
Chapter 8. Open Source Honeyclient: Proactive Detection of Client-Side Exploits
Client software vulnerabilities are currently being exploited at an increasing rate. Based on a September 2004 survey, Dell Computers estimates that 90% of Windows PCs harbor at least one spyware program. Microsoft’s Internet Explorer browser has had over 50 vulnerabilities in the past six months, according to the Common Vulnerabilities and Exposures (CVE) database. By taking advantage of client software vulnerabilities, attackers are able to infect and control systems that are protected by firewalls or otherwise inaccessible.
As is well known, client-side exploits can be used by the attacker for many other malicious activities once a victim machine is compromised. The exploit could steal valuable information, such as the user’s online banking credentials. Among other things, the attacker could hijack the victim machine and add it to growing bot networks, in which each bot becomes part of a distributed denial of service (DDoS) attack or a spam delivery system.
How will attackers utilize client software vulnerabilities? As far back as 2002, a paper titled How to 0wn the Internet In Your Spare Time[67] came up with a disturbing possible scenario: a contagion worm exploit that targets both server and client vulnerabilities. First, the attack uses typical Web server security flaws, such as buffer overflows or SQL injection, to upload malicious code that is then downloaded whenever a targeted browser visits the website. Then, the downloaded code exploits vulnerabilities on the browser client.
Today, attackers target client software because many of these software applications are developed by people who are not trained to create secure software. In addition, far more people use client software than server software, and many of them are just your average Internet user who is less likely to install security updates. Compare this to your average server administrator, who is more likely to be technically trained and follow through with updating the server software.
Even if the user is savvy enough to update her operating system software and diligently runs the most recent signatures in her anti-virus product, most malware that attacks through client software will still work on the user’s system, and it will not be detected by the anti-virus software. The anti-virus manufacturers just can’t keep up.
Enter Honeyclients
In network security management, the quality of a security analyst’s response to compromises often depends on his knowledge of existing vulnerabilities and exploits. This knowledge can be used to create intrusion detection system (IDS) signatures, or to proactively patch vulnerable systems. One popular tool for acquiring advanced knowledge is the honeypot, a specialized system that is intended as a target for new attacks and is instrumented to provide detailed information about an exploit when an attack is successful.
However, honeypots are passive devices, and all publicly known honeypot systems to date are limited to discovering server software attacks. A large and growing proportion of vulnerabilities these days are discovered in client software, such as web browsers or mail clients. Since existing honeypot systems cannot detect exploits for these vulnerabilities, we need a new technology, one that instruments client software and drives it in such a way as to detect new exploits. This concept is the honeyclient.
Honeyclients are systems that drive a piece of potentially vulnerable client software, such as a web browser, to potentially malicious websites, and then monitor system behavior for indicators of compromise. A honeyclient emulates the client side of a connection, and in normal mode acts as a spider or a bot, constantly surfing random sites. The client probably runs inside of a sandbox that monitors client behavior to see whether it falls outside of normal operational bounds. For example, the requests from the honeyclient could be monitored to see whether the honeyclient’s requests start deviating from a known good request (e.g., the honeyclient system isn’t writing an executable file). If the honeyclient begins to behave abnormally, we know that it has already been infected. This monitoring process would have the added benefit of detecting malicious or compromised web servers.
Traditional honeypots are passive, unable to detect malicious behavior until the attacker happens upon them. Honeyclients therefore possess the advantage of being able to seek out suspicious remote systems. Still, each is suited to its own domain: honeypots for server-side exploits and honeyclients for client-side exploits.
Introducing the World’s First Open Source Honeyclient
In 2004, I started designing a honeyclient prototype. One of the first decisions I made was to open-source the prototype code. My hope was that this would inspire others in the security community to start thinking about honeyclients as a technology area, and that a few might contribute to the project.
To detect exploits, I used a comprehensive check for changes on the client, just as Tripwire does on a server. I took a baseline of the honeyclient by recording MD5 hashes of files and enumerating Windows registry keys. After visiting each suspected website, I then looked for changes between the initial baseline and the new snapshot.
I had already decided to start with a Windows honeyclient host, because that’s what the average user has installed on his computer.
I also chose Microsoft Internet Explorer (IE) as the browser to use when visiting suspected websites. There may be exploits designed specifically for another operating system or another browser, and my honeyclient might not detect them. But I had to choose one operating system and browser, so it made sense to choose those with the largest population of users. These are the ones most likely to be chosen by the developers of malware, and the ones where exposing the exploits can help the most people.
The truly critical decision was to let a real web browser visit each site instead of simulating browser behavior by downloading files through a tool such as wget. A simulation would never reveal the hidden effects of malware that I wanted to uncover. The honeyclient software actually had to be compromised when it encountered a malicious website so that I could collect the malware and analyze it to better understand the latest attack vectors. Using that information, I could then warn the user community about bad websites and potential consequences of infections. If the honeyclient were to emulate a web browser, it would not necessarily get compromised, since there’s no underlying system to attack.
The honeyclient operational steps look something like this:
Create a baseline consisting of MD5 hashes and registry key values.
The honeyclient host invokes Internet Explorer (IE) by calling the iexplore.exe process.
A previously created URL list file is opened, and URLs are taken from the file one by one.
IE is driven to visit the specified URL.
As soon as the URL is visited, a snapshot of MD5 hashes and registry key values on the system is created.
If the snapshot in step 5 differs from the baseline created in step 1, the honeyclient considers a suspicious event to have occurred, and it sets a flag to warn the user.
If the snapshots match, the website is spidered (each link is visited recursively) until there are no more internal links left to visit on that website.
Once a website is completely spidered, the honeyclient pulls the next external link from the URL list, and the process begins again.
The original honeyclient prototype was also developed with a driver-proxy architecture (see Figure 8-1). The driver code was responsible for creating an initial baseline as well as invoking the Internet Explorer browser, while the proxy created sockets to pass HTTP requests from the IE browser. The driver also performed the checks on the state of the system.
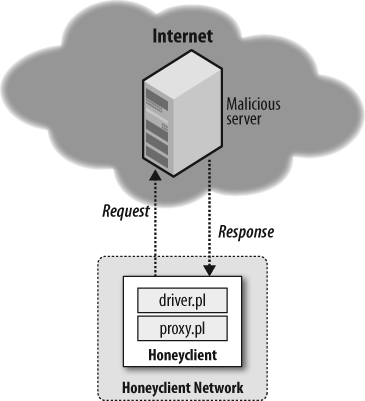
In June 2005, the initial honeyclient prototype was presented and released to the public at the RECon Conference in Montreal.[69] The audience showed a lot of interest and posed many questions to me after the talk. In addition to introducing the honeyclient prototype, I raised many related questions.
The technology is great, but what will the resulting arms race be like? Would attackers set up detectors of honeyclients via web bugs, color-on-color URLs, or robot.txt files? How about Flash sites that honeyclients will not be able to automatically “click” on? One enhancement I knew I should develop further was letting the honeyclient follow links embedded in JavaScript applications.
We will see shortly how honeyclient operations have been affected by these types of countermeasures to detection.
Second-Generation Honeyclients
Later on in the summer of 2005, the Honeyclient Project was funded at the MITRE Corporation, and our new project team[70] began to work on more advanced honeyclients. We wanted to keep parts of the original prototype, notably the baseline integrity check system, but we also wanted to add completely new features, such as running the honeyclients in virtual machines. It was tiring to run the original honeyclient up until it got compromised, and then reimage that operating system in preparation for the next attack. Also, if we wanted to quickly retain compromised operating systems for later attack forensics analysis, we needed to move toward honeyclient virtualization. Our team wanted speed, ease of use, and scalability. These factors were always on our minds as we worked to create our next honeyclient prototype.
One of the first decisions we made was to modularize the new honeyclient architecture. This allows us to develop optional plug-ins that can easily be enabled or disabled, depending on the user’s goal. Modularization makes it easier for contributors outside of our project team to develop a plug-in that will work with the rest of the existing honeyclient code. We also decided to license this second-generation honeyclient under the GNU Public License v2. I’ve always been a big supporter of open source code, and it is a great way to give back to the community, as well as encourage other people to create their own open source honeyclient prototypes.
Another important decision was to go with a client-server model, where the client or agent side of the honeyclient is located in the honeyclient virtual host and the server or manager side sits on the physical server that hosts the honeyclient virtual host. The server controls higher-level operations for the honeyclient, which include cloning and suspending virtual machines, detecting changes to the honeyclient system, communicating with an external honeyclient database, and logging full packet captures of the traffic between the honeyclient and the remote server. This new architecture is almost a complete rewrite of the old version. We changed our terminology as well, nixing “driver-proxy” in favor of “client-server.” Part of the reason for the semantic change is that client-server better reflects one of the main things we were able to accomplish with this generation: distributed honeyclients. Our team’s lead developer, Darien Kindlund, was responsible for implementing the virtual-machine-based honeyclient model.
From an architecture standpoint, the new honeyclient prototype is a virtual machine (VM) designed to drive a locally running target application to one or more remote resources (see Figure 8-2). In this architecture, the honeyclients are structured as follows:
Hosted on VMware[71] virtual machines
Running a variant of the Microsoft Windows[72] operating system
Configured to automatically log in as the system administrator upon boot
Upon login, automatically executes the Perl module, called
HoneyClient::Agent, that runs as a daemon inside a Cygwin[73] environment and starts the web visits
We chose VMware Server for virtualization because it is free to all users, and we didn’t want to burden the open source community users with having to purchase software to run our honeyclient prototype. Although VMware is not open source, we found it more suited to our needs than open source virtualization projects. It also runs on many operating systems; a later section explains why we chose Linux as the host.
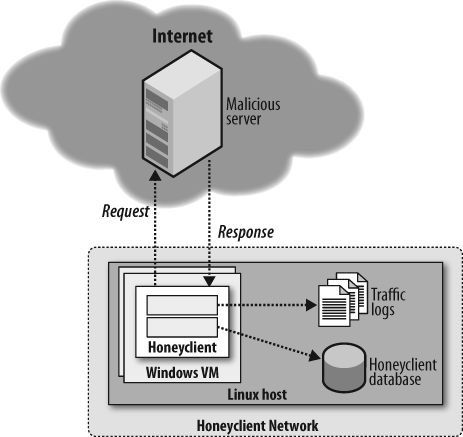
The honeyclient system is implemented as a series of Perl modules that execute on a Windows XP platform. The Perl modules drive a Microsoft Internet Explorer browser, and automatically spider given websites. After the driver script gives the honeyclient a URL (such as http://news.google.com) as a starting point, the simulated Internet Explorer browser grabs each URL on the site and recursively hits every link, with the driver script extracting links for future spidering.
The honeyclient Perl server checks file and registry key integrity. Even before the first connection to a remote server is made by the honeyclient, the integrity check module starts monitoring files, registry key values, and process-related information on the honeyclient host. After the honeyclient visits each site, the integrity-checking module compares the file checksums and registry key values against the known good list to see whether any changes have been made to sensitive system files or keys. If a change occurs, the server flags this URL as potentially malicious, saves all the network traffic generated during the spidering of this URL, and alerts the analyst that the site deserves further examination.
The honeyclient prototype is installed in a virtual machine environment (currently VMware) in order to ease the restoration of the system to a known good state. To further minimize risk, our physical host operating system is a Linux distribution. Because the honeyclient virtual host is Windows, for reasons explained earlier, deploying a different operating system as a physical host helps to limit the risks of breakout from the virtual host to the physical host. As we collect and analyze the payload data, we will better understand our honeyclient prototype’s limitations and modify it continually to improve its performance.
An exploit often enlists the client system in attacks such as spamming and denial of service, so we wanted to prevent our honeyclient from being used by the attacker as a springboard to launch other attacks. Therefore, another piece of our design is a firewall-enabled router running on a virtual host alongside the honeyclients’ virtual hosts. The firewall router filters honeyclient traffic as it passes between the internal network and the DMZ network. As a honeyclient is driven to a remote resource, the firewall is configured to permit that honeyclient to access the minimum set of resources required to process all fetched content from the remote resource. Honeywall, another open source effort by the Honeynet Project, filled our requirements very well, so team member JD Durick integrated it into our architecture for this purpose.
If the host system were to drive a honeyclient to the http://www.cnn.com page, the firewall would allow the honeyclient to contact all web servers that mapped to the http://www.cnn.com domain (including any additional servers that may host external inline content, such as externally linked advertisements from http://www.doubleclick.net) over TCP port 80. Once the firewall grants the honeyclient access, the honeyclient is then signaled to drive to http://www.cnn.com. The firewall allows us to protect the honeyclient from being utilized as a launching pad for other attacks once it becomes compromised. If the attacker tried to launch email or DDoS attacks from the honeyclient host, that action would be blocked by the firewall.
Although we initially utilized Honeywall, we quickly realized that restricting outbound traffic through this firewall prevented the honeyclient host from becoming compromised some of the time. For example, if a web page made use of third-party ad banners, where the exploit was hosted at a different server, the honeyclient would miss that exploit because the firewall would block access to the latter server’s domain. This scenario was a trade-off we needed to explore. Is it more important for us to get compromised so that we catch more exploits? Or is it more important to limit the chance of becoming part of a botnet? This is strictly a decision that each honeyclient user needs to make.
Besides utilizing Honeywall from the Honeynet Project, we also incorporated an integrity-checking algorithm from the Capture-HPC[74] honeyclient. Originally, our server simply checked for baseline changes in files and registry keys on our honeyclient system. A bit later, we decided to change the architecture to real-time checks for changes in files, registry keys, and system processes. Capture’s integrity check code met our criteria, and a member of our team, Xeno Kovah, worked with Christian Seifert to integrate the integrity check functionality for our honeyclients.
Honeyclient Operational Results
Our second-generation prototype went fully operational in 2006. While developing the honeyclient framework was a necessary step, going live with the second-generation prototype was a learning experience in itself. The first hurdle we had to resolve was the false positives generated with this new prototype.
Transparent Activity from Windows XP
For example, if we visited a foreign language website, IE would pop up a window asking if we wanted to install the language pack for the particular language the website was written in. During that process, we noticed that the same six Windows XP registry keys would be modified as follows:
HKEY_CURRENT_USERSoftwareMicrosoftInternet
ExplorerIntelliForms (added) |
HKEY_CURRENT_USERSoftwareMicrosoftInternet
ExplorerInternational (changed) |
HKEY_CURRENT_USERSoftwareMicrosoftInternet
ExplorerInternationalCpMRU (added) |
HKEY_USERSS.+SoftwareMicrosoftInternet
ExplorerIntelliForms (added) |
HKEY_USERSS.+SoftwareMicrosoftInternet
ExplorerInternational (changed) |
HKEY_USERSS.+SoftwareMicrosoftInternet
ExplorerInternationalCpMRU (added) |
Since we were able to replicate the same results while visiting a bunch of known benign foreign language websites, we knew this action alone was not an indication of malicious behavior. At that point, we decided to add these known benign actions to our whitelist. Another interesting case results consistently when we visit SSL-based URLs. The following files are repeatedly modified within the Windows XP environment:
Cab1.tmp, Cab2.tmp, ... Cabx.tmp Tar1.tmp, Tar2.tmp, ... Tarx.tmp
Building this whitelist has been—and continues to be—an interesting experience. Until we started testing known good websites, we had little insight as to how many modifications occur in the course of normal operations within the Windows XP environment. Even if we can see all of the modifications in files and registry keys, it doesn’t necessarily mean we know for sure whether a file or registry key change is malicious. For example, we encountered the following change in a file upon visiting a shady website:
| C:WINDOWSfla1.tmp |
Is this file benign or malicious? When we did a Google search on this filename, it seemed that even among anti-virus researchers there are questions about the “goodness” of this file. As the name suggests, it may be associated with Flash Player, but it also seems be associated with things you wouldn’t want on your system. In general, not only is there a lot of activity during normal (benign) operations, but many of the operations are also quite complex. Our current whitelist can be viewed on our project website.
The substantial time we had to invest in generating whitelists led us to realize that there’s very little sharing by the anti-virus research community with the public. So when we look into identifying false positives, we share our results with the public so that everyone can understand what “normal” behavior is for a particular operating system, such as Windows XP.
It’s ridiculous that even seasoned security researchers can have a hard time identifying whether a state change on the system is a malicious event. If experienced security researchers have trouble sorting out good from bad, how can we expect the rest of the users on the Internet to know better? This is one reason why client-side exploits are so pervasive today.
Storing and Correlating Honeyclient Data
Early during the development of my first-generation prototype, I realized that one of the real values behind honeyclient technology was the database of vulnerabilities and compromised websites it would produce. This database would store information associated with each honeyclient compromise, including filesystem changes, registry key modifications, and process executions that the remote web server caused when visited by a honeyclient. The database records the URLs visited when these system changes occurred, along with a timestamp marking when the incident happened. Team member Matt Briggs took on the role of implementing the exploit database.
In the process of developing the exploit database, we realized that we might want to store additional information that’s not necessarily related to an exploit itself, such as VMware identification numbers for the compromised images.
We also wanted the ability to store information in this database about what application the honeyclient was driving. For example, we will likely get different results by visiting a web page with IE 6 versus IE 7. (Our prototype can also support Mozilla Firefox browsers now.) We will also most likely get different results using Windows XP-based honeyclients versus Windows Vista-based honeyclients. I won’t even go into other future possibilities, such as driving non-HTTP-based applications. The database allows us to store all of this information about different environments and results, and allows us to correlate the data between results from driving different applications in various OS environments.
In short, our database grew to become much more than just an exploit database; it should really be called a honeyclient database.
This brings me to another reason why our modularized honeyclient architecture turned out to be a good idea. Because we develop in modules, we can now allow the user to decide which application she wants to send out onto the Internet.
Analysis of Exploits
Now let’s talk about some interesting malware that we discovered while operating honeyclients, along with some of the difficulties in detecting it.
Most malware appears to be financially motivated. Thus, we saw a lot of new malware variants that were gaming trojans, where the user’s game account information is sent to the attacker’s machine. Another type of malware that we saw often was banking trojans, which allow the attacker to obtain access to the victim’s online banking account credentials. But we have even seen politically motivated malware, where the attackers attempt to evangelize their political message by installing and/or printing HTML files on the user’s desktop.
Perhaps the most interesting example of malware we’ve seen is one that is able to detect that we’re using VMware and proceeds to shut down the guest operating system within seconds. Plenty of malware have the ability to detect virtual platforms such as VMware. Are there other honeyclient implementations that utilize different virtualization platforms? This leads us to the next section.
As I’ve explored the client-side exploit landscape over the past several years, it has become clear to me that attackers are extremely opportunistic. The bulk of client-side exploits today target Microsoft’s IE 6 browser, but this can change as market shares shift. Many people ask me whether it’s a good idea to use Mozilla Firefox instead. My answer is always something like, “Sure, but keep in mind that if everyone in the world used Firefox, there would be a lot of exploits that target the Firefox browser.” In other words, don’t rely on using Firefox alone to protect you from these attacks. The user still needs to be somewhat savvy and not get duped into clicking on every link that comes his way.
What about anti-virus software? It was not until we started capturing a lot of malware with our honeyclients that we were truly able to appreciate what a difficult job the anti-virus industry has. First of all, most anti-virus products are signature-based, which means that the company has isolated each attack and found an embedded set of byte-strings that uniquely identify the attack. Because products are signature-based, the manufacturers need to understand at some level how an attack works in order to detect that attack. Developing a signature can be as simple as running the strings utility against malware binaries and extracting a particular unique string that appears in all of them. Developing a signature can also involve more complex research, but as signature development is not the focus of this chapter, I recommend checking out other books if this topic interests you.[75]
It’s difficult to keep up with developing signatures for every new attack—I’m talking about new malware variants here, not just new exploits—and keep up with all the attacks. There are literally thousands of new malware variants released each day, and anti-virus companies have a finite amount of resources. So a lot of the malware that we capture with our honeyclients are very poorly detected by major anti-virus companies. The backlog of signatures to develop is so large that it sometimes takes these anti-virus companies weeks after new malware is found to actually develop the signature. Their users are not protected from the malware in the meantime. And some malware never yields a usable signature.
One of the things our project lacks is a dedicated malware analysis team; we currently just don’t have the resources. When we capture malware with the honeyclients, we have useful information in the form of filesystem modifications, registry key changes, and processes executed. We even have a module that will do full packet captures of network traffic between the honeyclient and the remote web server at the time of compromise. However, our prototype is not an automated malware analysis tool. This means we do not automatically reverse-engineer captured malware binaries to determine further information about the malicious binary. What we end up doing when we capture new malware is scan the malware binaries with tools such as VirusTotal.com. VirusTotal gives us a quick glance at how well known the malware is that was captured with our honeyclients. VirusTotal manages a backend of anti-virus scanning tools, all updated with the most recent detection signatures. Figure 8-3 shows a typical scan that we run on a malicious binary via the VirusTotal interface.
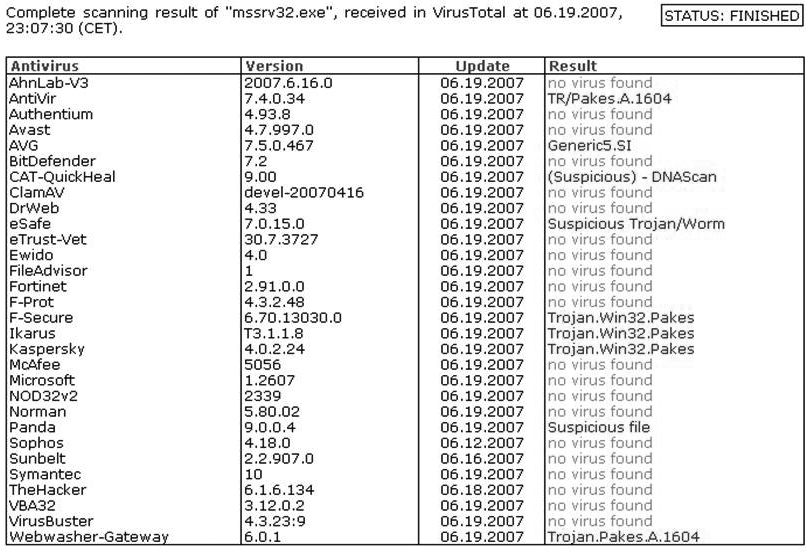
As you can see, very few anti-virus products even thought this file was suspicious to begin with. Apparently, this malware binary was obfuscated. Obfuscation is a popular technique used by malware authors to bypass detection by anti-virus scanners, as well as thwart further analysis of the malware binary itself by security researchers. This is why some of the vendors shown in the figure tagged this binary with a “Pakes” name. It means the binary was obfuscated, and the anti-virus scanner could not deobfuscate or unpack that binary.
Limitations of the Current Honeyclient Implementation
That is not to say that honeyclient detection is perfect. In information security, no solution is going to prevent attacks 100% of the time, and if you encounter someone who suggests otherwise, you should be very wary. While operating our honeyclient prototype, we came across several limitations. If a malicious website inserts a delay before launching an attack against the web browser client, honeyclients will not detect the attack. This is because honeyclients operate in such a manner that after the website contents are rendered and no suspicious changes are detected, the honeyclient moves on to the next URL.
Many websites host advertisement banners, and attackers have been known to buy ad banner space and embed malicious code in active ads. An active ad is based on JavaScript or Flash technology, and does not require the user to click on the ad for the content to animate. Therefore, users’ computers can be compromised via a web browser vulnerability through one of these active ads. Any site can host these ads, including popular sites that users know and trust. Our honeyclient prototype has the ability to detect these malicious ads, and we have detected these ads while operating. However, if we visit a website that another user also visits, we may not get served the same ads as the other user. Therefore, honeyclients have difficulties detecting malware when that malware is embedded in an ad that rotates. We are currently working on the ability to more accurately detect a particular component of a web page that causes a compromise. Being able to pinpoint this might allow us to identify certain advertising companies that are more prone to leasing ads to malicious parties.
While we were testing our second-generation honeyclient prototype, we encountered a lot of malware that required user interaction and acknowledgment in order to execute and compromise the machine. This type of malware can be in executable (.exe) format, and clicking on that .exe link will result in the Windows IE browser asking the user if she would like to allow install or download that .exe file. It was difficult (at least at the time) for us to develop an automatic “OK” or “Download” clicking mechanism for this prompt. So we made the decision that our honeyclients would be primarily focused on detecting drive-by malware downloads, not malware that requires user permission to execute. Drive-by malware downloads are not the majority of all client-side attacks, but they are more subtle (nearly impossible for the average user to stop, in fact) and their prevalence will only increase in the next couple of years.
Related Work
Although honeyclient technology is relatively new compared to honeypots, anti-virus, and intrusion detection system (IDS) technologies, currently there are at least several separate honeyclient efforts occurring. Various honeyclients were developed for different purposes, but most of them focused on detecting malicious websites.
Back when I started working on the first-generation open source honeyclient, Microsoft was developing honeyclients (which they call honeymonkeys). Microsoft and I were developing honeyclients in parallel, and it wasn’t until I had already written the first prototype that I found out about Microsoft honeyclients, and vice versa. Unfortunately, I was never able to get information from Microsoft about their honeymonkey internals, and there’s not a lot of information on the implementation details of honeymonkeys.[76]
As a researcher, I cannot emphasize enough the importance of communicating with other researchers about a technology that you’re working on. Some people I’ve talked to feel conflicted about this. On the one hand, if they share their ideas, they may be able to find others who have also thought about the idea, and in return, their original idea can get more refined. On the other hand, they are worried that people will steal their idea if they mention it. I would argue that very few people have such striking ideas that absolutely no one else in the world has ever thought of them. So in the end, the people who want to just hold onto their idea often find that other people came up with the same idea, and had even developed it further than they had! And even if someone was the first to think up something, he may end up losing the chance to claim some credit because he was too obsessed with perfecting the idea to tell anyone about it.
Many anti-virus companies operate software similar to honeyclients, mainly to collect malware for subsequent signature development. Mostly, these anti-virus companies prefer to talk about malware characteristics rather than honeyclient technology. I’ve talked to Dan Hubbard of Websense about the honeyclients they operate there. Robert Danford is another researcher who implemented the Pezzonavante honeyclient.[77] From prior conversations with Robert, I know his implementation is mainly focused on collecting malware and visiting as many URLs in as short of a time as possible. This is a valid approach, but it sacrifices accuracy in determining the specific URL that caused the compromise.
In late 2005, Aidan Lynch and Daragh Murray from Dublin City University developed a new extension to my original open source honeyclient. Lynch and Murray’s extension allowed the user to use Outlook to grab email URLs and send them back to the honeyclient. This allows the honeyclient user to use email as another source of URLs. They also added a feature to allow integrity checks for newly spawned processes. Their source code is currently hosted on one of our servers.[78]
Thorsten Holz had been involved with honeyclient technology through the efforts of the German Honeynet Project. The Honeynet Project calls honeyclient technology “client-side honeypots,” mainly because they were one of the pioneers of honeypot technology. Since traditional honeypots are server-side, it follows that they would choose the term “client-side” for their other honeypots. However, I have noticed in talking to many people over the years that often honeyclients are confused with honeypots, even though the two technologies address different areas. So, it probably does not help to have the word “honeypot” in the phrase when describing a honeyclient.
Through Thorsten Holz, our honeyclient project team started discussions with Christian Seifert and his Capture client-side honeypot team in 2006. Capture was designed to be a high-interaction honeyclient, like ours. What our honeyclient team really liked about Capture was the real-time integrity check capability. Essentially, it is installed as a benign rootkit on the honeyclient system and begins to monitor for changes in files, registry keys, and processes, right when the honeyclient starts up. There are many benefits to this, but one of the most important is that by integrating Capture’s integrity check, we were able to reduce the time we expended checking for system changes, from three or four minutes to less than five seconds.
Since our Honeyclient Project and the Capture Project shared a common GPLv2 license, we were able to utilize each other’s code without legal complications, and we were able to develop a wrapper script to call Capture as a module. The Capture code also added the process-checking feature I mentioned earlier.
Since then, there have been other honeyclient implementations,[79] especially in the low-interaction side of things. The implementations mentioned earlier have all been high-interaction honeyclients, where the web browser is actually driven as a process. Low-interaction honeyclients emulate web browsers rather than allow a real one to be infected. Examples of low-interaction honeyclients include SpyBye, developed by Niels Provos. Google has operational honeyclients that seek out bad websites and create blacklists based on those URLs. This blacklist is part of the Google Safe Browsing API, which is currently integrated with the Mozilla Firefox browser. Recently, Jose Nazario released PhoneyC, which focuses on the automatic browser script deobfuscation and analysis.
The Future of Honeyclients
There are over 240 million websites on the Internet today (and of course the number keeps growing by leaps and bounds), and there’s not one group that can cover all of those websites with honeyclient technology. To better fight these attackers that damage our machines and steal our data, we need to band together and learn from each other.
We should envision a future where honeyclients take a SETI@home (“Search for Extraterrestrial Intelligence at home”) approach, in which each honeyclient is able to process its own data and send it back to a central database repository that can more effectively correlate the data. This can help us identify targeted domains: for example, if company A’s employees are being targeted by company B in order to compromise someone’s computer and steal corporate documents.
For now, we’re supporting mainly web browsers, but I’m interested in seeing a peer-to-peer (P2P) honeyclient. There’s a lot of malware stored in P2P networks, and driving a P2P application could be a very interesting way to find new malware. We may make the decision to actually develop a P2P honeyclient in the future. Currently, our time is taken up just finding new and interesting web-based malware.
The average user should not have to live in fear when all she really wants to do is open her web browser and seek information on the Internet. We have already seen that many users think they are completely safe from being attacked because they installed a signature-based anti-virus scanner. We should help protect those users, many of whom are compromised, not from visiting “shady” websites, but because a supposedly safe site they visit happens to be hosting a malicious advertisement.
The field’s understanding of client-side exploits is about five years behind its understanding of server-side exploits. As an industry, we’ve only recently started to better understand how client-side exploits are developed. Clearly, there’s still a lot of work to be done, and I believe honeyclient technology will be an instrumental part of this process. Sharing both code and results is a critical step forward.
[67] S. Staniford, V. Paxson, and N. Weaver, How to 0wn the Internet In Your Spare Time, http://www.icir.org/vern/papers/cdc-usenix-sec02 (last visited September 4, 2008).
[68] InformationWeek article on Iframedollars.biz: http://www.informationweek.com/news/security/vulnerabilities/showArticle.jhtml?articleID=163701736.
[69] Honeyclient presentation at RECon: http://2005.recon.cx/recon2005/papers/Kathy_Wang/Wang-Honeyclients-RECON.pdf.
[70] The Honeyclient project team and contributors are listed at http://www.honeyclient.org/trac/wiki/about.
[71] VMware’s corporate website is http://www.vmware.com.
[72] Windows XP is found at http://www.microsoft.com/windowsxp.
[73] The Cygwin utility can be obtained at http://www.cygwin.com.
[74] The Capture-HPC honeyclient is at https://projects.honeynet.org/capture-hpc, and the project is described at https://projects.honeynet.org/capture-hpc/wiki/AboutCapture.
[75] One that I particularly like is The Art of Computer Virus Research and Defense by Peter Szor (Symantec Press).
[76] The Microsoft HoneyMonkey Project is discussed at http://research.microsoft.com/HoneyMonkey.
[77] A presentation on Pezzonavante can be found at http://handlers.dshield.org/rdanford/pub/Honeyclients_Danford_SANSfire06.pdf.
[78] The source code is at http://www.synacklabs.net/honeyclient/email-honeyclient.zip.
[79] See the Wikipedia entry on honeyclients: http://en.wikipedia.org/wiki/Honeyclient.