
More than many aspects of technology, data analytics is subject to a very powerful force: human nature. By its very nature, data reveals winners and losers, and everyone wants to win, of course. Making your product, your political candidate, or your brand seem more popular than it is can be very profitable. Social media presents myriad opportunities to create this fake popularity. One example is to friend new and unknown people and “spam” them with offers. This reality can very easily lead people to try and shade results in their favor, or even openly cheat the system.
More generally, any successful metric can be intentionally or unintentionally skewed by rewarding wrong behavior. After we have learned how marketing and PR use social media and social media data, we should spend some time on the shadow world of robots. This chapter describes the dark side: the abuse of the tools and metrics described earlier in this book. We have touched on many of the concepts in previous chapters. However, they are now used to intentionally skew metrics. Here, we look frankly at many of the ways that people can “game the system” with social media and data analytics, because you must often manage for human nature as well as numbers to succeed in this area.
The law of unintended consequences governs every system. For example, when email suddenly made it possible to communicate with large numbers of strangers for free, it immediately led to the problem of unsolicited commercial email, better known as spam.[103] When computers could communicate openly through networks, it spawned viruses and Trojan horses. And now that we live in a society of social media channels and information on demand, this world has become flooded with phony or even fraudulent information. Spam has grown into social spam. Viruses and unsolicited emails functioned well because of the ability to easily spread through digital networks.
But social media offered something new: openness. Anyone can post information that might be meant to distort reality or to benefit someone else. Social spam converted into social bots, algorithms that make people believe that they are humans.
While social networks such as Facebook or Twitter take corrective action to counteract these frauds, the detection is far from perfect, and moreover, this is an iterative process that is constantly being tested on all sides.
Over the last few chapters, we have argued that social media information can be data mined to help make business decisions. However, when there is phony or even fraudulent information that can make its way into your data, it will impact the quality and accuracy of your measurements and therefore your decision. How? Let’s say you analyze your competitor’s products by monitoring the public discussion. In Figure 6-1, each color represents one of those products you monitor. There are discussions from fraudulent sources aimed at selling the gray product. This inflates the amount of discussion about this product. If you are not careful, you might think that those artificially inflated discussions show a higher public interest in this competitor’s product.
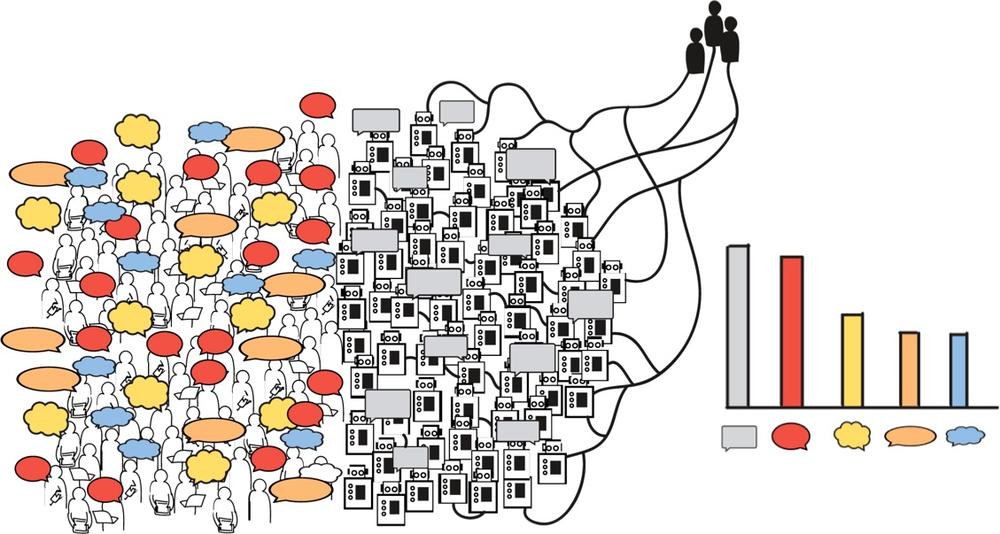
Sometimes the goal may in fact be to distort the measurements to misguide someone. We see in Figure 10-3 how often Google has to change its algorithm to not fall prey to search engine optimization (SEO) experts trying to misguide the algorithm for their purposes. This desire to influence Google’s ranking algorithm has spun off a multimillion-dollar industry of SEO. Automated influence can get to the point where it changes public opinion. How? Through sockpuppets, i.e., automated fake online identities. Those robots publish and discuss stories in Twitter, for example. But some 55% of journalists use Twitter to find sources for their stories, according to the Digital Journalism Study by Oriella.[104] To quickly and effectively sift through the daily clutter of information in online media, journalists use measurement systems. These systems help them find the most interesting, best trending stories. Bots in turn try to influence these measurements to influence the journalist and, in turn, to influence the public opinion.
In either case, whether the intent of social bots is to purposely disrupt our measurements, to manipulate, or only to use the network to spread unsolicited or fraudulent information, it is important to spot manipulative, phony, or fraudulent behavior. To remove those is critical in creating accurate measurements.
We stress the importance of starting any measurement process with the right question (see Chapter 8). Similarly, knowing the right motivations for fraud or manipulation will help you spot behavior that could lead to skewing. In the following sections we will see a few of the main motivations, ranging from swaying political opinions to artificially boosting popularity ratings.
Additionally, we will look at the most common ways to skew social media measurements through automated means and discuss ways to combat them. The most common aims of fraudulent or manipulative activity are the following:
To create reach and spread a message more widely
To smear opponents with false information
To influence others and/or to create an intention to purchase products or services
To suppress information that may be politically or commercially damaging
There is a fine line between what is manipulation and what is fraud. Using automated means and not disclosing it is definitely fraudulent. Cheating in any system seems unavoidable. To find the ones who cheat and to avoid being found will remain an ongoing battle in the use of online and social data. Counteracting fraudulent use of data has already spawned a discipline unto itself, whose efforts could in time rival the multibillion-dollar online security industry that sprang up in response to threats such as computer viruses and spam email.
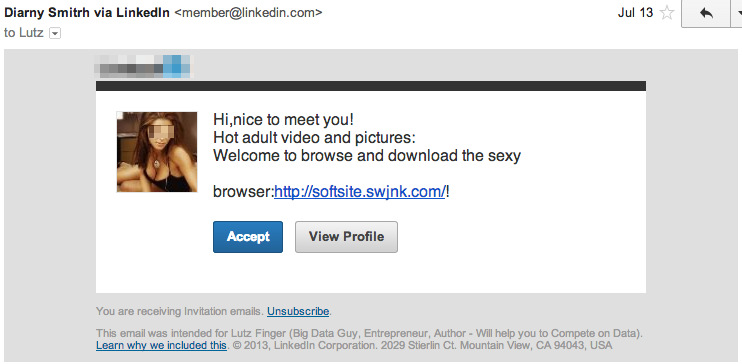
Have you met Diarny Smitrh? She recently contacted me via a social networking site as you can see in Figure 6-2. She had a beautiful face and asked me to visit her website containing adult content. Who is she in real life?
First of all, Diarny is most likely not a girl at all. Nor is she even human. Diarny is a robot, also known as a “bot.” She is an algorithm that connects to more or less random people on LinkedIn to generate traffic on the adult content page. But not only this, Diarny tries to connect to you to find out more about your connections and to be able to connect to them. Is it likely that you’ll connect to a bot? No! Research has shown that 16% of us would accept an unknown friend request.[105] In the case of bots like Diarny, this acceptance rate goes up to as high as 22%, according to Yazan Boshmaf. Moreover, this acceptance rate can be improved if the name sounds familiar. It’s not surprising that “Diarny Smitrh” has a name that looks like one big spelling mistake. The name is supposed to sound familiar despite the fact that this very spelling will result in zero results in a search engine. But even if you do not fall prey and you do not accept Diarny’s invitation, at least she tricked you into looking at her message. In a word, she has created reach at almost no cost. For Diarny, the cost to connect to one or to thousands of users of a social network is almost the same.
The Age of the Bots: We Are the Minority
Diarny Smitrh is not alone. She, the algorithm, is part of a majority: 61.5% of all Internet traffic is nonhuman, according to a study[106] released in 2013 by Incapsula, an Internet security firm. Surely much of this traffic comes from scrapers or search engines, but more and more, from bots like Diarny Smitrh. Life in social networks sometimes feels the opposite of being connected. Brands, governments, organizations, and spammers all would like to engage with you or to get you to respond to them (Figure 6-3).

Those who visit her profile see a link to her website and can read more information designed to create a potential deal. In this case, Diarny is a spammer who just went social. She used the social networks without really using the advantages of trust and connectivity. She made the same mistake that many marketeers did in the beginning of the social networks (see Chapter 1). She just used it as another channel. But reach does not necessarily create intention. Conversion rates of spammers are very low. A spammer like Diarny would need to reach out to everyone in LA to get to a single conversion.[107] Diarny is thus something that we call a spam bot of the first generation. Later on we will discuss the evolution of the bots, the second generation, which do not go for reach but aim to influence and create intention.
There are a lot of bots like Diarny Smitrh out there. If you are on Twitter, you could easily do a self-test. Companies like StatusPeople or PeekYou offer services to find out to find who is a bot. According to Michael Hussey (@HusseyMichael), the average Twitter user, like you and me, has anywhere from 40% to 65% robots as followers.[108] Bots like Diarny, thus bots from the first generation, which just use social media to distribute a message, are easily detected. Once detected, services like Twitter and Facebook will delete their profiles. But with each deletion, the creator of a bot learns how to circumnavigate the very issue that led to detection in the first place, creating a learning loop that leads to better and better bots.
Typical ways to spot bots are taken from how we would spot crawler attacks on a network. A person who is very active or active in bursts in a way that a human couldn’t be is a bot. Thus if Diarny Smitrh attempted to reach out to a couple of hundred people within a few minutes, then it’s clear she is a bot. Another indication of bots is ovely regular behavior:
- Regular messaging
Someone who reaches out to other people on the network 24/7 without sleep and weekends is likely a bot. And with conversion rates as low as described, Diarny Smitrh will need to do exactly this; otherwise, she will not become effective.
- Suspicious behavior
Fake social media accounts often do not show a lot of authentic activity. If a tweep uses only one hashtag over and over again or sends out only one link to click, then it is most likely a bot.
But it is easy for a program to “randomize” the activity of a bot and to ensure that the bot sleeps or has weekends. Also, personal behavior can be programmed quite easily. A bot could take a random RSS feed from somewhere in the Internet. That is not his content and is a copyright infringement, but it keeps the bot safe from detection. The algorithm analyzing behavior to spot bots will think that this is a normal person.
Less easy to overcome is the data of creation. Any bot will need to be created at some point.
- Recent data of joining
In the early days of commercial “bot business,” the bots were rather junior and recent but “acted” senior. Thus very junior accounts that already have a lot of conversations might be a sign of a robot.
- Similar date of joining
Often fake tweeps are created in “batches.” For example, a European social network told us that it had at one point a sudden growth of accounts from India. “Within days we had new applications that accumulated to 30% of our overall user base from India,” said one manager who didn’t want to be named.
But those detection measurements could be easily overcome. One would need to have waiting periods for bots to become active. The best way to spot a bot is by its friends, in other words, to analyze its network topology. Bots are lonely. At the end, who wants a talking billboard as a friend? Let’s use Twitter as an example. Each tweep has a network formed by his individual friends and followers. The topology of this personal network can be used as a kind of fingerprint for this person. A bot, however, will not be able to connect to other humans at first. Most real people would not become friends with someone who seems to have no connections at all and who is not very well known. Normally a social “newbie” would connect first to his or her closest friends. And those friends would answer the connection request in reciprocal order. A bot, however, has no real closest friends except other bots that will answer a connection request. Afterward, once the bot has gained a certain level of connectivity, it looks trustworthy to others, and only then will it try to infiltrate the network by slowly connecting to other parts of the network.
Such behavior can be spotted by analyzing a given cluster of social network connections. A network like the one in Figure 6-4 consists of people often called “nodes,” and connections between those nodes are often called “edges.” Two measures are especially helpful in detecting bot networks in an early stage:
- Density within subgroup
Density measures the amount of interlinking of a network. It compares the existing number of connections (also called edges) to the theoretical possible ones. Figure 6-4 shows one network that contains two very dense areas. A density of 1 would mean that each person has a connection to any of the others. Such a high density is normally not seen in real-life networks and is thus an indicator of a bot network.
- Cohesion
Assessing cohesion is another way to measure and detect bot accounts. The two groups in Figure 6-4 are interlinked by some people, indicated by all the edges that go from orange to green. That means that some accounts have contacts in the other group. Bot networks, however, are lonely, not very linked with the rest of the world. Or said differently, the “small world experiment” by Stanley Milgram will not work for bots. While each of us is connected by only a few degrees of separation, bots are not. The measure to describe this is cohesion, which counts the number of links you need to take away until the network is detached from the rest of the network.
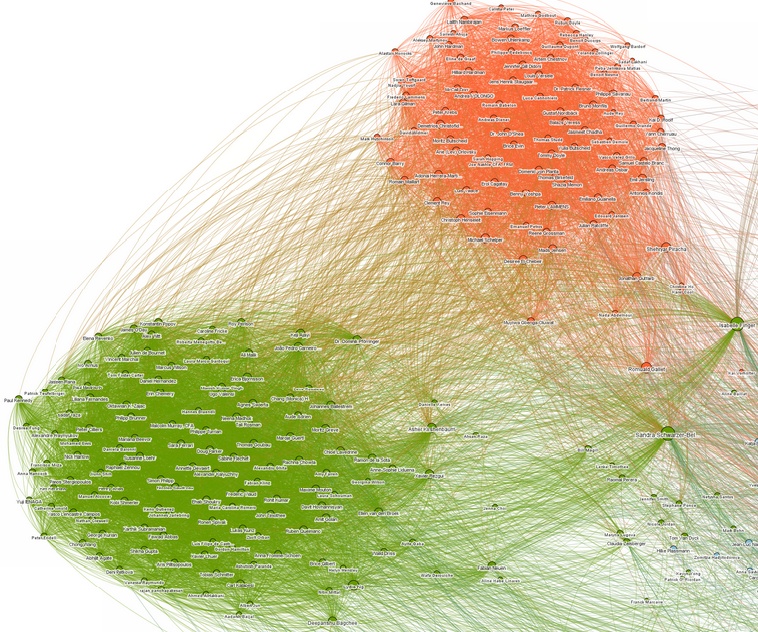
Since bot networks will first create their own group by linking to one another before they start to infiltrate the rest of the network, especially in the beginning, you will see a highly dense network with very low cohesion to the rest of the network. However, those measures using network topology only work in the beginning as the bot network is formed. Once the bots have started to integrate into their target network, it becomes harder and harder to distinguish the bots from just a normal tight community. It is, therefore, of great importance to detect those networks as they form.
This issue of bots is high on the agenda of all social networks. They try to build their own systems to detect fake identities because their business models depend on the trust of their users. Many, if not most, platforms are ultimately advertiser-supported, and no one would place advertisements with them if they knew that only 20% of their response traffic was from real people. Thus Twitter introduced an upper limit for people you can follow. This way it restricts Diarny Smitrh, and other bots from following a few million people in one go. And most networks created a way to flag spam or bots. This way, the network can not only catch them, but their early friends as well. Using network topology, as described previously, or using machine learning, the social networks spot other similar profiles and delete them. In the spring of 2013, Facebook instigated a massive purge of deceptive accounts and fake “likes” on business pages, deleting tens of thousands of these “likes” in some cases. Business Insider reported that the number of fake accounts dropped by around 83 million in the second quarter to 76 million in the fourth quarter. But because of the purge, Facebook’s own fanpage lost about 124,919 fake likes.[109]
These systems don’t mean the problem is solved. The Facebook bot-detection system is called the “Facebook Immune System.” Shortly after it was launched, researchers found out how to easily circumnavigate those control systems, as Yazan Boshmaf showed. He and his team operated a large number of robots on Facebook to infiltrate other users. They had a success rate of up to 80%.[110] Once people were connected to the network, the robots from Boshmaf’s group managed to get personal information, as well as spread messages. Twitter also used a system to reduce spam messages from 10% in August 2009, down to below 1% in 2010.[111] But soon researchers found out that this was only a temporary win. In 2013, Amit A. Amleshwaram et al. reported that 7% of all tweeps seem to be spammers.[112]
This will become an endless cycle where people try to spot bots while spammers try to circumnavigate those controls, as we have already seen with email spamming and with computer viruses and the antivirus software industry. It will be a cycle that technology can’t win because both sides have access to the same means. In 2012, Twitter went one step further (Figure 6-5) and sued alleged spammer companies such as TweetAttacks, TweetAdder, and TweetBuddy.[113]
Next to legal and technology actions, there is a third way to avoid spammers from the beginning: make sure that they are identified. There are several ways to do this. This could be done by techniques that include “captcha” codes. Once you register your social media account, you are forced to type in a letter combination that is either handwritten or difficult to read. Those codes should, at least in theory, only be readable by human beings. Unfortunately, technology soon caught up, and there are many tools to automatically read and enter captcha codes. The next level then is to ask sophisticated questions like “calculate one plus one.” But that can also be solved by potential spammers. In this case, one would need to use mechanical clerks, e.g., people from low-wage countries who identify CAPTCHA questions and type them in for less then a cent per security code.[114]
Surely the networks could raise the bar even higher to prevent automatic systems from generating fake identities. They could force everyone to enter a mobile phone number or ask for credit card details. Those measures will work best to keep bots who possess neither of those away. But unfortunately, they also keep a lot of potential customers out and such measures could be commercial suicide.
If spam bots have infiltrated and spread into the network, especially once they have found friends who are real humans, it can be extremely difficult to identify them. However, you can probe suspicious candidates by asking them questions that a computer would find difficult to answer. For example, Facebook sometimes requires users to identify people who are tagged in the real account owner’s photo library: they show seven images, allow the person to skip up to two of them, and do not allow any errors. Other approaches might be to ask questions based on a user’s profile or seek responses to things such as jokes that an algorithm would have difficulty responding to.
All of those approaches are far from perfect since they always will miss some bots and punish some real users. For example, Facebook users have been locked out of their own accounts because of unclear photos. Increasingly, sophisticated technology is being employed on both sides of this battle, and this trend is likely to continue for some time to come.
Since there is no cure for bots, “verified accounts” will be the future. Major social networks such as Facebook and Twitter have already introduced them. Since public institutions are using online tax filing and other digital systems more frequently, online identity verification will soon be even more mainstream. Something like a digital passport will become accepted. That will be the end for most bots, and it also be the end of individual privacy in the social networks.
How to Set Up a Bot
If you’re not a techie but want your own bot, you might be surprised by how easy it is to set one up. There are many services to choose from. Companies offer retweets and followers for little money. One company offers for as little as $21.44 more than 600 Facebook likes. Their service says:
100% Guaranteed Facebook Likes! We offer guaranteed Facebook fanpage “Likes” packages to kick start your Facebook marketing campaign. Whether you currently have zero likes or thousands of fans, when you buy Facebook likes cheap from Social Media Combo we always send additional “Likes” to your fan page so you can increase your social proof and fan page activity.
A short video from the German Deutsche Well shows how easy one could set up a bot with services like ifttt.com. The bot @spotthebot was created within a few minutes, and it got other bots as friends, and from then on it became more and more connected in the real world. [115]
One step further is to have your own bot software. That’s also easy to buy, as you can see in Figure 6-6. This company offers an easy-to-use service for all different networks, including a software to bypass CAPTCHA codes.
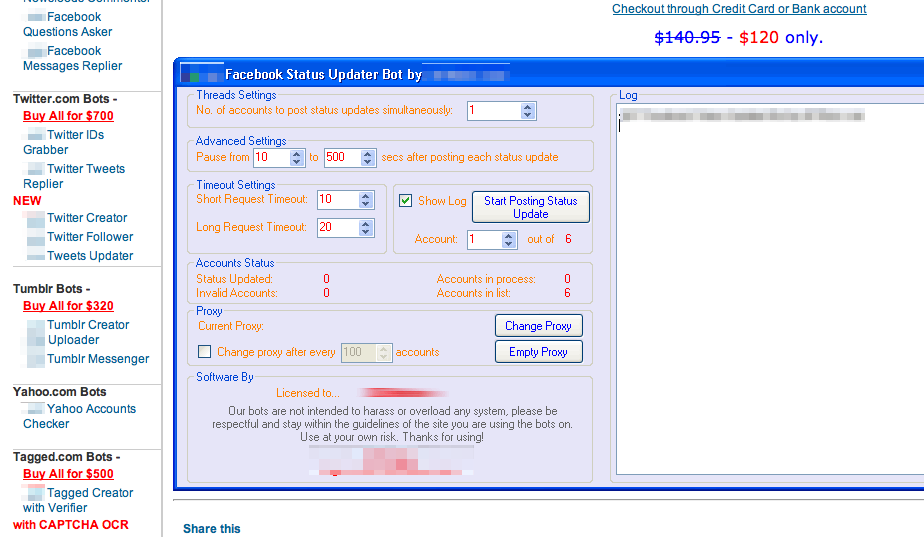
If you know how to code, you can download bot software and natural language toolkits from university websites under an open source license.
Diarny Smitrh wanted us to visit her website and potentially become her client. That is spam in its basic form. Sometimes bots can have consequences that go far beyond spamming people to buy things. They can also be used to harm the reputation of others. Bots can be used to smear others.
Suppose that you are a company that manufactures a household cleaning product. One of your competitors dominates the market for this type of product, and you would like to have a greater share of this market. Of course you will compete on the basis of things like pricing and features. However, it might be even more profitable for you to raise doubts about the safety of your competitor’s product.
If you were to publicly challenge your competitor in this way, you would be held accountable for what you say, and your credibility, of course, would be suspect as a competitor. But if you were to invent bogus “concerned citizens” who spread these concerns on your behalf through social media, you might be able to damage your competitor’s reputation much more effectively. This would especially be the case if these accusations are exaggerated or not entirely accurate.
One of the more common areas where smearing opponents happens is in politics. It should come as no surprise that this is where you will also find the most activity from social bots. Particularly during the time leading up to an election, there is often a gray area between spreading negative and exaggerated campaign messages versus disseminating outright lies. Unfortunately, both techniques are often employed in the heat of an election.
Take the case of the “Sununu War Room” scandal on Twitter during the 2012 US presidential campaign. The real John Sununu is a conservative politician and former White House chief of staff who had recently gotten into hot water for implying that another public figure had supported President Barack Obama, in part, because both were African-American. In response, a prankster created an account @SununuWarRoom pretending to be Sununu and posting racist and insulting tweets.
These tweets soon spread through social media channels, with many people believing that they in fact came from Sununu, even though they were clearly designed to be inflammatory. For example, the comment that Barack Obama would not be “3/5 of the president” that Mitt Romney would be alludes to legislation in the late 1700s that US slaves could be counted as three-fifths of a person for the sake of representation in Congress. Twitter soon shut down the account as being fraudulent.
Like the example of creating fraudulent reach for the sake of influence discussed previously, fake smear campaigns enable people to distort reality or spread falsehoods under the cloak of anonymity. This means that, as with other issues in social media and online data measurement, it is important to examine the underlying question that motivates what is being posted. If this question appears to be biased or suspicious, the possibility of fraud must be considered, triggering an examination of the validity of those who are posting.
While it is fairly easy to spot a prankster trying to smear John Sununu, smear campaigns can sometimes be very hard to detect. Let’s look at some of the recent “fake-follower” scandals in politics. During 2012, several politicians were accused of creating “fake followers” in order to look more important in social media. Were those accusations true or false? We will never know for sure. We know that this has happened, but we do not know who created those fake followers. Was it the politican himself (or his team) or someone who wanted to smear the politician by creating false accusations?
One of the first high-level accusations was against Newt Gingrich (@newtgingrich), who ran for the 2012 Republican presidential nomination. Gingrich had a surprisingly high number of Twitter followers—1.3 million—compared with other politicians, as Time.com reported.[116] Social Media company PeekYou said that 92% of Gingrich’s followers were fake followers. Other politicians and political parties accused of purchasing tweeps in 2012 were:
Nadine Morano, a minister in the French cabinet 2012[117]
The German conservative party (CDU)[118]
Mitt Romney (@MittRomney), another Republican and the GOP’s eventual candidate for the US presidential election[119]
It seems strange that all those politicians should have made the same PR mistake within less then six months. In all those cases, the fake followers were easy to spot. All of those accounts were very junior and were created on the same day or within the same week. As discussed in How to Spot Bots, there is a very basic method for identifying bots. Professionally created bots would be more difficult to spot.
As noted earlier, it is crucial to analyze the motivation behind any fraudulent behavior. Let’s analyze potential motivations of those followers scandals. We will see that politicians seem to gain very little from fake followers:
Higher follower count increases reach, which will help spread the message, for example, calls to do fundraising for the candidate. While it is true that reach can be linked somehow to follower count, it only works for real followers. Fake followers would not help to spread any message, because they are often not linked to real-life people, and thus no one would hear what they said anyhow.
More followers on an account might make real tweeps assume the politician has greater authority. This is certainly true. Evidence shows that tweeps are more likely to follow back if they meet someone with a high follower count. However, what kind of difference would that make for a politician who is a well-known personality and whose authority is analyzed in detail by mass media like TV? Fake followers will make no real difference at all!
Therefore, there is no real benefit to gain for politicians from high follower counts. For all those follower scandals, there might be only one of the following two explanations:
There is a hidden incentive structure for having a high follower count. For example, a politician would like to show that he has social media competence by displaying a high follower count. A similar type of explanation would be that there was some incentive structure which put the number of followers into the personal goals of someone within the media team.
The other possible explanation is that political opponents bought followers for those people to harm them and to create the accusation of “cheating.”
Which one of those scenarios is true would be hard to detect.
Diarny, the bot we described earlier, was not only looking to create reach. This reach had a larger purpose. By following lots of people on Twitter, she hoped that her spamming would create an action, such as a click on her website, and then, in turn, an intention to purchase the adult content she was selling. As discussed earlier in this book, the goal of many marketeers is to create intention. However, they often fall short by just aiming for reach. Bots are faced with the same issue if they aim only for reach. An effective bot will try to influence, to trigger an action, and to create intention.
The difference between reach and intention often lies in creating a human connection with a need. Following people on Twitter is relatively easy for a bot. Getting these people to click on a link for your website is less easy; there must be some attraction. (In the case of Diarny, this might take the form of physical attraction from the profile photo.) From there, translating this click into a purchasing intention requires both the perception of filling a need, and the credibility for people to trust you to fill it. Just recall the email spammers; response rates were one in 12.5 million for a fake pharmacy site.[120]
With spam emails, we have seen that click rates improve once the perceived credibility of the sender improves. While spam emails have only limited possibilities to increase this kind of perceived credibility, social media allows for a wide range of way to establish credibility. For bots to be able to improve click rates or gain information, they have to improve their own credibility in the real world. This can work quite successfully. There have even been reports of bots improving building trusted connections in social media. Rather than approaching a new contact directly, for example, you can use a Twitter bot or Facebook bot to first get an introduction. In an experiment reported by the MIT Technology Review, Twitter robots were built to lure potential connections. What the researchers found was that once a connection was established, those robots could introduce new connections, enabling them to build a network via recommendation.[121]
Once public relations was the domain of those who could afford large-scale access to the media; today even small businesses can wage PR wars using bots, or activists can invent an army of fraudulent identities that appear to back their causes. This, however, creates more and more skepticism within social media users and makes trust an even more important asset in today’s communication.
In the following sections, we will look at two examples of trying to influence people: Nigel Leck (@NigelLeck), who tried to influence debates on environmental issues and the recent efforts by the US military to create nonexistent personas for social media as a potential tool for influence.
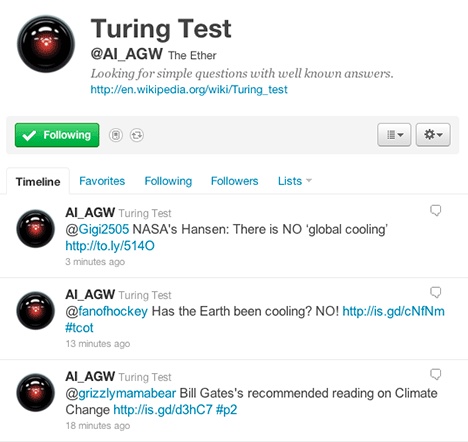
The case of Nigel Leck @NigelLeck was reported by Treehugger.[122] Nigel had realized that the same arguments were often used over and over within environmental debates, so he programmed a robot to tweet these arguments for him. Every five minutes the program searched within Twitter for arguments and gave predefined answers from a database. With some humor, he called the robot Turing Test in accordance with the similarly named experiment on computer intelligence (see Figure 6-7). Some 40,000 tweets later, after a lot of press attention, Twitter became aware of this bot and shut it down.
At another level, the potential for spreading influence through bots can attract interest and research at high levels. For example, public documents from the US Air Force showed that it solicited vendors for personal management software that could be used to build an array of nonexistent people within social media platforms.[123] The contract was awarded in 2011 to the US-based company called Ntrepid for $2.76 million.[124]
While the planned applications for this software are classified, such tools would enable virtual people to be placed strategically in locations around the world, to influence public opinion in ways that would benefit the US goverment. The Guardian quoted General David Petraeus, who said that this software is used to “counter extremist ideology and propaganda and to ensure that credible voices in the region are heard.”[125] Tools such as these represent the modern equivalent of dropping propaganda leaflets from airplanes in past world wars, but in a much more personal and credible way, and it can be done at the push of a button from within the safety and comfort of your own borders.
Social media has often been hailed as the purest form of democracy. Everyone can participate. In politics, social media is often connected to grassroots movements, which are local groups. Volunteers bound together by a mutual cause fight for their interest and may even cause change by getting the attention of the general public. Grassroots movements are often seen as being in contrast to the representative democracy, where political or social decisions are dominated by a few elected power sources.
Anyone can try to start a grassroots movement because anyone can create a social media account. However, the mass adoption of the given cause is far from certain. There are three main success factors for a grassroots movement to become engaging for a broader group of people:
Grassroots movements have existed since the onset of society. However, social media has made reach and access extremely easy. In the early days of the social Internet, you had to write a post to participate and to give an opinion. With Twitter or microblogs, the post, and thus the effort, became smaller. Today, making a statement or supporting a cause is down to one click such as a retweet or a Facebook like.
The power of this simplicity became clear in a worldwide online protest done in early 2012. There were concerns over how Internet piracy legislation might shut down free expression and require a damaging level of infrastructure on the part of service providers. Several companies like Google and Wikipedia (and this book’s publisher, O’Reilly) asked US visitors to contact their congressperson to protest the introduction of the SOPA (Stop Online Piracy Act) and PIPA (Protect Intellectual Property Act), bills that would add a great deal of unwanted cost and accountability to these sites by forcing them to shut down websites viewed as engaging in copyright infringement or selling fraudulent products, in an argument that was framed around the larger issue of free speech. Google blacked out its logo on its homepage, while Wikipedia blacked out service entirely, with both sites offering links to protest this legislation.
The turnout of online protestors was enormous, and social networks were full of arguments against the bills. This grassroot movement became very successful, and both bills were quickly shelved by their sponsors. This success was most likely not only due to the cause of stopping the legislation. It can even be safely assumed that not every protestor understood the underlying discussion. But it became successful because it was easy to participate and because the participating sites like Google and Wikipedia had considerable reach. The blogger Dan Rowinski pointed out that the protesting websites couched their advocacy in overly simplistic terms to stir up public opinion:
Censorship bad. You don’t want censorship? Of course not. Here’s a nice popup for you. Click the button that says censorship bad. You can do it. Good boy. [126]
This example underscores that movements can leverage the Internet and social media to build a base of support in a way that is potentially reflexive and simplistic.
Sometimes grassroot movements go even further. It is not a matter of simplification and reach, as in the SOPA protests, but skewing the picture like in the cases of Nigel and the US military. No matter how honest the intentions are, they created fake personas or “sockpuppets” and bots to create an illusion of a mass movement, or at least a widely supported opinion. This phenomenon is sometimes called “astroturfing.” This term implies that something is not a real grassroots movement, but rather a movement made up of artificial grass. (Astroturf is a brand name of artificial grass that was first implemented at the Houston Astrodome, when it was discovered that real grass could not grow under its domed roof.) Technology is the right fit for astroturfing because it can enable thousands of generic sockpuppets to vote for a given cause creating this illusion of a mass movement.
Astroturfing has existed for quite a while and is not restricted to the onset of social media. For example, when Microsoft tried to organize a movement against the antitrust suit against it in the late 1990s, its supporters received prepared letters urging President Bush or others representatives of Congress to drop the case.
Microsoft understood that ease of participation is key and offered prewritten letters on already personalized stationery with preaddressed envelopes. All the participants needed to do was go to the post office. Unfortunately some of the protestors even went one step further and sent the letters in the name of other people, some of which were already deceased. As this became known, newspapers scoffed that the dead were fed up with the government’s antitrust case against Microsoft Corp.
Some governments try to influence public opinion. China created a paid blogger army way before the US military started to look for personal management software. The phrase “5 Mao army,” or a 50-cent blogger in English, was coined for a group of Chinese citizens who get paid to comment on or to write in favor of the Chinese government. They pretend to be ordinary bloggers but use different identities to promote government opinions. David Bandurski at Hong Kong University estimated in 2008 that there were about 280,000 paid bloggers in China.[127] However, the use of paid bloggers appears to have decreased lately, perhaps due to the inefficiency of the process.
Fisheye Analytics saw a strong decline in these bloggers between 2010 and 2011. Ashwin Reddy, cofounder of the company, noted, “In 2011, total social media activity [from blogs] increased by more than 50% from the previous year. However, Chinese blogs showed a strong decline, down to only only a third of 2010’s level of activity.”
Why did this decline happen? Perhaps the Chinese government felt that the propagation of news did not equate to action, and that the influence of these bloggers was not sufficient. Or perhaps the 5 Mao army has now been focused on other areas of the social Internet, such as Twitter, Weibo, or Wechat. Either way, the existence of these bloggers serves as an example of how astroturfing can easily be accomplished by real people, as long as their services are sufficiently inexpensive. Moreover, the line between real and automated sources of opinion continues to constantly shift.
To create a grassroots movement, honestly or fraudulently, you need three things: a cause (such as allowing smoking or banning SOPA), access to the protest (like writing a letter, going to the street, or clicking on a button), and the reach to engage a lot of people and inform them about your protest. Newer electronic means of generating reach, such as using bots or multiple online personas, make it potentially easier to create such a movement and perhaps multiply it through contagiousness of a message. This makes astroturfing an even greater risk in today’s world of online and social media data.
As mentioned earlier, to say that a social media message or protest like the one against SOPA was “viral” is not quite the right use of the word. Information gains weight as it travels. The more people believe a given piece of information, the more true it is perceived to become. Thus the spread of a message is unlike a virus that is equally contagious at all times.
Contagious or viral messages will need to have the same ingredients as a successful grassroot movement: reach, access, or an easy way of spreading the message, and suitable content or a suitable cause.
As we saw in the last section, technology can make spreading information as easy as one click of the mouse. There is also a higher potential risk for “gaming the system” through the use of robots. And we saw that reach can be increased through technology. However, can we change or predict how contagious content is? If we could, might we create virality by design?
Did you know that Kony2012 was one of the most contagious YouTube videos ever? After only six days it had more than 100 million views on YouTube. This 30-minute video, created by Invisible Children, Inc., explains very emotionally, and even manipulatively, the situation in Uganda, calling for action against Joseph Kony, a warlord who abuses children.
How did the video gain such fame?
For sure the content was an important driver for this success. If the content was just not interesting, then the content would not be spreading, no matter whether it was distributed over a large network or not. The content of the video Kony2012 is very emotional, as it discusses war crimes toward children. But moreover, the video was extremely well done, in a kind of MTV format with lots of embedded emotions.
The second success factor was how Invisible Children created a strong reach through its network, as Gilad Lotan described in his blog.[128] The video was not just placed somewhere on YouTube waiting to become famous. No, Invisible Children already had an organization of supporters in place. Those supporters acted as spokespeople to promote the film immediately. There were several centers where people started to promote the film. Thus in a short time, at different places around the world, this video was viewed. This kind of viewing triggered YouTube’s ranking algorithm to believe that this had to be an important video. So YouTube then promoted the film even more.
The goal of this video was to generate reach, and YouTube rankings were integral to this process. Maybe the reaction of the measurement algorithm was even more important for the reach of the film than the reactions of the initial viewers.
At a broader level and independent of Kony2012, this example means that people trying to disseminate false information can also leverage the efforts of a fake crowd of bots to “game the system,” and potentially enhance its reach and virality.
In the end, no one will know whether this kind of contagiousness has happened by chance or whether there was a dedicated plan to influence the YouTube algorithm to promote the video. However, this last example begs the question of whether or not we could orchestrate virality. The answer is yes and no. Yes, with a lot of care, you can try to influence the algorithm and help spread a message similar to the way marketeers influence Google’s search rank algorithm. And also yes, money will buy reach, which would be an alternative route to create high awareness.
The “no” part is that so far, we can’t determine whether the message is contagious or not. And just the way that reach is no guarantee for intention (see Chapter 1), reach by itself is also not a guarantee of contagiousness of a message. This depends on the message content itself. In the case of Kony2012, the content was the right content to spread. But so far, research has not found a good way to predict up front whether content will spread or not.
For example, research by Eytan Bakshy from the University of Michigan published in 2011 showed that there is no good way to explain the spread of certain URLs.
Bakshy and colleagues studied this impact across 1.6 million Twitter followers and 74 million events over a two-month period in 2011. What they found is that tweeps with larger numbers of followers were more likely to create a greater spread of the message (measured by the number of retweets). On the other hand, they also found that the likelihood of a particular message being spread was quite low. More to the point, they found that predicted interest in the content had little bearing on the degree to which the message was spread. In other words, virality is much more likely to be observed in hindsight than predicted.[129]
In other words, the success of content is hard to predict. No one can accurately predict whether a message will spread, whether a song will be a hit, or whether a movie becomes a blockbuster. The spread of a message or the success of content is nondeterministic, or at least not sufficiently understood. Too many external factors take part in the question of whether a given message, song, movie, etc. resonates with society to make it simple or easy to find the answer.
Similar to how we are very cautious in talking about “influencers” being essential in creating sales intent (see Purchase Intent), we are cautious about concluding that you can orchestrate the spead of a message.
Despite the research findings, there are many companies offering to plan, deliver, and benchmark the spread of content, and they often imply the ability to create an “orchestrated virality.” If those promises were true, then everyone could design his or her own campaign to go viral. But if everyone does it and every campaign is viral or contagious, then virality would be the norm, and again, we would find ourselves in the situation where no message is exceptional or outstanding.
A real-life check will support the scientific findings from Bakshy and our logical reasoning: nondemocratic, dictatorial regimes would have loved to create such an automatic process to spread deceptive information. They have tried but so often have failed: the truth always comes out. Perhaps this is an indication that humans are not as easily fooled as marketeers would hope. However, many will still try, aided by the use of tools such as bots and social media platforms.
In sum, we do not believe that there is a secure, predictable method to generate virality or contagiousness. We think automated attempts to create contagiousness most likely are going to fail, as the human mind looks for the unexpected within the content, and unexpected also means unexpected for any algorithm. On one hand, the human mind is too multifaceted and too interested in the unexpected to predict its behavior; and on the other hand, any set system would ultimately lose the element of surprise and novelty and turn against its original objectives.
A message, contagious or not, can be true or false. False information in general has the issue that if people realize it is not trustworthy, then they are not going to believe it. In a way, it is similar to a newly created twitter bot without friends. No one wants to be friends with a stranger who has no friends. No one wants to spread a rumor that no one else believes in.
But once a messsage has traveled, it may gain some weight over time. This is true for false information as well. Once everyone has been touched by this false information, some may start to believe in it, at least to some extent. There is a belief that there is at least a grain of truth in every story, and this sense of truth is amplified as messages spread. Thus the ones planting false information will need to get the message viral, so that people start to believe the message before they can check the facts. As Ratkiewicz and colleagues pointed out in a study of political messages, once an idea or content starts to spread, it does so in the same manner as any viral phenomenon. This underscores the need for early intervention to prevent such a spread.[130]
Bots can not only spam people, smear opponents, and try to convince others, but they can also create “contagious messages” where it does not make a difference later whether they are true or not. To spot a deliberate attempt, you have to look at the instigation of a message and quickly react with counterarguments before the message starts to spread.
The more people have trusted a certain message, the more likely it will be passed on further. Thus, to identify a planted message, you can look over time at how a message evolves. If a message starts spreading very strongly in the beginning, supported by tightly connected accounts, it is likely that this is an attempted creation of virality or a false rumor in the making. If messages start spreading slowly supported by independently connected accounts, it is more likely that this is a true message.
Each message contains parts, each of which could start spreading. They are called memes and could be:
Hashtags in Twitter
Phrases forming all or a part of a message
Links to websites
Other users or accounts within the social network
You need to look at whether any of those parts show abnormal behavior at the beginning. As in the case of fake followers, astroturf needs to be detected in the beginning. Once a planted message has gained momentum, it is difficult to detect because the community starts to believe the message, and thus the propagation looks similar to a true message.
There are still relatively few tools available that look at the real truth of a message. One of the best available efforts to date comes from the School of Informatics and Computing at Indiana University. Professor Filippo Menczer has developed a service called “truthy,” the function of which is to watch out for astroturf messages. If you wish to try this program yourself, you can start with his publicly available code or read his research.[131] Other ways of detecting astroturfing involve not looking out for the message or meme but trying to spot the robots.
In much the same way that there is no bulletproof system to create virality, there is no sure way to spot fakes. As soon you have found out what a fake message consists off, there will be methods to avoid being detected. The algorithm truthy, for example, would be looking for a given URL and whether there is unnatural spreading visible. Spammers started to disguise a link getting tweeted over and over again by adding random queries on the end of the URL or using various short-link services.
Robots can not only be used to carefully formulate opinions or to influence people; they can also work to overlay any kind of discussion with a high volume of other opinions.
This kind of spamming behavior is similar to the DoS (denial of service) attacks where someone tries to put a server out of order by swamping it with too many useless requests. This can be used for the sake of activism against a particular corporation or industry, such as the case of flooding a Facebook page with useless or critical posts that make it impossible for the page owner to communicate effectively.
It can also be used by totalitarian regimes to stifle dissent, either online or in the real world. For example, during the Arab Spring movement that started in 2010, rebel movements often used social media to coordinate protests and other activities. Governments or others have the potential to use similar hashtags in Twitter to overwhelm communications by sending hundreds of irrelevant tweets, and such tools have been used against protesters to disrupt their activities. In a sense, spamming reduces the reach of other messages. The spam message starts to appear on top of the other messages, pushing the real message further down, reducing its visibility. Jillian York reported a very good example during the Syrian conflict.[132]
In both the political and business arenas, such moves serve as examples of the cat-and-mouse game that continues to exist behind the disruptive use of social media.
Are we being too hard on people trying to market ideas by calling them “fake” or “false”? Wouldn’t that be the dream of any marketeer, to get his brand message spread widely? Would this not be the typical call to action for a PR agency: “Please spread this information...make it go viral.” Is there always an answer whether information is true or not?
If one uses robots to spread a message, he most likely wants to do wrong. But there are also a lot of gray areas within PR that are neither easily detected nor easily judged as unethical.
Paid opinions, or opinions supported by lobby groups, can be another source of false wisdom. It is, unfortunately, often hard to distinguish between lobbying attempts and outright wrongdoing. The lines are blurred in many situations, and no good detection measurements exist. However, the few cases where someone clearly crossed into a gray area and got uncovered lead us to only guess the extent to which paid opinions are used in today’s world.
In 2011, Facebook came under considerable criticism after its PR firm Burson Marsteller tried to get a famous blogger, Christopher Soghoian, to smear Google on its behalf. Soghoian, who had publicly denounced Google for privacy and data-retention issues, was approached by the PR firm to write a bylined op-ed criticizing the new Google Circles social media capabilities, as Wired Magazine reported.[133] He was surprised by this request to denounce someone by proxy, and probed further. Asked for whom they were working, Burson Marsteller did not give any answer.
But Soghoian was cautious and went public. “I get pitches on a daily basis, but it’s usually a company talking about how great their product is, so this one made me immediately suspicious, even more so when they wouldn’t reveal who they were working for,” he told BetaBeat.[134] “It seemed pretty clear what they wanted was my name,” said Soghoian. What can we learn from this? Technology makes it easy to go beyond gray lines and the temptations are there for everyone.
There is clearly potential harm to be done via fraud within social media:
Spamming people, like Diarny Smitrh did, to fraudulently sell products and services
Smearing opponents by using robots
Trying to influence a discussion like the bot Turing Test did
Artificially creating contagiousness; in other words, artificially creating reach and ease of engagement for your content
Examples such as these only scratch the surface of what is possible. And beyond them, there is always the temptation to build a few bots to influence a metric. Any outcome that is desireable or measured is at risk of becoming a focus for behaviors that game the system. It could be as small as changing your Klout score or as large as impacting the financial insights of a hedge fund.
If there is good news in this situation, it is that we now have a broad range of technologies to protect people from fake social media, ranging from the automated fraud detection tools of firms such as Facebook and Twitter to procedures requiring human intervention, such as CAPTCHA type-ins and photo identification.
At a deeper level, the good thing is that as much as we overestimate influencers, we also overestimate the longterm perspective in trying to buy fake messages. The truth ultimately seems to prevail, and we prove to not to be as easily influenced as we thought. There is some research backing this view: Mendoza and colleagues found in 2010 that false information is more likely to be questioned by others.[135]
As with all forms of cyber fraud, such as viruses or identify theft, attempts to game the system using social media and online information continue to follow an iterative cycle. New ways of cheating are met with tools to counteract these moves, which in turn give way to even more sophisticated forms of fraud. This pattern will continue to evolve over time, in concert with the agendas of stakeholders on all sides.
In closing, there is an evolving social context behind both the use and misuse of social media channels. You could view it as an ecosystem that evolves from the motivations of everyone who uses the Internet. Some of the fraud being perpetrated online springs from criminal activity that seeks profit from false information, while some of it is thoughtfully chosen as a vehicle for social change: for example, many “hactivists” see themselves as modern-day freedom fighters using technology to achieve their goals. In either case, the benefits of misusing the human presence in cyberspace guarantee that it will remain an issue for the foreseeable future.
Fraud is a danger for any business. You need to be prepared to spot fraudlent behavior. Spot how your metric could be attacked:
What are most important metrics for your organizations? Write them down and list the variables used to calculate the metric.
Are those metrics closed and secret? (If you want to learn more about how to set metrics, turn to Part II and Chapter 10.) How often do you change them?
If you would like to attack or skew the metric, what would you need to do?
Ask your peers and employees to “hack” you. Ask them to build a bot to deceive your metric. Only this way will you learn about the weaknesses of your measurement system.
Please report any unethical attempt of bot-like behavior to the public. We will spread the word if you tell us via Twitter, @askmeasurelearn, or simply by writing on our LinkedIn or Facebook page.
[103] “Spam” is an acronym for “supply-processed American meat,” adapted to Internet email in 1988 by two scammers.
[104] Shea Bennett, “55% Of Journalists Worldwide Use Twitter, Facebook To Source News Stories,” All Twitter, June 2012, http://bit.ly/1hRyzCX.
[105] Yazan Boshmaf et al., “The Socialbot Network: When Bots Socialize for Fame and Money,” ACSAC, Dec 2011, http://bit.ly/18ZXVfk.
[106] Alexis C. Madrigal, “Welcome to the Internet of Thingies: 61.5% of Web Traffic Is Not Human,” The Atlantic Wire, Dec 2013, http://bit.ly/1a6ljpW.
[107] Lutz Finger, Conversion Rate—Spammer, Jan 2013, http://bit.ly/1b2Z0x3.
[108] Erica Ho, “Report: 92% of Newt Gingrich’s Twitter Followers Aren’t Real,” Time, Aug 2011, http://ti.me/18JkJ0b.
[109] Jim Edwards, “Facebook Targets 76 Million Fake Users In War On Bogus Accounts,” Business Insider, March 2013, http://read.bi/18JoXVF.
[110] Yazan Boshmaf et al., “The Socialbot Network: When Bots Socialize for Fame and Money,” ACSAC, Dec 2011, http://bit.ly/18ZXVfk.
[111] Twitter, “State of Twitter Spam,” Twitter Blog, http://bit.ly/1b345pe.
[112] Amit A. Amleshwaram et al., “CATS: Characterizing Automation of Twitter Spammers,” IEEE, Jan 2013, http://bit.ly/1fr2NJI.
[113] Gerry Shih, “Twitter Takes Spammers To Court In New Suit,” Reuters via Huffington Post, April 2012, http://huff.to/IUir4c.
[114] Vikas Bajaj, “Spammers Pay Others to Answer Security Tests,” April 2010, New York Times, http://nyti.ms/JgmJnb.
[115] Michael Wetzel, “Remote-Controlled Spin,” Sep 2013, Deutsche Well TV, http://youtu.be/TwOdxnkVP7Y.
[116] Erica Ho, “Report: 92% of Newt Gingrich’s Twitter Followers Aren’t Real,” Time, Aug 2011, http://ti.me/18JkJ0b.
[117] M.S., “Nadine Morano dément l’achat d’abonnés sur Twitter,” le Parisien, Feb 2012, http://bit.ly/1b366BR.
[118] ZDF Blog, July 2012, http://bit.ly/IKcaJ0.
[119] Zach Green, “Is Mitt Romney Buying Twitter Followers?” 140 Elect, July 2012, http://bit.ly/1jY96aC.
[120] Lutz Finger, Conversion Rate - Spammer, Jan 2013, http://bit.ly/1b2Z0x3.
[121] “Robots, Trolling & 3D Printing,” Feb 2011, @AeroFade’s Blog, http://aerofade.rk.net.nz/?p=152.
[122] Michael Graham Richard, “@AI_AGW Twitter Chatbot Argues with Global-Warming Deniers Automatically,” Treehugger, Nov 2010, http://bit.ly/19HGT05.
[123] Solicitation Number: RTB220610
[124] Stephen C. Webster, “Exclusive: Military’s ‘persona’ software cost millions, used for ‘classified social media activities,” The Raw Story, February 22, 2011, http://bit.ly/IKfIec.
[125] Nick Fielding and Ian Cobain, “ Revealed: US spy operation that manipulates social media,” the Guardian, March 2011, http://bit.ly/IUmrSj.
[126] Dan Rowinski, “Stop SOPA: What A Blacked Out Internet Looks Like,” Readwrite.com, Jan. 2012, http://bit.ly/190cr6K.
[127] David Bandurski, “China’s Guerrilla War for the Web,” The Far Eastern Economic Review, Jul 2008, http://bit.ly/19HMiUX.
[128] Gilad Lotan, “ See How Invisible Networks Helped a Campaign Capture the World’s Attention,” Gilad Lotan Blog, June 2012, http://bit.ly/1j415Tj.
[129] E. Bakshy et al., “Everyone’s an Influencer: Quantifying Influence on Twitter,” ACM WSDM ’11, Feb 2011.
[130] J Ratkiewicz et al “Detecting and Tracking Political Abuse in Social Media” Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Association for the Advancement of Artificial Intelligence, 2011, http://bit.ly/1gwfiXw.
[131] J Ratkiewicz, Filippo Menczer et al. “Truthy: Mapping the Spread of Astroturf in Microblog Streams” International World Wide Web Conference Committee (IW3C2), April 2011 http://bit.ly/1bDwHc3.
[132] Jillian York, “Twitter Trolling as Propaganda Tactic: Bahrain and Syria,” Jillian York’s Blog, Oct 2012, http://bit.ly/1gwggmp.
[133] Sam Gustin, “BOOM! Goes the Dynamite Under Facebook’s Google Smear Campaign,” Dec 2011, Wired.com, http://wrd.cm/1dbNdz6.
[134] Ben Popper, “ Smear Story Source Speaks: Facebook Wanted to Stab Google in the Back,” BetaBeat, Dec 2011, http://bit.ly/Jo6nJQ.
[135] Carlos Castillo, et al. “Information Credibility on Twitter,” ACM International World Wide Web Conference Committee (IW3C2), WWW 2011, April 1, 2011, http://bit.ly/1c1JyaK.