs, and outputs a prediction scores and a boundary for each input proposals. The framework in [38] uses a Feature Pyramid Network that is shown to improve the detection results for different scales of instances (especially, small-scale instances). A two-stream CNN [42], replicating the human brain, captures spatial and optical flow of the input video sequences for detecting pedestrian using deep motion features and deep still image features. Zhang et al. [43] focused on the detection of small-scale pedestrians using an asymmetrical CNN by considering the shape of the human body as rectangular. This facilitates to generate rectangular proposals that capture the complex features of a human body. A three-stage framework for the CNN deploys coarse-to-fine features to gently dismiss the false detections.
10.5.3 Occlusion
Occlusion has proved to be one of the major hindrances in PD. It becomes quite difficult to detect a pedestrian who is being blocked by an object or another pedestrian.
Mask R-CNN can be used to detect and segment faces in obscured images [44]. This is one way of handling occlusion and increasing robustness of face detection mechanism. GANs can be another intuitive way to handle occlusion. A generative and adversarial architecture integrated with attribute classification can be trained using transfer learning and a discriminator [45]. The generator generates the new image and the discriminator tries to authenticate it, depending on how well it is trained. This is a cool way of reconstructing occlusion-free images of a person which is credible in possible scenarios. Extensive Deep Part detectors are another way of handling occlusion. These detectors cover all the scales of different parts of human body and choose significant parts for occlusion handling [46]. Each part detector can be individually trained for different body parts using a quality training data or transfer learning. The output of each part detector can then be combined using weighted scheme or a direct score. A semantic head detection system [47] in parallel with the body detection system is used to handle occlusion. The head is one of the most crucial parts while detecting pedestrians. Predictions are inferred from the body detector and are used to manually label the semantic head regions for the training process. A Deep Neural Network has taken under consideration the semantic correlation among different attributes of the body parts [48]. The system uses element wise multiplication layer that avails the feature maps to extract different body feature representations from the input. Fei et al. [49] uses context information from the extracted features from the network to handle occlusion. A pixel-level context embedding technique to access multiple regions within the same image for context information using multibranched layers in CNN with varying input channels and an instance-level context prediction framework identifies distinguishing features among different pedestrians in a group.
10.5.4 Scene specific data
One of the factors in the limitation of the performance of the detection models is unavailability of the scene-specific dataset. A model can be trained on different types of generic dataset, but when it comes to real-world applications, it suffers due to scarcity of scene-specific datasets.
In an online learning technique to detect pedestrian in a scene-specific environment, Zhang et al. [50] designed a model on an augmented reality dataset which addresses the issue of unavailability of scene-specific data. Synthetic data is used to simulate scenes of need (which is also available publicly in [51]). The same model is gradually improved over the time as a specific scene changes. Cyget et al. [52] explored the importance of data augmentation toward improving the robustness of PD systems, evaluated the robustness of different available augmentation techniques, and then proposed a novel technique that uses Style-transfer, combining the input image and stylized version of the image in patches to maintain balance. Inspired from Patched Gaussian Augmentation, this work adds patches from the styled image to the original image at the same location to improve detection. Tumas et al. [40] introduced a new dataset, ZUT (Zachodniopomorski Uniwersytet Technologiczny), captured during severe weather conditions (cloudy, rainy, foggy, etc.) from four EU countries (Denmark, Germany, Poland, and Lithuania). It was collected using a 16 bit thermal camera at 30fps and is fine-grained annotated in nine different classes: pedestrian, occluded, body parts, cyclist, motorcyclist, scooterist, unknowns, baby carriage, pets and animals.
10.6 Advanced AI algorithms for robotic vision
With the advent of CNNs, deep learning approaches have been refined steadily for building a more robust pedestrian detector. Based on different challenges posed in the real-world situations, different types of Deep Neural Networks have been designed to improve the robotic vision. Over the years the systems have evolved significantly from preprocessing to detection to localization. Initially CNNs advanced to region-based CNN that gave rise to fast and faster R-CNNs which changed process of detection with the use of Region Proposal Networks (RPNs). Researchers further exploited these RPNs to extract customized spatial and temporal features to enhance trajectory plotting in a scene based on detection. Further, multistream Nets have been deployed to multiple instances as well as different body parts to handle occlusion in a scene. This has proved ingenious as pedestrians can also be recognized with their body parts even when they are partially visible.
Multistream Nets have also been able to manipulate color and thermal version of an image simultaneously to incorporate illumination changes. Multispectral or thermal images have significantly been used in recent works to enhance detection at nighttime or during bad weather. These images are incorporated with the normal version to observe changes and find differences. For data, researchers have also started generating synthetic data for scene-specific studies. As mentioned above, a number of datasets are publicly available and benchmarked for use but designing a real-world detection system still poses a serious challenge. GANs have been used frequently to generate data and simulate specific scenes. These help the system learn different scenarios and also be prepared for what it hasn’t yet seen (Table 10.1).
Table 10.1
| References | Deep learning method used | Challenges | Dataset | Result metrics | Performance |
|---|---|---|---|---|---|
| [25] | SVM | Illumination, nighttime | CVC-14 | F1-Score | 94.30 for Day time 87.24 for Night time |
| [37] | Region-Based Fully CNN (Feature Pyramid Network) | Instance size, illumination | KAIST | FPPI | 0.34 |
| [38] | CNN + Focal Loss | Illumination | KAIST | Miss Rate (%) | 27.60 |
| [34] | CNN | – | UMN | AUC (%) | Greater than 97 |
| PETS | Greater than 92 | ||||
| [41] | Fast R-CNN | Instance size | Caltech | Miss Rate (%) | 9 |
| INRIA | 8 | ||||
| ETH | 34 | ||||
| [39] | Faster R-CNN | Illumination | KAIST | Miss Rate (%) | 15.73 |
| [35] | FCN (Transfer learning with AlexNet) | – | UCSD Ped2 | EER (%) | 11 |
| Subway | 16 | ||||
| [46] | CNN (Transfer Learning on ImageNet) | Occlusion | Caltech | Miss Rate (%) | 11 |
| KITTI | Average Precision (%) | 74 | |||
| [2] | CNN | Illumination | KITTI | Accuracy (%) | 70 |
| [42] | CNN | Motion features | Caltech | Miss Rate (%) | 16.7 |
| DaimlerMono | 35.2 | ||||
| [17] | CNN | – | INRIA | Unspecified | Unspecified |
| MBOT | |||||
| [47] | Head Body Alignment Network | Occlusion | CityPersons | Log Average Miss Rate (%) | 11.26 on reasonable and 39.54 on heavy Occlusion |
| [44] | Mask R-CNN | Occlusion | LFW | AUC (%) | 77 |
| [45] | GAN (Transfer Learning with Resnet and VGG) | Occlusion | RAP | Mean Accuracy (%) | 81 |
| AiC | 90 | ||||
| [48] | CNN | Occlusion, instance size | RAP | Average Accuracy (%) | 92.23 |
| PETA | 91.70 | ||||
| [43] | Asymmetrical multi-stage CNN | Instance size | Caltech | Miss Rate (%) | 7.32 |
| CityPersons | 13.98 | ||||
| [50] | Faster R-CNN | Scene specific | TownCenter | Average Precision (%) | 34 |
| Atrium | 12.5 | ||||
| PETS 2009 | 0.9 | ||||
| [30] | Faster R-CNN with VGG16 | Feature representation | Caltech | Miss Rate (%) | 16.5 |
| ETH | 19.65 | ||||
| [31] | CNN with Kalman Filter | – | Custom data | Pixel error | 5.07 |
| [26] | CSP with ResNet-101 | – | CityPersons | Log Average Miss Rate (%) | 9.3 |
| [28] | Faster R-CNN | Occlusion | OTB-50 | Graphical | - |
| [32] | Two stream ResNet-50 | Pose estimation | Market-1501 | Mean Average Precision (%) | 90.78 |
| DukeMTMC | 84.82 | ||||
| CHUK03 | 71.67 | ||||
| [49] | CNN with ResNet-50 | Occlusion | Caltech | Miss Rate (%) | 44.48 |
| CityPersons | 11.4 | ||||
| [29] | Hourglass Network | Pose estimation | Custom data | Error Reduction (%) | 47 |
| [36] | SpatioTemporal Translation Network using GAN | – | UCSD | AUC (%) | 98.5 |
| UMN | 99.96 | ||||
| CUHK | 87.9 | ||||
| [40] | YOLOv3 | Bad weather, nighttime, scene specific | Custom Data | Mean Average Precision | 89.1 |
| [33] | CNN + Euclidean Distance + Focal Loss | – | CUHK03 | Accuracy (%) | Rank1 – 76 |
| Rank10 – 95.6 | |||||
| Rank20 – 99.5 | |||||
| [52] | Faster R-CNN and CSP | Data augmentation | CityPersons | ECE | 0.1429 |
| EuroCity | 0.1569 | ||||
| NightOwls | 0.331 | ||||
| [27] | RetinaNet using ResNet-50 and LSTM | Activity recognition | JAAD | Mean Average Precision (%) | 56.05 |
10.7 Discussion
A number of challenges have influenced PD but tackling them has been a giant step toward creating a lucrative robotic vision system for implementation in various fields. What recent years have achieved in this domain is incomparable to what we could only dream of a decade ago. The evolution of technology in terms of processing power has made it easier for the researchers across the globe to design sophisticated deep learning techniques that can even perform better than human experts. Starting from detecting and localizing objects and moving toward localizing anomalies in CCTV footage has indeed made it a significant achievement.
Fig. 10.4 shows timeline of evolution of deep learning techniques for PD. Evolution of self-driven cars has been possible due to accurate detection by Deep Neural Networks (DNN) and how well they process the input. Anomaly detection is another very important application of pedestrian detectors that has been built to identify any outlier activity in a scene. Some of the discussed work has tackled this issue and given promising results in terms of response time and recognition of the anomaly. Suspicious activities are context related and thus systems need to be designed to be able to process those contexts. Tracking and reidentification are a part of anomaly detection task where a person of interest (PoI) is tracked across the scene and should be reidentifiable across multiple cameras in a building (or place) in consecutive scenes. A number of factors come into play: human pose, camera angle, similarity index, and so on. All these factors need to be handled with precision to make those systems reliable and robust.
Mobile robots (or Mobots) are a significant achievement in the field of robotic vision. Detecting the obstacles (or persons) and predicting their trajectory in order to plan navigation comes under HAN. Several high-end systems have shown promising results in the field with a chance for improvement as well. These systems can be further optimized to design automated delivery systems, rescue operations, healthcare system, UAVs, and so on. All these robotic vision systems developed use deep learning algorithms in some way and have been optimized for better results as well.
Although the detectors are performing quite well on the available benchmark datasets, it will be interesting to see how they perform in real-world situations. None of the systems have been fully developed for use as a practical application tool in public places to replace humans. At some point or other they need humans in the loop. There are two significant reasons: none of the benchmark or available dataset can actually simulate real-world scenario, and there will always be something new (unique) that system does not know how to handle. This issue has gained a lot of attention in recent years. With the introduction of GAN, it is possible to create synthetic data according to one’s needs and create scene-specific detectors for real-world use.
Another reason is occlusion, no machine has been able to fully handle occlusion and there are justifications behind it. How much occlusion can human vision handle? We as a human learn to recognize things even if we see a part of it but that doesn’t happen overnight. It takes years of experience of practicing intuitions and familiarity. Researchers have tried designing part detectors, that can detect different parts of a body and infer a detection based on that, but still they have not been entirely accurate at times. It can be considered as a start toward a more robust and reliable solution for providing a better tool for future use.
10.8 Conclusions
A decade ago, pedestrian detection posed numerous challenges to the pioneers in computer vision. Identifying people in a video and differentiating them from other objects was crucial in solving the problem of crowd monitoring. Object detection through CNNs paved the way for detecting people in crowded scenes. Robotic vision has also seen a boom with these techniques. Smart homes, mobots, and autonomous vehicles are all being upgraded as a result of this development in robotic vision. Preprocessing the input data has also been crucial in difficult detection scenarios, which implies that data and its handling is as important as the tool it is being used with. Apart from that, several application-based systems have also been developed to automate the surveillance process and monitor crowded places. In the long run, deep learning has proven to be the most effective tool in evolving robotic vision systems and provide a useful baseline for other systems to work upon. In the coming years, we will be able to see these systems perform more robustly under occlusion and bad lighting/weather conditions, which is the growing need.