
Azure provides both Infrastructure as a Service (IaaS) and Platform as a Service (PaaS) services. These types of services provide organizations with different levels and controls over storage, compute, and networks. Storage is the resource used when working with the storage and transmission of data. Azure provides lots of options for storing data, such as Azure Blob storage, Table storage, Cosmos DB, Azure SQL Database, Azure Data Lake, and more. While some of these options are meant for big data storage, analytics, and presentation, there are others that are meant for applications that process transactions. Azure SQL is the primary resource in Azure that works with transactional data.
This chapter will focus on various aspects of using transactional data stores, such as Azure SQL Database and other open-source databases that are typically used in Online Transaction Processing (OLTP) systems, and will cover the following topics:
- OLTP applications
- Relational databases
- Deployment models
- Azure SQL Database
- Single Instance
- Elastic pools
- Managed Instance
- Cosmos DB
We will start this chapter by looking at what OLTP applications are and listing the OLTP services of Azure and their use cases.
OLTP applications
As mentioned earlier, OLTP applications are applications that help in the processing and management of transactions. Some of the most prevalent OLTP implementations can be found in retail sales, financial transaction systems, and order entry. These applications perform data capture, data processing, data retrieval, data modification, and data storage. However, it does not stop here. OLTP applications treat these data tasks as transactions. Transactions have a few important properties and OLTP applications account for these properties. These properties are grouped under the acronym ACID. Let's discuss these properties in detail:
- Atomicity: This property states that a transaction must consist of statements and either all statements should complete successfully or no statement should be executed. If multiple statements are grouped together, these statements form a transaction. Atomicity means each transaction is treated as the lowest single unit of execution that either completes successfully or fails.
- Consistency: This property focuses on the state of data in a database. It dictates that any change in state should be complete and based on the rules and constraints of the database, and that partial updates should not be allowed.
- Isolation: This property states that there can be multiple concurrent transactions executed on a system and each transaction should be treated in isolation. One transaction should not know about or interfere with any other transaction. If the transactions were to be executed in sequence, by the end, the state of data should be the same as before.
- Durability: This property states that the data should be persisted and available, even after failure, once it is committed to the database. A committed transaction becomes a fact.
Now that you know what OLTP applications are, let's discuss the role of relational databases in OLTP applications.
Relational databases
OLTP applications have generally relied on relational databases for their transaction management and processing. Relational databases typically come in a tabular format consisting of rows and columns. The data model is converted into multiple tables where each table is connected to another table (based on rules) using relationships. This process is also known as normalization.
There are multiple services in Azure that support OLTP applications and the deployment of relational databases. In the next section, we will take a look at the services in Azure that are related to OLTP applications.
Azure cloud services
A search for sql in the Azure portal provides multiple results. I have marked some of them to show the resources that can be used directly for OLTP applications:
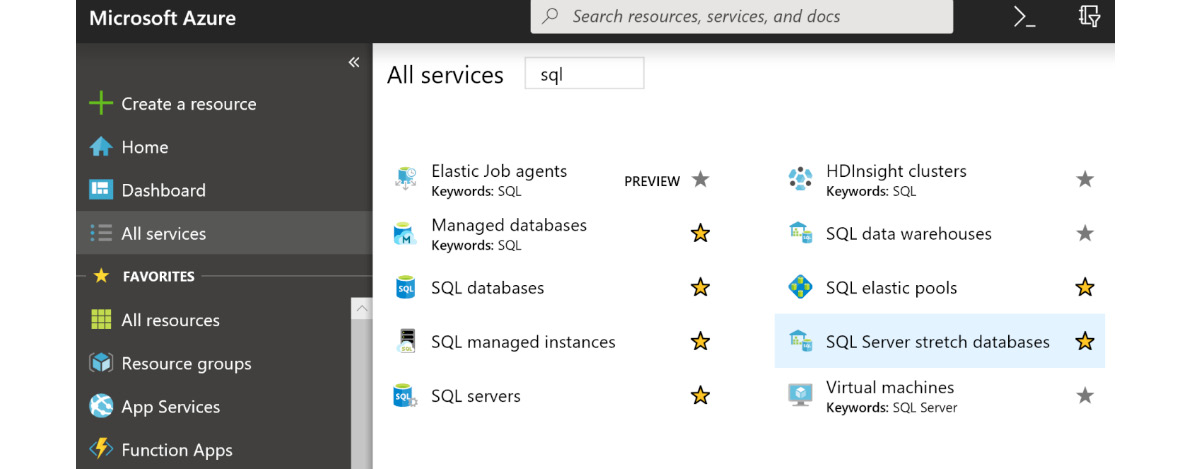
Figure 7.1: List of Azure SQL services
Figure 7.1 shows the varied features and options available for creating SQL Server–based databases on Azure.
Again, a quick search for database in the Azure portal provides multiple resources, and the marked ones in Figure 7.2 can be used for OLTP applications:
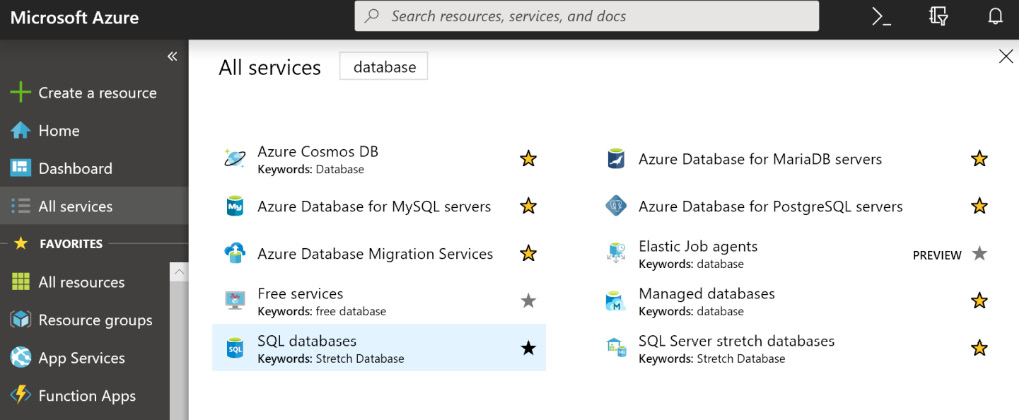
Figure 7.2: List of Azure services used for OLTP applications
Figure 7.2 shows resources provided by Azure that can host data in a variety of databases, including the following:
- MySQL databases
- MariaDB databases
- PostgreSQL databases
- Cosmos DB
Next, let's discuss deployment models.
Deployment models
Deployment models in Azure are classified based on the level of management or control. It's up to the user to select which level of management or control they prefer; either they can go for complete control by using services such as Virtual Machines, or they can use managed services where things will be managed by Azure for them.
There are two deployment models for deploying databases on Azure:
- Databases on Azure Virtual Machines (IaaS)
- Databases hosted as managed services (PaaS)
We will now try to understand the difference between deployment on Azure Virtual Machines and managed instances. Let's start with Virtual Machines.
Databases on Azure Virtual Machines
Azure provides multiple stock keeping units (SKUs) for virtual machines. There are high-compute, high-throughput (IOPS) machines that are also available along with general-use virtual machines. Instead of hosting a SQL Server, MySQL, or any other database on on-premises servers, it is possible to deploy these databases on these virtual machines. The deployment and configuration of these databases are no different than that of on-premises deployments. The only difference is that the database is hosted on the cloud instead of using on-premises servers. Administrators must perform the same activities and steps that they normally would for an on-premises deployment. Although this option is great when customers want full control over their deployment, there are models that can be more cost-effective, scalable, and highly available compared to this option, which will be discussed later in this chapter.
The steps to deploy any database on Azure Virtual Machines are as follows:
- Create a virtual machine with a size that caters to the performance requirements of the application.
- Deploy the database on top of it.
- Configure the virtual machine and database configuration.
This option does not provide any out-of-the-box high availability unless multiple servers are provisioned. It also does not provide any features for automatic scaling unless custom automation supports it.
Disaster recovery is also the responsibility of the customer. Servers should be deployed on multiple regions connected using services like global peering, VPN gateways, ExpressRoute, or Virtual WAN. It is possible for these virtual machines to be connected to an on-premises datacenter through site-to-site VPNs or ExpressRoute without having any exposure to the outside world.
These databases are also known as unmanaged databases. On the other hand, databases hosted with Azure, other than virtual machines, are managed by Azure and are known as managed services. In the next section, we will cover these in detail.
Databases hosted as managed services
Managed services mean that Azure provides management services for the databases. These managed services include the hosting of the database, ensuring that the host is highly available, ensuring that the data is replicated internally for availability during disaster recovery, ensuring scalability within the constraint of a chosen SKU, monitoring the hosts and databases and generating alerts for notifications or executing actions, providing log and auditing services for troubleshooting, and taking care of performance management and security alerts.
In short, there are a lot of services that customers get out of the box when using managed services from Azure, and they do not need to perform active management on these databases. In this chapter, we will look at Azure SQL Database in depth and provide information on other databases, such as MySQL and Postgres. Also, we will cover non-relational databases such as Cosmos DB, which is a NoSQL database.
Azure SQL Database
Azure SQL Server provides a relational database hosted as a PaaS. Customers can provision this service, bring their own database schema and data, and connect their applications to it. It provides all the features of SQL Server when deployed on a virtual machine. These services do not provide a user interface to create tables and its schema, nor do they provide any querying capabilities directly. SQL Server Management Studio and the SQL CLI tools should be used to connect to these services and directly work with them.
Azure SQL Database comes with three distinct deployment models:
- Single Instance: In this deployment model, a single database is deployed on a logical server. This involves the creation of two resources on Azure: a SQL logical server and a SQL database.
- Elastic pool: In this deployment mode, multiple databases are deployed on a logical server. Again, this involves the creation of two resources on Azure: a SQL logical server and a SQL elastic database pool—this holds all the databases.
- Managed Instance: This is a relatively new deployment model from the Azure SQL team. This deployment reflects a collection of databases on a logical server, providing complete control over the resources in terms of system databases. Generally, system databases are not visible in other deployment models, but they are available in the model. This model comes very close to the deployment of SQL Server on-premises:
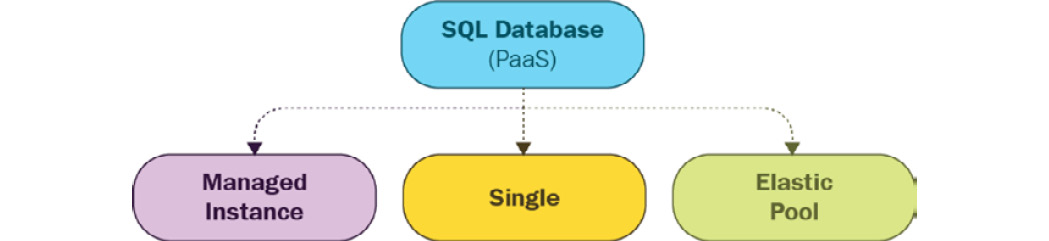
Figure 7.3: Azure SQL Database deployment models
If you are wondering when to use what, you should look at a feature comparison between SQL Database and SQL Managed Instance. A complete feature comparison is available at https://docs.microsoft.com/azure/azure-sql/database/features-comparison.
Next, we will cover some of the features of SQL Database. Let's start with application features.
Application features
Azure SQL Database provides multiple application-specific features that cater to the different requirements of OLTP systems:
- Columnar store: This feature allows the storage of data in a columnar format rather than in a row format.
- In-memory OLTP: Generally, data is stored in back-end files in SQL, and data is pulled from them whenever it is needed by the application. In contrast to this, in-memory OLTP puts all data in memory and there is no latency in reading the storage for data. Storing in-memory OLTP data on SSD provides the best possible performance for Azure SQL.
- All features of on-premises SQL Server.
The next feature we are going to discuss is high availability.
High availability
Azure SQL, by default, is 99.99% highly available. It has two different architectures for maintaining high availability based on SKUs. For the Basic, Standard, and General SKUs, the entire architecture is broken down into the following two layers.
- Compute layer
- Storage layer
There is redundancy built in for both of these layers to provide high availability:
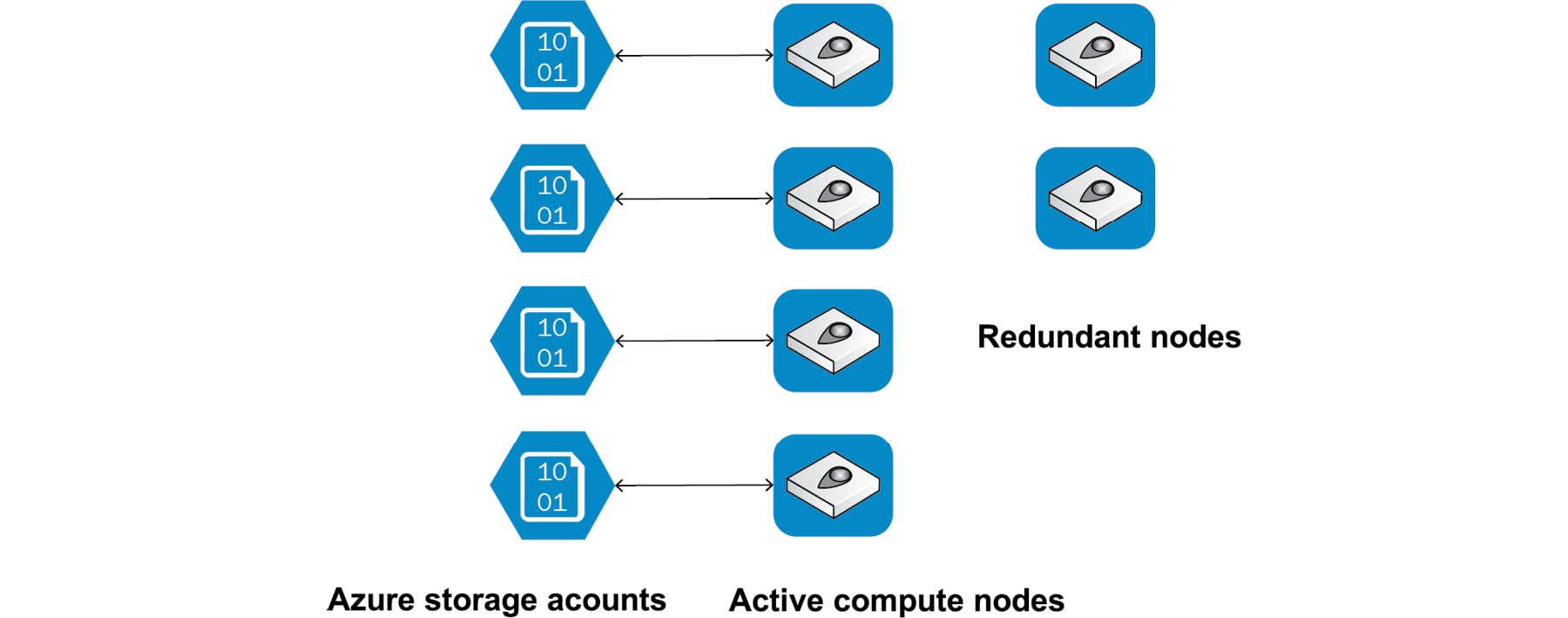
Figure 7.4: Compute and storage layers in standard SKUs
For the Premium and business-critical SKUs, both compute and storage are on the same layer. High availability is achieved by the replication of compute and storage deployed in a four-node cluster, using technology similar to SQL Server Always On availability groups:
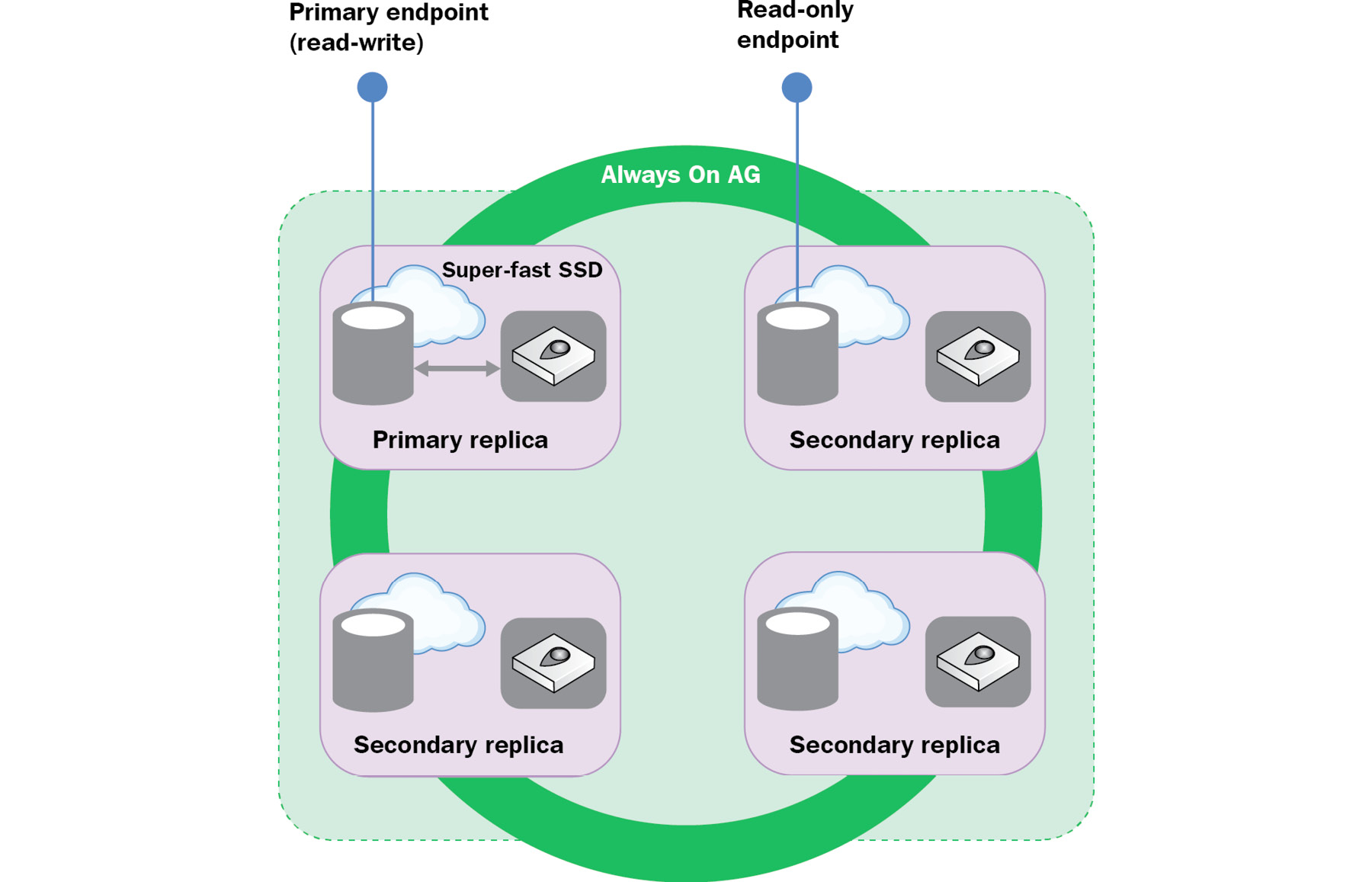
Figure 7.5: Four-node cluster deployment
Now that you know how high availability is handled, let's jump to the next feature: backups.
Backups
Azure SQL Database also provides features to automatically back up databases and store them on storage accounts. This feature is important especially in cases where a database becomes corrupt or a user accidentally deletes a table. This feature is available at the server level, as shown in Figure 7.6:
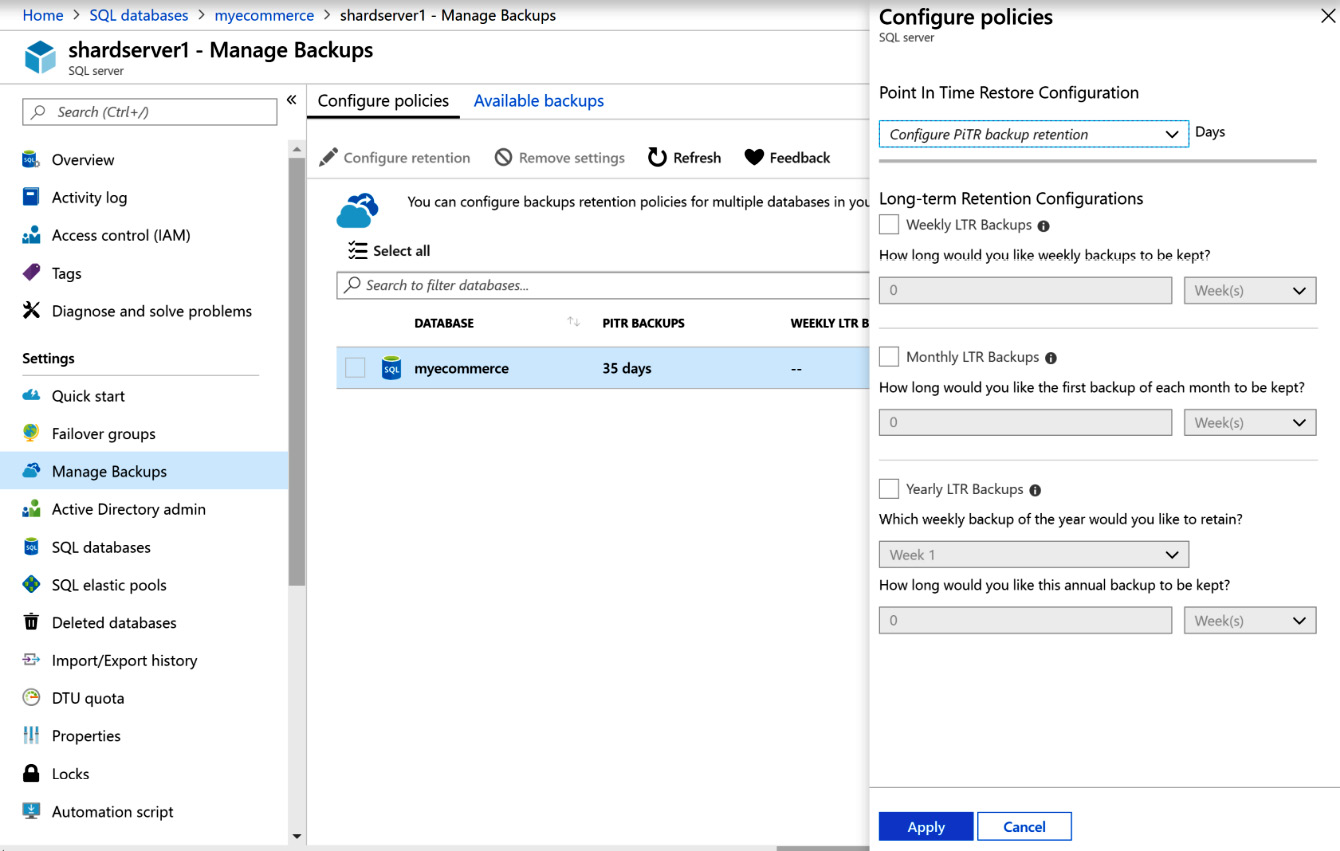
Figure 7.6: Backing up databases in Azure
Architects should prepare a backup strategy so that backups can be used in times of need. While configuring backups, ensure that your backups occur neither too infrequently nor too frequently. Based on the business needs, a weekly backup or even a daily backup should be configured, or even more frequently than that, if required. These backups can be used for restoration purposes.
Backups will help in business continuity and data recovery. You can also go for geo-replication to recover the data during a region failure. In the next section, we will cover geo-replication.
Geo-replication
Azure SQL Database also provides the benefit of being able to replicate a database to a different region, also known as a secondary region; this is completely based on the plan that you are choosing. The database at the secondary region can be read by applications. Azure SQL Database allows readable secondary databases. This is a great business continuity solution as a readable database is available at any point in time. With geo-replication, it is possible to have up to four secondaries of a database in different regions or the same region. With geo-replication, it is also possible to fail over to a secondary database in the event of a disaster. Geo-replication is configured at the database level, as shown in Figure 7.7:
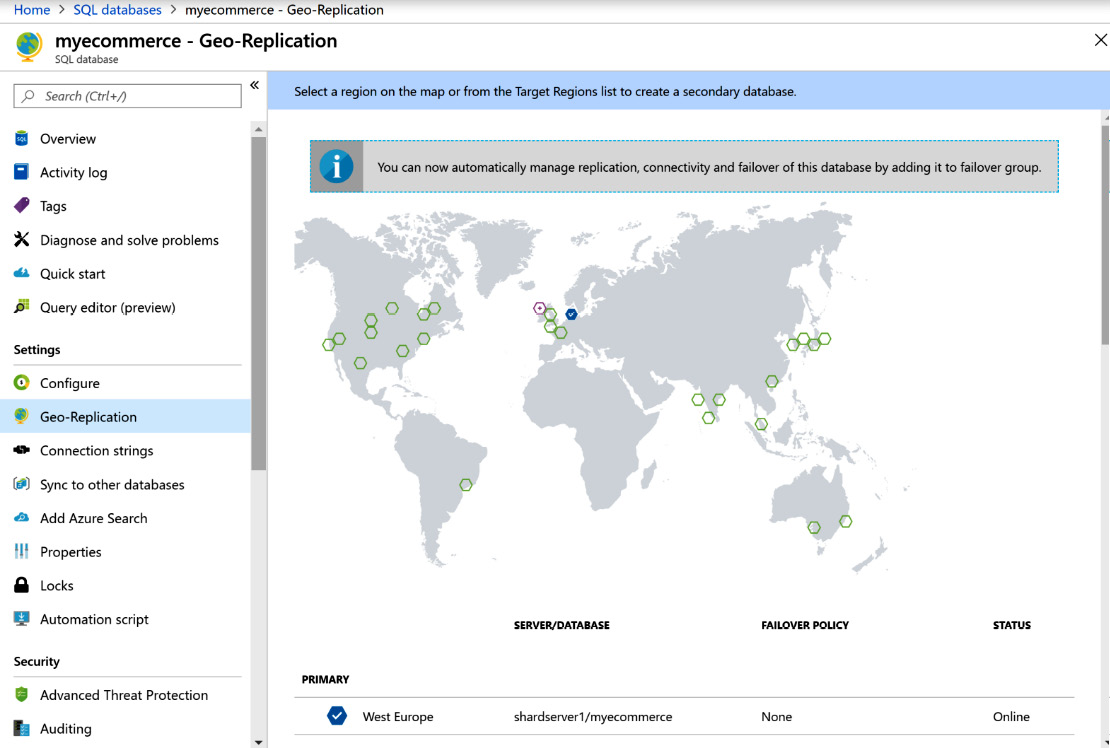
Figure 7.7: Geo-replication in Azure
If you scroll down on this screen, the regions that can act as secondaries are listed, as shown in Figure 7.8:
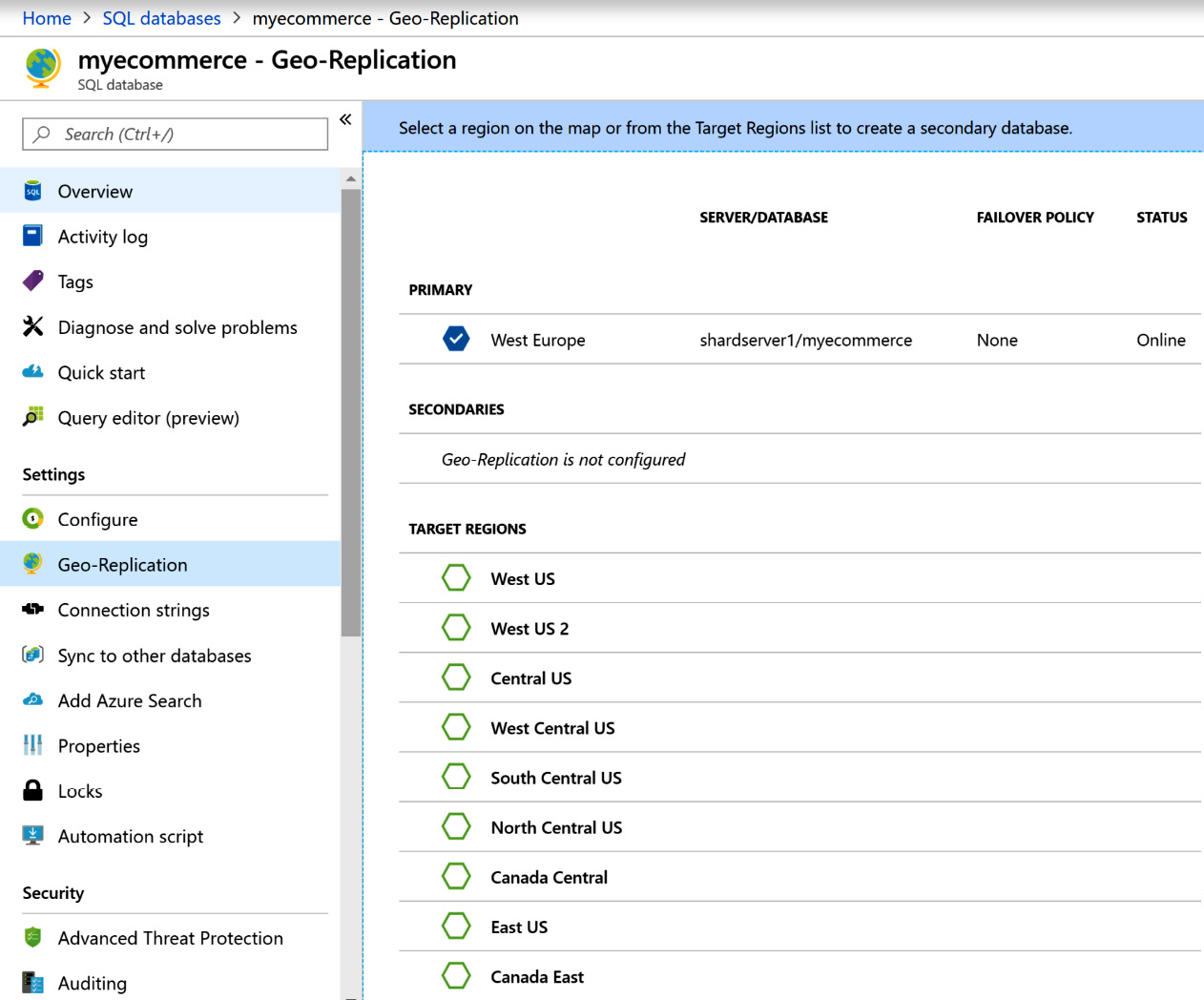
Figure 7.8: List of available secondaries for geo-replication
Before architecting solutions that involve geo-replication, we need to validate the data residency and compliance regulations. If customer data is not allowed to be stored outside a region due to compliance reasons, we shouldn't be replicating it to other regions.
In the next section, we will explore scalability options.
Scalability
Azure SQL Database provides vertical scalability by adding more resources (such as compute, memory, and IOPS). This can be done by increasing the number of Database Throughput Units (DTUs) or compute and storage resources in the case of the vCore model:
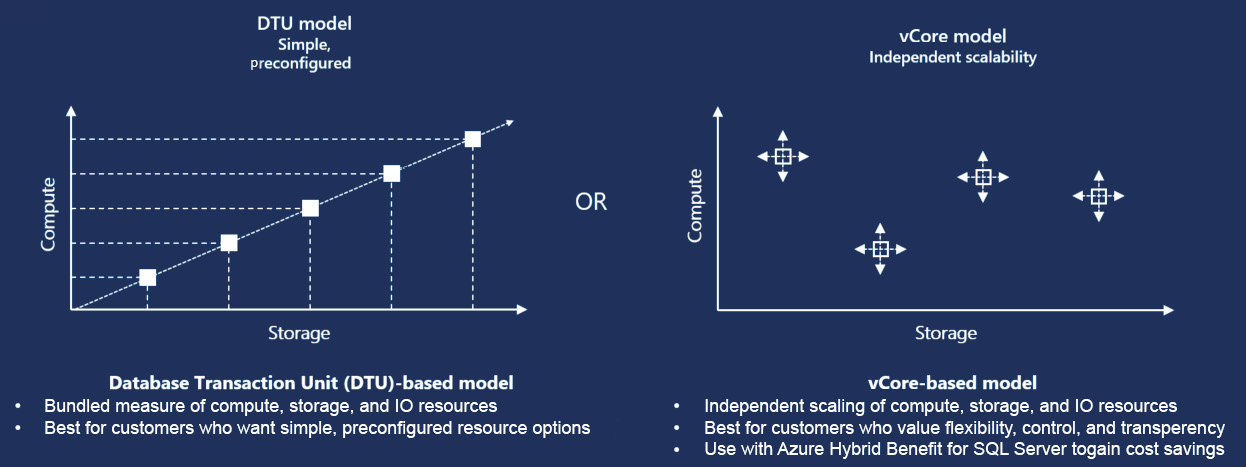
Figure 7.9: Scalability in Azure SQL Database
We have covered the differences between DTU-based model and the vCore-based model later in this chapter.
In the next section, we will cover security, which will help you understand how to build secure data solutions in Azure.
Security
Security is an important factor for any database solution and service. Azure SQL provides enterprise-grade security for Azure SQL, and this section will list some of the important security features in Azure SQL.
Firewall
Azure SQL Database, by default, does not provide access to any requests. Source IP addresses should be explicitly accepted for access to SQL Server. There is an option to allow all Azure-based services access to a SQL database as well. This option includes virtual machines hosted on Azure.
The firewall can be configured at the server level instead of the database level. The Allow access to Azure services option allows all services, including virtual machines, to access a database hosted on a logical server.
By default, this will be turned off due to security reasons; enabling this would allow access from all Azure services:
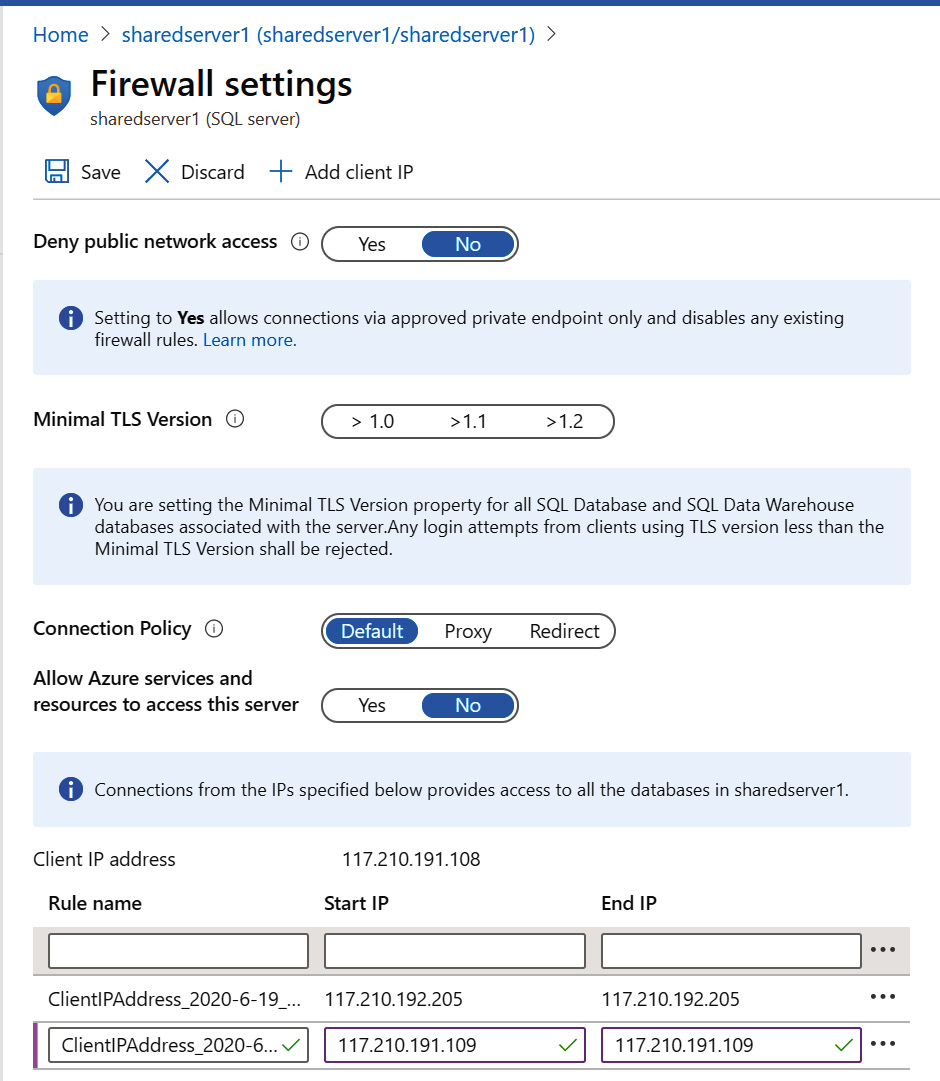
Figure 7.10: Configuring a firewall at the server level in Azure
Azure SQL Server on dedicated networks
Although access to SQL Server is generally available through the internet, it is possible for access to SQL Server to be limited to requests coming from virtual networks. This is a relatively new feature in Azure. This helps in accessing data within SQL Server from an application on another server of the virtual network without the request going through the internet.
For this, a service endpoint of the Microsoft.Sql type should be added within the virtual network, and the virtual network should be in the same region as that of Azure SQL Database:
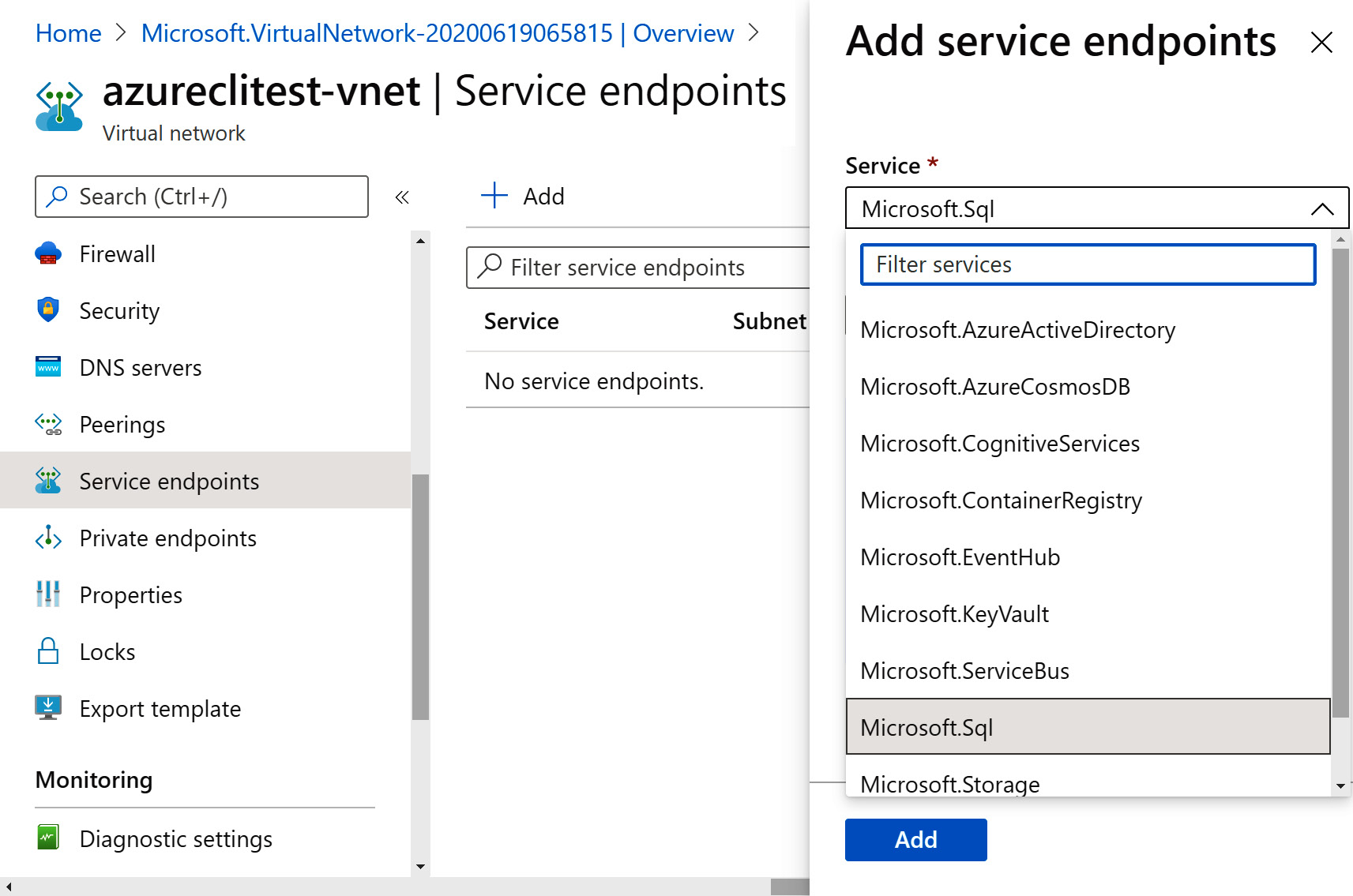
Figure 7.11: Adding a Microsoft.Sql service endpoint
An appropriate subnet within the virtual network should be chosen:
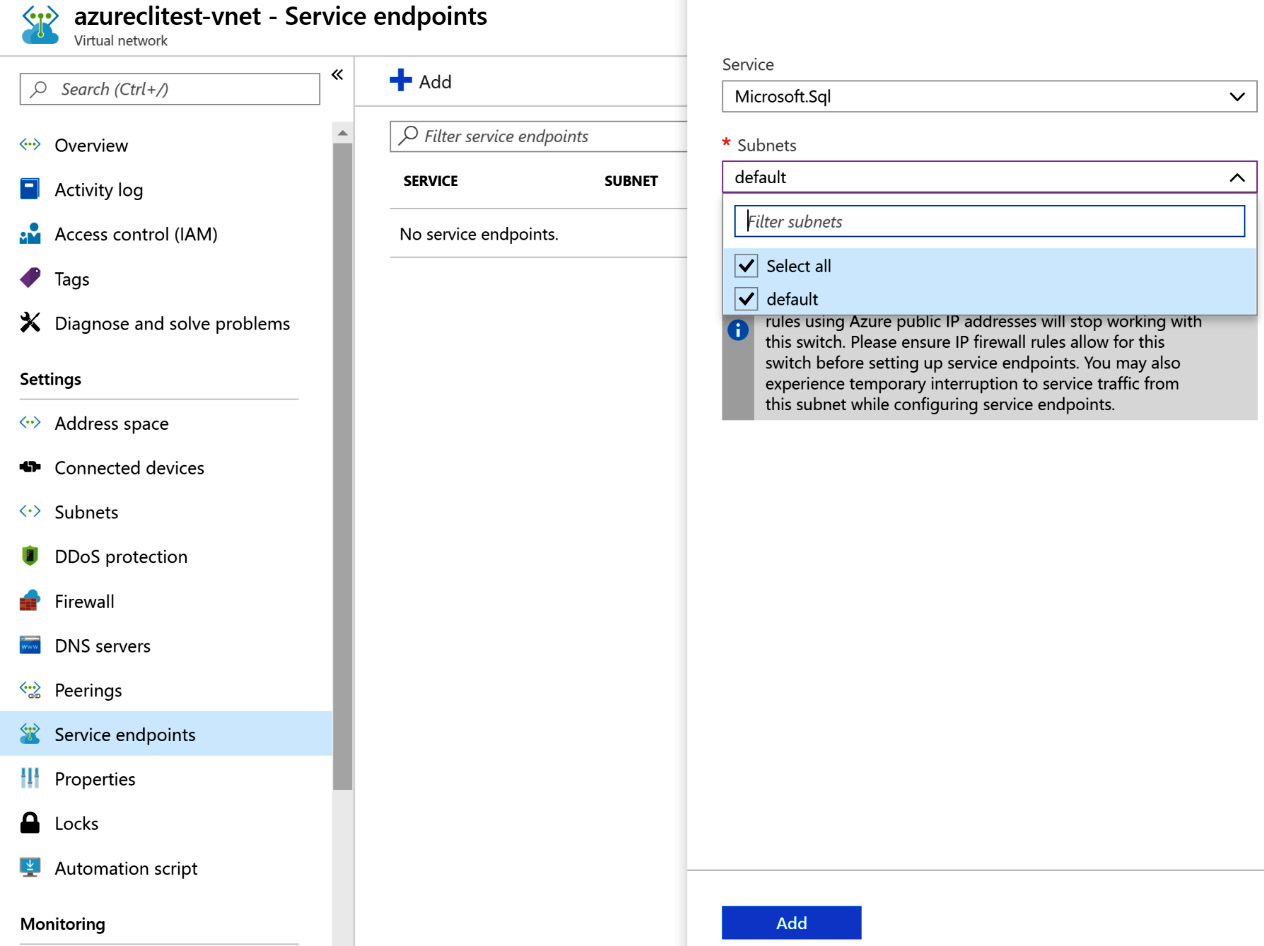
Figure 7.12: Choosing a subnet for the Microsoft.Sql service
Finally, from the Azure SQL Server configuration blade, an existing virtual network should be added that has a Microsoft.Sql service endpoint enabled:
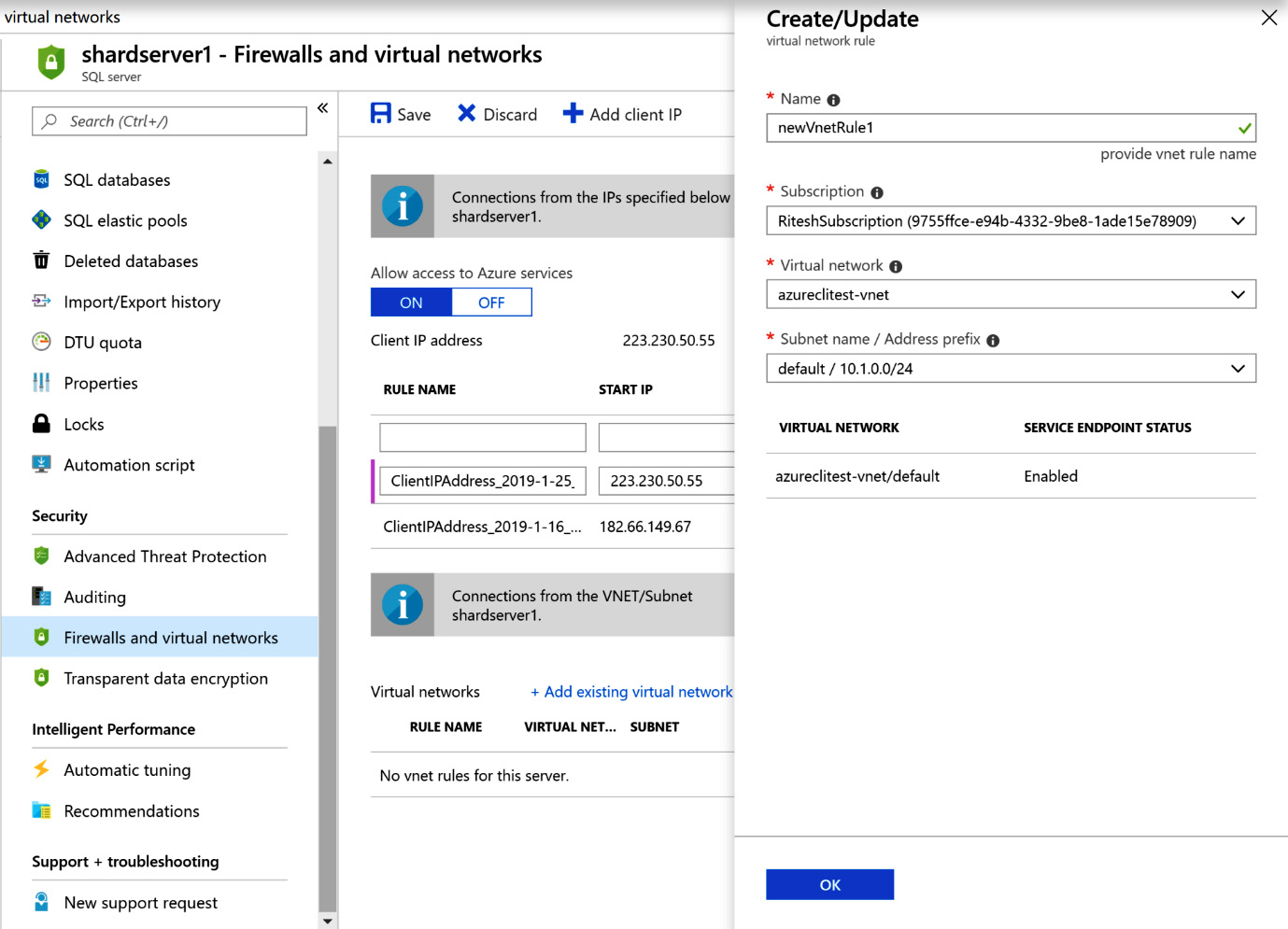
Figure 7.13: Adding a virtual network with the Microsoft.Sql service endpoint
Encrypted databases at rest
The databases should be in an encrypted form when at rest. At rest here means that the data is at the storage location of the database. Although you might not have access to SQL Server and its database, it is preferable to encrypt the database storage.
Databases on a filesystem can be encrypted using keys. These keys must be stored in Azure Key Vault and the vault must be available in the same region as that of Azure SQL Server. The filesystem can be encrypted by using the Transparent data encryption menu item of the SQL Server configuration blade and by selecting Yes for Use your own key.
The key is an RSA 2048 key and must exist within the vault. SQL Server will decrypt the data at the page level when it wants to read it and send it to the caller; then, it will encrypt it after writing to the database. No changes to the applications are required, and it is completely transparent to them:
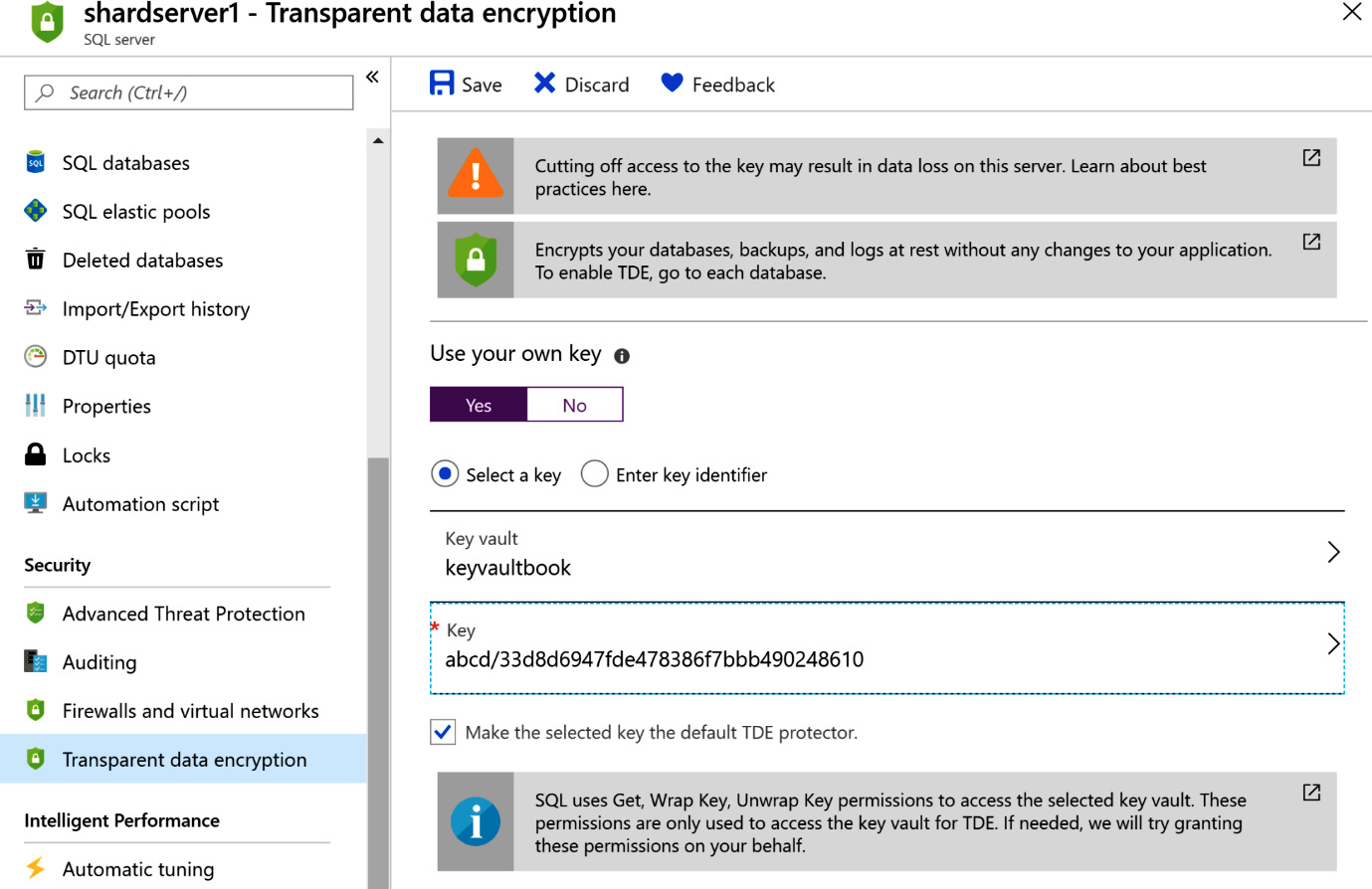
Figure 7.14: Transparent data encryption in SQL Server
Dynamic data masking
SQL Server also provides a feature that masks individual columns that contain sensitive data, so that no one apart from privileged users can view actual data by querying it in SQL Server Management Studio. Data will remain masked and will only be unmasked when an authorized application or user queries the table. Architects should ensure that sensitive data, such as credit card details, social security numbers, phone numbers, email addresses, and other financial details, is masked.
Masking rules may be defined on a column in a table. There are four main types of masks—you can check them out here: https://docs.microsoft.com/sql/relational-databases/security/dynamic-data-masking?view=sql-server-ver15#defining-a-dynamic-data-mask.
Figure 7.15 shows how data masking is added:
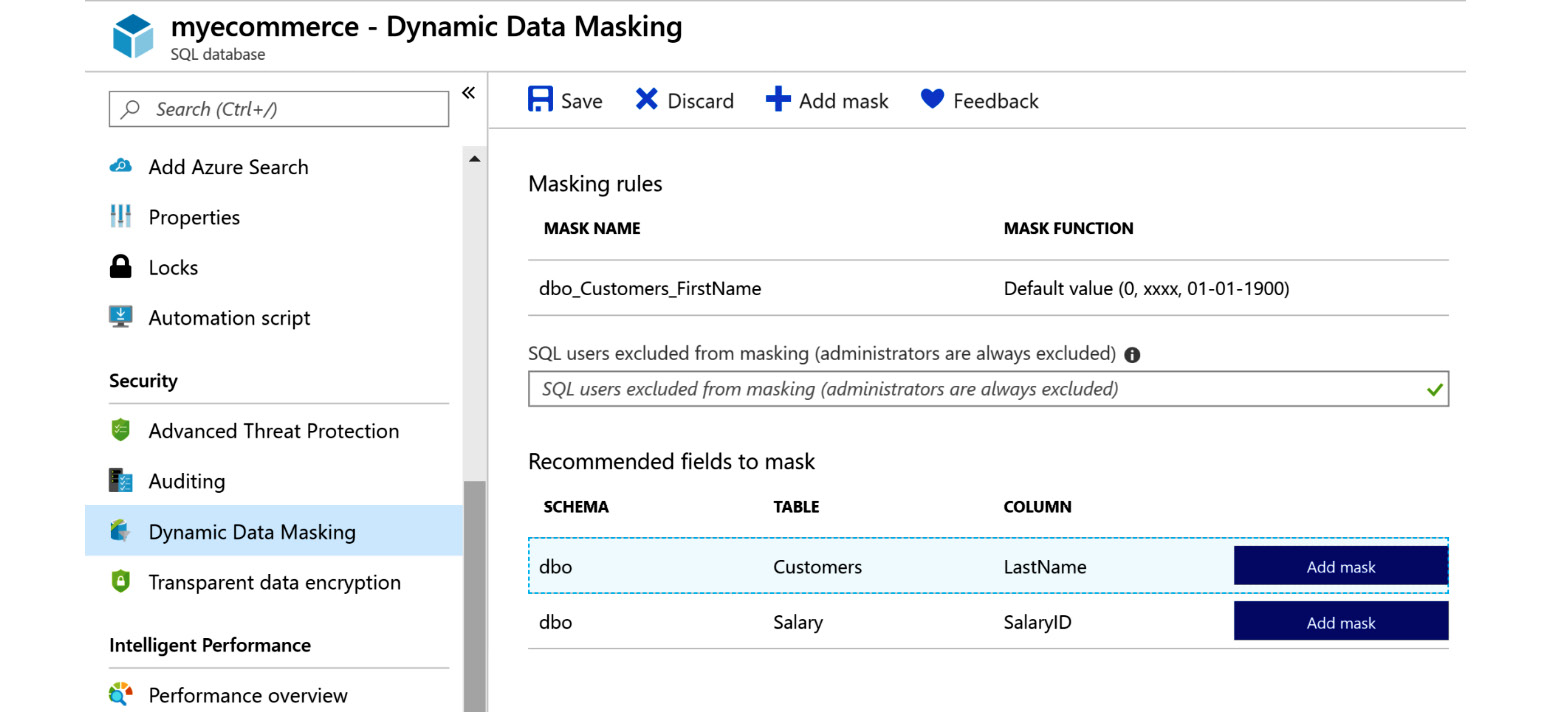
Figure 7.15: Dynamic data masking in SQL Database
Azure Active Directory integration
Another important security feature of Azure SQL is that it can be integrated with Azure Active Directory (AD) for authentication purposes. Without integrating with Azure AD, the only authentication mechanism available to SQL Server is via username and password authentication—that is, SQL authentication. It is not possible to use integrated Windows authentication. The connection string for SQL authentication consists of both the username and password in plaintext, which is not secure. Integrating with Azure AD enables the authentication of applications with Windows authentication, a service principal name, or token-based authentication. It is a good practice to use Azure SQL Database integrated with Azure AD.
There are other security features, such as advanced threat protection, auditing of the environment, and monitoring, that should be enabled on any enterprise-level Azure SQL Database deployments.
With that, we've concluded our look at the features of Azure SQL Database and can now move on to the types of SQL databases.
Single Instance
Single Instance databases are hosted as a single database on a single logical server. These databases do not have access to the complete features provided by SQL Server. Each database is isolated and portable. Single instances support the vCPU-based and DTU-based purchasing models that we discussed earlier.
Another added advantage of a single database is cost-efficiency. If you are in a vCore-based model, you can opt for lower compute and storage resources to optimize costs. If you need more compute or storage power, you can always scale up. Dynamic scalability is a prominent feature of single instances that helps to scale resources dynamically based on business requirements. Single instances allow existing SQL Server customers to lift and shift their on-premises applications to the cloud.
Other features include availability, monitoring, and security.
When we started our section on Azure SQL Database, we mentioned elastic pools as well. You can also transition a single database to an elastic pool for resource sharing. If you are wondering what resource sharing and what elastic pools are, in the next section, we will cover this.
Elastic pools
An elastic pool is a logical container that can host multiple databases on a single logical server. Elastic pools are available in the vCore-based and DTU-based purchasing models. The vCPU-based purchasing model is the default and recommended method of deployment, where you'll get the freedom to choose your compute and storage resources based on your business workloads. As shown in Figure 7.16, you can select how many cores and how much storage is required for your database:
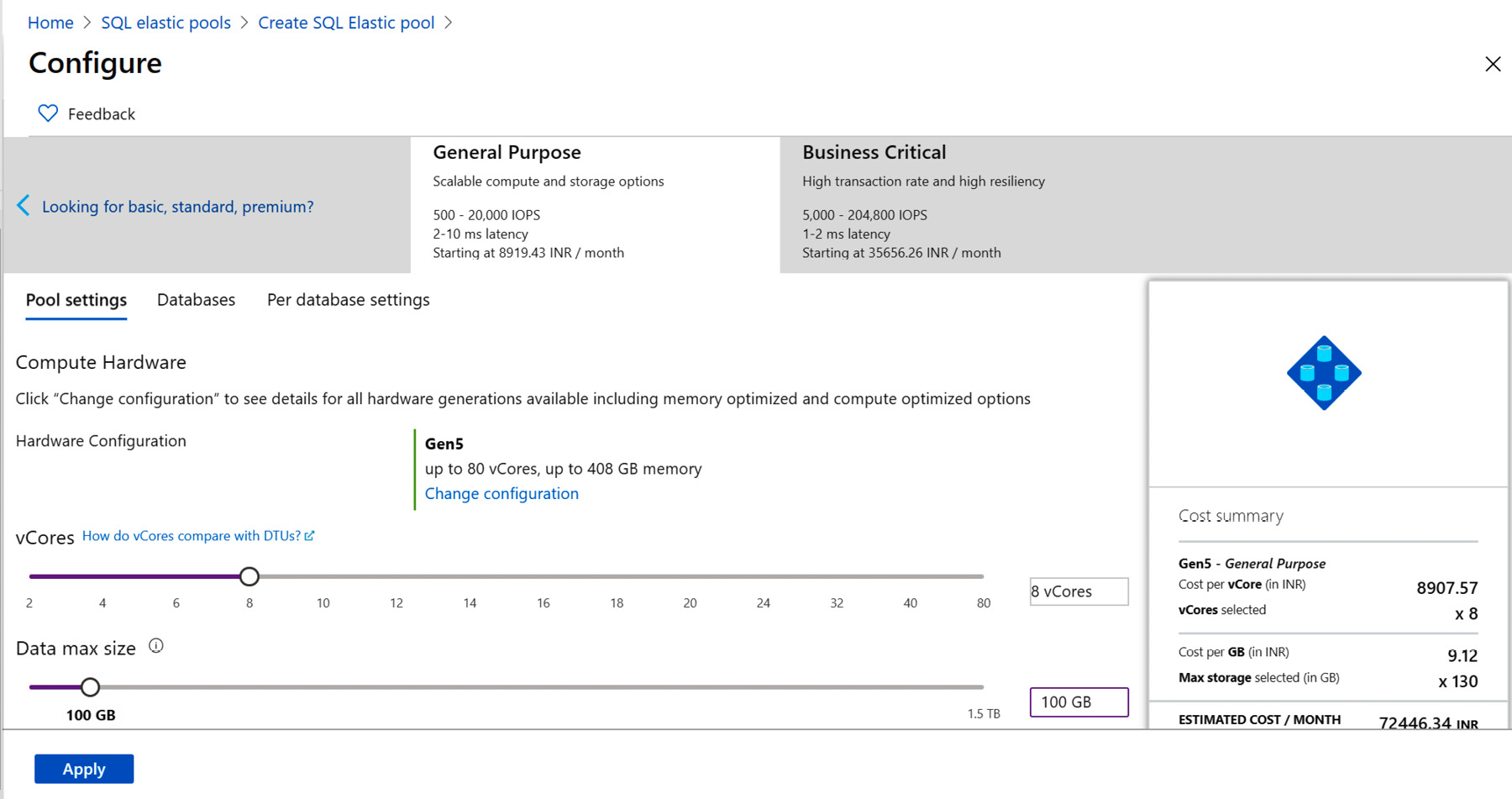
Figure 7.16: Setting up elastic pools in the vCore-based model
Also, at the top of the preceding figure, you can see there is an option that says Looking for basic, standard, premium? If you select this, the model will be switched to the DTU model.
The SKUs available for elastic pools in the DTU-based model are as follows:
- Basic
- Standard
- Premium
Figure 7.17 shows the maximum amounts of DTUs that can be provisioned for each SKU:
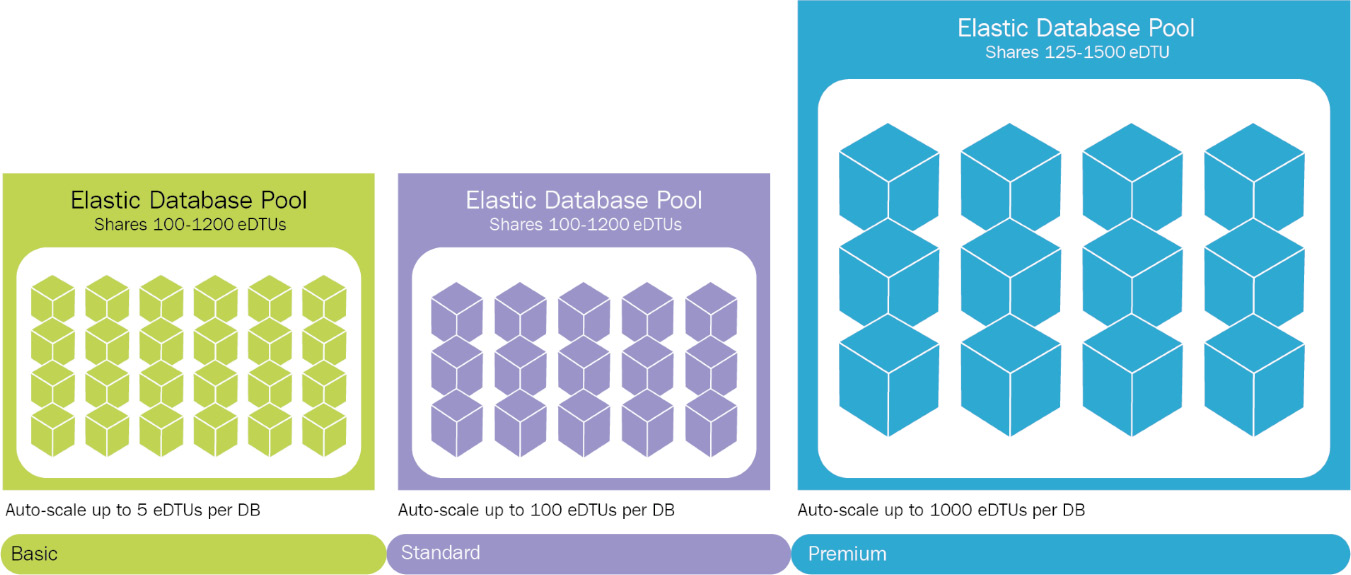
Figure 7.17: Amount of DTUs per SKU in an elastic pool
All the features discussed for Azure SQL single instances are available to elastic pools as well; however, horizontal scalability is an additional feature that enables sharding. Sharding refers to the vertical or horizontal partitioning of data and the storage of that data in separate databases. It is also possible to have autoscaling of individual databases in an elastic pool by consuming more DTUs than are actually allocated to that database.
Elastic pools also provide another advantage in terms of cost. You will see in a later section that Azure SQL Database is priced using DTUs, and DTUs are provisioned as soon as the SQL Server service is provisioned. DTUs are charged for irrespective of whether those DTUs are consumed. If there are multiple databases, then it is possible to put these databases into elastic pools and for them to share the DTUs among them.
All information for implementing sharding with Azure SQL elastic pools has been provided at https://docs.microsoft.com/azure/sql-database/sql-database-elastic-scale-introduction.
Next, we will discuss the Managed Instance deployment option, which is a scalable, intelligent, cloud-based, fully managed database.
Managed Instance
Managed Instance is a unique service that provides a managed SQL server similar to what's available on on-premises servers. Users have access to master, model, and other system databases. Managed Instance is ideal when there are multiple databases and customers migrating their instances to Azure. Managed Instance consists of multiple databases.
Azure SQL Database provides a new deployment model known as Azure SQL Database Managed Instance that provides almost 100% compatibility with the SQL Server Enterprise Edition Database Engine. This model provides a native virtual network implementation that addresses the usual security issues and is a highly recommended business model for on-premises SQL Server customers. Managed Instance allows existing SQL Server customers to lift and shift their on-premises applications to the cloud with minimal application and database changes while preserving all PaaS capabilities at the same time. These PaaS capabilities drastically reduce the management overhead and total cost of ownership, as shown in Figure 7.18:
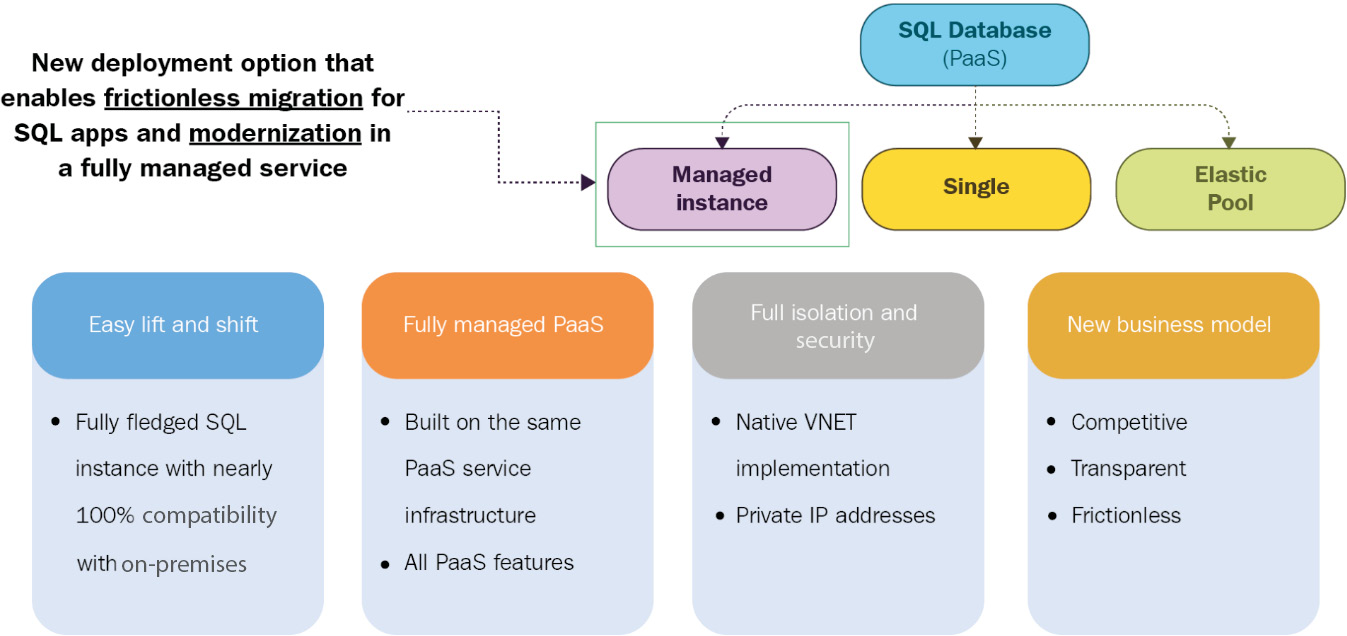
Figure 7.18: Azure SQL Database Managed Instance
The complete comparison between Azure SQL Database, Azure SQL Managed Instance, and SQL Server on an Azure virtual machine is available here: https://docs.microsoft.com/azure/azure-sql/azure-sql-iaas-vs-paas-what-is-overview#comparison-table.
The key features of Managed Instance are shown in the Figure 7.19:
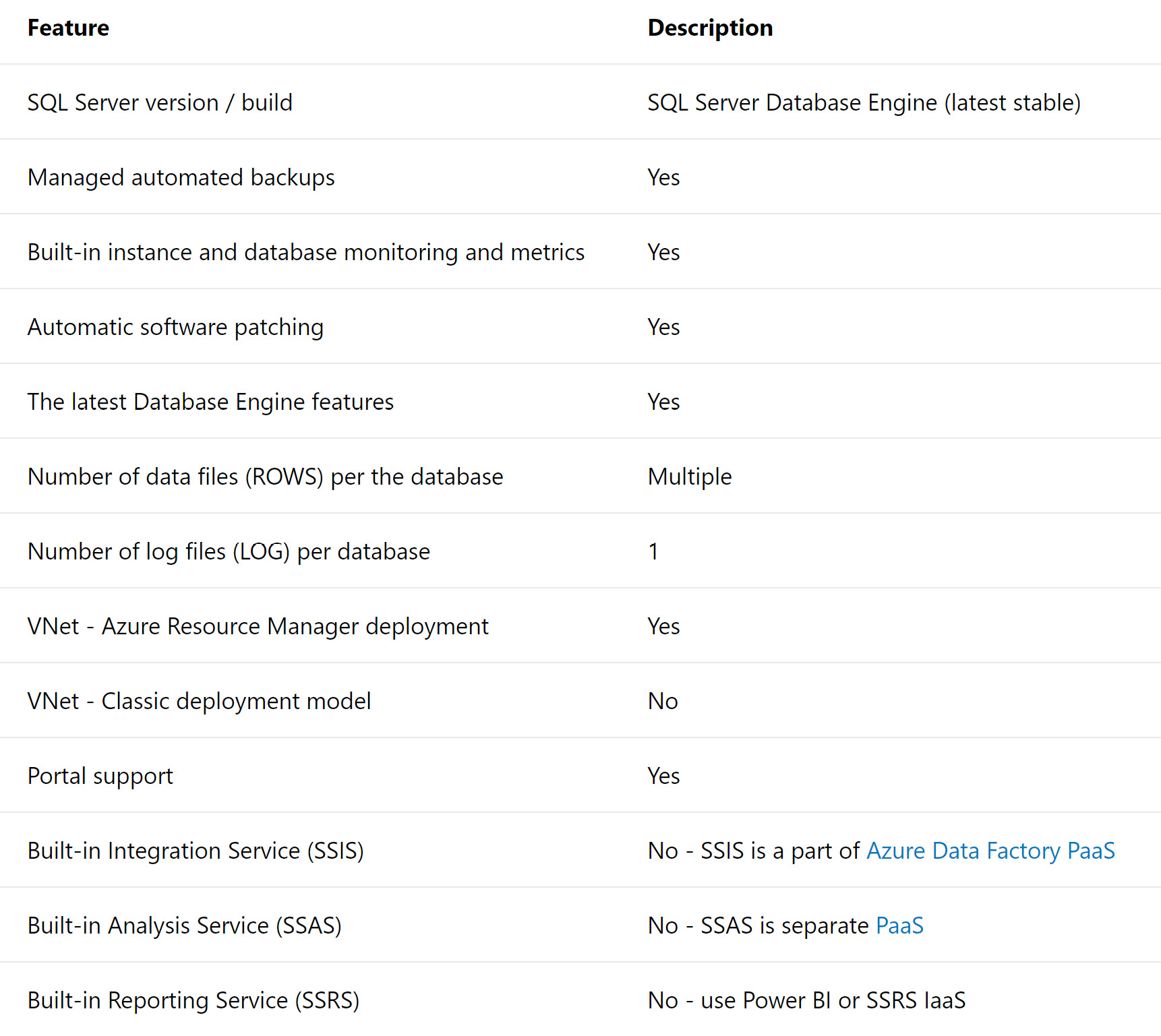
Figure 7.19: SQL Database Managed Instance features
We have mentioned the terms vCPU-based pricing model and DTU-based pricing model at several points throughout the chapter. It's time that we took a closer look at these pricing models.
SQL database pricing
Azure SQL previously had just one pricing model—a model based on DTUs—but an alternative pricing model based on vCPUs has also been launched. The pricing model is selected based on the customer's requirements. The DTU-based model is selected when the customer wants simple and preconfigured resource options. On the other hand, the vCore-based model offers the flexibility to choose compute and storage resources. It also provides control and transparency.
Let's take a closer look at each of these models.
DTU-based pricing
The DTU is the smallest unit of performance measure for Azure SQL Database. Each DTU corresponds to a certain amount of resources. These resources include storage, CPU cycles, IOPS, and network bandwidth. For example, a single DTU might provide three IOPS, a few CPU cycles, and IO latencies of 5 ms for read operations and 10 ms for write operations.
Azure SQL Database provides multiple SKUs for creating databases, and each of these SKUs has defined constraints for the maximum amount of DTUs. For example, the Basic SKU provides just 5 DTUs with a maximum 2 GB of data, as shown in Figure 7.20:
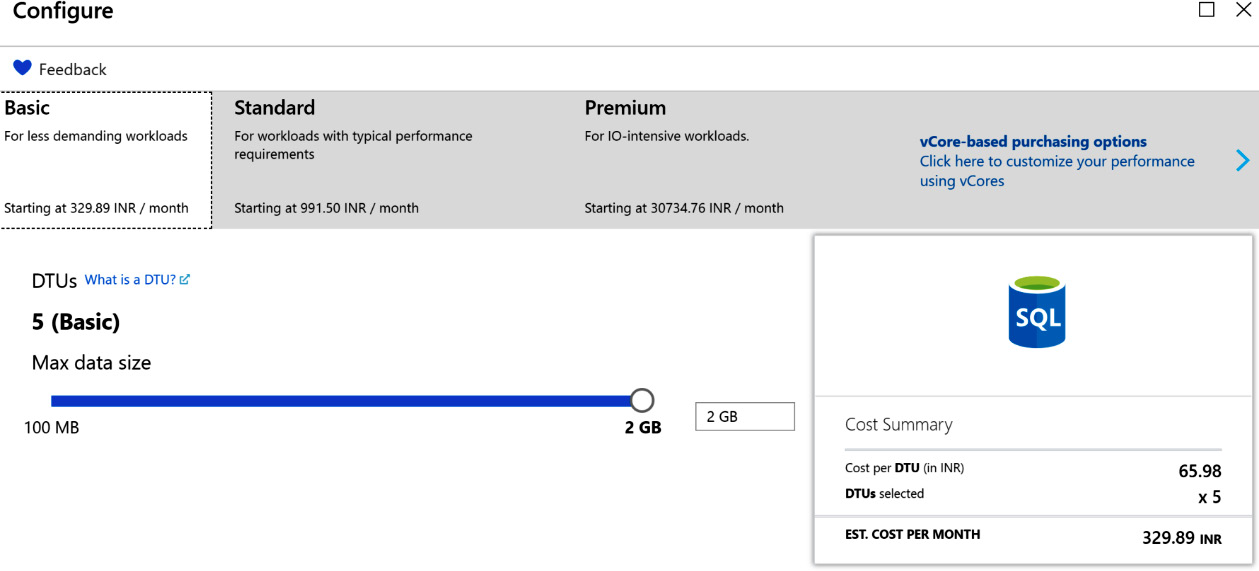
Figure 7.20: DTUs for different SKUs
On the other hand, the standard SKU provides anything between 10 DTUs and 300 DTUs with a maximum of 250 GB of data. As you can see here, each DTU costs around 991 rupees, or around $1.40:
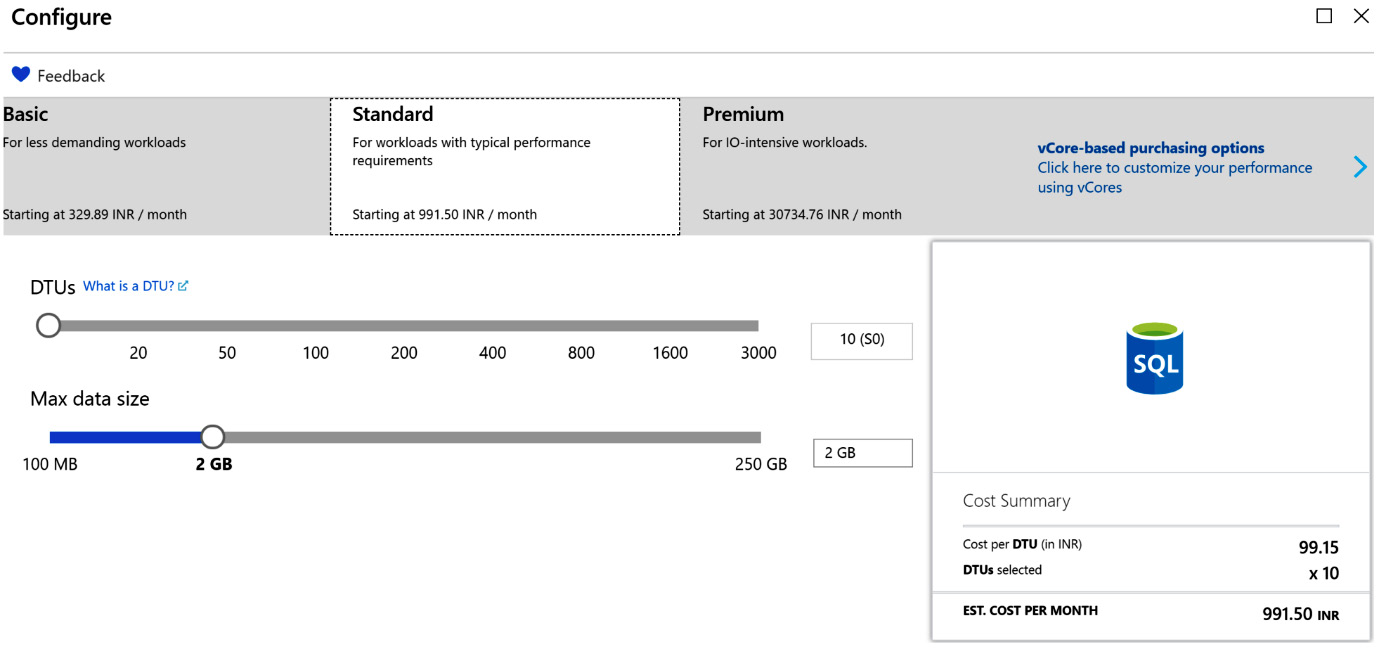
Figure 7.21: Cost summary for the selected number of DTUs in the Standard SKU
A comparison of these SKUs in terms of performance and resources is provided by Microsoft and is shown in the Figure 7.22:
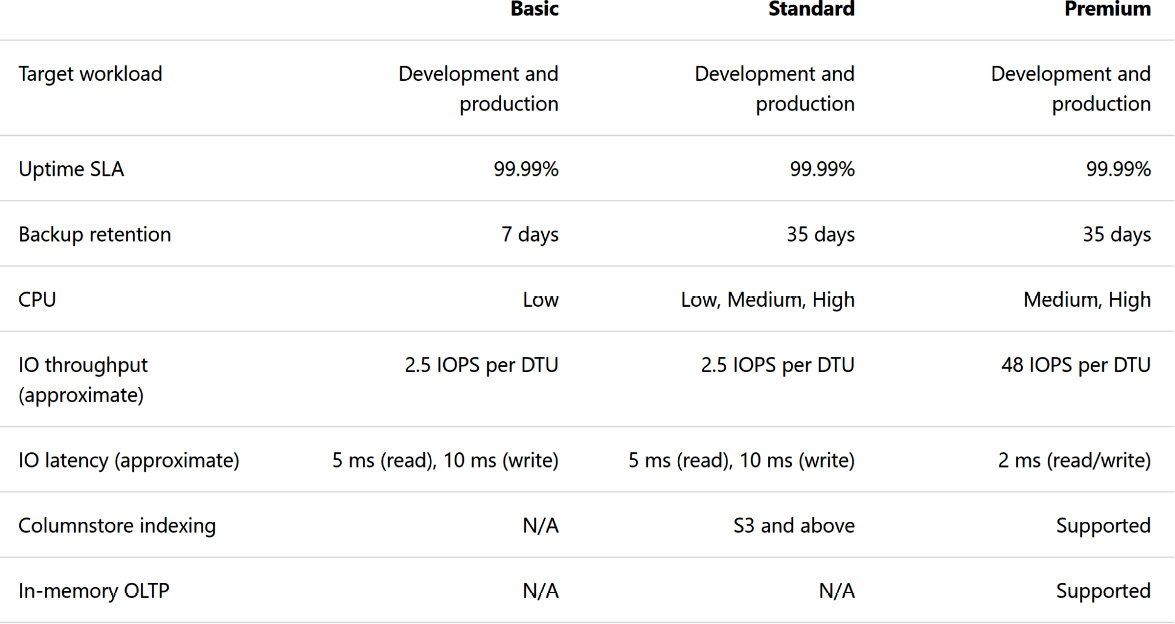
Figure 7.22: SKU comparison in Azure
Once you provision a certain number of DTUs, the back-end resources (CPU, IOPS, and memory) are allocated and are charged for whether they are consumed or not. If more DTUs are procured than are actually needed, it leads to waste, while there would be performance bottlenecks if insufficient DTUs were provisioned.
Azure provides elastic pools for this reason as well. As you know, there are multiple databases in an elastic pool and DTUs are assigned to elastic pools instead of individual databases. It is possible for all databases within a pool to share the DTUs. This means that if a database has low utilization and is consuming only five DTUs, there will be another database consuming 25 DTUs in order to compensate.
It is important to note that, collectively, DTU consumption cannot exceed the amount of DTUs provisioned for the elastic pool. Moreover, there is a minimum amount of DTUs that should be assigned to each database within the elastic pool, and this minimum DTU count is preallocated for the database.
An elastic pool comes with its own SKUs:
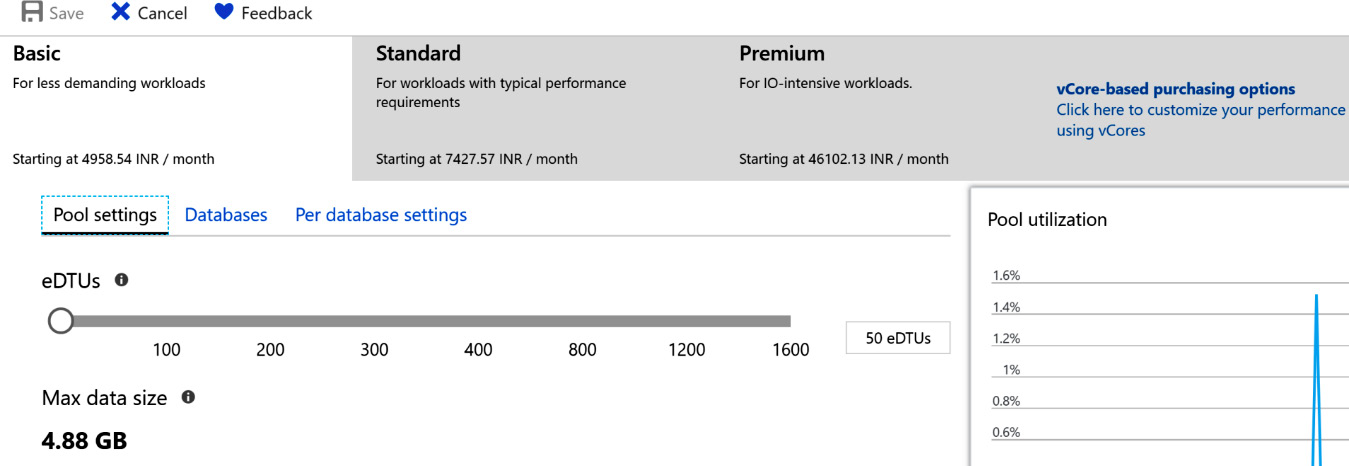
Figure 7.23: SKUs in an elastic pool
Also, there is a limit on the maximum number of databases that can be created within a single elastic pool. The complete limits can be reviewed here: https://docs.microsoft.com/azure/azure-sql/database/resource-limits-dtu-elastic-pools.
vCPU-based pricing
This is the new pricing model for Azure SQL. This pricing model provides options to procure the number of virtual CPUs (vCPUs) allocated to the server instead of setting the amount of DTUs required for an application. A vCPU is a logical CPU with attached hardware, such as storage, memory, and CPU cores.
In this model, there are three SKUs: General Purpose, Hyperscale, and Business Critical, with a varied number of vCPUs and resources available. This pricing is available for all SQL deployment models:
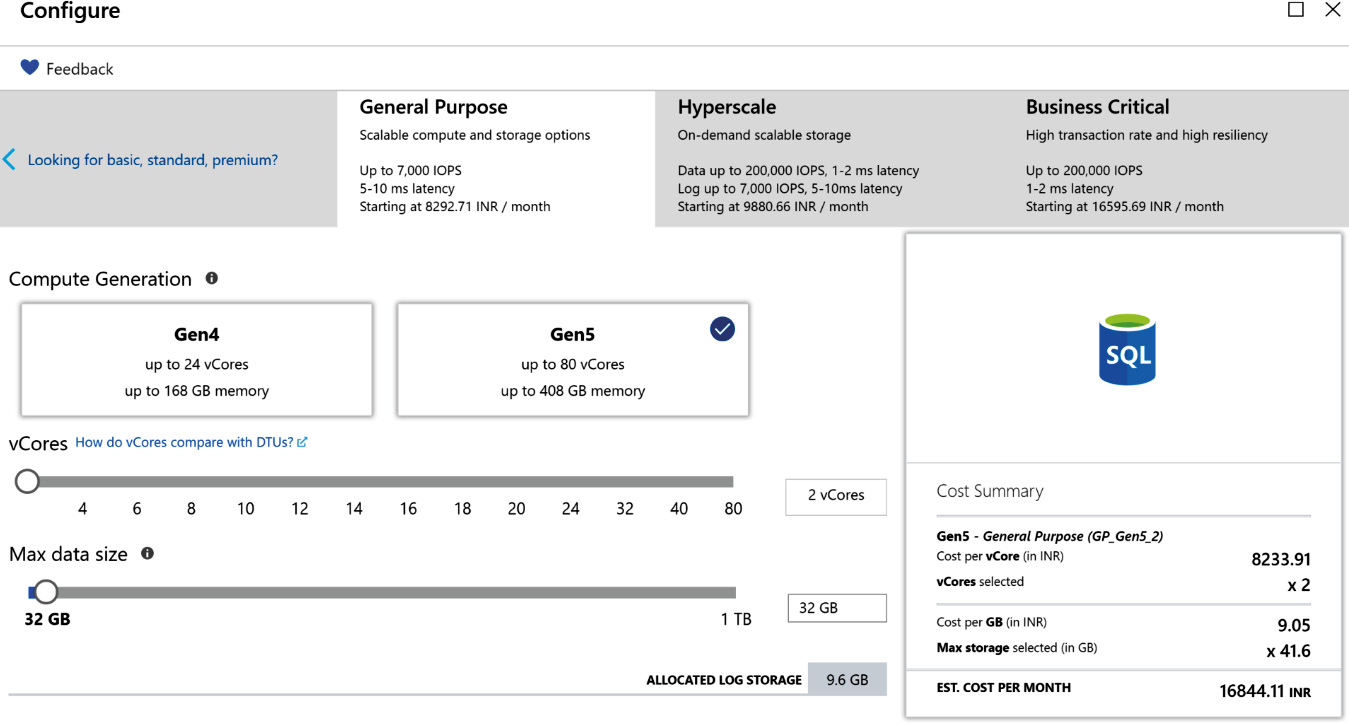
Figure 7.24: vCPU pricing for the General Purpose SKU
How to choose the appropriate pricing model
Architects should be able to choose an appropriate pricing model for Azure SQL Database. DTUs are a great mechanism for pricing where there is a usage pattern applicable and available for the database. Since resource availability in the DTU scheme of things is linear, as shown in the next diagram, it is quite possible for usage to be more memory-intensive than CPU-intensive. In such cases, it is possible to choose different levels of CPU, memory, and storage for a database.
In DTUs, resources come packaged, and it is not possible to configure these resources at a granular level. With a vCPU model, it is possible to choose different levels of memory and CPU for different databases. If the usage pattern for an application is known, using the vCPU pricing model could be a better option compared to the DTU model. In fact, the vCPU model also provides the benefit of hybrid licenses if an organization already has on-premises SQL Server licenses. There is a discount of up to 30% provided to these SQL Server instances.
In Figure 7.25, you can see from the left-hand graph that as the amount of DTUs increases, resource availability also grows linearly; however, with vCPU pricing (in the right-hand graph), it is possible to choose independent configurations for each database:
Figure 7.25: Storage-compute graph for the DTU and vCore models
With that, we can conclude our coverage of Azure SQL Database. We discussed different deployment methods, features, pricing, and plans related to Azure SQL Database. In the next section, we will be covering Cosmos DB, which is a NoSQL database service.
Azure Cosmos DB
Cosmos DB is Azure's truly cross-region, highly available, distributed, multi-model database service. Cosmos DB is for you if you would like your solution to be highly responsive and always available. As this is a cross-region multi-model database, we can deploy applications closer to the user's location and achieve low latency and high availability.
With the click of a button, throughput and storage can be scaled across any number of Azure regions. There are a few different database models to cover almost all non-relational database requirements, including:
- SQL (documents)
- MongoDB
- Cassandra
- Table
- Gremlin Graph
The hierarchy of objects within Cosmos DB starts with the Cosmos DB account. An account can have multiple databases, and each database can have multiple containers. Depending on the type of database, the container might consist of documents, as in the case of SQL; semi-structured key-value data within Table storage; or entities and relationships among those entities, if using Gremlin and Cassandra to store NoSQL data.
Cosmos DB can be used to store OLTP data. It accounts for ACID with regard to transaction data, with a few caveats.
Cosmos DB provides for ACID requirements at the single document level. This means data within a document, when updated, deleted, or inserted, will have its atomicity, consistency, isolation, and durability maintained. However, beyond documents, consistency and atomicity have to be managed by the developer themselves.
Pricing for Cosmos DB can be found here: https://azure.microsoft.com/pricing/details/cosmos-db.
Figure 7.26 shows some features of Azure Cosmos DB:
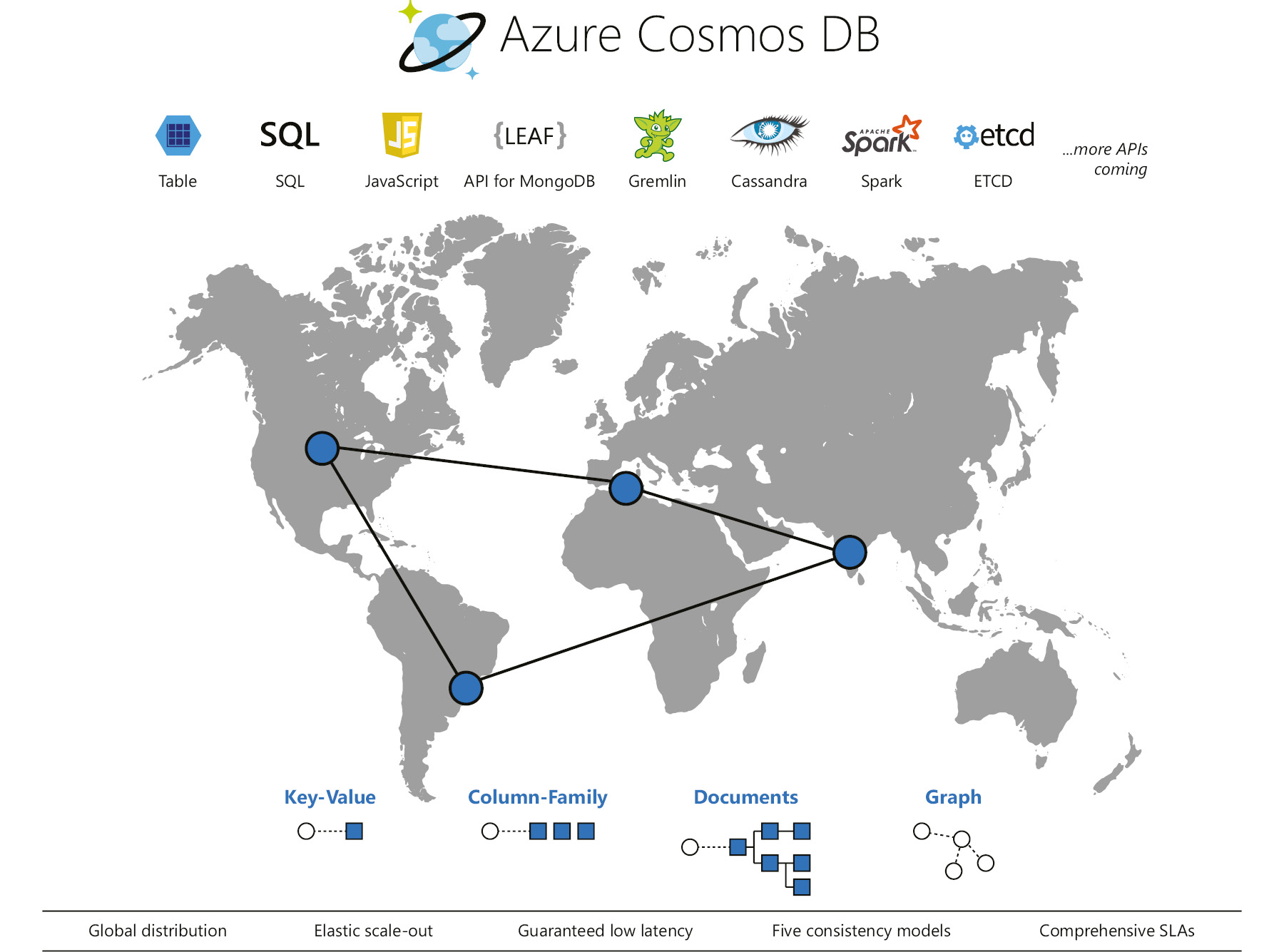
Figure 7.26: An overview of Azure Cosmos DB
In the next section, we will cover some key features of Azure Cosmos DB.
Features
Some of the key benefits of Azure Cosmos DB are:
- Global distribution: Highly responsive and highly available applications can be built worldwide using Azure Cosmos DB. With the help of replication, replicas of data can be stored in Azure regions that are close to users, hence providing less latency and global distribution.
- Replication: You can opt in to or opt out of replication to a region any time you like. Let's say you have a replica of your data available in the East US region, and your organization is planning to shut down their processes in East US and migrate to UK South. With just a few clicks, East US can be removed, and UK South can be added to the account for replication.
- Always On: Cosmos DB provides 99.999% of high availability for both read and write. The regional failover of a Cosmos DB account to another region can be invoked via the Azure portal or programmatically. This ensures business continuity and disaster recovery planning for your application during a region failure.
- Scalability: Cosmos DB offers unmatched elastic scalability for writes and reads all around the globe. The scalability response is massive, meaning that you can scale from thousands to hundreds of millions of requests/second with a single API call. The interesting thing is that this is done around the globe, but you need to pay only for throughput and storage. This level of scalability is ideal for handling unexpected spikes.
- Low latency: As mentioned earlier, replicating copies of data to locations nearer to users drastically reduces latency; it means that users can access their data in milliseconds. Cosmos DB guarantees less than 10 ms of latency for both reads and writes all around the world.
- TCO Savings: As Cosmos DB is a fully managed service, the level of management required from the customer is low. Also, the customer doesn't have to set up datacenters across the globe to accommodate users from other regions.
- SLA: It offers an SLA of 99.999% high availability.
- Support for Open-Source Software (OSS) APIs: The support for OSS APIs is another added advantage of Cosmos DB. Cosmos DB implements APIs for Cassandra, Mongo DB, Gremlin, and Azure Table storage.
Use case scenarios
If your application involves high levels of data reads and writes at a global scale, then Cosmos DB is the ideal choice. The common types of applications that have such requirements include web, mobile, gaming, and Internet of Things applications. These applications would benefit from the high availability, low latency, and global presence of Cosmos DB.
Also, the response time provided by Cosmos DB is near real time. The Cosmos DB SDKs can be leveraged to develop iOS and Android applications using the Xamarin framework.
A couple of the popular games that use Cosmos DB are The Walking Dead: No Man's Land, by Next Games, and Halo 5: Guardians.
A complete list of use case scenarios and examples can be found here: https://docs.microsoft.com/azure/cosmos-db/use-cases.
Cosmos DB is the go-to service in Azure for storing semi-structured data as part of OLTP applications. I could write a whole book on the features and capabilities of Cosmos DB alone; the intention of this section was to give you an introduction to Cosmos DB and the role it plays in handling OLTP applications.
Summary
In this chapter, you learned that Azure SQL Database is one of the flagship services of Azure. A plethora of customers are using this service today and it provides all the enterprise capabilities that are needed for a mission-critical database management system.
You discovered that there are multiple deployment types for Azure SQL Database, such as Single Instance, Managed Instance, and elastic pools. Architects should perform a complete assessment of their requirements and choose the appropriate deployment model. After they choose a deployment model, they should choose a pricing strategy between DTUs and vCPUs. They should also configure all the security, availability, disaster recovery, monitoring, performance, and scalability requirements in Azure SQL Database regarding data.
In the next chapter, we will be discussing how to build secure applications in Azure. We will cover the security practices and features of most services.