
CHAPTER 1
![]()
Relational Database Management Systems
Those who are in love with practice without knowledge are like the sailor who gets into a ship without rudder or compass and who never can be certain [where] he is going. Practice must always be founded on sound theory.
—The Discourse on Painting by Leonardo da Vinci
Thank you very much for buying this book (or for getting a legal copy). Database administrators have access to valuable and confidential data belonging to their organizations and therefore must possess high ethical standards. (Consider this your first lesson in Oracle Database administration.) Besides, royalties paid to textbook authors typically constitute no more than minimum wage for the long hours they spend writing, so the least you can do to respect their effort is to buy their books or get legal copies.
This book is really for beginners in database administration. If you aren’t a beginner in database administration, I recommend that you get Pro Oracle Database 12c Administration by my fellow Apress author Darl Kuhn instead (2013). Also, did you know that Oracle provides excellent free reference materials at http://docs.oracle.com? For beginners in database administration, I particularly recommend Oracle Database 2 Day DBA in the “2 Day” series of publications. In fact, I suggest that you take a moment to check out 2 Day DBA right now; it may be all that you want or need.
In general, I have found that most Oracle Database professionals don’t take enough advantage of the free Oracle publications. A plausible defense is that reference manuals are harder to read than books from Apress and other fine publishers. But, in addition to reference manuals, Oracle also provides many publications that are written in an extremely readable style. Consider this your second lesson in Oracle Database administration! Throughout this book, I frequently refer you to the free Oracle publications for more information because I want you to get into the habit of referring to the best source of detailed and reliable information. Besides, I view myself as an interpreter and a teacher, not a regurgitator of free material.
With those little lessons and cautions out of the way, let’s get our feet wet with Oracle Database 12c, shall we?
JOIN THE GOOGLE GROUP FOR THIS BOOK
Join the Google group Beginning Oracle Database 12c Administration at https://groups.google.com/forum/#!forum/beginning-oracle-database-12c-administration. There you can find errata and additional materials and can discuss the material in this book.
A First Look at Oracle Database 12c
I want to spend some time talking the theory of relational database management systems. What Leonardo da Vinci said is so important that I’ll quote it again: “Those who are in love with practice without knowledge are like the sailor who gets into a ship without rudder or compass and who never can be certain [where] he is going. Practice must always be founded on sound theory.” How can you competently administer a relational database management system like Oracle if you don’t really know what makes a “relational” database relational or what a database “management” system manages for you?
However, if you’re like most of my students, you won’t be satisfied until you’ve seen an Oracle database management system. I’ll grant that seeing a real system will make it easier for you to understand a few things. But it would take quite a while to coach you through the process of creating an Oracle database management system. Fortunately, there is a solution. Oracle provides a convenient virtual machine (VM) containing a complete and ready-to-use installation of Oracle Database 12c on Linux. All you need to do is to download and install the Oracle VirtualBox virtualization software and then import a ready-to-use VM. The instructions for doing so are at www.oracle.com/technetwork/community/developer-vm. Pick the Database App Development VM option, and follow the download and installation instructions. (I hope you don’t want me to regurgitate the instructions here.) The instructions are short and couldn’t be simpler, because you don’t need to install and configure Oracle Database; rather, you import a prebuilt VM into Oracle VirtualBox. The only difficulty you may experience is that the prebuilt VM is almost 5GB in size, so you need a reliable and fast Internet connection.
If you follow the instructions and fire up the VM, you see the screen in Figure 1-1. It looks like a Windows or Mac screen, doesn’t it? This is the Gnome Desktop, which makes it possible to use Linux without getting completely lost in a world of cryptic Linux commands.
Figure 1-1. Starting screen of the Database App) VM
Next, minimize the terminal window that’s taking up so much real estate, and click the SQL Developer icon in the top row of icons. SQL Developer is a GUI tool provided by Oracle for database administration. Because this is the first time, it will take a few minutes to start; that’s normal. Figure 1-2 shows what you see at startup.
Figure 1-2. Starting screen of SQL Developer
As shown in Figure 1-3, click Connections, and create a new connection. Give the connection the name “hr” (Human Resources) or any other name you like. Use the following settings:
- Username “hr”
- Password “oracle”
- Connection Type “Basic”
- Role “Default”
- Hostname “localhost”
- Service Name “PDB1”
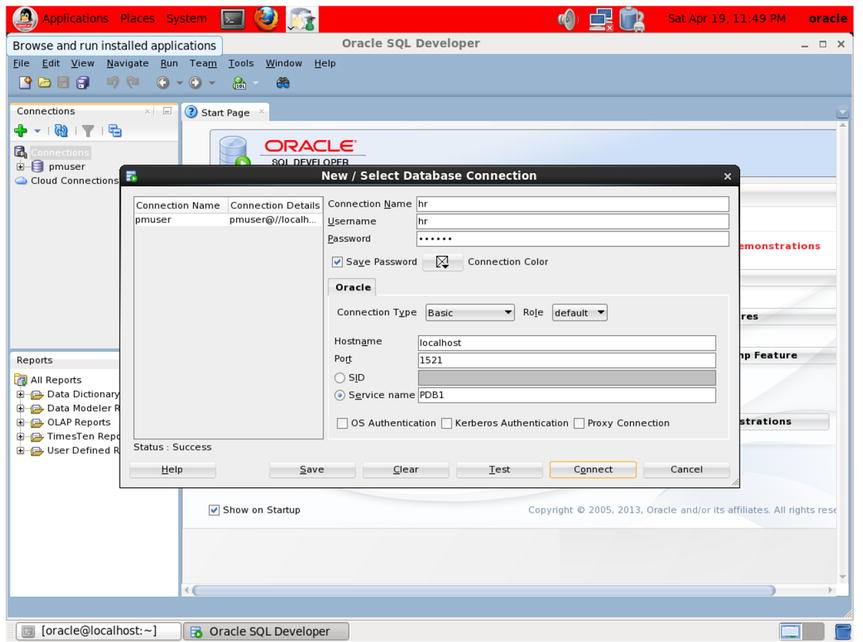
Figure 1-3. Create a new connection
Then click Connect. You see the screen shown in Figure 1-4.
Figure 1-4. New connection created
Expand the Tables item in the navigation pane on the left. Six tables are shown; click the EMPLOYEES table. The data in the EMPLOYEES table is listed in a full-screen editor, as shown in Figure 1-5. If you like, you can make changes to the data and then either save your changes (commit) or discard them (roll back) using the Commit Changes and Rollback Changes buttons or the F11 and F12 keys.
Figure 1-5. Full-screen editor
When I was a junior programmer, early in my career, my friends and I were assigned to work on a big software development project for which we would have to use unfamiliar technologies, although we were promised that training would be provided before the project started. All we knew in advance was that the operating system was something called VAX/VMS; we didn’t know which programming language or database would be used. The very first thing the instructor said was (paraphrasing), “First you have to insert your definitions into the CDD,” and then he walked to the chalkboard and wrote the commands that we needed for the purpose. Needless to say, we were quite flustered, because we had no idea what those “definitions” might be or what a “CDD” was and how it fit into the big picture.
I’m sure you’re eager to learn how to create an Oracle database. Anybody can issue a command such as CREATE DATABASE or push a button in a GUI tool such as the Database Creation Assistant. But the mere knowledge of a few commands (or even a lot of commands) doesn’t make anyone an Oracle Database administrator in my opinion.
What Is a Database?
Chris Date was the keynote speaker at one of the educational conferences organized by the Northern California Oracle Users Group (NoCOUG), of whose journal I am the editor. The local television news station sent out a crew to cover the event because Chris Date is a well-known database theoretician and one of the associates of Dr. Edgar Codd, an IBM researcher and the inventor of relational database theory. The news reporter cornered me and asked if I was willing to answer a few questions for the camera. I was flattered, but when the reporter pointed the camera at me and asked, “Why are databases important to society?” all I could think of to say was (paraphrasing), “Well, they’re important because they’re, like, really important, you know.” All those years of database administration under my belt, and I still flunked the final exam!
I’d therefore like to spend a few minutes at the outset considering what the word database signifies. An understanding of the implications of the word and the responsibilities that go along with them will serve you well as a good database administrator.
I’ll begin by saying that databases can contain data that is confidential and must be protected from prying eyes. Only authorized users should be able to access the data, their privileges must be suitably restricted, and their actions must be logged. Even if the data in the databases is for public consumption, you still may need to restrict who can update the data, who can delete from it, and who can add to it. Competent security management is therefore part of your job.
Databases can be critical to an organization’s ability to function properly. Organizations such as banks and e-commerce web sites require their databases to be available around the clock. Competent availability management is thus an important part of your job. In the event of a disaster such as a flood or fire, the databases may have to be relocated to an alternative location using backups. Competent continuitymanagement is therefore another important element of your job. You also need competent changemanagement to protect a database from unauthorized or badly tested changes, incident management to detect problems and restore service quickly, problem management to provide permanent fixes for known issues, configuration management to document infrastructure components and their dependencies, and release management to bring discipline to the never-ending task of applying patches and upgrades to software and hardware.
I’ll also observe that databases can be very big. The first database I worked with, for the semiconductor manufacturing giant Intel, was less than 100MB in size and had only a few dozen data tables. Today, databases used by enterprise application suites like PeopleSoft, Siebel, and Oracle Applications are tens or hundreds of gigabytes in size and might have 10,000 tables or more. One reason databases are now so large is that advancements in magnetic disk storage technology have made it feasible to efficiently store and retrieve large quantities of nontextual data such as pictures and sound. Databases can grow rapidly, and you need to plan for growth. In addition, database applications may consume huge amounts of computing resources. Capacity management is thus another important element of your job, and you need a capacity plan that accommodates both continuous data growth and increasing needs for computing resources.
When you stop thinking in terms of command-line syntax such as create database and GUI tools such as the Database Creation Assistant (dbca) and start thinking in terms such as security management, availability management, continuity management, change management, incident management, problem management, configuration management, release management, and capacity management, the business of database administration begins to make coherent sense and you become a more effective database administrator. These terms are part of the standard jargon of the IT Infrastructure Library (ITIL), a suite of best practices used by IT organizations throughout the world.
What Is a Relational Database?
Relational database theory was laid out by Codd in 1970 in a paper titled “A Relational Model for Data for Large Shared Data Banks.” His theory was meant as an alternative to the “programmer as navigator” paradigm that was prevalent in his day.
In pre-relational databases, records were chained together by pointers, as illustrated in Figure 1-6. Each chain has an owner and zero or more members. For example, all the employee records in a department could be chained to the corresponding department record in the departments table. In such a scheme, each employee record points to the next and previous records in the chain as well as to the department record. To list all the employees in a department, you would first navigate to the unique department record (typically using the direct-access technique known as hashing) and then follow the chain of employee records.
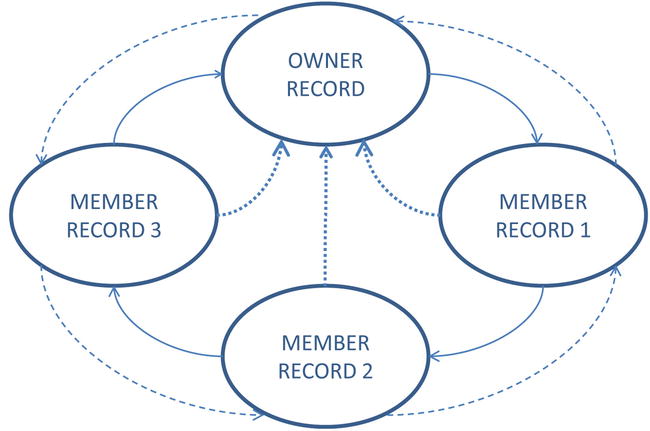
Figure 1-6. Chains of records
Records can participate in multiple chains; for example, all the employee records with the same job can be chained to the corresponding job record in the jobs table. To list all the employees performing a particular job, you can navigate to the job record and then follow the chain of employee records.
This scheme was invented by Charles Bachman, who received the ACM Turing Award in 1973 for his achievement. In his Turing Award lecture, titled “The Programmer as Navigator,” Bachman enumerated seven ways in which you can navigate through such a database:
- Records can be retrieved sequentially.
- A specific record can be retrieved using its physical address if it’s available.
- A specific record can be retrieved using a unique key. Either a unique index or hash addressing makes this possible.
- Multiple records can be retrieved using a non-unique key. A non-unique index is necessary.
- Starting from an owner record, all the records in a chain can be retrieved.
- Starting from any member record in a chain, the prior or next record in the chain can be retrieved.
- Starting at any member record in a chain, the owner of the chain can be retrieved.
Bachman noted, “Each of these access methods is interesting in itself, and all are very useful. However, it is the synergistic usage of the entire collection which gives the programmer great and expanded powers to come and go within a large database while accessing only those records of interest in responding to inquiries and updating the database in anticipation of future inquiries.”
In this scheme, you obviously need to know the access paths defined in the database. How else could you list all the employees in a record or all the employees holding a particular job without retrieving every single employee record?
STRANGE BUT TRUE
An example of a pre-relational database technology is so-called network database technology, one of the best examples of which was DEC/DBMS, created by Digital Equipment Corporation for the VAX/VMS and OpenVMS platforms—it still survives today as Oracle/DBMS. Yes, it’s strange but it’s true—Oracle, the maker of the world’s dominant relational database technology, also sells a pre-relational database technology. According to Oracle, Oracle/DBMS is a very powerful, reliable, and sophisticated database technology that has continued relevance and that Oracle is committed to supporting.
In 1979, Codd made the startling statement that programmers need not and should not have to be concerned about the access paths defined in the database. The opening words of the first paper on the relational model were, “Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation)” (“A Relational Model of Data for Large Shared Data Banks”).
Productivity and ease of use were the stated goals of the relational model. In “Normalized Data Base Structure: A Brief Tutorial” (1971), Codd said,
What is less understandable is the trend toward more and more complexity in the data structures with which application programmers and terminal users directly interact. Surely, in the choice of logical data structures that a system is to support, there is one consideration of absolutely paramount importance—and that is the convenience of the majority of users. … To make formatted data bases readily accessible to users (especially casual users) who have little or no training in programming we must provide the simplest possible data structures and almost natural language. … What could be a simpler, more universally needed, and more universally understood data structure than a table?
As IBM researcher Donald Chamberlin recalled later (The 1995 SQL Reunion: People, Projects, and Politics),
[Codd] gave a seminar and a lot of us went to listen to him. This was as I say a revelation for me because Codd had a bunch of queries that were fairly complicated queries and since I’d been studying CODASYL, I could imagine how those queries would have been represented in CODASYL by programs that were five pages long that would navigate through this labyrinth of pointers and stuff. Codd would sort of write them down as one-liners. These would be queries like, “Find the employees who earn more than their managers.” He just whacked them out and you could sort of read them, and they weren’t complicated at all, and I said, “Wow.” This was kind of a conversion experience for me, that I understood what the relational thing was about after that.”
Donald Chamberlin and fellow IBM researcher Raymond Boyce went on to create the first relational query language based on Codd’s proposals and described it in a short paper titled “SEQUEL: A Structured English Query Language” (1974). The acronym SEQUEL was later shortened to SQL because—as recounted by Chamberlin in The 1995 SQL Reunion: People, Projects, and Politics—SEQUEL was a trademarked name; this means the correct pronunciation of SQL is “sequel,” not “es-que-el.”
Codd emphasized the productivity benefits of the relational model in his acceptance speech for the 1981 Turing Award:
It is well known that the growth in demands from end users for new applications is outstripping the capability of data processing departments to implement the corresponding application programs. There are two complementary approaches to attacking this problem (and both approaches are needed): one is to put end users into direct touch with the information stored in computers; the other is to increase the productivity of data processing professionals in the development of application programs. It is less well known that a single technology, relational database management, provides a practical foundation to both approaches.
In fact, the ubiquitous data-access language SQL was intended for the use of non-programmers. As explained by the creators of SQL in their 1974 paper, there is “a large class of users who, while they are not computer specialists, would be willing to learn to interact with a computer in a reasonably high-level, non-procedural query language. Examples of such users are accountants, engineers, architects, and urban planners. [emphasis added] It’s for this class of users that SEQUEL is intended.”
The Secret Sauce
Codd’s secret was relational algebra, a collection of operations that could be used to combine tables. Just as you can combine numbers using the operations of addition, subtraction, multiplication, and division, you can combine tables using operations like selection, projection, union, difference, and join (more precisely, Cartesian join), listed in Table 1-1.
Table 1-1. Five Relational Operators
Operator | Definition |
|---|---|
Selection | Form another table by extracting a subset of the rows of a table of interest using some criteria. This can be expressed in SQL as follows (the * character is a wildcard that matches all columns in the table that is being operated on)”: select * |
Projection | Form another table by extracting a subset of the columns of a table of interest. Any duplicate rows that are formed as a result of the projection operation are eliminated: select <column list> |
Union | Form another table by selecting all rows from two tables of interest. If the first table has 10 rows and the second table has 20 rows, then the resulting table will have at most 30 rows, because duplicates are eliminated from the result: select * |
Difference | Form another table by extracting from one table of interest only those rows that don’t occur in a second table: select * |
Join | Form another table by concatenating records from two tables of interest. For example, if the first table has 10 rows and the second table has 20 rows, then the resulting table has 200 rows. And if the first table has 10 columns and the second table has 20 columns, then the resulting table has 30 columns: select * |
Why did Codd name this relational algebra? Codd based his theory on rigorous mathematical principles and used the esoteric mathematical term relation to denote what is loosely referred to as a table. I’m now ready to define what I mean by a relational database:
A relational database is a database in which: The data is perceived by the user as tables (and nothing but tables) and the operators available to the user for (for example) retrieval are operators that derive “new” tables from “old” ones.1
Examples of Relational Operations
Let’s use the five operations defined in Table 1-1 to answer this question: “Which employees have worked in all accounting positions—that is, those for which the job_id starts with the characters AC?” The current job of each employee is stored in the job_id column of the employees table. Any previous jobs are held in the job_history table. The list of job titles is held in the jobs table.
Here is the description of the employees table:
Name Null? Type
----------------------------------------- -------- ----------------------------
EMPLOYEE_ID NOT NULL NUMBER(6)
FIRST_NAME VARCHAR2(20)
LAST_NAME NOT NULL VARCHAR2(25)
EMAIL NOT NULL VARCHAR2(25)
PHONE_NUMBER VARCHAR2(20)
HIRE_DATE NOT NULL DATE
JOB_ID NOT NULL VARCHAR2(10)
SALARY NUMBER(8,2)
COMMISSION_PCT NUMBER(2,2)
MANAGER_ID NUMBER(6)
DEPARTMENT_ID NUMBER(4)
Here is the description of the job_history table:
Name Null? Type
----------------------------------------- -------- ----------------------------
EMPLOYEE_ID NOT NULL NUMBER(6)
START_DATE NOT NULL DATE
END_DATE NOT NULL DATE
JOB_ID NOT NULL VARCHAR2(10)
DEPARTMENT_ID NUMBER(4)
Here is the description of the jobs table:
Name Null? Type
----------------------------------------- -------- ----------------------------
JOB_ID NOT NULL VARCHAR2(10)
JOB_TITLE NOT NULL VARCHAR2(35)
MIN_SALARY NUMBER(6)
MAX_SALARY NUMBER(6)
Given these three tables, you can execute the following steps to answer the business question that has been posed:
- This step uses only the employee_id column from the employees table. To do this, you need the projection operation. Following are the SQL command and its results. The employees table contains 107 rows, so this command also produces 107 rows. Only the first five rows are shown here:
select employee_id
from employees
100
101
102
103
104Note that certain formatting aspects of SQL statements, such as lowercase, uppercase, white space, and line feeds, are immaterial except in the case of string literals—that is, strings of characters enclosed within quote marks.
- This step uses only the job_id column from the jobs table. To obtain this, you need the projection operation again. Following are the SQL command and its results. The jobs table contains 19 rows, so this command also produces 19 rows. Only the first five rows are shown here:
select job_id
from jobs
AC_ACCOUNT
AC_MGR
AD_ASST
AD_PRES
AD_VP - Remember that the result of any relational operation is always another table. You need a subset of rows from the table created by the projection operation used in step 2. To obtain this, you need the selection operation, as shown in the following SQL command and its results. * is a wildcard that matches all the columns of a table. % is a wildcard that matches any combination of characters. Note that the “table” that is operated on is actually the SQL command from step 2. The result contains only two rows:
select *
from (select job_id from jobs)
where job_id like ’AC%’
AC_ACCOUNT
AC_MGRYou can streamline this SQL command as follows. This version expresses both the projection from step 2 and the selection from step 3 using a unified syntax. Read it carefully, and make sure you understand it:
select job_id from jobs
where job_id like ’AC%’ - You need the job title of every employee; that is, you need the job_id column from the employees table. The employees table has 107 rows, so the resulting table also has 107 rows; five of them are shown here:
select employee_id, job_id
from employees
100 AD_PRES
101 AD_VP
102 AD_VP
103 IT_PROG
104 IT_PROG - Next, you need the employee_id and job_id columns from the job_history table. The jobs table contains 19 rows, so this command also produces 19 rows. Only the first five rows are shown here:
select employee_id, job_id
from job_history
101 AC_ACCOUNT
200 AC_ACCOUNT
101 AC_MGR
200 AD_ASST
102 IT_PROG - Remember that the current job of each employee is stored in the job_id column of the employees table. Any previous jobs are held in the job_history table. The complete job history of any employee is therefore the union of the tables created in step 4 and step 5:
select employee_id, job_id
from employees
union
select employee_id, job_id
from job_history - You need to join the tables created in step 1 and step 3. The resulting table contains all possible pairings of the 107 emp_id values in the employees table with the two job_id values of interest. There are 214 such pairings, a few of which are shown next:
select *
from
(select employee_id from employees),
(select job_id from jobs where job_id like ’AC%’)
100 AC_ACCOUNT
101 AC_ACCOUNT
102 AC_ACCOUNT
103 AC_ACCOUNT
104 AC_ACCOUNTYou can streamline this SQL command as follows. This version expresses the projections from step 1 and step 2, the selection from step 3, as well as the join in the current step using a unified syntax. Read it carefully, and make sure you understand it. This pattern of combining multiple projection, join, and selection operations is the most important SQL pattern, so you should make sure you understand it. Note that you prefix the table names to the column names. Such prefixes are required whenever there are ambiguities. In this case, there is a job_id column in the employees table in addition to the jobs table:
select employees.employee_id, jobs.job_id
from employees, jobs
where jobs.job_id like ’AC%’ - From the table created in step 7, you need to subtract the rows in the table created in step 6! To do this, you need the difference operation, the appropriate SQL keyword being minus. The resulting table contains those pairings of employee_id and job_id that are not found in the job_history table. Here is the SQL command you need. The resulting table contains exactly 211 rows, a few of which are shown:
select employees.employee_id, jobs.job_id
from employees, jobs
where jobs.job_id like ’AC%’
minus
select employee_id, job_id
from job_history
100 AC_ACCOUNT
100 AC_MGR
102 AC_ACCOUNT
102 AC_MGR
103 AC_ACCOUNT - Thus far, you’ve obtained pairings of employee_id and job_id that are not found in the employee’s job history—that is, the table constructed in step 6. Any employee who participates in such a pairing is not an employee of interest; that is, any employee who participates in such a pairing isn’t an employee who has worked in all positions for which the job_id starts with the characters AC. The first column of this table therefore contains the employees in which you’re not interested. You need another projection operation:
select employee_id from
(
select employees.employee_id, jobs.job_id
from employees, jobs
where jobs.job_id like ’AC%’
minus
select employee_id, job_id
from job_history
)
100
100
102
102
103 - You’ve identified the employees who don’t satisfy your criteria. All you have to do is to eliminate them from the table created in step 1! Exactly one employee satisfies your criteria:
select employee_id
from employees
minus
select employee_id from
(
select employees.employee_id, jobs.job_id
from employees, jobs
where jobs.job_id like ’AC%’
minus
(
select employee_id, job_id
from job_history
union
select employee_id, job_id
from job_history
)
)
101
You had to string together 10 operations to produce the final answer: 5 projection operations, 1 selection operation, 1 union operation, and 2 difference operations.
You can express the final answer in a self-documenting way using table expressions, as shown in Listing 1-1. In practice, you wouldn’t go to such great lengths to restrict yourself to a single relational operation in each step, because, as you saw in step 7, multiple projection, selection, and join operations can be expressed using a unified syntax. As I said earlier, this approach of combining multiple projection, join, and selection operations is the most important SQL pattern, so make sure you understand it.
I resume the discussion of SQL in the next chapter. For now, note how formatting improves readability—the formatted version with vertical “rivers” and capitalized “reserved words” shown in Listing 1-1 was produced using the formatting options in SQL Developer.
Efficiency of Relational Operators
You may have noticed that the previous section made no mention of efficiency. The definitions of the table operations don’t explain how the results can be efficiently obtained. This is intentional and is one of the greatest strengths of relational database technology—it’s left to the database management system to provide efficient implementations of the table operations. In particular, the selection operation depends heavily on indexing schemes, and Oracle Database provides a host of such schemes, including B-tree indexes, index-organized tables, partitioned tables, partitioned indexes, function indexes, reverse-key indexes, bitmap indexes, table clusters, and hash clusters. I discuss indexing possibilities as part of physical database design in Chapter 7.
Query Optimization
Perhaps the most important aspect of relational algebra expressions is that, except in very simple cases, they can be rearranged in different ways to gain a performance advantage without changing their meaning or causing the results to change. The following two expressions are equivalent, except perhaps in the order in which data columns occur in the result—a minor presentation detail, not one that changes the meaning of the result:
Table_1 JOIN Table_2
Table_2 JOIN Table_1
The number of ways in which a relational algebra expression can be rearranged increases dramatically as the expression grows longer. Even the relatively simple expression (Table_1 JOIN Table_2) JOIN Table_3 can be arranged in the following 12 equivalent ways that produce results differing only in the order in which columns are presented—a cosmetic detail that can be easily remedied before the results are shown to the user:
(Table_1 JOIN Table_2) JOIN Table_3
(Table_1 JOIN Table_3) JOIN Table_2
(Table_2 JOIN Table_1) JOIN Table_3
(Table_2 JOIN Table_3) JOIN Table_1
(Table_3 JOIN Table_1) JOIN Table_2
(Table_3 JOIN Table_2) JOIN Table_1
Table_1 JOIN (Table_2 JOIN Table_3)
Table_1 JOIN (Table_3 JOIN Table_2)
Table_2 JOIN (Table_1 JOIN Table_3)
Table_2 JOIN (Table_3 JOIN Table_1)
Table_3 JOIN (Table_1 JOIN Table_2)
Table_3 JOIN (Table_2 JOIN Table_1)
It isn’t obvious at this stage what performance advantage, if any, is gained by rearranging relational algebra expressions. Nor is it obvious what criteria should be used while rearranging expressions. Suffice it to say that a relational algebra expression is intended to be a nonprocedural specification of an intended result, and the query optimizer may take any actions intended to improve the efficiency of query processing as long as the result isn’t changed. Relational query optimization is the subject of much theoretical research, and the Oracle query optimizer continues to be improved in every release of Oracle Database. I return to the subject of SQL query tuning in Chapter 17.
What Is a Database Management System?
Database management systems such as Oracle are the interface between users and databases. Database management systems differ in the range of features they provide, but all of them offer certain core features such as transaction management, data integrity, and security. And, of course, they offer the ability to create databases and to define their structure, as well as to store, retrieve, update, and delete the data in the databases.
Transaction Management
A transaction is a unit of work that may involve several small steps, all of which are necessary in order not to compromise the integrity of the database. For example, a logical operation such as inserting a row into a table may involve several physical operations such as index updates, trigger operations, and recursive operations. A transaction may also involve multiple logical operations. For example, transferring money from one bank account to another may require that two separate rows be updated. A DBMS needs to ensure that transactions are atomic, consistent, isolated, and durable.
The Atomicity Property of Transactions
It’s always possible for a transaction to fail at any intermediate step. For example, users may lose their connection to the database, or the database may run out of space and may not be able to accommodate new data that a user is trying to store. If a failure occurs, the database management system performs automatic rollback of the work that has been performed so far. Transactions are therefore atomic or indivisible from a logical perspective. The end of a transaction is indicated by an explicit instruction such as COMMIT.
The Consistency Property of Transactions
Transactions also have the consistency property. That is, they don’t compromise the integrity of the database. However, it’s easy to see that a database may be temporarily inconsistent during the operation of the transaction. In the previous example, the database is in an inconsistent state when money has been subtracted from the balance in the first account but has not yet been added to the balance in the second account.
The Isolation Property of Transactions
Transactions also have the isolation property; that is, concurrently occurring transactions must not interact in ways that produce incorrect results. A database management system must be capable of ensuring that the results produced by concurrently executing transactions are serializable: the outcome must be the same as if the transactions were executed in serial fashion instead of concurrently.
For example, suppose that one transaction is withdrawing money from a bank customer’s checking account, and another transaction is simultaneously withdrawing money from the same customer’s savings account. Let’s assume that negative balances are permitted as long as the sum of the balances in the two accounts isn’t negative. Suppose that the operation of the two transactions proceeds in such a way that each transaction determines the balances in both accounts before either of them has had an opportunity to update either balance. Unless the database management system does something to prevent it, this can potentially result in a negative sum. This kind of problem is called write skew.
A detailed discussion of isolation and serializability properly belongs in an advanced course on application development, not in a beginner text on database administration. If you’re interested, you can find more information in the Oracle 12c Advanced Application Developer’s Guide, available at https://docs.oracle.com/cd/E11882_01/appdev.112/e41502/toc.htm.
The Durability Property of Transactions
Transactions also have the durability property. This means once all the steps in a transaction have been successfully completed and the user notified, the results must be considered permanent even if there is a subsequent computer failure, such as a damaged disk. I return to this topic in the chapters on database backups and recovery; for now, note that the end of a transaction is indicated by an explicit command such as COMMIT.
Data Integrity
Data loses its value if it can’t be trusted to be correct. A database management system provides the ability to define and enforce what are called integrity constraints. These are rules you define, with which data in the database must comply. For example, you can require that employees not be hired without being given a salary or an hourly pay rate.
The database management system rejects any attempt to violate the integrity constraints when inserting, updating, or deleting data records and typically displays an appropriate error code and message. In fact, the very first Oracle error code, ORA-00001, relates to attempts to violate an integrity constraint. It’s possible to enforce arbitrary constraints using trigger operations; these can include checks that are as complex as necessary, but the more common types of constraints are check constraints, uniqueness constraints, and referential constraints. These work as follows:
- Check constraints: Check constraints are usually simple checks on the value of a data item. For example, a price quote must not be less than $0.00.
- Uniqueness constraints: A uniqueness constraint requires that some part of a record be unique. For example, two employees may not have the same employee number. A unique part of a record is called a candidate key, and one of the candidate keys is designated as the primary key. Intuitively, you expect every record to have at least one candidate key; otherwise, you would have no way of specifying which records you needed. Note that the candidate key can consist of a single item from the data record, a combination of items, or even all the items.
- Referential constraints: Consider an employee database in which all payments to employees are recorded in a table called SALARY. The employee number in a salary record must obviously correspond to the employee number in some employee record; this is an example of a referential constraint.
Data Security
A database management system gives the owners of the data a lot of control over their data—they can delegate limited rights to others if they choose to. It also gives the database administrator the ability to restrict and monitor the actions of users. For example, the database administrator can disable the password of an employee who leaves the company, to prevent them from gaining access to the database. Relational database management systems use techniques such as views (virtual tables defined in terms of other tables) and query modification to give individual users access to just those portions of data they’re authorized to use.
Oracle also offers extensive query-modification capabilities under the heading Virtual Private Database (VPD). Additional query restrictions can be silently and transparently appended to the query by policy functions associated with the tables in the query. For example, the policy functions may generate additional query restrictions that allow employees to retrieve information only about themselves and their direct reports between the hours of 9 a.m. and 5 p.m. on weekdays only.
I return to the subject of data security in Chapter 8.
What Makes a Relational Database Management System Relational?
Having already discussed the meaning of both relational database and database management system, it may appear that the subject is settled. But the natural implications of the relational model are so numerous and profound that critics contend that, even today, a “truly relational” database management system doesn’t exist. For example, Dr. Edgar Codd wanted the database management system to treat views in the same manner as base tables whenever possible, but the problem of view updateability is unsolved to the present day. Codd listed more than 300 separate requirements that a database management system must meet in order to fulfill his vision properly, and I have time for just one of them: physical data independence. Here is the relevant quote from Codd’s book:
RP-1 Physical Data Independence : The DBMS permits a suitably authorized user to make changes in storage representation, in access method, or in both—for example, for performance reasons. Application programs and terminal activities remain logically unimpaired whenever any such changes are made.2
What Codd meant was that you and I shouldn’t have to worry about implementation details such as the storage structures used to store data.
Summary
I hope that you now have an appreciation for the theoretical foundations of Oracle Database 12c. You can find more information about the subjects I touched on in the books mentioned in the bibliography at the end of the chapter. Here is a short summary of the concepts discussed in this chapter:
- A database is an information repository that must be competently administered using the principles laid out in the IT Infrastructure Library (ITIL), including security management, availability management, continuity management, change management, incident management, problem management, configuration management, release management, and capacity management.
- Relation is a precise mathematical term for what is loosely called a data table. Relational database technology swept aside earlier technologies because of the power and expressiveness of relational algebra and because it made performance the responsibility of the database management system instead of the application developer.
- A database management system provides efficient algorithms for the processing of table operations as well as indexing schemes for data storage. The query optimizer rearranges relational algebra expressions in the interests of efficiency but without changing the meaning or the results that are produced.
- A database management system is defined as a software layer that provides services such as transaction management, data security, and data integrity.
- A transaction is a logical unit of work characterized by atomicity, consistency, isolation, and durability.
- Relational database theory has many consequences, including logical data independence, which implies that changes to the way in which data is stored or indexed shouldn’t affect the logical behavior of application programs.
Further Reading
- Bachman, Charles. “The Programmer as Navigator.” ACM Turing Award Lecture, 1973. http://amturing.acm.org/award_winners/bachman_9385610.cfm. To properly understand Codd’s theory, you must understand what preceded it.
- Codd, E. F. “Relational Database: A Practical Foundation for Productivity.” ACM Turing Award Lecture, 1981. http://amturing.acm.org/award_winners/codd_1000892.cfm. It’s a shame that almost no database professionals have read the papers and articles written by the inventor of relational database theory. In my opinion, the 1981 ACM Turing Award Lecture should be required reading for every database professional.
- Silberschatz, Abraham, Henry Korth, and S. Sudarshan. Database System Concepts. 6th ed. McGraw-Hill, 2010. If you’re going buy just one book on database theory, this is the one I recommend. This college textbook, now in its sixth edition, offers not only copious amounts of theory but also some coverage of commercial products such as Oracle Database.
Footnotes
1Chris Date, An Introduction to Database Systems, 8th ed. (Addison-Wesley, 2003).
2E. F. Codd, The Relational Model for Database Management: Version 2 (Addison Wesley, 1990).