
Integrated deep learning for self-driving robotic cars
Tad Gonsalves1 and Jaychand Upadhyay2, 1Department of Information and Communication Sciences, Sophia University, Tokyo, Japan, 2Xavier Institute of Engineering, Mumbai, India
Abstract
In recent years, autonomous driving has become a hotbed of research in academia and industry. However, the high cost of the infrastructure as well as of the specialized equipment makes it very difficult for academia as well as industry to pursue in-house research. This study presents a laboratory floor software model for learning self-driving using a robotic vehicle with only vision cameras and no other expensive sensors or equipment. The low-cost autonomous driving learning program is based on an analysis of the human driving cycle which consists of perception, scene generation, planning, and action. The software platform is an integration of deep supervision and reinforcement learning. Perception is done through deep supervision learning using the latest convolutional neural networks, while the driving actions such as steering, accelerating, slowing down, and braking are achieved through Deep Q learning. The major components of the autonomous driving agents are (1) fundamental driving functions, (2) hazard detection, and (3) warning systems, which are further composed of several independent subroutine modules. The learned agent is integrated and embedded in a miniature robotic vehicle and further trained manually through remotely controlled steering, accelerator, and brakes. Simulation on a multi-GPU workstation and laboratory floor verifications have produced encouraging results, leading to the development of an economically viable low-cost self-driving prototype.
Keywords
Autonomous vehicles; self-driving cars; deep learning; generative adversarial network
8.1 Introduction
According to a recent survey, in the United States alone approximately 1.35 million people die in road crashes each year. On average 3700 people lose their lives every day on the roads. An additional 20–50 million suffer non-fatal injuries, often resulting in long-term disabilities [1]. A 2015 study by the US Department of Transportation NHTSA attributed 94% of accidents to human error, with only 2% to vehicular malfunction, 2% to environmental factors, and 2% to unknown causes [2]. Advanced autonomous driving or self-driving where humans are eliminated from the driving loop is considered to be the safest transportation technology of the future. Most major automobile manufacturers and IT enterprises worldwide are intensely engaged in developing a commercially viable prototype to seize the market-share [3]. In Japan, the government has set aside enormous funds to make autonomous driving technology a reality for the upcoming Olympics. The Society of Automotive Engineers International has proposed a conceptual model defining six levels of driving automation which range from fully manual level 0 to fully autonomous level 5. The model has become the de facto global standard adopted by stakeholders in the automated vehicle industry [4]. Although a fully functional level 5 self-driving car is still a long way off, most major automakers have reached advanced stages of developing self-driving cars [5,6].
The current autonomous vehicle (AV) technology is exorbitantly expensive as it tends to rely on highly specialized infrastructure and equipment like Light Detection and Ranging (LIDAR) for navigation, Global Positioning for localization, and Laser Range Finder for obstacle detection [7,8] and so on. Some automakers have opted out of LIDARs because of their bulky size and exorbitant costs [9]. The focus of this study is to develop an agent that learns to drive by detecting road features and surroundings relying solely on camera vision.
A fully developed self-driving system needs countless experimental runs on public roads in all imaginable driving conditions. Autonomous driving cars have become a common site especially in some US cities and a few studies are found in the literature [10–14]. However, severe land restrictions and strict government laws do not permit firms in Japan to experiment autonomous driving on private and public roads. A viable solution is to create a fully functional but miniature driving circuit on a laboratory floor and thereby develop a self-driving prototype before launching it into a commercial product. We have developed such a self-driving machine learning environment in our laboratory. Through simulation and verification through a robocar we train and test individual self-driving agents to excel in the art of self-driving.
The self-driving software platform is built on the conceptual model of human driving which consists of four cyclic steps: perception, scene generation, planning, and action. The human driver takes in the traffic information through the senses, especially the vision and creates a 3D environment of the driving scenario around his/her car. Based on this scenario, the driver then plans the next action and finally executes the action via the steering, accelerator, brakes, indicators, and so on. The conscious cycle repeats itself throughout the course of driving. A self-driving software prototype can be built exactly along the same principles. It should be able to perceive the driving environment, generate the 3D scene, plan, and execute the action in rapidly iterating cycles.
Deep Learning algorithms, in general, perform supervised, unsupervised, semisupervised, and reinforcement learning (RL). The self-driving prototype integrates supervised and RL to achieve the autonomous driving goal. Perception and scene generation is achieved through supervised learning. Object detection and recognition algorithms break down the image picked up by the car cameras into individual components such as road signs, pedestrians, trees, buildings, traffic signals, vehicles, and so on. The isolated objects are then classified into as relevant or not relevant for driving. The relevant objects are then connected spatially to generate the 3D driving scene. The state-of-the-art technology used in image recognition is the convolutional neural network (CNN) [15] in various forms, such as AlexNet [16], VGGNet [17], and ResNet [18].
Deep Q Learning (DQL) is a subset of Deep Reinforced Learning. It combines CNN (to perceive the state of the environment in which the agent finds itself) and Deep Q Network (DQN) (to act on the perceived environment). Our driving agent (software program) learns to follow lanes and avoid randomly placed obstacles in the simulation environment using the DQL model. There is no dataset provided. Similarly, another agent learns to recognize traffic lights in the Laboratory for Intelligent and Safe Automobiles (LISA) dataset using the Faster R-CNN object recognition model. The agents are then integrated and loaded on robocar, which further continues learning on the laboratory floor.
Most of the car manufacturers and enterprises are engaged in performing self-driving experiments on private and public roads. This is possible if the government regulations allow self-driving vehicles on public roads. Traffic laws are strict in Japan making it very difficult for academia and industry to test self-driving vehicles on public roads. The only viable option is driving on private roads. Since land prices in Japan are exorbitantly high, most enterprises and universities do not venture into acquiring land and building infrastructure to deploy and test autonomous driving. What we propose in this study is a practical and viable option—design a miniature driving circuit on the laboratory floor and experiment with self-driving miniature robotic cars (Fig. 8.1). The laboratory driving circuit would contain the infrastructure essential for driving like roads, traffic signs, and signals. It will also contain peripheral objects like sidewalks, trees, buildings, pedestrians, etc., created by means of a 3D printer. The only difference from the real-life driving environment would be the scale. The fully developed self-driving prototype can then be deployed on public roads as a commercial product.
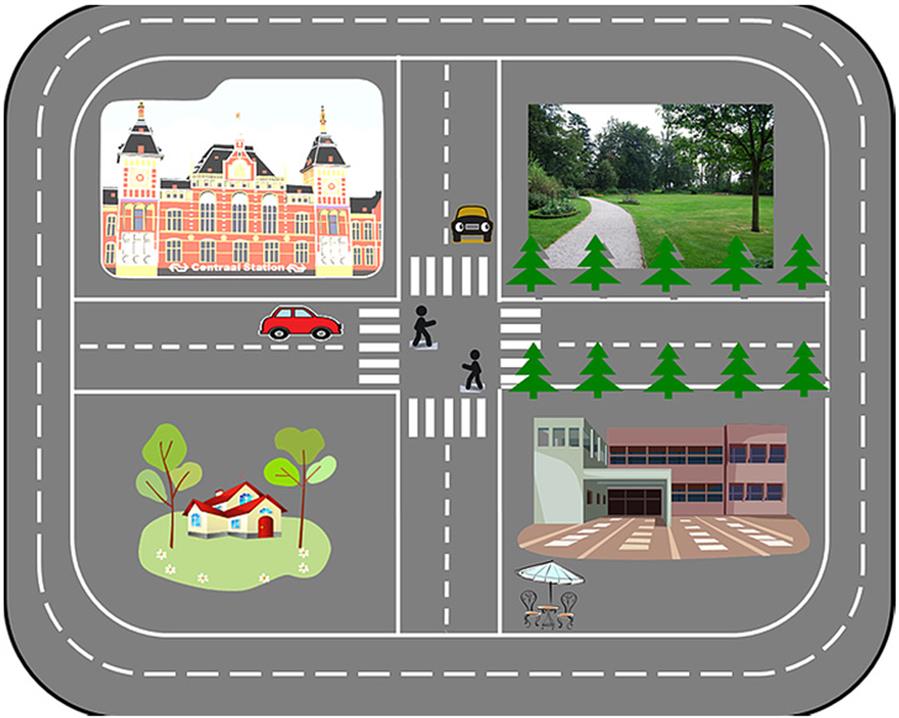
8.2 Self-driving program model
The self-driving program model is constructed on the human psychological autodriving cycle. The dynamic elements of the cycle and its imitation by autonomous driving cars is explained in the following subsections.
8.2.1 Human driving cycle
The self-driving program model described in this section is based on a psychological analysis of the human driving cycle which consists of the following four major steps: perception, scene generation, planning, and action (Fig. 8.2).
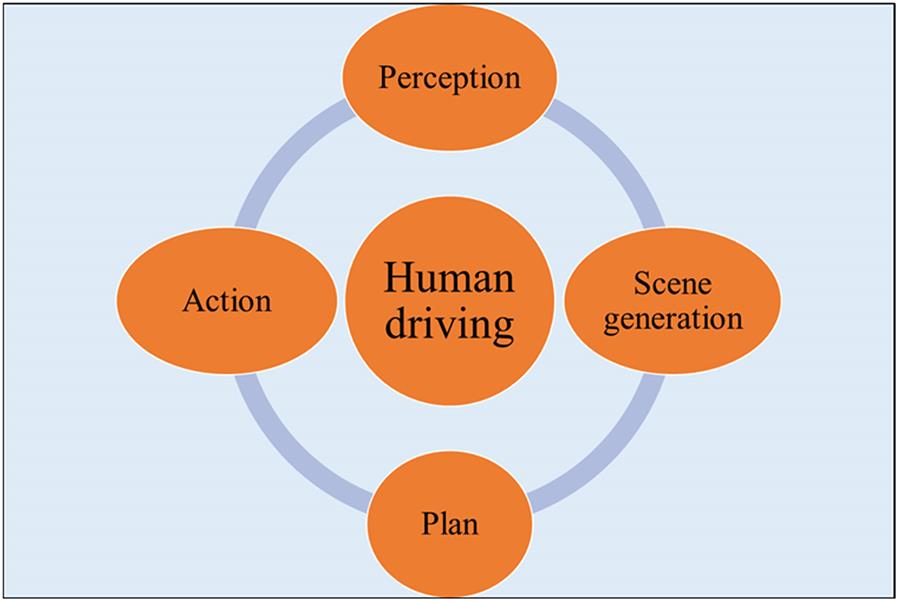
Perception
Perception refers to the taking in of all the information that impinges on our senses. Through our eyes, we perceive the signal and their colors, we read the traffic signs posted on the road, read the signs and words written on the road surface, and see the traffic moving in front of us. Mirrors fitted to the car and those by the roadsides act as secondary means of aiding our perception.
Scene generation
The information picked up by our sensory organs is transmitted to the brain via the nerves. The brain interprets the pieces of information supplied by each sense organ and combines them to build a world map of the surroundings in which the human driver’s car happens to be at that point in time. From perception, humans generate the driving scene surrounding their vehicle. The mental image contains other vehicles, cyclists, pedestrians, signals, road signs, weather conditions, and so on.
Planning
The human driver knows from the basic rules of driving and from experience, how the situation will change the moment the signals controlling the flow of traffic through the crossing will change. The crossing will soon bustle with activity with traffic and pedestrians moving in all directions indicated by the green signals, while those patiently waiting as indicted by the red signals. With this in mind the driver plans his/her future actions.
Action
Finally, all the planning is put into action, triggered by the signal change. The human driver will release the brakes, gently press the gas pedal, and steer the vehicle. However, driving does not end after executing the planned action. The perceiving, scene generating, planning, and acting cycle repeats rapidly.
8.2.2 Integration of supervised learning and reinforcement learning
Autonomous driving is achieved through a combination of two phases of learning described in the following subsections:
Supervised learning
Supervised learning takes place aided by a supervisor that guides the learning agent. The learning agent is the machine learning (ML) algorithm or model and the supervisor is the output in the data for a given set of inputs. The aim of the learning algorithm is to predict how a given set of inputs leads to the output. At first, the ML agent takes the inputs and randomly predicts the corresponding outputs. Since the random calculation is akin to shooting in the dark, the predicted outcomes are far away from the known outcomes. The supervisor at the output end indicates the error in prediction which again guides the learning agent to minimize the error.
The first two steps, namely, perception and scene generation in autonomous driving, are performed through supervised learning. The program is trained using a large number of digital photographs involving driving scenes. In the learning phase, the program identifies and classifies the various objects in the photo images. The master program in the AV controller computer calls the respective ML trained subroutines and combines their result to generate the driving scene surrounding the AV. This act corresponds to sensor readings fusion in real-life self-driving vehicles that use an array of sensors to generate a mapping of the surroundings.
Reinforcement learning
Loosely speaking, RL is very similar to teaching a dog learn new tricks. When the dog performs the trick as directed, it is rewarded; when it makes mistakes, it is corrected. The dog soon learns the tricks by mastering the policy of maximizing its rewards at the end of the training session. Technically, RL algorithms are used to train biped robots to walk without hitting obstacles, self-driving cars to drive by observing traffic rules and avoiding accidents, software programs to play games against human champions and win. The agent (software program engaged in learning) is not given a set of instructions to deal with every kind of situation it may encounter as it interacts with its environment. Instead, it is made to learn the art of responding correctly to the changing environment at every instant of time. RL consists of a series of state and actions. The agent is placed in an environment which is in some state at some time. When the agent performs an action, it changes the state of the environment which evaluates the action and immediately rewards or punishes the agent. A typical RL algorithm tries mapping observed states onto actions, while optimizing a short-term or a long-term reward. Interacting with the environment continuously, the RL agent tries to learn policies, which are sequences of actions that maximize the total reward. The policy learned is usually an optimal balance between the immediate and the delayed rewards [19]. There are a variety of RL algorithms and models found in literature [20]. This study concentrates on the use of Deep-Q learning, first to train the self-driving agent in the simulation environment and then fine-tune the robocar driving on the laboratory floor.
8.3 Self-driving algorithm
Driving functions are divided into three major categories as shown in Fig. 8.3:
- • Fundamental driving functions: these include functions like white lane detection, traffic signals detection, traffic signs recognition, and driving on paved roads that do not have lane markings (laneless driving).
- • Hazards detection like obstacle detection, collision detection, and risk level estimation.
- • Warning systems like driver monitoring, pedestrian hazard detection, and sidewalk cyclists detection.
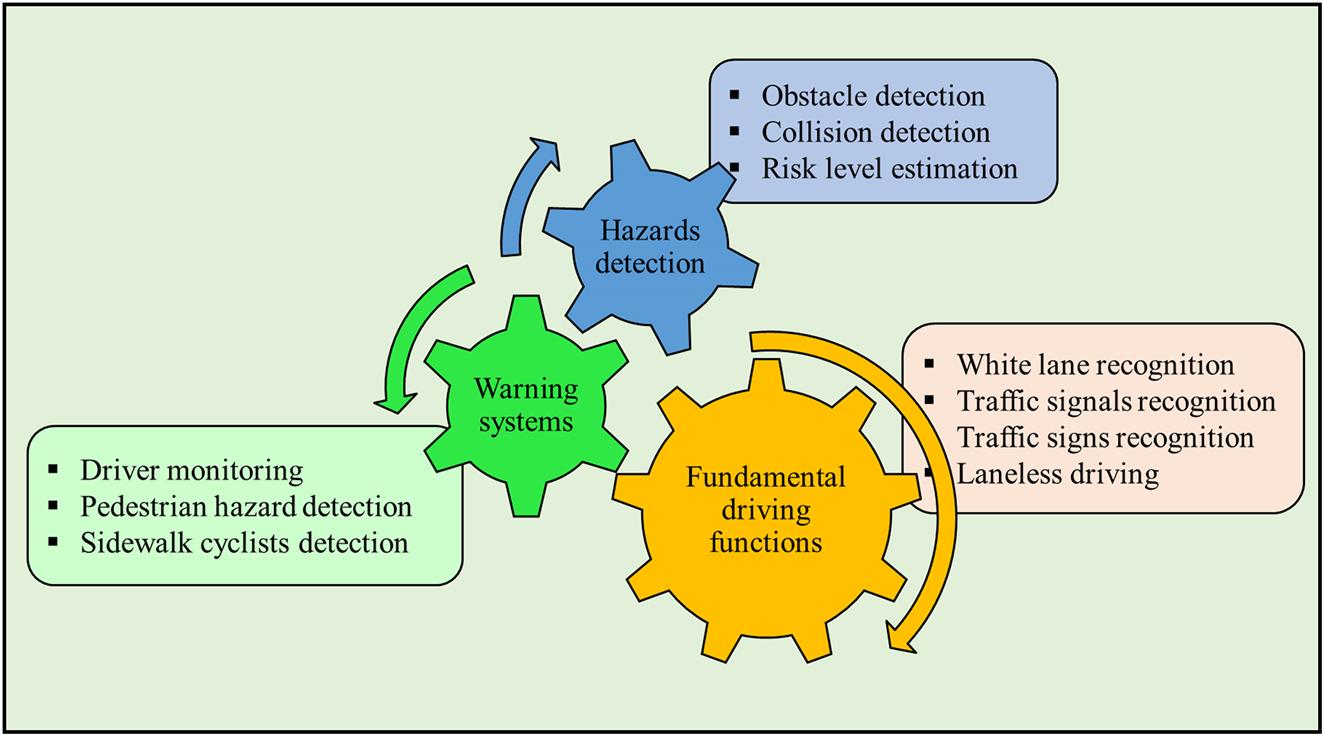
These categories of functions are seamlessly integrated in the autonomous driving prototype. The individual functions and their respective training are explained below.
8.3.1 Fundamental driving functions
White lane detection
Semantic segmentation technique is used to detect white lanes painted on the surface of the roads. VCG net is used in training and testing of white lane datasets. Fig. 8.4 shows the results obtained in detecting white lanes.

In Fig. 8.4, several white lanes are visible. There are also white metallic fences along the road signs which demark pedestrian zones. These lanes are colored in orange by the semantic segmentation learning network. As can be seen from the bottom diagram, the trained program does not color the white fences. In other words, it has learnt to clearly distinguish between the white lanes and the rest of the lane-like white objects.
Signals
Ross Girshick et al. proposed a Regions with CNN (R-CNN) approach for object detection in a given image [21]. This system takes an input image, extracts a large number of bottom-up region proposals (in the order of 2k), computes features for each proposal using a CNN. In the final step, it classifies each region using linear Support Vector Machines. The R-CNN is reported to have achieved a mean average precision (mAP) of 43.5% on the PASCAL VOC 2010 dataset, which is the standard benchmark for evaluating the performance of object detectors. The object detection system, although quite accurate on the standard dataset, is found to be relatively slow in computation. The authors further improved the computational speed by proposing a Fast R-CNN. The improved system, however, spends a significant amount of computational time and resources in computing the region proposals.
Ren et al. [22] proposed a Faster R-CNN that significantly reduces the computational time. Their object detection system is composed of two modules. The first module is a fully CNN that proposes regions; the second module is the Fast R-CNN detector that makes use of the proposed regions. Functioning as a single, unified network for object detection, the Region Proposal Network (RPN) module tells the Fast R-CNN module where to look for objects in the image (Fig. 8.5). By sharing convolutions at test-time, the marginal cost for computing proposals is found to be small (approximately 10 ms per image).
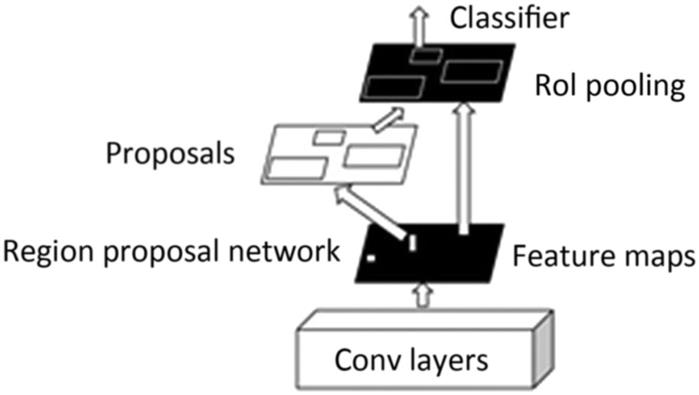
We use a variation of the Faster R-CNN for traffic signal recognition. The images are fed to the convolutional layers which give us the feature maps. These are in turn fed to the region proposal network that outputs region proposals. The region proposal along with the “Region of Interest” (RoI) obtained through the RoI pooling are finally fed into the classifier. The classifier classifies the input image as well as its relative location by means of a bounding box called the anchor.
8.3.2 Signals
Fig. 8.6 shows six classes of traffic lights in the LISA dataset. The average prediction (AP) for each of the classes is shown in Table 8.1. The first column shows the different classes of the signals in the LISA dataset. It should be noted that the classification is not just red, yellow, and green signals, but detailed versions of the signals as they are found in city areas with dense traffic. The next two columns depict the number of instances in the training and the test sets. The final column shows the AP accuracy of each class. This prediction accuracy is more than 92% in all the classes except the “goleft” class. The lower accuracy is due to the presence of noise in the dataset (Fig. 8.7).

Table 8.1

Traffic signs
The traffic signs posted along the sidewalks are picked up by the front camera and recognized in real-time by the deep learning network. To improve the learning accuracy of the traffic signs recognition system, learning is divided into two phases. In the first phase, signs that are clearly visible in the camera are used for training. The recognition results produced by the algorithm are shown in Fig. 8.8. However, just learning to recognize clearly visible road signs is not sufficient for safe driving in real life. The second phase consists of learning to recognize faded and not clearly visible road signs. The test results are shown in Fig. 8.9. Learning and extensive testing are carried out using the German Traffic Sign Dataset [23] containing 50,000 images belonging to 45 classes, and the Belgium Traffic Sign Dataset [24], which includes more than 7000 single-images of traffic signs found in Belgium divided into 62 classes.

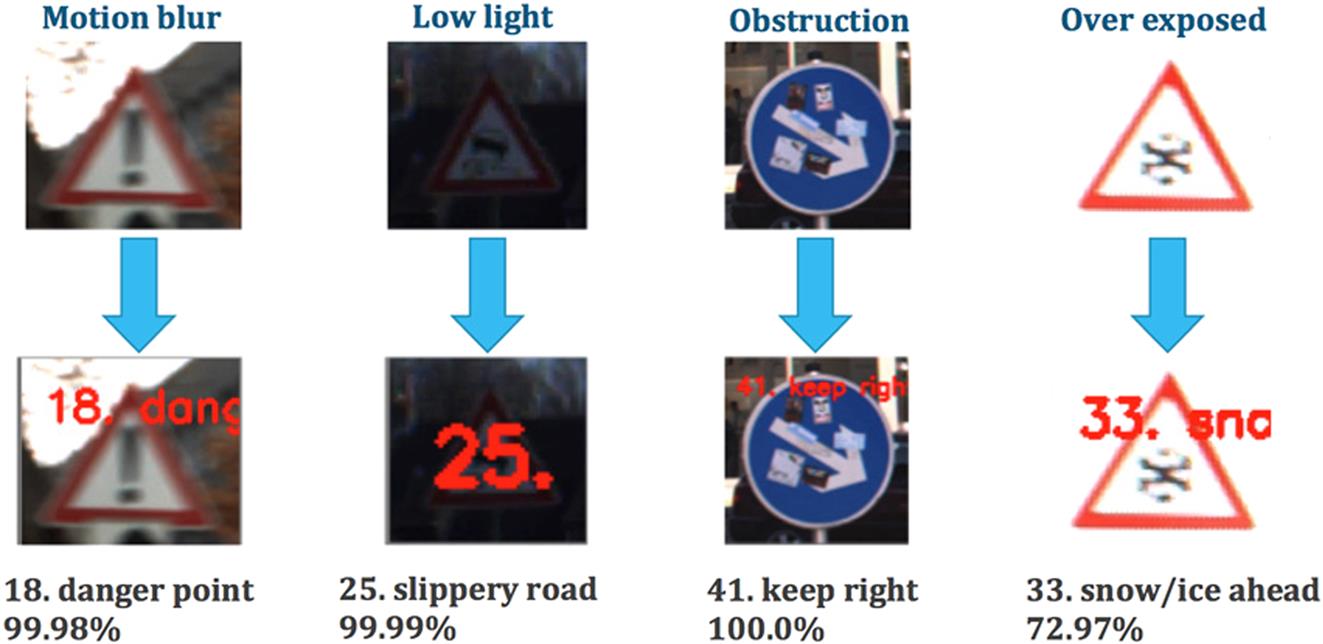
Laneless driving
It is easier to drive in cities and in other urban areas where the lanes are clearly marked on the road. The AV has to detect the nearest lane to its left and to its right and steer forward trying to keep itself in the middle of the two bounding lanes at all times. However, driving in the mountains or the countryside, even if the roads are paved, is a major challenge. There is no reference point for the vehicle to steer by. Although the other modules like obstacle detection, traffic signals and signs detection, pedestrian detection, and so on will function as in the urban setting, helping the AV to keep away from danger and accidents, there will not be any clear guidelines for the vehicle steering.
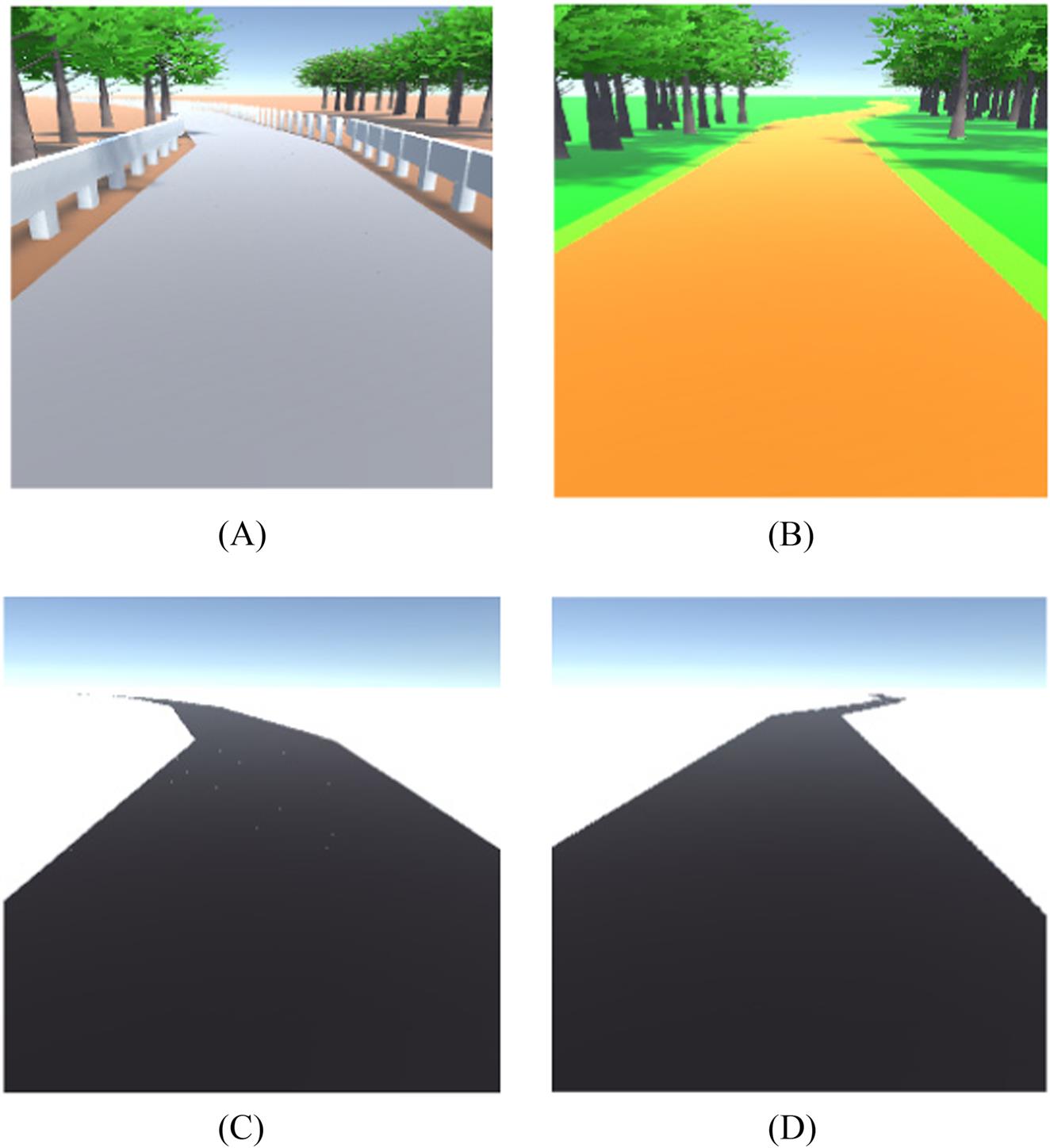
The laneless driving module deals with the recognition of the shoulder of the paved road, even if there are no clear markings. Sometimes, the edges are broken, at other times they are not clearly delineated. Semantic segmentation detects and segments the surface area of the road around the car which is safe for driving (Fig. 8.10A and B). The AV positions itself at the center of the two lateral edges and steers forward.
8.3.3 Hazards
YOLO and detection of objects
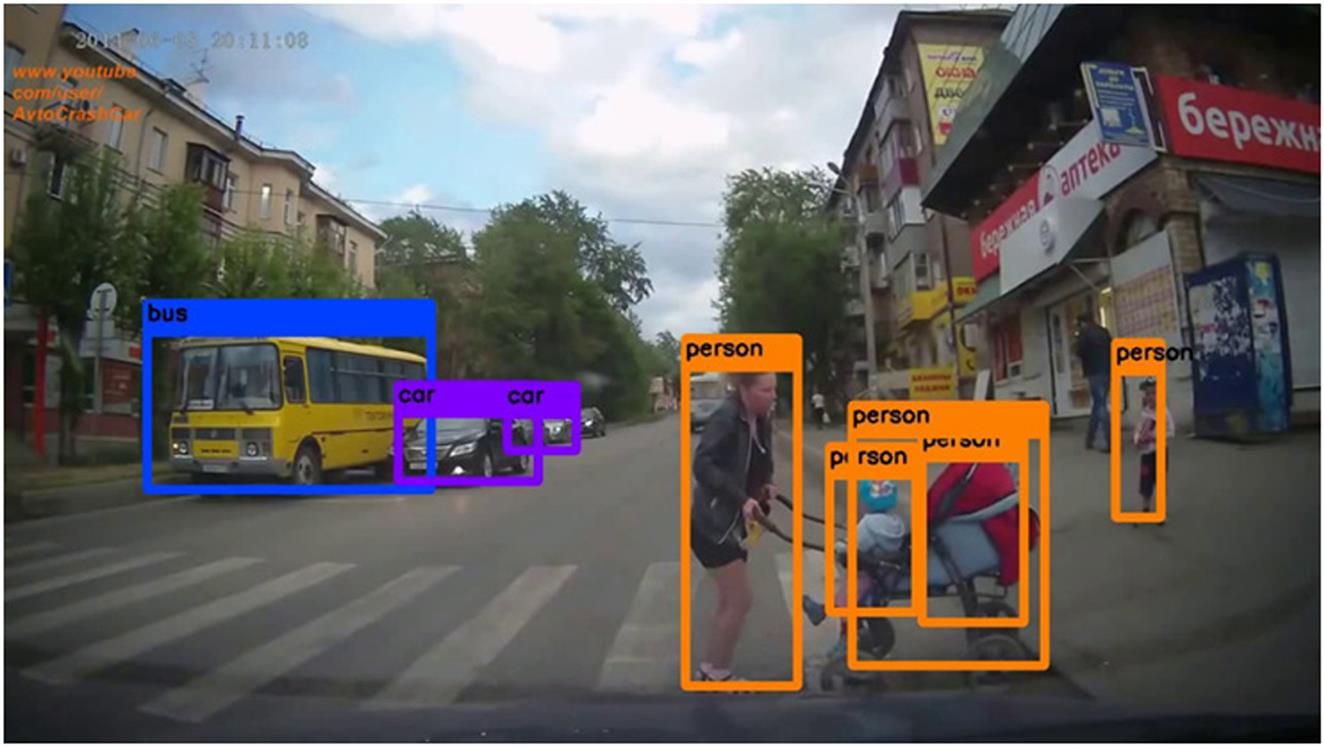
You Only Look Once (YOLO) v3 [25,26] is trained on the Open Images Dataset v4 which has 15,440,132 bounding boxes arranged in 600 categories of objects. The salient feature of YOLO is its speed of recognition of objects. The objects are placed into bounding boxes and then recognized as belonging to a particular class (Fig. 8.11).
Collision avoidance
Collision avoidance is one of the principal components of safe driving. Various scenarios and techniques for collision avoidance in the case of a single AV driving are found in the literature: integrated trajectory control [27], fuzzy danger level detection [28], side collision avoidance [29], collision avoidance at traffic intersections [30], collision avoidance, and vehicle stabilization [31]. However, currently AI collision avoidance techniques are mechanical and brittle; they do not take into consideration the human-way of driving and responding to uncertain situations. In our study, we go a step further and make our agent human-like in avoiding collisions.
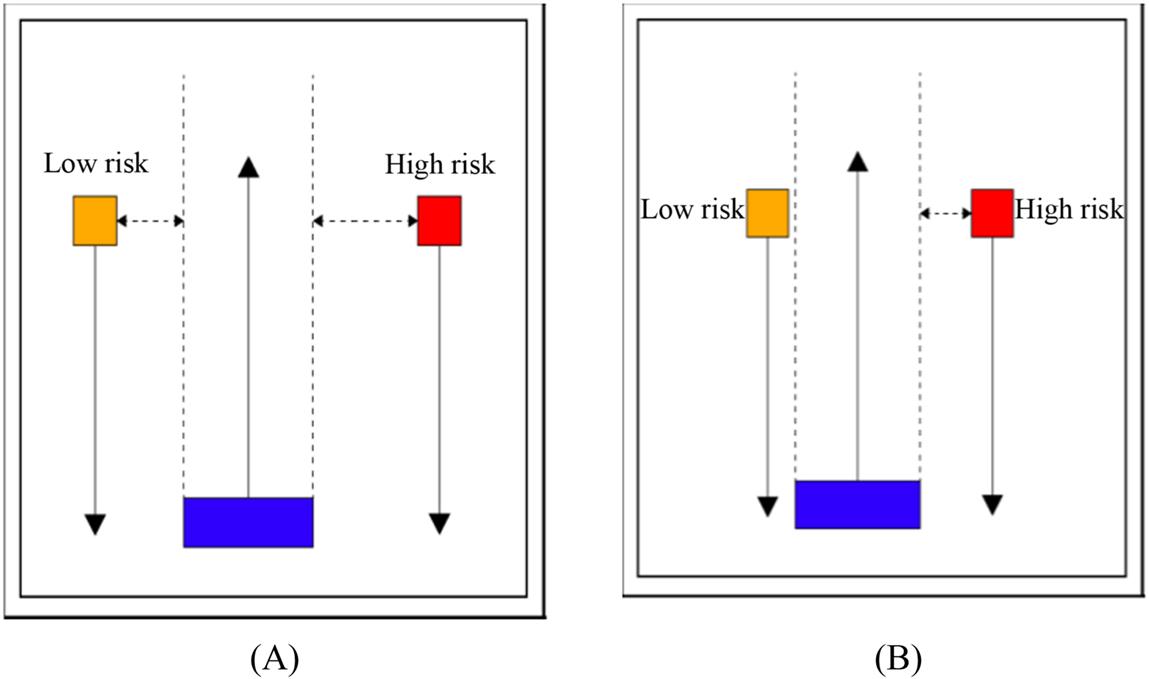
Humans do not wait until the last minute to avoid collisions, as shown in Fig. 8.12A. Relying on the visual information at hand, they try to avoid colliding with obstacles when viewed from far, as shown in Fig. 8.12B. The autonomous navigation system for obstacle avoidance in dynamic driving environments learns the art of maneuvering through roads strewn with moving obstacles using the Q-learning algorithm.
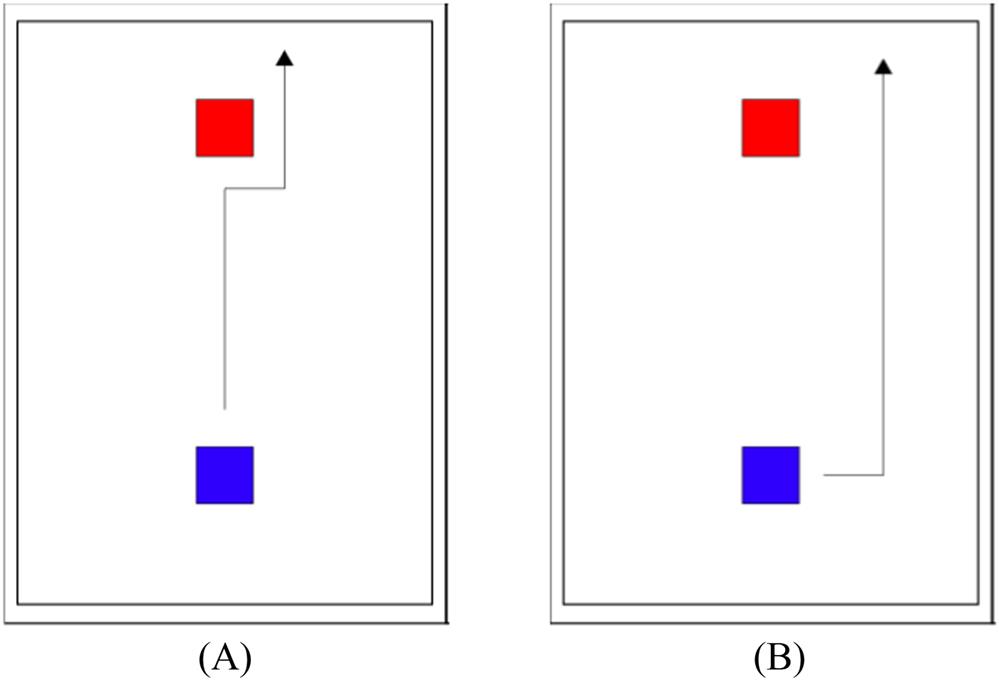
The above human-like collision avoidance system (Fig. 8.12) is further trained to drive in an extreme situation involving two obstacles with varying priority levels of collision avoidance. The Q-learning algorithm rewards the agent with greater score to avoid colliding with a high priority (high risk) object than with the low priority (low risk) object. The agent, accordingly, learns to avoid the higher risk obstacle when faced with two hazardous obstacles with varying priorities. The following two kinds of human-like behaviors are demonstrated by the AI navigation system:
- 1. When the two moving obstacles do not come within the danger zone, the AINS passes smoothly in-between the two keeping a fairly safe distance from them (Fig. 8.13A).
- 2. When the two moving obstacles come within the danger zone, the AINS chooses to avoid the high-priority obstacle at all costs even though it may near-miss hitting the low-priority obstacle (Fig. 8.13B).
Estimation of risk level for self-driving
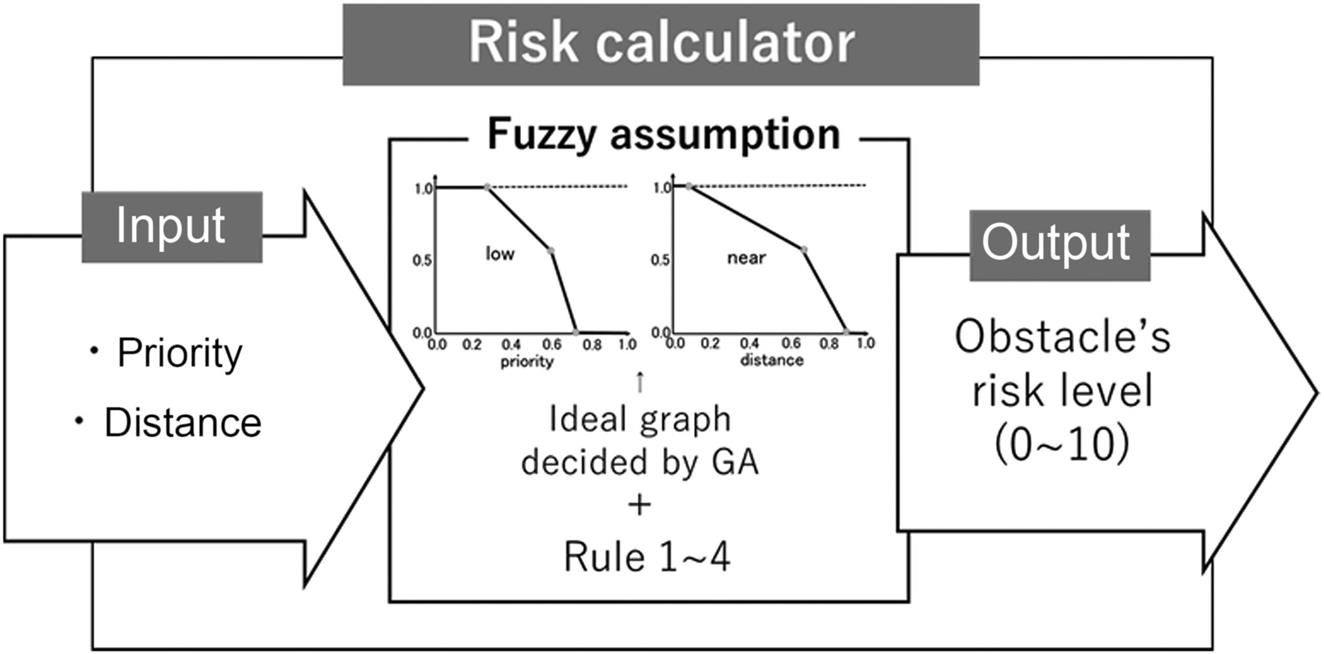
As a self-driving vehicle keeps on driving, following the various traffic rules like lanes, signals, traffic signs, it has to be aware of the other traffic around it at any given point in time. Pedestrians, motorcyclists, and cars often come very close to an AV. This section deals with the real-time computation of the risk level of nearby objects to an AV. The objects are given a priori priority, like humans, cars, motorbikes, animals, and leaves, which can be detected by the front, side, and back mirrors. The risk level is computed using fuzzy logic and the Genetic Algorithm (GA) [32].
The fuzzy rules are framed as follows:
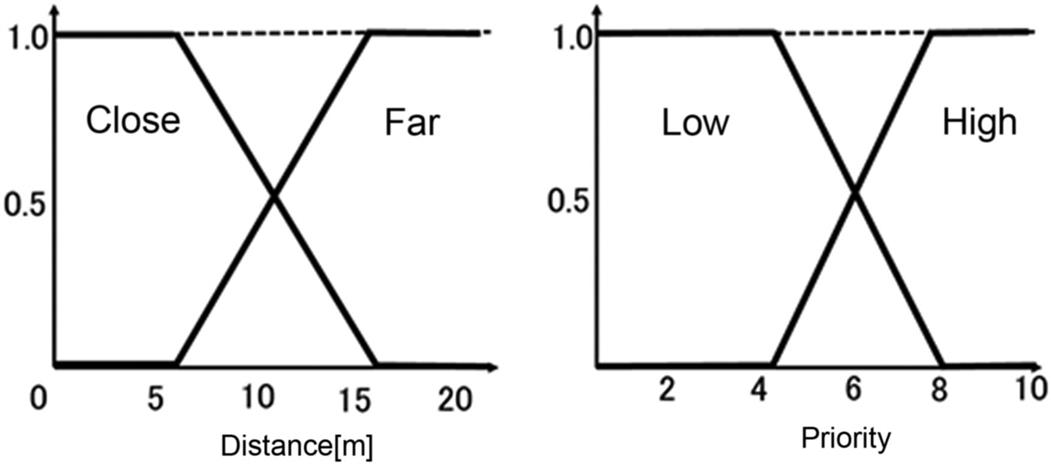
- Rule1: If the priority is low and the distance is far, then the risk level is 1.
- Rule2: If the priority is high and the distance is far, then the risk level is 5.
- Rule3: If the priority is low and the distance is close, then the risk level is 6.
- Rule4: If the priority is high and the distance is close, then the risk level is 10.
The membership functions shown in Fig. 8.14 are standard triangular functions. The shapes of thee membership functions are optimized to suit the risk calculator using the GA. The overall system resulting from the combination of fuzzy logic and GA is shown in Fig. 8.15. The inputs to the system are priority and distance of a traffic object (vehicle, human, animal, leaves). The resultant of the GA fuzzy controller is the risk level in the range 0–l.
8.3.4 Warning systems
Driver monitoring
Feeling drowsy or falling asleep at the steering wheel is one of the most frequent causes of car accidents and crashes. The driver-monitoring system takes real-time pictures of the driver’s face and feeds them into the trained VCG net [17]. The trained network determines if the driver is showing signs of drowsiness and sleepiness (Fig. 8.16).

Pedestrian hazard detection
Caltech Pedestrian Detection Benchmark [33,34] which is a 640×480, 30 Hz, 10 hour video containing 2300 pedestrians enclosed in 350,000 bounding boxes is used for training and testing. The DL program is a combination of YOLO and SE-ResNet. The hazard levels are computed taking into consideration not just the distance of the pedestrians from the self-driving vehicle, but their orientation and speed of walking as well. For example, Fig. 8.17A and B shows two pedestrians exactly at the same distance from the AV. However, pedestrian (A) is stationary and is about to cross the road, while pedestrian (B) is briskly walking away from the vehicle on the sidewalk. Similarly, the hazard level of the pedestrian who is about to cross the road (C) is much higher than the one who is walking away from the road after crossing (D).

Sidewalk cyclists’ detection
Moving object detection is one of the fundamental technologies necessary to realize autonomous driving. Object detection has received much attention in recent years and many methods have been proposed (Fig. 8.18).

However, most of them are not enough to realize moving object detection, chiefly because these technologies perform object detection from one single image. The future projected position of a moving object is learnt from its past and current positions. In this study, we use Deep Convolutional Generative Adversarial Networks (DCGANs) [35–40] to predict the future position of cyclists riding along the sidewalks. They pose a threat to vehicles on the road and suddenly jutting onto the road from the sides. Monitoring their movements and predicting their behavior is a great help in overcoming accidents.
8.4 Deep reinforcement learning
8.4.1 Deep Q learning
Q learning is a variation of RL. In Q learning, there is an agent with states and corresponding actions. At any moment, the agent is in some feasible state. In the next time step, the state is transformed to other state(s) by performing some action. This action is accompanied either by reward or a punishment. The goal of the agent is to maximize the reward gain. The Q learning algorithm is represented by the following update formula [39]:
where Q(st, at) represents the Q value of the agent in the state st, and action at time t, rewarded with reward rt., α is the learning rate and γ is the discount factor. The γ parameter is in the range [0,1]. If γ is closer to 0, the agent will tend to consider only immediate rewards. On the other hand, if it is closer to 1, the agent will consider future rewards with greater weight, and thus is willing to delay the reward. The Learning rate and Discount factor, described below, are the two most crucial parameters influencing the performances of the Q learning algorithm.
Learning rate
The learning rate determines the strength with which the newly acquired information will override the old information. A factor of 0 will make the agent not learn anything, while a factor of 1 will make the agent consider only the most recent information. In fully deterministic environments, the learning rate is optimal. When the problem is stochastic, the algorithm still converges under some technical conditions on the learning rate, that requires it to decrease to zero. In practice, often a constant learning rate is used.
Discount factor
The discount factor determines the importance of future rewards. A factor of 0 will make the agent short-sighted by only considering current rewards, while a factor approaching 1 will make it strive for a long-term high reward. If the discount factor exceeds 1, the action values may diverge. Even with a discount factor only slightly lower than 1, the Q learning leads to propagation of errors and instabilities when the value function is approximated with an artificial neural network. Starting with a lower discount factor and increasing it toward its final value yields accelerated learning.
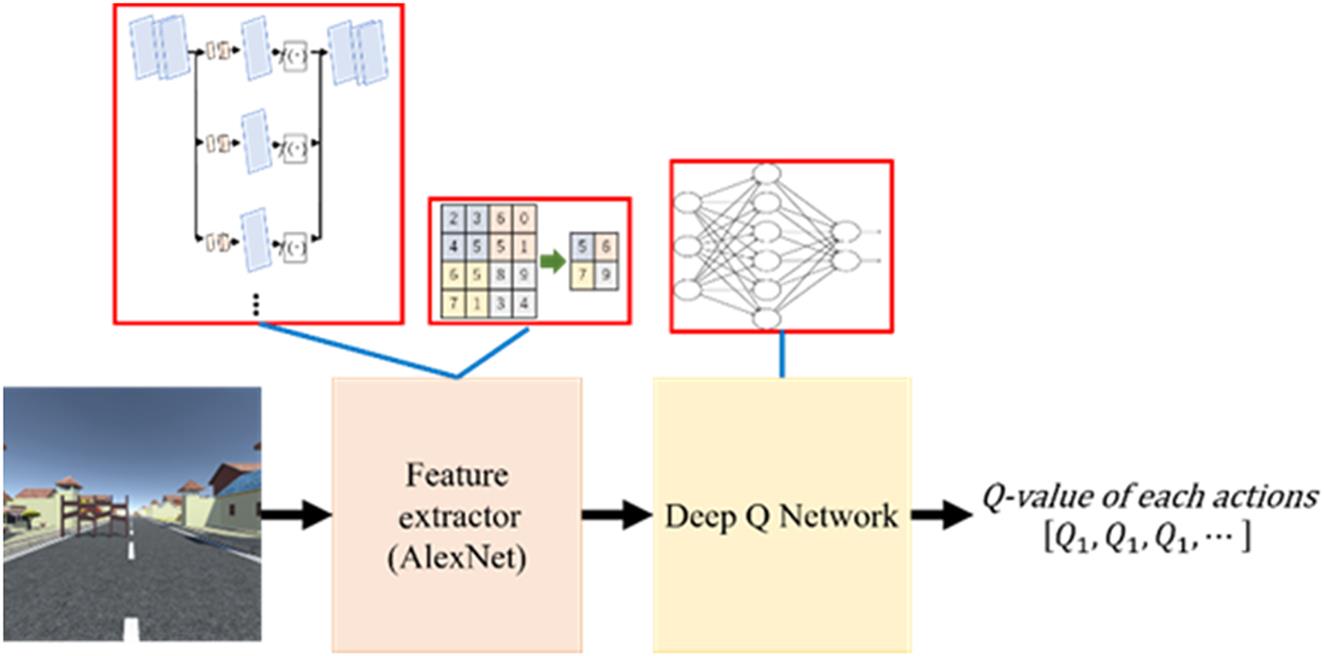
8.4.2 Deep Q Network
CNN is essentially a classification structure for classifying images into labeled classes. The various layers of the CNN extract image features and finally learn to classify the images. Hence, the outputs of a typical CNN represent the classes or the labels of the classes, the CNN has learnt to classify (Fig. 8.19). A DQN is a variation of CNN. The outputs are not classes, but the Q values (or rewards) corresponding to each of the actions the agent has learnt to take in response to its state in the environment. In our model, the input to the DQN is the image of the street the car sees in front of it at a given point of time. The output is the steering angle.
8.4.3 Deep Q Network experimental results
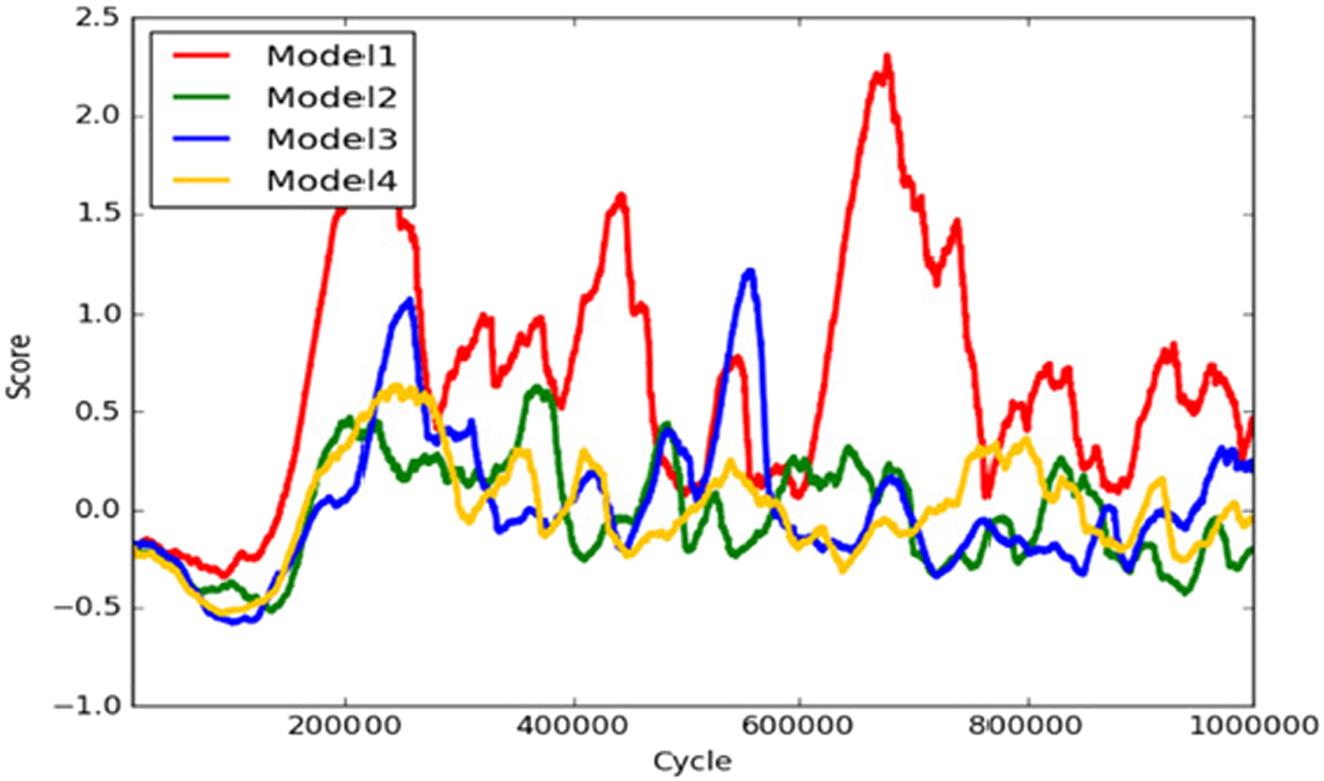
The action plan consists of the number of actions the agent can take for a given environment state captured by the front camera. In all, we trained four different agents, each with a different action plan. Table 8.2 shows the specification of each DQN model with its corresponding action plan (steering angle) (Fig. 8.20).
Table 8.2
| Model | Number of actions | Action list (steering angles) |
|---|---|---|
| 1 | 3 | [−25, 0, 25] |
| 2 | 5 | [−25, −20, 0, 20, 25] |
| 3 | 7 | [−30, −20, −10, 0, 10, 20, 30] |
| 4 | 7 | [−25, −20, −10, 0, 10, 20, 30] |
Each model has been trained for 1,000,000 cycles. The graph in Fig. 8.21 shows the simple moving averages of the score (reward) for time intervals of 500 episodes.
8.4.4 Verification using robocar
The laboratory driving circuit is shown in Fig. 8.10. The robotic car, called “Robocar 1/10” is 1/10th the size of the real car with all the real-life driving functions, manufactured by ZMP Inc., Japan (https://www.zmp.co.jp/en/products/robocar-110).
Two monovisual cameras are fitted on the car. The lower camera is dedicated to capturing the lanes and obstacles on the road and sidewalks, while the upper camera captures traffic lights and signs. The two separate program agents—lane and obstacles, and traffic lights detecting modules—are integrated in the hard disk of the Unix running Robocar. The test runs verify the extent to which the agents have learned to drive along the lanes, avoiding obstacles and recognizing and thereby obeying the signals (Fig. 8.22).

8.5 Conclusion
Current state-of-the-art autonomous driving is an extremely expensive technology because it relies heavily on expensive equipment and road infrastructure. In this study, we have presented an integrated ML approach based only on visual information obtained by the cameras mounted in the front of the car. The integrated approach consists of supervised learning for recognizing traffic objects like signals, road signs, obstacles, pedestrians, etc., and deep RL for driving safely observing the traffic rules and regulations.
The self-driving software platform is built on the conceptual model of human driving which consists of four cyclic steps: perception, scene generation, planning, and action. The human driver takes in the traffic information through the senses, especially the vision and creates a 3D environment of the driving scenario around his/her car. Based on this scenario, the driver then plans the next action and finally executes the action via the steering, accelerator, brakes, indicators, and so on. The conscious cycle repeats itself throughout the course of driving. A self-driving software prototype can be built exactly along the same principles. It can perceive the driving environment, generate the 3D scene, plan, and execute the action in rapidly iterating cycles.
The software agents trained in the simulation environment are embedded in Robocar 1/10 which verifies the self-driving learnt. It is further trained by manually operating a remote set of steering, acceleration, and brake controls. The end result is a fully trained self-driving prototype without providing expansive land with private or public roads embedded with specialized infrastructure.
In our future study, we plan to integrate all the driving modules (agents) into a unified entity and mount it on a computer installed on a car which can drive on private and public roads. The low-cost agent will further learn to assess real-life driving situations and be able to deliver safe drive.