
Chapter 10. Security by Design
“Beauty is truth, truth beauty,”—that is all
Ye know on earth, and all ye need to know.
Beauty is not skin deep. True beauty is a reflection of all aspects of a person, object, or system. In security, beauty appears in simplicity and graceful design, a product of treating security as a critical goal early in the system design lifecycle. In properly designed systems, security is an integral attribute of the system, designed, built, and tested; it is lightweight and adaptive, allowing the overall system to remain agile in the face of evolving requirements. When security is treated as an afterthought, or developed independently from the overall system design requirements, it is most often ugly and inflexible.
Several experiences during my career have had a profound impact on my views on information security and my overall system development philosophy. The first was at NASA’s Langley Research Center. The second was a four-year period where I worked on software quality, reliability, usability, and security, first at Reliable Software Technologies (now known as Cigital) and then as the vice president of the Software Technology Center at Bell Labs. The lessons I learned and the fantastic teams I had the opportunity to work with demonstrated to me that security and all of the other important “ilities” (e.g., quality, reliability, availability, maintainability, and usability) are highly interrelated, and are achievable in a cost-effective way. The early experience at NASA helped me understand what would not work and why it wouldn’t. The experiences at Cigital, Bell Labs, and a second stint at NASA helped me develop and refine a strategy for delivering high-quality, secure systems on schedule and on budget.
Both NASA and Lucent had the mistaken perception that the systems they were developing and deploying were “closed,” or on a highly controlled, dedicated network infrastructure. The reality was significantly different. The rapid growth of computer networking and the global Internet fundamentally changed the way systems were accessed and interconnected. Many of the networks the system administrators thought were “closed” were actually interconnected with research and academic networks that had significantly different security postures and access control mechanisms. The network interconnects provided new access points for attackers to exploit and increased the overall attack surface of the systems.
This misconception created a large blind spot in the overall security posture and fed the view that perimeter security was sufficient to protect the systems. Unfortunately, if you don’t have a clearly known, clearly defined perimeter, you can’t have an effective perimeter-based security posture. Since the perception of having a known, well-monitored perimeter was inaccurate, the systems were exposed to security risks they were not designed to protect against. The perimeter defense model was often referred to as the “M&M” model, or the “hard outer shell, soft center” model. Once the perimeter defenses were bypassed or overcome, the internal infrastructure elements and software of the systems were not properly secured and could not defend themselves.
Metrics with No Meaning
I was working at NASA in the early 1990s when a new administrator took the helm. He came from private industry and set out to improve the agency’s overall project performance. His goals were simple: reduce project cost, decrease project delivery time, and increase the overall quality of the resulting systems. While I greatly appreciated these goals, it soon became clear that the plan was not well thought out.
The new initiative focused on delivering “Better, Faster, Cheaper” programs. When someone pointed out that safety was key to human spaceflight and the aeronautics program, the initiative became “Better, Faster, Cheaper, and Safer.” The working-level folks at NASA added: “Pick any two.”
Why the humor? It was simple: the initiative assumed that all the key system characteristics—quality, schedule, cost, and safety—were independent and that the current processes in place were so poor that all aspects could be simultaneously improved. More importantly, other key system “ilities,” such as security, operability, and maintainability, were pushed to the side. The sharp focus of the initiative pulled resources and attention away from security just as new threats were emerging and swift action was necessary.
I admit that the existing system development lifecycle at NASA had room for improvement. This is not a criticism of the existing processes: all processes can benefit from continuous improvement programs. The “better, faster, cheaper, safer” initiative, however, was based on unvalidated assumptions about the root causes of the problems. The core business process analysis required to develop an effective program was missing. The metrics program and associated push for Total Quality Management were positive, but misdirected. There were no clear baselines for better, faster, cheaper, or safer, and in many cases the metrics developed were in direct conflict. Human flight (both spaceflight and aeronautics) is a difficult endeavor. Improving safety is not always aligned with faster delivery or cheaper overall program cost.
The metrics that were established to support the initiative were very stove-piped. For example, there were detailed metrics to measure cost versus planned budget, but the fundamental concepts of Earned Value Management (EVM) were not applied, so the metrics were a one-dimensional assessment. The metrics related to cost, schedule, and scope were not integrated or correlated. The cost metrics were based on the amount of the budget expended, not the value gained. For example, if a project manager accelerated the purchase of some critical items to provide for additional test and integration time, the metrics showed the project as over-budget. This false positive happened even though the costs were planned, just planned to occur later in the schedule. More importantly, the “flat” metrics were easily manipulated and could mask serious problems in a project. If a project deferred spending for a major item and spent a lesser amount on unforeseen items, the delayed purchase masked the budget risk. The metrics would show green until the planned expense occurred, suddenly tilting the metric from green to red.
The quality and security metrics suffered from similar shortcomings. They didn’t account for security’s role in quality, speed, cost reduction, or safety. The minimal security metrics that were included in the program addressed the security of final components and system perimeter defense. Quality and security were not tested at the component level. Key issues were masked by a lack of unit testing and system integration testing, only to be uncovered in final system test, or, even worse, when systems failed in flight.
There was no concept of good enough, fast enough, cost-effective enough, or safe enough. The metrics were binary, and often were not collected at the unit and component level. Overall program and project success criteria were not clearly defined. There was a lot of energy expended; a lot of flat, one-dimensional metrics defined and collected; and few tangible results. I watched in horror as we spiraled deeper into trouble, addressing the symptoms of problems without identifying the root causes. The “metrics for the sake of metrics” approach left a very bad impression on me.
Around the turn of the century I had the opportunity to spend an extended period focusing on security, quality, reliability, and supportability, first at Reliable Software Technologies (RST) and then at Lucent’s Bell Labs. At the height of the “Internet boom,” many companies focused on time to market or features that would differentiate their products. The single focus was on capturing market share, in many cases to drive the company to a large initial public offering (IPO). Unfortunately, most companies did not consider the core “ilities” (e.g., quality, reliability, availability, maintainability, security, and usability) to be market differentiators. The focus was on beating the competitors to market. Robust system architecture, security, design, development, testing, and deployment were often seen as detrimental to getting products to market quickly. A host of academic and industry research, as well as common sense, demonstrated the flaws in this approach, but the push for a quick market share dominated. Key strategic decisions were driven by perceived market opportunities and not by solid engineering best practices.
After the tech bubble burst, the impact to the broader IT community was clear: a host of poorly designed, poorly constructed products on the market. The companies that survived were in no position to clean up their products. They did not have the staff or financial resources to redesign their systems and applications. Recovery from the shortsighted “time to market” focus has been going on for six years now and is still not complete. Some companies have made the investment in re-architecting their products, with marked improvements as a result. Others have continued to deliver products based on failed design and development practices. Such systems have deep architectural and programming flaws that undermine their security.
Time to Market or Time to Quality?
Bell Labs has a proud history of excellence in computer science research, but the best practices developed in the labs were not being applied consistently across Lucent’s product development teams. The same design, development, and test practices that resulted in security vulnerabilities also contributed to poor system performance, low reliability, and overall poor quality. The lessons were not being transferred; they were being painstakingly documented and placed on shelves to gather dust. We had “lessons noted,” not “lessons learned.”
Poor project management and a weak system development lifecycle were allowing feature bloat and requirements creep to divert critical architecture, engineering, development, and test resources away from the core product elements. Instead of focusing on achieving quality and security at the product core and then expanding the feature set product, teams tried to deliver bloated products that could be all things for all people. As is often the case with the “be all things” approach, the products missed the core market requirements. In the drive for additional features, some products intended to solve simple problems became research projects that chased premature technologies, delivering complex, difficult to maintain solutions. Instead of investing in developing a simple solution to a common problem and reusing it across multiple products teams, we allowed, and in some cases actively encouraged, teams to develop custom solutions. The ever-growing code base made system design, development, testing, maintenance, and security more complex and more costly.
Soon after I arrived at Bell Labs, I had the opportunity to co-lead a team that was focused on addressing quality and security issues with the current family of products. The problem statement for the project was clear and concise: “To compete in the marketplace, Lucent needs to improve software quality, productivity, and predictability.”
Lucent had just completed an internal survey that evaluated perceived organization goals across several product development groups. Five goals were rated as “High,” “Medium,” or “Low” priority (Figure 10-1). Security did not appear at all. This is a critical point, that security was not even on the radar as an important organizational goal.
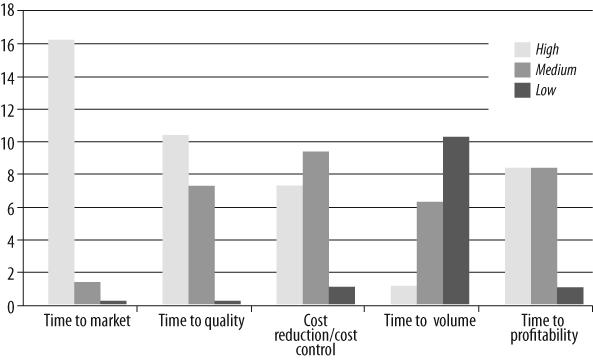
Nearly all survey respondents had a high focus on time to market (TTM). There was low focus on time to volume, which directly drives time to profitability. The dominant focus on TTM echoed weaknesses in reliability and performance engineering documented in the survey. The complex interrelationships between quality, security, reliability, availability, time to volume, and time to profitability were not recognized or managed effectively. Highly interrelated attributes were either treated as independent attributes or ignored.
In reality, you should not transition a product to volume production before achieving appropriate levels of quality and security. If you do, you directly impact overall product development and support costs and delay the time to profitability. In several cases at Lucent, products had been prematurely transitioned to volume production to meet TTM goals. The resulting products had high warranty and service costs that reduced overall product profitability, and the quality, reliability, and security issues harmed Lucent’s reputation for delivering quality products.
For all project or product development programs, it is important to determine the attributes that need to be measured, their interdependencies, and the acceptable levels for each attribute. The project team must have a consistent view of success. Success criteria must be realistic and driven by the overall goals of the project. It is important to know what is acceptable for each metric and to make the proper trades between metrics.
The survey also measured the respondents’ views of the gaps between Lucent’s current performance in critical practices areas and the performance required to ensure successful projects. Again, much to my surprise, the survey did not explicitly ask about security. The data collected showed gaps in all areas, with the largest gaps covering reliability, metrics, system performance, training, early requirements development, and management and system testing. It was clear that a set of system issues needed to be addressed by a comprehensive program; we could not just improve one of the “ilities” without addressing the related root-cause issues.
In addition, Software Engineering Institute (SEI) assessments showed that the majority (over 60%) of Lucent’s software development teams were performing at the lowest level of process maturity and effectiveness. Internal analysis and reviews documented a need to focus on deploying standard metrics and processes and improving the “ilities” of products prior to initial release.
In response to the findings, a cross-organizational team developed an end-to-end program focused on improving software by deploying a consistent set of software design and development best practices. Figure 10-2 shows the program’s three key best practice clusters: engineering for the “ilities,” engineering for test and configuration management (CM), and the deployment of standard foundational elements.
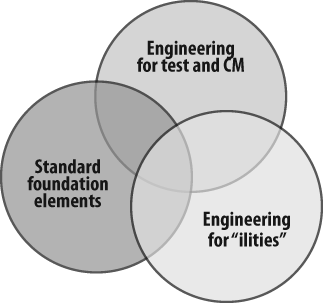
Engineering for the “ilities” focused on performance and capacity, reliability and availability, serviceability, and usability and security. Engineering for test and configuration management focused on test planning and architecture, test automation, and one-day build and test. The standard foundation elements were project management, standard operational metrics, and training.
The team recommended a pilot model with four pilot projects phased by fiscal quarters: one project would be started in the first quarter, the second in the second quarter, dependent upon a successful review by the project sponsors. In the two succeeding quarters, additional pilots would begin—again, dependent upon a successful review by the project sponsors.
At the start of the engagement, a pilot jump-start team conducted a lightweight self-assessment with the project team. The jump-start team worked directly with the project team, providing technical expertise to support the focused project improvement plan and transferring the detailed knowledge to the project team. The joint team developed and implemented the detailed project plan with the project team maintaining “ownership” of the identified issues and their resolution. The partnership worked well. It kept the project team fully engaged, and they maintained accountability for overall project success.
The team developed a high-level lifecycle to help understand the dependencies between best practices and the proper project lifecycle phase to deploy them. The three phases of the lifecycle were explore, execute, and volume deploy. Figure 10-3 shows the dependencies documented for the Performance and Capacity focus area of the Engineering for the “ilities” practice area, and Figure 10-4 shows the dependencies documented for the Reliability and Availability focus area.
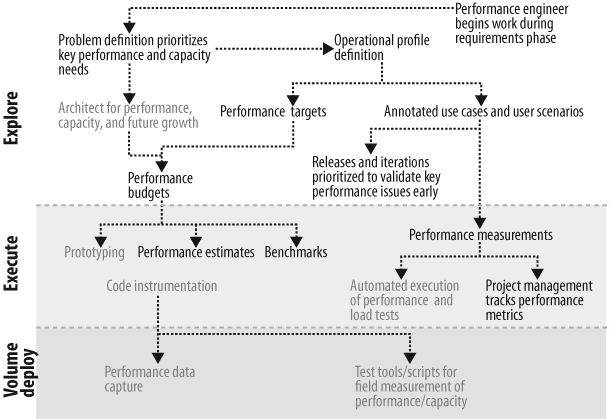
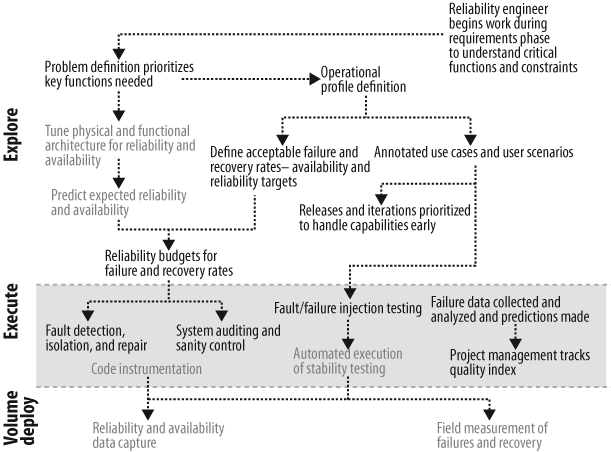
The program was very successful in focusing attention back onto the key behaviors and best practices required to improve Lucent’s products and properly position them in terms of security, cost and profitability, customer satisfaction, and timeliness.
How a Disciplined System Development Lifecycle Can Help
When I returned to NASA in January of 2003, I had the pleasure of working on a project to redesign the NASA nonmission (i.e., general purpose) wide area network. The project had strong support from two critical senior leaders who understood the value of applying a strong system development lifecycle approach, to ensure that the new design was secure, robust, and scalable. I co-led the project with Betsy Edwards, the owner of the current network. We assembled a cross-functional team that included Jim McCabe, an excellent network architect; John McDougle, a strong Project Manager; and a team of security specialists, end users, network architects, network operations engineers, and network test engineers.
John McDougle kept the team on a disciplined design process (shown in Figure 10-5), where we developed options and evaluated them against the full suite of metrics. The final design was a major departure from the existing network architecture, but all of the design decisions were clearly documented and founded on the prioritized system requirements. The final system was deployed on budget and on schedule; it provided 10 times the bandwidth of the network it replaced at a lower monthly operational cost. John did an excellent job keeping all of the disciplines supporting the project—including security and the operations and management staff—engaged throughout the lifecycle.
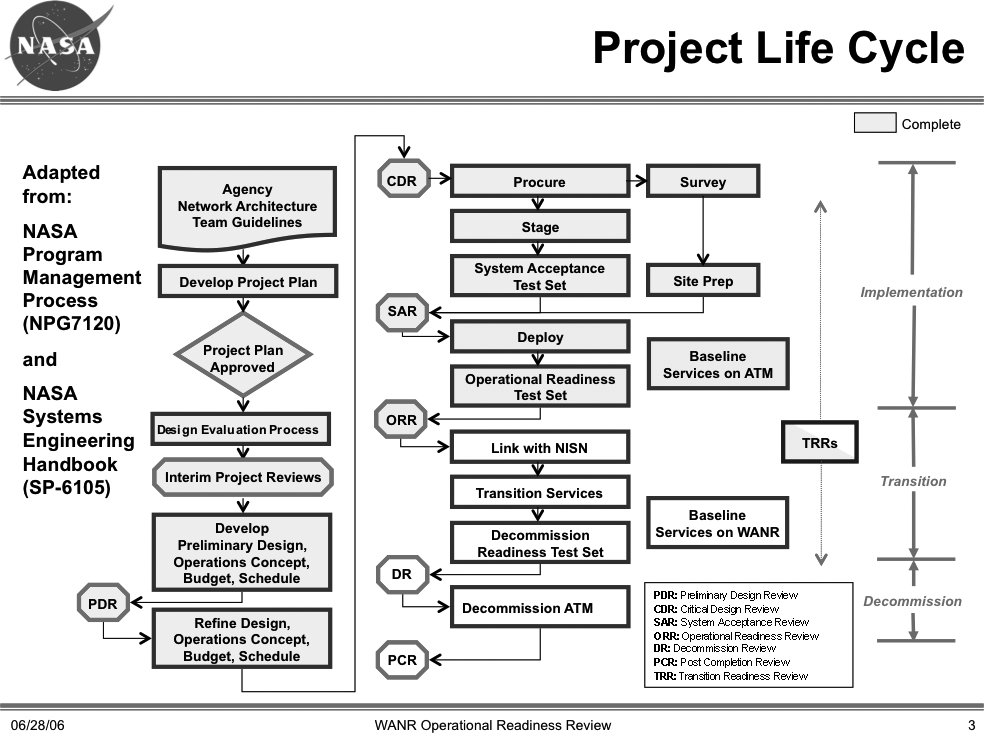
Jim McCabe led the team through a detailed requirements capture, prioritization, and management process. The resulting requirements documents captured not just the functional requirements (e.g., bandwidth, latency, etc.), but also all of the nonfunctional and operational requirements (e.g., security, maintainability, scalability) for the final system. At each phase in the development lifecycle, the requirements were updated and revalidated. The team used detailed modeling to evaluate preliminary design alternatives and assessed the nonfunctional requirements at each review. We also assessed security at each review, and our strategy and final implementation matured as a part of the overall system design.
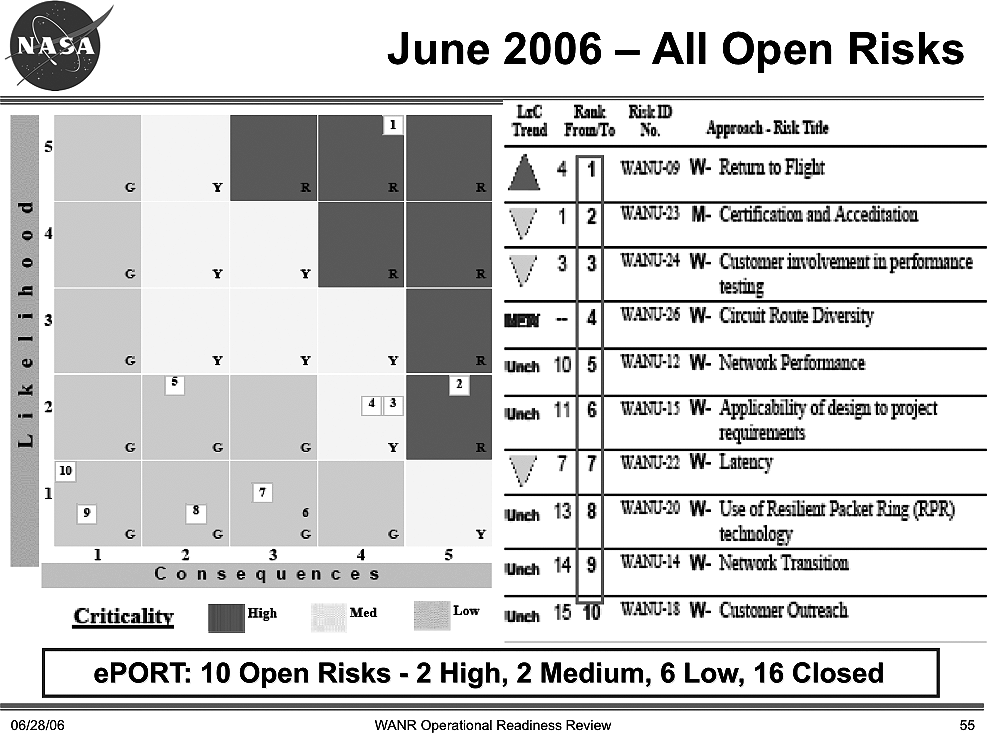
One of the critical lessons I learned during the project was the effective use of risk management tools. John used a 5×5 matrix (shown in Figure 10-6) to track project risks. The matrix has the likelihood of occurrence (rated low to high) on one axis and the consequence (low to high) on the other. During each project meeting, we added risks John identified to the project risk log and analyzed them. All risks were actively tracked until they were retired. The matrix created a powerful visual image that made communicating risk to project sponsors and review members easy, regardless of the type of risk.
This project was one of the most successful projects I have worked on in my career. A portion of its success was directly attributable to the strength of the team members (this was an all-star team) and the excellent leadership that John and Jim provided. The discipline the team applied was also a direct contributor to the project success. The team developed a clear set of requirements, including security, reliability, availability, bandwidth, latency, usability, and maintainability at the start of the projects. All of the “ilities,” including security, were addressed in the system design phase and alternatives analysis, and all of the requirements were prioritized. The resulting system is simple, yet beautiful. There are no extra layers or bolt-ons that detract from the design or prevent the system from adapting to evolving requirements and security threats.
I applied the same 5×5 risk model at the Department of Commerce to evaluate information security risks and the risks associated with the loss of Personally Identifiable Information (PII). We evaluated each PII loss against two axes: the controls that were in place to protect the information (High to Low) against the risk of identity theft if the information was compromised (Low to High). This approach allowed us to make consistent, risk-based decisions on how to respond to PII losses. We also applied the model as a part of the security assessments of systems under design and during our security audits. This model allows us to clearly identify specific risks and decide to either mitigate a risk or accept it. There are very few perfect systems: in most cases, you end up deciding (I hope it is a conscious decision) to accept some level of residual risk. As more teams move to risk-based security strategies, a clear risk identification and management strategy is critical to success.
Conclusion: Beautiful Security Is an Attribute of Beautiful Systems
I am gravely concerned by the “quick and dirty” approach that I still see being applied to security. It seems like we did not learn the lessons of the late 1990s and the dotcom bust. We documented the lessons and placed them in binders on a shelf to gather dust. As I said earlier, we have lessons noted, not lessons learned. It is not good enough to gather the lessons; we must apply them in order to improve. We are not developing risk-based security programs that address security at all phases of the system development lifecycle. Until we make that transition, we will have limited success.
I’ve been asked why “ugly” security is not good enough. The question disappoints me. We should have matured as a discipline beyond the point of asking that question. It drives home that we, as a community, have a long path of improvement in front of us. My answer to the question is simple: ugly solutions are piecemeal—not integrated into an overall system design. The security elements of the system are layered or bolted onto the system late in the development lifecycle. The resulting systems are fragile, difficult to operate, and difficult to maintain. Instead of designing security into the system, we try to test it in. Since the security layers and/or bolt-on elements were not a part of the system design, there are challenges at the integration points between the system and the security elements. The “quick and dirty” approach has a 25-year history of failing to deliver quality, reliability, or usability—why should we expect it to work for security?
A simple analogy is to look at the design of a Ferrari 430 Scuderia compared to the current wave of customized sport tuner cars. It is clear that the overall design of the Ferrari 430 integrates all aspects of vehicle (i.e., system) performance. The vehicle is beautiful, with clean lines and a balanced, lightweight chassis. Contrast that against the “customized” sport tuner vehicles, where items are independently designed, purchased separately, and then bolted onto the basic vehicle by the end user. In many cases the parts do not work well together and actually have a negative impact on the system’s performance. In the case of the Ferrari, it is clear that the vehicle was designed to work as a system—balancing speed, handling, weight, and strength.
I’m sure you are thinking that the cost of the Ferrari is much greater that the cost of the customized sport turner, and that if you spent as much money on the sport tuner, you would get the same results. I disagree with that assessment; in my experience, good design is independent of the target price point. Given the corporate (e.g., intellectual property) and personal assets (e.g., personally identifiable information) we are protecting, we are negligent in our responsibilities to our clients and customers if we do not invest properly in security. We have a responsibility to deliver the best products and services possible, and it is time we took the security element seriously and clearly faced up to the risks of not doing information security properly.
I strongly believe that a well-designed and consistently implemented system development lifecycle applied to all projects will provide significant benefits in improved security. The system development lifecycle approach is proven to improve a team’s ability to deliver projects and services. The lifecycle provides a lightweight framework that focuses on clear decision-making, communication, and risk management. It engages key stakeholders early in the lifecycle and provides a clear set of criteria for proceeding to the next phase in the lifecycle. The approach allows all attributes of the final system to be addressed throughout its design and development. It allows us to weave security into the fabric of the overall solution.
I have seen beautiful systems that are very cost effective and ugly systems that are very expensive. Good design discipline is not inherently expensive and, in many cases, reduces the total cost of designing, developing, and operating a system.
My experiences at NASA, Reliable Software Technologies (RST), and Bell Labs were positive and helped me develop a full lifecycle view of delivering the “ilities” and a strategy for managing project and security risks. I have a great respect for the people I’ve worked with and appreciate all of the time they spent helping me learn. The research and consulting teams at these organizations were talented and worked hard at improving all aspects of system performance.
In the end, beautiful security is not a standalone attribute. How do you define beautiful security for a system that has “ugly” reliability, availability, or usability? The key to beautiful security is to design, develop, and deliver overall systems that are beautiful.