
CHAPTER 3
![]()
Oracle Architecture
Try to imagine, how Confucius, Buddha, Jesus, Mohammed or Homer would have reacted when they had been offered a [computer].
—Edsger Dijkstra, advocate of structured programming and winner of the 1972 Turing Award, in “Correctness Concerns and, Among Other Things, Why They Are Resented”
Just as an automobile engine has a lot of interconnected parts that must all work well together, and just as an automobile mechanic must understand the individual parts and how they relate to the whole, the Oracle Database engine has a lot of interconnected parts, and the database administrator must understand the individual parts and how they relate to the whole. This chapter summarizes the Oracle engine. It is impossible to document the workings of a complex piece of machinery in a short chapter—for a full treatment, refer to Oracle Database 12c Concepts, which, like all the reference manuals, is searchable and downloadable for free at the Oracle web site.
As an introduction, Figure 3-1 shows an interesting diagram of the inner workings of the Oracle Database engine. This diagram was produced by a software tool called Spotlight from Quest Software. The name of the database—pdb1—is seen in the upper-right corner of the diagram.
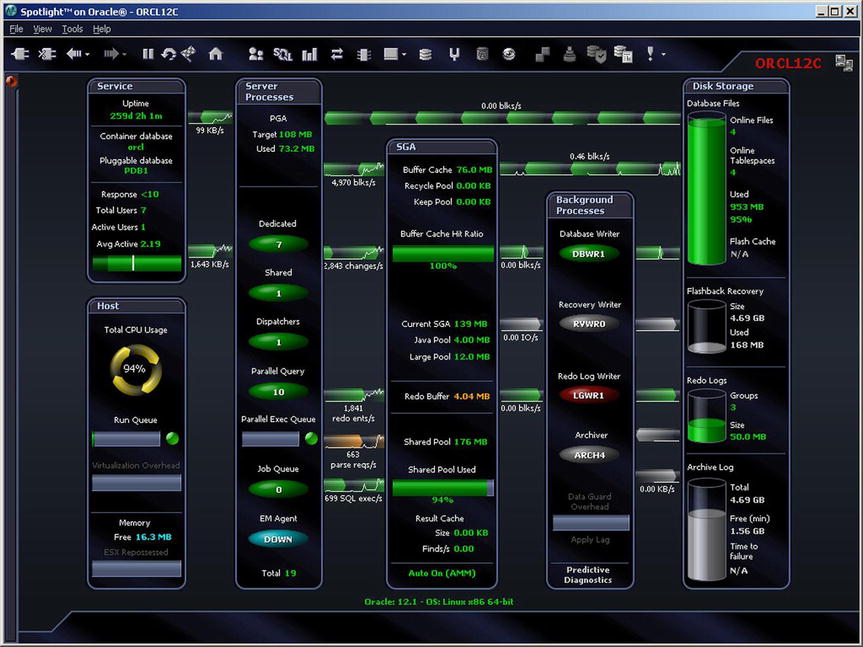
Figure 3-1. The Spotlight tool’s diagrammatic representation of the Oracle engine
In Figure 3-1, the various components of the Oracle Database architecture are grouped as follows:
- The Service panel represents the users who are using the database.
- The Host panel represents the host computer of the database.
- The Server Processes panel represents the computer processes on the host computer performing all the work requested by the users.
- The SGA panel represents an area of computer memory used as a work area by the database. SGA stands for System Global Area.
- The Background Processes panel represents a core set of computer processes that are independent of the user sessions and that perform specialized tasks such as storing information about transactions in the redo log files.
- The Disk Storage panel represents the files in which data is stored and supporting files such as redo log files and archived redo log files.
The other terms used in the diagram are explained in the following sections.
Database vs. Instance
In Oracle terminology, the word database is used to collectively indicate the data files and supporting files on the storage disks attached to the host computer, and the word instance is used to describe the computer processes resident in computer memory and memory areas shared by these processes. The relationship between Oracle instances and databases is one-to-one (one instance per database), many-to-one (multiple instances per database), or one-to-many (Oracle Database 12c only). The many-to-one configuration is called Real Application Clusters (RAC)—the database lives on shared disks, and instances on multiple computers attach to the database. The one-to-many configuration is called the Oracle Multitenant option and—as the name implies—is an extra-cost optional feature of Oracle Database 12c.
Database
The most concrete aspect of a database is the files on the storage disks connected to the database host. This section briefly discusses each category of file. Placement, sizing, and other configuration details are discussed in Chapters 5 and 6.
Software
The location of the database software is called the Oracle home, and the path to that location is usually stored in the environment variable ORACLE_HOME. There are two species of database software: server software and client software. Server software is necessary to create and manage the database and is required only on the database host. Client software is necessary to utilize the database and is required on every user’s computer—the most common example is the SQL*Plus command-line tool.
Configuration Files
The most important database configuration file is the one containing the settings used during database startup. It comes in two versions: a text version called a pfile and a binary version called an spfile. (You see an example in Chapter 6.) The pfile and spfile specify such details as the amount of computer memory that Oracle may use during operation. The pfile is traditionally referred to as the init.ora file.
Another important server-side configuration file is the listener.ora file. It controls the operation of the listener—an important process that comes into play when users start a database session. You see an example of this in Chapter 6. The tnsnames.ora file is a client-side configuration file that contains location information for databases. You see an example later in this chapter.
Data Files
The biggest component of a database is usually the files where data is stored. You could create a database with just one data file if you wanted to prove a point, but most databases have dozens of data files.
Data files are logically grouped into tablespaces and are usually given descriptive names such as DATA, INDEX, UNDO, and TEMP that indicate their intended purpose. Use a tablespace only for the purpose indicated by its name—for example, the SYSTEM tablespace should be used to store only the data dictionary (tables containing information about the rest of the database). Except for the SYSTEM and SYSAUX tablespaces, which are always created and whose names are mandated by Oracle, the number and names of the other tablespaces are left to you.
Each Oracle table and index is assigned to a single tablespace, and their growth is therefore limited by the availability of space in that assigned tablespace. They share the space with all the other tables or indexes also assigned to the tablespace. Data files can grow automatically as required; but, for reasons associated with manageability, you should limit how big they can grow. You can also create large data files of fixed size, and you can create additional data files during the life of the database.
The names chosen for data files typically include the name of the tablespace and the extension dbf or ora —for example, SYSTEM01.dbf might be the name given to the first data file in the SYSTEM tablespace. But this is only a convention, not a requirement, and you may invent your own convention or choose not to have one.
The space within data files is organized into data blocks (sometimes called pages) of equal size: 2, 4, 8, 16, 32, or 64 kilobytes (KB). 8KB is a commonly used block size. Each block contains data from just one table. The size of data records should be considered when deciding what size block to use. Oracle allows data records to span data blocks, but it is more efficient to retrieve one data block instead of multiple blocks from different locations on the storage disks. All the data files in one tablespace use blocks of the same size, and the block size should be a factor in the decision to assign a table or an index to a particular tablespace. When a table needs more space, it grabs a contiguous range of data blocks called an extent; it is conventional to use uniformly sized extents for all tables in the same tablespace.
Temporary Files
Each dedicated Oracle server process (a process that is dedicated to a single database connection) uses a private work area called a Program Global Area in computer memory to hold intermediate results: for example, data that must be sorted. The temporary files are used for intermediate storage when sufficient memory is unavailable.
Redo Log Files
Redo log files help Oracle ensure that the effects of a user’s transaction are durable even if there is a computer failure. Before any data in the data files is changed, the log-writer (LGWR) process stores a copy of the old data (undo information) and the new data (redo information) in the redo log file. In the event of a computer failure, the redo log files enable Oracle to undo the effects of incomplete transactions (uncommitted transactions) and redo committed transactions.
The sizes of the redo log files are decided by the database administrator. It is conventional but not required for all redo log files to be the same size. An Oracle database needs at least two redo log files. Oracle uses the redo log files in round-robin fashion; when one redo log file is filled, Oracle begins filling the next one, and so on.
Because the redo log files defend the database against computer failure, they must be well protected. It is typical to mirror each redo log file; a mirrored set of redo log files is referred to as a redo log group. It is also typical to put each member of a redo file group on a different storage disk. All the members of a redo file group have the same size; the log writer process stores the same information in all members of a redo file group. Oracle can therefore continue to operate as long as at least one member of each redo file group is undamaged.
Archived Redo Log Files
When a redo file fills up, an Oracle component called the archiver makes one or more copies in locations specified by the database administrator. Multiple copies improve the chances that at least one will survive if the storage disks are damaged.
These copies make it possible to reconstruct data files if they are ever damaged. If a data file is damaged, the database administrator can first restore the most recent backup copy of the data file, and the information contained in the archived redo files can be systematically processed to reproduce the effects of all the transactions that modified the data file since the backup copy was created.
It is possible to make copies of redo files directly on computer tapes, but it is more common to make copies on dedicated disks and to periodically sweep them to the tapes.
Control File
Oracle uses the control file while starting the database. This file contains information about the rest of the database, such as the names and locations of the data files. It also contains information—such as the names and locations of the archived redo log files—needed for recovery of damaged data files. It is continuously updated during the operation of the database.
Because of the criticality of the control file, it is conventional to have multiple copies—that is, mirrors. Oracle keeps all copies in perfect synchronization.
Event Logs
Oracle records important events in various log files. Events such as startup and shutdown, important Data Definition Language (DDL) operations such as ALTER TABLESPACE ADD DATAFILE, and space shortages are some of the events recorded in the alert log. A record is written to the listener log every time a user establishes a connection to the database. A detailed trace file is produced every time certain severe errors occur; examples include the ORA-600 error, which usually indicates that an Oracle bug has been encountered. You see examples of event logs in Chapters 10 and 11.
Database Backups
You must protect the database from storage failures by creating backup copies of the data files. If not enough disk space is available, backup copies of the data files can be stored on magnetic tapes. If enough disk space is available, backup copies can be stored on the disks, although they should not be stored on the disks where data files are stored. The location of the backup copies is traditionally referred to as the flashback recovery area. The backups stored on disk are usually copied to tapes for added safety.
We return to the topic of database backups in Chapters 12 and 13.
Instance
The Oracle instance is the engine that processes requests for data from the database—it is composed of foreground processes, background processes, and a large shared memory area called the System Global Area (SGA).
System Global Area
The SGA is typically a very large memory area shared by all Oracle processes. It is divided into distinct areas such as the buffer cache, the shared pool, and the log buffer, whose sizes are specified in the database configuration file (pfile or spfile). The Oracle processes coordinate their access to these areas by using inter-process communication (IPC) mechanisms called latches.
Buffer Cache
Typically, the buffer cache is the largest portion of the SGA. For reasons of efficiency, copies of data blocks (block buffers) are cached in computer memory whenever possible. When a foreground process needs a data block, it first checks the buffer cache, hoping to find the block there. If a block is not found in the cache, query processing has to be delayed until the foreground process retrieves the block from the storage disks.
When the buffer cache fills up, the least recently used blocks are removed to make space for new requests. You can try various strategies to improve the efficiency of the cache. A special keep pool can be created in the buffer cache to store data blocks from frequently used data tables—for example, lookup tables. A recycle pool can be created to hold data blocks that are not likely to be reused. Other techniques include partitioning and clusters—more information is provided in Chapter 7.
Shared Pool
The shared pool is another large component of the SGA and has many uses. The best-known use is caching query-execution plans for potential reuse by the user who first submitted the query or by any another user who submits the identical query—this is done in an area called the shared SQL area. Another well-known use is caching information from the data dictionary; this is done in an area within the shared pool called the dictionary cache.
Log Buffer
The log buffer is a queue of undo entries and redo entries. The log writer copies undo and redo entries to the redo log file. Typically, the size of this area is only a few megabytes.
Server Processes
A dedicated server process is typically started whenever a user connects to the database—it performs all the work requested by the user. An alternative model called multithreaded server (MTS), in which all user connections are serviced by a small set of dispatchers and shared servers, is also available but is not very suitable for general-purpose use and is not widely used.
These processes perform activities such as checking whether the user has permission to access the data, generating a query-execution plan for the SQL query submitted by the user, and retrieving data blocks into the buffer cache and modifying them. Before changing the contents of block buffers, it gains exclusive control to them by using a latch. Before modifying a data block, the foreground process first makes a copy of the block in an undo segment in the UNDO tablespace; it also creates the undo and redo entries that the log writer will store in the redo log files.
Dedicated server processes are terminated when the corresponding database sessions are terminated.
Background Processes
Unlike dedicated foreground processes, background processes live from database startup until database shutdown. The following are some of the better-known categories of background processes:
- The database writer (DBWn) processes are responsible for transferring all modified data blocks in the data caches to the data files. Multiple database writer processes can be created to share the load.
- The log writer (LGWR) process transfers all undo and redo entries in the log buffer to the redo log files.
- The archiver (ARCHn) processes are responsible for making copies of the redo log files when they fill up. These archived redo log files will be required if a data file is damaged and needs repair. Multiple archiver processes can be created to share the load.
- When a data block in the data cache is modified, it is not immediately transferred to the data files. In the interest of efficiency, it is better to copy changes in batches—this is the function of the database writer processes. However, at frequent intervals, the contents of the data caches are synchronized with the data files. Any modified data blocks remaining in memory are flushed to disk, and the file headers are updated with a special indicator called the system change number (SCN). This activity is called a checkpoint; coordination of this activity is performed by a dedicated process called the checkpoint process (CKPT).
- The process monitor (PMON) watches the progress of database connections. If a connection terminates abnormally, the process monitor initiates rollback activity on behalf of any transaction in progress.
- The system monitor (SMON) is responsible for any cleanup activities necessary if the database is restarted after an abnormal shutdown resulting from system failure. It uses the contents of the redo logs to perform cleanup activity. It also performs certain space-management activities during normal database operation.
One-to-Many Configuration
The one-to-many configuration has always been the standard configuration used by other database products including IBM DB2, Microsoft SQL, MySQL, and PostgreSQL; but Oracle Database 12c is the first version of Oracle Database to support this configuration. The official name for this feature is the Oracle Multitenant option, and—as the name implies—it is an extra-cost optional feature of Oracle Database 12c; that is, both the traditional one-to-one-configuration and the new one-to-many configurations are supported in Oracle Database 12c. In the one-to-many configuration, multiple databases share an Oracle home directory, SGA, background processes such as PMON and SMON, an UNDO tablespace, online redo logs, and (optionally) a TEMP tablespace. Each such database is referred to as a pluggable database (PDB) to indicate that it “plugs” into a container database (CDB) and can be plugged or unplugged when necessary. For example, a PDB can be unplugged from one CDB and plugged into another CDB with more hardware resources or a CDB to which software patches and upgrades have been applied. In other words, PDBs are easily transportable.
The one-to-many architecture is compatible with the one-to-one architecture. Oracle Distinguished Product Manager Bryn Llewellyn calls this the PDB/non-CDB compatibility guarantee. Any database application designed on the one-to-one architecture will continue to work without change in the one-to-many architecture. Llewellyn asserts that all questions about backward compatibility can immediately be answered in the affirmative by virtue of this guarantee. For example:
- Can two PDBs in same CDB each have a user called scott? Yes.
- Can you create a database link between two PDBs to allow applications connected to one PDB to access data in another PDB? Yes.
- Can you set up data replication between two PDBs or between a PDB and a non-CDB? Yes.
- Can a PDB be rolled back to a prior point in time without affecting other PDBs that share the same CDB? Yes.
The answer to the last question is particularly important because one of the defining characteristics of a database is that it is a logical unit of recovery.
Oracle Multitenant can only be licensed in conjunction with Enterprise Edition (Chapter 4 discusses the various editions of Oracle Database). However, a limited license is available for free. You can freely use Oracle Multitenant with any edition of Oracle Database and without paying any extra charges as long as you restrict yourself to a single PDB. You can reduce the downtime associated with database upgrades by creating an upgraded CDB and then painlessly unplugging a PDB from its current CDB and plugging it into the upgraded CDB. However, because of the PDB/non-CDB compatibility guarantee, this book does not need to spend much time on Oracle Multitenant, even though it is the signature feature of Oracle Database 12c.
Many-to-One Architecture
When you need to scale a database to support more users and transactions, there are two solutions: scale up or scale out. Scale up means additional hardware resources are added to the computer server housing the database. Scale out means the database is spread over multiple computer servers. Oracle Real Application Clusters (RAC) is Oracle’s scale-out architecture. In this architecture, multiple Oracle instances, each housed in a separate computer server, all connect to a single set of database files on a network-attached storage (NAS) or storage area network (SAN) storage server. This approach is called the shared disk approach to contrast it with the shared nothing or federated approach used by other database products such as IBM DB2. In the shared nothing approach, each instance manages a part of the database such that, if one instance stops, that part of the database becomes inaccessible until the failed instance is restarted. In the shared disk approach, the failure of one instance impacts the availability of the database. Another distinguishing feature of the Oracle scheme is cache fusion, in which each instance can request data held in the data caches of other instances.
The many-to-one architecture is much harder to configure and administer than the one-to-many architecture. In a nod to the increased complexity of RAC, Oracle Corporation sells an engineered system—that is, a combined hardware and software package—called the Oracle Database Appliance (ODA) . The ODA is a two-node RAC cluster with sufficient power for all but the largest organizations. Here are some of the advantages of the ODA:
- Push-button configuration: An ODA can be unboxed, installed, hooked up, and configured in just half a day, compared to the several weeks it typically takes to provision a RAC environment.
- Push-button patching: Oracle Corporation provides push-button patches for the entire technology stack—that is, operating system as well as database.
- Pay-as-you-go licensing: Oracle licensing is based on CPU cores (discussed in Chapter 4). However, not all the cores in the ODA need to be licensed at the same time. You can license only the CPU cores you need at the outset and license additional cores as time passes and your computing needs increase.
Oracle RAC is outside the scope of this introductory text, so it is not mentioned again.
Life Cycle of a Database Session
Now let’s consider the life cycle of a database session, from initiation to termination. For simplicity, I am restricting the example to a traditional client-server connection and assuming the use of dedicated servers instead of shared servers. Here are the phases that each database session goes through:
- The program residing on the user’s computer tries to connect to a database. One of the methods it can use to locate the database is to refer to the tnsnames.ora file in the ORACLE_HOME/network/admin directory on the user’s computer. There, it finds the name of the database host computer and the number of the network port where connections are being accepted. Here is an example of an entry for a database service called pdb1 on a host with IP address 192.168.56.101:
pdb1 =
(description =
(address = (protocol = tcp)(host = 192.168.56.101)(PORT = 1521))
(connect_data =
(server = dedicated)
(service:name = pdb1)
)
) - The user’s program sends a message to the port number specified in the tnsnames.ora file. The Oracle listener process receives the message and creates a dedicated server process to process the user’s requests.
- The user’s program provides the user’s credentials (name and password) to the dedicated server process. The dedicated server checks the data dictionary and verifies that the user’s credentials are valid and that the user has permission to access the database.
- The user’s program sends an SQL statement to the dedicated server for processing.
- The dedicated server prepares the SQL statement for execution. First it verifies that the SQL statement is syntactically correct. Next it verifies that the tables mentioned in the SQL statement exist and that the user has permission to access those tables. Then it creates a query-execution plan for the SQL statement. The query-execution plan is saved in the plan cache in the shared SQL area so it can be reused later by the same user or another user.
- The dedicated server checks whether the required blocks of data are in the buffer cache. If the needed blocks are not in the buffer cache, the dedicated server retrieves them from the data files.
- If the SQL statement involves no modifications to the data, the required data rows are transmitted to the user. If the SQL statement involves modification to the data, the dedicated server first copies the relevant data blocks to a rollback segment. It also creates undo and redo entries in the log buffer. The log writer copies undo and redo entries to the redo log files.
- If the SQL statement involved modification to the data, the user’s program sends a COMMIT command to the dedicated server process. The dedicated server process puts the COMMIT instruction in the log buffer and waits for confirmation from the log writer that it has recorded the transaction’s redo entries and the COMMIT instruction in the redo log files—this guarantees the durability of the modifications.
- The database writer processes copy-modified data blocks from the data cache to the data files. The checkpoint process wakes up periodically and initiates a systematic synchronization procedure on all data files that includes updating the system-change number in the heading of each data file.
- When the current redo log file fills up, the log writer closes the file and opens the next one. An archiver process subsequently makes a copy of the closed file in case a data file ever gets damaged and needs to be repaired.
- The user’s program disconnects from the database. This terminates the dedicated server process.
Summary
The information in this chapter summarizes the contents of Oracle Database 12c Concepts. Here is a summary of the concepts the chapter touched on:
- In Oracle terminology, the word database is used to collectively indicate the data files and supporting files on the storage disks attached to the host computer. The word instance is used to indicate the computer processes resident in computer memory and memory areas shared by these processes.
- The relationship between Oracle instances and databases is one-to-one, one-to-many (the Multitenant option of Oracle Database 12c), or many-to-one (Real Application Clusters).
- The location of the database software is called the Oracle home and is usually stored in the environment variable ORACLE_HOME.
- Well-known configuration files include init.ora, listener.ora, and tnsnames.ora.
- Data files are logically grouped into tablespaces. Each Oracle table or index is assigned to one tablespace and shares the space with the other tables assigned to the same tablespace. Data files can grow automatically if the database administrator wishes. The space within data files is organized into equally sized blocks; all data files belonging to a tablespace use the same block size. When a data table needs more space, it grabs a contiguous range of data blocks called an extent; it is conventional to use the same extent size for all tables in a tablespace.
- Temporary files are used if a large work area does not fit in computer memory.
- Redo log files guarantee atomicity and durability of a transaction. Redo logs are of fixed size and are mirrored for safety. Oracle fills the redo logs in round-robin fashion. The redo logs should be archived when they fill up—this makes it possible to repair data files if they get damaged.
- The control file is used by Oracle while starting the database; it contains the names and locations of the data files, among other things.
- Oracle records important events and errors in the alert log. A detailed trace file is created when a severe error occurs.
- The System Global Area (SGA) is composed of the buffer cache, the shared pool, and the log buffer. The best-known use of the shared pool is to cache query-execution plans. It is also used to store information from the data dictionary.
- A dedicated server is started whenever a user connects to the database; it is terminated when the user disconnects from the database. In the multithreaded server (MTS) mode of operation, all user connections are serviced by a few dispatchers and shared servers. Multithreaded server is a form of connection pooling for conserving memory and CPU resources but is rarely used today, having been overtaken by middle-tier connection pooling.
- Background processes are not tied to user connections and live from database startup until database shutdown. The best-known background processes are the database writer (DBWn), the log writer (LGWR), the archiver processes (ARCn), the checkpoint process (CKPT), the process monitor (PMON), and the system monitor (SMON).
- The Oracle Multitenant option is an extra-cost, optional feature of Oracle Database 12c only available in conjunction with the higher-cost Enterprise Edition. In this configuration, multiple databases share an Oracle home directory, SGA, background processes such as PMON and SMON, an UNDO tablespace, online redo logs, and optionally a TEMP tablespace. You can freely use Oracle Multitenant with any edition of Oracle Database and without paying any extra charges if you restrict yourself to a single pluggable database (PDB) in the container database (CDB). The PDB/non-CDB compatibility guarantee means any database application designed on the one-to-one architecture will continue to work without change in the one-to-many architecture.
- Oracle Real Application Clusters (RAC) is Oracle’s scale-out architecture. In this architecture, multiple Oracle instances, each housed in a separate computer server, all connect to a single set of database files on a network-attached storage (NAS) or storage area network (SAN) storage server. In a nod to the increased complexity of RAC, Oracle Corporation sells an engineered system—that is, a combined hardware and software package—called the Oracle Database Appliance (ODA). The ODA is a two-node RAC cluster with sufficient power for all but the largest organizations. Its advantages are push-button installations, push-button upgrades, and pay-as-you-go licensing.
Exercises
- In your virtual machine, connect to the service orcl using the SYSTEM account. The password is oracle. Issue the SQL command select * from cdb_pdbs. Interpret the result.
- Search Figure 3-1 for terms that have not been explained in this chapter. Find their definitions in the Oracle Database 12c Master Glossary available at http://docs.oracle.com.
Further Reading
- Llewellyn, Bryn. “Oracle Multitenant.” Oracle white paper, June 2013. A wonderfully eloquent white paper by am Oracle Distinguished Product Manager.
- Oracle Database 12c Concepts Chapter 11 (Physical Storage Structures), Chapter 14 (Memory Architecture), Chapter 15 (Process Architecture), and Chapter 17 (Introduction to the Multitenant Architecture). http://docs.oracle.com.